Gradle User Manual: Version 9.6.1
- OVERVIEW
- RELEASES
- FUNDAMENTALS
- Core Concepts
- Wrapper Basics
- Command-Line Interface Basics
- Settings File Basics
- Build File Basics
- Dependencies and Dependency Management Basics
- Task Basics
- Incremental Builds and Build Caching Basic
- Plugin Basics
- Build Scan Basics
- Anatomy of a Gradle Build
- Structuring Multi-Project Builds
- Gradle Build Lifecycle
- Writing Build Scripts
- Gradle Managed Types
- Declaring and Managing Dependencies
- Creating and Registering Tasks
- Working with Plugins
- Plugin Introduction
- Pre-compiled Script Plugins
- Binary Plugin
- Binary Plugin Development
- Binary Plugin Testing
- Binary Plugin Publishing
- BEST PRACTICES
- RUNTIME AND CONFIGURATION
- DSLS AND APIS
- CORE PLUGINS
- Gradle Plugin Reference
- The Java Plugin
- The Java Library Plugin
- The Java Platform Plugin
- The Groovy Plugin
- The Scala Plugin
- The ANTLR Plugin
- The JVM Test Suite Plugin
- The Test Report Aggregation Plugin
- C++ Application
- C++ Library
- C++ Unit Test
- Swift Application
- Swift Library
- XCTest
- The Application Plugin
- The War Plugin
- The Ear Plugin
- The Distribution Plugin
- The Java Library Distribution Plugin
- The Checkstyle Plugin
- The PMD Plugin
- The JaCoCo Plugin
- The JaCoCo Report Aggregation Plugin
- The CodeNarc Plugin
- The Eclipse Plugins
- The IDEA Plugin
- Visual Studio
- Xcode
- The Base Plugin
- Build Init Plugin
- The Signing Plugin
- Gradle Plugin Development Plugin
- The Project Report Plugin
- The Build Dashboard Plugin
- TASK DEVELOPMENT
- PLUGIN DEVELOPMENT
- DEPENDENCY MANAGEMENT
- Dependency Management
- 1. Declaring dependencies
- 2. Dependency Configurations
- 3. Declaring repositories
- 4. Centralizing dependencies
- 5. Dependency Constraints and Conflict Resolution
- Declaring Dependencies
- Viewing Dependencies
- Declaring Versions and Ranges
- Declaring Dependency Constraints
- Creating Dependency Configurations
- Gradle distribution-specific dependencies
- Declaring Repositories Basics
- Centralizing Repository Declarations
- Repository Types
- Metadata Formats
- Supported Protocols
- Filtering Repository Content
- Platforms
- Version Catalogs
- Using Catalogs with Platforms
- Dependency Resolution Consistency
- Resolving Specific Artifacts
- Capabilities
- Variants and Attributes
- Artifact Views
- Artifact Transforms
- Locking Versions
- Using Resolution Rules
- Modifying Dependency Metadata
- Dependency Caching
- Dependency Resolution
- Graph Resolution
- Variant Selection and Attribute Matching
- Artifact Resolution
- Publishing a project as module
- Gradle Module Metadata
- Signing artifacts
- Customizing publishing
- The Maven Publish Plugin
- The Ivy Publish Plugin
- GRADLE MANAGED TYPES
- JVM BUILDS
- C++ BUILDS
- SWIFT BUILDS
- GRADLE ON CI
- STRUCTURING BUILDS
- OPTIMIZING GRADLE BUILDS
- Improve the Performance of Gradle Builds
- Build Cache
- Use cases for the build cache
- Build cache performance
- Important concepts
- Caching Java projects
- Caching Android projects
- Debugging and diagnosing Build Cache misses
- Solving common problems
- Configuration Cache
- Enabling and Configuring the Configuration Cache
- Configuration Cache Requirements for your Build Logic
- Debugging and Troubleshooting the Configuration Cache
- Configuration Cache Status
- Isolated Projects
- SECURING BUILDS
- INTEGRATION
OVERVIEW
Gradle User Manual
Gradle Build Tool
 Gradle Build Tool is a fast, dependable, and adaptable open-source build automation tool with an elegant and extensible declarative build language.
Gradle Build Tool is a fast, dependable, and adaptable open-source build automation tool with an elegant and extensible declarative build language.
In this User Manual, Gradle Build Tool is abbreviated Gradle.
Supported Languages and Frameworks
Gradle supports Android, Java, Kotlin Multiplatform, Groovy, Scala, Javascript, and C/C++.

Compatible IDEs
All major IDEs support Gradle, including Android Studio, IntelliJ IDEA, Visual Studio Code, Eclipse, and NetBeans.

You can also invoke Gradle via its command-line interface (CLI) in your terminal or through your continuous integration (CI) server.
Releases
Information on Gradle releases is found on the Release page.
Installing Gradle
Most projects will start with an existing Gradle build which does not require the installation of Gradle. However, if you are starting a project from scratch, and you need to install Gradle, check out the installation guide.
DPE University
Want to get up and running with Gradle quickly? Take our free, self-paced Gradle Build Tool courses at DPE University.
For Software Engineers and Developers
For software developers that need to build, test, and publish their app, or add dependencies to their build, get started here:
For Build Engineers
Build engineers that are ready to configure custom build logic should start here:
For Plugin Developers
Plugin authors that are ready to develop and publish their own plugins should start here:
Support
-
Forum — The fastest way to get help is through the Gradle Forum.
-
Slack — Community members and core contributors answer questions directly on our Slack Channel.
Licenses
Gradle Build Tool source code is open and licensed under the Apache License 2.0. Gradle user manual and DSL reference manual are licensed under Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Copyright
© 2025 Gradle, Inc. Gradle®, Develocity®, Build Scan®, and the Gradlephant logo are registered trademarks of Gradle, Inc. On this resource, "Gradle" typically means "Gradle Build Tool" and does not reference Gradle, Inc. and/or its subsidiaries.
For inquiries related to commercial use or licensing, contact Gradle, Inc. directly.
Getting Started
Gradle for Software Engineers
Everyone has to start somewhere, and if you’re new to Gradle, this is where to begin.
1. Learn how to run Gradle Builds
This section goes through the Gradle core concepts so that you can quickly understand how to invoke tasks, turn on features, apply plugins, add dependencies to your project, and more.
This section covers:
Part 1. Core Concepts
Part 2. Wrapper Basics
Part 3. Command Line Interface Basics
Part 4. Settings File Basics
Part 5. Build Files Basics
Part 6. Dependencies and Dependency Management Basics
Part 7. Tasks Basics
Part 8. Incremental Builds and Build Caching Basics
Part 9. Plugins Basics
Part 10. Build Scan
2. Beginner Gradle Tutorial
The tutorial will take you from Gradle initialization all the way through to utilizing Gradle’s task caching for your basic Java App. No previous experience is necessary but a basic knowledge of Java and Kotlin is nice to have.
If you need to install Gradle before the tutorial, you can do so in the installation section.
The tutorial covers:
Gradle for Build Engineers
Build engineers that are ready to configure and organize custom build logic should start here.
1. Learn how to write Gradle scripts
This section goes through some Gradle authoring basics so that you can quickly understand how to configure builds, create tasks, and organize logic.
This section covers:
2. Intermediate Gradle Tutorial
The tutorial will take you from Gradle initialization all the way through registering tasks and the basics of plugins.
The tutorial covers:
Gradle for Plugin Developers
Plugin authors that are ready to write their own plugins and publish it should start here.
1. Learn how to develop Gradle Plugins
This section goes through developing tasks, writing, and publishing plugins.
This section covers:
2. Advanced Gradle Tutorial
The tutorial will take you from Gradle initialization all the way through creating and publishing a binary plugin.
The tutorial covers:
RELEASES
Installing Gradle
If all you want to do is run an existing Gradle project, then you don’t need to install Gradle if the build uses the Gradle Wrapper.
Gradle Installation
The Gradle Wrapper is identifiable by the presence of the gradlew or gradlew.bat files in the root of the project:
. // (1)
├── gradle
│ └── wrapper // (2)
├── gradlew // (3)
├── gradlew.bat // (3)
└── ⋮-
Project root directory.
-
Scripts for executing Gradle builds.
If the gradlew or gradlew.bat files are already present in your project, you do not need to install Gradle.
But you need to make sure your system satisfies Gradle’s prerequisites.
You can follow the steps in the Upgrading Gradle section if you want to update the Gradle version for your project. Please use the Gradle Wrapper to upgrade Gradle.
Android Studio comes with a working installation of Gradle, so you don’t need to install Gradle separately when only working within that IDE.
If you do not meet the criteria above and decide to install Gradle on your machine, first check if Gradle is already installed by running gradle -v in your terminal.
If the command does not return anything, then Gradle is not installed, and you can follow the instructions below.
You can install Gradle Build Tool on Linux, macOS, or Windows. The installation can be done manually or using a package manager like SDKMAN! or Homebrew.
You can find all Gradle releases and their checksums on the releases page.
Prerequisites
Gradle runs on all major operating systems. It requires Java Development Kit (JDK) version 17 or higher to run. You can check the compatibility matrix for more information.
To check, run java -version:
$ java -versionopenjdk version "17.0.6" 2023-01-17
OpenJDK Runtime Environment Temurin-17.0.6+10 (build 17.0.6+10)
OpenJDK 64-Bit Server VM Temurin-17.0.6+10 (build 17.0.6+10, mixed mode)Gradle uses the JDK it finds in your path, the JDK used by your IDE, or the JDK specified in your project.
In this example, the $PATH points to JDK17:
$ echo $PATH/opt/homebrew/opt/openjdk@17/binYou can also set the JAVA_HOME environment variable to point to a specific JDK installation directory.
This is especially useful when multiple JDKs are installed:
$ echo %JAVA_HOME%C:\Program Files\Java\jdk17.0_6$ echo $JAVA_HOME/Library/Java/JavaVirtualMachines/jdk-17.jdk/Contents/HomeLinux installation
Installing with a package manager
SDKMAN! is a tool for managing parallel versions of multiple Software Development Kits on most Unix-like systems (macOS, Linux, Cygwin, Solaris and FreeBSD). Gradle is deployed and maintained by SDKMAN!:
$ sdk install gradleOther package managers are available, but the version of Gradle distributed by them is not controlled by Gradle, Inc. Linux package managers may distribute a modified version of Gradle that is incompatible or incomplete when compared to the official version.
Installing manually
Step 1 - Download the latest Gradle distribution
The distribution ZIP file comes in two flavors:
-
Binary-only (bin)
-
Complete (all) with docs and sources
We recommend downloading the bin file; it is a smaller file that is quick to download (and the latest documentation is available online).
Step 2 - Unpack the distribution
Unzip the distribution zip file in the directory of your choosing, e.g.:
$ mkdir /opt/gradle
$ unzip -d /opt/gradle gradle-9.6.1-bin.zip
$ ls /opt/gradle/gradle-9.6.1LICENSE NOTICE bin README init.d lib mediaStep 3 - Configure your system environment
To install Gradle, the path to the unpacked files needs to be in your Path.
Configure your PATH environment variable to include the bin directory of the unzipped distribution, e.g.:
$ export PATH=$PATH:/opt/gradle/gradle-9.6.1/binAlternatively, you could also add the environment variable GRADLE_HOME and point this to the unzipped distribution.
Instead of adding a specific version of Gradle to your PATH, you can add $GRADLE_HOME/bin to your PATH.
When upgrading to a different version of Gradle, simply change the GRADLE_HOME environment variable.
$ export GRADLE_HOME=/opt/gradle/gradle-9.6.1
$ export PATH=${GRADLE_HOME}/bin:${PATH}macOS installation
Installing with a package manager
SDKMAN! is a tool for managing parallel versions of multiple Software Development Kits on most Unix-like systems (macOS, Linux, Cygwin, Solaris and FreeBSD). Gradle is deployed and maintained by SDKMAN!:
$ sdk install gradleUsing Homebrew:
$ brew install gradleUsing MacPorts:
$ sudo port install gradleOther package managers are available, but the version of Gradle distributed by them is not controlled by Gradle, Inc.
Installing manually
Step 1 - Download the latest Gradle distribution
The distribution ZIP file comes in two flavors:
-
Binary-only (bin)
-
Complete (all) with docs and sources
We recommend downloading the bin file; it is a smaller file that is quick to download (and the latest documentation is available online).
Step 2 - Unpack the distribution
Unzip the distribution zip file in the directory of your choosing, e.g.:
$ mkdir /usr/local/gradle
$ unzip gradle-9.6.1-bin.zip -d /usr/local/gradle
$ ls /usr/local/gradle/gradle-9.6.1LICENSE NOTICE README bin init.d libStep 3 - Configure your system environment
To install Gradle, the path to the unpacked files needs to be in your Path.
Configure your PATH environment variable to include the bin directory of the unzipped distribution, e.g.:
$ export PATH=$PATH:/usr/local/gradle/gradle-9.6.1/binAlternatively, you could also add the environment variable GRADLE_HOME and point this to the unzipped distribution.
Instead of adding a specific version of Gradle to your PATH, you can add $GRADLE_HOME/bin to your PATH.
When upgrading to a different version of Gradle, simply change the GRADLE_HOME environment variable.
It’s a good idea to edit .bash_profile in your home directory to add GRADLE_HOME variable:
$ export GRADLE_HOME=/usr/local/gradle/gradle-9.6.1
$ export PATH=$GRADLE_HOME/bin:$PATHWindows installation
Installing manually
Step 1 - Download the latest Gradle distribution
The distribution ZIP file comes in two flavors:
-
Binary-only (bin)
-
Complete (all) with docs and sources
We recommend downloading the bin file.
Step 2 - Unpack the distribution
Create a new directory C:\Gradle with File Explorer.
Open a second File Explorer window and go to the directory where the Gradle distribution was downloaded. Double-click the ZIP archive to expose the content.
Drag the content folder gradle-9.6.1 to your newly created C:\Gradle folder.
Alternatively, you can unpack the Gradle distribution ZIP into C:\Gradle using the archiver tool of your choice.
Step 3 - Configure your system environment
To install Gradle, the path to the unpacked files needs to be in your Path.
In File Explorer right-click on the This PC (or Computer) icon, then click Properties → Advanced System Settings → Environmental Variables.
Under System Variables select Path, then click Edit.
Add an entry for C:\Gradle\gradle-9.6.1\bin.
Click OK to save.
Alternatively, you can add the environment variable GRADLE_HOME and point this to the unzipped distribution.
Instead of adding a specific version of Gradle to your Path, you can add %GRADLE_HOME%\bin to your Path.
When upgrading to a different version of Gradle, just change the GRADLE_HOME environment variable.
Verify the installation
Open a console (or a Windows command prompt) and run gradle -v to run gradle and display the version, e.g.:
$ gradle -v------------------------------------------------------------
Gradle 9.0.0
------------------------------------------------------------
Build time: 2025-07-17 12:48:00 UTC
Revision: 2db9560bb68c367a265b10516c856c840f9bed8d
Kotlin: 2.2.0
Groovy: 4.0.28
Ant: Apache Ant(TM) version 1.10.15 compiled on August 25 2024
Launcher JVM: 17.0.11 (Amazon.com Inc. 17.0.11+9-LTS)
Daemon JVM: Compatible with Java 17, any vendor, nativeImageCapable=false (from gradle/gradle-daemon-jvm.properties)
OS: Mac OS X 14.7.4 aarch64You can verify the integrity of the Gradle distribution by downloading the SHA-256 file (available from the releases page) and following these verification instructions.
Upgrading within Gradle 9.x.y
This chapter provides the information you need to migrate your Gradle 9.x.y builds to the latest. For migrating to Gradle 9.0.0, see the older migration guide first.
We recommend the following steps for all users:
-
Try running
gradle help --scanand view the deprecations view of the generated Build Scan.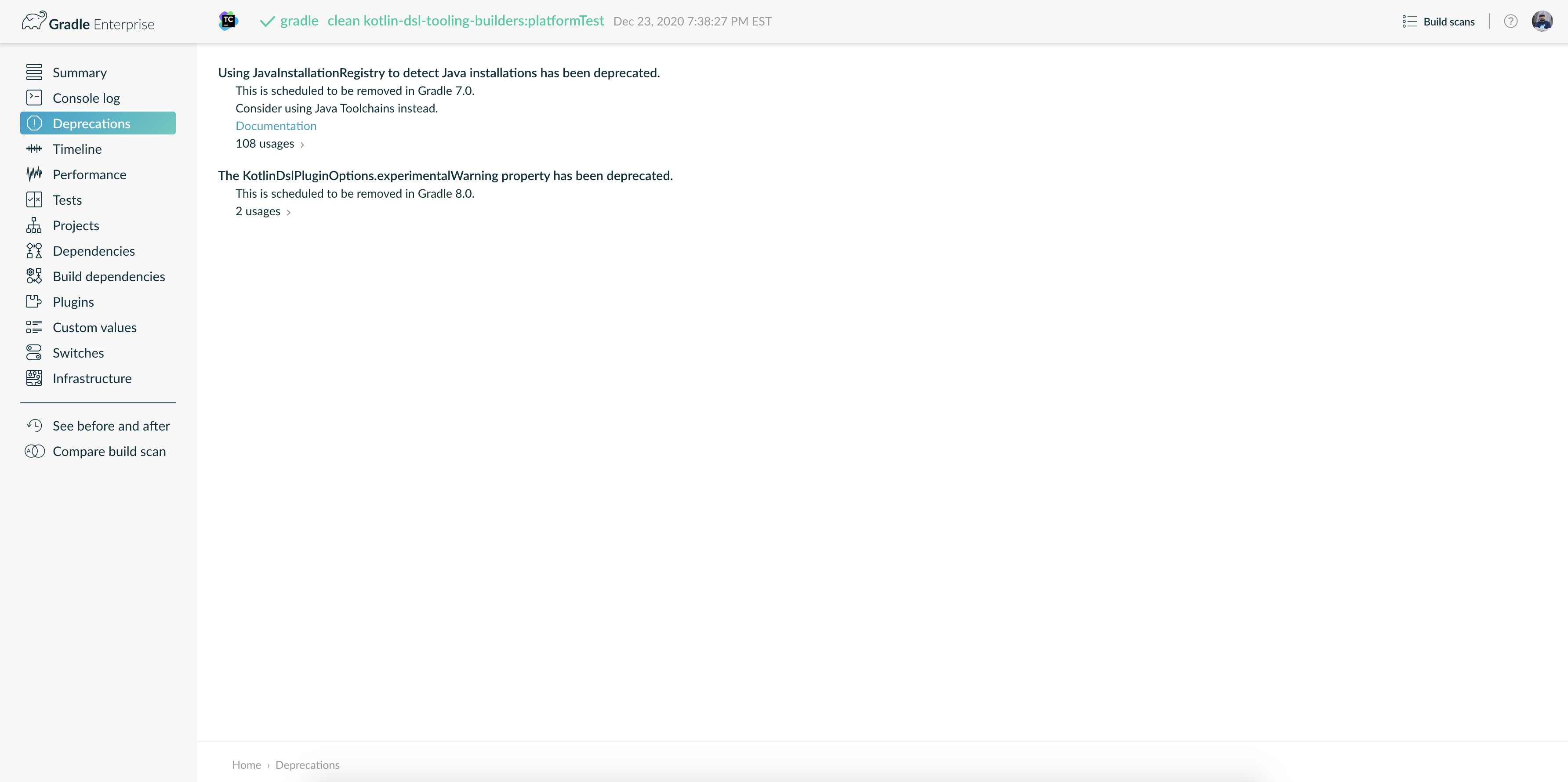
This lets you see any deprecation warnings that apply to your build.
Alternatively, you can run
gradle help --warning-mode=allto see the deprecations in the console, though it may not report as much detailed information. -
Update your plugins.
Some plugins will break with this new version of Gradle because they use internal APIs that have been removed or changed. The previous step will help you identify potential problems by issuing deprecation warnings when a plugin tries to use a deprecated part of the API.
-
Run
gradle :wrapper --gradle-version 9.6.1to update the project to 9.6.1. -
Try to run the project and debug any errors using the Troubleshooting Guide.
Upgrading from 9.5.0 and earlier
Potential breaking changes
Plugins relying on removed Problems API internals are no longer compatible with Gradle 9.6
Several internal classes of the Problems API, such as org.gradle.api.problems.internal.InternalProblems, have been removed in Gradle 9.6.
Plugins that bound to these internal classes directly fail at build time with an error mentioning the removed type.
The most common case is Android Gradle Plugin (AGP) 8.x, which relied on these internal classes. To resolve this, upgrade to AGP 9.x, which only uses the public Gradle API and fully supports Gradle 9.6. If the failure comes from another plugin, update it to a version that no longer uses Gradle internal APIs, or stay on Gradle 9.5 until such a version is available.
Concurrency primitives can no longer be serialized by the Configuration Cache
Configuration Cache serialization now reports a clear problem when attempting to serialize most of Java’s standard concurrency primitives.
This includes classes and interfaces from the java.util.concurrent and java.util.concurrent.locks packages, such as ReentrantLock, CountDownLatch, and SynchronousQueue.
Because the Configuration Cache enforces isolation between tasks, these primitives cannot be used correctly for cross-task synchronization.
Allowing serialization would silently give each task its own independent instance (for example, its own lock), so cross-task coordination would never actually occur — that is the bug this error prevents.
Previously, attempts to serialize these types could fail with exceptions such as java.lang.reflect.InaccessibleObjectException, without clearly indicating the underlying issue.
If your build requires shared, synchronized state, use shared build services, which are explicitly designed for safe coordination between tasks.
For a complete list of types that are incompatible with the Configuration Cache, see the documentation.
Upgrade to Kotlin 2.3.21
The embedded Kotlin has been upgraded from 2.3.20 to Kotlin 2.3.21.
Upgrade to PMD 7.24.0
The default version of PMD has been updated from 7.13.0 to 7.24.0.
Upgrade to CodeNarc 3.7.0
The default version of CodeNarc has been updated from 3.6.0 to 3.7.0.
Deprecations
Deprecation of implicit lookup of properties and methods in parent projects
In Gradle’s Groovy and Kotlin DSLs, when a child project’s build script references a property or method that isn’t defined locally, the resolution mechanism walks up the parent projects looking for a match:
ext.foo = "hello"println(foo) // Resolved through hierarchy — now deprecatedextra["foo"] = "hello"val foo: String? by project
println(foo) // Resolved through hierarchy — now deprecatedThis implicit inheritance is deprecated and will be removed in Gradle 10.
Implicit hierarchy lookup creates hidden coupling between projects, makes builds harder to reason about (a typo silently resolves to an ancestor’s definition instead of failing), and is fundamentally incompatible with Isolated Projects.
Here is a full list of affected APIs and DSL constructs:
-
Dynamic references such as a bare
fooorbar()in Groovy DSL -
Kotlin DSL property delegates such as
val foo: String by project -
Explicit API calls on the
Projectinstance or in a build script:-
findProperty("foo") -
property("foo") -
hasProperty("foo") -
getProperties()
-
To migrate, choose the approach that best fits your use case:
-
Build-wide configuration values — declare them in
gradle.propertiesat the root, and read them in subprojects viaproviders.gradleProperty("name"). They become typedProvider<String>values and are available everywhere without any walking. -
Plugin defaults / shared logic — extract into a convention plugin applied to each subproject. Each subproject gets its own configuration; nothing crosses project boundaries.
-
Explicit reference to an ancestor’s value — write
rootProject.ext.foo(orparent.ext.foo) in the child build script. This is a transitional fix: it preserves the cross-project coupling and is therefore not Isolated Projects compatible, but it removes the deprecation warning and makes the dependency explicit.
If you need to keep the original walking semantics, the following helper can be added to a build script or convention plugin:
tailrec fun Project.findExtraInHierarchy(name: String): Any? {
if (extra.has(name)) return extra[name]
val ancestor = parent ?: return null
return ancestor.findExtraInHierarchy(name)
}def findExtraInHierarchy(Project project, String name) {
if (project == null) return null
if (project.ext.has(name)) return project.ext.get(name)
return findExtraInHierarchy(project.parent, name)
}Once you have addressed all related deprecations, you can use a feature preview to adopt the Gradle 10 behavior early. This prevents new accidental implicit lookups from parent projects.
// settings.gradle.kts
enableFeaturePreview("NO_IMPLICIT_LOOKUP_IN_PARENT_PROJECTS")This will affect the behavior of APIs and DSL constructs mentioned above.
It will also affect the output of the properties task when invoked for subprojects.
Deprecation of Develocity plugin versions before 4.0
Earlier versions of the Develocity plugin rely on the implicit property lookup in parent projects, which is deprecated and will be removed in Gradle 10.
Upgrade to the latest Develocity plugin from the Gradle Plugin Portal. See the Develocity plugin compatibility matrix for details.
Deprecation of getProperties()
The following usages of getProperties() have been deprecated and will be removed in Gradle 10:
-
Project.getProperties()— callinggetProperties()or accessing thepropertiesproperty on aProjectinstance. -
Calling
getProperties()(or accessing thepropertiesproperty) on a build script, settings script, or init script. This is a separate API on the script base class, but has the same problems.
This method, which historically existed for convenience, makes build logic harder to understand and navigate due to the untyped nature of the properties and the fact that they are sourced from many different locations and containers. Using this method also hurts performance of builds by eagerly resolving properties from the environment, reducing the potential for more frequent Configuration Cache hits. The hierarchical look-up of properties through the parent projects chain creates implicit coupling of the mutable state between projects. This impedes the potential of scalability in the future model, where projects are isolated from each other.
To access project properties, prefer providers.gradleProperty("name") which returns a type-safe Provider and is compatible with lazy configuration.
Note that providers.gradleProperty() resolves properties at the build level — it does not include properties from gradle.properties files in subproject directories, nor extra properties or other properties set dynamically on individual projects.
If you need to access extra properties, use ext properties directly.
The following table shows common migration scenarios for project properties:
| Before (deprecated) | After (recommended) |
|---|---|
Accessing a single project property: |
Wire the provider as a task property for better Configuration Cache support: If you need the value immediately: |
Accessing a property with a default value (Kotlin, Java, or Groovy): Accessing a property with a default value (Groovy, idiomatic): |
Use |
Kotlin property delegation: |
Get the project property directly: |
Forwarding properties as system properties: |
Use |
Token replacement in resource files (common in Minecraft mods, Spring Boot, etc.): |
Build an explicit map of only the properties you need: |
Deprecation of Kotlin DSL delegated properties
All Kotlin DSL property delegate extensions have been deprecated and will be removed in Gradle 10. This includes container delegates (by registering, by creating, by existing, by getting), property delegates (by project, by settings, by extra), and value delegates (Property<T> and ConfigurableFileCollection getValue/setValue operators).
Use the explicit API instead.
The container delegates (registering, creating, existing, getting) are defined on NamedDomainObjectContainer and NamedDomainObjectCollection. They apply to any container, not just tasks or configurations.
The examples below use a generic container placeholder; replace it with tasks, configurations, sourceSets, or whichever container you use.
Container delegates:
| Deprecated delegate | Replacement |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
When a container holds exactly one element of a given type, you can look it up by type instead of by name. This is useful for plugin-contributed tasks whose names are not part of a public contract:
// Eagerly resolves the single task of type MyTaskType, regardless of its name.
val myTask = rootProject.tasks.withType<MyTaskType>().single()|
Note
|
withType(…).single() is eager. The task must already exist when this line runs.
For lazy configuration, use tasks.withType<MyTaskType>().configureEach { … } instead.
|
Property, extra, and value delegates:
| Deprecated delegate | Replacement |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Delegated properties are being removed because they create silent correctness bugs (e.g. no-op delegates, wrong extra property scope), couple entity names to variable names, diverge between build scripts and class-based plugins, and duplicate functionality already provided by explicit APIs or other DSL sugar.
Deprecation of accessing task dependency relationships from a task action
Calling the following methods from a task action at execution time is now deprecated and will become an error in Gradle 10:
These methods can still be used during configuration time.
The deprecation is only issued if the Configuration Cache is not enabled. When the Configuration Cache is enabled, calls to these methods are reported as Configuration Cache problems instead. This is another step towards moving users away from idioms that are incompatible with the Configuration Cache, which will become the only mode supported by Gradle in a future release. For example:
// Deprecated: inspecting dependencies from within the task action
tasks.register("report") {
dependsOn("compileJava")
doLast {
taskDependencies.getDependencies(this).forEach { println(it.name) }
}
}
// Recommended: capture what you need at configuration time
tasks.register("report") {
dependsOn("compileJava")
val dependencyNames = dependsOn.filterIsInstance<Task>().map { it.name }
doLast {
dependencyNames.forEach { println(it) }
}
}Please refer to the Configuration Cache documentation for alternatives that are compatible with the Configuration Cache.
Deprecation of accessing extensions from a task action
Calling Task.getExtensions() from a task action at execution time is now deprecated and will become an error in Gradle 10.
This method can still be used during configuration time.
The deprecation is only issued if the Configuration Cache is not enabled. When the Configuration Cache is enabled, calls to this method are reported as Configuration Cache problems instead. This is another step towards moving users away from idioms that are incompatible with the Configuration Cache, which will become the only mode supported by Gradle in a future release.
For example:
// Deprecated: reading the extension from within the task action
tasks.register("greet") {
doLast {
val ext = extensions.getByType<GreetingExtension>()
println(ext.message.get())
}
}
// Recommended: capture the value at configuration time
tasks.register("greet") {
val message = extensions.getByType<GreetingExtension>().message
doLast {
println(message.get())
}
}Please refer to the Configuration Cache documentation for alternatives that are compatible with the configuration cache.
Deprecation of accessing injected Project or Gradle services from a task action
Reading an injected service of type Project or Gradle from a task action at execution time is now deprecated and will become an error in Gradle 10.
These services can still be read during configuration time.
The deprecation is only issued if the Configuration Cache is not enabled. When the Configuration Cache is enabled, such accesses are reported as Configuration Cache problems instead. This is another step towards moving users away from idioms that are incompatible with the Configuration Cache, which will become the only mode supported by Gradle in a future release.
For example:
// Deprecated: reading from the injected Project at execution time
abstract class PrintVersionTask : DefaultTask() {
@get:Inject
abstract val project: Project
@TaskAction
fun run() {
println("Building ${project.name} version ${project.version}")
}
}
// Recommended: declare the values you need as task inputs
abstract class PrintVersionTask : DefaultTask() {
@get:Input
abstract val projectName: Property<String>
@get:Input
abstract val projectVersion: Property<String>
@TaskAction
fun run() {
println("Building ${projectName.get()} version ${projectVersion.get()}")
}
}
tasks.register<PrintVersionTask>("printVersion") {
projectName.set(project.name)
projectVersion.set(project.version.toString())
}Please refer to the Configuration Cache documentation for alternatives that are compatible with the Configuration Cache.
Deprecation of accessing Task in dependsOn closures
Using the Task argument provided to closures passed to the Task.dependsOn method has been deprecated.
Starting in Gradle 10, closures passed to Task.dependsOn will no longer receive a Task argument.
The following code will not be permitted starting in Gradle 10:
def foo = tasks.register("foo")
// The below usages of dependsOn access the Task object provided as a parameter.
// This is deprecated behavior.
tasks.register("bar") {
dependsOn { task ->
task.getName()
foo
}
}
tasks.register("baz") {
dependsOn {
it.getName()
foo
}
}
// Build logic may continue to pass closures to dependsOn without accessing the provided Task.
tasks.register("okay") {
dependsOn {
foo
}
}Deprecation of using Project objects as dependency notation
Passing a Project object directly as a dependency notation has been deprecated and will become an error in Gradle 10.
Previously, you could declare a project dependency by passing a Project instance directly:
def someProject = project(":some-project")
dependencies {
implementation(someProject) // Deprecated
}Instead, use the project() method on DependencyHandler or the createProjectDependency() method on DependencyFactory:
dependencies {
implementation(project(":some-project"))
}Or, when using the DependencyFactory directly (e.g., from a plugin):
Configuration implementation = project.getConfigurations().getByName("implementation");
ProjectDependency dependency = project.getDependencyFactory().createProjectDependency(":some-project");
implementation.getDependencies().add(dependency);Deprecation of artifactUrls on Maven repositories
The artifactUrls family of methods on MavenArtifactRepository is deprecated and will be removed in Gradle 10.
This includes:
-
MavenArtifactRepository.getArtifactUrls() -
MavenArtifactRepository.artifactUrls(Object…) -
MavenArtifactRepository.setArtifactUrls(Set) -
MavenArtifactRepository.setArtifactUrls(Iterable)
The same deprecation applies to passing artifactUrls as a key in the map argument to RepositoryHandler.mavenCentral(Map), since that path delegates to the methods above.
These methods let a single Maven repository declaration look for POMs at the base URL while looking for artifacts (such as JARs) at one or more additional URLs. This is a Gradle-specific extension with no equivalent in Maven, and there is no direct replacement.
Deprecation of RepositoryHandler.flatDir(Map) and RepositoryHandler.mavenCentral(Map)
The map-argument overloads RepositoryHandler.flatDir(Map) and RepositoryHandler.mavenCentral(Map) are deprecated and will be removed in Gradle 10.
Use the action-based overloads (flatDir(Action), mavenCentral(Action)) instead — they are typed, work in both the Groovy and Kotlin DSLs, and are the canonical way to configure a repository.
For flatDir:
repositories {
flatDir {
name = "libs"
dirs "libs1", "libs2"
}
}repositories {
flatDir {
name = "libs"
dirs("libs1", "libs2")
}
}For mavenCentral:
repositories {
mavenCentral {
name = "nonDefaultName"
}
}repositories {
mavenCentral {
name = "nonDefaultName"
}
}Deprecation of buildNeeded and buildDependents tasks
The buildNeeded and buildDependents tasks from the Java plugins are deprecated and will be removed in Gradle 10.
buildNeeded builds the current project along with all projects it depends on.
buildDependents does the opposite: it builds the current project and all projects that depend on it.
These tasks were introduced back in Gradle 0.8.
Their implementation is incompatible with Configure on Demand and Isolated Projects, and the tasks themselves are too rigid to cover the range of use cases users actually need.
Existing Gradle functionality covers these use cases, so rather than rework the tasks, we are removing them.
buildNeeded depends on the current project’s build task and on the buildNeeded task of each project that appears as a direct dependency in the testRuntimeClasspath configuration.
Because those buildNeeded tasks depend on each other, the result is that the entire project dependency closure is built.
Depending on what you were using buildNeeded for, one of the following may replace it:
-
If you only need to build or test a specific project, run that task directly (e.g.,
./gradlew :proj:build) and let Gradle resolve its task dependencies automatically. -
For running tests across all projects the current project depends on, use test report aggregation.
-
For plugin authors and advanced build logic, use Artifact Views to select artifacts from projects in a dependency graph and wire their producer tasks as dependencies.
There is no direct replacement for buildDependents.
For most workflows, running all tasks with a given name (e.g., ./gradlew test) combined with up-to-date checks and build caching will skip work for unaffected projects, at the cost of configuring all projects.
Deprecation of Configuration.getTaskDependencyFromProjectDependency()
The Configuration.getTaskDependencyFromProjectDependency(boolean, String) method has been deprecated and will be removed in Gradle 10.
It exists to support the buildNeeded and buildDependents tasks deprecated above, and has no other intended use.
Its implementation is fundamentally incompatible with Isolated Projects and Configure on Demand.
There is no direct replacement for this method. If you were using it to reach tasks across project boundaries, Artifact Views let you select artifacts from dependent projects and let Gradle wire the producer tasks through normal dependency resolution.
Deprecation of file generation tasks of IDE plugins
The idea and eclipse plugins contribute tasks for generating IDE specific files on disk.
These tasks were originally the primary way to set up a project for an IDE.
However, all modern IDEs now have built-in Gradle integration (IntelliJ IDEA’s Gradle import, Eclipse Buildship, etc.) and can import Gradle projects directly without needing these generated files.
We are deprecating these file generation tasks:
-
idea/ideaProject/ideaModule/ideaWorkspace(generate.ipr,.iml,.iwsfiles) -
eclipse/eclipseProject/eclipseClasspath/eclipseJdt/eclipseWtpComponent/eclipseWtpFacet(generate.project,.classpath,.settings/files) -
openIdea(generates files and opens IDEA) -
associated
clean*tasks
In addition to the tasks, certain model properties that only affect the generated files are also deprecated.
These include idea.module.iml { … }, idea.project.ipr { … }, idea.workspace { … }, eclipse.wtp { … }, and the file { … } merging hooks on EclipseJdt.
The model properties that affect how IDEs understand your project (source directories, language levels, dependency scopes, etc.) are not deprecated.
When you apply the plugins and configure the idea { … } or eclipse { … } blocks in your build scripts, you can customize how your IDE understands your project.
These customizations are picked up automatically by the Gradle integration built into IDEs.
This functionality will continue to work unchanged.
|
Note
|
Not all the functionality of the plugins is being deprecated, only the tasks and some model properties strictly related to them. |
Deprecation of targetJdk on the PMD plugin
The targetJdk property on Pmd and PmdExtension, along with the TargetJdk enum, are deprecated and will be removed in Gradle 10.
This includes:
-
Pmd.getTargetJdk()/Pmd.setTargetJdk(TargetJdk) -
PmdExtension.getTargetJdk()/PmdExtension.setTargetJdk(TargetJdk)/PmdExtension.setTargetJdk(Object) -
The
TargetJdkenum and itstoVersion(Object)static method -
PmdPlugin.getDefaultTargetJdk(JavaVersion)
These were used by PMD versions older than 5.0 to select the target Java language level via Ant’s targetjdk attribute.
PMD 5.0 and later infer the language version from the configured rule sets, so this property has been a no-op for all supported PMD versions. Gradle does not support PMD versions earlier than PMD 5.1.0.
There is no replacement.
Remove any targetJdk configuration from your build.
Deprecation of ProblemSpec.severity()
Setting problem severity explicitly when creating a new instance is now deprecated.
Severity is instead determined by the reporting method: ProblemReporter.report() produces warnings and ProblemReporter.throwing() produces errors.
Calling .severity() on ProblemSpec is now a no-op and will be removed in Gradle 10.
Upgrading from 9.4.0 and earlier
Potential breaking changes
Upgrade to Kotlin 2.3.20
The embedded Kotlin has been upgraded from 2.3.10 to Kotlin 2.3.20.
Plugins requested by precompiled settings plugins are now validated at compile time
Gradle now validates plugin requests in precompiled settings plugins (*.settings.gradle.kts) during compilation, failing the build if a requested plugin cannot be resolved.
This matches the existing behavior for precompiled script plugins targeting Project.
Previously, if a precompiled settings plugin was never applied, invalid plugin requests in its plugins {} block went undetected until the plugin was used by a consuming build, at which point the build would fail unexpectedly.
plugins {
id("com.example.invalid.plugin") // now fails at compile time if unresolvable
}If you have precompiled settings plugins that are declared but not currently applied, check their plugins {} blocks and remove or fix any plugin requests that cannot be resolved from the dependencies available in the build being compiled.
The Windows start script has been reworked to improve usability
The default Windows start script template (used for gradlew.bat and application start scripts) has been reworked to improve usability and consistency with the Unix shell script.
If you use a custom start script template or invoke gradlew.bat from another batch file, review the changes below, as some may affect your build.
The new script includes the following changes:
-
The
OSvariable check has been removed, since Gradle no longer supports non-NT-based versions of Windows. -
endlocalis now called before invoking the application, so environment variable changes made inside the script do not leak into the invoked process. Any environment variables needed by the application must be set before callinggradlew.bat. -
& CALLis now used after invoking the application, which suppresses the "Terminate batch job (Y/N)?" prompt. If your scripts rely on this prompt for flow control, they will need to be updated. -
exit /bhas been replaced with"%COMSPEC%" /c exit, enabling the use of&&and||operators when calling the script from another batch file.
Upgrading the wrapper to the new script may cause a one-time error if done before Gradle 8.14, because cmd.exe re-reads the script after it changes.
To avoid this, first upgrade to Gradle 8.14 or 9.0.0, then upgrade to 9.5.0.
Calling .values() on environment variables or system properties is now tracked as Configuration Cache input
Starting with Gradle 9.5.0, calling .values() on the maps returned from System.getenv() or System.getProperties() now records all environment variables or system properties as Configuration Cache inputs.
This is consistent with how .forEach() calls are already tracked.
As a result, if your build configuration uses System.getenv().values() or System.getProperties().values(), any change to any environment variable or system property will invalidate the Configuration Cache entry, not just the ones your build actually uses.
If you experience unexpected cache invalidations after upgrading, check whether your build or any plugins call .values() on these maps, and consider switching to targeted property lookups instead.
Dependency lockfiles are generated with a platform-independent line ending
In the context of Dependency Locking, lockfiles now use Unix line endings (LF, \n) instead of the system default.
Existing lockfiles using Windows line endings (CRLF, \r\n) can still be read, but newly generated lockfiles will always use LF.
When running a lock update with Gradle 9.5.0 or above, if your lockfiles were previously generated on Windows, all line endings will be updated to LF. This will appear as a large diff in version control even if no dependencies have changed. This is expected and only happens once.
Dependency verification armored key rings now render non-ASCII characters correctly
In the context of Dependency Verification, when a key has metadata that contains non-ASCII characters, it is now properly rendered in the key header.
When running a dependency verification key export with Gradle 9.5.0 or above, if your keyring already contained keys with non-ASCII metadata, the exported armored keyring will be updated to render those characters correctly. This is expected to happen only once.
The outgoingVariants and resolvableConfigurations reports now hide variants without attributes by default
The outgoingVariants and resolvableConfigurations report tasks now only show variants and configurations that have attributes defined, since only these can participate in variant-aware dependency resolution.
Previously, variants and configurations without attributes were included in the default output. They are now hidden unless the --all flag is passed.
When shown (via --all), attributeless entries are marked with (n) in the report to indicate they are not selectable via variant-aware resolution.
If you rely on seeing attributeless variants or configurations in these reports, add --all to your invocation:
./gradlew outgoingVariants --all
./gradlew resolvableConfigurations --allDeprecations
Deprecation of setting an exit environment variable
CreateStartScripts.getExitEnvironmentVar() and CreateStartScripts.setExitEnvironmentVar(String) have been deprecated and will be removed in Gradle 10.0.0.
As of this release, these methods are no-ops and have no effect, even with custom start script templates. This is a result of the Windows start script template no longer using an exit environment variable.
If you are using a custom start script template that references the exit environment variable, update your template to remove this dependency. There is no replacement API, the exit environment variable concept has been removed entirely.
Upgrading from 9.3.1 and earlier
Potential breaking changes
ProjectBuilder now enforces consistent build-scoped locations
ProjectBuilder allows you to configure a specific project directory for tests.
While project.projectDir and project.rootDir have always respected this setting, project.layout.settingsDirectory previously did not.
This discrepancy could cause file resolution to inadvertently escape the project directory.
Gradle now anchors the settings search directly to the configured project directory.
This ensures that layout.settingsDirectory, projectDir, and rootDir all point to the same consistent location.
Projects created via ProjectBuilder are now better isolated from the host build environment.
If your tests specifically relied on layout.settingsDirectory pointing to an external location, they will need to be adjusted.
Even if you do not use settingsDirectory directly, you may still observe changes in file resolution.
Previously, dependency management files could be "leaked" into the test from the host build environment; this is no longer the case.
For more details see the related issue.
The java-gradle-plugin plugin now adds the gradleApi() dependency to the compileOnlyApi scope
The gradleApi() dependency is now added to the compileOnlyApi scope instead of the api scope.
This prevents the gradleApi() from leaking into the runtime classpath of other dependents of the plugin project.
This might break projects that were implicitly relying on the gradleApi() being on the compilation or runtime classpath.
If this is the case, add a gradleApi() dependency to the appropriate scope to restore the previous behavior.
For most plugin projects, this change should be transparent as:
-
at compilation time, the plugin project will get the
gradleApi() -
the default test source set will also automatically get the
gradleApi()dependency on the compilation and runtime classpaths
If any additional test source set is used (e.g., integration tests), the plugin extension offers the plugins.testSourceSet method to register the source set for automatic management.
If this cannot be done, a regular declaration of the gradleApi() dependency on the test source can be used as well.
Stricter validation for published plugins
For plugin builds that apply any of the com.gradle.plugin-publish, ivy-publish, or maven-publish plugins, Gradle now automatically enables stricter validation of plugin code.
In order not to break your builds, this does not apply to local plugins (in buildSrc or included builds containing build logic).
However, we encourage you to always enable stricter validation:
tasks.validatePlugins {
enableStricterValidation = true
}CodeNarc compilation classpath is set by default
The CodeNarc plugin now automatically populates the compilationClasspath of a CodeNarc task with the compile classpath of its associated source set.
CodeNarc offers Enhanced Classpath Rules (like UnusedImport or DuplicateImport) that require the project’s compiled classes and dependencies to be analyzed for full accuracy.
Previously, you had to wire this up manually.
Now, it works out of the box.
This change introduces a task dependency.
The CodeNarc task must now wait for the compile task to finish so it can access the compiled classes.
If you do not use enhanced rules and want to restore parallel execution, you can manually empty the compilationClasspath:
plugins {
id("groovy")
id("codenarc")
}
tasks.withType<CodeNarc>().configureEach {
// Override the default compilation classpath
compilationClasspath = files()
}If your build relies on a custom configuration for the compilationClasspath of a CodeNarc task, you will need to continue explicitly setting it to override the new default behavior.
System property priority for Wrapper execution has changed
The priority of system properties passed to the Gradle Wrapper now correctly follows the documented order of precedence.
In previous versions, properties defined in gradle.properties files could unexpectedly override those passed via the command line.
If a property is defined in multiple locations, Gradle now strictly honors the following hierarchy (from highest to lowest):
| Priority | Source | Example |
|---|---|---|
1 (Highest) |
|
|
2 |
|
|
3 (Lowest) |
|
For more details see the related issue.
Upgrade to Kotlin 2.3.0
The embedded Kotlin has been upgraded from 2.2.21 to Kotlin 2.3.0.
Upgrade to Zinc 1.12.0
Zinc has been updated to 1.12.0.
Deprecations
Deprecation of DomainObjectCollection.findAll(Closure)
The findAll(Closure) method on Gradle collections is now deprecated and scheduled for removal in Gradle 10.0.0.
This method relies specifically on Groovy types and eagerly evaluates the contents of the container.
To fix this, use the similar DomainObjectCollection.matching(Spec).
While not a direct replacement for findAll, matching is lazy, it returns a new collection that only filters elements as they are actually needed by the build:
// Deprecated:
def checkTasks = tasks.findAll { it.name.startsWith("check") }
// Recommended:
def checkTasks = tasks.matching { it.name.startsWith("check") }Deprecation of methods taking Closure on Test tasks
The following APIs are deprecated and will be removed in Gradle 10.0.0:
-
AbstractTestTask.onOutput(Closure)can be replaced withAbstractTestTask.addTestOutputListener(TestOutputListener) -
AbstractTestTask.beforeTest(Closure)can be replaced withAbstractTestTask.addTestListener(TestListener) -
AbstractTestTask.afterTest(Closure)can be replaced withAbstractTestTask.addTestListener(TestListener) -
AbstractTestTask.beforeSuite(Closure)can be replaced withAbstractTestTask.addTestListener(TestListener) -
AbstractTestTask.beforeSuite(Closure)can be replaced withAbstractTestTask.addTestListener(TestListener) -
Test.testFramework(Closure)can be replaced withTest.options(Action)
Deprecation of apply false in precompiled script plugins
The use of apply false within precompiled script plugins is now deprecated and will result in an error in Gradle 10.0.0.
In a precompiled script, the plugins {} block behaves differently than in a standard build script.
Currently, if you write apply false, Gradle applies the plugin anyway.
This creates confusion because the syntax suggests you are merely adding a plugin to the classpath without activating it, which is not what actually happens.
The fix depends on whether you actually want the plugin to be active in your precompiled script:
-
If you want to use the plugin: Remove the
apply falsestatement. -
If you do NOT want to use the plugin: Delete the line entirely.
plugins {
// Deprecated (and misleading, as it is still applied)
id("org.gradle.test-retry") apply false
// The plugin will still be on the classpath,
// but it will not be applied as part of this precompiled script plugin.
// Recommended: Either remove 'apply false' to keep using it,
// or delete the line to stop using it.
id("org.gradle.test-retry")
}Deprecation of version in precompiled Settings script plugins
The use of version within precompiled Settings script plugins is now deprecated and will become an error in Gradle 10.0.0.
In precompiled scripts, version has no effect.
The plugin version is already fixed by the script’s own build file; declaring it again inside the script is ignored and causes confusion about which version is actually in use.
To fix this, remove the .version() or version "…" call from the plugins {} block:
plugins {
// Deprecated:
id("org.gradle.test-retry") version "x.y.z"
// Recommended:
id("org.gradle.test-retry")
}Deprecation of Dependencies.getProject() method
The getProject() method on Dependencies has been deprecated and will be removed in Gradle 10.0.0.
Dependencies is used to configure dependencies in test suites.
Previously, getProject() was used by Gradle internally to reference the current project.
While never intended for public use, it could be used unintentionally in build scripts.
For example, the following configuration accidentally invokes the deprecated method because project.path resolves against the Dependencies object rather than the top-level Project object:
testing {
suites {
val integrationTest by registering(JvmTestSuite::class) {
dependencies {
implementation(project(project.path)) // `project.path` accesses `Dependencies.getProject()`
}
}
}
}The configuration above may now fail to compile with an error in 9.5.0 if -Werror is set.
To depend on the current project, use the project() method without arguments.
This syntax is the idiomatic way to reference the project in both test suites and standard dependencies {} blocks:
testing {
suites {
val integrationTest by registering(JvmTestSuite::class) {
dependencies {
implementation(project())
}
}
}
}Upgrading from 9.2.0 and earlier
Potential breaking changes
Referential equality is not guaranteed for Project instances
Instances of Project type representing the same logical Gradle project do not provide any guarantee of being equal by reference (== in Java, === in Kotlin).
However, historically it was possible to observe that such Project instances were exactly the same.
In Gradle 9.3.0, Project instances (for the same logical project) can be different with respect to the referential equality,
even if obtained within the same context, e.g., in the same build script.
This change is necessary to facilitate future performance improvements of Gradle.
The Project.equals() equality behavior remains unchanged.
Avoid referential equality in Kotlin:
// DON'T do this
project.rootProject === project.parentAvoid referential equality in Groovy:
// DON'T do this
project.rootProject.is(project.parent)Avoid referential equality in Java:
MyPlugin.java
// DON'T do this
project.getRootProject() == project.getParent();In general, it is better to check project equality via Project.getPath() or Project.getBuildTreePath() for composite-build support.
The paths are also better suited to be keys in data structures, like maps.
TestNG output may change when using versions before 6.9.13.3
As part of the AbstractTestTask refactoring, Gradle’s integration with TestNG has been updated.
Gradle now relies on a correctly functioning IClassListener to report the hierarchy of test classes and methods.
When using TestNG versions earlier than 6.9.13.3, this can lead to different or degraded output:
-
With older versions, class information may be lost. For example, output that previously looked like:
org.gradle > TestClass > okmay now be reported simply as:ok. -
For TestNG versions from 6.9.10 up to (but not including) 6.9.13.3, the
IClassListenerAPI exists but is broken. This can result in even worse output, such as empty or missing names.
To get correct and stable output, we recommend upgrading to TestNG 6.9.13.3 or newer.
Upgrade to Kotlin 2.2.21
The embedded Kotlin has been upgraded from 2.2.20 to 2.2.21.
Upgrade to ASM 9.9
ASM was upgraded from 9.8 to 9.9 to ensure earlier compatibility for Java 26.
Upgrade to Groovy 4.0.29
Groovy has been updated to 4.0.29.
Upgrade to JaCoCo 0.8.14
JaCoCo has been updated to 0.8.14.
Deprecations
Deprecation of the Wrapper.getAvailableDistributionTypes() method
The method on the Wrapper task has been deprecated and will be removed in Gradle 10.
Use Wrapper.DistributionType.values() to obtain the available distribution types instead.
Deprecation of publishing dependencies on unpublished projects
When publishing a project, Gradle resolves project dependencies to the coordinates of the target project’s publication.
If the target project has no publication, Gradle currently resolves the dependency silently using that project’s group, name, and version.
Starting with Gradle 10, this behavior is deprecated. Gradle will no longer silently ignore the absence of a publication. Publishing a project that depends on another project without a publication will be forbidden and will cause the build to fail. This change prevents publishing broken metadata with dependency coordinates that cannot be resolved.
The example below demonstrates a build that triggers the deprecated behavior:
plugins {
id("java-library")
id("maven-publish")
}
group = "com.example"
version = "1.0.0"
dependencies {
api(project(":other"))
}
publishing {
publications {
create<MavenPublication>("maven") {
from(components["java"])
}
}
}plugins {
id("java-library")
}
group = "com.example"
version = "1.0.0"To avoid this deprecation, ensure that all project dependencies of published projects are also published.
In the example above, applying the maven-publish plugin and configuring a publication in the :other project resolves the issue:
plugins {
id("java-library")
id("maven-publish")
}
group = "com.example"
version = "1.0.0"
publishing {
publications {
create<MavenPublication>("maven") {
from(components["java"])
}
}
}Deprecation of legacy Usage attribute values
Since Gradle 5.6, the Usage attribute has been split into an additional LibraryElements attribute.
In the JVM ecosystem, Usage indicates whether a variant is intended for compilation or runtime, while LibraryElements specifies the format of the artifact (for example, a JAR file or a classes directory).
To ease migration, Gradle has automatically mapped legacy Usage values to their corresponding Usage and LibraryElements pairs:
Legacy |
Replaced |
Replaced |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Starting with Gradle 10, this automatic mapping will no longer occur when legacy Usage values are added directly to an AttributeContainer in build logic.
To maintain backward compatibility for already published modules, Gradle will continue translating legacy Usage values found in published Gradle Module Metadata.
Deprecation of using module coordinates to depend on the current project
Starting with Gradle 10, declaring a dependency on the current project using module coordinates (group, name, version) will no longer resolve to that project.
Instead, Gradle will attempt to resolve that dependency from a repository.
The example below demonstrates the change in behavior:
group = "com.example"
version = "1.0.0"
val deps = configurations.dependencyScope("deps")
val classpath = configurations.resolvable("classpath") {
extendsFrom(deps.get())
attributes.attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category.LIBRARY))
}
val elements = configurations.consumable("elements") {
attributes.attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category.LIBRARY))
}
dependencies {
// In Gradle 9.x, this dependency resolves to the `elements` configuration.
// In Gradle 10, this dependency will attempt to resolve from a repository.
deps("com.example:my-project:1.0.0")
}To continue depending on the current project, use a project dependency:
dependencies {
// Declare a dependency on the current project to continue resolving
// to the current project.
deps(project)
}Deprecation of ModuleVersionSelector to ModuleComponentSelector conversion
The conversion of ModuleVersionSelector to ModuleComponentSelector (used in
ResolutionStrategy.force(…),
DependencyResolveDetails.useTarget(Object), and
PluginResolveDetails.useModule(Object)
) has been deprecated and will be removed in Gradle 10.0.0.
Typically, ModuleVersionSelector instances are DependencyContstraint objects.
Note that this deprecation does not apply to ExternalDependency objects, despite them implementing ModuleVersionSelector.
To fix this deprecation, pass one of the supported notations (for example, a String in the group:name:version format).
Upgrading from 9.1.0 and earlier
Potential breaking changes
Upgrade to Kotlin 2.2.20
The embedded Kotlin has been upgraded from 2.2.0 to Kotlin 2.2.20.
Removed incubating ObjectFactory#dependencyCollector() method
The incubating ObjectFactory#dependencyCollector() method has been removed.
You can still create DependencyCollectors within Gradle managed types.
Consumable configurations in bundled plugins are now initialized lazily
Consumable configurations created by bundled Gradle plugins are now initialized only when needed.
Configure actions on these configurations no longer run at configuration time by default.
They only execute if the configuration is published, consumed as a variant, or otherwise realized by build logic.
For example:
plugins {
id("java-library")
}
configurations.named("apiElements").configure {
println("Configuring apiElements")
}With this change, the Configuring apiElements line is no longer printed during configuration time unless apiElements is actually realized.
See Declaring Configurations for more guidance.
ValidatePlugins now has stricter Java version requirements
The ValidatePlugins task must now run on a Java version that is supported by the Gradle daemon.
This change was made because the task depends on several core Gradle services, which may now be compiled to the same bytecode version supported by the daemon.
By default, the task’s convention has been updated:
-
If your project’s toolchain is compatible,
ValidatePluginswill use it. -
Otherwise, it will fall back to the Java version used to run Gradle.
If you explicitly set a toolchain like this:
tasks.withType<ValidatePlugins>().configureEach {
javaLauncher.set(
project.javaToolchains.launcherFor {
languageVersion.set(JavaLanguageVersion.of(17))
}
)
}tasks.withType(ValidatePlugins).configureEach {
javaLauncher.set(
project.javaToolchains.launcherFor {
languageVersion.set(JavaLanguageVersion.of(17))
}
)
}If the specified Java version is not compatible with the Gradle daemon, you must update it to a compatible version.
Deprecations
Deprecation of Project.container(…) methods
The Project.container(…) methods are deprecated and will be removed in Gradle 10.
These methods manually create named domain object containers.
Use a managed property to let Gradle instantiate containers automatically.
If a managed property isn’t possible, use ObjectFactory.domainObjectContainer(…) (available since Gradle 5.5).
Unlike Project.container(Class), the ObjectFactory version decorates container elements and makes them extension aware.
Deprecation of ruleSource-based dependency management APIs
The RuleSource-based dependency management APIs have been deprecated and will be removed in Gradle 10.0.0.
Deprecated APIs include:
Use the alternative methods that accept a ComponentMetadataRule class or an Action.
Deprecation of calling registerFeature without applying the Java plugin
Creating a JVM feature with JavaPluginExtension#registerFeature before applying the Java plugin has been deprecated and will become an error in Gradle 10.0.0.
Ensure the Java plugin is applied before invoking registerFeature.
The following bundled plugins apply the Java plugin automatically:
-
java-library -
application -
groovy -
scala -
war
Upgrading from 9.0.0 and earlier
Potential breaking changes
Upgrade to ASM 9.8
ASM was upgraded from 9.7.1 to 9.8 to ensure earlier compatibility for Java 25.
Upgrade to Groovy 4.0.28
Groovy has been updated to Groovy 4.0.28.
Deprecations
Deprecation of multi-string dependency notation
In an effort to simplify and standardize the Gradle API, the multi-string dependency notation used in dependency management has been deprecated and will no longer be permitted in Gradle 10. Gradle will primarily accept dependency declarations in the form of a single string, with each dependency coordinate separated by a colon.
Below are examples of the deprecated multi-string notation:
dependencies {
implementation(group = "org", name = "foo", version = "1.0")
implementation(group = "org", name = "foo", version = "1.0", configuration = "conf")
implementation(group = "org", name = "foo", version = "1.0", classifier = "classifier")
implementation(group = "org", name = "foo", version = "1.0", ext = "ext")
}
testing.suites.named<JvmTestSuite>("test") {
dependencies {
implementation(module(group = "org", name = "foo", version = "1.0"))
}
}dependencies {
implementation(group: 'org', name: 'foo', version: '1.0')
implementation(group: 'org', name: 'foo', version: '1.0', configuration: 'conf')
implementation(group: 'org', name: 'foo', version: '1.0', classifier: 'classifier')
implementation(group: 'org', name: 'foo', version: '1.0', ext: 'ext')
}
testing.suites.test {
dependencies {
implementation(module(group: 'org', name: 'foo', version: '1.0'))
}
}These declarations should be replaced with the single-string notation:
dependencies {
implementation("org:foo:1.0")
implementation("org:foo:1.0") {
targetConfiguration = "conf"
}
implementation("org:foo:1.0:classifier")
implementation("org:foo:1.0@ext")
}
testing.suites.named<JvmTestSuite>("test") {
dependencies {
implementation("org:foo:1.0")
}
}dependencies {
implementation("org:foo:1.0")
implementation("org:foo:1.0") {
targetConfiguration = "conf"
}
implementation("org:foo:1.0:classifier")
implementation("org:foo:1.0@ext")
}
testing.suites.test {
dependencies {
implementation("org:foo:1.0")
}
}In some cases, a complete single-string notation may not be known up front.
Instead of concatenating the coordinates into a new string, it is possible to use a DependencyFactory to create Dependency instances directly from the individual components:
val group = "org"
val artifactId = "foo"
val version = "1.0"
configurations.dependencyScope("implementation") {
dependencies.add(project.dependencyFactory.create(group, artifactId, version))
}def group = "org"
def artifactId = "foo"
def version = "1.0"
configurations.dependencyScope("implementation") {
dependencies.add(project.dependencyFactory.create(group, artifactId, version))
}Deprecation of ReportingExtension.file(String)
The file() method on ReportingExtension has been deprecated and will be removed in Gradle 10.0.0.
Instead, use ReportingExtension.getBaseDirectory() with file(String) or dir(String).
Deprecation of ReportingExtension.getApiDocTitle()
The getApiDocTitle() method on ReportingExtension has been deprecated and will be removed in Gradle 10.0.0.
There is no direct replacement for this method.
Deprecation of JavaForkOptions.setAllJvmArgs()
The setAllJvmArgs() method on JavaForkOptions and, by inheritance, on JavaExecSpec has been deprecated and will be removed in Gradle 10.0.0.
Instead, to overwrite existing JVM arguments, use:
-
JavaForkOptions.jvmArgs() -
JavaForkOptions.setJvmArgs() -
Provide a
CommandLineArgumentProviderto add arguments viaJavaForkOptions.getJvmArgumentProviders()
Note that setAllJvmArgs() method on JavaForkOptions cleared all fork options before setting jvmArgs.
The properties cleared included:
-
System properties configured via
JavaForkOptions.systemProperties -
JVM argument providers configured via
JavaForkOptions.jvmArgumentProviders -
Argument providers configured via
JavaExecSpec.argumentProviders -
Memory settings configured via
JavaForkOptions.minHeapSizeandJavaForkOptions.maxHeapSize -
All other JVM arguments configured via
JavaForkOptions.jvmArgs -
The assertion and debug flags configured via
JavaForkOptions.enableAssertionsandJavaForkOptions.debug
If the arguments you provide to setJvmArgs() or jvmArgs() depend on any of the above properties being cleared, you will need to manually clear them.
Consider the following snippets for examples of how to implement this change:
plugins {
id("java")
}
tasks.register<JavaExec>("myRunTask") {
jvmArgumentProviders.clear() // Clear existing JVM argument providers
maxHeapSize = null // Clear max heap size
jvmArgs = listOf("-Dfoo", "-Dbar") // Set new JVM arguments
}plugins {
id("java")
}
tasks.named('myRunTask', JavaExec) {
jvmArgumentProviders.clear() // Clear existing JVM argument providers
maxHeapSize = null // Clear max heap size
jvmArgs = ["-Dfoo", "-Dbar"] // Set new JVM arguments
}Deprecation of archives configuration
The archives configuration added by the base plugin has been deprecated and will be removed in Gradle 10.0.0.
Adding artifacts to the archives configuration will now result in a deprecation warning.
If you want the artifact to be built when running the assemble task, add the artifact (or the task that produces it) as a dependency on assemble:
val specialJar = tasks.register<Jar>("specialJar") {
archiveBaseName.set("special")
from("build/special")
}
tasks.named("assemble") {
dependsOn(specialJar)
}Deprecation of the Configuration.visible property
Prior to Gradle 9.0.0, any configuration with isVisible() returning true would implicitly trigger artifact creation when running the assemble task.
This behavior was removed in Gradle 9.0.0, and the Configuration.visible property no longer has any effect.
The property is now deprecated and will be removed in Gradle 10.0.0.
You can safely remove any usage of visible.
If you want the artifacts of a configuration to be built when running the assemble task, add an explicit task dependency on assemble:
val specialJar = tasks.register<Jar>("specialJar") {
archiveBaseName.set("special")
from("build/special")
}
configurations {
consumable("special") {
outgoing.artifact(specialJar)
}
}
tasks.named("assemble") {
dependsOn(specialJar)
}Deprecation of non-string projectProperties in GradleBuild task
The GradleBuild task now deprecates using non-String values in startParameter.projectProperties.
While the type is declared as Map<String, String>, there was no strict enforcement, allowing non-String values to be set.
This deprecated behavior will be removed in Gradle 10.0.0.
If you are using non-String values in project properties, convert them to String representation:
val myIntProp = 42
tasks.register<GradleBuild>("nestedBuild") {
startParameter.projectProperties.put("myIntProp", "$myIntProp") // Convert int to String
}def myIntProp = 42
tasks.register('nestedBuild', GradleBuild) {
startParameter.projectProperties.put('myIntProp', "$myIntProp") // Convert int to String
}Deprecation of project properties for toolchain configuration
In previous versions of Gradle, you could configure toolchains using project properties on the command line with the -P flag.
For example, to disable toolchain auto-detection, you could use -Porg.gradle.java.installations.auto-detect=false.
This behavior is deprecated and will be removed in Gradle 10.0.0.
Instead, you should specify these settings as Gradle properties using the -D flag:
-Dorg.gradle.java.installations.auto-detect=falseUpgrading to Gradle 9.0.0
This chapter provides the information you need to migrate your Gradle 8.14.4 builds to Gradle 9.0.0. For migrating within Gradle 8.x, see the older migration guide first.
We recommend the following steps for all users:
-
Try running
gradle help --scanand view the deprecations view of the generated Build Scan.
This lets you see any deprecation warnings that apply to your build.
Alternatively, you can run
gradle help --warning-mode=allto see the deprecations in the console, though it may not report as much detailed information. -
Update your plugins.
Some plugins may break with a new major version of Gradle, as these releases can remove public APIs. Using the latest version of a plugin increases the likelihood that it is already compatible with the new major Gradle version.
-
Run
gradle :wrapper --gradle-version 9.0.0to update the project to 9.0.0. -
Try to run the project and debug any errors using the Troubleshooting Guide.
Runtime requirements and DSL changes
Java Virtual Machine (JVM) 17 or higher is required
Gradle 9.0.0 requires a Java Virtual Machine (JVM) version 17 or higher to run the Gradle Daemon. This is a breaking change from previous versions, which supported JVM 8 and higher.
Your build can still target lower JVM versions using Toolchains for compilation, testing and other workers (Checkstyle, Javadoc, etc).
The Gradle wrapper and command-line launcher can run with JVM 8, but it still requires a newer JVM to start the build. For more, see the Running Gradle on older JVMs section below.
Gradle Tooling API and TestKit remain compatible with JVM 8 and higher.
Upgrade to Kotlin 2.2.0
Gradle now embeds Kotlin 2.2.0, upgrading from the previously embedded version 2.0.21.
For full details and potential breaking changes, consult the Kotlin release notes.
Kotlin DSL and plugins use the Kotlin language version 2.2
The Kotlin DSL has been upgraded to the latest stable Kotlin 2.2.x runtime and uses Kotlin language version 2.2 across the entire toolchain. This marks a shift from Gradle 8.x, which embedded Kotlin 2.0 starting in 8.11 but continued using Kotlin language version 1.8 for compatibility.
This change impacts not only Kotlin DSL scripts (.gradle.kts) but also build logic and plugins written in Kotlin (both classic and convention plugins).
Users should review their code for compatibility with Kotlin 2.2, as both Kotlin 2.0 and Kotlin 2.1 introduced several breaking language changes.
Due to changes in how the Kotlin 2 compiler handles script compilation, you can no longer refer to the script instance using labels like this@Build_gradle, this@Settings_gradle, or this@Init_gradle.
If they are used to reference the DSL script target object, then use project, settings, or gradle instead.
If they are used to reference a top-level symbol that happens to have the same name as a nested symbol, then use a different name, possibly by adding an intermediary variable.
This upgrade also includes an important change for build-logic and plugin authors: support for Kotlin language versions from 1.4 to 1.7 has been removed.
Read the JSpecify section below to learn about potential breaking changes in Kotlin build logic code related to nullability.
Upgrade to Groovy 4.0.27
Groovy has been upgraded from version 3.0.24 to 4.0.27. The update to Groovy 4 comes with many breaking changes, such as the removal of legacy packages, changes in the module structure, a parser rewrite, and bytecode output changes. For a complete overview of Groovy language changes from 3.x to 4.x, see the Groovy 4.0 release notes. These changes may affect those who use Groovy directly or indirectly in Gradle, and in rare cases, users relying on transitive dependencies.
|
Tip
|
Popular Groovy classes that used to be in packages like groovy.util are now in different packages to account for the JPMS "split package requirement".
See this specific entry.
|
is-prefixed Boolean properties no longer recognized by Groovy
Groovy 4 no longer treats getters with an is prefix and a Boolean return type as properties.
Gradle still recognizes these as properties for now, but this behavior will change in Gradle 10 to align with Groovy 4.
See the deprecation notice for more details.
DELEGATE_FIRST closures may now prefer the delegate in some cases
Groovy 4 has changed the behavior of closures using the DELEGATE_FIRST strategy.
Dynamic lookups for properties and methods will now prefer the delegate over the owner.
This can result in different behavior when using closures in Gradle scripts, such as certain methods not being found
or (e.g. with .with { }) some dynamic properties taking precedence over outer properties or methods.
Generally, this should not affect Gradle scripts, as Gradle does not use DELEGATE_FIRST closures with dynamic properties in its API.
Workarounds include using @CompileStatic to avoid dynamic lookups, or explicitly qualifying calls with owner., this., or super. as needed.
For full clarity, in Groovy 3, the lookup order was:
-
Delegate’s
invokeMethod, which chooses known methods and does no dynamic lookup. -
Owner’s
invokeMethod, which chooses known methods and does no dynamic lookup. -
Delegate’s
invokeMissingMethod, which does dynamic lookup including via properties. -
Owner’s
invokeMissingMethod, which does dynamic lookup including via properties.
In Groovy 4, the lookup order is:
-
Delegate’s
invokeMethod, which chooses known methods and does no dynamic lookup. -
Delegate’s
invokeMissingMethod, which does dynamic lookup including via properties. -
Owner’s
invokeMethod, which chooses known methods and does no dynamic lookup. -
Owner’s
invokeMissingMethod, which does dynamic lookup including via properties.
Private properties and methods may be inaccessible in closures
Closures defined in a parent class that reference its private properties or methods may no longer have access to them in subclasses. This is due to a Groovy bug that will not be resolved until Groovy 5. This applies to both buildscripts and plugins written in Groovy.
As a workaround, apply @CompileStatic to the class to remove the dynamic lookup.
This is tracked by https://github.com/gradle/gradle/issues/32476.
Super methods may be inaccessible from Groovy 3.x code
Groovy 4 changed how super method calls are resolved at runtime.
As a result, code compiled with Groovy 3.x may be unable to access super methods,
as the code does not contain the appropriate runtime code to locate them.
This only applies to plugins written in Groovy 3.x, from Gradle 8.x and earlier.
Plugin changes
Plugins written with the Kotlin DSL require Gradle >= 8.11
When building and publishing plugins using the Kotlin DSL on Gradle 9.x.x, those plugins will only be usable on Gradle 8.11 or newer. This is because Gradle 8.11 is the first release that embeds Kotlin 2.0 or higher, which is required to interpret Kotlin metadata version 2.
If you want your plugin to remain compatible with older Gradle versions, you must explicitly compile it against an earlier Kotlin version (1.x).
For example, to support Gradle 6.8 and newer, configure your plugin to target Kotlin 1.7 like this:
import org.jetbrains.kotlin.gradle.dsl.KotlinVersion
import org.jetbrains.kotlin.gradle.tasks.KotlinCompile
plugins {
`kotlin-dsl`
}
tasks.withType<KotlinCompile>().configureEach {
compilerOptions {
languageVersion = KotlinVersion.KOTLIN_1_7
apiVersion = KotlinVersion.KOTLIN_1_7
}
}Refer to Gradle’s compatibility matrix for details on which Kotlin version is embedded in each Gradle release.
|
Note
|
Plugins written using the Kotlin DSL and published with Gradle 7.x or 8.x remain compatible with Gradle 6.8 and newer. |
Plugins written with the Groovy DSL require Gradle >= 7.0
Plugins authored using the Groovy DSL and built with Gradle 9.x.x require Gradle 7.0 or newer to run. This is because Gradle 7.0 introduced Groovy 3.0 support, and Gradle 9 embeds Groovy 4.0.
Since Gradle 9.0.0 uses Groovy 4.0 internally, plugins built with it may not behave as expected when run on older Gradle versions. For best compatibility, such plugins should be used with Gradle 9.0.0 or later.
|
Note
|
Plugins written with the Groovy DSL and published using Gradle 7.x or 8.x remain compatible with Gradle 5.0 and above. |
Lowest supported Kotlin Gradle Plugin version change
Starting with Gradle 9.0.0, the minimum supported Kotlin Gradle Plugin version is 2.0.0. Earlier versions are no longer supported as they rely on Gradle APIs that have been removed.
For Gradle 8.x, the minimum supported version was 1.6.10.
Lowest supported Android Gradle Plugin version change
Starting with Gradle 9.0.0, the minimum supported Android Gradle Plugin version is 8.4.0. Earlier versions are no longer supported as they rely on Gradle APIs that have been removed.
For Gradle 8.x, the minimum supported version was 7.3.0.
Lowest supported Gradle Enterprise Plugin version change
Starting with Gradle 9.0.0, the minimum supported Gradle Enterprise Plugin version is 3.13.1. Earlier versions are no longer supported as they rely on Gradle APIs that have been removed.
Consider upgrading to the latest version of the Gradle Enterprise Plugin, or better yet, upgrade to the latest version of the Develocity Plugin.
For Gradle 8.x, the minimum supported version was 3.0.
C++ and Swift plugins no longer depend on software model based plugins
C++ Application Plugin, C++ Library Plugin, Swift Application Plugin, and Swift Library Plugin have been updated and no longer rely on the software model plugin infrastructure.
As a result, toolChains should be configured directly at the top-level of your build script instead of within a model { } block.
For example, instead of:
plugins {
id("cpp-library")
}
model {
toolChains {
clang(Clang) {
eachPlatform {
cCompiler.executable = "clang"
cppCompiler.executable = "clang++"
}
}
}
}This should become:
plugins {
id("cpp-library")
}
toolChains {
clang(Clang) {
eachPlatform {
cCompiler.executable = "clang"
cppCompiler.executable = "clang++"
}
}
}This change needs to be made in builds using the new C++ or Swift plugins or the existing software model based plugins.
Scala plugins no longer create unresolvable configurations
Previously, the Scala plugins used configurations named incrementalScalaAnalysisFor to resolve incremental analysis information between projects.
However, these configurations were unresolvable and could lead to errors in the dependencies report.
As of Gradle 9.0.0, these configurations are no longer created or used by the Scala plugins.
Settings file changes
Project directories must exist and be writeable
Gradle will fail if a project is included that does not correspond to an existing directory on the file system, or if the directory exists but is read-only.
For example, you may see an error like:
* What went wrong:
Configuring project ':subproject1' without an existing directory is not allowed. The configured projectDirectory '.../subproject1' does not exist, can't be written to or is not a directory.
* Try:
> Make sure the project directory exists and is writable.See Including projects without an existing directory for more details.
Task changes
ValidatePlugins task now requires Java Toolchains
In Gradle 9.0.0, using the ValidatePlugins task without applying the Java Toolchains plugin will result in an error.
To fix this, explicitly apply the jvm-toolchains plugin:
plugins {
id("jvm-toolchains")
}plugins {
id 'jvm-toolchains'
}|
Tip
|
The jvm-toolchains plugin is automatically applied by the Java Library Plugin and other JVM-related plugins.
If you are already applying one of those, no further action is needed.
|
Archive tasks (Jar, Ear, War, Zip, AbstractArchiveTask) produce reproducible archives by default
|
Note
|
This change may affect existing builds that relied on the previous behavior of archive tasks, where file order was not deterministic, and file timestamps and permissions were taken from the file system. |
In Gradle 9.0.0, the default behavior of archive tasks (such as Jar, Ear, War, Zip, and AbstractArchiveTask) has changed to produce reproducible archives by default.
That means that:
-
File order in the archive is now deterministic.
-
Files have fixed timestamps (timestamps depends on the archive type).
-
All directories have fixed permissions set to
0755. -
All files have fixed permissions set to
0644.
This change improves the reproducibility of builds and ensures that the generated archives are consistent across different environments.
You can restore the previous behaviour for one or more properties for your task with the following configuration:
tasks.withType<AbstractArchiveTask>().configureEach {
// Make file order based on the file system
isReproducibleFileOrder = false
// Use file timestamps from the file system
isPreserveFileTimestamps = true
// Use permissions from the file system
useFileSystemPermissions()
}tasks.withType(AbstractArchiveTask).configureEach {
// Makes file order non deterministic
reproducibleFileOrder = false
// Use file timestamps from the file system
preserveFileTimestamps = true
// Use permissions from the file system
useFileSystemPermissions()
}You can also preserve the file system permissions across archives tasks by configuring a property:
org.gradle.archives.use-file-system-permissions=trueTest tasks may no longer execute expected tests
In previous releases, it was possible to create Test tasks without any additional configuration.
By convention, Gradle used the classpath and test classes from the test source set.
plugins {
id("java-library")
}
// configure test dependencies
// ...
tasks.register<Test>("otherTest")plugins {
id 'java-library'
}
// configure test dependencies
// ...
tasks.register("otherTest", Test)In this example, otherTest relied on the deprecated convention. This scenario started to emit a deprecation warning in 8.1.
Gradle would execute the same tests with otherTest and the built-in test task because Gradle used the classpath and test classes from the test source set.
The convention has been removed, but builds will not fail if they were relying on this behavior. Builds that emitted the deprecation warning will silently stop executing tests.
In the example above, otherTest will be skipped and execute no tests because it has no test classes configured.
To return to the previous behavior, you must explicitly configure the Test task:
val test by testing.suites.existing(JvmTestSuite::class)
tasks.register<Test>("otherTest") {
testClassesDirs = files(test.map { it.sources.output.classesDirs })
classpath = files(test.map { it.sources.runtimeClasspath })
}tasks.register("otherTest", Test) {
testClassesDirs = testing.suites.test.sources.output.classesDirs
classpath = testing.suites.test.sources.runtimeClasspath
}or add the extra Test task through test suites:
testing {
suites {
named<JvmTestSuite>("test") {
targets {
register("otherTest")
}
}
}
}testing {
suites {
test {
targets {
otherTest
}
}
}
}test task fails when no tests are discovered
When test sources are present and no filters are applied, the test task will now fail with an error if it runs but doesn’t discover any tests.
This is to help prevent misconfigurations where the tests are written for one test framework but the test task is mistakenly configured to use another test framework.
If filters are applied, the outcome depends on the failOnNoMatchingTests property.
This behavior can be disabled by setting the failOnNoDiscoveredTests property to false in the test task configuration:
tasks.withType<AbstractTestTask>().configureEach {
failOnNoDiscoveredTests = false
}tasks.withType(AbstractTestTask).configureEach {
failOnNoDiscoveredTests = false
}Stale outputs outside the build directory are no longer deleted
In previous versions of Gradle, class files located outside the build directory were deleted when considered stale. This was a special case for class files registered as outputs of a source set.
Because this setup is uncommon and forced Gradle to eagerly realize all compile related tasks in every build, the behavior has been removed in Gradle 9.0.0.
Gradle will continue to clean up stale outputs inside the build directory as needed.
model and component tasks are no longer automatically added
The model and component tasks report on the structure of legacy software model objects configured for the project.
Previously, these tasks were automatically added to the project for every build.
These tasks are now only added to a project when a rule-based plugin is applied (such as those provided by Gradle’s support for building native software).
API changes
Gradle API now uses JSpecify nullability annotations
Gradle has supported null safety in its public API since Gradle 5.0, allowing early detection of nullability issues when writing Kotlin build scripts or plugin code in Java or Kotlin.
Previously, Gradle used annotations from the now-dormant JSR-305 to indicate nullability. While useful, JSR-305 had limitations and is no longer actively maintained.
Starting with Gradle 9.0.0, the Gradle API now uses JSpecify annotations. JSpecify provides a modern, standardized set of annotations and semantics for nullability in Java APIs, improving support in IDEs and during compilation.
Because JSpecify’s semantics differ slightly from JSR-305, you might see new warnings or errors in your Kotlin or Java plugin code. These typically indicate places where you need to clarify or adjust null handling, and modern compilers and IDEs should provide helpful messages to guide you.
Kotlin 2.1, when combined with JSpecify annotations in the Gradle API, introduces stricter nullability handling. Some formerly-valid code may now fail to compile due to more precise type checking.
Common breaking changes:
-
Unbounded generics for types that have generic bounds will now fail to compile.
For example if you have a Kotlin extension function on
Provider<T>whose signature isfun <T> Provider<T>.some()you must qualify<T>as<T : Any>becauseTisn’t nullable onProvider<T>. -
The nullability of generic bounds is now handled strictly.
For example, you can’t use
Property<String?>anymore because theTinProperty<T>is not nullable.Another example is using a function from the Gradle API that takes a
Map<String, *>parameter ; you could pass a map with nullable values before, you can’t do that anymore.
|
Note
|
Plugins that use javax.annotation (JSR-305) annotations will continue to work in Gradle 9.0.0 as they did before.
|
Methods on public API types made final
The methods AndSpec.and and GenerateBuildDashboard.aggregate have been declared final to support the use of the @SafeVarargs annotation.
These types were not intended to be subclassed. However, if your build logic or a plugin attempts to override these methods, it will now result in a runtime failure.
Injection getters are now abstract
All Gradle-provided classes that have @Inject annotated getters now have those getters declared as abstract.
This will require all classes that extend Gradle-provided classes to be abstract.
ConfigurationVariant.getDescription is now a Property<String>
This method was added in Gradle 7.5 and was previously a Optional<String>.
This property was not configurable by public APIs.
By making the description a Property<String>, secondary variants have a user configurable description that appears in the outgoingVariants report.
New subtypes of ComponentIdentifier introduced
Gradle 9.0.0 introduces RootComponentIdentifier, a new subtype of ComponentIdentifier.
APIs which return instances of ComponentIdentifier may now return identifier instances of this new type.
For example, the ComponentResult, ResolvedVariantResult, and ArtifactView APIs, among others, are affected.
In future Gradle versions, additional subtypes of ComponentIdentifier may be introduced.
Build logic should remain resilient to unknown ComponentIdentifier subtypes returned by Gradle APIs.
Packaging and artifact behavior changes
Artifact Signing now matches OpenPGP Key Version
Starting with Gradle 9.0.0, the signing plugin produces OpenPGP signatures that match the version of the key used. This change ensures compliance with RFC 9580 and introduces support for OpenPGP version 6 keys.
Previously, Gradle always generated OpenPGP version 4 signatures, regardless of the key version.
Ear and War plugins build all artifacts with assemble
Prior to Gradle 9.0.0, applying multiple packaging plugins (e.g., ear, war, java) to the same project resulted in special behavior where only one artifact type was built during assemble.
For example:
-
Applying the
earplugin would skip buildingwarandjarartifacts. -
Applying the
warplugin would skip building thejar.
This special handling has been removed in Gradle 9.0.0.
Now, if multiple packaging plugins are applied, all corresponding artifacts will be built when running the assemble task.
For example, a project applying the ear, war, and java plugins will now produce .ear, .war, and .jar files during assemble.
Ear and War plugins contribute all artifacts to the archives configuration
In previous versions of Gradle, applying multiple packaging plugins (ear, war, java) resulted in selective behavior for the archives configuration.
For example:
-
Applying the
earplugin excludedjarandwarartifacts from archives. -
Applying the
warplugin excluded thejarartifact from archives.
This behavior has been removed in Gradle 9.0.0.
Now, when multiple packaging plugins are applied, all related artifacts—EAR, WAR, and JAR—are included in the archives configuration.
Gradle no longer implicitly builds certain artifacts during assemble
In previous versions of Gradle, the assemble task would implicitly build artifacts from any configuration where the visible flag was not set to false.
This behavior has been removed in Gradle 9.0.0.
If you have a custom configuration and want its artifact to be built as part of assemble, you now need to explicitly declare the dependency between the artifact and the assemble task:
val specialJar = tasks.register<Jar>("specialJar") {
from("foo")
}
val special = configurations.create("special") {
// In previous versions, this would have been enough to build the specialJar
// artifact when running assemble
outgoing.artifact(specialJar)
}
// In Gradle 9.0.0, you need to add a dependency from the artifact to the assemble task
tasks.named("assemble") {
dependsOn(special.artifacts)
}def specialJar = tasks.register("specialJar". Jar) {
from("foo")
}
def special = configurations.create("special") {
// In previous versions, this would have been enough to build the specialJar
// artifact when running assemble
outgoing.artifact(specialJar)
}
// In Gradle 9.0.0, you need to add a dependency from the artifact to the assemble task
tasks.named("assemble") {
dependsOn(special.artifacts)
}Gradle no longer implicitly adds certain artifacts to the archives configuration
In previous versions of Gradle, the archives configuration would automatically include artifacts from any configuration where the visible flag was not set to false.
This implicit behavior has been removed in Gradle 9.0.0.
To include a custom artifact in the archives configuration, you must now add it explicitly:
val specialJar = tasks.register<Jar>("specialJar") {
from("foo")
}
configurations {
create("special") {
// In previous versions, this would have been enough to add the specialJar
// artifact to the archives configuration
outgoing.artifact(specialJar)
}
// In Gradle 9.0.0, you need to explicitly add the artifact to the archives
// configuration
named("archives") {
outgoing.artifact(specialJar)
}
}def specialJar = tasks.register("specialJar". Jar) {
from("foo")
}
configurations {
create("special") {
// In previous versions, this would have been enough to add the specialJar
// artifact to the archives configuration
outgoing.artifact(specialJar)
}
// In Gradle 9.0.0, you need to explicitly add the artifact to the archives
// configuration
named("archives") {
outgoing.artifact(specialJar)
}
}Gradle Module Metadata can no longer be modified after an eagerly created publication is created from the same component
This behavior previously caused a warning: Gradle Module Metadata is modified after an eagerly populated publication.
It will now fail with an error, suggesting a review of the relevant documentation.
Configuration Cache changes
Unsupported build event listeners are now configuration cache problems
The build event listener registration method BuildEventsListenerRegistry.onTaskCompletion
accepts arbitrary providers of any OperationCompletionListener implementations.
However, only providers returned from BuildServiceRegistry.registerIfAbsent
or BuildServiceRegistration.getService are currently supported when the Configuration Cache is enabled.
Previously, unsupported providers were silently discarded and never received events when the configuration cache was used. Starting with Gradle 9.0.0, registering such providers now causes a configuration cache problem and fails the build.
If your build was previously working with the configuration cache (e.g., the listeners were nonessential), you can temporarily revert to the old behavior by setting:
org.gradle.configuration-cache.unsafe.ignore.unsupported-build-events-listeners=trueThis property will be removed in Gradle 10.
Configuration Cache entry is now always discarded for incompatible tasks in warning mode
Configuration Cache enables gradual migration by allowing to explicitly mark tasks as incompatible.
When incompatible tasks are scheduled for execution, cache entry is not stored and tasks do not run in parallel to ensure correctness.
Configuration Cache can also run in the warning mode by enabling org.gradle.configuration-cache.problems=warn,
which hides problems and allows storing and loading of the cache entry, running tasks in parallel with potential issues.
The warning mode exists as a migration and troubleshooting aid and is not intended as a persistent way of ignoring incompatibilities.
Starting with Gradle 9.0.0, the presence of incompatible tasks in the work graph results in the cache entry being discarded regardless of the warning mode to ensure correctness. If you relied on the warning mode previously, consider marking the offending tasks as incompatible instead. However, at this stage of Configuration Cache maturity and ecosystem adoption, we recommend resolving the incompatibilities instead to ensure performance benefits this feature brings.
Updated versions
Upgraded default versions of code quality tools
The default version of Checkstyle is 10.24.0.
The default version of CodeNarc is 3.6.0.
The default version of Pmd is 7.13.0
Upgraded default versions of testing frameworks
When using test suites, the version of several testing frameworks has changed.
The default version of JUnit Jupiter is 5.12.2.
The default version of TestNG is 7.11.0.
The default version of Spock is 2.3.
Upgraded version of Eclipse JGit
Eclipse JGit has been updated from 5.13.3 to 7.2.1.
This update reworks how Gradle configures JGit for SSH operations and introduces support for using the SSH Agent, leveraging the new capabilities available in JGit’s SSH agent integration.
Removed APIs and features
Removal of deprecated jcenter()
The jcenter() repository API has been removed in Gradle 9.0.0. The API was deprecated in Gradle 7.0.
The JCenter repository was redirected to Maven Central in August 2024.
RepositoryHandler.mavenCentral() is the closest direct replacement.
Removal of deprecated JvmVendorSpec.IBM_SEMERU
The deprecated JvmVendorSpec.IBM_SEMERU constant has been removed.
Its usage should be replaced by JvmVendorSpec.IBM.
Removal of GroovySourceSet and ScalaSourceSet interfaces
The following source set interfaces have been removed in Gradle 9.0.0:
-
org.gradle.api.tasks.GroovySourceSet -
org.gradle.api.tasks.ScalaSourceSet
To configure Groovy or Scala sources, use the plugin-specific Source Directory Sets instead:
-
groovy: GroovySourceDirectorySet -
scala: ScalaSourceDirectorySet
For example, to configure Groovy sources in a plugin:
GroovySourceDirectorySet groovySources = sourceSet.getExtensions().getByType(GroovySourceDirectorySet.class);
groovySources.setSrcDirs(Arrays.asList("sources/groovy"));Removal of custom build layout options
The ability to specify custom locations for key build files from the command line has been removed in Gradle 9.0.0. The following options, deprecated in Gradle 8.x, are no longer supported:
-
-c,--settings-file— Specify a custom location for the settings file -
-b,--build-file— Specify a custom location for the build file
In addition, the buildFile property on the GradleBuild task has been removed.
This means it is no longer possible to set a custom build file path via the GradleBuild task.
Removal of conventions
The "convention" concept—represented by the org.gradle.api.plugins.Convention type—has been deprecated since Gradle 8.2 and is now fully removed in Gradle 9.0.0.
Core Gradle plugins that previously registered deprecated conventions have been updated accordingly.
This implies removal of the Conventions API. These have been removed:
-
org.gradle.api.Task.getConvention() -
org.gradle.api.Project.getConvention() -
org.gradle.api.plugins.Convention -
org.gradle.api.internal.HasConvention
Existing plugins that use these APIs will fail with Gradle 9.0.0+ and should be updated to use the Extensions API instead.
The table below shows which conventions have been removed and how to migrate:
| Plugin | Access | Type | Solution |
|---|---|---|---|
|
|
|
Configure the |
|
|
|
Replaced by |
|
|
|
Configure the report task ( |
|
|
|
Configure the |
Removal of org.gradle.cache.cleanup
The org.gradle.cache.cleanup property, which previously allowed users to disable automatic cache cleanup, has been removed in Gradle 9.0.0.
This property no longer has any effect. To control cache cleanup behavior in Gradle 9.0.0 and later, use an init script instead.
Removal of buildCache.local.removeUnusedEntriesAfterDays
In Gradle 9.0.0, the property buildCache.local.removeUnusedEntriesAfterDays has been removed.
This property was previously used to configure the retention period for the local build cache.
To configure retention for unused entries in the local build cache, use the Gradle User Home cache cleanup settings instead.
Removal of deprecated org.gradle.util members
The following members of the org.gradle.util package have been removed:
-
CollectionUtils -
ConfigureUtil,ClosureBackedActionThese classes used to provide utilities related to
groovy.lang.Closure. Plugins should avoid relying on Groovy specifics, such asClosure, in their APIs. Instead, plugins should create methods that use Action:abstract class MyExtension { // ... public void options(Action<? extends MyOptions> action) { action.execute(options) } }Gradle automatically generates a
Closure-taking method at runtime for each method with anActionas a single argument as long as the object is created with ObjectFactory#newInstance.As a last resort, to apply some configuration represented by a Groovy Closure, a plugin can use Project#configure.
Removal of deprecated testSourceDirs and testResourceDirs from IdeaModule
The deprecated testSourceDirs and testResourceDirs properties have been removed from org.gradle.plugins.ide.idea.model.IdeaModule.
This change does not affect the org.gradle.tooling.model.idea.IdeaModule type used in the Tooling API.
Use the testSources and testResources properties instead.
Removal of Unix mode based file permissions
Gradle 9.0.0 removes legacy APIs for specifying file permissions using raw Unix mode integers.
A new and more expressive API for configuring file permissions was introduced in Gradle 8.3 and promoted to stable in Gradle 8.8. See:
The following older methods, deprecated in Gradle 8.8, have now been removed:
-
org.gradle.api.file.CopyProcessingSpec.getFileMode() -
org.gradle.api.file.CopyProcessingSpec.setFileMode(Integer) -
org.gradle.api.file.CopyProcessingSpec.getDirMode() -
org.gradle.api.file.CopyProcessingSpec.setDirMode(Integer) -
org.gradle.api.file.FileTreeElement.getMode() -
org.gradle.api.file.FileCopyDetails.setMode(int)
Removal of select Groovy modules from the Gradle distribution
Gradle 9.0.0 removes certain Groovy modules from its bundled distribution.
They will no longer be available on the classpath or be available via localGroovy:
-
groovy-test -
groovy-console -
groovy-sql
Removal of kotlinDslPluginOptions.jvmTarget
In Gradle 9.0.0, the kotlinDslPluginOptions.jvmTarget property has been removed.
This property was previously used to configure the JVM target version for code compiled with the kotlin-dsl plugin.
To set the target JVM version, you should now configure a Java Toolchain instead.
Removal of the gradle-enterprise plugin block extension in Kotlin DSL
In Kotlin DSL based settings.gradle.kts files, you could previously use the gradle-enterprise plugin block extension to apply the Gradle Enterprise plugin using the same version bundled with gradle --scan:
plugins {
`gradle-enterprise`
}This shorthand had no equivalent in the Groovy DSL (settings.gradle) and has now been removed.
Gradle Enterprise has been renamed to Develocity, and the plugin ID has changed from com.gradle.enterprise to com.gradle.develocity.
As a result, you must now apply the plugin explicitly using its full ID and version:
plugins {
id("com.gradle.develocity") version "4.0.2"
}If you’re still using the legacy name, you may apply the deprecated plugin ID to ease the transition:
plugins {
id("com.gradle.enterprise") version "3.19.2"
}We strongly encourage users to adopt the latest released version of the Develocity plugin, even when using it with older versions of Gradle.
Removal of eager artifact configuration accessors in Kotlin DSL
In Gradle 5.0, the type of configuration accessors changed from Configuration to NamedDomainObjectProvider<Configuration> to support lazy configuration.
To maintain compatibility with plugins compiled against older Gradle versions, the Kotlin DSL provided eager accessor extensions such as:
configurations.compileClasspath.files // equivalent to configurations.compileClasspath.get().files
configurations.compileClasspath.singleFile // equivalent to configurations.compileClasspath.get().singleFileThese eager accessors were deprecated and removed from the public API in Gradle 8.0 but remained available for plugins compiled against older Gradle versions.
In Gradle 9.0.0, these legacy methods have now been fully removed.
Removal of libraries and bundles from version catalogs in the plugins {} block in Kotlin DSL
In Gradle 8.1, accessing libraries or bundles from dependency version catalogs within the plugins {} block of a Kotlin DSL script was deprecated.
In Gradle 9.0.0, this support has been fully removed.
Attempting to reference libraries or bundles in the plugins {} block will now result in a build failure.
Removal of "name"() task reference syntax in Kotlin DSL
In Gradle 9.0.0, referencing tasks or other domain objects using the "name"() syntax in Kotlin DSL has been removed.
Instead of using "name"() to reference a task or domain object, use named("name") or one of the other supported notations.
Removal of outputFile in WriteProperties task
The outputFile property in the WriteProperties task has been removed in Gradle 9.0.0.
This property was deprecated in Gradle 8.0 and was replaced with the destinationFile property.
Removal of Project#exec, Project#javaexec, and script-level counterparts
The following helper methods for launching external processes were deprecated in Gradle 8.11 and have now been removed in Gradle 9.0.0:
-
org.gradle.api.Project#exec(Closure) -
org.gradle.api.Project#exec(Action) -
org.gradle.api.Project#javaexec(Closure) -
org.gradle.api.Project#javaexec(Action) -
org.gradle.api.Script#exec(Closure) -
org.gradle.api.Script#exec(Action) -
org.gradle.api.Script#javaexec(Closure) -
org.gradle.api.Script#javaexec(Action) -
org.gradle.kotlin.dsl.InitScriptApi#exec(Action) -
org.gradle.kotlin.dsl.InitScriptApi#javaexec(Action) -
org.gradle.kotlin.dsl.KotlinScript#exec(Action) -
org.gradle.kotlin.dsl.KotlinScript#javaexec(Action) -
org.gradle.kotlin.dsl.SettingsScriptApi#exec(Action) -
org.gradle.kotlin.dsl.SettingsScriptApi#javaexec(Action)
Removal of unused public APIs
The following types have been removed in Gradle 9.0.0. These types are not used in Gradle’s public API and as such are not useful.
-
org.gradle.api.artifacts.ArtifactIdentifier -
org.gradle.api.publish.ivy.IvyDependency -
org.gradle.api.publish.maven.MavenDependency
Upgrading within Gradle 8.x
This chapter provides the information you need to migrate your Gradle 8.x builds to Gradle 8.14.4. For migrating from Gradle 7.x, see the older migration guide first.
We recommend the following steps for all users:
-
Try running
gradle help --scanand view the deprecations view of the generated Build Scan.
This lets you see any deprecation warnings that apply to your build.
Alternatively, you can run
gradle help --warning-mode=allto see the deprecations in the console, though it may not report as much detailed information. -
Update your plugins.
Some plugins will break with this new version of Gradle because they use internal APIs that have been removed or changed. The previous step will help you identify potential problems by issuing deprecation warnings when a plugin tries to use a deprecated part of the API.
-
Run
gradle :wrapper --gradle-version 8.14.4to update the project to 8.14.4. -
Try to run the project and debug any errors using the Troubleshooting Guide.
Upgrading from 8.13 and earlier
Potential breaking changes
The Gradle Wrapper is now an executable JAR
The Gradle Wrapper JAR has been converted into an executable JAR.
This means it now includes a Main-Class attribute, allowing it to be launched using the -jar option instead of specifying a classpath and main class manually.
When you update the wrapper scripts using the gradle :wrapper or ./gradlew :wrapper command, the wrapper JAR will be updated automatically to reflect this change.
Changes to Settings defaults
The incubating Settings.getDefaults() method, introduced in Gradle 8.10, has been removed.
Use the Settings.defaults(Action<SharedModelDefaults>) method instead, which accepts a lambda.
This change allows default values to be interpreted in the context of individual projects rather than at the Settings level.
Upgrade to Guava 33.4.6
Guava has been updated from version 32.1.2 to 33.4.6.
This release deprecates several core features, including Charsets.
For full details, see the Guava release notes.
EclipseClasspath.baseSourceOutputDir is now a DirectoryProperty
The incubating EclipseClasspath.baseSourceOutputDir was previously declared as a Property<File>.
It has now been correctly updated to a DirectoryProperty to reflect the intended type.
Upgrade to Groovy 3.0.24
Groovy has been updated to Groovy 3.0.24.
Since the previous version was 3.0.22, this includes changes for Groovy 3.0.23 as well.
Upgrade to JaCoCo 0.8.13
JaCoCo has been updated to 0.8.13.
JavaExec now uses the toolchain from the java extension by default
Previously, the JavaExec task used the same Java version as the Gradle process itself.
Starting in Gradle 9.0.0, when the java-base plugin is applied, JavaExec will instead default to the Java toolchain configured in the java extension.
You can override the toolchain explicitly in the JavaExec task configuration if needed.
Upgrade to SLF4J 2.0.17
SLF4J has been updated from 1.7.36 to 2.0.17.
Deprecations
Looking up attributes using null keys is deprecated
Passing null to getAttribute(Attribute) is now explicitly deprecated.
Previously, this would silently return null.
Now, a deprecation warning is emitted.
There should be no need to perform lookups with null keys in an AttributeContainer.
Groovy string-to-enum coercion for Property types is deprecated
Groovy supports string-to-enum coercion.
Assigning a String to a Property<T> where T is an enum is now deprecated.
This will become an error in Gradle 10.
This deprecation only affects plugins written in Groovy using the Groovy DSL.
Groovydoc.getAntGroovydoc() and org.gradle.api.internal.tasks.AntGroovydoc have been deprecated
These internal APIs were inadvertently exposed and are now deprecated. They will be removed in Gradle 9.0.0.
Deprecated methods in GradlePluginDevelopmentExtension
The constructor for GradlePluginDevelopmentExtension and its pluginSourceSet method are now deprecated.
These methods should not be used directly, they are intended to be configured solely by the Gradle Plugin Development plugin. Only the main source set is supported for plugin development.
These methods will be removed in Gradle 9.0.0.
Deprecated collections in IdeaModule now emit warnings
The testResourcesDirs and testSourcesDirs properties in org.gradle.plugins.ide.idea.model.IdeaModule were marked @Deprecated in Gradle 7.6, but no warnings were emitted until now.
Gradle now emits deprecation warnings when these properties are used. They will be removed in Gradle 9.0.0.
The ForkOptions.getJavaHome() and ForkOptions.setJavaHome() methods are no longer deprecated
These methods were deprecated in Gradle 8.11, but are no longer deprecated, as they do not yet have stable replacements.
Deprecated StartParameter.isConfigurationCacheRequested now emits warnings
The isConfigurationCacheRequested property in StartParameter was marked @Deprecated in Gradle 8.5, but no warnings were emitted until now.
Gradle now emits deprecation warnings when this property is used. It will be removed in Gradle 10.
Since Gradle 8.5, the same information can be obtained via the BuildFeatures service using configurationCache.requested property.
Deprecated configuration usages are no longer deprecated
Starting in 8.0, adding an artifact to a configuration that is neither resolvable nor consumable was deprecated. This deprecation was overly broad and also captured certain valid usages. It has been removed in Gradle 8.14.
Upgrading from 8.12 and earlier
Potential breaking changes
Changes to JvmTestSuite
The testType property was removed from JvmTestSuite and both the TestSuiteTargetName and TestSuiteType attributes have been removed.
Test reports and JaCoCo reports can now be aggregated between projects by specifying the name of the test suite in the target project to aggregate.
See below for additional details.
Changes to Test Report Aggregation and Jacoco Aggregation
Several changes have been made to the incubating Test Report Aggregation and JaCoCo Report Aggregation plugins.
The plugins now create a single test results variant for each test suite, containing all test results for the entire suite, instead of one variant for each test target. This change allows the aggregation plugins to aggregate test suites with multiple targets, where previously this would result in an ambiguous variant selection error.
In the future, as we continue to develop these plugins, we plan to once again create one results variant per test suite target, allowing test results from certain targets to be explicitly aggregated.
The testType property on JacocoCoverageReport and AggregateTestReport has been removed and replaced with a new testSuiteName property:
Previously:
reporting {
reports {
val testCodeCoverageReport by creating(JacocoCoverageReport::class) {
testType = TestSuiteType.UNIT_TEST
}
}
}Now:
reporting {
reports {
val testCodeCoverageReport by creating(JacocoCoverageReport::class) {
testSuiteName = "test"
}
}
}Changed behavior when calling BuildLauncher.addJvmArguments
Issue (#31426) was fixed, that caused BuildLauncher.addJvmArguments to override flags coming from the org.gradle.jvmargs system property.
Please ensure that you are not relying on this behavior when upgrading to Gradle 8.13.
If system properties needs to be overridden, BuildLauncher.setJvmArguments should be used instead.
val buildLauncher: BuildLauncher = connector.connect().newBuild()
buildLauncher.setJvmArguments("-Xmx2048m", "-Dmy.custom.property=value")Upgrade to ASM 9.7.1
ASM was upgraded from 9.6 to 9.7.1 to ensure earlier compatibility for Java 24.
Source level deprecation of Project.task methods
Eager task creation methods on the Project interface have been marked @Deprecated and will generate compiler and IDE warnings when used in build scripts or plugin code.
There is not yet a Gradle deprecation warning emitted for their use.
However, if the build is configured to fail on warnings during Kotlin script or plugin code compilation, this change may cause the build to fail.
A standard Gradle deprecation warning will be printed upon use when these methods are fully deprecated in a future version.
Deprecations
Recursively querying AttributeContainer in lazy provider
In Gradle 9.0.0, querying the contents of an AttributeContainer from within an attribute value provider of the same container will become an error.
The following example showcases the forbidden behavior:
AttributeContainer container = getAttributeContainer();
Attribute<String> firstAttribute = Attribute.of("first", String.class);
Attribute<String> secondAttribute = Attribute.of("second", String.class);
container.attributeProvider(firstAttribute, project.getProviders().provider(() -> {
// Querying the contents of the container within an attribute value provider
// will become an error.
container.getAttribute(secondAttribute);
return "first";
}));Deprecated org.gradle.api.artifacts.transform.VariantTransformConfigurationException
There is no good public use case for this exception, and it is not intended to be thrown by users.
It will be replaced by org.gradle.api.internal.artifacts.transform.VariantTransformConfigurationException for internal use only in Gradle 9.0.0.
Deprecated properties in the incubating UpdateDaemonJvm
The following properties of UpdateDaemonJvm are now deprecated:
-
jvmVersion -
jvmVendor
They are replaced by languageVersion and vendor respectively.
This allows the configuration of a Java toolchain spec and the UpdateDaemonJvm task to be interchangeable.
Note that due to the change of type for the vendor property, executing updateDaemonJvm with the jvmVendor property will result in the task failing.
See the documentation for the new configuration option.
Declaring boolean properties with is-prefix and Boolean types
Gradle property names are derived by following the Java Bean specification with one exception.
Gradle recognizes methods with a Boolean return type and a is-prefix as a boolean property. This is behavior inherited from Groovy originally.
Groovy 4 more closely follows the Java Bean specification and no longer supports this exception.
Gradle will emit a deprecation warning when it detects that a boolean property is derived from a method with a Boolean return type and is-prefix.
In Gradle 9.0.0, Groovy 4 will no longer recognize this as a property in build scripts and Groovy source files. Gradle’s property-based behavior will not change. Gradle will still consider these properties for up-to-date checks.
In Gradle 10, these methods will no longer be treated as defining a Gradle property. This may cause tasks to behave differently when a Boolean property is used as an input.
There are two options to fix this:
-
Introduce a new method that starts with
getinstead ofiswhich has the same behavior. The old method does not need to be removed (in order to preserve binary compatibility), but may need adjustments as indicated below.-
It is recommended to deprecate the
is-method, and then remove it in a future major version.
-
-
Change the type of the property (both get and set) to
boolean. This is a breaking change.
For task input properties using the first option, you should also annotate the old is- method with @Deprecated and @ReplacedBy to ensure it is not used by Gradle.
For example, this code:
class MyValue {
private final Boolean property = Boolean.TRUE;
@Input
Boolean isProperty() { return property; }
}Should be replaced with the following:
class MyValue {
private final Boolean property = Boolean.TRUE;
@Deprecated
@ReplacedBy("getProperty")
Boolean isProperty() { return property; }
@Input
Boolean getProperty() { return property; }
}Upgrading from 8.11 and earlier
Potential breaking changes
Upgrade to Kotlin 2.0.21
The embedded Kotlin has been updated from 2.0.20 to Kotlin 2.0.21.
Upgrade to Ant 1.10.15
Ant has been updated to Ant 1.10.15.
Upgrade to Zinc 1.10.4
Zinc has been updated to 1.10.4.
Swift SDK discovery
To determine the location of the Mac OS X SDK for Swift, Gradle now passes the --sdk macosx arguments to xcrun.
This is necessary because the SDK could be discovered inconsistently without this argument across different environments.
Source level deprecation of TaskContainer.create methods
Eager task creation methods on the TaskContainer interface have been marked @Deprecated and will generate compiler and IDE warnings when used in build scripts or plugin code.
There is not yet a Gradle deprecation warning emitted for their use.
However, if the build is configured to fail on warnings during Kotlin script or plugin code compilation, this behavior may cause the build to fail.
A standard Gradle deprecation warning will be printed upon use when these methods are fully deprecated in a future version.
Deprecations
Deprecated Ambiguous Transformation Chains
Previously, when at least two equal-length chains of artifact transforms were available that would produce compatible variants that would each satisfy a resolution request, Gradle would arbitrarily, and silently, pick one.
Now, Gradle emits a deprecation warning that explains this situation:
There are multiple distinct artifact transformation chains of the same length that would satisfy this request. This behavior has been deprecated. This will fail with an error in Gradle 9.0.0.
Found multiple transformation chains that produce a variant of 'root project :' with requested attributes:
- color 'red'
- texture 'smooth'
Found the following transformation chains:
- From configuration ':squareBlueSmoothElements':
- With source attributes:
- artifactType 'txt'
- color 'blue'
- shape 'square'
- texture 'smooth'
- Candidate transformation chains:
- Transformation chain: 'ColorTransform':
- 'BrokenColorTransform':
- Converts from attributes:
- color 'blue'
- texture 'smooth'
- To attributes:
- color 'red'
- Transformation chain: 'ColorTransform2':
- 'BrokenColorTransform2':
- Converts from attributes:
- color 'blue'
- texture 'smooth'
- To attributes:
- color 'red'
Remove one or more registered transforms, or add additional attributes to them to ensure only a single valid transformation chain exists.In such a scenario, Gradle has no way to know which of the two (or more) possible transformation chains should be used. Picking an arbitrary chain can lead to inefficient performance or unexpected behavior changes when seemingly unrelated parts of the build are modified. This is potentially a very complex situation and the message now fully explains the situation by printing all the registered transforms in order, along with their source (input) variants for each candidate chain.
When encountering this type of failure, build authors should either:
-
Add additional, distinguishing attributes when registering transforms present in the chain, to ensure that only a single chain will be selectable to satisfy the request
-
Request additional attributes to disambiguate which chain is selected (if they result in non-identical final attributes)
-
Remove unnecessary registered transforms from the build
This will become an error in Gradle 9.0.0.
init must run alone
The init task must run by itself.
This task should not be combined with other tasks in a single Gradle invocation.
Running init in the same invocation as other tasks will become an error in Gradle 9.0.0.
For instance, this wil not be allowed:
> gradlew init tasksCalling Task.getProject() from a task action
Calling Task.getProject() from a task action at execution time is now deprecated and will be made an error in Gradle 10. This method can still be used during configuration time.
The deprecation is only issued if the configuration cache is not enabled. When the configuration cache is enabled, calls to Task.getProject() are reported as configuration cache problems instead.
This deprecation was originally introduced in Gradle 7.4 but was only issued when the STABLE_CONFIGURATION_CACHE feature flag was enabled. That feature flag no longer controls this deprecation.
This is another step towards moving users away from idioms that are incompatible with the configuration cache, which will become the only mode supported by Gradle in a future release.
Please refer to the configuration cache documentation for alternatives to invoking Task.getProject() at execution time that are compatible with the configuration cache.
Groovy "space assignment" syntax
Currently, there are multiple ways to set a property with Groovy DSL syntax:
propertyName = value
setPropertyName(value)
setPropertyName value
propertyName(value)
propertyName valueThe latter one, "space-assignment", is a Gradle-specific feature that is not part of the Groovy language.
In regular Groovy, this is just a method call: propertyName(value), and Gradle generates propertyName method in the runtime if this method hasn’t been present already.
This feature may be a source of confusion (especially for new users) and adds an extra layer of complexity for users and the Gradle codebase without providing any significant value.
Sometimes, classes declare methods with the same name, and these may even have semantics that are different from a plain assignment.
These generated methods are now deprecated and will be removed in Gradle 10, and both propertyName value and propertyName(value) will stop working unless the explicit method propertyName is defined.
Use explicit assignment propertyName = value instead.
For explicit methods, consider using the propertyName(value) syntax instead of propertyName value for clarity.
For example, jvmArgs "some", "arg" can be replaced with jvmArgs("some", "arg") or with jvmArgs = ["some", "arg"] for Test tasks.
If you have a big project, to replace occurrences of space-assignment syntax you can use, for example, the following sed command:
find . -name 'build.gradle' -type f -exec sed -i.bak -E 's/([^A-Za-z]|^)(replaceme)[ \t]*([^= \t{])/\1\2 = \3/g' {} +You should replace replaceme with one or more property names you want to replace, separated by |, e.g. (url|group).
DependencyInsightReportTask.getDependencySpec
The method was deprecated because it was not intended for public use in build scripts.
ReportingExtension.baseDir
ReportingExtension.getBaseDir(), ReportingExtension.setBaseDir(File), and ReportingExtension.setBaseDir(Object) were deprecated.
They should be replaced with ReportingExtension.getBaseDirectory() property.
Upgrading from 8.10 and earlier
Potential breaking changes
Upgrade to Kotlin 2.0.20
The embedded Kotlin has been updated from 1.9.24 to Kotlin 2.0.20. Also see the Kotlin 2.0.10 and Kotlin 2.0.0 release notes.
The default kotlin-test version in JVM test suites has been upgraded to 2.0.20 as well.
Kotlin DSL scripts are still compiled with Kotlin language version set to 1.8 for backward compatibility.
Gradle daemon JVM configuration via toolchain
The type of the property UpdateDaemonJvm.jvmVersion is now Property<JavaLanguageVersion>.
If you configured the task in a build script, you will need to replace:
jvmVersion = JavaVersion.VERSION_17
With:
jvmVersion = JavaLanguageVersion.of(17)
Using the CLI options to configure which JVM version to use for the Gradle Daemon has no impact.
Name matching changes
The name-matching logic has been updated to treat numbers as word boundaries for camelCase names.
Previously, a request like unique would match both uniqueA and unique1.
Such a request will now fail due to ambiguity. To avoid issues, use the exact name instead of a shortened version.
This change impacts:
-
Task selection
-
Project selection
-
Configuration selection in dependency report tasks
Deprecations
Deprecated javaHome property of ForkOptions
The javaHome property of the ForkOptions type has been deprecated and will be removed in Gradle 9.0.0.
Use JVM Toolchains, or the executable property instead.
|
Note
|
This deprecation was later removed, and for Gradle versions starting with 8.14, these methods will no longer throw deprecation warnings. |
Deprecated mutating buildscript configurations
Starting in Gradle 9.0.0, mutating configurations in a script’s buildscript block will result in an error. This applies to project, settings, init, and standalone scripts.
The buildscript configurations block is only intended to control buildscript classpath resolution.
Consider the following script that creates a new buildscript configuration in a Settings script and resolves it:
buildscript {
configurations {
create("myConfig")
}
dependencies {
"myConfig"("org:foo:1.0")
}
}
val files = buildscript.configurations["myConfig"].filesThis pattern is sometimes used to resolve dependencies in Settings, where there is no other way to obtain a Configuration. Resolving dependencies in this context is not recommended. Using a detached configuration is a possible but discouraged alternative.
The above example can be modified to use a detached configuration:
val myConfig = buildscript.configurations.detachedConfiguration(
buildscript.dependencies.create("org:foo:1.0")
)
val files = myConfig.filesSelecting Maven variants by configuration name
Starting in Gradle 9.0.0, selecting variants by name from non-Ivy external components will be forbidden.
Selecting variants by name from local components will still be permitted; however, this pattern is discouraged. Variant aware dependency resolution should be preferred over selecting variants by name for local components.
The following dependencies will fail to resolve when targeting a non-Ivy external component:
dependencies {
implementation(group: "com.example", name: "example", version: "1.0", configuration: "conf")
implementation("com.example:example:1.0") {
targetConfiguration = "conf"
}
}Deprecated manually adding to configuration container
Starting in Gradle 9.0.0, manually adding configuration instances to a configuration container will result in an error. Configurations should only be added to the container through the eager or lazy factory methods. Detached configurations and copied configurations should not be added to the container.
Calling the following methods on ConfigurationContainer will be forbidden: - add(Configuration) - addAll(Collection) - addLater(Provider) - addAllLater(Provider)
Deprecated ProjectDependency#getDependencyProject()
The ProjectDependency#getDependencyProject() method has been deprecated and will be removed in Gradle 9.0.0.
Accessing the mutable project instance of other projects should be avoided.
To discover details about all projects that were included in a resolution, inspect the full ResolutionResult.
Project dependencies are exposed in the DependencyResult.
See the user guide section on programmatic dependency resolution for more details on this API.
This is the only reliable way to find all projects that are used in a resolution.
Inspecting only the declared ProjectDependencys may miss transitive or substituted project dependencies.
To get the identity of the target project, use the new Isolated Projects safe project path method: ProjectDependency#getPath().
To access or configure the target project, consider this direct replacement:
val projectDependency: ProjectDependency = getSomeProjectDependency()
// Old way:
val someProject = projectDependency.dependencyProject
// New way:
val someProject = project.project(projectDependency.path)This approach will not fetch project instances from different builds.
Deprecated ResolvedConfiguration.getFiles() and LenientConfiguration.getFiles()
The ResolvedConfiguration.getFiles() and LenientConfiguration.getFiles() methods have been deprecated and will be removed in Gradle 9.0.0.
These deprecated methods do not track task dependencies, unlike their replacements.
val deprecated: Set<File> = conf.resolvedConfiguration.files
val replacement: FileCollection = conf.incoming.files
val lenientDeprecated: Set<File> = conf.resolvedConfiguration.lenientConfiguration.files
val lenientReplacement: FileCollection = conf.incoming.artifactView {
isLenient = true
}.filesDeprecated AbstractOptions
The AbstractOptions class has been deprecated and will be removed in Gradle 9.0.0.
All classes extending AbstractOptions will no longer extend it.
As a result, the AbstractOptions#define(Map) method will no longer be present.
This method exposes a non-type-safe API and unnecessarily relies on reflection.
It can be replaced by directly setting the properties specified in the map.
Additionally, CompileOptions#fork(Map), CompileOptions#debug(Map), and GroovyCompileOptions#fork(Map), which depend on define, are also deprecated for removal in Gradle 9.0.0.
Consider the following example of the deprecated behavior and its replacement:
tasks.withType(JavaCompile) {
// Deprecated behavior
options.define(encoding: 'UTF-8')
options.fork(memoryMaximumSize: '1G')
options.debug(debugLevel: 'lines')
// Can be replaced by
options.encoding = 'UTF-8'
options.fork = true
options.forkOptions.memoryMaximumSize = '1G'
options.debug = true
options.debugOptions.debugLevel = 'lines'
}Deprecated Dependency#contentEquals(Dependency)
The Dependency#contentEquals(Dependency) method has been deprecated and will be removed in Gradle 9.0.0.
The method was originally intended to compare dependencies based on their actual target component, regardless of whether they were of different dependency type. The existing method does not behave as specified by its Javadoc, and we do not plan to introduce a replacement that does.
Potential migrations include using Object.equals(Object) directly, or comparing the fields of dependencies manually.
Deprecated Project#exec and Project#javaexec
The Project#exec(Closure), Project#exec(Action), Project#javaexec(Closure), Project#javaexec(Action) methods have been deprecated and will be removed in Gradle 9.0.0.
These methods are scheduled for removal as part of the ongoing effort to make writing configuration-cache-compatible code easier. There is no way to use these methods without breaking configuration cache requirements so it is recommended to migrate to a compatible alternative. The appropriate replacement for your use case depends on the context in which the method was previously called.
At execution time, for example in @TaskAction or doFirst/doLast callbacks, the use of Project instance is not allowed when the configuration cache is enabled.
To run external processes, tasks should use an injected ExecOperation service, which has the same API and can act as a drop-in replacement.
The standard Java/Groovy/Kotlin process APIs, like java.lang.ProcessBuilder can be used as well.
At configuration time, only special Provider-based APIs must be used to run external processes when the configuration cache is enabled.
You can use ProviderFactory.exec and
ProviderFactory.javaexec to obtain the output of the process.
A custom ValueSource implementation can be used for more sophisticated scenarios.
The configuration cache guide has a more elaborate example of using these APIs.
Detached Configurations should not use extendsFrom
Detached configurations should not extend other configurations using extendsFrom.
This behavior has been deprecated and will become an error in Gradle 9.0.0.
To create extension relationships between configurations, you should change to using non-detached configurations created via the other factory methods present in the project’s ConfigurationContainer.
Deprecated customized Gradle logging
The Gradle#useLogger(Object) method has been deprecated and will be removed in Gradle 9.0.0.
This method was originally intended to customize logs printed by Gradle. However, it only allows intercepting a subset of the logs and cannot work with the configuration cache. We do not plan to introduce a replacement for this feature.
Unnecessary options on compile options and doc tasks have been deprecated
Gradle’s API allowed some properties that represented nested groups of properties to be replaced wholesale with a setter method.
This was awkward and unusual to do and would sometimes require the use of internal APIs.
The setters for these properties will be removed in Gradle 9.0.0 to simplify the API and ensure consistent behavior.
Instead of using the setter method, these properties should be configured by calling the getter and configuring the object directly or using the convenient configuration method.
For example, in CompileOptions, instead of calling the setForkOptions setter, you can call getForkOptions() or forkOptions(Action).
The affected properties are:
Deprecated Javadoc.isVerbose() and Javadoc.setVerbose(boolean)
These methods on Javadoc have been deprecated and will be removed in Gradle 9.0.0.
-
isVerbose() is replaced by getOptions().isVerbose()
-
Calling setVerbose(boolean) with
trueis replaced by getOptions().verbose() -
Calling
setVerbose(false)did nothing.
Upgrading from 8.9 and earlier
Potential breaking changes
JavaCompile tasks may fail when using a JRE even if compilation is not necessary
The JavaCompile tasks may sometimes fail when using a JRE instead of a JDK.
This is due to changes in the toolchain resolution code, which enforces the presence of a compiler when one is requested.
The java-base plugin uses the JavaCompile tasks it creates to determine the default source and target compatibility when sourceCompatibility/targetCompatibility or release are not set.
With the new enforcement, the absence of a compiler causes this to fail when only a JRE is provided, even if no compilation is needed (e.g., in projects with no sources).
This can be fixed by setting the sourceCompatibility/targetCompatibility explicitly in the java extension, or by setting sourceCompatibility/targetCompatibility or release in the relevant task(s).
Upgrade to Kotlin 1.9.24
The embedded Kotlin has been updated from 1.9.23 to Kotlin 1.9.24.
Upgrade to Ant 1.10.14
Ant has been updated to Ant 1.10.14.
Upgrade to JaCoCo 0.8.12
JaCoCo has been updated to 0.8.12.
Upgrade to Groovy 3.0.22
Groovy has been updated to Groovy 3.0.22.
Deprecations
Running Gradle on older JVMs
Starting in Gradle 9.0.0, Gradle will require JVM 17 or later to run. Most Gradle APIs will be compiled to target JVM 17 bytecode.
Gradle will still support compiling Java code to target JVM version 6 or later. The target JVM version of the compiled code can be configured separately from the JVM version used to run Gradle.
All Gradle clients (wrapper, launcher, Tooling API and TestKit) will remain compatible with JVM 8 and will be compiled to target JVM 8 bytecode. Only the Gradle daemon will require JVM 17 or later. These clients can be configured to run Gradle builds with a different JVM version than the one used to run the client:
-
Using Daemon JVM criteria (an incubating feature)
-
Setting the
org.gradle.java.homeGradle property -
Using the ConfigurableLauncher#setJavaHome method on the Tooling API
Alternatively, the JAVA_HOME environment variable can be set to a JVM 17 or newer, which will run both the client and daemon with the same version of the JVM.
Running Gradle builds with --no-daemon or using ProjectBuilder in tests will require JVM version 17 or later. The worker API will remain compatible with JVM 8, and running JVM tests will require JVM 8.
We decided to upgrade the minimum version of the Java runtime for a number of reasons:
-
Dependencies are beginning to drop support for older versions and may not release security patches.
-
Significant language improvements between Java 8 and Java 17 cannot be used without upgrading.
-
Some of the most popular plugins already require JVM 17 or later.
-
Download metrics for Gradle distributions show that JVM 17 is widely used.
Deprecated consuming non-consumable configurations from Ivy
In prior versions of Gradle, it was possible to consume non-consumable configurations of a project using published Ivy metadata.
An Ivy dependency may sometimes be substituted for a project dependency, either explicitly through the DependencySubstitutions API or through included builds.
When this happens, configurations in the substituted project could be selected that were marked as non-consumable.
Consuming non-consumable configurations in this manner is deprecated and will result in an error in Gradle 9.0.0.
Deprecated extending configurations in the same project
In prior versions of Gradle, it was possible to extend a configuration in a different project.
The hierarchy of a Project’s configurations should not be influenced by configurations in other projects. Cross-project hierarchies can lead to unexpected behavior when configurations are extended in a way that is not intended by the configuration’s owner.
Projects should also never access the mutable state of another project. Since Configurations are mutable, extending configurations across project boundaries restricts the parallelism that Gradle can apply.
Extending configurations in different projects is deprecated and will result in an error in Gradle 9.0.0.
Upgrading from 8.8 and earlier
Potential breaking changes
Change to toolchain provisioning
In previous versions of Gradle, toolchain provisioning could leave a partially provisioned toolchain in place with a marker file indicating that the toolchain was fully provisioned.
This could lead to strange behavior with the toolchain.
In Gradle 8.9, the toolchain is fully provisioned before the marker file is written.
However, to not detect potentially broken toolchains, a different marker file (.ready) is used.
This means all your existing toolchains will be re-provisioned the first time you use them with Gradle 8.9.
Gradle 8.9 also writes the old marker file (provisioned.ok) to indicate that the toolchain was fully provisioned.
This means that if you return to an older version of Gradle, an 8.9-provisioned toolchain will not be re-provisioned.
Upgrade to Kotlin 1.9.23
The embedded Kotlin has been updated from 1.9.22 to Kotlin 1.9.23.
Change the encoding of daemon log files
In previous versions of Gradle, the daemon log file, located at $GRADLE_USER_HOME/daemon/9.6.1/, was encoded with the default JVM encoding.
This file is now always encoded with UTF-8 to prevent clients who may use different default encodings from reading data incorrectly.
This change may affect third-party tools trying to read this file.
Compiling against Gradle implementation classpath
In previous versions of Gradle, Java projects that had no declared dependencies could implicitly compile against Gradle’s runtime classes.
This means that some projects were able to compile without any declared dependencies even though they referenced Gradle runtime classes.
This situation is unlikely to arise in projects since IDE integration and test execution would be compromised.
However, if you need to utilize the Gradle API, declare a gradleApi dependency or apply the java-gradle-plugin plugin.
Configuration cache implementation packages now under org.gradle.internal
References to Gradle types not part of the public API should be avoided, as their direct use is unsupported. Gradle internal implementation classes may suffer breaking changes (or be renamed or removed) from one version to another without warning.
Users need to distinguish between the API and internal parts of the Gradle codebase.
This is typically achieved by including internal in the implementation package names.
However, before this release, the configuration cache subsystem did not follow this pattern.
To address this issue, all code initially under the org.gradle.configurationcache* packages has been moved to new internal packages (org.gradle.internal.*).
File-system watching on macOS 11 (Big Sur) and earlier is disabled
Since Gradle 8.8, file-system watching has only been supported on macOS 12 (Monterey) and later. We added a check to automatically disable file-system watching on macOS 11 (Big Sur) and earlier versions.
Possible change to JDK8-based compiler output when annotation processors are used
The Java compilation infrastructure has been updated to use the Problems API. This change will supply the Tooling API clients with structured, rich information about compilation issues.
The feature should not have any visible impact on the usual build output, with JDK8 being an exception. When annotation processors are used in the compiler, the output message differs slightly from the previous ones.
The change mainly manifests itself in typename printed.
For example, Java standard types like java.lang.String will be reported as java.lang.String instead of String.
Upgrading from 8.7 and earlier
Deprecations
Deprecate mutating configuration after observation
To ensure the accuracy of dependency resolution, Gradle checks that Configurations are not mutated after they have been used as part of a dependency graph.
-
Resolvable configurations should not have their resolution strategy, dependencies, hierarchy, etc., modified after they have been resolved.
-
Consumable configurations should not have their dependencies, hierarchy, attributes, etc. modified after they have been published or consumed as a variant.
-
Dependency scope configurations should not have their dependencies, constraints, etc., modified after a configuration that extends from them is observed.
In prior versions of Gradle, many of these circumstances were detected and handled by failing the build. However, some cases went undetected or did not trigger build failures. In Gradle 9.0.0, all changes to a configuration, once observed, will become an error. After a configuration of any type has been observed, it should be considered immutable. This validation covers the following properties of a configuration:
-
Resolution Strategy
-
Dependencies
-
Constraints
-
Exclude Rules
-
Artifacts
-
Role (consumable, resolvable, dependency scope)
-
Hierarchy (
extendsFrom) -
Others (Transitive, Visible)
Starting in Gradle 8.8, a deprecation warning will be emitted in cases that were not already an error.
Usually, this deprecation is caused by mutating a configuration in a beforeResolve hook.
This hook is only executed after a configuration is fully resolved but not when it is partially resolved for computing task dependencies.
Consider the following code that showcases the deprecated behavior:
plugins {
id("java-library")
}
configurations.runtimeClasspath {
// `beforeResolve` is not called before the configuration is partially resolved for
// build dependencies, but only before a full graph resolution.
// Configurations should not be mutated in this hook
incoming.beforeResolve {
// Add a dependency on `com:foo` if not already present
if (allDependencies.none { it.group == "com" && it.name == "foo" }) {
configurations.implementation.get().dependencies.add(project.dependencies.create("com:foo:1.0"))
}
}
}
tasks.register("resolve") {
val conf: FileCollection = configurations["runtimeClasspath"]
// Wire build dependencies
dependsOn(conf)
// Resolve dependencies
doLast {
assert(conf.files.map { it.name } == listOf("foo-1.0.jar"))
}
}For the following use cases, consider these alternatives when replacing a beforeResolve hook:
-
Adding dependencies: Use a DependencyFactory and
addLateroraddAllLateron DependencySet. -
Changing dependency versions: Use preferred version constraints.
-
Adding excludes: Use Component Metadata Rules to adjust dependency-level excludes, or withDependencies to add excludes to a configuration.
-
Roles: Configuration roles should be set upon creation and not changed afterward.
-
Hierarchy: Configuration hierarchy (
extendsFrom) should be set upon creation. Mutating the hierarchy prior to resolution is highly discouraged but permitted within a withDependencies hook. -
Resolution Strategy: Mutating a configuration’s ResolutionStrategy is still permitted in a
beforeResolvehook; however, this is not recommended.
Filtered Configuration file and fileCollection methods are deprecated
In an ongoing effort to simplify the Gradle API, the following methods that support filtering based on declared dependencies have been deprecated:
On Configuration:
-
files(Dependency…) -
files(Spec) -
files(Closure) -
fileCollection(Dependency…) -
fileCollection(Spec) -
fileCollection(Closure)
-
getFiles(Spec) -
getFirstLevelModuleDependencies(Spec)
-
getFirstLevelModuleDependencies(Spec) -
getFiles(Spec) -
getArtifacts(Spec)
To mitigate this deprecation, consider the example below that leverages the ArtifactView
API along with the componentFilter method to select a subset of a Configuration’s artifacts:
val conf by configurations.creating
dependencies {
conf("com.thing:foo:1.0")
conf("org.example:bar:1.0")
}
tasks.register("filterDependencies") {
val files: FileCollection = conf.incoming.artifactView {
componentFilter {
when(it) {
is ModuleComponentIdentifier ->
it.group == "com.thing" && it.module == "foo"
else -> false
}
}
}.files
doLast {
assert(files.map { it.name } == listOf("foo-1.0.jar"))
}
}configurations {
conf
}
dependencies {
conf "com.thing:foo:1.0"
conf "org.example:bar:1.0"
}
tasks.register("filterDependencies") {
FileCollection files = configurations.conf.incoming.artifactView {
componentFilter {
it instanceof ModuleComponentIdentifier
&& it.group == "com.thing"
&& it.module == "foo"
}
}.files
doLast {
assert files*.name == ["foo-1.0.jar"]
}
}Contrary to the deprecated Dependency filtering methods, componentFilter does not consider the transitive dependencies of the component being filtered.
This allows for more granular control over which artifacts are selected.
Deprecated Namer of Task and Configuration
Task and Configuration have a Namer inner class (also called Namer) that can be used as a common way to retrieve the name of a task or configuration.
Now that these types implement Named, these classes are no longer necessary and have been deprecated.
They will be removed in Gradle 9.0.0.
Use Named.Namer.INSTANCE instead.
The super interface, Namer, is not being deprecated.
Unix mode-based file permissions deprecated
A new API for defining file permissions has been added in Gradle 8.3, see:
The new API has now been promoted to stable, and the old methods have been deprecated:
Deprecated setting retention period directly on local build cache
In previous versions, cleanup of the local build cache entries ran every 24 hours, and this interval could not be configured.
The retention period was configured using buildCache.local.removeUnusedEntriesAfterDays.
In Gradle 8.0, a new mechanism was added to configure the cleanup and retention periods for various resources in Gradle User Home. In Gradle 8.8, this mechanism was extended to permit the retention configuration of local build cache entries, providing improved control and consistency.
-
Specifying
Cleanup.DISABLEDorCleanup.ALWAYSwill now prevent or force the cleanup of the local build cache -
Build cache entry retention is now configured via an
init-script, in the same manner as other caches.
If you want build cache entries to be retained for 30 days, remove any calls to the deprecated method:
buildCache {
local {
// Remove this line
removeUnusedEntriesAfterDays = 30
}
}Add a file like this in ~/.gradle/init.d/cache.init.gradle.kts:
beforeSettings {
caches {
buildCache.setRemoveUnusedEntriesAfterDays(30)
}
}Calling buildCache.local.removeUnusedEntriesAfterDays is deprecated, and this method will be removed in Gradle 9.0.0.
If set to a non-default value, this deprecated setting will take precedence over Settings.caches.buildCache.setRemoveUnusedEntriesAfterDays().
Deprecated Kotlin DSL gradle-enterprise plugin block extension
In settings.gradle.kts (Kotlin DSL), you can use gradle-enterprise in the plugins block to apply the Gradle Enterprise plugin with the same version as gradle --scan.
plugins {
`gradle-enterprise`
}There is no equivalent to this in settings.gradle (Groovy DSL).
Gradle Enterprise has been renamed Develocity, and the com.gradle.enterprise plugin has been renamed com.gradle.develocity.
Therefore, the gradle-enterprise plugin block extension has been deprecated and will be removed in Gradle 9.0.0.
The Develocity plugin must be applied with an explicit plugin ID and version.
There is no develocity shorthand available in the plugins block:
plugins {
id("com.gradle.develocity") version "3.17.3"
}If you want to continue using the Gradle Enterprise plugin, you can specify the deprecated plugin ID:
plugins {
id("com.gradle.enterprise") version "3.17.3"
}We encourage you to use the latest released Develocity plugin version, even when using an older Gradle version.
Potential breaking changes
Changes in the Problems API
We have implemented several refactorings of the Problems API, including a significant change in how problem definitions and contextual information are handled. The complete design specification can be found here.
In implementing this spec, we have introduced the following breaking changes to the ProblemSpec interface:
-
The
label(String)anddescription(String)methods have been replaced with theid(String, String)method and its overloaded variants.
Changes to collection properties
The following incubating API introduced in 8.7 have been removed:
-
MapProperty.insert*(…) -
HasMultipleValues.append*(…)
Replacements that better handle conventions are under consideration for a future 8.x release.
Upgrade to Groovy 3.0.21
Groovy has been updated to Groovy 3.0.21.
Some changes in static type checking have resulted in source-code incompatibilities.
Starting with 3.0.18, if you cast a closure to an Action without generics, the closure parameter will be Object instead of any explicit type specified.
This can be fixed by adding the appropriate type to the cast, and the redundant parameter declaration can be removed:
// Before
tasks.create("foo", { Task it -> it.description = "Foo task" } as Action)// Fixed
tasks.create("foo", { it.description = "Foo task" } as Action<Task>)Upgrade to ASM 9.7
ASM was upgraded from 9.6 to 9.7 to ensure earlier compatibility for Java 23.
Upgrading from 8.6 and earlier
Potential breaking changes
Upgrade to Kotlin 1.9.22
The embedded Kotlin has been updated from 1.9.10 to Kotlin 1.9.22.
Upgrade to Apache SSHD 2.10.0
Apache SSHD has been updated from 2.0.0 to 2.10.0.
Replacement and upgrade of JSch
JSch has been replaced by com.github.mwiede:jsch and updated from 0.1.55 to 0.2.16
Upgrade to Eclipse JGit 5.13.3
Eclipse JGit has been updated from 5.7.0 to 5.13.3.
This includes reworking the way that Gradle configures JGit for SSH operations by moving from JSch to Apache SSHD.
Upgrade to Apache Commons Compress 1.25.0
Apache Commons Compress has been updated from 1.21 to 1.25.0. This change may affect the checksums of the produced jars, zips, and other archive types because the metadata of the produced artifacts may differ.
Upgrade to ASM 9.6
ASM was upgraded from 9.5 to 9.6 for better support of multi-release jars.
Upgrade of the version catalog parser
The version catalog parser has been upgraded and is now compliant with version 1.0.0 of the TOML spec.
This should not impact catalogs that use the recommended syntax or were generated by Gradle for publication.
Deprecations
Deprecated registration of plugin conventions
Using plugin conventions has been emitting warnings since Gradle 8.2. Now, registering plugin conventions will also trigger deprecation warnings. For more information, see the section about plugin convention deprecation.
Referencing tasks and domain objects by "name"() in Kotlin DSL
In Kotlin DSL, it is possible to reference a task or other domain object by its name using the "name"() notation.
There are several ways to look up an element in a container by name:
tasks {
"wrapper"() // 1 - returns TaskProvider<Task>
"wrapper"(Wrapper::class) // 2 - returns TaskProvider<Wrapper>
"wrapper"(Wrapper::class) { // 3 - configures a task named wrapper of type Wrapper
}
"wrapper" { // 4 - configures a task named wrapper of type Task
}
}The first notation is deprecated and will be removed in Gradle 9.0.0.
Instead of using "name"() to reference a task or domain object, use named("name") or one of the other supported notations.
The above example would be written as:
tasks {
named("wrapper") // returns TaskProvider<Task>
}The Gradle API and Groovy build scripts are not impacted by this.
Deprecated invalid URL decoding behavior
Before Gradle 8.3, Gradle would decode a CharSequence given to Project.uri(Object) using an algorithm that accepted invalid URLs and improperly decoded others.
Gradle now uses the URI class to parse and decode URLs, but with a fallback to the legacy behavior in the event of an error.
Starting in Gradle 9.0.0, the fallback will be removed, and an error will be thrown instead.
To fix a deprecation warning, invalid URLs that require the legacy behavior should be re-encoded to be valid URLs, such as in the following examples:
| Original Input | New Input | Reasoning |
|---|---|---|
|
|
The |
|
|
Without a scheme, the path is taken as-is, without decoding. |
|
Spaces are not valid in URLs. |
|
|
||
|
|
URIs should be hierarchical. |
Deprecated SelfResolvingDependency
The SelfResolvingDependency interface has been deprecated for removal in Gradle 9.0.0.
This type dates back to the first versions of Gradle, where some dependencies could be resolved independently.
Now, all dependencies should be resolved as part of a dependency graph using a Configuration.
Currently, ProjectDependency and FileCollectionDependency implement this interface.
In Gradle 9.0.0, these types will no longer implement SelfResolvingDependency.
Instead, they will both directly implement Dependency.
As such, the following methods of ProjectDependency and FileCollectionDependency will no longer be available:
-
resolve -
resolve(boolean) -
getBuildDependencies
Consider the following scripts that showcase the deprecated interface and its replacement:
plugins {
id("java-library")
}
dependencies {
implementation(files("bar.txt"))
implementation(project(":foo"))
}
tasks.register("resolveDeprecated") {
// Wire build dependencies (calls getBuildDependencies)
dependsOn(configurations["implementation"].dependencies.toSet())
// Resolve dependencies
doLast {
configurations["implementation"].dependencies.withType<FileCollectionDependency>() {
assert(resolve().map { it.name } == listOf("bar.txt"))
assert(resolve(true).map { it.name } == listOf("bar.txt"))
}
configurations["implementation"].dependencies.withType<ProjectDependency>() {
// These methods do not even work properly.
assert(resolve().map { it.name } == listOf<String>())
assert(resolve(true).map { it.name } == listOf<String>())
}
}
}
tasks.register("resolveReplacement") {
val conf = configurations["runtimeClasspath"]
// Wire build dependencies
dependsOn(conf)
// Resolve dependencies
val files = conf.files
doLast {
assert(files.map { it.name } == listOf("bar.txt", "foo.jar"))
}
}Deprecated members of the org.gradle.util package now report their deprecation
These members will be removed in Gradle 9.0.0.
-
Collection.stringize(Collection)
Upgrading from 8.5 and earlier
Potential breaking changes
Upgrade to JaCoCo 0.8.11
JaCoCo has been updated to 0.8.11.
DependencyAdder renamed to DependencyCollector
The incubating DependencyAdder interface has been renamed to DependencyCollector.
A getDependencies method has been added to the interface that returns all declared dependencies.
Deprecations
Deprecated calling registerFeature using the main source set
Calling registerFeature on the java extension using the main source set is deprecated and will change behavior in Gradle 10.
Currently, features created while calling usingSourceSet with the main source set are initialized differently than features created while calling usingSourceSet with any other source set.
Previously, when using the main source set, new implementation, compileOnly, runtimeOnly, api, and compileOnlyApi configurations were created, and the compile and runtime classpaths of the main source set were configured to extend these configurations.
Starting in Gradle 10, the main source set will be treated like any other source set.
With the java-library plugin applied (or any other plugin that applies the java plugin), calling usingSourceSet with the main source set will throw an exception.
This is because the java plugin already configures a main feature.
Only if the java plugin is not applied will the main source set be permitted when calling usingSourceSet.
Code that currently registers features with the main source set, such as:
plugins {
id("java-library")
}
java {
registerFeature("feature") {
usingSourceSet(sourceSets["main"])
}
}plugins {
id("java-library")
}
java {
registerFeature("feature") {
usingSourceSet(sourceSets.main)
}
}Should instead, create a separate source set for the feature and register the feature with that source set:
plugins {
id("java-library")
}
sourceSets {
create("feature")
}
java {
registerFeature("feature") {
usingSourceSet(sourceSets["feature"])
}
}plugins {
id("java-library")
}
sourceSets {
feature
}
java {
registerFeature("feature") {
usingSourceSet(sourceSets.feature)
}
}Deprecated publishing artifact dependencies with explicit name to Maven repositories
Publishing dependencies with an explicit artifact with a name different from the dependency’s artifactId to Maven repositories has been deprecated.
This behavior is still permitted when publishing to Ivy repositories.
It will result in an error in Gradle 9.0.0.
When publishing to Maven repositories, Gradle will interpret the dependency below as if it were declared with coordinates org:notfoo:1.0:
dependencies {
implementation("org:foo:1.0") {
artifact {
name = "notfoo"
}
}
}dependencies {
implementation("org:foo:1.0") {
artifact {
name = "notfoo"
}
}
}Instead, this dependency should be declared as:
dependencies {
implementation("org:notfoo:1.0")
}dependencies {
implementation("org:notfoo:1.0")
}Deprecated ArtifactIdentifier
The ArtifactIdentifier class has been deprecated for removal in Gradle 9.0.0.
Deprecate mutating DependencyCollector dependencies after observation
Starting in Gradle 10, mutating dependencies sourced from a DependencyCollector, after those dependencies have been observed will result in an error.
The DependencyCollector interface is used to declare dependencies within the test suites DSL.
Consider the following example where a test suite’s dependency is mutated after it is observed:
plugins {
id("java-library")
}
testing.suites {
named<JvmTestSuite>("test") {
dependencies {
// Dependency is declared on a `DependencyCollector`
implementation("com:foo")
}
}
}
configurations.testImplementation {
// Calling `all` here realizes/observes all lazy sources, including the `DependencyCollector`
// from the test suite block. Operations like resolving a configuration similarly realize lazy sources.
dependencies.all {
if (this is ExternalDependency && group == "com" && name == "foo" && version == null) {
// Dependency is mutated after observation
version {
require("2.0")
}
}
}
}In the above example, the build logic uses iteration and mutation to try to set a default version for a particular dependency if the version is not already set.
Build logic like the above example creates challenges in resolving declared dependencies, as reporting tools will display this dependency as if the user declared the version as "2.0", even though they never did.
Instead, the build logic can avoid iteration and mutation by declaring a preferred version constraint on the dependency’s coordinates.
This allows the dependency management engine to use the version declared on the constraint if no other version is declared.
Consider the following example that replaces the above iteration with an indiscriminate preferred version constraint:
dependencies {
constraints {
testImplementation("com:foo") {
version {
prefer("2.0")
}
}
}
}Upgrading from 8.4 and earlier
Potential breaking changes
Upgrade to Kotlin 1.9.20
The embedded Kotlin has been updated to Kotlin 1.9.20.
Changes to Groovy task conventions
The groovy-base plugin is now responsible for configuring source and target compatibility version conventions on all GroovyCompile tasks.
If you are using this task without applying grooy-base, you will have to manually set compatibility versions on these tasks.
In general, the groovy-base plugin should be applied whenever working with Groovy language tasks.
Provider.filter
The type of argument passed to Provider.filter is changed from Predicate to Spec for a more consistent API.
This change should not affect anyone using Provider.filter with a lambda expression.
However, this might affect plugin authors if they don’t use SAM conversions to create a lambda.
Deprecations
Deprecated members of the org.gradle.util package now report their deprecation
These members will be removed in Gradle 9.0.0:
-
VersionNumber.parse(String) -
VersionNumber.compareTo(VersionNumber)
Deprecated depending on resolved configuration
When resolving a Configuration, selecting that same configuration as a variant is sometimes possible.
Configurations should be used for one purpose (resolution, consumption or dependency declarations), so this can only occur when a configuration is marked as both consumable and resolvable.
This can lead to circular dependency graphs, as the resolved configuration is used for two purposes.
To avoid this problem, plugins should mark all resolvable configurations as canBeConsumed=false or use the resolvable(String) configuration factory method when creating configurations meant for resolution.
In Gradle 9.0.0, consuming configurations in this manner will no longer be allowed and result in an error.
Including projects without an existing directory
Gradle will warn if a project is added to the build where the associated projectDir does not exist or is not writable.
Starting with version 9.0.0, Gradle will not run builds if a project directory is missing or read-only.
If you intend to dynamically synthesize projects, make sure to create directories for them as well:
include("project-without-directory")
project(":project-without-directory").projectDir.mkdirs()include 'project-without-directory'
project(":project-without-directory").projectDir.mkdirs()Upgrading from 8.3 and earlier
Potential breaking changes
Upgrade to Kotlin 1.9.10
The embedded Kotlin has been updated to Kotlin 1.9.10.
XML parsing now requires recent parsers
Gradle 8.4 now configures XML parsers with security features enabled. If your build logic depends on old XML parsers that don’t support secure parsing, your build may fail. If you encounter a failure, check and update or remove any dependency on legacy XML parsers.
If you are an Android user, please upgrade your AGP version to 8.3.0 or higher to fix the issue caused by AGP itself. See the Update XML parser used in AGP for Gradle 8.4 compatibility for more details.
If you are unable to upgrade XML parsers coming from your build logic dependencies, you can force the use of the XML parsers built into the JVM.
In OpenJDK, for example, this can be done by adding the following to gradle.properties:
systemProp.javax.xml.parsers.SAXParserFactory=com.sun.org.apache.xerces.internal.jaxp.SAXParserFactoryImpl
systemProp.javax.xml.transform.TransformerFactory=com.sun.org.apache.xalan.internal.xsltc.trax.TransformerFactoryImpl
systemProp.javax.xml.parsers.DocumentBuilderFactory=com.sun.org.apache.xerces.internal.jaxp.DocumentBuilderFactoryImplSee the CVE-2023-42445 advisory for more details and ways to enable secure XML processing on previous Gradle versions.
EAR plugin with customized JEE 1.3 descriptor
Gradle 8.4 forbids external XML entities when parsing XML documents.
If you use the EAR plugin and configure the application.xml descriptor via the EAR plugin’s DSL and customize the descriptor using withXml {} and use asElement{} in the customization block, then the build will now fail for security reasons.
plugins {
id("ear")
}
ear {
deploymentDescriptor {
version = "1.3"
withXml {
asElement()
}
}
}plugins {
id("ear")
}
ear {
deploymentDescriptor {
version = "1.3"
withXml {
asElement()
}
}
}If you happen to use asNode() instead of asElement(), then nothing changes, given asNode() simply ignores external DTDs.
You can work around this by running your build with the javax.xml.accessExternalDTD system property set to http.
On the command line, add this to your Gradle invocation:
-Djavax.xml.accessExternalDTD=httpTo make this workaround persistent, add the following line to your gradle.properties:
systemProp.javax.xml.accessExternalDTD=httpNote that this will enable HTTP access to external DTDs for the whole build JVM. See the JAXP documentation for more details.
Deprecations
Deprecated GenerateMavenPom methods
The following methods on GenerateMavenPom are deprecated and will be removed in Gradle 9.0.0.
They were never intended to be public API.
-
getVersionRangeMapper -
withCompileScopeAttributes -
withRuntimeScopeAttributes
Upgrading from 8.2 and earlier
Potential breaking changes
Deprecated Project.buildDir can cause script compilation failure
With the deprecation of Project.buildDir, buildscripts that are compiled with warnings as errors could fail if the deprecated field is used.
See the deprecation entry for details.
TestLauncher API no longer ignores build failures
The TestLauncher interface is part of the Tooling API, specialized for running tests.
It is a logical extension of the BuildLauncher that can only launch tasks.
A discrepancy has been reported in their behavior: if the same failing test is executed, BuildLauncher will report a build failure, but TestLauncher won’t.
Originally, this was a design decision in order to continue the execution and run the tests in all test tasks and not stop at the first failure.
At the same time, this behavior can be confusing for users as they can experience a failing test in a successful build.
To make the two APIs more uniform, we made TestLauncher also fail the build, which is a potential breaking change.
Tooling API clients should explicitly pass --continue to the build to continue the test execution even if a test task fails.
Fixed variant selection behavior with ArtifactView and ArtifactCollection
The dependency resolution APIs for selecting different artifacts or files (Configuration.getIncoming().artifactView { } and Configuration.getIncoming().getArtifacts()) captured immutable copies of the underlying `Configuration’s attributes to use for variant selection.
If the `Configuration’s attributes were changed after these methods were called, the artifacts selected by these methods could be unexpected.
Consider the case where the set of attributes on a Configuration is changed after an ArtifactView is created:
tasks {
myTask {
inputFiles.from(configurations.classpath.incoming.artifactView {
attributes {
// Add attributes to select a different type of artifact
}
}.files)
}
}
configurations {
classpath {
attributes {
// Add more attributes to the configuration
}
}
}The inputFiles property of myTask uses an artifact view to select a different type of artifact from the configuration classpath.
Since the artifact view was created before the attributes were added to the configuration, Gradle could not select the correct artifact.
Some builds may have worked around this by also putting the additional attributes into the artifact view. This is no longer necessary.
Upgrade to Kotlin 1.9.0
The embedded Kotlin has been updated from 1.8.20 to Kotlin 1.9.0. The Kotlin language and API levels for the Kotlin DSL are still set to 1.8 for backward compatibility. See the release notes for Kotlin 1.8.22 and Kotlin 1.8.21.
Kotlin 1.9 dropped support for Kotlin language and API level 1.3. If you build Gradle plugins written in Kotlin with this version of Gradle and need to support Gradle <7.0 you need to stick to using the Kotlin Gradle Plugin <1.9.0 and configure the Kotlin language and API levels to 1.3. See the Compatibility Matrix for details about other versions.
Eager evaluation of Configuration attributes
Gradle 8.3 updates the org.gradle.libraryelements and org.gradle.jvm.version attributes of JVM Configurations to be present at the time of creation, as opposed to previously, where they were only present after the Configuration had been resolved or consumed.
In particular, the value for org.gradle.jvm.version relies on the project’s configured toolchain, meaning that querying the value for this attribute will finalize the value of the project’s Java toolchain.
Plugins or build logic that eagerly queries the attributes of JVM configurations may now cause the project’s Java toolchain to be finalized earlier than before. Attempting to modify the toolchain after it has been finalized will result in error messages similar to the following:
The value for property 'implementation' is final and cannot be changed any further.
The value for property 'languageVersion' is final and cannot be changed any further.
The value for property 'vendor' is final and cannot be changed any further.This situation may arise when plugins or build logic eagerly query an existing JVM Configuration’s attributes to create a new Configuration with the same attributes. Previously, this logic would have omitted the two above-noted attributes entirely, while now, the same logic will copy the attributes and finalize the project’s Java toolchain. To avoid early toolchain finalization, attribute-copying logic should be updated to query the source Configuration’s attributes lazily:
fun <T> copyAttribute(attribute: Attribute<T>, from: AttributeContainer, to: AttributeContainer) =
to.attributeProvider<T>(attribute, provider { from.getAttribute(attribute)!! })
val source = configurations["runtimeClasspath"].attributes
configurations {
create("customRuntimeClasspath") {
source.keySet().forEach { key ->
copyAttribute(key, source, attributes)
}
}
}def source = configurations.runtimeClasspath.attributes
configurations {
customRuntimeClasspath {
source.keySet().each { key ->
attributes.attributeProvider(key, provider { source.getAttribute(key) })
}
}
}Deprecations
Deprecated Project.buildDir is to be replaced by Project.layout.buildDirectory
The Project.buildDir property is deprecated.
It uses eager APIs and has ordering issues if the value is read in build logic and then later modified.
It could result in outputs ending up in different locations.
It is replaced by a DirectoryProperty found at Project.layout.buildDirectory.
See the ProjectLayout interface for details.
Note that, at this stage, Gradle will not print deprecation warnings if you still use Project.buildDir.
We know this is a big change, and we want to give the authors of major plugins time to stop using it.
Switching from a File to a DirectoryProperty requires adaptations in build logic.
The main impact is that you cannot use the property inside a String to expand it.
Instead, you should leverage the dir and file methods to compute your desired location.
Here is an example of creating a file where the following:
// Returns a java.io.File
file("$buildDir/myOutput.txt")// Returns a java.io.File
file("$buildDir/myOutput.txt")Should be replaced by:
// Compatible with a number of Gradle lazy APIs that accept also java.io.File
val output: Provider<RegularFile> = layout.buildDirectory.file("myOutput.txt")
// If you really need the java.io.File for a non lazy API
output.get().asFile
// Or a path for a lazy String based API
output.map { it.asFile.path }// Compatible with a number of Gradle lazy APIs that accept also java.io.File
Provider<RegularFile> output = layout.buildDirectory.file("myOutput.txt")
// If you really need the java.io.File for a non lazy API
output.get().asFile
// Or a path for a lazy String based API
output.map { it.asFile.path }Here is another example for creating a directory where the following:
// Returns a java.io.File
file("$buildDir/outputLocation")// Returns a java.io.File
file("$buildDir/outputLocation")Should be replaced by:
// Compatible with a number of Gradle APIs that accept a java.io.File
val output: Provider<Directory> = layout.buildDirectory.dir("outputLocation")
// If you really need the java.io.File for a non lazy API
output.get().asFile
// Or a path for a lazy String based API
output.map { it.asFile.path }// Compatible with a number of Gradle APIs that accept a java.io.File
Provider<Directory> output = layout.buildDirectory.dir("outputLocation")
// If you really need the java.io.File for a non lazy API
output.get().asFile
// Or a path for a lazy String based API
output.map { it.asFile.path }Deprecated ClientModule dependencies
ClientModule dependencies are deprecated and will be removed in Gradle 9.0.0.
Client module dependencies were originally intended to allow builds to override incorrect or missing component metadata of external dependencies by defining the metadata locally. This functionality has since been replaced by Component Metadata Rules.
Consider the following client module dependency example:
dependencies {
implementation(module("org:foo:1.0") {
dependency("org:bar:1.0")
module("org:baz:1.0") {
dependency("com:example:1.0")
}
})
}dependencies {
implementation module("org:foo:1.0") {
dependency "org:bar:1.0"
module("org:baz:1.0") {
dependency "com:example:1.0"
}
}
}This can be replaced with the following component metadata rule:
@CacheableRule
abstract class AddDependenciesRule @Inject constructor(val dependencies: List<String>) : ComponentMetadataRule {
override fun execute(context: ComponentMetadataContext) {
listOf("compile", "runtime").forEach { base ->
context.details.withVariant(base) {
withDependencies {
dependencies.forEach {
add(it)
}
}
}
}
}
}dependencies {
components {
withModule<AddDependenciesRule>("org:foo") {
params(listOf(
"org:bar:1.0",
"org:baz:1.0"
))
}
withModule<AddDependenciesRule>("org:baz") {
params(listOf("com:example:1.0"))
}
}
implementation("org:foo:1.0")
}@CacheableRule
abstract class AddDependenciesRule implements ComponentMetadataRule {
List<String> dependencies
@Inject
AddDependenciesRule(List<String> dependencies) {
this.dependencies = dependencies
}
@Override
void execute(ComponentMetadataContext context) {
["compile", "runtime"].each { base ->
context.details.withVariant(base) {
withDependencies {
dependencies.each {
add(it)
}
}
}
}
}
}dependencies {
components {
withModule("org:foo", AddDependenciesRule) {
params([
"org:bar:1.0",
"org:baz:1.0"
])
}
withModule("org:baz", AddDependenciesRule) {
params(["com:example:1.0"])
}
}
implementation "org:foo:1.0"
}Earliest supported Develocity plugin version is 3.13.1
Starting in Gradle 9.0.0, the earliest supported Develocity plugin version is 3.13.1. The plugin versions from 3.0 up to 3.13 will be ignored when applied.
Upgrade to version 3.13.1 or later of the Develocity plugin. You can find the latest available version on the Gradle Plugin Portal. More information on the compatibility can be found here.
Upgrading from 8.1 and earlier
Potential breaking changes
Upgrade to Kotlin 1.8.20
The embedded Kotlin has been updated to Kotlin 1.8.20. For more information, see What’s new in Kotlin 1.8.20.
Note that there is a known issue with Kotlin compilation avoidance that can cause OutOfMemory exceptions in compileKotlin tasks if the compilation classpath contains very large JAR files.
This applies to builds applying the Kotlin plugin v1.8.20 or the kotlin-dsl plugin.
You can work around it by disabling Kotlin compilation avoidance in your gradle.properties file:
kotlin.incremental.useClasspathSnapshot=falseSee KT-57757 for more information.
Upgrade to Groovy 3.0.17
Groovy has been updated to Groovy 3.0.17.
Since the previous version was 3.0.15, the 3.0.16 changes are also included.
Upgrade to Ant 1.10.13
Ant has been updated to Ant 1.10.13.
Since the previous version was 1.10.11, the 1.10.12 changes are also included.
Upgrade to CodeNarc 3.2.0
The default version of CodeNarc has been updated to CodeNarc 3.2.0.
Upgrade to PMD 6.55.0
PMD has been updated to PMD 6.55.0.
Since the previous version was 6.48.0, all changes since then are included.
Upgrade to JaCoCo 0.8.9
JaCoCo has been updated to 0.8.9.
Plugin compatibility changes
A plugin compiled with Gradle >= 8.2 that makes use of the Kotlin DSL functions Project.the<T>(), Project.the(KClass) or Project.configure<T> {} cannot run on Gradle ⇐ 6.1.
Deferred or avoided configuration of some tasks
When performing dependency resolution, Gradle creates an internal representation of the available Configurations. This requires inspecting all configurations and artifacts. Processing artifacts created by tasks causes those tasks to be realized and configured.
This internal representation is now created more lazily, which can change the order in which tasks are configured. Some tasks may never be configured.
This change may cause code paths that relied on a particular order to no longer function, such as conditionally adding attributes to a configuration based on the presence of certain attributes.
This impacted the bnd plugin and JUnit5 build.
We recommend not modifying domain objects (configurations, source sets, tasks, etc) from configuration blocks for other domain objects that may not be configured.
For example, avoid doing something like this:
configurations {
val myConfig = create("myConfig")
}
tasks.register("myTask") {
// This is not safe, as the execution of this block may not occur, or may not occur in the order expected
configurations["myConfig"].attributes {
attribute(Usage.USAGE_ATTRIBUTE, objects.named(Usage::class.java, Usage.JAVA_RUNTIME))
}
}Deprecations
CompileOptions method deprecations
The following methods on CompileOptions are deprecated:
-
getAnnotationProcessorGeneratedSourcesDirectory() -
setAnnotationProcessorGeneratedSourcesDirectory(File) -
setAnnotationProcessorGeneratedSourcesDirectory(Provider<File>)
Current usages of these methods should migrate to DirectoryProperty getGeneratedSourceOutputDirectory()
Using configurations incorrectly
Gradle will now warn at runtime when methods of Configuration are called inconsistently with the configuration’s intended usage.
This change is part of a larger ongoing effort to make the intended behavior of configurations more consistent and predictable and to unlock further speed and memory improvements.
Currently, the following methods should only be called with these listed allowed usages:
-
resolve()- RESOLVABLE configurations only -
files(Closure),files(Spec),files(Dependency…),fileCollection(Spec),fileCollection(Closure),fileCollection(Dependency…)- RESOLVABLE configurations only -
getResolvedConfigurations()- RESOLVABLE configurations only -
defaultDependencies(Action)- DECLARABLE configurations only -
shouldResolveConsistentlyWith(Configuration)- RESOLVABLE configurations only -
disableConsistentResolution()- RESOLVABLE configurations only -
getDependencyConstraints()- DECLARABLE configurations only -
copy(),copy(Spec),copy(Closure),copyRecursive(),copyRecursive(Spec),copyRecursive(Closure)- RESOLVABLE configurations only
Intended usage is noted in the Configuration interface’s Javadoc.
This list is likely to grow in future releases.
Starting in Gradle 9.0.0, using a configuration inconsistently with its intended usage will be prohibited.
Also note that although it is not currently restricted, the getDependencies() method is only intended for use with DECLARABLE configurations.
The getAllDependencies() method, which retrieves all declared dependencies on a configuration and any superconfigurations, will not be restricted to any particular usage.
Deprecated access to plugin conventions
The concept of conventions is outdated and superseded by extensions to provide custom DSLs.
To reflect this in the Gradle API, the following elements are deprecated:
-
org.gradle.api.Project.getConvention() -
org.gradle.api.plugins.Convention -
org.gradle.api.internal.HasConvention
Gradle Core plugins still register their conventions in addition to their extensions for backwards compatibility.
It is deprecated to access any of these conventions and their properties. Doing so will now emit a deprecation warning. This will become an error in Gradle 9.0.0. You should prefer accessing the extensions and their properties instead.
For specific examples, see the next sections.
Prominent community plugins already migrated to using extensions to provide custom DSLs. Some of them still register conventions for backward compatibility. Registering conventions does not emit a deprecation warning yet to provide a migration window. Future Gradle versions will do.
Also note that Plugins compiled with Gradle ⇐ 8.1 that make use of the Kotlin DSL functions Project.the<T>(), Project.the(KClass) or Project.configure<T> {} will emit a deprecation warning when run on Gradle >= 8.2.
To fix this these plugins should be recompiled with Gradle >= 8.2 or changed to access extensions directly using extensions.getByType<T>() instead.
Deprecated base plugin conventions
The convention properties contributed by the base plugin have been deprecated and scheduled for removal in Gradle 9.0.0.
For more context, see the section about plugin convention deprecation.
The conventions are replaced by the base { } configuration block backed by BasePluginExtension.
The old convention object defines the distsDirName, libsDirName, and archivesBaseName properties with simple getter and setter methods.
Those methods are available in the extension only to maintain backward compatibility.
Build scripts should solely use the properties of type Property:
plugins {
base
}
base {
archivesName.set("gradle")
distsDirectory.set(layout.buildDirectory.dir("custom-dist"))
libsDirectory.set(layout.buildDirectory.dir("custom-libs"))
}plugins {
id 'base'
}
base {
archivesName = "gradle"
distsDirectory = layout.buildDirectory.dir('custom-dist')
libsDirectory = layout.buildDirectory.dir('custom-libs')
}Deprecated application plugin conventions
The convention properties the application plugin contributed have been deprecated and scheduled for removal in Gradle 9.0.0.
For more context, see the section about plugin convention deprecation.
The following code will now emit deprecation warnings:
plugins {
application
}
applicationDefaultJvmArgs = listOf("-Dgreeting.language=en") // Accessing a conventionplugins {
id 'application'
}
applicationDefaultJvmArgs = ['-Dgreeting.language=en'] // Accessing a conventionThis should be changed to use the application { } configuration block, backed by JavaApplication, instead:
plugins {
application
}
application {
applicationDefaultJvmArgs = listOf("-Dgreeting.language=en")
}plugins {
id 'application'
}
application {
applicationDefaultJvmArgs = ['-Dgreeting.language=en']
}Deprecated java plugin conventions
The convention properties the java plugin contributed have been deprecated and scheduled for removal in Gradle 9.0.0.
For more context, see the section about plugin convention deprecation.
The following code will now emit deprecation warnings:
plugins {
id("java")
}
configure<JavaPluginConvention> { // Accessing a convention
sourceCompatibility = JavaVersion.VERSION_18
}plugins {
id 'java'
}
sourceCompatibility = 18 // Accessing a conventionThis should be changed to use the java { } configuration block, backed by JavaPluginExtension, instead:
plugins {
id("java")
}
java {
sourceCompatibility = JavaVersion.VERSION_18
}plugins {
id 'java'
}
java {
sourceCompatibility = JavaVersion.VERSION_18
}Deprecated war plugin conventions
The convention properties contributed by the war plugin have been deprecated and scheduled for removal in Gradle 9.0.0.
For more context, see the section about plugin convention deprecation.
The following code will now emit deprecation warnings:
plugins {
id("war")
}
configure<WarPluginConvention> { // Accessing a convention
webAppDirName = "src/main/webapp"
}plugins {
id 'war'
}
webAppDirName = 'src/main/webapp' // Accessing a conventionClients should configure the war task directly.
Also, tasks.withType(War.class).configureEach(…) can be used to configure each task of type War.
plugins {
id("war")
}
tasks.war {
webAppDirectory.set(file("src/main/webapp"))
}plugins {
id 'war'
}
war {
webAppDirectory = file('src/main/webapp')
}Deprecated ear plugin conventions
The convention properties contributed by the ear plugin have been deprecated and scheduled for removal in Gradle 9.0.0.
For more context, see the section about plugin convention deprecation.
The following code will now emit deprecation warnings:
plugins {
id("ear")
}
configure<EarPluginConvention> { // Accessing a convention
appDirName = "src/main/app"
}plugins {
id 'ear'
}
appDirName = 'src/main/app' // Accessing a conventionClients should configure the ear task directly.
Also, tasks.withType(Ear.class).configureEach(…) can be used to configure each task of type Ear.
plugins {
id("ear")
}
tasks.ear {
appDirectory.set(file("src/main/app"))
}plugins {
id 'ear'
}
ear {
appDirectory = file('src/main/app') // use application metadata found in this folder
}Deprecated project-report plugin conventions
The convention properties contributed by the project-reports plugin have been deprecated and scheduled for removal in Gradle 9.0.0.
For more context, see the section about plugin convention deprecation.
The following code will now emit deprecation warnings:
plugins {
`project-report`
}
configure<ProjectReportsPluginConvention> {
projectReportDirName = "custom" // Accessing a convention
}plugins {
id 'project-report'
}
projectReportDirName = "custom" // Accessing a conventionConfigure your report task instead:
plugins {
`project-report`
}
tasks.withType<HtmlDependencyReportTask>() {
projectReportDirectory.set(project.layout.buildDirectory.dir("reports/custom"))
}plugins {
id 'project-report'
}
tasks.withType(HtmlDependencyReportTask) {
projectReportDirectory = project.layout.buildDirectory.dir("reports/custom")
}Configuration method deprecations
The following method on Configuration is deprecated for removal:
-
getAll()
Obtain the set of all configurations from the project’s configurations container instead.
Relying on automatic test framework implementation dependencies
In some cases, Gradle will load JVM test framework dependencies from the Gradle distribution to execute tests. This existing behavior can lead to test framework dependency version conflicts on the test classpath. To avoid these conflicts, this behavior is deprecated and will be removed in Gradle 9.0.0. Tests using TestNG are unaffected.
To prepare for this change in behavior, either declare the required dependencies explicitly or migrate to Test Suites, where these dependencies are managed automatically.
Builds that use test suites will not be affected by this change. Test suites manage the test framework dependencies automatically and do not require dependencies to be explicitly declared. See the user manual for further information on migrating to test suites.
In the absence of test suites, dependencies must be manually declared on the test runtime classpath:
-
If using JUnit 5, an explicit
runtimeOnlydependency onjunit-platform-launcheris required in addition to the existingimplementationdependency on the test engine. -
If using JUnit 4, only the existing
implementationdependency onjunit4 is required. -
If using JUnit 3, a test
runtimeOnlydependency onjunit4 is required in addition to acompileOnlydependency onjunit3.
dependencies {
// If using JUnit Jupiter
testImplementation("org.junit.jupiter:junit-jupiter:5.9.2")
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
// If using JUnit Vintage
testCompileOnly("junit:junit:4.13.2")
testRuntimeOnly("org.junit.vintage:junit-vintage-engine:5.9.2")
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
// If using JUnit 4
testImplementation("junit:junit:4.13.2")
// If using JUnit 3
testCompileOnly("junit:junit:3.8.2")
testRuntimeOnly("junit:junit:4.13.2")
}dependencies {
// If using JUnit Jupiter
testImplementation 'org.junit.jupiter:junit-jupiter:5.9.2'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
// If using JUnit Vintage
testCompileOnly 'junit:junit:4.13.2'
testRuntimeOnly 'org.junit.vintage:junit-vintage-engine:5.9.2'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
// If using JUnit 4
testImplementation 'junit:junit:4.13.2'
// If using JUnit 3
testCompileOnly 'junit:junit:3.8.2'
testRuntimeOnly 'junit:junit:4.13.2'
}BuildIdentifier and ProjectComponentSelector method deprecations
The following methods on BuildIdentifier are deprecated:
-
getName() -
isCurrentBuild()
You could use these methods to distinguish between different project components with the same name but from different builds. However, for certain composite build setups, these methods do not provide enough information to guarantee uniqueness.
Current usages of these methods should migrate to BuildIdentifier.getBuildPath().
Similarly, the method ProjectComponentSelector.getBuildName() is deprecated.
Use ProjectComponentSelector.getBuildPath() instead.
Upgrading from 8.0 and earlier
CACHEDIR.TAG files are created in global cache directories
Gradle now emits a CACHEDIR.TAG file in some global cache directories, as specified in Cache marking.
This may cause these directories to no longer be searched or backed up by some tools. To disable it, use the following code in an init script in the Gradle User Home:
beforeSettings {
caches {
// Disable cache marking for all caches
markingStrategy.set(MarkingStrategy.NONE)
}
}beforeSettings { settings ->
settings.caches {
// Disable cache marking for all caches
markingStrategy = MarkingStrategy.NONE
}
}Configuration cache options renamed
In this release, the configuration cache feature was promoted from incubating to stable.
As such, all properties originally mentioned in the feature documentation (which had an unsafe part in their names, e.g., org.gradle.unsafe.configuration-cache) were renamed, in some cases, by removing the unsafe part of the name.
| Incubating property | Finalized property |
|---|---|
|
|
|
|
|
|
Note that the original org.gradle.unsafe.configuration-cache… properties continue to be honored in this release,
and no warnings will be produced if they are used, but they will be deprecated and removed in a future release.
Potential breaking changes
Kotlin DSL scripts emit compilation warnings
Compilation warnings from Kotlin DSL scripts are printed to the console output. For example, the use of deprecated APIs in Kotlin DSL will emit warnings each time the script is compiled.
This is a potentially breaking change if you are consuming the console output of Gradle builds.
Configuring Kotlin compiler options with the kotlin-dsl plugin applied
If you are configuring custom Kotlin compiler options on a project with the kotlin-dsl plugin applied you might encounter a breaking change.
In previous Gradle versions, the kotlin-dsl plugin was adding required compiler arguments on afterEvaluate {}.
Now that the Kotlin Gradle Plugin provides lazy configuration properties, our kotlin-dsl plugin switched to adding required compiler arguments to the lazy properties directly.
As a consequence, if you were setting freeCompilerArgs the kotlin-dsl plugin is now failing the build because its required compiler arguments are overridden by your configuration.
plugins {
`kotlin-dsl`
}
tasks.withType(KotlinCompile::class).configureEach {
kotlinOptions { // Deprecated non-lazy configuration options
freeCompilerArgs = listOf("-Xcontext-receivers")
}
}With the configuration above you would get the following build failure:
* What went wrong
Execution failed for task ':compileKotlin'.
> Kotlin compiler arguments of task ':compileKotlin' do not work for the `kotlin-dsl` plugin. The 'freeCompilerArgs' property has been reassigned. It must instead be appended to. Please use 'freeCompilerArgs.addAll(\"your\", \"args\")' to fix this.You must change this to adding your custom compiler arguments to the lazy configuration properties of the Kotlin Gradle Plugin for them to be appended to the ones required by the kotlin-dsl plugin:
plugins {
`kotlin-dsl`
}
tasks.withType(KotlinCompile::class).configureEach {
compilerOptions { // New lazy configuration options
freeCompilerArgs.addAll("-Xcontext-receivers")
}
}If you were already adding to freeCompilerArgs instead of setting its value, you should not experience a build failure.
New API introduced may clash with existing Gradle DSL code
When a new property or method is added to an existing type in the Gradle DSL, it may clash with names already used in user code.
When a name clash occurs, one solution is to rename the element in user code.
This is a non-exhaustive list of API additions in 8.1 that may cause name collisions with existing user code.
Using unsupported API to start external processes at configuration time is no longer allowed with the configuration cache enabled
Since Gradle 7.5, using Project.exec, Project.javaexec, and standard Java and Groovy APIs to run external processes at configuration time has been considered an error only if the feature preview STABLE_CONFIGURATION_CACHE was enabled.
With the configuration cache promotion to a stable feature in Gradle 8.1, this error is detected regardless of the feature preview status.
The configuration cache chapter has more details to help with the migration to the new provider-based APIs to execute external processes at configuration time.
Builds that do not use the configuration cache, or only start external processes at execution time are not affected by this change.
Deprecations
Mutating core plugin configuration usage
The allowed usage of a configuration should be immutable after creation.
Mutating the allowed usage on a configuration created by a Gradle core plugin is deprecated.
This includes calling any of the following Configuration methods:
-
setCanBeConsumed(boolean) -
setCanBeResolved(boolean)
These methods now emit deprecation warnings on these configurations, except for certain special cases which make allowances for the existing behavior of popular plugins.
This rule does not yet apply to detached configurations or configurations created in buildscripts and third-party plugins.
Calling setCanBeConsumed(false) on apiElements or runtimeElements is not yet deprecated in order to avoid warnings that would be otherwise emitted when using select popular third-party plugins.
This change is part of a larger ongoing effort to make the intended behavior of configurations more consistent and predictable, and to unlock further speed and memory improvements in this area of Gradle.
The ability to change the allowed usage of a configuration after creation will be removed in Gradle 9.0.0.
Reserved configuration names
Configuration names "detachedConfiguration" and "detachedConfigurationX" (where X is any integer) are reserved for internal use when creating detached configurations.
The ability to create non-detached configurations with these names will be removed in Gradle 9.0.0.
Calling select methods on the JavaPluginExtension without the java component present
Starting in Gradle 8.1, calling any of the following methods on JavaPluginExtension without
the presence of the default java component is deprecated:
-
withJavadocJar() -
withSourcesJar() -
consistentResolution(Action)
This java component is added by the JavaPlugin, which is applied by any of the Gradle JVM plugins including:
-
java-library -
application -
groovy -
scala
Starting in Gradle 9.0.0, calling any of the above listed methods without the presence of the default java component will become an error.
WarPlugin#configureConfiguration(ConfigurationContainer)
Starting in Gradle 8.1, calling WarPlugin#configureConfiguration(ConfigurationContainer) is deprecated.
This method was intended for internal use and was never intended to be used as part of the public interface.
Starting in Gradle 9.0.0, this method will be removed without replacement.
Relying on conventions for custom Test tasks
By default, when applying the java plugin, the testClassesDirs and classpath of all Test tasks have the same convention.
Unless otherwise changed, the default behavior is to execute the tests from the default test TestSuite by configuring the task with the classpath and testClassesDirs from the test suite.
This behavior will be removed in Gradle 9.0.0.
While this existing default behavior is correct for the use case of executing the default unit test suite under a different environment, it does not support the use case of executing an entirely separate set of tests.
If you wish to continue including these tests, use the following code to avoid the deprecation warning in 8.1 and prepare for the behavior change in 9.0.0. Alternatively, consider migrating to test suites.
val test by testing.suites.existing(JvmTestSuite::class)
tasks.named<Test>("myTestTask") {
testClassesDirs = files(test.map { it.sources.output.classesDirs })
classpath = files(test.map { it.sources.runtimeClasspath })
}tasks.myTestTask {
testClassesDirs = testing.suites.test.sources.output.classesDirs
classpath = testing.suites.test.sources.runtimeClasspath
}Modifying Gradle Module Metadata after a publication has been populated
Altering the GMM (e.g., changing a component configuration variants) after a Maven or Ivy publication has been populated from their components is now deprecated. This feature will be removed in Gradle 9.0.0.
Eager population of the publication can happen if the following methods are called:
-
Maven
-
Ivy
Previously, the following code did not generate warnings, but it created inconsistencies between published artifacts:
publishing {
publications {
create<MavenPublication>("maven") {
from(components["java"])
}
create<IvyPublication>("ivy") {
from(components["java"])
}
}
}
// These calls eagerly populate the Maven and Ivy publications
(publishing.publications["maven"] as MavenPublication).artifacts
(publishing.publications["ivy"] as IvyPublication).artifacts
val javaComponent = components["java"] as AdhocComponentWithVariants
javaComponent.withVariantsFromConfiguration(configurations["apiElements"]) { skip() }
javaComponent.withVariantsFromConfiguration(configurations["runtimeElements"]) { skip() }publishing {
publications {
maven(MavenPublication) {
from components.java
}
ivy(IvyPublication) {
from components.java
}
}
}
// These calls eagerly populate the Maven and Ivy publications
publishing.publications.maven.artifacts
publishing.publications.ivy.artifacts
components.java.withVariantsFromConfiguration(configurations.apiElements) { skip() }
components.java.withVariantsFromConfiguration(configurations.runtimeElements) { skip() }In this example, the Maven and Ivy publications will contain the main JAR artifacts for the project, whereas the GMM module file will omit them.
Running tests on JVM versions 6 and 7
Running JVM tests on JVM versions older than 8 is deprecated. Testing on these versions will become an error in Gradle 9.0.0
Applying Kotlin DSL precompiled scripts published with Gradle < 6.0
Applying Kotlin DSL precompiled scripts published with Gradle < 6.0 is deprecated. Please use a version of the plugin published with Gradle >= 6.0.
Applying the kotlin-dsl together with Kotlin Gradle Plugin < 1.8.0
Applying the kotlin-dsl together with Kotlin Gradle Plugin < 1.8.0 is deprecated.
Please let Gradle control the version of kotlin-dsl by removing any explicit kotlin-dsl version constraints from your build logic.
This will let the kotlin-dsl plugin decide which version of the Kotlin Gradle Plugin to use.
If you explicitly declare which version of the Kotlin Gradle Plugin to use for your build logic, update it to >= 1.8.0.
Accessing libraries or bundles from dependency version catalogs in the plugins {} block of a Kotlin script
Accessing libraries or bundles from dependency version catalogs in the plugins {} block of a Kotlin script is deprecated.
Please only use versions or plugins from dependency version catalogs in the plugins {} block.
Using ValidatePlugins task without a Java Toolchain
Using a task of type ValidatePlugins without applying the Java Toolchains plugin
—or any other Java plugin that applies the Java Toolchains plugin—was deprecated in Gradle 8.1 and is now an error in Gradle 9.0.0.
Deprecated members of the org.gradle.util package now report their deprecation
These members will be removed in Gradle 9.0.0.
-
WrapUtil.toDomainObjectSet(…) -
GUtil.toCamelCase(…) -
GUtil.toLowerCase(…) -
ConfigureUtil
Deprecated JVM vendor IBM Semeru
The enum constant JvmVendorSpec.IBM_SEMERU is now deprecated and will be removed in Gradle 9.0.0.
Please replace it by its equivalent JvmVendorSpec.IBM to avoid warnings and potential errors in the next major version release.
Setting custom build layout on StartParameter and GradleBuild
Following the related previous deprecation of the behaviour in Gradle 7.1, it is now also deprecated to use related StartParameter and GradleBuild properties. These properties will be removed in Gradle 9.0.0.
Setting custom build file using buildFile property in GradleBuild task has been deprecated.
Please use the dir property instead to specify the root of the nested build. Alternatively, consider using one of the recommended alternatives for GradleBuild task.
Setting custom build layout using StartParameter methods setBuildFile(File) and setSettingsFile(File) as well as the counterpart getters getBuildFile() and getSettingsFile() have been deprecated.
Please use standard locations for settings and build files:
-
settings file in the root of the build
-
build file in the root of each subproject
Deprecated org.gradle.cache.cleanup property
The org.gradle.cache.cleanup property in gradle.properties under Gradle User Home has been deprecated.
Please use the cache cleanup DSL instead to disable or modify the cleanup configuration.
Since the org.gradle.cache.cleanup property may still be needed for older versions of Gradle, this property may still be present and no deprecation warnings will be printed as long as it is also configured via the DSL.
The DSL value will always take preference over the org.gradle.cache.cleanup property.
If the desired configuration is to disable cleanup for older versions of Gradle (using org.gradle.cache.cleanup), but to enable cleanup with the default values for Gradle versions at or above Gradle 8, then cleanup should be configured to use Cleanup.DEFAULT:
if (GradleVersion.current() >= GradleVersion.version("8.0")) {
apply(from = "gradle8/cache-settings.gradle.kts")
}if (GradleVersion.current() >= GradleVersion.version('8.0')) {
apply from: "gradle8/cache-settings.gradle"
}beforeSettings {
caches {
cleanup.set(Cleanup.DEFAULT)
}
}beforeSettings { settings ->
settings.caches {
cleanup = Cleanup.DEFAULT
}
}Deprecated using relative paths to specify Java executables
Using relative file paths to point to Java executables is now deprecated and will become an error in Gradle 10. This is done to reduce confusion about what such relative paths should resolve against.
Calling Task.getConvention(), Task.getExtensions() from a task action
Calling Task.getConvention(), Task.getExtensions() from a task action at execution time is now deprecated and will be made an error in Gradle 9.0.0.
See the configuration cache chapter for details on how to migrate these usages to APIs that are supported by the configuration cache.
Deprecated running test task successfully when no test executed
Running the Test task successfully when no test was executed is now deprecated and will become an error in Gradle 9.
Note that it is not an error when no test sources are present, in this case the test task is simply skipped.
It is only an error when test sources are present, but no test was selected for execution.
This is changed to avoid accidental successful test runs due to erroneous configuration.
Changes in the IDE integration
Workaround for false positive errors shown in Kotlin DSL plugins {} block using version catalog is not needed anymore
Version catalog accessors for plugin aliases in the plugins {} block aren’t shown as errors in IntelliJ IDEA and Android Studio Kotlin script editor anymore.
If you were using the @Suppress("DSL_SCOPE_VIOLATION") annotation as a workaround, you can now remove it.
If you were using the Gradle Libs Error Suppressor IntelliJ IDEA plugin, you can now uninstall it.
After upgrading Gradle to 8.1 you will need to clear the IDE caches and restart.
Upgrading from Gradle 7.x to 8.0
This chapter provides the information you need to migrate your Gradle 7.x builds to Gradle 8.0. For migrating from Gradle 6.x, see the older migration guide first.
We recommend the following steps for all users:
-
Try running
gradle help --scanand view the deprecations view of the generated Build Scan.
This is so that you can see any deprecation warnings that apply to your build.
Alternatively, you can run
gradle help --warning-mode=allto see the deprecations in the console, though it may not report as much detailed information. -
Update your plugins.
Some plugins will break with this new version of Gradle, for example because they use internal APIs that have been removed or changed. The previous step will help you identify potential problems by issuing deprecation warnings when a plugin does try to use a deprecated part of the API.
-
Run
gradle :wrapper --gradle-version 8.0.2to update the project to 8.0.2. -
Try to run the project and debug any errors using the Troubleshooting Guide.
Upgrading from 7.6 and earlier
Warnings that are now errors
Referencing tasks in an included build with finalizedBy, mustRunAfter or shouldRunAfter
Referencing tasks contained in an included build with any of the following methods now results in an execution time error:
-
finalizedBy -
mustRunAfter -
shouldRunAfter
Creating TAR trees from resources without backing files
Creating a TAR tree from a resource with no backing file is no longer supported.
Instead, convert the resource to a file and use project.tarTree() on the file.
For more information, see TAR trees from resources without backing files.
Using invalid Java toolchain specifications
Usage of invalid Java toolchain specifications is no longer supported. Related build errors can be avoided by making sure that language version is set on all toolchain specifications. See user manual for more information.
Using automatic toolchain downloading without having a repository configured
Automatic toolchain downloading without explicitly providing repositories to use is no longer supported. See user manual for more information.
Changing test framework after setting test framework options is now an error
When configuring the built-in test task for Java, Groovy, and Scala projects, Gradle no longer allows you to
change the test framework used by the Test task after configuring options.
This was deprecated since it silently discarded configuration in some cases.
The following code example now produces an error:
test {
options {
}
useJUnitPlatform()
}Instead, you can:
-
set the test framework before configuring options
-
migrate to the JVM Test Suite Plugin
test {
// select test framework before configuring options
useJUnitPlatform()
options {
}
}
Additionally, setting the test framework multiple times to the same framework now accumulates any options that might be set on the framework. Previously, each time the framework was set, it would cause the framework options to be overwritten.
The following code now results in both the "foo" and "bar" tags to be included for the test task:
test {
useJUnitPlatform {
includeTags("foo")
}
}
tasks.withType(Test).configureEach {
// previously, this would overwrite the included tags to only include "bar"
useJUnitPlatform {
includeTags("bar")
}
}Removed APIs
Legacy ArtifactTransform API
The legacy ArtifactTransform API has been removed.
For more information, see Registering artifact transforms extending ArtifactTransform.
Legacy IncrementalTaskInputs API
The legacy IncrementalTaskInputs API has been removed.
For more information, see IncrementalTaskInputs type is deprecated.
This change also affects Kotlin Gradle Plugin and Android Gradle Plugin.
With Gradle 8.0 you should use Kotlin Gradle Plugin 1.6.10 or later and Android Gradle Plugin 7.3.0 with android.experimental.legacyTransform.forceNonIncremental=true property or later.
Legacy AntlrSourceVirtualDirectory API
The legacy AntlrSourceVirtualDirectory API has been removed.
This change affects the antlr plugin.
In Gradle 8.0 and above, use the AntlrSourceDirectorySet source set extension instead.
JvmPluginsHelper
A deprecated configureDocumentationVariantWithArtifact method of the JvmPluginsHelper class which did not require a FileResolver has been removed.
This was an internal API, but may have been accessed by plugins.
Supply a FileResolver to the overloaded version of this method instead.
Groovydoc API Cleanup
The deprecated isIncludePrivate property of the Groovydoc task type has been removed.
Use the access property along with the GroovydocAccess#PRIVATE constant instead.
JavaApplication API Cleanup
The deprecated mainClassName property of the JavaApplication interface has been removed.
Use the mainClass property instead.
DefaultDomainObjectSet API Cleanup
The deprecated DefaultDomainObjectSet(Class) constructor has been removed.
This was an internal API, but may have been used by plugins.
JacocoPluginExtension API Cleanup
The deprecated reportsDir property of the JacocoPluginExtension has been removed.
Use the reportsDirectory property instead.
DependencyInsightReportTask API Cleanup
The deprecated legacyShowSinglePathToDependnecy property of the DependencyInsightReportTask task type has been removed.
Use the showSinglePathToDependency property instead.
Report and TestReport API Cleanup
The deprecated destination, and enabled properties of the Report type have been removed.
Use the outputLocation and required properties instead.
The deprecated testResultDirs property of the TestReport task type has been removed.
Use the testResults property instead.
JacocoMerge Task Removed
The deprecated JacocoMerge task type has been removed.
The same functionality is also available on the JacocoReport task.
JavaExec API Cleanup
The deprecated main property of the JavaExec task type has been removed.
Use the mainClass property instead.
AbstractExecTask API Cleanup
The deprecated execResult getter property of the AbstractExecTask task type has been removed.
Use the executionResult getter property instead.
AbstractTestTask API Cleanup
The deprecated binResultsDir property of the AbstractTestTask task type has been removed.
Use the binaryResultsDirectory property instead.
SourceDirectorySet API Cleanup
The deprecated outputDir property of the SourceDirectorySet type has been removed.
Use the destinationDirectory property instead.
VersionCatalog API Cleanup
The deprecated findDependency(String) method and dependencyAliases property of the VersionCatalog type have been removed.
Use the findLibrary(String) method and libraryAliases property instead.
The deprecated alias(String) method of the VersionCatalogBuilder type has been removed.
Use the library(String, String, String) or plugin(String, String) methods instead.
WorkerExecutor API Cleanup
The deprecated submit(Class, Action) method of the WorkerExecutor interface has been removed.
Instead, obtain a WorkQueue via the noIsolation(), classLoaderIsolation(), and processIsolation(), methods and use the submit(Class, Action) method on the WorkQueue instead.
DependencySubstitution API Cleanup
The deprecated with(ComponentSelector) method of the DependencySubstitution type’s inner Substitution type’s has been removed.
Use the using(ComponentSelector) method instead.
AbstractArchiveTask API Cleanup
The deprecated appendix, archiveName, archivePath, baseName, classifier, destinationDir, extension and version properties of the AbstractArchiveTask task type have been removed.
Use the archiveAppendix, archiveFileName , archiveFile, archiveBaseName, archiveClassifier, destinationDirectory, archiveExtension and archiveVersion properties instead.
AbstractCompile API Deprecations
The previously deprecated destinationDir property of the AbstractCompile remains deprecated, and will now emit a deprecation warning upon use.
It is now scheduled for removal in Gradle 9.0.0.
Use the destinationDirectory property instead.
ResolvedComponentResult API Cleanup
The deprecated getVariant method of the ResolvedComponentResult interface has been removed.
Use the getVariants method instead.
Code quality plugins API Cleanup
The deprecated antBuilder property of the Checkstyle, CodeNarc and Pmd task types has been removed.
Use the Project type’s ant property instead.
Usage API Cleanup
The deprecated public fields JAVA_API_CLASSES, JAVA_API_JARS, JAVA_RUNTIME_CLASSES, JAVA_RUNTIME_JARS and JAVA_RUNTIME_RESOURCES of the Usage type have been removed.
The values are available in the internal JavaEcosystemSupport class for compatibility with previously published modules, but should not be used for any new publishing.
ExternalDependency API Cleanup
The deprecated setForce(boolean) method of the ExternalDependency interface has been removed.
Use the version(Action) method to configure strict versions instead.
Build-scan method removed from Kotlin DSL
The deprecated build-scan plugin application method has been removed from the Kotlin DSL.
Use the gradle-enterprise method instead.
Configuration extension methods removed from Kotlin DSL
The Kotlin DSL added specialized extension methods for NamedDomainObjectProvider<Configuration> that are available when looking up a configuration by name.
These extensions allowed builds to access some properties of a Configuration when using an instance of NamedDomainObjectProvider<Configuration> directly:
configurations.compileClasspath.files // equivalent to configurations.compileClasspath.get().files
configurations.compileClasspath.singleFile // equivalent to configurations.compileClasspath.get().singleFileAll of these extensions have been removed from the API, but the methods are still available for plugins compiled against older versions of Gradle.
-
NamedDomainObjectProvider<Configuration>.addToAntBuilder
-
NamedDomainObjectProvider<Configuration>.all
-
NamedDomainObjectProvider<Configuration>.allArtifacts
-
NamedDomainObjectProvider<Configuration>.allDependencies
-
NamedDomainObjectProvider<Configuration>.allDependencyConstraints
-
NamedDomainObjectProvider<Configuration>.artifacts
-
NamedDomainObjectProvider<Configuration>.asFileTree
-
NamedDomainObjectProvider<Configuration>.asPath
-
NamedDomainObjectProvider<Configuration>.attributes
-
NamedDomainObjectProvider<Configuration>.buildDependencies
-
NamedDomainObjectProvider<Configuration>.contains
-
NamedDomainObjectProvider<Configuration>.copy
-
NamedDomainObjectProvider<Configuration>.copyRecursive
-
NamedDomainObjectProvider<Configuration>.defaultDependencies
-
NamedDomainObjectProvider<Configuration>.dependencies
-
NamedDomainObjectProvider<Configuration>.dependencyConstraints
-
NamedDomainObjectProvider<Configuration>.description
-
NamedDomainObjectProvider<Configuration>.exclude
-
NamedDomainObjectProvider<Configuration>.excludeRules
-
NamedDomainObjectProvider<Configuration>.extendsFrom
-
NamedDomainObjectProvider<Configuration>.fileCollection
-
NamedDomainObjectProvider<Configuration>.files
-
NamedDomainObjectProvider<Configuration>.filter
-
NamedDomainObjectProvider<Configuration>.getTaskDependencyFromProjectDependency
-
NamedDomainObjectProvider<Configuration>.hierarchy
-
NamedDomainObjectProvider<Configuration>.incoming
-
NamedDomainObjectProvider<Configuration>.isCanBeConsumed
-
NamedDomainObjectProvider<Configuration>.isCanBeResolved
-
NamedDomainObjectProvider<Configuration>.isEmpty
-
NamedDomainObjectProvider<Configuration>.isTransitive
-
NamedDomainObjectProvider<Configuration>.isVisible
-
NamedDomainObjectProvider<Configuration>.minus
-
NamedDomainObjectProvider<Configuration>.outgoing
-
NamedDomainObjectProvider<Configuration>.plus
-
NamedDomainObjectProvider<Configuration>.resolutionStrategy
-
NamedDomainObjectProvider<Configuration>.resolve
-
NamedDomainObjectProvider<Configuration>.resolvedConfiguration
-
NamedDomainObjectProvider<Configuration>.setDescription
-
NamedDomainObjectProvider<Configuration>.setExtendsFrom
-
NamedDomainObjectProvider<Configuration>.setTransitive
-
NamedDomainObjectProvider<Configuration>.singleFile
-
NamedDomainObjectProvider<Configuration>.state
-
NamedDomainObjectProvider<Configuration>.withDependencies
You should prefer to directly reference the methods from Configuration.
Potential breaking changes
JavaForkOptions getJvmArgs() and getAllJvmArgs() return immutable lists
The lists of JVM arguments retrieved from the JavaForkOptions interface are now immutable.
Previously, modifications of the returned list were silently ignored.
Nullable annotations better reflect actual nullability of API
In some APIs, nullability was not correctly annotated and APIs that did allow null or returned null were marked as non-null. In Java or Groovy, this mismatch did not cause problems at compile time. In Kotlin, this mismatch made valid code difficult to write because the language would not allow you to pass null.
One particular example was returning null from a Provider#map or Provider#flatMap. In both APIs, Gradle allows you to return null, but in the Kotlin DSL this was considered illegal.
This correction may cause compilation errors in code that expected non-null.
Plugins, tasks and extension classes are abstract
Most public classes for plugins, tasks and extensions have been made abstract. This was done to make it easier to remove boilerplate from Gradle’s implementation.
Plugins that are affected by this change should make their classes abstract as well.
Gradle uses runtime class decoration to implement abstract methods as long as the object is instantiated via ObjectFactory or some other automatic mechanism (like managed properties).
Those methods should never be directly implemented.
Wrapper task configuration
If gradle-wrapper.properties contains the distributionSha256Sum property, you must specify a sum.
You can specify a sum in the wrapped task configuration or with the --gradle-distribution-sha256-sum task option.
Changes in the AbstractCodeQualityPlugin class
The deprecated AbstractCodeQualityPlugin.getJavaPluginConvention() method was removed in Gradle 8.0.
You should use JavaPluginExtension instead.
Remove implicit --add-opens for Gradle workers
Before Gradle 8.0, Gradle workers on JDK9+ automatically opened JDK modules java.base/java.util and java.base/java.lang by passing --add-opens CLI arguments.
This enabled code executed in a Gradle worker to perform deep reflection on JDK internals without warning or failing.
Workers no longer use these implicit arguments.
This affects all internal Gradle workers, which are used for a variety of tasks:
-
code-quality plugins (Checkstyle, CodeNarc, Pmd)
-
ScalaDoc
-
AntlrTask
-
JVM compiler daemons
-
tasks executed using process isolation via the Worker API
New warnings and errors may appear in any tools, extensions, or plugins that perform deep reflection into JDK internals with the worker API.
These errors can be resolved by updating the violating code or dependency. Updates may include:
-
code-quality tools
-
annotation processors
-
any Gradle plugins which use the worker API
For some examples of possible error or warning outputs which may arise due to this change, see Removes implicit --add-opens for test workers.
SourceSet classesDirs no longer depends upon the entire SourceSet as a task dependency
Prior to Gradle 8.0, the task dependencies for SourceSetOutput.classesDirs
included tasks that did not produce class files.
This meant that a task which depends on classesDirs would also depend on classes, processResources, and any other task dependency added to SourceSetOutput.
This behavior was potentially an error because the classesDirs property did not contain the output for processResources.
Since 8.0, this implicit dependency is removed.
Now, depending on classesDirs only executes the tasks which directly produce files in the classes directories.
Consider the following buildscript:
plugins {
id 'java-library'
}
// Task lists all files in the given classFiles FileCollection
tasks.register("listClassFiles", ListClassFiles) {
classFiles.from(java.sourceSets.main.output.classesDirs)
}Previously, the listClassFiles task depended on compileJava, processResources, and classes.
Now, only compileJava is a task dependency of listClassFiles.
If a task in your build relied on the previous behavior, you can instead use the entire
SourceSetOutput as an input, which contains all classes and resources.
If that is not feasible, you can restore the previous behavior by adding more task dependencies to classesDirs:
java {
sourceSets {
main {
output.classesDirs.builtBy(output)
}
}
}Minimal supported Kotlin Gradle Plugin version changed
Gradle 7.x supports Kotlin Gradle Plugin 1.3.72 and above. Kotlin Gradle Plugin versions above 1.6.21 are not tested with Gradle 7.x. Gradle 8.x supports Kotlin Gradle Plugin 1.6.10 and above. You can use a lower Kotlin language version by modifying the language version and api version setting in the Kotlin compilation tasks.
Minimal supported Android Gradle Plugin version changed
Gradle 7.x supports Android Gradle Plugin (AGP) 4.1 and above. AGP versions above 7.3 are not tested with Gradle 7.x. Gradle 8.x supports AGP 8 and above. Gradle 8.x supports AGP 7.3 and above if you configure the following property:
android.experimental.legacyTransform.forceNonIncremental=trueChange to AntBuilder parent class
Previously, org.gradle.api.AntBuilder extended the deprecated groovy.util.AntBuilder class.
It now extends groovy.ant.AntBuilder.
PluginDeclaration is not serializable
org.gradle.plugin.devel.PluginDeclaration is not serializable anymore.
If you need to serialize it, you can convert it into your own, serializable class.
Gradle does not use equals for serialized values in up-to-date checks
Gradle now does not try to use equals when comparing serialized values in up-to-date checks. For more information see Relying on equals for up-to-date checks is deprecated.
Task and transform validation warnings introduced in Gradle 7.x are now errors
Gradle introduced additional task and artifact transform validation warnings in the Gradle 7.x series. Those warnings are now errors in Gradle 8.0 and will fail the build.
Warnings that became errors:
-
An input file collection that can’t be resolved.
-
An input or output file or directory that cannot be read. See Declaring input or output directories which contain unreadable content.
-
Using a
java.io.Fileas the@InputArtifactof an artifact transform. -
Using an input with an unknown implementation. See Cannot use an input with an unknown implementation.
-
Missing dependencies between tasks. See Implicit dependencies between tasks.
-
Converting files to a classpath where paths contain file separator.
Gradle does not ignore empty directories for file-trees with @SkipWhenEmpty
Previously Gradle used to detect if an input file collection annotated with @SkipWhenEmpty consisted only of file trees and then ignored directories automatically.
To ignore directories in Gradle 8.0 and later, the input property needs to be explicitly annotated with @IgnoreEmptyDirectories.
For more information see File trees and empty directory handling.
Format of JavaVersion has changed for Java 9 and Java 10
The string format of the JavaVersion has changed to match the official Java versioning.
Starting from Java 9, the language version must not contain the 1. prefix.
This affects the format of the sourceCompatiblity and targetCompatibility properties on the JavaCompile task and JavaExtension.
The old format is still supported when resolving the JavaVersion from a string.
Gradle 7.6 |
Gradle 8.0 |
|
|
|
|
|
|
|
|
Precompiled script plugins use strict Kotlin DSL accessor generation by default
In precompiled script plugins, type safe Kotlin DSL accessor generation now fails the build if a plugin fails to apply.
Starting in Gradle 7.6, builds could enable this behavior with the org.gradle.kotlin.dsl.precompiled.accessors.strict system property.
This behavior is now default.
The property has been deprecated and its usage should be removed.
You can find more information about this property below.
Init scripts are applied to buildSrc builds
Init scripts specified using --init-script are now applied to buildSrc builds. In previous releases these were applied to included builds but not `buildSrc builds.
This behavior is now consistent for buildSrc and included builds.
Gradle no longer runs the build task for buildSrc builds
When Gradle builds the output of buildSrc it runs only the tasks that produce that output, which is typically the jar task.
In previous releases Gradle would run the build task.
This means that the tests of buildSrc and its subprojects are not built and executed automatically and must now be explicitly requested.
This behavior is now consistent for buildSrc and included builds.
You can run the tests for buildSrc in the same way as projects in included builds, for example by running gradle buildSrc:build.
buildFinished { } hook for buildSrc runs after all tasks have executed
The buildFinished {} hook for buildSrc now runs after all tasks have completed. In previous releases this hook would run immediately after
the tasks for buildSrc completed and before any requested tasks started.
This behavior is now consistent for buildSrc and included builds.
Changes to paths of included builds
In order to handle conflicts between nested included build names better, Gradle now uses the directory hierarchy of included builds to assign the build path. If you are running tasks from the command line in nested included builds, then you may need to adjust your invocation.
For example, if you have the following hierarchy:
.
├── settings.gradle.kts
└── nested
├── settings.gradle.kts
└── nestedNested
└── settings.gradle.ktsincludeBuild("nested")includeBuild("nestedNested").
├── settings.gradle
└── nested
├── settings.gradle
└── nestedNested
└── settings.gradleincludeBuild("nested")includeBuild("nestedNested")Before Gradle 8.0, you ran gradle :nestedNested:compileJava.
In Gradle 8.0 the invocation changes to gradle :nested:nestedNested:compileJava.
Adding jst.ejb with the eclipse wtp plugin now removes the jst.utility facet
The eclipse wtp plugin adds the jst.utility facet to java projects.
Now, adding the jst.ejb facet implicitly removes the jst.utility facet:
eclipse {
wtp {
facet {
facet name: 'jst.ejb', version: '3.2'
}
}
}Simplifying PMD custom rules configuration
Previously, you had to explicitly configure PMD to ignore default rules with ruleSets = [].
In the Gradle 8.0, setting ruleSetConfig or ruleSetFiles to a non-empty value implicitly ignores default rules.
Report getOutputLocation return type changed from Provider to Property
The outputLocation property of the Report now returns a value of type Property<? extends FileSystemLocation>.
Previously, outputLocation returned a value of type Provider<? extends FileSystemLocation>.
This change makes the Report API more internally consistent, and allows for more idiomatic configuration of reporting tasks.
The former, now @Deprecated usage:
tasks.named('test') {
reports.junitXml.setDestination(layout.buildDirectory.file('reports/my-report-old').get().asFile) // DEPRECATED
}can be replaced with:
tasks.named('test') {
reports.junitXml.outputLocation = layout.buildDirectory.dir('reports/my-report')
}Many built-in and custom reports, such as those used by JUnit, implement this interface. Plugins compiled against an earlier version of Gradle containing the previous method signature may need to be recompiled to be used with newer versions of Gradle containing the new signature.
Removed external plugin validation plugin
The incubating plugin ExternalPluginValidationPlugin has been removed.
Use the java-gradle-plugin's validatePlugins task to validate plugins under development.
Reproducible archives can change compared to past versions
Gradle changes the compression library used for creating archives from an Ant based one to Apache Commons Compress™. As a consequence archives created from the same content, are unlikely to end up identical byte-by-byte to their older versions, created with the old library.
Upgrade to Kotlin 1.8.10
The embedded Kotlin has been updated to Kotlin 1.8.10. Also see Kotlin 1.8.0 release notes. For more information, see the release notes for Kotlin
Updated the Kotlin DSL to Kotlin API Level 1.8
Previously, the Kotlin DSL used Kotlin API level 1.4. Starting with Gradle 8.0, the Kotlin DSL uses Kotlin API level 1.8. This change brings all the improvements made to the Kotlin language and standard library since Kotlin 1.4.0.
For information about breaking and nonbreaking changes in this upgrade, see the following links to the Kotlin documentation:
-
Kotlin 1.5 language / standard library
-
Kotlin 1.6 language / standard library
-
Kotlin 1.7 language / standard library
-
Kotlin 1.8 language / standard library
Note that the Kotlin Gradle Plugin 1.8.0 started using Java toolchains.
It is recommended you configure a toolchain instead of defining Java sourceCompatibility/targetCompatibility in Kotlin projects.
Also note that the Kotlin Gradle Plugin 1.8.0 introduced compilerOptions with lazy configuration properties as a replacement for kotlinOptions which did not support lazy configuration.
It is recommended you configure Kotlin compilation using compilerOptions instead of kotlinOptions.
kotlinDslPluginOptions.jvmTarget is deprecated
Previously, you could use kotlinDslPluginOptions.jvmTarget to configure which JVM target should be used for compiling code when using the kotlin-dsl plugin.
Starting with Gradle 8.0, kotlinDslPluginOptions.jvmTarget is deprecated.
You should configure a Java Toolchain instead.
If you already have a Java Toolchain configured and kotlinDslPluginOptions.jvmTarget unset then Gradle 8.0 will now use the Java Toolchain as the JVM target instead of the previous default target (1.8).
Java Base Plugin now sets Jar, War, and Ear destination directory defaults
Previously, the base plugin configured the
destinationDirectory of
Jar, War, and
Ear tasks to the directory specified by
BasePluginExtension#getLibsDirectory.
In Gradle 8.0, java-base handles this configuration.
No changes are required for projects that already apply the
java-base plugin directly or indirectly through the java, application, java-library, or other JVM ecosystem plugins.
Upload Task should not be used
The Upload task remains deprecated and is now scheduled for removal in Gradle 9.0.0.
Although this type remains, it is no longer functional and will throw an exception upon running.
It is preserved solely to avoid breaking plugins.
Use the tasks in the maven-publish or ivy-publish plugins instead.
Configurations no longer allowed as Dependencies
Adding a Configuration as a dependency in the dependencies DSL block, or programmatically using the DependencyHandler classes' doAdd(Configuration, Object, Closure) method, is no longer allowed and will fail with an exception.
To replicate many aspects of this behavior, extend configurations using the extendsFrom(Configuration) method on Configuration instead.
Deprecated for consumption configurations are now non-consumable
The following configurations were never meant to be consumed:
-
The
antlrconfiguration created by theAntlrPlugin -
The
zincconfiguration created by theScalaBasePlugin -
The
providedCompileandprovidedRuntimeconfigurations created by theWarPlugin
These configurations were deprecated for consumption and are now no longer consumable. Attempting to consume them will result in an error.
Identical consumable configurations are now an error
If a project has multiple consumable configurations that share the same attributes and capabilities declaration, the build will fail when publishing or resolving as a dependency that project. This was previously deprecated.
The outgoingVariants report will warn about this for impacted configurations.
Toolchain-based tasks for JVM projects
Starting with Gradle 8.0, all core Java tasks that have toolchain support are now using toolchains unconditionally.
If JavaBasePlugin is applied, the convention value for tool properties on the task is defined by the toolchain configured on the java extension.
In case no toolchains are explicitly configured, the toolchain corresponding to the JVM running Gradle is used.
Similarly, tasks from the Groovy and Scala plugins also rely on toolchains to determine on which JVM they are executed.
Scala compilation target
With the toolchain changes described above, Scala compilation tasks are now always provided with a target or release parameter.
The exact parameter and value depend on toolchain usage, or not, and Scala version.
See the Scala plugin documentation for details.
pluginBundle dropped in Plugin Publish plugin
Gradle 8 no longer supports the pluginBundle extension.
Its functionality has been merged into the gradlePlugin block.
These changes require recent versions of the Plugin Publish plugin (1.0.+).
Documentation on configuring plugin publication can be found both on the Portal and in the user manual.
Upgrading from 7.5 and earlier
Updates to Attribute Disambiguation Rules related methods
The AttributeSchema.setAttributeDisambiguationPrecedence(List) and AttributeSchema.getAttributeDisambiguationPrecedence() methods now accept and return List instead of Collection to better indicate that the order of the elements in those collection is significant.
Strict Kotlin DSL precompiled script plugins accessors generation
Type safe Kotlin DSL accessors generation for precompiled script plugins does not fail the build by default if a plugin requested in such precompiled scripts fails to be applied. Because the cause could be environmental and for backwards compatibility reasons, this behaviour hasn’t changed yet.
Back in Gradle 7.1 the :generatePrecompiledScriptPluginAccessors task responsible for the accessors generation has been marked as non-cacheable by default.
The org.gradle.kotlin.dsl.precompiled.accessors.strict system property was introduced in order to offer an opt-in to a stricter mode of operation that fails the build when a plugin application fails, and enable the build cache for that task.
Starting with Gradle 7.6, non-strict accessors generation for Kotlin DSL precompiled script plugins has been deprecated.
This will change in Gradle 8.0.
Strict accessor generation will become the default.
To opt in to the strict behavior, set the 'org.gradle.kotlin.dsl.precompiled.accessors.strict' system property to true.
This can be achieved persistently in the gradle.properties file in your build root directory:
systemProp.org.gradle.kotlin.dsl.precompiled.accessors.strict=truePotential breaking changes
Upgrade to Kotlin 1.7.10
The embedded Kotlin has been updated to Kotlin 1.7.10.
Gradle doesn’t ship with the kotlin-gradle-plugin but the upgrade to 1.7.10 can bring the new version.
For example when you use the kotlin-dsl plugin.
The kotlin-gradle-plugin version 1.7.10 changes the type hierarchy of the KotlinCompile task type.
It doesn’t extend from AbstractCompile anymore.
If you used to select Kotlin compilation tasks by AbstractCompile you need to change that to KotlinCompile.
For example, this
tasks.named<AbstractCompile>("compileKotlin")needs to be changed to
tasks.named<KotlinCompile>("compileKotlin")In the same vein, if you used to filter tasks by AbstractCompile you won’t obtain the Kotlin compilation tasks anymore:
tasks.withType<AbstractCompile>().configureEach {
// ...
}needs to be changed to
tasks.withType<AbstractCompile>().configureEach {
// ...
}
tasks.withType<KotlinCompile>().configureEach {
// ...
}Upgrade to Groovy 3.0.13
Groovy has been updated to Groovy 3.0.13.
Upgrade to CodeNarc 3.1.0
The default version of CodeNarc has been updated to 3.1.0.
Upgrade to PMD 6.48.0
PMD has been updated to PMD 6.48.0.
Configuring a non-existing executable now fails
When configuring an executable explicitly for JavaCompile or Test tasks, Gradle will now emit an error if this executable does not exist.
In the past, the task would be executed with the default toolchain or JVM running the build.
Changes to dependency declarations in Test Suites
As part of the ongoing effort to evolve Test Suites, dependency declarations in the Test Suites dependencies block are now strongly typed.
This will help make this incubating API more discoverable and easier to use in an IDE.
In some cases, this requires syntax changes. For example, build scripts that previously added Test Suite dependencies with the following syntax:
testing {
suites {
register<JvmTestSuite>("integrationTest") {
dependencies {
implementation(project)
}
}
}
}will now fail to compile, with a message like:
None of the following functions can be called with the arguments supplied:
public operator fun DependencyAdder.invoke(dependencyNotation: CharSequence): Unit defined in org.gradle.kotlin.dsl
public operator fun DependencyAdder.invoke(dependency: Dependency): Unit defined in org.gradle.kotlin.dsl
public operator fun DependencyAdder.invoke(files: FileCollection): Unit defined in org.gradle.kotlin.dsl
public operator fun DependencyAdder.invoke(dependency: Provider<out Dependency>): Unit defined in org.gradle.kotlin.dsl
public operator fun DependencyAdder.invoke(externalModule: ProviderConvertible<out MinimalExternalModuleDependency>): Unit defined in org.gradle.kotlin.dslTo fix this, replace the reference to project with a call to project():
testing {
suites {
register<JvmTestSuite>("integrationTest") {
dependencies {
implementation(project())
}
}
}
}Other syntax effected by this change includes:
-
You cannot use
Provider<String>as a dependency declaration. -
You cannot use a
Mapas a dependency declaration for Kotlin or Java. -
You cannot use a bundle as a dependency declaration directly (
implementation(libs.bundles.testing)). Useimplementation.bundle(libs.bundles.testing)instead.
For more information, see the updated declare an additional test suite example in the JVM Test Suite Plugin section of the user guide.
Deprecations
Usage of invalid Java toolchain specifications is now deprecated
Along with the Java language version, the Java toolchain DSL allows configuring other criteria such as specific vendors or VM implementations. Starting with Gradle 7.6, toolchain specifications that configure other properties without specifying the language version are considered invalid. Invalid specifications are deprecated and will become build errors in Gradle 8.0.
See more details about toolchain configuration in the user manual.
Deprecated members of the org.gradle.util package now report their deprecation
These members will be removed in Gradle 9.0.0.
-
ClosureBackedAction -
CollectionUtils -
ConfigureUtil -
DistributionLocator -
GFileUtils -
GradleVersion.getBuildTime() -
GradleVersion.getNextMajor() -
GradleVersion.getRevision() -
GradleVersion.isValid() -
GUtil -
NameMatcher -
NameValidator -
RelativePathUtil -
TextUtil -
SingleMessageLogger -
VersionNumber -
WrapUtil
Internal DependencyFactory was renamed
The internal org.gradle.api.internal.artifacts.dsl.dependencies.DependencyFactory type was renamed to org.gradle.api.internal.artifacts.dsl.dependencies.DependencyFactoryInternal.
As an internal type, it should not be used, but for compatibility reasons the inner ClassPathNotation type is still available.
This name for the type is deprecated and will be removed in Gradle 8.0.
The public API for this is on DependencyHandler, with methods such as localGroovy() providing the same functionality.
Replacement collections in org.gradle.plugins.ide.idea.model.IdeaModule
The testResourcesDirs and testSourcesDirs fields and their getters and setters have been deprecated.
Replace usages with the now stable getTestSources() and getTestResources() methods and their respective setters.
These new methods return and are backed by ConfigurableFileCollection instances for improved flexibility of use.
Gradle now warns upon usage of these deprecated methods.
They will be removed in a future version of Gradle.
Replacement methods in org.gradle.api.tasks.testing.TestReport
The getDestinationDir(), setDestinationDir(File), and getTestResultDirs() and setTestResultDirs(Iterable) methods have been deprecated.
Replace usages with the now stable getDestinationDirectory() and getTestResults() methods and their associated setters.
These deprecated elements will be removed in a future version of Gradle.
Deprecated implicit references to outer scope methods in some configuration blocks
Prior to Gradle 7.6, Groovy scripts permitted access to root project configure methods within named container configure methods that throw `MissingMethodException`s. Consider the following snippets for examples of this behavior:
Gradle permits access to the top-level repositories block from within the configurations block
when the provided closure is otherwise an invalid configure closure for a Configuration.
In this case, the repositories closure executes as if it were called at the script-level, and
creates an unconfigured repositories Configuration:
configurations {
repositories {
mavenCentral()
}
someConf {
canBeConsumed = false
canBeResolved = false
}
}The behavior also applies to closures which do not immediately execute.
In this case, afterResolve only executes when the resolve task runs.
The distributions closure is a valid top-level script closure.
But it is an invalid configure closure for a Configuration.
This example creates the conf Configuration immediately.
During resolve task execution, the distributions block executed as if it were declared at the script-level:
configurations {
conf.incoming.afterResolve {
distributions {
myDist {
contents {}
}
}
}
}
task resolve {
dependsOn configurations.conf
doFirst {
configurations.conf.files() // Trigger `afterResolve`
}
}As of Gradle 7.6, this behavior is deprecated.
Starting with Gradle 8.0, this behavior will be removed.
Instead, Gradle will throw the underlying MissingMethodException.
To mitigate this change, consider the following solutions:
configurations {
conf.incoming.afterResolve {
// Fully qualify the reference.
project.distributions {
myDist {
contents {}
}
}
}
}configurations {
conf
}
// Extract the script-level closure to the script root scope.
configurations.conf.incoming.afterResolve {
distributions {
myDist {
contents {}
}
}
}Upgrading from 7.4 and earlier
IncrementalTaskInputs type is deprecated
The IncrementalTaskInputs type was used to implement incremental tasks, that is to say tasks that can be optimized to run on a subset of changed inputs instead of the whole input.
This type had a number of drawbacks.
In particular using this type it was not possible to determine what input a change was associated with.
You should now use the InputChanges type instead.
Please refer to the userguide section about implementing incremental tasks for more details.
Potential breaking changes
Version catalog only accepts a single TOML import file
Only a single file will be accepted when using a from import method.
This means that notations, which resolve to multiple files (e.g. the Project.files(java.lang.Object…) method, when more then one file is passed) will result in a build failure.
Updates to default tool integration versions
-
Checkstyle has been updated to Checkstyle 8.45.1.
-
JaCoCo has been updated to 0.8.8.
Classpath file generated by the eclipse plugin has changed
Project dependencies defined in test configurations get the test=true classpath attribute.
All source sets and dependencies defined by the JVM Test Suite plugin are also marked as test code by default.
You can now customize test source sets and dependencies via the eclipse plugin DSL:
eclipse {
classpath {
testSourceSets = [sourcesSets.test, sourceSets.myTestSourceSet]
testConfigurations = [configuration.myTestConfiguration]
}
}Alternatively, you can adjust or remove classpath attributes in the eclipse.classpath.file.whenMerged { } block.
Signing plugin defaults to gpg instead of gpg2 when using the GPG command
The signature plugin’s default executable when using the GPG command changed from gpg2 to gpg.
The change was motivated as GPG 2.x became stable, and distributions started to migrate by not linking the gpg2 executable.
In order to set the old default, the executable can be manually defined in gradle.properties:
signing.gnupg.executable=gpg2mustRunAfter constraints no longer violated by finalizedBy dependencies
In previous Gradle versions, mustRunAfter constraints between regular tasks and finalizer task dependencies would not be honored.
For a concrete example, consider the following task graph definition:
tasks {
register("dockerTest") {
dependsOn("dockerUp") // dependsOn createContainer mustRunAfter removeContainer
finalizedBy("dockerStop") // dependsOn removeContainer
}
register("dockerUp") {
dependsOn("createContainer")
}
register("dockerStop") {
dependsOn("removeContainer")
}
register("createContainer") {
mustRunAfter("removeContainer")
}
register("removeContainer") {
}
}The relevant constraints are:
-
dockerStopis a finalizer ofdockerTestso it must be run afterdockerTest; -
removeContaineris a dependency ofdockerStopso it must be run beforedockerStop; -
createContainermust run afterremoveContainer;
Prior to Gradle 7.5, gradle dockerTest would yield the following order of execution, in violation of the mustRunAfter constraint between :createContainer and :removeContainer:
> Task :createContainer UP-TO-DATE
> Task :dockerUp UP-TO-DATE
> Task :dockerTest UP-TO-DATE
> Task :removeContainer UP-TO-DATE
> Task :dockerStop UP-TO-DATEStarting with Gradle 7.5, mustRunAfter constraints are fully honored yielding the following order of execution:
> Task :removeContainer UP-TO-DATE
> Task :createContainer UP-TO-DATE
> Task :dockerUp UP-TO-DATE
> Task :dockerTest UP-TO-DATE
> Task :dockerStop UP-TO-DATEUpdates to bundled Gradle dependencies
-
Groovy has been updated to Groovy 3.0.11.
Scala Zinc version updated to 1.6.1
Zinc is the Scala incremental compiler that allows Gradle to always compile the minimal set of files needed by the current file changes. It takes into account which methods are being used and which have changed, which means it’s much more granular than just interfile dependencies.
Zinc version has been updated to the newest available one in order to benefit from all the recent bugfixes.
Due to that, if you use zincVersion setting it’s advised to remove it and only use the default version, because Gradle will only be able to compile Scala code with Zinc versions set to 1.6.x or higher.
Removes implicit --add-opens for test workers
Prior to Gradle 7.5, JDK modules java.base/java.util and java.base/java.lang were automatically opened in test workers on JDK9+ by passing --add-opens CLI arguments.
This meant any tests were able to perform deep reflection on JDK internals without warning or failing.
This caused tests to be unreliable by allowing code to pass when it would otherwise fail in a production environment.
These implicit arguments have been removed and are no longer added by default. If your code or any of your dependencies are performing deep reflection into JDK internals during test execution, you may see the following behavior changes:
Before Java 16, new build warnings are shown. These new warnings are printed to stderr and will not fail the build:
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by com.google.inject.internal.cglib.core.ReflectUtils$2 (file:/.../testng-5.12.1.jar) to <method>
WARNING: Please consider reporting this to the maintainers of com.google.inject.internal.cglib.core.ReflectUtils$2
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future releaseWith Java 16 or higher, exceptions are thrown that fail the build:
// Thrown by TestNG
java.lang.reflect.InaccessibleObjectException: Unable to make <method> accessible: module java.base does not "opens java.lang" to unnamed module @1e92bd61
at java.base/java.lang.reflect.AccessibleObject.checkCanSetAccessible(AccessibleObject.java:354)
at java.base/java.lang.reflect.AccessibleObject.checkCanSetAccessible(AccessibleObject.java:297)
at java.base/java.lang.reflect.Method.checkCanSetAccessible(Method.java:199)
at java.base/java.lang.reflect.Method.setAccessible(Method.java:193)
...
// Thrown by ProjectBuilder
org.gradle.api.GradleException: Could not inject synthetic classes.
at org.gradle.initialization.DefaultLegacyTypesSupport.injectEmptyInterfacesIntoClassLoader(DefaultLegacyTypesSupport.java:91)
at org.gradle.testfixtures.internal.ProjectBuilderImpl.getGlobalServices(ProjectBuilderImpl.java:182)
at org.gradle.testfixtures.internal.ProjectBuilderImpl.createProject(ProjectBuilderImpl.java:111)
at org.gradle.testfixtures.ProjectBuilder.build(ProjectBuilder.java:120)
...
Caused by: java.lang.RuntimeException: java.lang.IllegalAccessException: module java.base does not open java.lang to unnamed module @1e92bd61In most cases, these errors can be resolved by updating the code or dependency performing the illegal access.
If the code-under-test or the newest version of the dependency in question performs illegal access by design, the old behavior can be restored by opening the java.base/java.lang and java.base/java.util modules manually with --add-opens:
tasks.withType(Test).configureEach {
jvmArgs(["--add-opens=java.base/java.lang=ALL-UNNAMED",
"--add-opens=java.base/java.util=ALL-UNNAMED"]
}If you are developing Gradle plugins, ProjectBuilder relies on reflection in the java.base/java.lang module.
Gradle will automatically add the appropriate --add-opens flag to tests when the java-gradle-plugin plugin is applied.
If you are using TestNG, versions prior to 5.14.6 perform illegal reflection.
Updating to at least 5.14.6 should fix the incompatibility.
Checkstyle tasks use toolchains and execute in parallel by default
The Checkstyle plugin now uses the Gradle worker API to run Checkstyle as an external worker process. Multiple Checkstyle tasks may now run in parallel within a project.
Some projects will need to increase the amount of memory available to Checkstyle to avoid out of memory errors.
You can increase the maximum memory for the Checkstyle process by setting the maxHeapSize for the Checkstyle task.
By default, the process will start with a maximum heap size of 512MB.
We also recommend to update Checkstyle to version 9.3 or later.
Missing files specified with relative paths when running Checkstyle
Gradle 7.5 consistently sets the current working directory for the Checkstyle task to $GRADLE_USER_HOME/workers.
This may cause problems with custom Checkstyle tasks or Checkstyle configuration files that assume a different directory for relative paths.
Previously, Gradle selected the current working directory based on the directory where you ran Gradle. If you ran Gradle in:
-
the root directory of a project: Gradle uses the root directory as the current working directory.
-
a nested directory of a project: Gradle uses the root directory of the subproject as the current working directory.
In version 7.5 and above, Gradle consistently sets the current working directory for the Checkstyle task to $GRADLE_USER_HOME/workers.
Deprecations
Converting files to a classpath where paths contain file separator
Java has the concept of a path separator which is used to separate individual paths in a list of paths, for example in a classpath string.
The individual paths must not contain the path separator.
Consequently, using
@FileCollection.getAsPath() for files with paths that contain a path separator has been deprecated, and it will be an error in Gradle 8.0 and later.
Using a file collection with paths which contain a path separator may lead to incorrect builds, since Gradle doesn’t find the files as inputs, or even to build failures when the path containing the path separator is illegal on the operating system.
dependencyInsight --singlepath option is deprecated
For consistency, this was changed to --single-path.
The API method has remained the same, this only affects the CLI.
Groovydoc includePrivate property is deprecated
There is a new access property that allows finer control over what is included in the Groovydoc.
Provider-based API must be used to run external processes at the configuration time
Using Project.exec, Project.javaexec, and standard Java and Groovy APIs to run external processes at the configuration time is now deprecated when the configuration cache is enabled.
It will be an error in Gradle 8.0 and later.
Gradle 7.5 introduces configuration cache-compatible ways to execute and obtain output of an external process with the provider-based APIs or a custom implementation of the ValueSource interface.
The configuration cache chapter has more details to help with the migration to the new APIs.
Upgrading from 7.3 and earlier
Potential breaking changes
Updates to default tool integration versions
-
PMD has been updated to PMD 6.39.0.
Deprecations
AdoptOpenJDK toolchain download
Following the move from AdoptOpenJDK to Adoptium, under the Eclipse foundation, it is no longer possible to download an AdoptOpenJDK build from their end point. Instead, an Eclipse Temurin or IBM Semeru build is returned.
Gradle 7.4+ will now emit a deprecation warning when the AdoptOpenJDK vendor is specified in the toolchain specification and it is used by auto provisioning.
If you must use AdoptOpenJDK, you should turn off auto-download.
If an Eclipse Temurin or IBM Semeru build works for you, specify JvmVendorSpec.ADOPTIUM or JvmVendorSpec.IBM as the vendor or leave the vendor unspecified.
File trees and empty directory handling
When using @SkipWhenEmpty on an input file collection, Gradle skips the task when it determines that the input is empty.
If the input file collection consists only of file trees, Gradle ignores directories for the emptiness check.
Though when checking for changes to the input file collection, Gradle only ignores directories when the @IgnoreEmptyDirectories annotation is present.
Gradle will now ignore directories for both the @SkipWhenEmpty check and for determining changes consistently.
Until Gradle 8.0, Gradle will detect if an input file collection annotated with @SkipWhenEmpty consists only of file trees and then ignore directories automatically.
Moreover, Gradle will issue a deprecation warning to advise the user that the behavior will change in Gradle 8.0, and that the input property should be annotated with @IgnoreEmptyDirectories.
To ignore directories in Gradle 8.0 and later, the input property needs to be annotated with @IgnoreEmptyDirectories.
Finally, using @InputDirectory implies @IgnoreEmptyDirectories, so no changes are necessary when using this annotation.
The same is true for inputs.dir() when registering an input directory via the runtime API.
Using LazyPublishArtifact without a FileResolver is deprecated
When using a LazyPublishArtifact without a FileResolver, a different file resolution strategy is used, which duplicates some logic in the FileResolver.
To improve consistency, LazyPublishArtifact should be used with a FileResolver, and will require it in the future.
This also affects other internal APIs that use LazyPublishArtifact, which now also have deprecation warnings where needed.
TAR trees from resources without backing files
It is possible to create TAR trees from arbitrary resources.
If the resource is not created via project.resources, then it may not have a backing file.
Creating a TAR tree from a resource with no backing file has been deprecated.
Instead, convert the resource to a file and use project.tarTree() on the file.
To convert the resource to a file you can use a custom task or use dependency management to download the file via a URL.
This way, Gradle is able to apply optimizations like up-to-date checks instead of re-running the logic to create the resource every time.
Unique attribute sets
The set of Attributes associated with a consumable configuration within a project, must be unique across all other configurations within that project which share the same set of Capabilitys.
This will be checked at the end of configuring variant configurations, as they are locked against further mutation.
If the set of attributes is shared across configurations, consider adding an additional attribute to one of the variants for the sole purpose of disambiguation.
Provider#forUseAtConfigurationTime() has been deprecated
Provider#forUseAtConfigurationTime is now deprecated and scheduled for removal in Gradle 9.0.0. Clients should simply remove the call.
The call was mandatory on providers of external values such as system properties, environment variables, Gradle properties and file contents meant to be used at configuration time together with the configuration cache feature.
Starting with version 7.4 Gradle will implicitly treat an external value used at configuration time as a configuration cache input.
Clients are also free to use standard Java APIs such as System#getenv to read environment variables, System#getProperty to read system properties as well as Gradle APIs such as Project#property(String) and Project#findProperty(String) to read Gradle properties at configuration time.
The Provider based APIs are still the recommended way to connect external values to task inputs for maximum configuration cache reuse.
ConfigurableReport#setDestination(org.gradle.api.provider.Provider<java.io.File>) has been deprecated
ConfigurableReport#setDestination(org.gradle.api.provider.Provider<java.io.File>) is now deprecated and scheduled for removal in Gradle 8.0.
Use Report#getOutputLocation().set(…) instead.
Task execution listeners and events
The Gradle configuration cache does not support listeners and events that have direct access to Task and Project instances, which allows Gradle to execute tasks in parallel and to store the minimal amount of data in the configuration cache.
In order to move towards an API that is consistent whether the configuration cache is enabled or not, the following APIs are deprecated and will be removed or be made an error in Gradle 8.0:
-
Interface TaskExecutionListener
-
Interface TaskActionListener
-
Registering TaskExecutionListener, TaskActionListener, TestListener, TestOutputListener via Gradle.addListener()
See the configuration cache chapter for details on how to migrate these usages to APIs that are supported by the configuration cache.
Build finished events
Build finished listeners are not supported by the Gradle configuration cache. And so, the following API are deprecated and will be removed in Gradle 8.0:
-
Method Gradle.buildFinished()
See the configuration cache chapter for details on how to migrate these usages to APIs that are supported by the configuration cache.
Calling Task.getProject() from a task action
Calling Task.getProject() from a task action at execution time is now deprecated and will be made an error in Gradle 8.0. This method can be used during configuration time, but it is recommended to avoid doing this.
See the configuration cache chapter for details on how to migrate these usages to APIs that are supported by the configuration cache.
Calling Task.getTaskDependencies() from a task action
Calling Task.getTaskDependencies() from a task action at execution time is now deprecated and will be made an error in Gradle 8.0. This method can be used during configuration time, but it is recommended to avoid doing this.
See the configuration cache chapter for details on how to migrate these usages to APIs that are supported by the configuration cache.
Using a build service from a task without explicitly declaring usage
Gradle needs the information so it can properly honor the build service lifecycle and its usage constraints.
This will become an error in a future Gradle version.
This can be done either by consuming the service via a @ServiceReference property (since 8.0) or by invoking usesService() on the task (since 6.1).
Check the Shared Build Services documentation for more information.
VersionCatalog and VersionCatalogBuilder deprecations
Some methods in VersionCatalog and VersionCatalogBuilder are now deprecated and scheduled for removal in Gradle 8.0. Specific replacements can be found in the JavaDoc of the affected methods.
These methods were changed to improve the consistency between the libs.versions.toml file and the API classes.
Upgrading from 7.2 and earlier
Potential breaking changes
Updates to bundled Gradle dependencies
-
Kotlin has been updated to Kotlin 1.5.31.
-
Groovy has been updated to Groovy 3.0.9.
-
Ant has been updated to Ant 1.10.11 to fix CVE-2021-36373 and CVE-2021-36374.
-
Commons compress has been updated to Commons-compress 1.21 to fix CVE-2021-35515, CVE-2021-35516, CVE-2021-35517 and CVE-2021-36090.
Application order of plugins in the plugins block
The order in which plugins in the plugins block were actually applied was inconsistent and depended on how a plugin was added to the class path.
Now the plugins are always applied in the same order they are declared in the plugins block which in rare cases might change behavior of existing builds.
Effects of exclusion on substituted dependencies in dependency resolution
Prior to this version, a dependency substitution target could not be excluded from a dependency graph. This was caused by checking for exclusions prior to performing the substitution. Now Gradle will also check for exclusion on the substitution result.
Version catalog
Generated accessors no longer give access to the type unsafe API. You have to use the version catalog extension instead.
Toolchain support in Scala
When using toolchains in Scala, the -target option of the Scala compiler will now be set automatically.
This means that using a version of Java that cannot be targeted by a version of Scala will result in an error.
Providing this flag in the compiler options will disable this behaviour and allow to use a higher Java version to compile for a lower bytecode target.
Declaring input or output directories which contain unreadable content
For up-to-date checks Gradle relies on tracking the state of the inputs and the outputs of a task. Gradle used to ignore unreadable files in the input or outputs to support certain use-cases, although it cannot track their state. Declaring input or output directories on tasks which contain unreadable content has been deprecated and these use-cases are now supported by declaring the task to be untracked. Use the @UntrackedTask annotation or the Task.doNotTrackState() method to declare a task as untracked.
When you are using a Copy task for copying single files into a directory which contains unreadable files, use the method Task.doNotTrackState().
Upgrading from 7.1 and earlier
Potential breaking changes
Security changes to application start scripts and Gradle wrapper scripts
Due to CVE-2021-32751, gradle, gradlew and start scripts generated by Gradle’s application plugin have been updated to avoid situations where these
scripts could be used for arbitrary code execution when an attacker is able to change environment variables.
You can use the latest version of Gradle to generate a gradlew script and use it to execute an older version of Gradle.
This should be transparent for most users; however, there may be changes for Gradle builds that rely on the environment variables JAVA_OPTS or GRADLE_OPTS to pass parameters with complicated quote escaping.
Contact us if you suspect something has broken your build and you cannot find a solution.
Updates to bundled Gradle dependencies
-
Groovy has been updated to Groovy 3.0.8.
-
Kotlin has been updated to Kotlin 1.5.21.
Updates to default tool integration versions
-
PMD has been updated to PMD 6.36.0.
Deprecations
Using Java lambdas as task actions
When using a Java lambda to implement a task action, Gradle cannot track the implementation and the task will never be up-to-date or served from the build cache. Since it is easy to add such a task action, using task actions implemented by Java lambdas is now deprecated. See Validation problems for more details how to fix the issue.
Relying on equals for up-to-date checks is deprecated
When a task input is annotated with @Input and is not a type Gradle understand directly (like String), then Gradle uses the serialized form of the input for up-to-date checks and the build cache key.
Historically, Gradle also loads the serialized value from the last execution and then uses equals() to compare it to the current value for up-to-date checks.
Doing so is error prone, doesn’t work with the build cache and has a performance impact, therefore it has been deprecated.
Instead of using @Input on a type Gradle doesn’t understand directly, use @Nested and annotate the properties of the type accordingly.
Upgrading from 7.0 and earlier
Potential breaking changes
Updates to default tool integration versions
-
JaCoCo has been updated to 0.8.7.
The org.gradle.util package is now a public API
Officially, the org.gradle.util package is not part of the public API.
But, because this package name doesn’t contain the word internal, many Gradle plugins already consider as one.
Gradle 7.1 addresses the situation and marks the package as public.
The classes that were unintentionally exposed are either deprecated or removed, depending on their external usage.
-
GradleVersion -
Path -
Configurable
-
VersionNumber -
TextUtil -
WrapUtil -
RelativePathUtil -
DistributionLocator -
SingleMessageLogger -
ConfigureUtil
ConfigureUtil is being removed without a replacement.
Plugins can avoid the need for using ConfigureUtil.
org.gradle.util to the org.gradle.util.internal package:-
Resources -
RedirectStdOutAndErr -
Swapper -
StdInSwapper -
IncubationLogger -
RedirectStdIn -
MultithreadedTestRule -
DisconnectableInputStream -
BulkReadInputStream -
MockExecutor -
FailsWithMessage -
FailsWithMessageExtension -
TreeVisitor -
AntUtil -
JarUtil
-
DiffUtil -
NoopChangeListener -
EnumWithClassBody -
AlwaysTrue -
ReflectionEqualsMatcher -
DynamicDelegate -
IncubationLogger -
NoOpChangeListener -
DeferredUtil -
ChangeListener
The return type of source set extensions have changed
The following source sets are contributed via an extension with a custom type:
-
groovy: GroovySourceDirectorySet -
antlr: AntlrSourceDirectorySet -
scala: ScalaSourceDirectorySet
The 'idiomatic' DSL declaration is backward compatible:
sourceSets {
main {
groovy {
// ...
}
}
}However, the return type of the groovy block has changed to the extension type. This means that the following snippet no longer works in Gradle 7.1:
sourceSets {
main {
GroovySourceSet sourceSet = groovy {
// ...
}
}
}Start scripts require bash shell
The command used to start Gradle, the Gradle wrapper as well as the scripts generated by the application plugin now require bash shell.
Deprecations
Using convention mapping with properties with type Provider is deprecated
Convention mapping is an internal feature that is been replaced by the Provider API. When mixing convention mapping with the Provider API, unexpected behavior can occur. Gradle emits a deprecation warning when a property in a task, extension or other domain object uses convention mapping with the Provider API.
To fix this, the plugin that configures the convention mapping for the task, extension or domain object needs to be changed to use the Provider API only.
Setting custom build layout
Command line options:
-
-c,--settings-filefor specifying a custom settings file location -
-b,--build-filefor specifying a custom build file location
have been deprecated.
Setting custom build file using buildFile property in GradleBuild task has been deprecated.
Please use the dir property instead to specify the root of the nested build.
Setting custom build layout using StartParameter methods setBuildFile(File) and setSettingsFile(File) as well as the counterpart getters getBuildFile() and getSettingsFile() have been deprecated.
Please use standard locations for settings and build files:
-
settings file in the root of the build
-
build file in the root of each subproject
For the use case where custom settings or build files are used to model different behavior (similar to Maven profiles), consider using system properties with conditional logic. For example, given a piece of code in either settings or build file:
if (System.getProperty("profile") == "custom") {
println("custom profile")
} else {
println("default profile")
}You can pass the profile system property to Gradle using gradle -Dprofile=custom to execute the code in the custom profile branch.
Substitution.with replaced with Substitution.using
Dependency substitutions using with method have been deprecated and are replaced with using method that also allows chaining.
For example, a dependency substitution rule substitute(project(':a')).with(project(':b')) should be replaced with
substitute(project(':a')).using(project(':b')).
With chaining you can, for example, add a reason for a substitution like this: substitute(project(':a')).using(project(':b')).because("a reason").
Deprecated properties in compile task
-
The JavaCompile.destinationDir property has been deprecated. Use the JavaCompile.destinationDirectory property instead.
-
The GroovyCompile.destinationDir property has been deprecated. Use the GroovyCompile.destinationDirectory property instead.
-
The ScalaCompile.destinationDir property has been deprecated. Use the ScalaCompile.destinationDirectory property instead.
Non-hierarchical project layouts
Gradle 7.1 deprecated project layouts where subprojects were located outside of the project root. However, based on community feedback we decided to roll back in Gradle 7.4 and removed the deprecation. As a consequence, the Settings.includeFlat() method is deprecated in Gradle 7.1, 7.2, and 7.3 only.
Deprecated Upload task
Gradle used to have two ways of publishing artifacts.
Now, the situation has been cleared and all build should use the maven-publish plugin.
The last remaining artifact of the old way of publishing is the Upload task that has been deprecated and scheduled for removal in Gradle 8.0.
Existing clients should migrate to the maven-publish plugin.
Deprecated conventions
The concept of conventions is outdated and superseded by extensions. To reflect this in the Gradle API, the following elements are now deprecated:
-
org.gradle.api.internal.HasConvention(deprecated)
The internal usages of conventions have been also cleaned up (see the deprecated items below).
Plugin authors migrate to extensions if they replicate the changes we’ve done internally. Here are some examples:
-
Migrate plugin configuration: gradle/gradle#16900.
-
Migrate custom source sets: gradle/gradle#17149.
Deprecated consumption of internal plugin configurations
Some core Gradle plugins declare configurations that are used by the plugin itself and are not meant to be published or consumed by another subproject directly. Gradle did not explicitly prohibit this. Gradle 7.1 deprecates consumption of those configurations and this will become an error in Gradle 8.0.
The following plugin configurations have been deprecated for consumption:
| plugin | configurations deprecated for consumption |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
If your use case needs to consume any of the above mentioned configurations in another project, please create a separate consumable configuration that extends from the internal ones. For example:
plugins {
id("codenarc")
}
configurations {
codenarc {
// because currently this is consumable until Gradle 8.0 and can clash with the configuration below depending on the attributes set
canBeConsumed = false
}
codenarcConsumable {
extendsFrom(codenarc)
canBeConsumed = true
canBeResolved = false
// the attributes below make this configuration consumable by a `java-library` project using `implementation` configuration
attributes {
attribute(Usage.USAGE_ATTRIBUTE, objects.named(Usage, Usage.JAVA_RUNTIME))
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category, Category.LIBRARY))
attribute(LibraryElements.LIBRARY_ELEMENTS_ATTRIBUTE, objects.named(LibraryElements, LibraryElements.JAR))
attribute(Bundling.BUNDLING_ATTRIBUTE, objects.named(Bundling, Bundling.EXTERNAL))
attribute(TargetJvmEnvironment.TARGET_JVM_ENVIRONMENT_ATTRIBUTE, objects.named(TargetJvmEnvironment, TargetJvmEnvironment.STANDARD_JVM));
}
}
}Deprecated custom source set interfaces
The following source set interfaces are now deprecated and scheduled for removal in Gradle 8.0:
-
org.gradle.api.tasks.GroovySourceSet -
org.gradle.api.plugins.antlr.AntlrSourceVirtualDirectory(removed) -
org.gradle.api.tasks.ScalaSourceSet
Clients should configure the sources with their plugin-specific configuration:
-
groovy: GroovySourceDirectorySet -
antlr: AntlrSourceDirectorySet -
scala: ScalaSourceDirectorySet
For example, here’s how you configure the groovy sources from a plugin:
GroovySourceDirectorySet groovySources = sourceSet.getExtensions().getByType(GroovySourceDirectorySet.class);
groovySources.setSrcDirs(Arrays.asList("sources/groovy"));Registering artifact transforms extending ArtifactTransform
When Gradle first introduced artifact transforms, it used the base class ArtifactTransform for implementing them.
Gradle 5.3 introduced the interface TransformAction for implementing artifact transforms, replacing the previous class ArtifactTransform and addressing various shortcomings.
Using the registration method DependencyHandler.registerTransform(Action) for ArtifactTransform has been deprecated.
Migrate your artifact transform to use TransformAction and use DependencyHandler.registerTransform(Class, Action) instead.
See the user manual for more information on implementing TransformAction.
Compatibility Matrix
The sections below describe Gradle’s compatibility with several integrations. Versions not listed here may or may not work.
Java Runtime
Gradle runs on the Java Virtual Machine (JVM), which is often provided by either a JDK or JRE. A JVM version between 17 and 26 is required to execute Gradle. JVM 27 and later versions are not yet supported.
The Gradle wrapper, Gradle client, Tooling API client, and TestKit client are compatible with JVM 8.
JDK 6 and above can be used for compilation. JVM 8 and above can be used for executing tests.
Any fully supported version of Java can be used for compilation or testing. However, the latest Java version may only be supported for compilation or testing, not for running Gradle. Support is achieved using toolchains and applies to all tasks supporting toolchains.
See the table below for the Java version supported by a specific Gradle release:
| Java version | Support for toolchains | Support for running Gradle |
|---|---|---|
8 |
N/A |
2.0 to 8.14.x |
9 |
N/A |
4.3 to 8.14.x |
10 |
N/A |
4.7 to 8.14.x |
11 |
N/A |
5.0 to 8.14.x |
12 |
N/A |
5.4 to 8.14.x |
13 |
N/A |
6.0 to 8.14.x |
14 |
N/A |
6.3 to 8.14.x |
15 |
6.7 |
6.7 to 8.14.x |
16 |
7.0 |
7.0 to 8.14.x |
17 |
7.3 |
7.3 and after |
18 |
7.5 |
7.5 and after |
19 |
7.6 |
7.6 and after |
20 |
8.1 |
8.3 and after |
21 |
8.4 |
8.5 and after |
22 |
8.7 |
8.8 and after |
23 |
8.10 |
8.10 and after |
24 |
8.14 |
8.14 and after |
25 |
9.1.0 |
9.1.0 and after |
26 |
9.4.0 |
9.4.0 and after |
|
Note
|
We only list versions in the table above once we have tested that they work without any warnings. However, thanks to the toolchain support, Gradle will often work with the latest Java version before then. We encourage users to try it out and let us know. |
Kotlin
Gradle is tested with Kotlin 2.0.0 through 2.4.0-RC. Beta and RC versions may or may not work.
| Embedded Kotlin version | Minimum Gradle version | Kotlin Language version |
|---|---|---|
1.3.10 |
5.0 |
1.3 |
1.3.11 |
5.1 |
1.3 |
1.3.20 |
5.2 |
1.3 |
1.3.21 |
5.3 |
1.3 |
1.3.31 |
5.5 |
1.3 |
1.3.41 |
5.6 |
1.3 |
1.3.50 |
6.0 |
1.3 |
1.3.61 |
6.1 |
1.3 |
1.3.70 |
6.3 |
1.3 |
1.3.71 |
6.4 |
1.3 |
1.3.72 |
6.5 |
1.3 |
1.4.20 |
6.8 |
1.3 |
1.4.31 |
7.0 |
1.4 |
1.5.21 |
7.2 |
1.4 |
1.5.31 |
7.3 |
1.4 |
1.6.21 |
7.5 |
1.4 |
1.7.10 |
7.6 |
1.4 |
1.8.10 |
8.0 |
1.8 |
1.8.20 |
8.2 |
1.8 |
1.9.0 |
8.3 |
1.8 |
1.9.10 |
8.4 |
1.8 |
1.9.20 |
8.5 |
1.8 |
1.9.22 |
8.7 |
1.8 |
1.9.23 |
8.9 |
1.8 |
1.9.24 |
8.10 |
1.8 |
2.0.20 |
8.11 |
1.8 |
2.0.21 |
8.12 |
1.8 |
2.2.0 |
9.0.0 |
2.2 |
2.2.20 |
9.2.0 |
2.2 |
2.2.21 |
9.3.0 |
2.2 |
2.3.0 |
9.4.0 |
2.2 |
2.3.20 |
9.5.0 |
2.2 |
2.3.21 |
9.6.0 |
2.2 |
Groovy
Gradle is tested with Groovy 1.5.8 through 5.0.2.
Gradle plugins written in Groovy must use Groovy 4.x for compatibility with Gradle and Groovy DSL build scripts.
Android
Gradle is tested with Android Gradle Plugin 9.0 through 9.3.0-alpha06. Alpha and beta versions may or may not work.
Target Platforms
Gradle supports a defined set of platform targets, which are combinations of:
-
Operating system and version
-
Architecture
-
File system watching compatibility
The following table lists the officially supported platforms for Gradle:
| OS | Architecture |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
Note
|
Currently, all Gradle tests run with the default file-systems of the platform, i.e. ext4 for Ubuntu, Amazon Linux and CentOS, NTFS for Windows, and APFS for macOS.
|
Platforms not listed above may work with Gradle but are not actively tested.
The Feature Lifecycle
Gradle is under constant development. New versions are delivered on a regular and frequent basis (approximately every six weeks) as described in the section on end-of-life support.
Continuous improvement combined with frequent delivery allows new features to be available to users early. Early users provide invaluable feedback, which is incorporated into the development process.
Getting new functionality into the hands of users regularly is a core value of the Gradle platform.
At the same time, API and feature stability are taken very seriously and considered a core value of the Gradle platform. Design choices and automated testing are engineered into the development process and formalized by the section on backward compatibility.
The Gradle feature lifecycle has been designed to meet these goals. It also communicates to users of Gradle what the state of a feature is. The term feature typically means an API or DSL method or property in this context, but it is not restricted to this definition. Command line arguments and modes of execution (e.g. the Build Daemon) are two examples of other features.
1. Internal
Internal features are not designed for public use and are only intended to be used by Gradle itself. They can change in any way at any point in time without any notice. Therefore, we recommend avoiding the use of such features. Internal features are not documented. If it appears in this User Manual, the DSL Reference, or the API Reference, then the feature is not internal.
Internal features may evolve into public features.
2. Incubating
Features are introduced in the incubating state to allow real-world feedback to be incorporated into the feature before making it public. It also gives users willing to test potential future changes early access.
A feature in an incubating state may change in future Gradle versions until it is no longer incubating. Changes to incubating features for a Gradle release will be highlighted in the release notes for that release. The incubation period for new features varies depending on the feature’s scope, complexity, and nature.
Features in incubation are indicated. In the source code, all methods/properties/classes that are incubating are annotated with incubating. This results in a special mark for them in the DSL and API references.
If an incubating feature is discussed in this User Manual, it will be explicitly said to be in the incubating state.
Feature Preview API
The feature preview API allows certain incubating features to be activated by adding enableFeaturePreview('FEATURE') in your settings file.
Individual preview features will be announced in release notes.
When incubating features are either promoted to public or removed, the feature preview flags for them become obsolete, have no effect, and should be removed from the settings file.
3. Public
The default state for a non-internal feature is public. Anything documented in the User Manual, DSL Reference, or API reference that is not explicitly said to be incubating or deprecated is considered public. Features are said to be promoted from an incubating state to public. The release notes for each release indicate which previously incubating features are being promoted by the release.
A public feature will never be removed or intentionally changed without undergoing deprecation. All public features are subject to the backward compatibility policy.
4. Deprecated
Some features may be replaced or become irrelevant due to the natural evolution of Gradle. Such features will eventually be removed from Gradle after being deprecated. A deprecated feature may become stale until it is finally removed according to the backward compatibility policy.
Deprecated features are indicated to be so. In the source code, all methods/properties/classes that are deprecated are annotated with “@java.lang.Deprecated” which is reflected in the DSL and API References. In most cases, there is a replacement for the deprecated element, which will be described in the documentation. Using a deprecated feature will result in a runtime warning in Gradle’s output.
The use of deprecated features should be avoided. The release notes for each release indicate any features being deprecated by the release.
Backward compatibility Policy
Gradle provides backward compatibility across major versions (e.g., 1.x, 2.x, etc.).
Once a public feature is introduced in a Gradle release, it will remain indefinitely unless deprecated.
Once deprecated, it may be removed in the next major release.
Deprecated features may be supported across major releases, but this is not guaranteed.
Release end-of-life Policy
Every day, a new nightly build of Gradle is created.
This contains all of the changes made through Gradle’s extensive continuous integration tests during that day. Nightly builds may contain new changes that may or may not be stable.
The Gradle team creates a pre-release distribution called a release candidate (RC) for each minor or major release. When no problems are found after a short time (usually a week), the release candidate is promoted to a general availability (GA) release. If a regression is found in the release candidate, a new RC distribution is created, and the process repeats. Release candidates are supported for as long as the release window is open, but they are not intended to be used for production. Bug reports are greatly appreciated during the RC phase.
The Gradle team may create additional patch releases to replace the final release due to critical bug fixes or regressions. For instance, Gradle 5.2.1 replaces the Gradle 5.2 release.
Once a release candidate has been made, all feature development moves on to the next release for the latest major version. As such, each minor Gradle release causes the previous minor releases in the same major version to become end-of-life (EOL). EOL releases do not receive bug fixes or feature backports.
For major versions, Gradle will backport critical fixes and security fixes to the last minor in the previous major version. For example, when Gradle 7 was the latest major version, several releases were made in the 6.x line, including Gradle 6.9 (and subsequent releases).
As such, each major Gradle release causes:
-
The previous major version becomes maintenance only. It will only receive critical bug fixes and security fixes.
-
The major version before the previous one to become end-of-life (EOL), and that release line will not receive any new fixes.
FUNDAMENTALS
Core Concepts
Gradle automates building, testing, and deployment of software from information in build scripts.
Core concepts
Gradle builds are defined in terms of projects and tasks, configured using build scripts written in Groovy or Kotlin.
| Concept | What It Means |
|---|---|
Build |
The process and environment for producing outputs. A build includes one or more projects and their build scripts. |
Project |
A piece of software that can be built, such as an application or library. A build may have a single root project or multiple subprojects. |
Task |
A basic unit of work, like compiling code or running tests. Tasks are declared in build scripts or added by plugins. |
Build Script |
A configuration file ( |
Plugin |
Used to extend Gradle’s capabilities (like the |
Dependency |
External or internal resources required by a project. Gradle automatically resolves these during the build. |
Project structure
Many developers will interact with Gradle for the first time through an existing project.
The presence of the gradlew and gradlew.bat files in the root directory of a project is a clear indicator that Gradle is used.
A Gradle project will look similar to the following:
project
├── gradle // (1)
├── gradlew // (2)
├── gradlew.bat // (2)
├── settings.gradle(.kts) // (3)
├── subproject-a
│ ├── build.gradle(.kts) // (4)
│ └── src/ // (5)
└── subproject-b
├── build.gradle(.kts) // (4)
└── src/ // (5)-
Gradle directory to store wrapper files and more
-
Gradle wrapper scripts - THIS IS A GRADLE PROJECT!
-
Gradle settings file to define a root project name and subprojects
-
Gradle build scripts of the two subprojects -
subproject-aandsubproject-b -
Source code and/or additional files for the projects
Invoking Gradle
In the IDE
Gradle is built-in to many IDEs including Android Studio, IntelliJ IDEA, Visual Studio Code, Eclipse, and NetBeans.
Gradle can be automatically invoked when you build, clean, or run your app in the IDE.
Consult the manual for the IDE of your choice to learn more about how Gradle can be used and configured.
On the Command Line
Gradle can be invoked in the command line once installed:
$ gradle build$ gradle test$ gradle clean buildMost projects do not use the installed version of Gradle but rather the Gradle Wrapper.
With the Gradle Wrapper
The wrapper is a script that invokes a declared version of Gradle and is the recommended way to execute a Gradle build:
$ ./gradlew build
Next Step: Learn about the Gradle Wrapper >>
Wrapper Basics
The recommended way to execute any Gradle build is with the Gradle Wrapper.
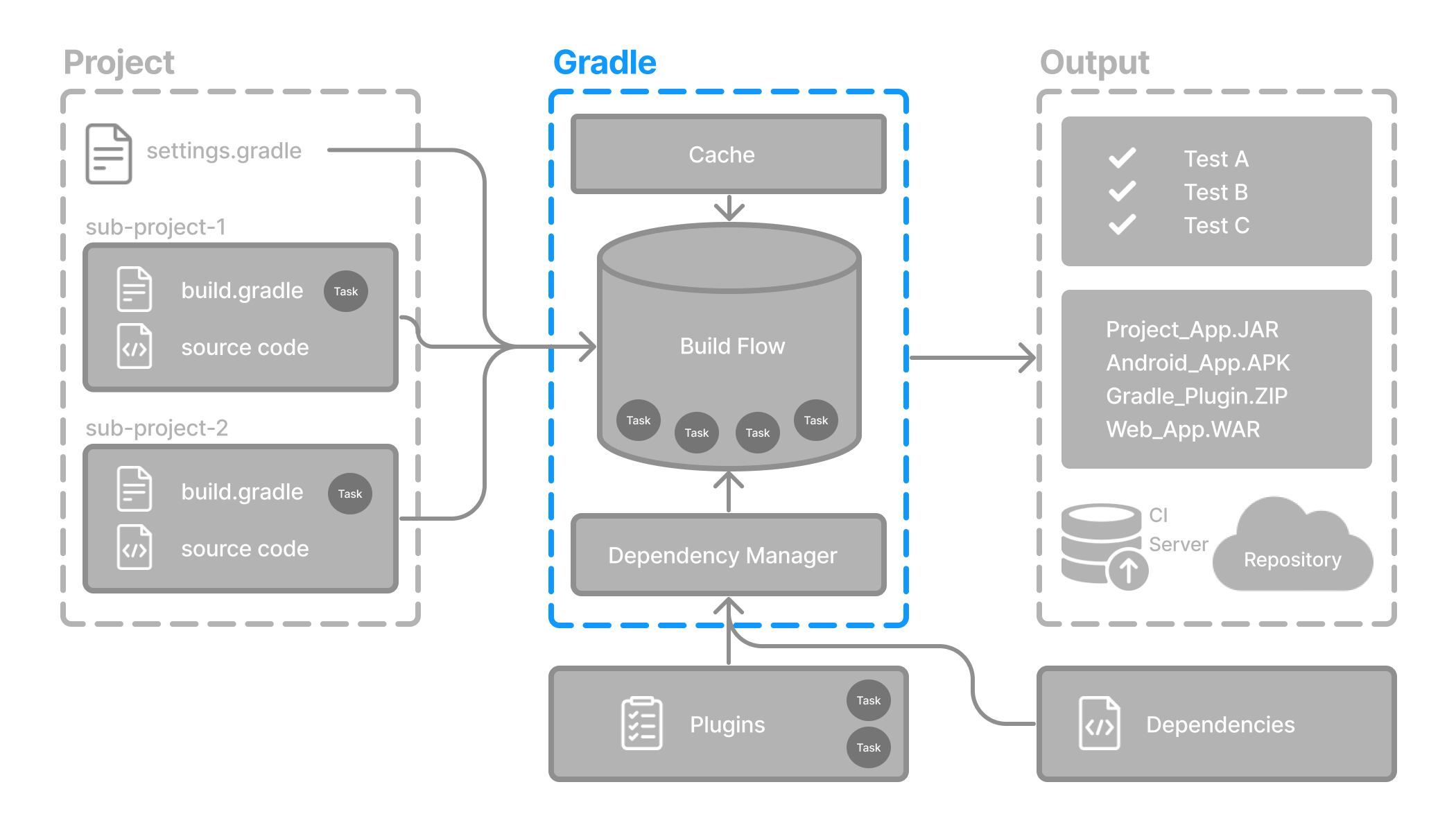
The wrapper script invokes a declared version of Gradle, downloading it beforehand if necessary.
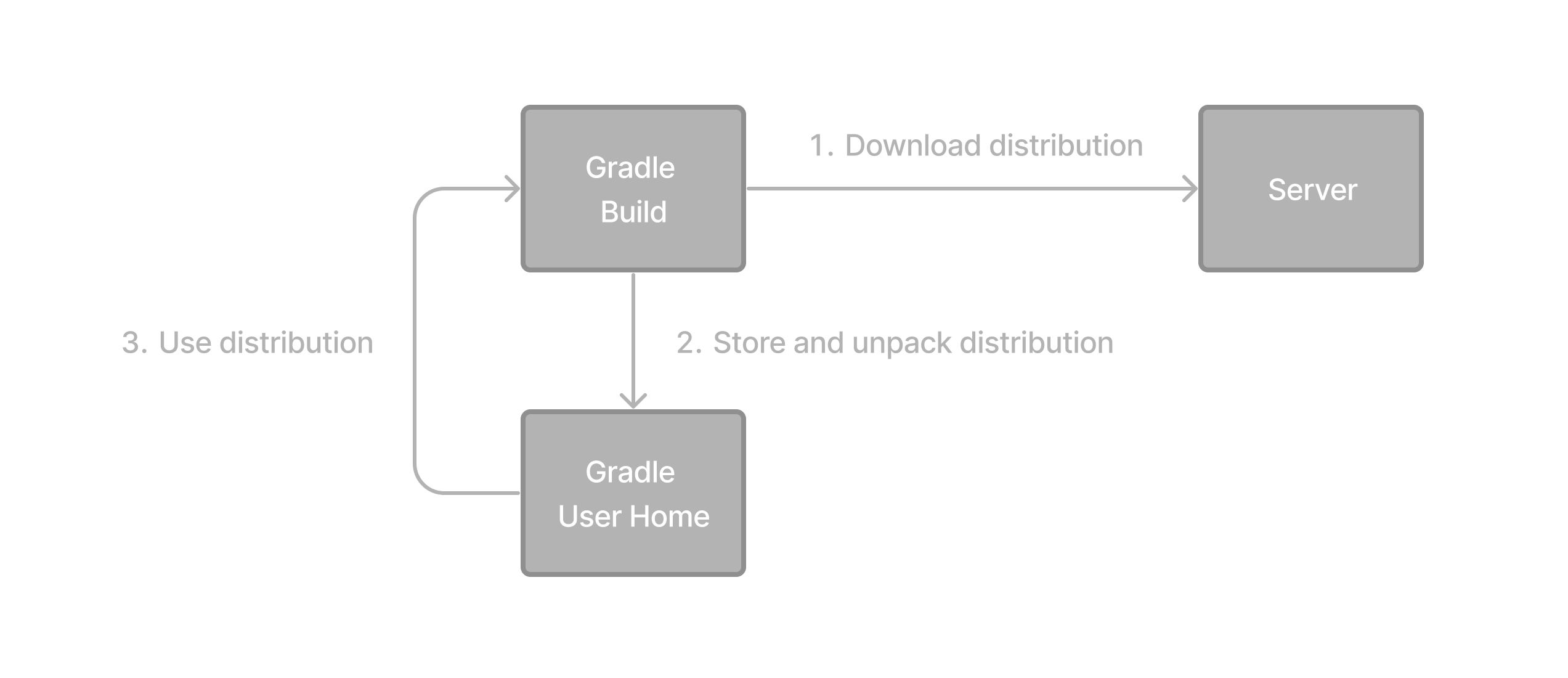
It is available as a gradlew or gradlew.bat file in the project root directory:
root
├── gradlew // THE WRAPPER FOR Linux / macOS
├── gradlew.bat // THE WRAPPER FOR Windows
└── ...If your project does not include these files, it is likely not a Gradle project—or the wrapper has not been set up yet.
|
Tip
|
The wrapper is not something you download from the internet.
You must generate it by running gradle :wrapper from a machine with Gradle installed.
|
The wrapper provides the following benefits:
-
Automatically downloads and uses a specific Gradle version.
-
Standardizes a project on a given Gradle version.
-
Provisions the same Gradle version for different users and environments (IDEs, CI servers…).
-
Makes it easy to run Gradle builds without installing Gradle manually.
Using the Gradle Wrapper
It’s important to distinguish between two ways of running Gradle:
-
Using a system-installed Gradle distribution — by running the
gradlecommand. -
Using the Gradle Wrapper — by running the
gradleworgradlew.batscript included in a Gradle project.
The Gradle Wrapper is always the recommended way to execute a build to ensure a reliable, controlled, and standardized execution of the build.
-
Using a system-installed Gradle distribution:
$ gradle build -
Using the Gradle Wrapper:
-
Wrapper invocation on a Linux or OSX machine:
$ ./gradlew build -
Wrapper invocation on Windows PowerShell:
$ gradlew.bat build
-
If you want to run the command in a different directory, you must provide the relative path to the wrapper:
$ ../gradlew buildThe following console output demonstrates the use of the wrapper on a Windows machine, in the command prompt (cmd), for a Java-based project:
$ gradlew.bat buildDownloading https://services.gradle.org/distributions/gradle-5.0-all.zip
.....................................................................................
Unzipping C:\Documents and Settings\Claudia\.gradle\wrapper\dists\gradle-5.0-all\ac27o8rbd0ic8ih41or9l32mv\gradle-5.0-all.zip to C:\Documents and Settings\Claudia\.gradle\wrapper\dists\gradle-5.0-al\ac27o8rbd0ic8ih41or9l32mv
Set executable permissions for: C:\Documents and Settings\Claudia\.gradle\wrapper\dists\gradle-5.0-all\ac27o8rbd0ic8ih41or9l32mv\gradle-5.0\bin\gradle
BUILD SUCCESSFUL in 12s
1 actionable task: 1 executedUnderstanding the Wrapper files
The following files are part of the Gradle Wrapper:
.
├── gradle
│ └── wrapper
│ ├── gradle-wrapper.jar // (1)
│ └── gradle-wrapper.properties // (2)
├── gradlew // (3)
└── gradlew.bat // (4)-
gradle-wrapper.jar: This is a small JAR file that contains the Gradle Wrapper code. It is responsible for downloading and installing the correct version of Gradle for a project if it’s not already installed. -
gradle-wrapper.properties: This file contains configuration properties for the Gradle Wrapper, such as the distribution URL (where to download Gradle from) and the distribution type (ZIP or TARBALL). -
gradlew: This is a shell script (Unix-based systems) that acts as a wrapper aroundgradle-wrapper.jar. It is used to execute Gradle tasks on Unix-based systems without needing to manually install Gradle. -
gradlew.bat: This is a batch script (Windows) that serves the same purpose asgradlewbut is used on Windows systems.
|
Important
|
You should never alter these files. |
If you want to view or update the Gradle version of your project, use the command line:
$ ./gradlew --version
$ ./gradlew :wrapper --gradle-version 7.2$ gradlew.bat --version
$ gradlew.bat :wrapper --gradle-version 7.2|
Warning
|
Do not edit the wrapper files manually. |
Next Step: Learn about the Gradle CLI >>
Command-Line Interface Basics
The command-line interface is the primary method of interacting with Gradle outside the IDE.
The Gradle CLI is the primary way to interact with a Gradle build from the terminal. You can use it to run tasks, inspect the build, manage dependencies, and control logging, all through flexible and powerful command-line options.
|
Tip
|
Use of the Gradle Wrapper is highly encouraged. Substitute ./gradlew (in macOS / Linux) or gradlew.bat (in Windows) for gradle in the following examples.
|
Running commands
To execute Gradle commands, use the following simple structure:
gradle [taskName...] [--option-name...]You can specify one or more tasks separated by spaces.
gradle [taskName1 taskName2...] [--option-name...]For example, to run a task named build, simply type:
gradle buildTo clean first, and then build:
gradle clean buildCommand-line options
Gradle commands can include various options to adjust their behavior. Options can appear before or after task names, like so:
gradle [--option-name...] [taskName...]For options that accept a value, use an equals sign (=) for clarity:
gradle [...] --console=plainSome options are toggles and have opposite forms. For instance, to enable or disable the build cache:
gradle build --build-cache
gradle build --no-build-cacheGradle also provides short-option equivalents for convenience. The following two commands are equivalent:
gradle --help
gradle -hExecuting tasks
In Gradle, tasks belong to specific projects.
To clearly indicate which task you want to run, especially in multi-project builds, use a colon (:) as a project separator.
To execute a task named test at the root project level, use:
gradle :testFor nested subprojects, specify the full path using colons:
gradle :subproject:testIf you run a task without any colons, Gradle executes the task in the current directory’s project context:
gradle testTask options
Some tasks accept their own specific options.
Pass these options directly after the task name, prefixed with --.
Here’s how you can pass a custom option:
gradle taskName --exampleOption=exampleValueNext Step: Learn about the Settings file >>
Settings File Basics
The settings file (settings.gradle(.kts)) is the entry point of every Gradle project.
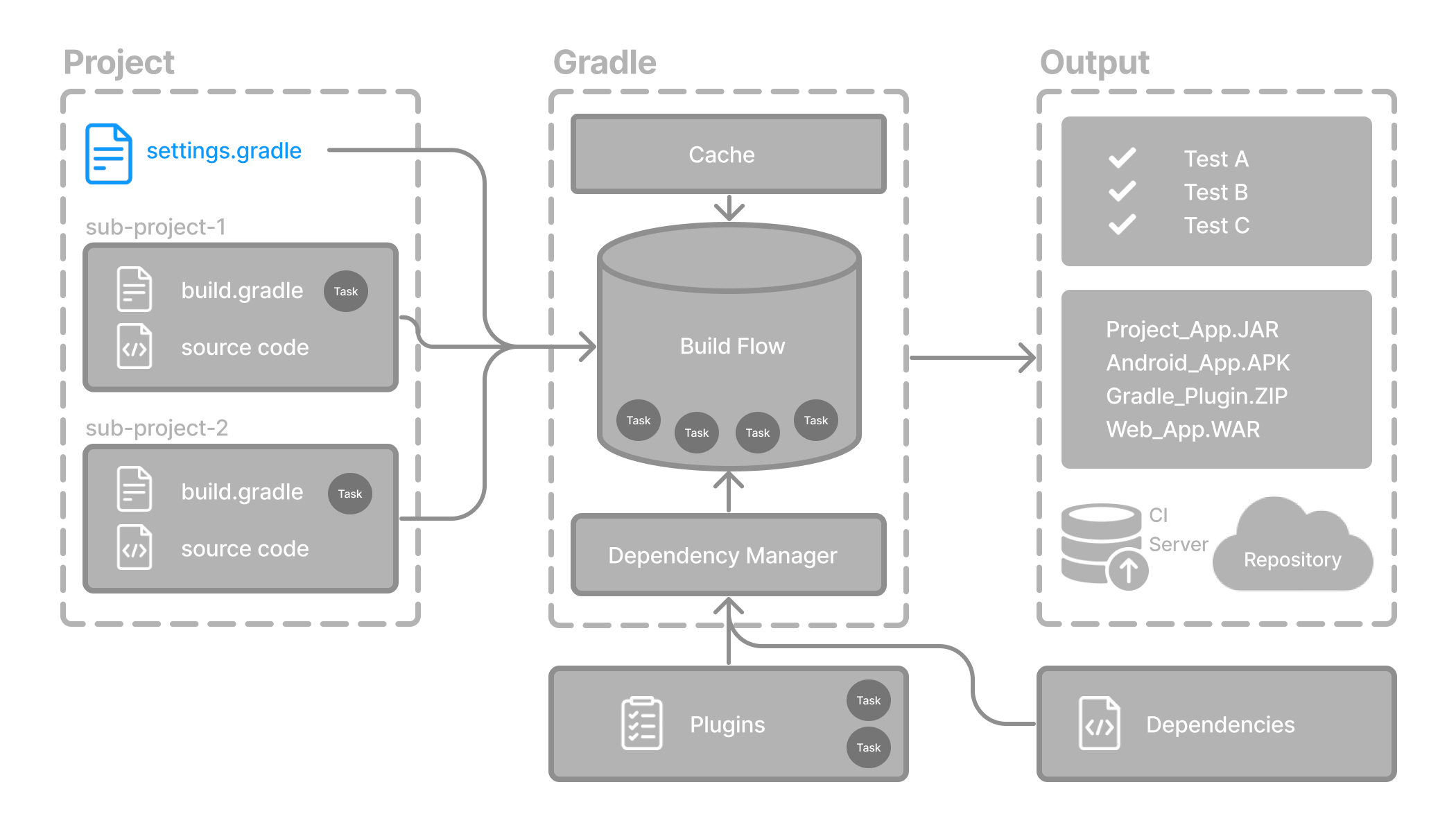
The primary purpose of the settings file is to define the project structure, usually adding subprojects to your build. Therefore in:
-
Single-project builds, the settings file is optional.
-
Multi-project builds, the settings file is mandatory and declares all subprojects.
Settings script
The settings file is a script.
It is either a settings.gradle file written in Groovy or a settings.gradle.kts file in Kotlin.
The Groovy DSL and the Kotlin DSL are the only accepted languages for Gradle scripts.
The settings file is typically located in the root directory of the project since it defines the structure of the build, such as which projects are included. Without a settings file, Gradle treats the build as a single-project build by default.
Let’s take a look at an example and break it down:
rootProject.name = "root-project" // (1)
include("sub-project-a") // (2)
include("sub-project-b")
include("sub-project-c")-
Define the project name.
-
Add subprojects.
rootProject.name = 'root-project' // (1)
include('sub-project-a') // (2)
include('sub-project-b')
include('sub-project-c')-
Define the project name.
-
Add subprojects.
1. Define the project name
The settings file defines your project name:
rootProject.name = "root-project"There is only one root project per build.
2. Add subprojects
The settings file defines the structure of the project by including subprojects, if there are any:
include("sub-project-a")
include("sub-project-b")
include("sub-project-c")The settings script is evaluated before any build scripts, making it the right place to enable or configure build-wide features such as plugin management, included builds, version catalogs, and more. We will explore these Gradle features in the advanced concepts section.
Based on the example settings file, Gradle expects the project to look as follows:
.
├── settings.gradle(.kts) // (1)
├── sub-project-a
│ └── build.gradle(.kts) // (2)
├── sub-project-b
│ └── build.gradle(.kts) // (2)
└── sub-project-c
└── build.gradle(.kts) // (2)-
The
settings.gradle(.kts)file. -
The three subprojects, each with their own
build.gradle(.kts)file.
Next Step: Learn about the Build scripts >>
Build File Basics
Generally, a build script (build.gradle(.kts)) details build configuration, tasks, and plugins.
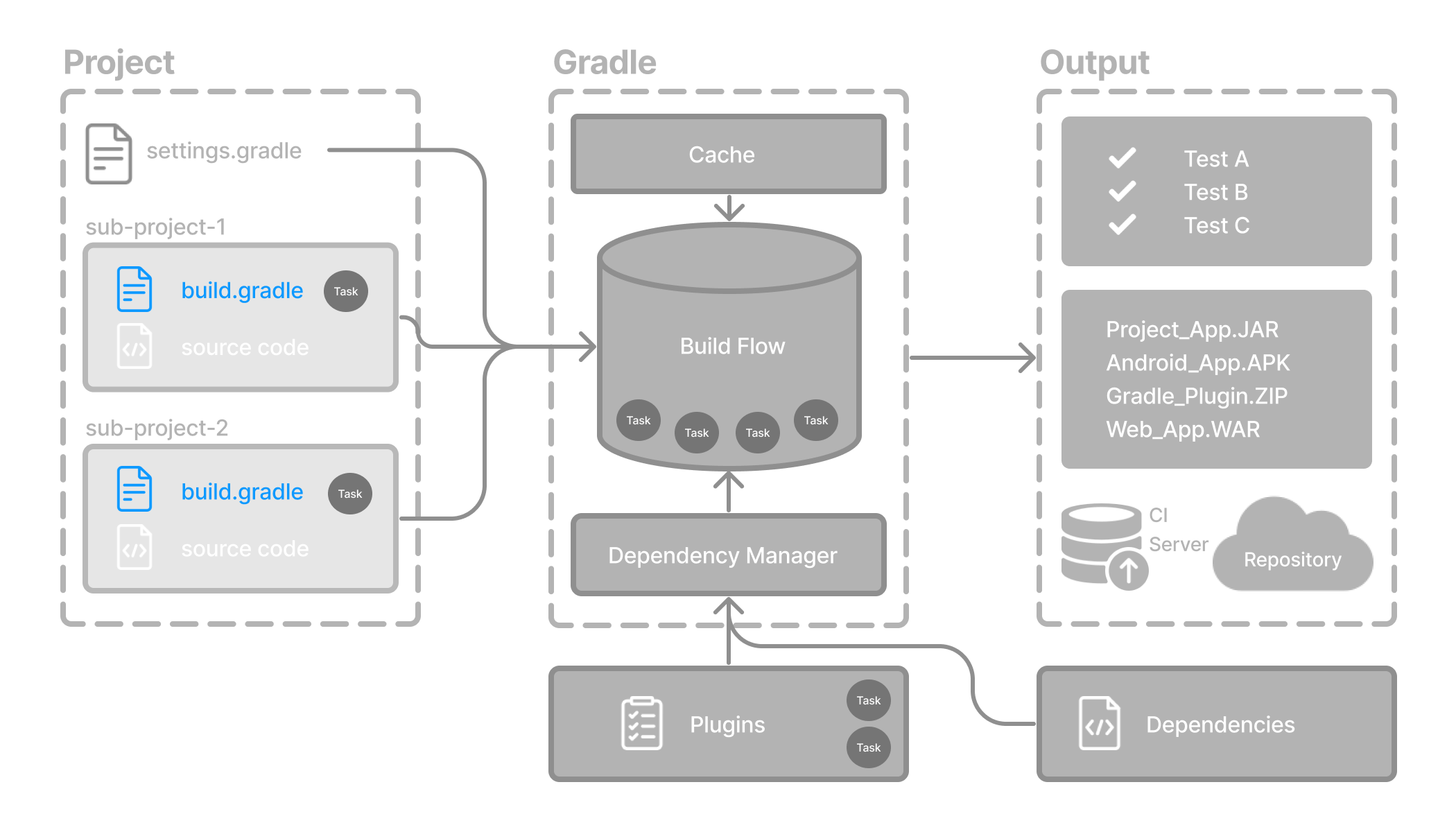
Every Gradle build comprises at least one build script.
Build scripts
The build script is either a build.gradle file written in Groovy or a build.gradle.kts file in Kotlin.
The Groovy DSL and the Kotlin DSL are the only accepted languages for Gradle scripts.
In multi-project builds, each subproject typically has its own build file located in its root directory.
Inside a build script, you’ll typically specify:
-
Plugins: Tools that extend Gradle’s functionality for tasks like compiling code, running tests, or packaging artifacts.
-
Dependencies: External libraries and tools your project uses.
Specifically, build scripts contain two main types of dependencies:
-
Gradle and Build Script Dependencies: These include plugins and libraries required by Gradle itself or the build script logic.
-
Project Dependencies: Libraries required directly by your project’s source code to compile and run correctly.
Let’s take a look at an example and break it down:
plugins { // (1)
// Apply the application plugin to add support for building a CLI application in Java.
application
}
dependencies { // (2)
// Use JUnit Jupiter for testing.
testImplementation(libs.junit.jupiter)
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
// This dependency is used by the application.
implementation(libs.guava)
}
application { // (3)
// Define the main class for the application.
mainClass = "org.example.App"
}plugins { // (1)
// Apply the application plugin to add support for building a CLI application in Java.
id 'application'
}
dependencies { // (2)
// Use JUnit Jupiter for testing.
testImplementation libs.junit.jupiter
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
// This dependency is used by the application.
implementation libs.guava
}
application { // (3)
// Define the main class for the application.
mainClass = 'org.example.App'
}-
Add plugins.
-
Add dependencies.
-
Use convention properties.
1. Add plugins
Plugins extend Gradle’s functionality and can contribute tasks to a project.
Adding a plugin to a build is called applying a plugin and makes additional functionality available.
plugins { // (1)
// Apply the application plugin to add support for building a CLI application in Java.
application
}plugins { // (1)
// Apply the application plugin to add support for building a CLI application in Java.
id 'application'
}The application plugin facilitates creating an executable JVM application.
Applying the Application plugin also implicitly applies the Java plugin.
The java plugin adds Java compilation along with testing and bundling capabilities to a project.
2. Add dependencies
Your project needs external libraries to compile, run, and test.
In this example, the project uses JUnit Jupiter for testing and Google’s Guava library in the main application code:
dependencies { // (2)
// Use JUnit Jupiter for testing.
testImplementation(libs.junit.jupiter)
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
// This dependency is used by the application.
implementation(libs.guava)
}dependencies { // (2)
// Use JUnit Jupiter for testing.
testImplementation libs.junit.jupiter
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
// This dependency is used by the application.
implementation libs.guava
}3. Use convention properties
A plugin adds tasks to a project. It also adds properties and methods to a project.
The application plugin defines tasks that package and distribute an application, such as the run task.
The Application plugin provides a way to declare the main class of a Java application, which is required to execute the code.
application { // (3)
// Define the main class for the application.
mainClass = "org.example.App"
}application { // (3)
// Define the main class for the application.
mainClass = 'org.example.App'
}In this example, the main class (i.e., the point where the program’s execution begins) is org.example.App.
Build scripts are evaluated during the configuration phase of a build, and they serve as the main entry point for defining a (sub)project’s build logic. In addition to applying plugins and setting convention properties, build scripts can:
-
Declare dependencies
-
Configure tasks
-
Reference shared settings (from version catalogs or convention plugins)
Next Step: Learn about Dependency Management >>
Dependencies and Dependency Management Basics
Gradle has built-in support for dependency management.
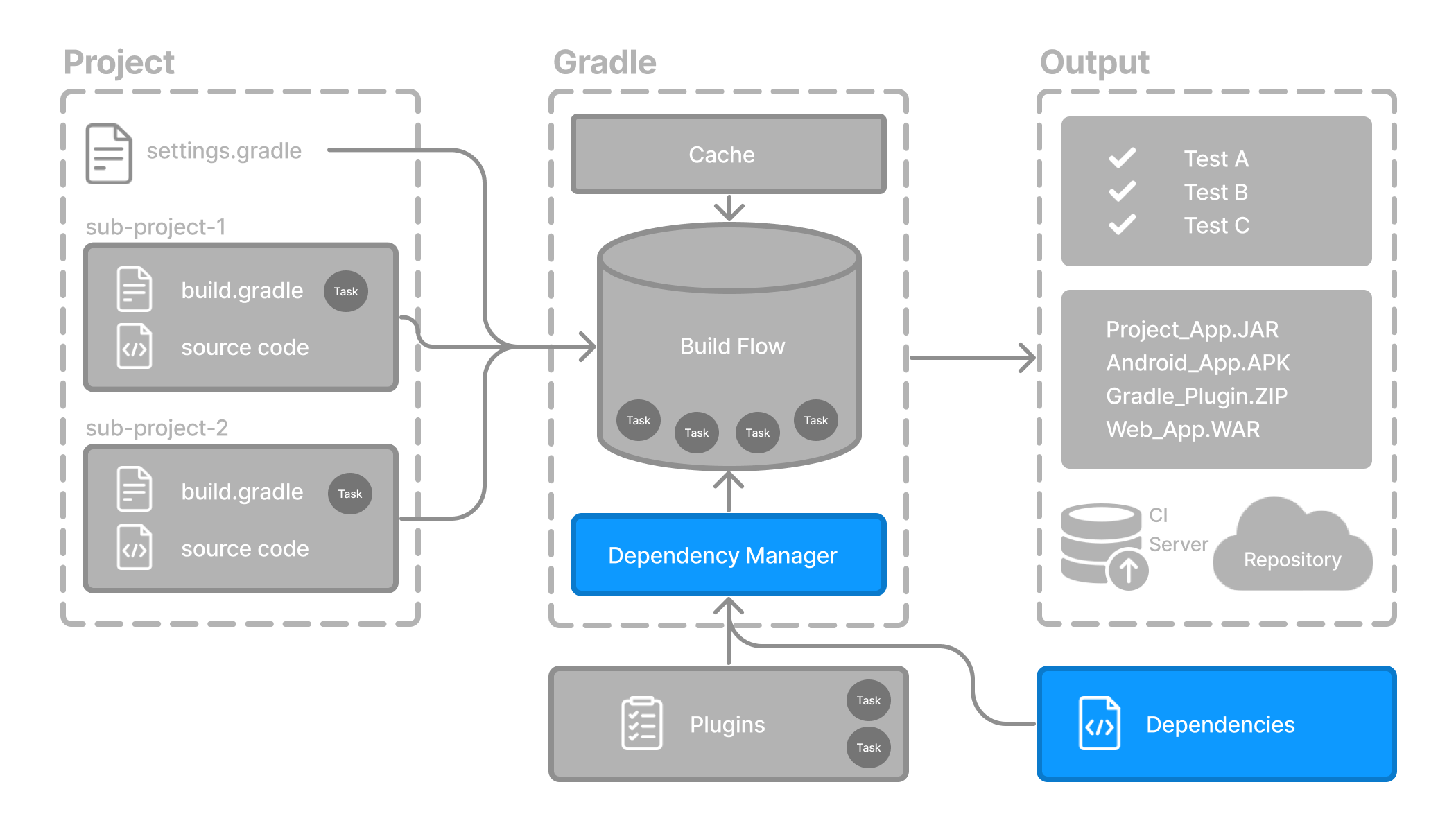
Dependency management is an automated technique for declaring and resolving external resources required by a project (i.e., dependencies).
Dependencies include JARs, libraries, or source code that support building your project. They are declared in build scripts.
Gradle automatically handles downloading, caching, and resolving these dependencies, saving you from managing them manually. It also handles version conflicts and supports flexible version declarations.
Declaring Your Dependencies
To add a dependency to your project, specify a dependency in the dependencies {} block of your build.gradle(.kts) file.
The following build.gradle(.kts) file adds two dependencies to the project:
plugins {
id("java-library") // (1)
}
dependencies {
implementation("com.google.guava:guava:32.1.2-jre") // (2)
api("org.apache.juneau:juneau-marshall:8.2.0") // (3)
}plugins {
id("java-library") // (1)
}
dependencies {
implementation("com.google.guava:guava:32.1.2-jre") // (2)
api("org.apache.juneau:juneau-marshall:8.2.0") // (3)
}-
Applies the Java Library plugin.
-
Adds a dependency on Google’s Guava library used in production code.
-
Adds a dependency on Apache’s Juneau Marshall library, used in library code.
Dependencies in Gradle are grouped by buckets called configurations, which define when, where, and how the dependency is used. Configurations define the scope of your dependencies. In the example above:
-
implementationis used for dependencies needed to compile and run your production code. -
apiis used for dependencies that should be exposed to consumers of your library.
When you apply certain plugins, Gradle automatically creates the right configurations for your project and makes them available to use.
For example, applying java or java-library adds configurations like implementation, api, compileOnly, runtimeOnly, and testImplementation so you can declare dependencies in the right place without extra setup.
The Android Gradle Plugin (AGP) adds variant-aware configs like debugImplementation, releaseImplementation, androidTestImplementation, and even per–build-type/flavor ones like freeDebugImplementation.
Kotlin Multiplatform (KMP) creates source set–scoped configs such as commonMainImplementation, commonTestImplementation, androidMainImplementation, iosArm64MainImplementation, etc.—so you depend exactly where the code runs.
Viewing Project Dependencies
You can inspect the dependency tree using the dependencies task.
For example, to view the dependencies of the :app project:
$ ./gradlew :app:dependenciesGradle will output the dependency tree, grouped by configuration:
$ ./gradlew :app:dependencies> Task :app:dependencies
------------------------------------------------------------
Project ':app'
------------------------------------------------------------
...
runtimeClasspath - Runtime classpath of source set 'main'.
+--- org.apache.juneau:juneau-marshall:8.2.0
| \--- org.apache.httpcomponents:httpcore:4.4.13
\--- com.google.guava:guava:32.1.2-jre
+--- com.google.guava:guava-parent:32.1.2-jre
| +--- com.google.code.findbugs:jsr305:3.0.2 (c)
| +--- org.checkerframework:checker-qual:3.33.0 (c)
| \--- com.google.errorprone:error_prone_annotations:2.18.0 (c)
+--- com.google.guava:failureaccess:1.0.1
+--- com.google.guava:listenablefuture:9999.0-empty-to-avoid-conflict-with-guava
+--- com.google.code.findbugs:jsr305 -> 3.0.2
+--- org.checkerframework:checker-qual -> 3.33.0
\--- com.google.errorprone:error_prone_annotations -> 2.18.0Using a Version Catalog
A version catalog provides a centralized and consistent way to manage dependency coordinates and versions across your entire build.
Instead of declaring versions directly in each build.gradle(.kts) file, you define them once in a libs.versions.toml file.
This makes it easier to:
-
Share common dependency declarations between subprojects
-
Avoid duplication and version inconsistencies
-
Enforce dependency and plugin versions across large projects
The version catalog typically contains four sections:
-
[versions]to declare the version numbers that plugins and libraries will reference. -
[libraries]to define the libraries used in the build files. -
[bundles]to define a set of dependencies. -
[plugins]to define plugins.
Here’s an example:
[versions]
guava = "32.1.2-jre"
juneau = "8.2.0"
[libraries]
guava = { group = "com.google.guava", name = "guava", version.ref = "guava" }
juneau-marshall = { group = "org.apache.juneau", name = "juneau-marshall", version.ref = "juneau" }Place this file in the gradle/ directory of your project as libs.versions.toml.
Gradle will pick it up automatically and expose its contents through the libs accessor in your build scripts.
IDEs like IntelliJ and Android Studio will also pick up this metadata for code completion.
Once defined, you can reference these aliases directly in your build file:
dependencies {
implementation(libs.guava)
api(libs.juneau.marshall)
}dependencies {
implementation(libs.guava)
api(libs.juneau.marshall)
}Next Step: Learn about Tasks >>
Task Basics
A task represents some independent unit of work that a build performs, such as compiling classes, creating a JAR, generating Javadoc, or publishing archives to a repository.
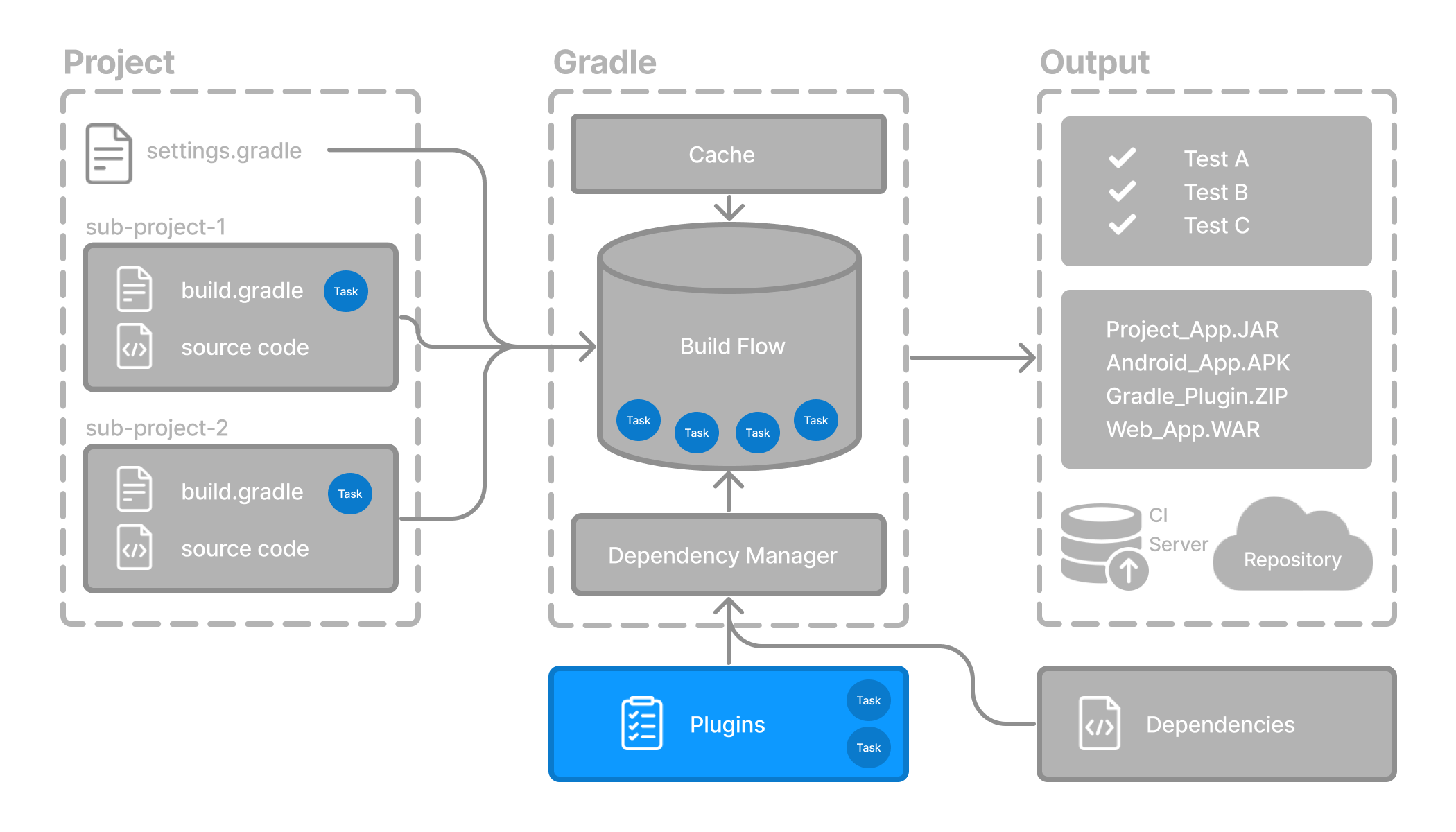
Tasks are the building blocks of every Gradle build.
Common types of tasks include:
-
Compiling source code
-
Running tests
-
Packaging output (e.g., creating a JAR or APK)
-
Generating documentation (e.g., Javadoc)
-
Publishing build artifacts to repositories
Each task is independent but can depend on other tasks to run first. Gradle uses this information to figure out the most efficient order to execute tasks — skipping anything that’s already up to date.
Running a task
To run a task, use the Gradle Wrapper from your project’s root directory.
For example, to run the build task:
$ ./gradlew buildThis will run the build task and all of its dependencies.
If you have the application plugin applied in your build file, the run task should be available.
You can run your project like this:
$ ./gradlew runExample output:
> Task :app:compileJava
> Task :app:processResources NO-SOURCE
> Task :app:classes
> Task :app:run
Hello World!
BUILD SUCCESSFUL in 904ms
2 actionable tasks: 2 executedGradle ran all the tasks required to execute your application, including compiling it first.
In this example, the output of the run task is a Hello World statement printed on the console.
Listing available tasks
Gradle plugins and your build script define which tasks are available in a project. To see them:
$ ./gradlew tasksThis shows a categorized list of tasks:
Application tasks
-----------------
run - Runs this project as a JVM application
Build tasks
-----------
assemble - Assembles the outputs of this project.
build - Assembles and tests this project.
...
Documentation tasks
-------------------
javadoc - Generates Javadoc API documentation for the main source code.
...
Other tasks
-----------
compileJava - Compiles main Java source.
...You can run any of these tasks directly using the ./gradlew <task-name> command.
Task dependencies
Most tasks don’t run in isolation. Gradle knows which tasks depend on which others, and will automatically run them in the correct order.
For example, when you run ./gradlew build, Gradle also runs tasks like compileJava, test, and jar first — because build depends on them:
$ ./gradlew build> Task :app:compileJava
> Task :app:processResources NO-SOURCE
> Task :app:classes
> Task :app:jar
> Task :app:startScripts
> Task :app:distTar
> Task :app:distZip
> Task :app:assemble
> Task :app:check
> Task :app:build
BUILD SUCCESSFUL in 764ms
7 actionable tasks: 7 executedYou don’t need to worry about ordering — Gradle figures it out for you.
Next Step: Learn about Incremental Builds and Build Caching >>
Incremental Builds and Build Caching Basic
Gradle uses two main features to reduce build time: incremental builds and build caching.
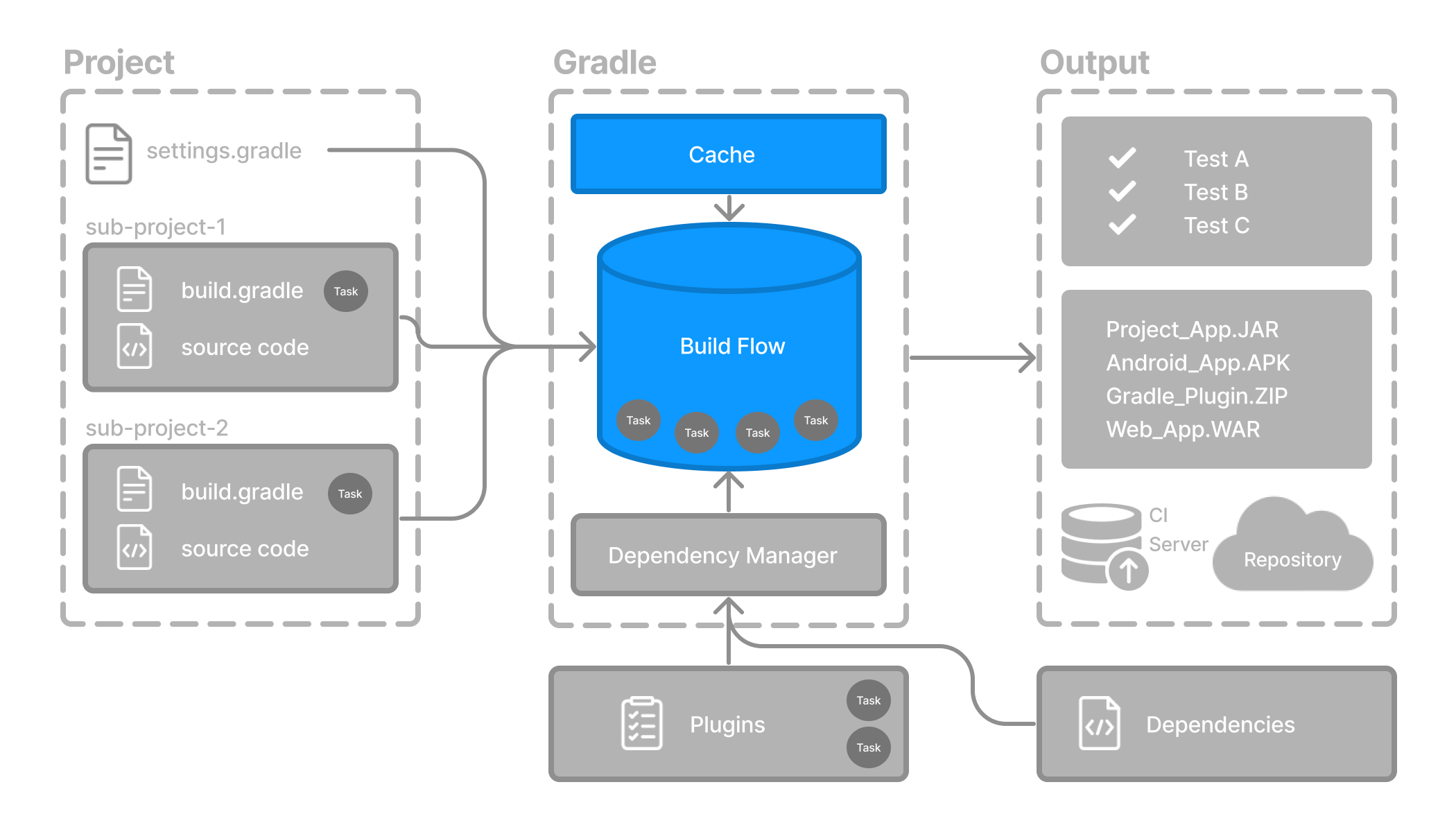
Task Outcome Labels
When you run a Gradle build with verbose mode turned on, each task prints a short outcome label that describes what happened during execution. These labels help you understand Gradle’s behavior and performance optimizations like incremental build and build caching:
> Task :compileJava UP-TO-DATE
> Task :processResources NO-SOURCE
> Task :jar FROM-CACHE
> Task :test SKIPPED
> Task :publish| Task Label | Meaning |
|---|---|
|
The task’s inputs and outputs haven’t changed since the last run, so it was skipped. |
|
The task was skipped and its outputs were restored from the local or remote build cache. |
|
The task had no source files to process (e.g., no Java files to compile), so it was skipped. |
|
The task was not executed due to a condition (e.g., only-if rule or command-line flags). |
The task ran normally and produced outputs. |
|
|
The task ran but encountered an error. |
Incremental Builds
An incremental build is a build that avoids running tasks whose inputs have not changed since the previous build. Re-executing such tasks is unnecessary if they would only re-produce the same output.
For incremental builds to work, tasks must define their inputs and outputs. Gradle will determine whether those input or outputs have changed at build time. If they have changed, Gradle will execute the task. Otherwise, it will skip execution.
Incremental builds are always enabled, and the best way to see them in action is to turn on verbose mode. With verbose mode, each task state is labeled during a build:
$ ./gradlew compileJava --console=verbose> Task :buildSrc:generateExternalPluginSpecBuilders UP-TO-DATE
> Task :buildSrc:extractPrecompiledScriptPluginPlugins UP-TO-DATE
> Task :buildSrc:compilePluginsBlocks UP-TO-DATE
> Task :buildSrc:generatePrecompiledScriptPluginAccessors UP-TO-DATE
> Task :buildSrc:generateScriptPluginAdapters UP-TO-DATE
> Task :buildSrc:compileKotlin UP-TO-DATE
> Task :buildSrc:compileJava NO-SOURCE
> Task :buildSrc:compileGroovy NO-SOURCE
> Task :buildSrc:pluginDescriptors UP-TO-DATE
> Task :buildSrc:processResources UP-TO-DATE
> Task :buildSrc:classes UP-TO-DATE
> Task :buildSrc:jar UP-TO-DATE
> Task :list:compileJava UP-TO-DATE
> Task :utilities:compileJava UP-TO-DATE
> Task :app:compileJava UP-TO-DATE
BUILD SUCCESSFUL in 374ms
12 actionable tasks: 12 up-to-dateWhen you run a task that has been previously executed and hasn’t changed, then UP-TO-DATE is printed next to the task.
|
Tip
|
To permanently enable verbose mode, add org.gradle.console=verbose to your gradle.properties file.
|
Build Caching
Incremental Builds are a great optimization that helps avoid work already done. If a developer continuously changes a single file, there is likely no need to rebuild all the other files in the project.
However, what happens when the same developer switches to a new branch created last week? The files are rebuilt, even though the developer is building something that has been built before.
This is where a build cache is helpful.
The build cache stores previous build results and restores them when needed. It prevents the redundant work and cost of executing time-consuming and expensive processes.
When the build cache has been used to repopulate the local directory, the tasks are marked as FROM-CACHE:
$ ./gradlew compileJava --build-cache> Task :buildSrc:generateExternalPluginSpecBuilders UP-TO-DATE
> Task :buildSrc:extractPrecompiledScriptPluginPlugins UP-TO-DATE
> Task :buildSrc:compilePluginsBlocks UP-TO-DATE
> Task :buildSrc:generatePrecompiledScriptPluginAccessors UP-TO-DATE
> Task :buildSrc:generateScriptPluginAdapters UP-TO-DATE
> Task :buildSrc:compileKotlin UP-TO-DATE
> Task :buildSrc:compileJava NO-SOURCE
> Task :buildSrc:compileGroovy NO-SOURCE
> Task :buildSrc:pluginDescriptors UP-TO-DATE
> Task :buildSrc:processResources UP-TO-DATE
> Task :buildSrc:classes UP-TO-DATE
> Task :buildSrc:jar UP-TO-DATE
> Task :list:compileJava FROM-CACHE
> Task :utilities:compileJava FROM-CACHE
> Task :app:compileJava FROM-CACHE
BUILD SUCCESSFUL in 364ms
12 actionable tasks: 3 from cache, 9 up-to-dateOnce the local directory has been repopulated, the next execution will mark tasks as UP-TO-DATE and not FROM-CACHE.
The build cache allows you to share and reuse unchanged build and test outputs across teams. This speeds up local and CI builds since cycles are not wasted re-building binaries unaffected by new code changes.
Next Step: Learn about Plugins >>
Plugin Basics
Gradle is built on a flexible plugin system.
Out of the box, Gradle provides core infrastructure like dependency resolution, task orchestration, and incremental builds. Most functionality — like compiling Java, building Android apps, or publishing artifacts — comes from plugins.
A plugin is a reusable piece of software that provides additional functionality to the Gradle build system. It can:
-
Add new tasks to your build (like
compileJavaortest) -
Add new configurations (like
implementationorruntimeOnly) -
Contribute DSL elements (like
application {}orpublishing {})
Plugins are applied to build scripts using the plugins block (Kotlin DSL or Groovy DSL), and they bring in all the logic needed for a specific domain or workflow.
Common Plugins
Here are some popular plugins and what they do:
- Java Library Plugin (
java-library) -
Compiles Java source code, generates Javadoc, and packages classes into a JAR. Adds tasks like
compileJava,javadoc, andjar. - Google Services Plugin (
com.google.gms.google-services) -
Configures Firebase and Google APIs in Android builds. Adds DSL like
googleServices {}and tasks likegenerateReleaseAssets. - Gradle Bintray Plugin (
com.jfrog.bintray) -
Publishes artifacts to Bintray (or other Maven-style repositories) using a
bintray {}configuration block.
Applying Plugins
Applying a plugin to a project allows the plugin to extend the project’s capabilities.
You apply plugins in the build script using a plugin id (a globally unique identifier / name) and a version:
plugins {
id("«plugin id»").version("«plugin version»")
}For example:
plugins {
id("java-library")
id("com.diffplug.spotless").version("6.25.0")
}This tells Gradle to:
-
Apply the built-in
java-libraryplugin, which adds tasks for compiling Java, running tests, and packaging libraries. -
Apply the community-maintained
spotlessplugin (version6.25.0), which adds code formatting tasks and integrates tools likektlint,prettier, andgoogle-java-format.
Plugin Distribution and Availability
Gradle plugins come from different sources, and you can choose the right type depending on your use case.
1. Core Plugins
Gradle Core plugins are a set of plugins that are included in the Gradle distribution itself. These plugins provide essential functionality for building and managing projects.
Core plugins are unique in that they provide short names, such as java-library for the core JavaLibraryPlugin.
You can apply them by ID with no extra setup:
plugins {
id("java-library")
}These plugins are maintained by the Gradle team. See the Core Plugin Reference for a full list.
2. Community Plugins
Community plugins are plugins developed by the Gradle community, rather than being part of the core Gradle distribution. These plugins provide additional functionality that may be specific to certain use cases or technologies.
Gradle’s plugin ecosystem includes thousands of open-source plugins shared by the community. These are typically published to the Gradle Plugin Portal and can be applied by ID and version:
plugins {
id("org.springframework.boot").version("3.1.5")
}Gradle will automatically download the plugin when the build runs. See the Gradle Plugin Portal to search for a plugin.
3. Custom / Local Plugins
You can also write your own plugins — either for use in a single project or shared across multiple projects in the same build.
Custom plugins are typically written in Java, Kotlin, or Groovy and follow the same structure as published plugins.
They are normally applied by name:
plugins {
id("my.custom-conventions")
}Next Step: Learn about Build Scan >>
Build Scan Basics
A Build Scan is a representation of metadata captured as you run your build.
About Build Scan
Gradle captures your build metadata and sends it to the Build Scan Service. The service then transforms the metadata into information you can analyze and share with others.
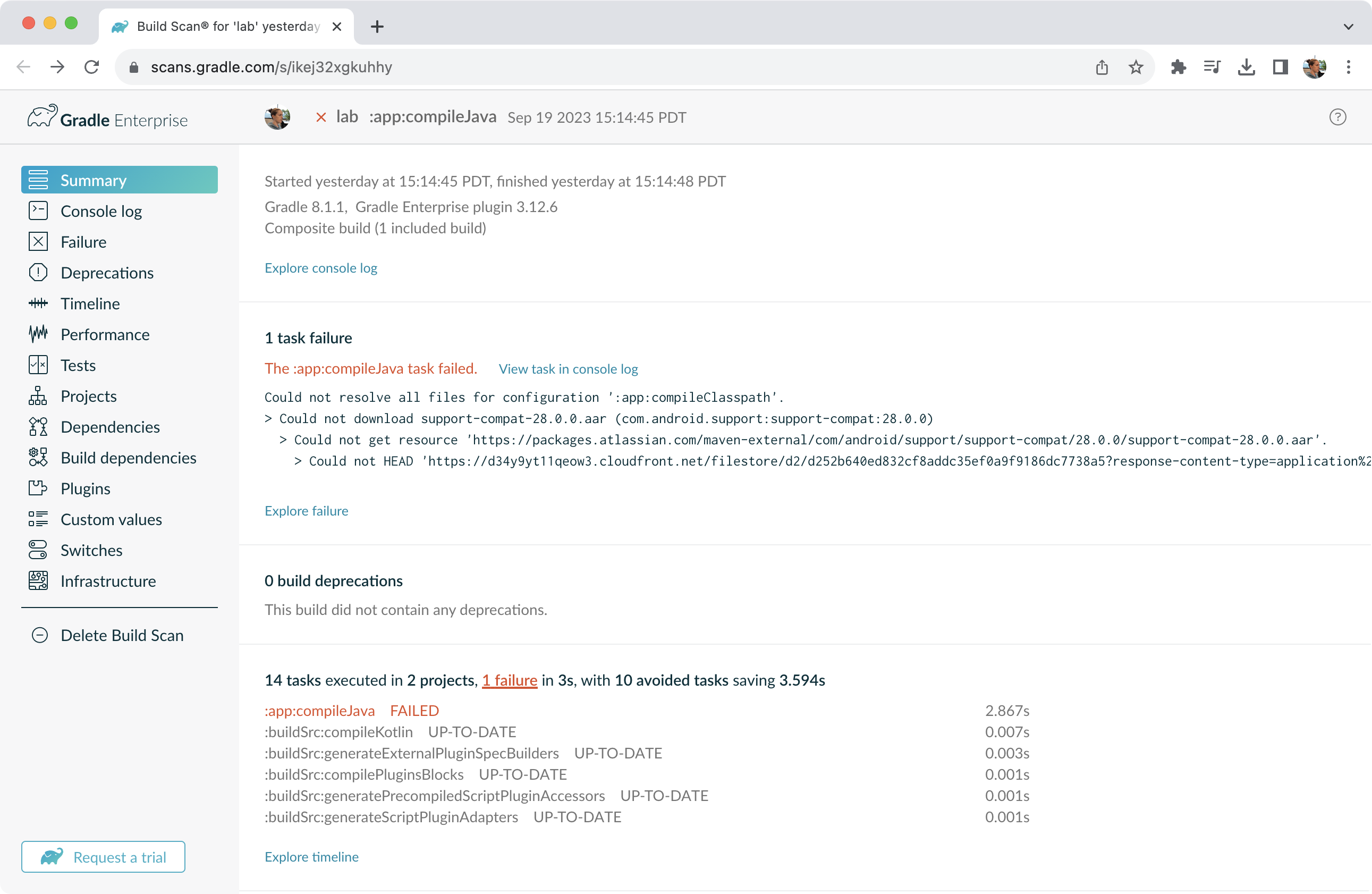
The information that Build Scan collects can be an invaluable resource when troubleshooting, collaborating on, or optimizing the performance of your builds.
For example, with a Build Scan, it’s no longer necessary to copy and paste error messages or include all the details about your environment each time you want to ask a question on Stack Overflow, Slack, or the Gradle Forum. Instead, copy the link to your latest Build Scan.
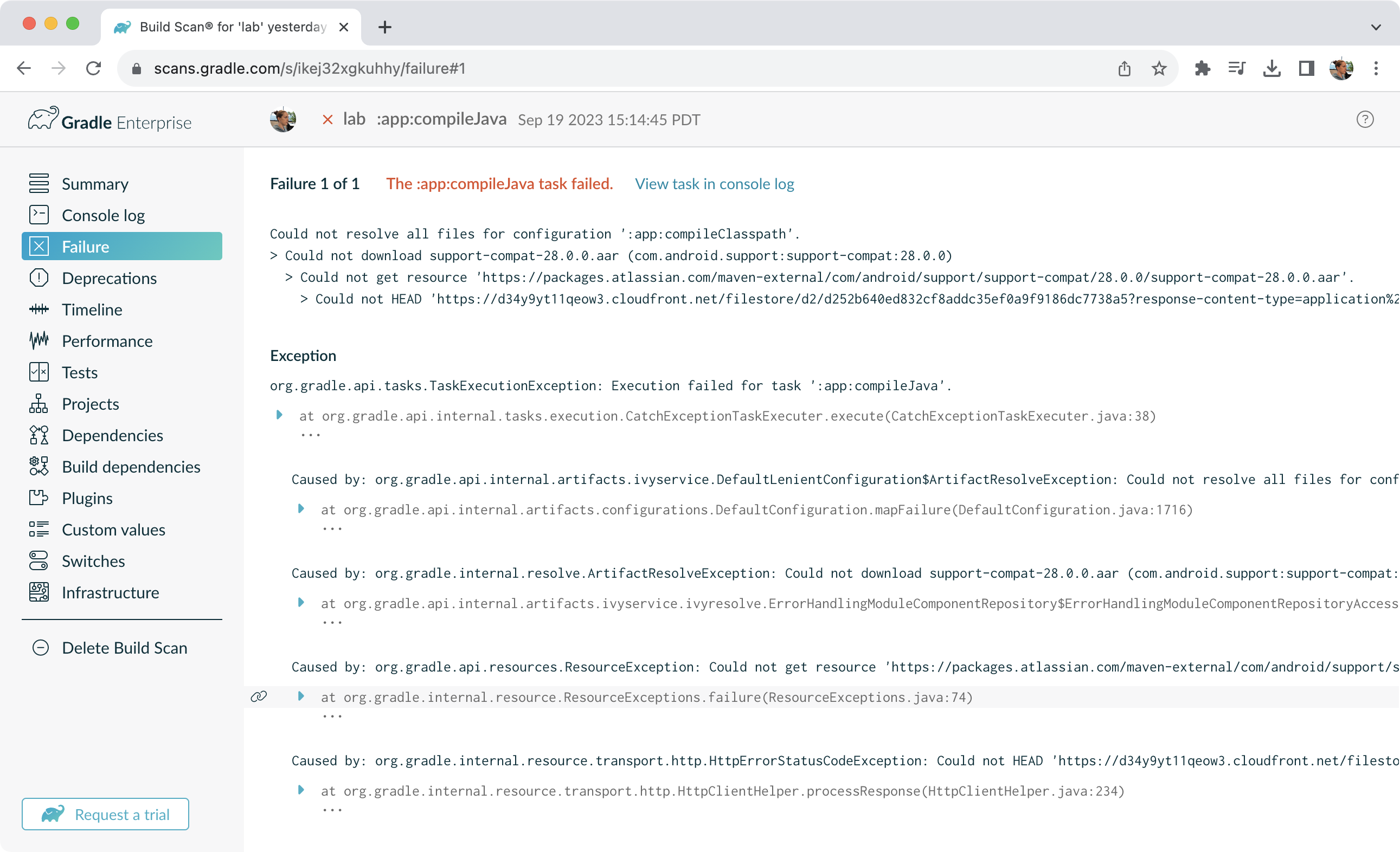
Enable Build Scan
To enable a Build Scan on a Gradle command, add --scan to the command line option:
$ ./gradlew build --scanYou may be prompted to agree to the terms to use Build Scan.
Visit Develocity at gradle.com to learn more.
Publishing to a specific Develocity server
If you have a Develocity server, you can publish your Build Scan reports to that server instead of Develocity at gradle.com.
You enable this with the --develocity-url command line option:
./gradlew build --develocity-url=https://develocity.example.comCheck the Develocity Gradle plugin documentation for more details.
Captured Information
To see what data is captured and sent in a Build Scan, refer to the Captured Information section in the Gradle Develocity Plugin documentation.
Ready to build something? Start with the Beginner Tutorial.
Next Step: Start the Tutorial >>
Anatomy of a Gradle Build
A Gradle build is made up of several key components that work together to automate tasks like compiling code, running tests, and packaging artifacts.
At a high level, a build includes:
-
Projects, which represent things you’re building (like apps or libraries)
-
Tasks, which define the work to do (like compiling or testing)
-
Build scripts, which configure the projects and tasks
-
Plugins, which extend the build with reusable logic
Let’s first quickly review the directories in a simple Gradle project to better understand the components of a build:
gradle-project // (1)
├── app
│ ├── build.gradle.kts // (2)
│ └── ...
├── settings.gradle.kts // (3)
├── gradle // (4)
│ └── ...
├── gradlew // (5)
└── gradlew.bat // (5)gradle-project // (1)
├── app
│ ├── build.gradle // (2)
│ └── ...
├── settings.gradle // (3)
├── gradle // (4)
│ └── ...
├── gradlew // (5)
└── gradlew.bat // (5)-
Root Directory - Gradle Project
-
Build Script - Project-level configuration
-
Settings File - Project inclusion and build identity
-
Gradle Files - Wrapper executables and version pinning
-
Gradle Wrapper - Script that automatically downloads and runs the correct Gradle version for a project
This basic Gradle build has a root project called gradle-project and contains one subproject called app.
The settings file in the root directory lets Gradle know about the structure of the build.
The build file in the app directory contains build logic specific to the app subproject such as declaring dependencies and applying plugins.
Build Directory
The build/ directory is the default output directory at the root of each project where Gradle places all generated files during a build.
It is created automatically when you run tasks like build, assemble, test, or others that produce outputs:
gradle-project
├── app
│ ├── build.gradle.kts
│ └── ...
├── settings.gradle.kts
├── gradle
│ └── ...
├── build // (1)
├── gradlew
└── gradlew.batgradle-project
├── app
│ ├── build.gradle
│ └── ...
├── settings.gradle
├── gradle
│ └── ...
├── build // (1)
├── gradlew
└── gradlew.bat-
Build directory
To remove the entire build/ directory and all its contents, use:
$ ./gradlew cleanThis is useful when you want to ensure a fresh build with no leftover outputs.
|
Warning
|
Gradle creates the build directory by default, so it must be writable. If a custom build directory is specified, it must exist and also be writable.
|
Gradle uses two main directories to perform and manage its work: the Gradle User Home Directory and the Project Root Directory.
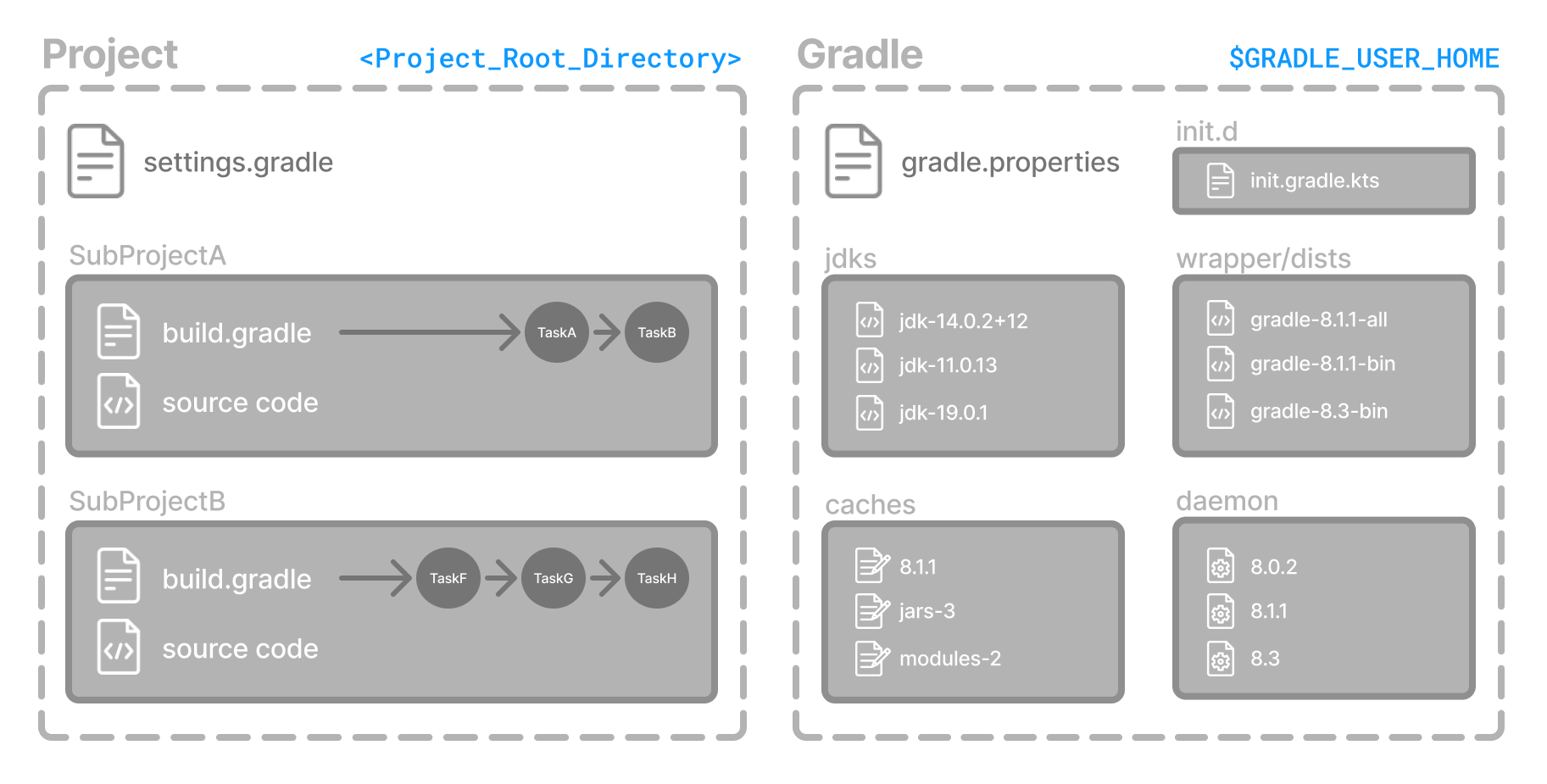
Project Root Directory
The Project Root Directory contains all source files from your project.
It also contains files and directories Gradle generates, such as .gradle and build, as well as the Gradle configuration directory: gradle.
|
Tip
|
The gradle and .gradle directories are different.
|
While gradle is usually checked into source control, build and .gradle directories contain the output of your builds, caches, and other transient files Gradle uses to support features like incremental builds.
In this case, ./gradle-project is the project root directory:
gradle-project // (1)
├── .gradle // (2)
│ ├── 4.8 // (3)
│ ├── 4.9 // (3)
│ └── ⋮
├── build // (4)
├── gradle
│ └── wrapper // (5)
├── gradle.properties // (6)
├── gradlew // (7)
├── gradlew.bat // (7)
├── settings.gradle(.kts) // (8)
├── subproject-one // (9)
| └── build.gradle(.kts) // (10)
├── subproject-two // (9)
| └── build.gradle(.kts) // (10)
└── ⋮-
Root Project
-
Project-specific cache directory generated by Gradle.
-
Version-specific caches (e.g., to support incremental builds).
-
The build directory of this project.
-
Contains the JAR file and configuration of the Gradle Wrapper.
-
Project-specific Gradle configuration properties.
-
Scripts for executing builds using the Gradle Wrapper.
-
The project’s settings file where the list of subprojects is defined.
-
Usually, a project is organized into one or multiple subprojects.
-
Each subproject has its own Gradle build script.
Gradle User Home Directory
By default, the Gradle User Home (~/.gradle or C:\Users\<USERNAME>\.gradle) stores global configuration properties, initialization scripts, caches, and log files.
It can be set with the environment variable GRADLE_USER_HOME.
Note that this directory is often abbreviated as GUH.
|
Warning
|
GRADLE_USER_HOME is not to be confused with the GRADLE_HOME, the optional installation directory for Gradle.
|
It is roughly structured as follows:
~/.gradle // (1)
├── caches // (2)
│ ├── 4.8 // (3)
│ ├── 4.9 // (3)
│ ├── ⋮
│ ├── jars-3 // (4)
│ └── modules-2 // (4)
├── daemon // (5)
│ ├── ⋮
│ ├── 4.8
│ └── 4.9
├── init.d // (6)
│ └── my-setup.gradle
├── jdks // (7)
│ ├── ⋮
│ └── jdk-14.0.2+12
├── wrapper
│ └── dists // (8)
│ ├── ⋮
│ ├── gradle-4.8-bin
│ ├── gradle-4.9-all
│ └── gradle-4.9-bin
└── gradle.properties // (9)-
Gradle User Home
-
Global cache directory (for everything that is not project-specific).
-
Version-specific caches (e.g., to support incremental builds).
-
Shared caches (e.g., for artifacts of dependencies).
-
Registry and logs of the Gradle Daemon.
-
Global initialization scripts.
-
JDKs downloaded by the toolchain support.
-
Distributions downloaded by the Gradle Wrapper.
-
Global Gradle configuration properties.
Next Step: Learn how to structure Multi-Project Builds >>
Structuring Multi-Project Builds
As your codebase grows, organizing it into multiple subprojects becomes essential for maintainability, performance, and reuse. Gradle supports this with multi-project builds.
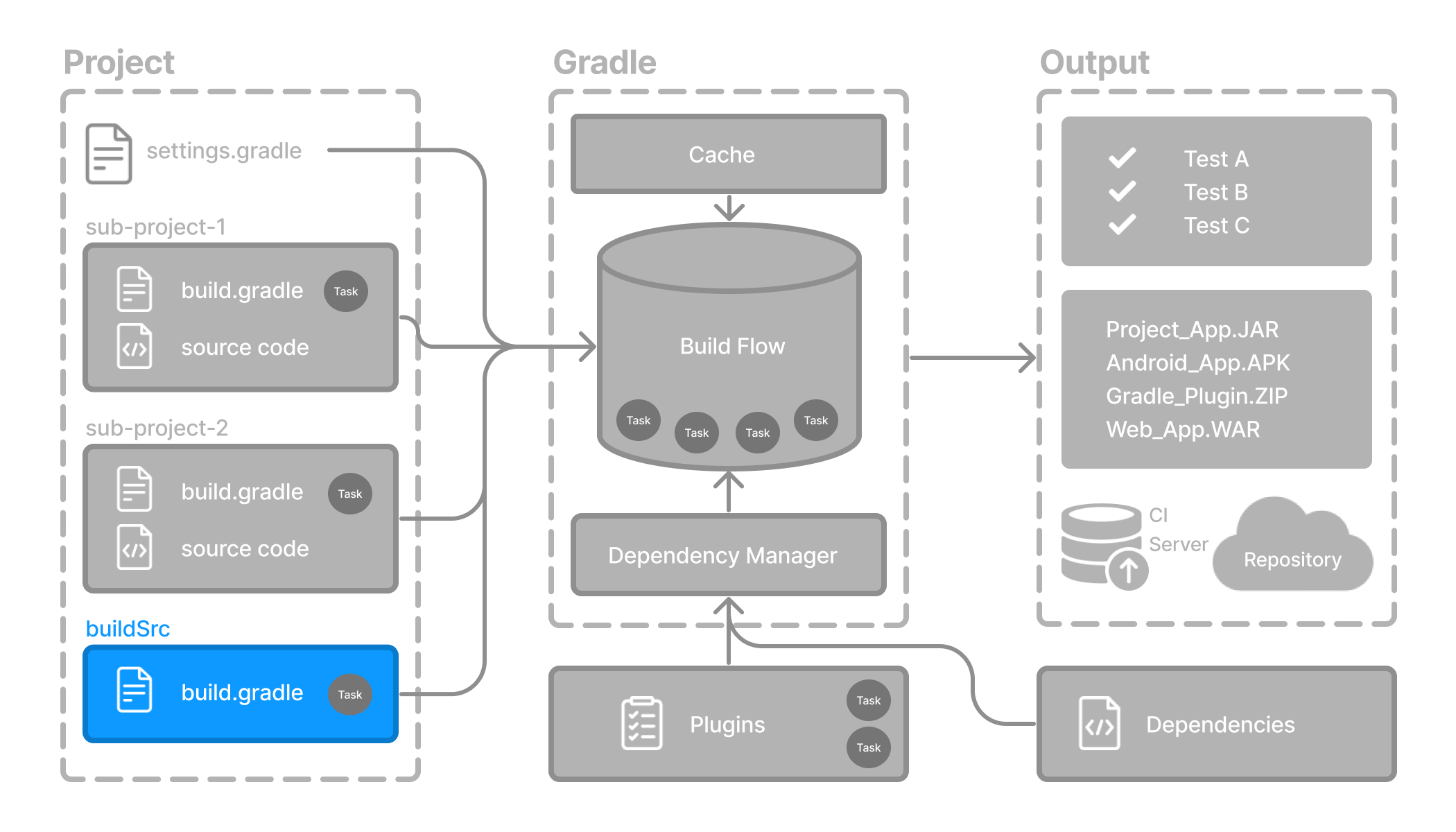
While some small projects and monolithic applications may contain a single build file and source tree, it is often more common for a project to have been split into smaller, interdependent modules. The word "interdependent" is vital, as you typically want to link the many modules together through a single build.
Gradle supports this scenario through multi-project builds. This is sometimes referred to as a multi-module project. Gradle refers to modules as subprojects.
A multi-project build consists of one root project and one or more subprojects.
Multi-Project Structure
The following represents the structure of a sample multi-project build that contains three subprojects:
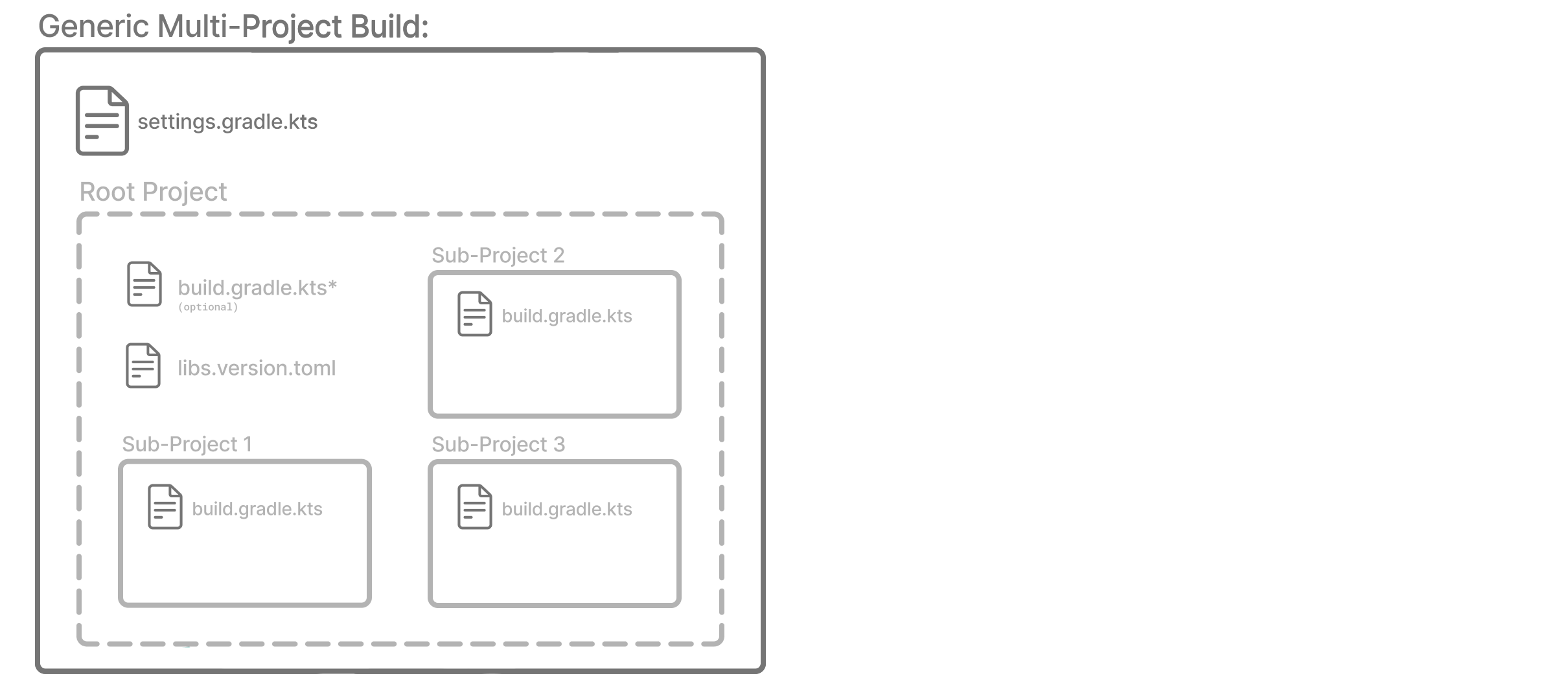
The directory structure should look as follows:
.
├── gradlew
├── gradlew.bat
├── settings.gradle(.kts) // (1)
├── sub-project-1
│ └── build.gradle(.kts) // (2)
├── sub-project-2
│ └── build.gradle(.kts) // (2)
└── sub-project-3
└── build.gradle(.kts) // (2)-
The
settings.gradle(.kts)file should include all subprojects. -
Each subproject should have its own
build.gradle(.kts)file.
In this example, the root settings file will look as follows:
include("sub-project-1", "sub-project-2", "sub-project-3")include('sub-project-1', 'sub-project-2', 'sub-project-3')|
Note
|
The order in which the subprojects (modules) are included does not matter. |
The Gradle community has two standards for multi-project build structures:
-
Multi-Project Builds using
buildSrc- wherebuildSrcis a subproject-like directory at the Gradle project root containing shared build logic. -
Composite Builds including
build-logic- a build that includes other builds wherebuild-logicis a build directory at the Gradle project root containing reusable build logic.
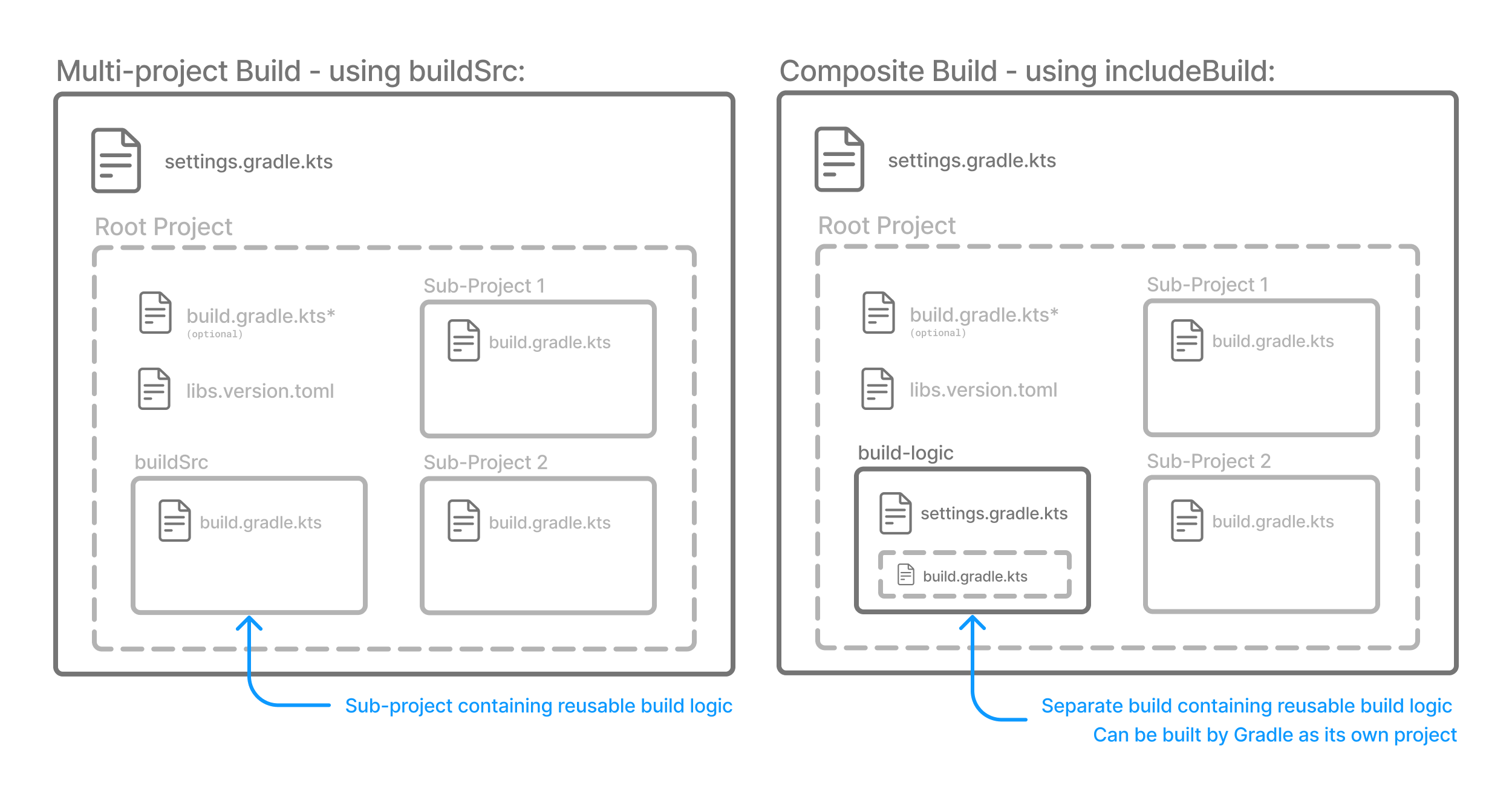
In either case, the build-logic and buildSrc folders are used to organize build logic.
Each approach has trade-offs.
buildSrc is easier to get started with but less flexible.
Composite builds require a bit more setup but scale better and align with Gradle’s long-term best practices for sharing build logic.
Multi-Project Paths
A project path has the following pattern: it starts with an optional colon, which denotes the root project.
The root project, :, is the only project in a path not specified by its name.
The rest of a project path is a colon-separated sequence of project names, where the next project is a subproject of the previous project:
:sub-project-1You can see the project paths when running gradle projects:
------------------------------------------------------------
Root project 'project'
------------------------------------------------------------
Root project 'project'
+--- Project ':sub-project-1'
\--- Project ':sub-project-2'Project paths usually reflect the filesystem layout, but there are exceptions. Most notably for composite builds.
Executing tasks by name
The command gradle test will execute the test task in any subprojects relative to the current working directory that has that task.
If you run the command from the root project directory, you will run test in sub-project-1, sub-project-2, and sub-project-3.
The basic rule behind Gradle’s behavior is to execute all tasks down the hierarchy with this name. And complain if there is no such task found in any of the subprojects traversed.
|
Note
|
Some task selectors, like help or dependencies, will only run the task on the project they are invoked on and not on all the subprojects to reduce the amount of information printed on the screen.
|
Executing tasks by fully qualified name
In a multi-project build, you can run tasks for a specific subproject by using the task’s fully qualified name. This name combines the project path and the task name.
For example, to run the build task in sub-project-1, use ./gradlew :sub-project-1:build.
This ensures that only sub-project-1’s `build task is executed, rather than running build across the entire build.
You can use this pattern for any task.
For example, to list all tasks available in sub-project-3, run ./gradlew :sub-project-3:tasks.
Multi-Project Builds using buildSrc
Multi-project builds allow you to organize projects with many modules, wire dependencies between those modules, and easily share common build logic amongst them.
For example, if the project above had common build logic between sub-project-1, sub-project-2 and sub-project-3, it could be structured as follows:
.
├── gradlew
├── gradlew.bat
├── settings.gradle(.kts)
├── buildSrc // (1)
│ ├── build.gradle.kts
│ └── src/main/*/shared-build-conventions.gradle(.kts) // (2)
├── sub-project-1
│ └── build.gradle(.kts) // (3)
├── sub-project-2
│ └── build.gradle(.kts) // (3)
└── sub-project-3
└── build.gradle(.kts) // (3)-
Gradle recognized
buildSrcfolder -
Contains common build logic from
sub-project-1,sub-project-2andsub-project-3 -
Applies
shared-build-conventions.gradle(.kts)
The buildSrc directory is automatically recognized by Gradle.
It is a good place to define and maintain shared configuration or imperative build logic, such as custom tasks or plugins.
buildSrc is automatically included in your build as a special subproject if a build.gradle(.kts) file is found under buildSrc.
Consult the Sharing Build Logic using buildSrc chapter to learn more.
Composite Builds including build-logic
Composite Builds, also referred to as included builds, are best for sharing logic between builds (not subprojects) or isolating access to shared build logic.
Let’s take the previous example.
The logic in buildSrc has been turned into a project that contains plugins and can be published and worked on independently of the root project build.
The plugin is moved to its own build called build-logic with its own build script and settings file:
.
├── gradlew
├── gradlew.bat
├── settings.gradle(.kts)
├── build-logic // (1)
│ ├── settings.gradle.kts
│ └── conventions
│ ├── build.gradle.kts
│ └── src/main/kotlin/shared-build-conventions.gradle.kts // (2)
├── sub-project-1
│ └── build.gradle(.kts) // (3)
├── sub-project-2
│ └── build.gradle(.kts) // (3)
└── sub-project-3
└── build.gradle(.kts) // (3)-
Separate Gradle build called
build-logic -
Contains common build logic from
sub-project-1,sub-project-2andsub-project-3 -
Applies
shared-build-conventions.gradle(.kts)
|
Note
|
The fact that build-logic is located in a subdirectory of the root project is irrelevant. The folder could be located outside the root project if desired.
|
The root settings file includes the entire build-logic build:
include("sub-project-1", "sub-project-2", "sub-project-3")
includeBuild("build-logic")include('sub-project-1', 'sub-project-2', 'sub-project-3')
includeBuild('build-logic')There’s no reason that any of the subprojects in a multi-project build couldn’t themselves be composite builds. This allows teams to independently develop and test build logic or components, then include them in a larger build as needed. For example:
.
├── gradlew
├── gradlew.bat
├── settings.gradle(.kts)
├── build-logic // (1)
│ ├── settings.gradle(.kts)
│ └── conventions
│ └── build.gradle(.kts)
├── project-1 // (2)
│ ├── settings.gradle(.kts)
│ ├── client
│ │ └── build.gradle(.kts)
│ └── server
│ └── build.gradle(.kts)
├── project-2 // (3)
│ ├── settings.gradle(.kts)
│ └── lib
│ └── build.gradle(.kts)
└── project-3 // (4)
├── settings.gradle(.kts)
├── app-plugin
│ └── build.gradle(.kts)
├── client-plugin
│ └── build.gradle(.kts)
└── server-plugin
└── build.gradle(.kts)-
Separate Gradle build called
build-logic -
Separate Gradle build called
project-1with 2 of its own subproject -
Separate Gradle build called
project-2with 1 of its own subproject -
Separate Gradle build called
project-3with 3 of its own subprojects
In this setup, a team could work on project-3 as an entirely independent build.
Once their changes are complete, another team could test and validate those changes by integrating `project-3’s changes into the full root build.
Consult the Composite Builds chapter to learn more.
Next Step: Learn about the Gradle Build Lifecycle >>
Gradle Build Lifecycle
The build lifecycle is the sequence of phases Gradle executes to turn your build scripts, source code, and more, into completed work. From initializing the build environment to configuring projects and finally executing tasks.
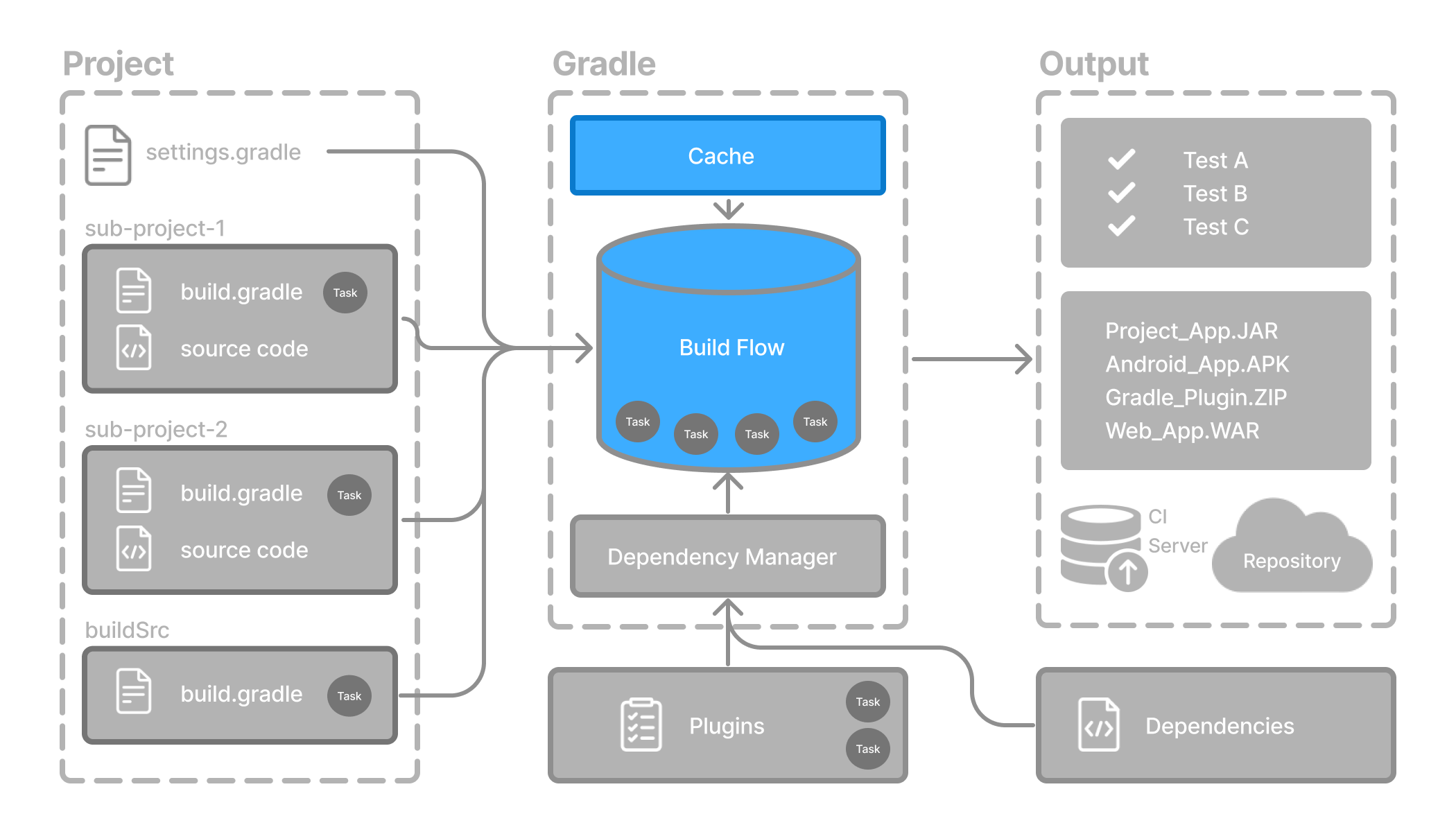
Build Phases
A Gradle build has three distinct phases.

Gradle runs these phases in order:
| Phase 1. Initialization | Phase 2. Configuration | Phase 3. Execution |
|---|---|---|
- Detects the settings file |
- Evaluates the build files of every project participating in the build |
- Schedules and executes the selected tasks |
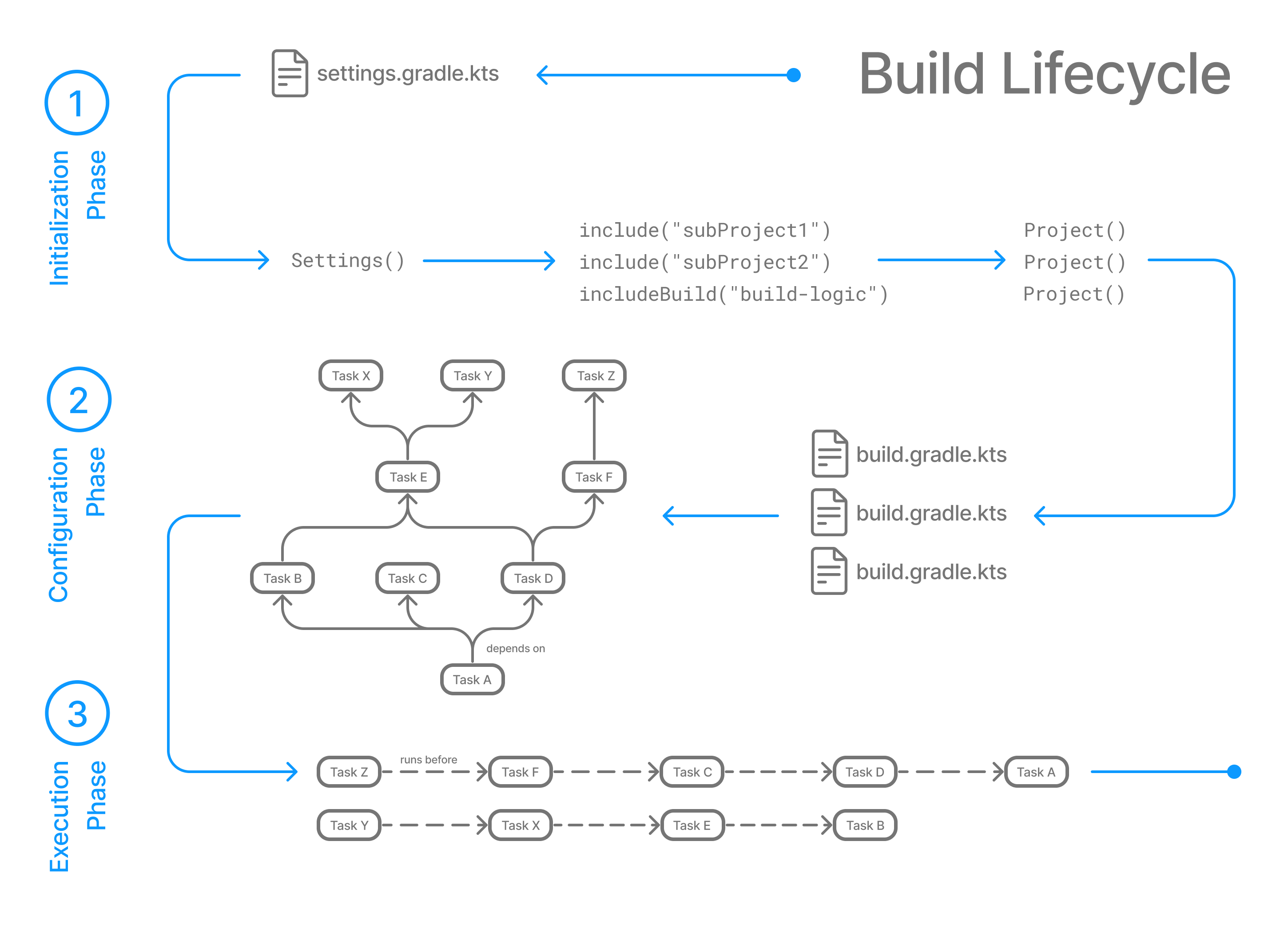
The following example shows which parts of settings and build files correspond to various build phases:
rootProject.name = "basic"
println("This is executed during the initialization phase.")// Configuration Phase
println("This is executed during the configuration phase.")
tasks.register("configured") {
println("This is also executed during the configuration phase.")
}
// Execution Phase
tasks.register("test") {
doLast {
println("This is executed during the execution phase.")
}
}
// Configurations AND Execution Phase
tasks.register("testBoth") {
println("This is executed during the configuration phase as well.")
doFirst {
println("This is executed first during the execution phase.")
}
doLast {
println("This is executed last during the execution phase.")
}
}rootProject.name = 'basic'
println 'This is executed during the initialization phase.'// Configuration Phase
println 'This is executed during the configuration phase.'
tasks.register('configured') {
println 'This is also executed during the configuration phase.'
}
// Execution Phase
tasks.register('test') {
doLast {
println 'This is executed during the execution phase.'
}
}
// Configurations AND Execution Phase
tasks.register('testBoth') {
println 'This is executed during the configuration phase as well.'
doFirst {
println 'This is executed first during the execution phase.'
}
doLast {
println 'This is executed last during the execution phase.'
}
}The following command executes the test task and testBoth task specified above.
Because Gradle only configures the tasks that are required to run (i.e., the requested task and its dependencies), the configured task will not be configured or executed:
$ ./gradlew test testBothThis is executed during the initialization phase.
> Configure project :
This is executed during the configuration phase.
This is executed during the configuration phase as well.
> Task :test
This is executed during the execution phase.
> Task :testBoth
This is executed first during the execution phase.
This is executed last during the execution phase.
BUILD SUCCESSFUL in 0s
2 actionable tasks: 2 executed$ ./gradlew test testBothThis is executed during the initialization phase.
> Configure project :
This is executed during the configuration phase.
This is executed during the configuration phase as well.
> Task :test
This is executed during the execution phase.
> Task :testBoth
This is executed first during the execution phase.
This is executed last during the execution phase.
BUILD SUCCESSFUL in 0s
2 actionable tasks: 2 executedPhase 1. Initialization
In the initialization phase, Gradle detects the set of projects (root and subprojects) and included builds participating in the build.
Gradle first evaluates the settings file, settings.gradle(.kts), and instantiates a Settings object.
Then, Gradle instantiates Project object instances for each project included in the build (using includeBuild() or include() in the settings file).
Phase 2. Configuration
In the configuration phase, Gradle adds tasks and other properties to the projects found by the initialization phase.
Gradle constructs the task graph by understanding the dependencies between tasks.
Phase 3. Execution
In the execution phase, Gradle runs tasks.
Gradle uses the task execution graphs generated by the configuration phase to determine which tasks to execute. Gradle can execute tasks in parallel.
Task Graphs
As a build author, you write build logic by defining tasks and declaring how they depend on one another. Gradle uses this information to construct a task graph during the configuration phase that models the relationships between these tasks.
For example, if your project includes tasks such as buildHtml, assembleDocs, and createDocs, and you declare that assembleDocs depends on buildHtml, and createDocs depends on assembleDocs, Gradle constructs a graph with this order: buildHtml → assembleDocs → createDocs.
Gradle builds the task graph before executing any task(s).
Across all projects in the build, tasks form a Directed Acyclic Graph (DAG).
This diagram shows two example task graphs, one abstract and the other concrete, with dependencies between tasks represented as arrows:
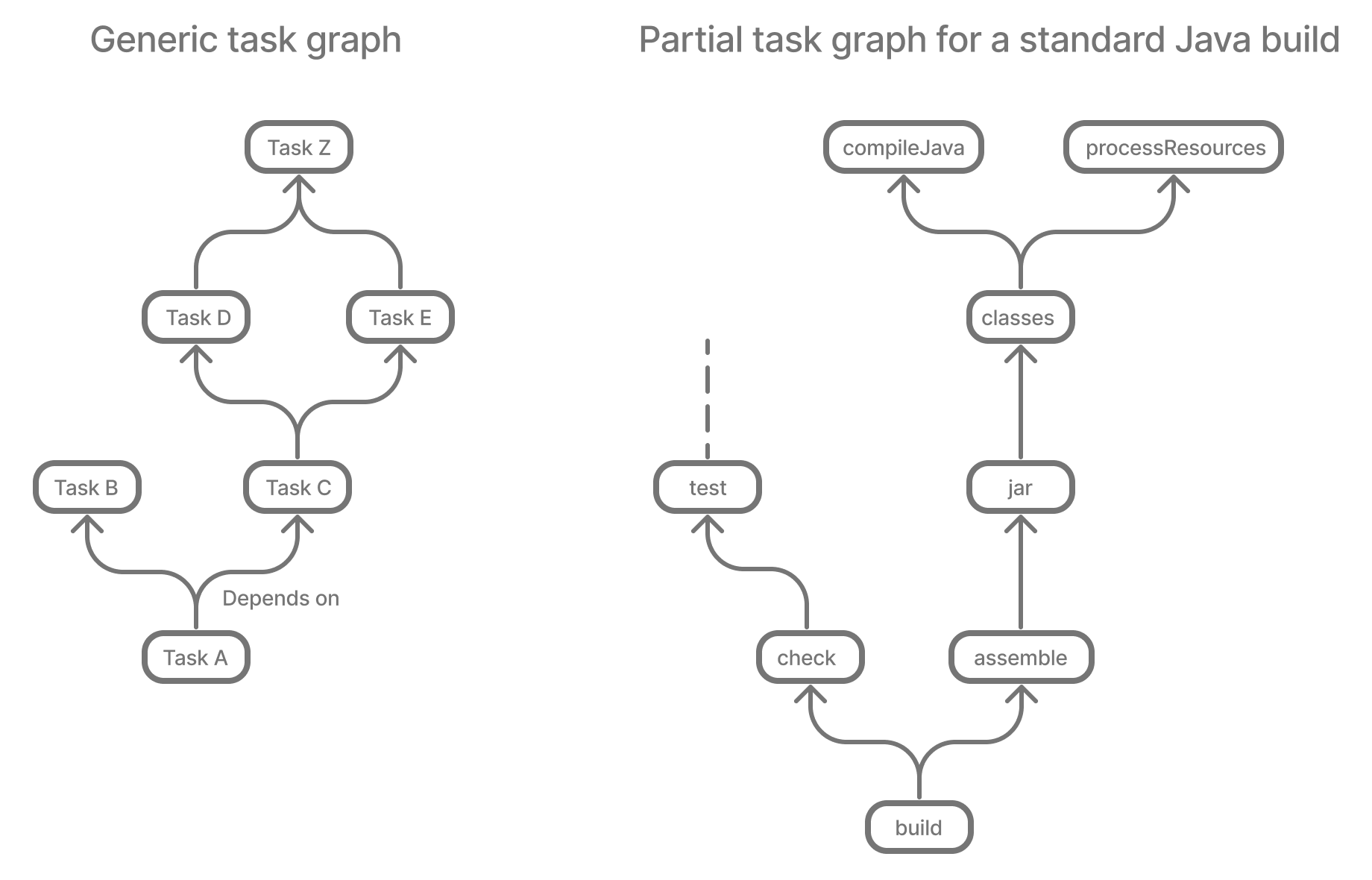
Your build scripts and plugins are responsible for declaring this task dependency graph, either explicitly via the task dependency mechanism (e.g., dependsOn) or implicitly using task annotation (e.g., by wiring task inputs and outputs).
Next Step: Learn how to write Build Scripts >>
Hooking into the Build Lifecycle
As your build logic becomes more advanced, you might need to execute custom actions during specific build phases. Gradle exposes several APIs that let you listen to or react to key events in the lifecycle.
For a detailed guide on available callbacks and listeners, refer to Lifecycle API.
Writing Build Scripts
The initialization phase in the Gradle Build lifecycle finds the settings file.
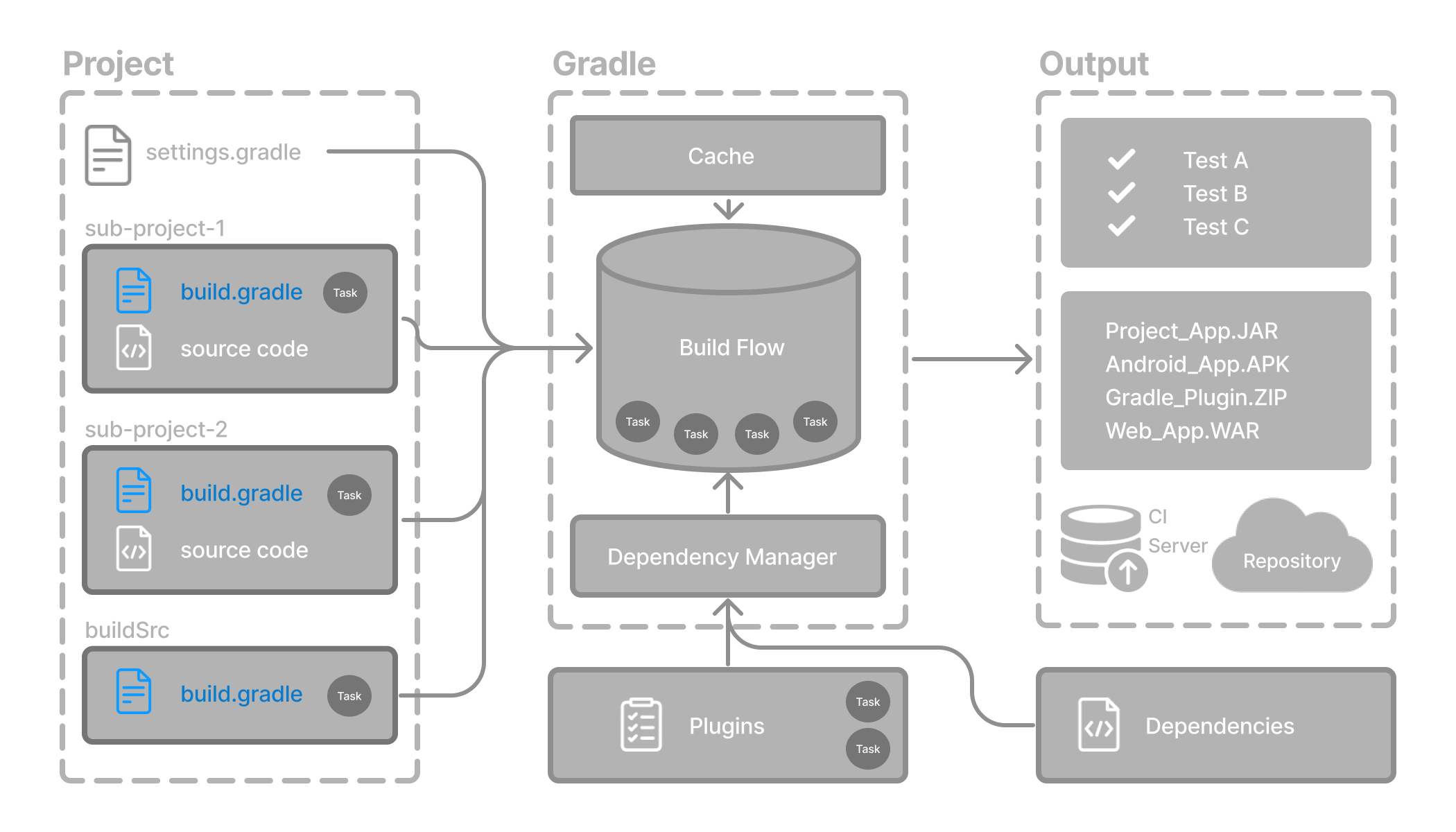
When Gradle evaluates the settings file, it creates a single Settings instance.
Then, for each project declared in the settings file, Gradle creates a corresponding Project instance.
Gradle then locates the associated build script (e.g., build.gradle(.kts)) and uses it during the configuration phase to configure each Project object.
Anatomy of a Build Script
Gradle build scripts are written in either Groovy DSL or Kotlin DSL (domain-specific language).
The build script is either a *.gradle file in Groovy or a *.gradle.kts file in Kotlin.
As a build script executes, it configures either a Settings object or Project object and its children.

|
Tip
|
There is a third type of build script that also configures a Gradle object, but it is not covered in the intermediate concepts.
|
Script Structure
A Gradle script consists of two main types of elements:
-
Statements: Top-level expressions that execute immediately during the initialization (for settings scripts) or configuration (for build scripts) phase.
-
Blocks: Nested sections (Groovy closures or Kotlin lambdas) passed to configuration methods. These blocks apply settings to Gradle objects like
project,pluginManagement,dependencyResolutionManagement,repositories, ordependencies.
Examples of common blocks include:
plugins {
id("java")
}
repositories {
mavenCentral()
}
dependencies {
testImplementation("junit:junit:4.13")
implementation(project(":shared"))
}plugins {
id 'java'
}
repositories {
mavenCentral()
}
dependencies {
testImplementation "junit:junit:4.13"
implementation project(':shared')
}In this case, we are looking at a build script.
Therefore, each block corresponds to a method on the Project object, also referred to as the Project API, and is evaluated with a delegate or receiver (more on that below).
Closures and Lambdas
Gradle scripts are based on dynamic closures in Groovy or static lambdas in Kotlin:
-
In Groovy, blocks are closures, and Gradle dynamically delegates method/property calls to a target object.
-
In Kotlin, blocks are lambdas with receivers, and Gradle statically types the
thisobject inside the block.
This delegation allows concise configuration:
repositories {
mavenCentral()
}In this case, the repositories {} block is a method call where the closure configures a RepositoryHandler instance.
repositories {
mavenCentral()
}In this case, the repositories {} block is a method call, and the lambda configures a RepositoryHandler instance.
Inside the block, mavenCentral() is a method on that receiver, so no qualifier is needed.
Delegates and Receivers
Every configuration block executes in the context of an object:
-
In Groovy, this is the block’s delegate.
-
In Kotlin, this is the block’s receiver.
Inside the dependencies {} block, for instance, the implementation(…) method is delegated to the DependencyHandler:
dependencies {
implementation("org.jetbrains.kotlin:kotlin-stdlib")
}This behavior allows intuitive configuration but can sometimes obscure where a method is coming from.
For clarity, you can use explicit references like project.dependencies.implementation(…).
Variables
Build scripts support two types of variables:
-
Local Variables
-
Extra Properties
Local Variables
Declare local variables with the val keyword. Local variables are only visible in the scope where they have been declared. They are a feature of the underlying Kotlin language.
Declare local variables with the def keyword. Local variables are only visible in the scope where they have been declared. They are a feature of the underlying Groovy language.
val dest = "dest"
tasks.register<Copy>("copy") {
from("source")
into(dest)
}def dest = 'dest'
tasks.register('copy', Copy) {
from 'source'
into dest
}Extra Properties
Gradle provides extra properties for storing user-defined data on enhanced objects such as project.
Extra properties are accessible via:
-
extraproperty in Kotlin.
-
extproperty in Groovy.
plugins {
id("java-library")
}
val springVersion = "3.1.0.RELEASE"
extra["springVersion"] = springVersion
val emailNotification = "build@master.org"
extra["emailNotification"] = emailNotification
sourceSets.all { extra["purpose"] = null }
sourceSets {
main {
extra["purpose"] = "production"
}
test {
extra["purpose"] = "test"
}
create("plugin") {
extra["purpose"] = "production"
}
}
tasks.register("printProperties") {
val springVersion = springVersion
val emailNotification = emailNotification
val productionSourceSets = provider {
sourceSets.matching { it.extra["purpose"] == "production" }.map { it.name }
}
doLast {
println(springVersion)
println(emailNotification)
productionSourceSets.get().forEach { println(it) }
}
}plugins {
id 'java-library'
}
ext {
springVersion = "3.1.0.RELEASE"
emailNotification = "build@master.org"
}
sourceSets.all { ext.purpose = null }
sourceSets {
main {
purpose = "production"
}
test {
purpose = "test"
}
plugin {
purpose = "production"
}
}
tasks.register('printProperties') {
def springVersion = springVersion
def emailNotification = emailNotification
def productionSourceSets = provider {
sourceSets.matching { it.purpose == "production" }.collect { it.name }
}
doLast {
println springVersion
println emailNotification
productionSourceSets.get().each { println it }
}
}$ gradle -q printProperties3.1.0.RELEASE
build@master.org
main
pluginGradle uses special syntax for defining extra properties to ensure fail-fast behavior. This means Gradle will immediately detect if you try to set a property that hasn’t been declared, helping you catch mistakes early.
Extra properties are attached to the object that owns them (such as project).
Unlike local variables, extra properties have a wider scope, you can access them anywhere the owning object is visible, including from subprojects accessing their parent project’s properties.
Line-by-Line Execution
Gradle executes build scripts top to bottom during the configuration phase. That means:
-
Code is evaluated immediately in order.
-
Statements outside of configuration blocks execute eagerly.
-
Properties and logic should be deferred using
Provideror lazy APIs when possible (more on this in the next section).
This top-down execution model means the order of declarations can affect behavior, especially when using variables or configuring tasks.
Example Breakdown
Now, let’s take a look at an example and break it down:
plugins { // (1)
id("application")
}
repositories { // (2)
mavenCentral()
}
dependencies { // (3)
testImplementation("org.junit.jupiter:junit-jupiter-engine:5.9.3")
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
implementation("com.google.guava:guava:32.1.1-jre")
}
application { // (4)
mainClass = "com.example.Main"
}
tasks.named<Test>("test") { // (5)
useJUnitPlatform()
}
tasks.named<Javadoc>("javadoc").configure {
exclude("app/Internal*.java")
exclude("app/internal/*")
}
tasks.register<Zip>("zip-reports") {
from("Reports/")
include("*")
archiveFileName.set("Reports.zip")
destinationDirectory.set(file("/dir"))
}plugins { // (1)
id 'application'
}
repositories { // (2)
mavenCentral()
}
dependencies { // (3)
testImplementation 'org.junit.jupiter:junit-jupiter-engine:5.9.3'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
implementation 'com.google.guava:guava:32.1.1-jre'
}
application { // (4)
mainClass = 'com.example.Main'
}
tasks.named('test', Test) { // (5)
useJUnitPlatform()
}
tasks.named('javadoc', Javadoc).configure {
exclude 'app/Internal*.java'
exclude 'app/internal/*'
}
tasks.register('zip-reports', Zip) {
from 'Reports/'
include '*'
archiveFileName = 'Reports.zip'
destinationDirectory = file('/dir')
}-
Apply plugins to the build.
-
Define the locations where dependencies can be found.
-
Add dependencies.
-
Set properties.
-
Register and configure tasks.
1. Apply plugins to the build
Plugins are used to extend Gradle. They are also used to modularize and reuse project configurations.
Plugins can be applied using the PluginDependenciesSpec plugins script block.
The plugins block is preferred:
plugins { // (1)
id("application")
}plugins { // (1)
id 'application'
}In the example, the application plugin, which is included with Gradle, has been applied, describing our project as a Java application.
2. Define the locations where dependencies can be found
A project generally has a number of dependencies it needs to do its work. Dependencies include plugins, libraries, or components that Gradle must download for the build to succeed.
The build script lets Gradle know where to look for the binaries of the dependencies. More than one location can be provided:
repositories { // (2)
mavenCentral()
}repositories { // (2)
mavenCentral()
}In the example, the guava library and the JetBrains Kotlin plugin (org.jetbrains.kotlin.jvm) will be downloaded from the Maven Central Repository.
3. Add dependencies
A project generally has a number of dependencies it needs to do its work. These dependencies are often libraries of precompiled classes that are imported in the project’s source code.
Dependencies are managed via configurations and are retrieved from repositories.
Use the DependencyHandler returned by Project.getDependencies() method to manage the dependencies.
Use the RepositoryHandler returned by Project.getRepositories() method to manage the repositories.
dependencies { // (3)
testImplementation("org.junit.jupiter:junit-jupiter-engine:5.9.3")
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
implementation("com.google.guava:guava:32.1.1-jre")
}dependencies { // (3)
testImplementation 'org.junit.jupiter:junit-jupiter-engine:5.9.3'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
implementation 'com.google.guava:guava:32.1.1-jre'
}In the example, the application code uses Google’s guava libraries.
Guava provides utility methods for collections, caching, primitives support, concurrency, common annotations, string processing, I/O, and validations.
4. Set properties
A plugin can add properties and methods to a project using extensions.
The Project object has an associated ExtensionContainer object that contains all the settings and properties for the plugins that have been applied to the project.
In the example, the application plugin added an application property, which is used to detail the main class of our Java application:
application { // (4)
mainClass = "com.example.Main"
}application { // (4)
mainClass = 'com.example.Main'
}5. Register and configure tasks
Tasks perform some basic piece of work, such as compiling classes, or running unit tests, or zipping up a WAR file.
While tasks are typically defined in plugins, you may need to register or configure tasks in build scripts.
Registering a task adds the task to your project.
You can register tasks in a project using the TaskContainer.register(java.lang.String) method:
tasks.register<Zip>("zip-reports") {
from("Reports/")
include("*")
archiveFileName.set("Reports.zip")
destinationDirectory.set(file("/dir"))
}tasks.register('zip-reports', Zip) {
from 'Reports/'
include '*'
archiveFileName = 'Reports.zip'
destinationDirectory = file('/dir')
}You may have seen usage of the TaskContainer.create(java.lang.String) method which should be avoided.
tasks.create<Zip>("zip-reports") { }|
Tip
|
register(), which enables task configuration avoidance, is preferred over create().
|
You can locate a task to configure it using the TaskCollection.named(java.lang.String) method:
tasks.named<Test>("test") { // (5)
useJUnitPlatform()
}tasks.named('test', Test) { // (5)
useJUnitPlatform()
}The example below configures the Javadoc task to automatically generate HTML documentation from Java code:
tasks.named<Javadoc>("javadoc").configure {
exclude("app/Internal*.java")
exclude("app/internal/*")
}tasks.named('javadoc', Javadoc).configure {
exclude 'app/Internal*.java'
exclude 'app/internal/*'
}Accessing Project Properties in Build Scripts
In a Gradle build script, you can refer to project-level properties like name, version, or group without needing to qualify them with project:
println(name)
println(project.name)println name
println project.name$ gradle -q checkproject-api
project-apiThis works because of how Gradle evaluates build scripts:
-
In Groovy, Gradle dynamically delegates unqualified references like
nameto theProjectobject. -
In Kotlin, the build script is compiled as an extension of the
Projecttype, so you can directly access its properties.
While you can always use project.name to be explicit, using the shorthand name is common and safe in most situations.
Accessing Settings Properties in Settings Scripts
Just like build scripts operate within a Project context, settings scripts (settings.gradle(.kts)) operate within a Settings context.
This means you can refer to properties and methods available on the Settings object, often without qualification.
For example:
println(rootProject.name)
println(name)In a settings.gradle(.kts) script, both of these print the name of the root project.
That’s because:
-
In Groovy, unqualified property references like
nameare dynamically delegated to theSettingsobject. -
In Kotlin, the script is compiled as an extension of the
Settingsclass, sonameandpluginManagement {}are directly accessible.
Unlike in build scripts, where name refers to the current subproject, in settings scripts name typically refers to the root project name, and it can be set explicitly:
rootProject.name = "my-awesome-project"Default Script Imports
To make build scripts more concise, Gradle automatically adds a set of import statements to scripts.
As a result, instead of writing throw new org.gradle.api.tasks.StopExecutionException(), you can write throw new StopExecutionException().
Next Step: Learn about Gradle Managed Types >>
Gradle Managed Types
Gradle Managed Types are the building blocks for writing modern, efficient, and cache-friendly build logic.
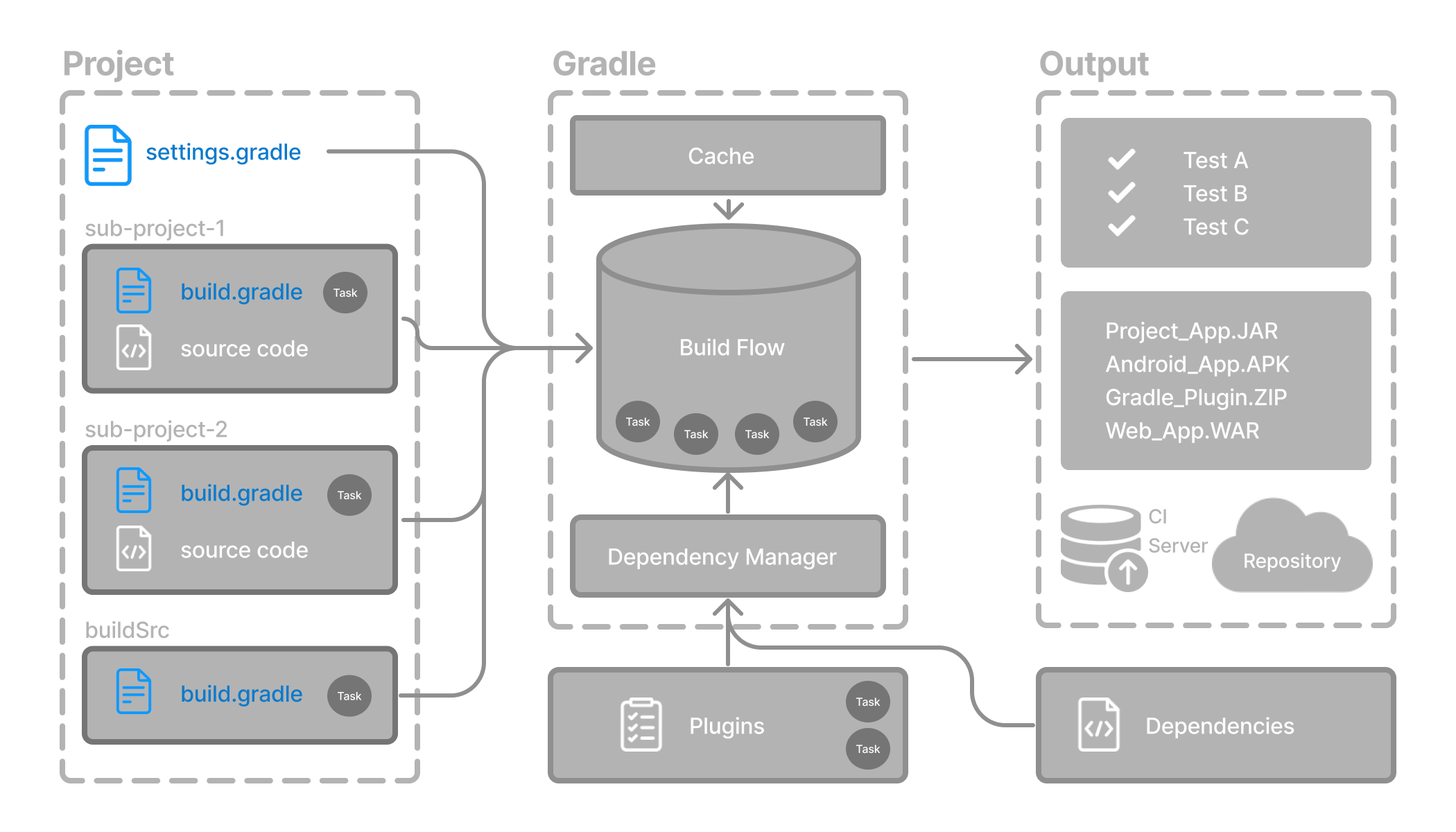
When writing build logic, you’ll often reach for standard Groovy or Kotlin types. However, Gradle provides its own managed types that are lazy, making them far better suited for build logic.
These types enable:
-
Incremental builds
-
Build cache support
-
Configuration cache compatibility
-
Accurate tracking of task inputs and outputs
For example, instead of using a String, you should use a Property<String>:
tasks.register("demoTask") {
// Eager evaluation: happens immediately during configuration
def eagerMessage = "Hello from eager"
// Lazy evaluation: will only be computed if the task runs during execution
def lazyMessage = objects.property(String)
lazyMessage.set(providers.provider {
return "Hello from lazy"
})
// This block runs during the configuration phase (when the build script is loaded)
println ">> DURING CONFIGURATION"
println ">>> eagerMessage type: ${eagerMessage.getClass()}"
println ">>> eagerMessage value: $eagerMessage"
println ">>> lazyMessage type: ${lazyMessage.getClass()}"
println ">>> lazyMessage value: $lazyMessage"
// This block runs during the execution phase (when the task is actually run)
doLast {
println ">> DURING EXECUTION"
println ">>> eagerMessage type: ${eagerMessage.getClass()}"
println ">>> eagerMessage value: $eagerMessage"
// Now the provider is evaluated and the actual value is computed and printed
println ">>> lazyMessage type: ${lazyMessage.getClass()}"
println ">>> lazyMessage value: ${lazyMessage.get()}"
}
}$ ./gradlew demoTask>> DURING CONFIGURATION
>>> eagerMessage type: class kotlin.String
>>> eagerMessage value: Hello from eager
>>> lazyMessage type: class org.gradle.api.internal.provider.DefaultProperty
>>> lazyMessage value: property(java.lang.String, map(java.lang.String provider(?) check-type()))
> Task :app:demoTask
>> DURING EXECUTION
>>> eagerMessage type: class kotlin.String
>>> eagerMessage value: Hello from eager
>>> lazyMessage type: class org.gradle.api.internal.provider.DefaultProperty
>>> lazyMessage value: Hello from lazyThis example showcases that:
-
Eager values are computed immediately when the script is loaded (configuration phase).
-
Lazy values (like
PropertyorProvider) defer computation until the task is executed (execution phase).
It’s always best to ensure Gradle evaluates task logic only during the execution phase to avoid wasting time during configuration. Using lazy types and values in Gradle ensures builds are fast, efficient, and compatible with performance features like incremental builds, the Build Cache, and the Configuration Cache.
Common Managed Types
Here is a list of common Gradle managed types you can use in your build logic:
| Type | Purpose | Use-Case |
|---|---|---|
|
Lazy scalar value (e.g., a version number) |
A version string |
|
Lazy list of values (e.g., compiler args) |
A list of compiler args |
|
Lazy map of values (e.g., environment vars) |
A map of Maven Pom properties |
|
Lazy reference to a single file (input or output) |
A single file input/output |
|
Lazy reference to a directory (input or output) |
A destination directory |
|
Lazily evaluated, read-only value (e.g., task output) |
A dependency on task output |
Gradle distinguishes between eager and lazy evaluation to control when values are computed and how they participate in up-to-date checks, caching, and task wiring. Let’s review the differences one more time:
Eager Evaluation
-
Happens immediately during the configuration phase.
-
Values are resolved as soon as the line is executed.
-
Prevents Gradle from optimizing build logic.
val version = project.version.toString() // evaluated now
val file = File("build/output.txt") // evaluated now
myTask.outputFile.set(file)def version = project.version.toString() // evaluated now
def file = new File('build/output.txt') // evaluated now
myTask.outputFile.set(file)These eager values are resolved even if the task isn’t run, breaking configuration cache compatibility and reducing build performance.
Lazy Evaluation
-
Defers computation until it’s actually needed (usually during task execution).
-
Enables Gradle to apply caching, parallel execution, and configuration avoidance.
-
Fully supports configuration cache and incremental builds.
val outputFile: RegularFileProperty = project.objects.fileProperty()
outputFile.set(layout.buildDirectory.file("output.txt")) // evaluated laterRegularFileProperty outputFile = project.objects.fileProperty()
outputFile.set(layout.buildDirectory.file('output.txt')) // evaluated laterHere, nothing is resolved immediately—Gradle delays evaluation until it’s actually required.
Let’s take a look at an example.
Example
This task will break the Configuration Cache due to eager access:
// Not Configuration Cache compatible
tasks.register("printVersion") {
doLast {
val eager_version = project.version.toString()
println("Version is $eager_version")
}
}// Not Configuration Cache compatible
tasks.register('printVersion') {
doLast {
def eager_version = project.version.toString()
println "Version is $eager_version"
}
}The fix: use a lazy Provider or a Property<String>:
// Configuration Cache compatible
tasks.register("printVersionLazy") {
val lazy_version: Property<String> = project.objects.property(String::class.java)
lazy_version.set(project.version.toString())
doLast {
println("Version is ${lazy_version.get()}")
}
}// Configuration Cache compatible
tasks.register('printVersionLazy') {
Property<String> lazy_version = project.objects.property(String)
lazy_version.set(project.version.toString())
doLast {
println "Version is ${lazy_version.get()}"
}
}Next Step: Learn about Declaring and Managing Dependencies >>
Declaring and Managing Dependencies
Gradle provides a rich and flexible model for declaring dependencies, managing versions, and resolving conflicts across builds.
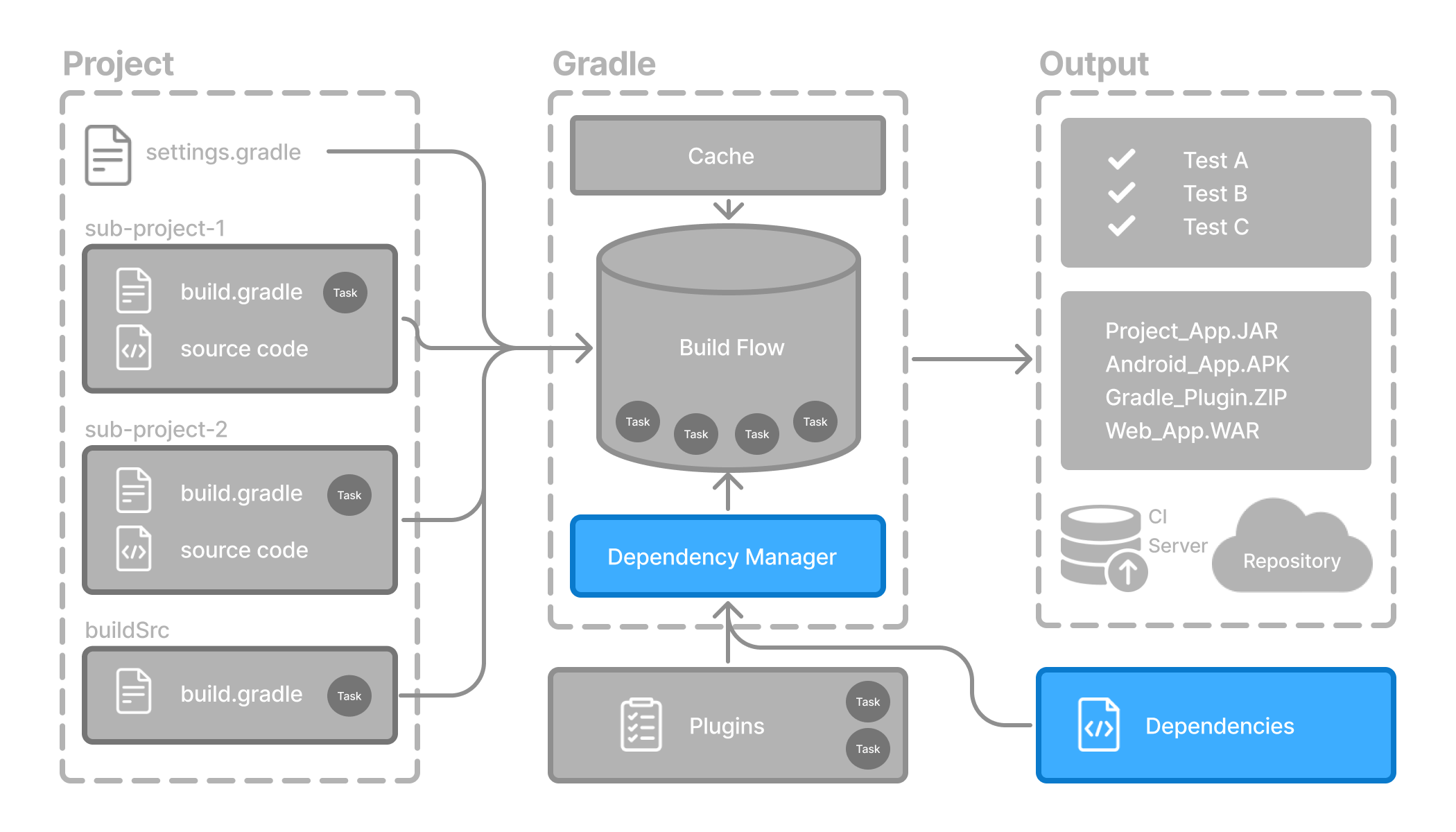
Declare Dependencies
The dependencies{} block is where you declare the external libraries, internal modules, or files your project needs to compile, run, or test:
dependencies {
implementation("com.google.guava:guava:30.0-jre")
runtimeOnly("org.apache.commons:commons-lang3:3.14.0")
}dependencies {
implementation("com.google.guava:guava:30.0-jre")
runtimeOnly("org.apache.commons:commons-lang3:3.14.0")
}Each dependency is added to a bucket configuration.
For example implementation, runtimeOnly, or testImplementation.
Bucket configurations defines where that dependency is used (compile classpath, runtime only, tests, etc.).
The set of configurations available depends on the plugins you apply (e.g., java/java-library, Android Gradle Plugin (AGP), Kotlin Multiplatform (KMP), etc.).
Gradle recommends the single-string notation for external modules. The map notation is deprecated as of Gradle 9.1.0 and will fail your build in Gradle 10:
dependencies {
// GOOD: single-string notation
implementation("com.google.guava:guava:32.1.2-jre")
// BAD: map notation
implementation(group = "com.google.guava", name = "guava", version = "32.1.2-jre")
}dependencies {
// GOOD: single-string notation
implementation 'com.google.guava:guava:32.1.2-jre'
// BAD: map notation (deprecated, triggers --warning-mode=fail)
implementation group: 'com.google.guava', name: 'guava', version: '32.1.2-jre'
}Centralize Versions with Version Catalogs
Gradle recommends using version catalogs to declare dependency versions in a single, reusable location:
[versions]
guava = "33.3.1-jre"
junit-jupiter = "5.11.3"
[libraries]
guava = { module = "com.google.guava:guava", version.ref = "guava" }
junit-jupiter = { module = "org.junit.jupiter:junit-jupiter", version.ref = "junit-jupiter" }You can then use these aliases in your build scripts:
dependencies { // (2)
// Use JUnit Jupiter for testing.
testImplementation(libs.junit.jupiter)
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
// This dependency is used by the application.
implementation(libs.guava)
}dependencies { // (2)
// Use JUnit Jupiter for testing.
testImplementation libs.junit.jupiter
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
// This dependency is used by the application.
implementation libs.guava
}Enforce and Constrain Versions
Gradle allows you to constrain dependency versions to avoid unwanted upgrades or enforce known good versions:
dependencies {
implementation("org.apache.httpcomponents:httpclient:4.5.4")
implementation("commons-codec:commons-codec") {
version {
strictly("1.9")
}
}
}dependencies {
implementation("org.apache.httpcomponents:httpclient:4.5.4")
implementation("commons-codec:commons-codec") {
version {
strictly("1.9")
}
}
}You can also constrain a module globally:
dependencies {
implementation("org.apache.httpcomponents:httpclient")
constraints {
implementation("org.apache.httpcomponents:httpclient:4.5.3") {
because("previous versions have a bug impacting this application")
}
implementation("commons-codec:commons-codec:1.11") {
because("version 1.9 pulled from httpclient has bugs affecting this application")
}
}
}dependencies {
implementation('org.apache.httpcomponents:httpclient')
constraints {
implementation('org.apache.httpcomponents:httpclient:4.5.3') {
because('previous versions have a bug impacting this application')
}
implementation('commons-codec:commons-codec:1.11') {
because('version 1.9 pulled from httpclient has bugs affecting this application')
}
}
}Resolve Conflicts with Capabilities
Sometimes multiple libraries provide the same functionality under different coordinates. This can lead to classpath conflicts:
dependencies {
implementation("jaxen:jaxen:1.1.6") // Transitive dependency that brings XPath functionality
implementation("org.jdom:jdom2:2.0.6") // Also offers XPath functionality
}dependencies {
implementation 'jaxen:jaxen:1.1.6' // Transitive dependency that brings XPath functionality
implementation 'org.jdom:jdom2:2.0.6' // Also offers XPath functionality
}Gradle lets you model these cases using capabilities. For example:
dependencies {
implementation("jaxen:jaxen:1.1.6") {
capabilities {
requireCapability("xml:xpath-support")
}
}
implementation("org.jdom:jdom2:2.0.6")
}dependencies {
implementation('jaxen:jaxen:1.1.6') {
capabilities {
requireCapability('xml:xpath-support')
}
}
implementation 'org.jdom:jdom2:2.0.6'
}Then declare capabilities via a component metadata rule:
dependencies {
components {
withModule("jaxen:jaxen") {
allVariants {
withCapabilities {
addCapability("xml", "xpath-support", "1.0")
}
}
}
withModule("org.jdom:jdom2") {
allVariants {
withCapabilities {
addCapability("xml", "xpath-support", "1.0")
}
}
}
}
}dependencies {
components {
withModule('jaxen:jaxen') {
allVariants {
withCapabilities {
addCapability('xml', 'xpath-support', '1.0')
}
}
}
withModule('org.jdom:jdom2') {
allVariants {
withCapabilities {
addCapability('xml', 'xpath-support', '1.0')
}
}
}
}
}Gradle will now treat jaxen and jdom2 as alternate implementations and select the one with a required capability.
There are many more ways to influence dependency resolution in Gradle. Consult the Dependency Management chapter to learn more.
Next Step: Learn about Creating and Registering Tasks >>
Creating and Registering Tasks
The work that Gradle can do on a project is defined by one or more tasks.
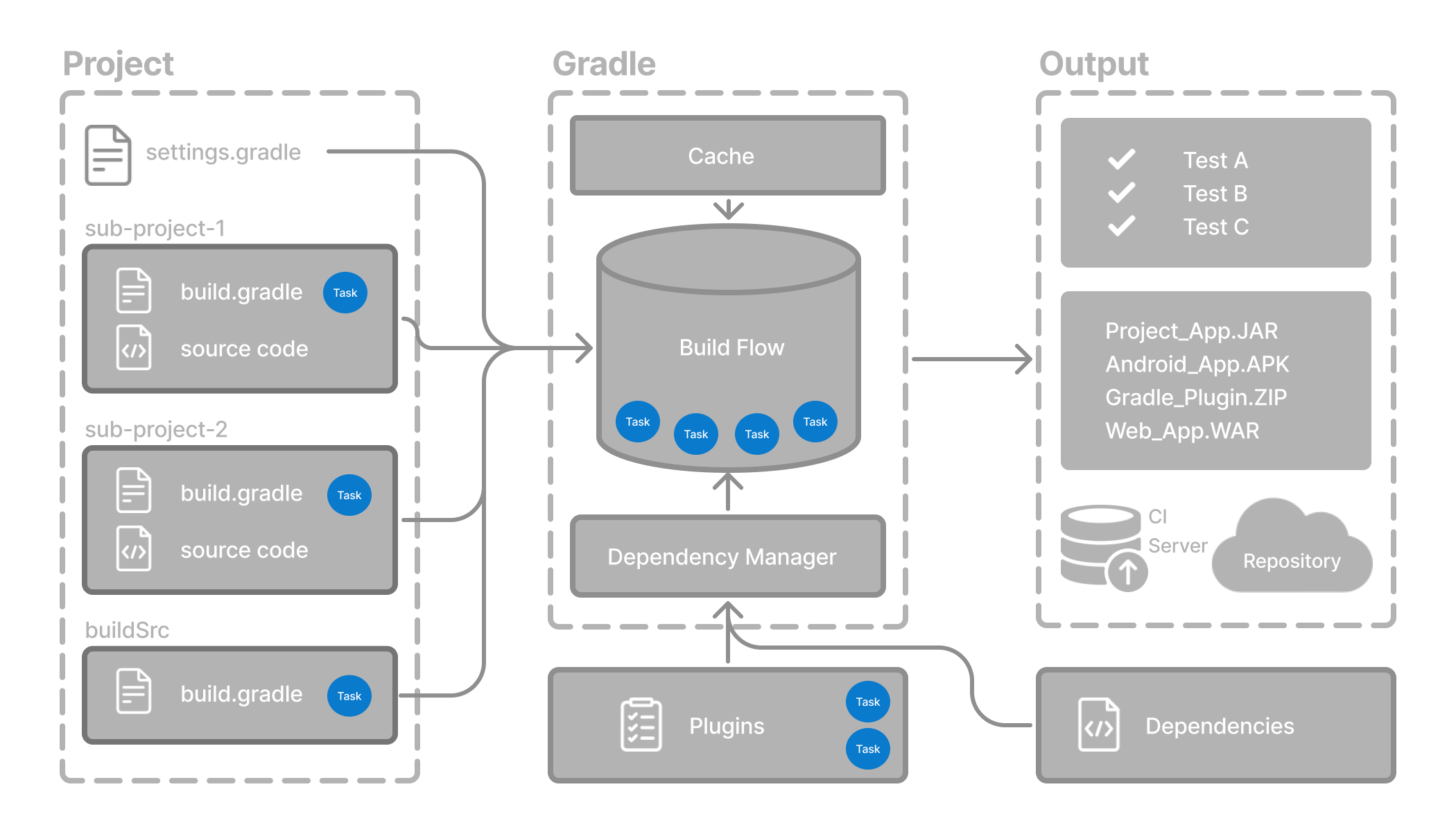
A task represents some independent unit of work that a build performs. This might be compiling some classes, creating a JAR, generating Javadoc, or publishing some archives to a repository.
When a user runs ./gradlew build in the command line, Gradle will execute the build task along with any other tasks it depends on.
Task Types
A task type defines what kind of work a task can do. It’s like a blueprint or class.
Gradle includes many built-in task types, such as Copy, Jar, and Test, and you can also define your own.
By default, a task is of type DefaultTask .
Let’s start with a simple custom task that prints a message:
tasks.register("hello") {
doLast {
println("Hello world!")
}
}tasks.register('hello') {
doLast {
println 'Hello world!'
}
}You just registered a task called hello of type DefaultTask and gave it an action using doLast{}.
A task is created in the build script using the TaskContainer.register() method, which allows it to be then used in the build logic.
When you run the hello task in the command-line using ./gradlew hello, it prints your message:
$ ./gradlew helloHello world!When you register (i.e. create) a task in your build script, you can:
-
Use the default task type (
DefaultTask) and define the behavior inline. -
Use a built-in task type, like
Copy, to take advantage of pre-defined behavior. -
Create and use a custom task type if you need reusable behavior across tasks.
This example registers a task called copyTask which copies \*.war files from the source directory to the target directory using the Copy built-in task type:
tasks.register<Copy>("copyTask") {
from("source")
into("target")
include("*.war")
}tasks.register('copyTask', Copy) {
from("source")
into("target")
include("*.war")
}Built-in Task Types
Gradle provides many built-in task types with common and popular functionality, such as copying or deleting files.
This registers a Gradle task named removeOutput of type Delete.
When the task runs, it will delete the file build/outputs/1.txt relative to the project directory.
tasks.register<Delete>("removeOutput") {
delete(layout.buildDirectory.file("outputs/1.txt"))
}tasks.register('removeOutput', Delete) {
delete layout.buildDirectory.file("outputs/1.txt")
}There are many task types developers can take advantage of, including GroovyDoc, Zip, Jar, JacocoReport, Sign, or Delete, which are detailed in the DSL.
Custom Task Types
Gradle tasks are a subclass of Task.
In the example below, the HelloTask class, a custom task type, is created by extending DefaultTask (our default task type):
// Extend the DefaultTask class to create a HelloTask class
abstract class HelloTask : DefaultTask() {
@TaskAction
fun hello() {
println("hello from HelloTask")
}
}
// Register the hello Task with type HelloTask
tasks.register<HelloTask>("hello") {
group = "Custom tasks"
description = "A lovely greeting task."
}// Extend the DefaultTask class to create a HelloTask class
class HelloTask extends DefaultTask {
@TaskAction
void hello() {
println("hello from HelloTask")
}
}
// Register the hello Task with type HelloTask
tasks.register("hello", HelloTask) {
group = "Custom tasks"
description = "A lovely greeting task."
}The hello task is registered with the new type HelloTask.
Executing our new hello task results in the following:
$ ./gradlew hello> Task :app:hello
hello from HelloTaskThe Gradle help task can reveal the specifications of the hello task:
$ ./gradlew help --task hello> Task :help
Detailed task information for hello
Path
:app:hello
Type
HelloTask (Build_gradle$HelloTask)
Options
--rerun Causes the task to be re-run even if up-to-date.
Description
A lovely greeting task.
Group
Custom tasksTask Input and Outputs
For a custom task to do useful work, it typically needs some inputs which it uses to produce outputs.
A task can declare those inputs (files, values) and outputs (files it creates). Ideally, these inputs and outputs leverage Gradle managed types. This helps Gradle skip work when nothing has changed:
abstract class CreateAFileTask : DefaultTask() {
@get:Input
abstract val fileText: Property<String>
@Input
val fileName = "myfile.txt"
@OutputFile
val myFile: File = File(fileName)
@TaskAction
fun action() {
myFile.createNewFile()
myFile.writeText(fileText.get())
}
}abstract class CreateAFileTask extends DefaultTask {
@Input
abstract Property<String> getFileText()
@Input
final String fileName = "myfile.txt"
@OutputFile
final File myFile = new File(fileName)
@TaskAction
void action() {
myFile.createNewFile()
myFile.text = fileText.get()
}
}Now Gradle knows what the task needs and what it produces. If nothing changes, the task is skipped.
Task Action
Task actions are the blocks of code that define what the custom task does when it runs.
Every task can have one or more actions, and they’re executed during the execution phase of the Gradle build lifecycle.
In the example below, a custom task type is created called GreetingTask.
The @TaskAction annotation marks a method that Gradle should call when the task of this type is executed:
abstract class GreetingTask : DefaultTask() {
@TaskAction
fun greet() {
println("hello from GreetingTask")
}
}
// Create a task using the task type
tasks.register<GreetingTask>("hello")abstract class GreetingTask extends DefaultTask {
@TaskAction
def greet() {
println 'hello from GreetingTask'
}
}
// Create a task using the task type
tasks.register('hello', GreetingTask)A task action can also be added using doLast {} or doFirst {}:
tasks.register("hello") {
doLast {
println("Hello world!")
}
}tasks.register('hello') {
doLast {
println 'Hello world!'
}
}In this example, the action is println("Hello world!").
It will run when the task is executed.
Task Group and Description
Group and description are metadata properties used to organize and document tasks. They are primarily used to make the project easier to navigate for developers.
-
The group acts as a category for the task. When you run
./gradlew tasks, Gradle clusters all tasks with the same group name together. -
The description is a short summary explaining what the task actually does.
Task Dependencies
You can declare tasks that depend on other tasks:
tasks.register("hello") {
doLast {
println("Hello world!")
}
}
tasks.register("intro") {
dependsOn("hello")
doLast {
println("I'm Gradle")
}
}tasks.register('hello') {
doLast {
println 'Hello world!'
}
}
tasks.register('intro') {
dependsOn tasks.hello
doLast {
println "I'm Gradle"
}
}$ gradle -q introHello world!
I'm Gradle
The dependency of taskX to taskY may be declared before taskY is defined:
tasks.register("taskX") {
dependsOn("taskY")
doLast {
println("taskX")
}
}
tasks.register("taskY") {
doLast {
println("taskY")
}
}tasks.register('taskX') {
dependsOn 'taskY'
doLast {
println 'taskX'
}
}
tasks.register('taskY') {
doLast {
println 'taskY'
}
}$ ./gradlew -q taskXtaskY
taskXThe hello task from the previous example is updated to include a dependency:
tasks.register("hello") {
group = "Custom"
description = "A lovely greeting task."
doLast {
println("Hello world!")
}
dependsOn(tasks.assemble)
}tasks.register('hello') {
group = "Custom"
description = "A lovely greeting task."
doLast {
println("Hello world!")
}
dependsOn(tasks.assemble)
}The hello task now depends on the assemble task, which means that Gradle must execute the assemble task before it can execute the hello task:
$ ./gradlew :app:hello> Task :app:compileJava UP-TO-DATE
> Task :app:processResources NO-SOURCE
> Task :app:classes UP-TO-DATE
> Task :app:jar UP-TO-DATE
> Task :app:startScripts UP-TO-DATE
> Task :app:distTar UP-TO-DATE
> Task :app:distZip UP-TO-DATE
> Task :app:assemble UP-TO-DATE
> Task :app:hello
Hello world!Task Configuration
Once registered, tasks can be accessed via the TaskProvider API for further configuration.
For instance, you can add behavior to an existing task:
tasks.register("hello") {
doLast {
println("Hello Earth")
}
}
tasks.named("hello") {
doFirst {
println("Hello Venus")
}
}
tasks.named("hello") {
doLast {
println("Hello Mars")
}
}
tasks.named("hello") {
doLast {
println("Hello Jupiter")
}
}tasks.register('hello') {
doLast {
println 'Hello Earth'
}
}
tasks.named('hello') {
doFirst {
println 'Hello Venus'
}
}
tasks.named('hello') {
doLast {
println 'Hello Mars'
}
}
tasks.named('hello') {
doLast {
println 'Hello Jupiter'
}
}$ ./gradlew -q helloHello Venus
Hello Earth
Hello Mars
Hello Jupiter|
Tip
|
The calls doFirst and doLast can be executed multiple times.
They add an action to the beginning or the end of the task’s actions list.
When the task executes, the actions in the action list are executed in order.
|
A task is optionally configured in a build script using the TaskCollection.named() method.
Task Classification
There are two classes of tasks that can be executed:
-
Actionable tasks have some action(s) attached to do work in your build:
compileJava. -
Lifecycle tasks are tasks with no actions attached:
assemble,build.
Typically, a lifecycle tasks depends on many actionable tasks, and is used to execute many tasks at once.
Task Performance
To write "good" Gradle tasks, you should focus on three things: speed, clarity, and intelligence.
1. Load configuration lazily
A "fast" task is one that loads configuration lazily.
Use lazy APIs like tasks.register() instead of eager ones like tasks.create().
register() tells Gradle to only configure the task if someone actually runs it.
If you use create(), Gradle sets up that task every single time you do anything (even just checking the version), which adds up to a very slow experience.
2. Define inputs and outputs
A "clear" task is one that knows when it doesn’t need to run.
By defining your inputs and outputs, Gradle can perform up-to-date checks.
If you run the task twice and nothing has changed, Gradle should say UP-TO-DATE and finish in milliseconds.
3. Do work during execution
A "smart" task does the work during the Execution Phase, not the Configuration Phase.
One of the most common beginner mistakes is putting code in the wrong place:
-
Configuration Block: Use this only to set up settings (like the
groupordescription). -
Execution Block (
doLastor@TaskAction): Use this for the actual work (moving files, compiling code, etc.)
4. Document Your Work
A "good" task defines a group and a description.
When a teammate runs ./gradlew tasks, your custom task will appear in a neat category with a clear explanation of what it does, rather than being buried in the "Other" category.
Next Step: Learn about Plugins >>
Working with Plugins
Much of Gradle’s functionality is delivered via plugins, including core plugins distributed with Gradle, third-party plugins, and custom plugins defined within builds.
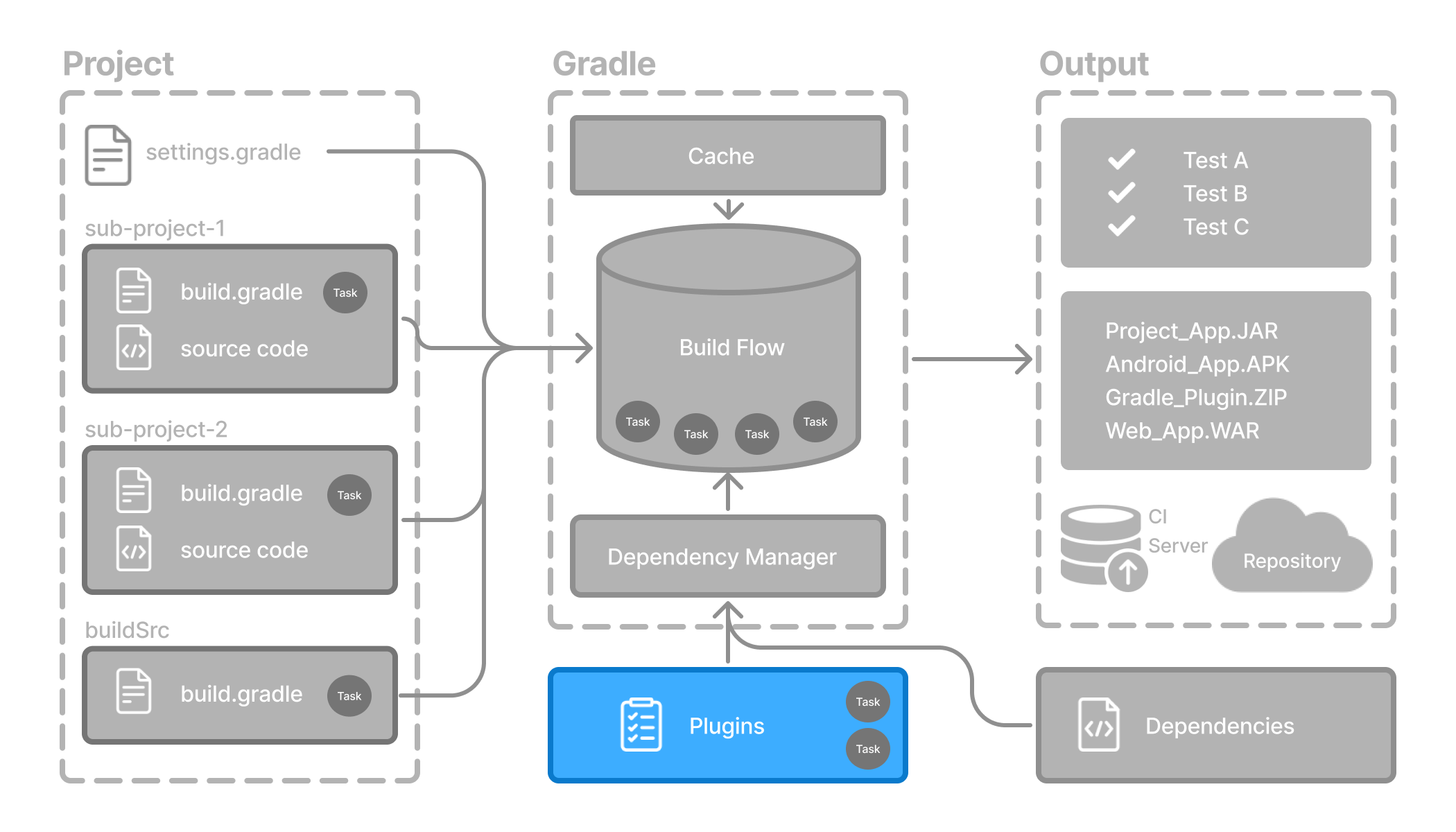
Plugins introduce new tasks (e.g., JavaCompile), domain objects (e.g., SourceSet), conventions (e.g., locating Java source at src/main/java), and extend core or other plugin objects.
Plugins in Gradle are essential for automating common build tasks, integrating with external tools or services, and tailoring the build process to meet specific project needs. They also serve as the primary mechanism for organizing build logic.
Plugin Distribution
You can leverage plugins from Gradle and the Gradle community or create your own.
Plugins are available in three ways:
-
Core plugins - Gradle develops and maintains a set of Core Plugins.
-
Community plugins - Gradle plugins shared in a remote repository such as Maven or the Gradle Plugin Portal.
-
Custom plugins - Gradle enables users to create plugins using APIs.
Gradle provides core plugins (e.g., JavaPlugin, GroovyPlugin, MavenPublishPlugin, etc.) as part of its distribution, which means they are available with Gradle itself.
Core plugins are applied in a build script using the plugin name:
plugins {
id «plugin name»
}For example:
plugins {
id("java")
}plugins {
id 'java'
}Non-core (community and custom) plugins must be resolved (i.e. located) before they can be applied. Non-core plugins are identified by a unique ID and a version in the build file:
plugins {
id «plugin id» version «plugin version»
}For example:
plugins {
id("com.gradleup.shadow") version "8.3.4"
}plugins {
id 'com.gradleup.shadow' version '8.3.4'
}And the location of the plugin must be specified in the settings file as needed:
pluginManagement { // (1)
repositories {
gradlePluginPortal()
}
}pluginManagement { // (1)
repositories {
gradlePluginPortal()
}
}The location of the plugin could also be an included build or buildSrc for example.
Applying Plugins
Over time, Gradle has introduced several ways to apply plugins, depending on their source and the scope in which they are needed (such as whether they apply to a single project or multiple subprojects).
Let’s take a look at all the available ways a plugin can be applied:
| # | To | Use | For example: |
|---|---|---|---|
Apply a plugin to a project. |
|
||
Apply a plugin to multiple projects. |
The |
|
|
Apply a plugin to multiple projects. |
|
||
Apply a plugin to multiple projects. |
A convention plugin in the |
|
|
Apply a plugin needed for the build script itself. |
|
||
Apply a script plugins. Applying a plugin when type-safe accessors are not available. |
The legacy |
|
1. Applying plugins using the plugins{} block
The plugin DSL provides a concise and convenient way to declare plugin dependencies.
The plugins block configures an instance of PluginDependenciesSpec:
plugins {
application // by name
java // by name
id("java") // by id - recommended
id("org.jetbrains.kotlin.jvm") version "1.9.0" // by id - recommended
}Core Gradle plugins are unique in that they provide short names, such as java for the core JavaPlugin.
To apply a core plugin, the short name can be used:
plugins {
java
}plugins {
id 'java'
}All other binary plugins must use the fully qualified form of the plugin id (e.g., com.github.foo.bar).
To apply a community plugin from Gradle plugin portal, the fully qualified plugin id, a globally unique identifier, must be used:
plugins {
id("org.springframework.boot") version "3.3.1"
}plugins {
id 'org.springframework.boot' version '3.3.1'
}See PluginDependenciesSpec for more information on using the Plugin DSL.
Limitations of the plugins DSL
The plugins DSL provides a convenient syntax for users and the ability for Gradle to determine which plugins are used quickly. This allows Gradle to:
-
Optimize the loading and reuse of plugin classes.
-
Provide editors with detailed information about the potential properties and values in the build script.
However, the DSL requires that plugins be defined statically.
There are some key differences between the plugins {} block mechanism and the "traditional" apply() method mechanism.
There are also some constraints and possible limitations.
The plugins{} block can only be used in a project’s build script build.gradle(.kts) and the settings.gradle(.kts) file.
It must appear before any other block.
It cannot be used in script plugins or init scripts.
The plugins {} block does not support arbitrary code.
It is constrained to be idempotent (produce the same result every time) and side effect-free (safe for Gradle to execute at any time).
The form is:
plugins {
id(«plugin id») // (1)
id(«plugin id») version «plugin version» // (2)
}-
for core Gradle plugins or plugins already available to the build script
-
for binary Gradle plugins that need to be resolved
Where «plugin id» and «plugin version» are a string.
Where «plugin id» and «plugin version» must be constant, literal strings.
The plugins{} block must also be a top-level statement in the build script.
It cannot be nested inside another construct (e.g., an if-statement or for-loop).
2. Applying plugins to all subprojects{} or allprojects{}
Suppose you have a multi-project build, you probably want to apply plugins to some or all of the subprojects in your build but not to the root project.
While the default behavior of the plugins{} block is to immediately resolve and apply the plugins, you can use the apply false syntax to tell Gradle not to apply the plugin to the current project. Then, use the plugins{} block without the version in subprojects' build scripts:
include("hello-a")
include("hello-b")
include("goodbye-c")plugins {
// These plugins are not automatically applied.
// They can be applied in subprojects as needed (in their respective build files).
id("com.example.hello") version "1.0.0" apply false
id("com.example.goodbye") version "1.0.0" apply false
}
allprojects {
// Apply the common 'java' plugin to all projects (including the root)
plugins.apply("java")
}
subprojects {
// Apply the 'java-library' plugin to all subprojects (excluding the root)
plugins.apply("java-library")
}plugins {
id("com.example.hello")
}plugins {
id("com.example.hello")
}plugins {
id("com.example.goodbye")
}include 'hello-a'
include 'hello-b'
include 'goodbye-c'plugins {
// These plugins are not automatically applied.
// They can be applied in subprojects as needed (in their respective build files).
id 'com.example.hello' version '1.0.0' apply false
id 'com.example.goodbye' version '1.0.0' apply false
}
allprojects {
// Apply the common 'java' plugin to all projects (including the root)
apply(plugin: 'java')
}
subprojects {
// Apply the 'java-library' plugin to all subprojects (excluding the root)
apply(plugin: 'java-library')
}plugins {
id 'com.example.hello'
}plugins {
id 'com.example.hello'
}plugins {
id 'com.example.goodbye'
}You can also encapsulate the versions of external plugins by composing the build logic using your own convention plugins.
3. Applying plugins declared in the root project
You can apply plugins from the root or parent project in a multi-project build to share common logic and behavior with other projects. The root/parent project is the project at the top of the directory hierarchy.
You should use the plugins {} block because it ensures that the plugin is applied and configured before the project’s evaluation phase.
This way, you can safely use type-safe accessors for any model elements introduced by the plugin:
rootProject.name = "multi-project-build"
include("domain", "infra", "http")plugins {
id("com.gradleup.shadow") version "8.3.4" apply false
id("io.ratpack.ratpack-java") version "2.0.0-rc-1" apply false
}plugins {
`java-library`
}
dependencies {
api("javax.measure:unit-api:1.0")
implementation("tec.units:unit-ri:1.0.3")
}plugins {
`java-library`
id("com.gradleup.shadow")
}plugins {
java
id("io.ratpack.ratpack-java")
}
dependencies {
implementation(project(":domain"))
implementation(project(":infra"))
implementation(ratpack.dependency("dropwizard-metrics"))
}In the root/parent build.gradle(.kts), plugins are declared but not applied (via apply false).
This approach, while optional, makes the plugins available to be explicitly applied in specific subprojects.
Without apply false, plugins declared in the root project cannot be explicitly applied only to certain subprojects.
|
Note
|
apply false is optional. If apply false is not used when declaring plugins in the root build file, those plugins would automatically be applied to the root project.
|
In the infra subproject, the com.gradleup.shadow plugin, which was made available in the root project, is explicitly applied.
The http subproject applies io.ratpack.ratpack-java.
The domain subproject does not apply a plugin from the root.
4. Applying convention plugins from the buildSrc directory
buildSrc is an optional directory at the Gradle project root that contains build logic (i.e., plugins) used in building the main project.
You can apply plugins that reside in a project’s buildSrc directory as long as they have a defined ID.
The following example shows how to tie the plugin implementation class my.MyPlugin, defined in buildSrc, to the id "my-plugin":
plugins {
`java-gradle-plugin`
}
gradlePlugin {
plugins {
create("myPlugins") {
id = "my-plugin"
implementationClass = "my.MyPlugin"
}
}
}plugins {
id 'java-gradle-plugin'
}
gradlePlugin {
plugins {
myPlugins {
id = 'my-plugin'
implementationClass = 'my.MyPlugin'
}
}
}The plugin can then be applied by ID:
plugins {
id("my-plugin")
}plugins {
id 'my-plugin'
}5. Applying plugins using the buildscript{} block
To define libraries or plugins used in the build script itself, you can use the buildscript block.
The buildscript block is also used for specifying where to find those dependencies.
This approach is less common with newer versions of Gradle, as the plugins {} block simplifies plugin usage.
However, buildscript {} may be necessary when dealing with custom or non-standard plugin repositories as well as libraries dependencies:
import org.yaml.snakeyaml.Yaml
import java.io.File
buildscript {
repositories {
maven {
url = uri("https://plugins.gradle.org/m2/")
}
mavenCentral() // Where to find the plugin
}
dependencies {
classpath("org.yaml:snakeyaml:1.19") // The library's classpath dependency
classpath("com.gradleup.shadow:shadow-gradle-plugin:8.3.4") // Plugin dependency for legacy plugin application
}
}
// Applies legacy Shadow plugin
apply(plugin = "com.gradleup.shadow")
// Uses the library in the build script
val yamlContent = """
name: Project
""".trimIndent()
val yaml = Yaml()
val data: Map<String, Any> = yaml.load(yamlContent)import org.yaml.snakeyaml.Yaml
buildscript {
repositories { // Where to find the plugin or library
maven {
url = uri("https://plugins.gradle.org/m2/")
}
mavenCentral()
}
dependencies {
classpath 'org.yaml:snakeyaml:1.19' // The library's classpath dependency
classpath 'com.gradleup.shadow:shadow-gradle-plugin:8.3.4' // Plugin dependency for legacy plugin application
}
}
// Applies legacy Shadow plugin
apply plugin: 'com.gradleup.shadow'
// Uses the library in the build script
def yamlContent = """
name: Project Name
"""
def yaml = new Yaml()
def data = yaml.load(yamlContent)6. Applying script plugins using the legacy apply() method
A script plugin is an ad-hoc plugin, typically written and applied in the same build script. It is applied using the legacy application method:
class MyPlugin : Plugin<Project> {
override fun apply(project: Project) {
println("Plugin ${this.javaClass.simpleName} applied on ${project.name}")
}
}
apply<MyPlugin>()class MyPlugin implements Plugin<Project> {
@Override
void apply(Project project) {
println("Plugin ${this.getClass().getSimpleName()} applied on ${project.name}")
}
}
apply plugin: MyPluginPlugin Management
The pluginManagement{} block is used to configure repositories for plugin resolution and to define version constraints for plugins that are applied in the build scripts.
The pluginManagement{} block can be used in a settings.gradle(.kts) file, where it must be the first block in the file:
pluginManagement {
plugins {
}
resolutionStrategy {
}
repositories {
}
}
rootProject.name = "plugin-management"pluginManagement {
plugins {
}
resolutionStrategy {
}
repositories {
}
}
rootProject.name = 'plugin-management'The block can also be used in Initialization Script:
settingsEvaluated {
pluginManagement {
plugins {
}
resolutionStrategy {
}
repositories {
}
}
}settingsEvaluated { settings ->
settings.pluginManagement {
plugins {
}
resolutionStrategy {
}
repositories {
}
}
}Custom Plugin Repositories
By default, the plugins{} DSL resolves plugins from the public Gradle Plugin Portal.
Many build authors would also like to resolve plugins from private Maven or Ivy repositories because they contain proprietary implementation details or to have more control over what plugins are available to their builds.
To specify custom plugin repositories, use the repositories{} block inside pluginManagement{}:
pluginManagement {
repositories {
maven(url = file("./maven-repo"))
gradlePluginPortal()
ivy(url = file("./ivy-repo"))
}
}pluginManagement {
repositories {
maven {
url = file('./maven-repo')
}
gradlePluginPortal()
ivy {
url = file('./ivy-repo')
}
}
}This tells Gradle to first look in the Maven repository at ../maven-repo when resolving plugins and then to check the Gradle Plugin Portal if the plugins are not found in the Maven repository.
If you don’t want the Gradle Plugin Portal to be searched, omit the gradlePluginPortal() line.
Finally, the Ivy repository at ../ivy-repo will be checked.
Plugin Version Management
A plugins{} block inside pluginManagement{} allows all plugin versions for the build to be defined in a single location.
Plugins can then be applied by id to any build script via the plugins{} block.
One benefit of setting plugin versions this way is that the pluginManagement.plugins{} does not have the same constrained syntax as the build script plugins{} block.
This allows plugin versions to be taken from gradle.properties, or loaded via another mechanism.
Managing plugin versions via pluginManagement:
pluginManagement {
val helloPluginVersion = providers.gradleProperty("helloPluginVersion").get()
plugins {
id("com.example.hello") version "${helloPluginVersion}"
}
}plugins {
id("com.example.hello")
}helloPluginVersion=1.0.0pluginManagement {
plugins {
id 'com.example.hello' version "${helloPluginVersion}"
}
}plugins {
id 'com.example.hello'
}helloPluginVersion=1.0.0The plugin version is loaded from gradle.properties and configured in the settings script, allowing the plugin to be added to any project without specifying the version.
Plugin Resolution Rules
Plugin resolution rules allow you to modify plugin requests made in plugins{} blocks, e.g., changing the requested version or explicitly specifying the implementation artifact coordinates.
To add resolution rules, use the resolutionStrategy{} inside the pluginManagement{} block:
pluginManagement {
resolutionStrategy {
eachPlugin {
if (requested.id.namespace == "com.example") {
useModule("com.example:sample-plugins:1.0.0")
}
}
}
repositories {
maven {
url = uri("./maven-repo")
}
gradlePluginPortal()
ivy {
url = uri("./ivy-repo")
}
}
}pluginManagement {
resolutionStrategy {
eachPlugin {
if (requested.id.namespace == 'com.example') {
useModule('com.example:sample-plugins:1.0.0')
}
}
}
repositories {
maven {
url = file('./maven-repo')
}
gradlePluginPortal()
ivy {
url = file('./ivy-repo')
}
}
}This tells Gradle to use the specified plugin implementation artifact instead of its built-in default mapping from plugin ID to Maven/Ivy coordinates.
Custom Maven and Ivy plugin repositories must contain plugin marker artifacts and the artifacts that implement the plugin. Read Gradle Plugin Development Plugin for more information on publishing plugins to custom repositories.
See PluginManagementSpec for complete documentation for using the pluginManagement{} block.
Plugin Marker Artifacts
Since the plugins{} DSL block only allows for declaring plugins by their globally unique plugin id and version properties, Gradle needs a way to look up the coordinates of the plugin implementation artifact.
To do so, Gradle will look for a Plugin Marker Artifact with the coordinates plugin.id:plugin.id.gradle.plugin:plugin.version.
This marker needs to have a dependency on the actual plugin implementation.
Publishing these markers is automated by the java-gradle-plugin.
For example, the following complete sample from the sample-plugins project shows how to publish a com.example.hello plugin and a com.example.goodbye plugin to both an Ivy and Maven repository using the combination of the java-gradle-plugin, the maven-publish plugin, and the ivy-publish plugin.
plugins {
`java-gradle-plugin`
`maven-publish`
`ivy-publish`
}
group = "com.example"
version = "1.0.0"
gradlePlugin {
plugins {
create("hello") {
id = "com.example.hello"
implementationClass = "com.example.hello.HelloPlugin"
}
create("goodbye") {
id = "com.example.goodbye"
implementationClass = "com.example.goodbye.GoodbyePlugin"
}
}
}
publishing {
repositories {
maven {
url = uri(layout.buildDirectory.dir("maven-repo"))
}
ivy {
url = uri(layout.buildDirectory.dir("ivy-repo"))
}
}
}plugins {
id 'java-gradle-plugin'
id 'maven-publish'
id 'ivy-publish'
}
group = 'com.example'
version = '1.0.0'
gradlePlugin {
plugins {
hello {
id = 'com.example.hello'
implementationClass = 'com.example.hello.HelloPlugin'
}
goodbye {
id = 'com.example.goodbye'
implementationClass = 'com.example.goodbye.GoodbyePlugin'
}
}
}
publishing {
repositories {
maven {
url = layout.buildDirectory.dir('maven-repo')
}
ivy {
url = layout.buildDirectory.dir('ivy-repo')
}
}
}Running gradle publish in the sample directory creates the following Maven repository layout (the Ivy layout is similar):
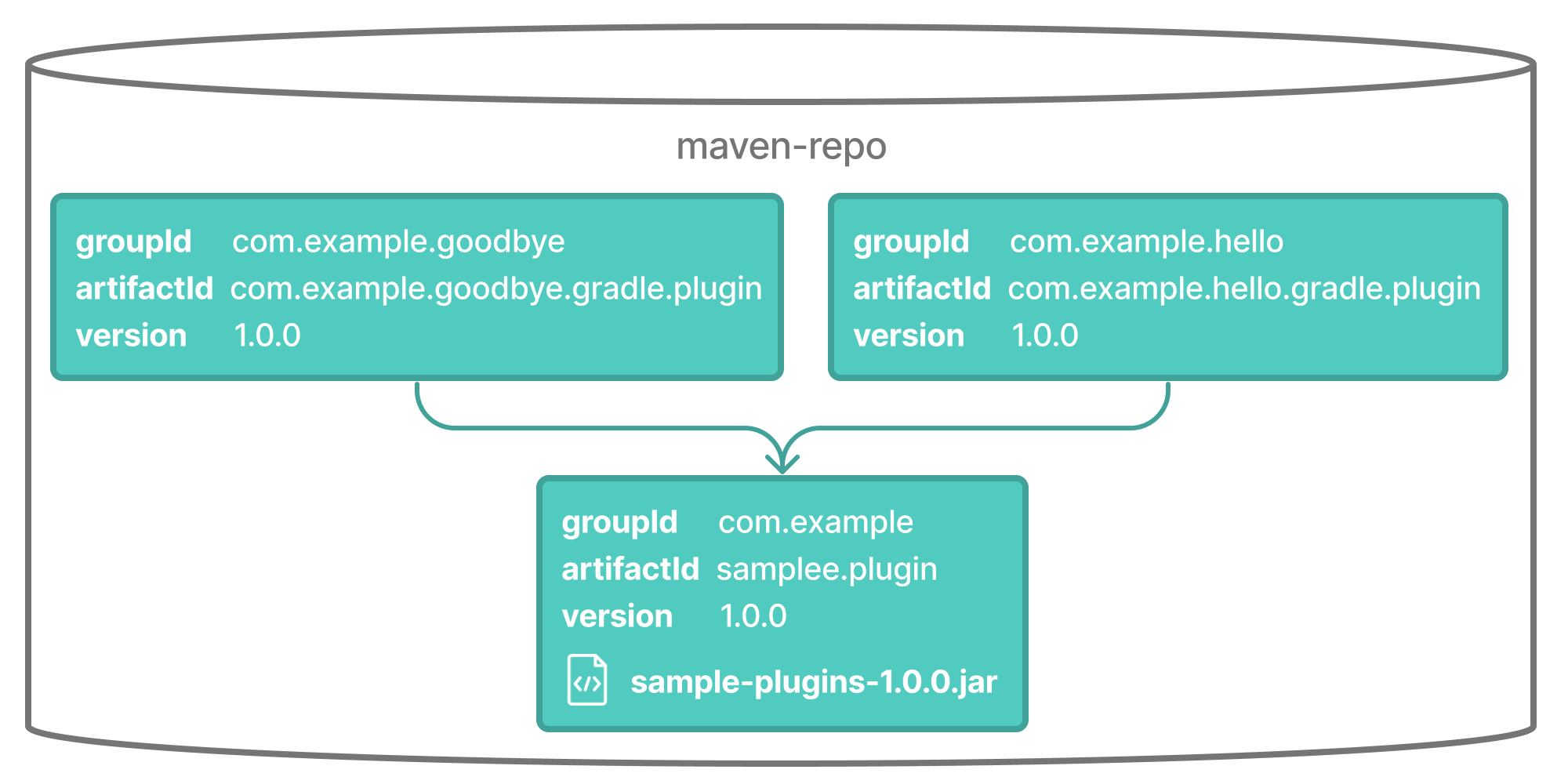
Legacy Plugin Application
With the introduction of the plugins DSL, users should have little reason to use the legacy method of applying plugins. It is documented here in case a build author cannot use the plugin DSL due to restrictions in how it currently works.
apply(plugin = "java")apply plugin: 'java'Plugins can be applied using a plugin id. In the above case, we are using the short name "java" to apply the JavaPlugin.
Rather than using a plugin id, plugins can also be applied by simply specifying the class of the plugin:
apply<JavaPlugin>()apply plugin: JavaPluginThe JavaPlugin symbol in the above sample refers to the JavaPlugin.
This class does not strictly need to be imported as the org.gradle.api.plugins package is automatically imported in all build scripts (see Default imports).
Furthermore, one needs to append the ::class suffix to identify a class literal in Kotlin instead of .class in Java.
Furthermore, it is unnecessary to append .class to identify a class literal in Groovy as it is in Java.
You may also see the apply method used to include an entire build file:
apply(from = "other.gradle.kts")apply from: 'other.gradle'Using a Version Catalog
When a project uses a version catalog, plugins can be referenced via aliases when applied.
Let’s take a look at a simple Version Catalog:
[versions]
groovy = "3.0.5"
checkstyle = "8.37"
[libraries]
groovy-core = { module = "org.codehaus.groovy:groovy", version.ref = "groovy" }
groovy-json = { module = "org.codehaus.groovy:groovy-json", version.ref = "groovy" }
groovy-nio = { module = "org.codehaus.groovy:groovy-nio", version.ref = "groovy" }
commons-lang3 = { group = "org.apache.commons", name = "commons-lang3", version = { strictly = "[3.8, 4.0[", prefer = "3.9" } }
[bundles]
groovy = ["groovy-core", "groovy-json", "groovy-nio"]
[plugins]
versions = { id = "com.github.ben-manes.versions", version = "0.45.0" }Then a plugin can be applied to any build script using the alias method:
plugins {
`java-library`
alias(libs.plugins.versions)
}plugins {
id 'java-library'
alias(libs.plugins.versions)
}|
Tip
|
Gradle generates type safe accessors for catalog items. |
Ready to build something? Start with the Intermediate Tutorial.
Next Step: Start the Tutorial >>
Plugin Introduction
A Gradle plugin is an add-on that enhances your build by adding tasks, applying conventions, or enabling specific configurations.
Plugins lets you extend and organize build logic in a modular and reusable way.
You apply plugins using the plugins block:
plugins {
id("org.springframework.boot") version "3.3.1"
}plugins {
id 'org.springframework.boot' version '3.3.1'
}When you apply a plugin, it typically does one or both of the following:
-
Adds tasks to your build - Plugins often expose tasks that perform a specific action.
For example, the Maven Publish Plugin adds a
publishToMavenLocaltask, which uploads artifacts to a local Maven repository. -
Applies behavior and conventions - Some plugins automatically configure parts of your build when applied.
For example, the Java Plugin creates the main and test source sets and applies sensible defaults for compiling and testing Java code.
Most plugins provide DSL blocks you can use to fine-tune their behavior in build scripts.
For instance, the Java plugin lets you configure how tests are run using the test task:
tasks.withType<Test>().configureEach {
useJUnitPlatform {
includeEngines("junit-vintage")
// excludeEngines("junit-jupiter")
}
}tasks.withType(Test).configureEach {
useJUnitPlatform {
includeEngines 'junit-vintage'
// excludeEngines 'junit-jupiter'
}
}And Java options using the java {} block:
java {
sourceCompatibility = JavaVersion.VERSION_1_8
targetCompatibility = JavaVersion.VERSION_1_8
}java {
sourceCompatibility = JavaVersion.VERSION_1_8
targetCompatibility = JavaVersion.VERSION_1_8
}Plugin Types
Gradle supports three types of plugins, each applied at a different phase of the build lifecycle. Init, settings, and project plugins.
The most common and popular plugins are project plugins.
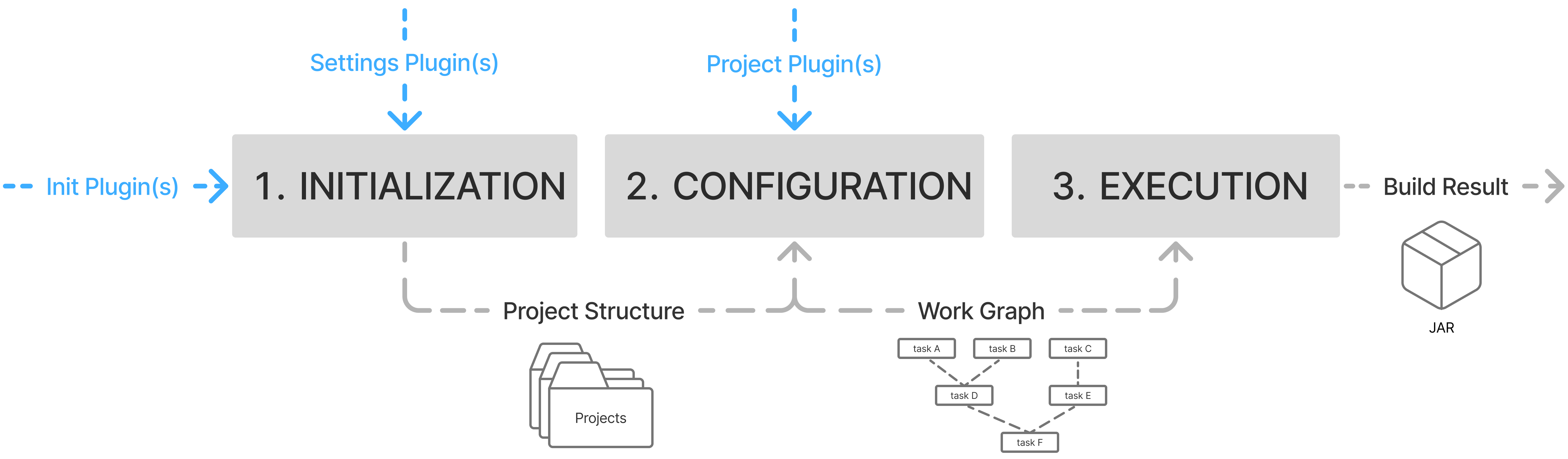
1. Init Plugins
-
Applied globally to all builds. Loaded from
~/.gradle/init.gradle[.kts]or passed via the--init-scriptcommand-line option. -
Configure the Gradle runtime before the build even starts. Useful for enforcing corporate policies, setting up shared CI configuration, or applying global conventions.
-
Implement the
Plugin<Gradle>interface.
2. Settings Plugins
-
Applied in
settings.gradle[.kts]files. -
Configure the build layout, such as which projects are included or how plugins are resolved.
-
Implement the
Plugin<Settings>interface.
3. Project Plugins
-
Applied in
build.gradle[.kts]files. -
Configure tasks, dependencies, and project-specific behavior.
-
Implement the
Plugin<Project>interface.
Plugin Scope
The scope of a plugin is determined by the interface it implements. The scope determines where the plugin can be applied and what parts of the Gradle lifecycle it can modify. Each scope gives you access to different configuration APIs.
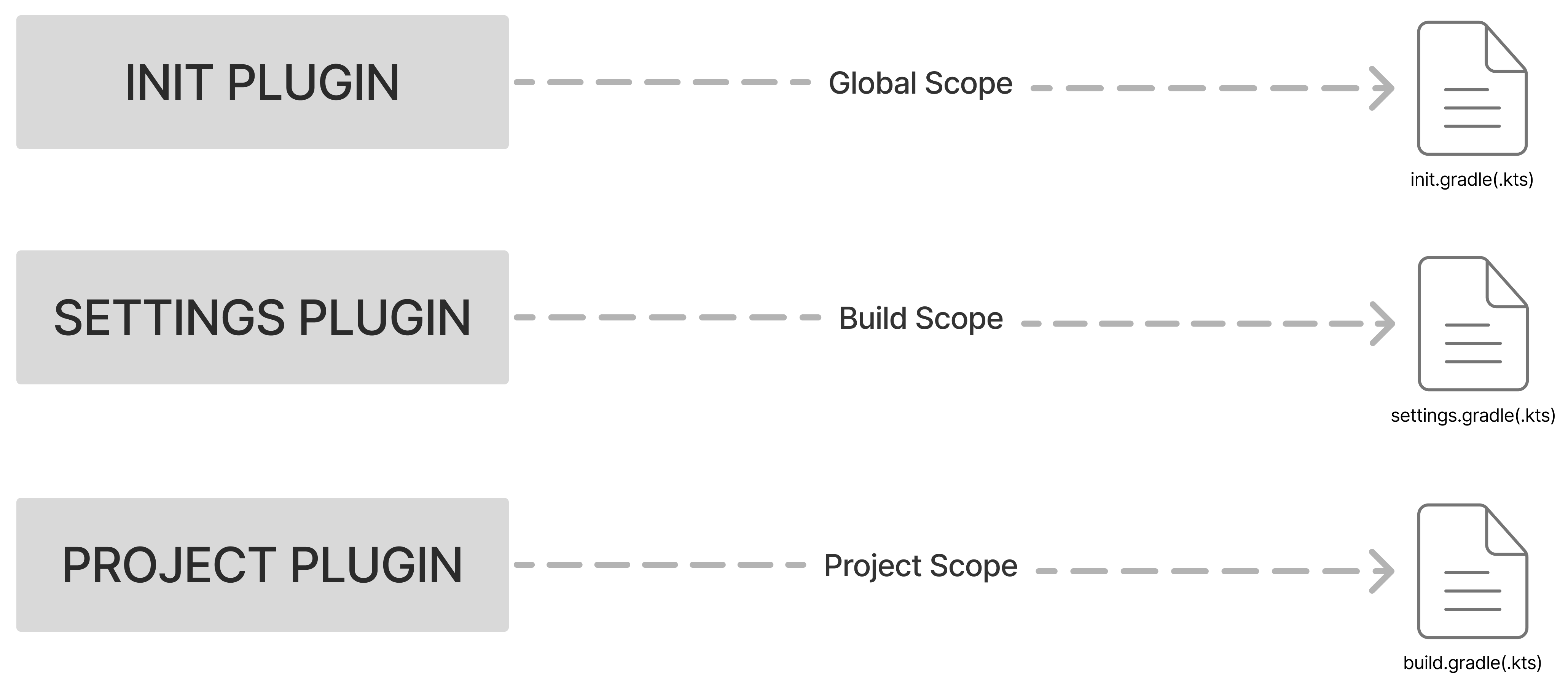
Each plugin type is defined by the interface it implements and the stage of the build lifecycle where it applies:
| Plugin Type | Interface | Scope | Applied In |
|---|---|---|---|
Init Plugin |
|
Global |
|
Settings Plugin |
|
Build Layout |
|
Project Plugin |
|
Per-Project |
|
Plugin Sources
Gradle plugins come from three different places, the Gradle distribution itself, external community sources, or your own internal builds.
1. Core Plugins
-
Bundled with Gradle itself (e.g.,
java,application). -
You don’t author or publish them, they’re built-in.
2. Community Plugins
-
Created and published by the community.
-
Typically hosted on the Gradle Plugin Portal.
-
Distributed as binary JARs.
3. Local Plugins
-
Custom plugins you write yourself, for your own builds.
-
Useful for sharing logic across subprojects or internal builds.
Authoring Plugins
Gradle provides two main ways to create your own custom plugins. This is code you write to extend Gradle’s capabilities and modularize your build logic.
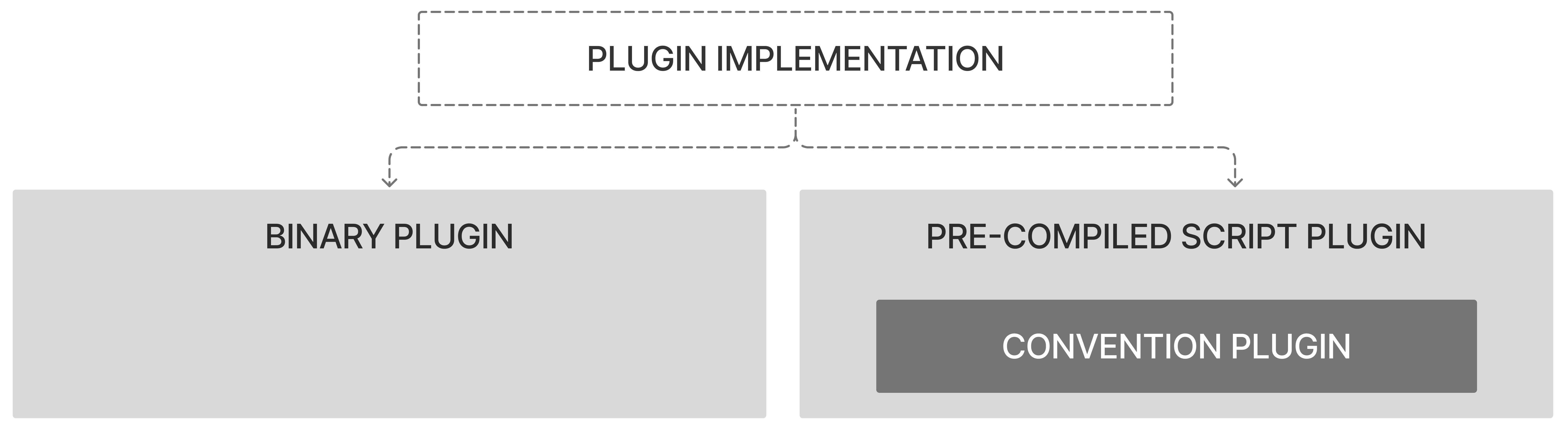
1. Precompiled Script Plugins
-
Written as
.gradle.ktsor.gradlefiles. -
Compiled automatically during the build.
-
Ideal for bundling simple conventions.
2. Binary Plugins
-
Typically written in Java, Kotlin, or Groovy.
-
Packaged as JARs and reusable across multiple builds.
-
Can be published to repositories for sharing.
Next Step: Learn about Pre-Compiled Script Plugins >>
Pre-compiled Script Plugins
The simplest plugin you can develop is called a precompiled script plugins.
These are Kotlin (.kts) or Groovy (.gradle) scripts.
They behave like normal Gradle plugins, but you write them using the same syntax as regular build scripts.
Some benefits of precompiled script plugins:
-
Encapsulation: Keep your
build.gradle(.kts)files clean by moving reusable logic into named plugins. -
Tooling support: Full IDE support, like autocomplete and navigation.
-
Avoid boilerplate: No need to write full plugin classes or register plugins manually.
-
Faster adoption: Use familiar script syntax while reaping the benefits of structured plugin development.
Convention Plugins
Most precompiled script plugins are used as convention plugins. A Gradle term for reusable build logic that applies standard plugin configurations, defaults, and behaviors across many projects.
Convention plugins are especially useful in large or multi-project builds where consistency is important.
They typically look like this:
plugins {
`java-library`
checkstyle
}
java {
sourceCompatibility = JavaVersion.VERSION_11
targetCompatibility = JavaVersion.VERSION_11
}
checkstyle {
maxWarnings = 0
// ...
}
tasks.withType<JavaCompile> {
options.isWarnings = true
// ...
}
dependencies {
testImplementation("junit:junit:4.13")
// ...
}plugins {
id 'java-library'
id 'checkstyle'
}
java {
sourceCompatibility = JavaVersion.VERSION_11
targetCompatibility = JavaVersion.VERSION_11
}
checkstyle {
maxWarnings = 0
// ...
}
tasks.withType(JavaCompile) {
options.warnings = true
// ...
}
dependencies {
testImplementation("junit:junit:4.13")
// ...
}And are applied in other projects like this:
plugins {
`java-library-convention`
}plugins {
id 'java-library-convention'
}Structuring Precompiled Script Plugins
Precompiled script plugins are typically placed in either:
-
A dedicated
buildSrcdirectory in your build, or -
A separate included build (often named
build-logic).
1. Using buildSrc
Precompiled script plugins or convention plugins will often be found in the special buildSrc directory:
.
└── buildSrc
├── build.gradle.kts
└── src
└── main
└── kotlin
└── myproject.java-conventions.gradle.kts.
└── buildSrc
├── build.gradle
└── src
└── main
└── groovy
└── myproject.java-conventions.gradle2. Using a Composite Build
Precompiled script plugins or convention plugins will often be found in a Composite Build with a name similar to build-logic:
build-logic
├── settings.gradle.kts
├── build.gradle.kts
└── src
└── main
└── kotlin
└── myproject.java-conventions.gradle.ktsbuild-logic
├── settings.gradle
├── build.gradle
└── src
└── main
└── groovy
└── myproject.java-conventions.gradleApplying a Precompiled Script Plugin
You apply a precompiled script plugin using its ID, derived from the script filename (excluding the .gradle.kts or .gradle extension).
plugins {
id("myproject.java-conventions")
}plugins {
id("myproject.java-conventions")
}The script itself acts as the plugin.
There is no need to explicitly implement the Plugin interface; a requirement for binary plugins.
Publishing a Precompiled Script Plugin
You can publish a precompiled script plugin to a repository, either a public one such as the Gradle Plugin Portal, or a private artifact repository like Maven, Artifactory, or Nexus.
However, publishing precompiled script plugins is not recommended (they are meant for internal use only). To publish them, you should first convert the precompiled script plugin into a binary plugin.
Example of a Precompiled Script Plugin
Let’s walk through creating a simple convention plugin using a precompiled script plugin in buildSrc.
1. Create a buildSrc directory
In the root of your project, add a buildSrc directory:
. // root project
├── ... // other project dirs and files
└── buildSrc
├── build.gradle.kts
└── src
└── main
└── kotlin. // root project
├── ... // other project dirs and files
└── buildSrc
├── build.gradle
└── src
└── main
└── groovy2. Add a build file
Create buildSrc/build.gradle.kts with the supporting build logic your convention plugin will need to compile:
plugins {
`kotlin-dsl`
}
repositories {
gradlePluginPortal()
}plugins {
id 'groovy-gradle-plugin'
}
repositories {
gradlePluginPortal()
}3. Create a plugin script
Inside buildSrc/src/main/kotlin or buildSrc/src/main/groovy, write your convention plugin as a .gradle(.kts) file:
.
└── buildSrc
├── build.gradle.kts
└── src
└── main
└── kotlin
└── myproject.java-conventions.gradle.ktsIn this example, the myproject.java-conventions.gradle(.kts) file contains the following code:
plugins {
id("java")
}
// Disable the test report for the individual test task
tasks.named<Test>("test") {
reports.html.required = false
}
// Share the test report data to be aggregated for the whole project
configurations.create("binaryTestResultsElements") {
isCanBeResolved = false
isCanBeConsumed = true
attributes {
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category.DOCUMENTATION))
attribute(DocsType.DOCS_TYPE_ATTRIBUTE, objects.named("test-report-data"))
}
outgoing.artifact(tasks.test.map { task -> task.getBinaryResultsDirectory().get() })
}
repositories {
mavenCentral()
}plugins {
id 'java'
}
// Disable the test report for the individual test task
test {
reports.html.required = false
}
// Share the test report data to be aggregated for the whole project
configurations {
binaryTestResultsElements {
canBeResolved = false
canBeConsumed = true
attributes {
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category, Category.DOCUMENTATION))
attribute(DocsType.DOCS_TYPE_ATTRIBUTE, objects.named(DocsType, 'test-report-data'))
}
outgoing.artifact(test.binaryResultsDirectory)
}
}
repositories {
mavenCentral()
}The name of the script (myproject.java-conventions.gradle(.kts)) becomes the plugin ID: myproject.java-conventions.
4. Apply the plugin in your project
In the build.gradle(.kts) of a consuming project, apply the plugin:
plugins {
id("myproject.java-conventions")
}
dependencies {
testImplementation("junit:junit:4.13")
}plugins {
id 'myproject.java-conventions'
}
dependencies {
testImplementation 'junit:junit:4.13'
}Next Step: Learn about Binary Plugins >>
Binary Plugin
Creating your own custom plugin might be a great solution when Gradle doesn’t offer the specific capabilities your project needs. This is where binary plugins come in.
A binary plugin is a plugin that is implemented in a compiled language and is packaged as a JAR file.
Binary plugins must implement the Plugin interface.
Implementing the Plugin Interface
For example, this is a very simple "Hello World" plugin:
abstract class SamplePlugin : Plugin<Project> { // (1)
override fun apply(project: Project) { // (2)
project.tasks.register("ScriptPlugin") {
doLast {
println("Hello world from the build file!")
}
}
}
}
apply<SamplePlugin>() // (3)class SamplePlugin implements Plugin<Project> { // (1)
void apply(Project project) { // (2)
project.tasks.register("ScriptPlugin") {
doLast {
println("Hello world from the build file!")
}
}
}
}
apply plugin: SamplePlugin // (3)-
Extend the
org.gradle.api.Plugininterface. -
Override the
applymethod.
1. Extend the org.gradle.api.Plugin interface
Create a class that extends the Plugin interface:
abstract class SamplePlugin : Plugin<Project> {
}class SamplePlugin implements Plugin<Project> {
}2. Override the apply method
Add tasks and other logic in the apply() method:
override fun apply() {
}void apply(Project project) {
}Let’s take a look at a more realistic example next.
Next Step: Learn how to develop Binary Plugins >>
Binary Plugin Development
When creating a plugin in Gradle, you will most likely offer tasks users can run and DSL blocks that users can use to configure your plugin.
Let’s create a binary plugin that offers both.
When you write a plugin in Gradle, if you want to share it between multiple projects then the best option is to create the plugin in a separate repository. This way, you can publish it to a private or public Maven repository, and then apply it in whatever project you need.
Components of a Plugin
First, let’s review the three components of a plugin:
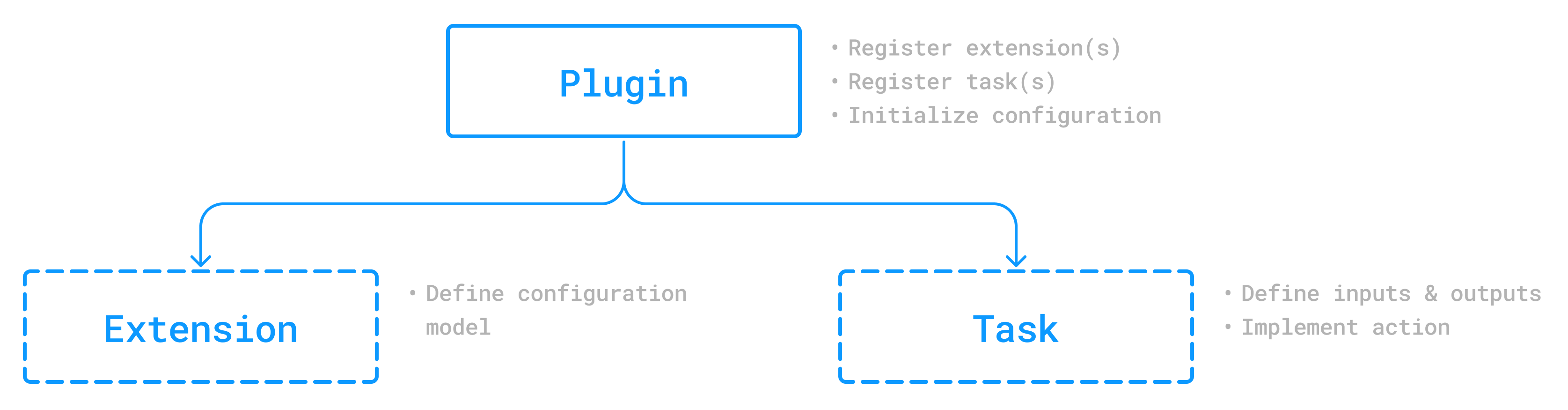
| Component | Role | Description |
|---|---|---|
Plugin Class |
Entry point |
Defines what happens when the plugin is applied. Typically, this involves registering tasks or modifying the project configuration. |
Extension Class |
Configuration |
Holds configuration data provided by users via the build script. |
Task Class |
Behavior |
Implements logic that is executed when the task is run. The plugin will typically register a task and wire it up with values from the extension. |
Our simple plugin compares the size of two files.
It is called FileSizeDiff.
Here’s the suggested directory structure:
.
└── plugin
├── settings.gradle.kts
├── build.gradle.kts
└── src
└── main
└── java/org/example
├── FileSizeDiffTask.java
├── FileSizeDiffPlugin.java
└── FileSizeDiffExtension.java.
└── plugin
├── settings.gradle
├── build.gradle
└── src
└── main
└── java/org/example
├── FileSizeDiffTask.java
├── FileSizeDiffPlugin.java
└── FileSizeDiffExtension.javaThis build.gradle(.kts) for this filesizediff plugin looks as follows:
plugins {
`java-gradle-plugin` // (1)
}
group = "org.example" // (3)
version = "1.0.0"
repositories {
mavenCentral()
}
dependencies { // (2)
testImplementation("org.junit.jupiter:junit-jupiter-api:5.10.0")
testRuntimeOnly("org.junit.jupiter:junit-jupiter-engine:5.10.0")
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
}
gradlePlugin { // (3)
plugins {
create("filesizediff") {
id = "org.example.filesizediff"
implementationClass = "org.example.FileSizeDiffPlugin"
}
}
}plugins {
id('java-gradle-plugin') // (1)
}
group = "org.example" // (3)
version = "1.0.0"
repositories {
mavenCentral()
}
dependencies { // (2)
testImplementation('org.junit.jupiter:junit-jupiter-api:5.10.0')
testRuntimeOnly('org.junit.jupiter:junit-jupiter-engine:5.10.0')
testRuntimeOnly('org.junit.platform:junit-platform-launcher')
}
gradlePlugin { // (3)
plugins {
filesizediff {
id = 'org.example.filesizediff'
implementationClass = 'org.example.FileSizeDiffPlugin'
}
}
}-
java-gradle-plugin- Sets up various configurations you need to do plugin development in Java -
junittesting framework - A popular Java testing framework -
Plugin configuration - Sets an id of
org.example.filesizediffwhich we can use to reference the plugin
1. Extension
The extension defines the plugin’s configurable inputs, two file properties in this case:
package org.example;
import org.gradle.api.file.RegularFileProperty;
public interface FileSizeDiffExtension {
RegularFileProperty getFile1();
RegularFileProperty getFile2();
}The two properties representing the input files are of the RegularFileProperty type which extends Property and are therefore lazy.
2. Task
The task does the bulk of the work:
package org.example;
import org.gradle.api.DefaultTask;
import org.gradle.api.file.RegularFileProperty;
import org.gradle.api.provider.Property;
import org.gradle.api.tasks.InputFile;
import org.gradle.api.tasks.OutputFile;
import org.gradle.api.tasks.TaskAction;
import java.nio.file.Files;
import java.io.File;
import java.io.IOException;
public abstract class FileSizeDiffTask extends DefaultTask {
@InputFile
public abstract RegularFileProperty getFile1();
@InputFile
public abstract RegularFileProperty getFile2();
@OutputFile
public abstract RegularFileProperty getResultFile();
@TaskAction
public void diff() throws IOException {
File f1 = getFile1().getAsFile().get();
File f2 = getFile2().getAsFile().get();
String output;
if (f1.length() == f2.length()) {
output = "Files have the same size: " + f1.length() + " bytes";
} else {
String larger = f1.length() > f2.length() ? f1.getName() : f2.getName();
long size = Math.max(f1.length(), f2.length());
output = larger + " was larger: " + size + " bytes";
}
File result = getResultFile().get().getAsFile();
Files.writeString(result.toPath(), output);
System.out.println(output);
System.out.println("Wrote diff result to " + result.getAbsolutePath());
}
}The task defines two input file properties and one output file property:
-
The input files represent the files to compare.
-
The output file is where the plugin writes the diff result, defaulting to
build/diff-result.txt.
The @InputFile and @OutputFile annotations tell Gradle to track these properties for incremental builds and caching, so the task will only re-run if the inputs or outputs change.
The plugin is responsible for mapping the user-defined values from the extension to the task’s input properties.
The task logic is implemented in a method annotated with @TaskAction, which:
-
Compares the size of the two input files.
-
Generates a descriptive text result.
-
Writes that result to the output file and prints it to standard output.
3. Plugin
This class wires up the extension and task when the plugin is applied:
package org.example;
import org.gradle.api.Plugin;
import org.gradle.api.Project;
import org.gradle.api.tasks.TaskProvider;
public class FileSizeDiffPlugin implements Plugin<Project> {
@Override
public void apply(Project project) {
// Register the extension
FileSizeDiffExtension extension = project.getExtensions().create("diff", FileSizeDiffExtension.class);
// Register and configure the task
project.getTasks().register("fileSizeDiff", FileSizeDiffTask.class, task -> {
task.getFile1().convention(extension.getFile1());
task.getFile2().convention(extension.getFile2());
task.getResultFile().convention(project.getLayout().getBuildDirectory().file("diff-result.txt"));
});
}
}In the plugin class, we override the apply method, which is invoked when the plugin is applied to a project via build.gradle(.kts).
Within this method, the plugin does two things:
-
Creates an extension named
filesizediff: This allows users to configure the plugin using adiff {}block in their build script. The configuration values are stored in an instance ofFileSizeDiffExtension. -
Registers a task of type
FileSizeDiffTask: The task is given the namefileSizeDiff, and its properties (file1andfile2) are mapped from the corresponding properties in thediffextension. This ensures the task uses the values provided by the user in their build script.
This enables the following usage in a build.gradle(.kts) file:
plugins {
id("org.example.filesizediff")
}
diff {
file1 = file("a.txt")
file2 = file("b.txt")
}plugins {
id("org.example.filesizediff")
}
diff {
file1 = file('a.txt')
file2 = file('b.txt')
}Next Step: Learn how to test Binary Plugins >>
Binary Plugin Testing
Gradle provides a robust mechanism for testing binary plugins.
Gradle’s TestKit allows you to programmatically execute synthetic builds that use the plugin under development, all within the plugin’s own build.
A well-tested plugin typically includes two levels of testing:
-
Unit Tests
-
Functional Tests
The directory of our plugin looks as follows:
.
└── plugin
├── settings.gradle.kts
├── build.gradle.kts
└── src
├── main
│ └── java/org/example
│ ├── FileSizeDiffTask.java
│ ├── FileSizeDiffPlugin.java
│ └── FileSizeDiffExtension.java
├── test
│ └── java/org/example
│ └── FileSizeDiffPluginTest.java
└── functionalTest
└── java/org/example
└── FileSizeDiffPluginFunctionalTest.java.
└── plugin
├── settings.gradle
├── build.gradle
└── src
├── main
│ └── java/org/example
│ ├── FileSizeDiffTask.java
│ ├── FileSizeDiffPlugin.java
│ └── FileSizeDiffExtension.java
├── test
│ └── java/org/example
│ └── FileSizeDiffPluginTest.java
└── functionalTest
└── java/org/example
└── FileSizeDiffPluginFunctionalTest.java1. Unit Test
Unit tests validate the internal behavior of your plugin in a lightweight, isolated project. These tests simulate applying your plugin without needing a full Gradle execution.
They test:
-
The plugin applies without errors
-
Tasks or extensions are registered correctly
The unit test for the filesizediff plugin looks as follows:
package org.example;
import org.gradle.testfixtures.ProjectBuilder;
import org.gradle.api.Project;
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.*;
class FileSizeDiffPluginTest {
@Test void pluginRegistersATask() {
// Create a test project and apply the plugin
Project project = ProjectBuilder.builder().build();
project.getPlugins().apply("org.example.filesizediff");
// Verify the result
assertNotNull(project.getTasks().findByName("fileSizeDiff"));
}
}This test checks that the org.example.filesizediff plugin is applied and a fileSizeDiff task is added.
Unit tests are fast and useful for verifying the basic mechanics of your plugin logic.
2. Functional Test
Functional tests (also known as end-to-end plugin tests) use Gradle’s TestKit to launch real Gradle builds in a temporary directory.
This is how you verify your plugin works correctly in real-world usage.
They test:
-
The plugin can be applied to a real build
-
The plugin task runs correctly and produces the expected output
-
Users can configure the plugin via the DSL
The functional test for the filesizediff plugin looks as follows:
package org.example;
import org.gradle.testkit.runner.BuildResult;
import org.gradle.testkit.runner.GradleRunner;
import org.gradle.testkit.runner.TaskOutcome;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.io.TempDir;
import java.io.File;
import java.io.IOException;
import java.nio.file.Files;
import static org.junit.jupiter.api.Assertions.assertEquals;
import static org.junit.jupiter.api.Assertions.assertTrue;
public class FileSizeDiffPluginFunctionalTest {
// Temporary directory for each test, automatically cleaned up after the test run
@TempDir
File projectDir;
// Helper to get reference to build.gradle in the temp project
private File getBuildFile() {
return new File(projectDir, "build.gradle");
}
// Helper to get reference to settings.gradle in the temp project
private File getSettingsFile() {
return new File(projectDir, "settings.gradle");
}
// Create minimal build and settings files before each test
@BeforeEach
void setup() throws IOException {
// Empty settings.gradle
writeString(getSettingsFile(), "");
// Apply the plugin and configure the extension in build.gradle
writeString(getBuildFile(), """
plugins {
id("org.example.filesizediff")
}
diff {
file1 = file("a.txt")
file2 = file("b.txt")
}
"""
);
}
// Test case: both input files have the same size (empty)
@Test
void canDiffTwoFilesOfTheSameSize() throws IOException {
// Create empty file a.txt
writeString(new File(projectDir, "a.txt"), "");
// Create empty file b.txt
writeString(new File(projectDir, "b.txt"), "");
// Run the build with the plugin classpath and invoke the fileSizeDiff task
BuildResult result = GradleRunner.create()
.withProjectDir(projectDir)
.withPluginClasspath()
.withArguments("fileSizeDiff")
.build();
// Verify the output message and successful task result
assertTrue(result.getOutput().contains("Files have the same size"));
assertEquals(TaskOutcome.SUCCESS, result.task(":fileSizeDiff").getOutcome());
}
// Test case: first file is larger than second file
@Test
void canDiffTwoFilesOfDiffSize() throws IOException {
// File a.txt has 7 bytes
writeString(new File(projectDir, "a.txt"), "dsdsdad");
// File b.txt is empty
writeString(new File(projectDir, "b.txt"), "");
// Run the build and invoke the plugin task
BuildResult result = GradleRunner.create()
.withProjectDir(projectDir)
.withPluginClasspath()
.withArguments("fileSizeDiff")
.build();
// Verify the output message indicates a.txt is larger
assertTrue(result.getOutput().contains("a.txt was larger: 7 bytes"));
assertEquals(TaskOutcome.SUCCESS, result.task(":fileSizeDiff").getOutcome());
}
// Helper method to write string content to a file
private static void writeString(File file, String string) throws IOException {
Files.writeString(file.toPath(), string);
}
}GradleRunner is the core API provided by TestKit for executing builds in a test environment.
GradleRunner simulates a Gradle invocation.
Each test creates a temporary project with a build.gradle file, input files, and runs the plugin task using GradleRunner.
Unlike unit tests in src/test/java that test individual classes, functional tests live in src/functionalTest/java and verify that your plugin behaves correctly in a real build.
Gradle doesn’t automatically recognize custom test source sets, so you need to declare a functionalTest source set and configure a task to run it.
Fortunately, gradle init can scaffold this setup for you:
plugins {
`java-gradle-plugin` // (1)
}
group = "org.example" // (3)
version = "1.0.0"
repositories {
mavenCentral()
}
dependencies { // (2)
testImplementation("org.junit.jupiter:junit-jupiter-api:5.10.0")
testRuntimeOnly("org.junit.jupiter:junit-jupiter-engine:5.10.0")
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
}
gradlePlugin { // (3)
plugins {
create("filesizediff") {
id = "org.example.filesizediff"
implementationClass = "org.example.FileSizeDiffPlugin"
}
}
}
// Created by gradle init
// Add a source set for the functional test suite
val functionalTestSourceSet = sourceSets.create("functionalTest") {
}
configurations["functionalTestImplementation"].extendsFrom(configurations["testImplementation"])
configurations["functionalTestRuntimeOnly"].extendsFrom(configurations["testRuntimeOnly"])
// Add a task to run the functional tests
val functionalTest = tasks.register<Test>("functionalTest") {
description = "Runs functional tests."
group = "verification"
testClassesDirs = functionalTestSourceSet.output.classesDirs
classpath = functionalTestSourceSet.runtimeClasspath
useJUnitPlatform()
}
gradlePlugin.testSourceSets.add(functionalTestSourceSet)
tasks.named<Task>("check") {
// Run the functional tests as part of `check`
dependsOn(functionalTest)
}
tasks.named<Test>("test") {
// Use JUnit Jupiter for unit tests.
useJUnitPlatform()
}plugins {
id('java-gradle-plugin') // (1)
}
group = "org.example" // (3)
version = "1.0.0"
repositories {
mavenCentral()
}
dependencies { // (2)
testImplementation('org.junit.jupiter:junit-jupiter-api:5.10.0')
testRuntimeOnly('org.junit.jupiter:junit-jupiter-engine:5.10.0')
testRuntimeOnly('org.junit.platform:junit-platform-launcher')
}
gradlePlugin { // (3)
plugins {
filesizediff {
id = 'org.example.filesizediff'
implementationClass = 'org.example.FileSizeDiffPlugin'
}
}
}
// Created by gradle init
// Add a source set for the functional test suite
sourceSets {
functionalTest {
}
}
configurations {
functionalTestImplementation.extendsFrom(testImplementation)
functionalTestRuntimeOnly.extendsFrom(testRuntimeOnly)
}
// Add a task to run the functional tests
tasks.register('functionalTest', Test) {
description = 'Runs functional tests.'
group = 'verification'
testClassesDirs = sourceSets.functionalTest.output.classesDirs
classpath = sourceSets.functionalTest.runtimeClasspath
useJUnitPlatform()
}
// Include functional test source set in plugin validation
gradlePlugin.testSourceSets.add(sourceSets.functionalTest)
// Run functional tests as part of check
tasks.named('check', Task) {
dependsOn tasks.named('functionalTest')
}
// Use JUnit Platform for unit tests
tasks.named('test', Test) {
useJUnitPlatform()
}Consumer Project
You can optionally create a consumer project that uses your plugin:
.
├── settings.gradle.kts // Include custom plugin
├── build.gradle.kts // Applies custom plugin
│
└── plugin
├── settings.gradle.kts
├── build.gradle.kts
└── src
....
├── settings.gradle // Include custom plugin
├── build.gradle // Applies custom plugin
│
└── plugin
├── settings.gradle
├── build.gradle
└── src
...
First you can point to the plugin as an included build in the consumer settings file:
rootProject.name = "consumer"
includeBuild("plugin")rootProject.name = 'consumer'
includeBuild("plugin")Then in the build file of the consumer project, you apply the plugin and test it:
plugins {
id("org.example.filesizediff")
}
diff {
file1 = file("a.txt")
file2 = file("b.txt")
}plugins {
id("org.example.filesizediff")
}
diff {
file1 = file('a.txt')
file2 = file('b.txt')
}In the consumer project, you can create dummy a.txt and b.txt files and run ./gradlew fileSizeDiff:
$ ./gradlew fileSizeDiff> Task :fileSizeDiff
Files have the same size: 0 bytes
Wrote diff result to /home/user/gradle/samples/build/diff-result.txt
BUILD SUCCESSFUL in 0sNext Step: Learn how to publish Binary Plugins >>
Binary Plugin Publishing
Once your plugin is complete and tested, you may want to publish it so it can be reused across multiple builds or even shared with others.
There are a number of plugins available to publish your plugin.
For now, we will use the core maven-publish plugin.
The maven-publish plugin lets you publish artifacts (like JARs, libraries, or plugins) to a Maven repository.
Apply the Maven Publish Plugin
In your plugin/build.gradle(.kts), apply the maven-publish plugin:
plugins {
`java-gradle-plugin`
`maven-publish`
}A lot of the information needed to publish the plugin - group, version, and id - is already in your build file:
group = "org.example" // (3)
version = "1.0.0"
gradlePlugin { // (3)
plugins {
create("filesizediff") {
id = "org.example.filesizediff"
implementationClass = "org.example.FileSizeDiffPlugin"
}
}
}group = "org.example" // (3)
version = "1.0.0"
gradlePlugin { // (3)
plugins {
filesizediff {
id = 'org.example.filesizediff'
implementationClass = 'org.example.FileSizeDiffPlugin'
}
}
}group = "org.example" sets the group ID of the plugin.
version = "1.0.0" sets the version of the plugin artifact.
The gradlePlugin {} block is part of the java-gradle-plugin and declares a binary plugin.
It registers the full plugin name org.example.filesizediff, backed by a class called FileDiffPlugin.
This is the class that implements Plugin<Project> and defines what happens when the plugin is applied.
Configure the Publishing Block
In your plugin/build.gradle(.kts) file, configure the plugin for publication by defining where to publish it.
Inside the publishing {} block, you specify the repository to publish to:
publishing {
repositories {
maven {
url = uri("${layout.projectDirectory}/publish")
}
}
}publishing {
repositories {
maven {
url = uri("${layout.projectDirectory}/publish")
}
}
}Publish the Plugin
To publish, run:
$ ./gradlew publishThis will generate and install the plugin JAR and associated metadata (like pom.xml) into the specified Maven repository.
Ready to build something? Start with the Advanced Tutorial.
Next Step: Start the Tutorial >>
BEST PRACTICES
Best Practices for Authoring Gradle Builds
Introduction
Gradle is a powerful and flexible tool for building software, but along with these benefits comes complexity and the need for clear guidance on best practices. There are many scenarios where how to best use Gradle is unclear, as Gradle provides several ways of accomplishing the same goals. Often there is a need to determine if a current solution is likely to cause problems down the line, or if problems could have been avoided in advance by using Gradle differently. This guide aims to help Gradle authors navigate these scenarios and make informed decisions about how to use Gradle effectively.
What this Guide is
This section outlines best practices for authoring Gradle builds that are maintainable, function properly, and are aligned with Gradle’s core design philosophy. Some of these practices are things to do, and some are things to avoid doing.
This guide is informed by real-world experience in some of the largest software ecosystems using Gradle. It targets all levels of Gradle expertise, from beginners to advanced users. Not every practice here will be applicable to every build, however these are meant to be widely applicable and beneficial to many different usage scenarios.
This guide is not meant as instructions for how to use Gradle. For that purpose, we provide extensive tutorials and reference materials elsewhere in the Gradle documentation.
Principles
The items in this guide are meant to be brief, understandable, and actionable.
-
Build authors should be able to quickly recognize when they are following best practices and when they are not.
-
After reading, they should understand why a particular approach is beneficial or problematic and where to find further reference material.
-
Recommendations should be widely applicable to many or most typical builds and should provide specific, concrete advice.
Index
To view all Gradle Best Practices at a glance, along with the Gradle version they were introduced in, visit the Index Page.
Best Practices Index
The table below provides a complete list of documented Gradle Best Practices.
Use this as a quick reference to track newly added recommendations, check adoption status, or explore areas for improving your build:
| Title | Section | Added in Gradle Version |
|---|---|---|
General |
8.14 |
|
General |
8.14 |
|
General |
8.14 |
|
General |
8.14 |
|
General |
9.0.0 |
|
General |
9.2.0 |
|
General |
9.2.0 |
|
General |
9.6.0 |
|
Structuring Builds |
9.0.0 |
|
Structuring Builds |
9.0.0 |
|
Structuring Builds |
9.0.0 |
|
Structuring Builds |
9.1.0 |
|
Structuring Builds |
9.3.0 |
|
Dependencies |
8.14 |
|
Dependencies |
9.0.0 |
|
Dependencies |
9.0.0 |
|
Dependencies |
9.0.0 |
|
Dependencies |
9.0.0 |
|
Dependencies |
9.0.0 |
|
Dependencies |
9.1.0 |
|
Dependencies |
9.2.0 |
|
Task |
8.14 |
|
Favor @CacheableTask and @DisableCachingByDefault over cacheIf(Spec) and doNotCacheIf(String, Spec) |
Task |
8.14 |
Task |
9.0.0 |
|
Task |
9.1.0 |
|
Task |
9.1.0 |
|
Task |
9.1.0 |
|
Prefer |
Task |
9.2.0 |
Task |
9.3.0 |
|
Performance |
9.0.0 |
|
Performance |
9.1.0 |
|
Performance |
9.1.0 |
|
Performance |
9.0.0 |
|
Performance |
9.4.0 |
|
Security |
9.1.0 |
|
Security |
9.3.0 |
|
Testing |
9.4.0 |
General Gradle Best Practices
Use Kotlin DSL
Prefer the Kotlin DSL (build.gradle.kts) over the Groovy DSL (build.gradle) when authoring new builds or creating new subprojects in existing builds.
Explanation
The Kotlin DSL offers several advantages over the Groovy DSL:
-
Strict typing: IDEs provide better auto-completion and navigation with the Kotlin DSL.
-
Improved readability: Code written in Kotlin is often easier to follow and understand.
-
Single-language stack: Projects that already use Kotlin for production and test code don’t need to introduce Groovy just for the build.
Since Gradle 8.0, Kotlin DSL is the default for new builds created with gradle init.
Android Studio also defaults to Kotlin DSL.
Use the Latest Minor Version of Gradle
Stay on the latest minor version of the major Gradle release you’re using, and regularly update your plugins to the latest compatible versions.
Explanation
Gradle follows a fairly predictable, time-based release cadence. Only the latest minor version of the current and previous major release is actively supported.
We recommend the following strategy:
-
Try upgrading directly to the latest minor version of your current major Gradle release.
-
If that fails, upgrade one minor version at a time to isolate regressions or compatibility issues.
Each new minor version includes:
-
Performance and stability improvements.
-
Deprecation warnings that help you prepare for the next major release.
-
Fixes for known bugs and security vulnerabilities.
Use the wrapper task to update your project:
./gradlew :wrapper --gradle-version <version>Plugin Compatibility
Always use the latest compatible version of each plugin:
-
Upgrade Gradle before plugins.
-
Test plugin compatibility using shadow jobs.
-
Consult changelogs when updating.
Subscribe to the Gradle newsletter to stay informed about new Gradle releases, features, and plugins.
Apply Plugins Using the plugins Block
You should always use the plugins block to apply plugins in your build scripts.
Explanation
The plugins block is the preferred way to apply plugins in Gradle.
The plugins API allows Gradle to better manage the loading of plugins and it is both more concise and less error-prone than adding dependencies to the buildscript’s classpath explicitly in order to use the apply method.
It allows Gradle to optimize the loading and reuse of plugin classes and helps inform tools about the potential properties and values in extensions the plugins will add to the build script. It is constrained to be idempotent (produce the same result every time) and side effect-free (safe for Gradle to execute at any time).
Example
Don’t Do This
buildscript {
repositories {
gradlePluginPortal() // (1)
}
dependencies {
classpath("com.google.protobuf:com.google.protobuf.gradle.plugin:0.9.4") // (2)
}
}
apply(plugin = "java") // (3)
apply(plugin = "com.google.protobuf") // (4)buildscript {
repositories {
gradlePluginPortal() // (1)
}
dependencies {
classpath("com.google.protobuf:com.google.protobuf.gradle.plugin:0.9.4") // (2)
}
}
apply plugin: "java" // (3)
apply plugin: "com.google.protobuf" // (4)-
Declare a Repository: To use the legacy plugin application syntax, you need to explicitly tell Gradle where to find a plugin.
-
Declare a Plugin Dependency: To use the legacy plugin application syntax with third-party plugins, you need to explicitly tell Gradle the full coordinates of the plugin.
-
Apply a Core Plugin: This is very similar using either method.
-
Apply a Third-Party Plugin: The syntax is the same as for core Gradle plugins, but the version is not present at the point of application in your buildscript.
Do This Instead
plugins {
id("java") // (1)
id("com.google.protobuf").version("0.9.4") // (2)
}plugins {
id("java") // (1)
id("com.google.protobuf").version("0.9.4") // (2)
}-
Apply a Core Plugin: This is very similar using either method.
-
Apply a Third-Party Plugin: You specify the version using method chaining in the
pluginsblock itself.
Don’t Assume your Plugin is Applied after Another
Gradle’s plugin application is deterministic but opaque. It is difficult to reason about, especially across multiple build scripts, projects, convention plugins, or included builds.
As a result, you should not write build logic or plugins that depend on a specific plugin application order.
Explanation
In a single build.gradle(.kts) file, plugins appear to be applied sequentially:
plugins {
id("pluginA")
id("pluginB")
}plugins {
id("pluginA")
id("pluginB")
}However, in multi-project builds, with multiple build.gradle(.kts) files or a convention plugin, plugin application can be hard to determine:
plugins {
id("pluginA")
id("pluginB")
}plugins {
id("pluginC")
id("pluginD")
}plugins {
id("pluginA")
id("pluginB")
}plugins {
id("pluginC")
id("pluginD")
}You cannot assume whether pluginA, pluginB, pluginC, or pluginD will be applied first because pluginA could apply pluginD.
Build Engineers
Writing build logic that assumes plugin ordering can lead to brittle behavior and fragile builds that break when project structure changes.
Don’t rely on blocks like allprojects {}, subprojects {}, or afterEvaluate {} that are highly dependent on project structure and file layout.
They can be difficult to decipher and may depend on configuration details that are hard to understand completely without running the build.
Avoid build logic that assumes ordering between different projects, included builds, or applied scripts. While the application order is deterministic, minor structural changes (such as adding a new project or renaming an include) can easily result in an unexpected change to that plugin application order.
Plugin Developers
Users should be able to apply your plugin in either order and have it behave correctly:
plugins {
id("my-plugin")
id("plugin-i-depend-on")
}plugins {
id("my-plugin")
id("plugin-i-depend-on")
}or
plugins {
id("plugin-i-depend-on")
id("my-plugin")
}plugins {
id("plugin-i-depend-on")
id("my-plugin")
}If your plugin only works in one of these cases, it’s relying on plugin order and will be fragile in real builds.
If your plugin cannot function without another plugin, apply it explicitly at the start of Plugin.apply:
// Ensure required plugin is applied
project.pluginManager.apply("com.example.required-plugin")// Ensure required plugin is applied
project.pluginManager.apply('com.example.required-plugin')If your plugin only needs to integrate with another plugin when it’s present, react to its application using pluginManager.withPlugin() or plugins.configureEach {}:
// Configure behavior that depends on required-plugin using the plugin id (preferred)
project.pluginManager.withPlugin("com.example.required-plugin") { }
// Configure behavior that depends on RequiredPlugin using the plugin class (if no id is available)
project.plugins.configureEach { plugin ->
when (plugin) { is com.example.RequiredPlugin -> { } }
}// Configure behavior that depends on required-plugin using the plugin id (preferred)
project.pluginManager.withPlugin('com.example.required-plugin') { }
// Configure behavior that depends on RequiredPlugin using the plugin class (if no id is available)
project.plugins.configureEach { plugin ->
if (plugin instanceof com.example.RequiredPlugin) { }
}This is order-independent and safe.
Example
Given the following project layout:
.
├── app/
│ └── build.gradle.kts
├── buildSrc/
│ ├── build.gradle.kts
│ └── src/main/kotlin/MyPlugin.kt
├── settings.gradle.kts
└── build.gradle.kts.
├── app/
│ └── build.gradle
├── buildSrc/
│ ├── build.gradle
│ └── src/main/groovy/MyPlugin.groovy
├── settings.gradle
└── build.gradleDon’t Do This
This setup makes several assumptions about the java plugin.
In the root build, subprojects {} and afterEvaluate {} obscure when a plugin is applied and attempt to force ordering:
subprojects {
// Apply the Java plugin to every subproject
afterEvaluate {
// This runs after the app subproject’s build script is evaluated and results in an error
pluginManager.apply("java")
}
}subprojects {
// Apply the Java plugin to every subproject
afterEvaluate {
// This runs after the app subproject’s build script is evaluated and results in an error
apply plugin: 'java'
}
}In the app subproject, the build file uses extensions.getByType(…) which assumes java has already been applied:
plugins {
id("myplugin")
}
// Assumes 'java' plugin is present
extensions.getByType<org.gradle.api.plugins.JavaPluginExtension>().apply {
toolchain.languageVersion.set(JavaLanguageVersion.of(21))
}plugins {
id 'myplugin'
}
// Assumes 'java' plugin is present
project.extensions.getByType(org.gradle.api.plugins.JavaPluginExtension).with {
toolchain.languageVersion.set(org.gradle.jvm.toolchain.JavaLanguageVersion.of(21))
}In the plugin implementation, MyPlugin.kt or MyPlugin.groovy also assumes java is already applied:
class MyPlugin : Plugin<Project> {
override fun apply(project: Project) {
// Assumes 'java' plugin is present
// WARNING: This will fail if the 'java' plugin hasn't been applied yet.
project.extensions.getByType(JavaPluginExtension::class.java).toolchain {
languageVersion.set(JavaLanguageVersion.of(21))
}
}
}class MyPlugin implements Plugin<Project> {
void apply(Project project) {
// Assumes 'java' plugin is present
// WARNING: This will fail if the 'java' plugin hasn't been applied yet.
project.extensions.configure(JavaPluginExtension) {
it.toolchain {
it.languageVersion.set(JavaLanguageVersion.of(21))
}
}
}
}Do This Instead
The fixed version removes afterEvaluate and avoids assumptions about when or where the java plugin is applied.
The root build file has been deleted as there is no longer a need to use subprojects {}.
In the app subproject, the build file uses plugins.withPlugin("java") {} to safely configure tasks once java is applied:
pluginManager.withPlugin("java") {
extensions.configure<org.gradle.api.plugins.JavaPluginExtension> {
toolchain.languageVersion.set(JavaLanguageVersion.of(21))
}
}project.pluginManager.withPlugin('java') {
project.extensions.configure(org.gradle.api.plugins.JavaPluginExtension) {
it.toolchain {
languageVersion.set(JavaLanguageVersion.of(21))
}
}
}In the plugin implementation, MyPlugin.kt or MyPlugin.groovy explicitly applies the java plugin:
class MyPlugin : Plugin<Project> {
override fun apply(project: Project) {
// If your plugin requires 'java', apply it so order doesn’t matter
project.pluginManager.apply("java")
// Now it's safe to configure Java things immediately
project.extensions.configure(JavaPluginExtension::class.java) {
toolchain.languageVersion.set(JavaLanguageVersion.of(21))
}
}
}class MyPlugin implements Plugin<Project> {
void apply(Project project) {
// If your plugin requires 'java', apply it so order doesn’t matter
project.pluginManager.apply('java')
// Now it's safe to configure Java things immediately
project.extensions.configure(JavaPluginExtension) {
it.toolchain {
it.languageVersion.set(JavaLanguageVersion.of(21))
}
}
}
}Do Not Use Internal APIs
Do not use APIs from a package where any segment of the package is internal, or types that have Internal or Impl as a suffix in the name.
Explanation
Using internal APIs is inherently risky and can cause significant problems during upgrades. Gradle and many plugins (such as Android Gradle Plugin and Kotlin Gradle Plugin) treat these internal APIs as subject to unannounced breaking changes during any new Gradle release, even during minor releases. There have been numerous cases where even highly experienced plugin developers have been bitten by their usage of such APIs leading to unexpected breakages for their users.
If you require specific functionality that is missing, it’s best to submit a feature request. As a temporary workaround consider copying the necessary code into your own codebase and extending a Gradle public type with your own custom implementation using the copied code.
Example
Don’t Do This
import org.gradle.api.internal.attributes.AttributeContainerInternal
configurations.create("bad") {
attributes {
attribute(Usage.USAGE_ATTRIBUTE, objects.named<Usage>(Usage.JAVA_RUNTIME))
attribute(Category.CATEGORY_ATTRIBUTE, objects.named<Category>(Category.LIBRARY))
}
val badMap = (attributes as AttributeContainerInternal).asMap() // (1)
logger.warn("Bad map")
badMap.forEach { (key, value) ->
logger.warn("$key -> $value")
}
}import org.gradle.api.internal.attributes.AttributeContainerInternal
configurations.create("bad") {
attributes {
attribute(Usage.USAGE_ATTRIBUTE, objects.named(Usage, Usage.JAVA_RUNTIME))
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category, Category.LIBRARY))
}
def badMap = (attributes as AttributeContainerInternal).asMap() // (1)
logger.warn("Bad map")
badMap.each {
logger.warn("${it.key} -> ${it.value}")
}
}-
Casting to
AttributeContainerInternaland usingtoMap()should be avoided as it relies on an internal API.
Do This Instead
configurations.create("good") {
attributes {
attribute(Usage.USAGE_ATTRIBUTE, objects.named<Usage>(Usage.JAVA_RUNTIME))
attribute(Category.CATEGORY_ATTRIBUTE, objects.named<Category>(Category.LIBRARY))
}
val goodMap = attributes.keySet().associate { // (1)
Attribute.of(it.name, it.type) to attributes.getAttribute(it)
}
logger.warn("Good map")
goodMap.forEach { (key, value) ->
logger.warn("$key -> $value")
}
}configurations.create("good") {
attributes {
attribute(Usage.USAGE_ATTRIBUTE, objects.named(Usage, Usage.JAVA_RUNTIME))
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category, Category.LIBRARY))
}
def goodMap = attributes.keySet().collectEntries {
[Attribute.of(it.name, it.type), attributes.getAttribute(it as Attribute<Object>)]
}
logger.warn("Good map")
goodMap.each {
logger.warn("$it.key -> $it.value")
}
}-
Implementing your own version of
toMap()that only uses public APIs is a lot more robust.
Set Build Flags in gradle.properties
Set Gradle build property flags in the gradle.properties file.
Explanation
Instead of using command-line options or environment variables, set build flags in the root project’s gradle.properties file.
Gradle comes with a long list of Gradle properties, which have names that begin with org.gradle and can be used to configure the behavior of the build tool.
These properties can have a major impact on build performance, so it’s important to understand how they work.
You should not rely on supplying these properties via the command-line for every Gradle invocation.
Providing these properties via the command line is intended for short-term testing and debugging purposes, but it’s prone to being forgotten or inconsistently applied across environments.
A permanent, idiomatic location to set and share these properties is in the gradle.properties file located in the root project directory.
This file should be added to source control in order to share these properties across different machines and between developers.
You should understand the default values of the properties your build uses and avoid explicitly setting properties to those defaults. Any change to a property’s default value in Gradle will follow the standard deprecation cycle, and users will be properly notified.
|
Note
|
Properties set this way are not inherited across build boundaries when using composite builds. |
Example
Don’t Do This
├── build.gradle.kts
└── settings.gradle.kts├── build.gradle
└── settings.gradletasks.register("first") {
doLast {
throw GradleException("First task failing as expected")
}
}
tasks.register("second") {
doLast {
logger.lifecycle("Second task succeeding as expected")
}
}
tasks.register("run") {
dependsOn("first", "second")
}tasks.register("first") {
doLast {
throw new GradleException("First task failing as expected")
}
}
tasks.register("second") {
doLast {
logger.lifecycle("Second task succeeding as expected")
}
}
tasks.register("run") {
dependsOn("first", "second")
}This build is run with gradle run -Dorg.gradle.continue=true, so that the failure of the first task does not prevent the second task from executing.
This relies on person running the build to remember to set this property, which is error prone and not portable across different machines and environments.
Do This Instead
├── build.gradle.kts
└── gradle.properties
└── settings.gradle.kts├── build.gradle
└── gradle.properties
└── settings.gradleorg.gradle.continue=trueThis build sets the org.gradle.continue property in the gradle.properties file.
Now it can be executed using only gradle run, and the continue property will always be set automatically across all environments.
Name Your Root Project
Always name your root project in the settings.gradle(.kts) file.
Explanation
While an empty settings.gradle(.kts) file is enough to create a multi-project build, you should always set the rootProject.name property.
By default, the root project’s name is taken from the directory containing the build. This can be problematic if the directory name contains spaces, Gradle logical path separators, or other special characters. It also makes task paths dependent on the directory name, rather than being reliably defined.
Explicitly setting the root project’s name ensures consistency across environments. Project names appear in error messages, logs, and reports, and builds often run on different machines, such as CI servers. Builds may execute on a variety of machines or environments, such as CI servers, and should report the same root project name anywhere to make the project more comprehensible.
Example
Don’t Do This
// Left empty// Left emptyIn this build, the settings file is empty and the root project has no explicit name.
Running the projects report shows that Gradle assigns an implicit name to the root project, derived from the build’s current directory.
Unfortunately that name varies based on where the project currently lives.
For example, if the project is checked out into a directory named some-directory-name, the output of ./gradlew projects will look like this:
> Task :projects
Projects:
------------------------------------------------------------
Root project 'some-directory-name'
------------------------------------------------------------Do This Instead
rootProject.name = "my-example-project"rootProject.name = "my-example-project"In this build, the root project is explicitly named.
The explicit name my-example-project will be used in all reports, logs, and error messages.
Regardless of where the project lives, the output of ./gradlew projects will look like this:
> Task :projects
Projects:
------------------------------------------------------------
Root project 'my-example-project'
------------------------------------------------------------
Project hierarchy:
Root project 'my-example-project'
No sub-projects
To see a list of the tasks of a project, run gradle <project-path>:tasks
For example, try running gradle :tasks
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executedDo not use gradle.properties in subprojects
Do not place a gradle.properties file inside subprojects to configure your build.
Explanation
Gradle allows gradle.properties files in both the root project and subprojects, but support for subproject properties is inconsistent.
Gradle itself and many popular plugins (such as the Android Gradle Plugin and Kotlin Gradle Plugin) do not reliably handle this pattern.
Using subproject gradle.properties files also makes it harder to understand and debug your build.
Property values may be scattered across multiple locations, overridden in unexpected ways, or difficult to trace back to their source.
If you need to set properties for a single subproject, define them directly in that subproject’s build.gradle(.kts).
If you need to apply properties across multiple subprojects, extract the configuration into a convention plugin.
Example
Don’t Do This
├── app
│ ├── ⋮
│ ├── build.gradle.kts
│ └── gradle.properties
├── utilities
│ ├── ⋮
│ ├── build.gradle.kts
│ └── gradle.properties
└── settings.gradle.kts├── app
│ ├── ⋮
│ ├── build.gradle
│ └── gradle.properties
├── utilities
│ ├── ⋮
│ ├── build.gradle
│ └── gradle.properties
└── settings.gradle# This file is located in /app
propertyA=fixedValue
propertyB=someValue// This file is located in /app
tasks.register("printProperties") { // (1)
val propA = project.findProperty("propertyA") // (2)
val propB = project.findProperty("propertyB")
doLast {
println("propertyA in app: $propA")
println("propertyB in app: $propB")
}
}// This file is located in /app
tasks.register("printProperties") { // (1)
def propA = project.findProperty("propertyA") // (2)
def propB = project.findProperty("propertyB")
doLast {
println "propertyA in app: $propA"
println "propertyB in app: $propB"
}
}# This file is located in /util
propertyA=fixedValue
propertyB=otherValue// This file is located in /util
tasks.register("printProperties") {
val propA = project.findProperty("propertyA")
val propB = project.findProperty("propertyB") // (3)
doLast {
println("propertyA in util: $propA")
println("propertyB in util: $propB")
}
}// This file is located in /util
tasks.register("printProperties") {
def propA = project.findProperty("propertyA")
def propB = project.findProperty("propertyB") // (3)
doLast {
println "propertyA in util: $propA"
println "propertyB in util: $propB"
}
}-
Register a task that uses the value of properties in each subproject.
-
The task reads properties, which are supplied by the project-local
app/gradle.propertiesfile.propertyAdoes not vary between subprojects. -
'util’s print task reads the properties which are supplied by
util/gradle.properties.propertyBvaries between subprojects.
This structure requires duplicating properties that are shared between subprojects and is not guaranteed to remain supported.
Do This Instead
├── buildSrc
│ └── ⋮
├── app
│ ├── ⋮
│ └── build.gradle.kts
├── utilities
│ ├── ⋮
│ └── build.gradle.kts
├── settings.gradle.kts
└── gradle.properties├── buildSrc
│ └── ⋮
├── app
│ ├── ⋮
│ └── build.gradle
├── utilities
│ ├── ⋮
│ └── build.gradle
├── settings.gradle
└── gradle.properties# This file is located in the root of the build
propertyA=fixedValue
propertyB=someValueimport org.gradle.api.provider.Property
interface ProjectProperties { // (1)
val propertyA: Property<String>
val propertyB: Property<String>
}import org.gradle.api.provider.Property
interface ProjectProperties { // (1)
Property<String> getPropertyA()
Property<String> getPropertyB()
}extensions.create<ProjectProperties>("myProperties") // (2)
tasks.register("printProperties") { // (3)
val myProperties = project.extensions.getByName("myProperties") as ProjectProperties
val projectName = project.name
doLast {
println("propertyA in ${projectName}: ${myProperties.propertyA.get()}")
println("propertyB in ${projectName}: ${myProperties.propertyB.get()}")
}
}extensions.create("myProperties", ProjectProperties) // (2)
tasks.register("printProperties") { // (3)
def myProperties = project.extensions.getByName("myProperties") as ProjectProperties
def projectName = project.name
doLast {
println("propertyA in ${projectName}: ${myProperties.propertyA.get()}")
println("propertyB in ${projectName}: ${myProperties.propertyB.get()}")
}
}// This file is located in /app
plugins { // (4)
id("project-properties")
}
myProperties { // (5)
propertyA = providers.gradleProperty("propertyA")
propertyB = providers.gradleProperty("propertyB")
}// This file is located in /app
plugins { // (4)
id "project-properties"
}
myProperties { // (5)
propertyA = providers.gradleProperty("propertyA")
propertyB = providers.gradleProperty("propertyB")
}// This file is located in /util
plugins {
id("project-properties")
}
myProperties {
propertyA = providers.gradleProperty("propertyA")
propertyB = "otherValue" // (6)
}// This file is located in /util
plugins {
id "project-properties"
}
myProperties {
propertyA = providers.gradleProperty("propertyA")
propertyB = "otherValue" // (6)
}-
Define a simple extension type in
buildSrcto hold property values. -
Register that property in a convention plugin.
-
Register tasks using property values in the convention plugin.
-
Apply the convention plugin in each subproject.
-
Set the extension’s property values in each subproject’s build script. This uses the values defined in the root
gradle.propertiesfile. The task reads values from the extension, not directly from the project properties. -
When values need to vary between subprojects, they can be set directly on the extension.
This structure uses an extension type to hold values, allowing properties to be strongly typed, and for property values and operations on properties to be defined in a single location. Overriding values per subproject remains straightforward.
Avoid afterEvaluate
Do not use project.afterEvaluate {} to configure tasks, wire properties, or react to plugin application.
Use lazy properties and pluginManager.withPlugin() instead.
Explanation
afterEvaluate registers a callback that runs after Gradle finishes evaluating and configuring a project.
It was historically used to "delay" reading a value until configuration was complete — for example, reading an extension property that users set at the bottom of their build script, or checking whether another plugin was applied.
This pattern is outdated, and problematic for several reasons:
-
Ordering is fragile. Multiple
afterEvaluatecallbacks execute in registration order. If two plugins or scripts both useafterEvaluate, one may see stale or incomplete configuration depending on which was registered first. This creates subtle bugs that are extremely difficult to diagnose. -
It defeats task configuration avoidance. Tasks registered or configured inside
afterEvaluateare touched eagerly during configuration, even if they will never execute. This may cause unnecessary work and slow down the configuration phase of the build. -
It is incompatible with the Configuration Cache.
afterEvaluatecallbacks capture mutable project state that cannot be serialized reliably.
Gradle’s lazy Property and Provider types solve the same underlying problem — deferring value resolution — without any of these drawbacks.
A Property<T> can be wired at configuration time but its value is resolved only when needed, typically during task execution.
This makes configuration order-independent and fully compatible with the configuration cache.
Similarly, pluginManager.withPlugin() reacts to plugin application safely and immediately, regardless of when the plugin is actually applied — no callback ordering to worry about.
When afterEvaluate may still be appropriate
There are narrow use cases where afterEvaluate remains the only available hook:
-
Fail-fast validation — verifying that required project configuration has been set and failing the build early with a clear error message.
-
Logging or reporting — printing diagnostic information about the project’s final configuration state.
Even in these cases, exercise caution: your afterEvaluate must be the last (or only) one registered to see the final configuration state.
If another plugin registers an afterEvaluate after yours, your callback may see incomplete configuration.
If you find yourself reaching for afterEvaluate because Gradle’s lazy APIs do not cover your use case, consider filing a bug.
afterEvaluate should be a last resort, not a first choice.
Example
Given the following project layout:
.
├── build.gradle.kts
├── buildSrc/
│ ├── build.gradle.kts
│ └── src/main/kotlin/
│ └── AppInfoPlugin.kt
└── settings.gradle.kts.
├── build.gradle
├── buildSrc/
│ ├── build.gradle
│ └── src/main/groovy/
│ └── AppInfoPlugin.groovy
└── settings.gradleDon’t Do This
The plugin uses afterEvaluate to delay reading the extension value and to check whether java-library was applied:
interface AppInfoExtension {
val appName: Property<String>
}
class AppInfoPlugin : Plugin<Project> {
override fun apply(project: Project) {
val extension = project.extensions.create("appInfo", AppInfoExtension::class.java)
project.afterEvaluate { // (1)
val name = extension.appName.getOrElse("unnamed") // (2)
tasks.register("printAppInfo") { // (3)
doLast {
println("App: $name")
}
}
if (plugins.hasPlugin("java-library")) { // (4)
tasks.named("printAppInfo") {
doLast {
println("Jar: $name.jar")
}
}
tasks.named("jar", Jar::class.java) {
archiveBaseName.set(name)
}
}
}
}
}interface AppInfoExtension {
Property<String> getAppName()
}
class AppInfoPlugin implements Plugin<Project> {
void apply(Project project) {
def extension = project.extensions.create("appInfo", AppInfoExtension)
project.afterEvaluate { // (1)
def name = extension.appName.getOrElse("unnamed") // (2)
project.tasks.register("printAppInfo") { // (3)
doLast {
println "App: $name"
}
}
if (project.plugins.hasPlugin("java-library")) { // (4)
project.tasks.named("printAppInfo") {
doLast {
println "Jar: ${name}.jar"
}
}
project.tasks.named("jar", Jar) {
archiveBaseName.set(name)
}
}
}
}
}-
The plugin’s
afterEvaluateruns before anyafterEvaluateregistered later in the build script — ordering depends on registration order. -
getOrElsereads the property’s current value immediately. If the value is set in a laterafterEvaluate, this will never see it. -
Registering a task inside
afterEvaluatedefeats task configuration avoidance. -
Checking plugin presence inside
afterEvaluateassumes all plugins have been applied before this callback runs.
The build script applies the plugin and sets the extension value in its own afterEvaluate:
plugins {
id("java-library")
id("app-info-plugin")
}
afterEvaluate {
the<AppInfoExtension>().appName.set("my-app") // (1)
}plugins {
id 'java-library'
id 'app-info-plugin'
}
afterEvaluate {
appInfo { // (1)
appName.set('my-app')
}
}-
This
afterEvaluateruns after the plugin’s — by the time it sets the name, the plugin has already captured the default value.
Running printAppInfo outputs unnamed — not my-app as the user intended:
> Task :printAppInfo
App: unnamed
Jar: unnamed.jar
BUILD SUCCESSFUL in 0s
5 actionable tasks: 5 executedThe plugin’s afterEvaluate callback was registered first (during Plugin.apply()) and ran first, reading the property before the build script’s afterEvaluate had a chance to set it.
Do This Instead
The proper way to write this plugin uses lazy Property types and pluginManager.withPlugin():
interface AppInfoExtension {
val appName: Property<String>
}
class AppInfoPlugin : Plugin<Project> {
override fun apply(project: Project) {
val extension = project.extensions.create("appInfo", AppInfoExtension::class.java)
extension.appName.convention("unnamed") // (1)
project.tasks.register("printAppInfo") {
val name = extension.appName
doLast {
println("App: ${name.get()}") // (2)
}
}
project.pluginManager.withPlugin("java-library") { // (3)
project.tasks.named("printAppInfo") {
val jarName = extension.appName
doLast {
println("Jar: ${jarName.get()}.jar")
}
}
project.tasks.named("jar", Jar::class.java) {
archiveBaseName.set(extension.appName)
}
}
}
}interface AppInfoExtension {
Property<String> getAppName()
}
class AppInfoPlugin implements Plugin<Project> {
void apply(Project project) {
def extension = project.extensions.create("appInfo", AppInfoExtension)
extension.appName.convention("unnamed") // (1)
project.tasks.register("printAppInfo") {
def name = extension.appName
doLast {
println "App: ${name.get()}" // (2)
}
}
project.pluginManager.withPlugin("java-library") { // (3)
project.tasks.named("printAppInfo") {
def jarName = extension.appName
doLast {
println "Jar: ${jarName.get()}.jar"
}
}
project.tasks.named("jar", Jar) {
archiveBaseName.set(extension.appName)
}
}
}
}-
convention()provides a default value that is used only if no explicit value is set viaset(). -
The value is resolved at execution time via
get()— configuration order does not matter. -
pluginManager.withPlugin()fires when the plugin is applied, regardless of order. If the plugin is never applied, the callback is never invoked.
The build script is nearly identical — the change is in the plugin, not the consumer:
plugins {
id("java-library")
id("app-info-plugin")
}
appInfo {
appName.set("my-app") // (1)
}plugins {
id 'java-library'
id 'app-info-plugin'
}
appInfo {
appName.set('my-app') // (1)
}-
The value is set during normal configuration. Because the plugin wires the
Propertylazily, it is only read at execution time.
Running printAppInfo now correctly outputs my-app:
$ gradlew printAppInfo
> Task :printAppInfo
App: my-app
Jar: my-app.jar
BUILD SUCCESSFUL in 0s
5 actionable tasks: 5 executedBest Practices for Structuring Builds
Modularize Your Builds
Modularize your builds by splitting your code into multiple projects.
Explanation
Splitting your build’s source into multiple Gradle projects (modules) is essential for leveraging Gradle’s automatic work avoidance and parallelization features. When a source file changes, Gradle only recompiles the affected projects. If all your sources reside in a single project, Gradle can’t avoid recompilation and won’t be able to run tasks in parallel. Splitting your source into multiple projects can provide additional performance benefits by minimizing each subproject’s compilation classpath and ensuring code generating tools such as annotation and symbol processors run only on the relevant files.
Do this soon. Don’t wait until you hit some arbitrary number of source files or classes to do this, instead structure your build into multiple projects from the start using whatever natural boundaries exist in your codebase.
Exactly how to best split your source varies with every build, as it depends on the particulars of that build. Here are some common patterns we found that can work well and make cohesive projects:
-
API vs. Implementation
-
Front-end vs. Back-end
-
Core business logic vs. UI
-
Vertical slices (e.g., feature modules each containing UI + business logic)
-
Inputs to source generation vs. their consumers
-
Or simply closely related classes.
Ultimately, the specific scheme matters less than ensuring that your build is split logically and consistently.
Expanding a build to hundreds of projects is common, and Gradle is designed to scale to this size and beyond. In the extreme, tiny projects containing only a class or two are probably counterproductive. However, you should typically err on the side of adding more projects rather than fewer.
Example
Don’t Do This
├── app // This project contains a mix of classes
│ ├── build.gradle.kts
│ └── src
│ └── main
│ └── java
│ └── org
│ └── example
│ └── CommonsUtil.java
│ └── GuavaUtil.java
│ └── Main.java
│ └── Util.java
├── settings.gradle.kts├── app // This project contains a mix of classes
│ ├── build.gradle
│ └── src
│ └── main
│ └── java
│ └── org
│ └── example
│ └── CommonsUtil.java
│ └── GuavaUtil.java
│ └── Main.java
│ └── Util.java
├── settings.gradleinclude("app") // (1)include("app") // (1)plugins {
application // (2)
}
dependencies {
implementation("com.google.guava:guava:31.1-jre") // (3)
implementation("commons-lang:commons-lang:2.6")
}
application {
mainClass = "org.example.Main"
}plugins {
id 'application' // (2)
}
dependencies {
implementation 'com.google.guava:guava:31.1-jre' // (3)
implementation 'commons-lang:commons-lang:2.6'
}
application {
mainClass = "org.example.Main"
}-
This build contains only a single project (in addition to the root project) that contains all the source code. If there is any change to any source file, Gradle will have to recompile and rebuild everything. While incremental compilation will help (especially in this simplified example) this is still less efficient then avoidance. Gradle also won’t be able to run any tasks in parallel, since all these tasks are in the same project, so this design won’t scale nicely.
-
As there is only a single project in this build, the
applicationplugin must be applied here. This means that theapplicationplugin will affect all source files in the build, even those which have no need for it. -
Likewise, the dependencies here are only needed by each particular implmentation of util. There’s no need for the implementation using Guava to have access to the Commons library, but it does because they are all in the same project. This also means that the classpath for each subproject is much larger than it needs to be, which can lead to longer build times and other confusion.
Do This Instead
├── app
│ ├── build.gradle.kts
│ └── src
│ └── main
│ └── java
│ └── org
│ └── example
│ └── Main.java
├── settings.gradle.kts
├── util
│ ├── build.gradle.kts
│ └── src
│ └── main
│ └── java
│ └── org
│ └── example
│ └── Util.java
├── util-commons
│ ├── build.gradle.kts
│ └── src
│ └── main
│ └── java
│ └── org
│ └── example
│ └── CommonsUtil.java
└── util-guava
├── build.gradle.kts
└── src
└── main
└── java
└── org
└── example
└── GuavaUtil.java├── app // App contains only the core application logic
│ ├── build.gradle
│ └── src
│ └── main
│ └── java
│ └── org
│ └── example
│ └── Main.java
├── settings.gradle
├── util // Util contains only the core utility logic
│ ├── build.gradle
│ └── src
│ └── main
│ └── java
│ └── org
│ └── example
│ └── Util.java
├── util-commons // One particular implementation of util, using Apache Commons
│ ├── build.gradle
│ └── src
│ └── main
│ └── java
│ └── org
│ └── example
│ └── CommonsUtil.java
└── util-guava // Another implementation of util, using Guava
├── build.gradle
└── src
└── main
└── java
└── org
└── example
└── GuavaUtil.javainclude("app") // (1)
include("util")
include("util-commons")
include("util-guava")include("app") // (1)
include("util")
include("util-commons")
include("util-guava")// This is the build.gradle file for the app module
plugins {
application // (2)
}
dependencies { // (3)
implementation(project(":util-guava"))
implementation(project(":util-commons"))
}
application {
mainClass = "org.example.Main"
}// This is the build.gradle file for the app module
plugins {
id "application" // (2)
}
dependencies { // (3)
implementation project(":util-guava")
implementation project(":util-commons")
}
application {
mainClass = "org.example.Main"
}// This is the build.gradle file for the util-commons module
plugins { // (4)
`java-library`
}
dependencies { // (5)
api(project(":util"))
implementation("commons-lang:commons-lang:2.6")
}// This is the build.gradle file for the util-commons module
plugins { // (4)
id "java-library"
}
dependencies { // (5)
api project(":util")
implementation "commons-lang:commons-lang:2.6"
}// This is the build.gradle file for the util-guava module
plugins {
`java-library`
}
dependencies {
api(project(":util"))
implementation("com.google.guava:guava:31.1-jre")
}// This is the build.gradle file for the util-guava module
plugins {
id "java-library"
}
dependencies {
api project(":util")
implementation "com.google.guava:guava:31.1-jre"
}-
This build logically splits the source into multiple projects. Each project can be built independently, and Gradle can run tasks in parallel. This means that if you change a single source file in one of the projects, Gradle will only need to recompile and rebuild that project, not the entire build.
-
The
applicationplugin is only applied to theappproject, which is the only project that needs it. -
Each project only adds the dependencies it needs. This means that the classpath for each subproject is much smaller, which can lead to faster build times and less confusion.
-
Each project only adds the specific plugins it needs.
-
Each project only adds the dependencies it needs. Projects can effectively use API vs. Implementation separation.
Do Not Put Source Files in the Root Project
Do not put source files in your root project; instead, put them in a separate project.
Explanation
The root project is a special Project in Gradle that serves as the entry point for your build.
It is the place to configure some settings and conventions that apply globally to the entire build, that are not configured via Settings. For example, you can declare (but not apply) plugins here to ensure the same plugin version is consistently available across all projects and define other configurations shared by all projects within the build.
|
Note
|
Be careful not to apply plugins unnecessarily in the root project - many plugins only affect source code and should only be applied to the projects that contain source code. |
The root project should not be used for source files, instead they should be located in a separate Gradle project.
Setting up your build like this from the start will also make it easier to add new projects as your build grows in the future.
Example
Don’t Do This
├── build.gradle.kts // Applies the `java-library` plugin to the root project
├── settings.gradle.kts
└── src // This directory shouldn't exist
└── main
└── java
└── org
└── example
└── MyClass1.java├── build.gradle // Applies the `java-library` plugin to the root project
├── settings.gradle
└── src // This directory shouldn't exist
└── main
└── java
└── org
└── example
└── MyClass1.javaplugins { // (1)
`java-library`
}plugins {
id 'java-library' // (1)
}-
The
java-libraryplugin is applied to the root project, as there are Java source files are in the root project.
Do This Instead
├── core
│ ├── build.gradle.kts // Applies the `java-library` plugin to only the `core` project
│ └── src // Source lives in a "core" (sub)project
│ └── main
│ └── java
│ └── org
│ └── example
│ └── MyClass1.java
└── settings.gradle.kts├── core
│ ├── build.gradle // Applies the `java-library` plugin to only the `core` project
│ └── src // Source lives in a "core" (sub)project
│ └── main
│ └── java
│ └── org
│ └── example
│ └── MyClass1.java
└── settings.gradleinclude("core") // (1)include("core") // (1)// This is the build.gradle.kts file for the core module
plugins { // (2)
`java-library`
}// This is the build.gradle file for the core module
plugins { // (2)
id 'java-library'
}-
The root project exists only to configure the build, informing Gradle of a (sub)project named
core. -
The
java-libraryplugin is only applied to thecoreproject, which contains the Java source files.
Favor build-logic Composite Builds for Build Logic
You should set up a Composite Build (often called an "included build") to hold your build logic—including any custom plugins, convention plugins, and other build-specific customizations.
Explanation
The preferred location for build logic is an included build (typically named build-logic), not in buildSrc.
The automatically available buildSrc is great for rapid prototyping, but it comes with some subtle disadvantages:
-
There are classloader differences in how these 2 approaches behave that can be surprising; included builds are treated just like external dependencies, which is a simpler mental model. Dependency resolution behaves subtly differently in
buildSrc. -
There can potentially be fewer task invalidations in a build when files in an included build are modified, leading to faster builds. Any change in
buildSrccauses the entire build to become out-of-date, whereas changes in a subproject of an included build only cause projects in the build using the products of that particular subproject to be out-of-date. -
Included builds are complete Gradle builds and can be opened, worked on, and built independently as standalone projects. It is straightforward to publish their products, including plugins, in order to share them with other projects.
-
The
buildSrcproject automatically applies thejavaplugin, which may be unnecessary.
One important caveat to this recommendation is when creating Settings plugins.
Defining these in a build-logic project requires it to be included in the pluginManagement block of the main build’s settings.gradle(.kts) file, in order to make these plugins available to the build early enough to be applied to the Settings instance.
This is possible, but reduces Build Caching capability, potentially impacting performance.
A better solution is to use a separate, minimal, included build (e.g. build-logic-settings) to hold only Settings plugins.
Another potential reason to use buildSrc is if you have a very large number of subprojects within your included build-logic.
Applying a different set of build-logic plugins to the subprojects in your including build will result in a different classpath being used for each.
This may have performance implications and make your build harder to understand.
Using different plugin combinations can cause features like Build Services to break in difficult to diagnose ways.
Ideally, there would be no difference between using buildSrc and an included build, as buildSrc is intended to behave like an implicitly available included build.
However, due to historical reasons, these subtle differences still exist.
As this changes, this recommendation may be revised in the future.
For now, these differences can introduce confusion.
Since setting up a composite build requires only minimal additional configuration, we recommend using it over buildSrc in most cases, especially for creating convention plugins.
Example
Don’t Do This
├── build.gradle.kts
├── buildSrc
│ ├── build.gradle.kts
│ └── src
│ └── main
│ └── java
│ └── org
│ └── example
│ ├── MyPlugin.java
│ └── MyTask.java
└── settings.gradle.kts├── build.gradle
├── buildSrc
│ ├── build.gradle
│ └── src
│ └── main
│ └── java
│ └── org
│ └── example
│ ├── MyPlugin.java
│ └── MyTask.java
└── settings.gradle// This file is located in /buildSrc
plugins {
`java-gradle-plugin`
}
gradlePlugin {
plugins {
create("myPlugin") {
id = "org.example.myplugin"
implementationClass = "org.example.MyPlugin"
}
}
}// This file is located in /buildSrc
plugins {
id "java-gradle-plugin"
}
gradlePlugin {
plugins {
create("myPlugin") {
id = "org.example.myplugin"
implementationClass = "org.example.MyPlugin"
}
}
}Set up a Plugin Build: This is the same using either method.
rootProject.name = "favor-composite-builds"rootProject.name = "favor-composite-builds"buildSrc products are automatically usable: There is no additional configuration with this method.
Do This Instead
├── build-logic
│ ├── plugin
│ │ ├── build.gradle.kts
│ │ └── src
│ │ └── main
│ │ └── java
│ │ └── org
│ │ └── example
│ │ ├── MyPlugin.java
│ │ └── MyTask.java
│ └── settings.gradle.kts
├── build.gradle.kts
└── settings.gradle.kts├── build-logic
│ ├── plugin
│ │ ├── build.gradle
│ │ └── src
│ │ └── main
│ │ └── java
│ │ └── org
│ │ └── example
│ │ ├── MyPlugin.java
│ │ └── MyTask.java
│ └── settings.gradle
├── build.gradle
└── settings.gradle// This file is located in /build-logic/plugin
plugins {
`java-gradle-plugin`
}
gradlePlugin {
plugins {
create("myPlugin") {
id = "org.example.myplugin"
implementationClass = "org.example.MyPlugin"
}
}
}// This file is located in /build-logic/plugin
plugins {
id "java-gradle-plugin"
}
gradlePlugin {
plugins {
create("myPlugin") {
id = "org.example.myplugin"
implementationClass = "org.example.MyPlugin"
}
}
}Set up a Plugin Build: This is the same using either method.
// This file is located in the root project
includeBuild("build-logic") // (1)
rootProject.name = "favor-composite-builds"// This file is located in the root project
includeBuild("build-logic") // (1)
rootProject.name = "favor-composite-builds"// This file is located in /build-logic
rootProject.name = "build-logic"
include("plugin") // (2)// This file is located in /build-logic
rootProject.name = "build-logic"
include("plugin") // (2)-
Composite builds must be explicitly included: Use the
includeBuildmethod to locate and include a build in order to use its products. -
Structure your included build into subprojects: This allows the main build to only depend on the necessary parts of the included build.
Avoid Unintentionally Creating Empty Projects
When using a hierarchical directory structure to organize your Gradle projects, make sure to avoid unintentionally creating empty projects in your build.
Explanation
When you use the Settings.include() method to include a project in your Grade settings file, you typically include projects by supplying the directory name like include("featureA").
This usage assumes that featureA is located at the root of your build.
You can include projects located in nested subdirectories by specifying their full project path using : as a separator between path segments.
For instance, if project search was located in a subdirectory named features, itself located in a subdirectory named subs, you could call include(":subs:features:search") to include it.
Nesting projects in a sensible hierarchical directory structure is common practice in larger Gradle builds. This approach helps organize large builds and improves comprehensibility, compared to placing all projects directly under the build’s root.
However, without further configuration, Gradle will create empty projects for each element in every hierarchical path, even if some of those directories do not contain actual Gradle projects.
In the example above, Gradle will create a project named :subs, a project named :subs:features, and a project named :subs:features:search.
This behavior is usually not intended, as you likely only want to include the search project.
Unused projects - even if empty - can surprise maintainers, clutter reports, and make your build harder to understand.
They also introduce unintended side effects.
If you use allprojects { … } or subprojects { … }, plugins and configuration blocks will apply to every project, including the empty ones.
This can degrade build performance.
Additionally, invoking tasks on deeply nested projects requires using the full project path, such as gradle :subs:features:search:build, instead of the shorter gradle :search:build.
To avoid these downsides when using a hierarchical project structure, you can provide a flat name when including the project and explicitly set the Project.projectDir property for any projects located in nested directories:
include(':my-web-module')
project(':my-web-module').projectDir = file("subs/web/my-web-module")This will prevent Gradle from creating empty projects for each element of the project’s path.
|
Note
|
Always use an identical logical project name and physical project location to avoid confusion.
Don’t include a project named :search and locate it at features/ui/default-search-toolbar, as this will lead to confusion about the location of the project.
Instead, locate this project at features/ui/search.
|
You should avoid unnecessarily deep directory structures.
For builds containing only a few projects, it’s usually better to keep the structure flat by placing all projects at the root of the build.
This eliminates the need to explicitly set projectDir.
Within the context of a particular build, the pathless project name should clearly indicate where the project is located.
You can also run the projects report for more information about the projects in your build and their locations.
If you find yourself facing ambiguity about project locations, consider simplifying the directory layout by flattening the structure, or using longer, more descriptive project names.
Example
Don’t Do This
├── settings.gradle.kts
├── app/ // (1)
│ ├── build.gradle.kts
│ └── src/
└── subs/ // (2)
└── web/ // (3)
├── my-web-module/ // (4)
├── src/
└── build.gradle.kts├── settings.gradle
├── app/ // (1)
│ ├── build.gradle
│ └── src/
└── subs/ // (2)
└── web/ // (3)
├── my-web-module/ // (4)
├── src/
└── build.gradle-
A project named
applocated at the root of the build -
A directory named
substhat is not intended to represent a Gradle project, but is used to organize the build -
Another organizational directory not intended to represent a Gradle project
-
A Gradle project named
my-web-modulethat should be included in the build
include(":app") // (1)
include(":subs:web:my-web-module") // (2)include(":app") // (1)
include(":subs:web:my-web-module") // (2)-
Including the
appproject located at the root of the build requires no additional configuration -
Including a project named
:subs:my-web-modulelocated in a nested subdirectory causes Gradle to create empty projects for each element of the path
> Task :projects
Projects:
------------------------------------------------------------
Root project 'avoidEmptyProjects-avoid'
------------------------------------------------------------
Location: /home/user/gradle/samples
Project hierarchy:
Root project 'avoidEmptyProjects-avoid'
+--- Project ':app'
\--- Project ':subs'
\--- Project ':subs:web'
\--- Project ':subs:web:my-web-module'
Project locations:
project ':app' - /app
project ':subs' - /subs
project ':subs:web' - /subs/web
project ':subs:web:my-web-module' - /subs/web/my-web-module
To see a list of the tasks of a project, run gradle <project-path>:tasks
For example, try running gradle :app:tasks
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executedThe output of running the projects report on the above build shows that Gradle created empty projects for :subs and :subs:web.
Do This Instead
include(":app")
include(":my-web-module")
project(":my-web-module").projectDir = file("subs/web/my-web-module") // (1)include(":app")
include(":my-web-module")
project(":my-web-module").projectDir = file("subs/web/my-web-module") // (1)-
After including the
:subs:web:my-web-moduleproject, itsprojectDirproperty is set to the physical location of the project
> Task :projects
Projects:
------------------------------------------------------------
Root project 'avoidEmptyProjects-do'
------------------------------------------------------------
Location: /home/user/gradle/samples
Project hierarchy:
Root project 'avoidEmptyProjects-do'
+--- Project ':app'
\--- Project ':my-web-module'
Project locations:
project ':app' - /app
project ':my-web-module' - /subs/web/my-web-module
To see a list of the tasks of a project, run gradle <project-path>:tasks
For example, try running gradle :app:tasks
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executedThe output of running the projects report on the above build shows that now Gradle only creates the intended projects for this build.
You can also now invoke tasks on the my-web-module project using the shorter name :my-web-module like gradle :my-web-module:build, instead of gradle :subs:web:my-web-module:build.
Use Convention Plugins for Common Build Logic
Use convention plugins to encapsulate and reuse shared build logic across multiple projects in your build.
Explanation
Instead of duplicating configuration across multiple build scripts, you can easily move common logic into a reusable convention plugins.
This approach offers several benefits:
-
Reduces duplication: Shared build logic lives in one place, making your build easier to understand.
-
Unlocks modularization: Convention plugins can apply other convention plugins, allowing you to orchestrate your build logic from small pieces.
-
Centralizes configuration: Updates to build behavior can be made in one file instead of many.
-
Keeps build files clean: Project build files stay focused on project-specific configuration.
-
Improves IDE support: IDEs can better understand and validate build logic when it is structured in plugins.
Convention plugins are quicker to create than typed binary plugins extending the Plugin class.
They are often a better choice for build logic that does not need to be shared outside a build, and that is simple enough to not require additional type safeness and testability benefits.
Unlike binary plugins, convention plugins allow accessing plugin extensions, tasks and configurations via static accessors in build scripts written in Kotlin.
While setting up convention plugins takes some initial effort, it pays off by simplifying maintenance, improving comprehensibility, and making it easier to add new projects as your codebase grows.
As mentioned in Favor build-logic Composite Builds for Build Logic, we recommend placing your convention plugins in an included build (often named build-logic) instead of buildSrc.
Example
Don’t Do This
plugins {
`java-library`
}
// Duplicated configuration across multiple build files
java {
sourceCompatibility = JavaVersion.VERSION_17
targetCompatibility = JavaVersion.VERSION_17
}
tasks.withType<JavaCompile>().configureEach {
options.encoding = "UTF-8"
options.compilerArgs.addAll(listOf("-Xlint:unchecked", "-Xlint:deprecation")) // (1)
}
tasks.test {
useJUnitPlatform()
maxParallelForks = (Runtime.getRuntime().availableProcessors() / 2).takeIf { it > 0 } ?: 1 // (2)
}
dependencies {
testImplementation("org.junit.jupiter:junit-jupiter:5.9.3") // (3)
}plugins {
`java-library`
}
// Duplicated configuration across multiple build files
java {
sourceCompatibility = JavaVersion.VERSION_17
targetCompatibility = JavaVersion.VERSION_17
}
tasks.withType<JavaCompile>().configureEach {
options.encoding = "UTF-8"
options.compilerArgs.addAll(listOf("-Xlint:unchecked", "-Xlint:deprecation")) // (1)
}
tasks.test {
useJUnitPlatform()
maxParallelForks = (Runtime.getRuntime().availableProcessors() / 2).takeIf { it > 0 } ?: 1 // (2)
}
dependencies {
testImplementation("org.junit.jupiter:junit-jupiter:5.9.3") // (3)
api("com.google.guava:guava:23.0") // (4)
}plugins {
id("java-library")
}
// Duplicated configuration across multiple build files
java {
sourceCompatibility = JavaVersion.VERSION_17
targetCompatibility = JavaVersion.VERSION_17
}
tasks.withType(JavaCompile).configureEach {
options.encoding = "UTF-8"
options.compilerArgs += ["-Xlint:unchecked", "-Xlint:deprecation"] // (1)
}
test {
useJUnitPlatform()
maxParallelForks = Runtime.runtime.availableProcessors().intdiv(2) ?: 1 // (2)
}
dependencies {
testImplementation("org.junit.jupiter:junit-jupiter:5.9.3") // (3)
}plugins {
id("java-library")
}
// Duplicated configuration across multiple build files
java {
sourceCompatibility = JavaVersion.VERSION_17
targetCompatibility = JavaVersion.VERSION_17
}
tasks.withType(JavaCompile).configureEach {
options.encoding = "UTF-8"
options.compilerArgs += ["-Xlint:unchecked", "-Xlint:deprecation"] // (1)
}
test {
useJUnitPlatform()
maxParallelForks = Runtime.runtime.availableProcessors().intdiv(2) ?: 1 // (2)
}
dependencies {
testImplementation("org.junit.jupiter:junit-jupiter:5.9.3") // (3)
api("com.google.guava:guava:23.0") // (4)
}-
Common compiler settings repeated across multiple projects.
-
Shared test configuration that must be maintained in multiple places.
-
Common dependencies that could be managed centrally.
-
Unique project dependencies.
Do This Instead
Create included build containing convention plugins for your build in build-logic and add it to your settings file:
pluginManagement {
includeBuild("build-logic") // (1)
}plugins {
`kotlin-dsl` // (2)
}pluginManagement {
includeBuild("build-logic") // (1)
}plugins {
id("groovy-gradle-plugin") // (2)
}-
Include the
build-logicbuild, which defines convention plugins. -
Enable the use of Kotlin DSL in
build-logic.
Create convention plugins for each type of project in build-logic:
plugins {
`java-library`
}
java { // (1)
sourceCompatibility = JavaVersion.VERSION_17
targetCompatibility = JavaVersion.VERSION_17
}
tasks.withType<JavaCompile>().configureEach {
options.encoding = "UTF-8"
options.compilerArgs.addAll(listOf("-Xlint:unchecked", "-Xlint:deprecation"))
}plugins { // (2)
id("my.base-java-library")
id("my.java-use-junit5")
}plugins {
`java-library`
}
tasks.withType<Test>().configureEach { // (3)
useJUnitPlatform()
maxParallelForks = (Runtime.getRuntime().availableProcessors() / 2).takeIf { it > 0 } ?: 1
}
dependencies {
testImplementation("org.junit.jupiter:junit-jupiter:5.9.3")
}plugins {
id("java-library")
}
java { // (1)
sourceCompatibility = JavaVersion.VERSION_17
targetCompatibility = JavaVersion.VERSION_17
}
tasks.withType(JavaCompile).configureEach {
options.encoding = "UTF-8"
options.compilerArgs += ["-Xlint:unchecked", "-Xlint:deprecation"]
}plugins { // (2)
id("my.base-java-library")
id("my.java-use-junit5")
}plugins {
id("java-library")
}
tasks.withType(Test).configureEach { // (3)
useJUnitPlatform()
maxParallelForks = Runtime.runtime.availableProcessors().intdiv(2) ?: 1
}
dependencies {
testImplementation("org.junit.jupiter:junit-jupiter:5.9.3")
}-
Default settings for a Java library plugin.
-
A convention plugin can apply other convention plugins.
-
JUnit 5 configuration moved to a convention plugin.
And apply these plugin in any build files to use the shared logic:
plugins {
id("my.java-library") // (6)
}plugins {
id("my.java-library") // (6)
}
dependencies {
api("com.google.guava:guava:23.0") // (7)
}plugins {
id("my.java-library") // (6)
}plugins {
id("my.java-library") // (6)
}
dependencies {
api("com.google.guava:guava:23.0") // (7)
}Best Practices for Dependencies
Use Version Catalogs to Centralize Dependency Versions
Version Catalogs provide a centralized, declarative way to manage dependency versions throughout a build.
Explanation
When you define your dependency versions in a single, shared version catalog, you reduce duplication and make upgrades easier.
Instead of changing dozens of build.gradle(.kts) files, you update the version in one place.
This simplifies maintenance, improves consistency, and reduces the risk of accidental version drift between modules.
Consistent version declarations across projects also make it easier to reason about behavior during testing—especially in modular builds where transitive upgrades can silently change runtime behavior in later stages of the build.
However, version catalogs only influence declared versions, not resolved versions. Use them in combination with dependency locking and version alignment to enforce consistency across builds. To influence resolved versions, check out platforms.
Example
Don’t Do This
Avoid declaring versions in project.ext, constants, or local variables:
plugins {
id("java-library")
id("com.github.ben-manes.versions").version("0.45.0")
}
val groovyVersion = "3.0.5"
dependencies {
api("org.codehaus.groovy:groovy:$groovyVersion")
api("org.codehaus.groovy:groovy-json:$groovyVersion")
api("org.codehaus.groovy:groovy-nio:$groovyVersion")
testImplementation("org.junit.jupiter:junit-jupiter:5.10.0")
implementation("org.apache.commons:commons-lang3") {
version {
strictly("[3.8, 4.0[")
prefer("3.9")
}
}
}plugins {
id('java-library')
id('com.github.ben-manes.versions').version('0.45.0')
}
def groovyVersion = '3.0.5'
dependencies {
api("org.codehaus.groovy:groovy:$groovyVersion")
api("org.codehaus.groovy:groovy-json:$groovyVersion")
api("org.codehaus.groovy:groovy-nio:$groovyVersion")
testImplementation("org.junit.jupiter:junit-jupiter:5.10.0")
implementation("org.apache.commons:commons-lang3") {
version {
strictly("[3.8, 4.0[")
prefer("3.9")
}
}
}Avoid misusing version catalogs for unrelated concerns:
-
Don’t use them to store shared strings or non-library constants
-
Don’t overload them with arbitrary logic or plugin-specific configuration
Do This Instead
Use a centralized libs.versions.toml file in your gradle/ directory:
[versions]
groovy = "3.0.5"
junit-jupiter = "5.10.0"
[libraries]
groovy-core = { module = "org.codehaus.groovy:groovy", version.ref = "groovy" }
groovy-json = { module = "org.codehaus.groovy:groovy-json", version.ref = "groovy" }
groovy-nio = { module = "org.codehaus.groovy:groovy-nio", version.ref = "groovy" }
commons-lang3 = { group = "org.apache.commons", name = "commons-lang3", version = { strictly = "[3.8, 4.0[", prefer = "3.9" } }
junit-jupiter = { module = "org.junit.jupiter:junit-jupiter", version.ref = "junit-jupiter" }
[bundles]
groovy = ["groovy-core", "groovy-json", "groovy-nio"]
[plugins]
versions = { id = "com.github.ben-manes.versions", version = "0.45.0" }plugins {
id("java-library")
alias(libs.plugins.versions)
}
dependencies {
api(libs.bundles.groovy)
testImplementation(libs.junit.jupiter)
implementation(libs.commons.lang3)
}plugins {
id('java-library')
alias(libs.plugins.versions)
}
dependencies {
api(libs.bundles.groovy)
testImplementation(libs.junit.jupiter)
implementation(libs.commons.lang3)
}Name Version Catalog Entries Appropriately
Consistent and descriptive names in your version catalog enhance readability and maintainability across your build scripts.
Explanation
Version catalogs provide a centralized way to manage dependencies by mapping full dependency coordinates to concise, reusable aliases like airlift-aircompressor.
Adopting clear naming conventions for those aliases ensures that developers can easily identify and use dependencies throughout the project.
Aliases are typically made up of 1 to 3 segments.
For example org.apache.commons:commons-lang3 could be represented as commonsLang3, apache-commonsLang3, or commons-lang3.
The following guidelines help in naming catalog entries effectively:
-
Use dashes to separate segments: Prefer hyphen/dashes (
-) over underscores (_) to separate different parts of the entry name.Example: For
org.apache.logging.log4j:log4j-api, uselog4j-api -
Derive the first segment from the project group: Use a unique identifier from the project’s group ID as the first segment. Do not include the top level domain in the segment (
com,org,net,dev).Example: For
com.fasterxml.jackson.core:jackson-databind, usejackson-databindorjackson-core-databind -
Derive the second segment from the artifact ID: Use a unique identifier from the artifact ID as the second segment.
Example: For
com.linecorp.armeria:armeria-grpc, usearmeria-grpc -
Avoid generic terms in the segments: Exclude terms that are obvious or implied in the context of your project (
core,java,gradle,module,sdk), especially if the term appears by itself.Example: For
com.google.googlejavaformat:google-java-format, usegoogle-java-format, notgoogle-javaorjava -
Omit redundant segments: If the group and artifact IDs are the same, avoid repeating them.
Example: For
io.ktor:ktor-client-core, usektor-client-core, notktor-ktor-client-core -
Convert internal dashes to camelCase: If the artifact ID contains dashes, convert them to camelCase for better readability in code.
Example:
spring-boot-starter-webbecomesspringBootStarterWeb -
Suffix plugin libraries with
-plugin: When referencing a plugin as a library (not in the[plugins]section), append-pluginto the name.Example: For
org.owasp:dependency-check-gradle, usedependency-check-plugin
Example
[versions]
slf4j = "2.0.13"
jackson = "2.17.1"
groovy = "3.0.5"
checkstyle = "8.37"
commonsLang = "3.9"
[libraries]
# SLF4J
slf4j-api = { module = "org.slf4j:slf4j-api", version.ref = "slf4j" }
# Jackson
jackson-databind = { module = "com.fasterxml.jackson.core:jackson-databind", version.ref = "jackson" }
jackson-dataformatCsv = { module = "com.fasterxml.jackson.dataformat:jackson-dataformat-csv", version.ref = "jackson" }
# Groovy bundle
groovy-core = { module = "org.codehaus.groovy:groovy", version.ref = "groovy" }
groovy-json = { module = "org.codehaus.groovy:groovy-json", version.ref = "groovy" }
groovy-nio = { module = "org.codehaus.groovy:groovy-nio", version.ref = "groovy" }
# Apache Commons Lang
commons-lang3 = { group = "org.apache.commons", name = "commons-lang3", version = { strictly = "[3.8, 4.0[", prefer = "3.9" } }
[bundles]
groovy = ["groovy-core", "groovy-json", "groovy-nio"]
[plugins]
versions = { id = "com.github.ben-manes.versions", version = "0.45.0" }plugins {
id("java-library")
alias(libs.plugins.versions)
}
repositories {
mavenCentral()
}
dependencies {
// SLF4J
implementation(libs.slf4j.api)
// Jackson
implementation(libs.jackson.databind)
implementation(libs.jackson.dataformatCsv)
// Groovy bundle
api(libs.bundles.groovy)
// Commons Lang
implementation(libs.commons.lang3)
}plugins {
id 'java-library'
alias(libs.plugins.versions)
}
repositories {
mavenCentral()
}
dependencies {
// SLF4J
implementation libs.slf4j.api
// Jackson
implementation libs.jackson.databind
implementation libs.jackson.dataformatCsv
// Groovy bundle
api libs.bundles.groovy
// Commons Lang
implementation libs.commons.lang3
}Set up your Dependency Repositories in the Settings file
Declare your repositories for your plugins and dependencies in settings.gradle.kts.
Explanation
Using settings.gradle.kts file to declare repositories has several benefits:
-
Avoids repetition: Centralizing repository declarations eliminates the need to repeat them in each project’s
build.gradle.kts. -
Improves debuggability: Ensures all projects resolve dependencies during resolution from the same repositories, in a consistent order.
-
Matches the build model: Repositories are not part of the project definition; they are part of global build logic, so settings is a more appropriate place for them.
|
Note
|
While dependencyResolutionManagement.repositories is an incubating API, it is the preferred way of declaring repositories.
|
Example
Don’t Do This
You could set up repositories in individual build.gradle.kts files with:
buildscript {
repositories {
mavenCentral()
gradlePluginPortal()
}
}
plugins {
id("java")
}
repositories {
mavenCentral()
}buildscript {
repositories {
mavenCentral()
gradlePluginPortal()
}
}
plugins {
id("java")
}
repositories {
mavenCentral()
}Do This Instead
Instead, you should set them up in settings.gradle.kts like this:
pluginManagement {
repositories {
mavenCentral()
gradlePluginPortal()
}
}
dependencyResolutionManagement {
repositoriesMode = RepositoriesMode.FAIL_ON_PROJECT_REPOS
repositories {
mavenCentral()
}
}pluginManagement {
repositories {
mavenCentral()
gradlePluginPortal()
}
}
dependencyResolutionManagement {
repositoriesMode = RepositoriesMode.FAIL_ON_PROJECT_REPOS
repositories {
mavenCentral()
}
}Don’t Explicitly Depend on the Kotlin Standard Library
The Kotlin Gradle Plugin automatically adds a dependency on the Kotlin standard library (stdlib) to each source set, so there is no need to declare it explicitly.
Explanation
The version of the standard library added is the same as the version of the Kotlin Gradle Plugin applied to the project. If your build does not require a specific or different version of the standard library, you should avoid adding it manually.
|
Note
|
Setting the kotlin.stdlib.default.dependency property to false prevents the Kotlin plugin from automatically adding the Kotlin standard library dependency to your project. This can be useful in specific scenarios, such as when you want to manage the Kotlin standard library dependency version manually.
|
Example
Don’t Do This
plugins {
kotlin("jvm").version("2.3.21")
}
dependencies {
api(kotlin("stdlib")) // (1)
}plugins {
id("org.jetbrains.kotlin.jvm") version "2.3.21"
}
dependencies {
api("org.jetbrains.kotlin:kotlin-stdlib:2.3.21") // (1)
}-
stdlibis explicitly depended upon: This project contains an implicit dependency on the Kotlin standard library, which is required to compile its source code.
Do This Instead
plugins {
kotlin("jvm").version("2.3.21") // (1)
}plugins {
id("org.jetbrains.kotlin.jvm") version "2.3.21" // (1)
}-
stdlibdependency is not included explicitly: The standard library remains available for use, and source code requiring it can be compiled without any issues.
Avoid Redundant Dependency Declarations
Avoid declaring the same dependency multiple times, especially when it is already available transitively or through another configuration.
Explanation
Duplicating dependencies in Gradle build scripts can lead to:
-
Increased maintenance: Declaring a dependency in multiple places makes it harder to manage.
-
Unexpected behavior: Declaring the same dependency in multiple configurations (e.g.,
compileOnlyandimplementation) can result in hard-to-diagnose classpath issues.
Example
Don’t Do This
plugins {
`java-library`
}
dependencies {
api("org.jetbrains.kotlinx:kotlinx-coroutines-core:1.10.0")
implementation("org.jetbrains.kotlinx:kotlinx-coroutines-core:1.10.0") // (1)
}plugins {
id 'java-library'
}
dependencies {
api("org.jetbrains.kotlinx:kotlinx-coroutines-core:1.10.0")
implementation("org.jetbrains.kotlinx:kotlinx-coroutines-core:1.10.0") // (1)
}-
Redundant dependency in
implementationscope.
Do This Instead
plugins {
`java-library`
}
dependencies {
api("org.jetbrains.kotlinx:kotlinx-coroutines-core:1.10.0") // (1)
}plugins {
id 'java-library'
}
dependencies {
api("org.jetbrains.kotlinx:kotlinx-coroutines-core:1.10.0") // (1)
}-
Declare dependency once
Declare Dependencies using a single GAV (group:artifact:version) String
When declaring dependencies without a version catalog, prefer using the single GAV string notation implementation("org.example:library:1.0").
Avoid using the named argument notation.
The named argument notation has been deprecated and will no longer be supported starting in Gradle 10.
Explanation
All of these declarations will be treated equivalently when Gradle resolves dependencies. However, the single-string form is more concise, easier to read, and is widely adopted in the broader JVM ecosystem.
This format is also recommended by Maven Central in its documentation and usage examples, making it the most familiar and consistent style for developers across tools.
Example
Don’t Do This
dependencies {
implementation(group = "com.fasterxml.jackson.core", name = "jackson-databind", version = "32.17.0") // (1)
api(group = "com.google.guava", name = "guava", version = "32.1.2-jre") {
exclude(group = "com.google.code.findbugs", module = "jsr305") // (2)
}
}dependencies {
implementation(group: 'com.fasterxml.jackson.core', name: 'jackson-databind', version: '2.17.0') // (1)
api(group: 'com.google.guava', name: 'guava', version: '32.1.2-jre') {
exclude(group: 'com.google.code.findbugs', module: 'jsr305') // (2)
}
}-
Avoid the named argument notation when declaring dependencies
-
Other modifiers methods and constraints like
excludeare not included in this recommendation and can use named argument notation as needed
Do This Instead
dependencies {
implementation("com.fasterxml.jackson.core:jackson-databind:2.17.0") // (1)
api("com.google.guava:guava:32.1.2-jre") {
exclude(group = "com.google.code.findbugs", module = "jsr305") // (2)
}
}dependencies {
implementation('com.fasterxml.jackson.core:jackson-databind:2.17.0') // (1)
api('com.google.guava:guava:32.1.2-jre') {
exclude(group: 'com.google.code.findbugs', module: 'jsr305') // (2)
}
}-
Use the string notation instead when declaring dependencies
-
Other modifiers methods and constraints like
excludeare not included in this recommendation and can use named argument notation as needed
Use Content Filtering with multiple Repositories
When using multiple repositories in a build, use repository content filtering to ensure that dependencies are resolved from an appropriate repository.
Explanation
If your build declares more than one repository, you should declare content filters on these repositories to ensure you search for and obtain dependencies from the correct place.
Content filtering is necessary if you have a reason to restrict searching for a dependency to a particular repository, and can be a good idea even if acceptable dependency artifacts exist in multiple locations.
When possible, you should use the exclusiveContent feature to restrict dependencies to a particular known repository.
Content filtering has three main benefits:
-
Performance, since you only query repositories for dependencies that should actually exist within them
-
Security, by avoiding asking potentially every repository for every dependency (even ones they shouldn’t contain), you improve resiliency to supply chain attacks by avoiding leaking information about your dependencies to other repositories, or even downloading potentially malicious artifacts
-
Reliability, by avoiding searching repositories that contain invalid or incorrect metadata for particular dependencies, which could result in obtaining incorrect transitive dependencies
Repositories will be searched for dependencies that pass their filters in the order they are declared. Often the last repository is declared without any filters in order to serve as a default fallback repository that is queried for any dependencies that don’t pass the filters present on the other repositories.
|
Warning
|
Carefully consider using content filtering with a fallback repository. This can pose a security risk, so make sure you fully trust the fallback repository. This setup can result in inadvertently (and silently) resolving dependencies from the fallback repository that were intended to come from filtered repositories if the dependencies were not available in those repositories. |
Example
Don’t Do This
Don’t add multiple repositories without content filtering:
dependencyResolutionManagement {
repositories {
mavenCentral()
google()
}
}dependencyResolutionManagement {
repositories {
mavenCentral()
google()
}
}Do This Instead
Use content filtering to ensure that the proper repositories are searched first for the expected artifacts:
dependencyResolutionManagement {
repositories {
google {
content {
// Use this repository for androidx and GMS dependencies
includeGroupByRegex("androidx.*")
includeGroup("com.google.gms")
}
}
// Specify the fallback repository last
mavenCentral()
}
}dependencyResolutionManagement {
repositories {
google {
content {
// Use this repository for androidx and GMS dependencies
includeGroupByRegex("androidx.*")
includeGroup("com.google.gms")
}
}
// Specify the fallback repository last
mavenCentral()
}
}In many cases, it is better to use exclusive content filtering, as it ensures that dependencies can only be found in the expected repository. If they are not present there, they will not be found at all.
dependencyResolutionManagement {
repositories {
exclusiveContent {
forRepository {
google()
}
filter {
// Only use this repository, and use this repository only, for androidx and GMS dependencies
includeGroupByRegex("androidx.*")
includeGroup("com.google.gms")
}
}
// Specify the fallback repository last
mavenCentral()
}
}dependencyResolutionManagement {
repositories {
exclusiveContent {
forRepository {
google()
}
filter {
// Only use this repository, and use this repository only, for androidx and GMS dependencies
includeGroupByRegex("androidx.*")
includeGroup("com.google.gms")
}
}
// Specify the fallback repository last
mavenCentral()
}
}Apply Exclusions Narrowly
When excluding transitive dependencies, apply exclusions as narrowly as possible.
Explanation
Sometimes you may need to exclude transitive dependencies that cause conflicts or issues in your project.
Exclusions can negatively affect dependency resolution performance. Applying exclusions as narrowly as possible minimizes this impact. It also reduces the risks of inadvertently and silently excluding dependencies that are required elsewhere in your build, and of accidental runtime dependency clashes.
Gradle offers several ways to exclude transitive dependencies. When excluding transitive dependencies, keep the scope as narrow as possible:
-
Attach exclusions to specific dependencies rather than applying them to an entire configuration.
-
Exclude a single
modulefrom agroup, instead of excluding the entiregroup. -
Avoid global exclusions using
configurations.all { … }orconfigurations.configureEach { … }.
Example
Don’t Do This
dependencies {
implementation("org.apache.commons:commons-pool2:2.12.1") // (1)
implementation("org.hibernate:hibernate-core:3.6.10.Final")
// ... other dependencies ...
}
configurations {
"implementation" {
exclude(group = "cglib") // (2)
}
"implementation" {
exclude(group = "org.ow2.asm", module = "asm-util") // (3)
}
}
configurations.configureEach {
exclude(group = "javassist", module = "javassist") // (4)
}dependencies {
implementation("org.apache.commons:commons-pool2:2.12.1") // (1)
implementation("org.hibernate:hibernate-core:3.6.10.Final")
// ... other dependencies ...
}
configurations {
implementation {
exclude(group: "cglib") // (2)
}
implementation {
exclude(group: "org.ow2.asm", module: "asm-util") // (3)
}
}
configurations.configureEach {
exclude(group: "javassist", module: "javassist") // (4)
}-
The
commons-pool2dependency transitively includescglib:cglibandorg.ow2.asm:asm-utilas optional dependencies - we want to exclude both.hibernate-coretransitively optionally includescglib:cglib, and alsojavaassist:javassist- we want to exclude both. -
This excludes every module provided by the
cglibgroup from every dependency in theimplementationconfiguration. If other current or future dependencies in this project rely on different modules fromcglib, those dependencies may fail to resolve, leading to compilation or runtime errors. -
This excludes
org.ow2.asm:asm-utilfrom every dependency in theimplementationconfiguration. If future dependencies rely onorg.ow2.asm:asm-util, they may fail at compile or runtime because the module will be silently excluded. -
This excludes
javaassist:javassistfrom all dependencies in all configurations, including those added by plugins or in the future, which carries the same risks as above, but on a larger scale.
Do This Instead
Exclude transitive dependencies as narrowly as possible, ideally on individual dependencies:
dependencies {
implementation("org.apache.commons:commons-pool2:2.12.1") { // (1)
exclude(group = "cglib", module = "cglib") // (2)
exclude(group = "org.ow2.asm", module = "asm-util")
}
implementation("org.hibernate:hibernate-core:3.6.10.Final") {
exclude(group = "cglib", module = "cglib")
exclude(group = "javassist", module = "javassist") // (3)
}
// ... other dependencies ...
}dependencies {
implementation("org.apache.commons:commons-pool2:2.12.1") { // (1)
exclude(group: "cglib", module: "cglib") // (2)
exclude(group: "org.ow2.asm", module: "asm-util")
}
implementation("org.hibernate:hibernate-core:3.6.10.Final") {
exclude(group: "cglib", module: "cglib")
exclude(group: "javassist", module: "javassist") // (3)
}
// ... other dependencies ...
}-
Exclusions are applied only to the dependency that actually transitively includes them.
-
All exclusions apply to a particular
moduleinstead of every module from a particulargroup. -
javaassist:javassistis only excluded from thehibernate-coredependency - the only dependency that transitively includes it.
Though it may seem repetitive to exclude the same transitive dependencies from multiple dependencies, this approach is safer, more performant, less likely to cause accidental runtime crashes, and makes it clearer which dependencies are affected by each exclusion.
Best Practices for Tasks
Avoid DependsOn
The task dependsOn method should only be used for lifecycle tasks (tasks without task actions).
Explanation
Tasks with actions should declare their inputs and outputs so that Gradle’s up-to-date checking can automatically determine when these tasks need to be run or rerun.
Using dependsOn to link tasks is a much coarser-grained mechanism that does not allow Gradle to understand why a task requires a prerequisite task to run, or which specific files from a prerequisite task are needed.
dependsOn forces Gradle to assume that every file produced by a prerequisite task is needed by this task.
This can lead to unnecessary task execution and decreased build performance.
Example
Here is a task that writes output to two separate files:
abstract class SimplePrintingTask : DefaultTask() {
@get:OutputFile
abstract val messageFile: RegularFileProperty
@get:OutputFile
abstract val audienceFile: RegularFileProperty
@TaskAction // (1)
fun run() {
messageFile.get().asFile.writeText("Hello")
audienceFile.get().asFile.writeText("World")
}
}
tasks.register<SimplePrintingTask>("helloWorld") { // (2)
messageFile.set(layout.buildDirectory.file("message.txt"))
audienceFile.set(layout.buildDirectory.file("audience.txt"))
}abstract class SimplePrintingTask extends DefaultTask {
@OutputFile
abstract RegularFileProperty getMessageFile()
@OutputFile
abstract RegularFileProperty getAudienceFile()
@TaskAction // (1)
void run() {
messageFile.get().asFile.write("Hello")
audienceFile.get().asFile.write("World")
}
}
tasks.register("helloWorld", SimplePrintingTask) { // (2)
messageFile = layout.buildDirectory.file("message.txt")
audienceFile = layout.buildDirectory.file("audience.txt")
}-
Task With Multiple Outputs:
helloWorldtask prints "Hello" to itsmessageFileand "World" to itsaudienceFile. -
Registering the Task:
helloWorldproduces "message.txt" and "audience.txt" outputs.
Don’t Do This
If you want to translate the greeting in the message.txt file using another task, you could do this:
abstract class SimpleTranslationTask : DefaultTask() {
@get:InputFile
abstract val messageFile: RegularFileProperty
@get:OutputFile
abstract val translatedFile: RegularFileProperty
init {
messageFile.convention(project.layout.buildDirectory.file("message.txt"))
translatedFile.convention(project.layout.buildDirectory.file("translated.txt"))
}
@TaskAction // (1)
fun run() {
val message = messageFile.get().asFile.readText(Charsets.UTF_8)
val translatedMessage = if (message == "Hello") "Bonjour" else "Unknown"
logger.lifecycle("Translation: " + translatedMessage)
translatedFile.get().asFile.writeText(translatedMessage)
}
}
tasks.register<SimpleTranslationTask>("translateBad") {
dependsOn(tasks.named("helloWorld")) // (2)
}abstract class SimpleTranslationTask extends DefaultTask {
@InputFile
abstract RegularFileProperty getMessageFile()
@OutputFile
abstract RegularFileProperty getTranslatedFile()
SimpleTranslationTask() {
messageFile.convention(project.layout.buildDirectory.file("message.txt"))
translatedFile.convention(project.layout.buildDirectory.file("translated.txt"))
}
@TaskAction // (1)
void run() {
def message = messageFile.get().asFile.text
def translatedMessage = message == "Hello" ? "Bonjour" : "Unknown"
logger.lifecycle("Translation: " + translatedMessage)
translatedFile.get().asFile.write(translatedMessage)
}
}
tasks.register("translateBad", SimpleTranslationTask) {
dependsOn(tasks.named("helloWorld")) // (2)
}-
Translation Task Setup:
translateBadrequireshelloWorldto run first to produce the message file otherwise it will fail with an error as the file does not exist. -
Explicit Task Dependency: Running
translateBadwill causehelloWorldto run first, but Gradle does not understand why.
Do This Instead
Instead, you should explicitly wire task inputs and outputs like this:
abstract class SimpleTranslationTask : DefaultTask() {
@get:InputFile
abstract val messageFile: RegularFileProperty
@get:OutputFile
abstract val translatedFile: RegularFileProperty
init {
messageFile.convention(project.layout.buildDirectory.file("message.txt"))
translatedFile.convention(project.layout.buildDirectory.file("translated.txt"))
}
@TaskAction // (1)
fun run() {
val message = messageFile.get().asFile.readText(Charsets.UTF_8)
val translatedMessage = if (message == "Hello") "Bonjour" else "Unknown"
logger.lifecycle("Translation: " + translatedMessage)
translatedFile.get().asFile.writeText(translatedMessage)
}
}
tasks.register<SimpleTranslationTask>("translateGood") {
inputs.file(tasks.named<SimplePrintingTask>("helloWorld").map { messageFile }) // (1)
}abstract class SimpleTranslationTask extends DefaultTask {
@InputFile
abstract RegularFileProperty getMessageFile()
@OutputFile
abstract RegularFileProperty getTranslatedFile()
SimpleTranslationTask() {
messageFile.convention(project.layout.buildDirectory.file("message.txt"))
translatedFile.convention(project.layout.buildDirectory.file("translated.txt"))
}
@TaskAction // (1)
void run() {
def message = messageFile.get().asFile.text
def translatedMessage = message == "Hello" ? "Bonjour" : "Unknown"
logger.lifecycle("Translation: " + translatedMessage)
translatedFile.get().asFile.write(translatedMessage)
}
}
tasks.register("translateGood", SimpleTranslationTask) {
inputs.file(tasks.named("helloWorld", SimplePrintingTask).map { messageFile }) // (1)
}-
Register Implicit Task Dependency:
translateGoodrequires only one of the files that is produced byhelloWorld.
Gradle now understands that translateGood requires helloWorld to have run successfully first because it needs to create the message.txt file which is then used by the translation task.
Gradle can use this information to optimize task scheduling.
Using the map method avoids eagerly retrieving the helloWorld task until the output is needed to determine if translateGood should run.
Favor @CacheableTask and @DisableCachingByDefault over cacheIf(Spec) and doNotCacheIf(String, Spec)
The cacheIf and doNotCacheIf methods should only be used in situations where the cacheability of a task varies between different task instances or cannot be determined until the task is executed by Gradle.
You should instead favor annotating the task class itself with @CacheableTask annotation for any task that is always cacheable.
Likewise, the @DisableCachingByDefault should be used to always disable caching for all instances of a task type.
Explanation
Annotating a task type will ensure that each task instance of that type is properly understood by Gradle to be cacheable (or not cacheable). This removes the need to remember to configure each of the task instances separately in build scripts.
Using the annotations also documents the intended cacheability of the task type within its own source, appearing in Javadoc and making the task’s behavior clear to other developers without requiring them to inspect each task instance’s configuration. It is also slightly more efficient than running a test to determine cacheability.
Remember that only tasks that produce reproducible and relocatable output should be marked as @CacheableTask.
Example
Don’t Do This
If you want to reuse the output of a task, you shouldn’t do this:
abstract class BadCalculatorTask : DefaultTask() { // (1)
@get:Input
abstract val first: Property<Int>
@get:Input
abstract val second: Property<Int>
@get:OutputFile
abstract val outputFile: RegularFileProperty
@TaskAction
fun run() {
val result = first.get() + second.get()
logger.lifecycle("Result: $result")
outputFile.get().asFile.writeText(result.toString())
}
}
tasks.register<Delete>("clean") {
delete(layout.buildDirectory)
}
tasks.register<BadCalculatorTask>("addBad1") {
first = 10
second = 25
outputFile = layout.buildDirectory.file("badOutput.txt")
outputs.cacheIf { true } // (2)
}
tasks.register<BadCalculatorTask>("addBad2") { // (3)
first = 3
second = 7
outputFile = layout.buildDirectory.file("badOutput2.txt")
}abstract class BadCalculatorTask extends DefaultTask {
@Input
abstract Property<Integer> getFirst()
@Input
abstract Property<Integer> getSecond()
@OutputFile
abstract RegularFileProperty getOutputFile()
@TaskAction
void run() {
def result = first.get() + second.get()
logger.lifecycle("Result: " + result)
outputFile.get().asFile.write(result.toString())
}
}
tasks.register("clean", Delete) {
delete layout.buildDirectory
}
tasks.register("addBad1", BadCalculatorTask) {
first = 10
second = 25
outputFile = layout.buildDirectory.file("badOutput.txt")
outputs.cacheIf { true }
}
tasks.register("addBad2", BadCalculatorTask) {
first = 3
second = 7
outputFile = layout.buildDirectory.file("badOutput2.txt")
}-
Define a Task: The
BadCalculatorTasktype is deterministic and produces relocatable output, but is not annotated. -
Mark the Task Instance as Cacheable: This example shows how to mark a specific task instance as cacheable.
-
Forget to Mark a Task Instance as Cacheable: Unfortunately, the
addBad2instance of theBadCalculatorTasktype is not marked as cacheable, so it will not be cached, despite behaving the same asaddBad1.
Do This Instead
As this task meets the criteria for cacheability (we can imagine a more complex calculation in the @TaskAction that would benefit from automatic work avoidance via caching), you should mark the task type itself as cacheable like this:
@CacheableTask // (1)
abstract class GoodCalculatorTask : DefaultTask() {
@get:Input
abstract val first: Property<Int>
@get:Input
abstract val second: Property<Int>
@get:OutputFile
abstract val outputFile: RegularFileProperty
@TaskAction
fun run() {
val result = first.get() + second.get()
logger.lifecycle("Result: $result")
outputFile.get().asFile.writeText(result.toString())
}
}
tasks.register<Delete>("clean") {
delete(layout.buildDirectory)
}
tasks.register<GoodCalculatorTask>("addGood1") { // (2)
first = 10
second = 25
outputFile = layout.buildDirectory.file("goodOutput.txt")
}
tasks.register<GoodCalculatorTask>("addGood2") {
first = 3
second = 7
outputFile = layout.buildDirectory.file("goodOutput2.txt")
}@CacheableTask // (1)
abstract class GoodCalculatorTask extends DefaultTask {
@Input
abstract Property<Integer> getFirst()
@Input
abstract Property<Integer> getSecond()
@OutputFile
abstract RegularFileProperty getOutputFile()
@TaskAction
void run() {
def result = first.get() + second.get()
logger.lifecycle("Result: " + result)
outputFile.get().asFile.write(result.toString())
}
}
tasks.register("clean", Delete) {
delete layout.buildDirectory
}
tasks.register("addGood1", GoodCalculatorTask) {
first = 10
second = 25
outputFile = layout.buildDirectory.file("goodOutput.txt")
}
tasks.register("addGood2", GoodCalculatorTask) { // (2)
first = 3
second = 7
outputFile = layout.buildDirectory.file("goodOutput2.txt")
}-
Annotate the Task Type: Applying the
@CacheableTaskto a task type informs Gradle that instances of this task should always be cached. -
Nothing Else Needs To Be Done: When we register task instances, nothing else needs to be done - Gradle knows to cache them.
Do not call get() on a Provider outside a Task action
When configuring tasks and extensions do not call get() on a provider, use map(), or flatMap() instead.
Explanation
A provider should be evaluated as late as possible.
Calling get() forces immediate evaluation, which can trigger unintended side effects, such as:
-
The value of the provider becomes an input to configuration, causing potential configuration cache misses.
-
The value may be evaluated too early, meaning you might not be using the final or correct value of the property. This may lead to painful and hard to debug ordering issues.
-
It breaks Gradle’s ability to build dependencies and to track task inputs and outputs, making automatic task dependency wiring impossible. See Working with task inputs and outputs
It is preferable to avoid explicitly evaluating a Provider at all, and deferring to map/flatMap to connect Providers to Providers implicitly.
Example
Here is a task that writes an input String to a file:
abstract class MyTask : DefaultTask() {
@get:Input
abstract val myInput: Property<String>
@get:OutputFile
abstract val myOutput: RegularFileProperty
@TaskAction
fun doAction() {
val outputFile = myOutput.get().asFile
val outputText = myInput.get() // (1)
println(outputText)
outputFile.writeText(outputText)
}
}
val currentEnvironment: Provider<String> = providers.gradleProperty("currentEnvironment").orElse("234") // (2)abstract class MyTask extends DefaultTask {
@Input
abstract Property<String> getMyInput()
@OutputFile
abstract RegularFileProperty getMyOutput()
@TaskAction
void doAction() {
def outputFile = myOutput.get().asFile
def outputText = myInput.get() // (1)
println(outputText)
outputFile.write(outputText)
}
}
Provider<String> currentEnvironment = providers.gradleProperty("currentEnvironment").orElse("234") // (2)-
Using
Provider.get()in the task action -
Gradle property that we wish to use as input
Don’t Do This
You could call get() at configuration time to set up this task:
tasks.register<MyTask>("avoidThis") {
myInput = "currentEnvironment=${currentEnvironment.get()}" // (1)
myOutput = layout.buildDirectory.get().asFile.resolve("output-avoid.txt") // (2)
}tasks.register("avoidThis", MyTask) {
myInput = "currentEnvironment=${currentEnvironment.get()}" // (1)
myOutput = new File(layout.buildDirectory.get().asFile, "output-avoid.txt") // (2)
}-
Reading the value of
currentEnvironmentat configuration time: This value might change by the time the task start executing. -
Reading the value of
buildDirectoryat configuration time: This value might change by the time the task start executing.
Do This Instead
Instead, you should explicitly wire task inputs and outputs like this:
tasks.register<MyTask>("doThis") {
myInput = currentEnvironment.map { "currentEnvironment=$it" } // (1)
myOutput = layout.buildDirectory.file("output-do.txt") // (2)
}tasks.register("doThis", MyTask) {
myInput = currentEnvironment.map { "currentEnvironment=$it" } // (1)
myOutput = layout.buildDirectory.file("output-do.txt") // (2)
}-
Using
map()to transformcurrentEnvironment:maptransform runs only when the value is read. -
Using
file()to create a newProvider<RegularFile>: the value of thebuildDirectoryis only checked when the value of the provider is read.
Group and Describe custom Tasks
When defining custom task types or registering ad-hoc tasks, always set a clear group and description.
Explanation
A good group name is short, lowercase, and reflects the purpose or domain of the task.
For example: documentation, verification, release, or publishing.
Before creating a new group, look for an existing group name that aligns with your task’s intent. It’s often better to reuse an established category to keep the task output organized and familiar to users.
This information is used in the Tasks Report (shown via ./gradlew tasks) to group and describe available tasks in a readable format.
Providing a group and description ensures that your tasks are:
-
Displayed clearly in the report
-
Categorized appropriately
-
Understandable to other users (and to your future self)
|
Note
|
Tasks with no group are hidden from the Tasks Report unless --all is specified.
|
Example
Don’t Do This
Tasks without a group appear under the "other" category in ./gradlew tasks --all output, making them harder to locate:
tasks.register("generateDocs") {
// Build logic to generate documentation
}tasks.register('generateDocs') {
// Build logic to generate documentation
}$ gradlew :app:tasks --all
> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
Other tasks
-----------
compileJava - Compiles main Java source.
compileTestJava - Compiles test Java source.
generateDocs
processResources - Processes main resources.
processTestResources - Processes test resources.
startScripts - Creates OS specific scripts to run the project as a JVM application.Do this Instead
When defining custom tasks, always assign a clear group and description:
tasks.register("generateDocs") {
group = "documentation"
description = "Generates project documentation from source files."
// Build logic to generate documentation
}tasks.register('generateDocs') {
group = 'documentation'
description = 'Generates project documentation from source files.'
// Build logic to generate documentation
}$ gradlew :app:tasks --all
> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
Documentation tasks
-------------------
generateDocs - Generates project documentation from source files.
javadoc - Generates Javadoc API documentation for the 'main' feature.Avoid using eager APIs on File Collections
When working with Gradle’s file collection types, be careful to avoid triggering dependency resolution during the configuration phase.
Explanation
Gradle’s Configuration and FileCollection types extend the JDK’s Collection<File> interface.
However, calling some available methods from this interface—such as .size(), .isEmpty(), getFiles(), asPath(), or .toList()—on these Gradle types will implicitly trigger resolution of their dependencies.
The same is possible using Kotlin stdlib collection extension methods or Groovy GDK collection extensions.
Converting a Configuration to a Set<File> also discards any implicit task dependencies it carries.
You should avoid using these methods when configuring your build. Instead, use the methods defined directly on the Gradle interfaces - this is a necessary first step towards preventing eager resolutions. Be sure to use lazy types and APIs that defer resolution to wire task dependencies and inputs correctly. Some methods that cause resolution are not obvious. Be sure to check the actual behavior when using configurations in an atypical way.
Example
Don’t Do This
abstract class FileCounterTask: DefaultTask() {
@get:InputFiles
abstract val countMe: ConfigurableFileCollection
@TaskAction
fun countFiles() {
logger.lifecycle("Count: " + countMe.files.size)
}
}
tasks.register<FileCounterTask>("badCountingTask") {
if (!configurations.runtimeClasspath.get().isEmpty()) { // (1)
logger.lifecycle("Resolved: " + (configurations.runtimeClasspath.get().state == RESOLVED))
countMe.from(configurations.runtimeClasspath)
}
}
tasks.register<FileCounterTask>("badCountingTask2") {
val files = configurations.runtimeClasspath.get().files // (2)
countMe.from(files)
logger.lifecycle("Resolved: " + (configurations.runtimeClasspath.get().state == RESOLVED))
}
tasks.register<FileCounterTask>("badCountingTask3") {
val files = configurations.runtimeClasspath.get() + layout.projectDirectory.file("extra.txt") // (3)
countMe.from(files)
logger.lifecycle("Resolved: " + (configurations.runtimeClasspath.get().state == RESOLVED))
}
tasks.register<Zip>("badZippingTask") { // (4)
if (!configurations.runtimeClasspath.get().isEmpty()) {
logger.lifecycle("Resolved: " + (configurations.runtimeClasspath.get().state == RESOLVED))
from(configurations.runtimeClasspath)
}
}abstract class FileCounterTask extends DefaultTask {
@InputFiles
abstract ConfigurableFileCollection getCountMe();
@TaskAction
void countFiles() {
logger.lifecycle("Count: " + countMe.files.size())
}
}
tasks.register("badCountingTask", FileCounterTask) {
if (!configurations.runtimeClasspath.isEmpty()) { // (1)
logger.lifecycle("Resolved: " + (configurations.runtimeClasspath.state == RESOLVED))
countMe.from(configurations.runtimeClasspath)
}
}
tasks.register("badCountingTask2", FileCounterTask) {
def files = configurations.runtimeClasspath.files // (2)
countMe.from(files)
logger.lifecycle("Resolved: " + (configurations.runtimeClasspath.state == RESOLVED))
}
tasks.register("badCountingTask3", FileCounterTask) {
def files = configurations.runtimeClasspath + layout.projectDirectory.file("extra.txt") // (3)
countMe.from(files)
logger.lifecycle("Resolved: " + (configurations.runtimeClasspath.state == RESOLVED))
}
tasks.register("badZippingTask", Zip) { // (4)
if (!configurations.runtimeClasspath.isEmpty()) {
logger.lifecycle("Resolved: " + (configurations.runtimeClasspath.state == RESOLVED))
from(configurations.runtimeClasspath)
}
}-
isEmpty()causes resolution: Many seemingly harmless Collection API methods likeisEmpty()cause Gradle to resolve dependencies. -
Accessing files directly: Using
getFiles()to access the files in aConfigurationwill also cause Gradle to resolve the file collection. -
Adding a file via plus operator: Using the plus operator will force the
runtimeClasspathconfiguration to be resolved implicitly. The implementation ofConfigurationdoesn’t override the plus operator for regular files, therefore it falls back to using the eager API, which causes resolution. -
Be careful with indirect inputs: Some built-in tasks, for example subtypes of
AbstractCopyTasklikeZip, allow adding inputs indirectly and can have the same problems.
Do This Instead
To avoid issues, always defer resolution until the execution phase. Use APIs that support lazy evaluation.
abstract class FileCounterTask: DefaultTask() {
@get:InputFiles
abstract val countMe: ConfigurableFileCollection
@TaskAction
fun countFiles() {
logger.lifecycle("Count: " + countMe.files.size)
}
}
tasks.register<FileCounterTask>("goodCountingTask") {
countMe.from(configurations.runtimeClasspath) // (1)
countMe.from(layout.projectDirectory.file("extra.txt"))
logger.lifecycle("Resolved: " + (configurations.runtimeClasspath.get().state == RESOLVED))
}abstract class FileCounterTask extends DefaultTask {
@InputFiles
abstract ConfigurableFileCollection getCountMe();
@TaskAction
void countFiles() {
logger.lifecycle("Count: " + countMe.files.size())
}
}
tasks.register("goodCountingTask", FileCounterTask) {
countMe.from(configurations.runtimeClasspath) // (1)
countMe.from(layout.projectDirectory.file("extra.txt")) // (2)
logger.lifecycle("Resolved: " + (configurations.runtimeClasspath.state == RESOLVED))
}-
Add configurations to Task properties or Specs directly: This will defer resolution until the task is executed.
-
Add files to Specs separately: This allows combining files with file collections without triggering implicit resolutions.
Don’t resolve Configurations before Task Execution
Resolving configurations before the task execution phase can lead to incorrect results and slower builds.
Explanation
Resolving a configuration - either directly via calling its resolve() method or indirectly via accessing its set of artifacts - returns a set of files that does not preserve references to the tasks that produced those files.
Configurations are file collections and can be added to @InputFiles properties on other tasks.
It is important to do this correctly to avoid breaking automatic task dependency wiring between a consumer task and any tasks that are implicitly required to produce the artifacts being consumed.
For example, if a configuration contains a project dependency, Gradle knows that consumers of the configuration must first run any tasks that produce that project’s artifacts.
In addition to correctness concerns, resolving configurations during the configuration phase can slow down the build, even when running unrelated tasks (e.g., help) that don’t require the resolved dependencies.
Example
Don’t Do This
dependencies {
runtimeOnly(project(":lib")) // (1)
}
abstract class BadClasspathPrinter : DefaultTask() {
@get:InputFiles
var classpath: Set<File> = emptySet() // (2)
private fun calculateDigest(fileOrDirectory: File): Int {
require(fileOrDirectory.exists()) { "File or directory $fileOrDirectory doesn't exist" }
return 0 // actual implementation is stripped
}
@TaskAction
fun run() {
logger.lifecycle(
classpath.joinToString("\n") {
val digest = calculateDigest(it) // (3)
"$it#$digest"
}
)
}
}
tasks.register("badClasspathPrinter", BadClasspathPrinter::class) {
classpath = configurations.named("runtimeClasspath").get().resolve() // (4)
}dependencies {
runtimeOnly(project(":lib")) // (1)
}
abstract class BadClasspathPrinter extends DefaultTask {
@InputFiles
Set<File> classpath = [] as Set // (2)
protected int calculateDigest(File fileOrDirectory) {
if (!fileOrDirectory.exists()) {
throw new IllegalArgumentException("File or directory $fileOrDirectory doesn't exist")
}
return 0 // actual implementation is stripped
}
@TaskAction
void run() {
logger.lifecycle(
classpath.collect { file ->
def digest = calculateDigest(file) // (3)
"$file#$digest"
}.join("\n")
)
}
}
tasks.register("badClasspathPrinter", BadClasspathPrinter) {
classpath = configurations.named("runtimeClasspath").get().resolve() // (4)
}-
Add project dependency: The
:libproject must be built in order to resolve the runtime classpath successfully. -
Declare input property as Set of files: A simple
Setinput doesn’t track task dependencies. -
Dependency artifacts are used to calculate digest: Artifacts from the already resolved classpath are used to calculate the digest.
-
Resolve runtimeClasspath: The implicit task dependency on
:library:jartask is lost here when the configuration is resolved prior to task execution. Thelibproject will not be built when the:app:badClasspathPrintertask is run, leading to a failure incalculateDigestbecause thelib.jarfile will not exist.
Do This Instead
To avoid issues, always defer resolution to the execution phase by using lazy APIs like FileCollection.
dependencies {
runtimeOnly(project(":lib")) // (1)
}
abstract class GoodClasspathPrinter : DefaultTask() {
@get:InputFiles
abstract val classpath: ConfigurableFileCollection // (2)
private fun calculateDigest(fileOrDirectory: File): Int {
require(fileOrDirectory.exists()) { "File or directory $fileOrDirectory doesn't exist" }
return 0 // actual implementation is stripped
}
@TaskAction
fun run() {
logger.lifecycle(
classpath.joinToString("\n") {
val digest = calculateDigest(it) // (3)
"$it#$digest"
}
)
}
}
tasks.register("goodClasspathPrinter", GoodClasspathPrinter::class.java) {
classpath.from(configurations.named("runtimeClasspath")) // (4)
}dependencies {
runtimeOnly(project(":lib")) // (1)
}
abstract class GoodClasspathPrinter extends DefaultTask {
@InputFiles
abstract ConfigurableFileCollection getClasspath() // (2)
protected int calculateDigest(File fileOrDirectory) {
if (!fileOrDirectory.exists()) {
throw new IllegalArgumentException("File or directory $fileOrDirectory doesn't exist")
}
return 0 // actual implementation is stripped
}
@TaskAction
void run() {
logger.lifecycle(
classpath.collect { file ->
def digest = calculateDigest(file) // (3)
"$file#$digest"
}.join("\n")
)
}
}
tasks.register("goodClasspathPrinter", GoodClasspathPrinter) {
classpath.from(configurations.named("runtimeClasspath")) // (4)
}-
Write to a file in the output directory: This is the same.
-
Declare input files property as ConfigurableFileCollection: This lazy collection type will track task dependencies.
-
Dependency artifacts are resolved to calculate digest: The classpath will be resolved at execution time to calculate the digest.
-
Configuration is passed to input property directly: Using
fromcauses the configuration to be lazily wired to the input proeprty. The configuration will be resolved when necessary, preserving task dependencies. The output reveals that thelibproject is now built when the:app:goodClasspathPrintertask is run because of the implicit task dependency, and thelib.jarfile is found when calculating the digest.
Use @PathSensitivity.NONE for file inputs and @PathSensitivity.RELATIVE for directories
Use @PathSensitivity.NONE for file inputs and @PathSensitivity.RELATIVE for directory inputs.
Explanation
Tasks should generally care about the contents of their input files, not their location on disk.
When annotating file-based input properties (for example, @InputFile or @InputFiles collections), use @PathSensitivity.NONE.
This tells Gradle to ignore the path and only consider the file contents when determining whether a task is up-to-date.
For directory-based inputs (for example, @InputDirectory or @InputFiles collections), use @PathSensitivity.RELATIVE.
This tells Gradle to also consider only the name of the directory (ignoring its absolute location) and to relativize the paths of all files within that directory to it when doing up-to-date checks.
Using PathSensitivity.NAME_ONLY or @PathSensitivity.ABSOLUTE is generally incorrect.
PathSensitivity.NAME_ONLY tells Gradle to consider a file’s name in addition to its contents, which is rarely useful.
@PathSensitivity.ABSOLUTE tells Gradle to consider a file’s complete absolute path.
This prevents Build Cache and Configuration Cache hits across different machines or checkout locations, making your build non-relocatable.
It can also lead to confusing behavior where the same build produces different task outcomes when run from different directories.
If no @PathSensitive annotation is provided, PathSensitivity.ABSOLUTE is the default.
Example
Don’t Do This
abstract class AnimalSearchTask : DefaultTask() {
@get:Input
abstract val find: Property<String>
@get:InputFile
@get:PathSensitive(PathSensitivity.ABSOLUTE) // (1)
abstract val candidatesFile: RegularFileProperty
@get:OutputFile
abstract val resultsFile: RegularFileProperty
@TaskAction
fun search() {
if (candidatesFile.get().getAsFile().readLines().contains(find.get())) {
val msg = "Found a " + find.get() + "!"
getLogger().lifecycle(msg)
resultsFile.get().asFile.writeText(msg)
}
}
}
val useAlternateInput = providers.gradleProperty("useAlternateInput").isPresent()
val copyTask = tasks.register<Copy>("copy") {
from(layout.projectDirectory.file("candidates.txt"))
destinationDir = (if (useAlternateInput) { layout.buildDirectory.dir("alternateSearchInput") } else { layout.buildDirectory.dir("searchInput") }).get().asFile
}
tasks.register<AnimalSearchTask>("search") {
find = "cat"
candidatesFile.fileProvider(copyTask.map { File(it.destinationDir, "candidates.txt") })
resultsFile = layout.buildDirectory.file("searchOutput/results.txt")
dependsOn(copyTask)
}abstract class AnimalSearchTask extends DefaultTask {
@Input
abstract Property<String> getFind()
@InputFile
@PathSensitive(PathSensitivity.ABSOLUTE) // (1)
abstract RegularFileProperty getCandidatesFile()
@OutputFile
abstract RegularFileProperty getResultsFile()
@TaskAction
void search() {
if (candidatesFile.get().getAsFile().readLines().contains(find.get())) {
def msg = "Found a " + find.get() + "!"
getLogger().lifecycle(msg)
resultsFile.get().asFile.text = msg
}
}
}
def useAlternateInput = providers.gradleProperty("useAlternateInput").isPresent()
def copyTask = tasks.register("copy", Copy) {
from(layout.projectDirectory.file("candidates.txt"))
destinationDir = (useAlternateInput ? layout.buildDirectory.dir("alternateSearchInput") : layout.buildDirectory.dir("searchInput")).get().asFile // (2)
}
tasks.register("search", AnimalSearchTask) {
find = "cat"
candidatesFile.fileProvider(copyTask.map { new File(it.destinationDir, "candidates.txt") }) // (3)
resultsFile = layout.buildDirectory.file("searchOutput/results.txt")
dependsOn(copyTask)
}-
The
AnimalSearchTasktask type uses a file input property annotated with@PathSensitivity.ABSOLUTE. This means that the absolute path of the input file is used to determine if the task isUP-TO-DATEor if it can be loaded from cache. Yet the path is irrelevant for the operation of the task’s@TaskAction, which only cares about file contents. -
The
copytask will move the exact samecandidates.txtto different destination directories, depending on if theuseAlternateInputproject property is set. -
The
searchtask is wired to use as input whatever the file thecopytask moved to itsdestinationDir. Despite the contents of the file being the same, when enabling the-PuseAlternateInputafter a successful build, thesearchtask will be out-of-date due to its different directory, and the search will be rerun.
Do this Instead
@get:InputFile
@get:PathSensitive(PathSensitivity.NONE) // (1)
abstract val candidatesFile: RegularFileProperty@InputFile
@PathSensitive(PathSensitivity.NONE) // (1)
abstract RegularFileProperty getCandidatesFile()-
Everything remains the same, except that the input property is now annotated with
@PathSensitivity.NONE. Only the contents of this input file matter to this task. When thesearchtask is rerun with-PuseAlternateInput, it remainsUP-TO-DATE.
Use unique output files and directories
Overlapping output files or directories cause tasks to rerun unnecessarily and waste work.
Explanation
Gradle tracks all output files and directories declared by tasks to decide whether a task needs to be rerun. For example, if the contents of a task’s output directory change after its last execution, Gradle will rerun that task.
Ensuring that each task uses its own unique output files and directories, both within a project and across the entire build, prevents unnecessary work.
Example
Don’t Do This
abstract class GreetingTask : DefaultTask() {
@get:Input
abstract val type: Property<String>
@get:OutputDirectory
abstract val outputDirectory: DirectoryProperty
@TaskAction
fun run() {
val outFileName = type.get() + ".txt"
val message = "Hello " + type.get()
outputDirectory.file(outFileName).get().asFile.writeText(message) // (1)
}
}
abstract class ConsumerTask : DefaultTask() {
@get:InputDirectory
abstract val inputDirectory: DirectoryProperty
@get:OutputFile
abstract val outputFile: RegularFileProperty
@TaskAction
fun run() {
val message = inputDirectory.get().file("a.txt").asFile.readText() // (2)
outputFile.get().asFile.writeText(message)
}
}
val greeterA = tasks.register<GreetingTask>("greeterA") {
type = "a"
outputDirectory = layout.buildDirectory.dir("greetings") // (3)
}
tasks.register<GreetingTask>("greeterB") {
type = "b"
outputDirectory = layout.buildDirectory.dir("greetings") // (4)
}
tasks.register<ConsumerTask>("consumer") {
inputDirectory = greeterA.flatMap { it.outputDirectory } // (5)
outputFile = layout.buildDirectory.file("consumerOutput.txt")
}abstract class GreetingTask extends DefaultTask {
@Input
abstract Property<String> getType()
@OutputDirectory
abstract DirectoryProperty getOutputDirectory()
@TaskAction
void run() {
def outFileName = type.get() + ".txt"
def message = "Hello " + type.get()
outputDirectory.file(outFileName).get().asFile.text = message // (1)
}
}
abstract class ConsumerTask extends DefaultTask {
@InputDirectory
abstract DirectoryProperty getInputDirectory()
@OutputFile
abstract RegularFileProperty getOutputFile()
@TaskAction
void run() {
def message = inputDirectory.get().file("a.txt").asFile.text // (2)
outputFile.get().asFile.write(message)
}
}
def greeterA = tasks.register("greeterA", GreetingTask) {
type = "a"
outputDirectory = layout.buildDirectory.dir("greetings") // (3)
}
tasks.register("greeterB", GreetingTask) {
type = "b"
outputDirectory = layout.buildDirectory.dir("greetings") // (4)
}
tasks.register("consumer", ConsumerTask) {
inputDirectory = greeterA.flatMap { it.outputDirectory } // (5)
outputFile = layout.buildDirectory.file("consumerOutput.txt")
}-
Write to a file in the output directory: This task produces a single file in the
outputDirectory, named based on thetypeinput. -
Read a specific file in the input directory: This task only needs to read a single
a.txtfile in the input directory. -
Set output directory: Sets
outputDirectoryto a subdirectory inbuildDirectory. -
Set output directory: Same as above, using the same shared
greetingsdirectory. -
Wire
greeterAto consumer: Makes sure thatgreeterAruns and produces the output directory before it is used byconsumer.
With this setup, if you run the consumer task, then greeterB, the consumer task will be invalidated.
The next time consumer is run it will not be UP-TO-DATE and will have to run again despite not using the output from greeterB.
This happens because greeterB changes the contents of the shared output directory greetings, which is an output of greeterA that consumer depends on (despite consumer only actually using the unchanged a.txt file in that directory).
Do This Instead
To avoid issues, avoid using shared task output directories and files.
Instead, tasks should only declare the exact outputs and consume the exact inputs that they actually produce and consume.
The simplest change to make here is to use distinct output directories for each GreetingTask.
This alone is sufficient to fix the problem.
val greeterA = tasks.register<GreetingTask>("greeterA") {
type = "a"
outputDirectory = layout.buildDirectory.dir("greetings")
}
tasks.register<GreetingTask>("greeterB") {
type = "b"
outputDirectory = layout.buildDirectory.dir("greetings-2") // (1)
}def greeterA = tasks.register("greeterA", GreetingTask) {
type = "a"
outputDirectory = layout.buildDirectory.dir("greetings")
}
tasks.register("greeterB", GreetingTask) {
type = "b"
outputDirectory = layout.buildDirectory.dir("greetings-2") // (1)
}-
Set unique output directories: Each
GreetingTaskis assigned its own unique output directory based on thetypeinput.
Now when running consumer task, then greeterB, then consumer task remains UP-TO-DATE as Gradle knows that it is not using the output from greeterB, since greeterA and greeterB write to distinct output directories.
However, a more complete and idiomatic approach realizes that:
-
Tasks that produce single output files should make this clear from the type of their
@Outputproperties. -
Tasks that only consume single input files should make this clear from the type of their
@Inputproperties.
abstract class GreetingTask : DefaultTask() {
@get:Input
abstract val type: Property<String>
@get:OutputFile
abstract val outputFile: RegularFileProperty // (1)
@TaskAction
fun run() {
val message = "Hello " + type.get()
outputFile.get().asFile.writeText(message)
}
}
abstract class ConsumerTask : DefaultTask() {
@get:InputFile
abstract val inputFile: RegularFileProperty // (2)
@get:OutputFile
abstract val outputFile: RegularFileProperty
@TaskAction
fun run() {
val message = inputFile.get().asFile.readText()
outputFile.get().asFile.writeText(message)
}
}
val greeterA = tasks.register<GreetingTask>("greeterA") {
type = "a"
outputFile = layout.buildDirectory.dir("greetings").map { it.file("a.txt") } // (3)
}
tasks.register<GreetingTask>("greeterB") {
type = "b"
outputFile = layout.buildDirectory.dir("greetings").map { it.file("b.txt") }
}
tasks.register<ConsumerTask>("consumer") {
inputFile = greeterA.map { it.outputFile.get() } // (4)
outputFile = layout.buildDirectory.file("consumerOutput.txt")
}abstract class GreetingTask extends DefaultTask {
@Input
abstract Property<String> getType()
@OutputFile
abstract RegularFileProperty getOutputFile() // (1)
@TaskAction
void run() {
def message = "Hello " + type.get()
outputFile.get().asFile.text = message
}
}
abstract class ConsumerTask extends DefaultTask {
@InputFile
abstract RegularFileProperty getInputFile() // (2)
@OutputFile
abstract RegularFileProperty getOutputFile()
@TaskAction
void run() {
def message = inputFile.get().asFile.text
outputFile.get().asFile.write(message)
}
}
def greeterA = tasks.register("greeterA", GreetingTask) {
type = "a"
outputFile = layout.buildDirectory.dir("greetings").map { it.file("a.txt") } // (3)
}
tasks.register("greeterB", GreetingTask) {
type = "b"
outputFile = layout.buildDirectory.dir("greetings").map { it.file("b.txt") }
}
tasks.register("consumer", ConsumerTask) {
inputFile = greeterA.map { it.outputFile.get() } // (4)
outputFile = layout.buildDirectory.file("consumerOutput.txt")
}-
Write to a specific output file: This task produces a single file to a directly specified
outputFilewithout registering an entire output directory. -
Read a specific file: Unlike the previous example the input is a single directly specified
inputFilefile. -
Set output file: Sets
outputFileto a file that is inside asharedsubdirectory ofbuildDirectory. -
Wire
greeterAto consumer: Makes sure thatgreeterAproduces the output file before it is used byconsumerby wiring task inputs to outputs directly.
Now when running consumer task, then greeterB, the consumer task remains UP-TO-DATE as Gradle knows that it is not using the output from greeterB, since greeterA and greeterB produce and consume distinct files (that happen to be in created in the same directory).
Best Practices for Performance
Prefer the -bin Gradle Distribution
Gradle publishes two distribution variants for each release: -bin (binaries only) and -all (binaries, sources, and documentation).
For most builds, you should prefer the smaller -bin distribution.
Using -bin reduces download size and verification effort, speeds up CI and developer builds, and limits the number of artifacts you need to trust.
Explanation
Each Gradle release provides:
-
gradle-<version>-bin.zip– binaries only -
gradle-<version>-all.zip– binaries plus sources and offline documentation
In modern setups:
-
IDEs and build tools can download sources and documentation directly from repositories or online docs (even when using
-binreleases). -
The
-alldistribution is rarely required outside of specific offline or air-gapped environments.
Preferring -bin helps because:
-
It reduces download and cache size for CI and local builds.
-
There is less to verify and fewer artifacts to trust (one smaller archive instead of a larger “everything included” zip).
-
It shortens the feedback loop when upgrading Gradle.
In special cases (for example, fully offline environments), you can still use -all, but it should be a conscious exception rather than the default.
Don’t Do This
Make sure your Wrapper doesn’t point to the -all distribution:
gradle/wrapper/gradle-wrapper.properties:
distributionUrl=https\://services.gradle.org/distributions/gradle-<version>-all.zipDo This Instead
Configure the Wrapper to use the -bin distribution:
gradle/wrapper/gradle-wrapper.properties:
distributionUrl=https\://services.gradle.org/distributions/gradle-<version>-bin.zipUse UTF-8 File Encoding
Set UTF-8 as the default file encoding to ensure consistent behavior across platforms.
Explanation
Use UTF-8 as the default file encoding to ensure consistent behavior across environments and avoid caching issues caused by platform-dependent default encodings.
This is especially important when working with build caching, since differences in file encoding between environments can cause unexpected cache misses.
To enforce UTF-8 encoding, add the following to your gradle.properties file:
org.gradle.jvmargs=-Dfile.encoding=UTF-8|
Note
|
Do not rely on the default encoding of the underlying JVM or operating system, as this may differ between environments and lead to inconsistent behavior. |
Use the Build Cache
Use the Build Cache to save time by reusing outputs produced by previous builds.
Explanation
The Build Cache avoids re-executing tasks when their inputs haven’t changed by reusing outputs from previous builds.
This prevents redundant work. If the inputs are the same, the outputs will be too, resulting in faster, more efficient builds.
Example
Don’t Do This
Build caching is disabled by default:
# caching is off by default
# org.gradle.caching=falseDo This Instead
To enable the Build Cache, add the following to your gradle.properties file:
org.gradle.caching=trueWhen you build your project for the first time, Gradle populates the cache with the outputs of tasks like compilation.
Even if you run ./gradlew clean to delete the build directory, Gradle can reuse cached outputs in subsequent builds.
$ ./gradlew clean:clean
BUILD SUCCESSFULOn subsequent builds, instead of executing the :compileJava task again, the outputs of the task will be loaded from the Build Cache:
$ ./gradlew compileJava> Task :compileJava FROM-CACHE
BUILD SUCCESSFUL in 0s
1 actionable task: 1 from cacheUse the Configuration Cache
Use the Configuration Cache to significantly improve build performance by caching the result of the configuration phase and reusing it in subsequent builds.
Explanation
The Configuration Cache works by saving the result of the configuration phase. On the next build, if nothing relevant has changed, Gradle skips configuration entirely and loads the cached task graph from disk, jumping straight to task execution.
This can dramatically reduce build time for large builds, but it’s just as valuable for smaller builds where configuration overhead can dominate short iterations. Faster feedback helps developers stay focused, without waiting on redundant configuration work.
It’s important to understand how this differs from the Build Cache. The Build Cache stores the outputs of task execution, while the Configuration Cache stores the configured task graph before execution begins. These are independent mechanisms that solve different problems, but they are designed to work together for optimal performance.
|
Note
|
The Configuration Cache is the preferred way to execute Gradle builds, but it is not enabled by default. Many existing builds and plugins are not yet fully compatible, and adopting it may involve refactoring of build logic. Enabling it by default could lead to unexpected build failures, so Gradle uses an opt-in adoption model to allow teams to verify compatibility and adopt configuration caching incrementally and safely. |
Example
Don’t Do This
Configuration Caching is not enabled by default:
# caching is off by default
# org.gradle.configuration-cache=falseDo This Instead
To enable the Configuration Cache, add the following to your gradle.properties file:
org.gradle.configuration-cache=trueWhen you build your project for the first time, Gradle stores the outcome of the configuration phase, including the task graph, in the Configuration Cache.
$ ./gradlew compileJavaConfiguration cache entry stored.
> Task :processResources NO-SOURCE
> Task :processTestResources NO-SOURCE
> Task :compileJava
> Task :classes
> Task :compileTestJava NO-SOURCE
> Task :testClasses UP-TO-DATE
> Task :test NO-SOURCE
> Task :check UP-TO-DATE
> Task :jar
> Task :assemble
> Task :build
BUILD SUCCESSFUL in 0s
2 actionable tasks: 2 executedOn subsequent builds, instead of reconfiguring tasks like :compileJava, Gradle loads the task graph from the Configuration Cache and proceeds directly to execution.
$ ./gradlew compileJavaConfiguration cache entry reused.
> Task :processResources NO-SOURCE
> Task :processTestResources NO-SOURCE
> Task :compileJava
> Task :classes
> Task :compileTestJava NO-SOURCE
> Task :testClasses UP-TO-DATE
> Task :test NO-SOURCE
> Task :check UP-TO-DATE
> Task :jar
> Task :assemble
> Task :build
BUILD SUCCESSFUL in 0s
2 actionable tasks: 2 executedAvoid Expensive Computations in Configuration Phase
Avoid expensive computations in the configuration phase, instead, move them to task actions.
Explanation
In order for Gradle to execute tasks it first needs to build the project task graph. As part of discovering what tasks to include in the task graph, Gradle will configure all the tasks that are directly requested, any task dependencies of the requested tasks, and also any tasks that are not lazily registered. This work is done in the configuration phase.
Performing expensive or slow operations such as file or network I/O, or CPU-heavy calculations in the configuration phase forces these to run even when they might be unnecessary to complete the requested work of the invoked tasks. It is better to move these operations to task actions so that they run only when required.
Example
Don’t Do This
abstract class MyTask : DefaultTask() {
@get:Input
lateinit var computationResult: String
@TaskAction
fun run() {
logger.lifecycle(computationResult)
}
}
fun heavyWork(): String {
println("Start heavy work")
Thread.sleep(5000)
println("Finish heavy work")
return "Heavy computation result"
}
tasks.register<MyTask>("myTask") {
computationResult = heavyWork() // (1)
}abstract class MyTask extends DefaultTask {
@Input
String computationResult
@TaskAction
void run() {
logger.lifecycle(computationResult)
}
}
String heavyWork() {
logger.lifecycle("Start heavy work")
Thread.sleep(5000)
logger.lifecycle("Finish heavy work")
return "Heavy computation result"
}
tasks.register("myTask", MyTask) {
computationResult = heavyWork() // (1)
}-
Performing heavy computation during configuration phase.
Do This Instead
abstract class MyTask : DefaultTask() {
@TaskAction
fun run() {
logger.lifecycle(heavyWork()) // (1)
}
fun heavyWork(): String {
logger.lifecycle("Start heavy work")
Thread.sleep(5000)
logger.lifecycle("Finish heavy work")
return "Heavy computation result"
}
}
tasks.register<MyTask>("myTask")abstract class MyTask extends DefaultTask {
@TaskAction
void run() {
logger.lifecycle(heavyWork()) // (1)
}
String heavyWork() {
logger.lifecycle("Start heavy work")
Thread.sleep(5000)
logger.lifecycle("Finish heavy work")
return "Heavy computation result"
}
}
tasks.register("myTask", MyTask)-
Performing heavy computation during execution phase in a task action.
Best Practices for Security
Validate the Gradle Distribution SHA-256 Checksum
Set distributionSha256Sum in gradle-wrapper.properties to verify the integrity of the downloaded Gradle distribution.
Explanation
Always set the distributionSha256Sum property in your gradle-wrapper.properties file to verify the integrity of the downloaded Gradle distribution.
This ensures the gradle-X.X-bin.zip file matches the official SHA-256 checksum published by Gradle, protecting your build from corruption or tampering.
distributionUrl=https\://services.gradle.org/distributions/gradle-8.6-bin.zip
distributionSha256Sum=2b3f4...sha256-here...f4511This validation step enhances security by preventing the execution of compromised or incomplete Gradle distributions.
The official SHA-256 checksums can be found on the Gradle releases page.
Validate the Gradle Wrapper on every Upgrade
The Gradle Wrapper runs before your build logic and can deeply affect your build. You should treat any change to the Wrapper as security-sensitive.
Validate the Wrapper JAR and distribution settings every time you upgrade Gradle.
Explanation
When you update Gradle, two Wrapper files typically change:
-
gradle/wrapper/gradle-wrapper.jar -
gradle/wrapper/gradle-wrapper.properties(distributionUrland optionallydistributionSha256Sum)
You should verify that:
-
The Wrapper JAR is the official binary published by Gradle (not tampered with).
-
The Wrapper JAR checksum matches one of the values published at gradle.org/release-checksums.
-
The distribution URL points to the expected Gradle release.
-
The distribution checksum (if configured via
distributionSha256Sum) matches the release you intend to use (also listed on gradle.org/release-checksums).
Running an unverified Wrapper risks executing untrusted code before any of your build’s safeguards run.
Do this
If you use the setup-gradle action (version v4 or newer) for GitHub Actions, Wrapper validation will be performed automatically.
The action validates the checksum of every gradle-wrapper.jar in your repository and fails the build if it finds any unknown Wrapper JAR.
If you use a different GitHub Actions setup, you can use the dedicated Gradle Wrapper validation action instead.
Best Practices for Testing
Test your custom Task and Plugins with TestKit
You should test any custom tasks or plugins you create using Gradle TestKit.
Explanation
Gradle’s flexibility supports a natural evolution of custom types as they mature.
Creating new tasks and plugins directly in a build.gradle(.kts) file is a great way to prototype new functionality.
As that functionality stabilizes, you should extract these definitions into buildSrc or a standalone plugin project for better reusability and maintainability.
Once types exist outside of a single build file, you can easily write functional tests for them using TestKit.
A mature build should include functional tests for its custom types to ensure they behave as expected.
Example
Don’t Do This
The following build defines a custom task and a custom plugin that applies it within the build.gradle(.kts) file.
The plugin adds multiple custom tasks that print a greeting using properties defined in a custom extension.
This is a common pattern for prototyping new functionality, but it lacks tests to verify the behavior of the custom types. The only way to verify that the task and plugin work as intended is to run the build manually and inspect the output.
import java.time.Instant
interface MyExtension {
val firstName: Property<String>
val lastName: Property<String>
}
var greeter = "Hello"
@CacheableTask // (1)
abstract class MyTask: DefaultTask() {
@get:Input
abstract val firstName: Property<String>
@get:Input
abstract val lastName: Property<String>
@get:Input
abstract val greeting: Property<String>
@get:OutputFile
abstract val outputFile: RegularFileProperty
private final val today = Instant.now() // (2)
@TaskAction
fun run() {
val output = outputFile.asFile.get()
val result = "${greeting.get()}, ${firstName.get()} ${lastName.get()}, it's currently\n$today"
println(result)
output.writeText(result)
}
}
abstract class MyPlugin: Plugin<Project> {
override fun apply(project: Project) {
val extension = project.extensions.create("myExtension", MyExtension::class.java)
project.tasks.register<MyTask>("task1") {
outputFile.convention(project.layout.buildDirectory.file("output1.txt"))
}
project.tasks.register<MyTask>("task2") {
outputFile.convention(project.layout.buildDirectory.file("output2.txt"))
}
project.tasks.withType<MyTask>().configureEach {
group = "Custom Tasks"
firstName.convention(extension.firstName)
lastName.convention(extension.firstName) // (3)
greeting.convention("Hi")
}
}
}
apply<MyPlugin>()
configure<MyExtension> {
firstName = "John"
lastName = "Smith"
}
tasks.named<MyTask>("task2") {
greeter = "Bonjour" // (4)
}import java.time.Instant
interface MyExtension {
Property<String> getFirstName()
Property<String> getLastName()
}
def greeter = "Hello"
@CacheableTask // (1)
abstract class MyTask extends DefaultTask {
@Input
abstract Property<String> getFirstName()
@Input
abstract Property<String> getLastName()
@Input
abstract Property<String> getGreeting()
@OutputFile
abstract RegularFileProperty getOutputFile()
private final Instant today = Instant.now() // (2)
@TaskAction
void run() {
def output = outputFile.asFile.get()
def result = "${greeting.get()}, ${firstName.get()} ${lastName.get()}, it's currently\n$today"
println result
output.text = result
}
}
abstract class MyPlugin implements Plugin<Project> {
@Override
void apply(Project project) {
def extension = project.extensions.create("myExtension", MyExtension)
project.tasks.register("task1", MyTask) { task ->
task.outputFile.convention(project.layout.buildDirectory.file("output1.txt"))
}
project.tasks.register("task2", MyTask) { task ->
task.outputFile.convention(project.layout.buildDirectory.file("output2.txt"))
}
project.tasks.withType(MyTask).configureEach { task ->
task.group = "Custom Tasks"
task.firstName.convention(extension.firstName)
task.lastName.convention(extension.firstName) // (3)
task.greeting.convention("Hi")
}
}
}
apply plugin: MyPlugin
myExtension {
firstName = "John"
lastName = "Smith"
}
tasks.named("task2", MyTask) {
greeter = "Bonjour" // (4)
}In this case, there are several problems:
-
The Task is declared as cacheable: However, the task’s output differs depending on when it is run, so it should not be cached.
-
The current time is used as an undeclared input: Inputs to a task must be explicitly declared using the appropriate annotations, otherwise Gradle cannot track changes to them.
-
Error in task property wiring: The
lastNameproperty is linked to thefirstNameproperty on the extension, which is likely a mistake. -
The wrong variable is assigned during task configuration: The
greetervariable from the buildscript is mistakenly assigned instead of the task’sgreetingproperty.
Do This Instead
In this updated version of the build, the custom types are defined in an included build-logic composite build, which now includes a basic set of functional tests using Gradle TestKit.
While these custom types are written in Java for demonstration purposes, they could just as easily be implemented in Groovy or Kotlin. Because they reside in a separate, complete Gradle build, they can be thoroughly tested using TestKit.
├── build-logic/
│ ├── src
│ │ ├── main
│ │ │ └── java
│ │ │ └── org
│ │ │ └── example
│ │ │ └── MyExtension.java
│ │ │ └── MyPlugin.java
│ │ │ └── MyTask.java
│ │ └── functionalTest
│ │ └── java
│ │ └── org
│ │ └── example
│ │ └── MyPluginFunctionalTest.java
│ ├── build.gradle.kts
│ └── settings.gradle.kts
├── settings.gradle.kts
└── build.gradle.kts├── build-logic/
│ ├── src
│ │ ├── main
│ │ │ └── java
│ │ │ └── org
│ │ │ └── example
│ │ │ └── MyExtension.java
│ │ │ └── MyPlugin.java
│ │ │ └── MyTask.java
│ │ └── functionalTest
│ │ └── java
│ │ └── org
│ │ └── example
│ │ └── MyPluginFunctionalTest.java
│ ├── build.gradle
│ └── settings.gradle
├── settings.gradle
└── build.gradleWe’ve corrected the issues with the plugin and task from the previous example:
package org.example;
import org.gradle.api.DefaultTask;
import org.gradle.api.file.RegularFileProperty;
import org.gradle.api.provider.Property;
import org.gradle.api.tasks.CacheableTask;
import org.gradle.api.tasks.Input;
import org.gradle.api.tasks.InputFile;
import org.gradle.api.tasks.OutputFile;
import org.gradle.api.tasks.TaskAction;
import java.io.File;
import java.nio.file.Files;
import java.time.Instant;
import java.io.IOException;
@CacheableTask
public abstract class MyTask extends DefaultTask {
@Input
public abstract Property<String> getFirstName();
@Input
public abstract Property<String> getLastName();
@Input
public abstract Property<String> getGreeting();
@OutputFile
public abstract RegularFileProperty getOutputFile();
@Input // (1)
public abstract Property<Instant> getToday();
@TaskAction
public void run() throws IOException {
File output = getOutputFile().getAsFile().get();
String result = String.format("%s, %s %s, it's currently\n%s", getGreeting().get(), getFirstName().get(), getLastName().get(), getToday().get());
System.out.println(result);
Files.writeString(output.toPath(), result);
}
}-
Todayis a proper@Input: This allows Gradle’sUP-TO-DATEchecking to properly consider it when rerunning the task.
package org.example;
import org.gradle.api.Plugin;
import org.gradle.api.Project;
import java.time.Instant;
public abstract class MyPlugin implements Plugin<Project> {
@Override
public void apply(Project project) {
MyExtension extension = project.getExtensions().create("myExtension", MyExtension.class);
project.getTasks().register("task1", MyTask.class, task -> {
task.getOutputFile().convention(project.getLayout().getBuildDirectory().file("output1.txt"));
});
project.getTasks().register("task2", MyTask.class, task -> {
task.getOutputFile().convention(project.getLayout().getBuildDirectory().file("output2.txt"));
});
project.getTasks().withType(MyTask.class).configureEach(task -> {
task.setGroup("Custom Tasks");
task.getFirstName().convention(extension.getFirstName());
task.getLastName().convention(extension.getLastName()); // (1)
task.getGreeting().convention("Hi");
task.getToday().convention(Instant.now()); // (2)
});
}
}-
Corrected typo in assignment: The last name convention set to the value of the last name from the extension.
-
Todayis set to the same value on all tasks: Only callingInstant.now()once, rather than every time a task is created.
Writing and running the tests as described below helped identify the bugs in the plugin implementation.
We defined a functional test suite within the build-logic project.
Because TestKit tests tend to be slower and more complex than unit tests, they are typically kept separate.
Locating these tests in a dedicated functionalTest suite also clarifies their purpose for other developers.
val functionalTest = testing.suites.register("functionalTest", JvmTestSuite::class) { // (1)
useJUnitJupiter()
dependencies {
implementation("commons-io:commons-io:2.16.1")
implementation(project())
implementation(gradleTestKit()) // (2)
}
}
tasks.check {
dependsOn(functionalTest)
}
gradlePlugin {
plugins {
register("org.example.myplugin") {
implementationClass = "org.example.MyPlugin"
}
}
testSourceSets(functionalTest.get().sources) // (3)
}def functionalTest = testing.suites.register("functionalTest", JvmTestSuite) { // (1)
useJUnitJupiter()
dependencies {
implementation("commons-io:commons-io:2.16.1")
implementation(project())
implementation(gradleTestKit()) // (2)
}
}
tasks.check {
dependsOn(functionalTest)
}
gradlePlugin {
plugins {
register("org.example.myplugin") {
implementationClass = "org.example.MyPlugin"
}
}
testSourceSets functionalTest.get().sources // (3)
}-
Define the new test suite: Creates a
functionalTestJVM Test Suite. -
Add TestKit dependency: This contains the
GradleRunnerclass we’ll use to write tests. -
Make the
java-gradle-pluginaware of the new test suite: Now the usable plugin source from the project’s main production code will be available to these tests.
With this setup in place, we can write functional tests for our plugin in the build-logic/src/functionalTest/java directory.
You can run ./gradlew :build-logic:functionalTest or ./gradlew :build-logic:check from the root project directory to execute these tests.
|
Note
|
By default, tests within the included build-logic build are not executed when you run tests in the root project.
Because the root project only requires the build artifacts from build-logic, Gradle will build the project without running its internal tests.
To run them, you must explicitly invoke the tasks: ./gradlew :build-logic:check.
|
In the functional test class, we use TestKit to initialize a temporary Gradle project, apply our plugin, and verify that it behaves as expected.
package org.example;
import org.gradle.testkit.runner.BuildResult;
import org.gradle.testkit.runner.GradleRunner;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.io.TempDir;
import java.nio.file.Files;
import java.io.File;
import java.io.IOException;
import org.apache.commons.io.FileUtils;
import static org.gradle.testkit.runner.TaskOutcome.FROM_CACHE;
import static org.gradle.testkit.runner.TaskOutcome.SUCCESS;
import static org.junit.jupiter.api.Assertions.assertEquals;
import static org.junit.jupiter.api.Assertions.assertTrue;
public class MyPluginFunctionalTest {
@TempDir File testProjectDir;
private File settingsFile;
private File buildFile;
private File cacheDir = new File("build-cache");
@BeforeEach
public void setup() throws IOException {
settingsFile = new File(testProjectDir, "settings.gradle");
Files.writeString(settingsFile.toPath(), "rootProject.name = 'test-project'");
buildFile = new File(testProjectDir, "build.gradle");
}
@Test
public void testTaskRegistration() throws IOException { // (1)
String buildFileContent = """
plugins {
id("org.example.myplugin")
}
""";
Files.writeString(buildFile.toPath(), buildFileContent);
BuildResult result = GradleRunner.create()
.withProjectDir(testProjectDir)
.withPluginClasspath()
.forwardOutput()
.withArguments("tasks", "--all")
.build();
assertContainsIgnoringEol("""
Custom Tasks tasks
------------------
task1
task2
""",
result.getOutput()
);
}
@Test
public void testTaskExecution() throws IOException { // (2)
File outputFile = new File(testProjectDir, "build/output.txt");
String buildFileContent = """
plugins {
id("org.example.myplugin")
}
myExtension {
firstName = "John"
lastName = "Smith"
}
tasks.task1 {
outputFile = project.layout.buildDirectory.file("output.txt")
}
""";
Files.writeString(buildFile.toPath(), buildFileContent);
GradleRunner.create()
.withProjectDir(testProjectDir)
.withPluginClasspath()
.withArguments("task1")
.build();
String actual = Files.readString(outputFile.toPath());
assertTrue(actual.startsWith("Hi, John Smith, it's currently"));
}
@Test
public void testTaskDeterminism() throws IOException { // (3)
File outputFile = new File(testProjectDir, "build/output.txt");
String buildFileContent = """
plugins {
id("org.example.myplugin")
}
myExtension {
firstName = "John"
lastName = "Smith"
}
tasks.task1 {
outputFile = project.layout.buildDirectory.file("output.txt")
today = ZonedDateTime.parse("2026-01-12T16:00:00-05:00").toInstant()
}
""";
Files.writeString(buildFile.toPath(), buildFileContent);
GradleRunner runner = GradleRunner.create()
.withProjectDir(testProjectDir)
.withPluginClasspath();
runner.withArguments("task1").build();
String output1 = Files.readString(outputFile.toPath());
runner.withArguments("task1", "--rerun-tasks").build();
String output2 = Files.readString(outputFile.toPath());
assertEquals(output1, output2);
}
@Test
public void testTaskCacheability() throws IOException { // (4)
String buildFileContent = """
plugins {
id("org.example.myplugin")
}
myExtension {
firstName = "John"
lastName = "Smith"
}
tasks.task1 {
outputFile = project.layout.buildDirectory.file("output.txt")
today = ZonedDateTime.parse("2026-01-12T16:00:00-05:00").toInstant()
}
""";
Files.writeString(buildFile.toPath(), buildFileContent);
GradleRunner runner = GradleRunner.create()
.withProjectDir(testProjectDir)
.withPluginClasspath()
.forwardOutput();
BuildResult result = runner.withArguments("--build-cache", "task1").build();
assertEquals(SUCCESS, result.task(":task1").getOutcome());
FileUtils.deleteDirectory(new File(testProjectDir, "build"));
result = runner.withArguments("--build-cache", "task1").build();
assertEquals(FROM_CACHE, result.task(":task1").getOutcome());
}
private static void assertContainsIgnoringEol(String expected, String actual) {
assertTrue(normalizeEol(actual).contains(normalizeEol(expected)));
}
private static String normalizeEol(String s) {
return s.replace("\r\n", "\n").replace("\r", "\n");
}
}Looking at the example tests here, you can see various techniques used to verify the plugin’s behavior against actual, ad-hoc Gradle builds defined within the tests:
-
testTaskRegistration: This test runs the
tasksreport and verifies the output. -
testTaskExecution: This test runs the custom task and verifies its output file.
-
testTaskDeterminism: This test runs the build twice - forcing tasks to rerun the second time - to ensure the output is identical, which is necessary for caching.
-
testTaskCacheability: This test checks that when the task is run twice in a row, the second run is loaded from cache.
These examples only scratch the surface of what you can achieve with TestKit. For instance, a comprehensive test for cacheability should verify that changes to inputs correctly trigger re-execution and include tests for relocatability.
You can find more information in the Gradle TestKit documentation.
RUNTIME AND CONFIGURATION
Command-Line Interface
The command-line interface is the primary method of interacting with Gradle.
The following is a reference for executing and customizing the Gradle command-line. It also serves as a reference when writing scripts or configuring continuous integration.
Use of the Gradle Wrapper is highly encouraged.
Substitute ./gradlew (in macOS / Linux) or gradlew.bat (in Windows) for gradle in the following examples.
Executing Gradle on the command-line conforms to the following structure:
gradle [taskName...] [--option-name...]Options are allowed before and after task names.
gradle [--option-name...] [taskName...]If multiple tasks are specified, you should separate them with a space.
gradle [taskName1 taskName2...] [--option-name...]Options that accept values can be specified with or without = between the option and argument. The use of = is recommended.
gradle [...] --console=plainOptions that enable behavior have long-form options with inverses specified with --no-. The following are opposites.
gradle [...] --build-cache
gradle [...] --no-build-cacheMany long-form options have short-option equivalents. The following are equivalent:
gradle --help
gradle -h|
Note
|
Many command-line flags can be specified in gradle.properties to avoid needing to be typed.
See the Configuring build environment guide for details.
|
Command-line usage
The following sections describe the use of the Gradle command-line interface.
Some plugins also add their own command line options.
For example, --tests, which is added by Java test filtering.
For more information on exposing command line options for your own tasks, see Declaring command-line options.
Executing tasks
You can learn about what projects and tasks are available in the project reporting section.
Most builds support a common set of tasks known as lifecycle tasks. These include the build, assemble, and check tasks.
To execute a task called myTask on the root project, type:
$ gradle :myTaskThis will run the single myTask and all of its dependencies.
Specify options for tasks
To pass an option to a task, prefix the option name with -- after the task name:
$ gradle :exampleTask --exampleOption=exampleValueDisambiguate task options from built-in options
Gradle does not prevent tasks from registering options that conflict with Gradle’s built-in options, like --profile or --help.
You can fix conflicting task options from Gradle’s built-in options with a -- delimiter before the task name in the command:
$ gradle [--built-in-option-name...] -- [taskName...] [--task-option-name...]Consider a task named mytask that accepts an option named profile:
-
In
gradle mytask --profile, Gradle accepts--profileas the built-in Gradle option. -
In
gradle -- mytask --profile=value, Gradle passes--profileas a task option.
Executing tasks in multi-project builds
In a multi-project build, subproject tasks can be executed with : separating the subproject name and task name.
The following are equivalent when run from the root project:
$ gradle :subproject:taskName$ gradle subproject:taskNameYou can also run a task for all subprojects using a task selector that consists of only the task name.
The following command runs the test task for all subprojects when invoked from the root project directory:
$ gradle testTo recap:
// Run a task in the root project only
$ gradle :exampleTask --exampleOption=exampleValue
// Run a task that may exist in the root or any subproject (ambiguous if defined in more than one)
$ gradle exampleTask --exampleOption=exampleValue
// Run a task in a specific subproject
$ gradle subproject:exampleTask --exampleOption=exampleValue
$ gradle :subproject:exampleTask --exampleOption=exampleValue|
Note
|
Some tasks selectors, like help or dependencies, will only run the task on the project they are invoked on and not on all the subprojects.
|
When invoking Gradle from within a subproject, the project name should be omitted:
$ cd subproject$ gradle taskName|
Tip
|
When executing the Gradle Wrapper from a subproject directory, reference gradlew relatively. For example: ../gradlew taskName.
|
Executing multiple tasks
You can also specify multiple tasks. The tasks' dependencies determine the precise order of execution, and a task having no dependencies may execute earlier than it is listed on the command-line.
For example, the following will execute the test and deploy tasks in the order that they are listed on the command-line and will also execute the dependencies for each task.
$ gradle test deployCommand line order safety
Although Gradle will always attempt to execute the build quickly, command line ordering safety will also be honored.
For example, the following will
execute clean and build along with their dependencies:
$ ./gradlew clean buildHowever, the intention implied in the command line order is that clean should run first and then build. It would be incorrect to execute clean after build, even if doing so would cause the build to execute faster since clean would remove what build created.
Conversely, if the command line order was build followed by clean, it would not be correct to execute clean before build. Although Gradle will execute the build as quickly as possible, it will also respect the safety of the order of tasks specified on the command line and ensure that clean runs before build when specified in that order.
Note that command line order safety relies on tasks properly declaring what they create, consume, or remove.
Excluding tasks from execution
You can exclude a task from being executed using the -x or --exclude-task command-line option and providing the name of the task to exclude:
$ gradle dist --exclude-task test> Task :compile
compiling source
> Task :dist
building the distribution
BUILD SUCCESSFUL in 0s
2 actionable tasks: 2 executed
You can see that the test task is not executed, even though the dist task depends on it.
The test task’s dependencies, such as compileTest, are not executed either.
The dependencies of test that other tasks depend on, such as compile, are still executed.
Forcing tasks to execute
You can force Gradle to execute all tasks ignoring up-to-date checks using the --rerun-tasks option:
$ ./gradlew test --rerun-tasksThis will force test and all task dependencies of test to execute. It is similar to running gradle clean test, but without the build’s generated output being deleted.
Alternatively, you can tell Gradle to rerun a specific task using the --rerun built-in task option.
Continue the build after a task failure
By default, Gradle aborts execution and fails the build when any task fails. This allows the build to complete sooner and prevents cascading failures from obfuscating the root cause of an error.
You can use the --continue option to force Gradle to execute every task when a failure occurs:
$ ./gradlew test --continueWhen executed with --continue, Gradle executes every task in the build if all the dependencies for that task are completed without failure.
For example, tests do not run if there is a compilation error in the code under test because the test task depends on the compilation task.
Gradle outputs each of the encountered failures at the end of the build.
|
Note
|
If any tests fail, many test suites fail the entire test task.
Code coverage and reporting tools frequently run after the test task, so "fail fast" behavior may halt execution before those tools run.
|
Name abbreviation
When you specify tasks on the command-line, you don’t have to provide the full name of the task.
You can provide enough of the task name to identify the task uniquely.
For example, it is likely gradle che is enough for Gradle to identify the check task.
The same applies to project names. You can execute the check task in the library subproject with the gradle lib:che command.
You can use camel case patterns for more complex abbreviations. These patterns are expanded to match camel case and kebab case names.
For example, the pattern foBa (or fB) matches fooBar and foo-bar.
More concretely, you can run the compileTest task in the my-awesome-library subproject with the command gradle mAL:cT.
$ ./gradlew mAL:cT> Task :my-awesome-library:compileTest
compiling unit tests
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executedAbbreviations can also be used with the -x command-line option.
Tracing name expansion
For complex projects, it might be ambiguous if the intended tasks were executed. When using abbreviated names, a single typo can lead to the execution of unexpected tasks.
When INFO, or more verbose logging is enabled, the output will contain extra information about the project and task name expansion.
For example, when executing the mAL:cT command on the previous example, the following log messages will be visible:
No exact project with name ':mAL' has been found. Checking for abbreviated names.
Found exactly one project that matches the abbreviated name ':mAL': ':my-awesome-library'.
No exact task with name ':cT' has been found. Checking for abbreviated names.
Found exactly one task name, that matches the abbreviated name ':cT': ':compileTest'.Common tasks
The following are task conventions applied by built-in and most major Gradle plugins.
Computing all outputs
It is common in Gradle builds for the build task to designate assembling all outputs and running all checks:
$ ./gradlew buildRunning applications
It is common for applications to run with the run task, which assembles the application and executes some script or binary:
$ ./gradlew runRunning all checks
It is common for all verification tasks, including tests and linting, to be executed using the check task:
$ ./gradlew checkCleaning outputs
You can delete the contents of the build directory using the clean task. Doing so will cause pre-computed outputs to be lost, causing significant additional build time for the subsequent task execution:
$ ./gradlew cleanProject reporting
Gradle provides several built-in tasks which show particular details of your build. This can be useful for understanding your build’s structure and dependencies, as well as debugging problems.
Listing projects
Running the projects task gives you a list of the subprojects of the selected project, displayed in a hierarchy:
$ ./gradlew projectsYou also get a project report with Build Scan.
Listing tasks
Running gradle tasks gives you a list of the main tasks of the selected project. This report shows the default tasks for the project, if any, and a description for each task:
$ ./gradlew tasksBy default, this report shows only those tasks assigned to a task group.
Groups (such as verification, publishing, help, build…) are available as the header of each section when listing tasks:
> Task :tasks
Build tasks
-----------
assemble - Assembles the outputs of this project.
Build Setup tasks
-----------------
init - Initializes a new Gradle build.
Distribution tasks
------------------
assembleDist - Assembles the main distributions
Documentation tasks
-------------------
javadoc - Generates Javadoc API documentation for the main source code.You can obtain more information in the task listing using the --all option:
$ ./gradlew tasks --allThe option --no-all can limit the report to tasks assigned to a task group.
If you need to be more precise, you can display only the tasks from a specific group using the --group option:
$ ./gradlew tasks --group="build setup"You can use the --provenance option to show where each task was registered (e.g., by a plugin or build script):
$ ./gradlew tasks --provenanceBuild tasks
-----------
assemble - Assembles the outputs of this project. (registered by plugin 'org.gradle.language.base.plugins.LifecycleBasePlugin')
build - Assembles and tests this project. (registered by plugin 'org.gradle.language.base.plugins.LifecycleBasePlugin')Show task usage details
Running gradle help --task someTask gives you detailed information about a specific task:
$ ./gradlew -q help --task libsDetailed task information for libs
Paths
:api:libs (registered in build file 'api/build.gradle')
:webapp:libs (registered in build file 'webapp/build.gradle')
Type
Task (org.gradle.api.Task)
Options
--rerun Causes the task to be re-run even if up-to-date.
Description
Builds the JAR
Group
buildThis information includes the full task path, the task type, possible task-specific command line options, and the description of the given task. The output also includes provenance information showing where the task was registered (e.g., in a build file or by a plugin).
You can get detailed information about the task class types using the --types option or using --no-types to hide this information.
Reporting dependencies
Build Scan gives a full, visual report of what dependencies exist on which configurations, transitive dependencies, and dependency version selection.
They can be invoked using the --scan options:
$ ./gradlew myTask --scanThis will give you a link to a web-based report, where you can find dependency information like this:
Listing project dependencies
Running the dependencies task gives you a list of the dependencies of the selected project, broken down by configuration. For each configuration, the direct and transitive dependencies of that configuration are shown in a tree.
Below is an example of this report:
$ ./gradlew dependencies> Task :app:dependencies
------------------------------------------------------------
Project ':app'
------------------------------------------------------------
compileClasspath - Compile classpath for source set 'main'.
+--- project :model
| \--- org.json:json:20220924
+--- com.google.inject:guice:5.1.0
| +--- javax.inject:javax.inject:1
| +--- aopalliance:aopalliance:1.0
| \--- com.google.guava:guava:30.1-jre -> 28.2-jre
| +--- com.google.guava:failureaccess:1.0.1
| +--- com.google.guava:listenablefuture:9999.0-empty-to-avoid-conflict-with-guava
| +--- com.google.code.findbugs:jsr305:3.0.2
| +--- org.checkerframework:checker-qual:2.10.0 -> 3.28.0
| +--- com.google.errorprone:error_prone_annotations:2.3.4
| \--- com.google.j2objc:j2objc-annotations:1.3
+--- com.google.inject:guice:{strictly 5.1.0} -> 5.1.0 (c)
+--- org.json:json:{strictly 20220924} -> 20220924 (c)
+--- javax.inject:javax.inject:{strictly 1} -> 1 (c)
+--- aopalliance:aopalliance:{strictly 1.0} -> 1.0 (c)
+--- com.google.guava:guava:{strictly [28.0-jre, 28.5-jre]} -> 28.2-jre (c)
+--- com.google.guava:guava:{strictly 28.2-jre} -> 28.2-jre (c)
+--- com.google.guava:failureaccess:{strictly 1.0.1} -> 1.0.1 (c)
+--- com.google.guava:listenablefuture:{strictly 9999.0-empty-to-avoid-conflict-with-guava} -> 9999.0-empty-to-avoid-conflict-with-guava (c)
+--- com.google.code.findbugs:jsr305:{strictly 3.0.2} -> 3.0.2 (c)
+--- org.checkerframework:checker-qual:{strictly 3.28.0} -> 3.28.0 (c)
+--- com.google.errorprone:error_prone_annotations:{strictly 2.3.4} -> 2.3.4 (c)
\--- com.google.j2objc:j2objc-annotations:{strictly 1.3} -> 1.3 (c)Concrete examples of build scripts and output available in Viewing and debugging dependencies.
Running the buildEnvironment task visualises the buildscript dependencies of the selected project, similarly to how gradle dependencies visualizes the dependencies of the software being built:
$ ./gradlew buildEnvironmentRunning the dependencyInsight task gives you an insight into a particular dependency (or dependencies) that match specified input:
$ ./gradlew dependencyInsight --dependency [...] --configuration [...]The --configuration parameter restricts the report to a particular configuration such as compileClasspath.
Listing project properties
Running the properties task gives you a list of the properties of the selected project:
$ ./gradlew -q api:properties------------------------------------------------------------
Project ':api'
------------------------------------------------------------
allprojects: [project ':api']
ant: org.gradle.api.internal.project.DefaultAntBuilder@12345
antBuilderFactory: org.gradle.api.internal.project.DefaultAntBuilderFactory@12345
artifacts: org.gradle.api.internal.artifacts.dsl.DefaultArtifactHandler_Decorated@12345
asDynamicObject: DynamicObject for project ':api'
baseClassLoaderScope: org.gradle.api.internal.initialization.DefaultClassLoaderScope@12345You can also query a single property with the optional --property argument:
$ ./gradlew -q api:properties --property allprojects------------------------------------------------------------
Project ':api'
------------------------------------------------------------
allprojects: [project ':api']Command-line completion
Gradle provides bash and zsh tab completion support for tasks, options, and Gradle properties through gradle-completion (installed separately):

Debugging options
-?,-h,--help-
Shows a help message with the built-in CLI options organized into logical sections. To show project-contextual options, including help on a specific task, see the
helptask. -v,--version-
Prints Gradle, Groovy, Ant, Launcher & Daemon JVM, and operating system version information and exit without executing any tasks.
-V,--show-version-
Prints Gradle, Groovy, Ant, Launcher & Daemon JVM, and operating system version information and continue execution of specified tasks.
-S,--full-stacktrace-
Print out the full (very verbose) stacktrace for any exceptions. See also logging options.
-s,--stacktrace-
Print out the stacktrace also for user exceptions (e.g. compile error). See also logging options.
--scan-
Create a Build Scan with fine-grained information about all aspects of your Gradle build.
-Dorg.gradle.debug=true-
A Gradle property that debugs the Gradle Daemon process. Gradle will wait for you to attach a debugger at
localhost:5005by default. -Dorg.gradle.debug.host=(host address)-
A Gradle property that specifies the host address to listen on or connect to when debug is enabled. In the server mode on Java 9 and above, passing
*for the host will make the server listen on all network interfaces. By default, no host address is passed to JDWP, so on Java 9 and above, the loopback address is used, while earlier versions listen on all interfaces. -Dorg.gradle.debug.port=(port number)-
A Gradle property that specifies the port number to listen on when debug is enabled. Default is
5005. -Dorg.gradle.debug.server=(true,false)-
A Gradle property that if set to
trueand debugging is enabled, will cause Gradle to run the build with the socket-attach mode of the debugger. Otherwise, the socket-listen mode is used. Default istrue. -Dorg.gradle.debug.suspend=(true,false)-
A Gradle property that if set to
trueand debugging is enabled, the JVM running Gradle will suspend until a debugger is attached. Default istrue.
Performance options
Try these options when optimizing and improving build performance.
Many of these options can be specified in the gradle.properties file, so command-line flags are unnecessary.
--build-cache,--no-build-cache-
Toggles the Gradle Build Cache. Gradle will try to reuse outputs from previous builds. Default is off.
--configuration-cache,--no-configuration-cache-
Toggles the Configuration Cache. Gradle will try to reuse the build configuration from previous builds. Default is off.
--configuration-cache-problems=(fail,warn)-
Configures how the configuration cache handles problems. Default is
fail.Set to
warnto report problems without failing the build.Set to
failto report problems and fail the build if there are any problems. --configure-on-demand,--no-configure-on-demandIncubating-
Toggles configure-on-demand. Only relevant projects are configured in this build run. Default is off.
--max-workers-
Sets the maximum number of workers that Gradle may use. Default is number of processors.
--parallel,--no-parallel-
Build projects in parallel. For limitations of this option, see Parallel Project Execution. Default is off.
--priority-
Specifies the scheduling priority for the Gradle daemon and all processes launched by it. Values are
normalorlow. Default is normal. --profile-
Generates a high-level performance report in the
layout.buildDirectory.dir("reports/profile")directory.--scanis preferred. --scan-
Generate a Build Scan with detailed performance diagnostics.
--watch-fs,--no-watch-fs-
Toggles watching the file system. When enabled, Gradle reuses information it collects about the file system between builds. Enabled by default on operating systems where Gradle supports this feature.
Gradle daemon options
You can manage the Gradle Daemon through the following command line options.
--daemon,--no-daemon-
Use the Gradle Daemon to run the build. Starts the daemon if not running or the existing daemon is busy. Default is on.
--foreground-
Starts the Gradle Daemon in a foreground process.
--status(Standalone command)-
Run
gradle --statusto list running and recently stopped Gradle daemons. It only displays daemons of the same Gradle version. --stop(Standalone command)-
Run
gradle --stopto stop all Gradle Daemons of the same version. -Dorg.gradle.daemon.idletimeout=(number of milliseconds)-
A Gradle property wherein the Gradle Daemon will stop itself after this number of milliseconds of idle time. Default is 10800000 (3 hours).
Logging options
Setting log level
You can customize the verbosity of Gradle logging with the following options, ordered from least verbose to most verbose.
-Dorg.gradle.logging.level=(quiet,warn,lifecycle,info,debug)-
A Gradle property that sets the logging level.
-q,--quiet-
Log errors only.
-w,--warn-
Set log level to warn.
-i,--info-
Set log level to info.
-d,--debug-
Log in debug mode (includes normal stacktrace).
Lifecycle is the default log level.
Customizing log format
You can control the use of rich output (colors and font variants) by specifying the console mode in the following ways:
-Dorg.gradle.console=(auto,plain,colored,rich,verbose)-
A Gradle property that specifies the console mode. Different modes are described immediately below.
--console=(auto,plain,colored,rich,verbose)-
Specifies which type of console output to generate.
Set to
plainto generate plain text only. This option disables all color and other rich output in the console output. This is the default when Gradle is not attached to a terminal.Set to
coloredto generate colored output without rich status information such as progress bars.Set to
auto(the default) to enable color and other rich output in the console output when the build process is attached to a console or to generate plain text only when not attached to a console. This is the default when Gradle is attached to a terminal.Set to
richto enable color and other rich output in the console output, regardless of whether the build process is not attached to a console. When not attached to a console, the build output will use ANSI control characters to generate the rich output.Set to
verboseto enable color and other rich output likerichwith output task names and outcomes at the lifecycle log level, (as is done by default in Gradle 3.5 and earlier).NoteWhen the NO_COLORenvironment variable is set and non-empty, Gradle suppresses color output regardless of the console mode. Bold, underline, and rich features like progress bars are unaffected. See no-color.org.
Reporting problems
--problems-report(enabled by default) Incubating-
Enable the generation of
build/reports/problems-report.html. This is the default behaviour. The report is generated with problems provided to the Problems API. --no-problems-reportIncubating-
Disable the generation of
build/reports/problems-report.html, by default this report is generated with problems provided to the Problems API.
Showing or hiding warnings
By default, Gradle won’t display all warnings (e.g. deprecation warnings). Instead, Gradle will collect them and render a summary at the end of the build like:
Deprecated Gradle features were used in this build, making it incompatible with Gradle 5.0.You can control the verbosity of warnings on the console with the following options:
-Dorg.gradle.warning.mode=(all,fail,none,summary)-
A Gradle property that specifies the warning mode. Different modes are described immediately below.
--warning-mode=(all,fail,none,summary)-
Specifies how to log warnings. Default is
summary.Set to
allto log all warnings.Set to
failto log all warnings and fail the build if there are any warnings.Set to
summaryto suppress all warnings and log a summary at the end of the build.Set to
noneto suppress all warnings, including the summary at the end of the build.
Rich console
Gradle’s rich console displays extra information while builds are running.
Features:
-
Progress bar and timer visually describe the overall status
-
Parallel work-in-progress lines below describe what is happening now
-
Colors and fonts are used to highlight significant output and errors
Execution options
The following options affect how builds are executed by changing what is built or how dependencies are resolved.
--include-build-
Run the build as a composite, including the specified build.
--offline-
Specifies that the build should operate without accessing network resources.
-U,--refresh-dependencies-
Refresh the state of dependencies.
--continue-
Continue task execution after a task failure.
-m,--dry-run-
Run Gradle with all task actions disabled. Use this to show which task would have executed.
--task-graphSince 9.1.0-
Run Gradle with all task actions disabled and print the task dependency graph.
-t,--continuous-
Enables continuous build. Gradle does not exit and will re-execute tasks when task file inputs change.
--write-locks-
Indicates that all resolved configurations that are lockable should have their lock state persisted.
--update-locks <group:name>[,<group:name>]*-
Indicates that versions for the specified modules have to be updated in the lock file.
This flag also implies
--write-locks. -a,--no-rebuild-
Do not rebuild project dependencies. Useful for debugging and fine-tuning
buildSrc, but can lead to wrong results. Use with caution!
Dependency verification options
Learn more about this in dependency verification.
-F=(strict,lenient,off),--dependency-verification=(strict,lenient,off)-
Configures the dependency verification mode.
The default mode is
strict. -M,--write-verification-metadata-
Generates checksums for dependencies used in the project (comma-separated list) for dependency verification.
--refresh-keys-
Refresh the public keys used for dependency verification.
--export-keys-
Exports the public keys used for dependency verification.
Environment options
You can customize many aspects of build scripts, settings, caches, and so on through the options below.
-g,--gradle-user-home-
Specifies the Gradle User Home directory. The default is the
.gradledirectory in the user’s home directory. -p,--project-dir-
Specifies the start directory for Gradle. Defaults to current directory.
--project-cache-dir-
Specifies the project-specific cache directory. Default value is
.gradlein the root project directory. -D,--system-prop-
Sets a system property of the JVM, for example
-Dmyprop=myvalue. -I,--init-script-
Specifies an initialization script.
-P,--project-prop-
Sets a project property of the root project, for example
-Pmyprop=myvalue. -Dorg.gradle.jvmargs-
A Gradle property that sets JVM arguments.
-Dorg.gradle.java.home-
A Gradle property that sets the JDK home dir.
Non-interactive mode
By default, Gradle may prompt the user for input on the console when an interactive terminal is available.
You can disable all interactive prompting by using the --non-interactive command-line option, or by setting the org.gradle.console.interactive Gradle property to false (for example in gradle.properties, GRADLE_OPTS, or via -D).
When interactive prompting is disabled, Gradle uses default values instead of prompting. This is useful for running Gradle in automated environments such as CI pipelines, scripts, and AI agents.
--non-interactiveIncubating-
Do not prompt for user input.
Task options
Tasks may define task-specific options which are different from most of the global options described in the sections above (which are interpreted by Gradle itself, can appear anywhere in the command line, and can be listed using the --help option).
Task options:
-
Are consumed and interpreted by the tasks themselves;
-
Must be specified immediately after the task in the command-line;
-
May be listed using
gradle help --task someTask(see Show task usage details).
To learn how to declare command-line options for your own tasks, see Declaring and Using Command Line Options.
Built-in task options
Built-in task options are options available as task options for all tasks. At this time, the following built-in task options exist:
--rerun-
Causes the task to be rerun even if up-to-date. Similar to
--rerun-tasks, but for a specific task.
Bootstrapping new projects
Creating new Gradle builds
Use the built-in gradle init task to create a new Gradle build, with new or existing projects.
$ gradle initMost of the time, a project type is specified.
Available types include basic (default), java-library, java-application, and more.
See init plugin documentation for details.
$ gradle init --type java-libraryStandardize and provision Gradle
The built-in gradle :wrapper task generates a script, gradlew, that invokes a declared version of Gradle, downloading it beforehand if necessary.
$ ./gradlew :wrapper --gradle-version=8.1You can also specify --distribution-type=(bin|all), --gradle-distribution-url, --gradle-distribution-sha256-sum in addition to --gradle-version.
Full details on using these options are documented in the Gradle wrapper section.
Continuous build
Continuous Build allows you to automatically re-execute the requested tasks when file inputs change.
You can execute the build in this mode using the -t or --continuous command-line option.
Learn more in Continuous Builds.
Logging and Output
The build log is the primary way Gradle communicates what’s happening during a build. Clear logging helps you quickly understand your build status, identify issues, and troubleshoot effectively. Too much noise in the logs can obscure important warnings or errors.
Gradle provides flexible logging controls, enabling you to adjust verbosity and detail according to your needs.
Gradle Log levels
Gradle defines six primary log levels:
| Level | Description |
|---|---|
|
Error messages |
|
Important information messages |
|
Warning messages |
|
Progress information messages |
|
Information messages |
|
Debug messages |
The default logging level is LIFECYCLE, providing progress updates without overwhelming detail.
Choosing and setting a log level
You can set the log level either through command-line options or by configuring the gradle.properties file.
| CLI Option | Property | Outputs Log Levels |
|---|---|---|
|
|
QUIET and higher |
|
|
WARN and higher |
no logging options |
LIFECYCLE and higher |
|
|
|
INFO and higher |
|
|
DEBUG and higher (all log messages) |
For example, to set a consistent log level in your project’s gradle.properties file:
org.gradle.logging.level=infoSimilarly on the command line:
$ ./gradlew run --infoYou can emit log messages directly from build scripts and tasks using Gradle’s built-in logger:
tasks.register("logtask") {
doLast {
logger.lifecycle("Lifecycle: Build progress info.")
logger.info("Info: Additional insights.")
logger.debug("Debug: Detailed troubleshooting info.")
}
}tasks.register('logtask') {
doLast {
logger.lifecycle('Lifecycle: Build progress info.')
logger.info('Info: Additional insights.')
logger.debug('Debug: Detailed troubleshooting info.')
}
}Use appropriate log levels (lifecycle, info, debug) to ensure your build output is clear and informative.
|
Caution
|
The DEBUG log level can expose sensitive security information to the console.
|
Stacktrace options
Stacktraces are useful for diagnosing issues during a build failure. You can control stacktrace output via command-line options or properties:
| CLI Option | Gradle Property | Stacktrace Shown |
|---|---|---|
|
|
Truncated stacktraces are printed. We recommend this over full stacktraces. Groovy full stacktraces are extremely verbose due to the underlying dynamic invocation mechanisms. Yet they usually do not contain relevant information about what has gone wrong in your code. This option renders stacktraces for deprecation warnings. |
|
|
The full stacktraces are printed out. This option renders stacktraces for deprecation warnings. |
(none) |
(none) |
No stacktraces are printed to the console in case of a build error (e.g., a compile error). Only in case of internal exceptions will stacktraces be printed. If the |
For example, to always display a full stacktrace on build errors, set in gradle.properties:
org.gradle.logging.stacktrace=fullLogging Sensitive Information
Running Gradle with the DEBUG log level can potentially expose sensitive information to the console and build log.
This information might include:
-
Environment variables
-
Private repository credentials
-
Build cache and Develocity credentials
-
Plugin Portal publishing credentials
It’s important to avoid using the DEBUG log level when running on public Continuous Integration (CI) services.
Build logs on these services are accessible to the public and can expose sensitive information.
Even on private CI services, logging sensitive credentials may pose a risk depending on your organization’s threat model.
It’s advisable to discuss this with your organization’s security team.
Some CI providers attempt to redact sensitive credentials from logs, but this process is not foolproof and typically only redacts exact matches of pre-configured secrets.
If you suspect that a Gradle Plugin may inadvertently expose sensitive information, please contact our security team for assistance with disclosure.
Custom log messages
A simple option for logging in your build file is to write messages to standard output.
Gradle redirects anything written to standard output to its logging system at the QUIET log level:
println("A message which is logged at QUIET level")println 'A message which is logged at QUIET level'Gradle also provides a logger property to a build script, which is an instance of Logger.
This interface extends the SLF4J Logger interface and adds a few Gradle-specific methods.
Below is an example of how this is used in the build script:
logger.quiet("An info log message which is always logged.")
logger.error("An error log message.")
logger.warn("A warning log message.")
logger.lifecycle("A lifecycle info log message.")
logger.info("An info log message.")
logger.debug("A debug log message.")
logger.trace("A trace log message.") // Gradle never logs TRACE level logslogger.quiet('An info log message which is always logged.')
logger.error('An error log message.')
logger.warn('A warning log message.')
logger.lifecycle('A lifecycle info log message.')
logger.info('An info log message.')
logger.debug('A debug log message.')
logger.trace('A trace log message.') // Gradle never logs TRACE level logsUse the link typical SLF4J pattern to replace a placeholder with an actual value in the log message.
logger.info("A {} log message", "info")logger.info('A {} log message', 'info')You can also hook into Gradle’s logging system from within other classes used in the build (classes from the buildSrc directory, for example) with an SLF4J logger.
You can use this logger the same way as you use the provided logger in the build script.
import org.slf4j.LoggerFactory
val slf4jLogger = LoggerFactory.getLogger("some-logger")
slf4jLogger.info("An info log message logged using SLF4j")import org.slf4j.LoggerFactory
def slf4jLogger = LoggerFactory.getLogger('some-logger')
slf4jLogger.info('An info log message logged using SLF4j')Logging from external tools and libraries
Internally, Gradle uses Ant and Ivy. Both have their own logging system. Gradle redirects their logging output into the Gradle logging system.
There is a 1:1 mapping from the Ant/Ivy log levels to the Gradle log levels, except the Ant/Ivy TRACE log level, which is mapped to the Gradle DEBUG log level.
This means the default Gradle log level will not show any Ant/Ivy output unless it is an error or a warning.
Many tools out there still use the standard output for logging.
By default, Gradle redirects standard output to the QUIET log level and standard error to the ERROR level.
This behavior is configurable.
The project object provides a LoggingManager, which allows you to change the log levels that standard out or error are redirected to when your build script is evaluated.
logging.captureStandardOutput(LogLevel.INFO)
println("A message which is logged at INFO level")logging.captureStandardOutput LogLevel.INFO
println 'A message which is logged at INFO level'To change the log level for standard out or error during task execution, use a LoggingManager.
tasks.register("logInfo") {
logging.captureStandardOutput(LogLevel.INFO)
doFirst {
println("A task message which is logged at INFO level")
}
}tasks.register('logInfo') {
logging.captureStandardOutput LogLevel.INFO
doFirst {
println 'A task message which is logged at INFO level'
}
}Gradle also integrates with the Java Util Logging, Jakarta Commons Logging and Log4j logging toolkits. Any log messages your build classes write using these logging toolkits will be redirected to Gradle’s logging system.
Changing what Gradle logs
|
Warning
|
This feature is deprecated and will be removed in the next major version without a replacement. The configuration cache limits the ability to customize Gradle’s logging UI. The custom logger can only implement supported listener interfaces. These interfaces do not receive events when the configuration cache entry is reused because the configuration phase is skipped. |
You can replace much of Gradle’s logging UI with your own. You could do this if you want to customize the UI somehow - to log more or less information or to change the formatting. Simply replace the logging using the Gradle.useLogger(java.lang.Object) method. This is accessible from a build script, an init script, or via the embedding API. Note that this completely disables Gradle’s default output. Below is an example init script that changes how task execution and build completion are logged:
useLogger(CustomEventLogger())
@Suppress("deprecation")
class CustomEventLogger() : BuildAdapter(), TaskExecutionListener {
override fun beforeExecute(task: Task) {
println("[${task.name}]")
}
override fun afterExecute(task: Task, state: TaskState) {
println()
}
override fun buildFinished(result: BuildResult) {
println("build completed")
if (result.failure != null) {
(result.failure as Throwable).printStackTrace()
}
}
}useLogger(new CustomEventLogger())
@SuppressWarnings("deprecation")
class CustomEventLogger extends BuildAdapter implements TaskExecutionListener {
void beforeExecute(Task task) {
println "[$task.name]"
}
void afterExecute(Task task, TaskState state) {
println()
}
void buildFinished(BuildResult result) {
println 'build completed'
if (result.failure != null) {
result.failure.printStackTrace()
}
}
}$ ./gradlew -I customLogger.init.gradle.kts build> Task :compile
[compile]
compiling source
> Task :testCompile
[testCompile]
compiling test source
> Task :test
[test]
running unit tests
> Task :build
[build]
build completed
3 actionable tasks: 3 executed$ ./gradlew -I customLogger.init.gradle build> Task :compile
[compile]
compiling source
> Task :testCompile
[testCompile]
compiling test source
> Task :test
[test]
running unit tests
> Task :build
[build]
build completed
3 actionable tasks: 3 executedYour logger can implement any of the listener interfaces listed below. When you register a logger, only the logging for the interfaces it implements is replaced. Logging for the other interfaces is left untouched. You can find out more about the listener interfaces in Build lifecycle events.
Gradle Wrapper
The recommended way to execute any Gradle build is with the help of the Gradle Wrapper (referred to as "Wrapper").
The Wrapper is a script (called gradlew or gradlew.bat) that invokes a declared version of Gradle, downloading it beforehand if necessary.
Instead of running gradle build using the installed Gradle, you use the Gradle Wrapper by calling ./gradlew build.
The Gradle Wrapper isn’t distributed as a standalone download—it’s created using the gradle :wrapper task.
There are three ways to use the Wrapper:
-
Adding the Wrapper - You set up a new Gradle project and add the Wrapper to it.
-
Using the Wrapper - You run a project with the Wrapper that already provides it.
-
Upgrading the Wrapper - You upgrade the Wrapper to a new version of Gradle.
When using the Wrapper instead of the installed Gradle, you gain the following benefits:
-
Standardizes a project on a given Gradle version for more reliable and robust builds.
-
Provisioning the Gradle version for different users is done with a simple Wrapper definition change.
-
Provisioning the Gradle version for different execution environments (e.g., IDEs or Continuous Integration servers) is done with a simple Wrapper definition change.
The following sections explain each of these use cases in more detail.
1. Adding the Gradle Wrapper
The Gradle Wrapper is not something you download.
Generating the Wrapper files requires an installed version of the Gradle runtime on your machine as described in Installation. Thankfully, generating the initial Wrapper files is a one-time process.
Every vanilla Gradle build comes with a built-in task called wrapper.
The task is listed under the group "Build Setup tasks" when listing the tasks.
Executing the wrapper task generates the necessary Wrapper files in the project directory:
$ gradle :wrapper> Task :wrapper
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executed|
Tip
|
To make the Wrapper files available to other developers and execution environments, you need to check them into version control. Wrapper files, including the JAR file, are small. Adding the JAR file to version control is expected. Some organizations do not allow projects to submit binary files to version control, and there is no workaround available. |
The generated Wrapper properties file, gradle/wrapper/gradle-wrapper.properties, stores the information about the Gradle distribution:
-
The server hosting the Gradle distribution.
-
The type of Gradle distribution. By default, the
-bindistribution contains only the runtime but no sample code and documentation. -
The Gradle version used for executing the build. By default, the
wrappertask picks the same Gradle version used to generate the Wrapper files. -
Optionally, a timeout in ms used when downloading the Gradle distribution.
-
Optionally, a boolean to set the validation of the distribution URL.
The following is an example of the generated distribution URL in gradle/wrapper/gradle-wrapper.properties:
distributionUrl=https\://services.gradle.org/distributions/gradle-9.6.1-bin.zip|
Tip
|
Use the The |
All of those aspects are configurable at the time of generating the Wrapper files with the help of the following command line options:
--gradle-version-
The Gradle version used for downloading and executing the Wrapper. The resulting distribution URL is validated before it is written to the properties file.
For Gradle versions starting with major version 9, the version can be specified using only the major or minor version number. In such cases, the latest normal release matching that major or minor version will be used. For example,
9resolves to the latest9.x.yrelease, and9.1resolves to the latest9.1.xrelease.The following labels are allowed:
--distribution-type-
The Gradle distribution type used for the Wrapper. Available options are
binandall. The default value isbin. --gradle-distribution-url-
The full URL pointing to the Gradle distribution ZIP file. This option makes
--gradle-versionand--distribution-typeobsolete, as the URL already contains this information. This option is valuable if you want to host the Gradle distribution inside your company’s network. The URL is validated before it is written to the properties file. --gradle-distribution-sha256-sum-
The SHA256 hash sum used for verifying the downloaded Gradle distribution.
--network-timeout-
The network timeout to use when downloading the Gradle distribution, in ms. The default value is
10000. --no-validate-url-
Disables the validation of the configured distribution URL.
--validate-url-
Enables the validation of the configured distribution URL. Enabled by default.
--retries-
The number of retries to attempt when downloading the Gradle distribution. The default value is
0, meaning retrying is disabled, downloading will be attempted a single time. Negative values will be ignored and the default will be used. --retry-back-off-ms-
The initial back off in milliseconds to wait between download retries (if enabled, see
--retries). The delay doubles after each consecutive failure. The default value is500milliseconds, meaning we will wait half a second after the first failed download attempt, 1 second after the second attempt and so on. Negative values will be ignored and the default will be used.
If the distribution URL is configured with --gradle-version or --gradle-distribution-url, the URL is validated by sending a HEAD request in the case of the https scheme or by checking the existence of the file in the case of the file scheme.
Let’s assume the following use-case to illustrate the use of the command line options.
You would like to generate the Wrapper with version 9.6.1 and use the -all distribution to enable your IDE to enable code-completion and being able to navigate to the Gradle source code.
The following command-line execution captures those requirements:
$ gradle :wrapper --gradle-version 9.6.1 --distribution-type all> Task :wrapper
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executedAs a result, you can find the desired information (the generated distribution URL) in the Wrapper properties file:
distributionUrl=https\://services.gradle.org/distributions/gradle-9.6.1-all.zipLet’s have a look at the following project layout to illustrate the expected Wrapper files:
.
├── a-subproject
│ └── build.gradle.kts
├── settings.gradle.kts
├── gradle
│ └── wrapper
│ ├── gradle-wrapper.jar
│ └── gradle-wrapper.properties
├── gradlew
└── gradlew.bat.
├── a-subproject
│ └── build.gradle
├── settings.gradle
├── gradle
│ └── wrapper
│ ├── gradle-wrapper.jar
│ └── gradle-wrapper.properties
├── gradlew
└── gradlew.batA Gradle project typically provides a settings.gradle(.kts) file and one build.gradle(.kts) file for each subproject.
The Wrapper files live alongside in the gradle directory and the root directory of the project.
The following list explains their purpose:
gradle-wrapper.jar-
The Wrapper JAR file containing code for downloading the Gradle distribution.
gradle-wrapper.properties-
A properties file responsible for configuring the Wrapper runtime behavior e.g. the Gradle version compatible with this version. Note that more generic settings, like configuring the Wrapper to use a proxy, need to go into a different file.
gradlew,gradlew.bat-
A shell script and a Windows batch script for executing the build with the Wrapper.
You can go ahead and execute the build with the Wrapper without installing the Gradle runtime. If the project you are working on does not contain those Wrapper files, you will need to generate them.
2. Using the Gradle Wrapper
It is always recommended to execute a build with the Wrapper to ensure a reliable, controlled, and standardized execution of the build.
Using the Wrapper looks like running the build with a Gradle installation.
Depending on the operating system you either run gradlew or gradlew.bat instead of the gradle command.
The following console output demonstrates the use of the Wrapper on a Windows machine for a Java-based project:
$ gradlew.bat buildDownloading https://services.gradle.org/distributions/gradle-5.0-all.zip
.....................................................................................
Unzipping C:\Documents and Settings\Claudia\.gradle\wrapper\dists\gradle-5.0-all\ac27o8rbd0ic8ih41or9l32mv\gradle-5.0-all.zip to C:\Documents and Settings\Claudia\.gradle\wrapper\dists\gradle-5.0-al\ac27o8rbd0ic8ih41or9l32mv
Set executable permissions for: C:\Documents and Settings\Claudia\.gradle\wrapper\dists\gradle-5.0-all\ac27o8rbd0ic8ih41or9l32mv\gradle-5.0\bin\gradle
BUILD SUCCESSFUL in 12s
1 actionable task: 1 executedIf the Gradle distribution was not provisioned to GRADLE_USER_HOME before, the Wrapper will download it and store it in GRADLE_USER_HOME.
Any subsequent build invocation will reuse the existing local distribution as long as the distribution URL in the Gradle properties doesn’t change.
|
Note
|
The Wrapper shell script and batch file reside in the root directory of a single or multi-project Gradle build. You will need to reference the correct path to those files in case you want to execute the build from a subproject directory e.g. ../../gradlew tasks.
|
3. Upgrading the Gradle Wrapper
Projects typically want to keep up with the times and upgrade their Gradle version to benefit from new features and improvements.
The recommended option is to run the wrapper task and provide the target Gradle version as described in Adding the Gradle Wrapper.
Using the wrapper task ensures that any optimizations made to the Wrapper shell script or batch file with that specific Gradle version are applied to the project.
As usual, you should commit the changes to the Wrapper files to version control.
Note that running the wrapper task once will update gradle-wrapper.properties only, but leave the wrapper itself in gradle-wrapper.jar untouched.
This is usually fine as new versions of Gradle can be run even with older wrapper files.
|
Note
|
If you want all the wrapper files to be completely up-to-date, you will need to run the wrapper task a second time.
|
The following command upgrades the Wrapper to the latest version:
$ ./gradlew :wrapper --gradle-version latest // MacOs, Linux$ gradlew.bat :wrapper --gradle-version latest // WindowsBUILD SUCCESSFUL in 4s
1 actionable task: 1 executedThe following command upgrades the Wrapper to a specific version:
$ ./gradlew :wrapper --gradle-version 9.6.1 // MacOs, Linux$ gradlew.bat :wrapper --gradle-version 9.6.1 // WindowsBUILD SUCCESSFUL in 4s
1 actionable task: 1 executedOnce you have upgraded the wrapper, you can check that it’s the version you expected by executing ./gradlew --version.
|
Tip
|
Don’t forget to run the wrapper task again to download the Gradle distribution binaries (if needed) and update the gradlew and gradlew.bat files.
|
Another way to upgrade the Gradle version is by manually changing the distributionUrl property in the Wrapper’s gradle-wrapper.properties file.
The tip above also applies in this case.
|
Note
|
Since Gradle 9.0.0, the version always uses the X.Y.Z format.
Using only the major or minor version is not supported in gradle-wrapper.properties.
|
Customizing the Gradle Wrapper
Most users of Gradle are happy with the default runtime behavior of the Wrapper. However, organizational policies, security constraints or personal preferences might require you to dive deeper into customizing the Wrapper.
Thankfully, the built-in wrapper task exposes numerous options to bend the runtime behavior to your needs.
Most configuration options are exposed by the underlying task type Wrapper.
Let’s assume you grew tired of defining the -all distribution type on the command line every time you upgrade the Wrapper.
You can save yourself some keyboard strokes by re-configuring the wrapper task.
tasks.wrapper {
distributionType = Wrapper.DistributionType.ALL
}tasks.named('wrapper') {
distributionType = Wrapper.DistributionType.ALL
}With the configuration in place, running ./gradlew :wrapper --gradle-version 9.6.1 is enough to produce a distributionUrl value in the Wrapper properties file that will request the -all distribution:
distributionUrl=https\://services.gradle.org/distributions/gradle-9.6.1-all.zipCheck out the API documentation for a more detailed description of the available configuration options. You can also find various samples for configuring the Wrapper in the Gradle distribution.
Authenticated Gradle distribution download
The Gradle Wrapper can download Gradle distributions from servers using HTTP Basic Authentication or with a static HTTP Bearer Token.
This enables you to host the Gradle distribution on a private protected server.
You can specify a username and password in two different ways depending on your use case: as system properties or directly embedded in the distributionUrl.
Credentials in system properties take precedence over the ones embedded in distributionUrl.
|
Tip
|
Any Authentication (HTTP Basic / Bearer Token) should only be used with |
System properties can be specified in the .gradle/gradle.properties file in the user’s home directory or by other means.
To specify the HTTP Basic Authentication credentials, add the following lines to the system properties file:
systemProp.gradle.wrapperUser=username
systemProp.gradle.wrapperPassword=passwordEmbedding credentials in the distributionUrl in the gradle/wrapper/gradle-wrapper.properties file also works.
Please note that this file is to be committed into your source control system.
|
Tip
|
Shared credentials embedded in distributionUrl should only be used in a controlled environment.
|
To specify the HTTP Basic Authentication credentials in distributionUrl, add the following line:
distributionUrl=https://username:password@somehost/path/to/gradle-distribution.zipThis can be used in conjunction with a proxy, authenticated or not.
See Accessing the web via a proxy for more information on how to configure the Wrapper to use a proxy.
|
Warning
|
Using systemProp.gradle.wrapperUser and systemProp.gradle.wrapperPassword may leak your credentials if the build attempts to download the Gradle Wrapper from a server other than your private one.
|
To safeguard your credentials, prefix these system properties with your private server’s hostname, replacing all dots (.) with underscores (_).
|
Note
|
Hostnames are not case-sensitive thus Gradle converts the hostname in the property name into lowercase.
That is, if you wrote EXAMPLE.COM in your wrapper configuration, then you have to use the string
example_com in the system property key.
|
For example, if your private server hostname is your.example.com, use the following system properties:
systemProp.gradle.your_example_com.wrapperUser=username
systemProp.gradle.your_example_com.wrapperPassword=passwordTo authenticate with a static HTTP Bearer Token, add the following line to your Gradle properties file:
systemProp.gradle.your_example_com.wrapperToken=some-api-token|
Note
|
If a wrapperToken is specified, it will take precedence over wrapperUser and wrapperPassword system properties (and also over user & password values embedded in the URL).
It is strongly recommended to include the hostname in the property to prevent the token from being sent to an unintended server by accident.
|
Configuring Wrapper Retries
The Gradle Wrapper can be configured to automatically retry downloading the Gradle distribution. This is useful in environments with unstable network connections.
You can configure the number of retries and the back off between attempts in the gradle-wrapper.properties file:
retries=3
retryBackOffMs=1000 # initial delay; doubles on each subsequent failureVerification of downloaded Gradle distributions
The Gradle Wrapper allows for verification of the downloaded Gradle distribution via SHA-256 hash sum comparison. This increases security against targeted attacks by preventing a man-in-the-middle attacker from tampering with the downloaded Gradle distribution.
To enable this feature, download the .sha256 file associated with the Gradle distribution you want to verify.
Downloading the SHA-256 file
You can download the .sha256 file from the stable releases or release candidate and nightly releases.
The format of the file is a single line of text that is the SHA-256 hash of the corresponding zip file.
You can also reference the list of Gradle distribution checksums.
Configuring checksum verification
Add the downloaded (SHA-256 checksum) hash sum to gradle-wrapper.properties using the distributionSha256Sum property or use --gradle-distribution-sha256-sum on the command-line:
distributionSha256Sum=371cb9fbebbe9880d147f59bab36d61eee122854ef8c9ee1ecf12b82368bcf10Gradle will report a build failure if the configured checksum does not match the checksum found on the server hosting the distribution. Checksum verification is only performed if the configured Wrapper distribution hasn’t been downloaded yet.
|
Note
|
The Wrapper task fails if gradle-wrapper.properties contains distributionSha256Sum, but the task configuration does not define a sum.
Executing the Wrapper task preserves the distributionSha256Sum configuration when the Gradle version does not change.
|
Verifying the integrity of the Gradle Wrapper JAR
The Wrapper JAR is a binary file that will be executed on the computers of developers and build servers. As with all such files, you should ensure it’s trustworthy before executing it.
Since the Wrapper JAR is usually checked into a project’s version control system, there is the potential for a malicious actor to replace the original JAR with a modified one by submitting a pull request that only upgrades the Gradle version.
To verify the integrity of the Wrapper JAR, Gradle has created a GitHub Action that automatically checks Wrapper JARs in pull requests against a list of known good checksums.
Gradle also publishes the checksums of all releases (except for version 3.3 to 4.0.2, which did not generate reproducible JARs), so you can manually verify the integrity of the Wrapper JAR.
Automatically verifying the Gradle Wrapper JAR on GitHub
The GitHub Action is released separately from Gradle, so please check its documentation for how to apply it to your project.
Manually verifying the Gradle Wrapper JAR
You can manually verify the checksum of the Wrapper JAR to ensure that it has not been tampered with by running the following commands on one of the major operating systems.
Manually verifying the checksum of the Wrapper JAR on Linux:
$ cd gradle/wrapper$ curl --location --output gradle-wrapper.jar.sha256 \
https://services.gradle.org/distributions/gradle-9.6.1-wrapper.jar.sha256$ echo " gradle-wrapper.jar" >> gradle-wrapper.jar.sha256$ sha256sum --check gradle-wrapper.jar.sha256gradle-wrapper.jar: OKManually verifying the checksum of the Wrapper JAR on macOS:
$ cd gradle/wrapper$ curl --location --output gradle-wrapper.jar.sha256 \
https://services.gradle.org/distributions/gradle-9.6.1-wrapper.jar.sha256$ echo " gradle-wrapper.jar" >> gradle-wrapper.jar.sha256$ sha256sum --check gradle-wrapper.jar.sha256gradle-wrapper.jar: OKManually verifying the checksum of the Wrapper JAR on Windows (using PowerShell):
> $expected = Invoke-RestMethod -Uri https://services.gradle.org/distributions/gradle-9.6.1-wrapper.jar.sha256> $actual = (Get-FileHash gradle\wrapper\gradle-wrapper.jar -Algorithm SHA256).Hash.ToLower()> @{$true = 'OK: Checksum match'; $false = "ERROR: Checksum mismatch!`nExpected: $expected`nActual: $actual"}[$actual -eq $expected]OK: Checksum matchTroubleshooting a checksum mismatch
If the checksum does not match the one you expected, chances are the wrapper task wasn’t executed with the upgraded Gradle distribution.
You should first check whether the actual checksum matches a different Gradle version.
Here are the commands you can run on the major operating systems to generate the actual checksum of the Wrapper JAR.
Generating the checksum of the Wrapper JAR on Linux:
$ sha256sum gradle/wrapper/gradle-wrapper.jar
d81e0f23ade952b35e55333dd5f1821585e887c6d24305aeea2fbc8dad564b95 gradle/wrapper/gradle-wrapper.jarGenerating the actual checksum of the Wrapper JAR on macOS:
$ sha256sum gradle/wrapper/gradle-wrapper.jar
d81e0f23ade952b35e55333dd5f1821585e887c6d24305aeea2fbc8dad564b95 gradle/wrapper/gradle-wrapper.jarGenerating the actual checksum of the Wrapper JAR on Windows (using PowerShell):
> (Get-FileHash gradle\wrapper\gradle-wrapper.jar -Algorithm SHA256).Hash.ToLower()
d81e0f23ade952b35e55333dd5f1821585e887c6d24305aeea2fbc8dad564b95Once you know the actual checksum, check whether it’s listed on https://gradle.org/release-checksums/.
If it is listed, you have verified the integrity of the Wrapper JAR.
If the version of Gradle that generated the Wrapper JAR doesn’t match the version in gradle/wrapper/gradle-wrapper.properties, it’s safe to run the wrapper task again to update the Wrapper JAR.
If the checksum is not listed on the page, the Wrapper JAR might be from a milestone, release candidate, or nightly build or may have been generated by Gradle 3.3 to 4.0.2. Try to find out how it was generated but treat it as untrustworthy until proven otherwise. If you think the Wrapper JAR was compromised, please let the Gradle team know by sending an email to security@gradle.com.
Gradle Daemon
The Gradle Daemon is a long-lived, persistent process that runs in the background and hosts Gradle’s execution engine. It dramatically reduces build times using caching, runtime optimizations, and eliminating JVM startup overhead.
The Gradle Client vs. the Gradle Daemon
To run any Gradle command, your system starts two separate Java Virtual Machine (JVM) processes, which can use different Java versions.
Understanding their distinct roles and how their respective JVM versions are determined is key to effective build configuration and debugging:
| Process | Role | JVM Version Source |
|---|---|---|
Gradle Client JVM |
Process that starts when you run |
Uses the JVM that launches the wrapper script (e.g. |
Gradle Daemon JVM |
Long-lived process that executes the build and caches state between runs. |
Uses the JVM set by: |
*Gradle reuses an existing daemon only if its Java home/version and JVM args (e.g., org.gradle.jvmargs, GRADLE_OPTS) are identical.
Changing JVM args (like increasing memory) will spawn a new daemon. In the rare case where the daemon has been disabled (--no-daemon or -Dorg.gradle.daemon=false) and the Client process is compatible, the Gradle Daemon uses the JVM that launched the Gradle Client.
Understanding the Daemon
A daemon is a computer program that runs as a background process rather than being under the direct control of an interactive user.
Gradle runs on the Java Virtual Machine (JVM) and uses several supporting libraries with non-trivial initialization time. Startups can be slow. The Gradle Daemon solves this problem.
The Gradle Daemon is a long-lived background process that reduces the time it takes to run a build.
The Gradle Daemon reduces build times by:
-
Caching project information across builds
-
Running in the background so every Gradle build doesn’t have to wait for JVM startup
-
Benefiting from continuous runtime optimization in the JVM
-
Watching the file system to calculate exactly what needs to be rebuilt before you run a build
The Gradle Client sends the Gradle Daemon build information such as command line arguments, project directories, and environment variables so that it can run the build. The Daemon is responsible for resolving dependencies, executing build scripts, creating and running tasks; when it is done, it sends the client the output. Communication between the client and the Daemon happens via a local socket connection.
Daemons use the JVM’s default minimum heap size.
If the requested build environment does not specify a maximum heap size, the Daemon uses up to 512MB of heap. 512MB is adequate for most builds. Larger builds with hundreds of subprojects, configuration, and source code may benefit from a larger heap size.
Check Daemon status
To get a list of running Daemons and their statuses, use the --status command:
$ gradle --status PID STATUS INFO
28486 IDLE 7.5
34247 BUSY 7.5Currently, a given Gradle version can only connect to Daemons of the same version. This means the status output only shows Daemons spawned running the same version of Gradle as the current project.
Find Daemons
If you have installed the Java Development Kit (JDK), you can view live daemons with the jps command.
$ jps33920 Jps
27171 GradleDaemon
22792Live Daemons appear under the name GradleDaemon.
Because this command uses the JDK, you can view Daemons running any version of Gradle.
Enable Daemon
Gradle enables the Daemon by default since Gradle 3.0.
If your project doesn’t use the Daemon, you can enable it for a single build with the --daemon flag when you run a build:
$ gradle <task> --daemonThis flag overrides any settings that disable the Daemon in your project or user gradle.properties files.
To enable the Daemon by default in older Gradle versions, add the following setting to the gradle.properties file in the project root or your Gradle User Home (GRADLE_USER_HOME):
org.gradle.daemon=trueDisable Daemon
You can disable the Daemon in multiple ways but there are important considerations:
- Single-use Daemon
-
If the JVM args of the client process don’t match what the build requires, a single-used Daemon (disposable JVM) is created. This means the Daemon is required for the build, so it is created, used, and then stopped at the end of the build.
- No Daemon
-
If the
JAVA_OPTSandGRADLE_OPTSmatchorg.gradle.jvmargs, the Daemon will not be used at all since the build happens in the client JVM.
Disable for a build
To disable the Daemon for a single build, pass the --no-daemon flag when you run a build:
$ gradle <task> --no-daemonThis flag overrides any settings that enable the Daemon in your project including the gradle.properties files.
Disable for a project
To disable the Daemon for all builds of a project, add org.gradle.daemon=false to the gradle.properties file in the project root.
Disable for a user
On Windows, this command disables the Daemon for the current user:
(if not exist "%USERPROFILE%/.gradle" mkdir "%USERPROFILE%/.gradle") && (echo. >> "%USERPROFILE%/.gradle/gradle.properties" && echo org.gradle.daemon=false >> "%USERPROFILE%/.gradle/gradle.properties")On UNIX-like operating systems, the following Bash shell command disables the Daemon for the current user:
mkdir -p ~/.gradle && echo "org.gradle.daemon=false" >> ~/.gradle/gradle.propertiesDisable globally
There are two recommended ways to disable the Daemon globally across an environment:
-
add
org.gradle.daemon=falseto the$GRADLE_USER_HOME/gradle.properties` file -
add the flag
-Dorg.gradle.daemon=falseto theGRADLE_OPTSenvironment variable
Don’t forget to make sure your JVM arguments and GRADLE_OPTS / JAVA_OPTS match if you want to completely disable the Daemon and not simply invoke a single-use one.
Stop Daemon
It can be helpful to stop the Daemon when troubleshooting or debugging a failure.
Daemons automatically stop given any of the following conditions:
-
Available system memory is low
-
Daemon has been idle for 3 hours
To stop running Daemon processes, use the following command:
$ gradle --stopThis terminates all Daemon processes started with the same version of Gradle used to execute the command.
You can also kill Daemons manually with your operating system. To find the PIDs for all Daemons regardless of Gradle version, see Find Daemons.
Troubleshooting the Daemon
The Gradle Daemon is a long-lived background process, as such, it can sometimes encounter issues.
If builds start behaving unexpectedly, try stopping and restarting the Daemon:
$ gradle --stopIf you see a warning like: Multiple Gradle daemons might be spawned because the Gradle JDK and JAVA_HOME locations are different.
Gradle is telling you that it’s using more than one Java version across your environment. This can lead to multiple daemons being started, increasing memory usage unnecessarily.
To resolve this, make sure your Java versions match across:
-
Your environment (
JAVA_HOME) -
Your build script (if using toolchains)
-
Your IDE’s configured JDK
To check JAVA_HOME, run this in your terminal:
echo $JAVA_HOMEYour project may be using a specific toolchain in your build.gradle(.kts) file.
Check for similar code:
java {
toolchain {
languageVersion = JavaLanguageVersion.of(11)
}
}If your build uses a toolchain, ensure it matches the JAVA_HOME value, or at least know they differ intentionally.
You should also check your IDE settings to make sure they match as well.
Daemon Logs
The Gradle Daemon writes detailed log files to help diagnose build issues and understand daemon behavior.
These logs are stored in the Gradle User Home directory under daemon/<gradle-version>/:
~/.gradle/daemon/9.4.0/
├── daemon-<pid>.out.log
├── daemon-<pid>.out.log
└── registry.binEach daemon process creates its own log file named daemon-<pid>.out.log, where <pid> is the process ID of that daemon instance.
Automatic Log Cleanup
Gradle automatically cleans up old daemon logs to prevent the daemon directory from growing indefinitely.
By default, daemon logs older than 14 days are deleted during build execution as part of Gradle’s periodic cache cleanup. This cleanup runs alongside other cache cleanup operations.
The cleanup is triggered during builds:
-
In the background between builds when using the daemon (default behavior)
-
In the foreground after the build when using
--no-daemon
The 14-day retention period for daemon logs can be configured via an init script, just like other cache retention periods. See Configuring cleanup of caches and distributions for configuration examples.
Daemon JVM Toolchains
By default, the Gradle Daemon runs with the same JVM installation that started the build.
Gradle defaults to the current shell path and JAVA_HOME environment variable to locate a usable JVM.
Alternatively, a different JVM installation can be specified for the build using the org.gradle.java.home Gradle property or programmatically through the Tooling API.
Building on the toolchain feature, you can now use declarative criteria to specify the JVM requirements for the build.
If the Daemon JVM criteria configuration is provided, it takes precedence over JAVA_HOME and org.gradle.java.home.
Daemon JVM criteria
The Daemon JVM criteria is controlled by the updateDaemonJvm task, similar to how the wrapper task updates the wrapper properties file.
|
Warning
|
This process requires toolchain download repositories to be configured. See below for details. |
When the task runs, it creates or updates the criteria in the gradle/gradle-daemon-jvm.properties file.
To configure the generation, you can use command line options:
$ ./gradlew updateDaemonJvm --jvm-version=17Or configure the task in the build script of the root project:
tasks.named<UpdateDaemonJvm>("updateDaemonJvm") {
languageVersion = JavaLanguageVersion.of(17)
}tasks.named("updateDaemonJvm") {
languageVersion = JavaLanguageVersion.of(17)
}And then run the task:
$ ./gradlew updateDaemonJvmBoth of these actions will produce a file like the following one:
#This file is generated by updateDaemonJvm
toolchainUrl.FREE_BSD.AARCH64=https\://example.com/...
toolchainUrl.FREE_BSD.X86_64=https\://example.com/...
toolchainUrl.LINUX.AARCH64=https\://example.com/...
toolchainUrl.LINUX.X86_64=https\://example.com/...
toolchainUrl.MAC_OS.AARCH64=https\://example.com/...
toolchainUrl.MAC_OS.X86_64=https\://example.com/...
toolchainUrl.UNIX.AARCH64=https\://example.com/...
toolchainUrl.UNIX.X86_64=https\://example.com/...
toolchainUrl.WINDOWS.X86_64=https\://example.com/...
toolchainVersion=17If you run the updateDaemonJvm task without any arguments, and the properties file does not exist, then the version of the current JVM used by the Daemon will be used.
On the next execution of the build, the Gradle client will use this file to locate a compatible JVM installation and start the Daemon with it.
Similar to the wrapper, the generated gradle-daemon-jvm.properties file should be checked into version control.
This ensures that any developer or CI server running the build will use the same JVM version.
Specifying a JVM vendor
The JVM vendor, like the JVM version, can be used as a criteria to select a compatible JVM installation for the build. If no vendor is specified, Gradle considers all vendors compatible.
By default, running updateDaemonJvm to create the gradle-daemon-jvm.properties file will not generate a JVM vendor criteria.
To specify a vendor, either configure it in the build script, using the same syntax as the Java toolchain spec, or pass it on the command line:
$ ./gradlew updateDaemonJvm --jvm-version=17 --jvm-vendor=adoptiumList of recognized vendors:
| Known Vendors | Acceptable Strings | toolchainVendor Value |
|---|---|---|
Adoptium / Eclipse Temurin |
|
ADOPTIUM |
AdoptOpenJDK |
|
ADOPTOPENJDK |
Amazon Corretto |
|
AMAZON |
Apple |
|
APPLE |
Azul Zulu |
|
AZUL |
BellSoft |
|
BELLSOFT |
GraalVM |
|
GRAAL_VM |
Hewlett Packard |
|
HEWLETT_PACKARD |
IBM |
|
IBM |
JetBrains |
|
JETBRAINS |
Microsoft |
|
MICROSOFT |
Oracle |
|
ORACLE |
SAP |
|
SAP |
Tencent |
|
TENCENT |
Some vendors will be recognized from more than one set of characters.
All vendor strings are case-insensitive.
You can view the list of recognized vendors by running ./gradlew help --task updateDaemonJvm.
If the specified vendor is not one of the recognized equivalents, Gradle will match it exactly. For example, "MyCustomJVM" would require an exact match of the vendor name.
Requesting a native-image capable JDK
Both the CLI options and the task configuration allow to request a JDK that is native-image capable.
$ ./gradlew updateDaemonJvm --jvm-version=17 --native-image-capableSee the toolchain documentation section for more information.
Auto-detection and auto-provisioning
The Daemon JVM is auto-detected using the same logic as project JVM toolchains.
With auto-provisioning, the logic is simpler, as Gradle can only look up a download URL matching the platform inside the gradle-daemon-jvm.properties file.
The URL is then used to download a JDK if none can be found locally.
The properties used for disabling auto-detection and auto-provisioning affect the Daemon toolchain resolution logic:
org.gradle.java.installations.auto-detect=false
org.gradle.java.installations.auto-download=falseConfiguring provisioning URLs
|
Note
|
There are currently no CLI options for configuring this. |
By default, the updateDaemonJvm task attempts to generate download URLs for JDKs on various platforms (OS and architecture) that match the specified criteria.
Gradle needs to consider more than the current running platform as the build could be run on different platforms.
Gradle sets, by convention, build platforms based on architectures X86_64 and AARCH64 for the following operating systems:
These platforms can be configured through the toolchainPlatforms property of the UpdateDaemonJvm task.
tasks.named<UpdateDaemonJvm>("updateDaemonJvm") {
val myPlatforms = mutableListOf(
BuildPlatformFactory.of(
org.gradle.platform.Architecture.AARCH64,
org.gradle.platform.OperatingSystem.MAC_OS
)
)
toolchainPlatforms.set(myPlatforms)
}tasks.named("updateDaemonJvm") {
def myPlatforms = [
BuildPlatformFactory.of(
org.gradle.platform.Architecture.AARCH64,
org.gradle.platform.OperatingSystem.MAC_OS
)
]
toolchainPlatforms.set(myPlatforms)
}Gradle resolves JDK download URLs for these platforms by using the configured toolchain download repositories.
If no such repositories are configured and the toolchainPlatforms property has at least one value, the updateDaemonJvm task will fail.
Alternatively, users can directly configure the JDK URLs for specific platforms using the toolchainDownloadUrls property.
This property is a Map<BuildPlatform, URI> and can be configured as shown in the following example:
tasks.named<UpdateDaemonJvm>("updateDaemonJvm") {
toolchainDownloadUrls = mapOf(
BuildPlatformFactory.of(org.gradle.platform.Architecture.AARCH64, org.gradle.platform.OperatingSystem.MAC_OS) to uri("https://server?platform=MAC_OS.AARCH64"),
BuildPlatformFactory.of(org.gradle.platform.Architecture.AARCH64, org.gradle.platform.OperatingSystem.WINDOWS) to uri("https://server?platform=WINDOWS.AARCH64")
)
}tasks.named("updateDaemonJvm") {
toolchainDownloadUrls = [(BuildPlatformFactory.of(org.gradle.platform.Architecture.AARCH64, org.gradle.platform.OperatingSystem.MAC_OS)) : uri("https://server?platform=MAC_OS.AARCH64"),
(BuildPlatformFactory.of(org.gradle.platform.Architecture.AARCH64, org.gradle.platform.OperatingSystem.WINDOWS)) : uri("https://server?platform=WINDOWS.AARCH64")]
}|
Tip
|
A full package name is required for org.gradle.platform.Architecture and org.gradle.platform.OperatingSystem due to a naming conflict with other types in different packages, which are resolved first alphabetically.
|
Running ./gradlew updateDaemonJvm produces the following:
#This file is generated by updateDaemonJvm
toolchainUrl.MAC_OS.AARCH64=https\://server?platform\=MAC_OS.AARCH64
toolchainUrl.WINDOWS.AARCH64=https\://server?platform\=WINDOWS.AARCH64
toolchainVersion=17If you want to disable the generation of URLs by the updateDaemonJvm task:
tasks.named<UpdateDaemonJvm>("updateDaemonJvm") {
toolchainDownloadUrls.empty()
}tasks.named("updateDaemonJvm") {
toolchainPlatforms = []
}Removing all platforms means that there is no longer a need for the toolchain download repositories to be configured.
Tools & IDEs
The Gradle Tooling API used by IDEs and other tools to integrate with Gradle always uses the Gradle Daemon to execute builds. If you execute Gradle builds from within your IDE, you already use the Gradle Daemon. There is no need to enable it for your environment.
Continuous Integration
We recommend using the Daemon for developer machines and Continuous Integration (CI) servers.
Compatibility
Gradle starts a new Daemon if no idle or compatible Daemons exist.
The following values determine compatibility:
-
Requested build environment, including the following:
-
Java version
-
JVM attributes
-
JVM properties
-
-
Gradle version
Compatibility is based on exact matches of these values. For example:
-
If a Daemon is available with a Java 8 runtime, but the requested build environment calls for Java 10, then the Daemon is not compatible.
-
If a Daemon is available running Gradle 7.0, but the current build uses Gradle 7.4, then the Daemon is not compatible.
Certain properties of a Java runtime are immutable: they cannot be changed once the JVM has started. The following JVM system properties are immutable:
-
file.encoding -
user.language -
user.country -
user.variant -
java.io.tmpdir -
javax.net.ssl.keyStore -
javax.net.ssl.keyStorePassword -
javax.net.ssl.keyStoreType -
javax.net.ssl.trustStore -
javax.net.ssl.trustStorePassword -
javax.net.ssl.trustStoreType -
com.sun.management.jmxremote
The following JVM attributes controlled by startup arguments are also immutable:
-
The maximum heap size (the
-XmxJVM argument) -
The minimum heap size (the
-XmsJVM argument) -
The boot classpath (the
-Xbootclasspathargument) -
The "assertion" status (the
-eaargument)
If the requested build environment requirements for any of these properties and attributes differ from the Daemon’s JVM requirements, the Daemon is not compatible.
|
Note
|
For more information about build environments, see the build environment documentation. |
Performance Impact
The Daemon can reduce build times by 15-75% when you build the same project repeatedly.
In between builds, the Daemon waits idly for the next build. As a result, your machine only loads Gradle into memory once for multiple builds instead of once per build. This is a significant performance optimization.
Runtime Code Optimizations
The JVM gains significant performance from runtime code optimization: optimizations applied to code while it runs.
JVM implementations like OpenJDK’s Hotspot progressively optimize code during execution. Consequently, subsequent builds can be faster purely due to this optimization process.
With the Daemon, perceived build times can drop dramatically between a project’s 1st and 10th builds.
Memory Caching
The Daemon enables in-memory caching across builds. This includes classes for plugins and build scripts.
Similarly, the Daemon maintains in-memory caches of build data, such as the hashes of task inputs and outputs for incremental builds.
Performance Monitoring
Gradle actively monitors heap usage to detect memory leaks in the Daemon.
When a memory leak exhausts available heap space, the Daemon:
-
Finishes the currently running build.
-
Restarts before running the next build.
Gradle enables this monitoring by default.
To disable this monitoring, set the org.gradle.daemon.performance.enable-monitoring Daemon option to false.
You can do this on the command line with the following command:
$ gradle <task> -Dorg.gradle.daemon.performance.enable-monitoring=falseOr you can configure the property in the gradle.properties file in the project root or your GRADLE_USER_HOME (Gradle User Home):
org.gradle.daemon.performance.enable-monitoring=falseGradle-managed Directories
Gradle uses two main directories to perform and manage its work:
1. Gradle User Home directory
By default, the Gradle User Home (~/.gradle or C:\Users\<USERNAME>\.gradle) stores global configuration properties, initialization scripts, caches, and log files.
It can be set with the environment variable GRADLE_USER_HOME.
|
Tip
|
Not to be confused with the GRADLE_HOME, the optional installation directory for Gradle.
|
It is roughly structured as follows:
├── caches // (1)
│ ├── 4.8 // (2)
│ ├── 9.2.0 // (2)
│ ├── ⋮
│ ├── jars-3 // (3)
│ └── modules-2 // (3)
├── daemon // (4)
│ ├── ⋮
│ ├── 4.8
│ └── 9.2.0
├── init.d // (5)
│ └── my-setup.gradle
├── jdks // (6)
│ ├── ⋮
│ └── jdk-14.0.2+12
├── wrapper
│ └── dists // (7)
│ ├── ⋮
│ ├── gradle-4.8-bin
│ ├── gradle-9.2.0-all
│ └── gradle-9.2.0-bin
└── gradle.properties // (8)-
Global cache directory (for everything that is not project-specific).
-
Version-specific caches (e.g., to support incremental builds).
-
Shared caches (e.g., for artifacts of dependencies).
-
Registry and logs of the Gradle Daemon.
-
Global initialization scripts.
-
JDKs downloaded by the toolchain support.
-
Distributions downloaded by the Gradle Wrapper.
-
Global Gradle configuration properties.
Cleanup of caches and distributions
Gradle automatically cleans its user home directory.
By default, the cleanup runs in the background when the Gradle daemon is stopped or shut down.
If using --no-daemon, it runs in the foreground after the build session.
The following cleanup strategies are applied periodically (by default, once every 24 hours):
-
Version-specific caches in all
caches/<GRADLE_VERSION>/directories are checked for whether they are still in use.If not, directories for release versions are deleted after 30 days of inactivity, and snapshot versions after 7 days.
-
Shared caches in
caches/(e.g.,jars-*) are checked for whether they are still in use.If no Gradle version still uses them, they are deleted.
-
Files in shared caches used by the current Gradle version in
caches/(e.g.,jars-3ormodules-2) are checked for when they were last accessed.Depending on whether the file can be recreated locally or downloaded from a remote repository, it will be deleted after 7 or 30 days, respectively.
-
Gradle distributions in
wrapper/dists/are checked for whether they are still in use, i.e., whether there’s a corresponding version-specific cache directory.Unused distributions are deleted.
-
Daemon log files in
daemon/<GRADLE_VERSION>/directories are checked for their last modification time.Log files older than 14 days are automatically deleted to prevent the daemon directory from growing indefinitely.
Configuring cleanup of caches and distributions
The retention periods of the various caches can be configured.
Caches are classified into six categories:
-
Released wrapper distributions: Distributions and related version-specific caches corresponding to released versions (e.g.,
4.6.2or8.0).Default retention for unused versions is 30 days.
-
Snapshot wrapper distributions: Distributions and related version-specific caches corresponding to snapshot versions (e.g.
7.6-20221130141522+0000).Default retention for unused versions is 7 days.
-
Downloaded resources: Shared caches downloaded from a remote repository (e.g., cached dependencies).
Default retention for unused resources is 30 days.
-
Created resources: Shared caches that Gradle creates during a build (e.g., artifact transforms).
Default retention for unused resources is 7 days.
-
Build cache: The local build cache (e.g., build-cache-1).
Default retention for unused build cache entries is 7 days.
-
Daemon logs: Log files from Gradle Daemon processes in
daemon/<GRADLE_VERSION>/directories.Default retention for daemon logs is 14 days.
The retention period for each category can be configured independently via an init script in the Gradle User Home:
beforeSettings {
caches {
releasedWrappers.setRemoveUnusedEntriesAfterDays(45)
snapshotWrappers.setRemoveUnusedEntriesAfterDays(10)
downloadedResources.setRemoveUnusedEntriesAfterDays(45)
createdResources.setRemoveUnusedEntriesAfterDays(10)
buildCache.setRemoveUnusedEntriesAfterDays(5)
daemonLogs.setRemoveUnusedEntriesAfterDays(14)
}
}beforeSettings { settings ->
settings.caches {
releasedWrappers.removeUnusedEntriesAfterDays = 45
snapshotWrappers.removeUnusedEntriesAfterDays = 10
downloadedResources.removeUnusedEntriesAfterDays = 45
createdResources.removeUnusedEntriesAfterDays = 10
buildCache.removeUnusedEntriesAfterDays = 5
daemonLogs.removeUnusedEntriesAfterDays = 14
}
}The frequency at which cache cleanup is invoked is also configurable.
There are three possible settings:
-
DEFAULT: Cleanup is performed periodically in the background (currently once every 24 hours).
-
DISABLED: Never cleanup Gradle User Home.
This is useful in cases where Gradle User Home is ephemeral or delaying cleanup is desirable until an explicit point.
-
ALWAYS: Cleanup is performed at the end of each build session.
This is useful in cases where it’s desirable to ensure that cleanup has occurred before proceeding.
However, this performs cache cleanup during the build (rather than in the background), which can be expensive, so this option should only be used when necessary.
To disable cache cleanup:
beforeSettings {
caches {
cleanup = Cleanup.DISABLED
}
}beforeSettings { settings ->
settings.caches {
cleanup = Cleanup.DISABLED
}
}|
Note
|
Cache cleanup settings can only be configured via init scripts and should be placed under the init.d directory in Gradle User Home.
This effectively couples the configuration of cache cleanup to the Gradle User Home those settings apply to and limits the possibility of different conflicting settings from different projects being applied to the same directory.
|
Multiple versions of Gradle sharing a Gradle User Home
It is common to share a single Gradle User Home between multiple versions of Gradle.
As stated above, caches in Gradle User Home are version-specific. Different versions of Gradle will perform maintenance on only the version-specific caches associated with each version.
On the other hand, some caches are shared between versions (e.g., the dependency artifact cache or the artifact transform cache).
Beginning with Gradle version 8.0, the cache cleanup settings can be configured to custom retention periods. However, older versions have fixed retention periods (7 or 30 days, depending on the cache). These shared caches could be accessed by versions of Gradle with different settings to retain cache artifacts.
This means that:
-
If the retention period is not customized, all versions that perform cleanup will have the same retention periods. There will be no effect due to sharing a Gradle User Home with multiple versions.
-
If the retention period is customized for Gradle versions greater than or equal to version 8.0 to use retention periods shorter than the previously fixed periods, there will also be no effect.
The versions of Gradle aware of these settings will cleanup artifacts earlier than the previously fixed retention periods, and older versions will effectively not participate in the cleanup of shared caches.
-
If the retention period is customized for Gradle versions greater than or equal to version 8.0 to use retention periods longer than the previously fixed periods, the older versions of Gradle may clean the shared caches earlier than what is configured.
In this case, if it is desirable to maintain these shared cache entries for newer versions for longer retention periods, they will not be able to share a Gradle User Home with older versions. They will need to use a separate directory.
Another consideration when sharing the Gradle User Home with versions of Gradle before version 8.0 is that the DSL elements to configure the cache retention settings are unavailable in earlier versions, so this must be accounted for in any init script shared between versions. This can easily be handled by conditionally applying a version-compliant script.
|
Note
|
The version-compliant script should reside somewhere other than the init.d directory (such as a sub-directory), so it is not automatically applied.
|
To configure cache cleanup in a version-safe manner:
if (GradleVersion.current() >= GradleVersion.version("8.0")) {
apply(from = "gradle8/cache-settings.init.gradle.kts")
}if (GradleVersion.current() >= GradleVersion.version('8.0')) {
apply from: "gradle8/cache-settings.init.gradle"
}Version-compliant cache configuration script:
beforeSettings {
caches {
releasedWrappers { setRemoveUnusedEntriesAfterDays(45) }
snapshotWrappers { setRemoveUnusedEntriesAfterDays(10) }
downloadedResources { setRemoveUnusedEntriesAfterDays(45) }
createdResources { setRemoveUnusedEntriesAfterDays(10) }
buildCache { setRemoveUnusedEntriesAfterDays(5) }
}
}beforeSettings { settings ->
settings.caches {
releasedWrappers.removeUnusedEntriesAfterDays = 45
snapshotWrappers.removeUnusedEntriesAfterDays = 10
downloadedResources.removeUnusedEntriesAfterDays = 45
createdResources.removeUnusedEntriesAfterDays = 10
buildCache.removeUnusedEntriesAfterDays = 5
}
}Cache marking
Beginning with Gradle version 8.1, Gradle supports marking caches with a CACHEDIR.TAG file.
It follows the format described in the Cache Directory Tagging Specification. The purpose of this file is to allow tools to identify the directories that do not need to be searched or backed up.
By default, the directories caches, wrapper/dists, daemon, and jdks in the Gradle User Home are marked with this file.
Configuring cache marking
The cache marking feature can be configured via an init script in the Gradle User Home:
beforeSettings {
caches {
// Disable cache marking for all caches
markingStrategy = MarkingStrategy.NONE
}
}beforeSettings { settings ->
settings.caches {
// Disable cache marking for all caches
markingStrategy = MarkingStrategy.NONE
}
}|
Note
|
Cache marking settings can only be configured via init scripts and should be placed under the init.d directory in Gradle User Home. This effectively couples the configuration of cache marking to the Gradle User Home to which those settings apply and limits the possibility of different conflicting settings from different projects being applied to the same directory.
|
2. Project Root directory
The project root directory contains all source files from your project.
It also contains files and directories Gradle generates, such as .gradle and build.
While the former are usually checked into source control, the latter are transient files Gradle uses to support features like incremental builds.
The anatomy of a typical project root directory looks as follows:
├── .gradle // (1)
│ ├── 4.8 // (2)
│ ├── 4.9 // (2)
│ └── ⋮
├── build // (3)
├── gradle
│ └── wrapper // (4)
├── gradle.properties // (5)
├── gradlew // (6)
├── gradlew.bat // (6)
├── settings.gradle.kts // (7)
├── subproject-one // (8)
| └── build.gradle.kts // (9)
├── subproject-two // (8)
| └── build.gradle.kts // (9)
└── ⋮-
Project-specific cache directory generated by Gradle.
-
Version-specific caches (e.g., to support incremental builds).
-
The build directory of this project into which Gradle generates all build artifacts.
-
Contains the JAR file and configuration of the Gradle Wrapper.
-
Project-specific Gradle configuration properties.
-
Scripts for executing builds using the Gradle Wrapper.
-
The project’s settings file where the list of subprojects is defined.
-
Usually, a project is organized into one or multiple subprojects.
-
Each subproject has its own Gradle build script.
Project cache cleanup
From version 4.10 onwards, Gradle automatically cleans the project-specific cache directory.
After building the project, version-specific cache directories in .gradle/9.6.1/ are checked periodically (at most, every 24 hours) to determine whether they are still in use.
They are deleted if they haven’t been used for 7 days.
Next Step: Learn about the Gradle Build Lifecycle >>
Build Environment Configuration
Configuring the build environment is a powerful way to customize the build process. There are many mechanisms available. By leveraging these mechanisms, you can make your Gradle builds more flexible and adaptable to different environments and requirements.
Available mechanisms
Gradle provides multiple mechanisms for configuring the behavior of Gradle itself and specific projects:
| Mechanism | Information | Example |
|---|---|---|
Flags that configure build behavior and Gradle features |
|
|
Properties specific to your Gradle project |
|
|
Properties that are passed to the Gradle runtime (JVM) |
|
|
Properties that configure Gradle settings and the Java process that executes your build |
|
|
Properties that configure build behavior based on the environment |
|
Priority for configurations
When configuring Gradle behavior, you can use these methods, but you must consider their priority.
Gradle reads gradle.properties configurations in the following order (highest precedence first):
| Priority | Method | Location | Notes |
|---|---|---|---|
1 |
> Command line |
Flags have precedence over properties and environment variables |
|
2 |
> Project Root Dir |
Stored in a |
|
3 |
> |
Stored in a |
|
4 |
> Environment |
Sourced by the environment that executes Gradle |
Here are all possible configurations of specifying the JDK installation directory in order of priority:
-
Command Line
$ ./gradlew exampleTask -Dorg.gradle.java.home=/path/to/your/java/home --scan -
Gradle Properties File
gradle.propertiesorg.gradle.java.home=/path/to/your/java/home -
Environment Variable
$ export JAVA_HOME=/path/to/your/java/home
The gradle.properties file
Gradle properties, system properties, and project properties can be found in the gradle.properties file:
# Gradle properties
org.gradle.parallel=true
org.gradle.caching=true
org.gradle.jvmargs=-Duser.language=en -Duser.country=US -Dfile.encoding=UTF-8
# System properties
systemProp.pts.enabled=true
systemProp.log4j2.disableJmx=true
systemProp.file.encoding = UTF-8
# Project properties
kotlin.code.style=official
android.nonTransitiveRClass=false
spring-boot.version = 2.2.1.RELEASEYou can place the gradle.properties file in the root directory of your project, the Gradle user home directory (GRADLE_USER_HOME), or the directory where Gradle is optionally installed (GRADLE_HOME).
When resolving properties, Gradle first looks in the user-level gradle.properties file located in GRADLE_USER_HOME, then in the project-level gradle.properties file, and finally in the gradle.properties file located in GRADLE_HOME, with user-level properties taking precedence over project-level and installation-level properties.
|
Note
|
See our Best Practice recommendation on where to locate |
Project properties
Project properties are specific to your Gradle project, they can be used to customize your build.
Project properties can be accessed in your build files and get passed in from an external source when your build is executed.
Project properties can be retrieved in build scripts lazily using providers.gradleProperty().
Setting a project property
You have four options to add project properties, listed in order of priority:
-
Command Line: You can add project properties directly to your Project object via the
-Pcommand line option.$ ./gradlew build -PmyProperty='Hi, world' -
System Property: Gradle creates specially-named system properties for project properties which you can set using the
-Dcommand line flag orgradle.propertiesfile. For the project propertymyProperty, the system property created is calledorg.gradle.project.myProperty.$ ./gradlew build -Dorg.gradle.project.myProperty='Hi, world'gradle.propertiesorg.gradle.project.myProperty='Hi, world' -
Gradle Properties File: You can also set project properties in
gradle.propertiesfiles.gradle.propertiesmyProperty='Hi, world'The
gradle.propertiesfile can be located in a number of places, including<GRADLE_USER_HOME>/gradle.properties,./gradle.properties(the project root) and<GRADLE_HOME>/gradle.properties.If the same property is defined in multiple locations, the file’s location determines its precedence.
-
Environment Variables: You can set project properties with environment variables. If the environment variable name looks like
ORG_GRADLE_PROJECT_myProperty='Hi, world', then Gradle will set amyPropertyproperty on your project object, with the value ofHi, world.$ export ORG_GRADLE_PROJECT_myProperty='Hi, world'This is typically the preferred method for supplying project properties, especially secrets, to unattended builds like those running on CI servers.
Accessing a project property
The recommended way to access a project property is through the Provider API:
val myProperty: Provider<String> = providers.gradleProperty("myProperty")The returned Provider is lazy and compatible with the Configuration Cache.
The provider resolves the property from the build-level sources listed above: command-line -P arguments, org.gradle.project.* system properties, ORG_GRADLE_PROJECT_* environment variables, and gradle.properties files in the Gradle User Home, build root, and Gradle installation directories.
|
Note
|
|
For other ways to access properties, see the following methods on the Project object:
-
findProperty("name")— returns the value ornull, checking dynamically configured containers, like extra properties, and parent projects as well. -
property("name")— returns the value or throws if the property is missing -
hasProperty("name")— checks if the property exists
It is possible to change the behavior of a task based on project properties specified at invocation time.
Suppose you’d like to ensure release builds are only triggered by CI.
A simple way to handle this is through an isCI project property:
tasks.register("performRelease") {
val isCI = providers.gradleProperty("isCI")
doLast {
if (isCI.isPresent) {
println("Performing release actions")
} else {
throw InvalidUserDataException("Cannot perform release outside of CI")
}
}
}tasks.register('performRelease') {
def isCI = providers.gradleProperty("isCI")
doLast {
if (isCI.present) {
println("Performing release actions")
} else {
throw new InvalidUserDataException("Cannot perform release outside of CI")
}
}
}$ ./gradlew performRelease -PisCI=true --quietPerforming release actionsNote that running ./gradlew performRelease yields the same results as long as your gradle.properties file includes isCI=true:
isCI=true$ ./gradlew performRelease --quietPerforming release actionsCommand-line flags
The command line interface and the available flags are described in its own section.
System properties
System properties are variables set at the JVM level and accessible to the Gradle build process.
System properties can be retrieved in build scripts lazily using providers.systemProperty().
Setting a system property
You have two options to add system properties listed in order of priority:
-
Command Line: Using the
-Dcommand-line option, you can pass a system property to the JVM, which runs Gradle. The-Doption of thegradlecommand has the same effect as the-Doption of thejavacommand.$ ./gradlew build -Dgradle.wrapperUser=myuser -
Gradle Properties File: You can also set system properties in
gradle.propertiesfiles with the prefixsystemProp.gradle.propertiessystemProp.gradle.wrapperUser=myuser
System properties reference
For a quick reference, the following are common system properties:
gradle.wrapperUser=(myuser)-
Specify username to download Gradle distributions from servers using HTTP Basic Authentication.
gradle.wrapperPassword=(mypassword)-
Specify password for downloading a Gradle distribution using the Gradle wrapper.
gradle.user.home=(path to directory)-
Specify the
GRADLE_USER_HOMEdirectory. https.protocols-
Specify the supported TLS versions in a comma-separated format. e.g.,
TLSv1.2,TLSv1.3.
Additional Java system properties are listed here.
In a multi-project build, systemProp properties set in any project except the root will be ignored.
Only the root project’s gradle.properties file will be checked for properties that begin with systemProp.
Gradle properties
Gradle properties configure Gradle itself and usually have the name org.gradle.*.
Gradle properties should not be used in build logic, their values should not be read/retrieved in build scripts.
Setting a Gradle property
You have two options to add Gradle properties listed in order of priority:
-
Command Line: Using the
-Dcommand-line option, you can pass a Gradle property:$ ./gradlew build -Dorg.gradle.caching.debug=false -
Gradle Properties File: Place these settings into a
gradle.propertiesfile and commit it to your version control system.gradle.propertiesorg.gradle.caching.debug=false
The final configuration considered by Gradle is a combination of all Gradle properties set on the command line and your gradle.properties files.
If an option is configured in multiple locations, the first one found in any of these locations wins:
| Priority | Method | Location | Details |
|---|---|---|---|
1 |
Command line interface |
. |
In the command line using |
2 |
|
|
Stored in a |
3 |
|
Project Root Dir |
Stored in a |
4 |
|
|
Stored in a |
|
Note
|
The location of the GRADLE_USER_HOME may have been changed beforehand via the -Dgradle.user.home system property passed on the command line.
|
Gradle properties reference
For reference, the following properties are common Gradle properties:
org.gradle.caching=(true,false)-
When set to
true, Gradle will reuse task outputs from any previous build when possible, resulting in much faster builds.Default is
false; the build cache is not enabled. org.gradle.caching.debug=(true,false)-
When set to
true, individual input property hashes and the build cache key for each task are logged on the console.Default is
false. org.gradle.configuration-cache=(true,false)-
Enables configuration caching. Gradle will try to reuse the build configuration from previous builds.
Default is
false. org.gradle.configureondemand=(true,false)-
Enables incubating configuration-on-demand, where Gradle will attempt to configure only necessary projects.
Default is
false. org.gradle.console=(auto,plain,colored,rich,verbose)-
Customize console output coloring or verbosity.
Default depends on how Gradle is invoked.
org.gradle.console.interactive=(true,false)Incubating-
When set to
false, Gradle does not prompt the user for input on the console and uses default values instead. This is useful for automated environments such as CI pipelines, scripts, and AI agents.Default is
true. org.gradle.continue=(true,false)-
If enabled, continue task execution after a task failure, else stop task execution after a task failure.
Default is
false. org.gradle.daemon=(true,false)-
When set to
truethe Gradle Daemon is used to run the build.Default is
true. org.gradle.daemon.idletimeout=(# of idle millis)-
Gradle Daemon will terminate itself after a specified number of idle milliseconds.
Default is
10800000(3 hours). org.gradle.debug=(true,false)-
When set to
true, Gradle will run the build with remote debugging enabled, listening on port 5005. Note that this is equivalent to adding-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005to the JVM command line and will suspend the virtual machine until a debugger is attached.Default is
false. org.gradle.java.home=(path to JDK home)-
Specifies the Java home for the Gradle build process. The value can be set to either a
jdkorjrelocation; however, using a JDK is safer depending on what your build does. This does not affect the version of Java used to launch the Gradle client VM.You can also control the JVM used to run Gradle itself using the Daemon JVM criteria.
Default is derived from your environment (
JAVA_HOMEor the path tojava) if the setting is unspecified. org.gradle.java.installations.auto-detect=(true,false)-
When set to
true, Gradle will automatically detect the JDK installations available on the system when locating Java toolchains. All JDK installation sources are additive, meaning if multiple sources are specified, Gradle will consider all sources when finding JDK installations.Default is
true. org.gradle.java.installations.auto-download=(true,false)-
When set to
true, Gradle will automatically download JDK installations when locating Java toolchains. All JDK installation sources are additive, meaning if multiple sources are specified, Gradle will consider all sources when finding JDK installations.Default is
true. org.gradle.java.installations.paths=(list of JDK installations)-
When set, Gradle will use the specified JDK installation paths when locating Java toolchains. This setting is a comma-separated list of paths to directories where JDK installations are located. All JDK installation sources are additive, meaning if multiple sources are specified, Gradle will consider all sources when finding JDK installations.
Default is empty, meaning Gradle will not use any explicitly declared paths to find JDK installations.
org.gradle.java.installations.fromEnv=(list of environment variables)-
When set, Gradle will use the JDK installations specified in the listed environment variables when locating Java toolchains. This setting is a comma-separated list of environment variable names. All JDK installation sources are additive, meaning if multiple sources are specified, Gradle will consider all sources when finding JDK installations.
Default is empty, meaning Gradle will not use any environment variables to find JDK installations.
org.gradle.jvmargs=(JVM arguments)-
Specifies the JVM arguments used for the Gradle Daemon. The setting is particularly useful for configuring JVM memory settings for build performance. This does not affect the JVM settings for the Gradle client VM.
Default is
-Xmx512m "-XX:MaxMetaspaceSize=384m". org.gradle.logging.level=(quiet,warn,lifecycle,info,debug)-
When set to quiet, warn, info, or debug, Gradle will use this log level. The values are not case-sensitive.
Default is
lifecyclelevel. org.gradle.parallel=(true,false)-
When configured, Gradle will fork up to
org.gradle.workers.maxJVMs to execute projects in parallel.Default is
false. org.gradle.priority=(low,normal)-
Specifies the scheduling priority for the Gradle daemon and all processes launched by it.
Default is
normal. org.gradle.projectcachedir=(directory)-
Specify the project-specific cache directory. Defaults to
.gradlein the root project directory."Default is
.gradle. org.gradle.problems.report=(true|false)-
Enable (
true) or disable (false) the generation ofbuild/reports/problems-report.html.trueis the default. The report is generated with problems provided to the Problems API. org.gradle.tooling.parallel=(true,false)Since 9.4.0-
Allows running Tooling Model Builders in parallel, which can improve IDE Sync times. An explicit value will override
org.gradle.parallelin this context.Default is the value of
org.gradle.parallel. org.gradle.unsafe.isolated-projects=(true,false)-
Enables Isolated Projects.
Default is
false. org.gradle.unsafe.isolated-projects.diagnostics=(true,false)Since 9.6.0-
Enables Diagnostics mode for Isolated Projects, which runs project configuration sequentially to surface violations across all projects in a deterministic manner. Requires Isolated Projects to be enabled.
Default is
false. org.gradle.vfs.verbose=(true,false)-
Configures verbose logging when watching the file system.
Default is
false. org.gradle.vfs.watch=(true,false)-
Toggles watching the file system. When enabled, Gradle reuses information it collects about the file system between builds.
Default is
trueon operating systems where Gradle supports this feature. org.gradle.warning.mode=(all,fail,summary,none)-
When set to
all,summary, ornone, Gradle will use different warning type display.Default is
summary.
org.gradle.workers.max=(max # of worker processes)-
When configured, Gradle will use a maximum of the given number of workers.
Default is the number of CPU processors.
Environment variables
Gradle provides a number of environment variables, which are listed below.
Environment variables can be retrieved in build scripts lazily using providers.environmentVariable().
Setting environment variables
Let’s take an example that sets the $JAVA_HOME environment variable:
$ set JAVA_HOME=C:\Path\To\Your\Java\Home // Windows
$ export JAVA_HOME=/path/to/your/java/home // Mac/LinuxYou can access environment variables as properties in the build script using the System.getenv() method:
task printEnvVariables {
doLast {
println "JAVA_HOME: ${System.getenv('JAVA_HOME')}"
}
}Environment variables reference
The following environment variables are available for the gradle command:
GRADLE_HOME-
Installation directory for Gradle.
Can be used to specify a local Gradle version instead of using the wrapper.
You can add
GRADLE_HOME/binto yourPATHfor specific applications and use cases (such as testing an early release for Gradle). JAVA_OPTS-
Used to pass JVM options and custom settings to the JVM.
export JAVA_OPTS="-Xmx18928m -XX:+HeapDumpOnOutOfMemoryError -Dfile.encoding=UTF-8 -Djava.awt.headless=true -Dkotlin.daemon.jvm.options=-Xmx6309m" GRADLE_OPTS-
Specifies JVM arguments to use when starting the Gradle client VM.
The client VM is lightweight and mainly handles command-line input and output, so it’s uncommon to change its VM options.
While
GRADLE_OPTStypically doesn’t affect the daemon, you can use it to pass arguments to the daemon by setting theorg.gradle.jvmargssystem property. This is the recommended way to configure the daemon’s JVM options, such as heap size or memory settings, via an environment variable. GRADLE_USER_HOME-
Specifies the
GRADLE_USER_HOMEdirectory for Gradle to store its global configuration properties, initialization scripts, caches, log files and more.Defaults to
USER_HOME/.gradleif not set. GRADLE_DAEMON_BIND_ADDRESS-
Specifies the IP address or hostname that Gradle uses to bind the local socket for client-daemon and cross-daemon communication.
By default, Gradle automatically selects the loopback address (or wildcard address as a fallback) for this socket. This may not work correctly in environments with specific network configurations, such as multiple network interfaces, multiple TCP/IP stacks etc.
Setting this variable skips auto-detection and uses the provided address directly:
GRADLE_DAEMON_BIND_ADDRESS=192.168.1.10 ./gradlew build JAVA_HOME-
Specifies the JDK installation directory to use for the client VM.
This VM is also used for the daemon unless a different one is specified in a Gradle properties file with
org.gradle.java.homeor using the Daemon JVM criteria. GRADLE_LIBS_REPO_OVERRIDE-
Overrides for the default Gradle library repository.
Can be used to specify a default Gradle repository URL in
org.gradle.plugins.ide.internal.resolver.Useful override to specify an internally hosted repository if your company uses a firewall/proxy.
NO_COLOR-
When present and non-empty, disables color output while preserving other styling (bold, underline) and rich features (progress bars, animations).
Follows the no-color.org convention. See Customizing log format for more options.
Build Lifecycle
The build lifecycle is the sequence of phases Gradle executes to turn your build scripts into completed work, from initializing the build environment to configuring projects and finally executing tasks.
Build Phases
A build has three distinct phases. Gradle runs these phases in order:
| Phase 1. Initialization | Phase 2. Configuration | Phase 3. Execution |
|---|---|---|
Detects projects and included builds |
Configures projects and builds a task graph |
Schedules and executes the selected tasks |
Phase 1. Initialization
In the initialization phase, Gradle detects the set of projects (root and subprojects) and included builds participating in the build.
Gradle first runs any init scripts, then evaluates the settings file, settings.gradle(.kts), and instantiates a Settings object.
Then, Gradle instantiates Project object instances for each project included in the build (using includeBuild() or include() in the settings file).
Phase 2. Configuration
In the configuration phase, Gradle registers tasks and other properties to the projects found by the initialization phase.
Gradle evaluates the build files of every participating project, then constructs the task graph by analyzing the input and output dependencies of tasks.
|
Note
|
When the Configuration Cache is enabled, the configuration phase also includes a serialization sub-phase, where Gradle stores the task graph while simultaneously precomputing some of the task state and resolving dependencies. This is work that would otherwise be deferred to execution. See Configuration Cache - How It Works for more details. |
Phase 3. Execution
In the execution phase, Gradle runs the selected tasks.
Gradle uses the task execution graph generated by the configuration phase to determine which tasks to execute and in what order.
Gradle can execute tasks that don’t depend on each other, in the same project, in parallel.
The Phases in Build Scripts
The following example shows which parts of settings and build files correspond to various build phases:
rootProject.name = "basic"
println("This is executed during the initialization phase.")// Configuration Phase
println("This is executed during the configuration phase.")
tasks.register("configured") {
println("This is also executed during the configuration phase.")
}
// Execution Phase
tasks.register("test") {
doLast {
println("This is executed during the execution phase.")
}
}
// Configurations AND Execution Phase
tasks.register("testBoth") {
println("This is executed during the configuration phase as well.")
doFirst {
println("This is executed first during the execution phase.")
}
doLast {
println("This is executed last during the execution phase.")
}
}rootProject.name = 'basic'
println 'This is executed during the initialization phase.'// Configuration Phase
println 'This is executed during the configuration phase.'
tasks.register('configured') {
println 'This is also executed during the configuration phase.'
}
// Execution Phase
tasks.register('test') {
doLast {
println 'This is executed during the execution phase.'
}
}
// Configurations AND Execution Phase
tasks.register('testBoth') {
println 'This is executed during the configuration phase as well.'
doFirst {
println 'This is executed first during the execution phase.'
}
doLast {
println 'This is executed last during the execution phase.'
}
}The following command executes the test and testBoth tasks specified above:
$ ./gradlew test testBothThis is executed during the initialization phase.
> Configure project :
This is executed during the configuration phase.
This is executed during the configuration phase as well.
> Task :test
This is executed during the execution phase.
> Task :testBoth
This is executed first during the execution phase.
This is executed last during the execution phase.
BUILD SUCCESSFUL in 0s
2 actionable tasks: 2 executed$ ./gradlew test testBothThis is executed during the initialization phase.
> Configure project :
This is executed during the configuration phase.
This is executed during the configuration phase as well.
> Task :test
This is executed during the execution phase.
> Task :testBoth
This is executed first during the execution phase.
This is executed last during the execution phase.
BUILD SUCCESSFUL in 0s
2 actionable tasks: 2 executedBecause Gradle only configures requested tasks and their prerequisites, the configured task never configures.
Build Lifecycle Timeline
Understanding the precise sequence in which Gradle evaluates scripts and triggers hooks is the key to mastering build logic. This timeline provides a comprehensive overview of the Gradle build flow when the Configuration Cache and Isolated Projects are disabled:
| Phase | Seq. | Hook / Block | Location | Purpose |
|---|---|---|---|---|
Initialization |
1 |
|
Global environment setup (e.g., enterprise repos). |
|
2 |
init script or |
Runs before the settings file is even parsed. |
||
3 |
|
|
Must be first. Defines plugin repos and version rules. |
|
4 |
|
|
Applies plugins to the |
|
5 |
Settings Script Body |
|
Evaluates |
|
6 |
init script or |
Settings are fully processed; Project objects are created. |
||
7 |
init script or |
All project instances exist but aren’t configured yet. |
||
Configuration |
8 |
init script or |
Not recommended. Fires immediately before each project starts evaluating. |
|
9 |
init script or parent project’s |
Runs before a specific project’s build script is evaluated. |
||
10 |
|
|
Sets the classpath for the build script itself. |
|
11 |
|
|
Applies plugins and adds DSL/Tasks. |
|
12 |
Build Script Body |
|
Registers tasks ( |
|
13 |
|
Not recommended. Runs after a specific project is evaluated; useful for reacting to another project’s configuration. |
||
14 |
init script or root |
Fires immediately after each project finishes evaluating. |
||
15 |
init script or root |
All project scripts have run; final chance to tweak the graph. |
||
16 |
Task Graph Construction |
Internal ( |
Gradle calculates the DAG based on requested tasks. |
|
Execution |
17a |
Task Input Snapshotting |
Internal ( |
Evaluated per task to determine whether it should be skipped or executed. |
17b |
Internal ( |
Constructs a dependency graph based on declared dependencies. |
||
17c |
Internal ( |
Dependencies are downloaded from repositories. |
||
18 |
Task Execution |
Console / CLI ( |
Tasks run. |
* Dependency Graph Resolution and Artifact Resolution are normally deferred until the Execution Phase.
However, any build logic that eagerly accesses a configuration’s resolved state, such as calling configuration.files,
configuration.resolvedConfiguration, or iterating a configuration directly, will trigger resolution immediately at that point in the build lifecycle.
|
Important
|
When the Configuration Cache is enabled, Dependency Graph Resolution and Artifact Resolution must be completed during the Configuration Phase rather than at execution time, since they are required to fully describe the task graph before the result can be serialized. You can refer to Configuration Cache - How It Works to learn more. |
Task Graphs
As a build author, you write build logic by defining tasks and declaring how they depend on one another. Gradle uses this information to construct a task graph during the configuration phase that models the relationships between these tasks.
For example, if your project includes tasks such as build, assemble, and createDocs, and you declare that assemble depends on build, and createDocs depends on assemble, Gradle constructs a graph with this order: build → assemble → createDocs.
Gradle builds the task graph before executing any task(s).
Across all projects in the build, tasks form a Directed Acyclic Graph (DAG).
This diagram shows two example task graphs, one abstract and the other concrete, with dependencies between tasks represented as arrows:
Hooks into the Gradle Build Lifecycle
Gradle exposes several APIs that let you listen to or react to key points in the build lifecycle.
Some APIs let you hook into those phases in init scripts, settings.gradle(.kts) or build.gradle(.kts) to customize or inspect the build as Gradle configures it.
These hooks let you:
-
react to the structure of the build (root + subprojects),
-
configure all projects before their own build scripts are evaluated,
-
debug or collect information during configuration.
Lifecycle API
The GradleLifecycle API, accessible through the gradle object, can be used to register actions to be executed at certain points in the build lifecycle:
buildStarted -> DEPRECATED in Gradle 6
└─ beforeSettings
└── settingsEvaluated
└── projectsLoaded
├── beforeProject
├── afterProject
└── projectsEvaluated
└── buildFinished -> DEPRECATED in Gradle 7Here is a quick overview:
| # | Hook | Best for |
|---|---|---|
Early wiring from an init script: global logging/metrics, tweaking |
||
Adjusting repositories, enabling build scans, reading environment variables, or changing build layout. |
||
Applying configuration to every project (for example, adding a plugin to all subprojects). |
||
Applying defaults, logging project configuration start. |
||
Validating configuration or detecting missing plugins. |
||
Performing cross-project validation, configuration summaries, or creating aggregated tasks. |
beforeSettings
Where: init script.
When: By the time settings.gradle(.kts) is executing, beforeSettings has already fired.
// 1. beforeSettings: tweak start parameters / log early info
// before the build settings have been loaded and evaluated.
gradle.beforeSettings {
println("[beforeSettings] gradleUserHome = ${gradle.gradleUserHomeDir}")
// Example: default to --parallel if an env var is set
if (System.getenv("CI") == "true") {
println("[beforeSettings] Enabling parallel execution on CI")
gradle.startParameter.isParallelProjectExecutionEnabled = true
} else {
println("[beforeSettings] Disabling parallel execution, not on CI")
gradle.startParameter.isParallelProjectExecutionEnabled = false
}
}// 1. beforeSettings: tweak start parameters / log early info
// before the build settings have been loaded and evaluated.
gradle.beforeSettings {
println("[beforeSettings] gradleUserHome = ${gradle.gradleUserHomeDir}")
// Example: default to --parallel if an env var is set
if (System.getenv("CI") == "true") {
println("[beforeSettings] Enabling parallel execution on CI")
gradle.startParameter.parallelProjectExecutionEnabled = true
} else {
println("[beforeSettings] Disabling parallel execution, not on CI")
gradle.startParameter.parallelProjectExecutionEnabled = false
}
println("")
}settingsEvaluated
Where: settings.gradle(.kts).
When: After the settings file finishes evaluating.
// 2. settingsEvaluated: adjust build layout / repositories / scan config
// when the build settings have been loaded and evaluated.
gradle.settingsEvaluated {
println("[settingsEvaluated] rootProject = ${rootProject.name}")
// Example: enforce a company-wide pluginManagement repo
pluginManagement.repositories.apply {
println("[settingsEvaluated] Ensuring company plugin repo is configured")
mavenCentral()
}
}// 2. settingsEvaluated: adjust build layout / repositories / scan config
// when the build settings have been loaded and evaluated.
gradle.settingsEvaluated { settings ->
println("[settingsEvaluated] rootProject = ${settings.rootProject.name}")
// Example: enforce a company-wide pluginManagement repo
settings.pluginManagement.repositories.with {
println("[settingsEvaluated] Ensuring company plugin repo is configured")
mavenCentral()
}
println("")
}projectsLoaded
Where: settings.gradle(.kts).
When: All projects have been discovered but not yet configured.
// 3. projectsLoaded: we know the full project graph, but nothing configured yet
// to be called when the projects for the build have been created from the settings.
gradle.projectsLoaded {
println("[projectsLoaded] Projects discovered: " + rootProject.allprojects.joinToString { it.name })
// Example: Add a custom property (using the extra properties extension)
allprojects {
println("[projectsLoaded] Setting extra property on ${name}")
extensions.extraProperties["isInitScriptConfigured"] = true
}
}// 3. projectsLoaded: we know the full project graph, but nothing configured yet
// to be called when the projects for the build have been created from the settings.
gradle.projectsLoaded {
println "[projectsLoaded] Projects discovered: " + rootProject.allprojects.collect { it.name }.join(', ')
// Example: Add a custom property (using the extra properties extension)
allprojects {
println("[projectsLoaded] Setting extra property on ${name}")
extensions.extraProperties["isInitScriptConfigured"] = true
}
}beforeProject
Where: build.gradle(.kts) or anywhere you have access to the Gradle instance.
When: For each project as its build script is evaluated.
// to be called immediately before a project is evaluated.
gradle.lifecycle.beforeProject {
println("[lifecycle.beforeProject] Started configuring ${path}")
}
// 4. beforeProject: runs before each build.gradle(.kts) is evaluated
// to be called immediately before a project is evaluated.
gradle.beforeProject {
println("[beforeProject] Started configuring ${path}")
println("[beforeProject] Setup a global build directory for ${name}")
layout.buildDirectory.set(
layout.projectDirectory.dir("build")
)
}// to be called immediately before a project is evaluated.
gradle.lifecycle.beforeProject {
println("[lifecycle.beforeProject] Started configuring ${path}")
}
// 4. beforeProject: runs before each build.gradle(.kts) is evaluated
// to be called immediately before a project is evaluated.
gradle.beforeProject { project ->
println("[beforeProject] Started configuring ${project.path}")
println("[beforeProject] Setup a global build directory for ${project.name}")
project.layout.buildDirectory.set(
project.layout.projectDirectory.dir("build")
)
}afterProject
Where: build.gradle(.kts) or anywhere you have access to the Gradle instance.
When: For each project as its build script is evaluated.
// 5. afterProject: runs after each build.gradle(.kts) is evaluated
// to be called immediately after a project is evaluated.
gradle.afterProject {
println("[afterProject] Finished configuring ${path}")
// Example: apply the Java plugin to all projects that don’t have any plugin yet
if (plugins.hasPlugin("java")) {
println("[afterProject] ${path} already has the java plugin")
} else {
println("[afterProject] Applying java plugin to ${path}")
apply(plugin = "java")
}
}
// to be called immediately after a project is evaluated.
gradle.lifecycle.afterProject {
println("[lifecycle.afterProject] Finished configuring ${path}")
}// 5. afterProject: runs after each build.gradle(.kts) is evaluated
// to be called immediately after a project is evaluated.
gradle.afterProject { project ->
println("[afterProject] Finished configuring ${project.path}")
// Example: apply the Java plugin to all projects that don’t have any plugin yet
if (project.plugins.hasPlugin("java")) {
println("[afterProject] ${project.path} already has the java plugin")
} else {
println("[afterProject] Applying java plugin to ${project.path}")
project.apply(plugin: "java")
}
}
// to be called immediately after a project is evaluated.
gradle.lifecycle.afterProject {
println("[lifecycle.afterProject] Finished configuring ${path}")
}projectsEvaluated
Where: build.gradle(.kts) or anywhere you have access to the Gradle instance.
When: After all projects have been evaluated (i.e., all build.gradle(.kts) files are read and configuration is complete), but before task graph is finalized and before execution starts.
// 6. projectsEvaluated: all projects are fully configured, safe for cross-project checks
// to be called when all projects for the build have been evaluated.
gradle.projectsEvaluated {
println("[projectsEvaluated] All projects evaluated")
// Example: globally configure the java plugin
allprojects {
extensions.findByType<JavaPluginExtension>()?.let { javaExtension ->
if (javaExtension.toolchain.languageVersion.isPresent) {
println("[projectsEvaluated] ${path} uses Java plugin with toolchain ${javaExtension.toolchain.displayName}")
} else {
println("[projectsEvaluated] WARNING: ${path} uses Java plugin but no toolchain is configured, setting Java 17")
javaExtension.toolchain.languageVersion.set(JavaLanguageVersion.of(17))
}
}
}
}// 6. projectsEvaluated: all projects are fully configured, safe for cross-project checks
// to be called when all projects for the build have been evaluated.
gradle.projectsEvaluated {
println("[projectsEvaluated] All projects evaluated")
// Example: globally configure the java plugin
allprojects { project ->
def javaExtension = project.extensions.findByType(JavaPluginExtension)
if(javaExtension) {
if (javaExtension.toolchain.languageVersion.orNull != null) {
println("[projectsEvaluated] ${path} uses Java plugin with toolchain ${javaExtension.toolchain.displayName}")
} else {
println("[projectsEvaluated] WARNING: ${path} uses Java plugin but no toolchain is configured, setting Java 17")
javaExtension.toolchain.languageVersion.set(JavaLanguageVersion.of(17))
}
}
}
}Build Listeners
Listeners are interfaces you implement to react to build lifecycle events.
Many BuildListeners are deprecated and/or are not Configuration Cache friendly, use them with caution:
| Interface | What it observes | Works with CC? |
|---|---|---|
Fires when projects are loaded/evaluated. |
❌ |
|
Fires when the execution of an operation progresses. |
✅ |
|
(Partially Deprecated) |
Fires when a task has started or completed its action. |
❌ |
(Deprecated) |
Fires before and after each task executes. |
❌ |
(Deprecated) |
Fires when the task execution graph has been populated. |
❌ |
Fires when an operation completes. |
✅ |
|
Fires before and after dependency resolution. |
❌ |
|
Fires before and after each project is evaluated. |
❌ |
|
Fires at different times during test execution. |
❌ |
You implement a listener interface and typically register it on the gradle object.
The TaskExecutionGraphListener fires once after the task graph has been calculated, but before any task executes.
This example uses graph.allTasks to inspect what Gradle plans to run, and graph.hasTask() to conditionally adjust behaviour:
gradle.taskGraph.addTaskExecutionGraphListener { graph ->
val tasks = graph.allTasks.joinToString("\n ") { it.path }
println("[TaskExecutionGraphListener] Graph is ready. Tasks to execute:\n $tasks")
if (graph.hasTask(":skippedTask")) {
println("[TaskExecutionGraphListener] :skippedTask is in the graph (it will still be skipped via onlyIf)")
}
}
tasks.register("hello") {
group = "demo"
description = "Prints a greeting. Always runs — observe TaskExecutionListener output."
doLast {
println("Hello from the :hello task!")
}
}
tasks.register("upToDateTask") {
group = "demo"
description = "Writes a file. Runs once, then reports UP-TO-DATE on subsequent runs."
val outputFile = layout.buildDirectory.file("up-to-date-output.txt")
outputs.file(outputFile)
doLast {
outputFile.get().asFile.writeText("generated")
println("upToDateTask: file written.")
}
}
tasks.register("skippedTask") {
group = "demo"
description = "Always skipped via onlyIf — observe SKIPPED in TaskExecutionListener."
onlyIf { false }
doLast {
println("This never prints.")
}
}gradle.taskGraph.addTaskExecutionGraphListener { graph ->
def tasks = graph.allTasks.collect { it.path }.join("\n ")
println("[TaskExecutionGraphListener] Graph is ready. Tasks to execute:\n ${tasks}")
if (graph.hasTask(":skippedTask")) {
println("[TaskExecutionGraphListener] :skippedTask is in the graph (it will still be skipped via onlyIf)")
}
}
tasks.register("hello") {
group = "demo"
description = "Prints a greeting. Always runs."
doLast {
println("Hello from the :hello task!")
}
}
tasks.register("upToDateTask") {
group = "demo"
description = "Writes a file. Runs once, then reports UP-TO-DATE on subsequent runs."
def outputFile = layout.buildDirectory.file("up-to-date-output.txt")
outputs.file(outputFile)
doLast {
outputFile.get().asFile.text = "generated"
println("upToDateTask: file written.")
}
}
tasks.register("skippedTask") {
group = "demo"
description = "Always skipped via onlyIf."
onlyIf { false }
doLast {
println("This never prints.")
}
}Note that tasks skipped via onlyIf still appear in the graph; skipping is evaluated later, per task, during execution:
[TaskExecutionGraphListener] Graph is ready. Tasks to execute:
:hello
:skippedTask
:upToDateTask
:runAll
[TaskExecutionGraphListener] :skippedTask is in the graph (it will still be skipped via onlyIf)
> Task :hello
Hello from the :hello task!
> Task :skippedTask SKIPPED
> Task :upToDateTask
upToDateTask: file written.
> Task :runAll
BUILD SUCCESSFUL in 0s
2 actionable tasks: 2 executedBuild Services
Build Services are used to share state or resources across tasks and across the build lifecycle.
This example implements OperationCompletionListener directly on the service to count tasks as they complete, and uses close() as an end-of-build hook to print the final summary, whether the build succeeded or failed:
abstract class BuildDurationService
: BuildService<BuildServiceParameters.None>, AutoCloseable {
private val startTime = System.currentTimeMillis()
// Called once at the end of the build — reliable teardown hook
override fun close() {
val elapsed = System.currentTimeMillis() - startTime
println("─────────────────────────────────────")
println(" Build duration : ${elapsed}ms")
println("─────────────────────────────────────")
}
}
val buildDurationService = gradle.sharedServices.registerIfAbsent("buildDuration", BuildDurationService::class) {
maxParallelUsages = 1
}
tasks.register("taskA") {
group = "demo"
usesService(buildDurationService)
val service = buildDurationService
doLast {
service.get()
println("taskA running...")
Thread.sleep(200)
}
}
tasks.register("taskB") {
group = "demo"
doLast {
println("taskB running...")
Thread.sleep(300)
}
}abstract class BuildDurationService
implements BuildService<BuildServiceParameters.None>, AutoCloseable {
private final long startTime = System.currentTimeMillis()
// Called once at the end of the build — reliable teardown hook
@Override
void close() {
def elapsed = System.currentTimeMillis() - startTime
println("─────────────────────────────────────")
println(" Build duration : ${elapsed}ms")
println("─────────────────────────────────────")
}
}
def buildDurationService = gradle.sharedServices.registerIfAbsent("buildDuration", BuildDurationService) {
maxParallelUsages = 1
}
tasks.register("taskA") {
group = "demo"
usesService(buildDurationService)
def service = buildDurationService
doLast {
service.get()
println("taskA running...")
Thread.sleep(200)
}
}
tasks.register("taskB") {
group = "demo"
doLast {
println("taskB running...")
Thread.sleep(300)
}
}The hooks are used to calculate the duration of the build:
> Task :taskA
taskA running...
> Task :taskB
taskB running...
> Task :runAll
─────────────────────────────────────
Build duration : 510ms
─────────────────────────────────────
BUILD SUCCESSFUL in 0s
2 actionable tasks: 2 executedFlow Actions Incubating
FlowAction is a newer API (introduced in Gradle 7.6) that lets you run logic in response to build lifecycle events, most commonly, when the build finishes.
It was introduced as a Configuration Cache and Isolated Projects compatible alternative to BuildListener and other deprecated lifecycle listeners.
To use a Flow Action, you define a class implementing FlowAction<T> and a matching Parameters interface that declares the inputs your action needs.
You then register it inside a Plugin using FlowScope, which is injected by Gradle alongside FlowProviders:
abstract class PrintBuildResultPlugin : Plugin<Project> {
@get:Inject
abstract val flowScope: FlowScope
@get:Inject
abstract val flowProviders: FlowProviders
override fun apply(target: Project) {
flowScope.always(BuildResultPrinter::class.java) {
parameters.buildResult.set(flowProviders.buildWorkResult)
}
}
}
abstract class BuildResultPrinter : FlowAction<BuildResultPrinter.Parameters> {
interface Parameters : FlowParameters {
@get:Input
val buildResult: Property<BuildWorkResult>
}
override fun execute(parameters: Parameters) {
val result = parameters.buildResult.get()
if (result.failure.isPresent) {
println("Build failed: ${result.failure.get().message}")
} else {
println("Build succeeded")
}
}
}abstract class PrintBuildResultPlugin implements Plugin<Project> {
@Inject
abstract FlowScope getFlowScope()
@Inject
abstract FlowProviders getFlowProviders()
@Override
void apply(Project target) {
flowScope.always(BuildResultPrinter) {
parameters.buildResult.set(flowProviders.buildWorkResult)
}
}
}
abstract class BuildResultPrinter implements FlowAction<BuildResultPrinter.Parameters> {
interface Parameters extends FlowParameters {
@Input
Property<BuildWorkResult> getBuildResult()
}
@Override
void execute(Parameters parameters) {
def result = parameters.buildResult.get()
if (result.failure.isPresent()) {
println "Build failed: ${result.failure.get().message}"
} else {
println "Build succeeded"
}
}
}As expected, we see the build finish success message:
Build succeeded
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executedBuild Scan
Gradle provides multiple ways to inspect your build:
-
Profile with a Build Scan
-
Local profile reports
-
Low level profiling
What is a Build Scan?
A Build Scan is a persistent, shareable record of what happened when running a build. They provide detailed insights you can use to diagnose performance issues, identify build failures, and share context with your team.
A Build Scan is created locally but published to a secure external server managed by Gradle. They do not run code on your machine, and they never modify your build. You can choose whether to publish a scan, and each scan is assigned a unique (private-by-default) URL.
|
Note
|
For information on what data is collected and how it’s handled, see the Gradle.com Privacy Policy. |
In Gradle 4.3 and above, you can create a Build Scan using the --scan command line option:
$ ./gradlew build --scanFor older Gradle versions, the Develocity Plugin User Manual explains how to generate a Build Scan.
At the end of your build, Gradle displays a URL where you can find your Build Scan:
BUILD SUCCESSFUL in 2s
4 actionable tasks: 4 executed
Publishing Build Scan...
https://gradle.com/s/e6ircx2wjbf7eThis section explains how to profile your build with a Build Scan.
1. Profile with a Build Scan
The performance page can help use a Build Scan to profile a build. To get there, click "Performance" in the left hand navigation menu or follow the "Explore performance" link on the Build Scan home page:
The performance page shows how long it took to complete different stages of a build. This page shows how long it took to:
-
start up
-
configure the build’s projects
-
resolve dependencies
-
execute tasks
You also get details about environmental properties, such as whether a daemon was used or not.
In the above Build Scan, configuration takes over 13 seconds. Click on the "Configuration" tab to break this stage into component parts, exposing the cause of the slowness.
Here you can see the scripts and plugins applied to the project in descending order of how long they took to apply.
The slowest plugin and script applications are good candidates for optimization.
For example, the script script-b.gradle was applied once but took 3 seconds.
Expand that row to see where the build applied this script.
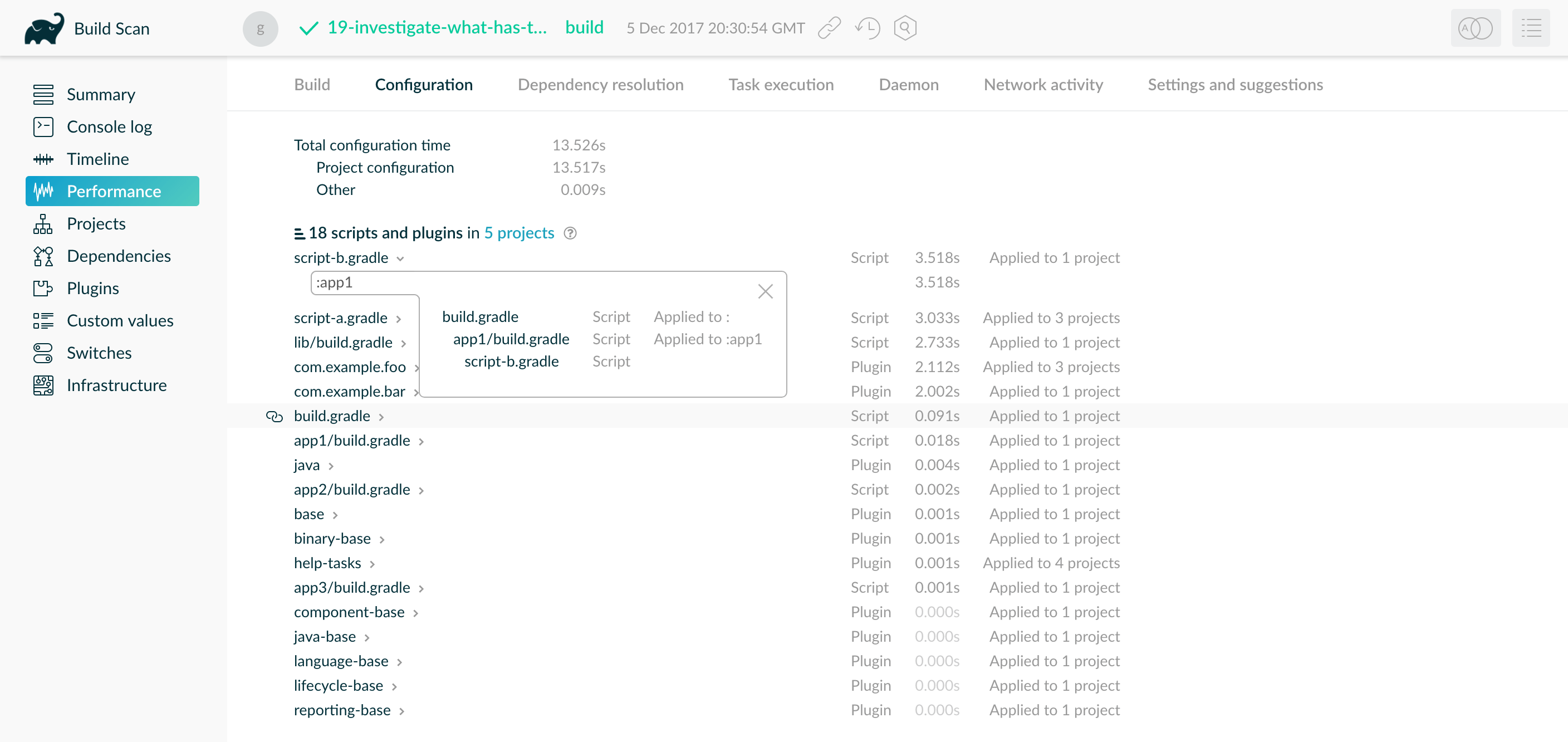
You can see that subproject :app1 applied the script once, from inside of that subproject’s build.gradle file.
2. Profile report
If you prefer not to use a Build Scan, you can generate an HTML report in the
build/reports/profile directory of your root project. To generate this report,
use the --profile command-line option:
$ ./gradlew --profile <tasks>Each profile report has a timestamp in its name to avoid overwriting existing ones.
The report displays a breakdown of the time taken to run the build. However, this breakdown is not as detailed as a Build Scan. The following profile report shows the different categories available:
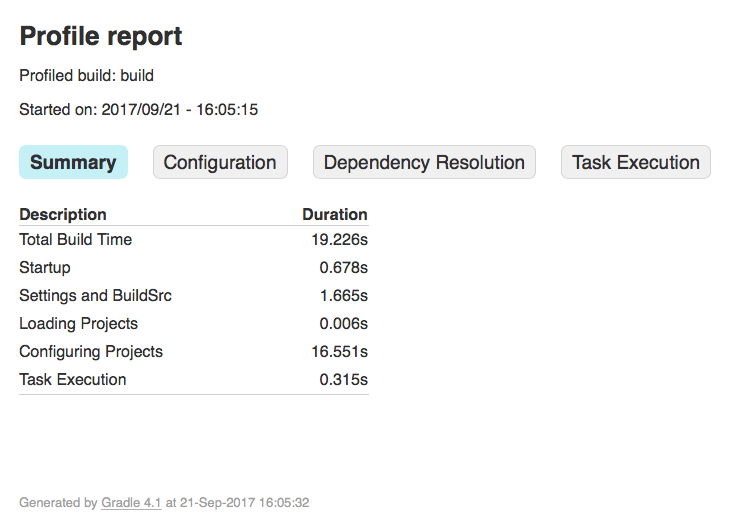
3. Low level profiling
Sometimes your build can be slow even though your build scripts do everything right. This often comes down to inefficiencies in plugins and custom tasks or constrained resources. Use the Gradle Profiler to find these kinds of bottlenecks. With the Gradle Profiler, you can define scenarios like "Running 'assemble' after making an ABI-breaking change" and run your build several times to collect profiling data. Use the Profiler to produce a Build Scan. Or combine it with method profilers like JProfiler and YourKit. These profilers can help you find inefficient algorithms in custom plugins. If you find that something in Gradle itself slows down your build, don’t hesitate to send a profiler snapshot to performance@gradle.com.
Performance categories
Both a Build Scan and local profile reports break down build execution into the same categories. The following sections explain those categories.
Startup
This reflects Gradle’s initialization time, which consists mostly of:
-
JVM initialization and class loading
-
Downloading the Gradle distribution if you’re using the wrapper
-
Starting the daemon if a suitable one isn’t already running
-
Executing Gradle initialization scripts
Even when a build execution has a long startup time, subsequent runs usually see a dramatic drop off in startup time. Persistently slow build startup times are usually the result of problems in your init scripts. Double check that the work you’re doing there is necessary and performant.
Settings and buildSrc
After startup, Gradle initializes your project. Usually, Gradle only processes your settings file.
If you have custom build logic in a buildSrc directory, Gradle also processes that logic.
After building buildSrc once, Gradle considers it up to date. The up-to-date checks take significantly less time than logic processing.
If your buildSrc phase takes too much time, consider breaking it out into a separate project.
You can then add that project’s JAR artifact as a dependency.
The settings file rarely contains code with significant I/O or computation. If you find that Gradle takes a long time to process it, use more traditional profiling methods, like the Gradle Profiler, to determine the cause.
Loading projects
It normally doesn’t take a significant amount of time to load projects, nor do you have any control over it. The time spent here is basically a function of the number of projects you have in your build.
Continuous Builds
Continuous Build allows you to automatically re-execute the requested tasks when file inputs change.
You can execute the build in this mode using the -t or --continuous command-line option.
For example, you can continuously run the test task and all dependent tasks by running:
$ ./gradlew test --continuousGradle will behave as if you ran gradle test after a change to sources or tests that contribute to the requested tasks.
This means unrelated changes (such as changes to build scripts) will not trigger a rebuild.
To incorporate build logic changes, the continuous build must be restarted manually.
Continuous build uses file system watching to detect changes to the inputs.
If file system watching does not work on your system, then continuous build won’t work either.
In particular, continuous build does not work when using --no-daemon.
When Gradle detects a change to the inputs, it will not trigger the build immediately.
Instead, it will wait until no additional changes are detected for a certain period of time - the quiet period.
You can configure the quiet period in milliseconds by the Gradle property org.gradle.continuous.quietperiod.
Terminating Continuous Build
If Gradle is attached to an interactive input source, such as a terminal, the continuous build can be exited by pressing CTRL-D (On Microsoft Windows, it is required to also press ENTER or RETURN after CTRL-D).
If Gradle is not attached to an interactive input source (e.g. is running as part of a script), the build process must be terminated (e.g. using the kill command or similar).
If the build is being executed via the Tooling API, the build can be cancelled using the Tooling API’s cancellation mechanism.
Limitations
Under some circumstances, continuous build may not detect changes to inputs.
Creating input directories
Sometimes, creating an input directory that was previously missing does not trigger a build, due to the way file system watching works.
For example, creating the src/main/java directory may not trigger a build.
Similarly, if the input is a filtered file tree and no files are matching the filter, the creation of matching files may not trigger a build.
Inputs of untracked tasks
Changes to the inputs of untracked tasks or tasks that have no outputs may not trigger a build.
Changes to files outside of project directories
Gradle only watches for changes to files inside the project directory. Changes to files outside the project directory will go undetected and not trigger a build.
Build cycles
Gradle starts watching for changes just before a task executes. If a task modifies its own inputs while executing, Gradle will detect the change and trigger a new build. If every time the task executes, the inputs are modified again, the build will be triggered again. This isn’t unique to continuous build. A task that modifies its own inputs will never be considered up-to-date when run "normally" without continuous build.
If your build enters a build cycle like this, you can track down the task by looking at the list of files reported changed by Gradle.
After identifying the file(s) that are changed during each build, you should look for a task that has that file as an input.
In some cases, it may be obvious (e.g., a Java file is compiled with compileJava).
In other cases, you can use --info logging to find the task that is out-of-date due to the identified files.
Changes to symbolic links
In general, Gradle will not detect changes to symbolic links or to files referenced via symbolic links.
Changes to build logic are not considered
The current implementation does not recalculate the build model on subsequent builds. This means that changes to task configuration, or any other change to the build model, are effectively ignored.
Continuous Build in IDEs
Most modern IDEs like IntelliJ IDEA, Android Studio, or Eclipse already offer their own form of continuous compilation and test execution.
For example, If you’re only interested in triggering something on file changes (e.g., running tests or generating docs), you might consider using IntelliJ’s File Watchers feature as an alternative for specific tasks.
Gradle’s --continuous mode is designed for command-line use and is not typically integrated into IDE workflows.
To use continuous build in an IDE environment, run ./gradlew <task> --continuous from a terminal window alongside the IDE.
File System Watching
Gradle maintains a Virtual File System (VFS) to calculate what needs to be rebuilt on repeat builds of a project. By watching the file system, Gradle keeps the VFS current between builds.
Enable
Gradle enables file system watching by default for supported operating systems since Gradle 7.
Run the build with the '--watch-fs' flag to force file system watching for a build.
To force file system watching for all builds (unless disabled with --no-watch-fs), add the following value to gradle.properties:
org.gradle.vfs.watch=trueDisable
To disable file system watching:
-
use the
--no-watch-fsflag -
set
org.gradle.vfs.watch=falseingradle.properties
Excluding files and directories
Gradle automatically excludes some common directories (like .git, .gradle, and build/) from file system watching.
There is no public mechanism to configure additional file system watch excludes.
To reduce unnecessary watching and re-execution, consider limiting the inputs of specific tasks using fileTree.exclude().
Supported Operating Systems
Gradle uses native operating system features to watch the file system. Gradle supports file system watching on the following operating systems:
-
Windows 10, version 1709 and later
-
Linux, tested on the following distributions:
-
Ubuntu 16.04
-
CentOS Stream 9
-
Red Hat Enterprise Linux (RHEL) 8
-
Amazon Linux 2
-
Alpine Linux 3.20
-
-
macOS 12 (Monterey) or later on Intel and ARM architectures
Supported File Systems
File system watching supports the following file system types:
-
APFS
-
btrfs
-
ext3
-
ext4
-
XFS
-
HFS+
-
NTFS
Gradle also supports VirtualBox’s shared folders.
Network file systems like Samba and NFS are not supported. Microsoft Dev Drives (ReFS) are also not supported.
Unsupported File Systems
When enabled by default, file system watching acts conservatively when it encounters content on unsupported file systems. This can happen if you mount a project directory or subdirectory from a network drive. Gradle doesn’t retain information about unsupported file systems between builds when enabled by default. If you explicitly enable file system watching, Gradle retains information about unsupported file systems between builds.
Symlinks
Files and directories in your project that are accessed via symlinks do not benefit from file system-watching optimizations.
Logging
To view information about Virtual File System (VFS) changes at the beginning and end of a build, enable verbose VFS logging.
Set the org.gradle.vfs.verbose Daemon option to true to enable verbose logging.
You can do this on the command line with the following command:
$ gradle <task> -Dorg.gradle.vfs.verbose=trueOr configure the property in the gradle.properties file in the project root or your Gradle User Home:
org.gradle.vfs.verbose=trueThis produces the following output at the start and end of the build:
$ ./gradlew assemble --watch-fs -Dorg.gradle.vfs.verbose=trueReceived 3 file system events since last build while watching 1 locations
Virtual file system retained information about 2 files, 2 directories and 0 missing files since last build
> Task :compileJava NO-SOURCE
> Task :processResources NO-SOURCE
> Task :classes UP-TO-DATE
> Task :jar UP-TO-DATE
> Task :assemble UP-TO-DATE
BUILD SUCCESSFUL in 58ms
1 actionable task: 1 up-to-date
Received 5 file system events during the current build while watching 1 locations
Virtual file system retains information about 3 files, 2 directories and 2 missing files until next buildOn Windows and macOS, Gradle might report changes received since the last build, even if you haven’t changed anything. These are harmless notifications about changes to Gradle’s caches and can be safely ignored.
Troubleshooting
- Gradle does not detect some changes
-
Please let us know on the Gradle community Slack. If a build declares its inputs and outputs correctly, this should not happen. So it’s either a bug we must fix or your build lacks declaration for some inputs or outputs.
- VFS state dropped due to lost state
-
Did you receive a message that reads
Dropped VFS state due to lost stateduring a build? Please let us know on the Gradle community Slack. This means that your build cannot benefit from file system watching for one of the following reasons:-
the Daemon received an unknown file system event
-
too many changes happened, and the watching API couldn’t handle it
-
- Too many open files on macOS
-
If you receive the
java.io.IOException: Too many open fileserror on macOS, raise your open files limit. See this post for more details.
Adjust inotify watches limit on Linux
File system watching uses inotify on Linux. Depending on the size of your build, it may be necessary to increase inotify limits. If you are using an IDE, then you probably already had to increase the limits in the past.
File system watching uses one inotify watch per watched directory. You can see the current limit of inotify watches per user by running:
cat /proc/sys/fs/inotify/max_user_watchesTo increase the limit to e.g. 512K watches run the following:
echo fs.inotify.max_user_watches=524288 | sudo tee -a /etc/sysctl.confsudo sysctl -p --systemEach used inotify watch takes up to 1KB of memory. Assuming inotify uses all the 512K watches then file system watching could use up to 500MB. In a memory-constrained environment, you may want to disable file system watching.
Inspect inotify instances limit on Linux
File system watching initializes one inotify instance per daemon. You can see the current limit of inotify instances per user by running:
cat /proc/sys/fs/inotify/max_user_instancesThe default per-user instances limit should be high enough, so we don’t recommend increasing that value manually.
DSLS AND APIS
Groovy
A Groovy Build Script Primer
Ideally, a Groovy build script looks mostly like configuration: setting some properties of the project, configuring dependencies, declaring tasks, and so on. That configuration is based on Groovy language constructs. This primer aims to explain what those constructs are and — most importantly — how they relate to Gradle’s API documentation.
The Project object
As Groovy is an object-oriented language based on Java, its properties and methods apply to objects. In some cases, the object is implicit — particularly at the top level of a build script, i.e. not nested inside a {} block.
Consider this fragment of build script, which contains an unqualified property and block:
version = '1.0.0.GA'
configurations {
...
}Both version and configurations {} are part of org.gradle.api.Project.
This example reflects how every Groovy build script is backed by an implicit instance of Project. If you see an unqualified element and you don’t know where it’s defined, always check the Project API documentation to see if that’s where it’s coming from.
|
Caution
|
Avoid using Groovy MetaClass programming techniques in your build scripts. Gradle provides its own API for adding dynamic runtime properties. Use of Groovy-specific metaprogramming can cause builds to retain large amounts of memory between builds that will eventually cause the Gradle daemon to run out-of-memory. |
Properties
<obj>.<name> // Get a property value
<obj>.<name> = <value> // Set a property to a new value
"$<name>" // Embed a property value in a string
"${<obj>.<name>}" // Same as previous (embedded value)version = '1.0.1'
myCopyTask.description = 'Copies some files'
file("$projectDir/src")
println "Destination: ${myCopyTask.destinationDir}"A property represents some state of an object. The presence of an = sign is a clear indicator that you’re looking at a property. Otherwise, a qualified name — it begins with <obj>. — without any other decoration is also a property.
If the name is unqualified, then it may be one of the following:
-
A task instance with that name.
-
A property on Project.
-
An extra property defined elsewhere in the project.
-
A property of an implicit object within a block.
-
A local variable defined earlier in the build script.
Note that plugins can add their own properties to the Project object. The API documentation lists all the properties added by core plugins. If you’re struggling to find where a property comes from, check the documentation for the plugins that the build uses.
|
Tip
|
When referencing a project property in your build script that is added by a non-core plugin, consider prefixing it with project. — it’s clear then that the property belongs to the project object.
|
Properties in the API documentation
The Groovy DSL reference shows properties as they are used in your build scripts, but the Javadocs only display methods. That’s because properties are implemented as methods behind the scenes:
-
A property can be read if there is a method named
get<PropertyName>with zero arguments that returns the same type as the property. -
A property can be modified if there is a method named
set<PropertyName>with one argument that has the same type as the property and a return type ofvoid.
Note that property names usually start with a lower-case letter, but that letter is upper case in the method names. So the getter method getProjectVersion() corresponds to the property projectVersion. This convention does not apply when the name begins with at least two upper-case letters, in which case there is not change in case. For example, getRAM() corresponds to the property RAM.
project.getVersion()
project.version
project.setVersion('1.0.1')
project.version = '1.0.1'Methods
<obj>.<name>() // Method call with no arguments
<obj>.<name>(<arg>, <arg>) // Method call with multiple arguments
<obj>.<name> <arg>, <arg> // Method call with multiple args (no parentheses)myCopyTask.include '**/*.xml', '**/*.properties'
ext.resourceSpec = copySpec() // `copySpec()` comes from `Project`
file('src/main/java')
println 'Hello, World!'A method represents some behavior of an object, although Gradle often uses methods to configure the state of objects as well. Methods are identifiable by their arguments or empty parentheses. Note that parentheses are sometimes required, such as when a method has zero arguments, so you may find it simplest to always use parentheses.
|
Note
|
Gradle has a convention whereby if a method has the same name as a collection-based property, then the method appends its values to that collection. |
Blocks
Blocks are also methods, just with specific types for the last argument.
<obj>.<name> {
...
}
<obj>.<name>(<arg>, <arg>) {
...
}plugins {
id 'java-library'
}
configurations {
assets
}
sourceSets {
main {
java {
srcDirs = ['src']
}
}
}
dependencies {
implementation project(':util')
}Blocks are a mechanism for configuring multiple aspects of a build element in one go. They also provide a way to nest configuration, leading to a form of structured data.
There are two important aspects of blocks that you should understand:
-
They are implemented as methods with specific signatures.
-
They can change the target ("delegate") of unqualified methods and properties.
Both are based on Groovy language features and we explain them in the following sections.
Block method signatures
You can easily identify a method as the implementation behind a block by its signature, or more specifically, its argument types. If a method corresponds to a block:
-
It must have at least one argument.
-
The last argument must be of type
groovy.lang.Closureor org.gradle.api.Action.
For example, Project.copy(Action) matches these requirements, so you can use the syntax:
copy {
into layout.buildDirectory.dir("tmp")
from 'custom-resources'
}That leads to the question of how into() and from() work. They’re clearly methods, but where would you find them in the API documentation? The answer comes from understanding object delegation.
Delegation
The section on properties lists where unqualified properties might be found. One common place is on the Project object. But there is an alternative source for those unqualified properties and methods inside a block: the block’s delegate object.
To help explain this concept, consider the last example from the previous section:
copy {
into layout.buildDirectory.dir("tmp")
from 'custom-resources'
}All the methods and properties in this example are unqualified. You can easily find copy() and layout in the Project API documentation, but what about into() and from()? These are resolved against the delegate of the copy {} block. What is the type of that delegate? You’ll need to check the API documentation for that.
There are two ways to determine the delegate type, depending on the signature of the block method:
-
For
Actionarguments, look at the type’s parameter.In the example above, the method signature is
copy(Action<? super CopySpec>)and it’s the bit inside the angle brackets that tells you the delegate type — CopySpec in this case. -
For
Closurearguments, the documentation will explicitly say in the description what type is being configured or what type the delegate it (different terminology for the same thing).
Hence you can find both into() and from() on CopySpec. You might even notice that both of those methods have variants that take an Action as their last argument, which means you can use block syntax with them.
All new Gradle APIs declare an Action argument type rather than Closure, which makes it very easy to pick out the delegate type. Even older APIs have an Action variant in addition to the old Closure one.
Local variables
def <name> = <value> // Untyped variable
<type> <name> = <value> // Typed variabledef i = 1
String errorMsg = 'Failed, because reasons'Local variables are a Groovy construct — unlike extra properties — that can be used to share values within a build script.
|
Caution
|
Avoid using local variables in the root of the project, i.e. as pseudo project properties. They cannot be read outside of the build script and Gradle has no knowledge of them. Within a narrower context — such as configuring a task — local variables can occasionally be helpful. |
Kotlin
Gradle Kotlin DSL Primer
Gradle’s Kotlin DSL offers an alternative to the traditional Groovy DSL, delivering an enhanced editing experience in supported IDEs with features like better content assist, refactoring, and documentation.
This chapter explores the key Kotlin DSL constructs and demonstrates how to use them to interact with the Gradle API.
|
Tip
|
If you are interested in migrating an existing Gradle build to the Kotlin DSL, please also check out the dedicated migration page. |
Prerequisites
-
The embedded Kotlin compiler supports the platforms and architectures listed in the Kotlin/Native target support documentation.
-
Familiarity with Kotlin syntax and basic language features is recommended. Refer to the Kotlin documentation and Kotlin Koans to learn the basics.
-
Using the
plugins {}block to declare Gradle plugins is highly recommended as it significantly improves the editing experience.
IDE support
The Kotlin DSL is fully supported by IntelliJ IDEA and Android Studio. While other IDEs lack advanced tools for editing Kotlin DSL files, you can still import Kotlin-DSL-based builds and work with them as usual.
| Build import | Syntax highlighting 1 | Semantic editor 2 | |
|---|---|---|---|
IntelliJ IDEA |
✓ |
✓ |
✓ |
Android Studio |
✓ |
✓ |
✓ |
Eclipse IDE |
✓ |
✓ |
✖ |
CLion |
✓ |
✓ |
✖ |
Apache NetBeans |
✓ |
✓ |
✖ |
Visual Studio Code (LSP) |
✓ |
✓ |
✖ |
Visual Studio |
✓ |
✖ |
✖ |
1 Kotlin syntax highlighting in Gradle Kotlin DSL scripts
2 Code completion, navigation to sources, documentation, refactorings etc… in Gradle Kotlin DSL scripts
As noted in the limitations, you must import your project using the Gradle model to enable content assist and refactoring tools for Kotlin DSL scripts in IntelliJ IDEA.
Builds with slow configuration time might affect the IDE responsiveness, so please check out the performance section to help resolve such issues.
Automatic build import vs. automatic reloading of script dependencies
Both IntelliJ IDEA and Android Studio will detect when you make changes to your build logic and offer two suggestions:
-
Import the whole build again:


-
Reload script dependencies when editing a build script:
We recommend disabling automatic build import while enabling automatic reloading of script dependencies. This approach provides early feedback when editing Gradle scripts while giving you control over when the entire build setup synchronizes with your IDE.
See the Troubleshooting section to learn more.
Kotlin DSL scripts
Just like its Groovy-based counterpart, the Kotlin DSL is built on Gradle’s Java API. Everything in a Kotlin DSL script is Kotlin code, compiled and executed by Gradle. Many of the objects, functions, and properties in your build scripts come from the Gradle API and the APIs of applied plugins.
|
Tip
|
Use the Kotlin DSL reference search to explore available members. |
Script file names
-
Groovy DSL script files use the
.gradlefile name extension. -
Kotlin DSL script files use the
.gradle.ktsfile name extension.
To activate the Kotlin DSL, use the .gradle.kts extension for your build scripts instead of .gradle.
This also applies to the settings file (e.g., settings.gradle.kts) and initialization scripts.
You can mix Groovy DSL and Kotlin DSL scripts within the same build. For example, a Kotlin DSL build script can apply a Groovy DSL one, and different projects in a multi-project build can use either.
To improve IDE support, we recommend following these conventions:
-
Name settings scripts (or any script backed by a Gradle
Settingsobject) using the pattern*.settings.gradle.kts. This includes script plugins applied from settings scripts. -
Name initialization scripts using the pattern
*.init.gradle.ktsor simplyinit.gradle.kts.
Implicit imports
All Kotlin DSL build scripts come with implicit imports, including:
-
The Kotlin DSL API, which includes types from the following packages:
-
org.gradle.kotlin.dsl -
org.gradle.kotlin.dsl.plugins.dsl -
org.gradle.kotlin.dsl.precompile -
java.util.concurrent.Callable -
java.util.concurrent.TimeUnit -
java.math.BigDecimal -
java.math.BigInteger -
java.io.File -
javax.inject.Inject
-
Avoid Using Internal Kotlin DSL APIs
Using internal Kotlin DSL APIs in plugins and build scripts can break builds when either Gradle or plugins are updated.
The Kotlin DSL API extends the public Gradle API with types listed in the corresponding API docs found in the packages above (but not in their subpackages).
Compilation warnings
Gradle Kotlin DSL scripts are compiled by Gradle during the configuration phase of your build.
Deprecation warnings found by the Kotlin compiler are reported on the console when compiling the scripts:
> Configure project :
w: build.gradle.kts:4:5: 'getter for uploadTaskName: String!' is deprecated. Deprecated in JavaIt is possible to configure your build to fail on any warning emitted during script compilation by setting the org.gradle.kotlin.dsl.allWarningsAsErrors Gradle property to true:
org.gradle.kotlin.dsl.allWarningsAsErrors=trueType-safe model accessors
The Groovy DSL allows you to reference many build model elements by name, even if they are defined at runtime, such as named configurations or source sets.
For example, when the Java plugin is applied, you can access the implementation configuration via configurations.implementation.
The Kotlin DSL replaces this dynamic resolution with type-safe model accessors, which work with model elements contributed by plugins.
Understanding when type-safe model accessors are available
The Kotlin DSL currently provides various sets of type-safe model accessors, each tailored to different scopes.
For the main project build scripts and precompiled project script plugins:
| Type-safe model accessors | Example |
|---|---|
Dependency and artifact configurations |
|
Project extensions and conventions, and extensions on them |
|
Extensions on the |
|
Elements in the |
|
Elements in project-extension containers |
Source sets contributed by the Java Plugin that are added to the |
For the main project settings script and precompiled settings script plugins:
| Type-safe model accessors | Example |
|---|---|
Project extensions and conventions, contributed by |
|
|
Important
|
Initialization scripts and script plugins do not have type-safe model accessors. These limitations will be removed in a future Gradle release. |
The set of type-safe model accessors available is determined right before evaluating the script body, immediately after the plugins {} block.
Model elements contributed after that point, such as configurations defined in your build script, will not work with type-safe model accessors:
// Applies the Java plugin
plugins {
id("java")
}
repositories {
mavenCentral()
}
// Access to 'implementation' (contributed by the Java plugin) works here:
dependencies {
implementation("org.apache.commons:commons-lang3:3.12.0")
testImplementation("org.junit.jupiter:junit-jupiter:5.10.0")
testRuntimeOnly("org.junit.platform:junit-platform-launcher") // Add this if needed for runtime
}
// Add a custom configuration
configurations.create("customConfiguration")
// Type-safe accessors for 'customConfiguration' will NOT be available because it was created after the plugins block
dependencies {
customConfiguration("com.google.guava:guava:32.1.2-jre") // ❌ Error: No type-safe accessor for 'customConfiguration'
}However, this means you can use type-safe accessors for any model elements contributed by plugins that are applied by parent projects.
The following project build script demonstrates how you can access various configurations, extensions and other elements using type-safe accessors:
plugins {
`java-library`
}
dependencies { // (1)
api("junit:junit:4.13")
implementation("junit:junit:4.13")
testImplementation("junit:junit:4.13")
}
configurations { // (1)
implementation {
resolutionStrategy.failOnVersionConflict()
}
}
sourceSets { // (2)
main { // (3)
java.srcDir("src/core/java")
}
}
java { // (4)
sourceCompatibility = JavaVersion.VERSION_11
targetCompatibility = JavaVersion.VERSION_11
}
tasks {
test { // (5)
testLogging.showExceptions = true
useJUnit()
}
}-
Uses type-safe accessors for the
api,implementationandtestImplementationdependency configurations contributed by the Java Library Plugin -
Uses an accessor to configure the
sourceSetsproject extension -
Uses an accessor to configure the
mainsource set -
Uses an accessor to configure the
javasource for themainsource set -
Uses an accessor to configure the
testtask
|
Tip
|
Your IDE is aware of the type-safe accessors and will include them in its suggestions. This applies both at the top level of your build scripts, where most plugin extensions are added to the |
Note that accessors for elements of containers such as configurations, tasks, and sourceSets leverage Gradle’s configuration avoidance APIs.
For example, on tasks, accessors are of type TaskProvider<T> and provide a lazy reference and lazy configuration of the underlying task.
Here are some examples illustrating when configuration avoidance applies:
tasks.test {
// lazy configuration
useJUnitPlatform()
}
// Lazy reference
val testProvider: TaskProvider<Test> = tasks.test
testProvider {
// lazy configuration
}
// Eagerly realized Test task, defeats configuration avoidance if done out of a lazy context
val test: Test = tasks.test.get()For all other containers, accessors for elements are of type NamedDomainObjectProvider<T>, providing the same behavior:
val mainSourceSetProvider: NamedDomainObjectProvider<SourceSet> = sourceSets.named("main")Understanding what to do when type-safe model accessors are not available
Consider the sample build script shown above, which demonstrates the use of type-safe accessors.
The following sample is identical, except it uses the apply() method to apply the plugin.
In this case, the build script cannot use type-safe accessors because the apply() call occurs in the body of the build script.
You must use another techniques instead, as demonstrated here:
apply(plugin = "java-library")
dependencies {
"api"("junit:junit:4.13")
"implementation"("junit:junit:4.13")
"testImplementation"("junit:junit:4.13")
}
configurations {
"implementation" {
resolutionStrategy.failOnVersionConflict()
}
}
configure<SourceSetContainer> {
named("main") {
java.srcDir("src/core/java")
}
}
configure<JavaPluginExtension> {
sourceCompatibility = JavaVersion.VERSION_11
targetCompatibility = JavaVersion.VERSION_11
}
tasks {
named<Test>("test") {
testLogging.showExceptions = true
}
}Type-safe accessors are unavailable for model elements contributed by the following:
-
Plugins applied via the
apply(plugin = "id")method. -
The project build script.
-
Script plugins, via
apply(from = "script-plugin.gradle.kts"). -
Plugins applied via cross-project configuration.
You cannot use type-safe accessors in binary Gradle plugins implemented in Kotlin.
If you can’t find a type-safe accessor, fall back to using the normal API for the corresponding types. To do so, you need to know the names and/or types of the configured model elements. We will now show you how these can be discovered by examining the script in detail.
The following sample demonstrates how to reference and configure artifact configurations without type-safe accessors:
apply(plugin = "java-library")
dependencies {
"api"("junit:junit:4.13")
"implementation"("junit:junit:4.13")
"testImplementation"("junit:junit:4.13")
}
configurations {
"implementation" {
resolutionStrategy.failOnVersionConflict()
}
}The code looks similar to that of the type-safe accessors, except that the configuration names are string literals.
You can use string literals for configuration names in dependency declarations and within the configurations {} block.
While the IDE won’t be able to help you discover the available configurations, you can look them up either in the corresponding plugin’s documentation or by running ./gradlew dependencies.
Project extensions have both a name and a unique type. However, the Kotlin DSL only needs to know the type to configure them.
The following sample shows the sourceSets {} and java {} blocks from the original example build script.
The configure<T>() function is used with the corresponding type:
apply(plugin = "java-library")
configure<SourceSetContainer> {
named("main") {
java.srcDir("src/core/java")
}
}
configure<JavaPluginExtension> {
sourceCompatibility = JavaVersion.VERSION_11
targetCompatibility = JavaVersion.VERSION_11
}Note that sourceSets is a Gradle extension on Project of type SourceSetContainer and java is an extension on Project of type JavaPluginExtension.
You can discover available extensions by either reviewing the documentation for the applied plugins or running ./gradlew kotlinDslAccessorsReport.
The report generates the Kotlin code needed to access the model elements contributed by the applied plugins, providing both names and types.
As a last resort, you can check the plugin’s source code, though this should not be necessary in most cases.
You can also use the the<T>() function if you only need a reference to the extension without configuring it, or if you want to perform a one-line configuration:
the<SourceSetContainer>()["main"].java.srcDir("src/main/java")The snippet above also demonstrates one way to configure elements of a project extension that is a container.
Container-based project extensions, such as SourceSetContainer, allow you to configure the elements they hold.
In our sample build script, we want to configure a source set named main within the source set container.
We can do this by using the named() method instead of an accessor:
apply(plugin = "java-library")
configure<SourceSetContainer> {
named("main") {
java.srcDir("src/core/java")
}
}All elements within a container-based project extension have a name, so you can use this technique in all such cases.
For project extensions and conventions, you can discover what elements are present in any container by either checking the documentation for the applied plugins or by running ./gradlew kotlinDslAccessorsReport.
As a last resort, you may also review the plugin’s source code to find out what it does.
Tasks are not managed through a container-based project extension, but they are part of a container that behaves in a similar way.
This means that you can configure tasks in the same way as you do for source sets. The following example illustrates this approach:
apply(plugin = "java-library")
tasks {
named<Test>("test") {
testLogging.showExceptions = true
}
}We are using the Gradle API to refer to tasks by name and type, rather than using accessors.
Note that it is necessary to specify the type of the task explicitly.
If you don’t, the script won’t compile because the inferred type will be Task, not Test, and the testLogging property is specific to the Test task type.
However, you can omit the type if you only need to configure properties or call methods that are common to all tasks, i.e., those declared on the Task interface.
You can discover what tasks are available by running ./gradlew tasks.
To find out the type of a given task, run ./gradlew help --task <taskName>, as demonstrated here:
❯ ./gradlew help --task test
...
Type
Test (org.gradle.api.tasks.testing.Test)The IDE can assist you with the required imports, so you only need the simple names of the types, without the package name part.
In this case, there’s no need to import the Test task type, as it is part of the Gradle API and is therefore imported implicitly.
Working with container objects
The Gradle build model makes extensive use of container objects (or simply "containers").
For example, configurations and tasks are containers that hold Configuration and Task objects, respectively.
Community plugins also contribute containers, such as the android.buildTypes container contributed by the Android Plugin.
The Kotlin DSL provides multiple ways for build authors to interact with containers.
We will explore each of these methods, using the tasks container as an example.
|
Tip
|
You can leverage the type-safe accessors described in another section when configuring existing elements on supported containers. That section also explains which containers support type-safe accessors. |
Using the container API
All containers in Gradle implement NamedDomainObjectContainer<DomainObjectType>. Some containers can hold objects of different types and implement PolymorphicDomainObjectContainer<BaseType>. The simplest way to interact with containers is through these interfaces.
The following example demonstrates how you can use the named() method to configure existing tasks, and the register() method to create new tasks:
tasks.named("check") // (1)
tasks.register("myTask1") // (2)
tasks.named<JavaCompile>("compileJava") // (3)
tasks.register<Copy>("myCopy1") // (4)
tasks.named("assemble") { // (5)
dependsOn(":myTask1")
}
tasks.register("myTask2") { // (6)
description = "Some meaningful words"
}
tasks.named<Test>("test") { // (7)
testLogging.showStackTraces = true
}
tasks.register<Copy>("myCopy2") { // (8)
from("source")
into("destination")
}-
Gets a reference of type
Taskto the existing task namedcheck -
Registers a new untyped task named
myTask1 -
Gets a reference to the existing task named
compileJavaof typeJavaCompile -
Registers a new task named
myCopy1of typeCopy -
Gets a reference to the existing (untyped) task named
assembleand configures it — you can only configure properties and methods that are available onTaskwith this syntax -
Registers a new untyped task named
myTask2and configures it — you can only configure properties and methods that are available onTaskin this case -
Gets a reference to the existing task named
testof typeTestand configures it — in this case you have access to the properties and methods of the specified type -
Registers a new task named
myCopy2of typeCopyand configures it
|
Note
|
The above sample relies on the configuration avoidance APIs. If you need or want to eagerly configure or register container elements, simply replace named() with getByName() and register() with create().
|
Configuring multiple container elements together
When configuring several elements of a container, you can group interactions in a block to avoid repeating the container’s name on each interaction.
The following example demonstrates a combination of type-safe accessors and the container API:
tasks {
test {
testLogging.showStackTraces = true
}
val myCheck = register("myCheck") {
doLast { /* assert on something meaningful */ }
}
check {
dependsOn(myCheck)
}
register("myHelp") {
doLast { /* do something helpful */ }
}
}Working with extra properties
Extra properties are available on any object that implements the ExtensionAware interface.
The Kotlin DSL provides the extra accessor for working with extra properties as a map:
extra["myNewProperty"] = "initial value" // (1)
val myExtraProperty = extra["myNewProperty"] as String // (2)
val myExtraNullableProperty = extra["myNullableProperty"] as String? // (3)-
Creates a new extra property called
myNewPropertyin the current context (the project in this case) and initializes it with the value"initial value" -
Access an existing extra property from the current context (the project in this case)
-
Does the same as the previous line but allows the property to have a null value
This approach works for all Gradle scripts: project build scripts, script plugins, settings scripts, and initialization scripts.
You can also access extra properties on a root project from a subproject using the following syntax:
val myNewProperty = rootProject.extra["myNewProperty"] as String // (1)-
Reads the root project’s
myNewPropertyextra property
Extra properties aren’t just limited to projects.
For example, Task extends ExtensionAware, so you can attach extra properties to tasks as well.
Here’s an example that defines a new reportType on the test task and then uses that property to initialize another task:
tasks {
test {
extra["reportType"] = "dev" // (1)
doLast {
// Use 'reportType' for post-processing of reports
}
}
register<Zip>("archiveTestReports") {
from(test.map { it.reports.html.outputLocation })
archiveAppendix = test.map { it.extra["reportType"] as String } // (2)
}
}-
Creates a new
reportTypeextra property on thetesttask -
Reads the
testtask’sreportTypeextra property to configure thearchiveTestReportstask
Working with Gradle types
Property, Provider, and NamedDomainObjectProvider are types that represent deferred and lazy evaluation of values and objects.
The Kotlin DSL provides a specialized syntax for working with these types.
Using a Property
A property represents a value that can be set and read lazily:
-
Setting a value:
property.set(value)orproperty = value -
Accessing the value:
property.get()
val myProperty: Property<String> = project.objects.property(String::class.java)
myProperty.set("Hello, Gradle!") // Set the value
println(myProperty.get()) // Access the value
// Using .get() to read the value
val propValue: String = myProperty.get()
println(propValue)
// Using assignment syntax
myProperty = "Hi, Gradle!" // Set the value
println(myProperty.get()) // Access the valueUsing a Provider
A provider represents a read-only, lazily-evaluated value:
-
Accessing the value:
provider.get() -
Chaining:
provider.map { transform(it) }
val versionProvider: Provider<String> = project.provider { "1.0.0" }
println(versionProvider.get()) // Access the value
// Chaining transformations
val majorVersion: Provider<String> = versionProvider.map { it.split(".")[0] }
println(majorVersion.get()) // Prints: "1"Using a NamedDomainObjectProvider
A named domain object provider represents a lazily-evaluated named object from a Gradle container (like tasks or extensions):
-
Accessing the object:
namedObjectProvider.get() -
Configuring the object:
namedObjectProvider.configure { … }
val myTaskProvider: NamedDomainObjectProvider<Task> = tasks.named("build")
// Configuring the task
myTaskProvider.configure {
doLast {
println("Build task completed!")
}
}
// Accessing the task
val myTask: Task = myTaskProvider.get()Lazy property assignment
Gradle’s Kotlin DSL supports lazy property assignment using the = operator.
Lazy property assignment reduces verbosity when lazy properties are used.
It works for properties that are publicly seen as final (without a setter) and have type Property or ConfigurableFileCollection.
Since properties must be final, we generally recommend avoiding custom setters for properties with lazy types and, if possible, implementing such properties via an abstract getter.
Using the = operator is the preferred way to call set() in the Kotlin DSL:
java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}
abstract class WriteJavaVersionTask : DefaultTask() {
@get:Input
abstract val javaVersion: Property<String>
@get:OutputFile
abstract val output: RegularFileProperty
@TaskAction
fun execute() {
output.get().asFile.writeText("Java version: ${javaVersion.get()}")
}
}
tasks.register<WriteJavaVersionTask>("writeJavaVersion") {
javaVersion.set("17") // (1)
javaVersion = "17" // (2)
javaVersion = java.toolchain.languageVersion.map { it.toString() } // (3)
output = layout.buildDirectory.file("writeJavaVersion/javaVersion.txt")
}-
Set value with the
.set()method -
Set value with lazy property assignment using the
=operator -
The
=operator can be used also for assigning lazy values
IDE support
Lazy property assignment is supported from IntelliJ 2022.3 and from Android Studio Giraffe.
Kotlin DSL Plugin
The Kotlin DSL Plugin provides a convenient way to develop Kotlin-based projects that contribute build logic. This includes buildSrc projects, included builds, and Gradle plugins.
The plugin achieves this by doing the following:
-
Applies the Kotlin Plugin, which adds support for compiling Kotlin source files.
-
Adds the
kotlin-stdlib,kotlin-reflect, andgradleKotlinDsl()dependencies to thecompileOnlyandtestImplementationconfigurations, enabling the use of those Kotlin libraries and the Gradle API in your Kotlin code. -
Configures the Kotlin compiler with the same settings used for Kotlin DSL scripts, ensuring consistency between your build logic and those scripts:
-
Registers the SAM-with-receiver Kotlin compiler plugin.
-
Enables support for precompiled script plugins.
Each Gradle release is meant to be used with a specific version of the kotlin-dsl plugin.
Compatibility between arbitrary Gradle releases and kotlin-dsl plugin versions is not guaranteed.
Using an unexpected version of the kotlin-dsl plugin will emit a warning and can cause hard-to-diagnose problems.
This is the basic configuration you need to use the plugin:
plugins {
`kotlin-dsl`
}
repositories {
// The org.jetbrains.kotlin.jvm plugin requires a repository
// where to download the Kotlin compiler dependencies from.
mavenCentral()
}The Kotlin DSL Plugin leverages Java Toolchains. By default, the code will target Java 8.
Embedded Kotlin
Gradle embeds Kotlin in order to provide support for Kotlin-based scripts.
Kotlin versions
Gradle ships with kotlin-compiler-embeddable plus matching versions of kotlin-stdlib and kotlin-reflect libraries.
For details, see the Kotlin section of Gradle’s compatibility matrix.
The kotlin package from those modules is visible through the Gradle classpath.
The compatibility guarantees provided by Kotlin apply for both backward and forward compatibility.
Our approach is to only make backward-incompatible Kotlin upgrades with major Gradle releases. We clearly document the Kotlin version shipped with each release and announce upgrade plans ahead of major releases.
Plugin authors aiming to maintain compatibility with older Gradle versions must limit their API usage to what is supported by those versions. This is no different from working with any new API in Gradle. For example, if a new API for dependency resolution is introduced, a plugin must either drop support for older Gradle versions or organize its code to conditionally execute the new code path on compatible versions.
The primary compatibility concern lies between the external kotlin-gradle-plugin version and the kotlin-stdlib version shipped with Gradle.
More broadly, this applies to any plugin that transitively depends on kotlin-stdlib and its version provided by Gradle.
As long as the versions are compatible, everything should work as expected.
This issue will diminish as the Kotlin language matures.
Kotlin compiler arguments
The following Kotlin compiler arguments are used for compiling Kotlin DSL scripts, as well as Kotlin sources and scripts in projects with the kotlin-dsl plugin applied:
-java-parameters-
Generate metadata for Java >= 1.8 reflection on method parameters. See Kotlin/JVM compiler options in the Kotlin documentation for more information.
-Xjvm-default=all-
Makes all non-abstract members of Kotlin interfaces default for the Java classes implementing them. This is to provide a better interoperability with Java and Groovy for plugins written in Kotlin. See Default methods in interfaces in the Kotlin documentation for more information.
-Xsam-conversions=class-
Sets up the implementation strategy for SAM (single abstract method) conversion to always generate anonymous classes, instead of using the
invokedynamicJVM instruction. This is to provide a better support for configuration cache and incremental build. See KT-44912 in the Kotlin issue tracker for more information. -Xjsr305=strict&-Xjspecify-annotations=strict-
Sets up Kotlin’s Java interoperability to strictly follow JSR-305 and JSpecify annotations for increased null safety. See Calling Java code from Kotlin in the Kotlin documentation for more information.
Interoperability
When mixing languages in your build logic, you may have to cross language boundaries. An extreme example would be a build that uses tasks and plugins that are implemented in Java, Groovy and Kotlin, while also using both Kotlin DSL and Groovy DSL build scripts.
Kotlin is designed with Java Interoperability in mind. Existing Java code can be called from Kotlin in a natural way, and Kotlin code can be used from Java rather smoothly as well.
Both calling Java from Kotlin and calling Kotlin from Java are very well covered in the Kotlin reference documentation.
The same mostly applies to interoperability with Groovy code. In addition, the Kotlin DSL provides several ways to opt into Groovy semantics, which we look at next.
Static extensions
Both the Groovy and Kotlin languages support extending existing classes via Groovy Extension modules and Kotlin extensions.
To call a Kotlin extension function from Groovy, call it as a static function, passing the receiver as the first parameter:
TheTargetTypeKt.kotlinExtensionFunction(receiver, "parameters", 42, aReference)Kotlin extension functions are package-level functions. You can learn how to locate the name of the type declaring a given Kotlin extension in the Package-Level Functions section of the Kotlin reference documentation.
To call a Groovy extension method from Kotlin, the same approach applies: call it as a static function passing the receiver as the first parameter:
TheTargetTypeGroovyExtension.groovyExtensionMethod(receiver, "parameters", 42, aReference)Named parameters and default arguments
Both the Groovy and Kotlin languages support named function parameters and default arguments, although they are implemented very differently.
Kotlin has fully-fledged support for both, as described in the Kotlin language reference under named arguments and default arguments.
Groovy implements named arguments in a non-type-safe way based on a Map<String, ?> parameter, which means they cannot be combined with default arguments.
In other words, you can only use one or the other in Groovy for any given method.
To call a Kotlin function that has named arguments from Groovy, just use a normal method call with positional parameters:
kotlinFunction("value1", "value2", 42)There is no way to provide values by argument name.
To call a Kotlin function that has default arguments from Groovy, always pass values for all the function parameters.
To call a Groovy function with named arguments from Kotlin, you need to pass a Map<String, ?>, as shown in this example:
groovyNamedArgumentTakingMethod(mapOf(
"parameterName" to "value",
"other" to 42,
"and" to aReference))To call a Groovy function with default arguments from Kotlin, always pass values for all the parameters.
Groovy closures from Kotlin
You may sometimes have to call Groovy methods that take Closure arguments from Kotlin code. For example, some third-party plugins written in Groovy expect closure arguments.
|
Note
|
Gradle plugins written in any language should prefer the type Action<T> type in place of closures. Groovy closures and Kotlin lambdas are automatically mapped to arguments of that type.
|
In order to provide a way to construct closures while preserving Kotlin’s strong typing, two helper methods exist:
-
closureOf<T> {} -
delegateClosureOf<T> {}
Both methods are useful in different circumstances and depend upon the method you are passing the Closure instance into.
Some plugins expect simple closures, as with the Bintray plugin:
bintray {
pkg(closureOf<PackageConfig> {
// Config for the package here
})
}In other cases, like with the Gretty Plugin when configuring farms, the plugin expects a delegate closure:
farms {
farm("OldCoreWar", delegateClosureOf<FarmExtension> {
// Config for the war here
})
}There sometimes isn’t a good way to tell, from looking at the source code, which version to use.
Usually, if you get a NullPointerException with closureOf<T> {}, using delegateClosureOf<T> {}
will resolve the problem.
These two utility functions are useful for configuration closures, but some plugins might expect Groovy closures for other purposes.
The KotlinClosure0 to KotlinClosure2 types allows adapting Kotlin functions to Groovy closures with more flexibility:
somePlugin {
// Adapt parameter-less function
takingParameterLessClosure(KotlinClosure0({
"result"
}))
// Adapt unary function
takingUnaryClosure(KotlinClosure1<String, String>({
"result from single parameter $this"
}))
// Adapt binary function
takingBinaryClosure(KotlinClosure2<String, String, String>({ a, b ->
"result from parameters $a and $b"
}))
}The Kotlin DSL Groovy Builder
If some plugin makes heavy use of Groovy metaprogramming, then using it from Kotlin or Java or any statically-compiled language can be very cumbersome.
The Kotlin DSL provides a withGroovyBuilder {} utility extension that attaches the Groovy metaprogramming semantics to objects of type Any.
The following example demonstrates several features of the method on the object target:
target.withGroovyBuilder { // (1)
// GroovyObject methods available // (2)
if (hasProperty("foo")) { /*...*/ }
val foo = getProperty("foo")
setProperty("foo", "bar")
invokeMethod("name", arrayOf("parameters", 42, aReference))
// Kotlin DSL utilities
"name"("parameters", 42, aReference) // (3)
"blockName" { // (4)
// Same Groovy Builder semantics on `blockName`
}
"another"("name" to "example", "url" to "https://example.com/") // (5)
}-
The receiver is a GroovyObject and provides Kotlin helpers
-
The
GroovyObjectAPI is available -
Invoke the
methodNamemethod, passing some parameters -
Configure the
blockNameproperty, maps to aClosuretaking method invocation -
Invoke
anothermethod taking named arguments, maps to a Groovy named argumentsMap<String, ?>taking method invocation
Using a Groovy script
Another option when dealing with problematic plugins that assume a Groovy DSL build script is to configure them in a Groovy DSL build script that is applied from the main Kotlin DSL build script:
native { // (1)
dynamic {
groovy as Usual
}
}plugins {
id("dynamic-groovy-plugin") version "1.0" // (2)
}
apply(from = "dynamic-groovy-plugin-configuration.gradle") // (3)-
The Groovy script uses dynamic Groovy to configure plugin
-
The Kotlin build script requests and applies the plugin
-
The Kotlin build script applies the Groovy script
Troubleshooting
The IDE support is provided by two components:
-
Kotlin Plugin (used by IntelliJ IDEA/Android Studio).
-
Gradle.
The level of support varies based on the versions of each.
If you encounter issues, first run ./gradlew tasks from the command line to determine if the problem is specific to the IDE.
If the issue persists on the command line, it likely originates from the build itself rather than IDE integration.
However, if the build runs successfully on the command line but your script editor reports errors, try restarting your IDE and invalidating its caches.
If the issue persists, and you suspect a problem with the Kotlin DSL script editor, try the following:
-
Run
./gradlew tasksto gather more details. -
Check the logs in one of these locations:
-
$HOME/Library/Logs/gradle-kotlin-dslon macOS -
$HOME/.gradle-kotlin-dsl/logon Linux -
$HOME/AppData/Local/gradle-kotlin-dsl/logon Windows
-
-
Report the issue on the Gradle issue tracker, including as much detail as possible.
From version 5.1 onward, the log directory is automatically cleaned. Logs are checked periodically (at most, every 24 hours), and files are deleted if unused for 7 days.
If this doesn’t help pinpoint the problem, you can enable the org.gradle.kotlin.dsl.logging.tapi system property in your IDE.
This causes the Gradle Daemon to log additional details in its log file located at $HOME/.gradle/daemon.
In IntelliJ IDEA, enable this property by navigating to Help > Edit Custom VM Options… and adding: -Dorg.gradle.kotlin.dsl.logging.tapi=true.
For IDE problems outside the Kotlin DSL script editor, please open issues in the corresponding IDE’s issue tracker:
Lastly, if you face problems with Gradle itself or with the Kotlin DSL, please open issues on the Gradle issue tracker.
Limitations
-
The Kotlin DSL is known to be slower than the Groovy DSL on first use, for example with clean checkouts or on ephemeral continuous integration agents. Changing something in the buildSrc directory also has an impact as it invalidates build-script caching. The main reason for this is the slower script compilation for Kotlin DSL.
-
In IntelliJ IDEA, you must import your project from the Gradle model in order to get content assist and refactoring support for your Kotlin DSL build scripts.
-
Kotlin DSL script compilation avoidance has known issues. If you encounter problems, it can be disabled by setting the
org.gradle.kotlin.dsl.scriptCompilationAvoidancesystem property tofalse. -
The Kotlin DSL will not support the
model {}block, which is part of the discontinued Gradle Software Model.
If you run into trouble or discover a suspected bug, please report the issue in the Gradle issue tracker.
Migrating build logic from Groovy to Kotlin
This section will walk you through converting your Groovy-based Gradle build scripts to Kotlin.
Gradle’s newer Kotlin DSL provides a pleasant editing experience in supported IDEs: content-assist, refactoring, documentation, and more.
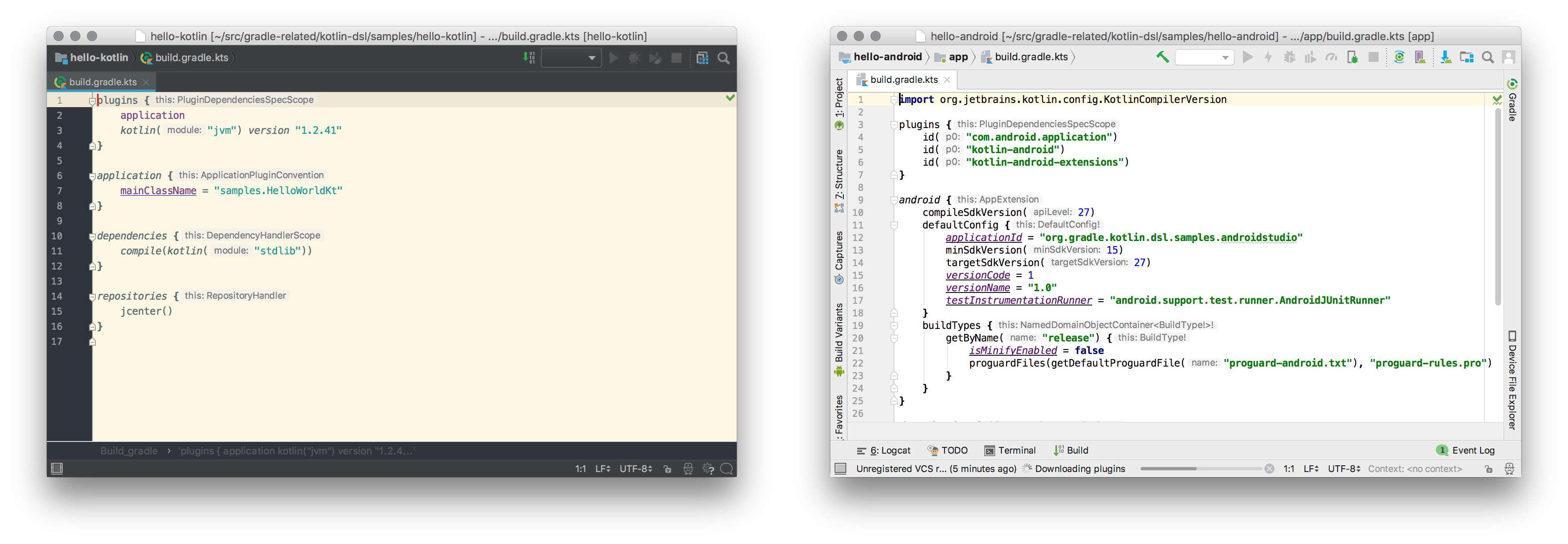
|
Tip
|
Please also read the Gradle Kotlin DSL Primer to learn the specificities, limitations and usage of the Gradle Kotlin DSL. The rest of the user manual contain build script excerpts that demonstrate both the Groovy DSL and the Kotlin DSL. This is the best place where to find how to do this and what with each DSL ; and it covers all Gradle features from using plugins to customizing the dependency resolution behavior. |
Before you start migrating
Please read: It’s helpful to understand the following important information before you migrate:
-
Using the latest versions of Gradle, applied plugins, and your IDE should be your first move.
-
Kotlin DSL is fully supported in Intellij IDEA and Android Studio. Other IDEs, such as Eclipse or NetBeans, do not yet provide helpful tools for editing Gradle Kotlin DSL files, however, importing and working with Kotlin DSL-based builds work as usual.
-
In IntelliJ IDEA, you must import your project from the Gradle model to get content-assist and refactoring tools for Kotlin DSL scripts.
-
There are some situations where the Kotlin DSL is slower. First use, on clean checkouts or ephemeral CI agents for example, are known to be slower. The same applies to the scenario in which something in the buildSrc directory changes, which invalidates build-script caching. Builds with slow configuration time might affect the IDE responsiveness, please check out the documentation on Gradle performance.
-
You must run Gradle with Java 8 or higher. Java 7 is not supported.
-
The embedded Kotlin compiler is known to work on Linux, macOS, Windows, Cygwin, FreeBSD and Solaris on x86-64 architectures.
-
Knowledge of Kotlin syntax and basic language features is very helpful. The Kotlin reference documentation and Kotlin Koans should be useful to you.
-
Use of the
plugins {}block to declare Gradle plugins significantly improves the editing experience, and is highly recommended. Consider adopting it in your Groovy build scripts before converting them to Kotlin. -
The Kotlin DSL will not support
model {}elements. This is part of the discontinued Gradle Software Model.
Read more in the Gradle Kotlin DSL Primer.
If you run to trouble or a suspected bug, please take advantage of the gradle/gradle issue tracker.
You don’t have to migrate all at once! Both Groovy and Kotlin-based build scripts can apply other scripts of either language. You can find inspiration for any Gradle features not covered in the Kotlin DSL samples.
Prepare your Groovy scripts
Some simple Kotlin and Groovy language differences can make converting scripts tedious:
-
Groovy strings can be quoted with single quotes
'string'or double quotes"string"whereas Kotlin requires double quotes"string". -
Groovy allows to omit parentheses when invoking functions whereas Kotlin always requires the parentheses.
-
The Gradle Groovy DSL allows to omit the
=assignment operator when assigning properties whereas Kotlin always requires the assignment operator.
As a first migration step, it is recommended to prepare your Groovy build scripts by
-
unifying quotes using double quotes,
-
disambiguating function invocations and property assignments (using respectively parentheses and assignment operator).
The former can easily be done by searching for ' and replacing by ".
For example,
group = 'com.acme'
dependencies {
implementation 'com.acme:example:1.0'
}becomes:
group "com.acme"
dependencies {
implementation "com.acme:example:1.0"
}The next step is a bit more involved as it may not be trivial to distinguish function invocations and property assignments in a Groovy script. A good strategy is to make all ambiguous statements property assignments first and then fix the build by turning the failing ones to function invocations.
For example,
group "com.acme"
dependencies {
implementation "com.acme:example:1.0"
}becomes:
group = "com.acme" // (1)
dependencies {
implementation("com.acme:example:1.0") // (2)
}-
Property assignment
-
Function invocation
While staying valid Groovy, it is now unambiguous and close to the Kotlin syntax, making it easier to then rename the script to turn it into a Gradle Kotlin DSL script.
It is important to note that while Groovy extra properties can be modified using an object’s ext property, in Kotlin they are modified using the extra property. It is important to look at each object and update the build scripts accordingly.
You can find an example in the userguide.
Script file naming
|
Note
|
Groovy DSL script files use the .gradle file name extension.
Kotlin DSL script files use the .gradle.kts file name extension.
|
To use the Kotlin DSL, simply name your files build.gradle.kts instead of build.gradle.
The settings file, settings.gradle, can also be renamed settings.gradle.kts.
In a multi-project build, you can have some modules using the Groovy DSL (with build.gradle) and others using the Kotlin DSL (with build.gradle.kts).
On top of that, apply the following conventions for better IDE support:
-
Name scripts that are applied to
Settingsaccording to the pattern*.settings.gradle.kts, -
Name init scripts according to the pattern
*.init.gradle.kts.
Applying plugins
Just like with the Groovy DSL, there are two ways to apply Gradle plugins:
Here’s an example using the declarative plugins {} block:
plugins {
java
jacoco
`maven-publish`
id("org.springframework.boot") version "3.4.4"
}plugins {
id 'java'
id 'jacoco'
id 'maven-publish'
id 'org.springframework.boot' version '3.4.4'
}The Kotlin DSL provides property extensions for all Gradle core plugins,
as shown above with the java, jacoco or maven-publish declaration.
Third party plugins can be applied the same way as with the Groovy DSL. Except for the double quotes and parentheses. You can also apply core plugins with that style. But the statically-typed accessors are recommended since they are type-safe and will be autocompleted by your IDE.
You can also use the imperative apply syntax, but then non-core plugins must be included on the classpath of the build script:
buildscript {
repositories {
gradlePluginPortal()
}
dependencies {
classpath("org.springframework.boot:spring-boot-gradle-plugin:3.4.4")
}
}
apply(plugin = "java")
apply(plugin = "jacoco")
apply(plugin = "org.springframework.boot")buildscript {
repositories {
gradlePluginPortal()
}
dependencies {
classpath('org.springframework.boot:spring-boot-gradle-plugin:3.4.4')
}
}
apply plugin: 'java'
apply plugin: 'jacoco'
apply plugin: 'org.springframework.boot'|
Note
|
We strongly recommend that you use the The declarative nature of the |
Configuring plugins
Many plugins come with extensions to configure them. If those plugins are applied using the declarative plugins {} block, then Kotlin extension functions are made available to configure their extension, the same way as in Groovy.
The following sample shows how this works for the Jacoco Plugin.
plugins {
jacoco
}
jacoco {
toolVersion = "0.8.1"
}plugins {
id 'jacoco'
}
jacoco {
toolVersion = '0.8.1'
}By contrast, if you use the imperative apply() function to apply a plugin, then you will have to use the configure<T>() function to configure that plugin.
The following sample shows how this works for the Checkstyle Plugin by explicitly declaring the plugin’s extension class — CheckstyleExtension — in the configure<T>() function:
apply(plugin = "checkstyle")
configure<CheckstyleExtension> {
maxErrors = 10
}apply plugin: "checkstyle"
checkstyle {
maxErrors = 10
}Again, we strongly recommend that you apply plugins declaratively via the plugins {} block.
Because your IDE knows about the configuration elements that a plugin provides, it will include those elements when you ask your IDE for suggestions.
This will happen both at the top level of your build scripts — most plugin extensions are added to the Project object — and within an extension’s configuration block.
You can also run the :kotlinDslAccessorsReport task to learn about the extensions contributed by all applied plugins.
It prints the Kotlin code you can use to access those extensions and provides the name and type of the accessor methods.
If the plugin you want to configure relies on groovy.lang.Closure in its method signatures or uses other dynamic Groovy semantics, more work will be required to configure that plugin from a Kotlin DSL build script.
See the interoperability section of the Gradle Kotlin DSL documentation for more information on how to call Groovy code from Kotlin code or to keep that plugin’s configuration in a Groovy script.
Plugins also contribute tasks that you may want to configure directly. This topic is covered in the Configuring tasks section below.
To get the most benefits of the Gradle Kotlin DSL you should strive to keep your build scripts declarative. The main thing to remember here is that in order to get type-safe accessors, plugins must be applied before the body of build scripts.
It is strongly recommended to read about configuring plugins with the Gradle Kotlin DSL in the Gradle user manual.
If your build is a multi-project build, like mostly all Android builds for example, please also read the subsequent section about multi-project builds.
Finally, there are strategies to use the plugins {} block with plugins that aren’t published with the correct metadata, such as the Android Gradle Plugin.
Configuration avoidance
Gradle 4.9 introduced a new API for creating and configuring tasks in build scripts and plugins. The intent is for this new API to eventually replace the existing API.
One of the major differences between the existing and new Gradle Tasks API is whether or not Gradle spends the time to create
Taskinstances and run configuration code. The new API allows Gradle to delay or completely avoid configuring tasks that will never be executed in a build. For example, when compiling code, Gradle does not need to configure tasks that run tests.
See the Evolving the Gradle API to reduce configuration time blog post and the Task Configuration Avoidance chapter in the user manual for more information.
The Gradle Kotlin DSL embraces configuration avoidance by making the type-safe model accessors leverage the new APIs and providing DSL constructs to make them easier to use. Rest assured, the whole Gradle API remains available.
Configuring tasks
The syntax for configuring tasks is where the Groovy and Kotlin DSLs start to differ significantly.
tasks.jar {
archiveFileName = "foo.jar"
}tasks.jar {
archiveFileName = 'foo.jar'
}Note that in Kotlin the tasks.jar {} notation leverage the configuration avoidance API and defer the configuration of the jar task.
If the type-safe task accessor tasks.jar isn’t available, see the configuring plugins section above, you can fallback to using the tasks container API. The Kotlin flavor of the following sample is strictly equivalent to the one using the type-safe accessor above:
tasks.named<Jar>("jar") {
archiveFileName = "foo.jar"
}tasks.named('jar') {
archiveFileName = 'foo.jar'
}Note that since Kotlin is a statically typed language, it is necessary to specify the type of the task explicitly. Otherwise, the script will not compile because the inferred type will be Task, not Jar, and the archiveName property is specific to the Jar task type.
If configuration avoidance is getting in your way migrating and you want to eagerly configure a task just like Groovy you can do so by using the eager configuration API on the tasks container:
tasks.getByName<Jar>("jar") {
archiveFileName = "foo.jar"
}tasks.getByName('jar') {
archiveFileName = 'foo.jar'
}Working with containers in the Gradle Kotlin DSL is documented in detail here.
If you don’t know what type a task has, then you can find that information out via the built-in help task.
Simply pass it the name of the task you’re interested in using the --task option, like so:
❯ ./gradlew help --task jar
...
Type
Jar (org.gradle.api.tasks.bundling.Jar)Let’s bring all this together by running through a quick worked example that configures the bootJar and bootRun tasks of a Spring Boot project:
plugins {
java
id("org.springframework.boot") version "3.4.4"
}
tasks.bootJar {
archiveFileName = "app.jar"
mainClass = "com.example.demo.Demo"
}
tasks.bootRun {
mainClass = "com.example.demo.Demo"
args("--spring.profiles.active=demo")
}plugins {
id 'java'
id 'org.springframework.boot' version '3.4.4'
}
tasks.bootJar {
archiveFileName = 'app.jar'
mainClass = 'com.example.demo.Demo'
}
tasks.bootRun {
mainClass = 'com.example.demo.Demo'
args '--spring.profiles.active=demo'
}This is pretty self explanatory. The main difference is that the task configuration automatically becomes lazy when using the Kotlin DSL accessors.
Now, for the sake of the example, let’s look at the same configuration applied using the API instead of the type-safe accessors that may not be available depending on the build logic structure, see the corresponding documentation in the Gradle user manual for more information.
We first determine the types of the bootJar and bootRun tasks via the help task:
❯ ./gradlew help --task bootJar
...
Type
BootJar (org.springframework.boot.gradle.tasks.bundling.BootJar)❯ ./gradlew help --task bootRun
...
Type
BootRun (org.springframework.boot.gradle.tasks.run.BootRun)Now that we know the types of the two tasks, we can import the relevant types — BootJar and BootRun — and configure the tasks as required.
Note that the IDE can assist us with the required imports, so we only need the simple names, i.e. without the full packages.
Here’s the resulting build script, complete with imports:
import org.springframework.boot.gradle.tasks.bundling.BootJar
import org.springframework.boot.gradle.tasks.run.BootRun
// TODO:Finalize Upload Removal - Issue #21439
plugins {
java
id("org.springframework.boot") version "3.4.4"
}
tasks.named<BootJar>("bootJar") {
archiveFileName = "app.jar"
mainClass = "com.example.demo.Demo"
}
tasks.named<BootRun>("bootRun") {
mainClass = "com.example.demo.Demo"
args("--spring.profiles.active=demo")
}plugins {
id 'java'
id 'org.springframework.boot' version '3.4.4'
}
tasks.named('bootJar') {
archiveFileName = 'app.jar'
mainClass = 'com.example.demo.Demo'
}
tasks.named('bootRun') {
mainClass = 'com.example.demo.Demo'
args '--spring.profiles.active=demo'
}Creating tasks
Creating tasks can be done using the script top-level function named task(…):
task("greeting") {
doLast { println("Hello, World!") }
}task greeting {
doLast { println 'Hello, World!' }
}Note that the above eagerly configures the created task with both Groovy and Kotlin DSLs.
Registering or creating tasks can also be done on the tasks container, respectively using the register(…) and create(…) functions as shown here:
tasks.register("greeting") {
doLast { println("Hello, World!") }
}tasks.register('greeting') {
doLast { println('Hello, World!') }
}tasks.create("greeting") {
doLast { println("Hello, World!") }
}tasks.create('greeting') {
doLast { println('Hello, World!') }
}The samples above create untyped, ad-hoc tasks, but you will more commonly want to create tasks of a specific type.
This can also be done using the same register() and create() methods.
Here’s an example that creates a new task of type Zip:
tasks.register<Zip>("docZip") {
archiveFileName = "doc.zip"
from("doc")
}tasks.register('docZip', Zip) {
archiveFileName = 'doc.zip'
from 'doc'
}tasks.create<Zip>("docZip") {
archiveFileName = "doc.zip"
from("doc")
}tasks.create(name: 'docZip', type: Zip) {
archiveFileName = 'doc.zip'
from 'doc'
}Configurations and dependencies
Declaring dependencies in existing configurations is similar to the way it’s done in Groovy build scripts, as you can see in this example:
plugins {
`java-library`
}
dependencies {
implementation("com.example:lib:1.1")
runtimeOnly("com.example:runtime:1.0")
testImplementation("com.example:test-support:1.3") {
exclude(module = "junit")
}
testRuntimeOnly("com.example:test-junit-jupiter-runtime:1.3")
}plugins {
id 'java-library'
}
dependencies {
implementation 'com.example:lib:1.1'
runtimeOnly 'com.example:runtime:1.0'
testImplementation('com.example:test-support:1.3') {
exclude(module: 'junit')
}
testRuntimeOnly 'com.example:test-junit-jupiter-runtime:1.3'
}Each configuration contributed by an applied plugin is also available as a member of the configurations container, so you can reference it just like any other configuration.
The easiest way to find out what configurations are available is by asking your IDE for suggestions within the configurations container.
You can also use the :kotlinDslAccessorsReport task, which prints the Kotlin code for accessing the configurations contributed by applied plugins and provides the names for all of those accessors.
Note that if you do not use the plugins {} block to apply your plugins, then you won’t be able to configure the dependency configurations provided by those plugins in the usual way. Instead, you will have to use string literals for the configuration names, which means you won’t get IDE support:
apply(plugin = "java-library")
dependencies {
"implementation"("com.example:lib:1.1")
"runtimeOnly"("com.example:runtime:1.0")
"testImplementation"("com.example:test-support:1.3") {
exclude(module = "junit")
}
"testRuntimeOnly"("com.example:test-junit-jupiter-runtime:1.3")
}apply plugin: 'java-library'
dependencies {
implementation 'com.example:lib:1.1'
runtimeOnly 'com.example:runtime:1.0'
testImplementation('com.example:test-support:1.3') {
exclude(module: 'junit')
}
testRuntimeOnly 'com.example:test-junit-jupiter-runtime:1.3'
}This is just one more reason to use the plugins {} block whenever you can!
Custom configurations and dependencies
Sometimes you need to create your own configurations and attach dependencies to them. The following example declares two new configurations:
-
db, to which we add a PostgreSQL dependency -
integTestImplementation, which is configured to extend thetestImplementationconfiguration and to which we add a different dependency
val db = configurations.create("db")
val integTestImplementation = configurations.create("integTestImplementation") {
extendsFrom(configurations["testImplementation"])
}
dependencies {
db("org.postgresql:postgresql")
integTestImplementation("com.example:integ-test-support:1.3")
}configurations {
db
integTestImplementation {
extendsFrom testImplementation
}
}
dependencies {
db 'org.postgresql:postgresql'
integTestImplementation 'com.example:integ-test-support:1.3'
}Note that we can only use the db(…) and integTestImplementation(…) notation within the dependencies {} block in the above example because both configurations are created and referenced beforehand via the create() method.
If the configurations were defined elsewhere, you could only reference them either by first accessing them via configurations — as opposed to configurations.create() — or by using string literals within the dependencies {} block.
The following example demonstrates both approaches:
// get the existing 'testRuntimeOnly' configuration
val testRuntimeOnly = configurations["testRuntimeOnly"]
dependencies {
testRuntimeOnly("com.example:test-junit-jupiter-runtime:1.3")
"db"("org.postgresql:postgresql")
"integTestImplementation"("com.example:integ-test-support:1.3")
}Migration strategies
As we’ve seen above, both scripts using the Kotlin DSL and those using the Groovy DSL can participate in the same build. In addition, Gradle plugins from the buildSrc directory, an included build or an external location can be implemented using any JVM language. This makes it possible to migrate a build progressively, piece by piece, without blocking your team.
Two approaches to migrations stand out:
-
Migrating the existing syntax of your build to Kotlin, bit by bit, while retaining the structure — what we call a mechanical migration
-
Restructuring your build logic towards Gradle best practices and switching to Kotlin DSL as part of that effort
Both approaches are viable. A mechanical migration will be enough for simple builds. A complex and highly dynamic build may require some restructuring anyway, so in such cases reimplementing build logic to follow Gradle best practice makes sense.
Since applying Gradle best practices will make your builds easier to use and faster, we recommend that you migrate all projects in that way eventually, but it makes sense to focus on the projects that have to be restructured first and those that would benefit most from the improvements.
Also consider that the more parts of your build logic rely on the dynamic aspects of Groovy, the harder they will be to use from the Kotlin DSL. You’ll find recipes on how to cross the dynamic boundaries from static Kotlin in the interoperability section of the Gradle Kotlin DSL documentation, regardless of where the dynamic Groovy build logic resides.
There are two key best practices that make it easier to work within the static context of the Kotlin DSL:
-
Using the
plugins {}block -
Putting local build logic in the build’s buildSrc directory
The plugins {} block is about keeping your build scripts declarative in order to get the best out of the Kotlin DSL.
Utilizing the buildSrc project is about organizing your build logic into shared local plugins and conventions that are easily testable and provide good IDE support.
Kotlin DSL build structure samples
Depending on your build structure you might be interested in the following user manual chapters:
-
The Writing Build Scripts chapter demonstrates the use of
apply(from = "")to modularize build scripts. -
The Multi-project Builds chapter demonstrates various multi-project build structures.
-
The Developing Custom Gradle Plugins and Gradle Kotlin DSL Primer chapters demonstrate how to develop custom Gradle plugins.
-
The Composing builds chapter demonstrates how to use Composite Builds.
Interoperability
When mixing languages in your build logic, you may have to cross language boundaries. An extreme example would be a build that uses tasks and plugins that are implemented in Java, Groovy and Kotlin, while also using both Kotlin DSL and Groovy DSL build scripts.
Quoting the Kotlin reference documentation:
Kotlin is designed with Java Interoperability in mind. Existing Java code can be called from Kotlin in a natural way, and Kotlin code can be used from Java rather smoothly as well.
Both calling Java from Kotlin and calling Kotlin from Java are very well covered in the Kotlin reference documentation.
The same mostly applies to interoperability with Groovy code. In addition, the Kotlin DSL provides several ways to opt into Groovy semantics.
Please find detailed documentation in the interoperability section of the Gradle Kotlin DSL Primer.
General
Public Gradle APIs
Gradle provides many public APIs that allow developers to interact with various build system components.
Only elements explicitly documented as part of the stable public API are supported for use.
All other classes, methods, or packages, including, but not limited to, those containing the name Internal or located in a package segment .internal., are considered internal implementation details and must not be relied upon for stable usage.
Use of Gradle internal APIs in plugins and build scripts can break builds when either Gradle or plugins change.
The list of public API packages is as follows:
org.gradle.* (top-level classes only — excludes subpackages)
org.gradle.api.** (includes subpackages)
org.gradle.authentication.**
org.gradle.build.**
org.gradle.buildconfiguration.**
org.gradle.buildinit.**
org.gradle.caching.**
org.gradle.concurrent.**
org.gradle.deployment.**
org.gradle.external.javadoc.**
org.gradle.ide.**
org.gradle.ivy.**
org.gradle.jvm.**
org.gradle.language.**
org.gradle.maven.**
org.gradle.nativeplatform.**
org.gradle.normalization.**
org.gradle.platform.**
org.gradle.plugin.devel.**
org.gradle.plugin.use.*
org.gradle.plugin.management.*
org.gradle.plugins.**
org.gradle.process.**
org.gradle.testfixtures.**
org.gradle.testing.jacoco.**
org.gradle.tooling.**
org.gradle.swiftpm.**
org.gradle.model.**
org.gradle.testkit.**
org.gradle.testing.**
org.gradle.vcs.**
org.gradle.work.**
org.gradle.workers.**
org.gradle.util.**|
Note
|
The * wildcard matches only classes directly in the package (e.g., org.gradle.Foo), but does not include subpackages like org.gradle.something.Foo.
Conversely, the ** wildcard matches the noted package and its subpackages.
|
Default Imports
To make build scripts more concise, Gradle automatically adds a set of import statements to scripts.
Gradle implicitly adds the following imports to each script (for both Groovy and Kotlin):
import org.gradle.*
import org.gradle.api.*
import org.gradle.api.artifacts.*
import org.gradle.api.artifacts.capability.*
import org.gradle.api.artifacts.component.*
import org.gradle.api.artifacts.dsl.*
import org.gradle.api.artifacts.ivy.*
import org.gradle.api.artifacts.maven.*
import org.gradle.api.artifacts.query.*
import org.gradle.api.artifacts.repositories.*
import org.gradle.api.artifacts.result.*
import org.gradle.api.artifacts.transform.*
import org.gradle.api.artifacts.type.*
import org.gradle.api.artifacts.verification.*
import org.gradle.api.attributes.*
import org.gradle.api.attributes.java.*
import org.gradle.api.attributes.plugin.*
import org.gradle.api.cache.*
import org.gradle.api.capabilities.*
import org.gradle.api.component.*
import org.gradle.api.configuration.*
import org.gradle.api.credentials.*
import org.gradle.api.distribution.*
import org.gradle.api.distribution.plugins.*
import org.gradle.api.execution.*
import org.gradle.api.file.*
import org.gradle.api.flow.*
import org.gradle.api.initialization.*
import org.gradle.api.initialization.definition.*
import org.gradle.api.initialization.dsl.*
import org.gradle.api.initialization.resolve.*
import org.gradle.api.invocation.*
import org.gradle.api.java.archives.*
import org.gradle.api.jvm.*
import org.gradle.api.launcher.cli.*
import org.gradle.api.logging.*
import org.gradle.api.logging.configuration.*
import org.gradle.api.model.*
import org.gradle.api.plugins.*
import org.gradle.api.plugins.antlr.*
import org.gradle.api.plugins.catalog.*
import org.gradle.api.plugins.jvm.*
import org.gradle.api.plugins.quality.*
import org.gradle.api.plugins.scala.*
import org.gradle.api.problems.*
import org.gradle.api.project.*
import org.gradle.api.provider.*
import org.gradle.api.publish.*
import org.gradle.api.publish.ivy.*
import org.gradle.api.publish.ivy.plugins.*
import org.gradle.api.publish.ivy.tasks.*
import org.gradle.api.publish.maven.*
import org.gradle.api.publish.maven.plugins.*
import org.gradle.api.publish.maven.tasks.*
import org.gradle.api.publish.plugins.*
import org.gradle.api.publish.tasks.*
import org.gradle.api.reflect.*
import org.gradle.api.reporting.*
import org.gradle.api.reporting.components.*
import org.gradle.api.reporting.dependencies.*
import org.gradle.api.reporting.dependents.*
import org.gradle.api.reporting.model.*
import org.gradle.api.reporting.plugins.*
import org.gradle.api.resources.*
import org.gradle.api.services.*
import org.gradle.api.specs.*
import org.gradle.api.tasks.*
import org.gradle.api.tasks.ant.*
import org.gradle.api.tasks.application.*
import org.gradle.api.tasks.bundling.*
import org.gradle.api.tasks.compile.*
import org.gradle.api.tasks.diagnostics.*
import org.gradle.api.tasks.diagnostics.artifact.transforms.*
import org.gradle.api.tasks.diagnostics.configurations.*
import org.gradle.api.tasks.incremental.*
import org.gradle.api.tasks.javadoc.*
import org.gradle.api.tasks.options.*
import org.gradle.api.tasks.scala.*
import org.gradle.api.tasks.testing.*
import org.gradle.api.tasks.testing.junit.*
import org.gradle.api.tasks.testing.junitplatform.*
import org.gradle.api.tasks.testing.source.*
import org.gradle.api.tasks.testing.testng.*
import org.gradle.api.tasks.util.*
import org.gradle.api.tasks.wrapper.*
import org.gradle.api.toolchain.management.*
import org.gradle.authentication.*
import org.gradle.authentication.aws.*
import org.gradle.authentication.http.*
import org.gradle.build.event.*
import org.gradle.buildconfiguration.tasks.*
import org.gradle.buildinit.*
import org.gradle.buildinit.plugins.*
import org.gradle.buildinit.specs.*
import org.gradle.buildinit.tasks.*
import org.gradle.caching.*
import org.gradle.caching.configuration.*
import org.gradle.caching.http.*
import org.gradle.caching.local.*
import org.gradle.concurrent.*
import org.gradle.external.javadoc.*
import org.gradle.ide.visualstudio.*
import org.gradle.ide.visualstudio.plugins.*
import org.gradle.ide.visualstudio.tasks.*
import org.gradle.ide.xcode.*
import org.gradle.ide.xcode.plugins.*
import org.gradle.ide.xcode.tasks.*
import org.gradle.ivy.*
import org.gradle.jvm.*
import org.gradle.jvm.application.scripts.*
import org.gradle.jvm.application.tasks.*
import org.gradle.jvm.tasks.*
import org.gradle.jvm.toolchain.*
import org.gradle.language.*
import org.gradle.language.assembler.*
import org.gradle.language.assembler.plugins.*
import org.gradle.language.assembler.tasks.*
import org.gradle.language.base.*
import org.gradle.language.base.artifact.*
import org.gradle.language.base.compile.*
import org.gradle.language.base.plugins.*
import org.gradle.language.base.sources.*
import org.gradle.language.c.*
import org.gradle.language.c.plugins.*
import org.gradle.language.c.tasks.*
import org.gradle.language.cpp.*
import org.gradle.language.cpp.plugins.*
import org.gradle.language.cpp.tasks.*
import org.gradle.language.java.artifact.*
import org.gradle.language.jvm.tasks.*
import org.gradle.language.nativeplatform.*
import org.gradle.language.nativeplatform.tasks.*
import org.gradle.language.objectivec.*
import org.gradle.language.objectivec.plugins.*
import org.gradle.language.objectivec.tasks.*
import org.gradle.language.objectivecpp.*
import org.gradle.language.objectivecpp.plugins.*
import org.gradle.language.objectivecpp.tasks.*
import org.gradle.language.plugins.*
import org.gradle.language.rc.*
import org.gradle.language.rc.plugins.*
import org.gradle.language.rc.tasks.*
import org.gradle.language.scala.tasks.*
import org.gradle.language.swift.*
import org.gradle.language.swift.plugins.*
import org.gradle.language.swift.tasks.*
import org.gradle.maven.*
import org.gradle.model.*
import org.gradle.nativeplatform.*
import org.gradle.nativeplatform.platform.*
import org.gradle.nativeplatform.plugins.*
import org.gradle.nativeplatform.tasks.*
import org.gradle.nativeplatform.test.*
import org.gradle.nativeplatform.test.cpp.*
import org.gradle.nativeplatform.test.cpp.plugins.*
import org.gradle.nativeplatform.test.cunit.*
import org.gradle.nativeplatform.test.cunit.plugins.*
import org.gradle.nativeplatform.test.cunit.tasks.*
import org.gradle.nativeplatform.test.googletest.*
import org.gradle.nativeplatform.test.googletest.plugins.*
import org.gradle.nativeplatform.test.plugins.*
import org.gradle.nativeplatform.test.tasks.*
import org.gradle.nativeplatform.test.xctest.*
import org.gradle.nativeplatform.test.xctest.plugins.*
import org.gradle.nativeplatform.test.xctest.tasks.*
import org.gradle.nativeplatform.toolchain.*
import org.gradle.nativeplatform.toolchain.plugins.*
import org.gradle.normalization.*
import org.gradle.platform.*
import org.gradle.platform.base.*
import org.gradle.platform.base.binary.*
import org.gradle.platform.base.component.*
import org.gradle.platform.base.plugins.*
import org.gradle.plugin.devel.*
import org.gradle.plugin.devel.plugins.*
import org.gradle.plugin.devel.tasks.*
import org.gradle.plugin.management.*
import org.gradle.plugin.use.*
import org.gradle.plugins.ear.*
import org.gradle.plugins.ear.descriptor.*
import org.gradle.plugins.ide.*
import org.gradle.plugins.ide.api.*
import org.gradle.plugins.ide.eclipse.*
import org.gradle.plugins.ide.idea.*
import org.gradle.plugins.signing.*
import org.gradle.plugins.signing.signatory.*
import org.gradle.plugins.signing.signatory.pgp.*
import org.gradle.plugins.signing.type.*
import org.gradle.plugins.signing.type.pgp.*
import org.gradle.process.*
import org.gradle.swiftpm.*
import org.gradle.swiftpm.plugins.*
import org.gradle.swiftpm.tasks.*
import org.gradle.testing.base.*
import org.gradle.testing.base.plugins.*
import org.gradle.testing.jacoco.plugins.*
import org.gradle.testing.jacoco.tasks.*
import org.gradle.testing.jacoco.tasks.rules.*
import org.gradle.testkit.runner.*
import org.gradle.util.*
import org.gradle.vcs.*
import org.gradle.vcs.git.*
import org.gradle.work.*
import org.gradle.workers.*Additionally, for Groovy, the following imports are added too:
import java.lang.*
import java.io.*
import java.net.*
import java.util.*
import java.time.*
import java.math.BigDecimal
import java.math.BigInteger
import javax.inject.InjectCORE PLUGINS
Gradle Plugin Reference
This page contains links and short descriptions for all the core plugins provided by Gradle itself.
JVM languages and frameworks
- Java
-
Provides support for building any type of Java project.
- Java Library
-
Provides support for building a Java library.
- Java Platform
-
Provides support for building a Java platform.
- Groovy
-
Provides support for building any type of Groovy project.
- Scala
-
Provides support for building any type of Scala project.
- ANTLR
-
Provides support for generating parsers using ANTLR.
- JVM Test Suite
-
Provides support for modeling and configuring multiple test suite invocations.
- Test Report Aggregation
-
Aggregates the results of multiple Test task invocations (potentially spanning multiple Gradle projects) into a single HTML report.
Native languages
- C++ Application
-
Provides support for building C++ applications on Windows, Linux, and macOS.
- C++ Library
-
Provides support for building C++ libraries on Windows, Linux, and macOS.
- C++ Unit Test
-
Provides support for building and running C++ executable-based tests on Windows, Linux, and macOS.
- Swift Application
-
Provides support for building Swift applications on Linux and macOS.
- Swift Library
-
Provides support for building Swift libraries on Linux and macOS.
- XCTest
-
Provides support for building and running XCTest-based tests on Linux and macOS.
Packaging and distribution
- Application
-
Provides support for building JVM-based, runnable applications.
- WAR
-
Provides support for building and packaging WAR-based Java web applications.
- EAR
-
Provides support for building and packaging Java EE applications.
- Maven Publish
-
Provides support for publishing artifacts to Maven-compatible repositories.
- Ivy Publish
-
Provides support for publishing artifacts to Ivy-compatible repositories.
- Distribution
-
Makes it easy to create ZIP and tarball distributions of your project.
- Java Library Distribution
-
Provides support for creating a ZIP distribution of a Java library project that includes its runtime dependencies.
Code analysis
- Checkstyle
-
Performs quality checks on your project’s Java source files using Checkstyle and generates associated reports.
- PMD
-
Performs quality checks on your project’s Java source files using PMD and generates associated reports.
- JaCoCo
-
Provides code coverage metrics for your Java project using JaCoCo.
- JaCoCo Report Aggregation
-
Aggregates the results of multiple JaCoCo code coverage reports (potentially spanning multiple Gradle projects) into a single HTML report.
- CodeNarc
-
Performs quality checks on your Groovy source files using CodeNarc and generates associated reports.
IDE integration
- Eclipse
-
Customizes how Eclipse/http://projects.eclipse.org/projects/tools.buildship[Buildship] understands your Gradle project during import.
- IntelliJ IDEA
-
Customizes how IntelliJ IDEA understands your Gradle project during import.
- Visual Studio
-
Generates Visual Studio solution and project files for build that can be opened by the IDE.
- Xcode
-
Generates Xcode workspace and project files for the build that can be opened by the IDE.
Utility
- Base
-
Provides common lifecycle tasks, such as
clean, and other features common to most builds. - Build Init
-
Generates a new Gradle build of a specified type, such as a Java library. It can also generate a build script from a Maven POM — see Migrating from Maven to Gradle for more details.
- Signing
-
Provides support for digitally signing generated files and artifacts.
- Plugin Development
-
Makes it easier to develop and publish a Gradle plugin.
- Project Report Plugin
-
Helps to generate reports containing useful information about your build.
- Build Dashboard Plugin
-
Generates a single HTML dashboard that provides a single point of access to all of the reports generated by your build.
The Java Plugin
The Java plugin adds Java compilation along with testing and bundling capabilities to a project. It serves as the basis for many of the other JVM language Gradle plugins. You can find a comprehensive introduction and overview to the Java Plugin in the Building Java Projects chapter.
|
Note
|
As indicated above, this plugin adds basic building blocks for working with JVM projects.
Its feature set has been superseded by other plugins, offering more features based on your project type.
Instead of applying it directly to your project, you should look into the |
Usage
To use the Java plugin, include the following in your build script:
plugins {
java
}plugins {
id 'java'
}Tasks
The Java plugin adds a number of tasks to your project, as shown below.
compileJava— JavaCompile-
Depends on: All tasks which contribute to the compilation classpath, including
jartasks from projects that are on the classpath via project dependenciesCompiles production Java source files using the JDK compiler.
processResources— ProcessResources-
Copies production resources into the production resources directory.
classes-
Depends on:
compileJava,processResourcesThis is an aggregate task that just depends on other tasks. Other plugins may attach additional compilation tasks to it.
compileTestJava— JavaCompile-
Depends on:
classes, and all tasks that contribute to the test compilation classpathCompiles test Java source files using the JDK compiler.
processTestResources— Copy-
Copies test resources into the test resources directory.
testClasses-
Depends on:
compileTestJava,processTestResourcesThis is an aggregate task that just depends on other tasks. Other plugins may attach additional test compilation tasks to it.
jar— Jar-
Depends on:
classesAssembles the production JAR file, based on the classes and resources attached to the
mainsource set. javadoc— Javadoc-
Depends on:
classesGenerates API documentation for the production Java source using Javadoc.
test— Test-
Depends on:
testClasses, and all tasks which produce the test runtime classpathRuns the unit tests using JUnit or TestNG.
clean— Delete-
Deletes the project build directory.
cleanTaskName— Delete-
Deletes files created by the specified task. For example,
cleanJarwill delete the JAR file created by thejartask andcleanTestwill delete the test results created by thetesttask.
SourceSet Tasks
For each source set you add to the project, the Java plugin adds the following tasks:
compileSourceSetJava— JavaCompile-
Depends on: All tasks which contribute to the source set’s compilation classpath
Compiles the given source set’s Java source files using the JDK compiler.
processSourceSetResources— Copy-
Copies the given source set’s resources into the resources directory.
sourceSetClasses— Task-
Depends on:
compileSourceSetJava,processSourceSetResourcesPrepares the given source set’s classes and resources for packaging and execution. Some plugins may add additional compilation tasks for the source set.
Lifecycle Tasks
The Java plugin attaches some of its tasks to the lifecycle tasks defined by the Base Plugin — which the Java Plugin applies automatically — and it also adds a few other lifecycle tasks:
assemble-
Depends on:
jarAggregate task that assembles all the archives in the project. This task is added by the Base Plugin.
check-
Depends on:
testAggregate task that performs verification tasks, such as running the tests. Some plugins add their own verification tasks to
check. You should also attach any customTesttasks to this lifecycle task if you want them to execute for a full build. This task is added by the Base Plugin. build-
Depends on:
check,assembleAggregate tasks that performs a full build of the project. This task is added by the Base Plugin.
buildConfigName— task rule-
Depends on: all tasks that generate the artifacts attached to the named — ConfigName — configuration
Assembles the artifacts for the specified configuration. This rule is added by the Base Plugin.
The following diagram shows the relationships between these tasks.
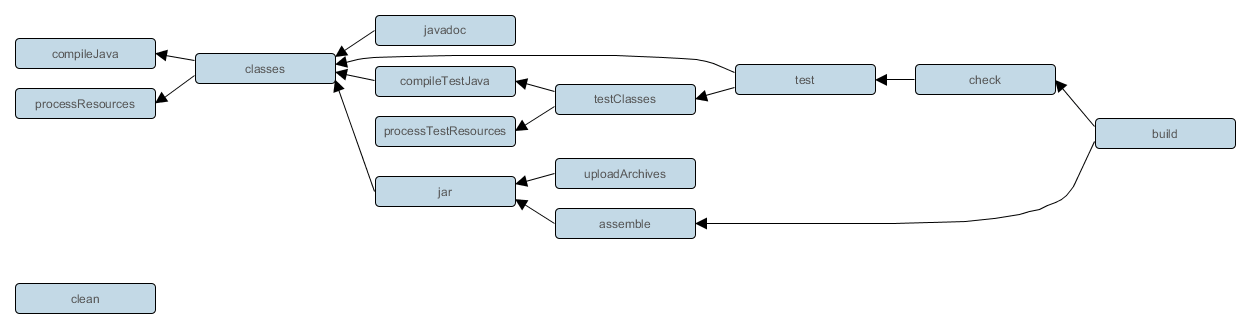
Project layout
The Java plugin assumes the project layout shown below. None of these directories need to exist or have anything in them. The Java plugin will compile whatever it finds, and handles anything which is missing.
src/main/java-
Production Java source.
src/main/resources-
Production resources, such as XML and properties files.
src/test/java-
Test Java source.
src/test/resources-
Test resources.
src/sourceSet/java-
Java source for the source set named sourceSet.
src/sourceSet/resources-
Resources for the source set named sourceSet.
Changing the project layout
You configure the project layout by configuring the appropriate source set. This is discussed in more detail in the following sections. Here is a brief example which changes the main Java and resource source directories.
sourceSets {
main {
java {
setSrcDirs(listOf("src/java"))
}
resources {
setSrcDirs(listOf("src/resources"))
}
}
}sourceSets {
main {
java {
srcDirs = ['src/java']
}
resources {
srcDirs = ['src/resources']
}
}
}Source sets
The plugin adds the following source sets:
main-
Contains the production source code of the project, which is compiled and assembled into a JAR.
test-
Contains your test source code, which is compiled and executed using JUnit or TestNG. These are typically unit tests, but you can include any test in this source set as long as they all share the same compilation and runtime classpaths.
Source set properties
The following table lists some of the important properties of a source set. You can find more details in the API documentation for SourceSet.
name— (read-only)String-
The name of the source set, used to identify it.
output— (read-only) SourceSetOutput-
The output files of the source set, containing its compiled classes and resources.
output.classesDirs— (read-only) FileCollection-
Default value:
layout.buildDirectory.dir("classes/java/$name"), e.g. build/classes/java/mainThe directories to generate the classes of this source set into. May contain directories for other JVM languages, e.g. build/classes/kotlin/main.
output.resourcesDir—File-
Default value:
layout.buildDirectory.dir("resources/$name"), e.g. build/resources/mainThe directory to generate the resources of this source set into.
compileClasspath— FileCollection-
Default value:
${name}CompileClasspathconfigurationThe classpath to use when compiling the source files of this source set.
annotationProcessorPath— FileCollection-
Default value:
${name}AnnotationProcessorconfigurationThe processor path to use when compiling the source files of this source set.
runtimeClasspath— FileCollection-
Default value:
$output,${name}RuntimeClasspathconfigurationThe classpath to use when executing the classes of this source set.
java— (read-only) SourceDirectorySet-
The Java source files of this source set. Contains only
.javafiles found in the Java source directories, and excludes all other files. java.srcDirs—Set<File>-
Default value:
src/$name/java, e.g. src/main/javaThe source directories containing the Java source files of this source set. You can set this to any value that is described in this section.
java.destinationDirectory—DirectoryProperty-
Default value:
layout.buildDirectory.dir("classes/java/$name"), e.g. build/classes/java/mainThe directory to generate compiled Java sources into. You can set this to any value that is described in this section.
resources— (read-only) SourceDirectorySet-
The resources of this source set. Contains only resources, and excludes any
.javafiles found in the resource directories. Other plugins, such as the Groovy Plugin, exclude additional types of files from this collection. resources.srcDirs—Set<File>-
Default value:
[src/$name/resources]The directories containing the resources of this source set. You can set this to any type of value that is described in this section.
allJava— (read-only) SourceDirectorySet-
Default value: Same as
javapropertyAll Java files of this source set. Some plugins, such as the Groovy Plugin, add additional Java source files to this collection.
allSource— (read-only) SourceDirectorySet-
Default value: Sum of everything in the
resourcesandjavapropertiesAll source files of this source set of any language. This includes all resource files and all Java source files. Some plugins, such as the Groovy Plugin, add additional source files to this collection.
Defining new source sets
See the integration test example in the Testing in Java & JVM projects chapter.
Some other simple source set examples
Adding a JAR containing the classes of a source set:
tasks.register<Jar>("intTestJar") {
from(sourceSets["intTest"].output)
}tasks.register('intTestJar', Jar) {
from sourceSets.intTest.output
}Generating Javadoc for a source set:
tasks.register<Javadoc>("intTestJavadoc") {
source(sourceSets["intTest"].allJava)
classpath = sourceSets["intTest"].compileClasspath
}tasks.register('intTestJavadoc', Javadoc) {
source sourceSets.intTest.allJava
classpath = sourceSets.intTest.compileClasspath
}Adding a test suite to run the tests in a source set:
tasks.register<Test>("intTest") {
testClassesDirs = sourceSets["intTest"].output.classesDirs
classpath = sourceSets["intTest"].runtimeClasspath
}tasks.register('intTest', Test) {
testClassesDirs = sourceSets.intTest.output.classesDirs
classpath = sourceSets.intTest.runtimeClasspath
}Dependency management
The Java plugin adds a number of dependency configurations to your project, as shown below.
Tasks such as compileJava and test then use one or more of those configurations to get the corresponding files and use them, for example by placing them on a compilation or runtime classpath.
Dependency configurations
The role of each configuration is described in the following tables.
|
Note
|
For information on the For information on the |
Declarable (Bucket) Configurations
| Configuration name | Role | Description |
|---|---|---|
|
Declarable |
Represents dependencies that are required both at compile time and runtime for the main source set of a project (i.e., implementation only dependencies). |
|
Declarable |
Represents dependencies that are required only at compile time and are not included in the runtime classpath (i.e., compile time only dependencies, not used at runtime). |
|
Declarable |
Represents dependencies that are required only at runtime and are not included in the compile classpath (i.e., dependencies required only at runtime). |
|
Declarable |
Represents dependencies that are required both at compile time and runtime for the test source set of a project (i.e., implementation only dependencies for tests). |
|
Declarable |
Represents dependencies that are required only at compile time for the test source set of a project and are not included in the runtime classpath (i.e., additional dependencies only for compiling tests, not used at runtime). |
|
Declarable |
Represents dependencies that are required only at runtime for the test source set of a project (i.e., runtime only dependencies for running tests). |
|
Declarable |
Represents annotation processors used during the compilation of a project’s source code (i.e., annotation processors used during compilation). |
Resolvable Configurations
| Configuration name | Role | Description |
|---|---|---|
|
Resolvable |
Represents the classpath used when compiling the main sources, which includes dependencies from both |
|
Resolvable |
Represents the classpath used to run the main sources, which includes dependencies from both |
|
Resolvable |
Represents the classpath used to compile the test sources, which includes dependencies from both |
|
Resolvable |
Represents the classpath used to run the test sources, which includes dependencies from both |
The following diagrams show the dependency configurations for the main source set. You can use this legend to interpret the colors:
-
blue background — you can declare dependencies against the configuration.
-
green background — the configuration is for consumption by tasks, not for you to declare dependencies.
-
grey background — a task.
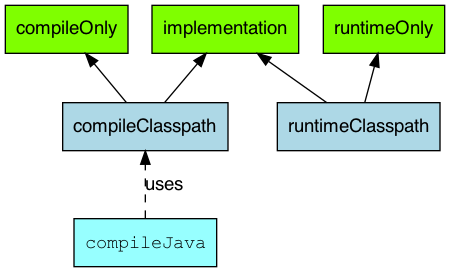
And the next graph describes the test source set:
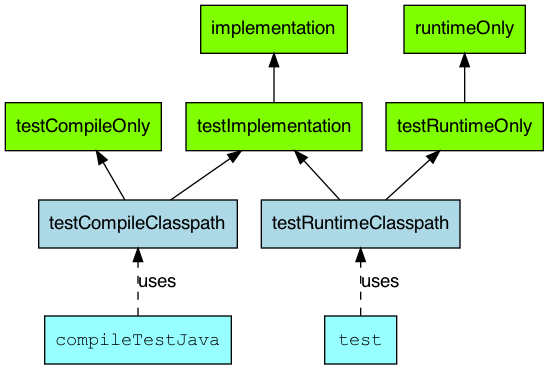
For each source set you add to the project, the Java plugins adds the following dependency configurations:
SourceSet dependency configurations
sourceSetImplementation-
Compile time dependencies for the given source set. Used by
sourceSetCompileClasspath, sourceSetRuntimeClasspath. sourceSetCompileOnly-
Compile time only dependencies for the given source set, not used at runtime.
sourceSetCompileClasspathextendssourceSetCompileOnly, sourceSetImplementation-
Compile classpath, used when compiling source. Used by
compileSourceSetJava. sourceSetAnnotationProcessor-
Annotation processors used during compilation of this source set.
sourceSetRuntimeOnly-
Runtime only dependencies for the given source set.
sourceSetRuntimeClasspathextendssourceSetRuntimeOnly, sourceSetImplementation-
Runtime classpath contains elements of the implementation, as well as runtime only elements.
Contributed extension
The Java plugin adds the java extension to the project.
This allows to configure a number of Java related properties inside a dedicated DSL block.
java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}Below is the list of properties and DSL functions with short explanations available inside the java extension.
Toolchain and compatibility
toolchain-
Java toolchain to be used by tasks using JVM tools, such as compilation and execution. Default value: build JVM toolchain.
JavaVersion sourceCompatibility-
Java version compatibility to use when compiling Java source. Default value: language version of the toolchain from this extension.
Note that using a toolchain is preferred to using a compatibility setting for most cases. JavaVersion targetCompatibility-
Java version to generate classes for. Default value:
sourceCompatibility.
Note that using a toolchain is preferred to using a compatibility setting for most cases.
Packaging
withJavadocJar()-
Automatically packages Javadoc and creates a variant
javadocElementswith an artifact-javadoc.jar, which will be part of the publication. withSourcesJar()-
Automatically packages source code and creates a variant
sourceElementswith an artifact-sources.jar, which will be part of the publication.
Directory properties
String reporting.baseDir-
The name of the directory to generate reports into, relative to the build directory. Default value:
reports (read-only) File reportsDir-
The directory to generate reports into. Default value:
reporting.baseDirectory String testResultsDirName-
The name of the directory to generate test result .xml files into, relative to the build directory. Default value:
test-results (read-only) File testResultsDir-
The directory to generate test result .xml files into. Default value:
layout.buildDirectory.dir(testResultsDirName) String testReportDirName-
The name of the directory to generate the test report into, relative to the reports directory. Default value:
tests (read-only) File testReportDir-
The directory to generate the test report into. Default value:
reportsDir/testReportDirName String libsDirName-
The name of the directory to generate libraries into, relative to the build directory. Default value:
libs (read-only) File libsDir-
The directory to generate libraries into. Default value:
layout.buildDirectory.dir(libsDirName) String distsDirName-
The name of the directory to generate distributions into, relative to the build directory. Default value:
distributions (read-only) File distsDir-
The directory to generate distributions into. Default value:
layout.buildDirectory.dir(distsDirName) String docsDirName-
The name of the directory to generate documentation into, relative to the build directory. Default value:
docs (read-only) File docsDir-
The directory to generate documentation into. Default value:
layout.buildDirectory.dir(docsDirName) String dependencyCacheDirName-
The name of the directory to cache source dependency information relative to the build directory. Default value:
dependency-cache.
Other properties
(read-only) SourceSetContainer sourceSets-
Contains the project’s source sets. Default value: Not null SourceSetContainer
String archivesBaseName-
The basename to use for archives, such as JAR or ZIP files. Default value:
projectName Manifest manifest-
The manifest to include in all JAR files. Default value: an empty manifest.
Testing
See the Testing in Java & JVM projects chapter for more details.
Publishing
components.java-
A SoftwareComponent for publishing the production JAR created by the
jartask. This component includes the runtime dependency information for the JAR.
See also the java extension.
Incremental Java compilation
Gradle comes with a sophisticated incremental Java compiler that is active by default.
This gives you the following benefits
-
Incremental builds are much faster.
-
The smallest possible number of class files are changed. Classes that don’t need to be recompiled remain unchanged in the output directory. An example scenario when this is really useful is using JRebel — the fewer output classes are changed the quicker the JVM can use refreshed classes.
To help you understand how incremental compilation works, the following provides a high-level overview:
-
Gradle will recompile all classes affected by a change.
-
A class is affected if it has been changed or if it depends on another affected class. This works no matter if the other class is defined in the same project, another project or even an external library.
-
A class’s dependencies are determined from type references in its bytecode or symbol analysis via a compiler plugin.
-
Since source-retention annotations are not visible in bytecode, changes to a source-retention annotation will result in full recompilation.
-
You can improve incremental compilation performance by applying good software design principles like loose coupling. For instance, if you put an interface between a concrete class and its dependents, the dependent classes are only recompiled when the interface changes, but not when the implementation changes.
-
The class analysis is cached in the project directory, so the first build after a clean checkout can be slower. Consider turning off the incremental compiler on your build server.
-
The class analysis is also an output stored in the build cache, which means that if a compilation output is fetched from the build cache, then the incremental compilation analysis will be too and the next compilation will be incremental.
Known issues
-
If you are using an annotation processor that reads resources (e.g. a configuration file), you need to declare those resources as an input of the compile task.
-
If a resource file is changed, Gradle will trigger a full recompilation.
-
Using a custom
executableorjavaHomedeactivates some optimizations. The compile task does not use incremental build immediately after a compile error or if a Java constant changes. Use toolchains instead if possible. -
Having a source structure that does not match the package names, while legal for compilation, might end up causing trouble in the toolchain. Even more if annotation processing and caching are involved.
Incremental annotation processing
Starting with Gradle 4.7, the incremental compiler also supports incremental annotation processing. All annotation processors need to opt in to this feature, otherwise they will trigger a full recompilation.
As a user you can see which annotation processors are triggering full recompilations in the --info log.
Incremental annotation processing will be deactivated if a custom executable or javaHome is configured on the compile task.
Making an annotation processor incremental
Please first have a look at incremental Java compilation, as incremental annotation processing builds on top of it.
Gradle supports incremental compilation for two common categories of annotation processors: "isolating" and "aggregating". Please consult the information below to decide which category fits your processor.
You can then register your processor for incremental compilation using a file in the processor’s META-INF directory. The format is one line per processor, with the fully qualified name of the processor class and its case-insensitive category separated by a comma.
Example: Registering incremental annotation processors
org.gradle.EntityProcessor,isolating
org.gradle.ServiceRegistryProcessor,dynamicIf your processor can only decide at runtime whether it is incremental or not, you can declare it as "dynamic" in the META-INF descriptor and return its true type at runtime using the Processor#getSupportedOptions() method.
Example: Registering incremental annotation processors dynamically
@Override
public Set<String> getSupportedOptions() {
return Collections.singleton("org.gradle.annotation.processing.aggregating");
}Both categories have the following limitations:
-
They can only read
CLASSorRUNTIMEretention annotations. -
They can only read parameter names if the user passes the
-parameterscompiler argument. -
They must generate their files using the Filer API. Writing files any other way will result in silent failures later on, as these files won’t be cleaned up correctly. If your processor does this, it cannot be incremental.
-
They must not depend on compiler-specific APIs like
com.sun.source.util.Trees. Gradle wraps the processing APIs, so attempts to cast to compiler-specific types will fail. If your processor does this, it cannot be incremental, unless you have some fallback mechanism. -
If they use Filer#createResource, the
locationargument must be one of these values from StandardLocation:CLASS_OUTPUT,SOURCE_OUTPUT, orNATIVE_HEADER_OUTPUT. Any other argument will disable incremental processing.
"Isolating" annotation processors
The fastest category, these look at each annotated element in isolation, creating generated files or validation messages for it.
For instance an EntityProcessor could create a <TypeName>Repository for each type annotated with @Entity.
Example: An isolated annotation processor
Set<? extends Element> entities = roundEnv.getElementsAnnotatedWith(entityAnnotation);
for (Element entity : entities) {
createRepository((TypeElement) entity);
}"Isolating" processors have the following additional limitations:
-
They must make all decisions (code generation, validation messages) for an annotated type based on information reachable from its AST. This means you can analyze the types' super-class, method return types, annotations etc., even transitively. But you cannot make decisions based on unrelated elements in the RoundEnvironment. Doing so will result in silent failures because too few files will be recompiled later. If your processor needs to make decisions based on a combination of otherwise unrelated elements, mark it as "aggregating" instead.
-
They must provide exactly one originating element for each file generated with the
FilerAPI. If zero or many originating elements are provided, Gradle will recompile all source files.
When a source file is recompiled, Gradle will recompile all files generated from it. When a source file is deleted, the files generated from it are deleted.
"Aggregating" annotation processors
These can aggregate several source files into one or more output files or validation messages.
For instance, a ServiceRegistryProcessor could create a single ServiceRegistry with one method for each type annotated with @Service.
Example: An aggregating annotation processor
JavaFileObject serviceRegistry = filer.createSourceFile("ServiceRegistry");
Writer writer = serviceRegistry.openWriter();
writer.write("public class ServiceRegistry {");
for (Element service : roundEnv.getElementsAnnotatedWith(serviceAnnotation)) {
addServiceCreationMethod(writer, (TypeElement) service);
}
writer.write("}");
writer.close();Gradle will always reprocess (but not recompile) all annotated files that the processor was registered for. Gradle will always recompile any files the processor generates.
State of support in popular annotation processors
|
Note
|
Many popular annotation processors support incremental annotation processing (see the table below). Check with the annotation processor project directly for the most up-to-date information and documentation. |
| Annotation Processor | Supported since | Details |
|---|---|---|
N/A |
||
N/A |
||
Partly supported. |
||
N/A |
||
N/A |
||
DataBinding |
Hidden behind a feature toggle |
|
Dagger |
2.18 Feature toggle support, 2.24 Enabled by default |
|
kapt |
Hidden behind a feature toggle |
|
Toothpick |
N/A |
|
Glide |
N/A |
|
Android-State |
N/A |
|
Parceler |
N/A |
|
Dart and Henson |
N/A |
|
N/A |
||
N/A |
||
N/A |
||
Requery |
N/A |
|
N/A |
||
N/A |
||
Immutables |
N/A |
|
2.2.0 Feature toggle support, 2.3.0-alpha02 Enabled by default |
||
N/A |
||
N/A |
||
DBFlow |
N/A |
|
AndServer |
N/A |
|
N/A |
||
N/A |
||
N/A |
||
N/A |
||
Hidden behind a feature toggle |
||
N/A |
Compilation avoidance
If a dependent project has changed in an ABI-compatible way (only its private API has changed), then Java compilation tasks will be up-to-date. This means that if project A depends on project B and a class in B is changed in an ABI-compatible way (typically, changing only the body of a method), then Gradle won’t recompile A.
Some of the types of changes that do not affect the public API and are ignored:
-
Changing a method body
-
Changing a comment
-
Adding, removing or changing private methods, fields, or inner classes
-
Adding, removing or changing a resource
-
Changing the name of jars or directories in the classpath
-
Renaming a parameter
Since implementation details matter for annotation processors, they must be declared separately on the annotation processor path. Gradle ignores annotation processors on the compile classpath.
dependencies {
// The dagger compiler and its transitive dependencies will only be found on annotation processing classpath
annotationProcessor("com.google.dagger:dagger-compiler:2.44")
// And we still need the Dagger library on the compile classpath itself
implementation("com.google.dagger:dagger:2.44")
}dependencies {
// The dagger compiler and its transitive dependencies will only be found on annotation processing classpath
annotationProcessor 'com.google.dagger:dagger-compiler:2.44'
// And we still need the Dagger library on the compile classpath itself
implementation 'com.google.dagger:dagger:2.44'
}Variant aware selection
The whole set of JVM plugins leverage variant aware resolution for the dependencies used. They also install a set of attributes compatibility and disambiguation rules to configure the Gradle attributes for the specifics of the JVM ecosystem.
The Java Library Plugin
The Java Library plugin expands the capabilities of the Java Plugin (java) by providing specific knowledge about Java libraries.
In particular, a Java library exposes an API to consumers (i.e., other projects using the Java or the Java Library plugin).
All the source sets, tasks and configurations exposed by the Java plugin are implicitly available when using this plugin.
Usage
To use the Java Library plugin, include the following in your build script:
plugins {
`java-library`
}plugins {
id 'java-library'
}API and implementation separation
The key difference between the standard Java plugin and the Java Library plugin is that the latter introduces the concept of an API exposed to consumers. A library is a Java component meant to be consumed by other components. It’s a very common use case in multi-project builds, but also as soon as you have external dependencies.
The plugin exposes two configurations that can be used to declare dependencies: api and implementation.
The api configuration should be used to declare dependencies which are exported by the library API, whereas the implementation configuration should be used to declare dependencies which are internal to the component.
dependencies {
api("org.apache.httpcomponents:httpclient:4.5.7")
implementation("org.apache.commons:commons-lang3:3.5")
}dependencies {
api 'org.apache.httpcomponents:httpclient:4.5.7'
implementation 'org.apache.commons:commons-lang3:3.5'
}Dependencies appearing in the api configurations will be transitively exposed to consumers of the library, and as such will appear on the compile classpath of consumers. Dependencies found in the implementation configuration will, on the other hand, not be exposed to consumers, and therefore not leak into the consumers' compile classpath. This comes with several benefits:
-
dependencies do not leak into the compile classpath of consumers anymore, so you will never accidentally depend on a transitive dependency
-
faster compilation thanks to reduced classpath size
-
less recompilations when implementation dependencies change: consumers would not need to be recompiled
-
cleaner publishing: when used in conjunction with the new
maven-publishplugin, Java libraries produce POM files that distinguish exactly between what is required to compile against the library and what is required to use the library at runtime (in other words, don’t mix what is needed to compile the library itself and what is needed to compile against the library).
|
Note
|
The compile and runtime configurations have been removed with Gradle 7.0.
Please refer to the upgrade guide how to migrate to implementation and api configurations`.
|
If your build consumes a published module with POM metadata, the Java and Java Library plugins both honor api and implementation separation through the scopes used in the POM.
Meaning that the compile classpath only includes Maven compile scoped dependencies, while the runtime classpath adds the Maven runtime scoped dependencies as well.
This often does not have an effect on modules published with Maven, where the POM that defines the project is directly published as metadata.
There, the compile scope includes both dependencies that were required to compile the project (i.e. implementation dependencies) and dependencies required to compile against the published library (i.e. API dependencies).
For most published libraries, this means that all dependencies belong to the compile scope.
If you encounter such an issue with an existing library, you can consider a component metadata rule to fix the incorrect metadata in your build.
However, as mentioned above, if the library is published with Gradle, the produced POM file only puts api dependencies into the compile scope and the remaining implementation dependencies into the runtime scope.
If your build consumes modules with Ivy metadata, you might be able to activate api and implementation separation as described here if all modules follow a certain structure.
|
Note
|
Separating compile and runtime scope of modules is active by default in Gradle 5.0+.
In Gradle 4.6+, you need to activate it by adding enableFeaturePreview('IMPROVED_POM_SUPPORT') in settings.gradle.
|
Recognizing API and implementation dependencies
This section will help you identify API and Implementation dependencies in your code using simple rules of thumb. The first of these is:
-
Prefer the
implementationconfiguration overapiwhen possible
This keeps the dependencies off of the consumer’s compilation classpath. In addition, the consumers will immediately fail to compile if any implementation types accidentally leak into the public API.
So when should you use the api configuration? An API dependency is one that contains at least one type that is exposed in the library binary interface, often referred to as its ABI (Application Binary Interface). This includes, but is not limited to:
-
types used in super classes or interfaces
-
types used in public method parameters, including generic parameter types (where public is something that is visible to compilers. I.e. , public, protected and package private members in the Java world)
-
types used in public fields
-
public annotation types
By contrast, any type that is used in the following list is irrelevant to the ABI, and therefore should be declared as an implementation dependency:
-
types exclusively used in method bodies
-
types exclusively used in private members
-
types exclusively found in internal classes (future versions of Gradle will let you declare which packages belong to the public API)
The following class makes use of a couple of third-party libraries, one of which is exposed in the class’s public API and the other is only used internally. The import statements don’t help us determine which is which, so we have to look at the fields, constructors and methods instead:
Example: Making the difference between API and implementation
// The following types can appear anywhere in the code
// but say nothing about API or implementation usage
import org.apache.commons.httpclient.*;
import org.apache.commons.httpclient.methods.*;
import org.apache.commons.lang3.exception.ExceptionUtils;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
public class HttpClientWrapper {
private final HttpClient client; // private member: implementation details
// HttpClient is used as a parameter of a public method
// so "leaks" into the public API of this component
public HttpClientWrapper(HttpClient client) {
this.client = client;
}
// public methods belongs to your API
public byte[] doRawGet(String url) {
GetMethod method = new GetMethod(url);
try {
int statusCode = doGet(method);
return method.getResponseBody();
} catch (Exception e) {
ExceptionUtils.rethrow(e); // this dependency is internal only
} finally {
method.releaseConnection();
}
return null;
}
// GetMethod is used in a private method, so doesn't belong to the API
private int doGet(GetMethod method) throws Exception {
int statusCode = client.executeMethod(method);
if (statusCode != HttpStatus.SC_OK) {
System.err.println("Method failed: " + method.getStatusLine());
}
return statusCode;
}
}The public constructor of HttpClientWrapper uses HttpClient as a parameter, so it is exposed to consumers and therefore belongs to the API. Note that HttpGet and HttpEntity are used in the signature of a private method, and so they don’t count towards making HttpClient an API dependency.
On the other hand, the ExceptionUtils type, coming from the commons-lang library, is only used in a method body (not in its signature), so it’s an implementation dependency.
Therefore, we can deduce that httpclient is an API dependency, whereas commons-lang is an implementation dependency. This conclusion translates into the following declaration in the build script:
dependencies {
api("commons-httpclient:commons-httpclient:3.1")
implementation("org.apache.commons:commons-lang3:3.5")
}dependencies {
api 'commons-httpclient:commons-httpclient:3.1'
implementation 'org.apache.commons:commons-lang3:3.5'
}Dependency configurations
The role of each configuration is described in the following tables.
Declarable (Bucket) Configurations
| Configuration name | Role | Description |
|---|---|---|
|
Declarable |
This configuration is used to declare annotation processors, ensuring they are available during the compile phase for code generation. |
|
Declarable |
This is where you declare dependencies which are transitively exported to consumers, for compile time and runtime. |
|
Declarable |
This is where you declare dependencies which are purely internal and not meant to be exposed to consumers (they are still exposed to consumers at runtime). |
|
Declarable |
This is where you declare dependencies which are required at compile time, but not at runtime. This typically includes dependencies which are shaded when found at runtime. |
|
Declarable |
This is where you declare dependencies which are required at compile time by your module and consumers, but not at runtime. This typically includes dependencies which are shaded when found at runtime. |
|
Declarable |
This is where you declare dependencies which are only required at runtime, and not at compile time. |
|
Declarable |
This is where you declare dependencies which are used to compile tests. |
|
Declarable |
This is where you declare dependencies which are only required at test compile time, but should not leak into the runtime. This typically includes dependencies which are shaded when found at runtime. |
|
Declarable |
This is where you declare dependencies which are only required at test runtime, and not at test compile time. |
Consumable Configurations
| Configuration name | Role | Description |
|---|---|---|
|
Consumable |
This configuration is meant to be used by consumers to retrieve all the elements necessary to compile against this library. |
|
Consumable |
This configuration is meant to be used by consumers to retrieve all the elements necessary to run this library. |
Resolvable Configurations
| Configuration name | Role | Description |
|---|---|---|
|
Resolvable |
This configuration contains the compile classpath of this library and is therefore used when invoking the Java compiler to compile it. |
|
Resolvable |
This configuration contains the runtime classpath of this library. |
|
Resolvable |
This configuration contains the test compile classpath of this library. |
|
Resolvable |
This configuration contains the test runtime classpath of this library. |
The following graph describes how configurations are setup when the Java Library plugin is in use. You can use this legend to interpret the colors:
-
The configurations in blue are the ones a user should use to declare dependencies.
-
The configurations in purple are the ones used when a component compiles, or runs against the library.
-
The configurations in green are internal to the component, for its own use.
-
The tasks in grey.
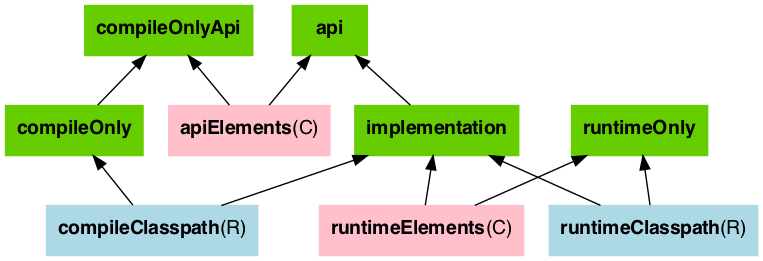
And the next graph describes the test configurations setup:
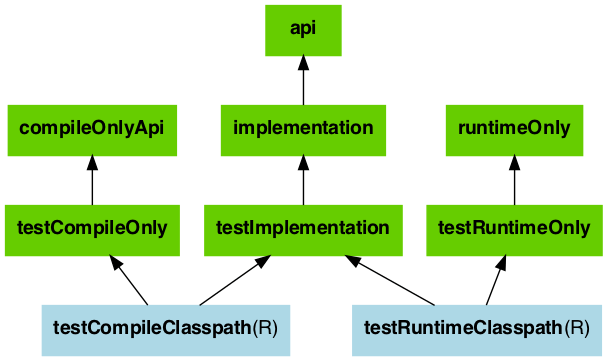
Building Modules for the Java Module System
Since Java 9, Java itself offers a module system that allows for strict encapsulation during compile and runtime.
You can turn a Java library into a Java Module by creating a module-info.java file in the main/java source folder.
src
└── main
└── java
└── module-info.javaIn the module info file, you declare a module name, which packages of your module you want to export and which other modules you require.
module org.gradle.sample {
requires com.google.gson; // real module
requires org.apache.commons.lang3; // automatic module
// commons-cli-1.4.jar is not a module and cannot be required
}To tell the Java compiler that a Jar is a module, as opposed to a traditional Java library, Gradle needs to place it on the so called module path. It is an alternative to the classpath, which is the traditional way to tell the compiler about compiled dependencies. Gradle will automatically put a Jar of your dependencies on the module path, instead of the classpath, if these three things are true:
-
java.modularity.inferModulePathis not turned off -
We are actually building a module (as opposed to a traditional library) which we expressed by adding the
module-info.javafile. (Another option is to add theAutomatic-Module-NameJar manifest attribute as described further down.) -
The Jar our module depends on is itself a module, which Gradles decides based on the presence of a
module-info.class— the compiled version of the module descriptor — in the Jar. (Or, alternatively, the presence of anAutomatic-Module-Nameattribute the Jar manifest)
Declaring module dependencies
There is a direct relationship to the dependencies you declare in the build file and the module dependencies you declare in the module-info.java file.
Ideally the declarations should be in sync as seen in the following table.
| Java Module Directive | Gradle Configuration | Purpose |
|---|---|---|
|
|
Declaring implementation dependencies |
|
|
Declaring API dependencies |
|
|
Declaring compile only dependencies |
|
|
Declaring compile only API dependencies |
Gradle currently does not automatically check if the dependency declarations are in sync. This may be added in future versions.
For more details on declaring module dependencies, please refer to documentation on the Java Module System.
Declaring package visibility and services
The Java module system supports additional more fine granular encapsulation concepts than Gradle itself currently does. For example, you explicitly need to declare which packages are part of your API and which are only visible inside your module. Some of these capabilities might be added to Gradle itself in future versions. For now, please refer to documentation on the Java Module System to learn how to use these features in Java Modules.
Declaring module versions
Java Modules also have a version that is encoded as part of the module identity in the module-info.class file.
This version can be inspected when a module is running.
version = "1.2"
tasks.compileJava {
// use the project's version or define one directly
options.javaModuleVersion = provider { version as String }
}version = '1.2'
tasks.named('compileJava') {
// use the project's version or define one directly
options.javaModuleVersion = provider { version }
}Using libraries that are not modules
You probably want to use external libraries, like OSS libraries from Maven Central, in your modular Java project.
Some libraries, in their newer versions, are already full modules with a module descriptor.
For example, com.google.code.gson:gson:2.8.9 that has the module name com.google.gson.
Others, like org.apache.commons:commons-lang3:3.10, may not offer a full module descriptor but will at least contain an Automatic-Module-Name entry in their manifest file to define the module’s name (org.apache.commons.lang3 in the example).
Such modules, that only have a name as module description, are called automatic module that export all their packages and can read all modules on the module path.
A third case are traditional libraries that provide no module information at all — for example commons-cli:commons-cli:1.4.
Gradle puts such libraries on the classpath instead of the module path.
The classpath is then treated as one module (the so called unnamed module) by Java.
dependencies {
implementation("com.google.code.gson:gson:2.13.1") // real module
implementation("org.apache.commons:commons-lang3:3.10") // automatic module
implementation("commons-cli:commons-cli:1.4") // plain library
}dependencies {
implementation 'com.google.code.gson:gson:2.13.1' // real module
implementation 'org.apache.commons:commons-lang3:3.10' // automatic module
implementation 'commons-cli:commons-cli:1.4' // plain library
}module org.gradle.sample.lib {
requires com.google.gson; // real module
requires org.apache.commons.lang3; // automatic module
// commons-cli-1.4.jar is not a module and cannot be required
}While a real module cannot directly depend on the unnamed module (only by adding command line flags), automatic modules can also see the unnamed module. Thus, if you cannot avoid to rely on a library without module information, you can wrap that library in an automatic module as part of your project. How you do that is described in the next section.
Another way to deal with non-modules is to enrich existing Jars with module descriptors yourself using artifact transforms.
Disabling Java Module support
In rare cases, you might want to disable the built-in Java Module support and define the module path by other means.
To achieve this, you can disable the functionality to automatically put any Jar on the module path.
Then Gradle puts Jars with module information on the classpath, even if you have a module-info.java in your source set.
This corresponds to the behaviour of Gradle versions <7.0.
To make this work, you need to set modularity.inferModulePath = false on the Java extension (for all tasks) or on individual tasks.
java {
modularity.inferModulePath = false
}
tasks.compileJava {
modularity.inferModulePath = false
}java {
modularity.inferModulePath = false
}
tasks.named('compileJava') {
modularity.inferModulePath = false
}Building an automatic module
If you can, you should always write complete module-info.java descriptors for your modules.
Still, there are a few cases where you might consider to (initally) only provide a module name for an automatic module:
-
You are working on a library that is not a module but you want to make it usable as such in the next release. Adding an
Automatic-Module-Nameis a good first step (most popular OSS libraries on Maven central have done it by now). -
As discussed in the previous section, an automatic module can be used as an adapter between your real modules and a traditional library on the classpath.
To turn a normal Java project into an automatic module, just add the manifest entry with the module name:
tasks.jar {
manifest {
attributes("Automatic-Module-Name" to "org.gradle.sample")
}
}tasks.named('jar') {
manifest {
attributes('Automatic-Module-Name': 'org.gradle.sample')
}
}|
Note
|
=== You can define an automatic module as part of a multi-project that otherwise defines real modules (e.g. as an adapter to another library). While this works fine in the Gradle build, such automatic module projects are not correctly recognized by IDEA/Eclipse at the moment. You can work around it by manually adding the Jar built for the automatic module to the dependencies of the project that does not find it in the IDE’s UI. === |
Using classes instead of jar for compilation
A feature of the java-library plugin is that projects which consume the library only require the classes folder for compilation, instead of the full JAR.
This enables lighter inter-project dependencies as resources processing (processResources task) and archive construction (jar task) are no longer executed when only Java code compilation is performed during development.
|
Note
|
The usage or not of the classes output instead of the JAR is a consumer decision. For example, Groovy consumers will request classes and processed resources as these may be needed for executing AST transformation as part of the compilation process. |
Increased memory usage for consumers
An indirect consequence is that up-to-date checking will require more memory, because Gradle will snapshot individual class files instead of a single jar.
This may lead to increased memory consumption for large projects, with the benefit of having the compileJava task up-to-date in more cases (e.g. changing resources no longer changes the input for compileJava tasks of upstream projects)
Significant build performance drop on Windows for huge multi-projects
Another side effect of the snapshotting of individual class files, only affecting Windows systems, is that the performance can significantly drop when processing a very large amount of class files on the compile classpath.
This only concerns very large multi-projects where a lot of classes are present on the classpath by using many api dependencies.
To mitigate this, you can set the org.gradle.java.compile-classpath-packaging system property to true to change the behavior of the Java Library plugin to use jars instead of class folders for everything on the compile classpath.
Note, since this has other performance impacts and potentially side effects, by triggering all jar tasks at compile time, it is only recommended to activate this if you suffer from the described performance issue on Windows.
Distributing a library
Aside from publishing a library to a component repository, you may sometimes need to package a library and its dependencies in a distribution deliverable. The Java Library Distribution Plugin is there to help you do just that.
The Java Platform Plugin
The Java Platform plugin brings the ability to declare platforms for the Java ecosystem. A platform can be used for different purposes:
-
a description of modules which are published together (and for example, share the same version)
-
a set of recommended versions for heterogeneous libraries. A typical example includes the Spring Boot BOM
-
sharing a set of dependency versions between subprojects
A platform is a special kind of software component which doesn’t contain any sources: it is only used to reference other libraries, so that they play well together during dependency resolution.
Platforms can be published as Gradle Module Metadata and Maven BOMs.
|
Note
|
The java-platform plugin cannot be used in combination with the java or java-library plugins in a given project.
Conceptually a project is either a platform, with no binaries, or produces binaries.
|
Usage
To use the Java Platform plugin, include the following in your build script:
plugins {
`java-platform`
}plugins {
id 'java-platform'
}API and runtime separation
A major difference between a Maven BOM and a Java platform is that in Gradle dependencies and constraints are declared and scoped to a configuration and the ones extending it. While many users will only care about declaring constraints for compile time dependencies, thus inherited by runtime and tests ones, it allows declaring dependencies or constraints that only apply to runtime or test.
For this purpose, the plugin exposes two configurations that can be used to declare dependencies: api and runtime.
The api configuration should be used to declare constraints and dependencies which should be used when compiling against the platform, whereas the runtime configuration should be used to declare constraints or dependencies which are visible at runtime.
dependencies {
constraints {
api("commons-httpclient:commons-httpclient:3.1")
runtime("org.postgresql:postgresql:42.2.5")
}
}dependencies {
constraints {
api 'commons-httpclient:commons-httpclient:3.1'
runtime 'org.postgresql:postgresql:42.2.5'
}
}Note that this example makes use of constraints and not dependencies. In general, this is what you would like to do: constraints will only apply if such a component is added to the dependency graph, either directly or transitively. This means that all constraints listed in a platform would not add a dependency unless another component brings it in: they can be seen as recommendations.
|
Note
|
For example, if a platform declares a constraint on |
By default, in order to avoid the common mistake of adding a dependency in a platform instead of a constraint, Gradle will fail if you try to do so. If, for some reason, you also want to add dependencies in addition to constraints, you need to enable it explicitly:
javaPlatform {
allowDependencies()
}javaPlatform {
allowDependencies()
}Local project constraints
If you have a multi-project build and want to publish a platform that links to subprojects, you can do it by declaring constraints on the subprojects which belong to the platform, as in the example below:
dependencies {
constraints {
api(project(":core"))
api(project(":lib"))
}
}dependencies {
constraints {
api project(":core")
api project(":lib")
}
}The project notation will become a classical group:name:version notation in the published metadata.
Sourcing constraints from another platform
Sometimes the platform you define is an extension of another existing platform.
In order to have your platform include the constraints from that third party platform, it needs to be imported as a platform dependency:
javaPlatform {
allowDependencies()
}
dependencies {
api(platform("com.fasterxml.jackson:jackson-bom:2.9.8"))
}javaPlatform {
allowDependencies()
}
dependencies {
api platform('com.fasterxml.jackson:jackson-bom:2.9.8')
}Publishing platforms
Publishing Java platforms is done by applying the maven-publish plugin and configuring a Maven publication that uses the javaPlatform component:
publishing {
publications {
create<MavenPublication>("myPlatform") {
from(components["javaPlatform"])
}
}
}publishing {
publications {
myPlatform(MavenPublication) {
from components.javaPlatform
}
}
}This will generate a BOM file for the platform, with a <dependencyManagement> block where its <dependencies> correspond to the constraints defined in the platform module.
Consuming platforms
Because a Java Platform is a special kind of component, a dependency on a Java platform has to be declared using the platform or enforcedPlatform keyword, as explained in the managing transitive dependencies section.
For example, if you want to share dependency versions between subprojects, you can define a platform module which would declare all versions:
dependencies {
constraints {
// Platform declares some versions of libraries used in subprojects
api("commons-httpclient:commons-httpclient:3.1")
api("org.apache.commons:commons-lang3:3.8.1")
}
}dependencies {
constraints {
// Platform declares some versions of libraries used in subprojects
api 'commons-httpclient:commons-httpclient:3.1'
api 'org.apache.commons:commons-lang3:3.8.1'
}
}And then have subprojects depend on the platform to get recommendations:
dependencies {
// get recommended versions from the platform project
api(platform(project(":platform")))
// no version required
api("commons-httpclient:commons-httpclient")
}dependencies {
// get recommended versions from the platform project
api platform(project(':platform'))
// no version required
api 'commons-httpclient:commons-httpclient'
}The Groovy Plugin
The Groovy plugin extends the Java plugin to add support for Groovy projects. It can deal with Groovy code, mixed Groovy and Java code, and even pure Java code (although we don’t necessarily recommend to use it for the latter). The plugin supports joint compilation, which allows you to freely mix and match Groovy and Java code, with dependencies in both directions. For example, a Groovy class can extend a Java class that in turn extends a Groovy class. This makes it possible to use the best language for the job, and to rewrite any class in the other language if needed.
Note that if you want to benefit from the API / implementation separation, you can also apply the java-library plugin to your Groovy project.
Usage
To use the Groovy plugin, include the following in your build script:
plugins {
groovy
}plugins {
id 'groovy'
}Tasks
The Groovy plugin adds the following tasks to the project. Information about altering the dependencies to Java compile tasks are found here.
compileGroovy— GroovyCompile-
Depends on:
compileJavaCompiles production Groovy source files.
compileTestGroovy— GroovyCompile-
Depends on:
compileTestJavaCompiles test Groovy source files.
compileSourceSetGroovy— GroovyCompile-
Depends on:
compileSourceSetJavaCompiles the given source set’s Groovy source files.
groovydoc— Groovydoc-
Generates API documentation for the production Groovy source files.
The Groovy plugin adds the following dependencies to tasks added by the Java plugin.
| Task name | Depends on |
|---|---|
|
|
|
|
|
|
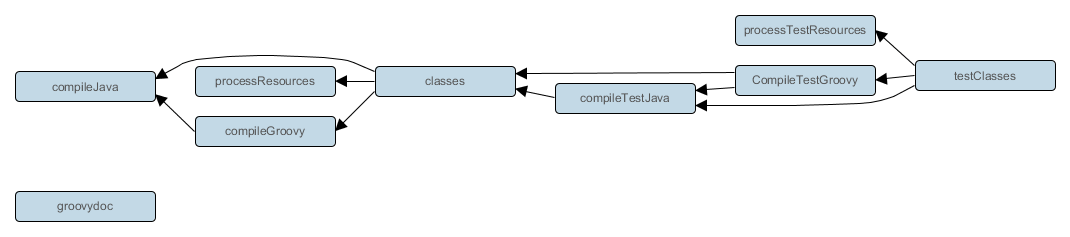
Project layout
The Groovy plugin assumes the project layout shown in Groovy Layout. All the Groovy source directories can contain Groovy and Java code. The Java source directories may only contain Java source code.[2] None of these directories need to exist or have anything in them; the Groovy plugin will simply compile whatever it finds.
src/main/java-
Production Java source.
src/main/resources-
Production resources, such as XML and properties files.
src/main/groovy-
Production Groovy source. May also contain Java source files for joint compilation.
src/test/java-
Test Java source.
src/test/resources-
Test resources.
src/test/groovy-
Test Groovy source. May also contain Java source files for joint compilation.
src/sourceSet/java-
Java source for the source set named sourceSet.
src/sourceSet/resources-
Resources for the source set named sourceSet.
src/sourceSet/groovy-
Groovy source files for the given source set. May also contain Java source files for joint compilation.
Changing the project layout
Just like the Java plugin, the Groovy plugin allows you to configure custom locations for Groovy production and test source files.
sourceSets {
main {
groovy {
setSrcDirs(listOf("src/groovy"))
}
}
test {
groovy {
setSrcDirs(listOf("test/groovy"))
}
}
}sourceSets {
main {
groovy {
srcDirs = ['src/groovy']
}
}
test {
groovy {
srcDirs = ['test/groovy']
}
}
}Dependency management
Because Gradle’s build language is based on Groovy, Gradle already ships with a Groovy library. Nevertheless, Groovy projects need to explicitly declare a Groovy dependency. This dependency will then be used on compile and runtime class paths. It will also be used to get hold of the Groovy compiler and Groovydoc tool, respectively.
If Groovy is used for production code, the Groovy dependency should be added to the implementation configuration:
dependencies {
implementation("org.codehaus.groovy:groovy-all:2.4.15")
}dependencies {
implementation 'org.codehaus.groovy:groovy-all:2.4.15'
}If Groovy is only used for test code, the Groovy dependency should be added to the testImplementation configuration:
dependencies {
testImplementation("org.codehaus.groovy:groovy-all:2.4.15")
}dependencies {
testImplementation 'org.codehaus.groovy:groovy-all:2.4.15'
}To use the Groovy library that ships with Gradle, declare a localGroovy() dependency. Note that different Gradle versions ship with different Groovy versions; as such, using localGroovy() is less safe then declaring a regular Groovy dependency.
dependencies {
implementation(localGroovy())
}dependencies {
implementation localGroovy()
}Automatic configuration of groovyClasspath
The GroovyCompile and Groovydoc tasks consume Groovy code in two ways: on their classpath, and on their groovyClasspath. The former is used to locate classes referenced by the source code, and will typically contain the Groovy library along with other libraries. The latter is used to load and execute the Groovy compiler and Groovydoc tool, respectively, and should only contain the Groovy library and its dependencies.
Unless a task’s groovyClasspath is configured explicitly, the Groovy (base) plugin will try to infer it from the task’s classpath. This is done as follows:
-
If a
groovy-all(-indy)Jar is found onclasspath, that jar will be added togroovyClasspath. -
If a
groovy(-indy)jar is found onclasspath, and the project has at least one repository declared, a correspondinggroovy(-indy)repository dependency will be added togroovyClasspath. -
Otherwise, execution of the task will fail with a message saying that
groovyClasspathcould not be inferred.
Note that the “-indy” variation of each jar refers to the version with invokedynamic support.
Convention properties
The Groovy plugin does not add any convention properties to the project.
Source set properties
The Groovy plugin adds the following extensions to each source set in the project. You can use these properties in your build script as though they were properties of the source set object.
Groovy Plugin — source set properties
groovy— GroovySourceDirectorySet (read-only)-
Default value: Not null
The Groovy source files of this source set. Contains all
.groovyand.javafiles found in the Groovy source directories, and excludes all other types of files. groovy.srcDirs—Set<File>-
Default value:
[projectDir/src/name/groovy]The source directories containing the Groovy source files of this source set. May also contain Java source files for joint compilation. Can set using anything described in Specifying Multiple Files.
The Groovy plugin also modifies some source set properties:
Groovy Plugin - modified source set properties
| Property name | Change |
|---|---|
|
Adds all |
|
Adds all source files found in the Groovy source directories. |
GroovyCompile
The Groovy plugin adds a GroovyCompile task for each source set in the project.
The task type shares much with the JavaCompile task by extending AbstractCompile (see the relevant Java Plugin section).
The GroovyCompile task supports most configuration options of the official Groovy compiler.
The task can also leverage the Java toolchain support.
| Task Property | Type | Default Value |
|---|---|---|
|
|
|
|
FileTree. Can set using anything described in Specifying Multiple Files. |
|
|
|
|
|
|
|
|
|
None but will be configured if a toolchain is defined on the |
Compilation avoidance
Caveat: Groovy compilation avoidance is an incubating feature since Gradle 5.6. There are known inaccuracies so please enable it at your own risk.
To enable the incubating support for Groovy compilation avoidance, add a enableFeaturePreview to your settings file:
enableFeaturePreview("GROOVY_COMPILATION_AVOIDANCE")enableFeaturePreview('GROOVY_COMPILATION_AVOIDANCE')If a dependent project has changed in an ABI-compatible way (only its private API has changed), then Groovy compilation tasks will be up-to-date.
This means that if project A depends on project B and a class in B is changed in an ABI-compatible way (typically, changing only the body of a method), then Gradle won’t recompile A.
See Java compile avoidance for a detailed list of the types of changes that do not affect the ABI and are ignored.
However, similar to Java’s annotation processing, there are various ways to customize the Groovy compilation process, for which implementation details matter.
Some well-known examples are Groovy AST transformations.
In these cases, these dependencies must be declared separately in a classpath called astTransformationClasspath:
val astTransformation = configurations.create("astTransformation")
dependencies {
astTransformation(project(":ast-transformation"))
}
tasks.withType<GroovyCompile>().configureEach {
astTransformationClasspath.from(astTransformation)
}configurations { astTransformation }
dependencies {
astTransformation(project(":ast-transformation"))
}
tasks.withType(GroovyCompile).configureEach {
astTransformationClasspath.from(configurations.astTransformation)
}Incremental Groovy compilation
Since 5.6, Gradle introduces an experimental incremental Groovy compiler. To enable incremental compilation for Groovy, you need:
-
Enable Groovy compilation avoidance.
-
Explicitly enable incremental Groovy compilation in the build script:
tasks.withType<GroovyCompile>().configureEach {
options.isIncremental = true
options.incrementalAfterFailure = true
}tasks.withType(GroovyCompile).configureEach {
options.incremental = true
options.incrementalAfterFailure = true
}This gives you the following benefits:
-
Incremental builds are much faster.
-
If only a small set of Groovy source files are changed, only the affected source files will be recompiled. Classes that don’t need to be recompiled remain unchanged in the output directory. For example, if you only change a few Groovy test classes, you don’t need to recompile all Groovy test source files — only the changed ones need to be recompiled.
To understand how incremental compilation works, see Incremental Java compilation for a detailed overview. Note that there’re several differences from Java incremental compilation:
The Groovy compiler doesn’t keep @Retention in generated annotation class bytecode (GROOVY-9185), thus all annotations are RUNTIME.
This means that changes to source-retention annotations won’t trigger a full recompilation.
Known issues
-
Changes to resources won’t trigger a recompilation, this might result in some incorrectness — for example Extension Modules.
Compiling and testing for Java 6 or Java 7
With toolchain support added to GroovyCompile, it is possible to compile Groovy code using a different Java version than the one running Gradle.
If you also have Java source files, this will also configure JavaCompile to use the right Java compiler is used, as can be seen in the Java plugin documentation.
Example: Configure Java 7 build for Groovy
java {
toolchain {
languageVersion = JavaLanguageVersion.of(7)
}
}java {
toolchain {
languageVersion = JavaLanguageVersion.of(7)
}
}The Scala Plugin
The Scala plugin extends the Java plugin to add support for Scala projects. The plugin also supports joint compilation, which allows you to freely mix and match Scala and Java code with dependencies in both directions. For example, a Scala class can extend a Java class that in turn extends a Scala class. This makes it possible to use the best language for the job, and to rewrite any class in the other language if needed.
Note that if you want to benefit from the API / implementation separation, you can also apply the java-library plugin to your Scala project.
Usage
To use the Scala plugin, include the following in your build script:
plugins {
id("scala")
}plugins {
id("scala")
}Tasks
The Scala plugin adds the following tasks to the project. Information about altering the dependencies to Java compile tasks are found here.
compileScala— ScalaCompile-
Depends on:
compileJavaCompiles production Scala source files.
compileTestScala— ScalaCompile-
Depends on:
compileTestJavaCompiles test Scala source files.
compileSourceSetScala— ScalaCompile-
Depends on:
compileSourceSetJavaCompiles the given source set’s Scala source files.
scaladoc— ScalaDoc-
Generates API documentation for the production Scala source files.
The ScalaCompile and ScalaDoc tasks support Java toolchains out of the box.
The Scala plugin adds the following dependencies to tasks added by the Java plugin.
| Task name | Depends on |
|---|---|
|
|
|
|
|
|
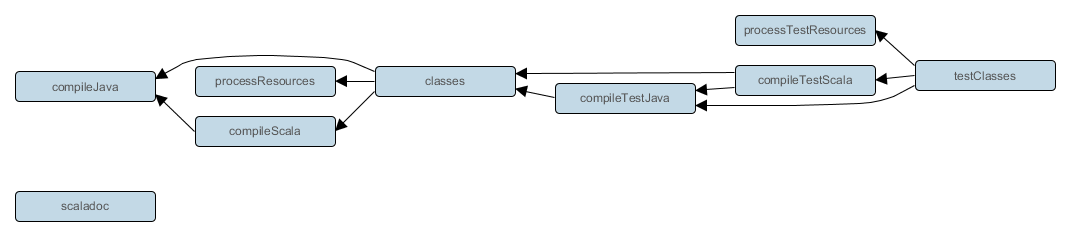
Project layout
The Scala plugin assumes the project layout shown below. All the Scala source directories can contain Scala and Java code. The Java source directories may only contain Java source code. None of these directories need to exist or have anything in them; the Scala plugin will simply compile whatever it finds.
src/main/java-
Production Java source.
src/main/resources-
Production resources, such as XML and properties files.
src/main/scala-
Production Scala source. May also contain Java source files for joint compilation.
src/test/java-
Test Java source.
src/test/resources-
Test resources.
src/test/scala-
Test Scala source. May also contain Java source files for joint compilation.
src/sourceSet/java-
Java source for the source set named sourceSet.
src/sourceSet/resources-
Resources for the source set named sourceSet.
src/sourceSet/scala-
Scala source files for the given source set. May also contain Java source files for joint compilation.
Changing the project layout
Just like the Java plugin, the Scala plugin allows you to configure custom locations for Scala production and test source files.
sourceSets {
main {
scala {
setSrcDirs(listOf("src/scala"))
}
}
test {
scala {
setSrcDirs(listOf("test/scala"))
}
}
}sourceSets {
main {
scala {
srcDirs = ['src/scala']
}
}
test {
scala {
srcDirs = ['test/scala']
}
}
}Scala version
The Scala version can be declared directly on the scala extension.
Dependencies are automatically added to the scalaToolchain configuration based on the declared Scala version.
The scalaToolchainRuntimeClasspath configuration resolves the dependencies declared on the scalaToolchain configuration and contains files required to run the Scala compiler.
|
Note
|
Direct dependencies on the Scala SDK do not need to be declared when the scalaVersion property is set.
|
repositories {
mavenCentral()
}
scala {
scalaVersion = "2.13.12"
}repositories {
mavenCentral()
}
scala {
scalaVersion = "2.13.12"
}Configuring Gradle to use Scala 3 is no different from Scala 2.
repositories {
mavenCentral()
}
scala {
scalaVersion = "3.6.3"
}repositories {
mavenCentral()
}
scala {
scalaVersion = "3.6.3"
}|
Note
|
The scalaVersion property is incubating.
|
Declaring Scala dependencies
When not using the scalaVersion property, the Scala SDK dependency must be declared manually on the implementation configuration.
This pattern is not preferred, as it relies on inferring the Scala classpath from the production runtime classpath.
Omitting the Scala version from the scala extension will be deprecated in a future Gradle version.
Scala 2 projects need to declare a scala-library dependency.
repositories {
mavenCentral()
}
dependencies {
implementation("org.scala-lang:scala-library:2.13.12")
}repositories {
mavenCentral()
}
dependencies {
implementation("org.scala-lang:scala-library:2.13.12")
}Scala 3 projects need to declare a scala3-library_3 dependency instead:
repositories {
mavenCentral()
}
dependencies {
implementation("org.scala-lang:scala3-library_3:3.6.3")
}repositories {
mavenCentral()
}
dependencies {
implementation("org.scala-lang:scala3-library_3:3.6.3")
}If Scala is only used for test code, the scala-library dependency should be added to the testImplementation configuration:
dependencies {
testImplementation("org.scala-lang:scala-library:2.13.12")
}dependencies {
testImplementation("org.scala-lang:scala-library:2.13.12")
}Automatic configuration of scalaClasspath
The ScalaCompile and ScalaDoc tasks consume Scala code in two ways: on their classpath, and on their scalaClasspath.
The former is used to locate classes referenced by the source code, and will typically contain scala-library along with other libraries.
The latter is used to load and execute the Scala compiler and Scaladoc tool, respectively, and should only contain the scala-compiler library and its dependencies.
If the scala extension’s scalaVersion property is not set and the task’s scalaClasspath is not configured explicitly, the Scala (base) plugin will try to infer the classpath from the task’s classpath. This is done as follows:
-
If a
scala-libraryjar is found onclasspath, and the project has at least one repository declared, a correspondingscala-compilerrepository dependency will be added toscalaClasspath. -
Otherwise, execution of the task will fail with a message saying that
scalaClasspathcould not be inferred.
Configuring the Zinc compiler
The Scala plugin uses a configuration named zinc to resolve the Zinc compiler and its dependencies.
Gradle will provide a default version of Zinc, but if you need to use a particular Zinc version, you can change it.
Gradle supports version 1.6.0 of Zinc and above.
scala {
scalaVersion = "2.13.12"
zincVersion = "1.12.0"
}scala {
scalaVersion = "2.13.12"
zincVersion = "1.12.0"
}The Zinc compiler itself needs a compatible version of scala-library that may be different from the version required by your application.
Gradle takes care of specifying a compatible version of scala-library for you.
You can diagnose problems with the version of the Zinc compiler selected by running dependencyInsight for the zinc configuration.
| Gradle version | Supported Zinc versions | Zinc coordinates | Required Scala version | Supported Scala compilation version |
|---|---|---|---|---|
7.5 and newer |
SBT Zinc. Versions 1.6.0 and above. |
|
Scala |
Scala |
6.0 to 7.5 |
SBT Zinc. Versions 1.2.0 and above. |
|
Scala |
Scala |
1.x through 5.x |
Deprecated Typesafe Zinc compiler. Versions 0.3.0 and above, except for 0.3.2 through 0.3.5.2. |
|
Scala |
Scala |
Adding plugins to the Scala compiler
The Scala plugin adds a configuration named scalaCompilerPlugins which is used to declare and resolve optional compiler plugins.
dependencies {
scalaCompilerPlugins("org.typelevel:kind-projector_2.13.12:0.13.2")
}dependencies {
scalaCompilerPlugins("org.typelevel:kind-projector_2.13.12:0.13.2")
}Convention properties
The Scala plugin does not add any convention properties to the project.
Source set properties
The Scala plugin adds the following extensions to each source set in the project. You can use these in your build script as though they were properties of the source set object.
scala— SourceDirectorySet (read-only)-
The Scala source files of this source set. Contains all
.scalaand.javafiles found in the Scala source directories, and excludes all other types of files. Default value: non-null. scala.srcDirs—Set<File>-
The source directories containing the Scala source files of this source set. May also contain Java source files for joint compilation. Can set using anything described in Understanding implicit conversion to file collections. Default value:
[projectDir/src/name/scala].
The Scala plugin also modifies some source set properties:
| Property name | Change |
|---|---|
|
Adds all |
|
Adds all source files found in the Scala source directories. |
Target bytecode level and Java APIs version
When running the Scala compile task, Gradle will always add a parameter to configure the Java target for the Scala compiler that is derived from the Gradle configuration:
-
When using toolchains, the
-releaseoption, ortargetfor older Scala versions, is selected, with a version matching the Java language level of the toolchain configured. -
When not using toolchains, Gradle will always pass a
targetflag — with exact value dependent on the Scala version — to compile to Java 8 bytecode.
|
Note
|
This means that using toolchains with a recent Java version and an old Scala version can result in failures because Scala only supported Java 8 bytecode for some time. The solution is then to either use the right Java version in the toolchain or explicitly downgrade the target when needed. |
The following table explains the values computed by Gradle:
| Scala version | Toolchain in use | Parameter value |
|---|---|---|
version < |
yes |
|
no |
|
|
|
yes |
|
no |
|
|
|
yes |
|
no |
|
|
|
yes |
|
no |
|
Setting any of these flags explicitly, or using flags containing java-output-version, on ScalaCompile.scalaCompileOptions.additionalParameters disables that logic in favor of the explicit flag.
Compiling in external process
Scala compilation takes place in an external process.
Memory settings for the external process default to the defaults of the JVM. To adjust memory settings, configure the scalaCompileOptions.forkOptions property as needed:
tasks.withType<ScalaCompile>().configureEach {
scalaCompileOptions.forkOptions.apply {
memoryMaximumSize = "1g"
jvmArgs = listOf("-XX:MaxMetaspaceSize=512m")
}
}tasks.withType(ScalaCompile) {
scalaCompileOptions.forkOptions.with {
memoryMaximumSize = '1g'
jvmArgs = ['-XX:MaxMetaspaceSize=512m']
}
}Incremental compilation
By compiling only classes whose source code has changed since the previous compilation, and classes affected by these changes, incremental compilation can significantly reduce Scala compilation time. It is particularly effective when frequently compiling small code increments, as is often done at development time.
The Scala plugin defaults to incremental compilation by integrating with Zinc, a standalone version of sbt's incremental Scala compiler. If you want to disable the incremental compilation, set force = true in your build file:
tasks.withType<ScalaCompile>().configureEach {
scalaCompileOptions.apply {
isForce = true
}
}tasks.withType(ScalaCompile) {
scalaCompileOptions.with {
force = true
}
}Note: This will only cause all classes to be recompiled if at least one input source file has changed. If there are no changes to the source files, the compileScala task will still be considered UP-TO-DATE as usual.
The Zinc-based Scala Compiler supports joint compilation of Java and Scala code. By default, all Java and Scala code under src/main/scala will participate in joint compilation. Even Java code will be compiled incrementally.
Incremental compilation requires dependency analysis of the source code. The results of this analysis are stored in the file designated by scalaCompileOptions.incrementalOptions.analysisFile (which has a sensible default). In a multi-project build, analysis files are passed on to downstream ScalaCompile tasks to enable incremental compilation across project boundaries. For ScalaCompile tasks added by the Scala plugin, no configuration is necessary to make this work. For other ScalaCompile tasks that you might add, the property scalaCompileOptions.incrementalOptions.publishedCode needs to be configured to point to the classes folder or Jar archive by which the code is passed on to compile class paths of downstream ScalaCompile tasks. Note that if publishedCode is not set correctly, downstream tasks may not recompile code affected by upstream changes, leading to incorrect compilation results.
Note that Zinc’s Nailgun based daemon mode is not supported. Instead, we plan to enhance Gradle’s own compiler daemon to stay alive across Gradle invocations, reusing the same Scala compiler. This is expected to yield another significant speedup for Scala compilation.
Eclipse Integration
When the Eclipse plugin encounters a Scala project, it adds additional configuration to make the project work with Scala IDE out of the box. Specifically, the plugin adds a Scala nature and dependency container.
IntelliJ IDEA Integration
When the IDEA plugin encounters a Scala project, it adds additional configuration to make the project work with IDEA out of the box. Specifically, the plugin adds a Scala SDK (IntelliJ IDEA 14+) and a Scala compiler library that matches the Scala version on the project’s class path. The Scala plugin is backwards compatible with earlier versions of IntelliJ IDEA and it is possible to add a Scala facet instead of the default Scala SDK by configuring targetVersion on IdeaModel.
idea {
targetVersion = "13"
}idea {
targetVersion = '13'
}The ANTLR Plugin
The ANTLR plugin extends the Java plugin to add support for generating parsers using ANTLR.
|
Note
|
The ANTLR plugin supports ANTLR version 2, 3 and 4. |
Usage
To use the ANTLR plugin, include the following in your build script:
plugins {
antlr
}plugins {
id 'antlr'
}Tasks
The ANTLR plugin adds a number of tasks to your project, as shown below.
generateGrammarSource— AntlrTask-
Generates the source files for all production ANTLR grammars.
generateTestGrammarSource— AntlrTask-
Generates the source files for all test ANTLR grammars.
generateSourceSetGrammarSource— AntlrTask-
Generates the source files for all ANTLR grammars for the given source set.
The ANTLR plugin adds the following dependencies to tasks added by the Java plugin.
| Task name | Depends on |
|---|---|
|
|
|
|
|
|
Project layout
src/main/antlr-
Production ANTLR grammar files. If the ANTLR grammar is organized in packages, the structure in the antlr folder should reflect the package structure. This ensures that the generated sources end up in the correct target subfolder.
src/test/antlr-
Test ANTLR grammar files.
src/sourceSet/antlr-
ANTLR grammar files for the given source set.
Dependency management
The ANTLR plugin adds an antlr dependency configuration which provides the ANTLR implementation to use. The following example shows how to use ANTLR version 3.
repositories {
mavenCentral()
}
dependencies {
antlr("org.antlr:antlr:3.5.2") // use ANTLR version 3
// antlr("org.antlr:antlr4:4.5") // use ANTLR version 4
}repositories {
mavenCentral()
}
dependencies {
antlr "org.antlr:antlr:3.5.2" // use ANTLR version 3
// antlr "org.antlr:antlr4:4.5" // use ANTLR version 4
}If no dependency is declared, antlr:antlr:2.7.7 will be used as the default. To use a different ANTLR version add the appropriate dependency to the antlr dependency configuration as above.
Contributed extension
antlr— AntlrSourceDirectorySet-
The ANTLR grammar files of this source set. Contains all
.gor.g4files found in the ANTLR source directories, and excludes all other types of files. Default value is non-null.
Convention properties (deprecated)
The ANTLR plugin adds one convention property.
antlr— SourceDirectorySet-
The ANTLR grammar files of this source set. Contains all
.gor.g4files found in the ANTLR source directories, and excludes all other types of files. Default value is non-null.
This convention property is deprecated and superseded by the extension described above.
Source set properties
The ANTLR plugin adds the following properties to each source set in the project.
antlr.srcDirs—Set<File>-
The source directories containing the ANTLR grammar files of this source set. Can set using anything that implicitly converts to a file collection. Default value is
[projectDir/src/name/antlr].
Controlling the ANTLR generator process
The ANTLR tool is executed in a forked process. This allows fine grained control over memory settings for the ANTLR process. To set the heap size of an ANTLR process, the maxHeapSize property of AntlrTask can be used. To pass additional command-line arguments, append to the arguments property of AntlrTask.
Setting the custom max heap size and extra arguments for ANTLR:
tasks.generateGrammarSource {
maxHeapSize = "64m"
arguments = arguments + listOf("-visitor", "-long-messages")
}generateGrammarSource {
maxHeapSize = "64m"
arguments += ["-visitor", "-long-messages"]
}The JVM Test Suite Plugin
The JVM Test Suite plugin (plugin id: jvm-test-suite) provides a DSL and API to model multiple groups of automated tests into test suites in JVM-based projects. Tests suites are intended to grouped by their purpose and can have separate dependencies and use different testing frameworks.
For instance, this plugin can be used to define a group of Integration Tests, which might run much longer than unit tests and have different environmental requirements.
|
Note
|
The JVM Test Suite plugin is an incubating API and is subject to change in a future release. |
Usage
This plugin is applied automatically by the java plugin but can be additionally applied explicitly if desired. The plugin cannot be used without a JVM language plugin applied as it relies on several conventions of the java plugin.
plugins {
java
`jvm-test-suite`
}plugins {
id 'java'
id 'jvm-test-suite'
}The plugins adds the following objects to the project:
-
A
testingextension (type: TestingExtension) to the project used to configure test suites.
When used with the Java Plugin:
-
A test suite named
test(type: JvmTestSuite). -
A
testSourceSet. -
Several configurations derived from the
testSourceSet name:testImplementation,testCompileOnly,testRuntimeOnly -
A single test suite target backed by a task named
test.
The test task, SourceSet and derived configurations are identical in name and function to those used in prior Gradle releases.
Tasks
The JVM Test Suite plugin adds the following task to the project:
test— Test-
Depends on:
testClassesfrom thejavaplugin, and all tasks which produce the test runtime classpathRuns the tests using the framework configured for the default test suite.
Additional instances of Test tasks will be automatically created for each test suite added via the testing extension.
Configuration
See the TestingExtension class in the API documentation.
Terminology and Modeling
The JVM Test Suite Plugin introduces some modeling concepts backed by new APIs. Here are their definitions.
Test Suite
A test suite is a collection of JVM-based tests.
Test Suite Target
For the initial release of this plugin, each test suite has a single target. This results in a 1:1:1 relationship between test suite, test suite target and a matching Test task. The name of the Test task is derived from the suite name. Future iterations of the plugin will allow defining multiple targets based other attributes, such as a particular JDK/JRE runtime.
Each test suite has some configuration that is common across for all tests contained in the suite:
-
Testing framework
-
Sources
-
Dependencies
In the future, other properties may be specified in the test suite which may influence the toolchains selected to compile and run tests.
The Test task associated with the target inherits its name from the suite. Other properties of the Test task are configurable.
Configuration Examples
Here are several examples to illustrate the configurability of test suites.
Declare an additional test suite
testing {
suites { // (1)
val test = named<JvmTestSuite>("test") { // (2)
useJUnitJupiter() // (3)
}
register<JvmTestSuite>("integrationTest") { // (4)
dependencies {
implementation(project()) // (5)
}
targets { // (6)
all {
testTask.configure {
shouldRunAfter(test)
}
}
}
}
}
}
tasks.named("check") { // (7)
dependsOn(testing.suites.named("integrationTest"))
}testing {
suites { // (1)
test { // (2)
useJUnitJupiter() // (3)
}
integrationTest(JvmTestSuite) { // (4)
dependencies {
implementation project() // (5)
}
targets { // (6)
all {
testTask.configure {
shouldRunAfter(test)
}
}
}
}
}
}
tasks.named('check') { // (7)
dependsOn(testing.suites.integrationTest)
}-
Configure all test suites for this project.
-
Configure the built-in
testsuite. This suite is automatically created for backwards compatibility. You must specify a testing framework to use in order to run these tests (e.g. JUnit 4, JUnit Jupiter). This suite is the only suite that will automatically have access to the production source’simplementationdependencies, all other suites must explicitly declare these. -
Declare this test suite uses JUnit Jupiter. The framework’s dependencies are automatically included. It is always necessary to explicitly configure the built-in
testsuite even if JUnit 4 is desired. -
Define a new suite called
integrationTest. Note that all suites other than the built-intestsuite will by convention work as ifuseJUnitJupiter()was called. You do not have to explicitly configure the testing framework on these additional suites, unless you wish to change to another framework. -
Add a dependency on the production code of the project to the
integrationTestsuite targets. By convention, only the built-intestsuite will automatically have a dependency on the production code of the project. -
Configure all targets of this suite. By convention, test suite targets have no relationship to other
Testtasks. This example shows that the slower integration test suite targets should run after all targets of thetestsuite are complete. -
Configure the
checktask to depend on allintegrationTesttargets. By convention, test suite targets are not associated with thechecktask.
Invoking the check task on the above configured build should show output similar to:
> Task :compileJava
> Task :processResources NO-SOURCE
> Task :classes
> Task :jar
> Task :compileTestJava
> Task :processTestResources NO-SOURCE
> Task :testClasses
> Task :test
> Task :compileIntegrationTestJava
> Task :processIntegrationTestResources NO-SOURCE
> Task :integrationTestClasses
> Task :integrationTest
> Task :check
BUILD SUCCESSFUL in 0s
6 actionable tasks: 6 executedNote that the integrationTest test suite does not run until after the test test suite completes.
Configure the built-in test suite
testing {
suites {
named<JvmTestSuite>("test") {
useTestNG() // (1)
targets {
all {
testTask.configure { // (2)
// set a system property for the test JVM(s)
systemProperty("some.prop", "value")
options { // (3)
val options = this as TestNGOptions
options.preserveOrder = true
}
}
}
}
}
}
}testing { // (1)
suites {
test {
useTestNG() // (1)
targets {
all {
testTask.configure { // (2)
// set a system property for the test JVM(s)
systemProperty 'some.prop', 'value'
options { // (3)
preserveOrder = true
}
}
}
}
}
}
}-
Declare the
testtest suite uses the TestNG test framework. -
Lazily configure the test task of all targets of the suite; note the return type of
testTaskisTaskProvider<Test>. -
Configure more detailed test framework options. The
optionswill be a subclass oforg.gradle.api.tasks.testing.TestFrameworkOptions, in this case it isorg.gradle.api.tasks.testing.testng.TestNGOptions.
Configure dependencies of a test suite
testing {
suites {
named<JvmTestSuite>("test") { // (1)
dependencies {
// Note that this is equivalent to adding dependencies to testImplementation in the top-level dependencies block
implementation("org.assertj:assertj-core:3.21.0") // (2)
annotationProcessor("com.google.auto.value:auto-value:1.9") // (3)
}
}
}
}testing {
suites {
test { // (1)
dependencies {
// Note that this is equivalent to adding dependencies to testImplementation in the top-level dependencies block
implementation 'org.assertj:assertj-core:3.21.0' // (2)
annotationProcessor 'com.google.auto.value:auto-value:1.9' // (3)
}
}
}
}-
Configure the built-in
testtest suite. -
Add the assertj library to the test’s compile and runtime classpaths. The
dependenciesblock within a test suite is already scoped for that test suite. Instead of having to know the global name of the configuration, test suites have a consistent name that you use in this block for declaringimplementation,compileOnly,runtimeOnlyandannotationProcessordependencies. -
Add the Auto Value annotation processor to the suite’s annotation processor classpath so that it will be run when compiling the tests.
Configure dependencies of a test suite to reference project outputs
dependencies {
api("com.google.guava:guava:30.1.1-jre") // (1)
implementation("com.fasterxml.jackson.core:jackson-databind:2.13.3") // (2)
}
testing {
suites {
register<JvmTestSuite>("integrationTest") {
dependencies {
implementation(project()) // (3)
}
}
}
}dependencies {
api 'com.google.guava:guava:30.1.1-jre' // (1)
implementation 'com.fasterxml.jackson.core:jackson-databind:2.13.3' // (2)
}
testing {
suites {
integrationTest(JvmTestSuite) {
dependencies {
implementation project() // (3)
}
}
}
}-
Add a production dependency which is used as part of the library’s public API.
-
Add a production dependency which is only used internally and is not exposed as part of this project’s public classes.
-
Configure a new test suite which adds a
project()dependency to the suite’s compile and runtime classpaths. This dependency provides access to the project’s outputs as well as any dependencies declared on itsapiandcompileOnlyApiconfigurations.
Configure source directories of a test suite
testing {
suites {
register<JvmTestSuite>("integrationTest") { // (1)
sources { // (2)
java { // (3)
setSrcDirs(listOf("src/it/java")) // (4)
}
}
}
}
}testing {
suites {
integrationTest(JvmTestSuite) { // (1)
sources { // (2)
java { // (3)
srcDirs = ['src/it/java'] // (4)
}
}
}
}
}-
Declare and configure a suite named
integrationTest. TheSourceSetand synthesizedTesttasks will be based on this name. -
Configure the
sourcesof the test suite. -
Configure the
javaSourceDirectorySet of the test suite. -
Overwrite the
srcDirsproperty, replacing the conventionalsrc/integrationTest/javalocation withsrc/it/java.
Configure the Test task for a test suite
testing {
suites {
named<JvmTestSuite>("integrationTest") {
targets {
all { // (1)
testTask.configure {
setMaxHeapSize("512m") // (2)
}
}
}
}
}
}testing {
suites {
integrationTest {
targets {
all { // (1)
testTask.configure {
maxHeapSize = '512m' // (2)
}
}
}
}
}
}-
Configure the
integrationTesttask created by declaring a suite of the same name. -
Configure the
Testtask properties.
Test tasks associated with a test suite target can also be configured directly, by name. It is not necessary to configure via the test suite DSL.
Sharing configuration between multiple test suites
There are several ways to share configuration between multiple test suites to avoid the duplication of dependencies or other configuration. Each method is a tradeoff between flexibility and the use of a declarative vs. imperative configuration style.
-
Use the
configureEachmethod on thesuitescontainer to configure every test suite the same way. -
Use
withTypeandmatchingwithconfigureEachto filter test suites and configure a subset of them. -
Extract the configuration block to a local variable and apply it only to the desired test suites.
Method 1: Use configureEach
This is the most straightforward way to share configuration across every test suite. The configuration is applied to each test suite.
testing {
suites {
withType<JvmTestSuite> { // (1)
useJUnitJupiter()
dependencies { // (2)
implementation("org.mockito:mockito-junit-jupiter:4.6.1")
}
}
// (3)
register<JvmTestSuite>("integrationTest")
register<JvmTestSuite>("functionalTest") {
dependencies { // (4)
implementation("org.apache.commons:commons-lang3:3.11")
}
}
}
}testing {
suites {
configureEach { // (1)
useJUnitJupiter()
dependencies { // (2)
implementation('org.mockito:mockito-junit-jupiter:4.6.1')
}
}
// (3)
integrationTest(JvmTestSuite)
functionalTest(JvmTestSuite) {
dependencies { // (4)
implementation('org.apache.commons:commons-lang3:3.11')
}
}
}
}-
Configure every JVM test suite
-
Provide the dependencies to be shared by all test suites
-
Define the additional test suites which will be configured upon creation
-
Add dependencies specific to the
functionalTesttest suite
Method 2: Use withType, matching and configureEach
This method adds filtering commands to only apply the configuration to a subset of the test suites, as identified by name.
testing {
suites {
withType(JvmTestSuite::class).matching { it.name in listOf("test", "integrationTest") }.configureEach { // (1)
useJUnitJupiter()
dependencies {
implementation("org.mockito:mockito-junit-jupiter:4.6.1")
}
}
register<JvmTestSuite>("integrationTest")
register<JvmTestSuite>("functionalTest") {
useJUnit() // (2)
dependencies { // (3)
implementation("org.apache.commons:commons-lang3:3.11")
}
}
}
}testing {
suites {
withType(JvmTestSuite).matching { it.name in ['test', 'integrationTest'] }.configureEach { // (1)
useJUnitJupiter()
dependencies {
implementation('org.mockito:mockito-junit-jupiter:4.6.1')
}
}
integrationTest(JvmTestSuite)
functionalTest(JvmTestSuite) {
useJUnit() // (2)
dependencies { // (3)
implementation('org.apache.commons:commons-lang3:3.11')
}
}
}
}-
Configure every JVM test suite matching the given criteria
-
Use a different testing framework for the
functionalTesttest suite -
Add dependencies specific to the
functionalTesttest suite
Method 3: Extract a custom configuration block
This method is the most flexible, but also the most imperative.
testing {
suites {
val applyMockito = { suite: JvmTestSuite -> // (1)
suite.useJUnitJupiter()
suite.dependencies {
implementation("org.mockito:mockito-junit-jupiter:4.6.1")
}
}
/* This is the equivalent of:
named<JvmTestSuite>("test") {
applyMockito(this)
}
*/
named<JvmTestSuite>("test", applyMockito) // (2)
/* This is the equivalent of:
register<JvmTestSuite>("integrationTest")
applyMockito(integrationTest.get())
*/
register<JvmTestSuite>("integrationTest", applyMockito) // (3)
register<JvmTestSuite>("functionalTest") {
useJUnit()
dependencies {
implementation("org.apache.commons:commons-lang3:3.11")
}
}
}
}testing {
suites {
def applyMockito = { suite -> // (1)
suite.useJUnitJupiter()
suite.dependencies {
implementation('org.mockito:mockito-junit-jupiter:4.6.1')
}
}
/* This is the equivalent of:
test {
applyMockito(this)
}
*/
test(applyMockito) // (2)
/* This is the equivalent of:
integrationTest(JvmTestSuite)
applyMockito(integrationTest)
*/
integrationTest(JvmTestSuite, applyMockito) // (3)
functionalTest(JvmTestSuite) {
useJUnit()
dependencies {
implementation('org.apache.commons:commons-lang3:3.11')
}
}
}
}-
Define a closure which takes a single
JvmTestSuiteparameter and configures it -
Apply the closure to a test suite, using the default (
test) test suite -
Alternate means of applying a configuration closure to a test suite outside of its declaration, using the
integrationTesttest suite
Differences between similar methods on JvmTestSuite and Test task types
Instances of JvmTestSuite have methods useJUnit() and useJUnitJupiter(), which are similar in name to methods on the Test task type: useJUnit() and useJUnitPlatform(). However, there are important differences.
Unlike the methods on the Test task, JvmTestSuite methods perform two additional pieces of configuration:
-
JvmTestSuite#useJUnit(), #useJUnitJupiter() and other framework-specific methods automatically apply the relevant testing framework libraries to the compile and runtime classpaths of the suite targets. Note the overloaded methods like JvmTestSuite#useJUnit(String) and #useJUnitJupiter(String) allow you to provide specific versions of the framework dependencies.
-
JvmTestSuite#useJUnit() and #useJUnitJupiter() automatically configure the suite targets' Test tasks to execute using the specified framework.
An example of this behavior is shown in the first configuration example above, Configuring the built-in test suite.
|
Note
|
Unlike the Test task, the aforementioned methods on JvmTestSuite do not accept a closure or action for configuring the framework. These framework configuration options can be set on the individual targets. |
Outgoing Variants
Each test suite creates an outgoing variant containing its test execution results. These variants are designed for consumption by the Test Report Aggregation Plugin.
The attributes will resemble the following. User-configurable attributes are highlighted below the sample.
--------------------------------------------------
Variant testResultsElementsForTest (i)
--------------------------------------------------
Description = Directory containing binary results of running tests for the test Test Suite's test target.
Capabilities
- org.gradle.sample:list:1.0.2 (default capability)
Attributes
- org.gradle.category = verification
- org.gradle.testsuite.name = test // (1)
- org.gradle.verificationtype = test-results
Artifacts
- build/test-results/test/binary (artifactType = directory)-
TestSuiteName attribute; value is derived from TestSuite#getName().
The Test Report Aggregation Plugin
The Test Report Aggregation plugin (plugin id: test-report-aggregation) provides tasks and configurations used to aggregate the results of multiple Test task invocations (potentially spanning multiple Gradle projects) into a single HTML report.
Usage
To use the Test Report Aggregation plugin, include the following in your build script:
plugins {
id 'test-report-aggregation'
}plugins {
id("test-report-aggregation")
}Note that this plugin takes no action unless applied in concert with the JVM Test Suite Plugin. The Java Plugin automatically applies the JVM Test Suite Plugin.
There are now two ways to collect test results across multiple subprojects:
-
From the distribution’s project, such as an application or WAR subproject
-
Using a standalone project to specify subprojects
Example 2 could also be used to aggregate results via the root project.
|
Warning
|
The Test Report Aggregation plugin does not currently work with the com.android.application plugin.
|
Tasks
When the project also applies the jvm-test-suite plugin, the following tasks are added for each test suite:
testSuiteAggregateTestReport— TestReport-
Depends on: Artifacts of variants matching the below attributes
Collects variants of direct and transitive project dependencies via the
testReportAggregationconfiguration. The following Attributes will be matched:
- org.gradle.category = verification // (1)
- org.gradle.testsuite.name = test // (2)
- org.gradle.verificationtype = test-results // (3)-
Category attribute; value is fixed.
-
TestSuiteName attribute; value is derived from TestSuite#getName().
-
VerificationType attribute; value is fixed.
More information about the variants produced by test execution are available in the Outgoing Variants section of the JVM Test Suite Plugin documentation.
Reports
|
Important
|
By default, Gradle stops executing tasks when any task fails — including test failures.
To ensure that your builds always generate aggregation reports, specify the |
Automatic report creation
When the project also applies the jvm-test-suite plugin, the following reporting objects are added for each test suite:
testSuiteAggregateTestReport— AggregateTestReport-
Creates an aggregate Jacoco report aggregating all test suites with a given name across all project dependencies.
Manual report creation
When the project does not apply the jvm-test-suite plugin, you must manually register one or more reports:
reporting {
reports {
create<AggregateTestReport>("testAggregateTestReport") { // (1)
testSuiteName = "test"
}
}
}reporting {
reports {
testAggregateTestReport(AggregateTestReport) { // (1)
testSuiteName = "test"
}
}
}-
Creates a report named
testAggregateTestReportof typeAggregateTestReport, aggregating all test suites from all project dependencies with a given TestSuite#getName().
Report creation automatically creates backing tasks to aggregate by the given test suite type value.
Dependency management
The Test Report Aggregation plugin adds the following dependency configurations:
| Name | Meaning |
|---|---|
|
The configuration used to declare all project dependencies having test result data to be aggregated. |
|
Consumes the project dependencies from the |
It is not necessary to explicitly add dependencies to the testReportAggregation configuration if the project also applies the jvm-test-suite plugin.
C++ Application
The C++ Application Plugin provides the tasks, configurations and conventions for a building C++ application.
Usage
plugins {
`cpp-application`
}plugins {
id 'cpp-application'
}Build variants
The C++ Application Plugin understands the following dimensions. Read the introduction to build variants for more information.
- Build types - always either debug or release
-
The build type controls the debuggability as well as the optimization of the generated binaries.
-
debug- Generate debug symbols and don’t optimized the binary -
release- Generate debug symbols and optimize, but extract the debug symbols from the binary
-
- Target machines - defaults to the build host
-
The target machine expresses which machines the application expects to run. A target machine is identified by its operating system and architecture. Gradle uses the target machine to decide which tool chain to choose based on availability on the host machine.
The target machine can be configured as follows:
application {
targetMachines = listOf(machines.linux.x86_64,
machines.windows.x86, machines.windows.x86_64,
machines.macOS.x86_64)
}application {
targetMachines = [
machines.linux.x86_64,
machines.windows.x86, machines.windows.x86_64,
machines.macOS.x86_64
]
}Tasks
The following diagram shows the relationships between tasks added by this plugin.
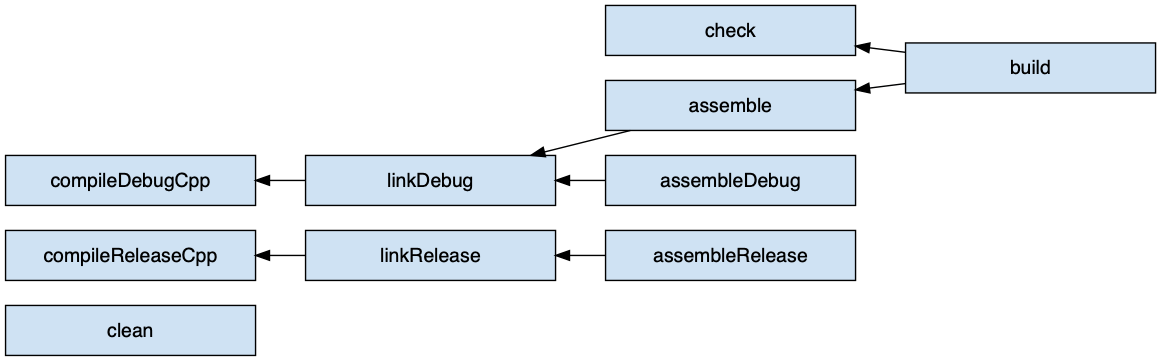
Variant-dependent Tasks
The C++ Application Plugin creates tasks based on the variants of the application component. Read the introduction to build variants for more information. The following diagram shows the relationship between variant-dependent tasks.
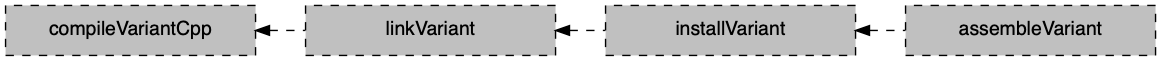
compileVariantCpp(e.g.compileDebugCppandcompileReleaseCpp) - CppCompile-
Depends on: All tasks that contribute source files to the compilation :: Compiles C++ source files using the selected compiler.
linkVariant(e.g.linkDebugandlinkRelease) - LinkExecutable-
Depends on: All tasks which contribute to the link executable, including
linkVariantandcreateVarianttasks from projects that are resolved via project dependencies :: Links executable from compiled object files using the selected linker. installVariant(e.g.installDebugandinstallRelease) - InstallExecutable-
Depends on:
linkVariantand all tasks which contribute to the runtime of the executable, includinglinkVarianttasks from projects that are resolved via project dependencies :: Installs the executable and all of it’s runtime dependencies for easy execution. assembleVariant(e.g.assembleDebugandassembleRelease) - Task (lifecycle)-
Depends on:
linkVariant:: Aggregates tasks that assemble the specific variant of this application.
Lifecycle Tasks
The C++ Application Plugin attaches some of its tasks to the standard lifecycle tasks documented in the Base Plugin chapter - which the C++ Application Plugin applies automatically:
assemble- Task (lifecycle)-
Depends on:
linkDebug:: Aggregate task that assembles the debug variant of the application for the current host (if present) in the project. This task is added by the Base Plugin. check- Task (lifecycle)-
Aggregate task that performs verification tasks, such as running the tests. Some plugins add their own verification task to
check. For example, the C++ Unit Test Plugin attaches a task to this lifecycle task to run tests. This task is added by the Base Plugin. build- Task (lifecycle)-
Depends on:
check,assemble:: Aggregate tasks that perform a full build of the project. This task is added by the Base Plugin. clean- Delete-
Deletes the build directory and everything in it, i.e. the path specified by the
layout.buildDirectoryproject property. This task is added by the Base Plugin.
Dependency management
Just like the tasks created by the C++ Application Plugin, multiple configurations are created based on the variants of the application component. Read the introduction to build variants for more information. The following graph describes the configurations added by the C++ Application Plugin:
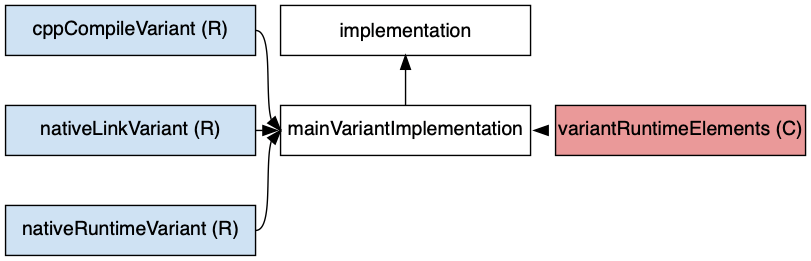
-
The configurations in white are the ones a user should use to declare dependencies
-
The configurations in pink, also known as consumable denoted by (C), are the ones used when a component runs against the library
-
The configurations in blue, also known as resolvable denoted by (R), are internal to the component, for its own use
The following configurations are used to declare dependencies:
implementation-
Used for declaring implementation dependencies for all variants of the main component. This is where you should declare dependencies of any variants.
mainVariantImplementation(e.g.mainDebugImplementationandmainReleaseImplementation) extendsimplementation-
Used for declaring implementation dependencies for a specific variant of the main component. This is where you should declare dependencies of the specific variant.
The following configurations are used by downstream consumers that depend on the application component:
variantRuntimeElements(e.g.debugRuntimeElementsandreleaseRuntimeElements) extends `mainVariantImplementation-
Used for executing the application. This configuration is meant to be used by consumers, to retrieve all the elements necessary to run the application.
The following configurations are used by the application itself:
cppCompileVariant(e.g.cppCompileDebugandcppCompileRelease) extendsmainVariantImplementation-
Used for compiling the application. This configuration contains the compile include roots of the application and is therefore used when invoking the C++ compiler to compile it.
nativeLinkVariant(e.g.nativeLinkDebugandnativeLinkRelease) extendsmainVariantImplementation-
Used for linking the application. This configuration contains the libraries of the application and is therefore used when invoking the C++ linker to link it.
nativeRuntimeVariant(e.g.nativeRuntimeDebugandnativeRuntimeRelease) extendsmainVariantImplementation-
Used for executing the application. This configuration contains the runtime libraries of the application.
Conventions
The C++ Application Plugin adds conventions for sources and tasks, shown below.
Project layout
The C++ Application Plugin assumes the project layout shown below. None of these directories need to exist or have anything in them. The C++ Application Plugin will compile whatever it finds and ignore anything missing.
src/main/cpp-
C++ source with extension of
.cpp,.c++or.cc src/main/headers-
Headers - headers needed to compile the application
You configure the project layout by configuring the source and privateHeaders respectively on the application script block.
compileVariantCpp Task
The C++ Application Plugin adds a CppCompile instance for each variant of the application component to build (e.g. compileDebugCpp and compileReleaseCpp).
Read the introduction to build variants for more information.
Some of the most common configuration options are shown below.
| compilerArgs |
[] |
| debuggable |
|
| includes |
|
| macros |
[:] |
| objectFileDir |
|
| optimized |
|
| positionIndependentCode |
|
| source |
|
| systemIncludes |
derived from the tool chain |
| targetPlatform |
derived from the |
| toolChain |
linkVariant Task
The C++ Application Plugin adds a LinkExecutable instance for each variant of the application — e.g. linkDebug and linkRelease.
Read the introduction to build variants for more information.
Some of the most common configuration options are shown below.
| debuggable |
|
| libs |
|
| linkedFile |
|
| linkerArgs |
[] |
| source |
|
| targetPlatform |
derived from the |
| toolChain |
installVariant Task
The C++ Application Plugin adds a InstallExecutable instance for each variant of the test component — e.g. installDebug and installRelease.
Read the introduction to build variants for more information.
There is no need to configure any properties on the task.
C++ Library
The C++ Library Plugin provides the tasks, conventions and conventions for building a C++ library. In particular, a C++ library provides functionality that can be used by consumers (i.e., other projects using this plugin or the C++ Application Plugin).
Usage
plugins {
`cpp-library`
}plugins {
id 'cpp-library'
}Build variants
The C++ Library Plugin understands the following dimensions. Read the introduction to build variants for more information.
- Build types - always set to debug and release
-
The build type controls the debuggability as well as the optimization of the generated binaries.
-
debug- Generate debug symbols and don’t optimized the binary -
release- Generate debug symbols and optimize, but extract the debug symbols from the binary
-
- Linkages - default to shared
-
The linkage expresses whether a shared library or static library should be created. Libraries can produce a shared library, a static library or both.
The linkage can be configured as follows:
library {
linkage = listOf(Linkage.STATIC, Linkage.SHARED)
}library {
linkage = [Linkage.STATIC, Linkage.SHARED]
}- Target machines - defaults to the build host
-
The target machine expresses which machines the application expects to run. A target machine is identified by its operating system and architecture. Gradle uses the target machine to decide which tool chain to choose based on availability on the host machine.
The target machine can be configured as follows:
library {
targetMachines = listOf(machines.linux.x86_64,
machines.windows.x86, machines.windows.x86_64,
machines.macOS.x86_64)
}library {
targetMachines = [
machines.linux.x86_64,
machines.windows.x86, machines.windows.x86_64,
machines.macOS.x86_64
]
}Tasks
The following diagram shows the relationships between tasks added by this plugin.
Note the default linkage of a C++ library is shared linkage as shown in the diagram.

With static linkage, the diagram changes to the following:

Variant-dependent Tasks
The C++ Library Plugin creates tasks based on variants of the library component. Read the introduction to build variants for more information. The following diagrams show the relationship between variant-dependent tasks.

|
Note
|
Depending on the linkage property |
compileVariantCpp(e.g.compileDebugCppandcompileReleaseCpp) - CppCompile-
Depends on: All tasks that contribute source files to the compilation :: Compiles C++ source files using the selected compiler.
linkVariant(e.g.linkDebugandlinkRelease) - LinkSharedLibrary (shared linkage)-
Depends on: All tasks which contribute to the link libraries, including
linkVariantandcreateVarianttasks from projects that are resolved via project dependencies :: Links shared library from compiled object files using the selected linker. createVariant(e.g.createDebugandcreateRelease) - CreateStaticLibrary (static linkage)-
Creates static library from compiled object files using selected archiver
assembleVariant(e.g.assembleDebugandassembleRelease) - Task (lifecycle)-
Depends on:
linkVariant(shared linkage) orcreateVariant(static linkage) :: Aggregates tasks that assemble the specific variant of this library.
Lifecycle Tasks
The C++ Library Plugin attaches some of its tasks to the standard lifecycle tasks documented in the Base Plugin chapter — which the C++ Library Plugin applies automatically:
assemble- Task (lifecycle)-
Depends on:
linkDebugwhen linkage includessharedorcreateDebugotherwise. :: Aggregate task that assembles the debug variant of the shared library (if available) for the current host (if present) in the project. This task is added by the Base Plugin. check- Task (lifecycle)-
Aggregate task that performs verification tasks, such as running the tests. Some plugins add their own verification task to
check. For example, the C++ Unit Test Plugin attach its test task to this lifecycle task. This task is added by the Base Plugin. build- Task (lifecycle)-
Depends on:
check,assemble:: Aggregate tasks that perform a full build of the project. This task is added by the Base Plugin. clean- Delete-
Deletes the build directory and everything in it, i.e. the path specified by the
layout.buildDirectoryproject property. This task is added by the Base Plugin.
Dependency management
Just like the tasks created by the C++ Library Plugin, multiple configurations are created based on the variants of the library component. Read the introduction to build variants for more information. The following graph describes the configurations added by the C++ Library Plugin:
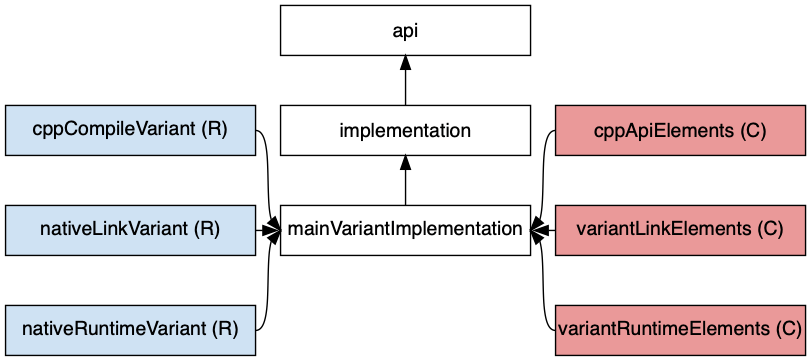
-
The configurations in white are the ones a user should use to declare dependencies
-
The configurations in pink, also known as consumable denoted by (C), are the ones used when a component compiles, links, or runs against the library
-
The configurations in blue, also known as resolvable denoted by (R), are internal to the component, for its own use
The following configurations are used to declare dependencies:
api-
Used for declaring API dependencies (see API vs implementation section). This is where you should declare dependencies which are transitively exported to consumers, for compile and link.
implementationextendsapi-
Used for declaring implementation dependencies for all variants of the main component (see API vs implementation section). This is where you should declare dependencies which are purely internal and not meant to be exposed to consumers of any variants.
mainVariantImplementation(e.g.mainDebugImplementationandmainReleaseImplementation) extendsimplementation-
Used for declaring implementation dependencies for a specific variant of the main component (see API vs implementation section). This is where you should declare dependencies which are purely internal and not meant to be exposed to consumers of this specific variant.
The following configurations are used by consumers:
cppApiElementsextendsmainVariantImplementation-
Used for compiling against the library. This configuration is meant to be used by consumers, to retrieve all the elements necessary to compile against the library.
variantLinkElements(e.g.debugLinkElementsandreleaseLinkElements) extendsmainVariantImplementation-
Used for linking against the library. This configuration is meant to be used by consumers, to retrieve all the elements necessary to link against the library.
variantRuntimeElements(e.g.debugRuntimeElementsandreleaseRuntimeElements) extends `mainVariantImplementation-
Used for executing the library. This configuration is meant to be used by consumers, to retrieve all the elements necessary to run against the library.
The following configurations are used by the library itself:
cppCompileVariant(e.g.cppCompileDebugandcppCompileRelease) extendsmainVariantImplementation-
Used for compiling the library. This configuration contains the compile include roots of the library and is therefore used when invoking the C++ compiler to compile it.
nativeLinkVariant(e.g.nativeLinkDebugandnativeLinkRelease) extendsmainVariantImplementation-
Used for linking the library the shared library only. This configuration contains the libraries of the library and is therefore used when invoking the C++ linker to link it.
nativeRuntimeVariant(e.g.nativeRuntimeDebugandnativeRuntimeRelease) extendsmainVariantImplementation-
Used for executing the library. This configuration contains the runtime libraries of the library.
API vs implementation
The plugin exposes two configurations that can be used to declare dependencies: api and implementation.
The api configuration should be used to declare dependencies which are exported by the library API, whereas the implementation configuration should be used to declare dependencies which are internal to the component.
library {
dependencies {
api("io.qt:core:5.1")
implementation("io.qt:network:5.1")
}
}library {
dependencies {
api "io.qt:core:5.1"
implementation "io.qt:network:5.1"
}
}Dependencies appearing in the api configurations will be transitively exposed to consumers of the library, and as such will appear on the compile include root and link libraries of consumers.
Dependencies found in the implementation configuration will, on the other hand, not be exposed to consumers, and therefore not leak into the consumer’s compile include root and link libraries.
This comes with several benefits:
-
dependencies do not leak into the compile include roots and link libraries of consumers, so they can never accidentally depend on a transitive dependency
-
faster compilation thanks to the reduced include roots and link libraries
-
fewer recompilations when implementation dependencies change since the consumer would not need to be recompiled
Conventions
The C++ Library Plugin adds conventions for sources and tasks, shown below.
Project layout
The C++ Library Plugin assumes the project layout shown below. None of these directories needs to exist or have anything in them. The C++ Library Plugin will compile whatever it finds and ignore anything missing.
src/main/cpp-
C++ source with extension of
.cpp,.C++or.cc src/main/headers-
Private headers - headers needed to compile the library but are not needed by consumers
src/main/public-
Public headers - headers needed to compile the library and required by consumers
You configure the project layout by configuring the source, privateHeaders and publicHeaders respectively on the library script block.
compileVariantCpp Task
The C++ Library Plugin adds a CppCompile instance for each variant of the library component to build (e.g. compileDebugCpp and compileReleaseCpp).
Read the introduction to build variants for more information.
Some of the most common configuration options are shown below.
| compilerArgs |
[] |
| debuggable |
|
| includes |
|
| macros |
[:] |
| objectFileDir |
|
| optimized |
|
| positionIndependentCode |
|
| source |
|
| systemIncludes |
derived from the tool chain |
| targetPlatform |
derived from the |
| toolChain |
linkVariant Task
The C++ Library Plugin adds a LinkSharedLibrary instance for each variant of the library containing shared linkage as a dimension - e.g. linkDebug and linkRelease.
Read the introduction to build variants for more information.
Some of the most common configuration options are shown below.
| debuggable |
|
| libs |
|
| linkedFile |
|
| linkerArgs |
[] |
| source |
|
| targetPlatform |
derived from the |
| toolChain |
createVariant Task
The C++ Library Plugin adds a CreateStaticLibrary instance for each variant of the library containing static linkage as a dimension - e.g. createDebug and createRelease.
Read the introduction to build variants for more information.
Some of the most common configuration options are shown below.
| outputFile |
|
| source |
|
| staticLibArgs |
[] |
| targetPlatform |
derived from the |
| toolChain |
C++ Unit Test
The C++ Unit Test Plugin provides the tasks, configurations and conventions for integrating with a C++ executable-based testing framework, such as Google Test.
Usage
plugins {
`cpp-unit-test`
}plugins {
id 'cpp-unit-test'
}Build variants
The C++ Unit Test Plugin understands the following dimensions. Read the introduction to build variants for more information.
- Target machines - defaults to the tested component (if present) or build host (otherwise)
-
The target machine expresses which machines the application expects to run. A target machine is identified by its operating system and architecture. Gradle uses the target machine to decide which tool chain to choose based on availability on the host machine.
The target machine can be configured as follows:
unitTest {
targetMachines = listOf(machines.linux.x86_64,
machines.windows.x86, machines.windows.x86_64,
machines.macOS.x86_64)
}unitTest {
targetMachines = [
machines.linux.x86_64,
machines.windows.x86, machines.windows.x86_64,
machines.macOS.x86_64
]
}Tasks
The following diagram shows the relationships between tasks added by this plugin.

Variant-dependent Tasks
The C++ Unit Test Plugin creates tasks based on the variants of the unit test component. Read the introduction to build variants for more information. The following diagrams show the relationship between variant-dependent tasks.
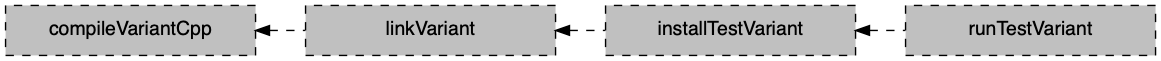
compileTestVariantCpp(e.g.compileTestCpp) - CppCompile-
Depends on: All tasks that contribute source files to the compilation :: Compiles C++ source files using the selected compiler.
linkTestVariant(e.g.linkTest) - LinkExecutable-
Depends on: All tasks which contribute to the link executable, including
linkVariantandcreateVarianttasks from projects that are resolved via project dependencies and tested component :: Links executable from compiled object files using the selected linker. installTestVariant(e.g.installTest) - InstallExecutable-
Depends on:
linkTestVariantand all tasks which contribute to the runtime of the executable, includinglinkVarianttasks from projects that are resolved via project dependencies :: Installs the executable and all of it’s runtime dependencies for easy execution. runTestVariant(e.g.runTest) - RunTestExecutable-
Depends on:
installTestVariant:: Run the installed executable.
Lifecycle Tasks
The C++ Unit Test Plugin attaches some of its tasks to the standard lifecycle tasks documented in the Base Plugin chapter — which the C++ Unit Test Plugin applies automatically:
assemble- Task (lifecycle)-
Aggregate task that assembles the debug variant of the tested component for the current host (if present) in the project. For example, the C++ Application Plugin and C++ Library Plugin attach their link and create tasks to this lifecycle task. This task is added by the Base Plugin.
test- Task (lifecycle)-
Depends on:
runTestVariantthat most closely matches the build host :: Aggregate task of the variant that most closely match the build host for testing the component. check- Task (lifecycle)-
Depends on:
test:: Aggregate task that performs verification tasks, such as running the tests. Some plugins add their own verification task tocheck. This task is added by the Base Plugin. build- Task (lifecycle)-
Depends on:
check,assemble:: Aggregate tasks that perform a full build of the project. This task is added by the Base Plugin. clean- Delete-
Deletes the build directory and everything in it, i.e. the path specified by the
layout.buildDirectoryproject property. This task is added by the Base Plugin.
Dependency management
Just like the tasks created by the C++ Unit Test Plugin, the configurations are created based on the variant of the application component. Read the introduction to build variants for more information. The following graph describes the configurations added by the C++ Unit Test Plugin:
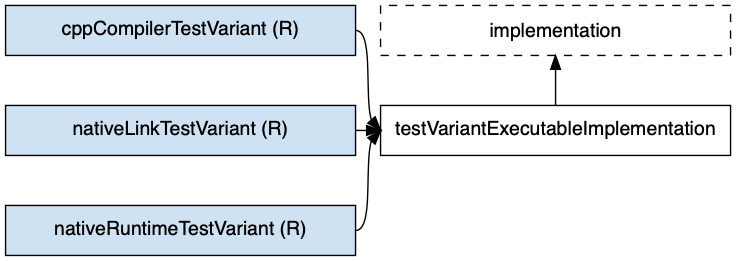
-
The configurations in white are the ones a user should use to declare dependencies
-
The configurations in blue, also known as resolvable denoted by (R), are internal to the component, for its own use
The following configurations are used to declare dependencies:
testImplementation-
Used for declaring implementation dependencies for all variants of the test component. This is where you should declare dependencies of any variants. Note this configuration inherit all dependencies declared on the tested component (library or application).
testVariantExecutableImplementation(e.g.testExecutableImplementation) extendstestImplementation-
Used for declaring implementation dependencies for a specific variant of the test component. This is where you should declare dependencies of the specific variant.
There is no configurations that can be used by consumers for this plugin.
The following configurations are used by the unit test itself:
cppCompileTestVariant(e.g.cppCompileTest) extendstestVariantExecutableImplementation-
Used for compiling the unit test. This configuration contains the compile include roots of the unit test and is therefore used when invoking the C++ compiler to compile it.
nativeLinkTestVariant(e.g.nativeLinkTest) extendstestVariantExecutableImplementation-
Used for linking the unit test. This configuration contains the libraries of the unit test and is therefore used when invoking the C++ linker to link it.
nativeRuntimeTestVariant(e.g.nativeRuntimeTest) extendstestVariantExecutableImplementation-
Used for executing the unit test. This configuration contains the runtime libraries of the unit test.
Conventions
The C++ Unit Test Plugin adds conventions for sources and tasks, shown below.
Project layout
The C++ Unit Test Plugin assumes the project layout shown below. None of these directories needs to exist or have anything in them. The C++ Unit Test Plugin will compile whatever it finds, and handles anything which is missing.
src/test/cpp-
C++ source with extension of
.cpp,.c++or.cc src/test/headers-
Headers - headers needed to compile the unit test
You configure the project layout by configuring the source and privateHeaders respectively on the unitTest script block.
compileTestVariantCpp Task
The C++ Unit Test Plugin adds a CppCompile instance for each variant of the test component to build (e.g. compileTestCpp).
Read the introduction to build variants for more information.
Some of the most common configuration options are shown below.
| compilerArgs |
[] |
| debuggable |
|
| includes |
|
| macros |
[:] |
| objectFileDir |
|
| optimized |
|
| positionIndependentCode |
|
| source |
|
| systemIncludes |
derived from the tool chain |
| targetPlatform |
derived from the |
| toolChain |
linkTestVariant Task
The C++ Unit Test Plugin adds a LinkExecutable instance for each variant of the test component - e.g. linkTest.
Read the introduction to build variants for more information.
Some of the most common configuration options are shown below.
| debuggable |
|
| libs |
|
| linkedFile |
|
| linkerArgs |
[] |
| source |
|
| targetPlatform |
derived from the |
| toolChain |
installTestVariant Task
The C++ Unit Test Plugin adds a InstallExecutable instance for each variant of the test component - e.g. installTest.
Read the introduction to build variants for more information.
There is no need to configure any properties on the task.
runTestVariant Task
The C++ Unit Test Plugin adds a RunTestExecutable instance for each variant of the test component - e.g. runTest.
Read the introduction to build variants for more information.
Some of the most common configuration options are shown below.
| args |
|
| ignoreFailures |
|
Swift Application
The Swift Application Plugin provides the tasks, configurations and conventions for a building Swift application.
Usage
plugins {
`swift-application`
}plugins {
id 'swift-application'
}Build variants
The Swift Application Plugin understands the following dimensions. Read the introduction to build variants for more information.
- Build types - always either debug or release
-
The build type controls the debuggability as well as the optimization of the generated binaries.
-
debug- Generate debug symbols and don’t optimized the binary -
release- Generate debug symbols and optimize, but extract the debug symbols from the binary
-
- Target machines - defaults to the build host
-
The target machine expresses which machines the application expects to run. A target machine is identified by its operating system and architecture. Gradle uses the target machine to decide which tool chain to choose based on availability on the host machine.
The target machine can be configured as follows:
application {
targetMachines = listOf(machines.linux.x86_64, machines.macOS.x86_64)
}application {
targetMachines = [
machines.linux.x86_64, machines.macOS.x86_64
]
}Tasks
The following diagram shows the relationships between tasks added by this plugin.
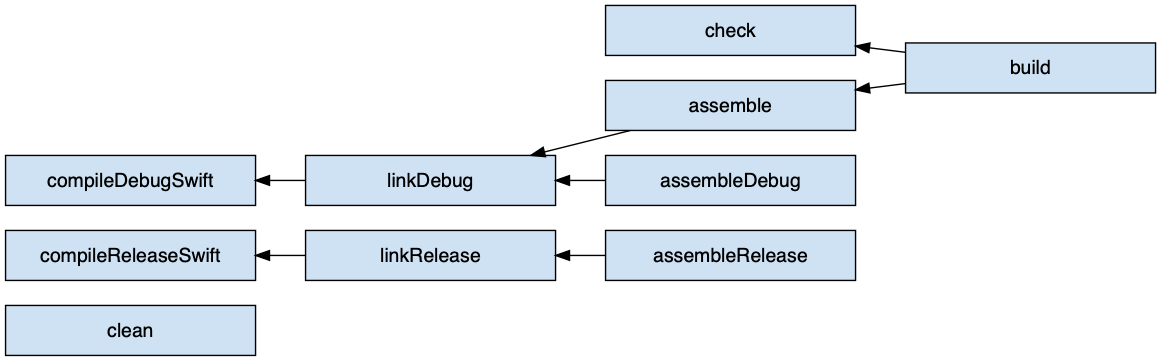
Variant-dependent Tasks
The Swift Application Plugin creates tasks based on the variants of the application component. Read the introduction to build variants for more information. The following diagram shows the relationship between variant-dependent tasks.
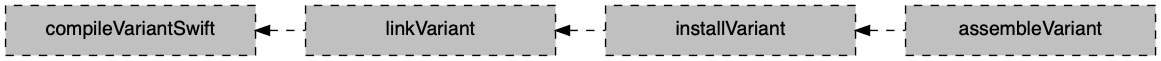
compileVariantSwift(e.g.compileDebugSwiftandcompileReleaseSwift) - SwiftCompile-
Depends on: All tasks that contribute source files to the compilation :: Compiles Swift source files using the selected compiler.
linkVariant(e.g.linkDebugandlinkRelease) - LinkExecutable-
Depends on: All tasks which contribute to the link executable, including
linkVariantandcreateVarianttasks from projects that are resolved via project dependencies :: Links executable from compiled object files using the selected linker. installVariant(e.g.installDebugandinstallRelease) - InstallExecutable-
Depends on:
linkVariantand all tasks which contribute to the runtime of the executable, includinglinkVarianttasks from projects that are resolved via project dependencies :: Installs the executable and all of it’s runtime dependencies for easy execution. assembleVariant(e.g.assembleDebugandassembleRelease) - Task (lifecycle)-
Depends on:
linkVariant:: Aggregates tasks that assemble the specific variant of this application.
Lifecycle Tasks
The Swift Application Plugin attaches some of its tasks to the standard lifecycle tasks documented in the Base Plugin chapter — which the Swift Application Plugin applies automatically:
assemble- Task (lifecycle)-
Depends on:
linkDebug:: Aggregate task that assembles the debug variant of the application for the current host (if present) in the project. This task is added by the Base Plugin. check- Task (lifecycle)-
Aggregate task that performs verification tasks, such as running the tests. Some plugins add their own verification task to
check. For example, the XCTest Plugin attaches a task to this lifecycle task to run tests. This task is added by the Base Plugin. build- Task (lifecycle)-
Depends on:
check,assemble:: Aggregate tasks that perform a full build of the project. This task is added by the Base Plugin. clean- Delete-
Deletes the build directory and everything in it, i.e. the path specified by the
layout.buildDirectoryproject property. This task is added by the Base Plugin.
Dependency management
Just like the tasks created by the Swift Application Plugin, multiple configurations are created based on the variants of the application component. Read the introduction to build variants for more information. The following graph describes the configurations added by the Swift Application Plugin:
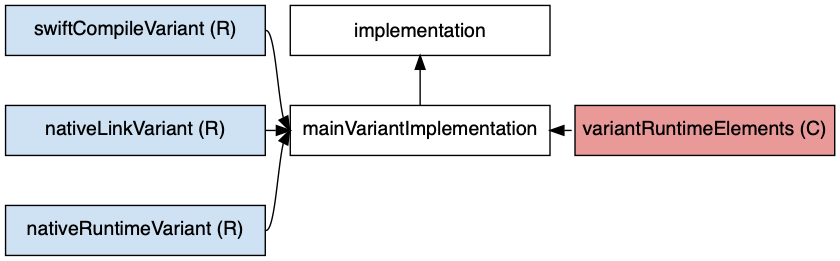
-
The configurations in white are the ones a user should use to declare dependencies
-
The configurations in pink, also known as consumable denoted by (C), are the ones used when a component runs against the library
-
The configurations in blue, also known as resolvable denoted by (R), are internal to the component, for its own use
The following configurations are used to declare dependencies:
implementation-
Used for declaring implementation dependencies for all variants of the main component. This is where you should declare dependencies of any variants.
mainVariantImplementation(e.g.mainDebugImplementationandmainReleaseImplementation) extendsimplementation-
Used for declaring implementation dependencies for a specific variant of the main component. This is where you should declare dependencies of the specific variant.
The following configurations are used by downstream consumers that depend on the application component:
variantRuntimeElements(e.g.debugRuntimeElementsandreleaseRuntimeElements) extends `mainVariantImplementation-
Used for executing the application. This configuration is meant to be used by consumers, to retrieve all the elements necessary to run the application.
The following configurations are used by the application itself:
swiftCompileVariant(e.g.swiftCompileDebugandswiftCompileRelease) extendsmainVariantImplementation-
Used for compiling the application. This configuration contains the compile include roots of the application and is therefore used when invoking the Swift compiler to compile it.
nativeLinkVariant(e.g.nativeLinkDebugandnativeLinkRelease) extendsmainVariantImplementation-
Used for linking the application. This configuration contains the libraries of the application and is therefore used when invoking the Swift linker to link it.
nativeRuntimeVariant(e.g.nativeRuntimeDebugandnativeRuntimeRelease) extendsmainVariantImplementation-
Used for executing the application. This configuration contains the runtime libraries of the application.
Conventions
The Swift Application Plugin adds conventions for sources and tasks, shown below.
Project layout
The Swift Application Plugin assumes the project layout shown below. None of these directories need to exist or have anything in them. The Swift Application Plugin will compile whatever it finds and ignore anything missing.
src/main/swift-
Swift source with extension of
.swift
You configure the project layout by configuring the source on the application script block.
compileVariantSwift Task
The Swift Application Plugin adds a SwiftCompile instance for each variant of the application component to build (e.g. compileDebugSwift and compileReleaseSwift).
Read the introduction to build variants for more information.
Some of the most common configuration options are shown below.
| compilerArgs |
[] |
| debuggable |
|
| modules |
|
| macros |
[] |
| objectFileDir |
|
| optimized |
|
| source |
|
| targetPlatform |
derived from the |
| toolChain |
linkVariant Task
The Swift Application Plugin adds a LinkExecutable instance for each variant of the application - e.g. linkDebug and linkRelease.
Read the introduction to build variants for more information.
Some of the most common configuration options are shown below.
| debuggable |
|
| libs |
|
| linkedFile |
|
| linkerArgs |
[] |
| source |
|
| targetPlatform |
derived from the |
| toolChain |
installVariant Task
The Swift Application Plugin adds a InstallExecutable instance for each variant of the test component - e.g. installDebug and installRelease.
Read the introduction to build variants for more information.
There is no need to configure any properties on the task.
Swift Library
The Swift Library Plugin provides the tasks, conventions and conventions for building a Swift library. In particular, a Swift library provides functionality that can be used by consumers (i.e., other projects using this plugin or the Swift Application Plugin).
Usage
plugins {
`swift-library`
}plugins {
id 'swift-library'
}Build variants
The Swift Library Plugin understands the following dimensions. Read the introduction to build variants for more information.
- Build types - always set to debug and release
-
The build type controls the debuggability as well as the optimization of the generated binaries.
-
debug- Generate debug symbols and don’t optimized the binary -
release- Generate debug symbols and optimize, but extract the debug symbols from the binary
-
- Linkages - default to shared
-
The linkage expresses whether a shared library or static library should be created. Libraries can produce a shared library, a static library or both.
The linkage can be configured as follows:
library {
linkage = listOf(Linkage.STATIC, Linkage.SHARED)
}library {
linkage = [Linkage.STATIC, Linkage.SHARED]
}- Target machines - defaults to the build host
-
The target machine expresses which machines the application expects to run. A target machine is identified by its operating system and architecture. Gradle uses the target machine to decide which tool chain to choose based on availability on the host machine.
The target machine can be configured as follows:
library {
targetMachines = listOf(machines.linux.x86_64, machines.macOS.x86_64)
}library {
targetMachines = [
machines.linux.x86_64,
machines.macOS.x86_64
]
}Tasks
The following diagram shows the relationships between tasks added by this plugin.
Note the default linkage of a Swift library is shared linkage as shown in the diagram.

With static linkage, the diagram changes to the following:

Variant-dependent Tasks
The Swift Library Plugin creates tasks based on variants of the library component. Read the introduction to build variants for more information. The following diagrams show the relationship between variant-dependent tasks.

|
Note
|
Depending on the linkage property |
compileVariantSwift(e.g.compileDebugSwiftandcompileReleaseSwift) - SwiftCompile-
Depends on: All tasks that contribute source files to the compilation :: Compiles Swift source files using the selected compiler.
linkVariant(e.g.linkDebugandlinkRelease) - LinkSharedLibrary (shared linkage)-
Depends on: All tasks which contribute to the link libraries, including
linkVariantandcreateVarianttasks from projects that are resolved via project dependencies :: Links shared library from compiled object files using the selected linker. createVariant(e.g.createDebugandcreateRelease) - CreateStaticLibrary (static linkage)-
Creates static library from compiled object files using selected archiver
assembleVariant(e.g.assembleDebugandassembleRelease) - Task (lifecycle)-
Depends on:
linkVariant(shared linkage) orcreateVariant(static linkage) :: Aggregates tasks that assemble the specific variant of this library.
Lifecycle Tasks
The Swift Library Plugin attaches some of its tasks to the standard lifecycle tasks documented in the Base Plugin chapter — which the Swift Library Plugin applies automatically:
assemble- Task (lifecycle)-
Depends on:
linkDebugwhen linkage includessharedorcreateDebugotherwise. :: Aggregate task that assembles the debug variant of the shared library (if available) for the current host (if present) in the project. This task is added by the Base Plugin. check- Task (lifecycle)-
Aggregate task that performs verification tasks, such as running the tests. Some plugins add their own verification task to
check. For example, the XCTest Plugin attach its test task to this lifecycle task. This task is added by the Base Plugin. build- Task (lifecycle)-
Depends on:
check,assemble:: Aggregate tasks that perform a full build of the project. This task is added by the Base Plugin. clean- Delete-
Deletes the build directory and everything in it, i.e. the path specified by the
layout.buildDirectoryproject property. This task is added by the Base Plugin.
Dependency management
Just like the tasks created by the Swift Library Plugin, multiple configurations are created based on the variants of the library component. Read the introduction to build variants for more information. The following graph describes the configurations added by the Swift Library Plugin:
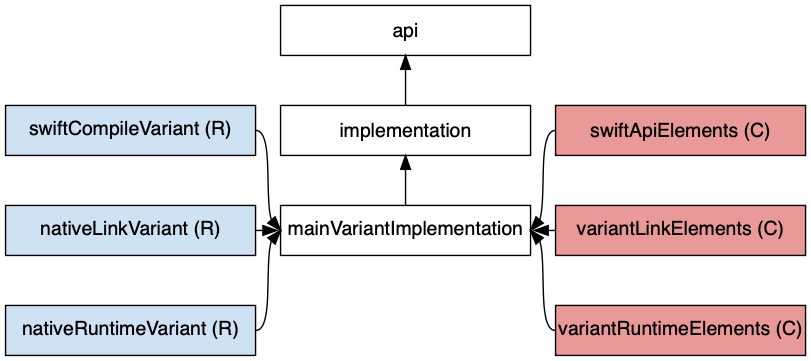
-
The configurations in white are the ones a user should use to declare dependencies
-
The configurations in pink, also known as consumable denoted by (C), are the ones used when a component compiles, links, or runs against the library
-
The configurations in blue, also known as resolvable denoted by (R), are internal to the component, for its own use
The following configurations are used to declare dependencies:
api-
Used for declaring API dependencies (see API vs implementation section). This is where you should declare dependencies which are transitively exported to consumers, for compile and link.
implementationextendsapi-
Used for declaring implementation dependencies for all variants of the main component (see API vs implementation section). This is where you should declare dependencies which are purely internal and not meant to be exposed to consumers of any variants.
mainVariantImplementation(e.g.mainDebugImplementationandmainReleaseImplementation) extendsimplementation-
Used for declaring implementation dependencies for a specific variant of the main component (see API vs implementation section). This is where you should declare dependencies which are purely internal and not meant to be exposed to consumers of this specific variant.
The following configurations are used by consumers:
variantSwiftApiElements(e.g.debugSwiftApiElementsandreleaseSwiftApiElements) extendsmainVariantImplementation-
Used for compiling against the library. This configuration is meant to be used by consumers, to retrieve all the elements necessary to compile against the library.
variantLinkElements(e.g.debugLinkElementsandreleaseLinkElements) extendsmainVariantImplementation-
Used for linking against the library. This configuration is meant to be used by consumers, to retrieve all the elements necessary to link against the library.
variantRuntimeElements(e.g.debugRuntimeElementsandreleaseRuntimeElements) extends `mainVariantImplementation-
Used for executing the library. This configuration is meant to be used by consumers, to retrieve all the elements necessary to run against the library.
The following configurations are used by the library itself:
swiftCompileVariant(e.g.swiftCompileDebugandswiftCompileRelease) extendsmainVariantImplementation-
Used for compiling the library. This configuration contains the compile include roots of the library and is therefore used when invoking the Swift compiler to compile it.
nativeLinkVariant(e.g.nativeLinkDebugandnativeLinkRelease) extendsmainVariantImplementation-
Used for linking the library the shared library only. This configuration contains the libraries of the library and is therefore used when invoking the Swift linker to link it.
nativeRuntimeVariant(e.g.nativeRuntimeDebugandnativeRuntimeRelease) extendsmainVariantImplementation-
Used for executing the library. This configuration contains the runtime libraries of the library.
API vs implementation
The plugin exposes two configurations that can be used to declare dependencies: api and implementation.
The api configuration should be used to declare dependencies which are exported by the library API, whereas the implementation configuration should be used to declare dependencies which are internal to the component.
library {
dependencies {
// FIXME: Put real deps here.
api("io.qt:core:5.1")
implementation("io.qt:network:5.1")
}
}library {
dependencies {
// FIXME: Write better deps here.
api "io.qt:core:5.1"
implementation "io.qt:network:5.1"
}
}Dependencies appearing in the api configurations will be transitively exposed to consumers of the library, and as such will appear on the compile include root and link libraries of consumers.
Dependencies found in the implementation configuration will, on the other hand, not be exposed to consumers, and therefore not leak into the consumer’s compile include root and link libraries.
This comes with several benefits:
-
dependencies do not leak into the compile include roots and link libraries of consumers, so they can never accidentally depend on a transitive dependency
-
faster compilation thanks to the reduced include roots and link libraries
-
fewer recompilations when implementation dependencies change since the consumer would not need to be recompiled
Conventions
The Swift Library Plugin adds conventions for sources and tasks, shown below.
Project layout
The Swift Library Plugin assumes the project layout shown below. None of these directories needs to exist or have anything in them. The Swift Library Plugin will compile whatever it finds and ignore anything missing.
src/main/swift-
Swift source with extension of
.swift
You configure the project layout by configuring the source on the library script block.
compileVariantSwift Task
The Swift Library Plugin adds a SwiftCompile instance for each variant of the library component to build (e.g. compileDebugSwift and compileReleaseSwift).
Read the introduction to build variants for more information.
Some of the most common configuration options are shown below.
| compilerArgs |
[] |
| debuggable |
|
| modules |
|
| macros |
[] |
| objectFileDir |
|
| optimized |
|
| source |
|
| targetPlatform |
derived from the |
| toolChain |
linkVariant Task
The Swift Library Plugin adds a LinkSharedLibrary instance for each variant of the library containing shared linkage as a dimension - e.g. linkDebug and linkRelease.
Read the introduction to build variants for more information.
Some of the most common configuration options are shown below.
| debuggable |
|
| libs |
|
| linkedFile |
|
| linkerArgs |
[] |
| source |
|
| targetPlatform |
derived from the |
| toolChain |
createVariant Task
The Swift Library Plugin adds a CreateStaticLibrary instance for each variant of the library containing static linkage as a dimension - e.g. createDebug and createRelease.
Read the introduction to build variants for more information.
Some of the most common configuration options are shown below.
| outputFile |
|
| source |
|
| staticLibArgs |
[] |
| targetPlatform |
derived from the |
| toolChain |
XCTest
The XCTest Plugin provides the tasks, configurations and conventions for integrating with a XCTest testing framework on macOS as well as Linux’s open source implementation.
Usage
plugins {
xctest
}plugins {
id 'xctest'
}Build variants
The XCTest Plugin understands the following dimensions. Read the introduction to build variants for more information.
- Target machines - defaults to the tested component (if present) or build host (otherwise)
-
The target machine expresses which machines the application expects to run. A target machine is identified by its operating system and architecture. Gradle uses the target machine to decide which tool chain to choose based on availability on the host machine.
The target machine can be configured as follows:
xctest {
targetMachines = listOf(machines.linux.x86_64, machines.macOS.x86_64)
}xctest {
targetMachines = [
machines.linux.x86_64,
machines.macOS.x86_64
]
}Tasks
The following diagram shows the relationships between tasks added by this plugin.

Variant-dependent Tasks
The XCTest Plugin creates tasks based on the variants of the test component. Read the introduction to build variants for more information. The following diagrams show the relationship between variant-dependent tasks.
compileTestVariantSwift(e.g.compileTestSwift) - SwiftCompile-
Depends on: All tasks that contribute source files to the compilation :: Compiles Swift source files using the selected compiler.
linkTestVariant(e.g.linkTest) - LinkMachOBundle (on macOS) or LinkExecutable (on Linux)-
Depends on: All tasks which contribute to the link executable, including
linkVariantandcreateVarianttasks from projects that are resolved via project dependencies and tested component :: Links executable from compiled object files using the selected linker. installTestVariant(e.g.installTest) - InstallXCTestBundle (on macOS) or InstallExecutable (on Linux)-
Depends on:
linkTestVariantand all tasks which contribute to the runtime of the executable, includinglinkVarianttasks from projects that are resolved via project dependencies :: Installs the executable and all of it’s runtime dependencies for easy execution. xcTestVariant(e.g.xcTest) - XCTest-
Depends on:
installTestVariant:: Run the installed executable.
Lifecycle Tasks
The XCTest Plugin attaches some of its tasks to the standard lifecycle tasks documented in the Base Plugin chapter — which the XCTest Plugin applies automatically:
assemble- Task (lifecycle)-
Aggregate task that assembles the debug variant of the tested component for the current host (if present) in the project. For example, the Swift Application Plugin and Swift Library Plugin attach their link and create tasks to this lifecycle task. This task is added by the Base Plugin.
test- Task (lifecycle)-
Depends on:
xcTestVariantthat most closely matches the build host :: Aggregate task of the variant that most closely match the build host for testing the component. check- Task (lifecycle)-
Depends on:
test:: Aggregate task that performs verification tasks, such as running the tests. Some plugins add their own verification task tocheck. This task is added by the Base Plugin. build- Task (lifecycle)-
Depends on:
check,assemble:: Aggregate tasks that perform a full build of the project. This task is added by the Base Plugin. clean- Delete-
Deletes the build directory and everything in it, i.e. the path specified by the
layout.buildDirectoryproject property. This task is added by the Base Plugin.
Dependency management
Just like the tasks created by the XCTest Plugin, the configurations are created based on the variant of the application component. Read the introduction to build variants for more information. The following graph describes the configurations added by the XCTest Plugin:
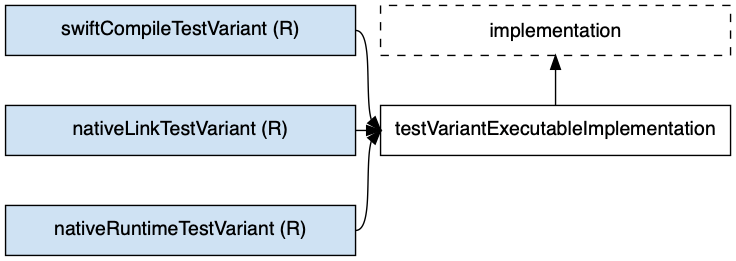
-
The configurations in white are the ones a user should use to declare dependencies
-
The configurations in blue, also known as resolvable denoted by (R), are internal to the component, for its own use
The following configurations are used to declare dependencies:
testImplementation-
Used for declaring implementation dependencies for all variants of the test component. This is where you should declare dependencies of any variants. Note this configuration inherit all dependencies declared on the tested component (library or application).
testVariantExecutableImplementation(e.g.testExecutableImplementation) extendstestImplementation-
Used for declaring implementation dependencies for a specific variant of the test component. This is where you should declare dependencies of the specific variant.
There is no configurations that can be used by consumers for this plugin.
The following configurations are used by the test component itself:
swiftCompileTestVariant(e.g.swiftCompileTest) extendstestVariantExecutableImplementation-
Used for compiling the test component. This configuration contains the compile module of the test component and is therefore used when invoking the Swift compiler to compile it.
nativeLinkTestVariant(e.g.nativeLinkTest) extendstestVariantExecutableImplementation-
Used for linking the test component. This configuration contains the libraries of the test component and is therefore used when invoking the Swift linker to link it.
nativeRuntimeTestVariant(e.g.nativeRuntimeTest) extendstestVariantExecutableImplementation-
Used for executing the test component. This configuration contains the runtime libraries of the test component.
Conventions
The XCTest Plugin adds conventions for sources and tasks, shown below.
Project layout
The XCTest Plugin assumes the project layout shown below. None of these directories needs to exist or have anything in them. The XCTest Plugin will compile whatever it finds, and handles anything which is missing.
src/test/swift-
Swift source with extension of
.swift
You configure the project layout by configuring the source on the xctest script block.
compileTestVariantSwift Task
The XCTest Plugin adds a SwiftCompile instance for each variant of the test component to build (e.g. compileTestSwift).
Read the introduction to build variants for more information.
Some of the most common configuration options are shown below.
| compilerArgs |
[] |
| debuggable |
|
| modules |
|
| macros |
[] |
| objectFileDir |
|
| optimized |
|
| source |
|
| targetPlatform |
derived from the |
| toolChain |
linkTestVariant Task
The XCTest Plugin adds a LinkMachOBundle instance on macOS or LinkExecutable instance on Linux for each variant of the test component - e.g. linkTest.
Read the introduction to build variants for more information.
Some of the most common configuration options are shown below.
macOS
| debuggable |
|
| libs |
|
| linkedFile |
|
| linkerArgs |
[] |
| source |
|
| targetPlatform |
derived from the |
| toolChain |
Linux
| debuggable |
|
| libs |
|
| linkedFile |
|
| linkerArgs |
[] |
| source |
|
| targetPlatform |
derived from the |
| toolChain |
installTestVariant Task
The XCTest Plugin adds a InstallXCTestBundle instance on macOS or InstallExecutable instance on Linux for each variant of the test component - e.g. installTest.
Read the introduction to build variants for more information.
There is no need to configure any properties on the task.
xcTestVariant Task
The XCTest Plugin adds a XCTest instance for each variant of the test component - e.g. xcTest.
Read the introduction to build variants for more information.
Some of the most common configuration options are shown below.
| binResultDir |
|
| ignoreFailures |
|
| reports |
|
| runScriptFile |
|
| testInstallDirectory |
|
| workingDirectory |
|
The Application Plugin
The Application plugin facilitates creating an executable JVM application. It makes it easy to start the application locally during development, and to package the application as a TAR and/or ZIP including operating system specific start scripts.
Applying the Application plugin also implicitly applies the Java plugin. The main source set is effectively the "application".
Applying the Application plugin also implicitly applies the Distribution plugin. A main distribution is created that packages up the application, including code dependencies and generated start scripts.
Building JVM applications
To use the application plugin, include the following in your build script:
plugins {
application
}plugins {
id 'application'
}The only mandatory configuration for the plugin is the specification of the main class (i.e. entry point) of the application.
application {
mainClass = "org.gradle.sample.Main"
}application {
mainClass = 'org.gradle.sample.Main'
}You can run the application by executing the run task (type: JavaExec). This will compile the main source set, and launch a new JVM with its classes (along with all runtime dependencies) as the classpath and using the specified main class. You can launch the application in debug mode with gradle run --debug-jvm (see JavaExec.setDebug(boolean)).
Since Gradle 4.9, the command line arguments can be passed with --args. For example, if you want to launch the application with command line arguments foo --bar, you can use gradle run --args="foo --bar" (see JavaExec.setArgsString(java.lang.String).
If your application requires a specific set of JVM settings or system properties, you can configure the applicationDefaultJvmArgs property. These JVM arguments are applied to the run task and also considered in the generated start scripts of your distribution.
application {
applicationDefaultJvmArgs = listOf("-Dgreeting.language=en")
}application {
applicationDefaultJvmArgs = ['-Dgreeting.language=en']
}If your application’s start scripts should be in a different directory than bin, you can configure the executableDir property.
application {
executableDir = "custom_bin_dir"
}application {
executableDir = 'custom_bin_dir'
}Building applications using the Java Module System
Gradle supports the building of Java Modules as described in the corresponding section of the Java Library plugin documentation. Java modules can also be runnable and you can use the application plugin to run and package such a modular application. For this, you need to do two things in addition to what you do for a non-modular application.
First, you need to add a module-info.java file to describe your application module.
Please refer to the Java Library plugin documentation for more details on this topic.
Second, you need to tell Gradle the name of the module you want to run in addition to the main class name like this:
application {
mainModule = "org.gradle.sample.app" // name defined in module-info.java
mainClass = "org.gradle.sample.Main"
}application {
mainModule = 'org.gradle.sample.app' // name defined in module-info.java
mainClass = 'org.gradle.sample.Main'
}That’s all.
If you run your application, by executing the run task or through a generated start script, it will run as module and respect module boundaries at runtime.
For example, reflective access to an internal package from another module can fail.
The configured main class is also baked into the module-info.class file of your application Jar.
If you run the modular application directly using the java command, it is then sufficient to provide the module name.
Building a distribution
A distribution of the application can be created, by way of the Distribution plugin (which is automatically applied). A main distribution is created with the following content:
| Location | Content |
|---|---|
(root dir) |
|
|
All runtime dependencies and main source set class files. |
|
Start scripts (generated by |
Static files to be added to the distribution can be simply added to src/dist. More advanced customization can be done by configuring the CopySpec exposed by the main distribution.
val createDocs = tasks.register("createDocs") {
val docs = layout.buildDirectory.dir("docs")
outputs.dir(docs)
doLast {
docs.get().asFile.mkdirs()
docs.get().file("readme.txt").asFile.writeText("Read me!")
}
}
distributions {
main {
contents {
from(createDocs) {
into("docs")
}
}
}
}tasks.register('createDocs') {
def docs = layout.buildDirectory.dir('docs')
outputs.dir docs
doLast {
docs.get().asFile.mkdirs()
docs.get().file('readme.txt').asFile.write('Read me!')
}
}
distributions {
main {
contents {
from(createDocs) {
into 'docs'
}
}
}
}By specifying that the distribution should include the task’s output files (see incremental builds), Gradle knows that the task that produces the files must be invoked before the distribution can be assembled and will take care of this for you.
You can run gradle installDist to create an image of the application in build/install/projectName. You can run gradle distZip to create a ZIP containing the distribution, gradle distTar to create an application TAR or gradle assemble to build both.
Customizing start script generation
The application plugin can generate Unix (suitable for Linux, macOS etc.) and Windows start scripts out of the box.
The start scripts launch a JVM with the specified settings defined as part of the original build and runtime environment (e.g. JAVA_OPTS env var).
The default script templates are based on the same scripts used to launch Gradle itself, that ship as part of a Gradle distribution.
The start scripts are completely customizable. Please refer to the documentation of CreateStartScripts for more details and customization examples.
Tasks
The Application plugin adds the following tasks to the project.
run— JavaExec-
Depends on:
classesStarts the application.
startScripts— CreateStartScripts-
Depends on:
jarCreates OS specific scripts to run the project as a JVM application.
installDist— Sync-
Depends on:
jar,startScriptsInstalls the application into a specified directory.
distZip— Zip-
Depends on:
jar,startScriptsCreates a full distribution ZIP archive including runtime libraries and OS specific scripts.
distTar— Tar-
Depends on:
jar,startScriptsCreates a full distribution TAR archive including runtime libraries and OS specific scripts.
Application extension
The Application Plugin adds an extension to the project, which you can use to configure its behavior. See the JavaApplication DSL documentation for more information on the properties available on the extension.
You can configure the extension via the application {} block shown earlier, for example using the following in your build script:
application {
executableDir = "custom_bin_dir"
}application {
executableDir = 'custom_bin_dir'
}License of start scripts
The start scripts generated for the application are licensed under the Apache 2.0 Software License.
Convention properties (deprecated)
This plugin also adds some convention properties to the project, which you can use to configure its behavior. These are deprecated and superseded by the extension described above. See the Project DSL documentation for information on them.
Unlike the extension properties, these properties appear as top-level project properties in the build script. For example, to change the application name you can just add the following to your build script:
application.applicationName = "my-app"application.applicationName = 'my-app'The War Plugin
The War plugin extends the Java plugin to add support for assembling web application WAR files. It disables the default JAR archive generation of the Java plugin and adds a default WAR archive task.
Usage
To use the War plugin, include the following in your build script:
plugins {
war
}plugins {
id 'war'
}Project layout
In addition to the standard Java project layout, the War Plugin adds:
src/main/webapp-
Web application sources
Tasks
The War plugin adds and modifies the following tasks:
war— War-
Depends on:
compileAssembles the application WAR file.
assemble- lifecycle task-
Depends on:
war
The War plugin adds the following dependencies to tasks added by the Java plugin;

Dependency management
The War plugin adds two dependency configurations:
providedCompile-
This configuration should be used for dependencies required at compilation but which are provided by the environment in which the WAR is deployed. Dependencies declared here are thus visible to the
mainandtestcompilation classpaths. providedRuntime-
This configuration should be used for dependencies required at runtime but which are provided by the environment in which the WAR is deployed. Dependencies declared here are only visible to the
mainandtestruntime classpaths.
|
Note
|
It is important to note that these Let’s say you add If you don’t want this transitive behavior, simply declare your |
Publishing
components.web-
A SoftwareComponent for publishing the production WAR created by the
wartask.
War
The default behavior of the War task is to copy the content of src/main/webapp to the root of the archive. Your webapp directory may of course contain a WEB-INF sub-directory, which may contain a web.xml file. Your compiled classes are compiled to WEB-INF/classes. All the dependencies of the runtime [3] configuration are copied to WEB-INF/lib.
The War class in the API documentation has additional useful information.
Customizing
Here is an example with the most important customization options:
repositories {
mavenCentral()
}
dependencies {
providedCompile("javax.servlet:servlet-api:2.5")
}
tasks.war {
webAppDirectory = file("src/main/webapp")
from("src/rootContent") // adds a file-set to the root of the archive
webInf { from("src/additionalWebInf") } // adds a file-set to the WEB-INF dir.
webXml = file("src/someWeb.xml") // copies a file to WEB-INF/web.xml
}repositories {
mavenCentral()
}
dependencies {
providedCompile "javax.servlet:servlet-api:2.5"
}
war {
webAppDirectory = file('src/main/webapp')
from 'src/rootContent' // adds a file-set to the root of the archive
webInf { from 'src/additionalWebInf' } // adds a file-set to the WEB-INF dir.
webXml = file('src/someWeb.xml') // copies a file to WEB-INF/web.xml
}Of course one can configure the different file-sets with a closure to define excludes and includes.
The Ear Plugin
The Ear plugin adds support for assembling web application EAR files. It adds a default EAR archive task. It doesn’t require the Java plugin, but for projects that also use the Java plugin it disables the default JAR archive generation.
Usage
To use the Ear plugin, include the following in your build script:
plugins {
ear
}plugins {
id 'ear'
}Tasks
The Ear plugin adds the following tasks to the project.
ear— Ear-
Depends on:
compile(only if the Java plugin is also applied)Assembles the application EAR file.
Dependencies added to other tasks
The Ear plugin adds the following dependencies to tasks added by the Base Plugin.
assemble-
Depends on:
ear.
Project layout
.
└── src
└── main
└── application // (1)-
Ear resources, such as a META-INF directory
Dependency management
The Ear plugin adds two dependency configurations: deploy and earlib. All dependencies in the deploy configuration are placed in the root of the EAR archive, and are not transitive. All dependencies in the earlib configuration are placed in the 'lib' directory in the EAR archive and are transitive.
Ear
The default behavior of the Ear task is to copy the content of src/main/application to the root of the archive. If your application directory doesn’t contain a META-INF/application.xml deployment descriptor then one will be generated for you.
The Ear class in the API documentation has additional useful information.
Customizing
Here is an example with the most important customization options:
plugins {
ear
java
}
repositories { mavenCentral() }
dependencies {
// The following dependencies will be the ear modules and
// will be placed in the ear root
deploy(project(path = ":war", configuration = "war"))
// The following dependencies will become ear libs and will
// be placed in a dir configured via the libDirName property
earlib("log4j:log4j:1.2.15@jar")
}
tasks.ear {
appDirectory = file("src/main/app") // use application metadata found in this folder
libDirName = "APP-INF/lib" // put dependent libraries into APP-INF/lib inside the generated EAR
deploymentDescriptor { // custom entries for application.xml:
// fileName = "application.xml" // same as the default value
// version = "6" // same as the default value
applicationName = "customear"
initializeInOrder = true
displayName = "Custom Ear" // defaults to project.name
// defaults to project.description if not set
description = "My customized EAR for the Gradle documentation"
// libraryDirectory = "APP-INF/lib" // not needed, above libDirName setting does this
// module("my.jar", "java") // won't deploy as my.jar isn't deploy dependency
// webModule("my.war", "/") // won't deploy as my.war isn't deploy dependency
securityRole("admin")
securityRole("superadmin")
withXml { // add a custom node to the XML
asElement().apply {
appendChild(ownerDocument.createElement("data-source").apply { textContent = "my/data/source" })
}
}
}
}plugins {
id 'ear'
id 'java'
}
repositories { mavenCentral() }
dependencies {
// The following dependencies will be the ear modules and
// will be placed in the ear root
deploy project(path: ':war', configuration: 'war')
// The following dependencies will become ear libs and will
// be placed in a dir configured via the libDirName property
earlib("log4j:log4j:1.2.15@jar")
}
tasks.named('ear') {
appDirectory = file('src/main/app') // use application metadata found in this folder
libDirName = 'APP-INF/lib' // put dependent libraries into APP-INF/lib inside the generated EAR
deploymentDescriptor { // custom entries for application.xml:
// fileName = "application.xml" // same as the default value
// version = "6" // same as the default value
applicationName = "customear"
initializeInOrder = true
displayName = "Custom Ear" // defaults to project.name
// defaults to project.description if not set
description = "My customized EAR for the Gradle documentation"
// libraryDirectory = "APP-INF/lib" // not needed, above libDirName setting does this
// module("my.jar", "java") // won't deploy as my.jar isn't deploy dependency
// webModule("my.war", "/") // won't deploy as my.war isn't deploy dependency
securityRole("admin")
securityRole("superadmin")
withXml { provider -> // add a custom node to the XML
provider.asNode().appendNode("data-source", "my/data/source")
}
}
}You can also use customization options that the Ear task provides, such as from and metaInf.
Skinny WAR Pattern
The Ear plugin supports the Skinny WAR deployment pattern, where shared libraries are placed in the EAR’s lib directory rather than being packaged within individual WAR files.
Basic Skinny WAR Setup
To implement the Skinny WAR pattern, configure your multi-module project with separate war and ear modules:
.
├── settings.gradle.kts
├── war/ // (1)
│ └── src/main/
│ ├── java/
│ └── webapp/
└── ear/ // (2)
└── src/main/application/
└── META-INF/
└── application.xml
-
Contains web application code and resources, produces skinny WAR with compileOnly dependencies
-
Assembles complete enterprise application, packages WAR and shared libraries in lib directory
WAR Module Configuration
Configure the WAR module to use compileOnly dependencies for libraries that will be provided by the EAR:
plugins {
war
}
repositories {
mavenCentral()
}
configurations {
create("war") {
isCanBeResolved = false
outgoing {
artifact(tasks["war"])
}
}
}
dependencies {
// Shared libraries provided by parent EAR - use compileOnly to avoid packaging in WAR
compileOnly("org.apache.commons:commons-lang3:3.14.0")
}plugins {
id 'war'
}
repositories {
mavenCentral()
}
configurations {
war {
canBeResolved = false
outgoing {
artifact(tasks.war)
}
}
}
dependencies {
// Shared libraries provided by parent EAR - use compileOnly to avoid packaging in WAR
compileOnly 'org.apache.commons:commons-lang3:3.14.0'
}EAR Module Configuration
Configure the EAR module to include the WAR and place shared libraries in the lib directory:
plugins {
ear
}
repositories {
mavenCentral()
}
dependencies {
// Include WAR module in EAR
deploy(project(":war", "war"))
// Shared libraries placed in EAR/lib directory
earlib("org.apache.commons:commons-lang3:3.14.0")
}plugins {
id 'ear'
}
repositories {
mavenCentral()
}
dependencies {
// Include WAR module in EAR
deploy project(path: ':war', configuration: 'war')
// Shared libraries placed in EAR/lib directory
earlib 'org.apache.commons:commons-lang3:3.14.0'
}Runtime Library Resolution
In the Skinny WAR pattern, shared dependencies are centralized in the EAR’s lib directory instead of being duplicated in each WAR file. The generated EAR file structure demonstrates this dependency organization:
ear.ear ├── META-INF/ │ ├── MANIFEST.MF │ └── application.xml ├── lib/ │ └── commons-lang3-3.14.0.jar └── war.war (skinny WAR - no shared libraries)
Using custom descriptor file
You may already have appropriate settings in a application.xml file and want to use that instead of configuring the ear.deploymentDescriptor section of the build script. To accommodate that goal, place the META-INF/application.xml in the right place inside your source folders (see the appDirName property). The file contents will be used and the explicit configuration in the ear.deploymentDescriptor will be ignored.
The Distribution Plugin
The Distribution Plugin facilitates building archives that serve as distributions of the project. Distribution archives typically contain the executable application and other supporting files, such as documentation.
Base Plugin
The distribution plugin is split into the distribution and distribution-base plugins.
The distribution-base plugin adds an extension named distributions of type DistributionContainer to the project.
The distribution plugin applies the distribution-base plugin and creates a single distribution in the distributions container extension named main.
If your build produces only one distribution, you only need to configure the distribution or rely on the defaults.
Usage
To use the Distribution Plugin, include the following in your build script:
plugins {
distribution
}plugins {
id 'distribution'
}You can run gradle distZip to package the main distribution as a ZIP, or gradle distTar to create a TAR file. To build both types of archives just run gradle assembleDist.
The files will be created at layout.buildDirectory.dir("distributions/${project.name}-${project.version}.«ext»").
You can run gradle installDist to assemble the uncompressed distribution into layout.buildDirectory.dir("install/${project.name}").
Tasks
The Distribution Plugin adds a number of tasks to your project, as shown below.
distZip— Zip-
Creates a ZIP archive of the distribution contents.
distTar— Task-
Creates a TAR archive of the distribution contents.
assembleDist— Task-
Depends on:
distTar,distZipCreates ZIP and TAR archives of the distribution contents.
installDist— Sync-
Assembles the distribution content and installs it on the current machine.
For each additional distribution you add to the project, the Distribution Plugin adds the following tasks, where distributionName comes from Distribution.getName():
distributionNameDistZip— Zip-
Creates a ZIP archive of the distribution contents.
distributionNameDistTar— Tar-
Creates a TAR archive of the distribution contents.
assembleDistributionNameDist— Task-
Depends on:
distributionNameDistTar,distributionNameDistZipCreates ZIP and TAR archives of the distribution contents.
installDistributionNameDist— Sync-
Assembles the distribution content and installs it on the current machine.
The following sample creates a custom distribution that will cause four additional tasks to be added to the project: customDistZip, customDistTar, assembleCustomDist, and installCustomDist:
distributions {
create("custom") {
// configure custom distribution
}
}distributions {
custom {
// configure custom distribution
}
}Given that the project name is myproject and version 1.2, running gradle customDistZip will produce a ZIP file named myproject-custom-1.2.zip.
Running gradle installCustomDist will install the distribution contents into layout.buildDirectory.dir("install/custom").
Distribution contents
All of the files in the src/$distribution.name/dist directory will automatically be included in the distribution. You can add additional files by configuring the Distribution object that is part of the container.
distributions {
main {
distributionBaseName = "someName"
distributionClassifier = "classifier"
contents {
from("src/readme")
}
}
}distributions {
main {
distributionBaseName = 'someName'
distributionClassifier = 'classifier'
contents {
from 'src/readme'
}
}
}In the example above, the content of the src/readme directory will be included in the distribution (along with the files in the src/main/dist directory which are added by default).
The distributionBaseName and distributionClassifier properties have also been changed. This will cause the distribution archives to be created with a different name.
distributions {
main {
distributionBaseName = "someName"
contents {
into("bin/config") {
from("config")
}
into("lib/samples") {
from("samples")
}
}
}
}distributions {
main {
distributionBaseName = 'someName'
contents {
into('bin/config') {
from 'config'
}
into('lib/samples') {
from 'samples'
}
}
}
}In the example above, CopySpec defines the contents, ensuring the bin/config directory is automatically created if it doesn’t already exist, and the contents of the config directory are copied into it. The same process applies to the lib/samples directory.
Gradle provides a robust set of APIs to simplify handling files, managing file dependencies, generating reports, and more. CopySpec is simply one example.
File operations are covered in Working With Files.
Publishing
A distribution can be published using the Ivy Publish Plugin or Maven Publish Plugin.
Using the Ivy/Maven Publish Plugins
To publish a distribution to an Ivy repository with the Ivy Publish Plugin, add one or both of its archive tasks to an IvyPublication. The following sample demonstrates how to add the ZIP archive of the main distribution and the TAR archive of the custom distribution to the myDistribution publication:
plugins {
`ivy-publish`
}
publishing {
publications {
create<IvyPublication>("myDistribution") {
artifact(tasks.distZip.get())
artifact(tasks["customDistTar"])
}
}
}plugins {
id 'ivy-publish'
}
publishing {
publications {
myDistribution(IvyPublication) {
artifact distZip
artifact customDistTar
}
}
}Similarly, to publish a distribution to a Maven repository using the Maven Publish Plugin, add one or both of its archive tasks to a MavenPublication as follows:
plugins {
`maven-publish`
}
publishing {
publications {
create<MavenPublication>("myDistribution") {
artifact(tasks.distZip)
artifact(tasks["customDistTar"])
}
}
}plugins {
id 'maven-publish'
}
publishing {
publications {
myDistribution(MavenPublication) {
artifact distZip
artifact customDistTar
}
}
}The Java Library Distribution Plugin
The Java library distribution plugin adds support for building a distribution ZIP for a Java library. The distribution contains the JAR file for the library and its dependencies.
Usage
To use the Java library distribution plugin, include the following in your build script:
plugins {
`java-library-distribution`
}plugins {
id 'java-library-distribution'
}To define the name for the distribution you have to set the baseName property as shown below:
distributions {
main {
distributionBaseName = "my-name"
}
}distributions {
main {
distributionBaseName = 'my-name'
}
}The plugin builds a distribution for your library. The distribution will package up the runtime dependencies of the library. All files stored in src/main/dist will be added to the root of the archive distribution. You can run “gradle distZip” to create a ZIP file containing the distribution.
Tasks
The Java library distribution plugin adds the following tasks to the project.
distZip— Zip-
Depends on:
jarCreates a full distribution ZIP archive including runtime libraries.
Including other resources in the distribution
All of the files from the src/dist directory are copied. To include any static files in the distribution, simply arrange them in the src/dist directory, or add them to the content of the distribution.
distributions {
main {
distributionBaseName = "my-name"
contents {
from("src/dist")
}
}
}distributions {
main {
distributionBaseName = 'my-name'
contents {
from 'src/dist'
}
}
}The Checkstyle Plugin
The Checkstyle plugin performs quality checks on your project’s Java source files using Checkstyle and generates reports from these checks.
Usage
To use the Checkstyle plugin, include the following in your build script:
plugins {
checkstyle
}plugins {
id 'checkstyle'
}The plugin adds a number of tasks to the project that perform the quality checks. You can execute the checks by running gradle check.
Note that Checkstyle will run with the same Java version used to run Gradle.
Tasks
The Checkstyle plugin adds the following tasks to the project:
checkstyleMain— Checkstyle-
Depends on:
classesRuns Checkstyle against the production Java source files.
checkstyleTest— Checkstyle-
Depends on:
testClassesRuns Checkstyle against the test Java source files.
checkstyleSourceSet— Checkstyle-
Depends on:
sourceSetClassesRuns Checkstyle against the given source set’s Java source files.
Dependencies added to other tasks
The Checkstyle plugin adds the following dependencies to tasks defined by the Java plugin.
check-
Depends on: All Checkstyle tasks, including
checkstyleMainandcheckstyleTest.
Project layout
By default, the Checkstyle plugin expects configuration files to be placed in the root project, but this can be changed.
<root>
└── config
└── checkstyle // (1)
└── checkstyle.xml // (2)
└── suppressions.xml-
Checkstyle configuration files go here
-
Primary Checkstyle configuration file
Dependency management
The Checkstyle plugin adds the following dependency configurations:
| Name | Meaning |
|---|---|
|
The Checkstyle libraries to use |
By default, the checkstyle configuration uses com.puppycrawl.tools:checkstyle.
The version of com.puppycrawl.tools:checkstyle used is derived from the extension’s tool version:
checkstyle {
toolVersion = "10.12.4"
}If another dependency is added, the default com.puppycrawl.tools:checkstyle dependency will be removed:
checkstyle {
toolVersion = "10.12.4"
}
dependencies {
checkstyle("group:artifact:version")
}checkstyle {
toolVersion = '10.12.4'
}
dependencies {
checkstyle 'group:artifact:version'
}To add a dependency to the checkstyle configuration while also retaining a dependency on com.puppycrawl.tools:checkstyle, use the following solution:
checkstyle {
toolVersion = "10.12.4"
}
dependencies {
checkstyle("com.puppycrawl.tools:checkstyle:${checkstyle.toolVersion}")
checkstyle("group:artifact:version")
}checkstyle {
toolVersion = '10.12.4'
}
dependencies {
checkstyle "com.puppycrawl.tools:checkstyle:${checkstyle.toolVersion}"
checkstyle 'group:artifact:version'
}Configuration
See the CheckstyleExtension class in the API documentation for comprehensive configuration options.
Configuring Checkstyle with Java Toolchains
Checkstyle imposes a minimum requirement of JDK 11, with an anticipated transition to JDK 17 in forthcoming releases. For projects targeting earlier JDK versions, such as JDK 8, this presents a compatibility challenge. Historically, users have resorted to backport dependencies (e.g., com.puppycrawl.tools:checkstyle-backport-jre8) to bridge this gap. However, as both Checkstyle and Gradle align with modern Java versions, a more robust and future-proof solution is available through Gradle’s Java toolchains.
By leveraging the javaLauncher property, you can explicitly configure Checkstyle tasks to execute with a designated JDK version, independent of the JDK used for your project’s compilation or Gradle’s runtime. The following configuration ensures that Checkstyle operates with JDK 17:
tasks.withType(Checkstyle).configureEach {
javaLauncher = javaToolchains.launcherFor {
languageVersion = JavaLanguageVersion.of(17)
}
}This approach offers several advantages:
-
Decoupling: Checkstyle execution is isolated from the project’s JDK, enabling compatibility without altering your build’s core environment.
-
Automation: Gradle’s toolchain support automatically provisions the specified JDK, streamlining setup and ensuring consistency across environments.
-
Sustainability: It eliminates reliance on community-maintained backports, which may lag behind official releases or introduce maintenance overhead.
We strongly recommend adopting this configuration as the preferred method for managing Checkstyle’s JDK requirements, particularly as the ecosystem progresses toward JDK 17 and beyond.
Built-in variables
The Checkstyle plugin defines a config_loc property that can be used in Checkstyle configuration files to define paths to other configuration files like suppressions.xml.
<module name="SuppressionFilter">
<property name="file" value="${config_loc}/suppressions.xml"/>
</module>Customizing the HTML report
The HTML report generated by the Checkstyle task can be customized using a XSLT stylesheet, for example to highlight specific errors or change its appearance:
tasks.withType<Checkstyle>().configureEach {
reports {
xml.required = false
html.required = true
html.stylesheet = resources.text.fromFile("config/xsl/checkstyle-custom.xsl")
}
}tasks.withType(Checkstyle) {
reports {
xml.required = false
html.required = true
html.stylesheet = resources.text.fromFile('config/xsl/checkstyle-custom.xsl')
}
}Generate SARIF report
SARIF report is supported on Checkstyle versions 10.3.3 and newer. It is not enabled by default.
checkstyle {
toolVersion = "10.3.3"
}
tasks.withType<Checkstyle>().configureEach {
reports {
sarif.required = true
}
}checkstyle {
toolVersion = '10.3.3'
}
tasks.withType(Checkstyle) {
reports {
sarif.required = true
}
}Changing the amount of memory given to Checkstyle
Checkstyle analysis is performed in a separate process. By default, the Checkstyle process is given a max heap of 512MB. When analyzing many source files, you may need to provide additional memory to this process. You can change the amount of memory for Checkstyle by configuring the Checkstyle.maxHeapSize.
tasks.withType<Checkstyle>().configureEach {
minHeapSize = "200m"
maxHeapSize = "1g"
}tasks.withType(Checkstyle) {
minHeapSize = "200m"
maxHeapSize = "1g"
}The PMD Plugin
The PMD plugin performs quality checks on your project’s Java source files using PMD and generates reports from these checks.
Usage
To use the PMD plugin, include the following in your build script:
plugins {
pmd
}plugins {
id 'pmd'
}The plugin adds a number of tasks to the project that perform the quality checks. You can execute the checks by running gradle check.
Note that PMD will run with the same Java version used to run Gradle.
Supported PMD versions
Gradle supports PMD versions from 5.1.0 through 7.24.0.
Older PMD releases may work but are not tested against.
Use pmd.toolVersion to select a specific PMD version.
Tasks
The PMD plugin adds the following tasks to the project:
The PMD plugin adds the following dependencies to tasks defined by the Java plugin.
| Task name | Depends on |
|---|---|
|
All PMD tasks, including |
Dependency management
The PMD plugin adds the following dependency configurations:
| Name | Meaning |
|---|---|
|
The PMD libraries to use |
|
The additional libraries that are available for type resolution during analysis. This might be useful if PMD complains about missing classes. |
Configuration
pmd {
isConsoleOutput = true
toolVersion = "7.16.0"
rulesMinimumPriority = 5
ruleSets = listOf("category/java/errorprone.xml", "category/java/bestpractices.xml")
}pmd {
consoleOutput = true
toolVersion = "7.16.0"
rulesMinimumPriority = 5
ruleSets = ["category/java/errorprone.xml", "category/java/bestpractices.xml"]
}See the PmdExtension class in the API documentation.
Parallel analysis
You can configure the number of threads to be used by PMD for running its analysis.
pmd {
threads = 4
}pmd {
threads = 4
}|
Note
|
This configuration is internal to PMD and is not linked to the number of workers used by Gradle.
It means that you have to pay attention to the value entered here and make sure it still makes sense in a multi project build.
This is because parallel Gradle task execution could result in different PMD tasks from different projects running in parallel.
If multiple PMD tasks execute simultaneously in n projects, then up to a maximum of (n * |
The JaCoCo Plugin
The JaCoCo plugin provides code coverage metrics for Java code via integration with JaCoCo.
Getting Started
To get started, apply the JaCoCo plugin to the project you want to calculate code coverage for.
plugins {
jacoco
}plugins {
id 'jacoco'
}If the Java plugin is also applied to your project, a new task named jacocoTestReport is created.
By default, a HTML report is generated at layout.buildDirectory.dir("reports/jacoco/test").
|
Note
|
While tests should be executed before generation of the report, the jacocoTestReport task does not depend on the test task.
|
Depending on your usecases, you may want to always generate the jacocoTestReport or run the test task before generating the report explicitly.
tasks.test {
finalizedBy(tasks.jacocoTestReport) // report is always generated after tests run
}
tasks.jacocoTestReport {
dependsOn(tasks.test) // tests are required to run before generating the report
}test {
finalizedBy jacocoTestReport // report is always generated after tests run
}
jacocoTestReport {
dependsOn test // tests are required to run before generating the report
}Configuring the JaCoCo Plugin
The JaCoCo plugin adds a project extension named jacoco of type JacocoPluginExtension, which allows configuring defaults for JaCoCo usage in your build.
jacoco {
toolVersion = "0.8.14"
reportsDirectory = layout.buildDirectory.dir("customJacocoReportDir")
}jacoco {
toolVersion = "0.8.14"
reportsDirectory = layout.buildDirectory.dir('customJacocoReportDir')
}| Property | Gradle default |
|---|---|
reportsDirectory |
|
JaCoCo Report configuration
The JacocoReport task can be used to generate code coverage reports in different formats. It implements the standard Gradle type Reporting and exposes a report container of type JacocoReportsContainer.
tasks.jacocoTestReport {
reports {
xml.required = false
csv.required = false
html.outputLocation = layout.buildDirectory.dir("jacocoHtml")
}
}jacocoTestReport {
reports {
xml.required = false
csv.required = false
html.outputLocation = layout.buildDirectory.dir('jacocoHtml')
}
}
Enforcing code coverage metrics
|
Note
|
This feature requires the use of JaCoCo version 0.6.3 or higher. |
The JacocoCoverageVerification task can be used to verify if code coverage metrics are met based on configured rules. Its API exposes the method JacocoCoverageVerification.violationRules(org.gradle.api.Action) which is used as main entry point for configuring rules. Invoking any of those methods returns an instance of JacocoViolationRulesContainer providing extensive configuration options. The build fails if any of the configured rules are not met. JaCoCo only reports the first violated rule.
Code coverage requirements can be specified for a project as a whole, for individual files, and for particular JaCoCo-specific types of coverage, e.g., lines covered or branches covered. The following example describes the syntax.
tasks.jacocoTestCoverageVerification {
violationRules {
rule {
limit {
minimum = "0.5".toBigDecimal()
}
}
rule {
isEnabled = false
element = "CLASS"
includes = listOf("org.gradle.*")
limit {
counter = "LINE"
value = "TOTALCOUNT"
maximum = "0.3".toBigDecimal()
}
}
}
}jacocoTestCoverageVerification {
violationRules {
rule {
limit {
minimum = 0.5
}
}
rule {
enabled = false
element = 'CLASS'
includes = ['org.gradle.*']
limit {
counter = 'LINE'
value = 'TOTALCOUNT'
maximum = 0.3
}
}
}
}The JacocoCoverageVerification task is not a task dependency of the check task provided by the Java plugin. There is a good reason for it. The task is currently not incremental as it doesn’t declare any outputs. Any violation of the declared rules would automatically result in a failed build when executing the check task. This behavior might not be desirable for all users. Future versions of Gradle might change the behavior.
JaCoCo specific task configuration
The JaCoCo plugin adds a JacocoTaskExtension extension to all tasks of type Test. This extension allows the configuration of the JaCoCo specific properties of the test task.
tasks.test {
extensions.configure(JacocoTaskExtension::class) {
destinationFile = layout.buildDirectory.file("jacoco/jacocoTest.exec").get().asFile
classDumpDir = layout.buildDirectory.dir("jacoco/classpathdumps").get().asFile
}
}test {
jacoco {
destinationFile = layout.buildDirectory.file('jacoco/jacocoTest.exec').get().asFile
classDumpDir = layout.buildDirectory.dir('jacoco/classpathdumps').get().asFile
}
}|
Note
|
Tasks configured for running with the JaCoCo agent delete the destination file for the execution data when the task starts executing. This ensures that no stale coverage data is present in the execution data. |
Default values of the JaCoCo Task extension
tasks.test {
configure<JacocoTaskExtension> {
isEnabled = true
destinationFile = layout.buildDirectory.file("jacoco/${name}.exec").get().asFile
includes = emptyList()
excludes = emptyList()
excludeClassLoaders = emptyList()
isIncludeNoLocationClasses = false
sessionId = "<auto-generated value>"
isDumpOnExit = true
classDumpDir = null
output = JacocoTaskExtension.Output.FILE
address = "localhost"
port = 6300
isJmx = false
}
}test {
jacoco {
enabled = true
destinationFile = layout.buildDirectory.file("jacoco/${name}.exec").get().asFile
includes = []
excludes = []
excludeClassLoaders = []
includeNoLocationClasses = false
sessionId = "<auto-generated value>"
dumpOnExit = true
classDumpDir = null
output = JacocoTaskExtension.Output.FILE
address = "localhost"
port = 6300
jmx = false
}
}While all tasks of type Test are automatically enhanced to provide coverage information when the java plugin has been applied, any task that implements JavaForkOptions can be enhanced by the JaCoCo plugin. That is, any task that forks Java processes can be used to generate coverage information.
For example you can configure your build to generate code coverage using the application plugin:
plugins {
application
jacoco
}
application {
mainClass = "org.gradle.MyMain"
}
jacoco {
applyTo(tasks.run.get())
}
tasks.register<JacocoReport>("applicationCodeCoverageReport") {
executionData(tasks.run.get())
sourceSets(sourceSets.main.get())
}plugins {
id 'application'
id 'jacoco'
}
application {
mainClass = 'org.gradle.MyMain'
}
jacoco {
applyTo run
}
tasks.register('applicationCodeCoverageReport', JacocoReport) {
executionData run
sourceSets sourceSets.main
}.
└── build
├── jacoco
│ └── run.exec
└── reports
└── jacoco
└── applicationCodeCoverageReport
└── html
└── index.htmlTasks
For projects that also apply the Java Plugin, the JaCoCo plugin automatically adds the following tasks:
jacocoTestReport— JacocoReport-
Generates code coverage report for the test task.
jacocoTestCoverageVerification— JacocoCoverageVerification-
Verifies code coverage metrics based on specified rules for the test task.
Dependency management
The JaCoCo plugin adds the following dependency configurations:
| Name | Meaning |
|---|---|
|
The JaCoCo Ant library used for running the |
|
The JaCoCo agent library used for instrumenting the code under test. |
Outgoing Variants
When a project producing JaCoCo coverage data is applied alongside the JVM Test Suite Plugin, additional outgoing variants will be created. These variants are designed for consumption by the JaCoCo Report Aggregation Plugin.
The attributes will resemble the following. User-configurable attributes are highlighted below the sample.
--------------------------------------------------
Variant coverageDataElementsForTest (i)
--------------------------------------------------
Binary results containing Jacoco test coverage for all targets in the 'test' Test Suite.
Capabilities
- org.gradle.sample:application:1.0.2 (default capability)
Attributes
- org.gradle.category = verification
- org.gradle.testsuite.name = test // (1)
- org.gradle.verificationtype = jacoco-coverage
Artifacts
- build/jacoco/test.exec (artifactType = binary)-
TestSuiteName attribute; value is derived from TestSuite#getName().
The JaCoCo Report Aggregation Plugin
The JaCoCo Report Aggregation plugin (plugin id: jacoco-report-aggregation) provides the ability to aggregate the results of multiple JaCoCo code coverage reports (potentially spanning multiple Gradle projects) into a single HTML report. The binary data backing the coverage reports are produced by Test task invocations; see more at the JaCoCo Plugin chapter.
Usage
To use the JaCoCo Report Aggregation plugin, include the following in your build script:
plugins {
id("jacoco-report-aggregation")
}plugins {
id 'jacoco-report-aggregation'
}Note that this plugin takes no action unless applied in concert with the JVM Test Suite Plugin. The Java Plugin automatically applies the JVM Test Suite Plugin.
There are now two ways to collect code coverage results across multiple subprojects:
-
From the distribution’s project, such as an application or WAR subproject
-
Using a standalone project to specify subprojects
Example 2 could also be used to aggregate results via the root project.
|
Warning
|
The JaCoCo Report Aggregation plugin does not currently work with the com.android.application plugin.
|
Tasks
When the project also applies the jvm-test-suite plugin, the following tasks are added for each test suite:
testSuiteCodeCoverageReport— JacocoReport-
Depends on: Artifacts of variants matching the below attributes
Collects variants of direct and transitive project dependencies via the
jacocoAggregationconfiguration. The following Attributes will be matched:
- org.gradle.category = verification // (1)
- org.gradle.testsuite.name = test // (2)
- org.gradle.verificationtype = jacoco-results // (3)-
Category attribute; value is fixed.
-
TestSuiteName attribute; value is derived from TestSuite#getName().
-
VerificationType attribute; value is fixed.
More information about the variants produced by test execution with JaCoCo are available in the Outgoing Variants section of the JaCoCo Plugin documentation.
Reports
|
Important
|
By default, Gradle stops executing tasks when any task fails — including test failures.
To ensure that your builds always generate aggregation reports, specify the |
Automatic report creation
When the project also applies the jvm-test-suite plugin, the following reporting objects are added for each test suite:
testSuiteCodeCoverageReport— JacocoCoverageReport-
Creates an aggregate Jacoco report aggregating all test suites with a given name across all project dependencies.
Manual report creation
When the project does not apply the jvm-test-suite plugin, you must manually register one or more reports:
reporting {
reports {
create<JacocoCoverageReport>("testCodeCoverageReport") { // (1)
testSuiteName = "test"
}
}
}reporting {
reports {
testCodeCoverageReport(JacocoCoverageReport) { // (1)
testSuiteName = "test"
}
}
}-
Creates a report named
testCodeCoverageReportof typeJacocoCoverageReport, aggregating all test suites from all project dependencies with a given TestSuite#getName().
Report creation automatically creates backing tasks to aggregate coverage results for the given test suite type value.
Dependency management
The JaCoCo Report Aggregation plugin adds the following dependency configurations:
| Name | Meaning |
|---|---|
|
The configuration used to declare all project dependencies having code coverage data to be aggregated. |
|
Consumes the project dependencies from the |
It is not necessary to explicitly add dependencies to the jacocoAggregation configuration if the project also applies the jvm-test-suite plugin.
The CodeNarc Plugin
The CodeNarc plugin performs quality checks on your project’s Groovy source files using CodeNarc and generates reports from these checks.
Usage
To use the CodeNarc plugin, include the following in your build script:
plugins {
codenarc
}plugins {
id 'codenarc'
}The plugin adds a number of tasks to the project that perform the quality checks when used with the Groovy Plugin. You can execute the checks by running gradle check.
Tasks
The CodeNarc plugin adds the following tasks to the project:
Dependencies added to other tasks
The CodeNarc plugin adds the following dependencies to tasks defined by the Groovy plugin.
check-
Depends on: All CodeNarc tasks, including
codenarcMainandcodenarcTest.
Project layout
The CodeNarc plugin expects the following project layout:
<root>
└── config
└── codenarc // (1)
└── codenarc.xml // (2)-
CodeNarc configuration files go here
-
Primary CodeNarc configuration file
Dependency management
The CodeNarc plugin adds the following dependency configurations:
| Name | Meaning |
|---|---|
|
The CodeNarc libraries to use |
|
Note
|
If CodeNarc requires a different Groovy version than that used to compile Groovy source, you can supply one using the |
dependencies {
"codenarc"("org.codehaus.groovy:groovy-all:3.0.3")
"codenarc"("org.codenarc:CodeNarc:1.6.1")
}dependencies {
codenarc 'org.codehaus.groovy:groovy-all:3.0.3'
codenarc 'org.codenarc:CodeNarc:1.6.1'
}Configuration
See the CodeNarcExtension class in the API documentation.
The Eclipse Plugins
The Eclipse plugins generate files that are used by the Eclipse IDE, thus making it possible to import the project into Eclipse (File - Import… - Existing Projects into Workspace).
The eclipse-wtp is automatically applied whenever the eclipse plugin is applied to a War or Ear project. For utility projects (i.e. Java projects used by other web projects), you need to apply the eclipse-wtp plugin explicitly.
What exactly the eclipse plugin generates depends on which other plugins are used:
| Plugin | Description |
|---|---|
None |
Generates minimal |
Adds Java configuration to |
|
Adds Groovy configuration to |
|
Adds Scala support to |
|
Adds web application support to |
|
Adds ear application support to |
The eclipse-wtp plugin generates all WTP settings files and enhances the .project file. If a Java or War is applied, .classpath will be extended to get a proper packaging structure for this utility library or web application project.
Both Eclipse plugins are open to customization and provide a standardized set of hooks for adding and removing content from the generated files.
Usage
To use either the Eclipse or the Eclipse WTP plugin, include one of the lines in your build script.
Using the Eclipse plugin:
plugins {
eclipse
}plugins {
id 'eclipse'
}Using the Eclipse WTP plugin:
plugins {
`eclipse-wtp`
}plugins {
id 'eclipse-wtp'
}Note: Internally, the eclipse-wtp plugin also applies the eclipse plugin so you don’t need to apply both.
Both Eclipse plugins add a number of tasks to your projects. The main tasks that you will use are the eclipse and cleanEclipse tasks.
Tasks
|
Warning
|
The tasks listed in this section are deprecated and will be removed in Gradle 10. Modern versions of Eclipse import Gradle projects directly via Buildship without needing these generated files. The rest of the plugin — including the eclipse { … } DSL for customizing how the IDE understands your project — is not deprecated and continues to be consumed by Buildship during Gradle import. See the upgrade guide for details.
|
The Eclipse plugins add the tasks shown below to a project.
Eclipse Plugin tasks
eclipse— Task-
Depends on: all Eclipse configuration file generation tasks
Generates all Eclipse configuration files
cleanEclipse— Delete-
Depends on: all Eclipse configuration file clean tasks
Removes all Eclipse configuration files
cleanEclipseProject— Delete-
Removes the
.projectfile. cleanEclipseClasspath— Delete-
Removes the
.classpathfile. cleanEclipseJdt— Delete-
Removes the
.settings/org.eclipse.jdt.core.prefsfile. eclipseProject— GenerateEclipseProject-
Generates the
.projectfile. eclipseClasspath— GenerateEclipseClasspath-
Generates the
.classpathfile. eclipseJdt— GenerateEclipseJdt-
Generates the
.settings/org.eclipse.jdt.core.prefsfile.
Eclipse WTP Plugin — additional tasks
cleanEclipseWtpComponent— Delete-
Removes the
.settings/org.eclipse.wst.common.componentfile. cleanEclipseWtpFacet— Delete-
Removes the
.settings/org.eclipse.wst.common.project.facet.core.xmlfile. eclipseWtpComponent— GenerateEclipseWtpComponent-
Generates the
.settings/org.eclipse.wst.common.componentfile. eclipseWtpFacet— GenerateEclipseWtpFacet-
Generates the
.settings/org.eclipse.wst.common.project.facet.core.xmlfile.
Configuration
| Model | Reference name | Description |
|---|---|---|
|
Top level element that enables configuration of the Eclipse plugin in a DSL-friendly fashion. |
|
|
Allows configuring project information |
|
|
Allows configuring classpath information. |
|
|
Allows configuring jdt information (source/target Java compatibility). |
|
|
Allows configuring wtp component information only if |
|
|
Allows configuring wtp facet information only if |
Customizing the generated files
The Eclipse plugins allow you to customize the generated metadata files. The plugins provide a DSL for configuring model objects that model the Eclipse view of the project. These model objects are then merged with the existing Eclipse XML metadata to ultimately generate new metadata. The model objects provide lower level hooks for working with domain objects representing the file content before and after merging with the model configuration. They also provide a very low level hook for working directly with the raw XML for adjustment before it is persisted, for fine tuning and configuration that the Eclipse and Eclipse WTP plugins do not model.
Merging
Sections of existing Eclipse files that are also the target of generated content will be amended or overwritten, depending on the particular section. The remaining sections will be left as-is.
Disabling merging with a complete rewrite
To completely rewrite existing Eclipse files, execute a clean task together with its corresponding generation task, like “gradle cleanEclipse eclipse” (in that order). If you want to make this the default behavior, add “tasks.eclipse.dependsOn(cleanEclipse)” to your build script. This makes it unnecessary to execute the clean task explicitly.
This strategy can also be used for individual files that the plugins would generate. For instance, this can be done for the “.classpath” file with “gradle cleanEclipseClasspath eclipseClasspath”.
Hooking into the generation lifecycle
The Eclipse plugins provide objects modeling the sections of the Eclipse files that are generated by Gradle. The generation lifecycle is as follows:
-
The file is read; or a default version provided by Gradle is used if it does not exist
-
The
beforeMergedhook is executed with a domain object representing the existing file -
The existing content is merged with the configuration inferred from the Gradle build or defined explicitly in the eclipse DSL
-
The
whenMergedhook is executed with a domain object representing contents of the file to be persisted -
The
withXmlhook is executed with a raw representation of the XML that will be persisted -
The final XML is persisted
Advanced configuration hooks
The following list covers the domain object used for each of the Eclipse model types:
- EclipseProject
-
-
beforeMerged { Project arg -> … } -
whenMerged { Project arg -> … } -
withXml { XmlProvider arg -> … }
-
- EclipseClasspath
-
-
beforeMerged { Classpath arg -> … } -
whenMerged { Classpath arg -> … } -
withXml { XmlProvider arg -> … }
-
- EclipseWtpComponent
-
-
beforeMerged { WtpComponent arg -> … } -
whenMerged { WtpComponent arg -> … } -
withXml { XmlProvider arg -> … }
-
- EclipseWtpFacet
-
-
beforeMerged { WtpFacet arg -> … } -
whenMerged { WtpFacet arg -> … } -
withXml { XmlProvider arg -> … }
-
- EclipseJdt
-
-
beforeMerged { Jdt arg -> … } -
whenMerged { Jdt arg -> … } -
withProperties { arg -> }argument type ⇒java.util.Properties
-
Partial overwrite of existing content
A complete overwrite causes all existing content to be discarded, thereby losing any changes made directly in the IDE. Alternatively, the beforeMerged hook makes it possible to overwrite just certain parts of the existing content. The following example removes all existing dependencies from the Classpath domain object:
import org.gradle.plugins.ide.eclipse.model.Classpath
eclipse.classpath.file {
beforeMerged(Action<Classpath> {
entries.removeAll { entry -> entry.kind == "lib" || entry.kind == "var" }
})
}eclipse.classpath.file {
beforeMerged { classpath ->
classpath.entries.removeAll { entry -> entry.kind == 'lib' || entry.kind == 'var' }
}
}The resulting .classpath file will only contain Gradle-generated dependency entries, but not any other dependency entries that may have been present in the original file. (In the case of dependency entries, this is also the default behavior.) Other sections of the .classpath file will be either left as-is or merged. The same could be done for the natures in the .project file:
import org.gradle.plugins.ide.eclipse.model.Project
eclipse.project.file.beforeMerged(Action<Project> {
natures.clear()
})eclipse.project.file.beforeMerged { project ->
project.natures.clear()
}Modifying the fully populated domain objects
The whenMerged hook allows to manipulate the fully populated domain objects. Often this is the preferred way to customize Eclipse files. Here is how you would export all the dependencies of an Eclipse project:
import org.gradle.plugins.ide.eclipse.model.AbstractClasspathEntry
import org.gradle.plugins.ide.eclipse.model.Classpath
eclipse.classpath.file {
whenMerged(Action<Classpath> { ->
entries.filter { entry -> entry.kind == "lib" }
.forEach { (it as AbstractClasspathEntry).isExported = false }
})
}eclipse.classpath.file {
whenMerged { classpath ->
classpath.entries.findAll { entry -> entry.kind == 'lib' }*.exported = false
}
}Modifying the XML representation
The withXml hook allows to manipulate the in-memory XML representation just before the file gets written to disk. Although Groovy’s XML support and Kotlin’s extension functions make up for a lot, this approach is less convenient than manipulating the domain objects. In return, you get total control over the generated file, including sections not modeled by the domain objects.
import org.w3c.dom.Element
eclipse.wtp.facet.file.withXml(Action<XmlProvider> {
fun Element.firstElement(predicate: Element.() -> Boolean) =
childNodes
.run { (0 until length).map(::item) }
.filterIsInstance<Element>()
.first { it.predicate() }
asElement()
.firstElement { tagName === "fixed" && getAttribute("facet") == "jst.java" }
.setAttribute("facet", "jst2.java")
})eclipse.wtp.facet.file.withXml { provider ->
provider.asNode().fixed.find { it.@facet == 'jst.java' }.@facet = 'jst2.java'
}Separation of test classpath entries
Eclipse defines only one classpath per project which implies limitations on how Gradle projects can be mapped. Eclipse 4.8 introduced the concept of test sources. This feature allows the Eclipse plugin to define better separation between test and non-test sources.
The Eclipse classpath consists of classpath entries: source directories, jar files, project dependencies, etc.
Each classpath entry can have a list of classpath attributes, where the attributes are string key-value pairs.
There are two classpath attribute relevant for test sources: test and without_test_code, both of which can have true or false as values.
If a source directory has the test=true classpath attribute then the contents are considered test sources.
Test sources have access to non-test sources, but non-test sources don’t have access to test sources.
Similarly, test sources can only reference classes from a jar file if the jar file has the test=true classpath attribute.
For project dependencies if the test=true attribute is present the classes in the target project are visible to test sources.
If the without_test_code=false attribute is present then the test sources of the target project are also accessible. By default, test code is not available (which can be thought of as implicitly having without_test_code=true).
The following rules apply for the test attribute declaration when generating the Eclipse classpath:
-
Source sets and dependency configurations are categorized as test if their name contain the 'test' substring, irrespective of case.
-
All source sets and dependency configurations defined by the JVM test suite plugin are categorized as test.
-
Source directories have the
test=trueclasspath attribute if the container source set is a test source set. -
Jar files and project dependencies have the
test=trueattribute if they are present only in test dependency configurations. -
Project dependencies have the
without_test_sources=falseattribute if the target project applies the java-test-fixtures plugin.
You can customize the test source sets and configurations:
eclipse {
classpath {
testSourceSets = testSourceSets.get() + setOf(integTest)
testConfigurations = testConfigurations.get() + setOf(functional)
}
}eclipse {
classpath {
testSourceSets = testSourceSets.get() + [sourceSets.integTest]
testConfigurations = testConfigurations.get() + [configurations.functional]
}
}|
Tip
|
Consider migrating away from manual definition of additional test source sets and towards the use of the JVM Test Suite Plugin in scenarios like this. |
You can also customize if a project should expose test sources to upstream project dependencies via the containsTestFixtures property.
eclipse {
classpath {
containsTestFixtures = true
}
}eclipse {
classpath {
containsTestFixtures = true
}
}Note, that this configuration also applies to the classpath of Buildship projects.
The IDEA Plugin
The IDEA plugin generates files that are used by IntelliJ IDEA, thus making it possible to open the project from IDEA (File - Open Project). Both external dependencies (including associated source and Javadoc files) and project dependencies are considered.
|
Note
|
If you simply want to load a Gradle project into IntelliJ IDEA, then use the IDE’s import facility. You do not need to apply this plugin to import your project into IDEA, although if you do, the import will take account of any extra IDEA configuration you have that doesn’t directly modify the generated files — see the Configuration section for more details. |
What exactly the IDEA plugin generates depends on which other plugins are used:
- Always
-
Generates an IDEA module file. Also generates an IDEA project and workspace file if the project is the root project.
- Java Plugin
-
Additionally adds Java configuration to the IDEA module and project files.
One focus of the IDEA plugin is to be open to customization. The plugin provides a standardized set of hooks for adding and removing content from the generated files.
Usage
To use the IDEA plugin, include this in your build script:
plugins {
idea
}plugins {
id 'idea'
}The IDEA plugin adds a number of tasks to your project. The idea task generates an IDEA module file for the project. When the project is the root project, the idea task also generates an IDEA project and workspace. The IDEA project includes modules for each of the projects in the Gradle build.
The IDEA plugin also adds an openIdea task when the project is the root project. This task generates the IDEA configuration files and opens the result in IDEA. This means you can simply run ./gradlew openIdea from the root project to generate and open the IDEA project in one convenient step.
The IDEA plugin also adds a cleanIdea task to the project. This task deletes the generated files, if present.
Tasks
|
Warning
|
The tasks listed in this section are deprecated and will be removed in Gradle 10. Modern versions of IntelliJ IDEA import Gradle projects directly via its built-in Gradle integration without needing these generated files. The rest of the plugin — including the idea { … } DSL for customizing how the IDE understands your project — is not deprecated and continues to be consumed by IntelliJ IDEA during Gradle import. See the upgrade guide for details.
|
The IDEA plugin adds the tasks shown below to a project. Notice that the clean task does not depend on the cleanIdeaWorkspace task. This is because the workspace typically contains a lot of user specific temporary data and it is not desirable to manipulate it outside IDEA.
idea-
Depends on:
ideaProject,ideaModule,ideaWorkspaceGenerates all IDEA configuration files
openIdea-
Depends on:
ideaGenerates all IDEA configuration files and opens the project in IDEA
cleanIdea— Delete-
Depends on:
cleanIdeaProject,cleanIdeaModuleRemoves all IDEA configuration files
cleanIdeaProject— Delete-
Removes the IDEA project file
cleanIdeaModule— Delete-
Removes the IDEA module file
cleanIdeaWorkspace— Delete-
Removes the IDEA workspace file
ideaProject— GenerateIdeaProject-
Generates the
.iprfile. This task is only added to the root project. ideaModule— GenerateIdeaModule-
Generates the
.imlfile ideaWorkspace— GenerateIdeaWorkspace-
Generates the
.iwsfile. This task is only added to the root project.
Configuration
The plugin adds some configuration options that allow to customize the IDEA project and module files that it generates. These take the form of both model properties and lower-level mechanisms that modify the generated files directly. For example, you can add source and resource directories, as well as inject your own fragments of XML. The former type of configuration is honored by IDEA’s import facility, whereas the latter is not.
Here are the configuration properties you can use:
idea— IdeaModel-
Top level element that enables configuration of the idea plugin in a DSL-friendly fashion
idea.projectIdeaProject-
Allows configuring project information
idea.moduleIdeaModule-
Allows configuring module information
idea.workspaceIdeaWorkspace-
Allows configuring the workspace XML
Follow the links to the types for examples of using these configuration properties.
Customizing the generated files
The IDEA plugin provides hooks and behavior for customizing the generated content in a more controlled and detailed way. In addition, the withXml hook is the only practical way to modify the workspace file because its corresponding domain object is essentially empty.
|
Note
|
The techniques we discuss in this section don’t work with IDEA’s import facility |
The tasks recognize existing IDEA files and merge them with the generated content.
Merging
Sections of existing IDEA files that are also the target of generated content will be amended or overwritten, depending on the particular section. The remaining sections will be left as-is.
Disabling merging with a complete overwrite
To completely rewrite existing IDEA files, execute a clean task together with its corresponding generation task, like “gradle cleanIdea idea” (in that order). If you want to make this the default behavior, add “tasks.idea.dependsOn(cleanIdea)” to your build script. This makes it unnecessary to execute the clean task explicitly.
This strategy can also be used for individual files that the plugin would generate. For instance, this can be done for the “.iml” file with “gradle cleanIdeaModule ideaModule”.
Hooking into the generation lifecycle
The plugin provides objects modeling the sections of the metadata files that are generated by Gradle. The generation lifecycle is as follows:
-
The file is read; or a default version provided by Gradle is used if it does not exist
-
The
beforeMergedhook is executed with a domain object representing the existing file -
The existing content is merged with the configuration inferred from the Gradle build or defined explicitly in the eclipse DSL
-
The
whenMergedhook is executed with a domain object representing contents of the file to be persisted -
The
withXmlhook is executed with a raw representation of the XML that will be persisted -
The final XML is persisted
The following are the domain objects used for each of the model types:
- IdeaProject
-
-
beforeMerged { Project arg -> … } -
whenMerged { Project arg -> … } -
withXml { XmlProvider arg -> … }
-
- IdeaModule
-
-
beforeMerged { Module arg -> … } -
whenMerged { Module arg -> … } -
withXml { XmlProvider arg -> … }
-
- IdeaWorkspace
-
-
beforeMerged { Workspace arg -> … } -
whenMerged { Workspace arg -> … } -
withXml { XmlProvider arg -> … }
-
Partial rewrite of existing content
A "complete rewrite" causes all existing content to be discarded, thereby losing any changes made directly in the IDE. The beforeMerged hook makes it possible to overwrite just certain parts of the existing content. The following example removes all existing dependencies from the Module domain object:
import org.gradle.plugins.ide.idea.model.Module
idea.module.iml {
beforeMerged(Action<Module> {
dependencies.clear()
})
}idea.module.iml {
beforeMerged { module ->
module.dependencies.clear()
}
}The resulting module file will only contain Gradle-generated dependency entries, but not any other dependency entries that may have been present in the original file. (In the case of dependency entries, this is also the default behavior.) Other sections of the module file will be either left as-is or merged. The same could be done for the module paths in the project file:
import org.gradle.plugins.ide.idea.model.Project
idea.project.ipr {
beforeMerged(Action<Project> {
modulePaths.clear()
})
}idea.project.ipr {
beforeMerged { project ->
project.modulePaths.clear()
}
}Modifying the fully populated domain objects
The whenMerged hook allows you to manipulate the fully populated domain objects. Often this is the preferred way to customize IDEA files. Here is how you would export all the dependencies of an IDEA module:
import org.gradle.plugins.ide.idea.model.Module
import org.gradle.plugins.ide.idea.model.ModuleDependency
idea.module.iml {
whenMerged(Action<Module> {
dependencies.forEach {
(it as ModuleDependency).isExported = true
}
})
}idea.module.iml {
whenMerged { module ->
module.dependencies*.exported = true
}
}Modifying the XML representation
The withXml hook allows you to manipulate the in-memory XML representation just before the file gets written to disk. Although Groovy’s XML support and Kotlin’s extension functions make up for a lot, this approach is less convenient than manipulating the domain objects. In return, you get total control over the generated file, including sections not modeled by the domain objects.
import org.w3c.dom.Element
idea.project.ipr {
withXml(Action<XmlProvider> {
fun Element.firstElement(predicate: (Element.() -> Boolean)) =
childNodes
.run { (0 until length).map(::item) }
.filterIsInstance<Element>()
.first { it.predicate() }
asElement()
.firstElement { tagName == "component" && getAttribute("name") == "VcsDirectoryMappings" }
.firstElement { tagName == "mapping" }
.setAttribute("vcs", "Git")
})
}idea.project.ipr {
withXml { provider ->
provider.node.component
.find { it.@name == 'VcsDirectoryMappings' }
.mapping.@vcs = 'Git'
}
}Identifying additional test directories
When using this plugin together with the Java plugin, after adding additional source sets you may wish to inform IDEA when they contain test source rather than production source, so that the IDE can treat the directories appropriately. This can be accomplished by using this plugin’s Module block.
sourceSets {
create("intTest") {
java {
setSrcDirs(listOf("src/integration"))
}
}
}
idea {
module {
testSources.from(sourceSets["intTest"].java.srcDirs)
}
}sourceSets {
intTest {
java {
srcDirs = ['src/integration']
}
}
}
idea {
module {
testSources.from(sourceSets.intTest.java.srcDirs)
}
}|
Note
|
When working with the JVM Test Suite Plugin, test sources will automatically identified correctly. |
Further things to consider
The paths of dependencies in the generated IDEA files are absolute. If you manually define a path variable pointing to the Gradle dependency cache, IDEA will automatically replace the absolute dependency paths with this path variable. you can configure this path variable via the “idea.pathVariables” property, so that it can do a proper merge without creating duplicates.
Visual Studio
The Visual Studio Plugin generate files that are used by the Visual Studio IDE, thus making it possible to open the solution into Visual Studio (File - Open - Project/Solution…).
What exactly the visual-studio plugin generates depends on which other plugins are used:
| Plugin | Description |
|---|---|
None |
Generates minimal solution file. |
Adds a project representing the C++ application to the solution file. |
|
Adds a project for each specified linkage representing the shared and/or static library to the solution file. |
Usage
plugins {
`visual-studio`
}plugins {
id 'visual-studio'
}The Visual Studio Plugin adds a number of tasks to your project.
The main tasks that you will use are the visualStudio, cleanVisualStudio and openVisualStudio tasks.
Tasks
The following diagram shows the relationships between tasks added by this plugin.
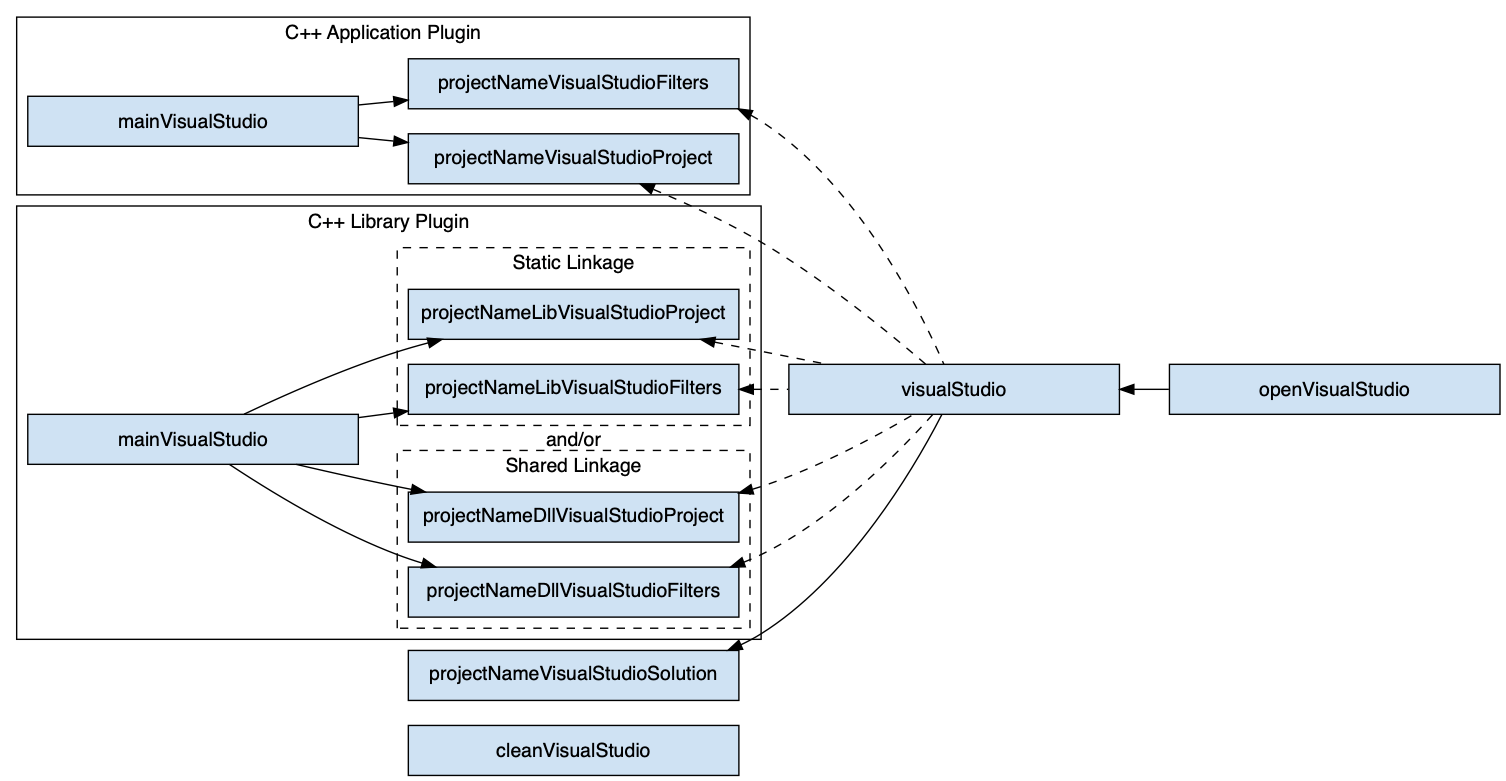
Lifecycle Tasks
visualStudio— Task-
Depends on:
projectNameVisualStudioSolutionand all Visual Studio project file generation tasksGenerates all Visual Studio configuration files.
cleanVisualStudio— Delete-
Depends on: all Visual Studio project and solution file clean tasks
Removes all Visual Studio configuration files.
openVisualStudio- Task-
Depends on:
visualStudioOpen the Visual Studio solution inside the IDE.
IDE Workspace Tasks
projectNameVisualStudioSolution- GenerateSolutionFileTask-
Generates the
.slnfile. This task is only available on the root project.
IDE Project Tasks
C++ Application Plugin Tasks
projectNameVisualStudioProject— GenerateProjectFileTask-
Generates the
.vcxprojfile for the application component. projectNameVisualStudioFilters— GenerateFiltersFileTask-
Generates the
.vcxproj.filtersfile for the application component. mainVisualStudio- Task (lifecycle)-
Depends on:
projectNameVisualStudioProjectandprojectNameVisualStudioFiltersGenerates all Visual Studio project files for the application component.
C++ Library Plugin Tasks
projectNameDllVisualStudioProject— GenerateProjectFileTask-
Generates the
.vcxprojfile for the shared linkage of themaincomponent. projectNameDllVisualStudioFilters— GenerateFiltersFileTask-
Generates the
.vcxproj.filtersfile for the shared linkage of themaincomponent. projectNameLibVisualStudioProject— GenerateProjectFileTask-
Generates the
.vcxprojfile for the static linkage of themaincomponent. projectNameLibVisualStudioFilters— GenerateFiltersFileTask-
Generates the
.vcxproj.filtersfile for the static linkage of themaincomponent. mainVisualStudio- Task (lifecycle)-
Depends on:
projectNameDllVisualStudioProject(for shared linkage),projectNameDllVisualStudioFilters(for shared linkage),projectNameLibVisualStudioProject(for static linkage) andprojectNameLibVisualStudioFilters(for static linkage)Generates all Visual Studio project files for the library component.
Configuration
The Visual Studio Plugin allows for some customization of the generated files. The following sections are shows the customization.
Change solution generated file location
The location of the generated solution can be configured on the root project:
visualStudio {
solution {
solutionFile.setLocation(file("solution.sln"))
}
}visualStudio {
solution {
solutionFile.location = file('solution.sln')
}
}Change project generated files location
The location of the generated project files can be configured on any project:
visualStudio {
projects.all {
projectFile.setLocation(file("project.vcxproj"))
filtersFile.setLocation(file("project.vcxproj.filters"))
}
}visualStudio {
projects.all {
projectFile.location = file('project.vcxproj')
filtersFile.location = file('project.vcxproj.filters')
}
}Xcode
The Xcode Plugin generate files that are used by the Xcode IDE to open Gradle projects into Xcode (File - Open…). The generated Xcode project delegates build actions to Gradle.
What exactly the xcode plugin generates depends on which other plugins are used:
| Plugin | Description |
|---|---|
None |
Generates minimal solution file. |
Adds a target representing the C++ application to the project file. |
|
Adds a target for each specified linkage representing the shared and/or static library to the project file. |
|
Adds a target representing the Swift application to the project file. |
|
Adds a target for each specified linkage representing the shared and/or static library to the project file. |
|
Adds a target representing the XCTest bundle to the project file. |
Usage
plugins {
xcode
}plugins {
id 'xcode'
}Tasks
The Xcode Plugin adds a number of tasks to your project.
The main tasks that you will use are the xcode, cleanXcode and openXcode tasks.
The following diagram shows the relationships between tasks added by this plugin.
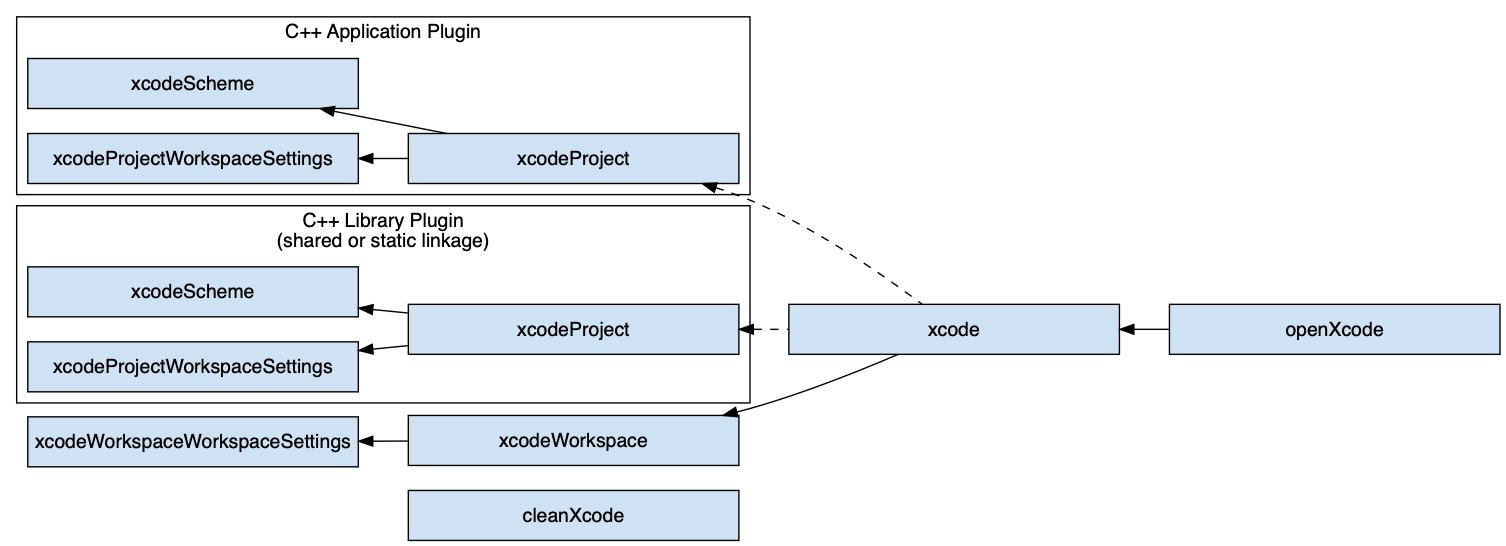
Lifecycle Tasks
xcode— Task-
Depends on:
projectNameXcodeWorkspaceand allxcodeProjecttasksGenerates all Xcode configuration files.
cleanXcode— Delete-
Depends on: all Xcode project and workspace file clean tasks
Removes all Xcode configuration files.
openXcode- Task-
Depends on:
xcodeOpen the Xcode workspace inside the IDE.
IDE Workspace Tasks
xcodeWorkspaceWorkspaceSettings- GenerateWorkspaceSettingsFileTask-
Generates the
projectName.xcworkspacefile. This task is only available on the root project. xcodeWorkspace- GenerateXcodeProjectFileTask-
Depends on:
xcodeWorkspaceWorkspaceSettingsGenerates the
projectName.xcworkspacefile. This task is only available on the root project.
IDE Project Tasks
Both the C++ Application Plugin and C++ Library Plugin introduce the same tasks for generating Xcode projects to be included in an Xcode workspace.
xcodeProjectWorkspaceSettings— GenerateWorkspaceSettingsFileTask-
Generates the
projectName.xcodeproj/project.xcworkspace/xcshareddata/WorkspaceSettings.xcsettingsfile. xcodeScheme— GenerateSchemeFileTask-
Generates the
projectName.xcodeproj/xcshareddata/xcschemes/ProjectName.xcschemefile. xcodeProject— GenerateXcodeProjectFileTask-
Depends on:
xcodeProjectWorkspaceSettingsandxcodeScheme(if buildable binary present)Generates the
projectName.xcodeproj/project.pbxprojfile.
Configuration
The Xcode Plugin doesn’t allows any customization of the generated files.
The Base Plugin
The Base Plugin provides some tasks and conventions that are common to most builds and adds a structure to the build that promotes consistency in how they are run. Its most significant contribution is a set of lifecycle tasks that act as an umbrella for the more specific tasks provided by other plugins and build authors.
Usage
Applying the Base Plugin:
plugins {
base
}plugins {
id 'base'
}Task
clean—Delete-
Deletes the build directory and everything in it, i.e. the path specified by the layout.buildDirectory project property.
check— lifecycle task-
Plugins and build authors should attach their verification tasks, such as ones that run tests, to this lifecycle task using
check.dependsOn(task). assemble— lifecycle task-
Plugins and build authors should attach tasks that produce distributions and other consumable artifacts to this lifecycle task. For example,
jarproduces the consumable artifact for Java libraries. Attach tasks to this lifecycle task usingassemble.dependsOn(task). build— lifecycle task-
Depends on:
check,assembleIntended to build everything, including running all tests, producing the production artifacts and generating documentation. You will probably rarely attach concrete tasks directly to
buildasassembleandcheckare typically more appropriate. buildConfiguration— task rule-
Assembles those artifacts attached to the named configuration. For example,
buildRuntimeElementswill execute any task that is required to create any artifact attached to theruntimeElementsconfiguration. cleanTask— task rule-
Removes the defined outputs of a task, e.g.
cleanJarwill delete the JAR file produced by thejartask of the Java Plugin.
Dependency management
The Base Plugin adds no configurations for dependencies, but it does add the following configurations:
default-
A fallback configuration used when dependency resolution is performed without request attributes.
New builds and plugins should not be using the
defaultconfiguration! It remains solely for backwards compatibility. Dependency resolution should be performed with request attributes. archives-
All artifacts defined on the
archivesconfiguration are automatically built by theassembletask.New builds and plugins should not be using the
archivesconfiguration! It remains solely for backwards compatibility. Instead, task dependencies should be declared directly on theassembletask.
Contributed extensions
The Base Plugin adds the base extension to the project.
This allows to configure the following properties inside a dedicated DSL block.
base {
archivesName = "gradle"
distsDirectory = layout.buildDirectory.dir("custom-dist")
libsDirectory = layout.buildDirectory.dir("custom-libs")
}base {
archivesName = "gradle"
distsDirectory = layout.buildDirectory.dir('custom-dist')
libsDirectory = layout.buildDirectory.dir('custom-libs')
}archivesName— default:$project.name-
Provides the default AbstractArchiveTask.getArchiveBaseName() for archive tasks.
distsDirectory— default:layout.buildDirectory.dir("distributions")-
Default name of the directory in which distribution archives, i.e. non-JARs, are created.
libsDirectory— default:layout.buildDirectory.dir("libs")-
Default name of the directory in which library archives, i.e. JARs, are created.
The plugin also provides default values for the following properties on any task that extends AbstractArchiveTask:
destinationDirectory-
Defaults to
distsDirectoryfor non-JAR archives andlibsDirectoryfor JARs and derivatives of JAR, such as WARs. archiveVersion-
Defaults to
$project.versionor 'unspecified' if the project has no version. archiveBaseName-
Defaults to
archivesName.
Build Init Plugin
The Build Init plugin can be used to create a new Gradle build. It supports creating brand new Gradle builds of various types as well as converting existing Apache Maven builds to Gradle.
Sample usage
gradle init \
--type java-application \
--dsl kotlin \
--test-framework junit-jupiter \
--package my.project \
--into ./my-project \
--project-name my-project \
--no-split-project \
--java-version 17Gradle enters interactive mode and prompts the user when a required parameter for the selected project type is missing.
Supported Gradle build types
The Build Init plugin supports generating various build types. These are listed below and more detail is available about each type in the following section.
| Type | Description |
|---|---|
Converts an existing Apache Maven build to Gradle |
|
A basic, empty, Gradle build |
|
A command-line application implemented in Java |
|
A Gradle plugin implemented in Java |
|
A Java library |
|
A command-line application implemented in Kotlin/JVM |
|
A Gradle plugin implemented in Kotlin/JVM |
|
A Kotlin/JVM library |
|
A command-line application implemented in Groovy |
|
A Gradle plugin implemented in Groovy |
|
A Groovy library |
|
A Scala application |
|
A Scala library |
|
A command-line application implemented in C++ |
|
A C++ library |
Tasks
The plugin adds the following tasks to the project:
init — InitBuild
Generates a Gradle build.
Gradle plugins usually need to be applied to a project before they can be used (see Using plugins). However, the Build Init plugin is automatically applied to the root project of every build, which means you do not need to apply it explicitly in order to use it. You can simply execute the task named init in the directory where you would like to create the Gradle build. There is no need to create a "stub" build.gradle file in order to apply the plugin.
What to create
The simplest, and recommended, way to use the init task is to run gradle init from an interactive console. Gradle will list the available build types and ask you to select one. It will then ask some additional questions to allow you to fine-tune the result.
There are several command-line options available for the init task that control what it will generate. You can use these when Gradle is not running from an interactive console.
You can see available options using the help task:
gradle help --task initThe build type can be specified by using the --type command-line option.
For example, to create a Java library project run:
gradle init --type java-libraryIf a --type option is not provided, Gradle will attempt to infer the type from the environment. For example, it will infer a type of “pom” if it finds a pom.xml file to convert to a Gradle build. If the type could not be inferred, the type “basic” will be used.
The init task also supports generating build scripts using either the Gradle Kotlin DSL or the Gradle Groovy DSL. The build script DSL defaults to the Kotlin DSL for most build types and to the Groovy DSL for Groovy build types. The DSL can be selected by using the --dsl command-line option.
For example, to create a Java library project with Kotlin DSL build scripts, run:
gradle init --type java-library --dsl kotlinYou can change the directory for the generated project using the --into option. It defaults to the directory where the init task is run.
You can change the name of the generated project using the --project-name option. It defaults to the name of the directory where the init task is run.
You can change the package used for generated source files using the --package option. It defaults to the project name.
If the --incubating option is provided, Gradle will generate build scripts which may use the latest versions of APIs, which are marked @Incubating and remain subject to change. To disable this behavior, use --no-incubating.
If the --overwrite option is provided, Gradle will overwrite any existing files in the directory where the init task runs. By default, init will prompt the user to continue if Gradle finds any files in the directory.
All build types also set up Gradle Wrapper in the build.
Options
| Option | Description | Example |
|---|---|---|
|
Include clarifying comments in files. User can also use the property |
|
|
Allow the generated build to use new features and APIs. |
|
|
Use default values for options not configured explicitly. |
|
|
Allow existing files in the build directory to be overwritten. |
|
|
Split functionality across multiple subprojects? |
|
|
Provides java version to use in the project. |
|
|
How to handle insecure URLs used for Maven Repositories. |
|
|
Set the type of project to generate. |
|
|
Set the build script DSL to be used in generated scripts. |
|
|
Set the test framework to be used. |
|
|
Set the project name. Defaults to the name of the directory. |
|
|
Set the package for source files. |
|
Build init types
pom build type (Maven conversion)
The “pom” type can be used to convert an Apache Maven build to a Gradle build. This works by converting the POM to one or more Gradle files. It is only able to be used if there is a valid “pom.xml” file in the directory that the init task is invoked in or, if invoked via the “-p” command line option, in the specified project directory. This “pom” type will be automatically inferred if such a file exists.
The Maven conversion implementation was inspired by the maven2gradle tool that was originally developed by Gradle community members.
The conversion process has the following features:
-
Uses effective POM and effective settings (support for POM inheritance, dependency management, properties)
-
Supports both single module and multimodule projects
-
Supports custom module names (that differ from directory names)
-
Generates general metadata - id, description and version
-
Applies Maven Publish, Java Library and War Plugins (as needed)
-
Supports packaging war projects as jars if needed
-
Generates dependencies (both external and inter-module)
-
Generates download repositories (inc. local Maven repository)
-
Adjusts Java compiler settings
-
Supports packaging of sources, tests, and javadocs
-
Supports TestNG runner
-
Generates global exclusions from Maven enforcer plugin settings
-
Generates dependency excludes from Maven
exclusions -
Provides an option for handling Maven repositories located at URLs using
http
|
Note
|
Due to fundamental differences between Maven and Gradle, not all features of a Maven build can be converted to Gradle. For example, Maven exclusions work differently from Gradle exclusions. The generated Gradle build should be considered a starting point for further refinement. |
The --insecure-protocol option
This option is used to tell the conversion process how to handle converting Maven repositories located at insecure http URLs. Insecure Repositories Set the
--insecure-protocol option. The default value is warn.
Available values are:
-
fail- Abort the build immediately upon encountering an insecure repository URL. -
allow- Automatically sets theallowInsecureProtocolproperty totruefor the Maven repository URL in the generated Gradle build script. -
warn- Emits a warning about each insecure URL. Generates commented-out lines to enable each repository, as per theallowoption. You will have to opt-in by editing the generated script and uncommenting each repository URL, or else the Gradle build will fail. -
upgrade- ConverthttpURLs tohttpsURLs automatically.
Compile-time dependencies
Maven automatically exposes dependencies using its implicit compile scope to the consumers of that project.
This behavior is undesirable, and Gradle takes steps to help library authors reduce their API footprint using the api and implementation configurations of the java-library plugin.
Nevertheless, many Maven projects rely on this leaking behavior. As such, the init task will map compile-scoped dependencies to the api configuration in the generated Gradle build script. The dependencies of the resulting Gradle project will most closely match the exposed dependencies of the existing Maven project; however, post-conversion to Gradle we strongly encourage moving as many api dependencies to the implementation configuration as possible. This has several benefits:
-
Library maintainability - By exposing fewer transitive dependencies to consumers, library maintainers can add or remove dependencies without fear of causing compile-time breakages for consumers.
-
Consumers' dependency hygiene - Leveraging the
implementationconfiguration in a library prevents its consumers from implicitly relying on the library’s transitive dependencies at compile-time, which is considered a bad practice. -
Increased compile avoidance - Reducing the number of transitive dependencies leaked from a project also reduces the likelihood that an ABI change will trigger recompilation of consumers. Gradle will also spend less time indexing the dependencies for its up-to-date checks.
-
Compilation speed increase - Reducing the number of transitive dependencies leaked from a project aids the compiler process of its consumers as there are fewer libraries to classload and fewer namespaces for Gradle’s incremental compiler to track.
See the API and implementation separation and Compilation avoidance sections for more information.
java-application build type
The “java-application” build type is not inferable. It must be explicitly specified.
It has the following features:
-
Uses the “application” plugin to produce a command-line application implemented in Java
-
Uses the “mavenCentral” dependency repository
-
Uses JUnit 4 for testing
-
Has directories in the conventional locations for source code
-
Contains a sample class and unit test, if there are no existing source or test files
Alternative test framework can be specified by supplying a --test-framework argument value. To use a different test framework, execute one of the following commands:
-
gradle init --type java-application --test-framework junit-jupiter: Uses JUnit Jupiter for testing instead of JUnit 4 -
gradle init --type java-application --test-framework spock: Uses Spock for testing instead of JUnit 4 -
gradle init --type java-application --test-framework testng: Uses TestNG for testing instead of JUnit 4
The --java-version option
When creating a java project you must set the java version. You can do that by supplying the major version of java you wish to use:
gradle init --type java-application --java-version 11 --dsl kotlin # and other parametersjava-library build type
The “java-library” build type is not inferable. It must be explicitly specified.
It has the following features:
-
Uses the “java” plugin to produce a library implemented in Java
-
Uses the “mavenCentral” dependency repository
-
Uses JUnit 4 for testing
-
Has directories in the conventional locations for source code
-
Contains a sample class and unit test, if there are no existing source or test files
Alternative test framework can be specified by supplying a --test-framework argument value. To use a different test framework, execute one of the following commands:
-
gradle init --type java-library --test-framework junit-jupiter: Uses JUnit Jupiter for testing instead of JUnit 4 -
gradle init --type java-library --test-framework spock: Uses Spock for testing instead of JUnit 4 -
gradle init --type java-library --test-framework testng: Uses TestNG for testing instead of JUnit 4
java-gradle-plugin build type
The “java-gradle-plugin” build type is not inferable. It must be explicitly specified.
It has the following features:
-
Uses the “java-gradle-plugin” plugin to produce a Gradle plugin implemented in Java
-
Uses the “mavenCentral” dependency repository
-
Uses JUnit 4 and TestKit for testing
-
Has directories in the conventional locations for source code
-
Contains a sample class and unit test, if there are no existing source or test files
kotlin-application build type
The “kotlin-application” build type is not inferable. It must be explicitly specified.
It has the following features:
-
Uses the “org.jetbrains.kotlin.jvm” and “application” plugins to produce a command-line application implemented in Kotlin
-
Uses the “mavenCentral” dependency repository
-
Uses Kotlin 1.x
-
Uses Kotlin test library for testing
-
Has directories in the conventional locations for source code
-
Contains a sample Kotlin class and an associated Kotlin test class, if there are no existing source or test files
kotlin-library build type
The “kotlin-library” build type is not inferable. It must be explicitly specified.
It has the following features:
-
Uses the “org.jetbrains.kotlin.jvm” plugin to produce a library implemented in Kotlin
-
Uses the “mavenCentral” dependency repository
-
Uses Kotlin 1.x
-
Uses Kotlin test library for testing
-
Has directories in the conventional locations for source code
-
Contains a sample Kotlin class and an associated Kotlin test class, if there are no existing source or test files
kotlin-gradle-plugin build type
The “kotlin-gradle-plugin” build type is not inferable. It must be explicitly specified.
It has the following features:
-
Uses the “java-gradle-plugin” and “org.jetbrains.kotlin.jvm” plugins to produce a Gradle plugin implemented in Kotlin
-
Uses the “mavenCentral” dependency repository
-
Uses Kotlin 1.x
-
Uses Kotlin test library and TestKit for testing
-
Has directories in the conventional locations for source code
-
Contains a sample class and unit test, if there are no existing source or test files
scala-application build type
The “scala-application” build type is not inferable. It must be explicitly specified.
It has the following features:
-
Uses the “scala” plugin to produce an application implemented in Scala
-
Uses the “mavenCentral” dependency repository
-
Uses Scala 2.13
-
Uses ScalaTest for testing
-
Has directories in the conventional locations for source code
-
Contains a sample Scala class and an associated ScalaTest test suite, if there are no existing source or test files
scala-library build type
The “scala-library” build type is not inferable. It must be explicitly specified.
It has the following features:
-
Uses the “scala” plugin to produce a library implemented in Scala
-
Uses the “mavenCentral” dependency repository
-
Uses Scala 2.13
-
Uses ScalaTest for testing
-
Has directories in the conventional locations for source code
-
Contains a sample Scala class and an associated ScalaTest test suite, if there are no existing source or test files
groovy-library build type
The “groovy-library” build type is not inferable. It must be explicitly specified.
It has the following features:
-
Uses the “groovy” plugin to produce a library implemented in Groovy
-
Uses the “mavenCentral” dependency repository
-
Uses Groovy 2.x
-
Uses Spock testing framework for testing
-
Has directories in the conventional locations for source code
-
Contains a sample Groovy class and an associated Spock specification, if there are no existing source or test files
groovy-application build type
The “groovy-application” build type is not inferable. It must be explicitly specified.
It has the following features:
-
Uses the “application” and “groovy” plugins to produce a command-line application implemented in Groovy
-
Uses the “mavenCentral” dependency repository
-
Uses Groovy 2.x
-
Uses Spock testing framework for testing
-
Has directories in the conventional locations for source code
-
Contains a sample Groovy class and an associated Spock specification, if there are no existing source or test files
groovy-gradle-plugin build type
The “groovy-gradle-plugin” build type is not inferable. It must be explicitly specified.
It has the following features:
-
Uses the “java-gradle-plugin” and “groovy” plugins to produce a Gradle plugin implemented in Groovy
-
Uses the “mavenCentral” dependency repository
-
Uses Groovy 2.x
-
Uses Spock testing framework and TestKit for testing
-
Has directories in the conventional locations for source code
-
Contains a sample class and unit test, if there are no existing source or test files
cpp-application build type
The “cpp-application” build type is not inferable. It must be explicitly specified.
It has the following features:
-
Uses the “cpp-application” plugin to produce a command-line application implemented in C++
-
Uses the “cpp-unit-test” plugin to build and run simple unit tests
-
Has directories in the conventional locations for source code
-
Contains a sample C++ class, a private header file and an associated test class, if there are no existing source or test files
cpp-library build type
The “cpp-library” build type is not inferable. It must be explicitly specified.
It has the following features:
-
Uses the “cpp-library” plugin to produce a C++ library
-
Uses the “cpp-unit-test” plugin to build and run simple unit tests
-
Has directories in the conventional locations for source code
-
Contains a sample C++ class, a public header file and an associated test class, if there are no existing source or test files
basic build type
The “basic” build type is useful for creating a new Gradle build. It creates sample settings and build files, with comments and links to help get started.
This type is used when no type was explicitly specified, and no type could be inferred.
POM exclusion importing
When generating a Gradle build from an existing Maven project, dependency exclusions in the pom.xml are translated into the equivalent Gradle syntax:
<dependencies>
<dependency>
<groupId>sample.Project</groupId>
<artifactId>Project</artifactId>
<version>1.0</version>
<exclusions>
<exclusion>
<groupId>excluded.group</groupId>
<artifactId>excluded-artifact</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>Because Maven and Gradle handle dependency resolution and exclusions differently, a direct translation may not always be perfectly equivalent.
To ensure build integrity, generated exclusions include a TODO comment for manual verification:
dependencies {
implementation("some.group:some-artifact:1.0") {
// TODO: This exclude was sourced from a POM exclusion and is NOT exactly equivalent
exclude(group = "excluded.group", module = "excluded-artifact")
}
}dependencies {
implementation('some.group:some-artifact:1.0') {
// TODO: This exclude was sourced from a POM exclusion and is NOT exactly equivalent
exclude group: 'excluded.group', module: 'excluded-artifact'
}
}The Signing Plugin
The Signing Plugin adds the ability to digitally sign built files and artifacts. These digital signatures can then be used to prove who built the artifact the signature is attached to as well as other information such as when the signature was generated.
The Signing Plugin currently only provides support for generating OpenPGP signatures (which is the signature format required for publication to the Maven Central Repository).
Usage
To use the Signing Plugin, include the following in your build script:
plugins {
signing
}plugins {
id 'signing'
}Signatory credentials
In order to create OpenPGP signatures, you will need a key pair (instructions on creating a key pair using the GnuPG tools can be found in the GnuPG HOWTOs). You need to provide the Signing Plugin with your key information, which means three things:
-
The public key ID (The last 8 symbols of the keyId. You can use
gpg -Kto get it). -
The absolute path to the secret key ring file containing your private key. (Since gpg 2.1, you need to export the keys with command
gpg --keyring secring.gpg --export-secret-keys > ~/.gnupg/secring.gpg). -
The passphrase used to protect your private key.
These items must be supplied as the values of the signing.keyId, signing.secretKeyRingFile, and signing.password properties, respectively.
|
Note
|
Given the personal and private nature of these values, a good practice is to store them in the gradle.properties file in the user’s Gradle home directory (described in System properties) instead of in the project directory itself.
|
signing.keyId=24875D73
signing.password=secret
signing.secretKeyRingFile=/Users/me/.gnupg/secring.gpgIf specifying this information (especially signing.password) in the user gradle.properties file is not feasible for your environment, you can supply the information via the command line:
$ ./gradlew sign -Psigning.secretKeyRingFile=/Users/me/.gnupg/secring.gpg -Psigning.password=secret -Psigning.keyId=24875D73Using in-memory ascii-armored keys
In some setups it is easier to use environment variables to pass the secret key and password used for signing.
For instance, when using a CI server to sign artifacts, securely providing the keyring file is often troublesome.
On the other hand, most CI servers provide means to securely store environment variables and provide them to builds.
Using the following setup, you can pass the secret key (in ascii-armored format) and the password using the ORG_GRADLE_PROJECT_signingKey and ORG_GRADLE_PROJECT_signingPassword environment variables, respectively:
signing {
val signingKey = project.findProperty("signingKey") as String?
val signingPassword = project.findProperty("signingPassword") as String?
useInMemoryPgpKeys(signingKey, signingPassword)
sign(tasks["stuffZip"])
}signing {
def signingKey = findProperty("signingKey")
def signingPassword = findProperty("signingPassword")
useInMemoryPgpKeys(signingKey, signingPassword)
sign stuffZip
}Using in-memory ascii-armored OpenPGP subkeys
To prevent sharing of the master key and to keep it secure it is also possible to use in-memory ascii-armored subkeys.
The main difference between using in-memory ascii-armored keys and subkeys is that it is necessary to specify key identifier as well.
Using the following setup, you can pass the key identifier, secret key (in ascii-armored format) and the password using the ORG_GRADLE_PROJECT_signingKeyId, ORG_GRADLE_PROJECT_signingKey and ORG_GRADLE_PROJECT_signingPassword
environment variables respectively:
signing {
val signingKeyId = project.findProperty("signingKeyId") as String?
val signingKey = project.findProperty("signingKey") as String?
val signingPassword = project.findProperty("signingPassword") as String?
useInMemoryPgpKeys(signingKeyId, signingKey, signingPassword)
sign(tasks["stuffZip"])
}signing {
def signingKeyId = findProperty("signingKeyId")
def signingKey = findProperty("signingKey")
def signingPassword = findProperty("signingPassword")
useInMemoryPgpKeys(signingKeyId, signingKey, signingPassword)
sign stuffZip
}Using OpenPGP subkeys
OpenPGP supports subkeys, which are like the normal keys, except they’re bound to a master key pair. One feature of OpenPGP subkeys is that they can be revoked independently of the master keys which makes key management easier. A practical case study of how subkeys can be leveraged in software development can be read on the Debian wiki.
The Signing Plugin supports OpenPGP subkeys out of the box. Just specify a subkey ID as the value in the signing.keyId property.
Using gpg-agent
By default the Signing Plugin uses a Java-based implementation of PGP for signing. This implementation cannot use the gpg-agent program for managing private keys, though. If you want to use the gpg-agent, you can change the signatory implementation used by the Signing Plugin:
signing {
useGpgCmd()
sign(configurations.runtimeElements.get())
}signing {
useGpgCmd()
sign configurations.runtimeElements
}This tells the Signing Plugin to use the GnupgSignatory instead of the default PgpSignatory. The GnupgSignatory relies on the gpg2 program to sign the artifacts. Of course, this requires that GnuPG is installed.
Without any further configuration the gpg (on Windows: gpg.exe) executable found on the PATH will be used. The password is supplied by the gpg-agent and the default key is used for signing.
Gnupg signatory configuration
The GnupgSignatory supports a number of configuration options for controlling how gpg is invoked. These are typically set in gradle.properties:
Example: Configure the GnupgSignatory
signing.gnupg.executable=gpg
signing.gnupg.useLegacyGpg=true
signing.gnupg.homeDir=gnupg-home
signing.gnupg.optionsFile=gnupg-home/gpg.conf
signing.gnupg.keyName=24875D73
signing.gnupg.passphrase=gradlesigning.gnupg.executable-
The gpg executable that is invoked for signing. The default value of this property depends on
useLegacyGpg. If that istruethen the default value of executable is "gpg" otherwise it is "gpg2". signing.gnupg.useLegacyGpg-
Must be
trueif GnuPG version 1 is used andfalseotherwise. The default value of the property isfalse. signing.gnupg.homeDir-
Sets the home directory for GnuPG. If not given the default home directory of GnuPG is used.
signing.gnupg.optionsFile-
Sets a custom options file for GnuPG. If not given GnuPG’s default configuration file is used.
signing.gnupg.keyName-
The id of the key that should be used for signing. If not given then the default key configured in GnuPG will be used.
signing.gnupg.passphrase-
The passphrase for unlocking the secret key. If not given then the gpg-agent program is used for getting the passphrase.
All configuration properties are optional.
Specifying what to sign
As well as configuring how things are to be signed (i.e. the signatory configuration), you must also specify what is to be signed. The Signing Plugin provides a DSL that allows you to specify the tasks and/or configurations that should be signed.
Signing Publications
When publishing artifacts, you often want to sign them so the consumer of your artifacts can verify their signature. For example, the Java plugin defines a component that you can use to define a publication to a Maven (or Ivy) repository using the Maven Publish Plugin (or the Ivy Publish Plugin, respectively). Using the Signing DSL, you can specify that all of the artifacts of this publication should be signed.
signing {
sign(publishing.publications["mavenJava"])
}signing {
sign publishing.publications.mavenJava
}This will create a task (of type Sign) in your project named signMavenJavaPublication that will build all artifacts that are part of the publication (if needed) and then generate signatures for them. The signature files will be placed alongside the artifacts being signed.
Example: Signing a publication output
$ ./gradlew signMavenJavaPublication> Task :compileJava
> Task :processResources
> Task :classes
> Task :jar
> Task :javadoc
> Task :javadocJar
> Task :sourcesJar
> Task :generateMetadataFileForMavenJavaPublication
> Task :generatePomFileForMavenJavaPublication
> Task :signMavenJavaPublication
BUILD SUCCESSFUL in 0s
9 actionable tasks: 9 executedIn addition, the above DSL allows to sign multiple comma-separated publications. Alternatively, you may specify publishing.publications to sign all publications, or use publishing.publications.matching { … } to sign all publications that match the specified predicate.
Signing Configurations
It is common to want to sign the artifacts of a configuration. For example, the Java plugin configures a jar to build and this jar artifact is added to the runtimeElements configuration. Using the Signing DSL, you can specify that all of the artifacts of this configuration should be signed.
signing {
sign(configurations.runtimeElements.get())
}signing {
sign configurations.runtimeElements
}This will create a task (of type Sign) in your project named signRuntimeElements, that will build any runtimeElements artifacts (if needed) and then generate signatures for them. The signature files will be placed alongside the artifacts being signed.
Example: Signing a configuration output
$ ./gradlew signRuntimeElements> Task :compileJava
> Task :processResources
> Task :classes
> Task :jar
> Task :signRuntimeElements
BUILD SUCCESSFUL in 0s
4 actionable tasks: 4 executedSigning Task Output
In some cases the artifact that you need to sign may not be part of a configuration. In this case you can directly sign the task that produces the artifact to sign.
tasks.register<Zip>("stuffZip") {
archiveBaseName = "stuff"
from("src/stuff")
}
signing {
sign(tasks["stuffZip"])
}tasks.register('stuffZip', Zip) {
archiveBaseName = 'stuff'
from 'src/stuff'
}
signing {
sign stuffZip
}This will create a task (of type Sign) in your project named signStuffZip, that will build the input task’s archive (if needed) and then sign it.
The signature file will be placed alongside the artifact being signed.
Example: Signing a task output
$ ./gradlew signStuffZip> Task :stuffZip
> Task :signStuffZip
BUILD SUCCESSFUL in 0s
2 actionable tasks: 2 executedConditional Signing
A common usage pattern is to require the signing of build artifacts only under certain conditions.
For example, you may not need to sign artifacts for non-release versions.
To achieve this, you can specify the condition as an argument of the required() method.
version = "1.0-SNAPSHOT"
extra["isReleaseVersion"] = !version.toString().endsWith("SNAPSHOT")
signing {
setRequired({
(project.extra["isReleaseVersion"] as Boolean) && gradle.taskGraph.hasTask("publish")
})
sign(publishing.publications["main"])
}version = '1.0-SNAPSHOT'
ext.isReleaseVersion = !version.endsWith("SNAPSHOT")
signing {
required = { isReleaseVersion && gradle.taskGraph.hasTask("publish") }
sign publishing.publications.main
}In this example, we only want to require signing if we are building a release version and we are going to publish it.
Because we are inspecting the task graph to determine if we are going to be publishing, we must set the signing.required property to a closure to defer the evaluation.
See SigningExtension.setRequired(java.lang.Object) for more information.
If the required condition does not hold true, artifacts will only be signed if signatory credentials are configured.
Alternatively, you may want to skip signing entirely whether or not signatory credentials are available.
If so, you can configure the Sign tasks to be skipped, for example by attaching a predicate using the onlyIf() method shown in the following example:
tasks.withType<Sign>().configureEach {
onlyIf("isReleaseVersion is set") { project.extra["isReleaseVersion"] as Boolean }
}tasks.withType(Sign) {
onlyIf("isReleaseVersion is set") { isReleaseVersion }
}Publishing the signatures
When signing publications, the resultant signature artifacts are automatically added to the corresponding publication.
Thus, when publishing to a repository, e.g. by executing the publish task, your signatures will be distributed along with the other artifacts without any additional configuration.
When signing configurations and tasks, the resultant signature artifacts are automatically added to the signatures dependency configuration.
Gradle Plugin Development Plugin
The Java Gradle Plugin development plugin can be used to assist in the development of Gradle plugins.
It automatically applies the Java Library (java-library) plugin, adds the gradleApi() dependency to the compileOnlyApi configuration and performs validation of plugin metadata during jar task execution.
The plugin also integrates with TestKit, a library that aids in writing and executing functional tests for plugin code.
It automatically adds the gradleTestKit() dependency to the testImplementation configuration and generates a plugin classpath manifest file consumed by a GradleRunner instance if found.
Please refer to Automatic classpath injection with the Plugin Development Plugin for more on its usage, configuration options and samples.
Usage
To use the Java Gradle Plugin Development plugin, include the following in your build script:
plugins {
`java-gradle-plugin`
}plugins {
id 'java-gradle-plugin'
}Applying the plugin automatically applies the Java Library(java-library) plugin and adds the gradleApi() dependency to the api configuration.
It also adds some validations to the build.
The following validations are performed:
-
There is a plugin descriptor defined for the plugin.
-
The plugin descriptor contains an
implementation-classproperty. -
The
implementation-classproperty references a valid class file in the jar. -
Each property getter or the corresponding field must be annotated with a property annotation like
@InputFileand@OutputDirectory. Properties that don’t participate in up-to-date checks should be annotated with@Internal.
Any failed validations will result in a warning message.
For each plugin you are developing, register it into the gradlePlugin {} script block:
gradlePlugin {
plugins {
register("org.gradle.sample.simple-plugin") {
// id is automatically inferred as "org.gradle.sample.simple-plugin"
implementationClass = "org.gradle.sample.SimplePlugin"
}
register("org.gradle.sample.convention-plugin") {
// id is overwritten to "convention-plugin"
id = "convention-plugin"
implementationClass = "org.gradle.sample.ConventionPlugin"
}
}
}gradlePlugin {
plugins {
register('org.gradle.sample.simple-plugin') {
// id is automatically inferred as "org.gradle.sample.simple-plugin"
implementationClass = 'org.gradle.sample.SimplePlugin'
}
register('org.gradle.sample.convention-plugin') {
// id is overwritten to "convention-plugin"
id = 'convention-plugin'
implementationClass = 'org.gradle.sample.ConventionPlugin'
}
}
}The gradlePlugin {} block defines the plugins being built by the project.
The plugin id is set from the registration name, here org.gradle.sample.simple-plugin.
Then, you define the implementationClass of the plugin, here org.gradle.sample.SimplePlugin.
You can override the plugin id by explicitly setting the id property such as id = "convention-plugin".
From this data about the plugins being developed, Gradle can automatically:
-
Generate the plugin descriptor in the
jarfile’sMETA-INFdirectory. -
Configure the Plugin Marker Artifact publications (Maven or Ivy) for each plugin.
-
Publish each plugin to the Gradle Plugin Portal (see Publishing Plugins to Gradle Plugin Portal for details), but only if the Plugin Publishing Plugin has also been applied.
Interactions
Some of the plugin’s behaviour depends on other, related plugins also being applied in your build, namely the Maven Publish (maven-publish) and Ivy Publish (ivy-publish) plugins.
Other plugins auto apply the Java Gradle Plugin, like the Plugin Publishing Plugin.
Maven Publish Plugin
When the Java Gradle Plugin (java-gradle-plugin) detects that the Maven Publish Plugin (maven-publish) is also applied by the build, it will automatically configure the following MavenPublications:
-
a single "main" publication, named
pluginMaven, based on the main Java component -
multiple "marker" publications (one for each plugin defined in the
gradlePlugin {}block), named<pluginName>PluginMarkerMaven(for example in the above example it would besimplePluginPluginMarkerMaven)
This automatic configuration happens in a Project.afterEvaluate() block (so at the end of the build configuration phase), and only if these publications haven’t already been defined, so it’s possible to create and customise them during the earlier stages of build configuration.
Ivy Publish Plugin
When the Java Gradle Plugin(java-gradle-plugin) detects that the Ivy Publish Plugin (ivy-publish) is also applied by the build, it will automatically configure the following IvyPublications:
-
a single "main" publication, named
pluginIvy, based on the main Java component -
multiple "marker" publications (one for each plugin defined in the
gradlePlugin {}block), named<pluginName>PluginMarkerIvy(for example in the above example it would besimplePluginPluginMarkerIvy)
This automatic configuration happens in a Project.afterEvaluate() block (so at the end of the build configuration phase), and only if these publications haven’t already been defined, so it’s possible to create and customise them during the earlier stages of build configuration.
Plugin Publish Plugin
Starting from version 1.0.0, the Plugin Publish Plugin always auto-applies the Java Gradle Plugin (java-gradle-plugin) and the Maven Publish Plugin (maven-publish).
The Project Report Plugin
The Project report plugin adds some tasks to your project which generate reports containing useful information about your build. These tasks generate the same content that you get by executing the tasks, dependencies, and properties tasks from the command line (see Command-line project reporting). In contrast to the command line reports, the report plugin generates the reports into a file. There is also an aggregating task that depends on all report tasks added by the plugin.
We plan to add much more to the existing reports and create additional ones in future releases of Gradle.
Usage
To use the Project report plugin, include the following in your build script:
plugins {
id 'project-report'
}Tasks
The project report plugin defines the following tasks:
dependencyReport— DependencyReportTask-
Generates the project dependency report.
htmlDependencyReport— HtmlDependencyReportTask-
Generates an HTML dependency and dependency insight report for the project or a set of projects.
propertyReport— PropertyReportTask-
Generates the project property report.
taskReport— TaskReportTask-
Generates the project task report.
projectReport— Task-
Depends on:
dependencyReport,propertyReport,taskReport,htmlDependencyReportGenerates all project reports.
Project layout
The project report plugin does not require any particular project layout.
Dependency management
The project report plugin does not define any dependency configurations.
The Build Dashboard Plugin
|
Warning
|
The Build Dashboard Plugin is not fully compatible with the Configuration Cache. When applied, the Configuration Cache is automatically disabled. |
The Build Dashboard plugin can be used to generate a single HTML dashboard that provides a single point of access to all of the reports generated by a build.
Usage
To use the Build Dashboard plugin, include the following in your build script:
plugins {
`build-dashboard`
}plugins {
id 'build-dashboard'
}Applying the plugin adds the buildDashboard task to your project. The task aggregates the reports for all tasks that implement the Reporting interface from all projects in the build. It is typically only applied to the root project.
The buildDashboard task does not depend on any other tasks. It will only aggregate the reporting tasks that are independently being executed as part of the build run. To generate the build dashboard, simply include this task in the list of tasks to execute. For example, “gradle buildDashboard build” will generate a dashboard for all of the reporting tasks that are dependents of the build task.
Tasks
The Build Dashboard plugin adds the following task to the project:
buildDashboard— GenerateBuildDashboard-
Generates build dashboard report.
Project layout
The Build Dashboard plugin does not require any particular project layout.
Dependency management
The Build Dashboard plugin does not define any dependency configurations.
Configuration
You can influence the location of build dashboard plugin generation via ReportingExtension.
TASK DEVELOPMENT
Understanding Tasks
A task represents some independent unit of work that a build performs, such as compiling classes, creating a JAR, generating Javadoc, or publishing archives to a repository.
Before reading this chapter, it’s recommended that you first read the Learning The Basics and complete the Tutorial.
Listing tasks
All available tasks in your project come from Gradle plugins and build scripts.
You can list all the available tasks in a project by running the following command in the terminal:
$ ./gradlew tasksLet’s take a very basic Gradle project as an example. The project has the following structure:
gradle-project
├── app
│ ├── build.gradle.kts // empty file - no build logic
│ └── ... // some java code
├── settings.gradle.kts // includes app subproject
├── gradle
│ └── ...
├── gradlew
└── gradlew.batgradle-project
├── app
│ ├── build.gradle // empty file - no build logic
│ └── ... // some java code
├── settings.gradle // includes app subproject
├── gradle
│ └── ...
├── gradlew
└── gradlew.batThe settings file contains the following:
rootProject.name = "gradle-project"
include("app")rootProject.name = 'gradle-project'
include('app')Currently, the app subproject’s build file is empty.
To see the tasks available in the app subproject, run ./gradlew :app:tasks:
$ ./gradlew :app:tasks> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
Help tasks
----------
buildEnvironment - Displays all buildscript dependencies declared in project ':app'.
dependencies - Displays all dependencies declared in project ':app'.
dependencyInsight - Displays the insight into a specific dependency in project ':app'.
help - Displays a help message.
javaToolchains - Displays the detected java toolchains.
kotlinDslAccessorsReport - Prints the Kotlin code for accessing the currently available project extensions and conventions.
outgoingVariants - Displays the outgoing variants of project ':app'.
projects - Displays the sub-projects of project ':app'.
properties - Displays the properties of project ':app'.
resolvableConfigurations - Displays the configurations that can be resolved in project ':app'.
tasks - Displays the tasks runnable from project ':app'.We observe that only a small number of help tasks are available at the moment. This is because the core of Gradle only provides tasks that analyze your build. Other tasks, such as the those that build your project or compile your code, are added by plugins.
Let’s explore this by adding the Gradle core base plugin to the app build script:
plugins {
id("base")
}plugins {
id('base')
}The base plugin adds central lifecycle tasks.
Now when we run ./gradlew app:tasks, we can see the assemble and build tasks are available:
$ ./gradlew :app:tasks> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
Build tasks
-----------
assemble - Assembles the outputs of this project.
build - Assembles and tests this project.
clean - Deletes the build directory.
Help tasks
----------
buildEnvironment - Displays all buildscript dependencies declared in project ':app'.
dependencies - Displays all dependencies declared in project ':app'.
dependencyInsight - Displays the insight into a specific dependency in project ':app'.
help - Displays a help message.
javaToolchains - Displays the detected java toolchains.
outgoingVariants - Displays the outgoing variants of project ':app'.
projects - Displays the sub-projects of project ':app'.
properties - Displays the properties of project ':app'.
resolvableConfigurations - Displays the configurations that can be resolved in project ':app'.
tasks - Displays the tasks runnable from project ':app'.
Verification tasks
------------------
check - Runs all checks.Task outcomes
When Gradle executes a task, it labels the task with outcomes via the console.
These labels are based on whether a task has actions to execute and if Gradle executed them. Actions include, but are not limited to, compiling code, zipping files, and publishing archives.
(no label)orEXECUTED-
Task executed its actions.
-
Task has actions and Gradle executed them.
-
Task has no actions and some dependencies, and Gradle executed one or more of the dependencies. See also Lifecycle Tasks.
-
UP-TO-DATE-
Task’s outputs did not change.
-
Task has outputs and inputs but they have not changed. See Incremental Build.
-
Task has actions, but the task tells Gradle it did not change its outputs.
-
Task has no actions and some dependencies, but all the dependencies are
UP-TO-DATE,SKIPPEDorFROM-CACHE. See Lifecycle Tasks. -
Task has no actions and no dependencies.
-
FROM-CACHE-
Task’s outputs could be found from a previous execution.
-
Task has outputs restored from the build cache. See Build Cache.
-
SKIPPED-
Task did not execute its actions.
-
Task has been explicitly excluded from the command-line. See Excluding tasks from execution.
-
Task has an
onlyIfpredicate return false. See Using a predicate.
-
NO-SOURCE-
Task did not need to execute its actions.
-
Task has inputs and outputs, but no sources (i.e., inputs were not found).
-
Task provenance
Gradle tracks where each task is registered, whether by a build script, settings script, or plugin. This provenance information appears in several places:
When a task fails, the error message includes its provenance to help you locate the source of the problem:
Execution failed for task ':app:compileJava' (registered by plugin 'org.gradle.api.plugins.JavaPlugin').|
Note
|
Provenance is omitted from failure messages for verification failures (e.g., test failures), since those are expected outcomes rather than configuration issues. |
The help --task and tasks commands also include provenance in their output.
You can use tasks --provenance to see where each task was registered.
Task group and description
Task groups and descriptions are used to organize and describe tasks.
- Groups
-
Task groups are used to categorize tasks. When you run
./gradlew tasks, tasks are listed under their respective groups, making it easier to understand their purpose and relationship to other tasks. Groups are set using thegroupproperty. - Descriptions
-
Descriptions provide a brief explanation of what a task does. When you run
./gradlew tasks, the descriptions are shown next to each task, helping you understand its purpose and how to use it. Descriptions are set using thedescriptionproperty.
Let’s consider a basic Java application as an example.
The build contains a subproject called app.
Let’s list the available tasks in app at the moment:
$ ./gradlew :app:tasks> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
Application tasks
-----------------
run - Runs this project as a JVM application.
Build tasks
-----------
assemble - Assembles the outputs of this project.Here, the :run task is part of the Application group with the description Runs this project as a JVM application.
In code, it would look something like this:
tasks.register("run") {
group = "Application"
description = "Runs this project as a JVM application."
}tasks.register("run") {
group = "Application"
description = "Runs this project as a JVM application."
}Private and hidden tasks
Gradle doesn’t support marking a task as private.
However, tasks will only show up when running :tasks if task.group is set or no other task depends on it.
For instance, the following task will not appear when running ./gradlew :app:tasks because it does not have a group; it is called a hidden task:
tasks.register("helloTask") {
println("Hello")
}tasks.register("helloTask") {
println 'Hello'
}Although helloTask is not listed, it can still be executed by Gradle:
$ ./gradlew :app:tasks> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
Application tasks
-----------------
run - Runs this project as a JVM application
Build tasks
-----------
assemble - Assembles the outputs of this project.Let’s add a group to the same task:
tasks.register("helloTask") {
group = "Other"
description = "Hello task"
println("Hello")
}tasks.register("helloTask") {
group = "Other"
description = "Hello task"
println 'Hello'
}Now that the group is added, the task is visible:
$ ./gradlew :app:tasks> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
Application tasks
-----------------
run - Runs this project as a JVM application
Build tasks
-----------
assemble - Assembles the outputs of this project.
Other tasks
-----------
helloTask - Hello taskIn contrast, ./gradlew tasks --all will show all tasks; hidden and visible tasks are listed.
Grouping tasks
If you want to customize which tasks are shown to users when listed, you can group tasks and set the visibility of each group.
|
Note
|
Remember, even if you hide tasks, they are still available, and Gradle can still run them. |
Let’s start with an example built by Gradle init for a Java application with multiple subprojects.
The project structure is as follows:
gradle-project
├── app
│ ├── build.gradle.kts
│ └── src // some java code
│ └── ...
├── utilities
│ ├── build.gradle.kts
│ └── src // some java code
│ └── ...
├── list
│ ├── build.gradle.kts
│ └── src // some java code
│ └── ...
├── buildSrc
│ ├── build.gradle.kts
│ ├── settings.gradle.kts
│ └── src // common build logic
│ └── ...
├── settings.gradle.kts
├── gradle
├── gradlew
└── gradlew.batgradle-project
├── app
│ ├── build.gradle
│ └── src // some java code
│ └── ...
├── utilities
│ ├── build.gradle
│ └── src // some java code
│ └── ...
├── list
│ ├── build.gradle
│ └── src // some java code
│ └── ...
├── buildSrc
│ ├── build.gradle
│ ├── settings.gradle
│ └── src // common build logic
│ └── ...
├── settings.gradle
├── gradle
├── gradlew
└── gradlew.batRun app:tasks to see available tasks in the app subproject:
$ ./gradlew :app:tasks> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
Application tasks
-----------------
run - Runs this project as a JVM application
Build tasks
-----------
assemble - Assembles the outputs of this project.
build - Assembles and tests this project.
buildDependents - Assembles and tests this project and all projects that depend on it.
buildNeeded - Assembles and tests this project and all projects it depends on.
classes - Assembles main classes.
clean - Deletes the build directory.
jar - Assembles a jar archive containing the classes of the 'main' feature.
testClasses - Assembles test classes.
Distribution tasks
------------------
assembleDist - Assembles the main distributions
distTar - Bundles the project as a distribution.
distZip - Bundles the project as a distribution.
installDist - Installs the project as a distribution as-is.
Documentation tasks
-------------------
javadoc - Generates Javadoc API documentation for the 'main' feature.
Help tasks
----------
buildEnvironment - Displays all buildscript dependencies declared in project ':app'.
dependencies - Displays all dependencies declared in project ':app'.
dependencyInsight - Displays the insight into a specific dependency in project ':app'.
help - Displays a help message.
javaToolchains - Displays the detected java toolchains.
kotlinDslAccessorsReport - Prints the Kotlin code for accessing the currently available project extensions and conventions.
outgoingVariants - Displays the outgoing variants of project ':app'.
projects - Displays the sub-projects of project ':app'.
properties - Displays the properties of project ':app'.
resolvableConfigurations - Displays the configurations that can be resolved in project ':app'.
tasks - Displays the tasks runnable from project ':app'.
Verification tasks
------------------
check - Runs all checks.
test - Runs the test suite.If we look at the list of tasks available, even for a standard Java project, it’s extensive. Many of these tasks are rarely required directly by developers using the build.
We can configure the :tasks task and limit the tasks shown to a certain group.
Let’s create our own group so that all tasks are hidden by default by updating the app build script:
val myBuildGroup = "my app build" // Create a group name
tasks.register<TaskReportTask>("tasksAll") { // Register the tasksAll task
group = myBuildGroup
description = "Show additional tasks."
setShowDetail(true)
}
tasks.named<TaskReportTask>("tasks") { // Move all existing tasks to the group
displayGroup = myBuildGroup
}def myBuildGroup = "my app build" // Create a group name
tasks.register("tasksAll", TaskReportTask) { // Register the tasksAll task
group = myBuildGroup
description = "Show additional tasks."
setShowDetail(true)
}
tasks.named("tasks", TaskReportTask) { // Move all existing tasks to the group
displayGroup = myBuildGroup
}Now, when we list tasks available in app, the list is shorter:
$ ./gradlew :app:tasks> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
My app build tasks
------------------
tasksAll - Show additional tasks.Task categories
Gradle distinguishes between two categories of tasks:
-
Lifecycle tasks
-
Actionable tasks
Lifecycle tasks define targets you can call, such as :build your project.
Lifecycle tasks do not provide Gradle with actions.
They must be wired to actionable tasks.
The base Gradle plugin only adds lifecycle tasks.
Actionable tasks define actions for Gradle to take, such as :compileJava, which compiles the Java code of your project.
Actions include creating JARs, zipping files, publishing archives, and much more.
Plugins like the java-library plugin adds actionable tasks.
Let’s update the build script of the previous example, which is currently an empty file so that our app subproject is a Java library:
plugins {
id("java-library")
}plugins {
id('java-library')
}Once again, we list the available tasks to see what new tasks are available:
$ ./gradlew :app:tasks> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
Build tasks
-----------
assemble - Assembles the outputs of this project.
build - Assembles and tests this project.
buildDependents - Assembles and tests this project and all projects that depend on it.
buildNeeded - Assembles and tests this project and all projects it depends on.
classes - Assembles main classes.
clean - Deletes the build directory.
jar - Assembles a jar archive containing the classes of the 'main' feature.
testClasses - Assembles test classes.
Documentation tasks
-------------------
javadoc - Generates Javadoc API documentation for the 'main' feature.
Help tasks
----------
buildEnvironment - Displays all buildscript dependencies declared in project ':app'.
dependencies - Displays all dependencies declared in project ':app'.
dependencyInsight - Displays the insight into a specific dependency in project ':app'.
help - Displays a help message.
javaToolchains - Displays the detected java toolchains.
outgoingVariants - Displays the outgoing variants of project ':app'.
projects - Displays the sub-projects of project ':app'.
properties - Displays the properties of project ':app'.
resolvableConfigurations - Displays the configurations that can be resolved in project ':app'.
tasks - Displays the tasks runnable from project ':app'.
Verification tasks
------------------
check - Runs all checks.
test - Runs the test suite.We see that many new tasks are available such as jar and testClasses.
Additionally, the java-library plugin has wired actionable tasks to lifecycle tasks.
If we call the :build task, we can see several tasks have been executed, including the :app:compileJava task.
$ ./gradlew :app:build> Task :app:compileJava
> Task :app:processResources NO-SOURCE
> Task :app:classes
> Task :app:jar
> Task :app:assemble
> Task :app:compileTestJava
> Task :app:processTestResources NO-SOURCE
> Task :app:testClasses
> Task :app:test
> Task :app:check
> Task :app:buildThe actionable :compileJava task is wired to the lifecycle :build task.
Incremental tasks
A key feature of Gradle tasks is their incremental nature.
Gradle can reuse results from prior builds.
Therefore, if we’ve built our project before and made only minor changes, rerunning :build will not require Gradle to perform extensive work.
For example, if we modify only the test code in our project, leaving the production code unchanged, executing the build will solely recompile the test code.
Gradle marks the tasks for the production code as UP-TO-DATE, indicating that it remains unchanged since the last successful build:
$ ./gradlew :app:buildgradle@MacBook-Pro temp1 % ./gradlew :app:build
> Task :app:compileJava UP-TO-DATE
> Task :app:processResources NO-SOURCE
> Task :app:classes UP-TO-DATE
> Task :app:jar UP-TO-DATE
> Task :app:assemble UP-TO-DATE
> Task :app:compileTestJava
> Task :app:processTestResources NO-SOURCE
> Task :app:testClasses
> Task :app:test
> Task :app:check UP-TO-DATE
> Task :app:build UP-TO-DATECaching tasks
Gradle can reuse results from past builds using the build cache.
To enable this feature, activate the build cache by using the --build-cache command line parameter or by setting org.gradle.caching=true in your gradle.properties file.
This optimization has the potential to accelerate your builds significantly:
$ ./gradlew :app:clean :app:build --build-cache> Task :app:compileJava FROM-CACHE
> Task :app:processResources NO-SOURCE
> Task :app:classes UP-TO-DATE
> Task :app:jar
> Task :app:assemble
> Task :app:compileTestJava FROM-CACHE
> Task :app:processTestResources NO-SOURCE
> Task :app:testClasses UP-TO-DATE
> Task :app:test FROM-CACHE
> Task :app:check UP-TO-DATE
> Task :app:buildWhen Gradle can fetch outputs of a task from the cache, it labels the task with FROM-CACHE.
The build cache is handy if you switch between branches regularly. Gradle supports both local and remote build caches.
Developing tasks
When developing Gradle tasks, you have two choices:
-
Use an existing Gradle task type such as
Zip,Copy, orDelete -
Create your own Gradle task type such as
MyResolveTaskorCustomTaskUsingToolchains.
Task types are simply subclasses of the Gradle Task class.
With Gradle tasks, there are three states to consider:
-
Registering a task - using a task (implemented by you or provided by Gradle) in your build logic.
-
Configuring a task - defining inputs and outputs for a registered task.
-
Implementing a task - creating a custom task class (i.e., custom class type).
Registration is commonly done with the register() method.
Configuring a task is commonly done with the named() method.
Implementing a task is commonly done by extending Gradle’s DefaultTask class:
tasks.register<Copy>("myCopy") // (1)
tasks.named<Copy>("myCopy") { // (2)
from("resources")
into("target")
include("**/*.txt", "**/*.xml", "**/*.properties")
}
abstract class MyCopyTask : DefaultTask() { // (3)
@TaskAction
fun copyFiles() {
val sourceDir = File("sourceDir")
val destinationDir = File("destinationDir")
sourceDir.listFiles()?.forEach { file ->
if (file.isFile && file.extension == "txt") {
file.copyTo(File(destinationDir, file.name))
}
}
}
}tasks.register("myCopy", Copy) // (1)
tasks.named("myCopy", Copy) { // (2)
from "resources"
into "target"
include "**/*.txt", "**/*.xml", "**/*.properties"
}
abstract class MyCopyTask extends DefaultTask { // (3)
@TaskAction
void copyFiles() {
fileTree('sourceDir').matching {
include '**/*.txt'
}.forEach { file ->
file.copyTo(file.path.replace('sourceDir', 'destinationDir'))
}
}
}-
Register the
myCopytask of typeCopyto let Gradle know we intend to use it in our build logic. -
Configure the registered
myCopytask with the inputs and outputs it needs according to its API. -
Implement a custom task type called
MyCopyTaskwhich extendsDefaultTaskand defines thecopyFilestask action.
1. Registering tasks
You define actions for Gradle to take by registering tasks in build scripts or plugins.
Tasks are defined using strings for task names:
tasks.register("hello") {
doLast {
println("hello")
}
}tasks.register('hello') {
doLast {
println 'hello'
}
}In the example above, the task is added to the TasksCollection using the register() method in TaskContainer.
2. Configuring tasks
Gradle tasks must be configured to complete their action(s) successfully.
If a task needs to ZIP a file, it must be configured with the file name and location.
You can refer to the API for the Gradle Zip task to learn how to configure it appropriately.
Let’s look at the Copy task provided by Gradle as an example.
We first register a task called myCopy of type Copy in the build script:
tasks.register<Copy>("myCopy")tasks.register('myCopy', Copy)This registers a copy task with no default behavior.
Since the task is of type Copy, a Gradle supported task type, it can be configured using its API.
The following examples show several ways to achieve the same configuration:
1. Using the named() method:
Use named() to configure an existing task registered elsewhere:
tasks.named<Copy>("myCopy") {
from("resources")
into("target")
include("**/*.txt", "**/*.xml", "**/*.properties")
}tasks.named('myCopy') {
from 'resources'
into 'target'
include('**/*.txt', '**/*.xml', '**/*.properties')
}2. Using a configuration block:
Use a block to configure the task immediately upon registering it:
tasks.register<Copy>("copy") {
from("resources")
into("target")
include("**/*.txt", "**/*.xml", "**/*.properties")
}tasks.register('copy', Copy) {
from 'resources'
into 'target'
include('**/*.txt', '**/*.xml', '**/*.properties')
}3. Name method as call:
A popular option that is only supported in Groovy is the shorthand notation:
copy {
from("resources")
into("target")
include("**/*.txt", "**/*.xml", "**/*.properties")
}|
Note
|
This option breaks task configuration avoidance and is not recommended! |
Regardless of the method chosen, the task is configured with the name of the files to be copied and the location of the files.
3. Implementing tasks
Gradle provides many task types including Delete, Javadoc, Copy, Exec, Tar, and Pmd.
You can implement a custom task type if Gradle does not provide a task type that meets your build logic needs.
To create a custom task class, you extend DefaultTask and make the extending class abstract:
abstract class MyCopyTask : DefaultTask() {
}abstract class MyCopyTask extends DefaultTask {
}Controlling Task Execution
Task dependencies allow tasks to be executed in a specific order based on their dependencies. This ensures that tasks dependent on others are only executed after those dependencies have completed.
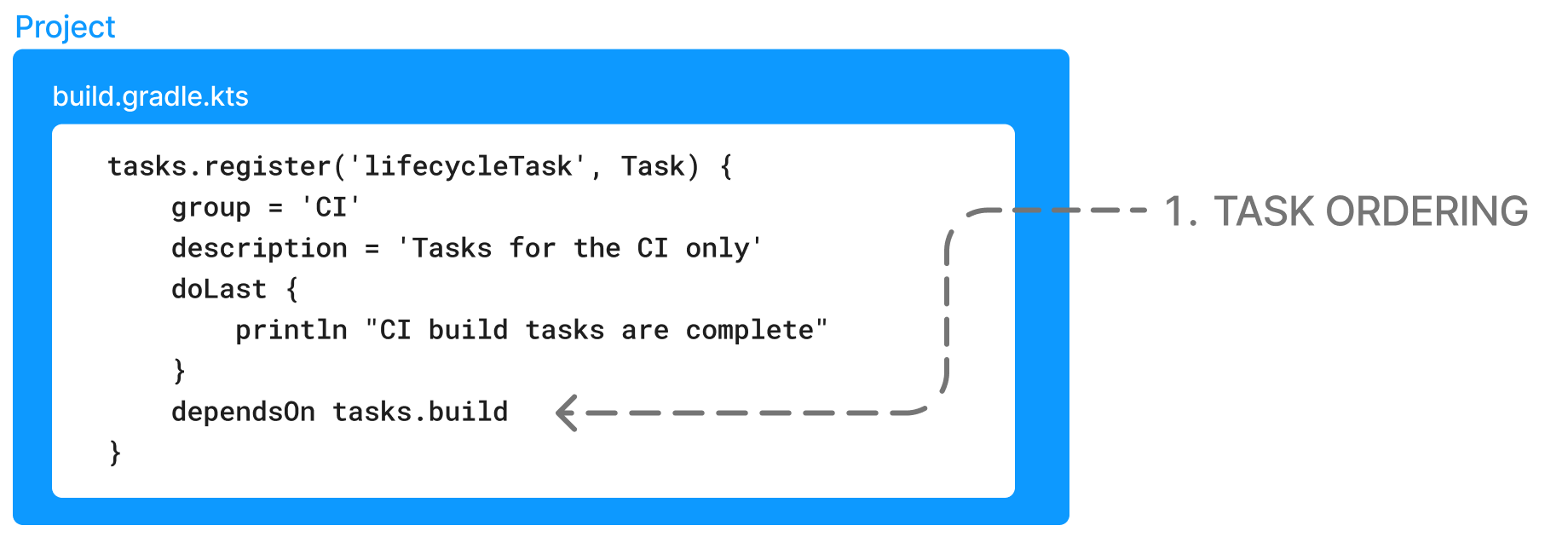
Task dependencies can be categorized as either implicit or explicit:
- Implicit dependencies
-
These dependencies are automatically inferred by Gradle based on the tasks' actions and configuration. For example, if
taskBuses the output oftaskA(e.g., a file generated bytaskA), Gradle will automatically ensure thattaskAis executed beforetaskBto fulfill this dependency. - Explicit dependencies
-
These dependencies are explicitly declared in the build script using the
dependsOn,mustRunAfter, orshouldRunAftermethods. For example, if you want to ensure thattaskBalways runs aftertaskA, you can explicitly declare this dependency usingtaskB.mustRunAfter(taskA).
Both implicit and explicit dependencies play a crucial role in defining the order of task execution and ensuring that tasks are executed in the correct sequence to produce the desired build output.
Task dependencies
Gradle inherently understands the dependencies among tasks. Consequently, it can determine the tasks that need execution when you target a specific task.
Let’s take an example application with an app subproject and a some-logic subproject:
rootProject.name = "gradle-project"
include("app")
include("some-logic")rootProject.name = 'gradle-project'
include('app')
include('some-logic')Let’s imagine that the app subproject depends on the subproject called some-logic, which contains some Java code.
We add this dependency in the app build script:
plugins {
id("application") // app is now a java application
}
application {
mainClass.set("hello.HelloWorld") // main class name required by the application plugin
}
dependencies {
implementation(project(":some-logic")) // dependency on some-logic
}plugins {
id('application') // app is now a java application
}
application {
mainClass = 'hello.HelloWorld' // main class name required by the application plugin
}
dependencies {
implementation(project(':some-logic')) // dependency on some-logic
}If we run :app:build again, we see the Java code of some-logic is also compiled by Gradle automatically:
$ ./gradlew :app:build> Task :app:processResources NO-SOURCE
> Task :app:processTestResources NO-SOURCE
> Task :some-logic:compileJava UP-TO-DATE
> Task :some-logic:processResources NO-SOURCE
> Task :some-logic:classes UP-TO-DATE
> Task :some-logic:jar UP-TO-DATE
> Task :app:compileJava
> Task :app:classes
> Task :app:jar UP-TO-DATE
> Task :app:startScripts
> Task :app:distTar
> Task :app:distZip
> Task :app:assemble
> Task :app:compileTestJava UP-TO-DATE
> Task :app:testClasses UP-TO-DATE
> Task :app:test
> Task :app:check
> Task :app:build
BUILD SUCCESSFUL in 430ms
9 actionable tasks: 5 executed, 4 up-to-dateAdding dependencies
There are several ways you can define the dependencies of a task.
Defining dependencies using task names and the dependsOn()` method is simplest.
The following is an example which adds a dependency from taskX to taskY:
tasks.register("taskX") {
dependsOn("taskY")
}tasks.register("taskX") {
dependsOn "taskY"
}$ ./gradlew -q taskXtaskY
taskXFor more information about task dependencies, see the Task API.
Ordering tasks
In some cases, it is useful to control the order in which two tasks will execute, without introducing an explicit dependency between those tasks.
The primary difference between a task ordering and a task dependency is that an ordering rule does not influence which tasks will be executed, only the order in which they will be executed.
Task ordering can be useful in a number of scenarios:
-
Enforce sequential ordering of tasks (e.g.,
buildnever runs beforeclean). -
Run build validations early in the build (e.g., validate I have the correct credentials before starting the work for a release build).
-
Get feedback faster by running quick verification tasks before long verification tasks (e.g., unit tests should run before integration tests).
-
A task that aggregates the results of all tasks of a particular type (e.g., test report task combines the outputs of all executed test tasks).
Two ordering rules are available: "must run after" and "should run after".
To specify a "must run after" or "should run after" ordering between 2 tasks, you use the Task.mustRunAfter(java.lang.Object...) and Task.shouldRunAfter(java.lang.Object...) methods. These methods accept a task instance, a task name, or any other input accepted by Task.dependsOn(java.lang.Object...).
When you use "must run after", you specify that taskY must always run after taskX when the build requires the execution of taskX and taskY.
So if you only run taskY with mustRunAfter, you won’t cause taskX to run.
This is expressed as taskY.mustRunAfter(taskX).
val taskX = tasks.register("taskX") {
doLast {
println("taskX")
}
}
val taskY = tasks.register("taskY") {
doLast {
println("taskY")
}
}
taskY {
mustRunAfter(taskX)
}def taskX = tasks.register('taskX') {
doLast {
println 'taskX'
}
}
def taskY = tasks.register('taskY') {
doLast {
println 'taskY'
}
}
taskY.configure {
mustRunAfter taskX
}$ ./gradlew -q taskY taskXtaskX
taskYThe "should run after" ordering rule is similar but less strict, as it will be ignored in two situations:
-
If using that rule introduces an ordering cycle.
-
When using parallel execution and all task dependencies have been satisfied apart from the "should run after" task, then this task will be run regardless of whether or not its "should run after" dependencies have been run.
You should use "should run after" where the ordering is helpful but not strictly required:
val taskX = tasks.register("taskX") {
doLast {
println("taskX")
}
}
val taskY = tasks.register("taskY") {
doLast {
println("taskY")
}
}
taskY {
shouldRunAfter(taskX)
}def taskX = tasks.register('taskX') {
doLast {
println 'taskX'
}
}
def taskY = tasks.register('taskY') {
doLast {
println 'taskY'
}
}
taskY.configure {
shouldRunAfter taskX
}$ ./gradlew -q taskY taskXtaskX
taskYIn the examples above, it is still possible to execute taskY without causing taskX to run:
$ ./gradlew -q taskYtaskYThe "should run after" ordering rule will be ignored if it introduces an ordering cycle:
val taskX = tasks.register("taskX") {
doLast {
println("taskX")
}
}
val taskY = tasks.register("taskY") {
doLast {
println("taskY")
}
}
val taskZ = tasks.register("taskZ") {
doLast {
println("taskZ")
}
}
taskX { dependsOn(taskY) }
taskY { dependsOn(taskZ) }
taskZ { shouldRunAfter(taskX) }def taskX = tasks.register('taskX') {
doLast {
println 'taskX'
}
}
def taskY = tasks.register('taskY') {
doLast {
println 'taskY'
}
}
def taskZ = tasks.register('taskZ') {
doLast {
println 'taskZ'
}
}
taskX.configure { dependsOn(taskY) }
taskY.configure { dependsOn(taskZ) }
taskZ.configure { shouldRunAfter(taskX) }$ ./gradlew -q taskXtaskZ
taskY
taskXNote that taskY.mustRunAfter(taskX) or taskY.shouldRunAfter(taskX) does not imply any execution dependency between the tasks:
-
It is possible to execute
taskXandtaskYindependently. The ordering rule only has an effect when both tasks are scheduled for execution. -
When run with
--continue, it is possible fortaskYto execute iftaskXfails.
Finalizer tasks
Finalizer tasks are useful when the build creates a resource that must be cleaned up, regardless of whether the build fails or succeeds. An example of such a resource is a web container that is started before an integration test task and must be shut down, even if some tests fail.
Finalizer tasks are automatically added to the task graph when the finalized task is scheduled to run.
To specify a finalizer task, you use the Task.finalizedBy(java.lang.Object…) method. This method accepts a task instance, a task name, or any other input accepted by Task.dependsOn(java.lang.Object…):
val taskX = tasks.register("taskX") {
doLast {
println("taskX")
}
}
val taskY = tasks.register("taskY") {
doLast {
println("taskY")
}
}
taskX { finalizedBy(taskY) }def taskX = tasks.register('taskX') {
doLast {
println 'taskX'
}
}
def taskY = tasks.register('taskY') {
doLast {
println 'taskY'
}
}
taskX.configure { finalizedBy taskY }$ ./gradlew -q taskXtaskX
taskYFinalizer tasks are executed even if the finalized task fails or if the finalized task is considered UP-TO-DATE:
val taskX = tasks.register("taskX") {
doLast {
println("taskX")
throw RuntimeException()
}
}
val taskY = tasks.register("taskY") {
doLast {
println("taskY")
}
}
taskX { finalizedBy(taskY) }def taskX = tasks.register('taskX') {
doLast {
println 'taskX'
throw new RuntimeException()
}
}
def taskY = tasks.register('taskY') {
doLast {
println 'taskY'
}
}
taskX.configure { finalizedBy taskY }$ ./gradlew -q taskXtaskX
taskY
FAILURE: Build failed with an exception.
* Where:
Build file '/home/user/gradle/samples/build.gradle' line: 4
* What went wrong:
Execution failed for task ':taskX' (registered in build file 'build.gradle').
> java.lang.RuntimeException (no error message)
* Try:
> Run with --stacktrace option to get the stack trace.
> Run with --info or --debug option to get more log output.
> Run with --scan to get full insights from a Build Scan (powered by Develocity).
> Get more help at https://help.gradle.org.
BUILD FAILED in 0sSkipping tasks
Gradle offers multiple ways to skip the execution of a task.
1. Using a predicate
You can use Task.onlyIf to attach a predicate to a task.
The task’s actions will only be executed if the predicate is evaluated to be true.
The predicate is passed to the task as a parameter and returns true if the task will execute and false if the task will be skipped.
The predicate is evaluated just before the task is executed.
Passing an optional reason string to onlyIf() is useful for explaining why the task is skipped:
val hello = tasks.register("hello") {
doLast {
println("hello world")
}
}
hello {
val skipProvider = providers.gradleProperty("skipHello")
onlyIf("there is no property skipHello") {
!skipProvider.isPresent()
}
}def hello = tasks.register('hello') {
doLast {
println 'hello world'
}
}
hello.configure {
def skipProvider = providers.gradleProperty("skipHello")
onlyIf("there is no property skipHello") {
!skipProvider.present
}
}$ ./gradlew hello -PskipHello> Task :hello SKIPPED
BUILD SUCCESSFUL in 0sTo find why a task was skipped, run the build with the --info logging level.
$ ./gradlew hello -PskipHello --info...
> Task :hello SKIPPED
Skipping task ':hello' as task onlyIf 'there is no property skipHello' is false.
:hello (Thread[included builds,5,main]) completed. Took 0.018 secs.
BUILD SUCCESSFUL in 13s2. Using StopExecutionException
If the logic for skipping a task can’t be expressed with a predicate, you can use the StopExecutionException.
If this exception is thrown by an action, the task action as well as the execution of any following action is skipped. The build continues by executing the next task:
val compile = tasks.register("compile") {
doLast {
println("We are doing the compile.")
}
}
compile {
doFirst {
// Here you would put arbitrary conditions in real life.
if (true) {
throw StopExecutionException()
}
}
}
tasks.register("myTask") {
dependsOn(compile)
doLast {
println("I am not affected")
}
}def compile = tasks.register('compile') {
doLast {
println 'We are doing the compile.'
}
}
compile.configure {
doFirst {
// Here you would put arbitrary conditions in real life.
if (true) {
throw new StopExecutionException()
}
}
}
tasks.register('myTask') {
dependsOn('compile')
doLast {
println 'I am not affected'
}
}$ ./gradlew -q myTaskI am not affectedThis feature is helpful if you work with tasks provided by Gradle. It allows you to add conditional execution of the built-in actions of such a task.[4]
3. Enabling and Disabling tasks
Every task has an enabled flag, which defaults to true.
Setting it to false prevents executing the task’s actions.
A disabled task will be labeled SKIPPED:
val disableMe = tasks.register("disableMe") {
doLast {
println("This should not be printed if the task is disabled.")
}
}
disableMe {
enabled = false
}def disableMe = tasks.register('disableMe') {
doLast {
println 'This should not be printed if the task is disabled.'
}
}
disableMe.configure {
enabled = false
}$ ./gradlew disableMe> Task :disableMe SKIPPED
BUILD SUCCESSFUL in 0s4. Task timeouts
Every task has a timeout property, which can be used to limit its execution time.
When a task reaches its timeout, its task execution thread is interrupted.
The task will be marked as FAILED.
Finalizer tasks are executed.
If --continue is used, other tasks continue running.
Tasks that don’t respond to interrupts can’t be timed out. All of Gradle’s built-in tasks respond to timeouts.
tasks.register("hangingTask") {
doLast {
Thread.sleep(100000)
}
timeout = Duration.ofMillis(500)
}tasks.register("hangingTask") {
doLast {
Thread.sleep(100000)
}
timeout = Duration.ofMillis(500)
}Task rules
Sometimes you want to have a task whose behavior depends on a large or infinite number value range of parameters. A very nice and expressive way to provide such tasks are task rules:
tasks.addRule("Pattern: ping<ID>") {
val taskName = this
if (startsWith("ping")) {
task(taskName) {
doLast {
println("Pinging: " + (taskName.replace("ping", "")))
}
}
}
}tasks.addRule("Pattern: ping<ID>") { String taskName ->
if (taskName.startsWith("ping")) {
task(taskName) {
doLast {
println "Pinging: " + (taskName - 'ping')
}
}
}
}$ ./gradlew -q pingServer1Pinging: Server1The String parameter is used as a description for the rule, which is shown with ./gradlew tasks.
Rules are not only used when calling tasks from the command line.
You can also create dependsOn relations on rule based tasks:
tasks.addRule("Pattern: ping<ID>") {
val taskName = this
if (startsWith("ping")) {
task(taskName) {
doLast {
println("Pinging: " + (taskName.replace("ping", "")))
}
}
}
}
tasks.register("groupPing") {
dependsOn("pingServer1", "pingServer2")
}tasks.addRule("Pattern: ping<ID>") { String taskName ->
if (taskName.startsWith("ping")) {
task(taskName) {
doLast {
println "Pinging: " + (taskName - 'ping')
}
}
}
}
tasks.register('groupPing') {
dependsOn 'pingServer1', 'pingServer2'
}$ ./gradlew -q groupPingPinging: Server1
Pinging: Server2If you run ./gradlew -q tasks, you won’t find a task named pingServer1 or pingServer2, but this script is executing logic based on the request to run those tasks.
Exclude tasks from execution
You can exclude a task from execution using the -x or --exclude-task command-line option and provide the task’s name to exclude.
$ ./gradlew build -x testFor instance, you can run the check task but exclude the test task from running.
This approach can lead to unexpected outcomes, particularly if you exclude an actionable task that produces results needed by other tasks.
Instead of relying on the -x parameter, defining a suitable lifecycle task for the desired action is recommended.
Using -x is a practice that should be avoided, although still commonly observed.
Organizing Tasks
There are two types of tasks, actionable and lifecycle tasks.
Actionable tasks in Gradle are tasks that perform actual work, such as compiling code. Lifecycle tasks are tasks that do not do work themselves. These tasks have no actions, instead, they bundle actionable tasks and serve as targets for the build.

A well-organized setup of lifecycle tasks enhances the accessibility of your build for new users and simplifies integration with CI.
Lifecycle tasks
Lifecycle tasks can be particularly beneficial for separating work between users or machines (CI vs local). For example, a developer on a local machine might not want to run an entire build on every single change.
Let’s take a standard app as an example which applies the base plugin.
|
Note
|
The Gradle base plugin defines several lifecycle tasks, including build, assemble, and check.
|
We group the build, check task, and the run task by adding the following lines to the app build script:
tasks.build {
group = myBuildGroup
}
tasks.check {
group = myBuildGroup
description = "Runs checks (including tests)."
}
tasks.named("run") {
group = myBuildGroup
}tasks.build {
group = myBuildGroup
}
tasks.check {
group = myBuildGroup
description = 'Runs checks (including tests).'
}
tasks.named('run') {
group = myBuildGroup
}If we now look at the app:tasks list, we can see the three tasks are available:
$ ./gradlew :app:tasks> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
My app build tasks
------------------
build - Assembles and tests this project.
check - Runs checks (including tests).
run - Runs this project as a JVM application
tasksAll - Show additional tasks.This is already useful if the standard lifecycle tasks are sufficient. Moving the groups around helps clarify the tasks you expect to used in your build.
In many cases, there are more specific requirements that you want to address.
One common scenario is running quality checks without running tests.
Currently, the :check task runs tests and the code quality checks.
Instead, we want to run code quality checks all the time, but not the lengthy test.
To add a quality check lifecycle task, we introduce an additional lifecycle task called qualityCheck and a plugin called spotbugs.
To add a lifecycle task, use tasks.register().
The only thing you need to provide is a name.
Put this task in our group and wire the actionable tasks that belong to this new lifecycle task using the dependsOn() method:
plugins {
id("com.github.spotbugs") version "6.0.7" // spotbugs plugin
}
tasks.register("qualityCheck") { // qualityCheck task
group = myBuildGroup // group
description = "Runs checks (excluding tests)." // description
dependsOn(tasks.classes, tasks.spotbugsMain) // dependencies
dependsOn(tasks.testClasses, tasks.spotbugsTest) // dependencies
}plugins {
id 'com.github.spotbugs' version '6.0.7' // spotbugs plugin
}
tasks.register('qualityCheck') { // qualityCheck task
group = myBuildGroup // group
description = 'Runs checks (excluding tests).' // description
dependsOn tasks.classes, tasks.spotbugsMain // dependencies
dependsOn tasks.testClasses, tasks.spotbugsTest // dependencies
}Note that you don’t need to list all the tasks that Gradle will execute. Just specify the targets you want to collect here. Gradle will determine which other tasks it needs to call to reach these goals.
In the example, we add the classes task, a lifecycle task to compile all our production code, and the spotbugsMain task, which checks our production code.
We also add a description that will show up in the task list that helps distinguish the two check tasks better.
Now, if run './gradlew :app:tasks', we can see that our new qualityCheck lifecycle task is available:
$ ./gradlew :app:tasks> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
My app build tasks
------------------
build - Assembles and tests this project.
check - Runs checks (including tests).
qualityCheck - Runs checks (excluding tests).
run - Runs this project as a JVM application
tasksAll - Show additional tasks.If we run it, we can see that it runs checkstyle but not the tests:
$ ./gradlew :app:qualityCheck> Task :buildSrc:checkKotlinGradlePluginConfigurationErrors
> Task :buildSrc:generateExternalPluginSpecBuilders UP-TO-DATE
> Task :buildSrc:extractPrecompiledScriptPluginPlugins UP-TO-DATE
> Task :buildSrc:compilePluginsBlocks UP-TO-DATE
> Task :buildSrc:generatePrecompiledScriptPluginAccessors UP-TO-DATE
> Task :buildSrc:generateScriptPluginAdapters UP-TO-DATE
> Task :buildSrc:compileKotlin UP-TO-DATE
> Task :buildSrc:compileJava NO-SOURCE
> Task :buildSrc:compileGroovy NO-SOURCE
> Task :buildSrc:pluginDescriptors UP-TO-DATE
> Task :buildSrc:processResources UP-TO-DATE
> Task :buildSrc:classes UP-TO-DATE
> Task :buildSrc:jar UP-TO-DATE
> Task :app:processResources NO-SOURCE
> Task :app:processTestResources NO-SOURCE
> Task :list:compileJava UP-TO-DATE
> Task :utilities:compileJava UP-TO-DATE
> Task :app:compileJava
> Task :app:classes
> Task :app:compileTestJava
> Task :app:testClasses
> Task :app:spotbugsTest
> Task :app:spotbugsMain
> Task :app:qualityCheck
BUILD SUCCESSFUL in 1s
16 actionable tasks: 5 executed, 11 up-to-dateSo far, we have looked at tasks in individual subprojects, which is useful for local development when you work on code in one subproject.
With this setup, developers only need to know that they can call Gradle with :subproject-name:tasks to see which tasks are available and useful for them.
Global lifecycle tasks
Another place to invoke lifecycle tasks is within the root build; this is especially useful for Continuous Integration (CI).
Gradle tasks play a crucial role in CI or CD systems, where activities like compiling all code, running tests, or building and packaging the complete application are typical. To facilitate this, you can include lifecycle tasks that span multiple subprojects.
|
Note
|
Gradle has been around for a long time, and you will frequently observe build files in the root directory serving various purposes. In older Gradle versions, many tasks were defined within the root Gradle build file, resulting in various issues. Therefore, exercise caution when determining the content of this file. |
One of the few elements that should be placed in the root build file is global lifecycle tasks.
Let’s continue using the Gradle init Java application multi-project as an example.
This time, we’re incorporating a build script in the root project. We’ll establish two groups for our global lifecycle tasks: one for tasks relevant to local development, such as running all checks, and another exclusively for our CI system.
Once again, we narrowed down the tasks listed to our specific groups:
val globalBuildGroup = "My global build"
val ciBuildGroup = "My CI build"
tasks.named<TaskReportTask>("tasks") {
displayGroups = listOf<String>(globalBuildGroup, ciBuildGroup)
}def globalBuildGroup = "My global build"
def ciBuildGroup = "My CI build"
tasks.named("tasks", TaskReportTask) {
displayGroups = [globalBuildGroup, ciBuildGroup]
}You could hide the CI tasks if you wanted to by updating displayGroups.
Currently, the root project exposes no tasks:
$ ./gradlew :tasks> Task :tasks
------------------------------------------------------------
Tasks runnable from root project 'gradle-project'
------------------------------------------------------------
No tasks|
Note
|
In this file, we don’t apply a plugin! |
Let’s add a qualityCheckApp task to execute all code quality checks in the app subproject.
Similarly, for CI purposes, we implement a checkAll task that runs all tests:
tasks.register("qualityCheckApp") {
group = globalBuildGroup
description = "Runs checks on app (globally)"
dependsOn(":app:qualityCheck" )
}
tasks.register("checkAll") {
group = ciBuildGroup
description = "Runs checks for all projects (CI)"
dependsOn(subprojects.map { ":${it.name}:check" })
dependsOn(gradle.includedBuilds.map { it.task(":checkAll") })
}tasks.register("qualityCheckApp") {
group = globalBuildGroup
description = "Runs checks on app (globally)"
dependsOn(":app:qualityCheck")
}
tasks.register("checkAll") {
group = ciBuildGroup
description = "Runs checks for all projects (CI)"
dependsOn subprojects.collect { ":${it.name}:check" }
dependsOn gradle.includedBuilds.collect { it.task(":checkAll") }
}So we can now ask Gradle to show us the tasks for the root project and, by default, it will only show us the qualityCheckAll task (and optionally the checkAll task depending on the value of displayGroups).
It should be clear what a user should run locally:
$ ./gradlew :tasks> Task :tasks
------------------------------------------------------------
Tasks runnable from root project 'gradle-project'
------------------------------------------------------------
My CI build tasks
-----------------
checkAll - Runs checks for all projects (CI)
My global build tasks
---------------------
qualityCheckApp - Runs checks on app (globally)If we run the :checkAll task, we see that it compiles all the code and runs the code quality checks (including spotbug):
$ ./gradlew :checkAll> Task :buildSrc:checkKotlinGradlePluginConfigurationErrors
> Task :buildSrc:generateExternalPluginSpecBuilders UP-TO-DATE
> Task :buildSrc:extractPrecompiledScriptPluginPlugins UP-TO-DATE
> Task :buildSrc:compilePluginsBlocks UP-TO-DATE
> Task :buildSrc:generatePrecompiledScriptPluginAccessors UP-TO-DATE
> Task :buildSrc:generateScriptPluginAdapters UP-TO-DATE
> Task :buildSrc:compileKotlin UP-TO-DATE
> Task :buildSrc:compileJava NO-SOURCE
> Task :buildSrc:compileGroovy NO-SOURCE
> Task :buildSrc:pluginDescriptors UP-TO-DATE
> Task :buildSrc:processResources UP-TO-DATE
> Task :buildSrc:classes UP-TO-DATE
> Task :buildSrc:jar UP-TO-DATE
> Task :utilities:processResources NO-SOURCE
> Task :app:processResources NO-SOURCE
> Task :utilities:processTestResources NO-SOURCE
> Task :app:processTestResources NO-SOURCE
> Task :list:compileJava
> Task :list:processResources NO-SOURCE
> Task :list:classes
> Task :list:jar
> Task :utilities:compileJava
> Task :utilities:classes
> Task :utilities:jar
> Task :utilities:compileTestJava NO-SOURCE
> Task :utilities:testClasses UP-TO-DATE
> Task :utilities:test NO-SOURCE
> Task :utilities:check UP-TO-DATE
> Task :list:compileTestJava
> Task :list:processTestResources NO-SOURCE
> Task :list:testClasses
> Task :app:compileJava
> Task :app:classes
> Task :app:compileTestJava
> Task :app:testClasses
> Task :list:test
> Task :list:check
> Task :app:test
> Task :app:spotbugsTest
> Task :app:spotbugsMain
> Task :app:check
> Task :checkAll
BUILD SUCCESSFUL in 1s
21 actionable tasks: 12 executed, 9 up-to-dateImplementing Custom Tasks
Actionable tasks describe work in Gradle.
These tasks have actions.
In Gradle core, the compileJava task compiles the Java source code.
The Jar and Zip tasks zip files into archives.
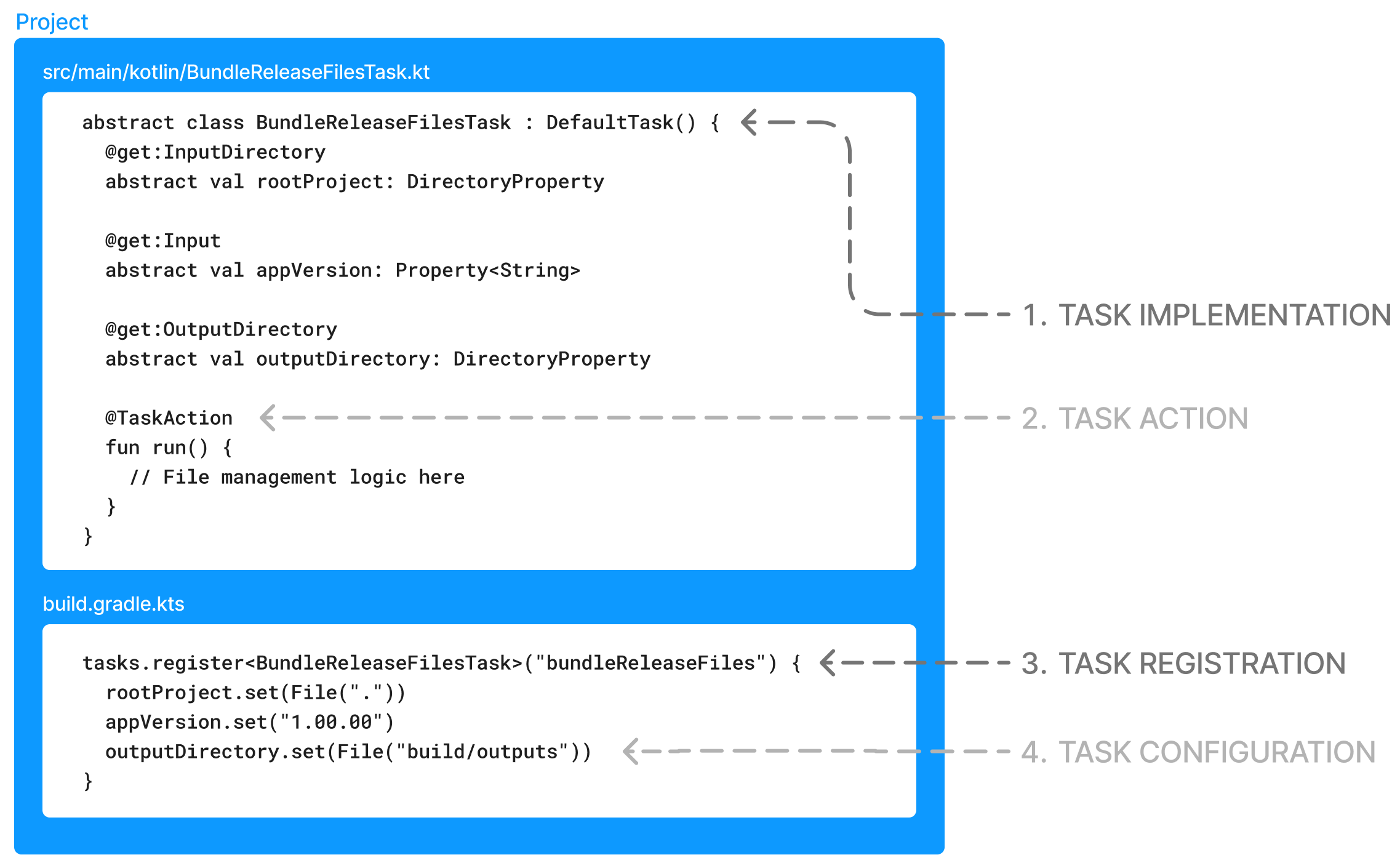
Custom actionable tasks can be created by extending the DefaultTask class and defining inputs, outputs, and actions.
Task inputs and outputs
Actionable tasks have inputs and outputs. Inputs and outputs can be files, directories, or variables.
In actionable tasks:
-
Inputs consist of a collection of files, folders, and/or configuration data.
For instance, thejavaCompiletask takes inputs such as Java source files and build script configurations like the Java version. -
Outputs refer to one or multiple files or folders.
For instance, thejavaCompileproduces class files as output.
Then, the jar task takes these class files as input and produces a JAR archive.
Clearly defined task inputs and outputs serve two purposes:
-
They inform Gradle about task dependencies.
For example, if Gradle understands that the output of thecompileJavatask serves as the input for thejartask, it will prioritize runningcompileJavafirst. -
They facilitate incremental building.
For example, suppose Gradle recognizes that the inputs and outputs of a task remain unchanged. In that case, it can leverage results from previous build runs or the build cache, avoiding rerunning the task action altogether.
When you apply a plugin like the java-library plugin, Gradle will automatically register some tasks and configure them with defaults.
Let’s define a task that packages JARs and a start script into an archive in an imaginary sample project:
gradle-project
├── app
│ ├── build.gradle.kts // app build logic
│ ├── run.sh // script file
│ └── ... // some java code
├── settings.gradle.kts // includes app subproject
├── gradle
├── gradlew
└── gradlew.batgradle-project
├── app
│ ├── build.gradle // app build logic
│ ├── run.sh // script file
│ └── ... // some java code
├── settings.gradle // includes app subproject
├── gradle
├── gradlew
└── gradlew.batThe run.sh script can execute the Java app (once packaged as a JAR) from the build:
java -cp 'libs/*' gradle.project.app.AppLet’s register a new task called packageApp using task.register():
tasks.register<Zip>("packageApp") {
}tasks.register(Zip, "packageApp") {
}We used an existing implementation from Gradle core which is the Zip task implementation (i.e., a subclass of DefaultTask).
Because we register a new task here, it’s not pre-configured.
We need to configure the inputs and outputs.
Defining inputs and outputs is what makes a task an actionable task.
For the Zip task type, we can use the from() method to add a file to the inputs.
In our case, we add the run script.
If the input is a file we create or edit directly, like a run file or Java source code, it’s usually located somewhere in our project directory.
To ensure we use the correct location, we use layout.projectDirectory and define a relative path to the project directory root.
We provide the outputs of the jar task as well as the JAR of all the dependencies (using configurations.runtimeClasspath) as additional inputs.
For outputs, we need to define two properties.
First, the destination directory, which should be a directory inside the build folder.
We can access this through layout.
Second, we need to specify a name for the zip file, which we’ve called myApplication.zip
Here is what the complete task looks like:
val packageApp = tasks.register<Zip>("packageApp") {
from(layout.projectDirectory.file("run.sh")) // input - run.sh file
from(tasks.jar) { // input - jar task output
into("libs")
}
from(configurations.runtimeClasspath) { // input - jar of dependencies
into("libs")
}
destinationDirectory.set(layout.buildDirectory.dir("dist")) // output - location of the zip file
archiveFileName.set("myApplication.zip") // output - name of the zip file
}def packageApp = tasks.register('packageApp', Zip) {
from layout.projectDirectory.file('run.sh') // input - run.sh file
from tasks.jar { // input - jar task output
into 'libs'
}
from configurations.runtimeClasspath { // input - jar of dependencies
into 'libs'
}
destinationDirectory.set(layout.buildDirectory.dir('dist')) // output - location of the zip file
archiveFileName.set('myApplication.zip') // output - name of the zip file
}If we run our packageApp task, myApplication.zip is produced:
$ ./gradlew :app:packageApp> Task :app:compileJava
> Task :app:processResources NO-SOURCE
> Task :app:classes
> Task :app:jar
> Task :app:packageApp
BUILD SUCCESSFUL in 1s
3 actionable tasks: 3 executedGradle executed a number of tasks it required to build the JAR file, which included the compilation of the code of the app project and the compilation of code dependencies.
Looking at the newly created ZIP file, we can see that it contains everything needed to run the Java application:
$ unzip -l ./app/build/dist/myApplication.zipArchive: ./app/build/dist/myApplication.zip
Length Date Time Name
--------- ---------- ----- ----
42 01-31-2024 14:16 run.sh
0 01-31-2024 14:22 libs/
847 01-31-2024 14:22 libs/app.jar
3041591 01-29-2024 14:20 libs/guava-32.1.2-jre.jar
4617 01-29-2024 14:15 libs/failureaccess-1.0.1.jar
2199 01-29-2024 14:15 libs/listenablefuture-9999.0-empty-to-avoid-conflict-with-guava.jar
19936 01-29-2024 14:15 libs/jsr305-3.0.2.jar
223979 01-31-2024 14:16 libs/checker-qual-3.33.0.jar
16017 01-31-2024 14:16 libs/error_prone_annotations-2.18.0.jar
--------- -------
3309228 9 filesActionable tasks should be wired to lifecycle tasks so that a developer only needs to run lifecycle tasks.
So far, we called our new task directly. Let’s wire it to a lifecycle task.
The following is added to the build script so that the packageApp actionable task is wired to the build lifecycle task using dependsOn():
tasks.build {
dependsOn(packageApp)
}tasks.build {
dependsOn(packageApp)
}We see that running :build also runs :packageApp:
$ ./gradlew :app:build> Task :app:compileJava UP-TO-DATE
> Task :app:processResources NO-SOURCE
> Task :app:classes UP-TO-DATE
> Task :app:jar UP-TO-DATE
> Task :app:startScripts
> Task :app:distTar
> Task :app:distZip
> Task :app:assemble
> Task :app:compileTestJava
> Task :app:processTestResources NO-SOURCE
> Task :app:testClasses
> Task :app:test
> Task :app:check
> Task :app:packageApp
> Task :app:build
BUILD SUCCESSFUL in 1s
8 actionable tasks: 6 executed, 2 up-to-dateYou could define your own lifecycle task if needed.
Task implementation by extending DefaultTask
To address more individual needs, and if no existing plugins provide the build functionality you need, you can create your own task implementation.
Implementing a class means creating a custom class (i.e., type), which is done by subclassing DefaultTask
Let’s start with an example built by Gradle init for a simple Java application with the source code in the app subproject and the common build logic in buildSrc:
gradle-project
├── app
│ ├── build.gradle.kts
│ └── src // some java code
│ └── ...
├── buildSrc
│ ├── build.gradle.kts
│ ├── settings.gradle.kts
│ └── src // common build logic
│ └── ...
├── settings.gradle.kts
├── gradle
├── gradlew
└── gradlew.batgradle-project
├── app
│ ├── build.gradle
│ └── src // some java code
│ └── ...
├── buildSrc
│ ├── build.gradle
│ ├── settings.gradle
│ └── src // common build logic
│ └── ...
├── settings.gradle
├── gradle
├── gradlew
└── gradlew.batWe create a class called GenerateReportTask in ./buildSrc/src/main/kotlin/GenerateReportTask.kt or ./buildSrc/src/main/groovy/GenerateReportTask.groovy.
To let Gradle know that we are implementing a task, we extend the DefaultTask class that comes with Gradle.
It’s also beneficial to make our task class abstract because Gradle will handle many things automatically:
import org.gradle.api.DefaultTask
abstract class GenerateReportTask : DefaultTask() {
}import org.gradle.api.DefaultTask
abstract class GenerateReportTask extends DefaultTask {
}Next, we define the inputs and outputs using properties and annotations. In this context, properties in Gradle act as references to the actual values behind them, allowing Gradle to track inputs and outputs between tasks.
For the input of our task, we use a DirectoryProperty from Gradle.
We annotate it with @InputDirectory to indicate that it is an input to the task:
import org.gradle.api.DefaultTask
import org.gradle.api.file.DirectoryProperty
import org.gradle.api.tasks.InputDirectory
abstract class GenerateReportTask : DefaultTask() {
@get:InputDirectory
abstract val sourceDirectory: DirectoryProperty
}import org.gradle.api.DefaultTask
import org.gradle.api.file.DirectoryProperty
import org.gradle.api.tasks.InputDirectory
abstract class GenerateReportTask extends DefaultTask {
@InputDirectory
abstract DirectoryProperty getSourceDirectory()
}Similarly, for the output, we use a RegularFileProperty and annotate it with @OutputFile.
import org.gradle.api.DefaultTask
import org.gradle.api.file.DirectoryProperty
import org.gradle.api.file.RegularFileProperty
import org.gradle.api.tasks.InputDirectory
import org.gradle.api.tasks.OutputFile
abstract class GenerateReportTask : DefaultTask() {
@get:InputDirectory
abstract val sourceDirectory: DirectoryProperty
@get:OutputFile
abstract val reportFile: RegularFileProperty
}import org.gradle.api.DefaultTask
import org.gradle.api.file.DirectoryProperty
import org.gradle.api.file.RegularFileProperty
import org.gradle.api.tasks.InputDirectory
import org.gradle.api.tasks.OutputFile
abstract class GenerateReportTask extends DefaultTask {
@InputDirectory
abstract DirectoryProperty getSourceDirectory()
@OutputFile
abstract RegularFileProperty getReportFile()
}With inputs and outputs defined, the only thing that remains is the actual task action, which is implemented in a method annotated with @TaskAction.
Inside this method, we write code accessing inputs and outputs using Gradle-specific APIs:
import org.gradle.api.DefaultTask
import org.gradle.api.file.DirectoryProperty
import org.gradle.api.file.RegularFileProperty
import org.gradle.api.tasks.InputDirectory
import org.gradle.api.tasks.OutputFile
import org.gradle.api.tasks.TaskAction
abstract class GenerateReportTask : DefaultTask() {
@get:InputDirectory
abstract val sourceDirectory: DirectoryProperty
@get:OutputFile
abstract val reportFile: RegularFileProperty
@TaskAction
fun generateReport() {
val sourceDirectory = sourceDirectory.asFile.get()
val reportFile = reportFile.asFile.get()
val fileCount = sourceDirectory.listFiles().count { it.isFile }
val directoryCount = sourceDirectory.listFiles().count { it.isDirectory }
val reportContent = """
|Report for directory: ${sourceDirectory.absolutePath}
|------------------------------
|Number of files: $fileCount
|Number of subdirectories: $directoryCount
""".trimMargin()
reportFile.writeText(reportContent)
println("Report generated at: ${reportFile.absolutePath}")
}
}import org.gradle.api.DefaultTask
import org.gradle.api.file.DirectoryProperty
import org.gradle.api.file.RegularFileProperty
import org.gradle.api.tasks.InputDirectory
import org.gradle.api.tasks.OutputFile
import org.gradle.api.tasks.TaskAction
abstract class GenerateReportTask extends DefaultTask {
@InputDirectory
abstract DirectoryProperty getSourceDirectory()
@OutputFile
abstract RegularFileProperty getReportFile()
@TaskAction
void generateReport() {
def sourceDirectory = sourceDirectory.asFile.get()
def reportFile = reportFile.asFile.get()
def fileCount = sourceDirectory.listFiles().count { it.isFile() }
def directoryCount = sourceDirectory.listFiles().count { it.isDirectory() }
def reportContent = """
Report for directory: ${sourceDirectory.absolutePath}
------------------------------
Number of files: $fileCount
Number of subdirectories: $directoryCount
""".trim()
reportFile.text = reportContent
println("Report generated at: ${reportFile.absolutePath}")
}
}The task action generates a report of the files in the sourceDirectory.
In the application build file, we register a task of type GenerateReportTask using task.register() and name it generateReport.
At the same time, we configure the inputs and outputs of the task:
tasks.register<GenerateReportTask>("generateReport") {
sourceDirectory = layout.projectDirectory.dir("src/main")
reportFile = layout.buildDirectory.file("reports/directoryReport.txt")
}
tasks.build {
dependsOn("generateReport")
}tasks.register("generateReport", GenerateReportTask) {
sourceDirectory = layout.projectDirectory.dir("src/main")
reportFile = layout.buildDirectory.file("reports/directoryReport.txt")
}
tasks.build.dependsOn("generateReport")The generateReport task is wired to the build task.
By running the build, we observe that our start script generation task is executed, and it’s UP-TO-DATE in subsequent builds.
Gradle’s incremental building and caching mechanisms work seamlessly with custom tasks:
$./gradlew :app:build> Task :buildSrc:checkKotlinGradlePluginConfigurationErrors
> Task :buildSrc:compileKotlin UP-TO-DATE
> Task :buildSrc:compileJava NO-SOURCE
> Task :buildSrc:compileGroovy NO-SOURCE
> Task :buildSrc:pluginDescriptors UP-TO-DATE
> Task :buildSrc:processResources NO-SOURCE
> Task :buildSrc:classes UP-TO-DATE
> Task :buildSrc:jar UP-TO-DATE
> Task :app:compileJava UP-TO-DATE
> Task :app:processResources NO-SOURCE
> Task :app:classes UP-TO-DATE
> Task :app:jar UP-TO-DATE
> Task :app:startScripts UP-TO-DATE
> Task :app:distTar UP-TO-DATE
> Task :app:distZip UP-TO-DATE
> Task :app:assemble UP-TO-DATE
> Task :app:compileTestJava UP-TO-DATE
> Task :app:processTestResources NO-SOURCE
> Task :app:testClasses UP-TO-DATE
> Task :app:test UP-TO-DATE
> Task :app:check UP-TO-DATE
> Task :app:generateReport
Report generated at: ./app/build/reports/directoryReport.txt
> Task :app:packageApp
> Task :app:build
BUILD SUCCESSFUL in 1s
13 actionable tasks: 10 executed, 3 up-to-dateTask actions
A task action is the code that implements what a task is doing, as demonstrated in the previous section.
For example, the javaCompile task action calls the Java compiler to transform source code into byte code.
It is possible to dynamically modify task actions for tasks that are already registered. This is helpful for testing, patching, or modifying core build logic.
Let’s look at an example of a simple Gradle build with one app subproject that makes up a Java application – containing one Java class and using Gradle’s application plugin.
The project has common build logic in the buildSrc folder where my-convention-plugin resides:
plugins {
id("my-convention-plugin")
}
version = "1.0"
application {
mainClass = "org.example.app.App"
}plugins {
id 'my-convention-plugin'
}
version = '1.0'
application {
mainClass = 'org.example.app.App'
}We define a task called printVersion in the build file of the app:
import org.gradle.api.DefaultTask
import org.gradle.api.provider.Property
import org.gradle.api.tasks.Input
import org.gradle.api.tasks.TaskAction
abstract class PrintVersion : DefaultTask() {
// Configuration code
@get:Input
abstract val version: Property<String>
// Execution code
@TaskAction
fun print() {
println("Version: ${version.get()}")
}
}import org.gradle.api.DefaultTask
import org.gradle.api.provider.Property
import org.gradle.api.tasks.Input
import org.gradle.api.tasks.TaskAction
abstract class PrintVersion extends DefaultTask {
// Configuration code
@Input
abstract Property<String> getVersion()
// Execution code
@TaskAction
void printVersion() {
println("Version: ${getVersion().get()}")
}
}This task does one simple thing: it prints out the version of the project to the command line.
The class extends DefaultTask and it has one @Input, which is of type Property<String>.
It has one method that is annotated with @TaskAction, which prints out the version.
Note that the task implementation clearly distinguishes between "Configuration code" and "Execution code".
The configuration code is executed during Gradle’s configuration phase. It builds up a model of the project in memory so that Gradle knows what it needs to do for a certain build invocation. Everything around the task actions, like the input or output properties, is part of this configuration code.
The code inside the task action method is the execution code that does the actual work. It accesses the inputs and outputs to do some work if the task is part of the task graph and if it can’t be skipped because it’s UP-TO-DATE or it’s taken FROM-CACHE.
Once a task implementation is complete, it can be used in a build setup.
In our convention plugin, my-convention-plugin, we can register a new task that uses the new task implementation:
tasks.register<PrintVersion>("printVersion") {
// Configuration code
version = project.version as String
}tasks.register(PrintVersion, "printVersion") {
// Configuration code
version = project.version.toString()
}Inside the configuration block for the task, we can write configuration phase code which modifies the values of input and output properties of the task. The task action is not referred to here in any way.
It is possible to write simple tasks like this one in a more compact way and directly in the build script without creating a separate class for the task.
Let’s register another task and call it printVersionDynamic.
This time, we do not define a type for the task, which means the task will be of the general type DefaultTask.
This general type does not define any task actions, meaning it does not have methods annotated with @TaskAction.
This type is useful for defining 'lifecycle tasks':
tasks.register("printVersionDynamic") {
}tasks.register("printVersionDynamic") {
}However, the default task type can also be used to define tasks with custom actions dynamically, without additional classes.
This is done by using the doFirst{} or doLast{} construct.
Similar to defining a method and annotating this @TaskAction, this adds an action to a task.
The methods are called doFirst{} and doLast{} because the task can have multiple actions.
If the task already has an action defined, you can use this distinction to decide if your additional action should run before or after the existing actions:
tasks.register("printVersionDynamic") {
doFirst {
// Task action = Execution code
// Run before exiting actions
}
doLast {
// Task action = Execution code
// Run after existing actions
}
}tasks.register("printVersionDynamic") {
doFirst {
// Task action = Execution code
// Run before exiting actions
}
doLast {
// Task action = Execution code
// Run after existing actions
}
}If you only have one action, which is the case here because we start with an empty task, we typically use the doLast{} method.
In the task, we first declare the version we want to print as an input dynamically.
Instead of declaring a property and annotating it with @Input, we use the general inputs properties that all tasks have.
Then, we add the action code, a println() statement, inside the doLast{} method:
tasks.register("printVersionDynamic") {
inputs.property("version", project.version.toString())
doLast {
println("Version: ${inputs.properties["version"]}")
}
}tasks.register("printVersionDynamic") {
inputs.property("version", project.version)
doLast {
println("Version: ${inputs.properties["version"]}")
}
}We saw two alternative approaches to implementing a custom task in Gradle.
The dynamic setup makes it more compact. However, it’s easy to mix configuration and execution time states when writing dynamic tasks. You can also see that 'inputs' are untyped in dynamic tasks, which can lead to issues. When you implement your custom task as a class, you can clearly define the inputs as properties with a dedicated type.
Dynamic modification of task actions can provide value for tasks that are already registered, but which you need to modify for some reason.
Let’s take the compileJava task as an example.
Once the task is registered, you can’t remove it. You could, instead, clear its actions:
tasks.compileJava {
// Clear existing actions
actions.clear()
// Add a new action
doLast {
println("Custom action: Compiling Java classes...")
}
}tasks.compileJava {
// Clear existing actions
actions.clear()
// Add a new action
doLast {
println("Custom action: Compiling Java classes...")
}
}It’s also difficult, and in certain cases impossible, to remove certain task dependencies that have been set up already by the plugins you are using. You could, instead, modify its behavior:
tasks.compileJava {
// Modify the task behavior
doLast {
val outputDir = File("$buildDir/compiledClasses")
outputDir.mkdirs()
val compiledFiles = sourceSets["main"].output.files
compiledFiles.forEach { compiledFile ->
val destinationFile = File(outputDir, compiledFile.name)
compiledFile.copyTo(destinationFile, true)
}
println("Java compilation completed. Compiled classes copied to: ${outputDir.absolutePath}")
}
}tasks.compileJava {
// Modify the task behavior
doLast {
def outputDir = file("$buildDir/compiledClasses")
outputDir.mkdirs()
def compiledFiles = sourceSets["main"].output.files
compiledFiles.each { compiledFile ->
def destinationFile = new File(outputDir, compiledFile.name)
compiledFile.copyTo(destinationFile)
}
println("Java compilation completed. Compiled classes copied to: ${outputDir.absolutePath}")
}
}Understanding inputs and outputs
Task inputs and outputs are important for:
-
Up-to-date checks - Gradle’s incremental build feature helps your build avoid doing the same work more than once by looking at changes for task inputs and outputs.
-
Linking task inputs and outputs - When outputs of one task are linked to the inputs of another, Gradle can automatically create task dependencies.
-
Using dependency configurations - Task outputs can be used to tell Gradle that an artifact produced by a task should be added to a specific configuration.
Declaring inputs and outputs
You can configure the inputs and outputs of a task in two main ways:
-
Static Configuration: Define inputs and outputs directly inside the task class. These inputs and outputs will always apply to the task whenever it is executed.
-
Dynamic Configuration: Add inputs and outputs to a task dynamically, meaning you can customize the inputs and outputs for each execution of the task based on specific conditions or requirements. This approach allows for more flexibility and fine-grained control over the task’s behavior.
abstract class ConfigurableTask : DefaultTask() {
@get:Input
abstract val inputProperty: Property<String>
@get:OutputFile
abstract val outputFile: RegularFileProperty
// Static Configuration: Inputs and Outputs defined in the task class
init {
group = "custom"
description = "A configurable task example"
}
@TaskAction
fun executeTask() {
println("Executing task with input: ${inputProperty.get()} and output: ${outputFile.asFile.get()}")
}
}
// Dynamic Configuration: Adding inputs and outputs to a task instance
tasks.register("dynamicTask", ConfigurableTask::class) {
// Set the input property dynamically
inputProperty = "dynamic input value"
// Set the output file dynamically
outputFile = layout.buildDirectory.file("dynamicOutput.txt")
}abstract class ConfigurableTask extends DefaultTask {
@Input
abstract Property<String> getInputProperty()
@OutputFile
abstract RegularFileProperty getOutputFile()
// Static Configuration: Inputs and Outputs defined in the task class
ConfigurableTask() {
group = 'custom'
description = 'A configurable task example'
}
@TaskAction
void executeTask() {
println "Executing task with input: ${inputProperty.get()} and output: ${outputFile.asFile.get()}"
}
}
// Dynamic Configuration: Adding inputs and outputs to a task instance
tasks.register('dynamicTask', ConfigurableTask) {
// Set the input property dynamically
inputProperty = 'dynamic input value'
// Set the output file dynamically
outputFile = layout.buildDirectory.file('dynamicOutput.txt')
}Creating lazy inputs and outputs
Gradle has the concept of lazy configuration, which allows task inputs and outputs to be referenced before they’re actually set.
This is done via a Property class type.
abstract class MyTask : DefaultTask() {
// Avoid Java Bean properties
@Input
var myEagerProperty: String = "default value"
// Use Gradle managed properties instead
@get:Input
abstract val myLazyProperty: Property<String>
@TaskAction
fun myAction() {
println("Use ${myLazyProperty.get()} and do NOT use $myEagerProperty")
}
}abstract class MyTask extends DefaultTask {
// Avoid Java Bean properties
@Input
String myEagerProperty = "default value"
// Use Gradle managed properties instead
@Input
abstract Property<String> getMyLazyProperty()
@TaskAction
void myAction() {
println("Use ${myLazyProperty.get()} and do NOT use $myEagerProperty")
}
}One advantage of this mechanism is that you can link the output file of one task to the input file of another, all before the filename has even been decided.
The Property class also knows about which task it’s linked to, so using inputs and outputs in this way enables Gradle to automatically add the required task dependency.
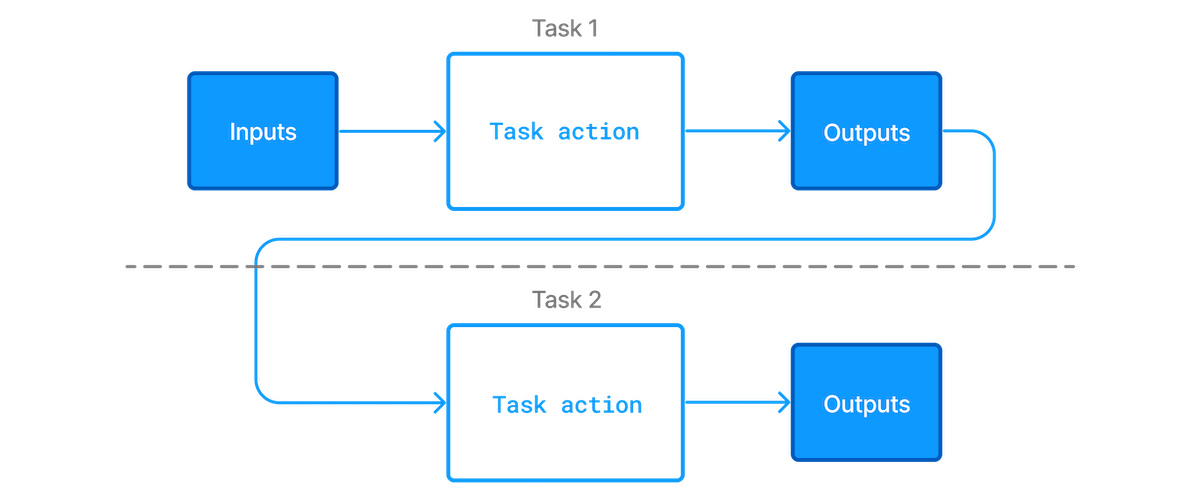
To ensure proper lazy configuration, you should avoid using Java Bean types. Let’s explore the common options for what Gradle lazy types can be declared as task inputs and outputs:
| Lazy Gradle Type | Java Bean Type | Input | Output |
|---|---|---|---|
|
|
X |
|
|
|
X |
X |
Iterable of files ( |
Iterable of files ( |
X |
X |
Map of files ( |
Map of files ( |
X |
|
|
|
X |
X |
Iterable of directories ( |
Iterable of directories ( |
X |
|
Map of directories ( |
Map of directories ( |
X |
Notes:
-
Strings are only supported for task inputs, not outputs. These are normally used for configuration options e.g.
sourceCompatibilityof thecompileJavatask type. -
Task outputs can only be files or directories.
-
Instead of
String,Boolean,Stringand other standard types, useProperty<T>. -
Instead of
List<T>, useListProperty<T>. -
Instead of
Set<T>, useSetProperty<T>.
|
Warning
|
Avoid using FileTree when order matters — it has no guaranteed, stable file order and may cause unpredictable behavior.
|
Annotating inputs and outputs
A good practice is to create a task class for your custom task. The class encapsulates the task action logic, but should also declare any inputs and outputs the task expects. To do this, we use annotations.
For task inputs we can use @Input, @InputFile, @InputDirectory, @InputFiles, @Classpath, and @CompileClasspath.
For task outputs we have @OutputFile, @OutputDirectory, @OutputFiles, @OutputDirectories.
Here are all available annotations in detail:
| Annotation | Usage |
|---|---|
|
Property is an input value for the task |
|
Property is an input file for the task |
|
Property is one or more input files for the task |
|
Property is an input directory for the task |
|
Property is a one or more input files or directories that represent a Java classpath |
|
Property is a one or more input files or directories that represent a Java compile classpath |
|
Property is an output file for the task[5] |
|
Property is one or more output files for the task |
|
Property is an output directory for the task |
|
Property is one or more output directories for the task |
|
Property is one or more files or directories (coming from other tasks) that the task destroys (deletes/removes)[6] |
|
Property is a local state for a task |
|
Property is a nested bean and should be checked for other annotations |
|
Property is not an input or an output and should not be taken into account for up-to-date checking |
|
Property is used internally and should not to be taken into account for up-to-date checking |
|
Property is a file or directory and the task should be skipped when the value of the property is empty |
|
Property is a file or directory and changes to it can be queried with |
|
Modifier annotation — marks an input or output property as not required. Must be combined with an input or output annotation such as |
|
Property is one or more files and only the given part of the file path is important |
|
Used with |
|
Used with |
Note that in Kotlin the annotations are prefixed with get:, so @InputFile becomes @get:InputFile.
abstract class AllTypes : DefaultTask() {
//inputs
@get:Input
abstract val inputString: Property<String>
@get:InputFile
abstract val inputFile: RegularFileProperty
@get:InputDirectory
abstract val inputDirectory: DirectoryProperty
@get:InputFiles
abstract val inputFileCollection: ConfigurableFileCollection
@get:Classpath
abstract val inputClasspath: ConfigurableFileCollection
// outputs
@get:OutputFile
abstract val outputFile: RegularFileProperty
@get:OutputDirectory
abstract val outputDirectory: DirectoryProperty
@get:OutputFiles
abstract val outputFiles: ConfigurableFileCollection
@get:OutputDirectories
abstract val outputDirectories: ConfigurableFileCollection
}abstract class AllTypes extends DefaultTask {
//inputs
@Input
abstract Property<String> getInputString()
@InputFile
abstract RegularFileProperty getInputFile()
@InputDirectory
abstract DirectoryProperty getInputDirectory()
@InputFiles
abstract ConfigurableFileCollection getInputFileCollection()
@Classpath
abstract ConfigurableFileCollection getInputClasspath()
// outputs
@OutputFile
abstract RegularFileProperty getOutputFile()
@OutputDirectory
abstract DirectoryProperty getOutputDirectory()
@OutputFiles
abstract ConfigurableFileCollection getOutputFiles()
@OutputDirectories
abstract ConfigurableFileCollection getOutputDirectories()
}Extending existing tasks
Sometimes writing tasks from scratch is not what’s needed.
Maybe you need a slightly modified version of an existing task, without altering or even having access to that task’s sources.
For example, a Copy task with some additional inputs.
In those cases you can write new tasks that extend the functionality of other tasks, either via inheritance (new task type extends existing one) or delegation (composition).
Take a look at this section of the manual (dealing with the cacheability of task inputs and outputs) for further information on what option there are for using delegation in the case of Gradle’s built-in tasks.
Configuring Tasks Lazily
Knowing when and where a particular value is configured is difficult to track as a build grows in complexity. Gradle provides several ways to manage this using lazy configuration.
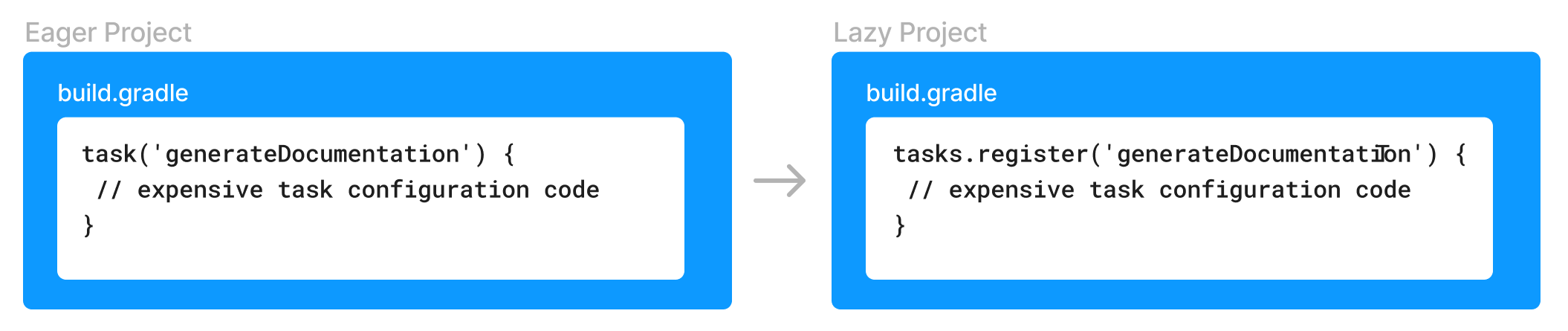
Understanding Lazy properties
Gradle provides lazy properties, which delay calculating a property’s value until it’s actually required.
Lazy properties provide three main benefits:
-
Deferred Value Resolution: Allows wiring Gradle models without needing to know when a property’s value will be known. For example, you may want to set the input source files of a task based on the source directories property of an extension, but the extension property value isn’t known until the build script or some other plugin configures them.
-
Automatic Task Dependency Management: Connects output of one task to input of another, automatically determining task dependencies. Property instances carry information about which task, if any, produces their value. Build authors do not need to worry about keeping task dependencies in sync with configuration changes.
-
Improved Build Performance: Avoids resource-intensive work during configuration, impacting build performance positively. For example, when a configuration value comes from parsing a file but is only used when functional tests are run, using a property instance to capture this means that the file is parsed only when the functional tests are run (and not when
cleanis run, for example).
Gradle represents lazy properties with two interfaces:
- Provider
-
Represents a value that can only be queried and cannot be changed.
-
Properties with these types are read-only.
-
The method Provider.get() returns the current value of the property.
-
A
Providercan be created from anotherProviderusing Provider.map(Transformer). -
Many other types extend
Providerand can be used wherever aProvideris required.
-
- Property
-
Represents a value that can be queried and changed.
-
Properties with these types are configurable.
-
Propertyextends theProviderinterface. -
The method Property.set(T) specifies a value for the property, overwriting whatever value may have been present.
-
The method Property.set(Provider) specifies a
Providerfor the value for the property, overwriting whatever value may have been present. This allows you to wire togetherProviderandPropertyinstances before the values are configured. -
A
Propertycan be created by the factory method ObjectFactory.property(Class).
-
Lazy properties are intended to be passed around and only queried when required. This typically happens during the execution phase.
The following demonstrates a task with a configurable greeting property and a read-only message property:
abstract class Greeting : DefaultTask() { // (1)
@get:Input
abstract val greeting: Property<String> // (2)
@Internal
val message: Provider<String> = greeting.map { it + " from Gradle" } // (3)
@TaskAction
fun printMessage() {
logger.quiet(message.get())
}
}
tasks.register<Greeting>("greeting") {
greeting.set("Hi") // (4)
greeting = "Hi" // (5)
}abstract class Greeting extends DefaultTask { // (1)
@Input
abstract Property<String> getGreeting() // (2)
@Internal
final Provider<String> message = greeting.map { it + ' from Gradle' } // (3)
@TaskAction
void printMessage() {
logger.quiet(message.get())
}
}
tasks.register("greeting", Greeting) {
greeting.set('Hi') // (4)
greeting = 'Hi' // (5)
}-
A task that displays a greeting
-
A configurable greeting
-
Read-only property calculated from the greeting
-
Configure the greeting
-
Alternative notation to calling Property.set()
$ ./gradlew greeting> Task :greeting
Hi from Gradle
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executedThe Greeting task has a property of type Property<String> to represent the configurable greeting and a property of type Provider<String> to represent the calculated, read-only, message.
The message Provider is created from the greeting Property using the map() method; its value is kept up-to-date as the value of the greeting property changes.
Creating a Property or Provider instance
Neither Provider nor its subtypes, such as Property, are intended to be implemented by a build script or plugin.
Gradle provides factory methods to create instances of these types instead.
In the previous example, two factory methods were presented:
-
ObjectFactory.property(Class) create a new
Propertyinstance. An instance of the ObjectFactory can be referenced from Project.getObjects() or by injectingObjectFactorythrough a constructor or method. -
Provider.map(Transformer) creates a new
Providerfrom an existingProviderorPropertyinstance.
See the Quick Reference for all of the types and factories available.
A Provider can also be created by the factory method ProviderFactory.provider(Callable).
|
Note
|
There are no specific methods to create a provider using a When writing a plugin or build script with Groovy, you can use the Similarly, when writing a plugin or build script with Kotlin, the Kotlin compiler will convert a Kotlin function into a |
Connecting properties together
An important feature of lazy properties is that they can be connected together so that changes to one property are automatically reflected in other properties.
Here is an example where the property of a task is connected to a property of a project extension:
// A project extension
interface MessageExtension {
// A configurable greeting
abstract val greeting: Property<String>
}
// A task that displays a greeting
abstract class Greeting : DefaultTask() {
// Configurable by the user
@get:Input
abstract val greeting: Property<String>
// Read-only property calculated from the greeting
@Internal
val message: Provider<String> = greeting.map { it + " from Gradle" }
@TaskAction
fun printMessage() {
logger.quiet(message.get())
}
}
// Create the project extension
val messages = project.extensions.create<MessageExtension>("messages")
// Create the greeting task
tasks.register<Greeting>("greeting") {
// Attach the greeting from the project extension
// Note that the values of the project extension have not been configured yet
greeting = messages.greeting
}
messages.apply {
// Configure the greeting on the extension
// Note that there is no need to reconfigure the task's `greeting` property. This is automatically updated as the extension property changes
greeting = "Hi"
}// A project extension
interface MessageExtension {
// A configurable greeting
Property<String> getGreeting()
}
// A task that displays a greeting
abstract class Greeting extends DefaultTask {
// Configurable by the user
@Input
abstract Property<String> getGreeting()
// Read-only property calculated from the greeting
@Internal
final Provider<String> message = greeting.map { it + ' from Gradle' }
@TaskAction
void printMessage() {
logger.quiet(message.get())
}
}
// Create the project extension
project.extensions.create('messages', MessageExtension)
// Create the greeting task
tasks.register("greeting", Greeting) {
// Attach the greeting from the project extension
// Note that the values of the project extension have not been configured yet
greeting = messages.greeting
}
messages {
// Configure the greeting on the extension
// Note that there is no need to reconfigure the task's `greeting` property. This is automatically updated as the extension property changes
greeting = 'Hi'
}$ ./gradlew greeting> Task :greeting
Hi from Gradle
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executedThis example calls the Property.set(Provider) method to attach a Provider to a Property to supply the value of the property.
In this case, the Provider happens to be a Property as well, but you can connect any Provider implementation, for example one created using Provider.map()
Working with files
In Working with Files, we introduced four collection types for File-like objects:
| Read-only Type | Configurable Type |
|---|---|
|
Warning
|
Avoid using FileTree when order matters — it has no guaranteed, stable file order and may cause unpredictable behavior.
|
All of these types are also considered lazy types.
There are more strongly typed models used to represent elements of the file system: Directory and RegularFile. These types shouldn’t be confused with the standard Java File type as they are used to tell Gradle that you expect more specific values such as a directory or a non-directory, regular file.
Gradle provides two specialized Property subtypes for dealing with values of these types:
RegularFileProperty and DirectoryProperty. ObjectFactory has methods to create these: ObjectFactory.fileProperty() and ObjectFactory.directoryProperty().
A DirectoryProperty can also be used to create a lazily evaluated Provider for a Directory and RegularFile via DirectoryProperty.dir(String) and DirectoryProperty.file(String) respectively.
These methods create providers whose values are calculated relative to the location for the DirectoryProperty they were created from.
The values returned from these providers will reflect changes to the DirectoryProperty.
// A task that generates a source file and writes the result to an output directory
abstract class GenerateSource : DefaultTask() {
// The configuration file to use to generate the source file
@get:InputFile
abstract val configFile: RegularFileProperty
// The directory to write source files to
@get:OutputDirectory
abstract val outputDir: DirectoryProperty
@TaskAction
fun compile() {
val inFile = configFile.get().asFile
logger.quiet("configuration file = $inFile")
val dir = outputDir.get().asFile
logger.quiet("output dir = $dir")
val className = inFile.readText().trim()
val srcFile = File(dir, "${className}.java")
srcFile.writeText("public class ${className} { }")
}
}
// Create the source generation task
tasks.register<GenerateSource>("generate") {
// Configure the locations, relative to the project and build directories
configFile = layout.projectDirectory.file("src/config.txt")
outputDir = layout.buildDirectory.dir("generated-source")
}
// Change the build directory
// Don't need to reconfigure the task properties. These are automatically updated as the build directory changes
layout.buildDirectory = layout.projectDirectory.dir("output")// A task that generates a source file and writes the result to an output directory
abstract class GenerateSource extends DefaultTask {
// The configuration file to use to generate the source file
@InputFile
abstract RegularFileProperty getConfigFile()
// The directory to write source files to
@OutputDirectory
abstract DirectoryProperty getOutputDir()
@TaskAction
def compile() {
def inFile = configFile.get().asFile
logger.quiet("configuration file = $inFile")
def dir = outputDir.get().asFile
logger.quiet("output dir = $dir")
def className = inFile.text.trim()
def srcFile = new File(dir, "${className}.java")
srcFile.text = "public class ${className} { ... }"
}
}
// Create the source generation task
tasks.register('generate', GenerateSource) {
// Configure the locations, relative to the project and build directories
configFile = layout.projectDirectory.file('src/config.txt')
outputDir = layout.buildDirectory.dir('generated-source')
}
// Change the build directory
// Don't need to reconfigure the task properties. These are automatically updated as the build directory changes
layout.buildDirectory = layout.projectDirectory.dir('output')$ gradle generate> Task :generate
configuration file = /home/user/gradle/samples/kotlin/src/config.txt
output dir = /home/user/gradle/samples/kotlin/output/generated-source
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executed$ gradle generate> Task :generate
configuration file = /home/user/gradle/samples/src/config.txt
output dir = /home/user/gradle/samples/output/generated-source
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executedThis example creates providers that represent locations in the project and build directories through Project.getLayout() with ProjectLayout.getBuildDirectory() and ProjectLayout.getProjectDirectory().
To close the loop, note that a DirectoryProperty, or a simple Directory, can be turned into a FileTree that allows the files and directories contained in the directory to be queried with DirectoryProperty.getAsFileTree() or Directory.getAsFileTree().
From a DirectoryProperty or a Directory, you can create FileCollection instances containing a set of the files contained in the directory with DirectoryProperty.files(Object...) or Directory.files(Object...).
Working with task inputs and outputs
Many builds have several tasks connected together, where one task consumes the outputs of another task as an input.
To make this work, we need to configure each task to know where to look for its inputs and where to place its outputs. Ensure that the producing and consuming tasks are configured with the same location and attach task dependencies between the tasks. This can be cumbersome and brittle if any of these values are configurable by a user or configured by multiple plugins, as task properties need to be configured in the correct order and locations, and task dependencies kept in sync as values change.
The Property API makes this easier by keeping track of the value of a property and the task that produces the value.
As an example, consider the following plugin with a producer and consumer task which are wired together:
abstract class Producer : DefaultTask() {
@get:OutputFile
abstract val outputFile: RegularFileProperty
@TaskAction
fun produce() {
val message = "Hello, World!"
val output = outputFile.get().asFile
output.writeText( message)
logger.quiet("Wrote '${message}' to ${output}")
}
}
abstract class Consumer : DefaultTask() {
@get:InputFile
abstract val inputFile: RegularFileProperty
@TaskAction
fun consume() {
val input = inputFile.get().asFile
val message = input.readText()
logger.quiet("Read '${message}' from ${input}")
}
}
val producer = tasks.register<Producer>("producer")
val consumer = tasks.register<Consumer>("consumer")
consumer {
// Connect the producer task output to the consumer task input
// Don't need to add a task dependency to the consumer task. This is automatically added
inputFile = producer.flatMap { it.outputFile }
}
producer {
// Set values for the producer lazily
// Don't need to update the consumer.inputFile property. This is automatically updated as producer.outputFile changes
outputFile = layout.buildDirectory.file("file.txt")
}
// Change the build directory.
// Don't need to update producer.outputFile and consumer.inputFile. These are automatically updated as the build directory changes
layout.buildDirectory = layout.projectDirectory.dir("output")abstract class Producer extends DefaultTask {
@OutputFile
abstract RegularFileProperty getOutputFile()
@TaskAction
void produce() {
String message = 'Hello, World!'
def output = outputFile.get().asFile
output.text = message
logger.quiet("Wrote '${message}' to ${output}")
}
}
abstract class Consumer extends DefaultTask {
@InputFile
abstract RegularFileProperty getInputFile()
@TaskAction
void consume() {
def input = inputFile.get().asFile
def message = input.text
logger.quiet("Read '${message}' from ${input}")
}
}
def producer = tasks.register("producer", Producer)
def consumer = tasks.register("consumer", Consumer)
consumer.configure {
// Connect the producer task output to the consumer task input
// Don't need to add a task dependency to the consumer task. This is automatically added
inputFile = producer.flatMap { it.outputFile }
}
producer.configure {
// Set values for the producer lazily
// Don't need to update the consumer.inputFile property. This is automatically updated as producer.outputFile changes
outputFile = layout.buildDirectory.file('file.txt')
}
// Change the build directory.
// Don't need to update producer.outputFile and consumer.inputFile. These are automatically updated as the build directory changes
layout.buildDirectory = layout.projectDirectory.dir('output')$ ./gradlew consumer> Task :producer
Wrote 'Hello, World!' to /home/user/gradle/samples/kotlin/output/file.txt
> Task :consumer
Read 'Hello, World!' from /home/user/gradle/samples/kotlin/output/file.txt
BUILD SUCCESSFUL in 0s
2 actionable tasks: 2 executed$ ./gradlew consumer> Task :producer
Wrote 'Hello, World!' to /home/user/gradle/samples/output/file.txt
> Task :consumer
Read 'Hello, World!' from /home/user/gradle/samples/output/file.txt
BUILD SUCCESSFUL in 0s
2 actionable tasks: 2 executedIn the example above, the task outputs and inputs are connected before any location is defined. The setters can be called at any time before the task is executed, and the change will automatically affect all related input and output properties.
Another important thing to note in this example is the absence of any explicit task dependency.
Task outputs represented using Providers keep track of which task produces their value, and using them as task inputs will implicitly add the correct task dependencies.
Implicit task dependencies also work for input properties that are not files:
abstract class Producer : DefaultTask() {
@get:OutputFile
abstract val outputFile: RegularFileProperty
@TaskAction
fun produce() {
val message = "Hello, World!"
val output = outputFile.get().asFile
output.writeText( message)
logger.quiet("Wrote '${message}' to ${output}")
}
}
abstract class Consumer : DefaultTask() {
@get:Input
abstract val message: Property<String>
@TaskAction
fun consume() {
logger.quiet(message.get())
}
}
val producer = tasks.register<Producer>("producer") {
// Set values for the producer lazily
// Don't need to update the consumer.inputFile property. This is automatically updated as producer.outputFile changes
outputFile = layout.buildDirectory.file("file.txt")
}
tasks.register<Consumer>("consumer") {
// Connect the producer task output to the consumer task input
// Don't need to add a task dependency to the consumer task. This is automatically added
message = producer.flatMap { it.outputFile }.map { it.asFile.readText() }
}abstract class Producer extends DefaultTask {
@OutputFile
abstract RegularFileProperty getOutputFile()
@TaskAction
void produce() {
String message = 'Hello, World!'
def output = outputFile.get().asFile
output.text = message
logger.quiet("Wrote '${message}' to ${output}")
}
}
abstract class Consumer extends DefaultTask {
@Input
abstract Property<String> getMessage()
@TaskAction
void consume() {
logger.quiet(message.get())
}
}
def producer = tasks.register('producer', Producer) {
// Set values for the producer lazily
// Don't need to update the consumer.inputFile property. This is automatically updated as producer.outputFile changes
outputFile = layout.buildDirectory.file('file.txt')
}
tasks.register('consumer', Consumer) {
// Connect the producer task output to the consumer task input
// Don't need to add a task dependency to the consumer task. This is automatically added
message = producer.flatMap { it.outputFile }.map { it.asFile.text }
}$ ./gradlew consumer> Task :producer
Wrote 'Hello, World!' to /home/user/gradle/samples/kotlin/build/file.txt
> Task :consumer
Hello, World!
BUILD SUCCESSFUL in 0s
2 actionable tasks: 2 executed$ ./gradlew consumer> Task :producer
Wrote 'Hello, World!' to /home/user/gradle/samples/build/file.txt
> Task :consumer
Hello, World!
BUILD SUCCESSFUL in 0s
2 actionable tasks: 2 executedWorking with collections
Gradle provides two lazy property types to help configure Collection properties.
These work exactly like any other Provider and, just like file providers, they have additional modeling around them:
-
For
Listvalues the interface is called ListProperty.
You can create a newListPropertyusing ObjectFactory.listProperty(Class) and specifying the element type. -
For
Setvalues the interface is called SetProperty.
You can create a newSetPropertyusing ObjectFactory.setProperty(Class) and specifying the element type.
This type of property allows you to overwrite the entire collection value with HasMultipleValues.set(Iterable) and HasMultipleValues.set(Provider) or add new elements through the various add methods:
-
HasMultipleValues.add(T): Add a single element to the collection
-
HasMultipleValues.add(Provider): Add a lazily calculated element to the collection
-
HasMultipleValues.addAll(Provider): Add a lazily calculated collection of elements to the list
Just like every Provider, the collection is calculated when Provider.get() is called. The following example shows the ListProperty in action:
abstract class Producer : DefaultTask() {
@get:OutputFile
abstract val outputFile: RegularFileProperty
@TaskAction
fun produce() {
val message = "Hello, World!"
val output = outputFile.get().asFile
output.writeText( message)
logger.quiet("Wrote '${message}' to ${output}")
}
}
abstract class Consumer : DefaultTask() {
@get:InputFiles
abstract val inputFiles: ListProperty<RegularFile>
@TaskAction
fun consume() {
inputFiles.get().forEach { inputFile ->
val input = inputFile.asFile
val message = input.readText()
logger.quiet("Read '${message}' from ${input}")
}
}
}
val producerOne = tasks.register<Producer>("producerOne")
val producerTwo = tasks.register<Producer>("producerTwo")
tasks.register<Consumer>("consumer") {
// Connect the producer task outputs to the consumer task input
// Don't need to add task dependencies to the consumer task. These are automatically added
inputFiles.add(producerOne.get().outputFile)
inputFiles.add(producerTwo.get().outputFile)
}
// Set values for the producer tasks lazily
// Don't need to update the consumer.inputFiles property. This is automatically updated as producer.outputFile changes
producerOne { outputFile = layout.buildDirectory.file("one.txt") }
producerTwo { outputFile = layout.buildDirectory.file("two.txt") }
// Change the build directory.
// Don't need to update the task properties. These are automatically updated as the build directory changes
layout.buildDirectory = layout.projectDirectory.dir("output")abstract class Producer extends DefaultTask {
@OutputFile
abstract RegularFileProperty getOutputFile()
@TaskAction
void produce() {
String message = 'Hello, World!'
def output = outputFile.get().asFile
output.text = message
logger.quiet("Wrote '${message}' to ${output}")
}
}
abstract class Consumer extends DefaultTask {
@InputFiles
abstract ListProperty<RegularFile> getInputFiles()
@TaskAction
void consume() {
inputFiles.get().each { inputFile ->
def input = inputFile.asFile
def message = input.text
logger.quiet("Read '${message}' from ${input}")
}
}
}
def producerOne = tasks.register('producerOne', Producer)
def producerTwo = tasks.register('producerTwo', Producer)
tasks.register('consumer', Consumer) {
// Connect the producer task outputs to the consumer task input
// Don't need to add task dependencies to the consumer task. These are automatically added
inputFiles.add(producerOne.get().outputFile)
inputFiles.add(producerTwo.get().outputFile)
}
// Set values for the producer tasks lazily
// Don't need to update the consumer.inputFiles property. This is automatically updated as producer.outputFile changes
producerOne.configure { outputFile = layout.buildDirectory.file('one.txt') }
producerTwo.configure { outputFile = layout.buildDirectory.file('two.txt') }
// Change the build directory.
// Don't need to update the task properties. These are automatically updated as the build directory changes
layout.buildDirectory = layout.projectDirectory.dir('output')$ ./gradlew consumer> Task :producerOne
Wrote 'Hello, World!' to /home/user/gradle/samples/kotlin/output/one.txt
> Task :producerTwo
Wrote 'Hello, World!' to /home/user/gradle/samples/kotlin/output/two.txt
> Task :consumer
Read 'Hello, World!' from /home/user/gradle/samples/kotlin/output/one.txt
Read 'Hello, World!' from /home/user/gradle/samples/kotlin/output/two.txt
BUILD SUCCESSFUL in 0s
3 actionable tasks: 3 executed$ ./gradlew consumer> Task :producerOne
Wrote 'Hello, World!' to /home/user/gradle/samples/output/one.txt
> Task :producerTwo
Wrote 'Hello, World!' to /home/user/gradle/samples/output/two.txt
> Task :consumer
Read 'Hello, World!' from /home/user/gradle/samples/output/one.txt
Read 'Hello, World!' from /home/user/gradle/samples/output/two.txt
BUILD SUCCESSFUL in 0s
3 actionable tasks: 3 executedWorking with maps
Gradle provides a lazy MapProperty type to allow Map values to be configured.
You can create a MapProperty instance using ObjectFactory.mapProperty(Class, Class).
Similar to other property types, a MapProperty has a set() method that you can use to specify the value for the property.
Some additional methods allow entries with lazy values to be added to the map.
abstract class Generator: DefaultTask() {
@get:Input
abstract val properties: MapProperty<String, Int>
@TaskAction
fun generate() {
properties.get().forEach { entry ->
logger.quiet("${entry.key} = ${entry.value}")
}
}
}
// Some values to be configured later
var b = 0
var c = 0
tasks.register<Generator>("generate") {
properties.put("a", 1)
// Values have not been configured yet
properties.put("b", providers.provider { b })
properties.putAll(providers.provider { mapOf("c" to c, "d" to c + 1) })
}
// Configure the values. There is no need to reconfigure the task
b = 2
c = 3abstract class Generator extends DefaultTask {
@Input
abstract MapProperty<String, Integer> getProperties()
@TaskAction
void generate() {
properties.get().each { key, value ->
logger.quiet("${key} = ${value}")
}
}
}
// Some values to be configured later
def b = 0
def c = 0
tasks.register('generate', Generator) {
properties.put("a", 1)
// Values have not been configured yet
properties.put("b", providers.provider { b })
properties.putAll(providers.provider { [c: c, d: c + 1] })
}
// Configure the values. There is no need to reconfigure the task
b = 2
c = 3$ ./gradlew generate> Task :generate
a = 1
b = 2
c = 3
d = 4
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executedApplying a convention to a property
Often, you want to apply some convention, or default value to a property to be used if no value has been configured.
You can use the convention() method for this.
This method accepts either a value or a Provider, and this will be used as the value until some other value is configured.
tasks.register("show") {
val property = objects.property(String::class)
// Set a convention
property.convention("convention 1")
println("value = " + property.get())
// Can replace the convention
property.convention("convention 2")
println("value = " + property.get())
property.set("explicit value")
// Once a value is set, the convention is ignored
property.convention("ignored convention")
doLast {
println("value = " + property.get())
}
}tasks.register("show") {
def property = objects.property(String)
// Set a convention
property.convention("convention 1")
println("value = " + property.get())
// Can replace the convention
property.convention("convention 2")
println("value = " + property.get())
property.set("explicit value")
// Once a value is set, the convention is ignored
property.convention("ignored convention")
doLast {
println("value = " + property.get())
}
}$ ./gradlew showvalue = convention 1
value = convention 2
> Task :show
value = explicit value
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executedWhere to apply conventions from?
There are several appropriate locations for setting a convention on a property at configuration time (i.e., before execution).
// setting convention when registering a task from plugin
class GreetingPlugin : Plugin<Project> {
override fun apply(project: Project) {
project.getTasks().register<GreetingTask>("hello") {
greeter.convention("Greeter")
}
}
}
apply<GreetingPlugin>()
tasks.withType<GreetingTask>().configureEach {
// setting convention from build script
guest.convention("Guest")
}
abstract class GreetingTask : DefaultTask() {
// setting convention from constructor
@get:Input
abstract val guest: Property<String>
init {
guest.convention("person2")
}
// setting convention from declaration
@Input
val greeter = project.objects.property<String>().convention("person1")
@TaskAction
fun greet() {
println("hello, ${guest.get()}, from ${greeter.get()}")
}
}// setting convention when registering a task from plugin
class GreetingPlugin implements Plugin<Project> {
void apply(Project project) {
project.getTasks().register("hello", GreetingTask) {
greeter.convention("Greeter")
}
}
}
apply plugin: GreetingPlugin
tasks.withType(GreetingTask).configureEach {
// setting convention from build script
guest.convention("Guest")
}
abstract class GreetingTask extends DefaultTask {
// setting convention from constructor
@Input
abstract Property<String> getGuest()
GreetingTask() {
guest.convention("person2")
}
// setting convention from declaration
@Input
final Property<String> greeter = project.objects.property(String).convention("person1")
@TaskAction
void greet() {
println("hello, ${guest.get()}, from ${greeter.get()}")
}
}From a plugin’s apply() method
Plugin authors may configure a convention on a lazy property from a plugin’s apply() method, while performing preliminary configuration of the task or extension defining the property.
This works well for regular plugins (meant to be distributed and used in the wild), and internal convention plugins (which often configure properties defined by third party plugins in a uniform way for the entire build).
// setting convention when registering a task from plugin
class GreetingPlugin : Plugin<Project> {
override fun apply(project: Project) {
project.getTasks().register<GreetingTask>("hello") {
greeter.convention("Greeter")
}
}
}// setting convention when registering a task from plugin
class GreetingPlugin implements Plugin<Project> {
void apply(Project project) {
project.getTasks().register("hello", GreetingTask) {
greeter.convention("Greeter")
}
}
}From a build script
Build engineers may configure a convention on a lazy property from shared build logic that is configuring tasks (for instance, from third-party plugins) in a standard way for the entire build.
apply<GreetingPlugin>()
tasks.withType<GreetingTask>().configureEach {
// setting convention from build script
guest.convention("Guest")
}tasks.withType(GreetingTask).configureEach {
// setting convention from build script
guest.convention("Guest")
}Note that for project-specific values, instead of conventions, you should prefer setting explicit values (using Property.set(…) or ConfigurableFileCollection.setFrom(…), for instance),
as conventions are only meant to define defaults.
From the task initialization
A task author may configure a convention on a lazy property from the task constructor or (if in Kotlin) initializer block. This approach works for properties with trivial defaults, but it is not appropriate if additional context (external to the task implementation) is required in order to set a suitable default.
// setting convention from constructor
@get:Input
abstract val guest: Property<String>
init {
guest.convention("person2")
}// setting convention from constructor
@Input
abstract Property<String> getGuest()
GreetingTask() {
guest.convention("person2")
}Next to the property declaration
You may configure a convention on a lazy property next to the place where the property is declared. Note this option is not available for managed properties, and has the same caveats as configuring a convention from the task constructor.
// setting convention from declaration
@Input
val greeter = project.objects.property<String>().convention("person1")// setting convention from declaration
@Input
final Property<String> greeter = project.objects.property(String).convention("person1")Making a property unmodifiable
Most properties of a task or project are intended to be configured by plugins or build scripts so that they can use specific values for that build.
For example, a property that specifies the output directory for a compilation task may start with a value specified by a plugin. Then a build script might change the value to some custom location, then this value is used by the task when it runs. However, once the task starts to run, we want to prevent further property changes. This way we avoid errors that result from different consumers, such as the task action, Gradle’s up-to-date checks, build caching, or other tasks, using different values for the property.
Lazy properties provide several methods that you can use to disallow changes to their value once the value has been configured. The finalizeValue() method calculates the final value for the property and prevents further changes to the property.
libVersioning.version.finalizeValue()When the property’s value comes from a Provider, the provider is queried for its current value, and the result becomes the final value for the property.
This final value replaces the provider and the property no longer tracks the value of the provider.
Calling this method also makes a property instance unmodifiable and any further attempts to change the value of the property will fail.
Gradle automatically makes the properties of a task final when the task starts execution.
The finalizeValueOnRead() method is similar, except that the property’s final value is not calculated until the value of the property is queried.
modifiedFiles.finalizeValueOnRead()In other words, this method calculates the final value lazily as required, whereas finalizeValue() calculates the final value eagerly.
This method can be used when the value may be expensive to calculate or may not have been configured yet.
You also want to ensure that all consumers of the property see the same value when they query the value.
Using the Provider API
Guidelines to be successful with the Provider API:
-
The Property and Provider types have all of the overloads you need to query or configure a value. For this reason, you should follow the following guidelines:
-
Do not try to simplify calls like
obj.getProperty().get()andobj.getProperty().set(T)in your code by introducing additional getters and setters. Using such wrapper methods would undermine the purpose ofPropertyand prevent wiring of properties together. It would cause the current value to be obtained immediately (rather than being lazily evaluated). -
When migrating your plugin to use providers, follow these guidelines:
-
If it’s a new property, expose it as a Property or Provider using a single getter.
-
If it’s incubating, change it to use a Property or Provider using a single getter.
-
If it’s a stable property, add a new Property or Provider and deprecate the old one. You should wire the old getter/setters into the new property as appropriate.
-
Provider Files API Reference
Use these types for read-only values:
- Provider<RegularFile>
-
File on disk
- Provider<Directory>
-
Directory on disk
- FileCollection
-
Unstructured collection of files
- FileTree
-
Hierarchy of files
- Factories
-
-
Project.fileTree(Object) will produce a ConfigurableFileTree, or you can use Project.zipTree(Object) and Project.tarTree(Object)
-
Property Files API Reference
Use these types for mutable values:
- RegularFileProperty
-
File on disk
- Factories
- DirectoryProperty
-
Directory on disk
- Factories
- ConfigurableFileCollection
-
Unstructured collection of files
- Factories
- ConfigurableFileTree
-
Hierarchy of files
- Factories
- SourceDirectorySet
-
Hierarchy of source directories
Lazy Collections API Reference
Use these types for mutable values:
- ListProperty<T>
-
a property whose value is
List<T>- Factories
- SetProperty<T>
-
a property whose value is
Set<T>- Factories
Lazy Objects API Reference
Use these types for read only values:
- Provider<T>
-
a property whose value is an instance of
T- Factories
-
-
ProviderFactory.provider(Callable). Always prefer one of the other factory methods over this method.
Use these types for mutable values:
- Property<T>
-
a property whose value is an instance of
T- Factories
Developing Parallel Tasks
Gradle provides an API that can split tasks into sections that can be executed in parallel.
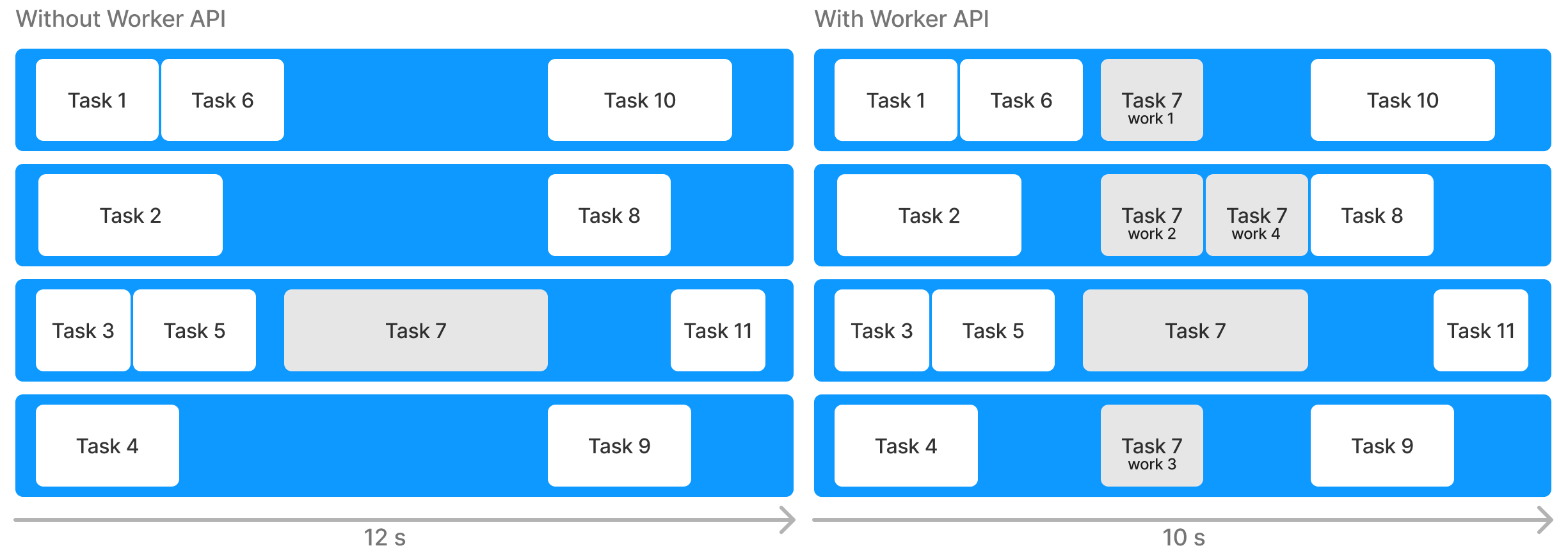
This allows Gradle to fully utilize the resources available and complete builds faster.
The Worker API
The Worker API provides the ability to break up the execution of a task action into discrete units of work and then execute that work concurrently and asynchronously.
Worker API example
The best way to understand how to use the API is to go through the process of converting an existing custom task to use the Worker API:
-
You’ll start by creating a custom task class that generates MD5 hashes for a configurable set of files.
-
Then, you’ll convert this custom task to use the Worker API.
-
Then, we’ll explore running the task with different levels of isolation.
In the process, you’ll learn about the basics of the Worker API and the capabilities it provides.
Step 1. Create a custom task class
First, create a custom task that generates MD5 hashes of a configurable set of files.
In a new directory, create a buildSrc/build.gradle(.kts) file:
repositories {
mavenCentral()
}
dependencies {
implementation("commons-io:commons-io:2.5")
implementation("commons-codec:commons-codec:1.9") // (1)
}repositories {
mavenCentral()
}
dependencies {
implementation 'commons-io:commons-io:2.5'
implementation 'commons-codec:commons-codec:1.9' // (1)
}-
Your custom task class will use Apache Commons Codec to generate MD5 hashes.
Next, create a custom task class in your buildSrc/src/main/java directory.
You should name this class CreateMD5:
import org.apache.commons.codec.digest.DigestUtils;
import org.apache.commons.io.FileUtils;
import org.gradle.api.file.DirectoryProperty;
import org.gradle.api.file.RegularFile;
import org.gradle.api.provider.Provider;
import org.gradle.api.tasks.OutputDirectory;
import org.gradle.api.tasks.SourceTask;
import org.gradle.api.tasks.TaskAction;
import org.gradle.workers.WorkerExecutor;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
abstract public class CreateMD5 extends SourceTask { // (1)
@OutputDirectory
abstract public DirectoryProperty getDestinationDirectory(); // (2)
@TaskAction
public void createHashes() {
for (File sourceFile : getSource().getFiles()) { // (3)
try {
InputStream stream = new FileInputStream(sourceFile);
System.out.println("Generating MD5 for " + sourceFile.getName() + "...");
// Artificially make this task slower.
Thread.sleep(3000); // (4)
Provider<RegularFile> md5File = getDestinationDirectory().file(sourceFile.getName() + ".md5"); // (5)
FileUtils.writeStringToFile(md5File.get().getAsFile(), DigestUtils.md5Hex(stream), (String) null);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
}-
SourceTask is a convenience type for tasks that operate on a set of source files.
-
The task output will go into a configured directory.
-
The task iterates over all the files defined as "source files" and creates an MD5 hash of each.
-
Insert an artificial sleep to simulate hashing a large file (the sample files won’t be that large).
-
The MD5 hash of each file is written to the output directory into a file of the same name with an "md5" extension.
Next, create a build.gradle(.kts) that registers your new CreateMD5 task:
plugins { id("base") } // (1)
tasks.register<CreateMD5>("md5") {
destinationDirectory = project.layout.buildDirectory.dir("md5") // (2)
source(project.layout.projectDirectory.file("src")) // (3)
}plugins { id 'base' } // (1)
tasks.register("md5", CreateMD5) {
destinationDirectory = project.layout.buildDirectory.dir("md5") // (2)
source(project.layout.projectDirectory.file('src')) // (3)
}-
Apply the
baseplugin so that you’ll have acleantask to use to remove the output. -
MD5 hash files will be written to
build/md5. -
This task will generate MD5 hash files for every file in the
srcdirectory.
You will need some source to generate MD5 hashes from.
Create three files in the src directory:
Intellectual growth should commence at birth and cease only at death.I was born not knowing and have had only a little time to change that here and there.Intelligence is the ability to adapt to change.At this point, you can test your task by running it ./gradlew md5:
$ gradle md5
The output should look similar to:
> Task :md5 Generating MD5 for einstein.txt... Generating MD5 for feynman.txt... Generating MD5 for hawking.txt... BUILD SUCCESSFUL in 9s 3 actionable tasks: 3 executed
In the build/md5 directory, you should now see corresponding files with an md5 extension containing MD5 hashes of the files from the src directory.
Notice that the task takes at least 9 seconds to run because it hashes each file one at a time (i.e., three files at ~3 seconds apiece).
Step 2. Convert to the Worker API
Although this task processes each file in sequence, the processing of each file is independent of any other file. This work can be done in parallel and take advantage of multiple processors. This is where the Worker API can help.
To use the Worker API, you need to define an interface that represents the parameters of each unit of work and extends org.gradle.workers.WorkParameters.
For the generation of MD5 hash files, the unit of work will require two parameters:
-
the file to be hashed and,
-
the file to write the hash to.
There is no need to create a concrete implementation because Gradle will generate one for us at runtime.
import org.gradle.api.file.RegularFileProperty;
import org.gradle.workers.WorkParameters;
public interface MD5WorkParameters extends WorkParameters {
RegularFileProperty getSourceFile(); // (1)
RegularFileProperty getMD5File();
}-
Use
Propertyobjects to represent the source and MD5 hash files.
Then, you need to refactor the part of your custom task that does the work for each individual file into a separate class.
This class is your "unit of work" implementation, and it should be an abstract class that extends org.gradle.workers.WorkAction:
import org.apache.commons.codec.digest.DigestUtils;
import org.apache.commons.io.FileUtils;
import org.gradle.workers.WorkAction;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
public abstract class GenerateMD5 implements WorkAction<MD5WorkParameters> { // (1)
@Override
public void execute() {
try {
File sourceFile = getParameters().getSourceFile().getAsFile().get();
File md5File = getParameters().getMD5File().getAsFile().get();
InputStream stream = new FileInputStream(sourceFile);
System.out.println("Generating MD5 for " + sourceFile.getName() + "...");
// Artificially make this task slower.
Thread.sleep(3000);
FileUtils.writeStringToFile(md5File, DigestUtils.md5Hex(stream), (String) null);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}-
Do not implement the
getParameters()method - Gradle will inject this at runtime.
Now, change your custom task class to submit work to the WorkerExecutor instead of doing the work itself.
import org.gradle.api.Action;
import org.gradle.api.file.RegularFile;
import org.gradle.api.provider.Provider;
import org.gradle.api.tasks.*;
import org.gradle.workers.*;
import org.gradle.api.file.DirectoryProperty;
import javax.inject.Inject;
import java.io.File;
abstract public class CreateMD5 extends SourceTask {
@OutputDirectory
abstract public DirectoryProperty getDestinationDirectory();
@Inject
abstract public WorkerExecutor getWorkerExecutor(); // (1)
@TaskAction
public void createHashes() {
WorkQueue workQueue = getWorkerExecutor().noIsolation(); // (2)
for (File sourceFile : getSource().getFiles()) {
Provider<RegularFile> md5File = getDestinationDirectory().file(sourceFile.getName() + ".md5");
workQueue.submit(GenerateMD5.class, parameters -> { // (3)
parameters.getSourceFile().set(sourceFile);
parameters.getMD5File().set(md5File);
});
}
}
}-
The WorkerExecutor service is required in order to submit your work. Create an abstract getter method annotated
javax.inject.Inject, and Gradle will inject the service at runtime when the task is created. -
Before submitting work, get a
WorkQueueobject with the desired isolation mode (described below). -
When submitting the unit of work, specify the unit of work implementation, in this case
GenerateMD5, and configure its parameters.
At this point, you should be able to rerun your task:
$ gradle clean md5 > Task :md5 Generating MD5 for einstein.txt... Generating MD5 for feynman.txt... Generating MD5 for hawking.txt... BUILD SUCCESSFUL in 3s 3 actionable tasks: 3 executed
The results should look the same as before, although the MD5 hash files may be generated in a different order since the units of work are executed in parallel. This time, however, the task runs much faster. This is because the Worker API executes the MD5 calculation for each file in parallel rather than in sequence.
Step 3. Change the isolation mode
The isolation mode controls how strongly Gradle will isolate items of work from each other and the rest of the Gradle runtime.
There are three methods on WorkerExecutor that control this:
-
noIsolation() -
classLoaderIsolation() -
processIsolation()
The noIsolation() mode is the lowest level of isolation and will prevent a unit of work from changing the project state.
This is the fastest isolation mode because it requires the least overhead to set up and execute the work item.
However, it will use a single shared classloader for all units of work.
This means that each unit of work can affect one another through static class state.
It also means that every unit of work uses the same version of libraries on the buildscript classpath.
If you wanted the user to be able to configure the task to run with a different (but compatible) version of the
Apache Commons Codec library, you would need to use a different isolation mode.
First, you must change the dependency in buildSrc/build.gradle to be compileOnly.
This tells Gradle that it should use this dependency when building the classes, but should not put it on the build script classpath:
repositories {
mavenCentral()
}
dependencies {
implementation("commons-io:commons-io:2.5")
compileOnly("commons-codec:commons-codec:1.9")
}repositories {
mavenCentral()
}
dependencies {
implementation 'commons-io:commons-io:2.5'
compileOnly 'commons-codec:commons-codec:1.9'
}Next, change the CreateMD5 task to allow the user to configure the version of the codec library that they want to use.
It will resolve the appropriate version of the library at runtime and configure the workers to use this version.
The classLoaderIsolation() method tells Gradle to run this work in a thread with an isolated classloader:
import org.gradle.api.Action;
import org.gradle.api.file.ConfigurableFileCollection;
import org.gradle.api.file.DirectoryProperty;
import org.gradle.api.file.RegularFile;
import org.gradle.api.provider.Provider;
import org.gradle.api.tasks.*;
import org.gradle.process.JavaForkOptions;
import org.gradle.workers.*;
import javax.inject.Inject;
import java.io.File;
import java.util.Set;
abstract public class CreateMD5 extends SourceTask {
@InputFiles
abstract public ConfigurableFileCollection getCodecClasspath(); // (1)
@OutputDirectory
abstract public DirectoryProperty getDestinationDirectory();
@Inject
abstract public WorkerExecutor getWorkerExecutor();
@TaskAction
public void createHashes() {
WorkQueue workQueue = getWorkerExecutor().classLoaderIsolation(workerSpec -> {
workerSpec.getClasspath().from(getCodecClasspath()); // (2)
});
for (File sourceFile : getSource().getFiles()) {
Provider<RegularFile> md5File = getDestinationDirectory().file(sourceFile.getName() + ".md5");
workQueue.submit(GenerateMD5.class, parameters -> {
parameters.getSourceFile().set(sourceFile);
parameters.getMD5File().set(md5File);
});
}
}
}-
Expose an input property for the codec library classpath.
-
Configure the classpath on the ClassLoaderWorkerSpec when creating the work queue.
Next, you need to configure your build so that it has a repository to look up the codec version at task execution time. We also create a dependency to resolve our codec library from this repository:
plugins { id("base") }
repositories {
mavenCentral() // (1)
}
val codec = configurations.create("codec") { // (2)
attributes {
attribute(Usage.USAGE_ATTRIBUTE, objects.named(Usage.JAVA_RUNTIME))
}
isCanBeConsumed = false
}
dependencies {
codec("commons-codec:commons-codec:1.10") // (3)
}
tasks.register<CreateMD5>("md5") {
codecClasspath.from(codec) // (4)
destinationDirectory = project.layout.buildDirectory.dir("md5")
source(project.layout.projectDirectory.file("src"))
}plugins { id 'base' }
repositories {
mavenCentral() // (1)
}
configurations.create('codec') { // (2)
attributes {
attribute(Usage.USAGE_ATTRIBUTE, objects.named(Usage, Usage.JAVA_RUNTIME))
}
canBeConsumed = false
}
dependencies {
codec 'commons-codec:commons-codec:1.10' // (3)
}
tasks.register('md5', CreateMD5) {
codecClasspath.from(configurations.codec) // (4)
destinationDirectory = project.layout.buildDirectory.dir('md5')
source(project.layout.projectDirectory.file('src'))
}-
Add a repository to resolve the codec library - this can be a different repository than the one used to build the
CreateMD5task class. -
Add a configuration to resolve our codec library version.
-
Configure an alternate, compatible version of Apache Commons Codec.
-
Configure the
md5task to use the configuration as its classpath. Note that the configuration will not be resolved until the task is executed.
Now, if you run your task, it should work as expected using the configured version of the codec library:
$ gradle clean md5 > Task :md5 Generating MD5 for einstein.txt... Generating MD5 for feynman.txt... Generating MD5 for hawking.txt... BUILD SUCCESSFUL in 3s 3 actionable tasks: 3 executed
Step 4. Create a Worker Daemon
Sometimes, it is desirable to utilize even greater levels of isolation when executing items of work. For instance, external libraries may rely on certain system properties to be set, which may conflict between work items. Or a library might not be compatible with the version of JDK that Gradle is running with and may need to be run with a different version.
The Worker API can accommodate this using the processIsolation() method that causes the work to execute in a separate "worker daemon".
These worker processes are session-scoped, meaning they live only for the duration of a single build and can be reused within that build.
They do not persist across multiple builds.
Gradle will stop these worker daemons when the build completes or if system resources get low during the build.
To utilize a worker daemon, use the processIsolation() method when creating the WorkQueue.
You may also want to configure custom settings for the new process:
import org.gradle.api.Action;
import org.gradle.api.file.ConfigurableFileCollection;
import org.gradle.api.file.DirectoryProperty;
import org.gradle.api.file.RegularFile;
import org.gradle.api.provider.Provider;
import org.gradle.api.tasks.*;
import org.gradle.process.JavaForkOptions;
import org.gradle.workers.*;
import javax.inject.Inject;
import java.io.File;
import java.util.Set;
abstract public class CreateMD5 extends SourceTask {
@InputFiles
abstract public ConfigurableFileCollection getCodecClasspath(); // (1)
@OutputDirectory
abstract public DirectoryProperty getDestinationDirectory();
@Inject
abstract public WorkerExecutor getWorkerExecutor();
@TaskAction
public void createHashes() {
// (1)
WorkQueue workQueue = getWorkerExecutor().processIsolation(workerSpec -> {
workerSpec.getClasspath().from(getCodecClasspath());
workerSpec.forkOptions(options -> {
options.setMaxHeapSize("64m"); // (2)
});
});
for (File sourceFile : getSource().getFiles()) {
Provider<RegularFile> md5File = getDestinationDirectory().file(sourceFile.getName() + ".md5");
workQueue.submit(GenerateMD5.class, parameters -> {
parameters.getSourceFile().set(sourceFile);
parameters.getMD5File().set(md5File);
});
}
}
}-
Change the isolation mode to
PROCESS. -
Set up the JavaForkOptions for the new process.
Now, you should be able to run your task, and it will work as expected but using worker daemons instead:
$ gradle clean md5 > Task :md5 Generating MD5 for einstein.txt... Generating MD5 for feynman.txt... Generating MD5 for hawking.txt... BUILD SUCCESSFUL in 3s 3 actionable tasks: 3 executed
Note that the execution time may be high. This is because Gradle has to start a new process for each worker daemon, which is expensive.
However, if you run your task a second time, you will see that it runs much faster. This is because the worker daemon(s) started during the initial build have persisted and are available for use immediately during subsequent builds:
$ gradle clean md5 > Task :md5 Generating MD5 for einstein.txt... Generating MD5 for feynman.txt... Generating MD5 for hawking.txt... BUILD SUCCESSFUL in 1s 3 actionable tasks: 3 executed
Isolation modes
Gradle provides three isolation modes that can be configured when creating a WorkQueue and are specified using one of the following methods on WorkerExecutor:
WorkerExecutor.noIsolation()-
This states that the work should be run in a thread with minimal isolation.
For instance, it will share the same classloader that the task is loaded from. This is the fastest level of isolation. WorkerExecutor.classLoaderIsolation()-
This states that the work should be run in a thread with an isolated classloader.
The classloader will have the classpath from the classloader that the unit of work implementation class was loaded from as well as any additional classpath entries added throughClassLoaderWorkerSpec.getClasspath(). WorkerExecutor.processIsolation()-
This states that the work should be run with a maximum isolation level by executing the work in a separate process.
The classloader of the process will use the classpath from the classloader that the unit of work was loaded from as well as any additional classpath entries added throughClassLoaderWorkerSpec.getClasspath(). Furthermore, the process will be a worker daemon that will stay alive and can be reused for future work items with the same requirements. This process can be configured with different settings than the Gradle JVM using ProcessWorkerSpec.forkOptions(org.gradle.api.Action).
Worker Daemons
When using processIsolation(), Gradle will start a long-lived worker daemon process that can be reused for future work items.
// Create a WorkQueue with process isolation
val workQueue = workerExecutor.processIsolation() {
// Configure the options for the forked process
forkOptions {
maxHeapSize = "512m"
systemProperty("org.gradle.sample.showFileSize", "true")
}
}
// Create and submit a unit of work for each file
source.forEach { file ->
workQueue.submit(ReverseFile::class) {
fileToReverse = file
destinationDir = outputDir
}
}// Create a WorkQueue with process isolation
WorkQueue workQueue = workerExecutor.processIsolation() { ProcessWorkerSpec spec ->
// Configure the options for the forked process
forkOptions { JavaForkOptions options ->
options.maxHeapSize = "512m"
options.systemProperty "org.gradle.sample.showFileSize", "true"
}
}
// Create and submit a unit of work for each file
source.each { file ->
workQueue.submit(ReverseFile.class) { ReverseParameters parameters ->
parameters.fileToReverse = file
parameters.destinationDir = outputDir
}
}When a unit of work for a worker daemon is submitted, Gradle will first look to see if a compatible, idle daemon already exists. If so, it will send the unit of work to the idle daemon, marking it as busy. If not, it will start a new daemon. When evaluating compatibility, Gradle looks at a number of criteria, all of which can be controlled through ProcessWorkerSpec.forkOptions(org.gradle.api.Action).
By default, a worker daemon starts with a maximum heap of 512MB. This can be changed by adjusting the workers' fork options.
- executable
-
A daemon is considered compatible only if it uses the same Java executable.
- classpath
-
A daemon is considered compatible if its classpath contains all the classpath entries requested.
Note that a daemon is considered compatible only if the classpath exactly matches the requested classpath. - heap settings
-
A daemon is considered compatible if it has at least the same heap size settings as requested.
In other words, a daemon that has higher heap settings than requested would be considered compatible. - jvm arguments
-
A daemon is compatible if it has set all the JVM arguments requested.
Note that a daemon is compatible if it has additional JVM arguments beyond those requested (except for those treated especially, such as heap settings, assertions, debug, etc.). - system properties
-
A daemon is considered compatible if it has set all the system properties requested with the same values.
Note that a daemon is compatible if it has additional system properties beyond those requested. - environment variables
-
A daemon is considered compatible if it has set all the environment variables requested with the same values.
Note that a daemon is compatible if it has more environment variables than requested. - bootstrap classpath
-
A daemon is considered compatible if it contains all the bootstrap classpath entries requested.
Note that a daemon is compatible if it has more bootstrap classpath entries than requested. - debug
-
A daemon is considered compatible only if debug is set to the same value as requested (
trueorfalse). - enable assertions
-
A daemon is considered compatible only if enable assertions are set to the same value as requested (
trueorfalse). - default character encoding
-
A daemon is considered compatible only if the default character encoding is set to the same value as requested.
Worker daemons will remain running until the build daemon that started them is stopped or system memory becomes scarce. When system memory is low, Gradle will stop worker daemons to minimize memory consumption.
|
Note
|
A step-by-step description of converting a normal task action to use the worker API can be found in the section on developing parallel tasks. |
Cancellation and timeouts
To support cancellation (e.g., when the user stops the build with CTRL+C) and task timeouts, custom tasks should react to interrupting their executing thread. The same is true for work items submitted via the worker API. If a task does not respond to an interrupt within 10s, the daemon will shut down to free up system resources.
Advanced Tasks
Incremental tasks
In Gradle, implementing a task that skips execution when its inputs and outputs are already UP-TO-DATE is simple and efficient, thanks to the Incremental Build feature.
However, there are times when only a few input files have changed since the last execution, and it is best to avoid reprocessing all the unchanged inputs. This situation is common in tasks that transform input files into output files on a one-to-one basis.
To optimize your build process you can use an incremental task. This approach ensures that only out-of-date input files are processed, improving build performance.
Implementing an incremental task
For a task to process inputs incrementally, that task must contain an incremental task action.
This is a task action method that has a single InputChanges parameter. That parameter tells Gradle that the action only wants to process the changed inputs.
In addition, the task needs to declare at least one incremental file input property by using either @Incremental or @SkipWhenEmpty:
public class IncrementalReverseTask : DefaultTask() {
@get:Incremental
@get:InputDirectory
val inputDir: DirectoryProperty = project.objects.directoryProperty()
@get:OutputDirectory
val outputDir: DirectoryProperty = project.objects.directoryProperty()
@get:Input
val inputProperty: RegularFileProperty = project.objects.fileProperty() // File input property
@TaskAction
fun execute(inputs: InputChanges) { // InputChanges parameter
val msg = if (inputs.isIncremental) "CHANGED inputs are out of date"
else "ALL inputs are out of date"
println(msg)
}
}class IncrementalReverseTask extends DefaultTask {
@Incremental
@InputDirectory
def File inputDir
@OutputDirectory
def File outputDir
@Input
def inputProperty // File input property
@TaskAction
void execute(InputChanges inputs) { // InputChanges parameter
println inputs.incremental ? "CHANGED inputs are out of date"
: "ALL inputs are out of date"
}
}|
Important
|
To query incremental changes for an input file property, that property must always return the same instance.
The easiest way to accomplish this is to use one of the following property types: You can learn more about |
The incremental task action can use InputChanges.getFileChanges() to find out what files have changed for a given file-based input property, be it of type RegularFileProperty, DirectoryProperty or ConfigurableFileCollection.
The method returns an Iterable of type FileChanges, which in turn can be queried for the following:
-
the affected file
-
the change type (
ADDED,REMOVEDorMODIFIED) -
the normalized path of the changed file
-
the file type of the changed file
The following example demonstrates an incremental task that has a directory input. It assumes that the directory contains a collection of text files and copies them to an output directory, reversing the text within each file:
abstract class IncrementalReverseTask : DefaultTask() {
@get:Incremental
@get:PathSensitive(PathSensitivity.NAME_ONLY)
@get:InputDirectory
abstract val inputDir: DirectoryProperty
@get:OutputDirectory
abstract val outputDir: DirectoryProperty
@get:Input
abstract val inputProperty: Property<String>
@TaskAction
fun execute(inputChanges: InputChanges) {
println(
if (inputChanges.isIncremental) "Executing incrementally"
else "Executing non-incrementally"
)
inputChanges.getFileChanges(inputDir).forEach { change ->
if (change.fileType == FileType.DIRECTORY) return@forEach
println("${change.changeType}: ${change.normalizedPath}")
val targetFile = outputDir.file(change.normalizedPath).get().asFile
if (change.changeType == ChangeType.REMOVED) {
targetFile.delete()
} else {
targetFile.writeText(change.file.readText().reversed())
}
}
}
}abstract class IncrementalReverseTask extends DefaultTask {
@Incremental
@PathSensitive(PathSensitivity.NAME_ONLY)
@InputDirectory
abstract DirectoryProperty getInputDir()
@OutputDirectory
abstract DirectoryProperty getOutputDir()
@Input
abstract Property<String> getInputProperty()
@TaskAction
void execute(InputChanges inputChanges) {
println(inputChanges.incremental
? 'Executing incrementally'
: 'Executing non-incrementally'
)
inputChanges.getFileChanges(inputDir).each { change ->
if (change.fileType == FileType.DIRECTORY) return
println "${change.changeType}: ${change.normalizedPath}"
def targetFile = outputDir.file(change.normalizedPath).get().asFile
if (change.changeType == ChangeType.REMOVED) {
targetFile.delete()
} else {
targetFile.text = change.file.text.reverse()
}
}
}
}|
Note
|
The type of the inputDir property, its annotations, and the execute() action use getFileChanges() to process the subset of files that have changed since the last build.
The action deletes a target file if the corresponding input file has been removed.
|
If, for some reason, the task is executed non-incrementally (by running with --rerun-tasks, for example), all files are reported as ADDED, irrespective of the previous state.
In this case, Gradle automatically removes the previous outputs, so the incremental task must only process the given files.
For a simple transformer task like the above example, the task action must generate output files for any out-of-date inputs and delete output files for any removed inputs.
|
Important
|
A task may only contain a single incremental task action. |
Which inputs are considered out of date?
When a task has been previously executed, and the only changes since that execution are to incremental input file properties, Gradle can intelligently determine which input files need to be processed, a concept known as incremental execution.
In this scenario, the InputChanges.getFileChanges() method, available in the org.gradle.work.InputChanges class, provides details for all input files associated with the given property that have been ADDED, REMOVED or MODIFIED.
However, there are many cases where Gradle cannot determine which input files need to be processed (i.e., non-incremental execution). Examples include:
-
There is no history available from a previous execution.
-
You are building with a different version of Gradle. Currently, Gradle does not use task history from a different version.
-
An
upToDateWhencriterion added to the task returnsfalse. -
An input property has changed since the previous execution.
-
A non-incremental input file property has changed since the previous execution.
-
One or more output files have changed since the previous execution.
In these cases, Gradle will report all input files as ADDED, and the getFileChanges() method will return details for all the files that comprise the given input property.
You can check if the task execution is incremental or not with the InputChanges.isIncremental() method.
An incremental task in action
Consider an instance of IncrementalReverseTask executed against a set of inputs for the first time.
In this case, all inputs will be considered ADDED, as shown here:
tasks.register<IncrementalReverseTask>("incrementalReverse") {
inputDir = file("inputs")
outputDir = layout.buildDirectory.dir("outputs")
inputProperty = project.findProperty("taskInputProperty") as String? ?: "original"
}tasks.register('incrementalReverse', IncrementalReverseTask) {
inputDir = file('inputs')
outputDir = layout.buildDirectory.dir("outputs")
inputProperty = project.findProperty('taskInputProperty') ?: 'original'
}The build layout:
.
├── build.gradle
└── inputs
├── 1.txt
├── 2.txt
└── 3.txt$ ./gradlew -q incrementalReverseExecuting non-incrementally
ADDED: 1.txt
ADDED: 2.txt
ADDED: 3.txtNaturally, when the task is executed again with no changes, then the entire task is UP-TO-DATE, and the task action is not executed:
$ ./gradlew incrementalReverse> Task :incrementalReverse UP-TO-DATE
BUILD SUCCESSFUL in 0s
1 actionable task: 1 up-to-dateWhen an input file is modified in some way or a new input file is added, then re-executing the task results in those files being returned by InputChanges.getFileChanges().
The following example modifies the content of one file and adds another before running the incremental task:
tasks.register("updateInputs") {
val inputsDir = layout.projectDirectory.dir("inputs")
outputs.dir(inputsDir)
doLast {
inputsDir.file("1.txt").asFile.writeText("Changed content for existing file 1.")
inputsDir.file("4.txt").asFile.writeText("Content for new file 4.")
}
}tasks.register('updateInputs') {
def inputsDir = layout.projectDirectory.dir('inputs')
outputs.dir(inputsDir)
doLast {
inputsDir.file('1.txt').asFile.text = 'Changed content for existing file 1.'
inputsDir.file('4.txt').asFile.text = 'Content for new file 4.'
}
}$ ./gradlew -q updateInputs incrementalReverseExecuting incrementally
MODIFIED: 1.txt
ADDED: 4.txt|
Note
|
The various mutation tasks (updateInputs, removeInput, etc) are only present to demonstrate the behavior of incremental tasks.
They should not be viewed as the kinds of tasks or task implementations you should have in your own build scripts.
|
When an existing input file is removed, then re-executing the task results in that file being returned by InputChanges.getFileChanges() as REMOVED.
The following example removes one of the existing files before executing the incremental task:
tasks.register<Delete>("removeInput") {
delete("inputs/3.txt")
}tasks.register('removeInput', Delete) {
delete 'inputs/3.txt'
}$ ./gradlew -q removeInput incrementalReverseExecuting incrementally
REMOVED: 3.txtGradle cannot determine which input files are out-of-date when an output file is deleted (or modified).
In this case, details for all the input files for the given property are returned by InputChanges.getFileChanges().
The following example removes one of the output files from the build directory.
However, all the input files are considered to be ADDED:
tasks.register<Delete>("removeOutput") {
delete(layout.buildDirectory.file("outputs/1.txt"))
}tasks.register('removeOutput', Delete) {
delete layout.buildDirectory.file("outputs/1.txt")
}$ ./gradlew -q removeOutput incrementalReverseExecuting non-incrementally
ADDED: 1.txt
ADDED: 2.txt
ADDED: 3.txtThe last scenario we want to cover concerns what happens when a non-file-based input property is modified.
In such cases, Gradle cannot determine how the property impacts the task outputs, so the task is executed non-incrementally.
This means that all input files for the given property are returned by InputChanges.getFileChanges() and they are all treated as ADDED.
The following example sets the project property taskInputProperty to a new value when running the incrementalReverse task.
That project property is used to initialize the task’s inputProperty property, as you can see in the first example of this section.
Here is the expected output in this case:
$ ./gradlew -q -PtaskInputProperty=changed incrementalReverseExecuting non-incrementally
ADDED: 1.txt
ADDED: 2.txt
ADDED: 3.txtCommand Line options
Sometimes, a user wants to declare the value of an exposed task property on the command line instead of the build script. Passing property values on the command line is particularly helpful if they change more frequently.
The task API supports a mechanism for marking a property to automatically generate a corresponding command line parameter with a specific name at runtime.
Step 1. Declare a command-line option
To expose a new command line option for a task property, annotate the corresponding setter method of a property with Option:
@Option(option = "flag", description = "Sets the flag")An option requires a mandatory identifier. You can provide an optional description.
A task can expose as many command line options as properties available in the class.
Options may be declared in superinterfaces of the task class as well. If multiple interfaces declare the same property but with different option flags, they will both work to set the property.
In the example below, the custom task UrlVerify verifies whether a URL can be resolved by making an HTTP call and checking the response code. The URL to be verified is configurable through the property url.
The setter method for the property is annotated with @Option:
import org.gradle.api.tasks.options.Option;
public class UrlVerify extends DefaultTask {
private String url;
@Option(option = "url", description = "Configures the URL to be verified.")
public void setUrl(String url) {
this.url = url;
}
@Input
public String getUrl() {
return url;
}
@TaskAction
public void verify() {
getLogger().quiet("Verifying URL '{}'", url);
// verify URL by making a HTTP call
}
}All options declared for a task can be rendered as console output by running the help task and the --task option.
Step 2. Use an option on the command line
There are a few rules for options on the command line:
-
The option uses a double-dash as a prefix, e.g.,
--url. A single dash does not qualify as valid syntax for a task option. -
The option argument follows directly after the task declaration, e.g.,
verifyUrl --url=http://www.google.com/. -
Multiple task options can be declared in any order on the command line following the task name.
Building upon the earlier example, the build script creates a task instance of type UrlVerify and provides a value from the command line through the exposed option:
tasks.register<UrlVerify>("verifyUrl")tasks.register('verifyUrl', UrlVerify)$ ./gradlew -q verifyUrl --url=http://www.google.com/Verifying URL 'http://www.google.com/'Supported data types for options
Gradle limits the data types that can be used for declaring command line options.
The use of the command line differs per type:
boolean,Boolean,Property<Boolean>-
Describes an option with the value
trueorfalse.
Passing the option on the command line treats the value astrue. For example,--fooequates totrue.
The absence of the option uses the default value of the property. For each boolean option, an opposite option is created automatically. For example,--no-foois created for the provided option--fooand--baris created for--no-bar. Options whose name starts with--noare disabled options and set the option value tofalse. An opposite option is only created if no option with the same name already exists for the task. Double,Property<Double>-
Describes an option with a double value.
Passing the option on the command line also requires a value, e.g.,--factor=2.2or--factor 2.2. Integer,Property<Integer>-
Describes an option with an integer value.
Passing the option on the command line also requires a value, e.g.,--network-timeout=5000or--network-timeout 5000. Long,Property<Long>-
Describes an option with a long value.
Passing the option on the command line also requires a value, e.g.,--threshold=2147483648or--threshold 2147483648. String,Property<String>-
Describes an option with an arbitrary String value.
Passing the option on the command line also requires a value, e.g.,--container-id=2x94heldor--container-id 2x94held. enum,Property<enum>-
Describes an option as an enumerated type.
Passing the option on the command line also requires a value e.g.,--log-level=DEBUGor--log-level debug.
The value is not case-sensitive. List<T>whereTisDouble,Integer,Long,String,enum-
Describes an option that can take multiple values of a given type.
The values for the option have to be provided as multiple declarations, e.g.,--image-id=123 --image-id=456.
Other notations, such as comma-separated lists or multiple values separated by a space character, are currently not supported. ListProperty<T>,SetProperty<T>whereTisDouble,Integer,Long,String,enum-
Describes an option that can take multiple values of a given type.
The values for the option have to be provided as multiple declarations, e.g.,--image-id=123 --image-id=456.
Other notations, such as comma-separated lists or multiple values separated by a space character, are currently not supported. DirectoryProperty,RegularFileProperty-
Describes an option with a file system element.
Passing the option on the command line also requires a value representing a path, e.g.,--output-file=file.txtor--output-dir outputDir.
Relative paths are resolved relative to the project directory of the project that owns this property instance. SeeFileSystemLocationProperty.set().
Documenting available values for an option
Theoretically, an option for a property type String or List<String> can accept any arbitrary value.
Accepted values for such an option can be documented programmatically with the help of the annotation OptionValues:
@OptionValues('file')This annotation may be assigned to any method that returns a List of one of the supported data types.
You need to specify an option identifier to indicate the relationship between the option and available values.
|
Note
|
Passing a value on the command line not supported by the option does not fail the build or throw an exception. You must implement custom logic for such behavior in the task action. |
The example below demonstrates the use of multiple options for a single task.
The task implementation provides a list of available values for the option output-type:
import org.gradle.api.tasks.options.Option;
import org.gradle.api.tasks.options.OptionValues;
public abstract class UrlProcess extends DefaultTask {
private String url;
private OutputType outputType;
@Input
@Option(option = "http", description = "Configures the http protocol to be allowed.")
public abstract Property<Boolean> getHttp();
@Option(option = "url", description = "Configures the URL to send the request to.")
public void setUrl(String url) {
if (!getHttp().getOrElse(true) && url.startsWith("http://")) {
throw new IllegalArgumentException("HTTP is not allowed");
} else {
this.url = url;
}
}
@Input
public String getUrl() {
return url;
}
@Option(option = "output-type", description = "Configures the output type.")
public void setOutputType(OutputType outputType) {
this.outputType = outputType;
}
@OptionValues("output-type")
public List<OutputType> getAvailableOutputTypes() {
return new ArrayList<OutputType>(Arrays.asList(OutputType.values()));
}
@Input
public OutputType getOutputType() {
return outputType;
}
@TaskAction
public void process() {
getLogger().quiet("Writing out the URL response from '{}' to '{}'", url, outputType);
// retrieve content from URL and write to output
}
private static enum OutputType {
CONSOLE, FILE
}
}Listing command line options
Command line options using the annotations Option and OptionValues are self-documenting.
You will see declared options and their available values reflected in the console output of the help task.
The output renders options alphabetically, except for boolean disable options, which appear following the enable option:
$ ./gradlew -q help --task processUrlDetailed task information for processUrl
Path
:processUrl (registered in build file 'build.gradle.kts')
Type
UrlProcess (UrlProcess)
Options
--http Configures the http protocol to be allowed.
--no-http Disables option --http.
--output-type Configures the output type.
Available values are:
CONSOLE
FILE
--url Configures the URL to send the request to.
--rerun Causes the task to be re-run even if up-to-date.
Description
-
Group
-Limitations
Support for declaring command line options currently comes with a few limitations.
-
Command line options can only be declared for custom tasks via annotation. There’s no programmatic equivalent for defining options.
-
Options cannot be declared globally, e.g., on a project level or as part of a plugin.
-
When assigning an option on the command line, the task exposing the option needs to be spelled out explicitly, e.g.,
gradle check --tests abcdoes not work even though thechecktask depends on thetesttask. -
If you specify a task option name that conflicts with the name of a built-in Gradle option, use the
--delimiter before calling your task to reference that option. For more information, see Disambiguate Task Options from Built-in Options.
Verification failures
Normally, exceptions thrown during task execution result in a failure that immediately terminates a build.
The outcome of the task will be FAILED, the result of the build will be FAILED, and no further tasks will be executed.
When running with the --continue flag, Gradle will continue to run other requested tasks in the build after encountering a task failure.
However, any tasks that depend on a failed task will not be executed.
There is a special type of exception that behaves differently when downstream tasks only rely on the outputs of a failing task.
A task can throw a subtype of VerificationException to indicate that it has failed in a controlled manner such that its output is still valid for consumers.
A task depends on the outcome of another task when it directly depends on it using dependsOn.
When Gradle is run with --continue, consumer tasks that depend on a producer task’s output (via a relationship between task inputs and outputs) can still run after the producer fails.
A failed unit test, for instance, will cause a failing outcome for the test task.
However, this doesn’t prevent another task from reading and processing the (valid) test results the task produced.
Verification failures are used in exactly this manner by the Test Report Aggregation Plugin.
Verification failures are also useful for tasks that need to report a failure even after producing useful output consumable by other tasks.
val process = tasks.register("process") {
val outputFile = layout.buildDirectory.file("processed.log")
outputs.files(outputFile) // (1)
doLast {
val logFile = outputFile.get().asFile
logFile.appendText("Step 1 Complete.") // (2)
throw VerificationException("Process failed!") // (3)
logFile.appendText("Step 2 Complete.") // (4)
}
}
tasks.register("postProcess") {
inputs.files(process) // (5)
doLast {
println("Results: ${inputs.files.singleFile.readText()}") // (6)
}
}tasks.register("process") {
def outputFile = layout.buildDirectory.file("processed.log")
outputs.files(outputFile) // (1)
doLast {
def logFile = outputFile.get().asFile
logFile << "Step 1 Complete." // (2)
throw new VerificationException("Process failed!") // (3)
logFile << "Step 2 Complete." // (4)
}
}
tasks.register("postProcess") {
inputs.files(tasks.named("process")) // (5)
doLast {
println("Results: ${inputs.files.singleFile.text}") // (6)
}
}$ ./gradlew postProcess --continue> Task :process FAILED
> Task :postProcess
Results: Step 1 Complete.
2 actionable tasks: 2 executed
FAILURE: Build failed with an exception.-
Register Output: The
processtask writes its output to a log file. -
Modify Output: The task writes to its output file as it executes.
-
Task Failure: The task throws a
VerificationExceptionand fails at this point. -
Continue to Modify Output: This line never runs due to the exception stopping the task.
-
Consume Output: The
postProcesstask depends on the output of theprocesstask due to using that task’s outputs as its own inputs. -
Use Partial Result: With the
--continueflag set, Gradle still runs the requestedpostProcesstask despite theprocesstask’s failure.postProcesscan read and display the partial (though still valid) result.
Using Shared Build Services
Shared build services allow tasks to share state or resources. For example, tasks might share a cache of pre-computed values or use a web service or database instance.
A build service is an object that holds the state for tasks to use. It provides an alternative mechanism for hooking into a Gradle build and receiving information about task execution and operation completion.
Build services are configuration cacheable.
Gradle manages the service lifecycle, creating the service instance only when required and cleaning it up when no longer needed. Gradle can also coordinate access to the build service, ensuring that no more than a specified number of tasks use the service concurrently.
Implementing a build service
To implement a build service, create an abstract class that implements BuildService. Then, define methods you want the tasks to use on this type.
abstract class BaseCountingService implements BuildService<CountingParams>, AutoCloseable {
}A build service implementation is treated as a custom Gradle type and can use any of the features available to custom Gradle types.
A build service can optionally take parameters, which Gradle injects into the service instance when creating it.
To provide parameters, you define an abstract class (or interface) that holds the parameters.
The parameters type must implement (or extend) BuildServiceParameters.
The service implementation can access the parameters using this.getParameters().
The parameters type is also a custom Gradle type.
When the build service does not require any parameters, you can use BuildServiceParameters.None as the type of parameter.
interface CountingParams extends BuildServiceParameters {
Property<Integer> getInitial()
}A build service implementation can also optionally implement AutoCloseable, in which case Gradle will call the build service instance’s close() method when it discards the service instance.
This happens sometime between the completion of the last task that uses the build service and the end of the build.
Here is an example of a service that takes parameters and is closeable:
import org.gradle.api.file.DirectoryProperty;
import org.gradle.api.provider.Property;
import org.gradle.api.services.BuildService;
import org.gradle.api.services.BuildServiceParameters;
import java.net.URI;
import java.net.URISyntaxException;
public abstract class WebServer implements BuildService<WebServer.Params>, AutoCloseable {
// Some parameters for the web server
interface Params extends BuildServiceParameters {
Property<Integer> getPort();
DirectoryProperty getResources();
}
private final URI uri;
public WebServer() throws URISyntaxException {
// Use the parameters
int port = getParameters().getPort().get();
uri = new URI(String.format("https://localhost:%d/", port));
// Start the server ...
System.out.println(String.format("Server is running at %s", uri));
}
// A public method for tasks to use
public URI getUri() {
return uri;
}
@Override
public void close() {
// Stop the server ...
}
}Note that you should not implement the BuildService.getParameters() method, as Gradle will provide an implementation of this.
A build service implementation must be thread-safe, as it will potentially be used by multiple tasks concurrently.
Registering a build service and connecting it to a task
To create a build service, you register the service instance using the BuildServiceRegistry.registerIfAbsent() method.
Registering the service does not create the service instance. This happens on demand when a task first uses the service. The service instance will not be created if no task uses the service during a build.
Currently, build services are scoped to a build, rather than a project, and these services are available to be shared by the tasks of all projects.
You can access the registry of shared build services via Project.getGradle().getSharedServices().
Registering a build service to be consumed via @ServiceReference task properties
Here is an example of a plugin that registers the previous service when the task property consuming the service is annotated with @ServiceReference:
import org.gradle.api.Plugin;
import org.gradle.api.Project;
import org.gradle.api.provider.Provider;
public class DownloadPlugin implements Plugin<Project> {
public void apply(Project project) {
// Register the service
project.getGradle().getSharedServices().registerIfAbsent("web", WebServer.class, spec -> {
// Provide some parameters
spec.getParameters().getPort().set(5005);
});
project.getTasks().register("download", Download.class, task -> {
task.getOutputFile().set(project.getLayout().getBuildDirectory().file("result.zip"));
});
}
}As you can see, there is no need to assign the build service provider returned by registerIfAbsent() to the task, the service is automatically injected into all matching properties that were annotated with @ServiceReference.
Here is an example of a task that consumes the previous service via a property annotated with @ServiceReference:
import org.gradle.api.DefaultTask;
import org.gradle.api.file.RegularFileProperty;
import org.gradle.api.provider.Property;
import org.gradle.api.services.ServiceReference;
import org.gradle.api.tasks.OutputFile;
import org.gradle.api.tasks.TaskAction;
import java.net.URI;
public abstract class Download extends DefaultTask {
// This property provides access to the service instance
@ServiceReference("web")
abstract Property<WebServer> getServer();
@OutputFile
abstract RegularFileProperty getOutputFile();
@TaskAction
public void download() {
// Use the server to download a file
WebServer server = getServer().get();
URI uri = server.getUri().resolve("somefile.zip");
System.out.println(String.format("Downloading %s", uri));
}
}Automatic matching of registered build services with service reference properties is done by type and (optionally) by name (for properties that declare the name of the service they expect).
In case multiple services would match the requested service type (i.e. multiple services were registered for the same type, and a service name was not provided in the @ServiceReference annotation),
you will need also to assign the shared build service provider manually to the task property.
Read on to compare that to when the task property consuming the service is instead annotated with @Internal.
Registering a build service to be consumed via @Internal task properties
import org.gradle.api.Plugin;
import org.gradle.api.Project;
import org.gradle.api.provider.Provider;
public class DownloadPlugin implements Plugin<Project> {
public void apply(Project project) {
// Register the service
Provider<WebServer> serviceProvider = project.getGradle().getSharedServices().registerIfAbsent("web", WebServer.class, spec -> {
// Provide some parameters
spec.getParameters().getPort().set(5005);
});
project.getTasks().register("download", Download.class, task -> {
// Connect the service provider to the task
task.getServer().set(serviceProvider);
// Declare the association between the task and the service
task.usesService(serviceProvider);
task.getOutputFile().set(project.getLayout().getBuildDirectory().file("result.zip"));
});
}
}In this case, the plugin registers the service and receives a Provider<WebService> back.
This provider can be connected to task properties to pass the service to the task.
Note that for a task property annotated with @Internal, the task property needs to (1) be explicitly assigned with the provider obtained during registation, and (2) you must tell Gradle the task uses the service via Task.usesService.
None of that is needed when the task property consuming the service is annotated with @ServiceReference.
Here is an example of a task that consumes the previous service via a property annotated with @Internal:
import org.gradle.api.DefaultTask;
import org.gradle.api.file.RegularFileProperty;
import org.gradle.api.provider.Property;
import org.gradle.api.tasks.Internal;
import org.gradle.api.tasks.OutputFile;
import org.gradle.api.tasks.TaskAction;
import java.net.URI;
public abstract class Download extends DefaultTask {
// This property provides access to the service instance
@Internal
abstract Property<WebServer> getServer();
@OutputFile
abstract RegularFileProperty getOutputFile();
@TaskAction
public void download() {
// Use the server to download a file
WebServer server = getServer().get();
URI uri = server.getUri().resolve("somefile.zip");
System.out.println(String.format("Downloading %s", uri));
}
}Note that using a service with any annotation other than @ServiceReference or @Internal is currently not supported.
For example, it is currently impossible to mark a service as an input to a task.
Using shared build services from configuration actions
Generally, build services are intended to be used by tasks, and as they usually represent some potentially expensive state to create, you should avoid using them at configuration time. However, sometimes, using the service at configuration time can make sense.
This is possible; call get() on the provider.
Using a build service with the Worker API
In addition to using a build service from a task, you can use a build service from a Worker API action, an artifact transform or another build service.
To do this, pass the build service Provider as a parameter of the consuming action or service, in the same way you pass other parameters to the action or service.
For example, to pass a MyServiceType service to Worker API action, you might add a property of type Property<MyServiceType> to the action’s parameters object and then connect the Provider<MyServiceType> that you receive when registering the service to this property:
import org.gradle.api.DefaultTask;
import org.gradle.api.provider.Property;
import org.gradle.api.services.ServiceReference;
import org.gradle.api.tasks.TaskAction;
import org.gradle.workers.WorkAction;
import org.gradle.workers.WorkParameters;
import org.gradle.workers.WorkQueue;
import org.gradle.workers.WorkerExecutor;
import javax.inject.Inject;
import java.net.URI;
public abstract class Download extends DefaultTask {
public static abstract class DownloadWorkAction implements WorkAction<DownloadWorkAction.Parameters> {
interface Parameters extends WorkParameters {
// This property provides access to the service instance from the work action
abstract Property<WebServer> getServer();
}
@Override
public void execute() {
// Use the server to download a file
WebServer server = getParameters().getServer().get();
URI uri = server.getUri().resolve("somefile.zip");
System.out.println(String.format("Downloading %s", uri));
}
}
@Inject
abstract public WorkerExecutor getWorkerExecutor();
// This property provides access to the service instance from the task
@ServiceReference("web")
abstract Property<WebServer> getServer();
@TaskAction
public void download() {
WorkQueue workQueue = getWorkerExecutor().noIsolation();
workQueue.submit(DownloadWorkAction.class, parameter -> {
parameter.getServer().set(getServer());
});
}
}Currently, it is impossible to use a build service with a worker API action that uses ClassLoader or process isolation modes.
Accessing the build service concurrently
You can constrain concurrent execution when you register the service, by using the Property object returned from BuildServiceSpec.getMaxParallelUsages().
When this property has no value, which is the default, Gradle does not constrain access to the service.
When this property has a value > 0, Gradle will allow no more than the specified number of tasks to use the service concurrently.
|
Important
|
When the consuming task property is annotated with @Internal, for the constraint to take effect, the build service must be registered with the consuming task via
Task.usesService. NOTE: at this time, Gradle cannot discover indirect usage of services (for instance, if an additional service is used only by a service that the task uses directly).
As a workaround, indirect usage may be declared explicitly to Gradle by either adding a @ServiceReference property to the task and assigning the service that is only used indirectly to it (making it a direct reference),
or invoking Task.usesService.
|
Receiving information about task execution
A build service can be used to receive events as tasks are executed. To do this, create and register a build service that implements OperationCompletionListener:
import org.gradle.api.services.BuildService;
import org.gradle.api.services.BuildServiceParameters;
import org.gradle.tooling.events.FinishEvent;
import org.gradle.tooling.events.OperationCompletionListener;
import org.gradle.tooling.events.task.TaskFinishEvent;
public abstract class TaskEventsService implements BuildService<BuildServiceParameters.None>,
OperationCompletionListener { // (1)
@Override
public void onFinish(FinishEvent finishEvent) {
if (finishEvent instanceof TaskFinishEvent) { // (2)
// Handle task finish event...
}
}
}-
Implement the
OperationCompletionListenerinterface and theBuildServiceinterface. -
Check if the finish event is a TaskFinishEvent.
Then, in the plugin, you can use the methods on the BuildEventsListenerRegistry service to start receiving events:
import org.gradle.api.Plugin;
import org.gradle.api.Project;
import org.gradle.api.provider.Provider;
import org.gradle.build.event.BuildEventsListenerRegistry;
import javax.inject.Inject;
public abstract class TaskEventsPlugin implements Plugin<Project> {
@Inject
public abstract BuildEventsListenerRegistry getEventsListenerRegistry(); // (1)
@Override
public void apply(Project project) {
Provider<TaskEventsService> serviceProvider =
project.getGradle().getSharedServices().registerIfAbsent(
"taskEvents", TaskEventsService.class, spec -> {}); // (2)
getEventsListenerRegistry().onTaskCompletion(serviceProvider); // (3)
}
}-
Use service injection to obtain an instance of the
BuildEventsListenerRegistry. -
Register the build service as usual.
-
Use the service
Providerto subscribe to the build service to build events.
Avoiding Unnecessary Task Configuration
We recommend that the configuration avoidance APIs be used whenever tasks are created.
Task configuration avoidance API
The configuration avoidance API avoids configuring tasks if they will not be used for a build, which can significantly impact total configuration time.
For example, when running a compile task (with the java plugin applied), other unrelated tasks (such as clean, test, javadocs), will not be executed.
To avoid creating and configuring a task not needed for a build, we can register that task instead.
When a task is registered, it is known to the build. It can be configured, and references to it can be passed around, but the task object itself has not been created, and its actions have not been executed. The registered task will remain in this state until something in the build needs the instantiated task object. If the task object is never needed, the task will remain registered, and the cost of creating and configuring the task will be avoided.
In Gradle, you register a task using TaskContainer.register(java.lang.String).
Instead of returning a task instance, the register(…) method returns a TaskProvider, which is a reference to the task that can be used in many places where a normal task object might be used (i.e., when creating task dependencies).
Guidelines
Defer task creation
Effective task configuration avoidance requires build authors to change instances of TaskContainer.create(java.lang.String) to TaskContainer.register(java.lang.String).
Older versions of Gradle only support the create(…) API.
The create(…) API eagerly creates and configures tasks when called and should be avoided.
|
Note
|
Using register(…) alone may not be enough to avoid all task configuration completely.
You may need to change other code that configures tasks by name or by type, see below.
|
Defer task configuration
Eager APIs like DomainObjectCollection.all(org.gradle.api.Action) and DomainObjectCollection.withType(java.lang.Class, org.gradle.api.Action) will immediately create and configure any registered task.
To defer task configuration, you must migrate to a configuration avoidance API equivalent.
See the table below to identify the best alternative.
Reference a registered task
Instead of referencing a task object, you can work with a registered task via a TaskProvider object.
A TaskProvider can be obtained in several ways including the TaskContainer.register(java.lang.String) and the TaskCollection.named(java.lang.String) method.
Calling Provider.get() or looking up a task by name with TaskCollection.getByName(java.lang.String) will cause the task to be created and configured.
Methods like Task.dependsOn(java.lang.Object) and ConfigurableFileCollection.builtBy(java.lang.Object) work with TaskProvider the same way as Task so you do not need to unwrap a Provider for explicit dependencies to continue to work.
You must use the configuration avoidance equivalent to configure a task by name. See the table below to identify the best alternative.
Reference a task instance
In the event you need to get access to a Task instance, you can use TaskCollection.named(java.lang.String) and Provider.get().
This will cause the task to be created and configured, but everything should work as it had with the eager APIs.
Task ordering with configuration avoidance
Calling ordering methods will not cause task creation by itself. All these methods do is declare relationships.
|
Note
|
The existence of these relationships might indirectly cause task creation in later stages of the build process. |
When task relationships need to be established (i.e., dependsOn, finalizedBy, mustRunAfter, shouldRunAfter), a distinction can be made between soft and strong relationships.
Their effects on task creation during the configuration phase differ:
-
Task.mustRunAfter(…)andTask.shouldRunAfter(…)represent soft relationships, which can only change the order of existing tasks, but can’t trigger their creation. -
Task.dependsOn(…)andTask.finalizedBy(…)represent strong relationships, which force the execution of referenced tasks, even if they hadn’t been created otherwise. -
If a task is not executed, regardless if it was created with
Task.register(…)orTask.create(…), the defined relationships will not trigger task creation at configuration time. -
If a task is executed, all strongly associated tasks must be created and configured at configuration time, as they might have other
dependsOnorfinalizedByrelationships. This will happen transitively until the task graph contains all strong relationships.
Migration guide
The following sections will go through some general guidelines to adhere to when migrating your build logic. We’ve also provided some recommended steps to follow along with troubleshooting and common pitfalls.
Migration guidelines
1. Use help task as a benchmark during the migration
The help task is the perfect candidate to benchmark your migration process.
In a build that uses only the configuration avoidance API, a Build Scan shows no tasks created during configuration, and only the tasks executed are created.
2. Only mutate the current task inside a configuration action
Because the task configuration action can now run immediately, later, or never, mutating anything other than the current task can cause indeterminate behavior in your build.
Consider the following code:
val check = tasks.register("check")
tasks.register("verificationTask") {
// Configure verificationTask
// Run verificationTask when someone runs check
check.get().dependsOn(this)
}def check = tasks.register("check")
tasks.register("verificationTask") { verificationTask ->
// Configure verificationTask
// Run verificationTask when someone runs check
check.get().dependsOn verificationTask
}Executing the check task should execute verificationTask, but with this example, it won’t.
This is because the dependency between verificationTask and check only happens when verificationTask is realized.
To avoid issues like this, you must only modify the task associated with the configuration action.
Other tasks should be modified in their own configuration action:
val check = tasks.register("check")
val verificationTask = tasks.register("verificationTask") {
// Configure verificationTask
}
check { dependsOn(verificationTask) }def check = tasks.register("check")
def verificationTask = tasks.register("verificationTask") {
// Configure verificationTask
}
check.configure { dependsOn verificationTask }In the future, Gradle will consider this sort of antipattern an error and produce an exception.
3. Prefer small incremental changes
Smaller changes are easier to sanity check. If you ever break your build logic, analyzing the changelog since the last successful verification will be easier.
4. Ensure a good plan is established for validating the build logic
Usually, a simple build task invocation should do the trick to validate your build logic. However, some builds may need additional verification — understand the behavior of your build and make sure you have a good verification plan.
5. Prefer automatic testing to manual testing
Writing integration test for your build logic using TestKit is good practice.
6. Avoid referencing a task by name
Usually, referencing a task by name is a fragile pattern and should be avoided.
Although the task name is available on the TaskProvider, an effort should be made to use references from a strongly typed model instead.
7. Use the new task API as much as possible.
Eagerly realizing some tasks may cause a cascade of other tasks to be realized.
Using TaskProvider helps create an indirection that protects against transitive realization.
8. Some APIs may be disallowed if you try to access them from the new API’s configuration blocks.
For example, Project.afterEvaluate() cannot be called when configuring a task registered with the new API.
Since afterEvaluate is used to delay configuring a Project, mixing delayed configuration with the new API can cause errors that are hard to diagnose because tasks registered with the new API are not always configured, but an afterEvaluate block may always be expected to execute.
Migration steps
The first part of the migration process is to go through the code and manually migrate eager task creation and configuration to use configuration avoidance APIs.
1. Migrate task configuration that affects all tasks (tasks.all {}) or subsets by type (tasks.withType(…) {})
This will cause your build to eagerly create fewer tasks that are registered by plugins.
2. Migrate tasks configured by name
This will cause your build to eagerly create fewer tasks that are registered by plugins.
For example, logic that uses TaskContainer#getByName(String, Closure) should be converted to TaskContainer#named(String, Action).
This also includes task configuration via DSL blocks.
3. Migrate tasks creation to register(…)
At this point, you should change any task creation (using create(…) or similar) to use register instead.
After making these changes, you should see an improvement in the number of tasks eagerly created at configuration time.
Migration troubleshooting
What tasks are being realized?
Use a Build Scan to troubleshoot by following these steps:
-
Execute the Gradle command using the --scan flag.
-
Navigate to the configuration performance tab:
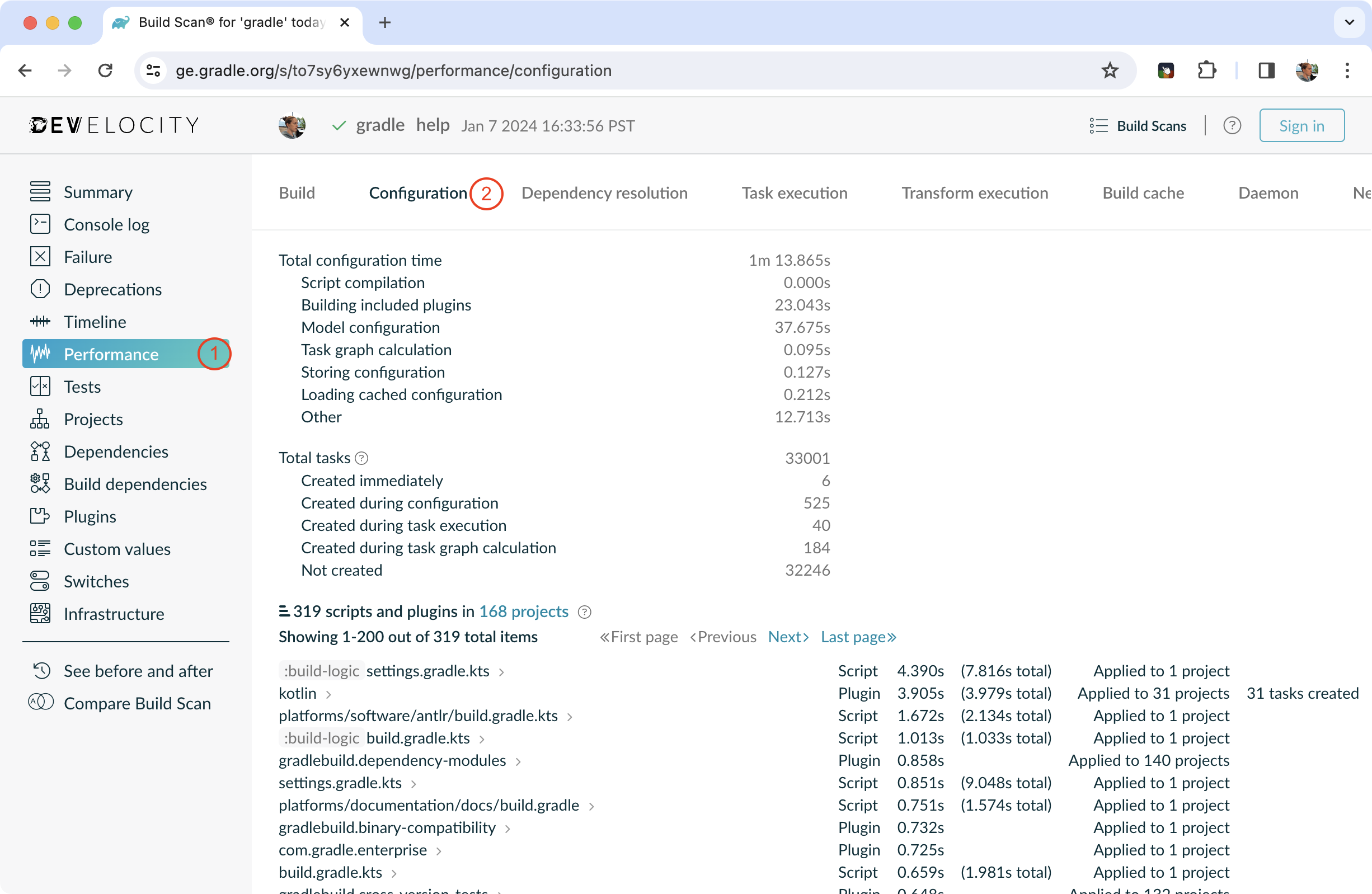
-
All the information required will be presented:
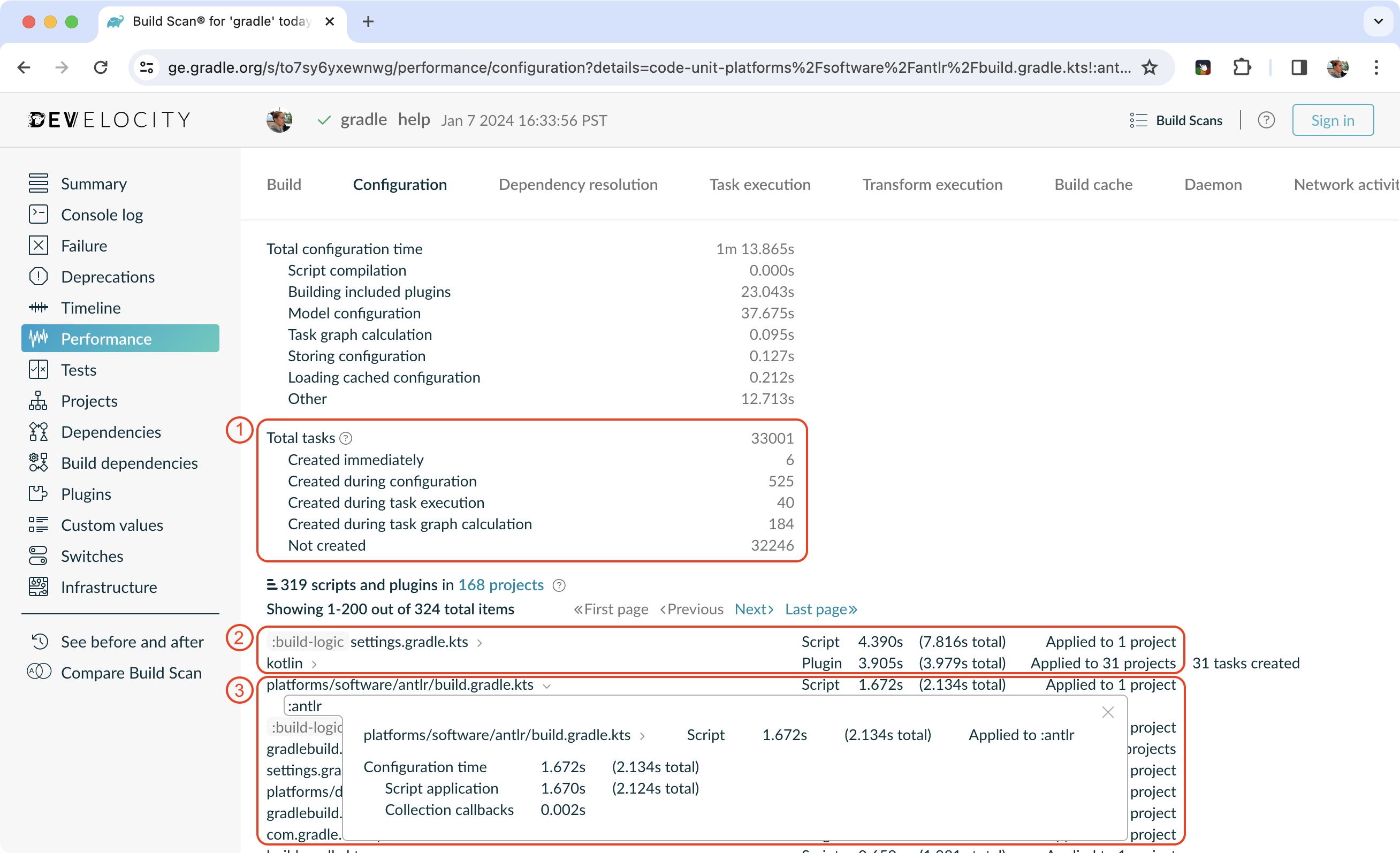
-
Total tasks present when each task is created or not.
-
Created immediately represents tasks created using the eager task APIs.
-
Created during configuration represents tasks created using the configuration avoidance APIs, but were realized explicitly (via
TaskProvider#get()) or implicitly using the eager task query APIs. -
Both Created immediately and Created during configuration numbers are considered "bad" numbers that should be minimized as much as possible.
-
Created during task execution represents the tasks created after the task graph has been created. Any tasks created at this point won’t be executed as part of the graph. Ideally, this number should be zero.
-
Created during task graph calculation represents the tasks created when building the execution task graph. Ideally, this number would be equal to the number of tasks executed.
-
Not Created represents the tasks avoided in this build session. Ideally, this number is as large as possible.
-
-
The next section helps answer the question of where a task was realized. For each script, plugin, or lifecycle callback, the last column represents the tasks created immediately or during configuration. Ideally, this column should be empty.
-
Focusing on a script, plugin, or lifecycle callback will show a breakdown of the tasks that were created.
-
Migration pitfalls
Beware of the hidden eager task realization
There are many ways that a task can be configured eagerly. For example, configuring a task using the task name and a DSL block will cause the task to be created (when using the Groovy DSL) immediately:
// Given a task lazily created with
tasks.register("someTask")
// Some time later, the task is configured using a DSL block
someTask {
// This causes the task to be created and this configuration to be executed immediately
}Instead, use the named() method to acquire a reference to the task and configure it:
tasks.named("someTask")
{
// ...
// Beware of the pitfalls here
}Similarly, Gradle has syntactic sugar that allows tasks to be referenced by name without an explicit query method. This can also cause the task to be immediately created:
tasks.register("someTask")
// Sometime later, an eager task is configured like task
anEagerTask {
// The following will cause "someTask" to be looked up and immediately created
dependsOn someTask
}There are several ways this premature creation can be avoided:
TaskProvider variableUseful when the task is referenced multiple times in the same build script.
val someTask = tasks.register("someTask")
task("anEagerTask") {
dependsOn(someTask)
}def someTask = tasks.register("someTask")
task anEagerTask {
dependsOn someTask
}tasks.register("someTask")
tasks.register("anEagerTask") {
dependsOn someTask
}Useful when the tasks are not created by the same plugin.
tasks.register("someTask")
task("anEagerTask") {
dependsOn(tasks.named("someTask"))
}tasks.register("someTask")
task anEagerTask {
dependsOn tasks.named("someTask")
}Lazy APIs to use
| API | Note |
|---|---|
Returns a |
|
Returns a |
|
Ok to use, but adding a closure (e.g., |
|
Returns void, so it cannot be chained. |
Eager APIs to avoid
| API | Note |
|---|---|
|
Do not use the shorthand notation. Use |
Use |
|
Do not use. |
|
Do not use. |
|
Avoid calling this. The behavior may change in the future. |
|
Use |
|
Use |
|
Use |
|
If you are matching based on the name, use |
|
Use |
|
Use |
|
Use |
|
Use |
|
Avoid calling this method. |
|
Do not use. |
|
|
Avoid doing this as it requires creating and configuring all tasks. |
|
Avoid calling this. The behavior may change in the future. |
PLUGIN DEVELOPMENT
Introduction to Plugins
Gradle comes with a set of powerful core systems such as dependency management, task execution, and project configuration. But everything else it can do is supplied by plugins.
Plugins encapsulate logic for specific tasks or integrations, such as compiling code, running tests, or deploying artifacts. By applying plugins, users can easily add new features to their build process without having to write complex code from scratch.
This plugin-based approach allows Gradle to be lightweight and modular. It also promotes code reuse and maintainability, as plugins can be shared across projects or within an organization.
Before reading this chapter, it’s recommended that you first complete the Advanced Tutorial and Reading.
Sources for Plugins
Plugins can be sourced from Gradle or the Gradle community. But when users want to organize their build logic or need specific build capabilities not provided by existing plugins, they can develop their own.
As such, we distinguish between three different sources for Gradle plugins:
-
Core Plugins - plugins that come from Gradle itself.
-
Community Plugins - plugins that come from the Gradle Plugin Portal or a public repository.
-
Local or Custom Plugins - plugins that you develop yourself.
Core Plugins
The term core plugin refers to a plugin that is part of the Gradle distribution such as the Java Library Plugin. They are always available.
Community Plugins
The term community plugin refers to a plugin published to the Gradle Plugin Portal (or another public repository) such as the Spotless Plugin.
Local or Custom Plugins
The term local plugin or custom plugin refers to a plugin you write yourself for your own build.
Types of Plugins
There are three types of plugins you can develop:
| # | Type | Location: | Most likely: | Benefit: |
|---|---|---|---|---|
A |
A local plugin |
The plugin is automatically compiled and included in the classpath of the build script. |
||
A convention plugin |
The plugin is automatically compiled, tested, and available on the classpath of the build script. The plugin is visible to every build script used by the build. |
|||
Standalone project |
A shared plugin |
The plugin JAR is produced and can be published. The plugin can be used in multiple builds and shared with others. |
Script plugins
A script plugin is a plugin written directly in a build file (.gradle or .gradle.kts).
They are usually small, local utilities for one project and not intended for reuse.
Script plugins are useful for quick experiments but not recommended for production builds.
They often evolve into proper plugins placed in buildSrc or published as standalone plugins.
The simplest plugin is a class that implements Plugin<Project> and configures the project when applied:
class GreetingPlugin : Plugin<Project> {
override fun apply(project: Project) {
project.task("hello") {
doLast {
println("Hello from the GreetingPlugin")
}
}
}
}
// Apply the plugin
apply<GreetingPlugin>()class GreetingPlugin implements Plugin<Project> {
void apply(Project project) {
project.task('hello') {
doLast {
println 'Hello from the GreetingPlugin'
}
}
}
}
// Apply the plugin
apply plugin: GreetingPlugin$ ./gradlew -q helloHello from the GreetingPluginYou can also put such a plugin in a separate script file and apply it with apply(from = "other.gradle.kts") or apply from: 'other.gradle':
class GreetingScriptPlugin : Plugin<Project> {
override fun apply(project: Project) {
project.task("hi") {
doLast {
println("Hi from the GreetingScriptPlugin")
}
}
}
}
// Apply the plugin
apply<GreetingScriptPlugin>()class GreetingScriptPlugin implements Plugin<Project> {
void apply(Project project) {
project.task('hi') {
doLast {
println 'Hi from the GreetingScriptPlugin'
}
}
}
}
// Apply the plugin
apply plugin: GreetingScriptPluginapply(from = "other.gradle.kts")apply from: 'other.gradle'$ ./gradlew -q hiHi from the GreetingScriptPluginScript plugins should be avoided. Script plugins are convenient for local, throwaway logic but make builds harder to maintain.
Precompiled script plugins
Precompiled script plugins are compiled into class files and packaged into a JAR before they are executed. These plugins use the Gradle DSLs instead of pure Java, Kotlin, or Groovy.
To create a precompiled script plugin, you can:
-
Use Gradle’s Kotlin DSL - The plugin is a
.gradle.ktsfile, and appliesid("kotlin-dsl"). -
Use Gradle’s Groovy DSL - The plugin is a
.gradlefile, and applyid("groovy-gradle-plugin").
To apply a precompiled script plugin, you need to know its ID. The ID is derived from the plugin script’s filename and its (optional) package declaration.
For example, the script src/main/kotlin/some-java-library.gradle.kts has a plugin ID of some-java-library (assuming it has no package declaration).
Likewise, src/main/kotlin/my/some-java-library.gradle(.kts) has a plugin ID of my.some-java-library as long as it has a package declaration of my.
Precompiled script plugin names have two important limitations:
-
They cannot start with
org.gradle. -
They cannot have the same name as a core plugin.
When the plugin is applied to a project, Gradle creates an instance of the plugin class and calls the instance’s Plugin.apply() method.
Let’s rewrite the GreetingPlugin script plugin as a precompiled script plugin.
The script plugin is moved to its own file in buildSrc:
tasks.register("hello") {
doLast {
println("Hello from the convention GreetingPlugin")
}
}tasks.register("hello") {
doLast {
println("Hello from the convention GreetingPlugin")
}
}The GreetingPlugin can now be applied in other subprojects' builds by using its ID:
plugins {
application
id("GreetingPlugin")
}plugins {
id 'application'
id('GreetingPlugin')
}$ ./gradlew -q helloHello from the convention GreetingPluginConvention plugins
A convention plugin is typically a precompiled script plugin that configures existing core and community plugins with your own conventions (i.e. default values) such as setting the Java version by using java.toolchain.languageVersion = JavaLanguageVersion.of(17).
Convention plugins are also used to enforce project standards and help streamline the build process. They can apply and configure plugins, create new tasks and extensions, set dependencies, and much more.
Let’s take an example build with three subprojects: one for data-model, one for database-logic and one for app code.
The project has the following structure:
.
├── buildSrc
│ ├── src
│ │ └──...
│ └── build.gradle.kts
├── data-model
│ ├── src
│ │ └──...
│ └── build.gradle.kts
├── database-logic
│ ├── src
│ │ └──...
│ └── build.gradle.kts
├── app
│ ├── src
│ │ └──...
│ └── build.gradle.kts
└── settings.gradle.ktsThe build file of the database-logic subproject is as follows:
plugins {
id("java-library")
id("org.jetbrains.kotlin.jvm") version "2.3.21"
}
repositories {
mavenCentral()
}
java {
toolchain.languageVersion.set(JavaLanguageVersion.of(11))
}
tasks.test {
useJUnitPlatform()
}
kotlin {
jvmToolchain(11)
}
// More build logicplugins {
id 'java-library'
id 'org.jetbrains.kotlin.jvm' version '2.3.21'
}
repositories {
mavenCentral()
}
java {
toolchain.languageVersion.set(JavaLanguageVersion.of(11))
}
tasks.test {
useJUnitPlatform()
}
kotlin {
jvmToolchain {
languageVersion.set(JavaLanguageVersion.of(11))
}
}
// More build logicWe apply the java-library plugin and add the org.jetbrains.kotlin.jvm plugin for Kotlin support.
We also configure Kotlin, Java, tests and more.
Our build file is beginning to grow.
The more plugins we apply and the more plugins we configure, the larger it gets.
There’s also repetition in the build files of the app and data-model subprojects, especially when configuring common extensions like setting the Java version and Kotlin support.
To address this, we use convention plugins. This allows us to avoid repeating configuration in each build file and keeps our build scripts more concise and maintainable. In convention plugins, we can encapsulate arbitrary build configuration or custom build logic.
To develop a convention plugin, you can use the protected buildSrc folder, which represents a completely separate Gradle build.
buildSrc has its own settings file to define where dependencies of this build are located.
We add a Kotlin script called my-java-library.gradle.kts inside the buildSrc/src/main/kotlin directory.
Or conversely, a Groovy script called my-java-library.gradle inside the buildSrc/src/main/groovy directory.
We put all the plugin application and configuration from the database-logic build file into it:
plugins {
id("java-library")
id("org.jetbrains.kotlin.jvm")
}
repositories {
mavenCentral()
}
java {
toolchain.languageVersion.set(JavaLanguageVersion.of(11))
}
tasks.test {
useJUnitPlatform()
}
kotlin {
jvmToolchain(11)
}plugins {
id 'java-library'
id 'org.jetbrains.kotlin.jvm'
}
repositories {
mavenCentral()
}
java {
toolchain.languageVersion.set(JavaLanguageVersion.of(11))
}
tasks.test {
useJUnitPlatform()
}
kotlin {
jvmToolchain {
languageVersion.set(JavaLanguageVersion.of(11))
}
}The name of the file my-java-library is the ID of our plugin, which we can now reference in all of our subprojects.
|
Tip
|
Why is the version of id 'org.jetbrains.kotlin.jvm' missing? See Applying External Plugins to Pre-Compiled Script Plugins.
|
The database-logic build file becomes much simpler by removing all the redundant build logic and applying our convention my-java-library plugin instead:
plugins {
id("my-java-library")
}plugins {
id('my-java-library')
}This convention plugin enables us to easily share common configurations across all our build files. Any modifications can be made in one place, simplifying maintenance.
Binary plugins
Binary plugins in Gradle are plugins that are built as standalone JAR files and applied to a project using the plugins {} block in the build script.
Let’s move our GreetingPlugin to a standalone project so that we can publish it and share it with others.
The plugin is essentially moved from the buildSrc folder to its own build called greeting-plugin.
|
Note
|
You can publish the plugin from buildSrc, but this is not recommended practice. Plugins that are ready for publication should be in their own build.
|
greeting-plugin is simply a Java project that produces a JAR containing the plugin classes.
The easiest way to package and publish a plugin to a repository is to use the Gradle Plugin Development Plugin. This plugin provides the necessary tasks and configurations (including the plugin metadata) to compile your script into a plugin that can be applied in other builds.
Here is a simple build script for the greeting-plugin project using the Gradle Plugin Development Plugin:
plugins {
`java-gradle-plugin`
}
gradlePlugin {
plugins {
create("simplePlugin") {
id = "org.example.greeting"
implementationClass = "org.example.GreetingPlugin"
}
}
}plugins {
id 'java-gradle-plugin'
}
gradlePlugin {
plugins {
simplePlugin {
id = 'org.example.greeting'
implementationClass = 'org.example.GreetingPlugin'
}
}
}For more on publishing plugins, see Publishing Plugins.
Scope of Plugins
In earlier examples, GreetingScriptPlugin was defined against a
Project parameter:
class GreetingScriptPlugin : Plugin<Project> { }Gradle plugins can in fact target three different scopes:
Project,
Settings,
and Gradle.
Each scope controls different aspects of the build lifecycle and represents an interface.
| Interface | Scope | Description |
|---|---|---|
Project |
Applied to an individual project. |
Used to define build logic, register tasks, and configure project-specific settings. |
Settings |
Applied to the build as a whole. |
Used to include subprojects, configure plugin management, or define buildscript repositories. |
Gradle (init) |
Applied globally. |
Affects all builds on a machine. Commonly used to configure enterprise build tooling, inject repositories, or enforce conventions across builds. |
When writing precompiled script plugins, Gradle determines the intended plugin target (Project, Settings, or Gradle) based on the file name of the plugin source file:
| Plugin | Filename Suffix | Applies To | Scope |
|---|---|---|---|
Project plugin |
|
|
Project scope |
Settings plugin |
|
|
Build scope |
Init plugin |
|
|
Global scope |
For example, a file named myplugin.gradle.kts will always be treated as a Project plugin—even if it’s applied from a settings.gradle.kts file. To create a plugin for the settings context, it must be named something like myplugin.settings.gradle.kts.
Pre-compiled Script Plugins
A precompiled script plugin is a .gradle.kts (Kotlin DSL) or .gradle (Groovy DSL) script stored in a plugin source set (e.g. buildSrc or an included build like build-logic).
Gradle automatically compiles it into a proper plugin class, packages it like a normal plugin, and assigns the plugin ID based on the file name.
For example, you place a script in build-logic/src/main/kotlin/java-library-conventions.gradle.kts:
some-project/
├─ settings.gradle.kts
├─ build-logic/
│ ├─ build.gradle.kts
│ └─ src/
│ └─ main/
│ └─ kotlin/
│ └─ java-library-conventions.gradle.kts // (1)
└─ app/
├─ build.gradle.kts // (2)
└─ src/-
Pre-compiled script plugin
-
Build file applies the plugin
Gradle automatically compiles that script into a plugin.
The plugin ID is derived from the file name: java-library-conventions.gradle.kts.
You can now apply it in any build like a regular plugin.
In the build file of the app project:
plugins {
// Apply by ID derived from the file name:
id("java-library-conventions")
}Setting the plugin ID
The plugin ID for a precompiled script is derived from its file name and optional package declaration.
For example, a script named code-quality.gradle(.kts) located in src/main/groovy (or src/main/kotlin) without a package declaration would be exposed as the code-quality plugin:
plugins {
`kotlin-dsl`
}plugins {
id("code-quality")
}plugins {
id 'groovy-gradle-plugin'
}plugins {
id 'code-quality'
}On the other hand, a script named code-quality.gradle.kts located in src/main/kotlin/my with the package declaration my would be exposed as the my.code-quality plugin:
plugins {
`kotlin-dsl`
}plugins {
id("my.code-quality")
}When creating precompiled script plugins intended for settings or init scripts, the filename suffix determines where Gradle applies them:
-
.settings.gradleor.settings.gradle.kts→ interpreted asPlugin<Settings> -
.init.gradleor.init.gradle.kts→ interpreted asPlugin<Gradle> -
.gradleor.gradle.kts→ interpreted as the defaultPlugin<Project>
|
Important
|
Groovy pre-compiled script plugins cannot have packages. |
Making a plugin configurable using extensions
Extension objects are commonly used in plugins to expose configuration options and additional functionality to build scripts.
When you apply a plugin that defines an extension, you can access the extension object and configure its properties or call its methods to customize the behavior of the plugin or tasks provided by the plugin.
A Project has an associated ExtensionContainer object that contains all the settings and properties for the plugins that have been applied to the project. You can provide configuration for your plugin by adding an extension object to this container.
Let’s update our greetings example:
// Create extension object
interface GreetingPluginExtension {
val message: Property<String>
}
// Add the 'greeting' extension object to project
val extension = project.extensions.create<GreetingPluginExtension>("greeting")// Create extension object
interface GreetingPluginExtension {
Property<String> getMessage()
}
// Add the 'greeting' extension object to project
def extension = project.extensions.create("greeting", GreetingPluginExtension)You can set the value of the message property directly with extension.message.set("Hi from Gradle,").
However, the GreetingPluginExtension object becomes available as a project property with the same name as the extension object.
You can now access message like so:
// Where the<GreetingPluginExtension>() is equivalent to project.extensions.getByType(GreetingPluginExtension::class.java)
the<GreetingPluginExtension>().message.set("Hi from Gradle")extensions.findByType(GreetingPluginExtension).message.set("Hi from Gradle")If you apply the greetings plugin, you can set the convention in your build script:
plugins {
application
id("greetings")
}
greeting {
message = "Hello from Gradle"
}plugins {
id 'application'
id('greetings')
}
configure(greeting) {
message = "Hello from Gradle"
}Adding default configuration as conventions
In plugins, you can define default values, also known as conventions, using the project object.
Convention properties are properties that are initialized with default values but can be overridden:
// Create extension object
interface GreetingPluginExtension {
val message: Property<String>
}
// Add the 'greeting' extension object to project
val extension = project.extensions.create<GreetingPluginExtension>("greeting")
// Set a default value for 'message'
extension.message.convention("Hello from Gradle")// Create extension object
interface GreetingPluginExtension {
Property<String> getMessage()
}
// Add the 'greeting' extension object to project
def extension = project.extensions.create("greeting", GreetingPluginExtension)
// Set a default value for 'message'
extension.message.convention("Hello from Gradle")extension.message.convention(…) sets a convention for the message property of the extension.
This convention specifies that the value of message should default to "Hello from Gradle".
If the message property is not explicitly set, its value will be automatically set to "Hello from Gradle".
Mapping extension properties to task properties
Using an extension and mapping it to a custom task’s input/output properties is common in plugins.
In this example, the message property of the GreetingPluginExtension is mapped to the message property of the GreetingTask as an input:
// Create extension object
interface GreetingPluginExtension {
val message: Property<String>
}
// Add the 'greeting' extension object to project
val extension = project.extensions.create<GreetingPluginExtension>("greeting")
// Set a default value for 'message'
extension.message.convention("Hello from Gradle")
// Create a greeting task
abstract class GreetingTask : DefaultTask() {
@Input
val message = project.objects.property<String>()
@TaskAction
fun greet() {
println("Message: ${message.get()}")
}
}
// Register the task and set the convention
tasks.register<GreetingTask>("hello") {
message.convention(extension.message)
}// Create extension object
interface GreetingPluginExtension {
Property<String> getMessage()
}
// Add the 'greeting' extension object to project
def extension = project.extensions.create("greeting", GreetingPluginExtension)
// Set a default value for 'message'
extension.message.convention("Hello from Gradle")
// Create a greeting task
abstract class GreetingTask extends DefaultTask {
@Input
abstract Property<String> getMessage()
@TaskAction
void greet() {
println("Message: ${message.get()}")
}
}
// Register the task and set the convention
tasks.register("hello", GreetingTask) {
message.convention(extension.message)
}$ ./gradlew -q helloMessage: Hello from GradleThis means that changes to the extension’s message property will trigger the task to be considered out-of-date, ensuring that the task is re-executed with the new message.
You can find out more about types that you can use in task implementations and extensions in Lazy Configuration.
Applying external plugins
In order to apply an external plugin in a precompiled script plugin, it has to be added to the plugin project’s implementation classpath in the plugin’s build file:
plugins {
`kotlin-dsl`
}
repositories {
mavenCentral()
}
dependencies {
implementation("com.bmuschko:gradle-docker-plugin:6.4.0")
}plugins {
id 'groovy-gradle-plugin'
}
repositories {
mavenCentral()
}
dependencies {
implementation 'com.bmuschko:gradle-docker-plugin:6.4.0'
}It can then be applied in the precompiled script plugin:
plugins {
id("com.bmuschko.docker-remote-api")
}plugins {
id 'com.bmuschko.docker-remote-api'
}The plugin version in this case is defined in the dependency declaration.
The version "…" and apply false syntax are not supported in precompiled script plugins. The version for the plugin is determined by the version declared in the plugin’s build file.
If a plugin needs to be on the classpath but not applied, it can be left out of the plugins {} block and only added as a dependency in the plugin’s build file.
Example of a precompiled script plugin in the Project scope
You can see an example here.
Example of a precompiled script plugin in the Settings scope
Precompiled script plugins can also target the
Settings scope.
The following example defines a simple plugin in a separate build called settings-plugin.
Configure plugin management for the plugin build:
pluginManagement {
repositories {
gradlePluginPortal()
mavenCentral()
}
}pluginManagement {
repositories {
gradlePluginPortal()
mavenCentral()
}
}Set up the build to support precompiled script plugins:
plugins {
`kotlin-dsl`
}
repositories {
mavenCentral()
gradlePluginPortal()
}
dependencies {
implementation("com.gradle:develocity-gradle-plugin:4.1")
}plugins {
id('groovy-gradle-plugin')
}
repositories {
mavenCentral()
gradlePluginPortal()
}
dependencies {
implementation('com.gradle:develocity-gradle-plugin:4.1')
}|
Tip
|
Notice that we used the practice described in Applying external plugins. |
Write the precompiled script plugin itself:
plugins {
id("com.gradle.develocity")
}plugins {
id('com.gradle.develocity')
}Because the file name ends with .settings.gradle.kts, Gradle compiles it into a plugin with a Settings scope.
The plugin ID is my-plugin.
You can use it as follows in a consumer project (root settings file of the consuming project):
pluginManagement {
repositories {
mavenCentral()
gradlePluginPortal()
}
includeBuild("./settings-plugin")
}
plugins {
id("my-plugin")
}pluginManagement {
repositories {
mavenCentral()
gradlePluginPortal()
}
includeBuild('./settings-plugin')
}
plugins {
id('my-plugin')
}|
Warning
|
Because the plugin was precompiled as a Settings plugin (the .settings.gradle(.kts) suffix), you apply it in the settings file’s plugins {} block, not in a project build.gradle(.kts) file.
|
Convention Plugins
A convention plugin is a type of pre-compiled script plugin.
A convention plugin is a plugin that normally configures existing core and community plugins with your own conventions (i.e. default values) such as setting the Java version by using java.toolchain.languageVersion = JavaLanguageVersion.of(17).
Convention plugins are also used to enforce project standards and help streamline the build process. They can apply and configure plugins, create new tasks and extensions, set dependencies, and much more.
Convention plugins are preferred over allprojects {} / subprojects {} blocks.
Creating a convention plugin
Convention plugins are typically placed in either:
-
buildSrc/— simplest approach, automatically on the classpath of the build. -
an included build (commonly named
build-logic/) — more scalable, especially for multi-project builds or organizations.
Any .gradle.kts (or .gradle) script file in src/main/kotlin/ or src/main/groovy/ of that plugin build becomes a precompiled script plugin, and its file name defines the plugin ID.
Example of a convention plugin
Convention plugins really shine when you want to capture organization-wide defaults once, and apply them consistently across many subprojects.
Imagine you want every module that publishes artifacts to use the same Maven configuration.
Instead of copy–pasting publishing { … } blocks into every build.gradle(.kts), you can extract them into a convention plugin.
The project layout is as follows:
.
├── core/
├── utils/
├── platform/
└── buildSrc/
├── build.gradle.kts
└── src/
└── main/
└── kotlin/
└── java-conventions.gradle.kts.
├── core/
├── utils/
├── platform/
└── buildSrc/
├── build.gradle
└── src/
└── main/
└── groovy/
└── java-conventions.gradleHere’s a precompiled script plugin that standardizes publishing.
Notice how it sets the group and version from the root project and configures a local Maven repository in build/repo:
plugins {
id("maven-publish")
}
group = rootProject.group
version = rootProject.version
publishing {
repositories {
maven {
url = uri(rootProject.layout.buildDirectory.dir("repo"))
}
}
}plugins {
id 'maven-publish'
}
group = rootProject.group
version = rootProject.version
publishing {
repositories {
maven {
url = layout.buildDirectory.dir("repo")
}
}
}With this in place, any subproject can opt in simply by applying id("myproject.publishing-conventions").
Our platform subproject applies the convention plugin alongside the java-platform plugin.
It declares dependency constraints and sets up a publication for the BOM:
plugins {
`java-platform`
id("myproject.publishing-conventions")
}
publishing {
publications {
create("maven", MavenPublication::class.java) {
from(components["javaPlatform"])
}
}
}plugins {
id 'java-platform'
id 'myproject.publishing-conventions'
}
publishing {
publications {
maven(MavenPublication) {
from components.javaPlatform
}
}
}Binary Plugins
Binary plugins refer to plugins that are compiled and distributed as JAR files. These plugins are usually written in Java or Kotlin and provide custom functionality or tasks to a Gradle build.
Anatomy of a binary plugin
A typical Gradle plugin is composed of three cooperating parts:
| Part | Purpose | Notes |
|---|---|---|
Plugin class |
Applies behavior to a target ( |
Implements |
Extension |
Holds user configuration exposed as a DSL block. |
Use |
Task type |
Implements the actual work when executed. |
Model inputs/outputs with |
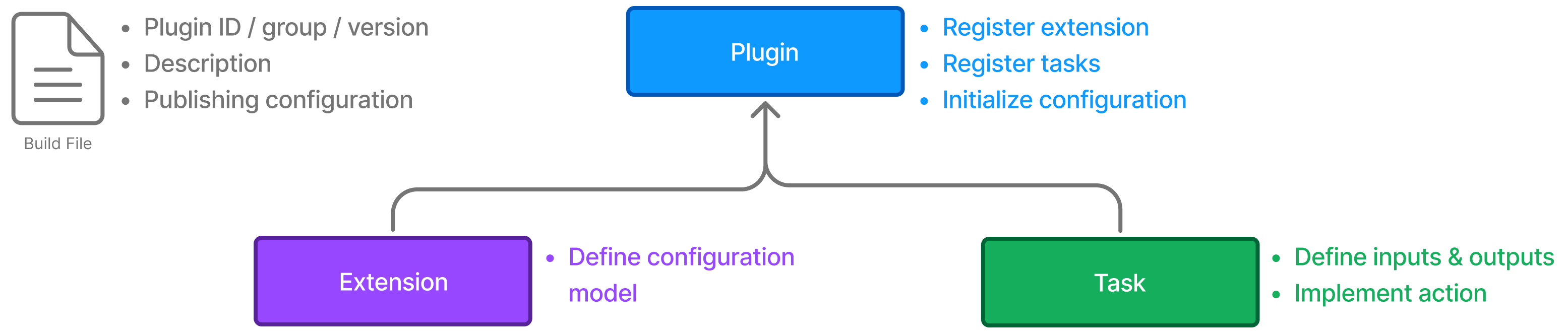
Example of a binary plugin
Here’s a detailed look at the project structure for a simple Greeting plugin:
plugin/ // (1)
├── build.gradle.kts // (2)
└── src/
└── main/
└── kotlin/
└── org/
└── example/ // (3)
├── GreetingPlugin.kt
├── GreetingPluginExtension.kt
└── GreetingTask.kt-
plugin/: This is the root directory for the Gradle plugin project. -
build.gradle.kts: The build script for the plugin itself. It specifies dependencies like the Gradle API and Kotlin, and it’s where you apply thekotlin-dslorjava-gradle-pluginto make your code a runnable Gradle plugin. -
src/main/kotlin/org/example/: This is the standard source directory for Kotlin code, organized by package name.
plugin/ // (1)
├── build.gradle // (2)
└── src/
└── main/
└── groovy/
└── org/
└── example/ // (3)
├── GreetingPlugin.groovy
├── GreetingPluginExtension.groovy
└── GreetingTask.groovy-
plugin/: This is the root directory for the Gradle plugin project. -
build.gradle: The build script for the plugin itself. It specifies dependencies like the Gradle API and Groovy, and it’s where you apply thegroovy-gradle-pluginorjava-gradle-pluginto make your code a runnable Gradle plugin. -
src/main/groovy/org/example/: This is the standard source directory for Groovy code, organized by package name.
The plugin class (GreetingPlugin.kt)
The core of the plugin is the GreetingPlugin class.
It implements the Plugin<Project> interface and overrides the apply method, which is the entry point for your plugin’s logic:
package org.example
import org.gradle.api.Plugin
import org.gradle.api.Project
class GreetingPlugin : Plugin<Project> {
override fun apply(project: Project) {
// Create extension and set sensible defaults (conventions)
val ext = project.extensions.create("greeting", GreetingExtension::class.java).apply { // (1)
message.convention("Hello from plugin")
outputFile.convention(project.layout.buildDirectory.file("greeting.txt"))
}
// Register task and map extension -> task inputs (lazy wiring)
project.tasks.register("greet", GreetTask::class.java) { // (2)
group = "example"
description = "Writes a greeting to a file"
message.set(ext.message)
outputFile.set(ext.outputFile)
}
}
}package org.example
import org.gradle.api.Plugin
import org.gradle.api.Project
import org.example.GreetingExtension
import org.example.GreetTask
class GreetingPlugin implements Plugin<Project> {
void apply(Project project) {
// Create extension and set sensible defaults (conventions)
def ext = project.extensions.create("greeting", GreetingExtension) // (1)
ext.message.convention("Hello from plugin")
ext.outputFile.convention(project.layout.buildDirectory.file("greeting.txt"))
// Register task and map extension -> task inputs (lazy wiring)
project.tasks.register("greet", GreetTask) { // (2)
group = "example"
description = "Writes a greeting to a file"
message.set(ext.message)
outputFile.set(ext.outputFile)
}
}
}-
project.extensions.create(): This creates an extension named greeting. This is how users of your plugin can configure its behavior in their build.gradle file. The apply block sets convention values, which are default values that the user can override. -
project.tasks.register(): This registers a task of type GreetTask named greet. This is the action that your plugin provides.
Lazy Wiring: The message.set(ext.message) and outputFile.set(ext.outputFile) lines are examples of lazy wiring.
The task’s inputs are not read immediately.
Instead, they are connected to the extension’s properties, and the values are only resolved when the task actually runs.
This is crucial for performance and correctness in Gradle builds.
The extension (GreetingExtension.kt)
The extension defines the properties that a user can configure.
It uses Property and RegularFileProperty types, which are designed for lazy evaluation:
package org.example
import org.gradle.api.provider.Property
import org.gradle.api.file.RegularFileProperty
abstract class GreetingExtension {
abstract val message: Property<String> // (1)
abstract val outputFile: RegularFileProperty // (2)
}package org.example
import org.gradle.api.provider.Property
import org.gradle.api.file.RegularFileProperty
abstract class GreetingExtension {
abstract Property<String> getMessage() // (1)
abstract RegularFileProperty getOutputFile() // (2)
}-
Property<T>: This is a container for a value of type T. The actual value is not read until it’s needed, which enables lazy configuration. -
RegularFileProperty: A specific type of property for file paths. Gradle uses this to track file inputs and outputs for up-to-date checks and the build cache.
The custom task (GreetTask.kt)
This is the class for the custom task. It defines the inputs and outputs, and the action to perform:
package org.example
import org.gradle.api.DefaultTask
import org.gradle.api.file.RegularFileProperty
import org.gradle.api.provider.Property
import org.gradle.api.tasks.Input
import org.gradle.api.tasks.OutputFile
import org.gradle.api.tasks.TaskAction
abstract class GreetTask : DefaultTask() {
@get:Input // (1)
abstract val message: Property<String>
@get:OutputFile // (2)
abstract val outputFile: RegularFileProperty
@TaskAction // (3)
fun run() {
val file = outputFile.get().asFile
file.parentFile.mkdirs()
file.writeText(message.get())
logger.lifecycle("Wrote greeting to ${file}")
}
}package org.example
import org.gradle.api.DefaultTask
import org.gradle.api.file.RegularFileProperty
import org.gradle.api.provider.Property
import org.gradle.api.tasks.Input
import org.gradle.api.tasks.OutputFile
import org.gradle.api.tasks.TaskAction
abstract class GreetTask extends DefaultTask {
@Input // (1)
abstract Property<String> getMessage()
@OutputFile // (2)
abstract RegularFileProperty getOutputFile()
@TaskAction // (3)
void run() {
def file = getOutputFile().get().asFile
file.parentFile.mkdirs()
file.write(getMessage().get())
logger.lifecycle("Wrote greeting to ${file}")
}
}-
@Input: This annotation marks a property as a task input. When a task has an input, Gradle will automatically track its value. If the value changes between builds, Gradle knows the task is out-of-date and needs to be re-run. -
@OutputFile: This annotation marks a property as a task output. Gradle tracks the location of this file. If the file is missing or its contents are older than the inputs, Gradle considers the task out-of-date. -
@TaskAction: This annotation marks the method that contains the work to be done. This method is executed when the task runs.
Up-to-Date Checks: By properly annotating inputs and outputs, Gradle can perform up-to-date checks. If the task’s inputs and outputs haven’t changed since the last build, Gradle can skip the task entirely, which dramatically speeds up the build process.
Applying the plugin
To use this Greeting plugin, you need to apply the plugin in your build.gradle(.kts) file.
This makes the plugin’s tasks and extensions available to your project:
plugins {
id("org.example.greeting")
}Configuring the plugin
Once the plugin is applied, you can configure it using the extension you defined, which is named greeting.
This allows you to override the default values set in the GreetingPlugin.
Using the greeting extension block:
greeting {
// Override the default message
message = "Hola from my custom build"
// Set a custom output file path
outputFile = layout.buildDirectory.file("custom-greeting.txt")
}Running the task
The plugin registers a task named greet.
After applying and configuring the plugin, you can execute this task from the command line.
$ ./gradlew greetRunning the greet task will:
-
Use the
messageandoutputFileproperties, either with their default values or your custom configured values. -
Write the specified message to the output file (e.g.,
build/custom-greeting.txt). -
Print a log message to the console confirming the file has been written.
Using the Plugin Development plugin
The Gradle Plugin Development plugin can be used to assist in developing Gradle plugins.
This plugin will automatically apply the Java Plugin, add the gradleApi() dependency to the api configuration, generate the required plugin descriptors in the resulting JAR file, and configure the Plugin Marker Artifact to be used when publishing.
To apply and configure the plugin, add the following code to your build file:
plugins {
`java-gradle-plugin`
}
gradlePlugin {
plugins {
create("simplePlugin") {
id = "org.example.greeting"
implementationClass = "org.example.GreetingPlugin"
}
}
}plugins {
id 'java-gradle-plugin'
}
gradlePlugin {
plugins {
simplePlugin {
id = 'org.example.greeting'
implementationClass = 'org.example.GreetingPlugin'
}
}
}Writing and using custom task types is recommended when developing plugins as it automatically benefits from incremental builds.
As an added benefit of applying the plugin to your project, the task validatePlugins automatically checks for an existing input/output annotation for every public property defined in a custom task type implementation.
Creating a plugin ID
Plugin IDs are meant to be globally unique, similar to Java package names (i.e., a reverse domain name). This format helps prevent naming collisions and allows grouping plugins with similar ownership.
An explicit plugin identifier simplifies applying the plugin to a project.
Your plugin ID should combine components that reflect the namespace (a reasonable pointer to you or your organization) and the name of the plugin it provides.
For example, if your Github account is named foo and your plugin is named bar, a suitable plugin ID might be com.github.foo.bar.
Similarly, if the plugin was developed at the baz organization, the plugin ID might be org.baz.bar.
Plugin IDs should adhere to the following guidelines:
-
May contain any alphanumeric character, '.', and '-'.
-
Must contain at least one '.' character separating the namespace from the plugin’s name.
-
Conventionally use a lowercase reverse domain name convention for the namespace.
-
Conventionally use only lowercase characters in the name.
-
org.gradle,com.gradle, andcom.gradlewarenamespaces may not be used. -
Cannot start or end with a '.' character.
-
Cannot contain consecutive '.' characters (i.e., '..').
A namespace that identifies ownership and a name is sufficient for a plugin ID.
When bundling multiple plugins in a single JAR artifact, adhering to the same naming conventions is recommended. This practice helps logically group related plugins.
There is no limit to the number of plugins that can be defined and registered (by different identifiers) within a single project.
The identifiers for plugins written as a class should be defined in the project’s build script containing the plugin classes.
For this, the java-gradle-plugin needs to be applied:
plugins {
id("java-gradle-plugin")
}
gradlePlugin {
plugins {
create("androidApplicationPlugin") {
id = "com.android.application"
implementationClass = "com.android.AndroidApplicationPlugin"
}
create("androidLibraryPlugin") {
id = "com.android.library"
implementationClass = "com.android.AndroidLibraryPlugin"
}
}
}plugins {
id 'java-gradle-plugin'
}
gradlePlugin {
plugins {
androidApplicationPlugin {
id = 'com.android.application'
implementationClass = 'com.android.AndroidApplicationPlugin'
}
androidLibraryPlugin {
id = 'com.android.library'
implementationClass = 'com.android.AndroidLibraryPlugin'
}
}
}Working with files
When developing plugins, it’s a good idea to be flexible when accepting input configuration for file locations.
It is recommended to use Gradle’s managed properties and project.layout to select file or directory locations.
This will enable lazy configuration so that the actual location will only be resolved when the file is needed and can be reconfigured at any time during build configuration.
This Gradle build file defines a task GreetingToFileTask that writes a greeting to a file.
It also registers two tasks: greet, which creates the file with the greeting, and sayGreeting, which prints the file’s contents.
The greetingFile property is used to specify the file path for the greeting:
abstract class GreetingToFileTask : DefaultTask() {
@get:OutputFile
abstract val destination: RegularFileProperty
@TaskAction
fun greet() {
val file = destination.get().asFile
file.parentFile.mkdirs()
file.writeText("Hello!")
}
}
val greetingFile = objects.fileProperty()
tasks.register<GreetingToFileTask>("greet") {
destination = greetingFile
}
tasks.register("sayGreeting") {
dependsOn("greet")
val greetingFile = greetingFile
doLast {
val file = greetingFile.get().asFile
println("${file.readText()} (file: ${file.name})")
}
}
greetingFile = layout.buildDirectory.file("hello.txt")abstract class GreetingToFileTask extends DefaultTask {
@OutputFile
abstract RegularFileProperty getDestination()
@TaskAction
def greet() {
def file = getDestination().get().asFile
file.parentFile.mkdirs()
file.write 'Hello!'
}
}
def greetingFile = objects.fileProperty()
tasks.register('greet', GreetingToFileTask) {
destination = greetingFile
}
tasks.register('sayGreeting') {
dependsOn greet
doLast {
def file = greetingFile.get().asFile
println "${file.text} (file: ${file.name})"
}
}
greetingFile = layout.buildDirectory.file('hello.txt')$ ./gradlew -q sayGreetingHello! (file: hello.txt)In this example, we configure the greet task destination property as a closure/provider, which is evaluated with
the Project.file(java.lang.Object) method to turn the return value of the closure/provider into a File object at the last minute.
Note that we specify the greetingFile property value after the task configuration.
This lazy evaluation is a key benefit of accepting any value when setting a file property and then resolving that value when reading the property.
You can learn more about working with files lazily in Working with Files.
Making a plugin configurable using extensions
Most plugins offer configuration options for build scripts and other plugins to customize how the plugin works. Plugins do this using extension objects.
A Project has an associated ExtensionContainer object that contains all the settings and properties for the plugins that have been applied to the project. You can provide configuration for your plugin by adding an extension object to this container.
An extension object is simply an object with Java Bean properties representing the configuration.
Let’s add a greeting extension object to the project, which allows you to configure the greeting:
interface GreetingPluginExtension {
val message: Property<String>
}
class GreetingPlugin : Plugin<Project> {
override fun apply(project: Project) {
// Add the 'greeting' extension object
val extension = project.extensions.create<GreetingPluginExtension>("greeting")
// Add a task that uses configuration from the extension object
project.task("hello") {
doLast {
println(extension.message.get())
}
}
}
}
apply<GreetingPlugin>()
// Configure the extension
the<GreetingPluginExtension>().message = "Hi from Gradle"interface GreetingPluginExtension {
Property<String> getMessage()
}
class GreetingPlugin implements Plugin<Project> {
void apply(Project project) {
// Add the 'greeting' extension object
def extension = project.extensions.create('greeting', GreetingPluginExtension)
// Add a task that uses configuration from the extension object
project.task('hello') {
doLast {
println extension.message.get()
}
}
}
}
apply plugin: GreetingPlugin
// Configure the extension
greeting.message = 'Hi from Gradle'$ ./gradlew -q helloHi from GradleIn this example, GreetingPluginExtension is an object with a property called message.
The extension object is added to the project with the name greeting.
This object becomes available as a project property with the same name as the extension object.
the<GreetingPluginExtension>() is equivalent to project.extensions.getByType(GreetingPluginExtension::class.java).
Often, you have several related properties you need to specify on a single plugin. Gradle adds a configuration block for each extension object, so you can group settings:
interface GreetingPluginExtension {
val message: Property<String>
val greeter: Property<String>
}
class GreetingPlugin : Plugin<Project> {
override fun apply(project: Project) {
val extension = project.extensions.create<GreetingPluginExtension>("greeting")
project.task("hello") {
doLast {
println("${extension.message.get()} from ${extension.greeter.get()}")
}
}
}
}
apply<GreetingPlugin>()
// Configure the extension using a DSL block
configure<GreetingPluginExtension> {
message = "Hi"
greeter = "Gradle"
}interface GreetingPluginExtension {
Property<String> getMessage()
Property<String> getGreeter()
}
class GreetingPlugin implements Plugin<Project> {
void apply(Project project) {
def extension = project.extensions.create('greeting', GreetingPluginExtension)
project.task('hello') {
doLast {
println "${extension.message.get()} from ${extension.greeter.get()}"
}
}
}
}
apply plugin: GreetingPlugin
// Configure the extension using a DSL block
greeting {
message = 'Hi'
greeter = 'Gradle'
}$ ./gradlew -q helloHi from GradleIn this example, several settings can be grouped within the configure<GreetingPluginExtension> block.
The configure function is used to configure an extension object.
It provides a convenient way to set properties or apply configurations to these objects.
The type used in the build script’s configure function (GreetingPluginExtension) must match the extension type.
Then, when the block is executed, the receiver of the block is the extension.
In this example, several settings can be grouped within the greeting closure. The name of the closure block in the build script (greeting) must match the extension object name.
Then, when the closure is executed, the fields on the extension object will be mapped to the variables within the closure based on the standard Groovy closure delegate feature.
Declaring a DSL configuration container
Using an extension object extends the Gradle DSL to add a project property and DSL block for the plugin. Because an extension object is a regular object, you can provide your own DSL nested inside the plugin block by adding properties and methods to the extension object.
Let’s consider the following build script for illustration purposes.
plugins {
id("org.myorg.server-env")
}
environments {
create("dev") {
url = "http://localhost:8080"
}
create("staging") {
url = "http://staging.enterprise.com"
}
create("production") {
url = "http://prod.enterprise.com"
}
}plugins {
id 'org.myorg.server-env'
}
environments {
dev {
url = 'http://localhost:8080'
}
staging {
url = 'http://staging.enterprise.com'
}
production {
url = 'http://prod.enterprise.com'
}
}The DSL exposed by the plugin exposes a container for defining a set of environments. Each environment the user configures has an arbitrary but declarative name and is represented with its own DSL configuration block. The example above instantiates a development, staging, and production environment, including its respective URL.
Each environment must have a data representation in code to capture the values. The name of an environment is immutable and can be passed in as a constructor parameter. Currently, the only other parameter the data object stores is a URL.
The following ServerEnvironment object fulfills those requirements:
abstract public class ServerEnvironment {
private final String name;
@javax.inject.Inject
public ServerEnvironment(String name) {
this.name = name;
}
public String getName() {
return name;
}
abstract public Property<String> getUrl();
}Gradle exposes the factory method ObjectFactory.domainObjectContainer(Class, NamedDomainObjectFactory) to create a container of data objects. The parameter the method takes is the class representing the data. The created instance of type NamedDomainObjectContainer can be exposed to the end user by adding it to the extension container with a specific name.
It’s common for a plugin to post-process the captured values within the plugin implementation, e.g., to configure tasks:
public class ServerEnvironmentPlugin implements Plugin<Project> {
@Override
public void apply(final Project project) {
ObjectFactory objects = project.getObjects();
NamedDomainObjectContainer<ServerEnvironment> serverEnvironmentContainer =
objects.domainObjectContainer(ServerEnvironment.class, name -> objects.newInstance(ServerEnvironment.class, name));
project.getExtensions().add("environments", serverEnvironmentContainer);
serverEnvironmentContainer.all(serverEnvironment -> {
String env = serverEnvironment.getName();
String capitalizedServerEnv = env.substring(0, 1).toUpperCase() + env.substring(1);
String taskName = "deployTo" + capitalizedServerEnv;
project.getTasks().register(taskName, Deploy.class, task -> task.getUrl().set(serverEnvironment.getUrl()));
});
}
}In the example above, a deployment task is created dynamically for every user-configured environment.
You can find out more about implementing project extensions in Developing Custom Gradle Types.
Modeling DSL-like APIs
DSLs exposed by plugins should be readable and easy to understand.
For example, let’s consider the following extension provided by a plugin. In its current form, it offers a "flat" list of properties for configuring the creation of a website:
plugins {
id("org.myorg.site")
}
site {
outputDir = layout.buildDirectory.file("mysite")
websiteUrl = "https://gradle.org"
vcsUrl = "https://github.com/gradle/gradle-site-plugin"
}plugins {
id 'org.myorg.site'
}
site {
outputDir = layout.buildDirectory.file("mysite")
websiteUrl = 'https://gradle.org'
vcsUrl = 'https://github.com/gradle/gradle-site-plugin'
}As the number of exposed properties grows, you should introduce a nested, more expressive structure.
The following code snippet adds a new configuration block named siteInfo as part of the extension.
This provides a stronger indication of what those properties mean:
plugins {
id("org.myorg.site")
}
site {
outputDir = layout.buildDirectory.file("mysite")
siteInfo {
websiteUrl = "https://gradle.org"
vcsUrl = "https://github.com/gradle/gradle-site-plugin"
}
}plugins {
id 'org.myorg.site'
}
site {
outputDir = layout.buildDirectory.file("mysite")
siteInfo {
websiteUrl = 'https://gradle.org'
vcsUrl = 'https://github.com/gradle/gradle-site-plugin'
}
}Implementing the backing objects for such an extension is simple.
First, introduce a new data object for managing the properties websiteUrl and vcsUrl:
abstract public class SiteInfo {
abstract public Property<String> getWebsiteUrl();
abstract public Property<String> getVcsUrl();
}In the extension, create an instance of the siteInfo class and a method to delegate the captured values to the data instance.
To configure underlying data objects, define a parameter of type Action.
The following example demonstrates the use of Action in an extension definition:
abstract public class SiteExtension {
abstract public RegularFileProperty getOutputDir();
@Nested
abstract public SiteInfo getSiteInfo();
public void siteInfo(Action<? super SiteInfo> action) {
action.execute(getSiteInfo());
}
}Mapping extension properties to task properties
Plugins commonly use an extension to capture user input from the build script and map it to a custom task’s input/output properties. The build script author interacts with the extension’s DSL, while the plugin implementation handles the underlying logic:
// Extension class to capture user input
class MyExtension {
@Input
var inputParameter: String? = null
}
// Custom task that uses the input from the extension
class MyCustomTask : org.gradle.api.DefaultTask() {
@Input
var inputParameter: String? = null
@TaskAction
fun executeTask() {
println("Input parameter: $inputParameter")
}
}
// Plugin class that configures the extension and task
class MyPlugin : Plugin<Project> {
override fun apply(project: Project) {
// Create and configure the extension
val extension = project.extensions.create("myExtension", MyExtension::class.java)
// Create and configure the custom task
project.tasks.register("myTask", MyCustomTask::class.java) {
group = "custom"
inputParameter = extension.inputParameter
}
}
}// Extension class to capture user input
class MyExtension {
@Input
String inputParameter = null
}
// Custom task that uses the input from the extension
class MyCustomTask extends DefaultTask {
@Input
String inputParameter = null
@TaskAction
def executeTask() {
println("Input parameter: $inputParameter")
}
}
// Plugin class that configures the extension and task
class MyPlugin implements Plugin<Project> {
void apply(Project project) {
// Create and configure the extension
def extension = project.extensions.create("myExtension", MyExtension)
// Create and configure the custom task
project.tasks.register("myTask", MyCustomTask) {
group = "custom"
inputParameter = extension.inputParameter
}
}
}In this example, the MyExtension class defines an inputParameter property that can be set in the build script.
The MyPlugin class configures this extension and uses its inputParameter value to configure the MyCustomTask task.
The MyCustomTask task then uses this input parameter in its logic.
You can learn more about types you can use in task implementations and extensions in Lazy Configuration.
Adding default configuration with conventions
Plugins should provide sensible defaults and standards in a specific context, reducing the number of decisions users need to make.
Using the project object, you can define default values.
These are known as conventions.
Conventions are properties that are initialized with default values and can be overridden by the user in their build script. For example:
interface GreetingPluginExtension {
val message: Property<String>
}
class GreetingPlugin : Plugin<Project> {
override fun apply(project: Project) {
// Add the 'greeting' extension object
val extension = project.extensions.create<GreetingPluginExtension>("greeting")
extension.message.convention("Hello from GreetingPlugin")
// Add a task that uses configuration from the extension object
project.task("hello") {
doLast {
println(extension.message.get())
}
}
}
}
apply<GreetingPlugin>()interface GreetingPluginExtension {
Property<String> getMessage()
}
class GreetingPlugin implements Plugin<Project> {
void apply(Project project) {
// Add the 'greeting' extension object
def extension = project.extensions.create('greeting', GreetingPluginExtension)
extension.message.convention('Hello from GreetingPlugin')
// Add a task that uses configuration from the extension object
project.task('hello') {
doLast {
println extension.message.get()
}
}
}
}
apply plugin: GreetingPlugin$ ./gradlew -q helloHello from GreetingPluginIn this example, GreetingPluginExtension is a class that represents the convention.
The message property is the convention property with a default value of 'Hello from GreetingPlugin'.
Users can override this value in their build script:
GreetingPluginExtension {
message = "Custom message"
}GreetingPluginExtension {
message = 'Custom message'
}$ ./gradlew -q helloCustom messageSeparating capabilities from conventions
Separating capabilities from conventions in plugins allows users to choose which tasks and conventions to apply.
For example, the Java Base plugin provides un-opinionated (i.e., generic) functionality like SourceSets, while the Java plugin adds tasks and conventions familiar to Java developers like classes, jar or javadoc.
When designing your own plugins, consider developing two plugins — one for capabilities and another for conventions — to offer flexibility to users.
In the example below, MyPlugin contains conventions, and MyBasePlugin defines capabilities.
Then, MyPlugin applies MyBasePlugin, this is called plugin composition.
To apply a plugin from another one:
import org.gradle.api.Plugin;
import org.gradle.api.Project;
public class MyBasePlugin implements Plugin<Project> {
public void apply(Project project) {
// define capabilities
}
}import org.gradle.api.Plugin;
import org.gradle.api.Project;
public class MyPlugin implements Plugin<Project> {
public void apply(Project project) {
project.getPluginManager().apply(MyBasePlugin.class);
// define conventions
}
}Reacting to plugins
A common pattern in Gradle plugin implementations is configuring the runtime behavior of existing plugins and tasks in a build.
For example, a plugin could assume that it is applied to a Java-based project and automatically reconfigure the standard source directory:
public class InhouseStrongOpinionConventionJavaPlugin implements Plugin<Project> {
public void apply(Project project) {
// Careful! Eagerly appyling plugins has downsides, and is not always recommended.
project.getPluginManager().apply(JavaPlugin.class);
SourceSetContainer sourceSets = project.getExtensions().getByType(SourceSetContainer.class);
SourceSet main = sourceSets.getByName(SourceSet.MAIN_SOURCE_SET_NAME);
main.getJava().setSrcDirs(Arrays.asList("src"));
}
}The drawback to this approach is that it automatically forces the project to apply the Java plugin, imposing a strong opinion on it (i.e., reducing flexibility and generality). In practice, the project applying the plugin might not even deal with Java code.
Instead of automatically applying the Java plugin, the plugin could react to the fact that the consuming project applies the Java plugin. Only if that is the case, then a certain configuration is applied:
public class InhouseConventionJavaPlugin implements Plugin<Project> {
public void apply(Project project) {
project.getPluginManager().withPlugin("java", javaPlugin -> {
SourceSetContainer sourceSets = project.getExtensions().getByType(SourceSetContainer.class);
SourceSet main = sourceSets.getByName(SourceSet.MAIN_SOURCE_SET_NAME);
main.getJava().setSrcDirs(Arrays.asList("src"));
});
}
}Reacting to plugins is preferred over applying plugins if there is no good reason to assume that the consuming project has the expected setup.
The same concept applies to task types:
public class InhouseConventionWarPlugin implements Plugin<Project> {
public void apply(Project project) {
project.getTasks().withType(War.class).configureEach(war ->
war.setWebXml(project.file("src/someWeb.xml")));
}
}Reacting to build features
Plugins can access the status of build features in the build. The Build Features API allows checking whether the user requested a particular Gradle feature and if it is active in the current build. An example of a build feature is the configuration cache.
There are two main use cases:
-
Using the status of build features in reports or statistics.
-
Incrementally adopting experimental Gradle features by disabling incompatible plugin functionality.
Below is an example of a plugin that utilizes both of the cases.
public abstract class MyPlugin implements Plugin<Project> {
@Inject
protected abstract BuildFeatures getBuildFeatures(); // (1)
@Override
public void apply(Project p) {
BuildFeatures buildFeatures = getBuildFeatures();
Boolean configCacheRequested = buildFeatures.getConfigurationCache().getRequested() // (2)
.getOrNull(); // could be null if user did not opt in nor opt out
String configCacheUsage = describeFeatureUsage(configCacheRequested);
MyReport myReport = new MyReport();
myReport.setConfigurationCacheUsage(configCacheUsage);
boolean isolatedProjectsActive = buildFeatures.getIsolatedProjects().getActive() // (3)
.get(); // the active state is always defined
if (!isolatedProjectsActive) {
myOptionalPluginLogicIncompatibleWithIsolatedProjects();
}
}
private String describeFeatureUsage(Boolean requested) {
return requested == null ? "no preference" : requested ? "opt-in" : "opt-out";
}
private void myOptionalPluginLogicIncompatibleWithIsolatedProjects() {
}
}-
The
BuildFeaturesservice can be injected into plugins, tasks, and other managed types. -
Accessing the
requestedstatus of a feature for reporting. -
Using the
activestatus of a feature to disable incompatible functionality.
Build feature properties
A BuildFeature status properties are represented with Provider<Boolean> types.
The BuildFeature.getRequested() status of a build feature determines if the user requested to enable or disable the feature.
When the requested provider value is:
-
true— the user opted in for using the feature -
false— the user opted out from using the feature -
undefined— the user neither opted in nor opted out from using the feature
The BuildFeature.getActive() status of a build feature is always defined.
It represents the effective state of the feature in the build.
When the active provider value is:
-
true— the feature may affect the build behavior in a way specific to the feature -
false— the feature will not affect the build behavior
Note that the active status does not depend on the requested status.
Even if the user requests a feature, it may still not be active due to other build options being used in the build.
Gradle can also activate a feature by default, even if the user did not specify a preference.
Using a custom dependencies block
A plugin can provide dependency declarations in custom blocks that allow users to declare dependencies in a type-safe and context-aware way.
For instance, instead of users needing to know and use the underlying Configuration name to add dependencies, a custom dependencies block lets the plugin pick a meaningful name that
can be used consistently.
Adding a custom dependencies block
To add a custom dependencies block, you need to create a new type that will represent the set of dependency scopes available to users.
That new type needs to be accessible from a part of your plugin (from a domain object or extension).
Finally, the dependency scopes need to be wired back to underlying Configuration objects that will be used during dependency resolution.
See JvmComponentDependencies and JvmTestSuite for an example of how this is used in a Gradle core plugin.
1. Create an interface that extends Dependencies
|
Note
|
You can also extend GradleDependencies to get access to Gradle-provided dependencies like gradleApi().
|
/**
* Custom dependencies block for the example plugin.
*/
public interface ExampleDependencies extends Dependencies {2. Add accessors for dependency scopes
For each dependency scope your plugin wants to support, add a getter method that returns a DependencyCollector.
/**
* Dependency scope called "implementation"
*/
DependencyCollector getImplementation();3. Add accessors for custom dependencies block
To make the custom dependencies block configurable, the plugin needs to add a getDependencies method that returns the new type from above and a configurable block method named dependencies.
By convention, the accessors for your custom dependencies block should be called getDependencies()/dependencies(Action).
This method could be named something else, but users would need to know that a different block can behave like a dependencies block.
/**
* Custom dependencies for this extension.
*/
@Nested
ExampleDependencies getDependencies();
/**
* Configurable block
*/
default void dependencies(Action<? super ExampleDependencies> action) {
action.execute(getDependencies());
}4. Wire dependency scope to Configuration
Finally, the plugin needs to wire the custom dependencies block to some underlying Configuration objects. If this is not done, none of the dependencies declared in the custom block will
be available to dependency resolution.
project.getConfigurations().dependencyScope("exampleImplementation", conf -> {
conf.fromDependencyCollector(example.getDependencies().getImplementation());
});|
Note
|
In this example, the name users will use to add dependencies is "implementation", but the underlying Configuration is named exampleImplementation.
|
example {
dependencies {
implementation("junit:junit:4.13")
}
}example {
dependencies {
implementation("junit:junit:4.13")
}
}Differences between the custom dependencies and the top-level dependencies blocks
Each dependency scope returns a DependencyCollector that provides strongly-typed methods to add and configure dependencies.
There is also a DependencyFactory with factory methods to create new dependencies from different notations.
Dependencies can be created lazily using these factory methods, as shown below.
A custom dependencies block differs from the top-level dependencies block in the following ways:
-
Dependencies must be declared using a
String, an instance ofDependency, aFileCollection, aProviderofDependency, or aProviderConvertibleofMinimalExternalModuleDependency. -
Outside of Gradle build scripts, you must explicitly call a getter for the
DependencyCollectorandadd.-
dependencies.add("implementation", x)becomesgetImplementation().add(x)
-
-
You cannot add a dependency with an instance of
Project. You must turn it into aProjectDependencyfirst. -
You cannot add version catalog bundles directly. Instead, use the
bundlemethod on each configuration.-
Kotlin and Groovy:
implementation(libs.bundles.testing)becomesimplementation.bundle(libs.bundles.testing)
-
-
You cannot use providers for non-
Dependencytypes directly. Instead, map them to aDependencyusing theDependencyFactory.-
Kotlin and Groovy:
implementation(myStringProvider)becomesimplementation(myStringProvider.map { dependencyFactory.create(it) }) -
Java:
implementation(myStringProvider)becomesgetImplementation().add(myStringProvider.map(getDependencyFactory()::create)
-
-
Unlike the top-level
dependenciesblock, constraints are not in a separate block.-
Instead, constraints are added by decorating a dependency with
constraint(…)likeimplementation(constraint("org:foo:1.0")).
-
Keep in mind that the dependencies block may not provide access to the same methods as the top-level dependencies block.
|
Note
|
Plugins should prefer adding dependencies via their own dependencies block.
|
Providing default dependencies
The implementation of a plugin sometimes requires the use of an external dependency.
You might want to automatically download an artifact using Gradle’s dependency management mechanism and later use it in the action of a task type declared in the plugin. Ideally, the plugin implementation does not need to ask the user for the coordinates of that dependency - it can simply predefine a sensible default version.
Let’s look at an example of a plugin that downloads files containing data for further processing. The plugin implementation declares a custom configuration that allows for assigning those external dependencies with dependency coordinates:
public class DataProcessingPlugin implements Plugin<Project> {
public void apply(Project project) {
Configuration dataFiles = project.getConfigurations().create("dataFiles", c -> {
c.setVisible(false);
c.setCanBeConsumed(false);
c.setCanBeResolved(true);
c.setDescription("The data artifacts to be processed for this plugin.");
c.defaultDependencies(d -> d.add(project.getDependencies().create("org.myorg:data:1.4.6")));
});
project.getTasks().withType(DataProcessing.class).configureEach(
dataProcessing -> dataProcessing.getDataFiles().from(dataFiles));
}
}abstract public class DataProcessing extends DefaultTask {
@InputFiles
abstract public ConfigurableFileCollection getDataFiles();
@TaskAction
public void process() {
System.out.println(getDataFiles().getFiles());
}
}This approach is convenient for the end user as there is no need to actively declare a dependency. The plugin already provides all the details about this implementation.
But what if the user wants to redefine the default dependency?
No problem. The plugin also exposes the custom configuration that can be used to assign a different dependency. Effectively, the default dependency is overwritten:
plugins {
id("org.myorg.data-processing")
}
dependencies {
dataFiles("org.myorg:more-data:2.6")
}plugins {
id 'org.myorg.data-processing'
}
dependencies {
dataFiles 'org.myorg:more-data:2.6'
}You will find that this pattern works well for tasks that require an external dependency when the task’s action is executed.
You can go further and abstract the version to be used for the external dependency by exposing an extension property (e.g.
toolVersion in the JaCoCo plugin).
Minimizing the use of external libraries
Using external libraries in your Gradle projects can bring great convenience, but be aware that they can introduce complex dependency graphs.
Gradle’s buildEnvironment task can help you visualize these dependencies, including those of your plugins.
Keep in mind that plugins share the same classloader, so conflicts may arise with different versions of the same library.
To demonstrate let’s assume the following build script:
plugins {
id("org.asciidoctor.jvm.convert") version "4.0.2"
}plugins {
id 'org.asciidoctor.jvm.convert' version '4.0.2'
}The output of the task clearly indicates the classpath of the classpath configuration:
$ ./gradlew buildEnvironment> Task :buildEnvironment
------------------------------------------------------------
Root project 'external-libraries'
------------------------------------------------------------
classpath
\--- org.asciidoctor.jvm.convert:org.asciidoctor.jvm.convert.gradle.plugin:4.0.2
\--- org.asciidoctor:asciidoctor-gradle-jvm:4.0.2
+--- org.ysb33r.gradle:grolifant-rawhide:3.0.0
| \--- org.tukaani:xz:1.6
+--- org.ysb33r.gradle:grolifant-herd:3.0.0
| +--- org.tukaani:xz:1.6
| +--- org.ysb33r.gradle:grolifant40:3.0.0
| | +--- org.tukaani:xz:1.6
| | +--- org.apache.commons:commons-collections4:4.4
| | +--- org.ysb33r.gradle:grolifant-core:3.0.0
| | | +--- org.tukaani:xz:1.6
| | | +--- org.apache.commons:commons-collections4:4.4
| | | \--- org.ysb33r.gradle:grolifant-rawhide:3.0.0 (*)
| | \--- org.ysb33r.gradle:grolifant-rawhide:3.0.0 (*)
| +--- org.ysb33r.gradle:grolifant50:3.0.0
| | +--- org.tukaani:xz:1.6
| | +--- org.ysb33r.gradle:grolifant40:3.0.0 (*)
| | +--- org.ysb33r.gradle:grolifant-core:3.0.0 (*)
| | \--- org.ysb33r.gradle:grolifant40-legacy-api:3.0.0
| | +--- org.tukaani:xz:1.6
| | +--- org.apache.commons:commons-collections4:4.4
| | +--- org.ysb33r.gradle:grolifant-core:3.0.0 (*)
| | \--- org.ysb33r.gradle:grolifant40:3.0.0 (*)
| +--- org.ysb33r.gradle:grolifant60:3.0.0
| | +--- org.tukaani:xz:1.6
| | +--- org.ysb33r.gradle:grolifant40:3.0.0 (*)
| | +--- org.ysb33r.gradle:grolifant50:3.0.0 (*)
| | +--- org.ysb33r.gradle:grolifant-core:3.0.0 (*)
| | \--- org.ysb33r.gradle:grolifant-rawhide:3.0.0 (*)
| +--- org.ysb33r.gradle:grolifant70:3.0.0
| | +--- org.tukaani:xz:1.6
| | +--- org.ysb33r.gradle:grolifant40:3.0.0 (*)
| | +--- org.ysb33r.gradle:grolifant50:3.0.0 (*)
| | +--- org.ysb33r.gradle:grolifant60:3.0.0 (*)
| | \--- org.ysb33r.gradle:grolifant-core:3.0.0 (*)
| +--- org.ysb33r.gradle:grolifant80:3.0.0
| | +--- org.tukaani:xz:1.6
| | +--- org.ysb33r.gradle:grolifant40:3.0.0 (*)
| | +--- org.ysb33r.gradle:grolifant50:3.0.0 (*)
| | +--- org.ysb33r.gradle:grolifant60:3.0.0 (*)
| | +--- org.ysb33r.gradle:grolifant70:3.0.0 (*)
| | \--- org.ysb33r.gradle:grolifant-core:3.0.0 (*)
| +--- org.ysb33r.gradle:grolifant-core:3.0.0 (*)
| \--- org.ysb33r.gradle:grolifant-rawhide:3.0.0 (*)
+--- org.asciidoctor:asciidoctor-gradle-base:4.0.2
| \--- org.ysb33r.gradle:grolifant-herd:3.0.0 (*)
\--- org.asciidoctor:asciidoctorj-api:2.5.7
(*) - Indicates repeated occurrences of a transitive dependency subtree. Gradle expands transitive dependency subtrees only once per project; repeat occurrences only display the root of the subtree, followed by this annotation.
A web-based, searchable dependency report is available by adding the --scan option.
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executedA Gradle plugin does not run in its own, isolated classloader, so you must consider whether you truly need a library or if a simpler solution suffices.
For logic that is executed as part of task execution, use the Worker API that allows you to isolate libraries.
Providing multiple variants of a plugin
Variants of a plugin refer to different flavors or configurations of the plugin that are tailored to specific needs or use cases. These variants can include different implementations, extensions, or configurations of the base plugin.
The most convenient way to configure additional plugin variants is to use feature variants, a concept available in all Gradle projects that apply one of the Java plugins:
dependencies {
implementation 'com.google.guava:guava:30.1-jre' // Regular dependency
featureVariant 'com.google.guava:guava-gwt:30.1-jre' // Feature variant dependency
}In the following example, each plugin variant is developed in isolation. A separate source set is compiled and packaged in a separate jar for each variant.
The following sample demonstrates how to add a variant that is compatible with Gradle 7.0+ while the "main" variant is compatible with older versions:
val gradle7 = sourceSets.create("gradle7")
java {
registerFeature(gradle7.name) {
usingSourceSet(gradle7)
capability(project.group.toString(), project.name, project.version.toString()) // (1)
}
}
configurations.configureEach {
if (isCanBeConsumed && name.startsWith(gradle7.name)) {
attributes {
attribute(GradlePluginApiVersion.GRADLE_PLUGIN_API_VERSION_ATTRIBUTE, // (2)
objects.named("7.0"))
}
}
}
tasks.named<Copy>(gradle7.processResourcesTaskName) { // (3)
val copyPluginDescriptors = rootSpec.addChild()
copyPluginDescriptors.into("META-INF/gradle-plugins")
copyPluginDescriptors.from(tasks.pluginDescriptors)
}
dependencies {
"gradle7CompileOnly"(gradleApi()) // (4)
}def gradle7 = sourceSets.create('gradle7')
java {
registerFeature(gradle7.name) {
usingSourceSet(gradle7)
capability(project.group.toString(), project.name, project.version.toString()) // (1)
}
}
configurations.configureEach {
if (canBeConsumed && name.startsWith(gradle7.name)) {
attributes {
attribute(GradlePluginApiVersion.GRADLE_PLUGIN_API_VERSION_ATTRIBUTE, // (2)
objects.named(GradlePluginApiVersion, '7.0'))
}
}
}
tasks.named(gradle7.processResourcesTaskName) { // (3)
def copyPluginDescriptors = rootSpec.addChild()
copyPluginDescriptors.into('META-INF/gradle-plugins')
copyPluginDescriptors.from(tasks.pluginDescriptors)
}
dependencies {
gradle7CompileOnly(gradleApi()) // (4)
}|
Note
|
Only Gradle versions 7 or higher can be explicitly targeted by a variant, as support for this was only added in Gradle 7. |
First, we declare a separate source set and a feature variant for our Gradle 7 plugin variant. Then, we do some specific wiring to turn the feature into a proper Gradle plugin variant:
-
Assign the implicit capability that corresponds to the components GAV to the variant.
-
Assign the Gradle API version attribute to all consumable configurations of our Gradle7 variant. Gradle uses this information to determine which variant to select during plugin resolution.
-
Configure the
processGradle7Resourcestask to ensure the plugin descriptor file is added to the Gradle7 variant Jar. -
Add a dependency to the
gradleApi()for our new variant so that the API is visible during compilation time.
Note that there is currently no convenient way to access the API of other Gradle versions as the one you are building the plugin with. Ideally, every variant should be able to declare a dependency on the API of the minimal Gradle version it supports. This will be improved in the future.
The above snippet assumes that all variants of your plugin have the plugin class at the same location.
That is, if your plugin class is org.example.GreetingPlugin, you need to create a second variant of that class in src/gradle7/java/org/example.
Using version-specific variants of multi-variant plugins
Given a dependency on a multi-variant plugin, Gradle will automatically choose its variant that best matches the current Gradle version when it resolves any of:
-
plugins specified in the
plugins {}block; -
buildscriptclasspath dependencies; -
dependencies in the root project of the build source (
buildSrc) that appear on the compile or runtime classpath; -
dependencies in a project that applies the Java Gradle Plugin Development plugin or the Kotlin DSL plugin, appearing on the compile or runtime classpath.
The best matching variant is the variant that targets the highest Gradle API version and does not exceed the current build’s Gradle version.
In all other cases, a plugin variant that does not specify the supported Gradle API version is preferred if such a variant is present.
In projects that use plugins as dependencies, requesting the variants of plugin dependencies that support a different Gradle version is possible. This allows a multi-variant plugin that depends on other plugins to access their APIs, which are exclusively provided in their version-specific variants.
This snippet makes the plugin variant gradle7 defined above consume the matching variants of its dependencies on other multi-variant plugins:
configurations.configureEach {
if (isCanBeResolved && name.startsWith(gradle7.name)) {
attributes {
attribute(GradlePluginApiVersion.GRADLE_PLUGIN_API_VERSION_ATTRIBUTE,
objects.named("7.0"))
}
}
}configurations.configureEach {
if (canBeResolved && name.startsWith(gradle7.name)) {
attributes {
attribute(GradlePluginApiVersion.GRADLE_PLUGIN_API_VERSION_ATTRIBUTE,
objects.named(GradlePluginApiVersion, '7.0'))
}
}
}Testing Plugins
Testing plays a crucial role in the development process by ensuring reliable and high-quality software. This principle applies to build code, including Gradle plugins.
The sample project
This section revolves around a sample project called the "URL verifier plugin".
This plugin creates a task named verifyUrl that checks whether a given URL can be resolved via HTTP GET.
The end user can provide the URL via an extension named verification.
The following build script assumes that the plugin JAR file has been published to a binary repository. The script demonstrates how to apply the plugin to the project and configure its exposed extension:
plugins {
id("org.myorg.url-verifier") // (1)
}
verification {
url = "https://www.google.com/" // (2)
}plugins {
id 'org.myorg.url-verifier' // (1)
}
verification {
url = 'https://www.google.com/' // (2)
}-
Applies the plugin to the project
-
Configures the URL to be verified through the exposed extension
Executing the verifyUrl task renders a success message if the HTTP GET call to the configured URL returns with a 200 response code:
$ ./gradlew verifyUrl> Task :verifyUrl
Successfully resolved URL 'https://www.google.com/'
BUILD SUCCESSFUL in 0s
5 actionable tasks: 5 executedBefore diving into the code, let’s first revisit the different types of tests and the tooling that supports implementing them.
The importance of testing
Testing is a crucial part of the software development life cycle, ensuring that software functions correctly and meets quality standards before release. Automated testing allows developers to refactor and improve code with confidence.
The testing pyramid
- Manual Testing
-
While manual testing is straightforward, it is error-prone and requires human effort. For Gradle plugins, manual testing involves using the plugin in a build script.
- Automated Testing
-
Automated testing includes unit, integration, and functional testing.
The testing pyramid introduced by Mike Cohen in his book Succeeding with Agile: Software Development Using Scrum describes three types of automated tests:
-
Unit Testing: Verifies the smallest units of code, typically methods, in isolation. It uses Stubs or Mocks to isolate code from external dependencies.
-
Integration Testing: Validates that multiple units or components work together, often with external systems like file I/O or HTTP.
-
Functional Testing: Tests the system from the end user’s perspective, ensuring correct functionality. End-to-end tests for Gradle plugins simulate a build, apply the plugin, and execute specific tasks to verify functionality.
Tooling support
Testing Gradle plugins, both manually and automatically, is simplified with the appropriate tools. The table below provides a summary of each testing approach. You can choose any test framework you’re comfortable with.
For detailed explanations and code examples, refer to the specific sections below:
| Test type | Tooling support |
|---|---|
Any JVM-based test framework + |
|
Any JVM-based test framework |
|
Any JVM-based test framework + Gradle TestKit ( |
Setting up manual tests
The composite builds feature of Gradle makes it easy to test a plugin manually. The standalone plugin project and the consuming project can be combined into a single unit, making it straightforward to try out or debug changes without re-publishing the binary file:
.
├── include-plugin-build // (1)
│ ├── build.gradle
│ └── settings.gradle
└── url-verifier-plugin // (2)
├── build.gradle
├── settings.gradle
└── src-
Consuming project that includes the plugin project
-
The plugin project
There are two ways to include a plugin project in a consuming project:
-
By using the command line option
--include-build. -
By using the method
includeBuildinsettings.gradle.
The following code snippet demonstrates the use of the settings file:
pluginManagement {
includeBuild("../url-verifier-plugin")
}pluginManagement {
includeBuild '../url-verifier-plugin'
}The command line output of the verifyUrl task from the project include-plugin-build looks exactly the same as shown in the introduction, except that it now executes as part of a composite build.
Manual testing has its place in the development process, but it is not a replacement for automated testing.
Setting up automated tests
Setting up a suite of tests early on is crucial to the success of your plugin. Automated tests become an invaluable safety net when upgrading the plugin to a new Gradle version or enhancing/refactoring the code.
Organizing test source code
We recommend implementing a good distribution of unit, integration, and functional tests to cover the most important use cases. Separating the source code for each test type automatically results in a project that is more maintainable and manageable.
By default, the Java project creates a convention for organizing unit tests in the directory src/test/java.
Additionally, if you apply the Groovy plugin, source code under the directory src/test/groovy is considered for compilation (with the same standard for Kotlin under the directory src/test/kotlin).
Consequently, source code directories for other test types should follow a similar pattern:
.
└── src
├── functionalTest
│ └── groovy // (1)
├── integrationTest
│ └── groovy // (2)
├── main
│ ├── java // (3)
└── test
└── groovy // (4)-
Source directory containing functional tests
-
Source directory containing integration tests
-
Source directory containing production source code
-
Source directory containing unit tests
|
Note
|
The directories src/integrationTest/groovy and src/functionalTest/groovy are not based on an existing standard convention for Gradle projects.
You are free to choose any project layout that works best for you.
|
You can configure the source directories for compilation and test execution.
The Test Suite plugin provides a DSL and API to model multiple groups of automated tests into test suites in JVM-based projects. You can also rely on third-party plugins for convenience, such as the Nebula Facet plugin or the TestSets plugin.
Modeling test types
In Gradle, source code directories are represented using the concept of source sets. A source set is configured to point to one or more directories containing source code. When you define a source set, Gradle automatically sets up compilation tasks for the specified directories.
A pre-configured source set can be created with one line of build script code. The source set automatically registers configurations to define dependencies for the sources of the source set:
// Define a source set named 'test' for test sources
sourceSets {
test {
java {
setSrcDirs(listOf("src/test/java"))
}
}
}
// Specify a test implementation dependency on JUnit
dependencies {
testImplementation("junit:junit:4.12")
}// Define a source set named 'test' for test sources
sourceSets {
test {
java {
srcDirs = ['src/test/java']
}
}
}
// Specify a test implementation dependency on JUnit
dependencies {
testImplementation 'junit:junit:4.12'
}We use that to define an integrationTestImplementation dependency to the project itself, which represents the "main" variant of our project (i.e., the compiled plugin code):
val integrationTest = sourceSets.create("integrationTest")
dependencies {
"integrationTestImplementation"(project())
}def integrationTest = sourceSets.create("integrationTest")
dependencies {
integrationTestImplementation(project())
}Source sets are responsible for compiling source code, but they do not deal with executing the bytecode. For test execution, a corresponding task of type Test needs to be established. The following setup shows the execution of integration tests, referencing the classes and runtime classpath of the integration test source set:
val integrationTestTask = tasks.register<Test>("integrationTest") {
description = "Runs the integration tests."
group = "verification"
testClassesDirs = integrationTest.output.classesDirs
classpath = integrationTest.runtimeClasspath
mustRunAfter(tasks.test)
}
tasks.check {
dependsOn(integrationTestTask)
}def integrationTestTask = tasks.register("integrationTest", Test) {
description = 'Runs the integration tests.'
group = "verification"
testClassesDirs = integrationTest.output.classesDirs
classpath = integrationTest.runtimeClasspath
mustRunAfter(tasks.named('test'))
}
tasks.named('check') {
dependsOn(integrationTestTask)
}Configuring a test framework
Gradle does not dictate the use of a specific test framework. Popular choices include JUnit, TestNG and Spock. Once you choose an option, you have to add its dependency to the compile classpath for your tests.
The following code snippet shows how to use Spock for implementing tests:
repositories {
mavenCentral()
}
dependencies {
testImplementation(platform("org.spockframework:spock-bom:2.4-groovy-4.0"))
testImplementation("org.spockframework:spock-core")
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
"integrationTestImplementation"(platform("org.spockframework:spock-bom:2.4-groovy-4.0"))
"integrationTestImplementation"("org.spockframework:spock-core")
"integrationTestRuntimeOnly"("org.junit.platform:junit-platform-launcher")
"functionalTestImplementation"(platform("org.spockframework:spock-bom:2.4-groovy-4.0"))
"functionalTestImplementation"("org.spockframework:spock-core")
"functionalTestRuntimeOnly"("org.junit.platform:junit-platform-launcher")
}
tasks.withType<Test>().configureEach {
// Using JUnitPlatform for running tests
useJUnitPlatform()
}repositories {
mavenCentral()
}
dependencies {
testImplementation platform("org.spockframework:spock-bom:2.4-groovy-4.0")
testImplementation 'org.spockframework:spock-core'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
integrationTestImplementation platform("org.spockframework:spock-bom:2.4-groovy-4.0")
integrationTestImplementation 'org.spockframework:spock-core'
integrationTestRuntimeOnly 'org.junit.platform:junit-platform-launcher'
functionalTestImplementation platform("org.spockframework:spock-bom:2.4-groovy-4.0")
functionalTestImplementation 'org.spockframework:spock-core'
functionalTestRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}
tasks.withType(Test).configureEach {
// Using JUnitPlatform for running tests
useJUnitPlatform()
}|
Note
|
Spock is a Groovy-based BDD test framework that even includes APIs for creating Stubs and Mocks. The Gradle team prefers Spock over other options for its expressiveness and conciseness. |
Implementing automated tests
This section discusses representative implementation examples for unit, integration, and functional tests.
Implementing unit tests
The URL verifier plugin emits HTTP GET calls to check if a URL can be resolved successfully.
The method DefaultHttpCaller.get(String) is responsible for calling a given URL and returns an instance of type HttpResponse. HttpResponse is a POJO containing information about the HTTP response code and message:
package org.myorg.http;
public class HttpResponse {
private int code;
private String message;
public HttpResponse(int code, String message) {
this.code = code;
this.message = message;
}
public int getCode() {
return code;
}
public String getMessage() {
return message;
}
@Override
public String toString() {
return "HTTP " + code + ", Reason: " + message;
}
}The class HttpResponse represents a good candidate for a unit test.
It does not reach out to any other classes nor does it use the Gradle API.
package org.myorg.http
import spock.lang.Specification
class HttpResponseTest extends Specification {
private static final int OK_HTTP_CODE = 200
private static final String OK_HTTP_MESSAGE = 'OK'
def "can access information"() {
when:
def httpResponse = new HttpResponse(OK_HTTP_CODE, OK_HTTP_MESSAGE)
then:
httpResponse.code == OK_HTTP_CODE
httpResponse.message == OK_HTTP_MESSAGE
}
def "can get String representation"() {
when:
def httpResponse = new HttpResponse(OK_HTTP_CODE, OK_HTTP_MESSAGE)
then:
httpResponse.toString() == "HTTP $OK_HTTP_CODE, Reason: $OK_HTTP_MESSAGE"
}
}|
Important
|
When writing unit tests, it’s important to test boundary conditions and various forms of invalid input. Try to extract as much logic as possible from classes that use the Gradle API to make it testable as unit tests. It will result in maintainable code and faster test execution. |
Unit tests for Gradle plugins typically use the ProjectBuilder API.
This allows you to create an in-memory Project instance, apply your plugin, and verify that it registers extensions or tasks correctly.
ProjectBuilder does not execute tasks — it is only suitable for verifying configuration logic.
Here is a simple example:
public class GreetingPluginTest {
@Test
public void greeterPluginAddsGreetingTaskToProject() {
Project project = ProjectBuilder.builder().build();
project.getPluginManager().apply("org.example.greeting");
assertTrue(project.getTasks().getByName("hello") instanceof GreetingTask);
}
}Implementing integration tests
Let’s look at a class that reaches out to another system, the piece of code that emits the HTTP calls.
At the time of executing a test for the class DefaultHttpCaller, the runtime environment needs to be able to reach out to the internet:
package org.myorg.http;
import java.io.IOException;
import java.net.HttpURLConnection;
import java.net.URI;
import java.net.URISyntaxException;
public class DefaultHttpCaller implements HttpCaller {
@Override
public HttpResponse get(String url) {
try {
HttpURLConnection connection = (HttpURLConnection) new URI(url).toURL().openConnection();
connection.setConnectTimeout(5000);
connection.setRequestMethod("GET");
connection.connect();
int code = connection.getResponseCode();
String message = connection.getResponseMessage();
return new HttpResponse(code, message);
} catch (IOException e) {
throw new HttpCallException(String.format("Failed to call URL '%s' via HTTP GET", url), e);
} catch (URISyntaxException e) {
throw new RuntimeException(e);
}
}
}Implementing an integration test for DefaultHttpCaller doesn’t look much different from the unit test shown in the previous section:
package org.myorg.http
import spock.lang.Specification
import spock.lang.Subject
class DefaultHttpCallerIntegrationTest extends Specification {
@Subject HttpCaller httpCaller = new DefaultHttpCaller()
def "can make successful HTTP GET call"() {
when:
def httpResponse = httpCaller.get('https://www.google.com/')
then:
httpResponse.code == 200
httpResponse.message == 'OK'
}
def "throws exception when calling unknown host via HTTP GET"() {
when:
httpCaller.get('https://www.example.invalid/')
then:
def t = thrown(HttpCallException)
t.message == "Failed to call URL 'https://www.example.invalid/' via HTTP GET"
t.cause instanceof UnknownHostException
}
}Implementing functional tests
Functional tests verify the correctness of the plugin end-to-end.
In practice, this means applying, configuring, and executing the functionality of the plugin implementation.
The UrlVerifierPlugin class exposes an extension and a task instance that uses the URL value configured by the end user:
package org.myorg;
import org.gradle.api.Plugin;
import org.gradle.api.Project;
import org.myorg.tasks.UrlVerify;
public class UrlVerifierPlugin implements Plugin<Project> {
@Override
public void apply(Project project) {
UrlVerifierExtension extension = project.getExtensions().create("verification", UrlVerifierExtension.class);
UrlVerify verifyUrlTask = project.getTasks().create("verifyUrl", UrlVerify.class);
verifyUrlTask.getUrl().set(extension.getUrl());
}
}Every Gradle plugin project should apply the plugin development plugin to reduce boilerplate code. By applying the plugin development plugin, the test source set is preconfigured for the use with TestKit. If we want to use a custom source set for functional tests and leave the default test source set for only unit tests, we can configure the plugin development plugin to look for TestKit tests elsewhere.
gradlePlugin {
testSourceSets(functionalTest)
}gradlePlugin {
testSourceSets(sourceSets.functionalTest)
}Functional tests for Gradle plugins use an instance of GradleRunner to execute the build under test.
GradleRunner is an API provided by TestKit, which internally uses the Tooling API to execute the build.
Unlike ProjectBuilder, which is limited to configuration, GradleRunner runs actual builds.
This makes it possible to assert that tasks succeed, fail, or produce expected output.
The following example applies the plugin to the build script under test, configures the extension and executes the build with the task verifyUrl.
Please see the TestKit documentation to get more familiar with the functionality of TestKit.
package org.myorg
import org.gradle.testkit.runner.GradleRunner
import spock.lang.Specification
import spock.lang.TempDir
import static org.gradle.testkit.runner.TaskOutcome.SUCCESS
class UrlVerifierPluginFunctionalTest extends Specification {
@TempDir File testProjectDir
File buildFile
def setup() {
buildFile = new File(testProjectDir, 'build.gradle')
buildFile << """
plugins {
id 'org.myorg.url-verifier'
}
"""
}
def "can successfully configure URL through extension and verify it"() {
buildFile << """
verification {
url = 'https://www.google.com/'
}
"""
when:
def result = GradleRunner.create()
.withProjectDir(testProjectDir)
.withArguments('verifyUrl')
.withPluginClasspath()
.build()
then:
result.output.contains("Successfully resolved URL 'https://www.google.com/'")
result.task(":verifyUrl").outcome == SUCCESS
}
}IDE integration
TestKit determines the plugin classpath by running a specific Gradle task.
You will need to execute the assemble task to initially generate the plugin classpath or to reflect changes to it even when running TestKit-based functional tests from the IDE.
Example of a unit test
The following is an example of a unit test of the Greeting plugin from Binary Plugins:
package org.example
import org.gradle.api.Project
import org.gradle.testfixtures.ProjectBuilder
import org.junit.jupiter.api.Test
import kotlin.test.assertEquals
import kotlin.test.assertNotNull
class GreetingPluginTest {
@Test
fun `plugin registers greet task`() {
// Create an in-memory project and apply the plugin
val project: Project = ProjectBuilder.builder().build()
project.plugins.apply("org.example.greeting")
// Verify the task is registered
assertNotNull(project.tasks.findByName("greet"))
}
@Test
fun `extension has sensible defaults`() {
val project: Project = ProjectBuilder.builder().build()
project.plugins.apply("org.example.greeting")
val ext = project.extensions.getByType(GreetingExtension::class.java)
// Defaults from the plugin:
assertEquals("Hello from plugin", ext.message.get())
// Default output file is build/greeting.txt
val defaultFile = ext.outputFile.get().asFile
assertEquals(project.layout.buildDirectory.file("greeting.txt").get().asFile, defaultFile)
}
}package org.example
import org.gradle.api.Project
import org.gradle.testfixtures.ProjectBuilder
import org.junit.jupiter.api.Test
import static org.junit.jupiter.api.Assertions.assertEquals
import static org.junit.jupiter.api.Assertions.assertNotNull
class GreetingPluginTest {
@Test
void 'plugin registers greet task'() {
// Create an in-memory project and apply the plugin
Project project = ProjectBuilder.builder().build()
project.plugins.apply("org.example.greeting")
// Verify the task is registered
assertNotNull(project.tasks.findByName("greet"))
}
@Test
void 'extension has sensible defaults'() {
Project project = ProjectBuilder.builder().build()
project.plugins.apply("org.example.greeting")
def ext = project.extensions.getByType(GreetingExtension)
// Defaults from the plugin:
assertEquals("Hello from plugin", ext.message.get())
// Default output file is build/greeting.txt
def defaultFile = ext.outputFile.get().asFile
assertEquals(project.layout.buildDirectory.file("greeting.txt").get().asFile, defaultFile)
}
}Example of a functional test
The following is an example of a functional test of the Greeting plugin from Binary Plugins:
package org.example
import java.io.File
import kotlin.test.assertTrue
import org.gradle.testkit.runner.GradleRunner
import org.gradle.testkit.runner.TaskOutcome
import org.junit.jupiter.api.Test
import org.junit.jupiter.api.io.TempDir
class GreetingPluginFunctionalTest {
@field:TempDir
lateinit var projectDir: File
private val settingsFile by lazy { projectDir.resolve("settings.gradle.kts") }
private val buildFile by lazy { projectDir.resolve("build.gradle.kts") }
@Test
fun `can run greeting task`() {
// Arrange: write a tiny build that applies the plugin
settingsFile.writeText("") // single-project build
buildFile.writeText(
"""
plugins {
id("org.example.greeting")
}
""".trimIndent()
)
// Act: execute the task in an isolated Gradle build
val result = GradleRunner.create()
.withProjectDir(projectDir)
.withPluginClasspath() // picks up your plugin-under-test from the test classpath
.withArguments("greet")
.forwardOutput()
.build()
// Assert: verify console output and successful task outcome
assertTrue(result.task(":greet")?.outcome == TaskOutcome.SUCCESS)
}
}package org.example
import java.io.File
import static org.junit.jupiter.api.Assertions.assertTrue
import org.gradle.testkit.runner.GradleRunner
import org.gradle.testkit.runner.TaskOutcome
import org.junit.jupiter.api.Test
import org.junit.jupiter.api.io.TempDir
class GreetingPluginFunctionalTest {
@TempDir
File projectDir
private File getSettingsFile() {
return new File(projectDir, "settings.gradle")
}
private File getBuildFile() {
return new File(projectDir, "build.gradle")
}
@Test
void 'can run greeting task'() {
// Arrange: write a tiny build that applies the plugin
settingsFile.write("") // single-project build
buildFile.write("""
plugins {
id 'org.example.greeting'
}
""".stripIndent())
// Act: execute the task in an isolated Gradle build
def result = GradleRunner.create()
.withProjectDir(projectDir)
.withPluginClasspath() // picks up your plugin-under-test from the test classpath
.withArguments("greet")
.forwardOutput()
.build()
// Assert: verify console output and successful task outcome
assertTrue(result.task(":greet")?.outcome == TaskOutcome.SUCCESS)
}
}Preparing to Publish Plugins
To share a Gradle plugin, package it into JAR files and generate the accompanying metadata so other builds can resolve and apply it.
Gradle’s publishing plugins add tasks and conventions to prepare artifacts and metadata for distribution to repositories such as a local Maven repository, Maven Central, JFrog Artifactory, or the Gradle Plugin Portal.
Applying a Publishing Plugin
Apply one or more publishing plugins in your plugin project:
-
For the Gradle Plugin Portal: Plugin Publish Plugin
-
For Maven repositories (e.g., Maven Central, Artifactory, GitHub Packages): Maven Publish Plugin
-
For Ivy repositories: Ivy Publish Plugin
plugins {
id("maven-publish") // Maven
id("ivy-publish") // Ivy
id("com.gradle.plugin-publish") version "<latest-version>" // Plugin Portal
}Applying a publishing plugin registers tasks that assemble your plugin JAR(s) and generate metadata files (POM, Gradle Module Metadata, and the plugin marker module).
Minimum Configuration
A plugin project must at least declare:
-
A plugin ID and implementation class (so Gradle knows what to apply)
-
A group and version (so the plugin can be published and resolved)
group = "org.example"
version = "1.0"
gradlePlugin {
plugins.create("greeting") {
id = "org.example.greeting"
implementationClass = "org.example.GreetingPlugin"
}
}group = 'org.example'
version = '1.0'
gradlePlugin {
plugins.create('greeting') {
id = 'org.example.greeting'
implementationClass = 'org.example.GreetingPlugin'
}
}This lets Gradle generate the plugin marker module (org.example.greeting.gradle.plugin) and other metadata required by repositories and consumers.
Local Publishing and Testing
Before publishing remotely, publish to a local Maven directory:
publishing {
repositories {
maven { url = uri(layout.buildDirectory.dir("local-repo")) }
}
}publishing {
repositories {
maven { url = layout.buildDirectory.dir('local-repo') }
}
}Run:
./gradlew publishGradle writes plugin artifacts and metadata to build/local-repo:
build/local-repo/
└── org/
└── example/
├── greeting/
│ └── 1.0.0/
│ ├── greeting-1.0.0.jar // compiled plugin classes
│ ├── greeting-1.0.0.jar.sha1 // checksum (SHA-1)
│ ├── greeting-1.0.0.jar.sha256 // checksum (SHA-256)
│ ├── greeting-1.0.0.module // Gradle Module Metadata (variants, capabilities, deps)
│ ├── greeting-1.0.0.module.sha1
│ ├── greeting-1.0.0.module.sha256
│ ├── greeting-1.0.0.pom // Maven POM: GAV + dependencies
│ ├── greeting-1.0.0.pom.sha1
│ ├── greeting-1.0.0.pom.sha256
│ └── greeting-1.0.0-sources.jar // optional (java { withSourcesJar() })
│ ├── greeting-1.0.0-sources.jar.sha1
│ └── greeting-1.0.0-sources.jar.sha256
│
└── org.example.greeting.gradle.plugin/
└── 1.0.0/
├── org.example.greeting.gradle.plugin-1.0.0.module // plugin marker metadata
├── org.example.greeting.gradle.plugin-1.0.0.module.sha1
├── org.example.greeting.gradle.plugin-1.0.0.module.sha256
├── org.example.greeting.gradle.plugin-1.0.0.pom // plugin marker POM
├── org.example.greeting.gradle.plugin-1.0.0.pom.sha1
└── org.example.greeting.gradle.plugin-1.0.0.pom.sha256You’ll see:
-
Plugin JAR(s) — compiled classes
-
.pom— Maven metadata (coordinates, dependencies) -
.module— Gradle Module Metadata (variants, capabilities) -
Plugin marker module — enables
plugins { id("…") }resolution by plugin ID -
Optional sources JAR — if enabled via
withSourcesJar() -
Checksums — integrity files (many repos prefer SHA-256/SHA-512)
To consume locally, point the consumer project’s pluginManagement to the local repo:
pluginManagement {
repositories {
maven {
url = uri("../plugin/build/local-repo")
}
gradlePluginPortal()
}
}pluginManagement {
repositories {
maven {
url = uri('../plugin/build/local-repo')
}
gradlePluginPortal()
}
}Consumers can then apply your plugin by ID without publishing to a public repository.
Validating
To validate a Plugin Portal publication (no upload):
$ ./gradlew publishPlugins --validate-onlyPublishing Plugins to the Gradle Plugin Portal
Publishing your plugin is the primary way to make it available to other builds. While you can publish to private repositories to restrict access, publishing to the Gradle Plugin Portal makes your plugin discoverable and usable worldwide.
Account setup
Before publishing, create a Gradle Plugin Portal account and generate an API key:
-
Register at the Portal registration page.
-
Retrieve your API key from the “API Keys” tab in your profile.
|
Tip
|
You can also retrieve your API key using the login task when the plugin-publish plugin is applied.
|
Provide the credentials as Gradle properties (gradle.publish.key and gradle.publish.secret), usually in $HOME/.gradle/gradle.properties, or supply them via environment variables (GRADLE_PUBLISH_KEY and GRADLE_PUBLISH_SECRET), which is convenient for CI/CD.
Adding the Plugin Publish Plugin
Add the com.gradle.plugin-publish plugin to your build:
plugins {
id("com.gradle.plugin-publish") version "2.0.0"
}plugins {
id 'com.gradle.plugin-publish' version '2.0.0'
}The latest version is listed on the Gradle Plugin Portal.
|
Note
|
Since version 1.0.0, the Plugin Publish Plugin automatically applies the Java Gradle Plugin Development Plugin (for building plugins) and the Maven Publish Plugin (for generating metadata). Older versions required applying these plugins manually. |
Configuring the Plugin Publish Plugin
Configure the plugin in build.gradle(.kts):
group = "io.github.johndoe" // (1)
version = "1.0" // (2)
gradlePlugin { // (3)
website = "<substitute your project website>" // (4)
vcsUrl = "<uri to project source repository>" // (5)
// ... // (6)
}group = 'io.github.johndoe' // (1)
version = '1.0' // (2)
gradlePlugin { // (3)
website = '<substitute your project website>' // (4)
vcsUrl = '<uri to project source repository>' // (5)
// ... // (6)
}-
Set
groupto identify your published artifacts. -
Set
versionfor the plugin release. -
Use the
gradlePluginblock to define plugin metadata. -
Add your project website.
-
Add a source repository link.
-
Provide per-plugin details; see the next section.
|
Warning
|
The group and artifact must reasonably represent the organization, person, and the plugin. |
Define plugin-specific properties inside the gradlePlugin {} block:
gradlePlugin { // (1)
// ... // (2)
plugins { // (3)
register("greetingsPlugin") { // (4)
id = "<your plugin identifier>" // (5)
displayName = "<short displayable name for plugin>" // (6)
description = "<human-readable description of what your plugin is about>" // (7)
tags = listOf("tags", "for", "your", "plugins") // (8)
implementationClass = "<your plugin class>"
}
}
}gradlePlugin { // (1)
// ... // (2)
plugins { // (3)
register('greetingsPlugin') { // (4)
id = '<your plugin identifier>' // (5)
displayName = '<short displayable name for plugin>' // (6)
description = '<human-readable description of what your plugin is about>' // (7)
tags.set(['tags', 'for', 'your', 'plugins']) // (8)
implementationClass = '<your plugin class>'
}
}
}-
Plugin specific configuration also goes into the
gradlePluginblock. -
This is where we previously added global properties.
-
Each plugin you publish will have its own block inside
plugins. -
The name of a plugin block must be unique for each plugin you publish; this is a property used only locally by your build and will not be part of the publication.
-
Set the unique
idof the plugin, as it will be identified in the publication. -
Set the plugin name in human-readable form.
-
Set a description to be displayed on the portal. It provides useful information to people who want to use your plugin.
-
Specifies the categories your plugin covers. It makes the plugin more likely to be discovered by people needing its functionality.
For example, take a look at the configuration for the GradleTest plugin:
gradlePlugin {
website = "https://github.com/ysb33r/gradleTest"
vcsUrl = "https://github.com/ysb33r/gradleTest.git"
plugins {
register("gradletestPlugin") {
id = "org.ysb33r.gradletest"
displayName = "Plugin for compatibility testing of Gradle plugins"
description = "A plugin that helps you test your plugin against a variety of Gradle versions"
tags = listOf("testing", "integrationTesting", "compatibility")
implementationClass = "org.ysb33r.gradle.gradletest.GradleTestPlugin"
}
}
}gradlePlugin {
website = 'https://github.com/ysb33r/gradleTest'
vcsUrl = 'https://github.com/ysb33r/gradleTest.git'
plugins {
register('gradletestPlugin') {
id = 'org.ysb33r.gradletest'
displayName = 'Plugin for compatibility testing of Gradle plugins'
description = 'A plugin that helps you test your plugin against a variety of Gradle versions'
tags.addAll('testing', 'integrationTesting', 'compatibility')
implementationClass = 'org.ysb33r.gradle.gradletest.GradleTestPlugin'
}
}
}
Sources and Javadoc
The Plugin Publish Plugin automatically creates and publishes Javadoc and sources JARs.
Signing artifacts
From version 1.0.0, applying the signing plugin automatically signs plugin artifacts.
Shadow dependencies
From version 1.0.0, applying com.gradleup.shadow automatically creates fat JARs for plugins.
Publishing the plugin
To validate a Plugin Portal publication (no upload):
$ ./gradlew publishPlugins --validate-onlyTo publish to the Gradle Plugin Portal:
$ ./gradlew publishPluginsYou can also pass credentials on the command line:
$ ./gradlew publishPlugins -Pgradle.publish.key=<key> -Pgradle.publish.secret=<secret>Your plugin will then go through the approval process. This process can take a few days.
After approval, your plugin appears on the Portal and is available for anyone to use.
Plugins published without Gradle Plugin Portal
If you published a plugin without using the Java Gradle Plugin Development Plugin, the publication will lack the Plugin Marker Artifact required by the plugins DSL.
To use such a plugin, add a resolutionStrategy block inside pluginManagement {} in the consuming project’s settings.gradle(.kts):
resolutionStrategy {
eachPlugin {
if (requested.id.namespace == "org.example") {
useModule("org.example:custom-plugin:${requested.version}")
}
}
}resolutionStrategy {
eachPlugin {
if (requested.id.namespace == 'org.example') {
useModule("org.example:custom-plugin:${requested.version}")
}
}
}Reporting Plugin Problems with the Problems API
Gradle’s Problems API lets plugins report rich, structured information about issues that occur during a failing build.
The following example shows how a plugin can report a problem:
public class ProblemReportingPlugin implements Plugin<Project> {
public static final ProblemGroup PROBLEM_GROUP = ProblemGroup.create("sample-group", "Sample Group");
private final ProblemReporter problemReporter;
interface SomeData extends AdditionalData {
void setName(String name);
String getName();
}
@Inject
public ProblemReportingPlugin(Problems problems) { // (1)
this.problemReporter = problems.getReporter(); // (2)
}
public void apply(Project project) {
ProblemId problemId = ProblemId.create("adhoc-deprecation", "Plugin 'x' is deprecated", PROBLEM_GROUP);
this.problemReporter.report(problemId, builder -> builder // (3)
.details("The plugin 'x' is deprecated since version 2.5")
.solution("Please use plugin 'y'")
.additionalData(SomeData.class, additionalData -> {
additionalData.setName("Some name"); // (4)
})
);
}
}-
Inject the
Problemservice into the plugin. -
Create a
ProblemReporterfor the plugin. -
Report a recoverable problem so the build can continue.
-
Add optional extra data to the problem.
Problems API Usage
The following simple plugin adds a greet task:
-
It prints a
Hello Worldgreeting when used correctly:./gradlew greet -Precipient=World -
It warns if no recipient is set:
./gradlew greet -
It fails if the recipient is
fail:./gradlew greet -Precipient=fail
The details of the failure will be provided in the HTML Problems Report:
package org.example
import org.gradle.api.DefaultTask
import org.gradle.api.GradleException
import org.gradle.api.Plugin
import org.gradle.api.Project
import org.gradle.api.provider.Property
import org.gradle.api.problems.*
import org.gradle.api.tasks.Input
import org.gradle.api.tasks.TaskAction
import javax.inject.Inject
/**
* Simple demo plugin for the Gradle Problems API.
*/
abstract class HelloProblemsPlugin : Plugin<Project> {
override fun apply(project: Project) {
project.tasks.register("greet", GreetTask::class.java) {
group = "demo"
description = "Greets a recipient. Demonstrates Problems API."
}
}
}
/**
* Extra structured data to attach to problem reports.
* Tools like Build Scans or IDEs could show this.
*/
interface GreetProblemData : AdditionalData {
var configuredRecipient: String?
}
/**
* Custom task that uses the Gradle Problems API.
*/
abstract class GreetTask : DefaultTask() {
@get:Input
abstract val recipient: Property<String>
@get:Inject
abstract val problems: Problems
private val GROUP: ProblemGroup =
ProblemGroup.create("org.example.hello-problems", "Hello Problems")
private val WARN_ID: ProblemId =
ProblemId.create("missing-recipient", "Recipient not set", GROUP)
private val FAIL_ID: ProblemId =
ProblemId.create("forbidden-recipient", "Forbidden recipient 'fail'", GROUP)
@TaskAction
fun run() {
val reporter = problems.reporter
val name = recipient.orNull?.trim().orEmpty()
// Warning: missing recipient -> provide a helpful suggestion
if (name.isEmpty()) {
reporter.report(WARN_ID) {
details("No recipient configured")
severity(Severity.WARNING)
solution("""Set the recipient: tasks.greet { recipient = "World" }""")
documentedAt("https://gradle.org/hello-problems#recipient")
additionalData(GreetProblemData::class.java) {
configuredRecipient = null
}
}
}
// Fatal: a specific value is disallowed to show throwing()
else if (name.equals("fail", ignoreCase = true)) {
throw reporter.throwing(GradleException("forbidden value"), FAIL_ID) {
details("Recipient 'fail' is not allowed")
severity(Severity.ERROR)
solution("""Choose another value, e.g. recipient = "World".""")
documentedAt("https://gradle.org/hello-problems#forbidden")
additionalData(GreetProblemData::class.java) {
configuredRecipient = name
}
}
}
logger.lifecycle("Hello, $name!")
}
}package org.example
import org.gradle.api.DefaultTask
import org.gradle.api.GradleException
import org.gradle.api.Plugin
import org.gradle.api.Project
import org.gradle.api.provider.Property
import org.gradle.api.problems.*
import org.gradle.api.tasks.Input
import org.gradle.api.tasks.TaskAction
import javax.inject.Inject
/**
* Simple demo plugin for the Gradle Problems API.
*/
class HelloProblemsPlugin implements Plugin<Project> {
@Override
void apply(Project project) {
project.tasks.register("greet", GreetTask) { task ->
task.group = "demo"
task.description = "Greets a recipient. Demonstrates Problems API."
}
}
}
/**
* Extra structured data to attach to problem reports.
* Tools like Build Scans or IDEs could show this.
*/
interface GreetProblemData extends AdditionalData {
String getConfiguredRecipient()
void setConfiguredRecipient(String value)
}
/**
* Custom task that uses the Gradle Problems API.
*/
abstract class GreetTask extends DefaultTask {
@Input
abstract Property<String> getRecipient()
@Inject
abstract Problems getProblems()
private static final ProblemGroup GROUP =
ProblemGroup.create("org.example.hello-problems", "Hello Problems")
private static final ProblemId WARN_ID =
ProblemId.create("missing-recipient", "Recipient not set", GROUP)
private static final ProblemId FAIL_ID =
ProblemId.create("forbidden-recipient", "Forbidden recipient 'fail'", GROUP)
@TaskAction
void run() {
def reporter = problems.reporter
def name = recipient.orNull?.trim() ?: ""
// Warning: missing recipient -> provide a helpful suggestion
if (name.isEmpty()) {
reporter.report(WARN_ID) { spec ->
spec.details("No recipient configured")
.solution('Set the recipient: tasks.greet { recipient = "World" }')
.documentedAt("https://gradle.org/hello-problems#recipient")
.additionalData(GreetProblemData) {
it.configuredRecipient = null
}
}
}
// Fatal: a specific value is disallowed to show throwing()
else if (name.equalsIgnoreCase("fail")) {
throw reporter.throwing(new GradleException("forbidden value"), FAIL_ID) { spec ->
spec.details("Recipient 'fail' is not allowed")
.solution('Choose another value, e.g. recipient = "World".')
.documentedAt("https://gradle.org/hello-problems#forbidden")
.additionalData(GreetProblemData) {
it.configuredRecipient = name
}
}
}
logger.lifecycle("Hello, $name!")
}
}How it works:
-
Injects the
Problemsservice into the task. -
Creates a
ProblemGroupto group related problems. -
Creates a
ProblemIdfor each distinct issue. -
Reports warnings with the
ProblemReporter.report()when the build can continue. -
Throws structured failures with
ProblemReporter.throwing()when the build must stop. -
Optionally attaches
AdditionalDatatoProblemSpecso advanced tools can show extra info.
Injecting the Problems service
Gradle will automatically provide the Problems service when injected into the custom task type:
@get:Inject
abstract val problems: Problems@Inject
abstract Problems getProblems()Creating a ProblemId and ProblemGroup
Problem IDs and Groups help Gradle deduplicate, summarize, and link to solutions:
private val GROUP: ProblemGroup =
ProblemGroup.create("org.example.hello-problems", "Hello Problems")
private val WARN_ID: ProblemId =
ProblemId.create("missing-recipient", "Recipient not set", GROUP)
private val FAIL_ID: ProblemId =
ProblemId.create("forbidden-recipient", "Forbidden recipient 'fail'", GROUP)private static final ProblemGroup GROUP =
ProblemGroup.create("org.example.hello-problems", "Hello Problems")
private static final ProblemId WARN_ID =
ProblemId.create("missing-recipient", "Recipient not set", GROUP)
private static final ProblemId FAIL_ID =
ProblemId.create("forbidden-recipient", "Forbidden recipient 'fail'", GROUP)Choosing a reporting mode for the ProblemReporter
Plugins can report problems in two ways:
-
report()— use for recoverable problems when the build should continue. -
throwing()— use for non-recoverable problems that should fail the build.
Once you have decided what type of problem you want to report, get the ProblemReporter using problem.getReporter():
val reporter = problems.reporterdef reporter = problems.reporterReporting a recoverable problem
Use problems.getReporter().report {} to signal something went wrong but allow the build to continue:
reporter.report(WARN_ID) {
details("No recipient configured")
severity(Severity.WARNING)
solution("""Set the recipient: tasks.greet { recipient = "World" }""")
documentedAt("https://gradle.org/hello-problems#recipient")
additionalData(GreetProblemData::class.java) {
configuredRecipient = null
}
}reporter.report(WARN_ID) { spec ->
spec.details("No recipient configured")
.solution('Set the recipient: tasks.greet { recipient = "World" }')
.documentedAt("https://gradle.org/hello-problems#recipient")
.additionalData(GreetProblemData) {
it.configuredRecipient = null
}
}Reporting a fatal problem
Use problems.getReporter().throwing {} to fail the build with a structured error:
throw reporter.throwing(GradleException("forbidden value"), FAIL_ID) {
details("Recipient 'fail' is not allowed")
severity(Severity.ERROR)
solution("""Choose another value, e.g. recipient = "World".""")
documentedAt("https://gradle.org/hello-problems#forbidden")
additionalData(GreetProblemData::class.java) {
configuredRecipient = name
}
}throw reporter.throwing(new GradleException("forbidden value"), FAIL_ID) { spec ->
spec.details("Recipient 'fail' is not allowed")
.solution('Choose another value, e.g. recipient = "World".')
.documentedAt("https://gradle.org/hello-problems#forbidden")
.additionalData(GreetProblemData) {
it.configuredRecipient = name
}
}This throws an exception tied to a rich problem report so Gradle clients can display meaningful failure info.
Add data using ProblemSpec
When reporting a problem, you can provide a wide variety of metadata such as descriptions, severity, solutions, and additional data:
details("No recipient configured")
severity(Severity.WARNING)
solution("""Set the recipient: tasks.greet { recipient = "World" }""")
documentedAt("https://gradle.org/hello-problems#recipient")
additionalData(GreetProblemData::class.java) {
configuredRecipient = null
}spec.details("No recipient configured")
.solution('Set the recipient: tasks.greet { recipient = "World" }')
.documentedAt("https://gradle.org/hello-problems#recipient")
.additionalData(GreetProblemData) {
it.configuredRecipient = null
}See ProblemSpec for all available fields.
Problem Summarization
Gradle avoids spamming users with duplicate problem messages:
-
The first few instances of a problem are reported individually as
Problemevents. -
Subsequent duplicates are summarized at the end of the build as a
ProblemSummary, delivered with aProblemSummariesEvent.
Build Failures
The standard way to fail a build is by throwing an exception. The Problems API enhances this by allowing you to throw exceptions tied to detailed problem reports:
ProblemId id = ProblemId.create("sample-error", "FailingTask execution problem", StandardPlugin.PROBLEM_GROUP);
throw getProblems().getReporter().throwing((new RuntimeException("Message from runtime exception")), id, problemSpec -> {
problemSpec.contextualLabel("This happened because ProblemReporter.throwing() was called")
.details("This is a demonstration of how to add\ndetailed information to a build failure")
.documentedAt("https://example.com/docs")
.solution("Remove the Problems.throwing() method call from the task action");
});This ensures build failures are clearly associated with their underlying issues and are visible across all Gradle clients (CLI, Build Scan, IDEs, Tooling API).
Command-line Interface
Gradle CLI output shows detailed information from the reported problem:
FAILURE: Build failed with an exception.
* What went wrong:
Execution failed for task ':myFailingTask'.
> FailingTask execution problem // (1)
This happened because ProblemReporter.throwing() was called // (2)
This is a demonstration of how to add // (3)
detailed information to a build failure
* Try: // (4)
> Remove the Problems.throwing() method call from the task action
> Run with --scan to generate a Build Scan (powered by Develocity).
BUILD FAILED in 0ms // (5)-
The display name of the problem ID.
-
The contextual label (or the supplied exception’s message if the contextual label is missing).
-
The content of the
detailsproperty. -
The solutions or recommended actions.
-
The
AdditionalDatais not shown in CLI output.
Tooling API Clients
Tooling API clients can access reported problems tied to failures:
-
Register a progress listener for
OperationType.ROOT. -
Check if the result is a
FailureResultand retrieve problems withFailure.getProblems().
Alternatively, configure the project connection with LongRunningOperation.withFailureDetails().
Then failure details, including problems, are automatically available via GradleConnectionException.getFailures().
Generated HTML Report
Gradle generates an HTML report at the end of the build if any problems were reported. It’s a central place to review issues and complements the console and Build Scan outputs.
-
The report is skipped if no problems are found.
-
Disable report generation with the
--no-problems-reportflag.
Console output includes a link to the report:
[Incubating] Problem report is available at: <project-dir>/build/reports/problems/problems-report.html
BUILD SUCCESSFUL in 1s
AdditionalData is not included in the HTML report.
Plugins can log their own problem events, which appear alongside Gradle’s built-in reports.
Console rendering
All problem reports are now rendered in the console output if --warning-mode=all is configured.
Initialization Scripts and Init Plugins
Initialization scripts (init scripts) are Gradle scripts that run during the initialization phase, before the build’s settings.gradle(.kts) and project build scripts are evaluated.
Init scripts are useful for setting up common configuration such as enterprise repositories, plugin resolution rules, build listeners, or applying custom plugins across many builds without modifying each repository.
|
Warning
|
Init scripts affect every build they are attached to (local or CI), so treat them like production code. |
Using an init script
Init scripts are Groovy/Kotlin scripts whose receiver is the Gradle object.
They can:
-
Configure enterprise-wide defaults (e.g.,
pluginManagement, mirrors) -
Vary configuration by environment (dev vs. CI)
-
Provide user-specific data (e.g., credentials via providers)
-
Define machine-specific details (e.g., JDK/SDK locations)
-
Register build listeners and custom loggers
One important limitation is that init scripts cannot access classes from buildSrc in the target build.
Invoking an init script
Init scripts are discovered and executed in this order:
-
Command line:
-I/--init-script path/to/init.gradle(.kts)(can be repeated) -
$GRADLE_USER_HOME/init.gradle(.kts) -
Any
\*.init.gradle(.kts)in$GRADLE_USER_HOME/init.d/(alphabetical) -
Any
\*.init.gradle(.kts)in$GRADLE_HOME/init.d/(alphabetical)
All found scripts run; scripts in the same directory run alphabetically.
Writing an init script
|
Note
|
Properties from gradle.properties are available on Settings/Project, not on Gradle.
|
Useful Gradle callbacks include: settingsEvaluated {}, projectsLoaded {}, beforeProject {}, afterProject {}.
You can see more in the Gradle Lifecycle API.
Configuring projects from an init script
You can use an init script to configure the projects in the build. This works similarly to configuring projects in a multi-project build.
The following sample shows how to perform extra configuration from an init script before the projects are evaluated:
repositories {
mavenCentral()
}
tasks.register('showRepos') {
def repositoryNames = repositories.collect { it.name }
doLast {
println "All repos:"
println repositoryNames
}
}allprojects {
repositories {
mavenLocal()
}
}repositories {
mavenCentral()
}
tasks.register("showRepos") {
val repositoryNames = repositories.map { it.name }
doLast {
println("All repos:")
println(repositoryNames)
}
}allprojects {
repositories {
mavenLocal()
}
}This sample uses this feature to configure an additional repository to be used only for specific environments.
$ ./gradlew --init-script init.gradle.kts -q showReposAll repos:
[MavenLocal, MavenRepo]$ ./gradlew --init-script init.gradle -q showReposAll repos:
[MavenLocal, MavenRepo]Adding external dependencies
Use initscript { } to declare the init script’s classpath (repositories + dependencies):
initscript {
repositories {
mavenCentral()
}
dependencies {
classpath("org.apache.commons:commons-math:2.0")
}
}initscript {
repositories {
mavenCentral()
}
dependencies {
classpath 'org.apache.commons:commons-math:2.0'
}
}The closure passed to initscript configures a ScriptHandler instance.
You declare the init script classpath by adding dependencies to the classpath configuration.
This is the same way you declare, for example, the Java compilation classpath. You can use any of the dependency types described in Declaring Dependencies, except project dependencies.
Having declared the init script classpath, you can use the classes in your init script as you would any other classes on the classpath. The following example adds to the previous example and uses classes from the init script classpath:
import org.apache.commons.math.fraction.Fraction
initscript {
repositories {
mavenCentral()
}
dependencies {
classpath("org.apache.commons:commons-math:2.0")
}
}
println(Fraction.ONE_FIFTH.multiply(2))tasks.register("doNothing")import org.apache.commons.math.fraction.Fraction
initscript {
repositories {
mavenCentral()
}
dependencies {
classpath 'org.apache.commons:commons-math:2.0'
}
}
println Fraction.ONE_FIFTH.multiply(2)tasks.register('doNothing')$ ./gradlew --init-script init.gradle.kts -q doNothing2 / 5$ ./gradlew --init-script init.gradle -q doNothing2 / 5Init plugins
An init plugin is a Gradle plugin whose target type is Plugin<Gradle> and is applied in an init script.
Unlike project (Plugin<Project>) or settings (Plugin<Settings>) plugins, an init plugin attaches to the Gradle object during the initialization phase, before the settings and projects are configured:
-
Scope: Runs at init; can access
settingsEvaluated,projectsLoaded,beforeProject,afterProjectcallbacks to safely interact with settings/projects when they exist. -
Distribution: Applied from an init script (
~/.gradle/init.d/*.init.gradle(.kts)or$GRADLE_HOME/init.d) so it affects every build on that machine/agent. However, this does not include all builds: for example, builds run viaTestKituse an isolated Gradle user home, and different users or build agents may each have their own init scripts.
The init plugin in the init script ensures that only a specified repository is used when running the build:
apply<EnterpriseRepositoryPlugin>()
class EnterpriseRepositoryPlugin : Plugin<Gradle> {
companion object {
const val ENTERPRISE_REPOSITORY_URL = "https://repo.gradle.org/gradle/repo"
}
override fun apply(gradle: Gradle) {
// ONLY USE ENTERPRISE REPO FOR DEPENDENCIES
gradle.allprojects {
repositories {
// Remove all repositories not pointing to the enterprise repository url
all {
if (this !is MavenArtifactRepository || url.toString() != ENTERPRISE_REPOSITORY_URL) {
project.logger.lifecycle("Repository ${(this as? MavenArtifactRepository)?.url ?: name} removed. Only $ENTERPRISE_REPOSITORY_URL is allowed")
remove(this)
}
}
// add the enterprise repository
add(maven {
name = "STANDARD_ENTERPRISE_REPO"
url = uri(ENTERPRISE_REPOSITORY_URL)
})
}
}
}
}repositories{
mavenCentral()
}
data class RepositoryData(val name: String, val url: URI)
tasks.register("showRepositories") {
val repositoryData = repositories.withType<MavenArtifactRepository>().map { RepositoryData(it.name, it.url) }
doLast {
repositoryData.forEach {
println("repository: ${it.name} ('${it.url}')")
}
}
}apply plugin: EnterpriseRepositoryPlugin
class EnterpriseRepositoryPlugin implements Plugin<Gradle> {
private static String ENTERPRISE_REPOSITORY_URL = "https://repo.gradle.org/gradle/repo"
void apply(Gradle gradle) {
// ONLY USE ENTERPRISE REPO FOR DEPENDENCIES
gradle.allprojects { project ->
project.repositories {
// Remove all repositories not pointing to the enterprise repository url
all { ArtifactRepository repo ->
if (!(repo instanceof MavenArtifactRepository) ||
repo.url.toString() != ENTERPRISE_REPOSITORY_URL) {
project.logger.lifecycle "Repository ${repo.url} removed. Only $ENTERPRISE_REPOSITORY_URL is allowed"
remove repo
}
}
// add the enterprise repository
maven {
name = "STANDARD_ENTERPRISE_REPO"
url = ENTERPRISE_REPOSITORY_URL
}
}
}
}
}repositories{
mavenCentral()
}
@Immutable
class RepositoryData {
String name
URI url
}
tasks.register('showRepositories') {
def repositoryData = repositories.collect { new RepositoryData(it.name, it.url) }
doLast {
repositoryData.each {
println "repository: ${it.name} ('${it.url}')"
}
}
}$ ./gradlew --init-script init.gradle.kts -q showRepositoriesrepository: STANDARD_ENTERPRISE_REPO ('https://repo.gradle.org/gradle/repo')$ ./gradlew --init-script init.gradle -q showRepositoriesrepository: STANDARD_ENTERPRISE_REPO ('https://repo.gradle.org/gradle/repo')Applying plugins from an init script
You can apply plugins in an init script just like in build.gradle(.kts)/settings.gradle(.kts).
When applying plugins within the init script, Gradle instantiates the plugin and calls the plugin instance’s Plugin.apply(T) method.
The gradle object is passed as a parameter, which can be used to configure all aspects of a build.
Of course, the applied plugin can be resolved as an external dependency as described in External dependencies for the init script.
In this example, the init script is its own project called baseline-init-plugin:
package com.example
import org.gradle.api.Plugin
import org.gradle.api.invocation.Gradle
import org.gradle.api.initialization.Settings
class BaselineInitPlugin : Plugin<Gradle> {
override fun apply(gradle: Gradle) {
println("[INIT-PLUGIN] apply() called")
// Project-time: apply lightweight conventions
gradle.beforeProject { project ->
project.repositories.apply {
if (isEmpty()) {
println("🔧 [INIT-PLUGIN] Adding default repositories to ${project.name}")
mavenCentral()
google()
}
}
}
}
}package com.example
import org.gradle.api.Plugin
import org.gradle.api.invocation.Gradle
class BaselineInitPlugin implements Plugin<Gradle> {
void apply(Gradle gradle) {
println("[INIT-PLUGIN] apply() called")
// Project-time: apply lightweight conventions
gradle.beforeProject { project ->
project.repositories.with { repo ->
if (repo.isEmpty()) {
println("🔧 [INIT-PLUGIN] Adding default repositories to ${project.name}")
mavenCentral()
google()
}
}
}
}
}You can publish it to a local Maven repository by running:
$ ./gradlew :baseline-init-plugin:publishPluginMavenPublicationToMavenRepoInLocalBuildRepositoryHere it is applied in an init script of the app project:
import com.example.BaselineInitPlugin
// This init script loads the baseline init plugin from mavenLocal and applies it to the build.
println("[INIT-SCRIPT] Loaded (Gradle ${gradle.gradleVersion})")
initscript {
repositories {
maven { url = uri("./baseline-init-plugin/build/repo") }
mavenCentral()
gradlePluginPortal()
}
// Either coordinates work; the ID form below relies on the classpath JAR containing the descriptor
dependencies {
classpath("com.example:baseline-init-plugin:0.1.0")
}
}
// Apply the plugin
apply<BaselineInitPlugin>()// This init script loads the baseline init plugin from mavenLocal and applies it to the build.
println "[INIT-SCRIPT] Loaded (Gradle ${gradle.gradleVersion})"
def pluginClass = Class.forName('com.example.BaselineInitPlugin')
initscript {
repositories {
maven { url = uri('./baseline-init-plugin/build/repo') }
mavenCentral()
gradlePluginPortal()
}
// Either coordinates work; this relies on the classpath JAR containing the plugin descriptor
dependencies {
classpath 'com.example:baseline-init-plugin:0.1.0'
}
}
// Apply the plugin
apply plugin: pluginClassThen you can run the app with:
$ ./gradlew :app:build -I init.gradle(.kts)Testing Build Logic with TestKit
The Gradle TestKit helps you functionally test Gradle plugins and build logic by executing real builds in an isolated temp project and asserting on their results. You’ll typically pair TestKit with a test framework (JUnit or Spock) and a few small fixtures to generate test projects on the fly. Over time, TestKit has focused on functional/black-box testing, and that remains its sweet spot.
Using TestKit
Add TestKit to your test dependencies:
dependencies {
testImplementation(gradleTestKit())
}dependencies {
testImplementation gradleTestKit()
}The gradleTestKit() encompasses the classes of the TestKit, as well as the Gradle Tooling API client.
It does not include a version of JUnit, TestNG, or any other test execution framework.
Such a dependency must be explicitly declared.
For JUnit 5:
dependencies {
testImplementation("org.junit.jupiter:junit-jupiter:5.7.1")
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
}
tasks.named<Test>("test") {
useJUnitPlatform()
}dependencies {
testImplementation("org.junit.jupiter:junit-jupiter:5.7.1")
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
}
tasks.named('test', Test) {
useJUnitPlatform()
}Functional testing with the Gradle runner
A modern way to organize plugin tests is to add a dedicated functional test suite using the JVM Test Suite plugin (added transitively by java-gradle-plugin).
This cleanly separates unit and functional tests and wires TestKit for you.
The GradleRunner allows you to programmatically execute Gradle builds and inspect their results.
A test can create a minimal or contrived build (either programmatically or from a template) that exercises the logic under test. The functional test then runs that build, potentially using different tasks, arguments, or Gradle versions, and verifies correctness by asserting any combination of the following:
-
The build output
-
The build’s logging
-
The tasks that executed and their outcomes (e.g., FAILED, UP-TO-DATE, FROM-CACHE)
After creating and configuring a runner instance, execute the build using GradleRunner.build() or GradleRunner.buildAndFail(), depending on whether the build is expected to succeed or fail.
The following demonstrates the usage of the Gradle runner in a Java JUnit test:
import org.gradle.testkit.runner.BuildResult;
import org.gradle.testkit.runner.GradleRunner;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.io.TempDir;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import static org.gradle.testkit.runner.TaskOutcome.SUCCESS;
import static org.junit.jupiter.api.Assertions.assertEquals;
import static org.junit.jupiter.api.Assertions.assertTrue;
public class BuildLogicFunctionalTest {
@TempDir File testProjectDir;
private File settingsFile;
private File buildFile;
@BeforeEach
public void setup() {
settingsFile = new File(testProjectDir, "settings.gradle");
buildFile = new File(testProjectDir, "build.gradle");
}
@Test
public void testHelloWorldTask() throws IOException {
writeFile(settingsFile, "rootProject.name = 'hello-world'");
String buildFileContent = "task helloWorld {" +
" doLast {" +
" println 'Hello world!'" +
" }" +
"}";
writeFile(buildFile, buildFileContent);
BuildResult result = GradleRunner.create()
.withProjectDir(testProjectDir)
.withArguments("helloWorld")
.build();
assertTrue(result.getOutput().contains("Hello world!"));
assertEquals(SUCCESS, result.task(":helloWorld").getOutcome());
}
private void writeFile(File destination, String content) throws IOException {
BufferedWriter output = null;
try {
output = new BufferedWriter(new FileWriter(destination));
output.write(content);
} finally {
if (output != null) {
output.close();
}
}
}
}Any test framework can be used.
Because Gradle build scripts are often written in Groovy, many users find it productive to write functional tests in Groovy as well. The Spock framework provides expressive assertions, data-driven tests, and powerful fixtures that work well with TestKit. Similarly, Kotlin users often choose either JUnit Jupiter or Kotest for a more idiomatic Kotlin testing experience.
The following demonstrates the usage of the Gradle runner in a Groovy Spock test:
import org.gradle.testkit.runner.GradleRunner
import static org.gradle.testkit.runner.TaskOutcome.*
import spock.lang.TempDir
import spock.lang.Specification
class BuildLogicFunctionalTest extends Specification {
@TempDir File testProjectDir
File settingsFile
File buildFile
def setup() {
settingsFile = new File(testProjectDir, 'settings.gradle')
buildFile = new File(testProjectDir, 'build.gradle')
}
def "hello world task prints hello world"() {
given:
settingsFile << "rootProject.name = 'hello-world'"
buildFile << """
task helloWorld {
doLast {
println 'Hello world!'
}
}
"""
when:
def result = GradleRunner.create()
.withProjectDir(testProjectDir)
.withArguments('helloWorld')
.build()
then:
result.output.contains('Hello world!')
result.task(":helloWorld").outcome == SUCCESS
}
}When implementing more complex build logic (such as custom plugins or task types), you can package that logic into external classes and test them in isolation using "normal" unit tests. Functional tests using TestKit then validate that the plugin behaves correctly when applied to a real Gradle build.
Getting the plugin-under-test into the test build
The GradleRunner uses the Tooling API to execute builds.
This means that builds run in a separate process from your tests.
As a result:
-
The test build does not share the same classpath or classloaders as the test process.
-
The code under test (for example, your plugin implementation) is not automatically visible to the build executed by
GradleRunner.
|
Note
|
Builds with older Gradle versions may still work, but there are no guarantees. |
To make your plugin (or other build logic under test) available to the test build, Gradle provides a conventional mechanism to inject the plugin-under-test onto the classpath used by GradleRunner.
Automatic injection with the Java Gradle Plugin Development plugin
The Java Gradle Plugin Development plugin provides built-in integration with TestKit. When applied to a project, it automatically:
-
adds the
gradleTestKit()dependency to the appropriate test configuration, and -
generates the plugin-under-test classpath and injects it into any
GradleRunnerinstance created by your tests viaGradleRunner.withPluginClasspath().
This allows functional tests to execute a “real” Gradle build that can apply and exercise your plugin without requiring any manual classpath wiring.
|
Note
|
Automatic classpath injection only works when the plugin-under-test is applied in the test build using the plugins {} DSL.
|
By default, the Java Gradle Plugin Development plugin uses the following conventions:
-
Code under test is taken from:
sourceSets.main -
The generated plugin classpath metadata is produced from:
sourceSets.test
These conventions can be customized using the GradlePluginDevelopmentExtension.
The following sample shows the default setup for automatic plugin classpath injection:
plugins {
groovy
`java-gradle-plugin`
}
dependencies {
testImplementation("org.spockframework:spock-core:2.4-groovy-4.0") {
exclude(group = "org.apache.groovy")
}
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
}plugins {
id 'groovy'
id 'java-gradle-plugin'
}
dependencies {
testImplementation('org.spockframework:spock-core:2.4-groovy-4.0') {
exclude group: 'org.apache.groovy'
}
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}The following example automatically injects the code under test classes into test builds:
def "hello world task prints hello world"() {
given:
settingsFile << "rootProject.name = 'hello-world'"
buildFile << """
plugins {
id 'org.gradle.sample.helloworld'
}
"""
when:
def result = GradleRunner.create()
.withProjectDir(testProjectDir)
.withArguments('helloWorld')
.withPluginClasspath()
.build()
then:
result.output.contains('Hello world!')
result.task(":helloWorld").outcome == SUCCESS
}If your project uses a custom test source set (for example, a dedicated functional test suite), you can reconfigure the plugin development extension to generate the plugin classpath metadata from that source set instead.
|
Note
|
A dedicated DSL for modeling such test suites is provided by the incubating JVM Test Suite plugin. |
plugins {
groovy
`java-gradle-plugin`
}
val functionalTest = sourceSets.create("functionalTest")
val functionalTestTask = tasks.register<Test>("functionalTest") {
group = "verification"
testClassesDirs = functionalTest.output.classesDirs
classpath = functionalTest.runtimeClasspath
useJUnitPlatform()
}
tasks.check {
dependsOn(functionalTestTask)
}
gradlePlugin {
testSourceSets(functionalTest)
}
dependencies {
"functionalTestImplementation"("org.spockframework:spock-core:2.4-groovy-4.0") {
exclude(group = "org.apache.groovy")
}
"functionalTestRuntimeOnly"("org.junit.platform:junit-platform-launcher")
}plugins {
id 'groovy'
id 'java-gradle-plugin'
}
def functionalTest = sourceSets.create('functionalTest')
def functionalTestTask = tasks.register('functionalTest', Test) {
group = 'verification'
testClassesDirs = sourceSets.functionalTest.output.classesDirs
classpath = sourceSets.functionalTest.runtimeClasspath
useJUnitPlatform()
}
tasks.named("check") {
dependsOn functionalTestTask
}
gradlePlugin {
testSourceSets sourceSets.functionalTest
}
dependencies {
functionalTestImplementation('org.spockframework:spock-core:2.4-groovy-4.0') {
exclude group: 'org.apache.groovy'
}
functionalTestRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}Controlling the build environment
GradleRunner executes test builds in an isolated environment.
Each build runs in its own dedicated working directory inside the JVM’s temporary directory (the location defined by the java.io.tmpdir system property, typically /tmp).
Because the test build runs in this isolated directory:
-
Configuration from the default Gradle User Home (for example,
~/.gradle/gradle.properties) is not used. -
The test build does not inherit settings, caches, or environment customizations from the machine running the tests.
The TestKit does not currently expose fine-grained control over all environmental aspects—for example, selecting a JDK for the executed build. Future versions of TestKit may offer more explicit configuration options.
TestKit uses dedicated Gradle daemon processes for the builds it runs. These daemons are distinct from any daemons used by "normal" Gradle invocations and are automatically shut down after the tests complete.
By default, the working directories created for each test build are not deleted.
To keep the filesystem clean or to store TestKit state in a location managed by your build (such as a project’s build/ directory), you can specify a custom TestKit directory using one of the following:
-
The
org.gradle.testkit.dirsystem property
Setting the Gradle version used to test
The Gradle runner requires a Gradle distribution in order to execute the build. The TestKit does not depend on all of Gradle’s implementation.
By default, the runner will attempt to find a Gradle distribution based on where the GradleRunner class was loaded from.
That is, it is expected that the class was loaded from a Gradle distribution, as is the case when using the gradleTestKit() dependency declaration.
When using the runner as part of tests being executed by Gradle (e.g. executing the test task of a plugin project), the same distribution used to execute the tests will be used by the runner.
When using the runner as part of tests being executed by an IDE, the same Gradle distribution that was used when importing the project will be used.
This means that the plugin will be effectively tested with the same version of Gradle that it is being built with.
Alternatively, a different and specific version of Gradle to use can be specified by the following GradleRunner methods:
This can potentially be used to test build logic across Gradle versions. The following demonstrates a cross-version compatibility test written as a Groovy Spock test:
import org.gradle.testkit.runner.GradleRunner
import static org.gradle.testkit.runner.TaskOutcome.*
import spock.lang.TempDir
import spock.lang.Specification
class BuildLogicFunctionalTest extends Specification {
@TempDir File testProjectDir
File settingsFile
File buildFile
def setup() {
settingsFile = new File(testProjectDir, 'settings.gradle')
buildFile = new File(testProjectDir, 'build.gradle')
}
def "can execute hello world task with Gradle version #gradleVersion"() {
given:
buildFile << """
task helloWorld {
doLast {
logger.quiet 'Hello world!'
}
}
"""
settingsFile << ""
when:
def result = GradleRunner.create()
.withGradleVersion(gradleVersion)
.withProjectDir(testProjectDir)
.withArguments('helloWorld')
.build()
then:
result.output.contains('Hello world!')
result.task(":helloWorld").outcome == SUCCESS
where:
gradleVersion << ['5.0', '6.0.1']
}
}Debugging build logic
The runner uses the Tooling API to execute builds. An implication of this is that the builds are executed in a separate process (i.e., not the same process executing the tests). Therefore, executing your tests in debug mode does not allow you to debug your build logic as you may expect. Any breakpoints set in your IDE will be not be tripped by the code being exercised by the test build.
The TestKit provides two different ways to enable the debug mode:
-
Setting “org.gradle.testkit.debug” system property to
truefor the JVM using theGradleRunner(i.e., not the build being executed with the runner); -
Calling the
GradleRunner.withDebug(boolean)method.
The system property approach can be used when it is desirable to enable debugging support without making an ad hoc change to the runner configuration. Most IDEs offer the capability to set JVM system properties for test execution, and this feature can be used to set the desired system property.
Testing with the Build Cache
To enable the Build Cache in your tests, you can pass the --build-cache argument to GradleRunner or use one of the other methods described in Enable the Build Cache.
You can then check for the task outcome TaskOutcome.FROM_CACHE when your plugin’s custom task is cached.
def "cacheableTask is loaded from cache"() {
given:
buildFile << """
plugins {
id 'org.gradle.sample.helloworld'
}
"""
when:
def result = runner()
.withArguments( '--build-cache', 'cacheableTask')
.build()
then:
result.task(":cacheableTask").outcome == SUCCESS
when:
new File(testProjectDir, 'build').deleteDir()
result = runner()
.withArguments( '--build-cache', 'cacheableTask')
.build()
then:
result.task(":cacheableTask").outcome == FROM_CACHE
}Note that TestKit re-uses a Gradle User Home between tests (see GradleRunner.withTestKitDir(java.io.File)), which contains the default location for the local Build Cache.
For testing with the build cache, the Build Cache directory should be cleaned between tests.
The easiest way to accomplish this is to configure the local Build Cache to use a temporary directory:
@TempDir File testProjectDir
File buildFile
File localBuildCacheDirectory
def setup() {
localBuildCacheDirectory = new File(testProjectDir, 'local-cache')
buildFile = new File(testProjectDir,'settings.gradle') << """
buildCache {
local {
directory = '${localBuildCacheDirectory.toURI()}'
}
}
"""
buildFile = new File(testProjectDir,'build.gradle')
}DEPENDENCY MANAGEMENT
Dependency Management
Software projects typically depend on other libraries to function. These libraries can either be sourced from other projects in the same build or from external repositories.
Gradle’s dependency management infrastructure provides APIs to declare, resolve, and expose binaries required by and provided by a project.
Understanding dependency management in Gradle is important for structuring projects into components. It is also important when you want to reuse existing libraries, or you need to upgrade those libraries while managing their versions.
Let’s look at a Java project where the code relies on Guava which is a suite of Google Core libraries for Java. The build file of the project includes the following:
dependencies {
implementation("com.google.guava:guava:32.1.2-jre") // (2)
api("org.apache.juneau:juneau-marshall:8.2.0") // (3)
}dependencies {
implementation("com.google.guava:guava:32.1.2-jre") // (2)
api("org.apache.juneau:juneau-marshall:8.2.0") // (3)
}Within the dependencies block, there are three things to notice when a dependency is declared:
-
The bucket:
-
The configuration:
implementationis the scope the dependency is applied to
-
-
The dependency:
-
The module ID:
com.google.guava:guavais made up of agroupand an artifactnamewhich are uniquely identifiable -
The version:
32.1.2-jrewhich is not always required
-
Dependencies can be local or external.
To let Gradle know where to find external dependencies, use the repositories{} block in the Build File.
Let’s expand our example:
repositories {
google()
mavenCentral()
}
dependencies {
implementation("com.google.guava:guava:32.1.2-jre") // (2)
api("org.apache.juneau:juneau-marshall:8.2.0") // (3)
}repositories {
google()
mavenCentral()
}
dependencies {
implementation("com.google.guava:guava:32.1.2-jre") // (2)
api("org.apache.juneau:juneau-marshall:8.2.0") // (3)
}In this example, Gradle fetches the guava and juneau-marshall dependencies from the Maven Central and Google repositories.
Learning the Basics
If you want to understand the basics of dependency management and you are new to Gradle, start here.
1. Declaring Dependencies
You can add external libraries to your Java project, such as Guava.
These libraries are dependencies of your project.
They are added using the dependencies{} block in your build file.
2. Dependency Configurations
Every dependency declared for a Gradle project applies to a specific scope, known as a configurations. These configurations are typically created by applying plugins or must be created directly using APIs.
3. Declaring Repositories
You can declare repositories to tell Gradle where to fetch external dependencies. During a build, Gradle locates and downloads the dependencies, a process called dependency resolution.
4. Centralizing Dependencies
To keep dependencies and their versions declared in a single, manageable location (i.e., centralized), you can use platforms and version catalogs.
A platform is a set of modules intended to be used together. A version catalog is a centralized list of dependency coordinates that can be referenced in multiple projects.
5. Managing Constraints and Conflicts
Conflicts can arise when the same library is declared multiple times or when different libraries provide the same functionality. This usually leads to failing builds.
You can manage conflicts using resolution rules or dependency locking.
Advanced Concepts
In order to influence how Gradle resolves dependencies, it’s important to understand how it works.
1. Dependency Resolution
Gradle’s dependency resolution process determines which modules and versions are required to fulfill a build’s declared dependencies. It is done in two steps, graph resolution and artifact resolution.
2. Graph Resolution
During graph resolution, Gradle constructs a dependency graph, resolving version conflicts and ensuring the intended dependencies are selected.
3. Variant Selection
Variant selection traverses the resolved dependency graph by choosing the most compatible variant of each module based on attributes and capabilities.
4. Artifact Resolution
Finally, Artifact resolution is how Gradle determines which files or artifacts published by the selected variants to download and use during the build.
1. Declaring dependencies
Declaring dependencies in Gradle involves specifying libraries or files that your project depends on.
Understanding producers and consumers
In dependency management, it is essential to understand the distinction between producers and consumers.
When you build a library, you are acting as a producer, creating artifacts that will be consumed by others, the consumers.
When you depend on that library, you are acting as a consumer. Consumers can be broadly defined as:
-
Projects that depend on other projects.
-
Configurations that declare dependencies on specific artifacts.
The decisions we make in dependency management often depend on the type of project we are building, specifically, what kind of consumer we are.
Adding a dependency
To add a dependency in Gradle, you use the dependencies{} block in your build script.
The dependencies block allows you to specify various types of dependencies such as external libraries, local JAR files, or other projects within a multi-project build.
External dependencies in Gradle are declared using a configuration name (e.g., implementation, compileOnly, testImplementation) followed by the dependency notation, which includes the group ID (group), artifact ID (name), and version.
dependencies {
// Configuration Name + Dependency Notation - GroupID : ArtifactID (Name) : Version
configuration('<group>:<name>:<version>')
}Note:
-
Gradle automatically includes transitive dependencies, which are dependencies of your dependencies.
-
Gradle offers several configuration options for dependencies, which define the scope in which dependencies are used, such as compile-time, runtime, or test-specific scenarios.
-
You can specify the repositories where Gradle should look for dependencies in your build file.
Understanding types of dependencies
There are three kinds of dependencies: module dependencies, project dependencies, and file dependencies.
1. Module dependencies
Module dependencies are the most common dependencies. They refer to a module in a repository:
dependencies {
implementation("org.codehaus.groovy:groovy:3.0.5")
implementation("org.codehaus.groovy:groovy-json:3.0.5")
implementation("org.codehaus.groovy:groovy-nio:3.0.5")
}dependencies {
implementation 'org.codehaus.groovy:groovy:3.0.5'
implementation 'org.codehaus.groovy:groovy-json:3.0.5'
implementation 'org.codehaus.groovy:groovy-nio:3.0.5'
}2. Project dependencies
Project dependencies allow you to declare dependencies on other projects within the same build. This is useful in multi-project builds where multiple projects are part of the same Gradle build.
Project dependencies are declared by referencing the project path:
dependencies {
implementation(project(":utils"))
implementation(project(":api"))
}dependencies {
implementation project(':utils')
implementation project(':api')
}3. File dependencies
In some projects, you might not rely on binary repository products like JFrog Artifactory or Sonatype Nexus for hosting and resolving external dependencies. Instead, you might host these dependencies on a shared drive or to check them into version control alongside the project source code.
These are known as file dependencies because they represent files without any metadata (such as information about transitive dependencies, origin, or author) attached to them.
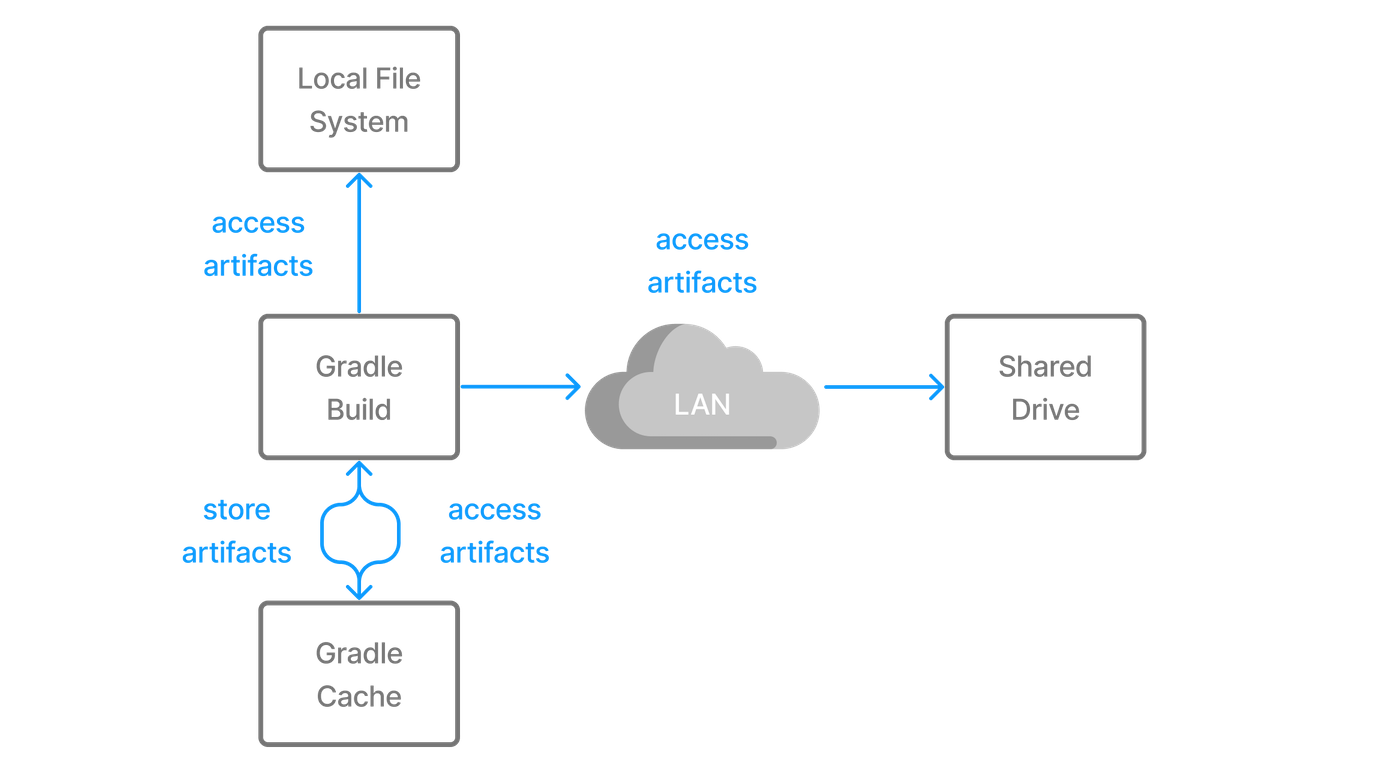
To add files as dependencies for a configuration, you simply pass a file collection as a dependency:
dependencies {
runtimeOnly(files("libs/a.jar", "libs/b.jar"))
runtimeOnly(fileTree("libs") { include("*.jar") })
}dependencies {
runtimeOnly files('libs/a.jar', 'libs/b.jar')
runtimeOnly fileTree('libs') { include '*.jar' }
}|
Warning
|
It is recommended to use project dependencies or external dependencies over file dependencies. |
Looking at an example
Let’s imagine an example for a Java application which uses Guava, a set of core Java libraries from Google:

The Java app contains the following Java class:
package org.example;
import com.google.common.collect.ImmutableMap; // Comes from the Guava library
public class InitializeCollection {
public static void main(String[] args) {
ImmutableMap<String, Integer> immutableMap
= ImmutableMap.of("coin", 3, "glass", 4, "pencil", 1);
}
}To add the Guava library to your Gradle project as a dependency, you must add the following line to your build file:
dependencies {
implementation("com.google.guava:guava:23.0")
}dependencies {
implementation 'com.google.guava:guava:23.0'
}Where:
-
implementationis the configuration. -
com.google.guava:guava:23.0specifies the group, name, and version of the library:-
com.google.guavais the group ID. -
guavais the artifact ID (i.e., name). -
23.0is the version.
-
Take a quick look at the Guava page in Maven Central as a reference.
Listing project dependencies
The dependencies task provides an overview of the dependencies of your project.
It helps you understand what dependencies are being used, how they are resolved, and their relationships, including any transitive dependencies by rendering a dependency tree from the command line.
This task can be particularly useful for debugging dependency issues, such as version conflicts or missing dependencies.
For example, let’s say our app project contains the follow lines in its build script:
dependencies {
implementation("com.google.guava:guava:30.0-jre")
runtimeOnly("org.apache.commons:commons-lang3:3.14.0")
}dependencies {
implementation("com.google.guava:guava:30.0-jre")
runtimeOnly("org.apache.commons:commons-lang3:3.14.0")
}Running the dependencies task on the app project yields the following:
$ ./gradlew app:dependencies> Task :app:dependencies
------------------------------------------------------------
Project ':app'
------------------------------------------------------------
implementation - Implementation dependencies for the 'main' feature. (n)
\--- com.google.guava:guava:30.0-jre (n)
runtimeClasspath - Runtime classpath of source set 'main'.
+--- com.google.guava:guava:30.0-jre
| +--- com.google.guava:failureaccess:1.0.1
| +--- com.google.guava:listenablefuture:9999.0-empty-to-avoid-conflict-with-guava
| +--- com.google.code.findbugs:jsr305:3.0.2
| +--- org.checkerframework:checker-qual:3.5.0
| +--- com.google.errorprone:error_prone_annotations:2.3.4
| \--- com.google.j2objc:j2objc-annotations:1.3
\--- org.apache.commons:commons-lang3:3.14.0
runtimeOnly - Runtime-only dependencies for the 'main' feature. (n)
\--- org.apache.commons:commons-lang3:3.14.0 (n)We can clearly see that for the implementation configuration, the com.google.guava:guava:30.0-jre dependency has been added.
As for the runtimeOnly configuration, the org.org.apache.commons:commons-lang3:3.14.0 dependency has been added.
We also see a list of transitive dependencies for com.google.guava:guava:30.0-jre (which are the dependencies for the guava library), such as com.google.guava:failureaccess:1.0.1 in the runtimeClasspath configuration.
Next Step: Learn about Dependency Configurations >>
2. Dependency Configurations
Every dependency declared for a Gradle project applies to a specific scope.
For example, some dependencies should be used for compiling source code whereas others only need to be available at runtime:
dependencies {
implementation("com.google.guava:guava:30.0-jre") // Needed to compile and run the app
runtimeOnly("org.slf4j:slf4j-simple:2.0.13") // Only needed at runtime
}dependencies {
implementation("com.google.guava:guava:30.0-jre") // Needed to compile and run the app
runtimeOnly("org.slf4j:slf4j-simple:2.0.13") // Only needed at runtime
}Dependency configurations are a way to define different sets of dependencies for different purposes within a project. They determine how and when dependencies are used in various stages of the build process.
Configurations are a fundamental part of dependency resolution in Gradle.
Understanding dependency configurations
Gradle represents the scope of a dependency with the help of a Configuration. Every configuration can be identified by a unique name.
Many Gradle plugins add pre-defined configurations to your project.
The Java Library plugin is used to define a project that produces a Java library. The plugin adds many dependency configurations. These configurations represent the various classpaths needed for source code compilation, executing tests, and more. The configurations below are used to declare dependencies for different purposes:
| Configuration Name | Description |
|---|---|
|
Dependencies required for both compilation and runtime, and included in the published API. |
|
Dependencies required for both compilation and runtime. |
|
Dependencies needed only for compilation, not included in runtime or publication. |
|
Dependencies needed only for compilation, but included in the published API. |
|
Dependencies needed only at runtime, not included in the compile classpath. |
|
Dependencies required for compiling and running tests. |
|
Dependencies needed only for test compilation. |
|
Dependencies needed only for running tests. |
Dependency declaration Configurations
The dependency declaration configurations (compileOnly, implementation, runtimeOnly) focus on declaring and managing dependencies based on their usage (compile time, runtime, API exposure):
dependencies {
implementation("com.google.guava:guava:30.1.1-jre") // Implementation dependency
compileOnly("org.projectlombok:lombok:1.18.20") // Compile-only dependency
runtimeOnly("mysql:mysql-connector-java:8.0.23") // Runtime-only dependency
}dependencies {
implementation("com.google.guava:guava:30.1.1-jre") // Implementation dependency
compileOnly("org.projectlombok:lombok:1.18.20") // Compile-only dependency
runtimeOnly("mysql:mysql-connector-java:8.0.23") // Runtime-only dependency
}Other Configurations
There are other types of configurations (such as runtimeClasspath, compileClasspath, apiElements, runtimeElements), but they are not used to declare dependencies.
They are used internally by Gradle to assemble the classpaths for application or to configure dependencies between projects.
It is also possible to create custom configurations.
A custom configuration allows you to define a distinct group of dependencies that can be used for specific purposes, such as toolchains or code generation, separate from the standard configurations (e.g., implementation, testImplementation):
val customConfig = configurations.create("customConfig")
dependencies {
customConfig("org.example:example-lib:1.0")
}configurations {
customConfig
}
dependencies {
customConfig("org.example:example-lib:1.0")
}Creating a custom configuration helps manage and isolate dependencies, ensuring they are only included in the relevant classpaths and build processes.
Viewing configurations
The dependencies task provides an overview of the dependencies of your project.
To focus on the information about one dependency configuration, provide the optional parameter --configuration.
The following example show dependencies in the implementation dependency configuration of a Java project:
$ ./gradlew -q app:dependencies --configuration implementation------------------------------------------------------------
Project ':app'
------------------------------------------------------------
implementation - Implementation only dependencies for source set 'main'.
\--- com.google.guava:guava:30.0-jreNext Step: Learn about Declaring Repositories >>
3. Declaring repositories
Gradle needs to know where it can download the dependencies used in the project.
For example, the com.google.guava:guava:30.0-jre dependency can be downloaded from the public Maven Central repository mavenCentral().
Gradle will find and download the guava source code (as a jar) from Maven Central and use it build the project.
You can add any number of repositories for your dependencies by configuring the repositories block in your build.gradle(.kts) file:
repositories {
mavenCentral() // (1)
maven { // (2)
url = uri("https://company/com/maven2")
}
mavenLocal() // (3)
flatDir { // (4)
dirs("libs")
}
}-
Public repository
-
Private/Custom repository
-
Local repository
-
File location
repositories {
mavenCentral() // (1)
maven { // (2)
url = uri("https://company/com/maven2")
}
mavenLocal() // (3)
flatDir { // (4)
dirs "libs"
}
}-
Public repository
-
Private/Custom repository
-
Local repository
-
File location
Gradle can resolve dependencies from one or many repositories based on Maven, Ivy or flat directory formats.
If a library is available from more than one of the listed repositories, Gradle will simply pick the first one.
Declaring a public repository
Organizations building software may want to leverage public binary repositories to download and consume open source dependencies. Popular public repositories include Maven Central and the Google Android repository.
Gradle provides built-in shorthand notations for these widely-used repositories:
repositories {
mavenCentral()
google()
gradlePluginPortal()
}repositories {
mavenCentral()
google()
gradlePluginPortal()
}Under the covers Gradle resolves dependencies from the respective URL of the public repository defined by the shorthand notation. All shorthand notations are available via the RepositoryHandler API.
Declaring a private or custom repository
Most enterprise projects establish a binary repository accessible only within their intranet. In-house repositories allow teams to publish internal binaries, manage users and security, and ensure uptime and availability.
Specifying a custom URL is useful for declaring less popular but publicly-available repositories. Repositories with custom URLs can be specified as Maven or Ivy repositories by calling the corresponding methods available on the RepositoryHandler API:
repositories {
maven {
url = uri("https://maven-central.storage.apis.com")
}
ivy {
url = uri("https://github.com/ivy-rep/")
}
}repositories {
maven {
url = uri("https://maven-central.storage.apis.com")
}
ivy {
url = uri("https://github.com/ivy-rep/")
}
}Declaring a local repository
Gradle can consume dependencies available in a local Maven repository.
To declare the local Maven cache as a repository, add this to your build script:
repositories {
mavenLocal()
}repositories {
mavenLocal()
}Understanding supported repository types
Gradle supports a wide range of sources for dependencies, both in terms of format and in terms of connectivity. You may resolve dependencies from:
-
Different formats
-
a Maven compatible artifact repository (e.g: Maven Central)
-
an Ivy compatible artifact repository (including custom layouts)
-
-
with different connectivity
-
a wide variety of remote protocols such as HTTPS, SFTP, AWS S3 and Google Cloud Storage based on the presence of artifacts.
Here is a quick snapshot:
repositories {
// Ivy Repository with Custom Layout
ivy {
url = uri("https://your.ivy.repo/url")
patternLayout {
ivy("[organisation]/[module]/[revision]/[type]s/[artifact]-[revision].[ext]")
artifact("[organisation]/[module]/[revision]/[type]s/[artifact]-[revision].[ext]")
}
}
// Authenticated HTTPS Maven Repository
maven {
url = uri("https://your.secure.repo/url")
credentials {
username = "your-username"
password = "your-password"
}
}
// SFTP Repository
maven {
url = uri("sftp://your.sftp.repo/url")
credentials {
username = "your-username"
password = "your-password"
}
}
// AWS S3 Repository
maven {
url = uri("s3://your-bucket/repository-path")
credentials(AwsCredentials::class) {
accessKey = "your-access-key"
secretKey = "your-secret-key"
}
}
// Google Cloud Storage Repository
maven {
url = uri("gcs://your-bucket/repository-path")
}
}repositories {
// Ivy Repository with Custom Layout
ivy {
url = 'https://your.ivy.repo/url'
layout 'pattern', {
ivy '[organisation]/[module]/[revision]/[type]s/[artifact]-[revision].[ext]'
artifact '[organisation]/[module]/[revision]/[type]s/[artifact]-[revision].[ext]'
}
}
// Authenticated HTTPS Maven Repository
maven {
url = 'https://your.secure.repo/url'
credentials {
username = 'your-username'
password = 'your-password'
}
}
// SFTP Repository
maven {
url = 'sftp://your.sftp.repo/url'
credentials {
username = 'your-username'
password = 'your-password'
}
}
// AWS S3 Repository
maven {
url = "s3://your-bucket/repository-path"
credentials(AwsCredentials) {
accessKey = 'your-access-key'
secretKey = 'your-secret-key'
}
}
// Google Cloud Storage Repository
maven {
url = "gcs://your-bucket/repository-path"
}
}Next Step: Learn about Centralizing Dependencies >>
4. Centralizing dependencies
Central dependencies can be managed in Gradle using various techniques such as platforms and version catalogs. Each approach offers its own advantages and helps in centralizing and managing dependencies efficiently.
Using platforms
A platform is a set of dependency constraints designed to manage the transitive dependencies of a library or application.
When you define a platform in Gradle, you’re essentially specifying a set of dependencies that are meant to be used together, ensuring compatibility and simplifying dependency management:
plugins {
id("java-platform")
}
dependencies {
constraints {
api("org.apache.commons:commons-lang3:3.12.0")
api("com.google.guava:guava:30.1.1-jre")
api("org.slf4j:slf4j-api:1.7.30")
}
}plugins {
id("java-platform")
}
dependencies {
constraints {
api("org.apache.commons:commons-lang3:3.12.0")
api("com.google.guava:guava:30.1.1-jre")
api("org.slf4j:slf4j-api:1.7.30")
}
}Then, you can use that platform in your project:
plugins {
id("java-library")
}
dependencies {
implementation(platform(project(":platform")))
}plugins {
id("java-library")
}
dependencies {
implementation(platform(":platform"))
}Here, platform defines versions for commons-lang3, guava, and slf4j-api, ensuring they are compatible.
Maven’s BOM (Bill of Materials) is a popular type of platform that Gradle supports. A BOM file lists dependencies with specific versions, allowing you to manage these versions in a centralized way.
For example, a popular platform is the Spring Boot Bill of Materials. To use the BOM, you add it to the dependencies of your project:
dependencies {
// import a BOM
implementation(platform("org.springframework.boot:spring-boot-dependencies:1.5.8.RELEASE"))
// define dependencies without versions
implementation("com.google.code.gson:gson")
implementation("dom4j:dom4j")
}dependencies {
// import a BOM
implementation platform('org.springframework.boot:spring-boot-dependencies:1.5.8.RELEASE')
// define dependencies without versions
implementation 'com.google.code.gson:gson'
implementation 'dom4j:dom4j'
}By including the spring-boot-dependencies platform dependency, you ensure that all Spring components use the versions defined in the BOM file.
Using a Version catalog
A version catalog is a centralized list of dependency coordinates that can be referenced in multiple projects. You can reference this catalog in your build scripts to ensure each project depends on a common set of well-known dependencies.
First, create a libs.versions.toml file in the gradle directory of your project.
This file will define the versions of your dependencies and plugins:
[versions]
groovy = "3.0.5"
checkstyle = "8.37"
[libraries]
groovy-core = { module = "org.codehaus.groovy:groovy", version.ref = "groovy" }
groovy-json = { module = "org.codehaus.groovy:groovy-json", version.ref = "groovy" }
groovy-nio = { module = "org.codehaus.groovy:groovy-nio", version.ref = "groovy" }
commons-lang3 = { group = "org.apache.commons", name = "commons-lang3", version = { strictly = "[3.8, 4.0[", prefer = "3.9" } }
[bundles]
groovy = ["groovy-core", "groovy-json", "groovy-nio"]
[plugins]
versions = { id = "com.github.ben-manes.versions", version = "0.45.0" }Then, you can use the version catalog in you build file:
plugins {
`java-library`
alias(libs.plugins.versions)
}
dependencies {
api(libs.bundles.groovy)
}plugins {
id 'java-library'
alias(libs.plugins.versions)
}
dependencies {
api libs.bundles.groovy
}5. Dependency Constraints and Conflict Resolution
When the same library is declared multiple times or when two different libraries provide the same functionality, a conflict can occur during dependency resolution.
Understanding types of conflicts
During dependency resolution, Gradle handles two types of conflicts:
-
Version conflicts: That is when two or more dependencies require a given module but with different versions.
-
Capability conflicts: That is when the dependency graph contains multiple artifacts that provide the same functionality.
Resolving version conflicts
A version conflict occurs when a component declares two dependencies that:
-
Depend on the same module, let’s say
com.google.guava:guava -
But on different versions, let’s say
20.0and25.1-android-
Our project itself depends on
com.google.guava:guava:20.0 -
Our project also depends on
com.google.inject:guice:4.2.2which itself depends oncom.google.guava:guava:25.1-android
-
Gradle will consider all requested versions, wherever they appear in the dependency graph. By default, it will select the highest one out of these versions.
Resolving capability conflicts
Gradle uses attributes and capabilities to identify which artifacts a component provides. A capability conflict occurs whenever two or more variants of a component in dependency graph declare the same capability.
Gradle will generally fail the build and report the conflict.
You can resolve conflicts manually by specifying which capability to use in the resolutionStrategy block:
configurations.configureEach {
resolutionStrategy.capabilitiesResolution.withCapability("com.example:logging") {
selectHighestVersion()
}
}In this example, Gradle is instructed to select the highest version of the com.example:logging capability whenever a conflict arises.
Understanding dependency constraints
In order to help Gradle resolve issue with dependencies, a number of solutions are provided.
For example, the dependencies block provides a constraints block which can be used to help Gradle pick a specific version of a dependency:
dependencies {
constraints {
implementation("org.apache.commons:commons-lang3:3.12.0")
}
}In this example, if any version of org.apache.commons:commons-lang3 is requested in the dependency graph (either directly or transitively), Gradle will pick version 3.12.0.
Advanced Concepts: Learn about Dependency Resolution >>
Declaring Dependencies
Types of dependencies
There are three main types of dependencies in Gradle:
-
Module Dependencies: Refer to libraries from external repositories.
-
Project Dependencies: Refer to other projects in the same multi-project build.
-
File Dependencies: Refer to local files or directories, such as
.jaror.aarfiles.
1. Module dependencies
Module dependencies are the most common dependencies.
They refer to a published module by its coordinates (group:name:version).
Every dependency is added to a bucket configuration that defines its scope.
Use the single string "group:name:version" (you can also include classifier/extension if needed, e.g., group:name:version:classifier@ext):
dependencies {
// 1) Regular module dependency using string notation (JAR)
runtimeOnly("org.springframework:spring-core:2.5",
"org.springframework:spring-aop:2.5")
// 2) Regular module dependency with a config block
runtimeOnly("org.hibernate:hibernate:3.0.5") {
isTransitive = true
}
// 3) Classifier + extension (:resources@zip) — fetches a ZIP artifact instead of a JAR
runtimeOnly("net.sf.docbook:docbook-xsl:1.75.2:resources@zip")
// 4) Extension only (@aar) — Android AAR instead of JAR
implementation("com.google.android.material:material:1.11.0@aar")
}dependencies {
// 1) Regular module dependency using string notation (JAR)
runtimeOnly("org.springframework:spring-core:2.5",
"org.springframework:spring-aop:2.5")
// 2) Regular module dependency with a config block
runtimeOnly("org.hibernate:hibernate:3.0.5") {
transitive = true
}
// 3) Classifier + extension (:resources@zip) — fetches a ZIP artifact instead of a JAR
runtimeOnly("net.sf.docbook:docbook-xsl:1.75.2:resources@zip")
// 4) Extension only (@aar) — Android AAR instead of JAR
implementation("com.google.android.material:material:1.11.0@aar")
}|
Warning
|
The map notation is deprecated and will be removed in Gradle 10. Prefer the single-string form. For example: runtimeOnly(group: 'org.springframework', name: 'spring-core', version: '2.5').Should be: runtimeOnly('org.springframework:spring-core:2.5').
|
Module dependencies use the ExternalModuleDependency and DependencyHandler APIs.
These APIs provide expose properties and configuration methods for defining dependencies such a transitive, because, and a version {} block for strictly, prefer, and reject.
2. Project dependencies
Project dependencies allow you to reference other projects within a multi-project Gradle build.
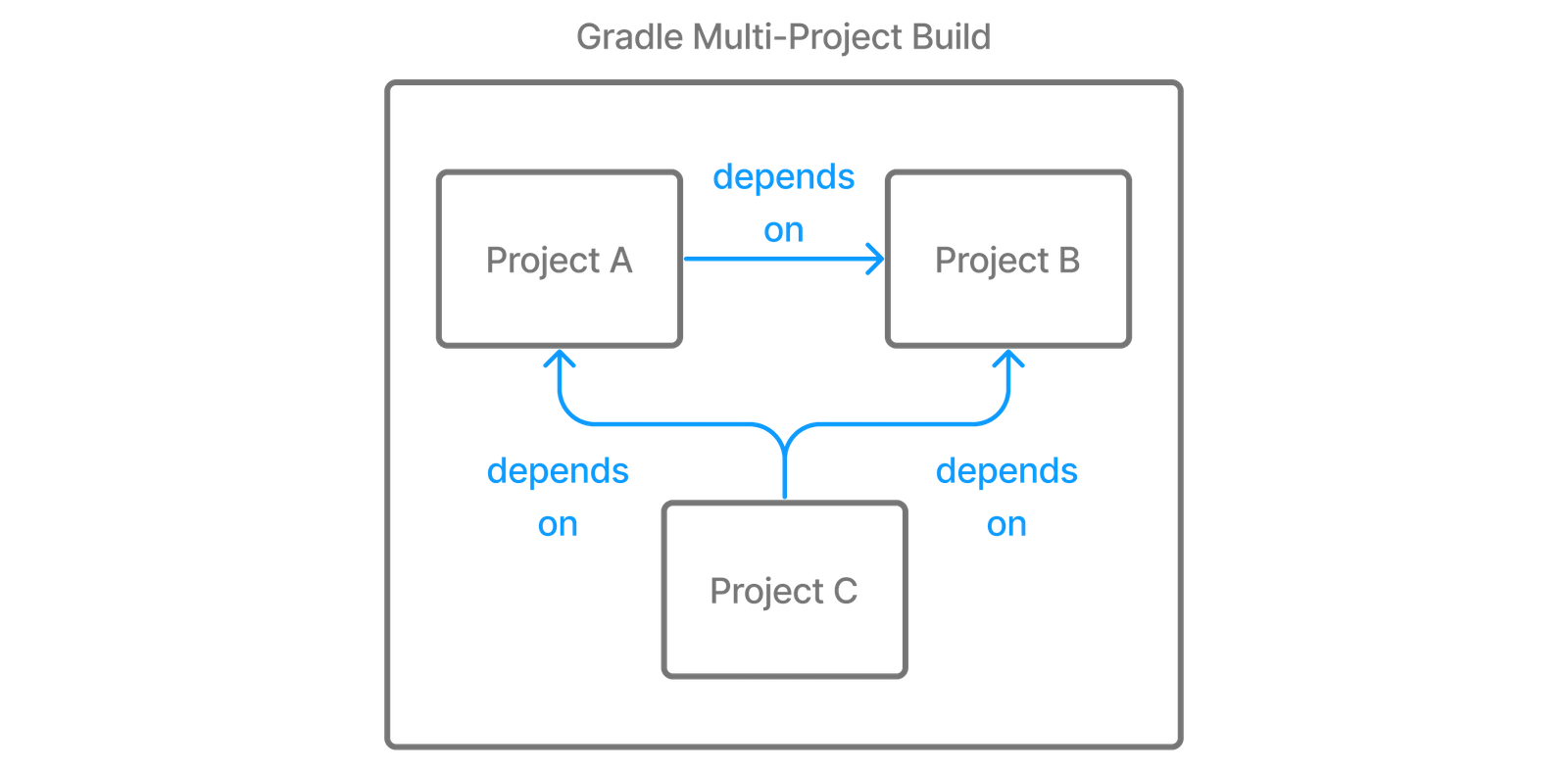
This is useful for organizing large projects into smaller, modular components:
dependencies {
implementation(project(":utils"))
implementation(project(":api"))
}dependencies {
implementation project(':utils')
implementation project(':api')
}Gradle uses the project() function to define a project dependency.
This function takes the relative path to the target project within the build.
The path is typically defined using a colon (:) to separate different levels of the project structure.
Project dependencies are automatically resolved such that the dependent project is always built before the project that depends on it.
Type-safe project dependencies
Type-safe project accessors are an incubating feature which must be enabled explicitly. Implementation may change at any time.
To add support for type-safe project accessors, add enableFeaturePreview("TYPESAFE_PROJECT_ACCESSORS") this to your settings.gradle(.kts) file:
enableFeaturePreview("TYPESAFE_PROJECT_ACCESSORS")enableFeaturePreview 'TYPESAFE_PROJECT_ACCESSORS'One downside of using the project(":some:path") notation is the need to remember project paths for dependencies.
Moreover, changing a project path requires manually updating every occurrence, increasing the risk of missing one.
Instead, the experimental type-safe project accessors API provides IDE completion, making it easier to declare dependencies:
dependencies {
implementation(projects.utils)
implementation(projects.api)
}dependencies {
implementation projects.utils
implementation projects.api
}With this API, incorrectly specified projects in Kotlin DSL scripts trigger compilation errors, helping you avoid missed updates.
Project accessors are based on project paths.
For instance, the path :commons:utils:some:lib becomes projects.commons.utils.some.lib, while kebab-case (some-lib) and snake-case (some_lib) are converted to camel case: projects.someLib.
3. File dependencies
File dependencies allow you to include external JARs or other files directly into your project by referencing their file paths. File dependencies also allow you to add a set of files directly to a configuration without using a repository.
|
Note
|
File dependencies are generally discouraged.
Instead, prefer declaring dependencies on an external repository, or if necessary, declaring a maven or ivy repository using a file:// URL.
|
File dependencies are unique because they represent a direct reference to files on the filesystem without any associated metadata, such as transitive dependencies, origin, or author information.
configurations {
create("antContrib")
create("externalLibs")
create("deploymentTools")
}
dependencies {
"antContrib"(files("ant/antcontrib.jar"))
"externalLibs"(files("libs/commons-lang.jar", "libs/log4j.jar"))
"deploymentTools"(fileTree("tools") { include("*.exe") })
}configurations {
antContrib
externalLibs
deploymentTools
}
dependencies {
antContrib files('ant/antcontrib.jar')
externalLibs files('libs/commons-lang.jar', 'libs/log4j.jar')
deploymentTools(fileTree('tools') { include '*.exe' })
}In this example, each dependency explicitly specifies its location within the file system. Common methods for referencing these files include:
-
link:
Project.files(): Accepts one or more file paths directly. -
ProjectLayout.files(): Accepts one or more file paths directly. -
Project.fileTree(): Defines a directory and includes or excludes specific file patterns.
|
Note
|
The order of files in a |
Alternatively, you can use a flat directory repository to specify the source directory for multiple file dependencies.
Ideally, you should use Maven or Ivy repository with a local URL:
repositories {
maven {
url = 'file:///path/to/local/files' // Replace with your actual path
}
}To add files as dependencies, pass a file collection to the configuration:
dependencies {
runtimeOnly(files("libs/a.jar", "libs/b.jar"))
runtimeOnly(fileTree("libs") { include("*.jar") })
}dependencies {
runtimeOnly files('libs/a.jar', 'libs/b.jar')
runtimeOnly fileTree('libs') { include '*.jar' }
}Note that file dependencies are not included in the published dependency descriptor for your project. However, they are available in transitive dependencies within the same build, meaning they can be used within the current build but not outside it.
You should specify which tasks produce the files for a file dependency. Otherwise, the necessary tasks might not run when you depend on them transitively from another project:
dependencies {
implementation(files(layout.buildDirectory.dir("classes")) {
builtBy("compile")
})
}
tasks.register("compile") {
doLast {
println("compiling classes")
}
}
tasks.register("list") {
val compileClasspath: FileCollection = configurations["compileClasspath"]
dependsOn(compileClasspath)
doLast {
println("classpath = ${compileClasspath.map { file: File -> file.name }}")
}
}dependencies {
implementation files(layout.buildDirectory.dir('classes')) {
builtBy 'compile'
}
}
tasks.register('compile') {
doLast {
println 'compiling classes'
}
}
tasks.register('list') {
FileCollection compileClasspath = configurations.compileClasspath
dependsOn compileClasspath
doLast {
println "classpath = ${compileClasspath.collect { File file -> file.name }}"
}
}$ ./gradlew -q listcompiling classes
classpath = [classes]Gradle distribution-specific dependencies
Gradle provides special methods to declare dependencies on components that are part of the Gradle distribution. See more in the Gradle distribution-specific dependencies.
Documenting dependencies
When declaring a dependency or a dependency constraint, you can provide a reason to clarify why the dependency is included. This helps make your build script and the dependency insight report easier to interpret:
plugins {
`java-library`
}
repositories {
mavenCentral()
}
dependencies {
implementation("org.ow2.asm:asm:7.1") {
because("we require a JDK 9 compatible bytecode generator")
}
}plugins {
id 'java-library'
}
repositories {
mavenCentral()
}
dependencies {
implementation('org.ow2.asm:asm:7.1') {
because 'we require a JDK 9 compatible bytecode generator'
}
}In this example, the because() method provides a reason for including the asm library, which helps explain its purpose in the context of the build:
$ ./gradlew -q dependencyInsight --dependency asmorg.ow2.asm:asm:7.1
Variant compile:
| Attribute Name | Provided | Requested |
|--------------------------------|----------|--------------|
| org.gradle.status | release | |
| org.gradle.category | library | library |
| org.gradle.libraryelements | jar | classes |
| org.gradle.usage | java-api | java-api |
| org.gradle.dependency.bundling | | external |
| org.gradle.jvm.environment | | standard-jvm |
| org.gradle.jvm.version | | 11 |
Selection reasons:
- Was requested: we require a JDK 9 compatible bytecode generator
org.ow2.asm:asm:7.1
\--- compileClasspath
A web-based, searchable dependency report is available by adding the --scan option.Viewing Dependencies
Gradle offers tools to navigate the results of dependency management, allowing you to more precisely understand how and why Gradle resolves dependencies. You can render a full dependency graph, identify the origin of a given dependency, and see why specific versions were selected. Dependencies can come from build script declarations or transitive relationships.
To visualize dependencies, you can use:
-
The
dependenciestask -
The
dependencyInsighttask
List project dependencies using the dependencies task
Gradle provides the built-in dependencies task to render a dependency tree from the command line.
By default, the task shows dependencies for all configurations within a single project.
The dependency tree shows the selected version of each dependency and provides information on conflict resolution.
The dependencies task is particularly useful for analyzing transitive dependencies.
While your build file lists direct dependencies, the task helps you understand which transitive dependencies are resolved during the build.
$ ./gradlew dependencies|
Tip
|
To render the graph of dependencies declared in the buildscript classpath configuration, use the buildEnvironment task.
|
Understanding output annotations
$ ./gradlew :app:dependencies> Task :app:dependencies
------------------------------------------------------------
Project ':app'
------------------------------------------------------------
annotationProcessor - Annotation processors and their dependencies for source set 'main'.
No dependencies
compileClasspath - Compile classpath for source set 'main'.
\--- com.fasterxml.jackson.core:jackson-databind:2.17.2
+--- com.fasterxml.jackson.core:jackson-annotations:2.17.2
| \--- com.fasterxml.jackson:jackson-bom:2.17.2
| +--- com.fasterxml.jackson.core:jackson-annotations:2.17.2 (c)
| +--- com.fasterxml.jackson.core:jackson-core:2.17.2 (c)
| \--- com.fasterxml.jackson.core:jackson-databind:2.17.2 (c)
+--- com.fasterxml.jackson.core:jackson-core:2.17.2
| \--- com.fasterxml.jackson:jackson-bom:2.17.2 (*)
\--- com.fasterxml.jackson:jackson-bom:2.17.2 (*)
...The dependencies task marks dependency trees with the following annotations:
-
(*): Indicates repeated occurrences of a transitive dependency subtree. Gradle expands transitive dependency subtrees only once per project; repeat occurrences only display the root of the subtree, followed by this annotation. -
(c): This element is a dependency constraint, not a dependency. Look for the matching dependency elsewhere in the tree. -
(n): A dependency or dependency configuration that cannot be resolved.
Specifying a dependency configuration
To focus on a specific dependency configuration, use the optional --configuration parameter.
Like project and task names, Gradle allows abbreviated names for dependency configurations.
For example, you can use tRC instead of testRuntimeClasspath, as long as it matches a unique configuration.
The following examples display dependencies for the testRuntimeClasspath configuration in a Java project:
$ ./gradlew -q dependencies --configuration testRuntimeClasspath$ ./gradlew -q dependencies --configuration tRCTo view a list of all configurations in a project, including those provided by plugins, run the resolvableConfigurations report.
For more details, refer to the plugin’s documentation, such as the Java Plugin here.
Looking at an example
Consider a project that uses the JGit library to execute Source Control Management (SCM) operations for a release process. You can declare dependencies for external tooling with the help of a custom dependency configuration. This avoids polluting other contexts, such as the compilation classpath for your production source code.
The following example declares a custom dependency configuration named scm that contains the JGit dependency:
configurations {
create("scm")
}
dependencies {
"scm"("org.eclipse.jgit:org.eclipse.jgit:4.9.2.201712150930-r")
}configurations {
scm
}
dependencies {
scm 'org.eclipse.jgit:org.eclipse.jgit:4.9.2.201712150930-r'
}Use the following command to view a dependency tree for the scm dependency configuration:
$ ./gradlew -q dependencies --configuration scm------------------------------------------------------------
Root project 'dependencies-report'
------------------------------------------------------------
scm
\--- org.eclipse.jgit:org.eclipse.jgit:4.9.2.201712150930-r
+--- com.jcraft:jsch:0.1.54
+--- com.googlecode.javaewah:JavaEWAH:1.1.6
+--- org.apache.httpcomponents:httpclient:4.3.6
| +--- org.apache.httpcomponents:httpcore:4.3.3
| +--- commons-logging:commons-logging:1.1.3
| \--- commons-codec:commons-codec:1.6
\--- org.slf4j:slf4j-api:1.7.2
A web-based, searchable dependency report is available by adding the --scan option.Identify the selected version using the dependencyInsight task
A project may request two different versions of the same dependency either directly or transitively that may result in a version conflict.
The following example introduces a conflict with commons-codec:commons-codec, added both as a direct dependency and a transitive dependency of JGit:
repositories {
mavenCentral()
}
configurations {
create("scm")
}
dependencies {
"scm"("org.eclipse.jgit:org.eclipse.jgit:4.9.2.201712150930-r")
"scm"("commons-codec:commons-codec:1.7")
}repositories {
mavenCentral()
}
configurations {
scm
}
dependencies {
scm 'org.eclipse.jgit:org.eclipse.jgit:4.9.2.201712150930-r'
scm 'commons-codec:commons-codec:1.7'
}Gradle provides the built-in dependencyInsight task to render a dependency insight report from the command line.
Dependency insights provide information about a single dependency within a single configuration. Given a dependency, you can identify the reason and origin for its version selection.
dependencyInsight accepts the following parameters:
--dependency <dependency>(mandatory)-
The dependency to investigate. You can supply a complete
group:name, or part of it. If multiple dependencies match, Gradle generates a report covering all matching dependencies. --configuration <name>(mandatory)-
The dependency configuration which resolves the given dependency. This parameter is optional for projects that use the Java plugin, since the plugin provides a default value of
compileClasspath. --single-path(optional)-
Render only a single path to the dependency.
--all-variants(optional)-
Render information about all variants, not only the selected variant.
The following code snippet demonstrates how to run a dependency insight report for all paths to a dependency named commons-codec within the scm configuration:
$ ./gradlew -q dependencyInsight --dependency commons-codec --configuration scmcommons-codec:commons-codec:1.7
Variant default:
| Attribute Name | Provided | Requested |
|-------------------|----------|-----------|
| org.gradle.status | release | |
Selection reasons:
- By conflict resolution: between versions 1.7 and 1.6
commons-codec:commons-codec:1.7
\--- scm
commons-codec:commons-codec:1.6 -> 1.7
\--- org.apache.httpcomponents:httpclient:4.3.6
\--- org.eclipse.jgit:org.eclipse.jgit:4.9.2.201712150930-r
\--- scm
A web-based, searchable dependency report is available by adding the --scan option.Understanding the selection reasons
The "Selection reasons" section of the dependency insight report lists the reasons why a dependency was selected.
| Reason | Meaning |
|---|---|
(Absent) |
No reason other than a reference, direct or transitive, was present. |
Was requested : <text> |
The dependency appears in the graph, and the inclusion came with a |
Was requested : didn’t match versions <versions> |
The dependency appears with a dynamic version which did not include the listed versions.
May be followed by a |
Was requested : reject version <versions> |
The dependency appears with a rich version containing one or more |
By conflict resolution : between versions <version> |
The dependency appeared multiple times, with different version requests. This resulted in conflict resolution to select the most appropriate version. |
By constraint |
A dependency constraint participated in the version selection.
May be followed by a |
By ancestor |
There is a rich version with a |
Selected by rule |
A dependency resolution rule overruled the default selection process.
May be followed by a |
Rejection : <version> by rule because <text> |
A |
Rejection: version <version>: <attributes information> |
The dependency has a dynamic version and some versions did not match the requested attributes. |
Forced |
The build enforces the version of the dependency through an enforced platform or resolution strategy. |
If multiple selection reasons exist, the insight report lists all of them.
Get a holistic view using Build Scan
The dependency tree in a Build Scan shows information about conflicts.
A Build Scan was created for the commons-codec example above and a URL was provided with the results.
Head over to the Dependencies tab and navigate to your desired dependency.
Select the Required By tab to see the selection reason and origin of the dependency:
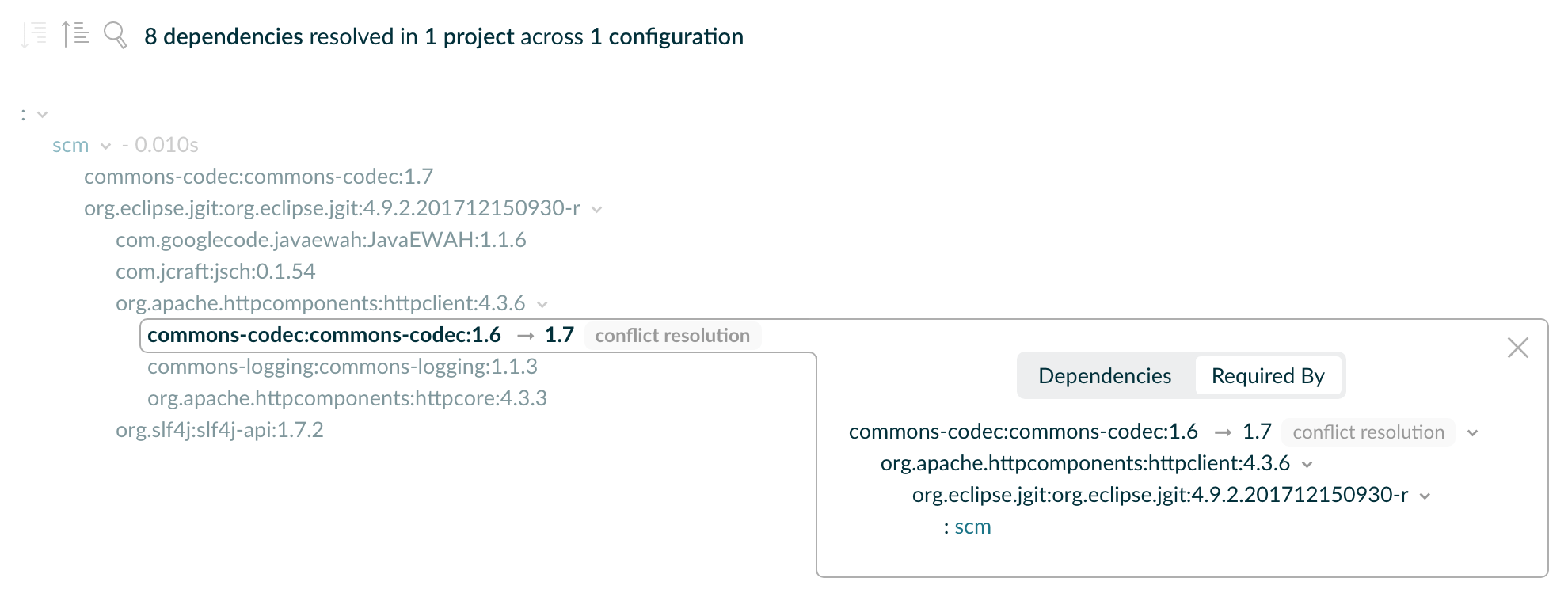
Resolving unsafe configuration resolution errors
Resolving a configuration can have side effects on Gradle’s project model, so Gradle needs manage access to each project’s configurations. There are a number of ways a configuration might be resolved unsafely. Gradle will produce a deprecation warning for each unsafe access. Each of these are bad practices and can cause strange and indeterminate errors.
If your build has an unsafe access deprecation warning, it needs to be fixed.
For example:
-
A task from one project directly resolves a configuration in another project in the task’s action.
-
A task specifies a configuration from another project as an input file collection.
-
A build script for one project resolves a configuration in another project during evaluation.
-
Project configurations are resolved in the settings file.
In most cases, this issue can be resolved by creating a cross-project dependency on the other project. See the how-to guide for sharing outputs between projects for more information.
If you find a use case that can’t be resolved using these techniques, please let us know by filing a GitHub Issue adhering to our issue guidelines.
Declaring Versions and Ranges
You can specify dependencies with exact versions or version ranges to define which versions your project can use:
dependencies {
implementation("org.springframework:spring-core:5.3.8")
implementation("org.springframework:spring-core:5.3.+")
implementation("org.springframework:spring-core:latest.release")
implementation("org.springframework:spring-core:[5.2.0, 5.3.8]")
implementation("org.springframework:spring-core:[5.2.0,)")
}Understanding version declaration
Gradle supports various ways to declare versions and ranges:
| Version | Example | Note |
|---|---|---|
Exact version |
|
A specific version. |
Maven-style range |
|
When the upper or lower bound is missing, the range has no upper or lower bound. An upper bound exclude acts as a prefix exclude. |
Prefix version range |
|
Only versions exactly matching the portion before the Declaring a version as |
|
|
Matches the highest version with the specified status. See ComponentMetadata.getStatus(). |
Maven |
|
Indicates a snapshot version. |
Maven-style range
There are a number of options to indicate bounds in the Maven-style:
-
[and]indicate an inclusive bound →[1.1, 2.0] -
(and)indicate an exclusive bound →(1.1, 2.0)or(1.2, 1.5]or[1.1, 2.0) -
]can be used instead of(for an exclusive lower bound →]1.2, 1.5]instead of(1.2, 1.5] -
[can be used instead of)for exclusive upper bound →[1.1, 2.0[instead of[1.1, 2.0)
Understanding version ordering
dependencies {
implementation("org.springframework:spring-core:1.1") // This is a newer version than 1.a
implementation("org.springframework:spring-core:1.a") // This is a older version than 1.1
}Version ordering is used to:
-
Determine if a particular version is included in a range.
-
Determine which version is newest when performing conflict resolution (using "base versions").
Versions are ordered based on the following rules:
-
Splitting Versions into Parts:
-
Versions are divided into parts using the characters
[. - _ +]. -
Parts containing both digits and letters are split further, e.g.,
1a1becomes1.a.1. -
Only the parts are compared, not the separators, so
1.a.1,1-a+1,1.a-1, and1a1are equivalent. (Note: There are exceptions during conflict resolution).
-
-
Comparing Equivalent Parts:
-
Numeric vs. Numeric: Higher numeric value is considered higher:
1.1 < 1.2. -
Numeric vs. Non-numeric: Numeric parts are higher than non-numeric parts:
1.a < 1.1. -
Non-numeric vs. Non-numeric: Parts are compared alphabetically and case-sensitively:
1.A < 1.B < 1.a < 1.b. -
Extra Numeric Part: A version with an additional numeric part is higher, even if it’s zero:
1.1 < 1.1.0. -
Extra Non-numeric Part: A version with an extra non-numeric part is lower:
1.1.a < 1.1.
-
-
Special Non-numeric Parts:
-
devis lower than any other non-numeric part:1.0-dev < 1.0-ALPHA < 1.0-alpha < 1.0-rc. -
rc,snapshot,final,ga,release, andspare higher than any other string part, in this order:1.0-zeta < 1.0-rc < 1.0-snapshot < 1.0-final < 1.0-ga < 1.0-release < 1.0-sp. -
These special values are not case-sensitive and their ordering does not depend on the separator used:
1.0-RC-1==1.0.rc.1.
-
Declaring rich versions
When you declare a version using the shorthand notation, then the version is considered a required version:
dependencies {
implementation("org.slf4j:slf4j-api:1.7.15")
}dependencies {
implementation('org.slf4j:slf4j-api:1.7.15')
}This means the minimum version will be 1.7.15 and it can be optimistically upgraded by the engine.
To enforce a strict version and ensure that only the specified version of a dependency is used, rejecting any other versions even if they would normally be compatible:
dependencies {
implementation("org.slf4j:slf4j-api") {
version {
strictly("[1.7, 1.8[")
prefer("1.7.25")
}
}
}dependencies {
implementation('org.slf4j:slf4j-api') {
version {
strictly '[1.7, 1.8['
prefer '1.7.25'
}
}
}Gradle supports a model for rich version declarations, allowing you to combine different levels of version specificity.
The key terms, listed from strongest to weakest, are:
strictlyor!!-
This is the strongest version declaration. Any version not matching this notation will be excluded. If used on a declared dependency,
strictlycan downgrade a version. For transitive dependencies, if no acceptable version is found, dependency resolution will fail.Dynamic versions are supported.
When defined, it overrides any previous
requiredeclaration and clears any previousrejectalready declared on that dependency.
require-
This ensures that the selected version cannot be lower than what
requireaccepts, but it can be higher through conflict resolution, even if the higher version has an exclusive upper bound. This is the default behavior for a direct dependency.Dynamic versions are supported.
When defined, it overrides any previous
strictlydeclaration and clears any previousrejectalready declared on that dependency.
prefer-
This is the softest version declaration. It applies only if there is no stronger non-dynamic version specified.
This term does not support dynamic versions and can complement
strictlyorrequire.When defined, it overrides any previous
preferdeclaration and clears any previousrejectalready declared on that dependency.
Additionally, there is a term outside the hierarchy:
reject-
This term specifies versions that are not accepted for the module, causing dependency resolution to fail if a rejected version is selected.
Dynamic versions are supported.
Rich version declaration is accessed through the version DSL method on a dependency or constraint declaration, which gives you access to MutableVersionConstraint:
dependencies {
implementation("org.slf4j:slf4j-api") {
version {
strictly("[1.7, 1.8[")
prefer("1.7.25")
}
}
constraints {
add("implementation", "org.springframework:spring-core") {
version {
require("4.2.9.RELEASE")
reject("4.3.16.RELEASE")
}
}
}
}dependencies {
implementation('org.slf4j:slf4j-api') {
version {
strictly '[1.7, 1.8['
prefer '1.7.25'
}
}
constraints {
implementation('org.springframework:spring-core') {
version {
require '4.2.9.RELEASE'
reject '4.3.16.RELEASE'
}
}
}
}To enforce strict versions, you can also use the !! notation:
dependencies {
// short-hand notation with !!
implementation("org.slf4j:slf4j-api:1.7.15!!")
// is equivalent to
implementation("org.slf4j:slf4j-api") {
version {
strictly("1.7.15")
}
}
// or...
implementation("org.slf4j:slf4j-api:[1.7, 1.8[!!1.7.25")
// is equivalent to
implementation("org.slf4j:slf4j-api") {
version {
strictly("[1.7, 1.8[")
prefer("1.7.25")
}
}
}dependencies {
// short-hand notation with !!
implementation('org.slf4j:slf4j-api:1.7.15!!')
// is equivalent to
implementation("org.slf4j:slf4j-api") {
version {
strictly '1.7.15'
}
}
// or...
implementation('org.slf4j:slf4j-api:[1.7, 1.8[!!1.7.25')
// is equivalent to
implementation('org.slf4j:slf4j-api') {
version {
strictly '[1.7, 1.8['
prefer '1.7.25'
}
}
}The notation [1.7, 1.8[!!1.7.25 above is equivalent to:
-
strictly
[1.7, 1.8[ -
prefer
1.7.25
This means that the engine must select a version between 1.7 (included) and 1.8 (excluded).
If no other component in the graph needs a different version, it should prefer 1.7.25.
|
Tip
|
A strict version cannot be upgraded and overrides any transitive dependency versions, therefore using ranges with strict versions is recommended. |
The following table illustrates several use cases:
| Which version(s) of this dependency are acceptable? | strictly |
require |
prefer |
rejects |
Selection result |
|---|---|---|---|---|---|
Tested with version |
1.5 |
Any version starting from |
|||
Tested with |
[1.0, 2.0[ |
1.5 |
Any version between |
||
Tested with |
[1.0, 2.0[ |
1.5 |
Any version between |
||
Same as above, with |
[1.0, 2.0[ |
1.5 |
1.4 |
Any version between |
|
No opinion, works with |
1.5 |
|
|||
No opinion, prefer the latest release. |
|
The latest release at build time. |
|||
On the edge, latest release, no downgrade. |
|
The latest release at build time. |
|||
No other version than 1.5. |
1.5 |
1.5, or failure if another |
|||
|
[1.5,1.6[ |
Latest |
Lines annotated with a lock (🔒) indicate situations where leveraging dependency locking is recommended. NOTE: When using dependency locking, publishing resolved versions is always recommended.
Using strictly in a library requires careful consideration, as it affects downstream consumers.
However, when used correctly, it helps consumers understand which combinations of libraries may be incompatible in their context.
For more details, refer to the section on overriding dependency versions.
|
Note
|
Rich version information is preserved in the Gradle Module Metadata format.
However, converting this information to Ivy or Maven metadata formats is lossy.
The highest level of version declaration— |
Endorsing strict versions
Gradle resolves any dependency version conflicts by selecting the greatest version found in the dependency graph. Some projects might need to divert from the default behavior and enforce an earlier version of a dependency e.g. if the source code of the project depends on an older API of a dependency than some of the external libraries.
In general, forcing dependencies is done to downgrade a dependency. There are common use cases for downgrading:
-
A bug was discovered in the latest release.
-
Your code depends on an older version that is not binary compatible with the newer one.
-
Your code does not use the parts of the library that require a newer version.
|
Warning
|
Forcing a version of a dependency requires careful consideration, as changing the version of a transitive dependency might lead to runtime errors if external libraries expect a different version. It is often better to upgrade your source code to be compatible with newer versions if possible. |
Let’s say a project uses the HttpClient library for performing HTTP calls.
HttpClient pulls in Commons Codec as transitive dependency with version 1.10.
However, the production source code of the project requires an API from Commons Codec 1.9 which is no longer available in 1.10.
The dependency version can be enforced by declaring it as strict it in the build script:
dependencies {
implementation("org.apache.httpcomponents:httpclient:4.5.4")
implementation("commons-codec:commons-codec") {
version {
strictly("1.9")
}
}
}dependencies {
implementation 'org.apache.httpcomponents:httpclient:4.5.4'
implementation('commons-codec:commons-codec') {
version {
strictly '1.9'
}
}
}Consequences of using strict versions
Using a strict version must be carefully considered:
-
For Library Authors: Strict versions effectively act like forced versions. They take precedence over transitive dependencies and override any other strict versions found transitively. This could lead to build failures if the consumer project requires a different version.
-
For Consumers: Strict versions are considered globally during resolution. If a strict version conflicts with a consumer’s version requirement, it will trigger a resolution error.
For example, if project B strictly depends on C:1.0, but consumer project A requires C:1.1, a resolution error will occur.
To avoid this, it is recommended to use version ranges and a preferred version within those ranges.
For example, B might say, instead of strictly 1.0, that it strictly depends on the [1.0, 2.0[ range, but prefers 1.0.
Then if a consumer chooses 1.1 (or any other version in the range), the build will no longer fail.
Declaring without version
For larger projects, it’s advisable to declare dependencies without versions and manage versions using platforms:
dependencies {
implementation("org.springframework:spring-web")
}
dependencies {
constraints {
implementation("org.springframework:spring-web:5.0.2.RELEASE")
}
}dependencies {
implementation 'org.springframework:spring-web'
}
dependencies {
constraints {
implementation 'org.springframework:spring-web:5.0.2.RELEASE'
}
}This approach centralizes version management, including transitive dependencies.
Declaring dynamic versions
There are many situations where you might need to use the latest version of a specific module dependency or the latest within a range of versions. This is often necessary during development or when creating a library that needs to be compatible with various dependency versions. Projects might adopt a more aggressive approach to consuming dependencies by always integrating the latest version to access cutting-edge features.
You can easily manage these ever-changing dependencies by using a dynamic version.
A dynamic version can be either a version range (e.g., 2.+) or a placeholder for the latest available version (e.g., latest.integration):
plugins {
`java-library`
}
repositories {
mavenCentral()
}
dependencies {
implementation("org.springframework:spring-web:5.+")
}plugins {
id 'java-library'
}
repositories {
mavenCentral()
}
dependencies {
implementation 'org.springframework:spring-web:5.+'
}Using dynamic versions and changing modules can lead to unreproducible builds. As new versions of a module are published, its API may become incompatible with your source code. Therefore, use this feature with caution.
|
Caution
|
For reproducible builds, it’s crucial to use dependency locking when declaring dependencies with dynamic versions. Without this, the module you request may change even for the same version, which is known as a changing version.
For example, a Maven SNAPSHOT module always points to the latest artifact published, making it a "changing module."
|
Declaring changing versions
A team may implement a series of features before releasing a new version of the application or library. A common strategy to allow consumers to integrate an unfinished version of their artifacts early is to release a module with a changing version. A changing version indicates that the feature set is still under active development and hasn’t released a stable version for general availability yet.
In Maven repositories, changing versions are commonly referred to as snapshot versions.
Snapshot versions contain the suffix -SNAPSHOT.
The following example demonstrates how to declare a snapshot version on the Spring dependency:
plugins {
`java-library`
}
repositories {
mavenCentral()
maven {
url = uri("https://repo.spring.io/snapshot/")
}
}
dependencies {
implementation("org.springframework:spring-web:5.0.3.BUILD-SNAPSHOT")
}plugins {
id 'java-library'
}
repositories {
mavenCentral()
maven {
url = 'https://repo.spring.io/snapshot/'
}
}
dependencies {
implementation 'org.springframework:spring-web:5.0.3.BUILD-SNAPSHOT'
}Gradle is flexible enough to treat any version as a changing version.
All you need to do is to set the property ExternalModuleDependency.setChanging(boolean) to true.
Versioning file dependencies
It is recommended to clearly express the intention and specify a concrete version when using file dependencies.
File dependencies are not considered by Gradle’s version conflict resolution. Therefore, assigning a version to the file name is crucial to indicate the distinct set of changes included in each release.
For example, using commons-beanutils-1.3.jar allows tracking changes in the library through its release notes.
By following this practice:
-
Project dependencies become easier to maintain and organize.
-
Potential API incompatibilities are easier to identify through the assigned version.
Declaring Dependency Constraints
Version declarations (including ranges) only affect the dependencies you declare directly. To control versions of transitive dependencies, use dependency constraints.
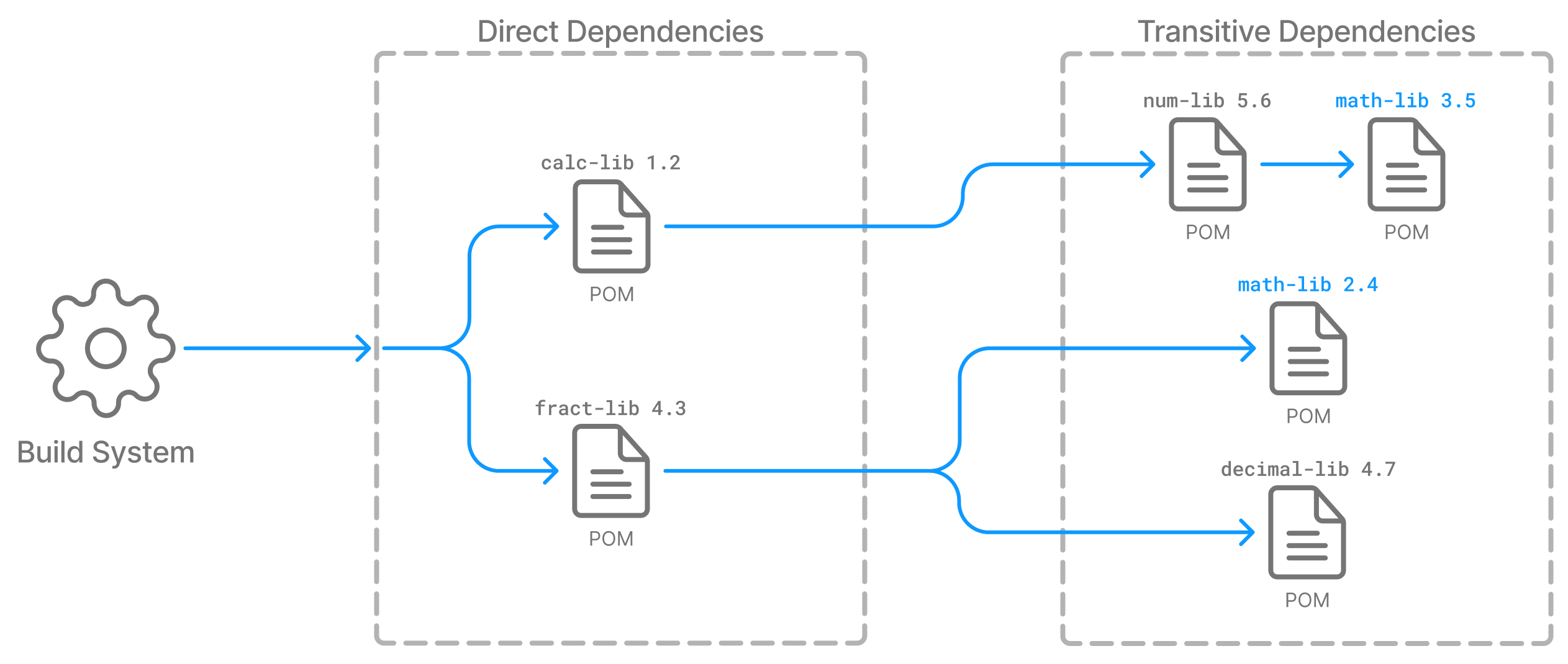
A dependency constraint sets version requirements for a module without adding that module as a dependency. When the module is pulled in, the constraint participates in version conflict resolution just like a declared dependency version:
-
Constraints are not strict by default (they usually express "at least this version").
-
You can make them strict or use rich versions (e.g., ranges,
prefer,reject,strictly) when needed.
|
Tip
|
Use constraints when you want to control versions centrally and avoid adding extra dependencies just to force a version. |
You can declare constraints:
-
Alongside dependencies in a single project (scoped to the same configuration buckets like
implementation,runtimeOnly,testImplementation, etc.). -
Centrally in a platform (recommended for multi-project builds) using the
java-platformplugin:
plugins {
`java-platform`
}
dependencies {
constraints {
// Platform declares some versions of libraries used in subprojects
api("commons-httpclient:commons-httpclient:3.1")
api("org.apache.commons:commons-lang3:3.8.1")
}
}plugins {
id 'java-platform'
}
dependencies {
constraints {
// Platform declares some versions of libraries used in subprojects
api 'commons-httpclient:commons-httpclient:3.1'
api 'org.apache.commons:commons-lang3:3.8.1'
}
}You cannot declare constraints in version catalogs.
Declaring constraints alongside direct dependencies
Constraints are scoped by bucket configurations (e.g., implementation, runtimeOnly).
They apply whenever that dependency is encountered during resolution.
The constraints {} block is used within the dependencies {} block to declare these constraints:
plugins {
`java-platform`
}
dependencies {
constraints {
api("commons-httpclient:commons-httpclient:3.1")
runtime("org.postgresql:postgresql:42.2.5")
}
}plugins {
id 'java-platform'
}
dependencies {
constraints {
api 'commons-httpclient:commons-httpclient:3.1'
runtime 'org.postgresql:postgresql:42.2.5'
}
}-
api("commons-httpclient:commons-httpclient:3.1"): ensures ≥ 3.1 forapi. -
runtime("org.postgresql:postgresql:42.2.5"): ensures ≥ 42.2.5 forruntime.
If multiple requirements exist, Gradle picks a version that satisfies all. If none exists, resolution fails with an error describing the conflict.
Adding constraints on transitive dependencies
Use constraints to select transitive modules without introducing them as direct dependencies:
dependencies {
implementation("org.apache.httpcomponents:httpclient")
constraints {
implementation("org.apache.httpcomponents:httpclient:4.5.3") {
because("previous versions have a bug impacting this application")
}
implementation("commons-codec:commons-codec:1.11") {
because("version 1.9 pulled from httpclient has bugs affecting this application")
}
}
}dependencies {
implementation('org.apache.httpcomponents:httpclient')
constraints {
implementation('org.apache.httpcomponents:httpclient:4.5.3') {
because('previous versions have a bug impacting this application')
}
implementation('commons-codec:commons-codec:1.11') {
because('version 1.9 pulled from httpclient has bugs affecting this application')
}
}
}If commons-codec isn’t brought in transitively, the constraint is a no-op (it doesn’t add the module).
If it is brought in, the constraint guides the version selection.
Rich versions and strict versions for constraints
You can attach rich versions to constraints:
dependencies {
constraints {
implementation("com.google.guava:guava") {
version {
strictly("33.1.0-jre")
}
because("avoid older versions with known issues")
}
}
}dependencies {
constraints {
implementation("com.google.guava:guava") {
version {
strictly("33.1.0-jre")
}
because("avoid older versions with known issues")
}
}
}Transitivity of constraints
Dependency constraints are transitive.
If library A depends on library B, and library B declares a constraint on module C, that constraint will affect the version of module C that library A depends on.
For example, if library A depends on module C version 2, but library B declares a constraint on module C version 3, library A will resolve module C version 3.
Publishing constraints
Dependency constraints are only published when using Gradle Module Metadata. This means they are fully supported only when both publishing and consuming modules with Gradle.
If modules are consumed with Maven or Ivy, the constraints may not be preserved.
Creating Dependency Configurations
In Gradle, dependencies are associated with specific scopes, such as compile-time or runtime. These scopes are represented by configurations, each identified by a unique name.
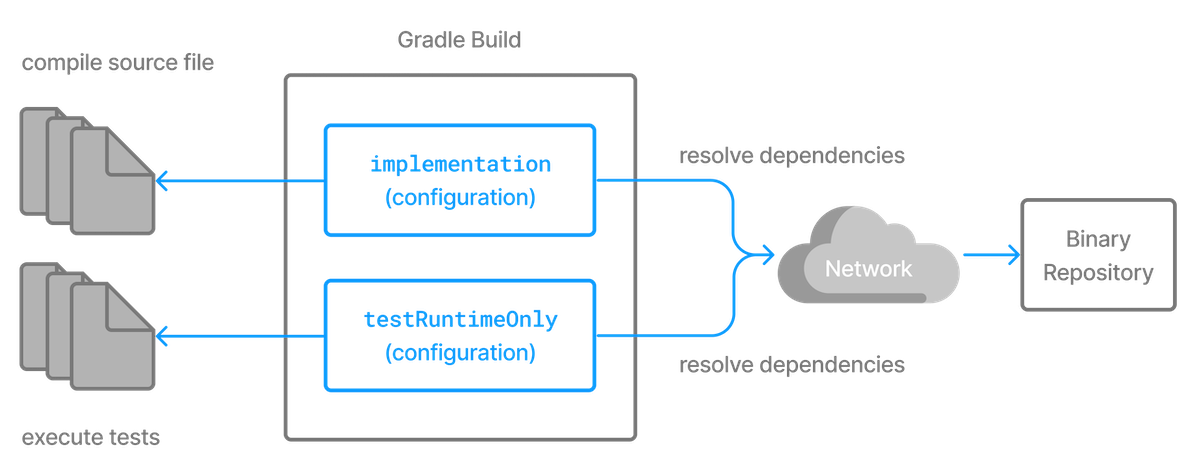
Configurations are added automatically by applied plugins or can be created manually within your build.
Configurations aren’t used just for declaring dependencies, they serve various roles in dependency management.
Declarable, Resolvable, and Consumable configurations
There are 3 types of configurations that fulfil different roles:
| # | Role | Name | What it means | Java example |
|---|---|---|---|---|
1 |
Bucket Role |
Declarable configuration |
Define a set of dependencies. |
|
2 |
Consumer Role |
Resolvable configuration |
Resolve dependencies into concrete artifacts/files. |
|
3 |
Producer Role |
Consumable configuration |
Expose built artifacts for other projects to consume. |
|
1. Declarable configurations
To declare dependencies in your project, you can use or create declarable configurations.
These configurations help organize and categorize dependencies for different parts of the project.
For example, to express a dependency on another project, you would use a declarable configurations like implementation:
dependencies {
// add a project dependency to the implementation configuration
implementation(project(":lib"))
}dependencies {
// add a project dependency to the implementation configuration
implementation project(":lib")
}Configurations used for declaring dependencies define and manage the specific libraries or projects your code requires for tasks such as compilation or testing.
2. Resolvable configurations
To control how dependencies are resolved and used within your project, you can use or create resolvable configurations.
These configurations define classpaths and other sets of artifacts that your project needs during different stages, like compilation or runtime.
For example, the implementation configuration declares the dependencies, while compileClasspath and runtimeClasspath are resolvable configurations designed for specific purposes.
When resolved, they represent the classpaths needed for compilation and runtime, respectively.
The following shows three different APIs available to create a resolvable configuration called compileClasspath:
configurations {
// declare a resolvable configuration that is going to resolve the compile classpath of the application
// Using lazy & newer API: realized only when needed
resolvable("compileClasspath") {
extendsFrom(implementation)
}
// Using lazy & older API: realized only when needed
register("compileClasspath-lazy") {
isCanBeConsumed = false
isCanBeDeclared = false
extendsFrom(implementation)
}
// Using eager & older API: realized immediately - avoid
create("compileClasspath-eager") {
isCanBeConsumed = false
isCanBeDeclared = false
extendsFrom(implementation)
}
}configurations {
// declare a resolvable configuration that is going to resolve the compile classpath of the application
// Using lazy & newer API: realized only when needed
resolvable("compileClasspath") {
extendsFrom(implementation)
}
// Using lazy & older API: realized only when needed
register("compileClasspath-lazy") {
canBeConsumed = false
canBeDeclared = false
extendsFrom(implementation)
}
// Using eager & older API: realized immediately - avoid
create("compileClasspath-eager") {
canBeConsumed = false
canBeDeclared = false
extendsFrom(implementation)
}
}Resolvable configurations are those that can be resolved to produce a set of files or artifacts. These configurations are used to define the classpath for different stages of a build process, such as compilation or runtime.
3. Consumable configurations
Consumable configurations are used to expose artifacts to other projects.
These configurations define what parts of your project can be consumed by others, like APIs or runtime dependencies, but are not meant to be resolved directly within your project.
For example, the exposedApi configuration is a consumable configuration that exposes the API of a component to consumers.
The following shows three different APIs available to create a consumable configuration called exposedApi:
configurations {
// a consumable configuration meant for consumers that need the API of this component
// Using lazy & newer API: realized only when needed
consumable("exposedApi") {
extendsFrom(implementation)
}
// Using lazy & older API: realized only when needed
register("exposedApi-lazy") {
isCanBeResolved = false
isCanBeDeclared = false
extendsFrom(implementation)
}
// Using eager & older API: realized immediately - avoid
create("exposedApi-eager") {
isCanBeResolved = false
isCanBeDeclared = false
extendsFrom(implementation)
}
}configurations {
// a consumable configuration meant for consumers that need the API of this component
// Using lazy & newer API: realized only when needed
consumable("exposedApi") {
extendsFrom(implementation)
}
// Using lazy & older API: realized only when needed
register("exposedApi-lazy") {
canBeResolved = false
canBeDeclared = false
extendsFrom(implementation)
}
// Using eager & older API: realized immediately - avoid
create("exposedApi-eager") {
canBeResolved = false
canBeDeclared = false
extendsFrom(implementation)
}
}A library typically provides consumable configurations like apiElements (for compilation) and runtimeElements (for runtime dependencies).
These configurations expose the necessary artifacts for other projects to consume, without being resolvable within the current project.
The canBeDeclared, canBeConsumed and canBeResolved flags help distinguish the roles of these configurations and are required when using older APIs.
Configurations added by Plugins
Gradle plugins often create configurations (like implementation, api, testImplementation) for you.
Let’s look at a few popular ones.
Java Plugin
When you apply the Java or Java Library (java, java-library, application) plugin, Gradle adds the following configurations.
-
Declarable (you put dependencies into these):
-
api(java-libraryonly),implementation,compileOnly,runtimeOnly, plus test variants (testImplementation,testCompileOnly,testRuntimeOnly), etc.
-
-
Resolvable (you resolve these to get jars/dirs):
-
compileClasspath,runtimeClasspath, and their test equivalents (testCompileClasspath,testRuntimeClasspath).
-
-
Consumable (Gradle publishes these so other projects can depend on you):
-
apiElements(java-libraryonly) andruntimeElements.
-
plugins {
`java-library`
}
dependencies {
implementation("org.hibernate:hibernate-core:3.6.7.Final")
testImplementation("junit:junit:4.+")
api("com.google.guava:guava:23.0")
}plugins {
id 'java-library'
}
dependencies {
implementation 'org.hibernate:hibernate-core:3.6.7.Final'
testImplementation 'junit:junit:4.+'
api 'com.google.guava:guava:23.0'
}There is a relationship between these configurations.
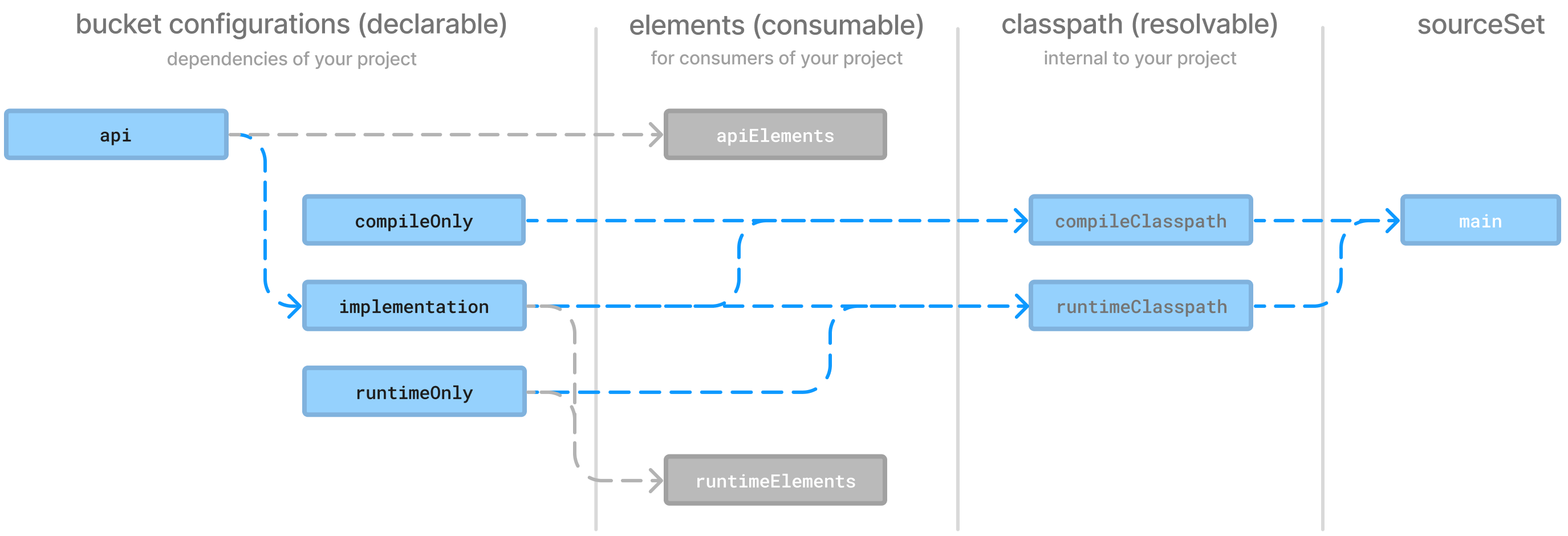
-
What you declare in
api:-
Your project: on
compileClasspathand (if needed)runtimeClasspath. -
Consumers: exported via
apiElements→ ends up on consumers’ compile and runtime classpaths.
-
-
What you declare in
implementation:-
Your project: on
compileClasspathandruntimeClasspath. -
Consumers: not exported (kept internal). It’s not on consumers’ compile classpath; the runtime part is included in your
runtimeElementsso consumers can run you without needing to compile against those internals.
-
-
What you declare in
compileOnly:-
Your project: only on
compileClasspath(not onruntimeClasspath). -
Consumers: not exported (neither
apiElementsnorruntimeElements).
-
-
What you declare in
runtimeOnly:-
Your project: only on
runtimeClasspath. -
Consumers: included in
runtimeElements(so they can run you), but not inapiElements.
-
-
Test configurations (
testImplementation, etc.) affect only test resolvable classpaths (testCompileClasspath,testRuntimeClasspath) and are never published to consumers.
Android Gradle Plugin
When you apply the Android plugin (com.android.application or com.android.library), Gradle and the Android Gradle Plugin (AGP) add a richer set of configurations to handle multiple build variants (combinations of build types and product flavors).
Each variant has its own declarable, resolvable, and consumable configurations, following the same conceptual model as the Java plugin.
-
Declarable (you put dependencies into these):
-
implementation,compileOnly,runtimeOnly,annotationProcessor, and test equivalents (androidTestImplementation,androidTestCompileOnly,androidTestRuntimeOnly,testImplementation,testCompileOnly,testRuntimeOnly), plus variant-specific versions such asdebugImplementation,releaseImplementation, and flavor-specific configurations (e.g.,freeImplementation,paidImplementation).
-
-
Resolvable (Gradle resolves these to get the actual JARs, AARs, or directories):
-
Each build variant defines its own resolvable classpaths:
debugCompileClasspath,debugRuntimeClasspath,releaseCompileClasspath,releaseRuntimeClasspath, and similar sets for test variants (testDebugCompileClasspath,testDebugRuntimeClasspath, etc.). These are used internally by AGP tasks such ascompileDebugJavaWithJavacormergeReleaseResources.
-
-
Consumable (Gradle publishes these so other modules can depend on your Android library):
-
For library modules (
com.android.library), AGP defines variant-specific consumable configurations:debugApiElements,debugRuntimeElements,releaseApiElements, andreleaseRuntimeElements. These control what other modules receive when they declare a dependency on a particular variant of your library.
-
plugins {
id("com.android.application") version "9.0.1"
}
dependencies {
implementation("androidx.core:core-ktx:1.13.1")
annotationProcessor("androidx.room:room-compiler:2.6.1")
implementation("androidx.room:room-ktx:2.6.1")
debugImplementation("com.squareup.leakcanary:leakcanary-android:2.14")
testImplementation("junit:junit:4.13.2")
androidTestImplementation("androidx.test.ext:junit:1.2.1")
androidTestImplementation("androidx.test.espresso:espresso-core:3.6.1")
}plugins {
id("com.android.application") version '9.0.1'
}
dependencies {
implementation("androidx.core:core-ktx:1.13.1")
annotationProcessor("androidx.room:room-compiler:2.6.1")
implementation("androidx.room:room-ktx:2.6.1")
debugImplementation("com.squareup.leakcanary:leakcanary-android:2.14")
testImplementation("junit:junit:4.13.2")
androidTestImplementation("androidx.test.ext:junit:1.2.1")
androidTestImplementation("androidx.test.espresso:espresso-core:3.6.1")
}There is a relationship between these configurations, similar to the Java plugin, but scoped per variant.
-
What you declare in
implementation:-
Your module: included in that variant’s
compileClasspathandruntimeClasspath. -
Consumers: not exported; remains internal to that variant.
-
-
What you declare in
api(for Android library modules):-
Your module: visible on that variant’s
compileClasspathandruntimeClasspath. -
Consumers: exported via that variant’s
apiElementsconfiguration → appears on consumers’ compile and runtime classpaths.
-
-
What you declare in
compileOnlyorannotationProcessor:-
Your module: used only for compilation; not packaged or exposed to consumers.
-
-
What you declare in
runtimeOnly:-
Your module: added only to the variant’s runtime classpath.
-
Consumers: included in the corresponding
runtimeElementsvariant, so downstream modules can run your library.
-
-
Test configurations (
testImplementation,androidTestImplementation, etc.) affect only their respective resolvable classpaths (testCompileClasspath,androidTestCompileClasspath, etc.) and are never published to consumers.
Kotlin Multiplatform Plugin
When you apply the Kotlin Multiplatform plugin (org.jetbrains.kotlin.multiplatform), Gradle creates configurations for each source set and target.
The same underlying concepts apply — declarable, resolvable, and consumable — but they’re managed per source set instead of per variant or build type.
-
Declarable (you put dependencies into these):
-
Each source set has its own declarable configuration, for example:
-
commonMainImplementation,commonMainApi,commonMainCompileOnly -
jvmMainImplementation,jsMainImplementation,iosMainImplementation, etc. -
and corresponding test configurations such as
commonTestImplementation,jvmTestImplementation, and so on. -
These are where you declare dependencies that apply to a specific source set or to all targets sharing that source set.
-
-
Resolvable (Gradle resolves these to get JARs, KLIBs, or directories):
-
Every compilable source set has a corresponding resolvable configuration, such as:
-
commonMainCompileClasspath,jvmMainCompileClasspath,iosArm64MainCompileClasspath, etc. -
These are used internally by Kotlin compilation tasks like
compileKotlinJvm,compileKotlinJs, andcompileKotlinIosArm64to obtain the appropriate libraries and dependencies for that target.
-
-
Consumable (Gradle publishes these so other modules or projects can depend on your multiplatform component):
-
KMP creates consumable configurations for each target, such as:
-
jvmApiElements,jvmRuntimeElements,jsApiElements,iosArm64ApiElements, etc. -
When you publish a KMP library, these configurations define the artifacts and metadata that Gradle and consumers use to resolve the right variant for their platform.
-
plugins {
alias(libs.plugins.kotlinMultiplatform)
alias(libs.plugins.androidApplication)
alias(libs.plugins.composeMultiplatform)
alias(libs.plugins.composeCompiler)
}
kotlin {
androidTarget {
compilerOptions {
jvmTarget.set(JvmTarget.JVM_11)
}
}
sourceSets {
androidMain.dependencies {
implementation(compose.preview)
implementation(libs.androidx.activity.compose)
}
commonMain.dependencies {
implementation(compose.runtime)
implementation(compose.foundation)
implementation(compose.material3)
implementation(compose.ui)
implementation(compose.components.resources)
implementation(compose.components.uiToolingPreview)
implementation(libs.androidx.lifecycle.viewmodelCompose)
implementation(libs.androidx.lifecycle.runtimeCompose)
}
commonTest.dependencies {
implementation(libs.kotlin.test)
}
}
}plugins {
alias(libs.plugins.kotlinMultiplatform)
alias(libs.plugins.androidApplication)
alias(libs.plugins.composeMultiplatform)
alias(libs.plugins.composeCompiler)
}
kotlin {
androidTarget {
compilerOptions {
jvmTarget.set(JvmTarget.JVM_11)
}
}
sourceSets {
androidMain.dependencies {
implementation(compose.preview)
implementation(libs.androidx.activity.compose)
}
commonMain.dependencies {
implementation(compose.runtime)
implementation(compose.foundation)
implementation(compose.material3)
implementation(compose.ui)
implementation(compose.components.resources)
implementation(compose.components.uiToolingPreview)
implementation(libs.androidx.lifecycle.viewmodelCompose)
implementation(libs.androidx.lifecycle.runtimeCompose)
}
commonTest.dependencies {
implementation(libs.kotlin.test)
}
}
}There is a relationship between these configurations, similar to Java and Android, but organized per source set and target.
-
What you declare in
commonMainApi:-
Shared source sets: visible to all targets depending on
commonMain. -
Consumers: exported via the relevant
apiElementsfor each target (e.g.,jvmApiElements,iosApiElements), so downstream projects can compile against the shared API.
-
-
What you declare in
commonMainImplementation:-
Your project: included in compilation for all targets that depend on
commonMain. -
Consumers: not exported — internal only.
-
-
What you declare in target-specific configurations (e.g.,
jvmMainImplementation,iosMainImplementation):-
Your project: visible only to that target’s compilation and runtime.
-
Consumers: packaged and published through that target’s consumable configuration (
jvmRuntimeElements, etc.), but not exposed as API.
-
-
compileOnlyandruntimeOnlyequivalents work similarly per source set: used only during compilation or runtime for that target, not exported to consumers. -
Test source sets (
commonTest,jvmTest, etc.) have their own declarable and resolvable configurations, but are never published to consumers.
Configuration flags and roles
Configurations have three key flags:
-
canBeResolved: Indicates that this configuration is intended for resolving a set of dependencies into a dependency graph. A resolvable configuration should not be declarable or consumable. -
canBeConsumed: Indicates that this configuration is intended for exposing artifacts outside this project. A consumable configuration should not be declarable or resolvable. -
canBeDeclared: Indicates that this configuration is intended for declaring dependencies. A declarable configuration should not be resolvable or consumable.
|
Tip
|
Configurations should only have one of these flags enabled. |
In short, a configuration’s role is determined by the canBeResolved, canBeConsumed, or canBeDeclared flag:
| Configuration role | Can be resolved | Can be consumed | Can be declared |
|---|---|---|---|
Dependency Scope |
false |
false |
true |
Resolve for certain usage |
true |
false |
false |
Exposed to consumers |
false |
true |
false |
Legacy, don’t use |
true |
true |
true |
For backwards compatibility, the flags have a default value of true, but as a plugin author, you should always determine the right values for those flags, or you might accidentally introduce resolution errors.
This example demonstrates how to manually declare the core Java configurations (normally provided by the Java plugin) in Gradle:
// declare a "configuration" named "implementation"
val implementation = configurations.create("implementation") {
isCanBeConsumed = false
isCanBeResolved = false
}
dependencies {
// add a project dependency to the implementation configuration
implementation(project(":lib"))
}
configurations {
// declare a resolvable configuration that is going to resolve the compile classpath of the application
resolvable("compileClasspath") {
extendsFrom(implementation)
}
// declare a resolvable configuration that is going to resolve the runtime classpath of the application
resolvable("runtimeClasspath") {
extendsFrom(implementation)
}
}
configurations {
// a consumable configuration meant for consumers that need the API of this component
consumable("exposedApi") {
extendsFrom(implementation)
}
// a consumable configuration meant for consumers that need the implementation of this component
consumable("exposedRuntime") {
extendsFrom(implementation)
}
}// declare a "configuration" named "implementation"
configurations {
// declare a "configuration" named "implementation"
implementation {
canBeConsumed = false
canBeResolved = false
}
}
dependencies {
// add a project dependency to the implementation configuration
implementation project(":lib")
}
configurations {
// declare a resolvable configuration that is going to resolve the compile classpath of the application
resolvable("compileClasspath") {
extendsFrom(implementation)
}
// declare a resolvable configuration that is going to resolve the runtime classpath of the application
resolvable("runtimeClasspath") {
extendsFrom(implementation)
}
}
configurations {
// a consumable configuration meant for consumers that need the API of this component
consumable("exposedApi") {
extendsFrom(implementation)
}
// a consumable configuration meant for consumers that need the implementation of this component
consumable("exposedRuntime") {
extendsFrom(implementation)
}
}The following configurations are created:
-
implementation: Used for declaring project dependencies but neither consumed nor resolved. -
compileClasspath+runtimeClasspath: Resolvable configurations that collect compile-time and runtime dependencies fromimplementation. -
exposedApi+exposedRuntime: Consumable configurations that expose artifacts (API and runtime) to other projects, but aren’t meant for internal resolution.
This setup mimics the behavior of the implementation, compileClasspath, runtimeClasspath, apiElements, and runtimeElements configurations in the Java plugin.
Avoiding eager configuration
With lazy configuration, Gradle only initializes configurations when they’re actually needed, for example, when they’re published or consumed. To benefit from this, make sure your build logic doesn’t force configurations to realize early.
For example:
// Instead of
configurations.all {} // Eagerly realizes all configurations
// Use
configurations.configureEach {} // Only called for realized configurations
// Instead of
configurations.getByName("name").description = "example" // Eagerly realizes the "name" configuration
// Use
configurations.named("name").configure {
description = "example" // Only called if "name" configuration is realized
}// Instead of
configurations.all {} // Eagerly realizes all configurations
// Use
configurations.configureEach {} // Only called for realized configurations
// Instead of
configurations.getByName('name').description = 'example' // Eagerly realizes the 'name' configuration
// Use
configurations.named('name').configure {
description = 'example' // Only called if 'name' configuration is realized
}all {} iterates every configuration eagerly at configuration time, while configureEach {} registers the action but delays running it until the configuration is actually realized.
getByName() returns and realizes the configuration immediately.
While named() returns a lazy handle so you can configure it without triggering realization.
By using these lazy APIs, Gradle can skip unnecessary work for configurations that aren’t needed, reducing configuration time and memory use.
Deprecated configurations
In the past, some configurations did not define which role they were intended to be used for.
A deprecation warning is emitted when a configuration is used in a way that was not intended. To fix the deprecation, you will need to stop using the configuration in the deprecated role. The exact changes required depend on how the configuration is used and if there are alternative configurations that should be used instead.
Creating custom configurations
You can define custom configurations to declare separate scopes of dependencies for specific purposes.
Suppose you want to generate Javadocs with AsciiDoc formatting embedded within your Java source code comments.
By setting up the asciidoclet configuration, you enable Gradle to use Asciidoclet, allowing your Javadoc task to produce HTML documentation with enhanced formatting options:
val asciidoclet = configurations.create("asciidoclet")
dependencies {
asciidoclet("org.asciidoctor:asciidoclet:1.+")
}
tasks.register("configureJavadoc") {
doLast {
tasks.javadoc {
options.doclet = "org.asciidoctor.Asciidoclet"
options.docletpath = asciidoclet.files.toList()
}
}
}configurations {
asciidoclet
}
dependencies {
asciidoclet 'org.asciidoctor:asciidoclet:1.+'
}You can manage custom configurations using the configurations block.
Configurations must have names and can extend each other.
For more details, refer to the ConfigurationContainer API.
|
Note
|
Configurations are intended to be used for a single role: declaring dependencies, performing resolution, or defining consumable variants. |
There are three main use cases for creating custom configurations:
-
API/Implementation Separation: Create custom configurations to separate API dependencies (exposed to consumers) from implementation dependencies (used internally during compilation or runtime).
-
You might create an
apiconfiguration for libraries that consumers will depend on, and animplementationconfiguration for libraries that are only needed internally. Theapiconfiguration is typically consumed by downstream projects, whileimplementationdependencies are hidden from consumers but used internally. -
This separation ensures that your project maintains clean boundaries between its public API and strictly internal mechanisms.
-
-
Resolvable Configuration Creation: Create a custom resolvable configuration to resolve specific sets of dependencies, like classpaths, at various build stages.
-
You might create a
compileClasspathconfiguration that resolves only the dependencies needed to compile your project. Similarly, you could create aruntimeClasspathconfiguration to resolve the dependencies needed to run the project at runtime. -
This allows fine-grained control over which dependencies are available during different build phases, such as compilation or testing.
-
-
Consumable Configuration from Dependency Configuration: Create a custom consumable configuration to expose artifacts or dependencies for other projects to consume, typically when your project produces artifacts like JARs.
-
You might create an
exposedApiconfiguration to expose the API dependencies of your project for consumption by other projects. Similarly, aruntimeElementsconfiguration could be created to expose the runtime dependencies or artifacts that other projects need. -
Consumable configurations ensure that only the necessary artifacts or dependencies are exposed to consumers.
-
Configuration API incubating methods
Several incubating factory methods—resolvable(), consumable(), and dependencyScope()—within the ConfigurationContainer API can be used to simplify the creation of configurations with specific roles.
These methods help build authors document the purpose of a configuration and avoid manually setting various configuration flags, streamlining the process and ensuring consistency:
-
resolvable(): Creates a configuration intended for resolving dependencies. This means the configuration can be used to resolve dependencies but not consumed by other projects. -
consumable(): Creates a configuration meant to be consumed by other projects but not used to resolve dependencies itself. -
dependencyScope(): Creates a configuration that establishes a dependency scope, setting up the necessary properties to act both as a consumer and provider, depending on the use case.
Configuration inheritance
Configurations can inherit from other configurations, creating an inheritance hierarchy.
Configurations form an inheritance hierarchy using the Configuration.extendsFrom(Configuration…) method.
A configuration can extend any other configuration other than a detached configuration, regardless of how it is defined in the build script or plugin.
|
Tip
|
Avoid extending consumable or resolvable configurations with configurations that are not consumable or resolvable, respectively. |
For example, in a project that already uses JUnit for testing, you can define a dedicated configuration named smokeTest to run smoke tests.
Each smoke test performs an HTTP request to verify a web service endpoint.
To reuse the existing test framework dependencies, the smokeTest configuration should extend from testImplementation.
This allows smoke tests to leverage the same dependencies as unit tests without duplication.
The configuration can be declared in build.gradle(.kts) as follows:
val smokeTest = configurations.create("smokeTest") {
extendsFrom(configurations.testImplementation.get())
}
dependencies {
testImplementation("junit:junit:4.13")
smokeTest("org.apache.httpcomponents:httpclient:4.5.5")
}configurations {
smokeTest.extendsFrom testImplementation
}
dependencies {
testImplementation 'junit:junit:4.13'
smokeTest 'org.apache.httpcomponents:httpclient:4.5.5'
}This setup enables the smokeTest source set to inherit JUnit and any other testing dependencies, making it easier to define and execute smoke tests while keeping them separate from unit tests.
|
Tip
|
Configurations can only extend configurations within the same project. |
When extending a configuration, the new configuration inherits:
-
dependencies
-
dependency constraints
-
exclude rules
-
artifacts
-
capabilities
The extension does not include attributes. It also does not extend consumable/resolvable/declarable status.
Dependency resolution
The entrypoint to all dependency resolution APIs is a resolvable Configuration.
The Java plugins primarily use the compileClasspath, and runtimeClasspath configurations to resolve jars for compilation and runtime respectively.
A resolvable configuration is intended for initiating dependency resolution.
The dependencies to be resolved are declared on dependency scope configurations.
The Java plugins use the api, implementation, and runtimeOnly dependency scope configurations, among others, as a source of dependencies to be resolved by the resolvable configurations.
Consider the following example that demonstrates how to declare a set of configurations intended for resolution:
|
Note
|
This example uses incubating APIs. |
val implementation = configurations.dependencyScope("implementation")
val runtimeClasspath = configurations.resolvable("runtimeClasspath") {
extendsFrom(implementation.get())
}configurations {
dependencyScope("implementation")
resolvable("runtimeClasspath") {
extendsFrom(implementation)
}
}Dependencies can be declared on the implementation configuration using the dependencies block. See the Declaring Dependencies chapter for more information on the types of dependencies that can be declared, and the various options for customizing dependency declarations.
dependencies {
implementation("com.google.guava:guava:33.2.1-jre")
}dependencies {
implementation("com.google.guava:guava:33.2.1-jre")
}Now that we’ve created a dependency scope configuration for declaring dependencies, and a resolvable configuration for resolving those dependencies, we can use Gradle’s dependency resolution APIs to access the results of resolution.
Unsafe configuration resolution errors
Resolving a configuration can have side effects on Gradle’s project model. As a result, Gradle must manage access to each project’s configurations.
There are a number of ways a configuration might be resolved unsafely. For example:
-
A task from one project directly resolves a configuration in another project in the task’s action.
-
A task specifies a configuration from another project as an input file collection.
-
A build script for one project resolves a configuration in another project during evaluation.
-
Project configurations are resolved in the settings file.
Gradle produces a deprecation warning for each unsafe access.
Unsafe access can cause indeterminate errors. You should fix unsafe access warnings in your build.
In most cases, you can resolve unsafe accesses by creating a proper cross-project dependency.
Gradle distribution-specific dependencies
Gradle provides special dependency notations for projects that build Gradle plugins or tools that integrate with Gradle.
Using these dependencies ensures compatibility with Gradle’s internal APIs while keeping plugin and build logic development streamlined.
Gradle API dependency
You can declare a dependency on the API of the current version of Gradle by using the DependencyHandler.gradleApi() method.
This is useful when you are developing custom Gradle tasks or plugins:
dependencies {
implementation(gradleApi())
}dependencies {
implementation gradleApi()
}Gradle TestKit dependency
You can declare a dependency on the TestKit API of the current version of Gradle by using the DependencyHandler.gradleTestKit() method.
This is useful for writing and executing functional tests for Gradle plugins and build scripts:
dependencies {
testImplementation(gradleTestKit())
}dependencies {
testImplementation gradleTestKit()
}The TestKit chapter explains the use of TestKit by example.
Local Groovy dependency
You can declare a dependency on the Groovy that is distributed with Gradle by using the DependencyHandler.localGroovy() method.
This is useful when you are developing custom Gradle tasks or plugins in Groovy:
dependencies {
implementation(localGroovy())
}dependencies {
implementation localGroovy()
}Declaring Repositories Basics
Gradle can resolve local or external dependencies from one or many repositories based on Maven, Ivy or flat directory formats.
Repositories intended for use in a single project are declared in your build.gradle(.kts) file:
repositories {
mavenCentral()
maven {
url = uri("https://repo.spring.io/snapshot/")
}
}repositories {
mavenCentral()
maven {
url = 'https://repo.spring.io/snapshot/'
}
}To centralize repository declarations in your settings.gradle(.kts) file, head over to Centralizing Repository Declarations.
Declaring a publicly-available repository
Organizations building software may want to leverage public binary repositories to download and consume publicly available dependencies. Popular public repositories include Maven Central and the Google Android repository.
Gradle provides built-in shorthand notations for these widely-used repositories.
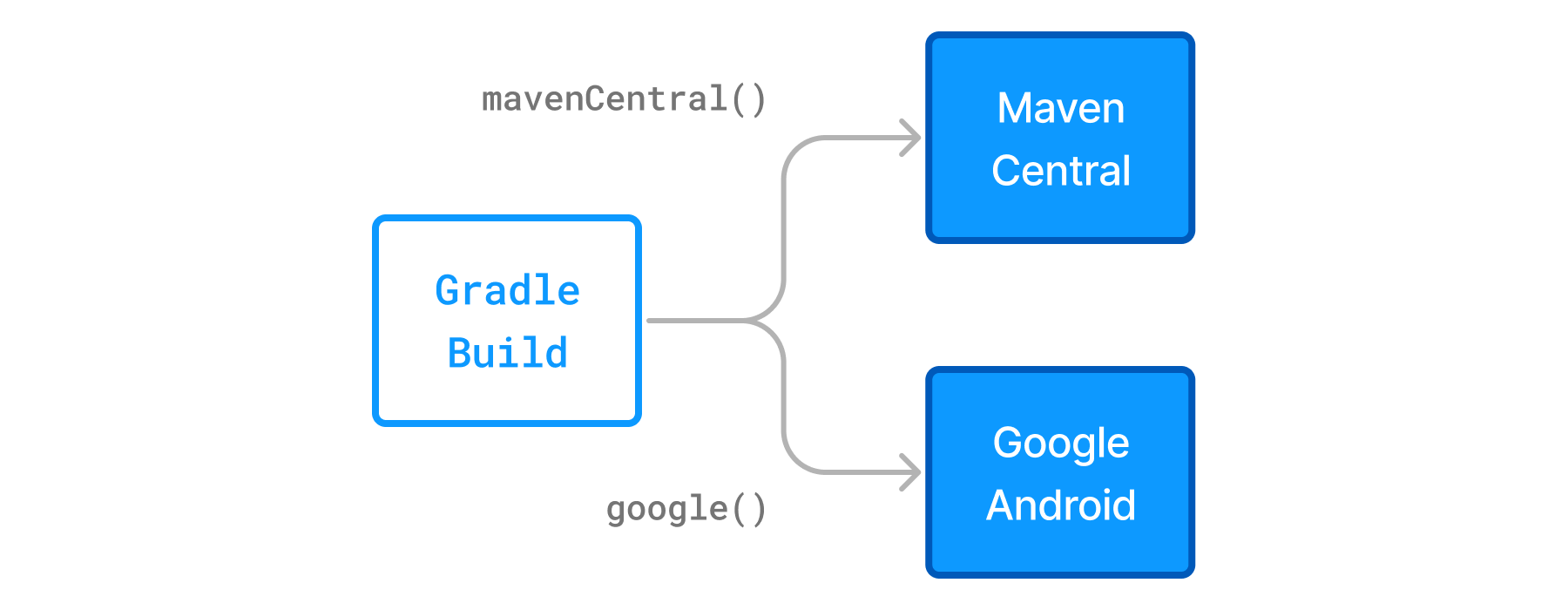
Under the covers, Gradle resolves dependencies from the respective URL of the public repository defined by the shorthand notation. All shorthand notations are available via the RepositoryHandler API.
Alternatively, you can explicitly specify the URL of the repository for more fine-grained control.
Maven Central repository
Maven Central is a popular repository hosting open source libraries for consumption by Java projects.
To declare the Maven Central repository for your build add this to your script:
repositories {
mavenCentral()
}repositories {
mavenCentral()
}Google Maven repository
The Google repository hosts Android-specific artifacts including the Android SDK. For usage examples, see the relevant Android documentation.
To declare the Google Maven repository add this to your build script:
repositories {
google()
}repositories {
google()
}Declaring a custom repository by URL
Most enterprise projects set up a binary repository available only within an intranet. In-house repositories enable teams to publish internal binaries, setup user management and security measures, and ensure uptime and availability.
Specifying a custom URL is also helpful if you want to declare publicly-available repository that Gradle does not provide a shorthand for.
Repositories with custom URLs can be specified as Maven or Ivy repositories by calling the corresponding methods available on the RepositoryHandler API:
repositories {
maven {
url = uri("http://repo.mycompany.com/maven2")
}
}repositories {
maven {
url = "http://repo.mycompany.com/maven2"
}
}Gradle supports additional protocols beyond http and https, such as file, sftp, and s3 for custom URLs.
For full coverage, see the section on supported repository types.
You can also define your own repository layout by using ivy { } repositories, as they are very flexible in terms of how modules are organised in a repository:
repositories {
ivy {
url = uri("http://repo.mycompany.com/repo")
}
}repositories {
ivy {
url = "http://repo.mycompany.com/repo"
}
}Declaring a local repository
You can declare local repositories using the mavenLocal() or flatDir methods inside the repositories block:
repositories {
mavenLocal()
maven {
setUrl("/path/to/local/repo")
}
flatDir {
dirs("libs")
}
}repositories {
mavenLocal()
maven {
url = '/path/to/local/repo'
}
flatDir {
dirs 'libs'
}
}Maven or Ivy can be declared as local repositories by specifying a local filesystem path. Unlike a flat directory repository, they adhere to a structured format and include metadata.
When such a repository is configured, Gradle completely bypasses its dependency cache for it, as there is no guarantee that the content will remain unchanged between executions. This limitation can negatively impact performance.
Additionally, using local Maven or Ivy repositories makes build reproducibility much harder to achieve. Therefore, their use should be restricted to prototyping rather than production builds.
Declaring multiple repositories
You can define more than one repository for resolving dependencies. Declaring multiple repositories is helpful if some dependencies are only available in one repository but not the other.
You can mix any type of repository described in the reference section.
repositories {
mavenCentral()
maven {
url = uri("https://repo.spring.io/release")
}
maven {
url = uri("https://repository.jboss.org/maven2")
}
}repositories {
mavenCentral()
maven {
url = "https://repo.spring.io/release"
}
maven {
url = "https://repository.jboss.org/maven2"
}
}The order of repository declaration determines the order that Gradle will search for dependencies during resolution. If Gradle finds a dependency’s metadata in a particular repository, it will attempt to download all the artifacts for that module from the same repository.
You can learn more about the inner workings of dependency downloads.
Declaring plugin repositories
Gradle uses a different set of repositories for resolving Gradle plugins and resolving project dependencies:
-
Plugin dependencies: When resolving plugins for build scripts, Gradle uses a distinct set of repositories to locate and load the required plugins.
-
Project dependencies: When resolving project dependencies, Gradle only uses the repositories declared in the build script and ignores the plugin repositories.
By default, Gradle uses the Gradle Plugin Portal to search for plugins:
pluginManagement {
repositories {
mavenCentral()
gradlePluginPortal()
}
}pluginManagement {
repositories {
mavenCentral()
gradlePluginPortal()
}
}However, some plugins may be hosted in other repositories (public or private). To include these plugins, you need to specify additional repositories in your build script so Gradle knows where to search.
Since declaring repositories depends on how the plugin is applied, refer to the Custom Plugin Repositories for more details on configuring repositories for plugins from different sources.
Centralizing Repository Declarations
Instead of declaring repositories in every subproject of your build or via an allprojects block, Gradle provides a way to declare them centrally for all projects.
|
Note
|
Central declaration of repositories is an incubating feature. |
You can declare repositories that will be used by convention in every subproject in the settings.gradle(.kts) file:
dependencyResolutionManagement {
repositories {
mavenCentral()
}
}dependencyResolutionManagement {
repositories {
mavenCentral()
}
}The dependencyResolutionManagement repositories block accepts the same notations as in a project, including Maven or Ivy repositories, with or without credentials.
Repositories mode
By default, repositories declared in a project’s build.gradle(.kts) file will override those declared in settings.gradle(.kts).
However, you can control this behavior using the repositoriesMode setting:
dependencyResolutionManagement {
repositoriesMode = RepositoriesMode.PREFER_PROJECT
}dependencyResolutionManagement {
repositoriesMode = RepositoriesMode.PREFER_PROJECT
}Available modes
There are three modes for dependency resolution management:
| Mode | Description | Default? | Use-Case |
|---|---|---|---|
|
Repositories declared in a project override those declared in |
Yes |
Useful when teams need to use different repositories specific to their subprojects. |
|
Repositories declared in |
No |
Useful for enforcing the use of approved repositories across large teams. |
|
Declaring a repository in a project triggers a build error. |
No |
Strictly enforces the use of repositories declared in |
You can change the behavior to prefer the repositories in settings.gradle(.kts):
dependencyResolutionManagement {
repositoriesMode = RepositoriesMode.PREFER_SETTINGS
}dependencyResolutionManagement {
repositoriesMode = RepositoriesMode.PREFER_SETTINGS
}Gradle will warn you if a project or plugin declares a repository when using this mode.
To enforce that only repositories declared in settings.gradle(.kts) are used, you can configure Gradle to fail the build when a project plugin is declared:
dependencyResolutionManagement {
repositoriesMode = RepositoriesMode.FAIL_ON_PROJECT_REPOS
}dependencyResolutionManagement {
repositoriesMode = RepositoriesMode.FAIL_ON_PROJECT_REPOS
}Repository Types
Gradle supports various sources for resolving dependencies, accommodating different metadata formats and connectivity methods. You can resolve dependencies from:
-
Maven-compatible artifact repositories (e.g., Maven Central)
-
Ivy-compatible artifact repositories (including custom layouts)
Maven repositories
Many organizations host dependencies in Maven repositories. Gradle can declare Maven repositories by specifying their URL:
repositories {
maven {
url = uri("http://repo.mycompany.com/maven2")
}
}repositories {
maven {
url = "http://repo.mycompany.com/maven2"
}
}Strict limitation for Maven repositories
Maven POM metadata can specify additional repositories, but Gradle ignores them. Instead, Gradle strictly uses only the repositories declared in the build script.
|
Note
|
This serves as both a reproducibility safeguard and a security measure. Without this restriction, an updated dependency version could unexpectedly introduce artifacts from unverified sources into your build. |
Authenticated Maven repository
You can specify credentials for Maven repositories that require authentication. See Supported Repository Protocols for authentication options.
Local Maven repository
Gradle can consume dependencies from a local Maven repository, that is repositories on the local file system:
repositories {
maven {
url = uri(layout.buildDirectory.dir("repo"))
}
}repositories {
maven {
url = uri(layout.buildDirectory.dir("repo"))
}
}Gradle can consume dependencies from the local Maven repository. This is useful for teams that want to test their setup locally before publishing their plugin.
You should ensure that using the local Maven repository is necessary before adding mavenLocal() to your build script:
repositories {
mavenLocal()
}repositories {
mavenLocal()
}|
Note
|
Gradle manages its own cache and doesn’t need to declare the local Maven repository even if you resolve dependencies from a remote Maven repository. |
Gradle uses the same logic as Maven to identify the location of your local Maven cache.
If a settings.xml file is defined in the user’s home directory (~/.m2/settings.xml), this location takes precedence over M2_HOME/conf
Otherwise, Gradle defaults to ~/.m2/repository.
The case against mavenLocal()
As a general rule, you should avoid adding mavenLocal() as a repository in your Gradle builds.
There are several issues with relying on it:
-
Not a true repository, just a cache:
-
Maven treats
mavenLocal()as a cache, not a reliable repository. -
It may contain incomplete modules—for example, missing sources or Javadoc files—leading to issues in Gradle when resolving dependencies.
-
-
Trust and security issues
-
Gradle does not trust local repositories because artifacts’ origins cannot be verified.
-
Dependencies can be easily overwritten, creating risks for security, correctness, and reproducibility.
-
-
Performance degradation
-
Since metadata and artifacts can change at any time (see item 2), Gradle disables caching for local repositories.
-
This results in slower builds—especially when
mavenLocal()is declared before remote repositories, as Gradle checks it first.
-
Despite its drawbacks, there are rare cases where mavenLocal() can be useful:
-
Interoperability with Maven:
-
Example: If Project A (Maven) and Project B (Gradle) share artifacts during development,
mavenLocal()can act as a temporary bridge. -
Prefer an internal repository instead, but if that’s not feasible, limit
mavenLocal()to local builds only.
-
-
Interoperability with Gradle (Multi-Repo Development):
-
Example: If you need to validate that Project A’s changes work with Project B,
mavenLocal()might be used. -
Prefer composite builds for better dependency resolution.
-
Only use
mavenLocal()as a last resort.
-
To mitigate risks, consider restricting mavenLocal() to specific dependencies using a repository filter:
repositories {
mavenLocal {
content {
includeGroup("com.example.myproject")
}
}
}repositories {
mavenLocal {
content {
includeGroup("com.example.myproject")
}
}
}This ensures that mavenLocal() is only used for expected dependencies and avoids unexpected resolution issues.
Ivy repositories
Many organizations host dependencies in Ivy repositories.
Standard layout Ivy repository
To declare an Ivy repository with the standard layout, simply specify the URL:
repositories {
ivy {
url = uri("http://repo.mycompany.com/repo")
}
}repositories {
ivy {
url = "http://repo.mycompany.com/repo"
}
}Named layout Ivy repository
You can specify that your repository follows the Ivy default layout:
repositories {
ivy {
url = uri("http://repo.mycompany.com/repo")
layout("maven")
}
}repositories {
ivy {
url = "http://repo.mycompany.com/repo"
layout "maven"
}
}Valid named layout values are gradle (default), maven, and ivy.
Refer to IvyArtifactRepository.layout(java.lang.String) in the API documentation for more details.
Custom pattern layout Ivy repository
To define an Ivy repository with a non-standard layout, you can set up a pattern layout:
repositories {
ivy {
url = uri("http://repo.mycompany.com/repo")
patternLayout {
artifact("[module]/[revision]/[type]/[artifact].[ext]")
}
}
}repositories {
ivy {
url = "http://repo.mycompany.com/repo"
patternLayout {
artifact "[module]/[revision]/[type]/[artifact].[ext]"
}
}
}For an Ivy repository that fetches Ivy files and artifacts from different locations, define separate patterns:
repositories {
ivy {
url = uri("http://repo.mycompany.com/repo")
patternLayout {
artifact("3rd-party-artifacts/[organisation]/[module]/[revision]/[artifact]-[revision].[ext]")
artifact("company-artifacts/[organisation]/[module]/[revision]/[artifact]-[revision].[ext]")
ivy("ivy-files/[organisation]/[module]/[revision]/ivy.xml")
}
}
}repositories {
ivy {
url = "http://repo.mycompany.com/repo"
patternLayout {
artifact "3rd-party-artifacts/[organisation]/[module]/[revision]/[artifact]-[revision].[ext]"
artifact "company-artifacts/[organisation]/[module]/[revision]/[artifact]-[revision].[ext]"
ivy "ivy-files/[organisation]/[module]/[revision]/ivy.xml"
}
}
}Optionally, you can enable Maven-style layout for the 'organisation' part, with forward slashes replacing dots:
repositories {
ivy {
url = uri("http://repo.mycompany.com/repo")
patternLayout {
artifact("[organisation]/[module]/[revision]/[artifact]-[revision].[ext]")
setM2compatible(true)
}
}
}repositories {
ivy {
url = "http://repo.mycompany.com/repo"
patternLayout {
artifact "[organisation]/[module]/[revision]/[artifact]-[revision].[ext]"
m2compatible = true
}
}
}Authenticated Ivy repository
You can specify credentials for Ivy repositories that require authentication. See Supported Repository Protocols for authentication options.
Local Ivy repository
Gradle can consume dependencies from a local Ivy repository, that is repositories on the local file system:
repositories {
ivy {
// URL can refer to a local directory
url = uri("../local-repo")
}
}repositories {
ivy {
// URL can refer to a local directory
url = file("../local-repo")
}
}Flat directory repository
Some projects store dependencies on a shared drive or within the project’s source code rather than using a binary repository. To use a flat filesystem directory as a repository, you can configure it like this:
repositories {
flatDir {
dirs("lib")
}
flatDir {
dirs("lib1", "lib2")
}
}repositories {
flatDir {
dirs 'lib'
}
flatDir {
dirs 'lib1', 'lib2'
}
}This configuration adds repositories that search specified directories for dependencies.
|
Note
|
Flat directory repositories are discouraged, as they do not support metadata formats like Ivy XML or Maven POM files. |
In general, binary dependencies should be sourced from an external repository, but if storing dependencies externally is not an option, prefer declaring a Maven or Ivy repository using a local file URL instead.
When resolving dependencies from a flat dir repo, Gradle dynamically generates adhoc dependency metadata based on the presence of artifacts. Gradle prefers modules with real metadata over those generated by flat directory repositories. For this reason, flat directories cannot override artifacts with real metadata from other declared repositories.
For instance, if Gradle finds jmxri-1.2.1.jar in a flat directory and jmxri-1.2.1.pom in another repository, it will use the metadata from the latter.
Metadata Formats
Dependency metadata refers to the information associated with a dependency that describes its characteristics, relationships, and requirements.
This metadata includes details such as:
-
Identity: Module dependencies are uniquely identified by their group, name, and version (GAV) coordinates.
-
Dependencies: A list of other binaries that this dependency requires, including their versions.
-
Variants: Different forms of the component (e.g., compile, runtime, apiElements, runtimeElements) that can be consumed in different contexts.
-
Artifacts: The actual files (like JARs, ZIPs, etc.) produced by the component, which may include compiled code, resources, or documentation.
-
Capabilities: Describes the functionality or features that a module provides or consumes, helping to avoid conflicts when different modules provide the same capability.
-
Attributes: Key-value pairs used to differentiate between variants (e.g.
org.gradle.jvm.version:8).
Depending on the repository type, dependency metadata are stored in different formats:
-
Gradle: Gradle Module Metadata (
.module) files -
Maven: Maven POM (
pom.xml) files -
Ivy: Ivy Descriptor (
ivy.xml) files
Some repositories may contain multiple types of metadata for a single component. When Gradle publishes to a Maven repository, it publishes both a Gradle Module Metadata (GMM) files and a Maven POM file.
This metadata plays a crucial role in dependency resolution, by allowing the dependencies of binary artifacts to be tracked alongside the artifact itself. By reading dependency metadata, Gradle is able to determine which versions of other artifacts a given dependency requires.
|
Tip
|
In Maven, a module can have one and only one artifact. In Gradle and Ivy, a module can have multiple artifacts. |
Supported metadata formats
External module dependencies require module metadata so that Gradle can determine the transitive dependencies of a module. Gradle supports various metadata formats to achieve this.
Gradle Module Metadata (GMM) files
Gradle Module Metadata is specifically designed to support all features of Gradle’s dependency management model, making it the preferred format.
You can find the specification here.
{
"formatVersion": "1.1",
"component": {
"group": "com.example",
"module": "my-library",
"version": "1.0"
}
}POM files
Gradle natively supports Maven POM files. By default, Gradle will first look for a POM file. However, if the file contains a special marker, Gradle will use Gradle Module Metadata instead.
<project xmlns="http://maven.apache.org/POM/4.0.0">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>my-library</artifactId>
<version>1.0</version>
</project>Ivy files
Gradle also supports Ivy descriptor files.
Gradle will first look for an ivy.xml file, but if this file contains a special marker, it will use Gradle Module Metadata instead.
<ivy-module version="2.0">
<info organisation="com.example" module="my-library" revision="1.0"/>
<dependencies>
<dependency org="org.example" name="dependency" rev="1.2"/>
</dependencies>
</ivy-module>Supported metadata sources
When searching for a component in a repository, Gradle checks for supported metadata file formats by default:
-
Gradle first looks for
.module(Gradle module metadata) files. -
In a Maven repository, Gradle then looks for
.pomfiles. -
In an Ivy repository, it checks for
ivy.xmlfiles. -
In a flat directory repository, it looks directly for
.jarfiles without expecting any metadata.
If you define a custom repository, you can configure how Gradle searches for metadata. For instance, you can set up a Maven repository will optionally resolve JARs that don’t have associated POM files. This is done by configuring metadata sources for the repository:
repositories {
maven {
url = uri("http://repo.mycompany.com/repo")
metadataSources {
mavenPom()
artifact()
}
}
}repositories {
maven {
url = "http://repo.mycompany.com/repo"
metadataSources {
mavenPom()
artifact()
}
}
}You can specify multiple metadata sources, and Gradle will search through them in a predefined order. The following metadata sources are supported:
| Metadata source | Description | Default Order | Maven | Ivy / flat dir |
|---|---|---|---|---|
|
Look for Gradle |
1st |
yes |
yes |
|
Look for Maven |
2nd |
yes |
yes |
|
Look for |
2nd |
no |
yes |
|
Look directly for artifact without associated metadata |
3rd |
yes |
yes |
By default, Gradle will require that a dependency has associated metadata.
To relax this requirement and allow Gradle to resolve artifacts without associated metadata, specify the artifact metadata source:
mavenCentral {
metadataSources {
mavenPom()
artifact()
}
}mavenCentral {
metadataSources {
mavenPom()
artifact()
}
}The above example instructs Gradle to first look for component metadata from a POM file, and if not present, to derive metadata from the artifact itself.
For example, if you declare a module dependency, Gradle looks for a module metadata file (.module, .pom, or ivy.xml) in the repositories.
If such a module metadata file exists, it is parsed, and the artifacts of this module (e.g., hibernate-3.0.5.jar) as well as its dependencies (e.g., cglib) are downloaded.
If no such module metadata file exists, you need to configure metadata sources definitions to look for an artifact file called hibernate-3.0.5.jar directly:
repositories {
maven {
setUrl("https://repo.example.com/maven")
metadataSources {
mavenPom()
artifact()
}
}
}repositories {
maven {
url = "https://repo.example.com/maven"
metadataSources {
mavenPom()
artifact()
}
}
}When parsing metadata files (Ivy or Maven), Gradle checks for a marker that indicates the presence of a matching Gradle Module Metadata file. If found, Gradle will prefer the Gradle metadata.
To disable this behavior, use the ignoreGradleMetadataRedirection() option:
repositories {
maven {
url = uri("http://repo.mycompany.com/repo")
metadataSources {
mavenPom()
artifact()
ignoreGradleMetadataRedirection()
}
}
}repositories {
maven {
url = "http://repo.mycompany.com/repo"
metadataSources {
mavenPom()
artifact()
ignoreGradleMetadataRedirection()
}
}
}Supported Protocols
Gradle supports a variety of transport protocols for Maven and Ivy repositories.
Supported transport protocols
These protocols determine how Gradle communicates with the repositories to resolve dependencies.
| Type | Credential types | Link |
|---|---|---|
|
none |
|
|
username/password |
|
|
username/password |
|
|
username/password |
|
|
access key/secret key/session token or Environment variables |
|
|
default application credentials sourced from well known files, Environment variables etc. |
|
Note
|
Usernames and passwords should never be stored in plain text in your build files. Instead, store credentials in a local gradle.properties file, or provide the credentials via environment variables.
|
The transport protocol is specified as part of the repository URL.
Below are examples of how to declare repositories using various protocols:
repositories {
maven {
url = uri("http://repo.mycompany.com/maven2")
}
ivy {
url = uri("http://repo.mycompany.com/repo")
}
}repositories {
maven {
url = "http://repo.mycompany.com/maven2"
}
ivy {
url = "http://repo.mycompany.com/repo"
}
}repositories {
maven {
url = uri("sftp://repo.mycompany.com:22/maven2")
credentials {
username = providers.environmentVariable("username").orNull
password = providers.environmentVariable("password").orNull
}
}
ivy {
url = uri("sftp://repo.mycompany.com:22/repo")
credentials {
name = "mySecureCompanyRepository"
credentials(PasswordCredentials::class)
}
}
}repositories {
maven {
url = "sftp://repo.mycompany.com:22/maven2"
credentials {
username = providers.environmentVariable("username").orNull
password = providers.environmentVariable("password").orNull
}
}
ivy {
url = "sftp://repo.mycompany.com:22/repo"
credentials {
name = "mySecureCompanyRepository"
credentials(PasswordCredentials)
}
}
}repositories {
maven {
url = uri("s3://myCompanyBucket/maven2")
credentials(AwsCredentials::class) {
accessKey = "someKey"
secretKey = "someSecret"
// optional
sessionToken = "someSTSToken"
}
}
ivy {
url = uri("s3://myCompanyBucket/ivyrepo")
credentials(AwsCredentials::class) {
accessKey = "someKey"
secretKey = "someSecret"
// optional
sessionToken = "someSTSToken"
}
}
}repositories {
maven {
url = "s3://myCompanyBucket/maven2"
credentials(AwsCredentials) {
accessKey = "someKey"
secretKey = "someSecret"
// optional
sessionToken = "someSTSToken"
}
}
ivy {
url = "s3://myCompanyBucket/ivyrepo"
credentials(AwsCredentials) {
accessKey = "someKey"
secretKey = "someSecret"
// optional
sessionToken = "someSTSToken"
}
}
}repositories {
maven {
url = uri("s3://myCompanyBucket/maven2")
authentication {
create<AwsImAuthentication>("awsIm") // load from EC2 role or env var
}
}
ivy {
url = uri("s3://myCompanyBucket/ivyrepo")
authentication {
create<AwsImAuthentication>("awsIm")
}
}
}repositories {
maven {
url = "s3://myCompanyBucket/maven2"
authentication {
awsIm(AwsImAuthentication) // load from EC2 role or env var
}
}
ivy {
url = "s3://myCompanyBucket/ivyrepo"
authentication {
awsIm(AwsImAuthentication)
}
}
}repositories {
maven {
url = uri("gcs://myCompanyBucket/maven2")
}
ivy {
url = uri("gcs://myCompanyBucket/ivyrepo")
}
}repositories {
maven {
url = "gcs://myCompanyBucket/maven2"
}
ivy {
url = "gcs://myCompanyBucket/ivyrepo"
}
}Configuring authentication schemes
HTTP(S) authentication schemes configuration
When configuring a repository that uses HTTP or HTTPS transport protocols, several authentication schemes are available. By default, Gradle attempts to use all schemes supported by the Apache HttpClient library. However, you may want to explicitly specify which authentication schemes should be used when interacting with a remote server. When explicitly declared, only those specified schemes will be used.
Basic authentication
You can specify credentials for Maven repositories secured by basic authentication using PasswordCredentials:
repositories {
maven {
url = uri("http://repo.mycompany.com/maven2")
credentials {
username = providers.environmentVariable("username").orNull
password = providers.environmentVariable("password").orNull
}
}
}repositories {
maven {
url = "http://repo.mycompany.com/maven2"
credentials {
username = "user"
password = "password"
}
}
}Digest Authentication
To configure a repository to use only DigestAuthentication:
repositories {
maven {
url = uri("https://repo.mycompany.com/maven2")
credentials {
username = providers.environmentVariable("username").orNull
password = providers.environmentVariable("password").orNull
}
authentication {
create<DigestAuthentication>("digest")
}
}
}repositories {
maven {
url = 'https://repo.mycompany.com/maven2'
credentials {
username = "user"
password = "password"
}
authentication {
digest(DigestAuthentication)
}
}
}Supported Authentication Schemes
- BasicAuthentication
-
Basic access authentication over HTTP. Credentials are sent preemptively.
- DigestAuthentication
-
Digest access authentication over HTTP.
- HttpHeaderAuthentication
-
Authentication based on a custom HTTP header, such as private tokens or OAuth tokens.
Using preemptive authentication
By default, Gradle submits credentials only when a server responds with an authentication challenge (HTTP 401). However, some servers might respond with a different code (e.g., GitHub returns a 404) that could cause dependency resolution to fail. In such cases, you can configure Gradle to send credentials preemptively by explicitly using the BasicAuthentication scheme:
repositories {
maven {
url = uri("https://repo.mycompany.com/maven2")
credentials {
username = providers.environmentVariable("username").orNull
password = providers.environmentVariable("password").orNull
}
authentication {
create<BasicAuthentication>("basic")
}
}
}repositories {
maven {
url = 'https://repo.mycompany.com/maven2'
credentials {
username = "user"
password = "password"
}
authentication {
basic(BasicAuthentication)
}
}
}Using HTTP header authentication
For Maven repositories that require token-based, OAuth2, or other HTTP header-based authentication, you can use HttpHeaderCredentials and HttpHeaderAuthentication:
repositories {
maven {
url = uri("http://repo.mycompany.com/maven2")
credentials(HttpHeaderCredentials::class) {
name = "Private-Token"
value = "TOKEN"
}
authentication {
create<HttpHeaderAuthentication>("header")
}
}
}repositories {
maven {
url = "http://repo.mycompany.com/maven2"
credentials(HttpHeaderCredentials) {
name = "Private-Token"
value = "TOKEN"
}
authentication {
header(HttpHeaderAuthentication)
}
}
}AWS S3 repositories configuration
When configuring a repository that uses AWS S3, several options and settings are available.
S3 configuration properties
The following system properties can be used to configure interactions with S3 repositories:
org.gradle.s3.endpoint-
Overrides the AWS S3 endpoint when using a non-AWS, S3 API-compatible storage service.
org.gradle.s3.maxErrorRetry-
Specifies the maximum number of retry attempts when the S3 server responds with an HTTP 5xx status code. The default value is 3 if not specified.
S3 URL formats
S3 URLs must use the 'virtual-hosted-style' format:
s3://<bucketName>[.<regionSpecificEndpoint>]/<s3Key>Example: s3://myBucket.s3.eu-central-1.amazonaws.com/maven/release
-
myBucket: The AWS S3 bucket name. -
s3.eu-central-1.amazonaws.com: The optional region-specific endpoint. -
/maven/release: The AWS S3 key (a unique identifier for an object within a bucket).
S3 proxy settings
A proxy for S3 can be configured using the following system properties:
-
For HTTPS:
-
https.proxyHost -
https.proxyPort -
https.proxyUser -
https.proxyPassword -
http.nonProxyHosts(NOTE: this is not a typo.) *For HTTP (if org.gradle.s3.endpoint is set with an HTTP URI): -
http.proxyHost -
http.proxyPort -
http.proxyUser -
http.proxyPassword -
http.nonProxyHosts
-
S3 V4 Signatures (AWS4-HMAC-SHA256)
Some S3 regions (e.g., eu-central-1 in Frankfurt) require that all HTTP requests are signed using AWS’s signature version 4.
It is recommended to specify S3 URLs containing the region-specific endpoint when using buckets that require V4 signatures:
s3://somebucket.s3.eu-central-1.amazonaws.com/maven/releaseIf the region-specific endpoint is not specified for buckets requiring V4 Signatures, Gradle defaults to the us-east-1 region and will issue a warning:
Attempting to re-send the request to .... with AWS V4 authentication. To avoid this warning in the future, use region-specific endpoint to access buckets located in regions that require V4 signing.Failing to specify the region-specific endpoint for such buckets results in:
-
Increased network traffic: Three round-trips to AWS per file upload/download instead of one.
-
Slower builds: Due to increased network latency.
-
Higher transmission failure rates: Due to additional network overhead.
S3 Cross Account Access
In organizations with multiple AWS accounts (e.g., one per team), the bucket owner may differ from the artifact publisher or consumers.
To ensure consumers can access the artifacts, the bucket owner must grant the appropriate access.
Gradle automatically applies the bucket-owner-full-control Canned ACL to uploaded objects.
Ensure the publisher has the required IAM permissions (PutObjectAcl and PutObjectVersionAcl if bucket versioning is enabled), either directly or through an assumed IAM Role. For more details, see AWS S3 Access Permissions.
Google Cloud Storage repositories configuration
When configuring a repository that uses Google Cloud Storage (GCS), several configuration options and settings are available.
GCS configuration properties
You can use the following system properties to configure interactions with GCS repositories:
org.gradle.gcs.endpoint-
Overrides the Google Cloud Storage endpoint, useful when working with a storage service compatible with the GCS API but not hosted on Google Cloud Platform.
org.gradle.gcs.servicePath-
Specifies the root service path from which the GCS client builds requests, with a default value of
/.
GCS URL formats
GCS URLs use a 'virtual-hosted-style' format and must adhere to the following structure:
gcs://<bucketName>/<objectKey>-
<bucketName>: The name of the Google Cloud Storage bucket. -
<objectKey>: The unique identifier for an object within a bucket.
Example: gcs://myBucket/maven/release
-
myBucket: The bucket name. -
/maven/release: The GCS object key.
Handling credentials
Repository credentials should never be hardcoded in your build script but kept external. Gradle provides an API in artifact repositories that allows you to declare the type of credentials required, with their values being looked up from Gradle properties during the build.
For example, consider the following repository configuration:
repositories {
maven {
name = "mySecureRepository"
credentials(PasswordCredentials::class)
// url = uri(<<some repository url>>)
}
}repositories {
maven {
name = 'mySecureRepository'
credentials(PasswordCredentials)
// url = uri(<<some repository url>>)
}
}In this example, the username and password are automatically looked up from properties named mySecureRepositoryUsername and mySecureRepositoryPassword.
Configuration property prefix
The configuration property prefix, known as the identity, is derived from the repository name.
Credentials can be provided through any of the supported Gradle property mechanisms: gradle.properties file, command-line arguments, environment variables, or a combination of these.
Conditional credential requirement
Credentials are only required when the build process needs them. For example, if a project is configured to publish artifacts to a secured repository, but the publishing task isn’t invoked, Gradle won’t require the credentials. However, if a task requiring credentials is part of the build process, Gradle will check for their presence before running any tasks to prevent build failures due to missing credentials.
Supported credential types
Lookup is only supported for the credential types listed in the table below:
| Type | Argument | Base property name | Required? |
|---|---|---|---|
|
|
required |
|
|
|
required |
|
|
|
required |
|
|
|
required |
|
|
|
optional |
|
|
|
required |
|
|
|
required |
Filtering Repository Content
Gradle exposes an API to declare what a repository may or may not contain. There are different use cases for it:
-
Performance when you know a dependency will never be found in a specific repository
-
Security by avoiding leaking what dependencies are used in a private project
-
Reliability when some repositories contain invalid or incorrect metadata or artifacts
It’s even more important when considering that the declared order of repositories matter.
Declaring a repository filter
repositories {
maven {
url = uri("https://repo.mycompany.com/maven2")
content {
// this repository *only* contains artifacts with group "my.company"
includeGroup("my.company")
}
}
mavenCentral {
content {
// this repository contains everything BUT artifacts with group starting with "my.company"
excludeGroupByRegex("my\\.company.*")
}
}
}repositories {
maven {
url = "https://repo.mycompany.com/maven2"
content {
// this repository *only* contains artifacts with group "my.company"
includeGroup "my.company"
}
}
mavenCentral {
content {
// this repository contains everything BUT artifacts with group starting with "my.company"
excludeGroupByRegex "my\\.company.*"
}
}
}By default, repositories include everything and exclude nothing:
-
If you declare an include, then it excludes everything but what is included.
-
If you declare an exclude, then it includes everything but what is excluded.
-
If you declare both includes and excludes, then it includes only what is explicitly included and not excluded.
It is possible to filter either by explicit group, module or version, either strictly or using regular expressions. When using a strict version, it is possible to use a version range, using the format supported by Gradle. In addition, there are filtering options by resolution context: configuration name or even configuration attributes. See RepositoryContentDescriptor for details.
Declaring content exclusively found in one repository
Filters declared using the repository-level content filter are not exclusive. This means that declaring that a repository includes an artifact doesn’t mean that the other repositories can’t have it either: you must declare what every repository contains in extension.
Alternatively, Gradle provides an API which lets you declare that a repository exclusively includes an artifact. If you do so:
-
an artifact declared in a repository can’t be found in any other
-
exclusive repository content must be declared in extension (just like for repository-level content)
|
Note
|
Using exclusive repository content filters is a Gradle Best Practice. |
repositories {
// This repository will _not_ be searched for artifacts in my.company
// despite being declared first
mavenCentral()
exclusiveContent {
forRepository {
maven {
url = uri("https://repo.mycompany.com/maven2")
}
}
filter {
// this repository *only* contains artifacts with group "my.company"
includeGroup("my.company")
}
}
}repositories {
// This repository will _not_ be searched for artifacts in my.company
// despite being declared first
mavenCentral()
exclusiveContent {
forRepository {
maven {
url = "https://repo.mycompany.com/maven2"
}
}
filter {
// this repository *only* contains artifacts with group "my.company"
includeGroup "my.company"
}
}
}It is possible to filter either by explicit group, module or version, either strictly or using regular expressions. See InclusiveRepositoryContentDescriptor for details.
When setting up exclusive content filters be sure to also consider what repository will contain the transitives dependencies your build will resolve.
|
Note
|
If you leverage exclusive content filtering in the Your options are either to declare all repositories in settings or to use non-exclusive content filtering. |
Maven repository filtering
For Maven repositories, it’s often the case that a repository would either contain releases or snapshots. Gradle lets you declare what kind of artifacts are found in a repository using this DSL:
repositories {
maven {
url = uri("https://repo.mycompany.com/releases")
mavenContent {
releasesOnly()
}
}
maven {
url = uri("https://repo.mycompany.com/snapshots")
mavenContent {
snapshotsOnly()
}
}
}repositories {
maven {
url = "https://repo.mycompany.com/releases"
mavenContent {
releasesOnly()
}
}
maven {
url = "https://repo.mycompany.com/snapshots"
mavenContent {
snapshotsOnly()
}
}
}Enabling Ivy dynamic resolve mode
Normally, in an Ivy repository, dependencies are specified using the rev (revision) attribute in ivy.xml.
However, dynamic resolve mode allows Gradle to prefer the revConstraint attribute over rev:
-
If
revConstraintis present inivy.xml, Gradle will use it instead ofrev. -
If
revConstraintis not present, Gradle falls back torev.
This provides more flexibility in dependency resolution, particularly when working with Ivy repositories that define constraints on acceptable versions.
You need to explicitly enable dynamic resolve mode when declaring an Ivy repository:
// Can enable dynamic resolve mode when you define the repository
repositories {
ivy {
url = uri("http://repo.mycompany.com/repo")
resolve.isDynamicMode = true
}
}
// Can use a rule instead to enable (or disable) dynamic resolve mode for all repositories
repositories.withType<IvyArtifactRepository> {
resolve.isDynamicMode = true
}// Can enable dynamic resolve mode when you define the repository
repositories {
ivy {
url = "http://repo.mycompany.com/repo"
resolve.dynamicMode = true
}
}
// Can use a rule instead to enable (or disable) dynamic resolve mode for all repositories
repositories.withType(IvyArtifactRepository) {
resolve.dynamicMode = true
}|
Note
|
Dynamic resolve mode is only available for Gradle’s Ivy repositories. It is not available for Maven repositories, or custom Ivy DependencyResolver implementations.
|
Platforms
Platforms are used to ensure that all dependencies in a project align with a consistent set of versions.
Platforms help you manage and enforce version consistency across different modules or libraries, especially when you are working with a set of related dependencies that need to be kept in sync.
Using a platform
A platform is a specialized software component used to control transitive dependency versions. Typically, it consists of dependency constraints that either recommend or enforce specific versions. Platforms are particularly useful when you need to share consistent dependency versions across multiple projects.
In a typical setup you have:
-
A Platform Project: Which defines constraints for dependencies used across different subprojects.
-
A Number of Subprojects: Which depend on the platform and declare dependencies without specifying versions.
The java-platform plugin supports creating platforms in the Java ecosystem.
Platforms are also commonly published as Maven BOMs (Bill of Materials), which Gradle natively supports.
To use a platform, declare a dependency with the platform keyword:
dependencies {
// get recommended versions from the platform project
api(platform(project(":platform")))
// no version required
api("commons-httpclient:commons-httpclient")
}dependencies {
// get recommended versions from the platform project
api platform(project(':platform'))
// no version required
api 'commons-httpclient:commons-httpclient'
}This notation automatically performs several actions:
-
Sets the
org.gradle.categoryattribute to platform, ensuring Gradle selects the platform component. -
Enables the
endorseStrictVersionsbehavior by default, enforcing strict versions defined in the platform.
If strict version enforcement isn’t needed, you can disable it using the doNotEndorseStrictVersions method.
Creating a platform
In Java projects, the java-platform plugin combined with dependency constraints can be used to create a platform:
plugins {
`java-platform`
}
dependencies {
constraints {
// Platform declares some versions of libraries used in subprojects
api("commons-httpclient:commons-httpclient:3.1")
api("org.apache.commons:commons-lang3:3.8.1")
}
}plugins {
id 'java-platform'
}
dependencies {
constraints {
// Platform declares some versions of libraries used in subprojects
api 'commons-httpclient:commons-httpclient:3.1'
api 'org.apache.commons:commons-lang3:3.8.1'
}
}This defines a custom platform with specific versions of commons-httpclient and commons-lang3 that can be applied in other projects.
Importing a platform
Gradle supports importing BOMs, which are POM files containing <dependencyManagement> sections that manage dependency versions.
In order to qualify as a BOM, a .pom file needs to have pom set.
This means that the POM file should explicitly specify <packaging>pom</packaging> in its metadata.
Gradle treats all entries in the block of a BOM similar to Adding Constraints On Dependencies.
Regular Platform
To import a BOM, declare a dependency on it using the platform dependency modifier method:
dependencies {
// import a BOM
implementation(platform("org.springframework.boot:spring-boot-dependencies:1.5.8.RELEASE"))
// define dependencies without versions
implementation("com.google.code.gson:gson")
implementation("dom4j:dom4j")
}dependencies {
// import a BOM
implementation platform('org.springframework.boot:spring-boot-dependencies:1.5.8.RELEASE')
// define dependencies without versions
implementation 'com.google.code.gson:gson'
implementation 'dom4j:dom4j'
}In this example, the Spring Boot BOM provides the versions for gson and dom4j, so no explicit versions are needed.
Enforced Platform
The enforcedPlatform keyword can be used to override any versions found in the dependency graph, but should be used with caution as it is effectively transitive and exports forced versions to all consumers of your project:
dependencies {
// import a BOM. The versions used in this file will override any other version found in the graph
implementation(enforcedPlatform("org.springframework.boot:spring-boot-dependencies:1.5.8.RELEASE"))
// define dependencies without versions
implementation("com.google.code.gson:gson")
implementation("dom4j:dom4j")
// this version will be overridden by the one found in the BOM
implementation("org.codehaus.groovy:groovy:1.8.6")
}dependencies {
// import a BOM. The versions used in this file will override any other version found in the graph
implementation enforcedPlatform('org.springframework.boot:spring-boot-dependencies:1.5.8.RELEASE')
// define dependencies without versions
implementation 'com.google.code.gson:gson'
implementation 'dom4j:dom4j'
// this version will be overridden by the one found in the BOM
implementation 'org.codehaus.groovy:groovy:1.8.6'
}When using enforcedPlatform, exercise caution if your software component is intended for consumption by others.
This declaration is transitive and affects the dependency graph of your consumers.
If they disagree with any enforced versions, they’ll need to use exclude.
Instead, if your reusable component strongly favors specific third-party dependency versions, consider using a rich version declaration with strictly.
Version Catalogs
A version catalog is a selected list of dependencies that can be referenced in build scripts, simplifying dependency management.
Instead of specifying dependencies directly using string notation, you can pick them from a version catalog:
dependencies {
implementation(libs.groovy.core)
}dependencies {
implementation(libs.groovy.core)
}In this example, libs represents the catalog, and groovy is a dependency available in it.
Where the version catalog defining libs.groovy.core is a libs.versions.toml file in the gradle directory:
[libraries]
groovy-core = { group = "org.codehaus.groovy", name = "groovy", version = "3.0.5" }Version catalogs offer several advantages:
-
Type-Safe Accessors: Gradle generates type-safe accessors for each catalog, enabling autocompletion in IDEs.
-
Centralized Version Management: Each catalog is visible to all projects in a build.
-
Dependency Bundles: Catalogs can group commonly used dependencies into bundles.
-
Version Separation: Catalogs can separate dependency coordinates from version information, allowing shared version declarations.
-
Conflict Resolution: Like regular dependency notation, version catalogs declare requested versions but do not enforce them during conflict resolution.
|
Note
|
Version catalogs declare requested versions but do not enforce them. Gradle may still select different versions due to dependency graph conflicts or constraints applied through platforms or other dependency management APIs. |
Using a catalog
To access items in a version catalog defined in the standard libs.versions.toml file located in the gradle directory, you use the libs object in your build scripts.
For example, to reference a library, you can use libs.<alias>, and for a plugin, you can use libs.plugins.<alias>.
Declaring dependencies using a version catalog:
dependencies {
implementation(libs.groovy.core)
implementation(libs.groovy.json)
implementation(libs.groovy.nio)
}dependencies {
implementation libs.groovy.core
implementation libs.groovy.json
implementation libs.groovy.nio
}Is the same as:
dependencies {
implementation("org.codehaus.groovy:groovy:3.0.5")
implementation("org.codehaus.groovy:groovy-json:3.0.5")
implementation("org.codehaus.groovy:groovy-nio:3.0.5")
}dependencies {
implementation 'org.codehaus.groovy:groovy:3.0.5'
implementation 'org.codehaus.groovy:groovy-json:3.0.5'
implementation 'org.codehaus.groovy:groovy-nio:3.0.5'
}If the catalog looks as follows:
[versions]
groovy = "3.0.5"
[libraries]
groovy-core = { module = "org.codehaus.groovy:groovy", version.ref = "groovy" }
groovy-json = { module = "org.codehaus.groovy:groovy-json", version.ref = "groovy" }
groovy-nio = { module = "org.codehaus.groovy:groovy-nio", version.ref = "groovy" }Where the catalog can be imported from a local file or a repository.
Version catalogs use a TOML format in which accessors map directly to the aliases and versions defined in it, providing type-safe access to dependencies and plugins. This enables IDEs to provide autocompletion, highlight typos, and identify missing dependencies as errors.
Aliases and type-safe accessors
Aliases in a version catalog consist of identifiers separated by a dash (-) or underscore (_).
Type-safe accessors are generated for each alias, normalized to dot notation.
Consider the following catalog:
[libraries]
# Dashes create nested accessor groups
ktor-client-core = "io.ktor:ktor-client-core:3.1.0"
ktor-client-cio = "io.ktor:ktor-client-cio:3.1.0"
ktor-client-logging = "io.ktor:ktor-client-logging:3.1.0"
# A single-segment alias stays flat
junit = "junit:junit:4.13.2"Each dash in the alias maps to a dot in the accessor, creating a nested group that IDEs can autocomplete:
| Alias | Generated accessor |
|---|---|
|
|
|
|
|
|
|
|
Classifiers, artifact types, and capabilities
Version catalogs intentionally capture only dependency coordinates: group, name, and version.
They do not support classifiers, artifact types (@aar, @zip), excludes, or capabilities directly in the TOML file.
[libraries]
my-lib = { module = "com.example:my-lib", version = "1.0.0" }When you need a specific classifier for a dependency declared in a version catalog, use variantOf() at the dependency declaration site in your build script:
dependencies {
implementation(variantOf(libs.my.lib) { classifier("test-fixtures") })
}dependencies {
implementation(variantOf(libs.my.lib) { classifier('test-fixtures') })
}This keeps the catalog focused on coordinates while letting each consumer choose the appropriate classifier.
For artifact types (common in Android projects needing @aar), use the artifact block:
dependencies {
implementation(libs.my.lib) {
artifact {
name = "my-lib"
type = "aar"
}
}
}dependencies {
implementation(libs.my.lib) {
artifact {
name = 'my-lib'
type = 'aar'
}
}
}See TOML Limitations to learn more.
Importing a published catalog
A catalog published with the version-catalog plugin can be imported in a consumer’s settings.gradle(.kts) file using the Settings API:
dependencyResolutionManagement {
versionCatalogs {
create("libs") {
from("com.mycompany:catalog:1.0")
}
}
}dependencyResolutionManagement {
versionCatalogs {
libs {
from("com.mycompany:catalog:1.0")
}
}
}The from() method accepts standard dependency notation ("group:artifact:version").
Gradle downloads the TOML file from whatever repositories are configured in the dependencyResolutionManagement block and makes its entries available as type-safe accessors.
Once imported, all projects in the build can reference the catalog’s libraries, plugins, and bundles using the catalog name (e.g., libs.someLibrary).
Importing a catalog from a file
|
Important
|
Gradle automatically imports a catalog in the gradle directory named libs.versions.toml. You do not need to import it programmatically.
|
The version catalog builder API allows importing a catalog from an external file, enabling reuse across different parts of a build, such as sharing the main build’s catalog with buildSrc.
For example, you can include a catalog in the buildSrc/settings.gradle(.kts) file as follows:
dependencyResolutionManagement {
versionCatalogs {
create("libs") {
from(files("../gradle/libs.versions.toml"))
}
}
}dependencyResolutionManagement {
versionCatalogs {
libs {
from(files("../gradle/libs.versions.toml"))
}
}
}The VersionCatalogBuilder.from(Object dependencyNotation) method accepts only a single file, meaning that notations like Project.files(java.lang.Object…) must refer to one file. Otherwise, the build will fail.
|
Tip
|
Remember that you don’t need to import the version catalog named libs.versions.toml if it resides in your gradle folder. It will be imported automatically.
|
Importing multiple catalogs
You can declare multiple catalogs using the Settings API.
For example, the default libs catalog is auto-imported from gradle/libs.versions.toml.
To add additional catalogs for build tools and test dependencies, create gradle/tools.versions.toml and gradle/test.versions.toml files and register them:
versionCatalogs {
create("tools") {
from(files("gradle/tools.versions.toml"))
}
create("testLibs") {
from(files("gradle/test.versions.toml"))
}
// HOWEVER THIS IS NOT ALLOWED - IT WILL NOT WORK
/* In version catalog libs, you can only call the 'from' method a single time:
create("libs") {
from(files("gradle/base.versions.toml"))
from(files("gradle/extras.versions.toml")) // Error!
}
*/
}versionCatalogs {
tools {
from(files("gradle/tools.versions.toml"))
}
testLibs {
from(files("gradle/test.versions.toml"))
}
// HOWEVER THIS IS NOT ALLOWED - IT WILL NOT WORK
/* In version catalog libs, you can only call the 'from' method a single time:
libs {
from(files("gradle/base.versions.toml"))
from(files("gradle/extras.versions.toml")) // Error!
}
*/
}Each catalog generates its own extension, so you reference them by name in build scripts:
dependencies {
implementation(libs.guava)
implementation(libs.commons.lang3)
implementation(tools.errorprone.annotations)
implementation(tools.jsr305)
testImplementation(testLibs.junit.api)
testImplementation(testLibs.mockito)
}dependencies {
implementation libs.guava
implementation libs.commons.lang3
implementation tools.errorprone.annotations
implementation tools.jsr305
testImplementation testLibs.junit.api
testImplementation testLibs.mockito
}|
Note
|
To minimize the risk of naming conflicts, each catalog generates an extension applied to all projects, so it’s advisable to choose a unique name. One effective approach is to select a name that ends with |
Creating a catalog
Version catalogs are conventionally declared using a libs.versions.toml file located in the gradle subdirectory of the root build.
They use the TOML format:
[versions]
groovy = "3.0.5"
checkstyle = "8.37"
[libraries]
groovy-core = { module = "org.codehaus.groovy:groovy", version.ref = "groovy" }
groovy-json = { module = "org.codehaus.groovy:groovy-json", version.ref = "groovy" }
groovy-nio = { module = "org.codehaus.groovy:groovy-nio", version.ref = "groovy" }
commons-lang3 = { group = "org.apache.commons", name = "commons-lang3", version = { strictly = "[3.8, 4.0[", prefer = "3.9" } }
[bundles]
groovy = ["groovy-core", "groovy-json", "groovy-nio"]
[plugins]
versions = { id = "com.github.ben-manes.versions", version = "0.45.0" }However, they can reside in other folders and use different names. See Importing a catalog from a file for importing a catalog from a custom location, or Importing multiple catalogs for registering additional catalogs.
The TOML format
The version catalog TOML file has four sections:
-
[versions]– Declares version identifiers. -
[libraries]– Maps aliases to GAV coordinates. -
[bundles]– Defines dependency bundles. -
[plugins]– Declares plugin versions.
The TOML file format is very lenient and allows you to write "dotted" properties as shortcuts for full object declarations.
Versions
Versions can be declared either as a single string, in which case they are interpreted as a required version, or as a rich version:
[versions]
other-lib = "5.5.0" # Required version
my-lib = { strictly = "[1.0, 2.0[", prefer = "1.2" } # Rich versionSupported members of a version declaration are:
-
require: the required version -
strictly: the strict version -
prefer: the preferred version -
reject: the list of rejected versions -
rejectAll: a boolean to reject all versions
Libraries
Each library is mapped to a GAV coordinate: group, artifact, version.
They can be declared as a simple string, in which case they are interpreted as coordinates, or a separate group and name:
[versions]
common = "1.4"
[libraries]
my-lib = "com.mycompany:mylib:1.4"
my-lib-no-version.module = "com.mycompany:mylib"
my-other-lib = { module = "com.mycompany:other", version = "1.4" }
my-other-lib2 = { group = "com.mycompany", name = "alternate", version = "1.4" }
mylib-full-format = { group = "com.mycompany", name = "alternate", version = { require = "1.4" } }You can also define strict or preferred versions using strictly or prefer:
[libraries]
commons-lang3 = { group = "org.apache.commons", name = "commons-lang3", version = { strictly = "[3.8, 4.0[", prefer = "3.9" } }In case you want to reference a version declared in the [versions] section, use the version.ref property:
[versions]
some = "1.4"
[libraries]
my-lib = { group = "com.mycompany", name="mylib", version.ref="some" }Bundles
Bundles group multiple library aliases, so they can be referenced together in the build script.
[versions]
groovy = "3.0.9"
[libraries]
groovy-core = { group = "org.codehaus.groovy", name = "groovy", version.ref = "groovy" }
groovy-json = { group = "org.codehaus.groovy", name = "groovy-json", version.ref = "groovy" }
groovy-nio = { group = "org.codehaus.groovy", name = "groovy-nio", version.ref = "groovy" }
[bundles]
groovy = ["groovy-core", "groovy-json", "groovy-nio"]This is useful for pulling in several related dependencies with a single alias:
dependencies {
implementation(libs.bundles.groovy)
}dependencies {
implementation libs.bundles.groovy
}Plugins
This section defines the plugins and their versions by mapping plugin IDs to version numbers.
Just like libraries, you can define plugin versions using aliases from the [versions] section or directly specify the version.
[plugins]
versions = { id = "com.github.ben-manes.versions", version = "0.45.0" }Which can be accessed in any project of the build using the plugins {} block.
To refer to a plugin from the catalog, use the alias() function:
plugins {
`java-library`
checkstyle
alias(libs.plugins.versions)
}plugins {
id 'java-library'
id 'checkstyle'
// Use the plugin `versions` as declared in the `libs` version catalog
alias(libs.plugins.versions)
}|
Warning
|
You cannot use a plugin declared in a version catalog in your settings file or settings plugin. |
Avoiding subgroup accessors
To avoid generating subgroup accessors, use camelCase notation:
| Aliases | Accessors |
|---|---|
|
|
|
|
If you cannot rename aliases, for example, when consuming a published catalog, use asProvider() to access the parent version directly.
Given a catalog with both jackson and jackson-databind version aliases, libs.versions.jackson returns the subgroup accessor (because jackson-databind creates a jackson.databind subgroup).
To get the jackson version itself, call asProvider():
val jacksonVersion = libs.versions.jackson.asProvider()def jacksonVersion = libs.versions.jackson.asProvider()Reserved keywords
Certain keywords, like extensions, class, and convention, are reserved and cannot be used as aliases.
Additionally, bundles, versions, and plugins cannot be the first subgroup in a dependency alias.
For example, the alias versions-dependency is not valid, but versionsDependency or dependency-versions are valid.
Limitations
These are explicit limitations the catalog TOML format does not support:
-
classifierattributes -
type = "aar"orext = "zip"artifact types -
excluderules -
capabilitiesrequirements
Programming catalogs
Version catalogs can be declared programmatically in the settings.gradle(.kts) file using the Settings API:
dependencyResolutionManagement {
versionCatalogs {
create("libs") {
version("groovy", "3.0.5")
version("checkstyle", "8.37")
library("groovy-core", "org.codehaus.groovy", "groovy").versionRef("groovy")
library("groovy-json", "org.codehaus.groovy", "groovy-json").versionRef("groovy")
library("groovy-nio", "org.codehaus.groovy", "groovy-nio").versionRef("groovy")
library("commons-lang3", "org.apache.commons", "commons-lang3").version {
strictly("[3.8, 4.0[")
prefer("3.9")
}
}
}
}dependencyResolutionManagement {
versionCatalogs {
libs {
version('groovy', '3.0.5')
version('checkstyle', '8.37')
library('groovy-core', 'org.codehaus.groovy', 'groovy').versionRef('groovy')
library('groovy-json', 'org.codehaus.groovy', 'groovy-json').versionRef('groovy')
library('groovy-nio', 'org.codehaus.groovy', 'groovy-nio').versionRef('groovy')
library('commons-lang3', 'org.apache.commons', 'commons-lang3').version {
strictly '[3.8, 4.0['
prefer '3.9'
}
}
}
}|
Tip
|
Don’t use libs for your programmatic version catalog name if you have the default libs.versions.toml in your project.
|
Publishing a catalog
There are three ways to share a version catalog across builds:
-
Check the TOML file into source control — The simplest approach. Place
gradle/libs.versions.tomlin a shared repository that all builds can access. This works well for monorepos or when teams can reference a common Git repository. -
Write a settings plugin — Create a plugin that programmatically declares catalog entries, publish it to the Gradle Plugin Portal or an internal repository, and have consumers apply it in their settings file. This offers the most flexibility but requires more effort.
-
Use the
version-catalogplugin — Publish the catalog as a Maven or Ivy artifact so it can be consumed like any other dependency. This is the best approach for organizations that need to distribute a catalog to many independent builds.
Using the version-catalog plugin
The version-catalog plugin lets you publish a catalog as a Maven or Ivy artifact.
It works with both an existing TOML file and programmatic catalog declarations.
If you already have a gradle/libs.versions.toml file, you can publish it directly by importing it into the catalog extension:
plugins {
`version-catalog`
`maven-publish`
}
catalog {
versionCatalog {
from(files("gradle/libs.versions.toml"))
}
}
group = "com.mycompany"
version = "1.0"
publishing {
publications {
create<MavenPublication>("maven") {
from(components["versionCatalog"])
}
}
}plugins {
id 'version-catalog'
id 'maven-publish'
}
catalog {
versionCatalog {
from(files("gradle/libs.versions.toml"))
}
}
group = 'com.mycompany'
version = '1.0'
publishing {
publications {
maven(MavenPublication) {
from components.versionCatalog
}
}
}This keeps the TOML file as the single source of truth — there is no need to redeclare entries in the build script.
Alternatively, you can declare the catalog entries programmatically in the catalog extension:
catalog {
// declare the aliases, bundles and versions in this block
versionCatalog {
library("my-lib", "com.mycompany:mylib:1.2")
}
}catalog {
// declare the aliases, bundles and versions in this block
versionCatalog {
library('my-lib', 'com.mycompany:mylib:1.2')
}
}In both cases, configure a publication using the versionCatalog component:
publishing {
publications {
create<MavenPublication>("maven") {
from(components["versionCatalog"])
}
}
}publishing {
publications {
maven(MavenPublication) {
from components.versionCatalog
}
}
}When you run ./gradlew publish, the catalog is uploaded as a Maven artifact (with the .toml extension).
This artifact can then be imported by other Gradle builds.
|
Note
|
The published artifact is a standard TOML file attached to Maven coordinates (e.g., com.mycompany:catalog:1.0).
Consumers reference these coordinates to import the catalog — they do not need access to the original source code or build script.
|
For example, a consumer imports the published catalog in their settings.gradle(.kts) file:
dependencyResolutionManagement {
versionCatalogs {
create("libs") {
from("com.mycompany:catalog:1.0")
}
}
}dependencyResolutionManagement {
versionCatalogs {
libs {
from("com.mycompany:catalog:1.0")
}
}
}Changing the catalog name
By default, the libs.versions.toml file is used as input for the libs catalog.
However, you can rename the default catalog if an extension with the same name already exists:
dependencyResolutionManagement {
defaultLibrariesExtensionName = "projectLibs"
}dependencyResolutionManagement {
defaultLibrariesExtensionName = 'projectLibs'
}Overwriting catalog versions
You can overwrite versions when importing a catalog:
dependencyResolutionManagement {
versionCatalogs {
create("amendedLibs") {
from("com.mycompany:catalog:1.0")
// overwrite the "groovy" version declared in the imported catalog
version("groovy", "3.0.6")
}
}
}dependencyResolutionManagement {
versionCatalogs {
amendedLibs {
from("com.mycompany:catalog:1.0")
// overwrite the "groovy" version declared in the imported catalog
version("groovy", "3.0.6")
}
}
}In the examples above, any dependency referencing the groovy version will automatically be updated to use 3.0.6.
You can see how this is used in Working with multiple version catalogs.
|
Note
|
Overwriting a version only affects what is imported and used when declaring dependencies. The actual resolved dependency version may differ due to conflict resolution. |
Using a catalog in buildSrc
Version catalogs provide a centralized way to manage dependencies in a project.
However, buildSrc does not automatically inherit the version catalog from the main project, so additional configuration is required.
To access a version catalog inside buildSrc, you need to explicitly import it in buildSrc/settings.gradle(.kts):
// Add the version catalog to buildSrc using dependencyResolutionManagement
dependencyResolutionManagement {
versionCatalogs {
create("libs") {
from(files("../gradle/libs.versions.toml"))
}
}
}// Add the version catalog to buildSrc using dependencyResolutionManagement
dependencyResolutionManagement {
versionCatalogs {
create("libs") {
from(files("../gradle/libs.versions.toml"))
}
}
}Once the version catalog is imported, dependencies can be referenced using a few tricks:
plugins {
`kotlin-dsl`
alias(libs.plugins.versions) // Access version catalog in buildSrc build file for plugin
}
repositories {
gradlePluginPortal()
}
dependencies {
// Access version catalog in buildSrc build file for dependencies
implementation(plugin(libs.plugins.jacocolog)) // Plugin dependency
implementation(libs.groovy.core) // Regular library from version catalog
implementation("org.apache.commons:commons-lang3:3.9") // Direct dependency
}
// Helper function that transforms a Gradle Plugin alias from a
// Version Catalog into a valid dependency notation for buildSrc
fun DependencyHandlerScope.plugin(plugin: Provider<PluginDependency>) =
plugin.map { "${it.pluginId}:${it.pluginId}.gradle.plugin:${it.version}" }plugins {
id 'groovy-gradle-plugin'
alias(libs.plugins.versions) // Access version catalog in buildSrc for plugin
}
repositories {
gradlePluginPortal()
}
def catalogs = project.extensions.getByType(VersionCatalogsExtension)
def libs = catalogs.named("libs")
dependencies {
// Access version catalog in buildSrc for dependencies
implementation plugin(libs.findPlugin("jacocolog").get()) // Plugin dependency
implementation libs.findLibrary("groovy-core").get() // Regular library from version catalog
implementation "org.apache.commons:commons-lang3:3.9" // Direct dependency
}
// Helper function that transforms a Gradle Plugin alias from a
// Version Catalog into a valid dependency notation for buildSrc
def plugin(Provider<PluginDependency> plugin) {
return plugin.map { it.pluginId + ":" + it.pluginId + ".gradle.plugin:" + it.version }
}In precompiled script plugins inside buildSrc, the version catalog can be accessed using extensions.getByType(VersionCatalogsExtension) as demonstrated in the dependencies block of this convention plugin:
plugins {
id("java-library")
//alias(libs.plugins.jacocolog) // Unfortunately it is not possible the version catalog in buildSrc code for plugins
// Remember that unlike regular Gradle projects, convention plugins in buildSrc do not automatically resolve
// external plugins. We must declare them as dependencies in buildSrc/build.gradle.kts.
id("org.barfuin.gradle.jacocolog") // Apply the plugin manually as a workaround with the external plugin
// version from the version catalog specified in implementation dependency
// artifact in build file
}
repositories {
mavenCentral()
}
// Access the version catalog
val libs = extensions.getByType(VersionCatalogsExtension::class.java).named("libs")
//val libs = the<VersionCatalogsExtension>().named("libs")
dependencies {
// Access version catalog in buildSrc code for dependencies
implementation(libs.findLibrary("guava").get()) // Regular library from version catalog
testImplementation(platform("org.junit:junit-bom:5.9.1")) // Platform dependency
testImplementation("org.junit.jupiter:junit-jupiter") // Direct dependency
}
tasks.test {
useJUnitPlatform()
}plugins {
id 'java-library'
// alias(libs.plugins.jacocolog) - Unfortunately, it is not possible to use the version catalog for plugins in buildSrc
// Unlike regular Gradle projects, convention plugins in buildSrc do not automatically resolve
// external plugins. We must declare them as dependencies in buildSrc/build.gradle.
id 'org.barfuin.gradle.jacocolog' // Apply the plugin manually as a workaround
// The external plugin version comes from the implementation dependency
// artifact in the build file
}
repositories {
mavenCentral()
}
// Access the version catalog
def libs = project.extensions.getByType(VersionCatalogsExtension).named("libs")
dependencies {
// Access version catalog in buildSrc for dependencies
implementation libs.findLibrary("guava").get() // Regular library from version catalog
testImplementation platform("org.junit:junit-bom:5.9.1") // Platform dependency
testImplementation "org.junit.jupiter:junit-jupiter" // Direct dependency
}
tasks.withType(Test).configureEach {
useJUnitPlatform()
}However, the plugins block in the precompiled script plugin cannot access the version catalog.
Working with multiple version catalogs
Most builds should use a single libs.versions.toml file.
A single catalog centralizes all dependency coordinates, avoids version duplication, and lets every subproject share the same type-safe accessors.
Use naming conventions, such as alias prefixes, to logically separate groups of dependencies within that file:
[versions]
kotlin = "2.3.21"
junit = "5.12.0"
[libraries]
# ── Production ───────────────────────────────
guava = { module = "com.google.guava:guava", version = "33.4.0-jre" }
commons-lang3 = { module = "org.apache.commons:commons-lang3", version = "3.17.0" }
# ── Testing ──────────────────────────────────
junit-jupiter = { module = "org.junit.jupiter:junit-jupiter", version.ref = "junit" }
mockito-core = { module = "org.mockito:mockito-core", version = "5.14.0" }Consider splitting into multiple catalogs only when you have a concrete need to enforce boundaries between dependency scopes. Typical reasons include:
-
Auditing shipped artifacts. When you must clearly distinguish which dependencies end up in a published distribution from those used only for testing or code generation, separate catalogs make accidental cross-contamination visible at the declaration site.
-
Independent build-logic dependencies. Plugins applied inside
build-logicorbuildSrcmay need their own catalog that is resolved in the settings classpath — before the main build’s catalog is available. -
Organizational sharing. An organization-wide "platform" catalog is published as a Maven artifact and imported by many repositories, while each repository maintains a local catalog for project-specific dependencies.
If none of these situations apply, a single catalog with clear naming conventions is simpler and avoids the version-sharing challenges described below.
Sharing Versions Across Multiple Catalogs
Each version catalog TOML file is self-contained.
There is no built-in syntax, such as an include directive or cross-file version.ref, that lets one TOML file reference a version declared in another.
If the same library version must appear in two catalogs, you must arrange for it to reach both catalogs yourself.
The from() method, which loads a catalog from a TOML file or a published artifact, may only be called once per catalog.
Attempting to call it twice produces an error:
|
Note
|
In version catalog libs, you can only call the from method a single time.
|
This means you cannot merge two TOML files into a single catalog.
Below are three concrete workarounds, ordered from simplest to most flexible.
Workaround 1 — Duplicate and verify
Declare the shared version in every TOML file that needs it, and add a lightweight check that the values stay in sync:
[versions]
errorProne = "2.28.0"[versions]
errorProne = "2.28.0"Add a small verification task (or a CI script) that parses both files and fails the build if the values diverge:
tasks.register("verifySharedVersions") {
val distToml = file("gradle/distribution.versions.toml").readText()
val testToml = file("gradle/test.versions.toml").readText()
doLast {
// Extract the errorProne version from each file
val regex = """errorProne\s*=\s*"(.+?)"""".toRegex()
val distVersion = regex.find(distToml)?.groupValues?.get(1)
val testVersion = regex.find(testToml)?.groupValues?.get(1)
require(distVersion == testVersion) {
"errorProne version mismatch: distribution=$distVersion, test=$testVersion"
}
}
}tasks.register('verifySharedVersions') {
def distToml = file('gradle/distribution.versions.toml').text
def testToml = file('gradle/test.versions.toml').text
doLast {
// Extract the errorProne version from each file
def regex = /errorProne\s*=\s*"(.+?)"/
def distMatcher = distToml =~ regex
def testMatcher = testToml =~ regex
def distVersion = distMatcher ? distMatcher[0][1] : null
def testVersion = testMatcher ? testMatcher[0][1] : null
assert distVersion == testVersion :
"errorProne version mismatch: distribution=$distVersion, test=$testVersion"
}
}This approach is straightforward and keeps each TOML file independently readable, but it requires discipline and will not scale well beyond a handful of shared versions.
Workaround 2 — External properties file injected programmatically
Extract shared versions into a plain properties file and inject them into each catalog in settings.gradle(.kts).
errorProne=2.28.0
kotlin=2.3.21val sharedVersions = java.util.Properties().apply {
file("gradle/shared-versions.properties").inputStream().use { load(it) }
}
dependencyResolutionManagement {
repositories {
mavenCentral()
}
versionCatalogs {
create("distributionLibs") {
from(files("gradle/distribution.versions.toml"))
version("errorProne", sharedVersions.getProperty("errorProne"))
version("kotlin", sharedVersions.getProperty("kotlin"))
}
create("testLibs") {
from(files("gradle/test.versions.toml"))
version("errorProne", sharedVersions.getProperty("errorProne"))
version("kotlin", sharedVersions.getProperty("kotlin"))
}
}
}def sharedVersions = new Properties()
file('gradle/shared-versions.properties').withInputStream { sharedVersions.load(it) }
dependencyResolutionManagement {
repositories {
mavenCentral()
}
versionCatalogs {
distributionLibs {
from(files('gradle/distribution.versions.toml'))
version('errorProne', sharedVersions.getProperty('errorProne'))
version('kotlin', sharedVersions.getProperty('kotlin'))
}
testLibs {
from(files('gradle/test.versions.toml'))
version('errorProne', sharedVersions.getProperty('errorProne'))
version('kotlin', sharedVersions.getProperty('kotlin'))
}
}
}The TOML files use version.ref to reference these versions as if they were declared locally:
# The "errorProne" and "kotlin" versions are injected
# programmatically in settings.gradle.kts — do not
# declare them here.
[libraries]
errorProne-core = { module = "com.google.errorprone:error_prone_core", version.ref = "errorProne" }
kotlin-stdlib = { module = "org.jetbrains.kotlin:kotlin-stdlib", version.ref = "kotlin" }When you call version("errorProne", "2.28.0") on the catalog builder after from(files(…)), the programmatic call adds or overrides the version in the catalog that was loaded from the TOML file.
Libraries in the TOML file that reference version.ref = "errorProne" will pick up the injected value.
This is the pattern the Gradle Build Tool team uses in the gradle/gradle repository, where a shared-versions.properties file feeds versions into four separate catalogs (distribution, provided, test, build).
Workaround 3 — Published base catalog with local overrides
For organizations that share a common set of dependency versions across many repositories, publish a base catalog as a Maven artifact and let each repository layer project-specific versions on top.
Publishing project (build.gradle(.kts)):
plugins {
`version-catalog`
`maven-publish`
}
catalog {
versionCatalog {
version("kotlin", "2.3.21")
version("errorProne", "2.28.0")
library("kotlin-stdlib", "org.jetbrains.kotlin", "kotlin-stdlib").versionRef("kotlin")
library("errorProne-core", "com.google.errorprone", "error_prone_core").versionRef("errorProne")
}
}
group = "com.mycompany"
version = "1.0"
publishing {
publications {
create<MavenPublication>("catalog") {
from(components["versionCatalog"])
}
}
}plugins {
id 'version-catalog'
id 'maven-publish'
}
catalog {
versionCatalog {
version('kotlin', '2.3.21')
version('errorProne', '2.28.0')
library('kotlin-stdlib', 'org.jetbrains.kotlin', 'kotlin-stdlib').versionRef('kotlin')
library('errorProne-core', 'com.google.errorprone', 'error_prone_core').versionRef('errorProne')
}
}
group = 'com.mycompany'
version = '1.0'
publishing {
publications {
maven(MavenPublication) {
from components.versionCatalog
}
}
}Consuming project (settings.gradle(.kts)):
dependencyResolutionManagement {
versionCatalogs {
// Import the organization-wide catalog
create("libs") {
from("com.mycompany:catalog:1.0")
// Override a specific version for this project
version("kotlin", "2.3.21")
}
// A local catalog for project-specific dependencies
create("projectLibs") {
from(files("gradle/project.versions.toml"))
}
}
}dependencyResolutionManagement {
versionCatalogs {
// Import the organization-wide catalog
libs {
from('com.mycompany:catalog:1.0')
// Override a specific version for this project
version('kotlin', '2.3.21')
}
// A local catalog for project-specific dependencies
projectLibs {
from(files('gradle/project.versions.toml'))
}
}
}This pattern cleanly separates organizational standards from project-level concerns, but it introduces a publishing and versioning lifecycle for the catalog artifact itself.
Combining from() with Programmatic version() Calls
The version catalog builder API allows you to mix a TOML file import with programmatic declarations in the same catalog.
The from() call loads the base content, and subsequent version(), library(), bundle(), or plugin() calls add to or override that content.
dependencyResolutionManagement {
versionCatalogs {
create("libs") {
from(files("gradle/catalog.versions.toml"))
// Override an existing version
version("groovy", "3.0.6")
// Add a new version not present in the TOML file
version("errorProne", "2.28.0")
// Add a library that uses the injected version
library("errorProne-core", "com.google.errorprone", "error_prone_core").versionRef("errorProne")
}
}
}dependencyResolutionManagement {
versionCatalogs {
libs {
from(files("gradle/catalog.versions.toml"))
// Override an existing version
version("groovy", "3.0.6")
// Add a new version not present in the TOML file
version("errorProne", "2.28.0")
// Add a library that uses the injected version
library("errorProne-core", "com.google.errorprone", "error_prone_core").versionRef("errorProne")
}
}
}This works identically when importing from a published artifact:
create("libs") {
from("com.mycompany:catalog:1.0")
version("guava", "33.5.0-jre") // override the published version
}libs {
from("com.mycompany:catalog:1.0")
version("guava", "33.5.0-jre") // override the published version
}A common scenario is needing the same Kotlin version for both the kotlin("jvm") plugin and the kotlin-stdlib library dependency.
Plugins are resolved from the [plugins] section, while libraries come from [libraries] — and both need the same version.
[libraries]
kotlin-stdlib = { module = "org.jetbrains.kotlin:kotlin-stdlib", version.ref = "kotlin" }
kotlin-reflect = { module = "org.jetbrains.kotlin:kotlin-reflect", version.ref = "kotlin" }
[plugins]
kotlin-jvm = { id = "org.jetbrains.kotlin.jvm", version.ref = "kotlin" }dependencyResolutionManagement {
versionCatalogs {
create("libs") {
from(files("gradle/catalog.versions.toml"))
// Single source of truth for the Kotlin version
version("kotlin", "2.3.21")
}
}
}dependencyResolutionManagement {
versionCatalogs {
libs {
from(files("gradle/catalog.versions.toml"))
// Single source of truth for the Kotlin version
version("kotlin", "2.3.21")
}
}
}Both the plugin alias and the library aliases resolve to 2.3.21, and updating requires changing only one line in settings.gradle(.kts).
Using catalog entries in Gradle APIs
A version catalog accessor such as libs.groovy.core returns a Provider<MinimalExternalModuleDependency>.
Calling .get() on it unwraps the provider and gives you the MinimalExternalModuleDependency directly.
In dependency declarations, both forms work identically:
dependencies {
// Provider<MinimalExternalModuleDependency>
implementation(libs.groovy.core)
// MinimalExternalModuleDependency
implementation(libs.groovy.core.get())
}dependencies {
// Provider<MinimalExternalModuleDependency>
implementation(libs.groovy.core)
// MinimalExternalModuleDependency
implementation(libs.groovy.core.get())
}However, in other Gradle APIs, such as dependency substitution rules, dependency constraints, or any API that accepts a dependency notation, try to pass the provider (libs.groovy.core) rather than the unwrapped value (libs.groovy.core.get()):
configurations.configureEach {
resolutionStrategy.dependencySubstitution {
all {
val componentSelector = requested
if (componentSelector is ModuleComponentSelector
&& componentSelector.group == "org.codehaus.groovy"
&& componentSelector.module == "groovy-all") {
useTarget(libs.groovy.core)
}
}
}
}configurations.configureEach {
resolutionStrategy.dependencySubstitution {
all {
if (requested instanceof ModuleComponentSelector
&& requested.group == "org.codehaus.groovy"
&& requested.module == "groovy-all") {
useTarget(libs.groovy.core)
}
}
}
}When you pass the provider, Gradle handles any necessary type conversions internally.
Unwrapping with .get() gives you a MinimalExternalModuleDependency, which implements ExternalDependency and ModuleVersionSelector — but some resolution APIs expect ModuleComponentSelector, a different type.
Passing the provider avoids mismatches between these types.
Using Catalogs with Platforms
Both platforms and version catalogs help manage dependency versions in a project, but they serve different purposes and have different effects on dependency resolution:
Version Catalogs
-
Purpose: A version catalog centralizes and standardizes dependency coordinates (group, name, version) and provides type-safe accessors in the build script, making dependencies easier to manage.
-
Effect on Dependency Graph: Version catalogs do not directly affect dependency resolution. The versions defined in the catalog must be explicitly referenced in a
dependenciesblock, and once referenced, they behave the same as any locally declared dependency. Additionally, the catalog’s contents are transparent to downstream consumers, meaning that consumers cannot identify whether a dependency was declared locally or sourced from a catalog.
[libraries]
mylib = { group = "com.example", name = "mylib", version = "1.0.0" }Platforms
-
Purpose: A platform is a module in the dependency graph that enforces or aligns versions of dependencies (including transitive dependencies). It influences dependency resolution and ensures version consistency across different modules.
-
Effect on Dependency Graph: Platforms apply or enforce versions to dependencies that are declarated locally without versions. These versions in a platform are propagated through the dependency graph, affecting transitive dependencies and downstream consumers. They are a formal part of the dependency graph and can dictate the version chosen during resolution.
plugins {
`java-platform`
}
dependencies {
constraints {
api("com.example:mylib:2.0.0")
}
}plugins {
id 'java-platform'
}
dependencies {
constraints {
api 'com.example:mylib:2.0.0'
}
}Using a catalog with a platform
Even if a version catalog defines a version for a dependency, Gradle might pick a different version during resolution if another component (e.g., a platform or a transitive dependency) suggests a different version (unless enforcedPlatform is used).
For example, a version catalog may define mylib as version 1.0.0, but if a platform enforces 2.0.0, Gradle will select version 2.0.0.
To ensure consistent version alignment, a good approach is to use a version catalog to define dependency versions alongside a platform to enforce them.
Version Catalog:
[versions]
junit-jupiter = "5.10.3"
[libraries]
guava = { module = "com.google.guava:guava"}
junit-jupiter = { module = "org.junit.jupiter:junit-jupiter", version.ref = "junit-jupiter" }
junit-jupiter-launcher = { module = "org.junit.platform:junit-platform-launcher" }Platform:
plugins {
`java-platform`
}
javaPlatform {
allowDependencies()
}
dependencies {
constraints {
api("org.junit.jupiter:junit-jupiter:5.11.1") // Enforcing specific version
api("com.google.guava:guava:[33.1.0-jre,)") // Enforcing version range
}
}plugins {
id 'java-platform'
}
javaPlatform {
allowDependencies()
}
dependencies {
constraints {
api 'org.junit.jupiter:junit-jupiter:5.11.1' // Enforcing specific version
api 'com.google.guava:guava:[33.1.0-jre,)' // Enforcing version range
}
}Consumer:
dependencies {
// Platform
implementation(platform(project(":platform")))
// Catalog
testImplementation(libs.junit.jupiter)
testRuntimeOnly(libs.junit.jupiter.launcher)
implementation(libs.guava)
}dependencies {
// Platform
implementation platform(project(":platform"))
// Catalog
testImplementation libs.junit.jupiter
testRuntimeOnly libs.junit.jupiter.launcher
implementation libs.guava
}Best Practices for using both a catalog and a platform:
-
Use version catalogs for defining and sharing dependency coordinates across projects. They make dependency declarations consistent and easier to manage but do not guarantee version alignment.
-
Use platforms when you need to influence or enforce version alignment across modules. Platforms ensure that dependencies resolve to the desired version, particularly in large or multi-module projects.
Dependency Resolution Consistency
In a typical Gradle project, multiple configurations exist, such as compileClasspath and runtimeClasspath.
dependencies {
implementation("org.codehaus.groovy:groovy:3.0.1")
runtimeOnly("io.vertx:vertx-lang-groovy:3.9.4")
}dependencies {
implementation 'org.codehaus.groovy:groovy:3.0.1'
runtimeOnly 'io.vertx:vertx-lang-groovy:3.9.4'
}These configurations are resolved independently, which can lead to situations where the same dependency appears in different versions across configurations.
For instance, a library used during compilation (compileClasspath) might resolve to version 1.0, while at runtime (runtimeClasspath), due to additional transitive dependencies, it might resolve to version 1.1.
This discrepancy can cause unexpected behavior or runtime errors.
To address this, Gradle allows you to enforce consistent resolution of dependencies across configurations. By declaring that certain configurations should resolve dependencies consistently with others, you ensure that shared dependencies have the same version in both configurations.
|
Note
|
Dependency resolution consistency is an incubating feature. |
Implementing Consistent Resolution
For example, to ensure that the runtimeClasspath is consistent with the compileClasspath, you can configure your build.gradle(.kts) as follows:
configurations {
runtimeClasspath.get().shouldResolveConsistentlyWith(compileClasspath.get())
}configurations {
runtimeClasspath.shouldResolveConsistentlyWith(compileClasspath)
}This setup directs Gradle to align the versions of dependencies in the runtimeClasspath with those resolved in the compileClasspath.
If a version conflict arises that cannot be reconciled, Gradle will fail the build, prompting you to address the inconsistency.
Automatic Configuration in the Java Ecosystem
For Java projects, Gradle provides a convenient method to enforce this consistency across all source sets:
java {
consistentResolution {
useCompileClasspathVersions()
}
}java {
consistentResolution {
useCompileClasspathVersions()
}
}This configuration ensures that all runtime classpaths are consistent with their corresponding compile classpaths, promoting reliable and predictable builds.
By implementing dependency resolution consistency, you can prevent subtle bugs and maintain uniformity in your project’s dependency versions across different classpaths.
Resolving Specific Artifacts
When resolving a module from a Maven or Ivy repository, Gradle looks for metadata (e.g., .module, pom.xml, ivy.xml) and a default artifact file (typically a JAR).
If neither is found, the resolution fails.
In some cases, you may want to override this behavior and request only a specific artifact from a module:
-
The module provides only a non-standard artifact (e.g., a ZIP file) with no metadata.
-
The module publishes multiple artifacts, and you only want one of them.
-
You want to avoid resolving transitive dependencies declared in metadata.
Gradle supports this use case with artifact-only notation, where you append an @<extension> to the dependency coordinates.
This instructs Gradle to resolve only the artifact with that file extension and skip metadata-based resolution entirely.
|
Warning
|
The @<extension> only works for module dependencies.
|
For example, suppose you’re building a web application and want to fetch a JavaScript library directly from a repository rather than checking it into version control. The Google Hosted Libraries platform distributes many open-source JavaScript libraries this way.
To download the .js artifact directly, use the @js syntax:
repositories {
ivy {
url = 'https://ajax.googleapis.com/ajax/libs'
patternLayout {
artifact '[organization]/[revision]/[module].[ext]'
}
metadataSources {
artifact()
}
}
}
configurations {
js
}
dependencies {
js 'jquery:jquery:3.2.1@js'
}repositories {
ivy {
url = uri("https://ajax.googleapis.com/ajax/libs")
patternLayout {
artifact("[organization]/[revision]/[module].[ext]")
}
metadataSources {
artifact()
}
}
}
configurations {
create("js")
}
dependencies {
"js"("jquery:jquery:3.2.1@js")
}Some modules publish multiple "flavors" of the same artifact—for example, compiled classes, source code, or Javadocs. In JavaScript, a library may publish both an uncompressed and a minified version. These variants are often distinguished using a classifier, a common concept in Maven and Ivy.
To request an artifact with a specific classifier, include it in the dependency notation.
The following example resolves the minified version of a JQuery library using the classifier min:
repositories {
ivy {
url = 'https://ajax.googleapis.com/ajax/libs'
patternLayout {
artifact '[organization]/[revision]/[module](.[classifier]).[ext]'
}
metadataSources {
artifact()
}
}
}
configurations {
js
}
dependencies {
js 'jquery:jquery:3.2.1:min@js'
}repositories {
ivy {
url = uri("https://ajax.googleapis.com/ajax/libs")
patternLayout {
artifact("[organization]/[revision]/[module](.[classifier]).[ext]")
}
metadataSources {
artifact()
}
}
}
configurations {
create("js")
}
dependencies {
"js"("jquery:jquery:3.2.1:min@js")
}Using @extension bypasses metadata-based resolution.
Gradle will not attempt to download or interpret module metadata (e.g., .module, pom.xml, ivy.xml), and will treat the coordinates as a direct request for a single artifact.
As a result, variant-aware resolution, capabilities, and transitive dependencies are all bypassed.
If no metadata is available and the requested artifact cannot be found, the build may fail.
In such cases, you may need to provide module metadata using component metadata rules.
Capabilities
In a dependency graph, it’s common for multiple implementations of the same API to be accidentally included, especially with libraries like logging frameworks where different bindings are selected by various transitive dependencies.
Since these implementations typically reside at different group, artifact, and version (GAV) coordinates, build tools often can’t detect the conflict.
To address this, Gradle introduces the concept of capability.
Understanding capabilities
A capability is essentially a way to declare that different components (dependencies) offer the same functionality.
It’s illegal for Gradle to include more than one component providing the same capability in a single dependency graph. If Gradle detects two components providing the same capability (e.g., different bindings for a logging framework), it will fail the build with an error, indicating the conflicting modules. This ensures that conflicting implementations are resolved, avoiding issues on the classpath.
For instance, suppose you have dependencies on two different libraries for database connection pooling:
dependencies {
implementation("com.zaxxer:HikariCP:4.0.3") // A popular connection pool
implementation("org.apache.commons:commons-dbcp2:2.8.0") // Another connection pool
}
configurations.all {
resolutionStrategy.capabilitiesResolution.withCapability("database:connection-pool") {
select("com.zaxxer:HikariCP")
}
}dependencies {
implementation 'com.zaxxer:HikariCP:4.0.3' // A popular connection pool
implementation 'org.apache.commons:commons-dbcp2:2.8.0' // Another connection pool
}
configurations.all {
resolutionStrategy.capabilitiesResolution.withCapability('database:connection-pool') {
select('com.zaxxer:HikariCP')
}
}In this case, both HikariCP and commons-dbcp2 provide the same functionality (connection pooling).
Gradle will fail if both are on the classpath.
Since only one should be used, Gradle’s resolution strategy allows you to select HikariCP, resolving the conflict.
Understanding capability coordinates
A capability is identified by a (group, module, version) triplet.
Every component defines an implicit capability based on its GAV coordinates: group, artifact, and version.
For instance, the org.apache.commons:commons-lang3:3.8 module has an implicit capability with the group org.apache.commons, name commons-lang3, and version 3.8:
dependencies {
implementation("org.apache.commons:commons-lang3:3.8")
}It’s important to note that capabilities are versioned.
Declaring component capabilities
To detect conflicts early, it’s useful to declare component capabilities through rules, allowing conflicts to be caught during the build instead of at runtime.
One common scenario is when a component is relocated to different coordinates in a newer release.
For example, the ASM library was published under asm:asm until version 3.3.1, and then relocated to org.ow2.asm:asm starting with version 4.0.
Including both versions on the classpath is illegal because they provide the same feature, under different coordinates.
Since each component has an implicit capability based on its GAV coordinates, we can address this conflict by using a rule that declares the asm:asm module as providing the org.ow2.asm:asm capability:
class AsmCapability : ComponentMetadataRule {
override
fun execute(context: ComponentMetadataContext) = context.details.run {
if (id.group == "asm" && id.name == "asm") {
allVariants {
withCapabilities {
// Declare that ASM provides the org.ow2.asm:asm capability, but with an older version
addCapability("org.ow2.asm", "asm", id.version)
}
}
}
}
}@CompileStatic
class AsmCapability implements ComponentMetadataRule {
void execute(ComponentMetadataContext context) {
context.details.with {
if (id.group == "asm" && id.name == "asm") {
allVariants {
it.withCapabilities {
// Declare that ASM provides the org.ow2.asm:asm capability, but with an older version
it.addCapability("org.ow2.asm", "asm", id.version)
}
}
}
}
}
}With this rule in place, the build will fail if both asm:asm ( < = 3.3.1) and org.ow2.asm:asm (4.0+) are present in the dependency graph.
|
Note
|
Gradle won’t resolve the conflict automatically, but this helps you realize that the problem exists. It’s recommended to package such rules into plugins for use in builds, allowing users to decide which version to use or to fix the classpath conflict. |
Declaring capabilities for external modules
Gradle allows you to declare capabilities not only for components you build but also for external components that don’t define them.
For example, consider the following dependencies in your build file:
dependencies {
// This dependency will bring log4:log4j transitively
implementation("org.apache.zookeeper:zookeeper:3.4.9")
// We use log4j over slf4j
implementation("org.slf4j:log4j-over-slf4j:1.7.10")
}dependencies {
// This dependency will bring log4:log4j transitively
implementation 'org.apache.zookeeper:zookeeper:3.4.9'
// We use log4j over slf4j
implementation 'org.slf4j:log4j-over-slf4j:1.7.10'
}As it stands, it’s not obvious that this setup results in two logging frameworks on the classpath.
Specifically, zookeeper brings in log4j, but we want to use log4j-over-slf4j.
To proactively detect this conflict, we can define a rule stating that both frameworks provide the same capability:
dependencies {
// Activate the "LoggingCapability" rule
components.all(LoggingCapability::class.java)
}
class LoggingCapability : ComponentMetadataRule {
val loggingModules = setOf("log4j", "log4j-over-slf4j")
override
fun execute(context: ComponentMetadataContext) = context.details.run {
if (loggingModules.contains(id.name)) {
allVariants {
withCapabilities {
// Declare that both log4j and log4j-over-slf4j provide the same capability
addCapability("log4j", "log4j", id.version)
}
}
}
}
}dependencies {
// Activate the "LoggingCapability" rule
components.all(LoggingCapability)
}
@CompileStatic
class LoggingCapability implements ComponentMetadataRule {
final static Set<String> LOGGING_MODULES = ["log4j", "log4j-over-slf4j"] as Set<String>
void execute(ComponentMetadataContext context) {
context.details.with {
if (LOGGING_MODULES.contains(id.name)) {
allVariants {
it.withCapabilities {
// Declare that both log4j and log4j-over-slf4j provide the same capability
it.addCapability("log4j", "log4j", id.version)
}
}
}
}
}
}This ensures that Gradle detects the conflict and fails with a clear error message:
log4j:log4j:1.2.16 FAILED
Failures:
- Could not resolve log4j:log4j:1.2.16.
- Module 'log4j:log4j' has been rejected:
Cannot select module with conflict on capability 'log4j:log4j:1.2.16' also provided by ['org.slf4j:log4j-over-slf4j:1.7.10' (compile)]
log4j:log4j:1.2.16 FAILED
\--- org.apache.zookeeper:zookeeper:3.4.9
\--- compileClasspath
org.slf4j:log4j-over-slf4j:1.7.10 FAILED
Failures:
- Could not resolve org.slf4j:log4j-over-slf4j:1.7.10.
- Module 'org.slf4j:log4j-over-slf4j' has been rejected:
Cannot select module with conflict on capability 'log4j:log4j:1.7.10' also provided by ['log4j:log4j:1.2.16' (compile)]
org.slf4j:log4j-over-slf4j:1.7.10 FAILED
\--- compileClasspathDeclaring capabilities for a local component
Every component has an implicit capability matching its GAV coordinates. However, you can also declare additional explicit capabilities, which is useful when a library published under different GAV coordinates serves as an alternate implementation of the same API:
configurations {
apiElements {
outgoing {
capability("com.acme:my-library:1.0")
capability("com.other:module:1.1")
}
}
runtimeElements {
outgoing {
capability("com.acme:my-library:1.0")
capability("com.other:module:1.1")
}
}
}configurations {
apiElements {
outgoing {
capability("com.acme:my-library:1.0")
capability("com.other:module:1.1")
}
}
runtimeElements {
outgoing {
capability("com.acme:my-library:1.0")
capability("com.other:module:1.1")
}
}
}Capabilities must be attached to outgoing configurations, which are consumable configurations of a component.
In this example, we declare two capabilities:
-
com.acme:my-library:1.0- the implicit capability of the library. -
com.other:module:1.1- an additional capability assigned to this library.
It’s important to declare the implicit capability explicitly because once you define any explicit capability, all capabilities must be declared, including the implicit one.
The second capability can either be specific to this library or match a capability provided by an external component.
If com.other:module appears elsewhere in the dependency graph, the build will fail, and consumers must choose which module to use.
Capabilities are published in Gradle Module Metadata but have no equivalent in POM or Ivy metadata files. As a result, when publishing such a component, Gradle warns that this feature is only supported for Gradle consumers:
Maven publication 'maven' contains dependencies that cannot be represented in a published pom file.
- Declares capability com.acme:my-library:1.0
- Declares capability com.other:module:1.1Selecting between candidates
At some point, a dependency graph is going to include either incompatible modules, or modules which are mutually exclusive.
For example, you may have different logger implementations, and you need to choose one binding. Capabilities help understand the conflict, then Gradle provides you with tools to solve the conflicts.
Selecting between different capability candidates
In the relocation example above, Gradle was able to tell you that you have two versions of the same API on classpath: an "old" module and a "relocated" one. We can solve the conflict by automatically choosing the component which has the highest capability version:
configurations.configureEach {
resolutionStrategy.capabilitiesResolution.withCapability("org.ow2.asm:asm") {
selectHighestVersion()
}
}configurations.configureEach {
resolutionStrategy.capabilitiesResolution.withCapability('org.ow2.asm:asm') {
selectHighestVersion()
}
}However, choosing the highest capability version conflict resolution is not always suitable.
For a logging framework, for example, it doesn’t matter what version of the logging frameworks we use.
In this case, we explicitly select slf4j as the preferred option:
configurations.configureEach {
resolutionStrategy.capabilitiesResolution.withCapability("log4j:log4j") {
val toBeSelected = candidates.firstOrNull { it.id.let { id -> id is ModuleComponentIdentifier && id.module == "log4j-over-slf4j" } }
if (toBeSelected != null) {
select(toBeSelected)
}
because("use slf4j in place of log4j")
}
}configurations.configureEach {
resolutionStrategy.capabilitiesResolution.withCapability("log4j:log4j") {
def toBeSelected = candidates.find { it.id instanceof ModuleComponentIdentifier && it.id.module == 'log4j-over-slf4j' }
if (toBeSelected != null) {
select(toBeSelected)
}
because 'use slf4j in place of log4j'
}
}This approach works also well if you have multiple slf4j bindings on the classpath; bindings are basically different logger implementations, and you need only one.
However, the selected implementation may depend on the configuration being resolved.
For instance, in testing environments, the lightweight slf4j-simple logging implementation might be sufficient, while in production, a more robust solution like logback may be preferable.
Resolution can only be made in favor of a module that is found in the dependency graph.
The select method accepts only a module from the current set of candidates.
If the desired module is not part of the conflict, you can choose not to resolve that particular conflict, effectively leaving it unresolved.
Another conflict in the graph may have the module you want to select.
If no resolution is provided for all conflicts on a given capability, the build will fail because the module chosen for resolution was not found in the graph.
Additionally, calling select(null) will result in an error and should be avoided.
For more information, refer to the capabilities resolution API.
Variants and Attributes
Variants represent different versions or aspects of a component, like api vs implementation.
Attributes define which variant is selected based on the consumer’s requirements.
For example, a library may have an api and an implementation variant.
Here, the consumer wants an external implementation variant:
configurations {
compileClasspath {
attributes {
attribute(Bundling.BUNDLING_ATTRIBUTE, objects.named(Bundling.EXTERNAL))
}
}
}configurations {
compileClasspath {
attributes {
attribute(Bundling.BUNDLING_ATTRIBUTE, objects.named(Bundling, Bundling.EXTERNAL))
}
}
}For example, a build might have debug and release variants.
This selects the debug variant based on the attribute.
configurations {
compileClasspath {
attributes {
attribute(TargetConfiguration.TARGET_ATTRIBUTE, objects.named("debug"))
}
}
}configurations {
compileClasspath {
attributes {
attribute(TargetConfiguration.TARGET_ATTRIBUTE, objects.named(TargetConfiguration, 'debug'))
}
}
}Attributes help Gradle match the right variant by comparing the requested attributes with what’s available:
attribute(TargetConfiguration.TARGET_ATTRIBUTE, objects.named("debug"))attribute(TargetConfiguration.TARGET_ATTRIBUTE, objects.named(TargetConfiguration, 'debug'))This sets the TargetConfiguration.TARGET_ATTRIBUTE to "debug", meaning Gradle will attempt to resolve dependencies that have a "debug" variant, instead of other available variants (like "release").
Standard attributes defined by Gradle
As a user of Gradle, attributes are often hidden as implementation details. But it might be useful to understand the standard attributes defined by Gradle and its core plugins.
As a plugin author, these attributes, and the way they are defined, can serve as a basis for building your own set of attributes in your ecosystem plugin.
Ecosystem-independent standard attributes
| Attribute name | Description | Values | compatibility and disambiguation rules |
|---|---|---|---|
Indicates main purpose of variant |
|
Following ecosystem semantics (e.g. |
|
Indicates the category of this software component |
|
Following ecosystem semantics (e.g. |
|
Indicates the contents of a |
|
Following ecosystem semantics(e.g. in the JVM world, |
|
Indicates the contents of a |
|
No default, no compatibility |
|
Indicates how dependencies of a variant are accessed. |
|
Following ecosystem semantics (e.g. in the JVM world, |
|
Indicates what kind of verification task produced this output. |
|
No default, no compatibility |
When the Category attribute is present with the incubating value org.gradle.category=verification on a variant, that variant is considered to be a verification-time only variant.
These variants are meant to contain only the results of running verification tasks, such as test results or code coverage reports. They are not publishable, and will produce an error if added to a component which is published.
| Attribute name | Description | Values | compatibility and disambiguation rules |
|---|---|---|---|
|
Component level attribute, derived |
Based on a status scheme, with a default one existing based on the source repository. |
Based on the scheme in use |
JVM ecosystem specific attributes
In addition to the ecosystem independent attributes defined above, the JVM ecosystem adds the following attribute:
| Attribute name | Description | Values | compatibility and disambiguation rules |
|---|---|---|---|
Indicates the JVM version compatibility. |
Integer using the version after the |
Defaults to the JVM version used by Gradle, lower is compatible with higher, prefers highest compatible. |
|
Indicates that a variant is optimized for a certain JVM environment. |
Common values are |
The attribute is used to prefer one variant over another if multiple are available, but in general all values are compatible. The default is |
|
Indicates the name of the TestSuite that produced this output. |
Value is the name of the Suite. |
No default, no compatibility |
|
Indicates that native binaries are included requiring the defined target architecture |
|
None |
|
Indicates that native binaries are included requiring the defined operating system |
|
None |
The JVM ecosystem also contains a number of compatibility and disambiguation rules over the different attributes.
The reader willing to know more can take a look at the code for org.gradle.api.internal.artifacts.JavaEcosystemSupport.
Native ecosystem specific attributes
In addition to the ecosystem independent attributes defined above, the native ecosystem adds the following attributes:
| Attribute name | Description | Values | compatibility and disambiguation rules |
|---|---|---|---|
Indicates if the binary was built with debugging symbols |
Boolean |
N/A |
|
Indicates if the binary was built with optimization flags |
Boolean |
N/A |
|
Indicates the target architecture of the binary |
|
None |
|
Indicates the target operating system of the binary |
|
None |
Gradle plugin ecosystem specific attributes
For Gradle plugin development, the following attribute is supported since Gradle 7.0. A Gradle plugin variant can specify compatibility with a Gradle API version through this attribute.
| Attribute name | Description | Values | compatibility and disambiguation rules |
|---|---|---|---|
Indicates the Gradle API version compatibility. |
Valid Gradle version strings. |
Defaults to the currently running Gradle, lower is compatible with higher, prefers highest compatible. |
Using a standard attribute
For this example, let’s assume you are creating a library with different variants for different JVM versions.
plugins {
id("java-library")
}
configurations {
named("apiElements") {
attributes {
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, 17)
}
}
}plugins {
id 'java-library'
}
configurations {
apiElements {
attributes {
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, 17)
}
}
}In the consumer project (that uses the library), you can specify the JVM version attribute when declaring dependencies.
plugins {
id("application")
}
dependencies {
implementation(project(":lib")) {
attributes {
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, 17)
}
}
}plugins {
id 'application'
}
dependencies {
implementation(project(':lib')) {
attributes {
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, 17)
}
}
}By defining and using the JVM version attribute, you ensure that your library and its consumers are compatible with the specified JVM version. Essentially, this ensures that Gradle resolves to the variant that matches the desired JVM version.
Viewing and debugging attributes
The dependencyInsight task is useful for inspecting specific dependencies and their attributes, including how they are resolved:
$ ./gradlew dependencyInsight --configuration compileClasspath --dependency com.example:your-library> Task :dependencyInsight
com.example:your-library:1.0 (compileClasspath)
variant "apiElements" [
org.gradle.api.attributes.Attribute: org.gradle.api.attributes.Usage = [java-api]
org.gradle.api.attributes.Attribute: org.gradle.api.attributes.Usage = [java-runtime]
org.gradle.api.attributes.Attribute: org.gradle.api.attributes.JavaLanguageVersion = [1.8]
]
variant "runtimeElements" [
org.gradle.api.attributes.Attribute: org.gradle.api.attributes.Usage = [java-runtime]
org.gradle.api.attributes.Attribute: org.gradle.api.attributes.JavaLanguageVersion = [1.8]
]
Selection reasons:
- By constraint from configuration ':compileClasspath'
- Declared in build.gradle.kts
Resolved to:
com.example:your-library:1.0 (runtime)
Additional Information:
- Dependency declared in the 'implementation' configuration
- No matching variants found for the requested attributes in the 'compileClasspath' configurationDeclaring custom attributes
When extending Gradle with custom attributes, it’s important to consider their long-term impact, especially if you plan to publish libraries. Custom attributes allow you to integrate variant-aware dependency management in your plugin, but libraries using these attributes must also ensure consumers can interpret them correctly. This is typically done by applying the corresponding plugin, which defines compatibility and disambiguation rules.
If your plugin is publicly available and libraries are published to public repositories, introducing new attributes becomes a significant responsibility. Published attributes must remain supported or have a compatibility layer in future versions of the plugin to ensure backward compatibility.
Here’s an example of declaring and using custom attributes in a Gradle plugin:
// Define a custom attribute
val myAttribute = Attribute.of("com.example.my-attribute", String::class.java)
configurations {
create("myConfig") {
// Set custom attribute
attributes {
attribute(myAttribute, "special-value")
}
}
}
dependencies {
// Apply the custom attribute to a dependency
add("myConfig","com.google.guava:guava:31.1-jre") {
attributes {
attribute(myAttribute, "special-value")
}
}
}// Define a custom attribute
def myAttribute = Attribute.of("com.example.my-attribute", String)
// Create a custom configuration
configurations {
create("myConfig") {
// Set custom attribute
attributes {
attribute(myAttribute, "special-value")
}
}
}
dependencies {
// Apply the custom attribute to a dependency
add("myConfig", "com.google.guava:guava:31.1-jre") {
attributes {
attribute(myAttribute, "special-value")
}
}
}In this example:
- A custom attribute my-attribute is defined.
- The attribute is set on a custom configuration (myConfig).
- When adding a dependency, the custom attribute is applied to match the configuration.
If publishing a library with this attribute, ensure that consumers apply the plugin that understands and handles my-attribute.
Creating attributes in a build script or plugin
Attributes are typed.
An attribute can be created via the Attribute<T>.of method:
// An attribute of type `String`
val myAttribute = Attribute.of("my.attribute.name", String::class.java)
// An attribute of type `Usage`
val myUsage = Attribute.of("my.usage.attribute", Usage::class.java)// An attribute of type `String`
def myAttribute = Attribute.of("my.attribute.name", String)
// An attribute of type `Usage`
def myUsage = Attribute.of("my.usage.attribute", Usage)Attribute types support most Java primitive classes; such as String and Integer.
Or anything extending org.gradle.api.Named.
Attributes should always be declared in the attribute schema found on the dependencies handler:
dependencies.attributesSchema {
// registers this attribute to the attributes schema
attribute(myAttribute)
attribute(myUsage)
}dependencies.attributesSchema {
// registers this attribute to the attributes schema
attribute(myAttribute)
attribute(myUsage)
}Registering an attribute with the schema is required in order to use Compatibility and Disambiguation rules that can resolve ambiguity between multiple selectable variants during Attribute Matching.
Each configuration has a container of attributes. Attributes can be configured to set values:
configurations {
create("myConfiguration") {
attributes {
attribute(myAttribute, "my-value")
}
}
}configurations {
myConfiguration {
attributes {
attribute(myAttribute, 'my-value')
}
}
}For attributes which type extends Named, the value of the attribute must be created via the object factory:
configurations {
"myConfiguration" {
attributes {
attribute(myUsage, project.objects.named(Usage::class.java, "my-value"))
}
}
}configurations {
myConfiguration {
attributes {
attribute(myUsage, project.objects.named(Usage, 'my-value'))
}
}
}Dealing with attribute matching
In Gradle, attribute matching and attribute disambiguation are key mechanisms for resolving dependencies with varying attributes.
Attribute matching allows Gradle to select compatible dependency variants based on predefined rules, even if an exact match isn’t available. Attribute disambiguation, on the other hand, helps Gradle choose the most suitable variant when multiple compatible options exist.
Attribute compatibility rules
Attributes let the engine select compatible variants. There are cases where a producer may not have exactly what the consumer requests but has a variant that can be used.
This example defines and registers a custom compatibility rule to ensure that dependencies are selected based on their compatibility with specific Java versions:
// Define the compatibility rule class
class TargetJvmVersionCompatibilityRule : AttributeCompatibilityRule<Int> {
// Implement the execute method which will check compatibility
override fun execute(details: CompatibilityCheckDetails<Int>) {
// Switch case to check the consumer value for supported Java versions
when (details.consumerValue) {
8, 11 -> details.compatible() // Compatible with Java 8 and 11
else -> details.incompatible()
}
}
}
// Register the compatibility rule within the dependencies block
dependencies {
attributesSchema {
// Add the compatibility rule for the TargetJvmVersion attribute
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE) {
// Add the defined compatibility rule to this attribute
compatibilityRules.add(TargetJvmVersionCompatibilityRule::class.java)
}
}
}// Define the compatibility rule
class TargetJvmVersionCompatibilityRule implements AttributeCompatibilityRule<Integer> {
@Override
void execute(CompatibilityCheckDetails<Integer> details) {
switch (details.consumerValue) {
case 8:
case 11:
details.compatible() // Compatible with Java 8 and 11
break
default:
details.incompatible("Unsupported Java version: ${details.consumerValue}")
}
}
}
// Register a compatibility rule
dependencies {
attributesSchema {
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE) {
compatibilityRules.add(TargetJvmVersionCompatibilityRule)
}
}
}Gradle provides attribute compatibility rules that can be defined for each attribute. The role of a compatibility rule is to explain which attribute values are compatible based on what the consumer asked for.
Attribute compatibility rules have to be registered via the attributes schema.
Attribute disambiguation rules
When multiple variants of a dependency are compatible with the consumer’s requested attributes, Gradle needs to decide which variant to select. This process of determining the "best" candidate among compatible options is called attribute disambiguation.
In Gradle, different variants might satisfy the consumer’s request, but not all are equal. For example, you might have several versions of a library that are compatible with a Java version requested by the consumer. Disambiguation helps Gradle choose the most appropriate one based on additional criteria.
You can define disambiguation rules to guide Gradle in selecting the most suitable variant when multiple candidates are found.
This is done by implementing an AttributeDisambiguationRule and registering it via the attributes schema within the dependencies block:
dependencies {
attributesSchema {
attribute(Usage.USAGE_ATTRIBUTE) { // (1)
disambiguationRules.add(CustomDisambiguationRule::class.java) // (2)
}
}
}
abstract class CustomDisambiguationRule @Inject constructor(
private val objects: ObjectFactory
) : AttributeDisambiguationRule<Usage> {
override fun execute(details: MultipleCandidatesDetails<Usage>) {
// Prefer the JAVA_API usage over others (e.g., JAVA_RUNTIME) when multiple candidates exist
details.closestMatch(objects.named(Usage::class.java, Usage.JAVA_API)) // (3)
}
}dependencies {
attributesSchema {
attribute(Usage.USAGE_ATTRIBUTE) { // (1)
disambiguationRules.add(CustomDisambiguationRule) // (2)
}
}
}
abstract class CustomDisambiguationRule implements AttributeDisambiguationRule<Usage> {
private final ObjectFactory objects
@Inject
CustomDisambiguationRule(ObjectFactory objects) {
this.objects = objects
}
@Override
void execute(MultipleCandidatesDetails<Usage> details) {
// Prefer the JAVA_API usage over others (e.g., JAVA_RUNTIME) when multiple candidates exist
details.closestMatch(objects.named(Usage, Usage.JAVA_API)) // (3)
}
}-
Attribute Selection: Specify the attribute to disambiguate (e.g.,
Usage.USAGE_ATTRIBUTE, a built-in Gradle attribute). -
Rule Registration: Register the custom disambiguation rule using
disambiguationRules.add()within theattributesSchemablock ofdependencies. -
Custom Logic: Implement the
AttributeDisambiguationRuleinterface in a separate class. Theexecutemethod defines how Gradle selects among candidates. In this example, it prefers theJAVA_APIusage.
Attribute disambiguation rules must be registered via the attribute matching strategy, which is accessed through the attributes schema in the DependencyHandler. This ensures the rules apply globally to dependency resolution.
Mapping from Maven/Ivy to Gradle variants
Neither Maven nor Ivy have the concept of variants, which are only natively supported by Gradle Module Metadata. Gradle can still work with Maven and Ivy by using different variant derivation strategies.
Gradle Module Metadata is a metadata format for modules published on Maven, Ivy and other kinds of repositories.
It is similar to the pom.xml or ivy.xml metadata file, but this format contains details about variants.
See the Gradle Module Metadata specification for more information.
Mapping of Maven POM metadata to variants
Modules published to a Maven repository are automatically converted into variant-aware modules when resolved by Gradle.
There is no way for Gradle to know which kind of component was published:
-
a BOM that represents a Gradle platform
-
a BOM used as a super-POM
-
a POM that is both a platform and a library
The default strategy used by Java projects in Gradle is to derive 8 different variants:
-
two "library" variants (attribute
org.gradle.category=library)-
the
compilevariant maps the<scope>compile</scope>dependencies. This variant is equivalent to theapiElementsvariant of the Java Library plugin. All dependencies of this scope are considered API dependencies. -
the
runtimevariant maps both the<scope>compile</scope>and<scope>runtime</scope>dependencies. This variant is equivalent to theruntimeElementsvariant of the Java Library plugin. All dependencies of those scopes are considered runtime dependencies.-
in both cases, the
<dependencyManagement>dependencies are not converted to constraints
-
-
-
a "sources" variant that represents the sources jar for the component
-
a "javadoc" variant that represents the javadoc jar for the component
-
four "platform" variants derived from the
<dependencyManagement>block (attributeorg.gradle.category=platform):-
the
platform-compilevariant maps the<scope>compile</scope>dependency management dependencies as dependency constraints. -
the
platform-runtimevariant maps both the<scope>compile</scope>and<scope>runtime</scope>dependency management dependencies as dependency constraints. -
the
enforced-platform-compileis similar toplatform-compilebut all the constraints are forced -
the
enforced-platform-runtimeis similar toplatform-runtimebut all the constraints are forced
-
You can understand more about the use of platform and enforced platforms variants by looking at the importing BOMs section of the manual.
By default, whenever you declare a dependency on a Maven module, Gradle is going to look for the library variants.
However, using the platform or enforcedPlatform keyword, Gradle is now looking for one of the "platform" variants, which allows you to import the constraints from the POM files, instead of the dependencies.
Mapping of Ivy files to variants
Gradle has no built-in derivation strategy implemented for Ivy files. Ivy is a flexible format that allows you to publish arbitrary files and can be heavily customized.
If you want to implement a derivation strategy for compile and runtime variants for Ivy, you can do so with component metadata rule.
The component metadata rules API allows you to access Ivy configurations and create variants based on them.
If you know that all the Ivy modules your are consuming have been published with Gradle without further customizations of the ivy.xml file, you can add the following rule to your build:
abstract class IvyVariantDerivationRule @Inject internal constructor(objectFactory: ObjectFactory) : ComponentMetadataRule {
private val jarLibraryElements: LibraryElements
private val libraryCategory: Category
private val javaRuntimeUsage: Usage
private val javaApiUsage: Usage
init {
jarLibraryElements = objectFactory.named(LibraryElements.JAR)
libraryCategory = objectFactory.named(Category.LIBRARY)
javaRuntimeUsage = objectFactory.named(Usage.JAVA_RUNTIME)
javaApiUsage = objectFactory.named(Usage.JAVA_API)
}
override fun execute(context: ComponentMetadataContext) {
// This filters out any non Ivy module
if(context.getDescriptor(IvyModuleDescriptor::class) == null) {
return
}
context.details.addVariant("runtimeElements", "default") {
attributes {
attribute(LibraryElements.LIBRARY_ELEMENTS_ATTRIBUTE, jarLibraryElements)
attribute(Category.CATEGORY_ATTRIBUTE, libraryCategory)
attribute(Usage.USAGE_ATTRIBUTE, javaRuntimeUsage)
}
}
context.details.addVariant("apiElements", "compile") {
attributes {
attribute(LibraryElements.LIBRARY_ELEMENTS_ATTRIBUTE, jarLibraryElements)
attribute(Category.CATEGORY_ATTRIBUTE, libraryCategory)
attribute(Usage.USAGE_ATTRIBUTE, javaApiUsage)
}
}
}
}
dependencies {
components { all<IvyVariantDerivationRule>() }
}abstract class IvyVariantDerivationRule implements ComponentMetadataRule {
final LibraryElements jarLibraryElements
final Category libraryCategory
final Usage javaRuntimeUsage
final Usage javaApiUsage
@Inject
IvyVariantDerivationRule(ObjectFactory objectFactory) {
jarLibraryElements = objectFactory.named(LibraryElements, LibraryElements.JAR)
libraryCategory = objectFactory.named(Category, Category.LIBRARY)
javaRuntimeUsage = objectFactory.named(Usage, Usage.JAVA_RUNTIME)
javaApiUsage = objectFactory.named(Usage, Usage.JAVA_API)
}
void execute(ComponentMetadataContext context) {
// This filters out any non Ivy module
if(context.getDescriptor(IvyModuleDescriptor) == null) {
return
}
context.details.addVariant("runtimeElements", "default") {
attributes {
attribute(LibraryElements.LIBRARY_ELEMENTS_ATTRIBUTE, jarLibraryElements)
attribute(Category.CATEGORY_ATTRIBUTE, libraryCategory)
attribute(Usage.USAGE_ATTRIBUTE, javaRuntimeUsage)
}
}
context.details.addVariant("apiElements", "compile") {
attributes {
attribute(LibraryElements.LIBRARY_ELEMENTS_ATTRIBUTE, jarLibraryElements)
attribute(Category.CATEGORY_ATTRIBUTE, libraryCategory)
attribute(Usage.USAGE_ATTRIBUTE, javaApiUsage)
}
}
}
}
dependencies {
components { all(IvyVariantDerivationRule) }
}The rule creates an apiElements variant based on the compile configuration and a runtimeElements variant based on the default configuration of each ivy module.
For each variant, it sets the corresponding Java ecosystem attributes.
Dependencies and artifacts of the variants are taken from the underlying configurations.
If not all consumed Ivy modules follow this pattern, the rule can be adjusted or only applied to a selected set of modules.
For all Ivy modules without variants, Gradle has a fallback selection method. Gradle does not perform variant aware resolution and instead selects either the default configuration or an explicitly named configuration.
Artifact Views
In some cases, it is desirable to customize the artifact resolution process.
The ArtifactView API is the primary mechanism for influencing artifact selection in Gradle.
An ArtifactView operates on top of the resolved graph but allows you to apply different attributes.
It lets you retrieve artifacts that match a new set of criteria, even if they were not part of the original graph resolution.
An ArtifactView can:
-
Select Alternative Variants such as sources or javadoc, for an entire resolution: Normally, an artifact must match both the graph’s attributes and the
ArtifactViewattributes. WithwithVariantReselection, you can select artifacts from any available variants within a component. -
Perform Lenient Artifact Selection and resolution: Using
ArtifactViewwithlenient=trueallows you to ignore missing dependencies and other errors. -
Filter Selected Artifacts: Using
ArtifactViewwithcomponentFilterlets you exclude specific components from the selected artifacts. -
Trigger Transforms: Trigger an
ArtifactTransformto change an artifact from one type to another.
|
Note
|
The ArtifactView can produce results as both a FileCollection and an ArtifactCollection.
The examples below only demonstrate using a FileCollection as the output.
|
1. Performing variant reselection
Standard artifact selection can only select between variants of the component selected by the result of graph selection. However, in some cases, it may be desirable to select artifacts from a variant parallel to the graph node being selected.
Consider the example component structure below, describing a typical local Java library with sources and javadoc:
variant 'apiElements'
artifact set 'jar'
artifact set 'classes'
artifact set 'resources'
variant 'runtimeElements'
artifact set 'jar'
artifact set 'classes'
artifact set 'resources'
variant 'javadocElements'
artifact set 'jar'
variant 'sourcesElements'
artifact set 'jar'Resolving a Java runtime classpath will select the runtimeElements variant from the above example component.
During standard artifact selection, Gradle will select solely from the artifact sets under runtimeElements.
However, it is common to want to select all sources or all javadoc for every node in the graph. Consider the following example which selects all sources for a given runtime classpath:
|
Note
|
This example uses incubating APIs. |
tasks.register<ResolveFiles>("resolveSources") {
files.from(configurations.runtimeClasspath.map {
it.incoming.artifactView {
withVariantReselection()
attributes {
attribute(Usage.USAGE_ATTRIBUTE, objects.named(Usage.JAVA_RUNTIME));
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category.DOCUMENTATION));
attribute(Bundling.BUNDLING_ATTRIBUTE, objects.named(Bundling.EXTERNAL));
attribute(DocsType.DOCS_TYPE_ATTRIBUTE, objects.named(DocsType.SOURCES));
}
}.files
})
}tasks.register("resolveSources", ResolveFiles) {
files.from(configurations.runtimeClasspath.incoming.artifactView {
withVariantReselection()
attributes {
attribute(Usage.USAGE_ATTRIBUTE, objects.named(Usage, Usage.JAVA_RUNTIME));
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category, Category.DOCUMENTATION));
attribute(Bundling.BUNDLING_ATTRIBUTE, objects.named(Bundling, Bundling.EXTERNAL));
attribute(DocsType.DOCS_TYPE_ATTRIBUTE, objects.named(DocsType, DocsType.SOURCES));
}
}.files)
}Using the ArtifactView.withVariantReselection() API, Gradle will optionally perform graph variant selection again before performing artifact selection on the new selected variant.
When Gradle selects artifacts for the runtimeElements node, it will use the attributes specified on the ArtifactView to reselect the graph variant, thus selecting the sourcesElements variant instead.
Then, traditional artifact selection will be performed on the sourcesElements variant to select the jar artifact set.
As a result, the sources jar is resolved for each node:
junit-platform-commons-1.11.0-sources.jar
junit-jupiter-api-5.11.0-sources.jar
opentest4j-1.3.0-sources.jarWhen this API is used, the attributes used for variant reselection are specified solely by the ArtifactView.getAttributes() method.
The graph resolution attributes specified on the configuration are completely ignored during variant reselection.
2. Performing lenient artifact selection and resolution
The ArtifactView API can also be used to perform lenient artifact resolution.
This allows artifact resolution to be performed on a graph that contains failures — for example when a requested module was not found, the requested module version did not exist, or a conflict was not resolved.
Furthermore, lenient artifact resolution can be used to resolve artifacts when the graph was successfully resolved, but the corresponding artifacts could not be downloaded.
Consider the following example, where some dependencies may not exist:
dependencies {
implementation("does:not:exist")
implementation("org.junit.jupiter:junit-jupiter-api:5.11.0")
}dependencies {
implementation("does:not:exist")
implementation("org.junit.jupiter:junit-jupiter-api:5.11.0")
}Lenient resolution is performed by using the ArtifactView.lenient() method:
tasks.register<ResolveFiles>("resolveLenient") {
files.from(configurations.runtimeClasspath.map {
it.incoming.artifactView {
isLenient = true
}.files
})
}tasks.register("resolveLenient", ResolveFiles) {
files.from(configurations.runtimeClasspath.incoming.artifactView {
lenient = true
}.files)
}We can see that the task succeeds with the failing artifact omitted:
> Task :resolveLenient
junit-platform-commons-1.11.0.jar
junit-jupiter-api-5.11.0.jar
opentest4j-1.3.0.jar
BUILD SUCCESSFUL in 0s3. Filtering selected artifacts
The ArtifactView API can be used to filter specific artifacts from the resulting FileCollection or ArtifactCollection.
ArtifactViews allow results to be filtered on a per-component basis.
Using the ArtifactView.componentFilter(Action) method, artifacts from the selected variant can be filtered from the resolved result.
The action is passed the ComponentIdentifier of the component that owns the variant that artifacts are being selected for.
Consider the following example, where we have one project dependency and one external dependency:
dependencies {
implementation(project(":other"))
implementation("org.junit.jupiter:junit-jupiter-api:5.11.0")
}dependencies {
implementation(project(":other"))
implementation("org.junit.jupiter:junit-jupiter-api:5.11.0")
}Using the componentFilter method, we can specify filters that select only artifacts of a certain type:
tasks.register<ResolveFiles>("resolveProjects") {
files.from(configurations.runtimeClasspath.map {
it.incoming.artifactView {
componentFilter {
it is ProjectComponentIdentifier
}
}.files
})
}
tasks.register<ResolveFiles>("resolveModules") {
files.from(configurations.runtimeClasspath.map {
it.incoming.artifactView {
componentFilter {
it is ModuleComponentIdentifier
}
}.files
})
}tasks.register("resolveProjects", ResolveFiles) {
files.from(configurations.runtimeClasspath.incoming.artifactView {
componentFilter {
it instanceof ProjectComponentIdentifier
}
}.files)
}
tasks.register("resolveModules", ResolveFiles) {
files.from(configurations.runtimeClasspath.incoming.artifactView {
componentFilter {
it instanceof ModuleComponentIdentifier
}
}.files)
}Notice how we resolve project dependencies and module dependencies separately:
> Task :resolveProjects
other.jar
> Task :resolveModules
junit-platform-commons-1.11.0.jar
junit-jupiter-api-5.11.0.jar
opentest4j-1.3.0.jar4. Triggering artifact transforms
An ArtifactView can be used to trigger artifact selection using attributes different from those used to resolve the graph.
For each node in the graph, artifact selection is performed for that node. Most commonly, this API is used to request attributes that are not present on the selected artifact. When Gradle cannot find a matching set of artifacts from the node in question, it will attempt to satisfy the request by transforming the available artifact using the artifact transforms registered on the project.
Below, we use the unzip example from the artifact transforms chapter to demonstrate how to use the ArtifactView API to request attributes that trigger a transform:
tasks.register<ResolveFiles>("resolveTransformedFiles") {
files.from(configurations.runtimeClasspath.map {
it.incoming.artifactView {
attributes {
attribute(LibraryElements.LIBRARY_ELEMENTS_ATTRIBUTE, objects.named(LibraryElements.CLASSES_AND_RESOURCES))
attribute(ArtifactTypeDefinition.ARTIFACT_TYPE_ATTRIBUTE, ArtifactTypeDefinition.DIRECTORY_TYPE)
}
}.files
})
}tasks.register("resolveTransformedFiles", ResolveFiles) {
files.from(configurations.runtimeClasspath.incoming.artifactView {
attributes {
attribute(LibraryElements.LIBRARY_ELEMENTS_ATTRIBUTE, objects.named(LibraryElements, LibraryElements.CLASSES_AND_RESOURCES))
attribute(ArtifactTypeDefinition.ARTIFACT_TYPE_ATTRIBUTE, ArtifactTypeDefinition.DIRECTORY_TYPE)
}
}.files)
}Gradle performs artifact selection using the graph resolution attributes specified on the configuration, concatenated with the attributes specified in the attributes block of the ArtifactView.
The task output shows that the artifacts have been transformed:
junit-platform-commons-1.11.0.jar-unzipped
junit-jupiter-api-5.11.0.jar-unzipped
opentest4j-1.3.0.jar-unzippedThe transform code (ArtifactTransform) used uncompress the JAR file (from ZIP to UNZIP) can be seen in the next chapter.
Next Step: Learn about Artifact Transforms >>
Artifact Transforms
What if you want to make changes to the files contained in one of your dependencies before you use it?
For example, you might want to unzip a compressed file, adjust the contents of a JAR, or delete unnecessary files from a dependency that contains multiple files prior to using the result in a task.
Gradle has a built-in feature for this called Artifact Transforms. With Artifact Transforms, you can modify, add to, remove from the set files (or artifacts) - like JAR files - contained in a dependency. This is done as the last step when resolving artifacts, before tasks or tools like the IDE can consume the artifacts.
Artifact Transforms Overview
Each component exposes a set of variants, where each variant is identified by a set of attributes (i.e., key-value pairs such as debug=true).
When Gradle resolves a configuration, it looks at each dependency, resolves it to a component, and selects the corresponding variant from that component that matches the requested attributes. The variant contains one or more artifacts, which represent the concrete outputs produced by a component (such as JAR files, resources, or native binaries). However, a consumer may need artifacts in a format that doesn’t directly match any available variant. Rather than requiring producers to explicitly publish every possible variant, Gradle provides a powerful mechanism to dynamically adapt artifacts to the required form.
Artifact Transforms are a mechanism for converting one type of artifact into another during the build process. They provide the consumer an efficient and flexible mechanism for transforming the artifacts of a given producer to the required format without needing the producer to expose variants in that format.

Artifact Transforms are a lot like tasks.
They are units of work with some inputs and outputs.
Mechanisms like UP-TO-DATE and caching work for transforms as well.

The primary difference between tasks and transforms is how they are scheduled and put into the chain of actions Gradle executes when a build configures and runs. At a high level, transforms always run before tasks because they are executed during dependency resolution. Transforms modify artifacts BEFORE they become an input to a task.
Here’s a brief overview of how to create and use Artifact Transforms:

-
Implement a Transform: You define an artifact transform by creating a class that implements the
TransformActioninterface. This class specifies how the input artifact should be transformed into the output artifact. -
Declare request Attributes: Attributes (key-value pairs used to describe different variants of a component) like
org.gradle.usage=java-apiandorg.gradle.usage=java-runtimeare used to specify the desired artifact format or type. -
Register a Transform: You register the transform by using the
registerTransform()method of thedependenciesblock. This method tells Gradle that a transform can be used to modify the artifacts of any variant that possesses the given "from" attributes. It also tells Gradle what new set of "to" attributes will describe the format or type of the resulting artifacts. -
Use the Transform: When a resolution requires an artifact that isn’t already present in the selected component (because none of the actual artifact possess compatible attributes to the requested attributes), Gradle doesn’t just give up! Instead, Gradle first automatically searches all registered transforms to see if it can construct a chain of transformations that will ultimately produce a match. If Gradle finds such a chain, it then runs each transform in sequence, and delivers the transformed artifacts as a result.
1. Implement a Transform
A transform is typically written as an abstract class that implements the TransformAction interface.
It can optionally have parameters defined in a separate interface.
Each transform has exactly one input artifact.
It must be annotated with the @InputArtifact annotation.
Then, you implement the transform(TransformOutputs) method from the TransformAction interface.
This method’s implementation defines what the transform should do when triggered.
The method has a TransformOutputs parameter that you use to tell Gradle what artifacts the transform produces.
Here, MyTransform is the custom transform action that converts a jar artifact to a transformed-jar artifact:
abstract class MyTransform : TransformAction<TransformParameters.None> {
@get:InputArtifact
abstract val inputArtifact: Provider<FileSystemLocation>
override fun transform(outputs: TransformOutputs) {
val inputFile = inputArtifact.get().asFile
val outputFile = outputs.file(inputFile.name.replace(".jar", "-transformed.jar"))
// Perform transformation logic here
inputFile.copyTo(outputFile, overwrite = true)
}
}abstract class MyTransform implements TransformAction<TransformParameters.None> {
@InputArtifact
abstract Provider<FileSystemLocation> getInputArtifact()
@Override
void transform(TransformOutputs outputs) {
def inputFile = inputArtifact.get().asFile
def outputFile = outputs.file(inputFile.name.replace(".jar", "-transformed.jar"))
// Perform transformation logic here
inputFile.withInputStream { input ->
outputFile.withOutputStream { output ->
output << input
}
}
}
}2. Declare request Attributes
Attributes specify the required properties of a dependency.
Here we specify that we need the transformed-jar format for the runtimeClasspath configuration:
configurations.named("runtimeClasspath") {
attributes {
attribute(ArtifactTypeDefinition.ARTIFACT_TYPE_ATTRIBUTE, "transformed-jar")
}
}configurations.named("runtimeClasspath") {
attributes {
attribute(ArtifactTypeDefinition.ARTIFACT_TYPE_ATTRIBUTE, "transformed-jar")
}
}3. Register a Transform
A transform must be registered using the dependencies.registerTransform() method.
Here, our transform is registered with the dependencies block:
dependencies {
registerTransform(MyTransform::class) {
from.attribute(ArtifactTypeDefinition.ARTIFACT_TYPE_ATTRIBUTE, "jar")
to.attribute(ArtifactTypeDefinition.ARTIFACT_TYPE_ATTRIBUTE, "transformed-jar")
}
}dependencies {
registerTransform(MyTransform) {
from.attribute(ArtifactTypeDefinition.ARTIFACT_TYPE_ATTRIBUTE, "jar")
to.attribute(ArtifactTypeDefinition.ARTIFACT_TYPE_ATTRIBUTE, "transformed-jar")
}
}"To" attributes are used to describe the format or type of the artifacts that this transform can use as an input, and "from" attributes to describe the format or type of the artifacts that it produces as an output.
4. Use the Transform
During a build, Gradle automatically runs registered transforms to satisfy a resolution request if a match is not directly available.
Since no variants exist supplying artifacts of requested format (as none contain the artifactType attribute with a value of "transformed-jar"), Gradle attempts to construct a chain of transformations that will supply an artifact matching the requested attributes.
Gradle’s search finds MyTransform, which is registered as producing the requested format, so it will automatically be run.
Running this transform action modifies the artifacts of an existing source variant to produce new artifacts that are delivered to the consumer, in the requested format.
Gradle produces a "virtual artifact set" of the component as part of this process.
Understanding Artifact Transforms
Dependencies can have different variants, essentially different versions or forms of the same dependency. These variants can each provide a different artifact set, meant to satisfy different use cases, such as compiling code, browsing documentation or running applications.
Each variant is identified by a set of attributes. Attributes are key-value pairs that describe specific characteristics of the variant.

Let’s use the following example where an external Maven dependency has two variants:
| Variant | Description |
|---|---|
|
Used for compiling against the dependency. |
|
Used for running an application that uses the dependency. |
And a project dependency has even more variants:
| Variant | Description |
|---|---|
|
Represents classes directories. |
|
Represents a packaged JAR file, containing classes and resources. |
The variants of a dependency may differ in their transitive dependencies or in the set of artifacts they contain, or both.
For example, the java-api and java-runtime variants of the Maven dependency only differ in their transitive dependencies, and both use the same artifact — the JAR file.
For the project dependency, the java-api,classes and the java-api,jars variants have the same transitive dependencies but different artifacts — the classes directories and the JAR files respectively.
When Gradle resolves a configuration, it uses the attributes defined to select the appropriate variant of each dependency. The attributes that Gradle uses to determine which variant to select are called the requested attributes.
For example, if a configuration requests org.gradle.usage=java-api and org.gradle.libraryelements=classes, Gradle will select the variant of each dependency that matches these attributes (in this case, classes directories intended for use as an API during compilation).
Matches do not have to exact, as some attribute values can be identified to Gradle as compatible with other values and used interchangeably during
matching.
Sometimes, a dependency might not have a variant with attributes that match the requested attributes. In such cases, Gradle can transform one variant’s artifacts into another "virtual artifact set" by modifying its artifacts without changing its transitive dependencies.
|
Important
|
Gradle will not attempt to select or run Artifact Transforms when a variant of the dependency matching the requested attributes already exists. |
For example, if the requested variant is java-api,classes, but the dependency only has java-api,jar, Gradle can potentially transform the JAR file into a classes directory by unzipping it using an Artifact Transform that is registered with these attributes.
|
Tip
|
Gradle applies transformations to artifacts, not variants. |
Executing Artifact Transforms
Gradle automatically selects Artifact Transforms as needed to satisfy resolution requests.
To run an Artifact Transform, you can configure a custom Artifact View to request an artifact set that is not exposed by any variant of the target component.
When resolving the ArtifactView Gradle will search for appropriate Artifact Transforms based on the requested attributes in the view.
Gradle will run these transformations on the original artifacts found in a variant of the target component to produce a result compatible with the attributes in the view.
In the example below, the TestTransform class defines a transformation that is registered to process artifacts of type "jar" into artifacts of type "stub":
// The TestTransform class implements TransformAction,
// transforming input JAR files into text files with specific content
abstract class TestTransform : TransformAction<TransformParameters.None> {
@get:InputArtifact
abstract val inputArtifact: Provider<FileSystemLocation>
override fun transform(outputs: TransformOutputs) {
val outputFile = outputs.file("transformed-stub.txt")
outputFile.writeText("Transformed from ${inputArtifact.get().asFile.name}")
}
}
// The transform is registered to convert artifacts from the type "jar" to "stub"
dependencies {
registerTransform(TestTransform::class.java) {
from.attribute(ArtifactTypeDefinition.ARTIFACT_TYPE_ATTRIBUTE, "jar")
to.attribute(ArtifactTypeDefinition.ARTIFACT_TYPE_ATTRIBUTE, "stub")
}
}
dependencies {
runtimeOnly("com.github.javafaker:javafaker:1.0.2")
}
// The testArtifact task queries and prints the attributes of resolved artifacts,
// showing the type conversion in action.
tasks.register("testArtifact") {
val resolvedArtifacts = configurations.runtimeClasspath.get().incoming.artifactView {
attributes {
attribute(ArtifactTypeDefinition.ARTIFACT_TYPE_ATTRIBUTE, "stub")
}
}.artifacts
inputs.files(resolvedArtifacts.artifactFiles)
doLast {
resolvedArtifacts.resolvedArtifacts.get().forEach {
println("Resolved artifact variant:")
println("- ${it.variant}")
println("Resolved artifact attributes:")
println("- ${it.variant.attributes}")
println("Resolved artifact type:")
println("- ${it.variant.attributes.getAttribute(ArtifactTypeDefinition.ARTIFACT_TYPE_ATTRIBUTE)}")
}
}
}// The TestTransform class implements TransformAction,
// transforming input JAR files into text files with specific content
abstract class TestTransform implements TransformAction<TransformParameters.None> {
@InputArtifact
abstract Provider<FileSystemLocation> getInputArtifact()
@Override
void transform(TransformOutputs outputs) {
def outputFile = outputs.file("transformed-stub.txt")
outputFile.text = "Transformed from ${getInputArtifact().get().asFile.name}"
}
}
// The transform is registered to convert artifacts from the type "jar" to "stub"
dependencies {
registerTransform(TestTransform) {
from.attribute(ArtifactTypeDefinition.ARTIFACT_TYPE_ATTRIBUTE, "jar")
to.attribute(ArtifactTypeDefinition.ARTIFACT_TYPE_ATTRIBUTE, "stub")
}
}
dependencies {
runtimeOnly("com.github.javafaker:javafaker:1.0.2")
}
// The testArtifact task queries and prints the attributes of resolved artifacts,
// showing the type conversion in action.
tasks.register("testArtifact") {
def resolvedArtifacts = configurations.runtimeClasspath.incoming.artifactView {
attributes {
attribute(ArtifactTypeDefinition.ARTIFACT_TYPE_ATTRIBUTE, "stub")
}
}.artifacts
inputs.files(resolvedArtifacts.artifactFiles)
doLast {
resolvedArtifacts.resolvedArtifacts.get().each {
println "Resolved artifact variant:"
println "- ${it.variant}"
println "Resolved artifact attributes:"
println "- ${it.variant.attributes}"
println "Resolved artifact type:"
println "- ${it.variant.attributes.getAttribute(ArtifactTypeDefinition.ARTIFACT_TYPE_ATTRIBUTE)}"
}
}
}The testArtifact task resolves artifacts of type "stub" using the runtimeClasspath configuration.
This is achieved by creating an ArtifactView that filters for artifacts with ARTIFACT_TYPE_ATTRIBUTE = "stub".
Understanding Artifact Transforms Chains
When Gradle resolves a configuration and a variant in the graph does not have an artifact set with the requested attributes, it attempts to find a chain of one or more Artifact Transforms that can be run sequentially to create the desired artifact set. This process is called Artifact Transform selection:
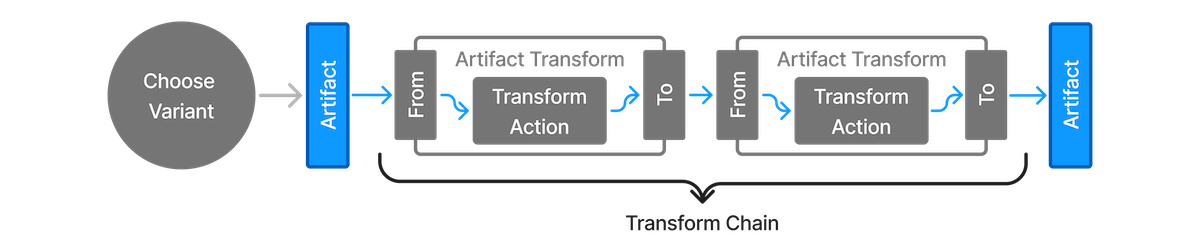
The Artifact Transform Selection Process:
-
Start with requested Attributes:
-
Gradle starts with the attributes specified on the configuration being resolved, appends any attributes specified on an
ArtifactView, and finally appends any attributes declared directly on the dependency. -
It considers all registered transforms that modify these attributes.
-
-
Find a path to existing Variants:
-
Gradle works backwards, trying to find a path from the requested attributes to an existing variant.
-
For example, if the minified attribute has values true and false, and a transform can change minified=false to minified=true, Gradle will use this transform if only minified=false variants are available but minified=true is requested.
Gradle selects a chain of transforms using the following process:
-
If there is only one possible chain that produces the requested attributes, it is selected.
-
If there are multiple such chains, then only the shortest chains are considered.
-
If there are still multiple chains remaining that are equally suitable but produce different results, the selection fails, and an error is reported.
-
If all the remaining chains produce the same set of resulting attributes, Gradle arbitrarily selects one.
How can multiple chains produce different suitable results? Transforms can alter multiple attributes at a time. A suitable result of a transformation chain is one possessing attributes compatible with the requested attributes. But a result may contain other attributes as well, that were not requested, and are irrelevant to the result.
For example: if attributes A=a and B=b are requested, and variant V1 contains attributes A=a, B=b, and C=c, and variant V2 contains attributes A=a, B=b, and D=d, then since all the values of A and B are identical (or compatible) either V1 or V2 would satisfy the request.
A Full Example
Let’s continue exploring the minified example begun above: a configuration requests org.gradle.usage=java-runtime, org.gradle.libraryelements=jar, minified=true.
The dependencies are:
-
External
guavadependency with variants:-
org.gradle.usage=java-runtime, org.gradle.libraryelements=jar, minified=false -
org.gradle.usage=java-api, org.gradle.libraryelements=jar, minified=false
-
-
Project
producerdependency with variants:-
org.gradle.usage=java-runtime, org.gradle.libraryelements=jar, minified=false -
org.gradle.usage=java-runtime, org.gradle.libraryelements=classes, minified=false -
org.gradle.usage=java-api, org.gradle.libraryelements=jar, minified=false -
org.gradle.usage=java-api, org.gradle.libraryelements=classes, minified=false
-
Gradle uses the minify transform to convert minified=false variants to minified=true.
-
For
guava, Gradle converts-
org.gradle.usage=java-runtime, org.gradle.libraryelements=jar, minified=falseto -
org.gradle.usage=java-runtime, org.gradle.libraryelements=jar, minified=true.
-
-
For
producer, Gradle converts-
org.gradle.usage=java-runtime, org.gradle.libraryelements=jar, minified=falseto -
org.gradle.usage=java-runtime, org.gradle.libraryelements=jar, minified=true.
-
Then, during execution:
-
Gradle downloads the
guavaJAR and runs the transform to minify it. -
Gradle executes the
producer:jartask to produce the JAR and then runs the transform to minify it. -
These tasks and transforms are executed in parallel where possible.
To set up the minified attribute so that the above works you must add the attribute to all JAR variants being produced, and also add it to all resolvable configurations being requested.
You should also register the attribute in the attributes schema.
val artifactType = Attribute.of("artifactType", String::class.java)
val minified = Attribute.of("minified", Boolean::class.javaObjectType)
dependencies {
attributesSchema {
attribute(minified) // (1)
}
artifactTypes.getByName("jar") {
attributes.attribute(minified, false) // (2)
}
}
configurations.runtimeClasspath.configure {
attributes {
attribute(minified, true) // (3)
}
}
dependencies {
registerTransform(Minify::class) {
from.attribute(minified, false).attribute(artifactType, "jar")
to.attribute(minified, true).attribute(artifactType, "jar")
}
}
dependencies { // (4)
implementation("com.google.guava:guava:27.1-jre")
implementation(project(":producer"))
}
tasks.register<Copy>("resolveRuntimeClasspath") { // (5)
from(configurations.runtimeClasspath)
into(layout.buildDirectory.dir("runtimeClasspath"))
}def artifactType = Attribute.of('artifactType', String)
def minified = Attribute.of('minified', Boolean)
dependencies {
attributesSchema {
attribute(minified) // (1)
}
artifactTypes.getByName("jar") {
attributes.attribute(minified, false) // (2)
}
}
configurations.runtimeClasspath {
attributes {
attribute(minified, true) // (3)
}
}
dependencies {
registerTransform(Minify) {
from.attribute(minified, false).attribute(artifactType, "jar")
to.attribute(minified, true).attribute(artifactType, "jar")
}
}
dependencies { // (4)
implementation('com.google.guava:guava:27.1-jre')
implementation(project(':producer'))
}
tasks.register("resolveRuntimeClasspath", Copy) {// (5)
from(configurations.runtimeClasspath)
into(layout.buildDirectory.dir("runtimeClasspath"))
}-
Add the attribute to the schema
-
All JAR files are not minified
-
Request that the runtime classpath is minified
-
Add the dependencies which will be transformed
-
Add task that requires the transformed artifacts
You can now see what happens when we run the resolveRuntimeClasspath task, which resolves the runtimeClasspath configuration.
Gradle transforms the project dependency before the resolveRuntimeClasspath task starts.
Gradle transforms the binary dependencies when it executes the resolveRuntimeClasspath task:
$ ./gradlew resolveRuntimeClasspath> Task :producer:compileJava
> Task :producer:processResources NO-SOURCE
> Task :producer:classes
> Task :producer:jar
> Transform producer.jar (project ':producer') with Minify
Nothing to minify - using producer.jar unchanged
> Task :resolveRuntimeClasspath
Minifying guava-27.1-jre.jar
Nothing to minify - using listenablefuture-9999.0-empty-to-avoid-conflict-with-guava.jar unchanged
Nothing to minify - using jsr305-3.0.2.jar unchanged
Nothing to minify - using checker-qual-2.5.2.jar unchanged
Nothing to minify - using error_prone_annotations-2.2.0.jar unchanged
Nothing to minify - using j2objc-annotations-1.1.jar unchanged
Nothing to minify - using animal-sniffer-annotations-1.17.jar unchanged
Nothing to minify - using failureaccess-1.0.1.jar unchanged
BUILD SUCCESSFUL in 0s
3 actionable tasks: 3 executedImplementing Artifact Transforms
Similar to task types, an artifact transform consists of an action and some optional parameters. The major difference from custom task types is that the action and the parameters are implemented as two separate classes.
Artifact Transforms without Parameters
An artifact transform action is provided by a class implementing TransformAction.
Such a class implements the transform() method, which converts the input artifacts into zero, one, or multiple output artifacts.
Most Artifact Transforms are one-to-one, so the transform method will be used to transform each input artifact contained in the from variant into exactly one output artifact.
The implementation of the artifact transform action needs to register each output artifact by calling TransformOutputs.dir() or TransformOutputs.file().
You can supply two types of paths to the dir or file methods:
-
An absolute path to the input artifact or within the input artifact (for an input directory).
-
A relative path.
Gradle uses the absolute path as the location of the output artifact.
For example, if the input artifact is an exploded WAR, the transform action can call TransformOutputs.file() for all JAR files in the WEB-INF/lib directory.
The output of the transform would then be the library JARs of the web application.
For a relative path, the dir() or file() method returns a workspace to the transform action.
The transform action needs to create the transformed artifact(s) at the location of the provided workspace.
The output artifact(s) replace the input artifact(s) in the transformed variant in the order they were registered.
For example, if the selected input variant contains the artifacts lib1.jar, lib2.jar, lib3.jar, and the transform action registers a minified output artifact <artifact-name>-min.jar for each input artifact, then the transformed configuration will consist of the artifacts lib1-min.jar, lib2-min.jar, and lib3-min.jar.
Here is the implementation of an Unzip transform, which unzips a JAR file into a classes directory.
The Unzip transform does not require any parameters:
abstract class Unzip : TransformAction<TransformParameters.None> { // (1)
@get:InputArtifact // (2)
abstract val inputArtifact: Provider<FileSystemLocation>
override
fun transform(outputs: TransformOutputs) {
val input = inputArtifact.get().asFile
val unzipDir = outputs.dir(input.name + "-unzipped") // (3)
unzipTo(input, unzipDir) // (4)
}
private fun unzipTo(zipFile: File, unzipDir: File) {
// implementation...
}
}abstract class Unzip implements TransformAction<TransformParameters.None> { // (1)
@InputArtifact // (2)
abstract Provider<FileSystemLocation> getInputArtifact()
@Override
void transform(TransformOutputs outputs) {
def input = inputArtifact.get().asFile
def unzipDir = outputs.dir(input.name + "-unzipped") // (3)
unzipTo(input, unzipDir) // (4)
}
private static void unzipTo(File zipFile, File unzipDir) {
// implementation...
}
}-
Use
TransformParameters.Noneif the transform does not use parameters -
Inject the input artifact
-
Request an output location for the unzipped files
-
Do the actual work of the transform
Note how the implementation uses @InputArtifact to inject an artifact to transform into the action class, so that it can be accessed within the transform method.
This method requests a directory for the unzipped classes by using TransformOutputs.dir() and then unzips the JAR file into this directory.
Artifact Transforms with Parameters
An artifact transform may require parameters, such as a String for filtering or a file collection used to support the transformation of the input artifact.
To pass these parameters to the transform action, you must define a new type with the desired parameters.
This type must implement the marker interface TransformParameters.
The parameters must be represented using managed properties and the parameter type must be a managed type. You can use an interface or abstract class to declare the getters, and Gradle will generate the implementation. All getters need to have proper input annotations, as described in the incremental build annotations table.
Here is the implementation of a Minify transform that makes JARs smaller by only keeping certain classes in them.
The Minify transform requires knowledge of the classes to keep within each JAR, which is provided as an Map property within its parameters:
abstract class Minify : TransformAction<Minify.Parameters> { // (1)
interface Parameters : TransformParameters { // (2)
@get:Input
var keepClassesByArtifact: Map<String, Set<String>>
}
@get:PathSensitive(PathSensitivity.NAME_ONLY)
@get:InputArtifact
abstract val inputArtifact: Provider<FileSystemLocation>
override
fun transform(outputs: TransformOutputs) {
val fileName = inputArtifact.get().asFile.name
for (entry in parameters.keepClassesByArtifact) { // (3)
if (fileName.startsWith(entry.key)) {
val nameWithoutExtension = fileName.substring(0, fileName.length - 4)
minify(inputArtifact.get().asFile, entry.value, outputs.file("${nameWithoutExtension}-min.jar"))
return
}
}
println("Nothing to minify - using ${fileName} unchanged")
outputs.file(inputArtifact) // (4)
}
private fun minify(artifact: File, keepClasses: Set<String>, jarFile: File) {
println("Minifying ${artifact.name}")
// Implementation ...
}
}abstract class Minify implements TransformAction<Parameters> { // (1)
interface Parameters extends TransformParameters { // (2)
@Input
Map<String, Set<String>> getKeepClassesByArtifact()
void setKeepClassesByArtifact(Map<String, Set<String>> keepClasses)
}
@PathSensitive(PathSensitivity.NAME_ONLY)
@InputArtifact
abstract Provider<FileSystemLocation> getInputArtifact()
@Override
void transform(TransformOutputs outputs) {
def fileName = inputArtifact.get().asFile.name
for (entry in parameters.keepClassesByArtifact) { // (3)
if (fileName.startsWith(entry.key)) {
def nameWithoutExtension = fileName.substring(0, fileName.length() - 4)
minify(inputArtifact.get().asFile, entry.value, outputs.file("${nameWithoutExtension}-min.jar"))
return
}
}
println "Nothing to minify - using ${fileName} unchanged"
outputs.file(inputArtifact) // (4)
}
private void minify(File artifact, Set<String> keepClasses, File jarFile) {
println "Minifying ${artifact.name}"
// Implementation ...
}
}-
Declare the parameter type
-
Interface for the transform parameters
-
Use the parameters
-
Use the unchanged input artifact when no minification is required
Observe how you can obtain the parameters by TransformAction.getParameters() in the transform() method.
The implementation of the transform() method requests a location for the minified JAR by using TransformOutputs.file() and then creates the minified JAR at this location.
Remember that the input artifact is a dependency, which may have its own dependencies.
Suppose your artifact transform needs access to those transitive dependencies.
In that case, it can declare an abstract getter returning a FileCollection and annotate it with @InputArtifactDependencies.
When your transform runs, Gradle will inject the transitive dependencies into the FileCollection property by implementing the getter.
Note that using input artifact dependencies in a transform has performance implications; only inject them when needed.
Artifact Transforms with Caching
Artifact Transforms can make use of the build cache to store their outputs and avoid rerunning their transform actions when the result is known.
To enable the build cache to store the results of an artifact transform, add the @CacheableTransform annotation on the action class.
For cacheable transforms, you must annotate its @InputArtifact property — and any property marked with @InputArtifactDependencies — with normalization annotations such as @PathSensitive.
The following example demonstrates a more complex transform that relocates specific classes within a JAR to a different package. This process involves rewriting the bytecode of both the relocated classes and any classes that reference them (class relocation):
@CacheableTransform // (1)
abstract class ClassRelocator : TransformAction<ClassRelocator.Parameters> {
interface Parameters : TransformParameters { // (2)
@get:CompileClasspath // (3)
val externalClasspath: ConfigurableFileCollection
@get:Input
val excludedPackage: Property<String>
}
@get:Classpath // (4)
@get:InputArtifact
abstract val primaryInput: Provider<FileSystemLocation>
@get:CompileClasspath
@get:InputArtifactDependencies // (5)
abstract val dependencies: FileCollection
override
fun transform(outputs: TransformOutputs) {
val primaryInputFile = primaryInput.get().asFile
if (parameters.externalClasspath.contains(primaryInputFile)) { // (6)
outputs.file(primaryInput)
} else {
val baseName = primaryInputFile.name.substring(0, primaryInputFile.name.length - 4)
relocateJar(outputs.file("$baseName-relocated.jar"))
}
}
private fun relocateJar(output: File) {
// implementation...
val relocatedPackages = (dependencies.flatMap { it.readPackages() } + primaryInput.get().asFile.readPackages()).toSet()
val nonRelocatedPackages = parameters.externalClasspath.flatMap { it.readPackages() }
val relocations = (relocatedPackages - nonRelocatedPackages).map { packageName ->
val toPackage = "relocated.$packageName"
println("$packageName -> $toPackage")
Relocation(packageName, toPackage)
}
JarRelocator(primaryInput.get().asFile, output, relocations).run()
}
}@CacheableTransform // (1)
abstract class ClassRelocator implements TransformAction<Parameters> {
interface Parameters extends TransformParameters { // (2)
@CompileClasspath // (3)
ConfigurableFileCollection getExternalClasspath()
@Input
Property<String> getExcludedPackage()
}
@Classpath // (4)
@InputArtifact
abstract Provider<FileSystemLocation> getPrimaryInput()
@CompileClasspath
@InputArtifactDependencies // (5)
abstract FileCollection getDependencies()
@Override
void transform(TransformOutputs outputs) {
def primaryInputFile = primaryInput.get().asFile
if (parameters.externalClasspath.contains(primaryInput)) { // (6)
outputs.file(primaryInput)
} else {
def baseName = primaryInputFile.name.substring(0, primaryInputFile.name.length - 4)
relocateJar(outputs.file("$baseName-relocated.jar"))
}
}
private relocateJar(File output) {
// implementation...
def relocatedPackages = (dependencies.collectMany { readPackages(it) } + readPackages(primaryInput.get().asFile)) as Set
def nonRelocatedPackages = parameters.externalClasspath.collectMany { readPackages(it) }
def relocations = (relocatedPackages - nonRelocatedPackages).collect { packageName ->
def toPackage = "relocated.$packageName"
println("$packageName -> $toPackage")
new Relocation(packageName, toPackage)
}
new JarRelocator(primaryInput.get().asFile, output, relocations).run()
}
}-
Declare the transform cacheable
-
Interface for the transform parameters
-
Declare input type for each parameter
-
Declare a normalization for the input artifact
-
Inject the input artifact dependencies
-
Use the parameters
Note the classes to be relocated are determined by examining the packages of the input artifact and its dependencies. Additionally, the transform ensures that packages contained in JAR files on an external classpath are not relocated.
Incremental Artifact Transforms
Similar to incremental tasks, Artifact Transforms can avoid some work by only processing files that have changed since the last execution. This is done by using the InputChanges interface.
For Artifact Transforms, only the input artifact is an incremental input; therefore, the transform can only query for changes there. To use InputChanges in the transform action, inject it into the action.
For more information on how to use InputChanges, see the corresponding documentation for incremental tasks.
Here is an example of an incremental transform that counts the lines of code in Java source files:
abstract class CountLoc : TransformAction<TransformParameters.None> {
@get:Inject // (1)
abstract val inputChanges: InputChanges
@get:PathSensitive(PathSensitivity.RELATIVE)
@get:InputArtifact
abstract val input: Provider<FileSystemLocation>
override
fun transform(outputs: TransformOutputs) {
val outputDir = outputs.dir("${input.get().asFile.name}.loc")
println("Running transform on ${input.get().asFile.name}, incremental: ${inputChanges.isIncremental}")
inputChanges.getFileChanges(input).forEach { change -> // (2)
val changedFile = change.file
if (change.fileType != FileType.FILE) {
return@forEach
}
val outputLocation = outputDir.resolve("${change.normalizedPath}.loc")
when (change.changeType) {
ChangeType.ADDED, ChangeType.MODIFIED -> {
println("Processing file ${changedFile.name}")
outputLocation.parentFile.mkdirs()
outputLocation.writeText(changedFile.readLines().size.toString())
}
ChangeType.REMOVED -> {
println("Removing leftover output file ${outputLocation.name}")
outputLocation.delete()
}
}
}
}
}abstract class CountLoc implements TransformAction<TransformParameters.None> {
@Inject // (1)
abstract InputChanges getInputChanges()
@PathSensitive(PathSensitivity.RELATIVE)
@InputArtifact
abstract Provider<FileSystemLocation> getInput()
@Override
void transform(TransformOutputs outputs) {
def outputDir = outputs.dir("${input.get().asFile.name}.loc")
println("Running transform on ${input.get().asFile.name}, incremental: ${inputChanges.incremental}")
inputChanges.getFileChanges(input).forEach { change -> // (2)
def changedFile = change.file
if (change.fileType != FileType.FILE) {
return
}
def outputLocation = new File(outputDir, "${change.normalizedPath}.loc")
switch (change.changeType) {
case ADDED:
case MODIFIED:
println("Processing file ${changedFile.name}")
outputLocation.parentFile.mkdirs()
outputLocation.text = changedFile.readLines().size()
case REMOVED:
println("Removing leftover output file ${outputLocation.name}")
outputLocation.delete()
}
}
}
}-
Inject
InputChanges -
Query for changes in the input artifact
This transform will only run on source files that have changed since the last run, as otherwise the line count would not need to be recalculated.
Registering Artifact Transforms
You need to register the artifact transform actions, providing parameters if necessary so that they can be selected when resolving dependencies.
To register an artifact transform, you must use registerTransform() within the dependencies {} block.
There are a few points to consider when using registerTransform():
-
At least one
fromandtoattributes are required. -
Each
toattribute must have a correspondingfromattribute. -
Additional
fromattributes can be included which do not have correspondingtoattributes. -
The transform action itself can have configuration options. You can configure them with the
parameters {}block. -
You must register the transform on the project that has the configuration that will be resolved.
-
You can supply any type implementing TransformAction to the
registerTransform()method.
For example, imagine you want to unpack some dependencies and put the unpacked directories and files on the classpath.
You can do so by registering an artifact transform action of type Unzip, as shown here:
dependencies {
registerTransform(Unzip::class.java) {
from.attribute(LibraryElements.LIBRARY_ELEMENTS_ATTRIBUTE, objects.named<LibraryElements>(LibraryElements.JAR))
from.attribute(ArtifactTypeDefinition.ARTIFACT_TYPE_ATTRIBUTE, ArtifactTypeDefinition.JAR_TYPE)
to.attribute(LibraryElements.LIBRARY_ELEMENTS_ATTRIBUTE, objects.named<LibraryElements>(LibraryElements.CLASSES_AND_RESOURCES))
to.attribute(ArtifactTypeDefinition.ARTIFACT_TYPE_ATTRIBUTE, ArtifactTypeDefinition.DIRECTORY_TYPE)
}
}dependencies {
registerTransform(Unzip) {
from.attribute(LibraryElements.LIBRARY_ELEMENTS_ATTRIBUTE, objects.named(LibraryElements, LibraryElements.JAR))
from.attribute(ArtifactTypeDefinition.ARTIFACT_TYPE_ATTRIBUTE, ArtifactTypeDefinition.JAR_TYPE)
to.attribute(LibraryElements.LIBRARY_ELEMENTS_ATTRIBUTE, objects.named(LibraryElements, LibraryElements.CLASSES_AND_RESOURCES))
to.attribute(ArtifactTypeDefinition.ARTIFACT_TYPE_ATTRIBUTE, ArtifactTypeDefinition.DIRECTORY_TYPE)
}
}Another example is that you want to minify JARs by only keeping some class files from them.
Note the use of the parameters {} block to provide the classes to keep in the minified JARs to the Minify transform:
val artifactType = Attribute.of("artifactType", String::class.java)
val minified = Attribute.of("minified", Boolean::class.javaObjectType)
val keepPatterns = mapOf(
"guava" to setOf(
"com.google.common.base.Optional",
"com.google.common.base.AbstractIterator"
)
)
dependencies {
registerTransform(Minify::class) {
from.attribute(minified, false).attribute(artifactType, "jar")
to.attribute(minified, true).attribute(artifactType, "jar")
parameters {
keepClassesByArtifact = keepPatterns
}
}
}def artifactType = Attribute.of('artifactType', String)
def minified = Attribute.of('minified', Boolean)
def keepPatterns = [
"guava": [
"com.google.common.base.Optional",
"com.google.common.base.AbstractIterator"
] as Set
]
dependencies {
registerTransform(Minify) {
from.attribute(minified, false).attribute(artifactType, "jar")
to.attribute(minified, true).attribute(artifactType, "jar")
parameters {
keepClassesByArtifact = keepPatterns
}
}
}Executing Artifact Transforms
On the command line, Gradle runs tasks; not Artifact Transforms: ./gradlew build.
So how and when does it run transforms?
There are two ways Gradle executes a transform:
-
Artifact Transforms execution for project dependencies can be discovered ahead of task execution and therefore can be scheduled before the task execution.
-
Artifact Transforms execution for external module dependencies cannot be discovered ahead of task execution and, therefore are scheduled inside the task execution.
In well-declared builds, project dependencies can be fully discovered during task configuration ahead of task execution scheduling. If the project dependency is badly declared (e.g., missing a task input), the transform execution will happen inside the task.
It’s important to remember that Artifact Transforms:
-
will only ever be run if no matching variants exist to satisfy a request
-
can be run in parallel
-
will not be rerun if possible (if multiple resolution requests require the same transform to be executed on the same artifacts, and the transform is cacheable, the transform will only be run once and the results fetched from the cache on each subsequent request)
|
Important
|
`TransformAction`s are only instantiated and run if input artifacts exist. If there are no artifacts present in an input variant to a transform, that transform will be skipped. This can happen in the middle of a chain of actions, resulting in all subsequent transforms being skipped. |
Debugging Artifact Transforms
You can use the artifactTransforms task to inspect the artifact transforms registered in your build.
This task makes it easier to debug unexpected transform behavior, understand which transforms are applied, and see how artifacts flow through your build.
To generate the report, run:
$ ./gradlew artifactTransformsThis will produce output listing all registered transforms, including details such as:
-
The input and output artifact types for each transform
-
Attributes required for the transform to apply
-
Implementation details of custom transforms
This report is especially helpful if you encounter issues with artifact selection or resolution errors related to transforms.
It’s important to note that the artifactTransforms task operates on a single project.
If you run it on a subproject, it will report the transforms registered only in that specific project.
For example, to view the artifact transforms in the app subproject, you would run:
$ ./gradlew :app:artifactTransforms> Task :app:artifactTransforms
--------------------------------------------------
CopyTransform
--------------------------------------------------
Type: dagger.hilt.android.plugin.transform.CopyTransform
Cacheable: No
From Attributes:
- artifactType = android-classes
To Attributes:
- artifactType = jar-for-dagger
--------------------------------------------------
CopyTransform
--------------------------------------------------
Type: dagger.hilt.android.plugin.transform.CopyTransform
Cacheable: No
From Attributes:
- artifactType = directory
To Attributes:
- artifactType = jar-for-dagger
--------------------------------------------------
AggregatedPackagesTransform
--------------------------------------------------
Type: dagger.hilt.android.plugin.transform.AggregatedPackagesTransform
Cacheable: Yes
From Attributes:
- artifactType = jar-for-dagger
To Attributes:
- artifactType = aggregated-jar-for-hilt
Some artifact transforms are not cacheable. This can have negative performance impacts.Because the task only inspects the current project, running it on the root project, where no transforms are registered, will produce empty output:
$ ./gradlew artifactTransforms> Task :artifactTransforms
There are no transforms registered in root project 'gradle'.Locking Versions
Using dynamic dependency versions (e.g., 1.+ or [1.0,2.0)) can cause builds to break unexpectedly because the exact version of a dependency that gets resolved can change over time:
dependencies {
// Depend on the latest 5.x release of Spring available in the searched repositories
implementation("org.springframework:spring-web:5.+")
}dependencies {
// Depend on the latest 5.x release of Spring available in the searched repositories
implementation 'org.springframework:spring-web:5.+'
}To ensure reproducible builds, it’s necessary to lock versions of dependencies and their transitive dependencies. This guarantees that a build with the same inputs will always resolve to the same module versions, a process known as dependency locking.
Dependency locking is a process where Gradle saves the resolved versions of dependencies to a lock file, ensuring that subsequent builds use the same dependency versions. This lock state is stored in a file and helps to prevent unexpected changes in the dependency graph.
Dependency locking offers several key advantages:
-
Avoiding Cascading Failures: Teams managing multiple repositories no longer need to rely on
-SNAPSHOTor changing dependencies, which can lead to unexpected failures if a dependency introduces a bug or incompatibility. -
Dynamic Version Flexibility with Stability: Teams that use the latest versions of dependencies can rely on dynamic versions during development and testing phases, locking them only for releases.
-
Publishing Resolved Versions: By combining dependency locking with the practice of publishing resolved versions, dynamic versions are replaced with the actual resolved versions at the time of publication.
-
Optimizing Build Cache Usage: Since dynamic or changing dependencies violate the principle of stable task inputs, locking dependencies ensures that tasks have consistent inputs.
-
Enhanced Development Workflow: Developers can lock dependencies locally for stability while working on a feature or debugging an issue, while CI environments can test the latest
SNAPSHOTor nightly versions to provide early feedback on integration issues. This allows teams to balance stability and early feedback during development.
Activate locking for specific configurations
Locking is enabled per dependency configuration.
Once enabled, you must create an initial lock state, causing Gradle to verify that resolution results do not change. This ensures that if the selected dependencies differ from the locked ones (due to newer versions being available), the build will fail, preventing unexpected version changes.
|
Warning
|
Dependency locking is effective with dynamic versions, but it should not be used with changing versions (e.g., Using dependency locking with changing versions indicates a misunderstanding of these features and can lead to unpredictable results. Gradle will emit a warning when persisting the lock state if changing dependencies are present in the resolution result. |
Locking of a configuration happens through the ResolutionStrategy API:
configurations {
compileClasspath {
resolutionStrategy.activateDependencyLocking()
}
}configurations {
compileClasspath {
resolutionStrategy.activateDependencyLocking()
}
}Only configurations that can be resolved will have lock state attached to them. Applying locking on non resolvable-configurations is a no-op.
Activate locking for all configurations
The following locks all configurations:
dependencyLocking {
lockAllConfigurations()
}dependencyLocking {
lockAllConfigurations()
}The above will lock all project configurations, but not the buildscript ones.
Disable locking for specific configurations
You can also disable locking on a specific configuration.
This can be useful if a plugin configured locking on all configurations, but you happen to add one that should not be locked:
configurations.compileClasspath {
resolutionStrategy.deactivateDependencyLocking()
}configurations {
compileClasspath {
resolutionStrategy.deactivateDependencyLocking()
}
}Activate locking for a buildscript classpath configuration
If you apply plugins to your build, you may want to leverage dependency locking there as well.
To lock the classpath configuration used for script plugins:
buildscript {
configurations.classpath {
resolutionStrategy.activateDependencyLocking()
}
}buildscript {
configurations.classpath {
resolutionStrategy.activateDependencyLocking()
}
}Generating and updating dependency locks
To generate or update the lock state, add the --write-locks argument while invoking whatever tasks that would trigger the locked configurations to be resolved:
$ ./gradlew dependencies --write-locksThis will create or update the lock state for each resolved configuration during that build execution. If a lock state already exists, it will be overwritten.
# This is a Gradle generated file for dependency locking.
# Manual edits can break the build and are not advised.
# This file is expected to be part of source control.
com.google.code.findbugs:jsr305:3.0.2=classpath
com.google.errorprone:error_prone_annotations:2.3.2=classpath
com.google.gradle:osdetector-gradle-plugin:1.7.1=classpath
com.google.guava:failureaccess:1.0.1=classpath
com.google.guava:guava:28.1-jre=classpath
com.google.guava:listenablefuture:9999.0-empty-to-avoid-conflict-with-guava=classpath
com.google.j2objc:j2objc-annotations:1.3=classpath
empty=|
Note
|
Gradle won’t write the lock state to disk if the build fails, preventing the persistence of potentially invalid states. |
Lock all configurations in a single build execution
When working with multiple configurations, you may want to lock them all at once in a single build execution. You have two options for this:
-
Run
gradle dependencies --write-locks:-
This command will lock all resolvable configurations that have locking enabled.
-
In a multi-project setup, note that
dependenciesis executed only on one project, typically the root project.
-
-
Declare a Custom Task to Resolve All Configurations:
-
This approach is particularly useful if you need more control over which configurations are locked.
-
This custom task resolves all configurations, locking them in the process:
tasks.register("resolveAndLockAll") {
notCompatibleWithConfigurationCache("Filters configurations at execution time")
doFirst {
require(gradle.startParameter.isWriteDependencyLocks) { "$path must be run from the command line with the `--write-locks` flag" }
}
doLast {
configurations.filter {
// Add any custom filtering on the configurations to be resolved
it.isCanBeResolved
}.forEach { it.resolve() }
}
}tasks.register('resolveAndLockAll') {
notCompatibleWithConfigurationCache("Filters configurations at execution time")
doFirst {
assert gradle.startParameter.writeDependencyLocks : "$path must be run from the command line with the `--write-locks` flag"
}
doLast {
configurations.matching {
// Add any custom filtering on the configurations to be resolved
it.canBeResolved
}.each { it.resolve() }
}
}By filtering and resolving specific configurations, you ensure that only the relevant ones are locked, tailoring the locking process to your project’s needs. This is especially useful in environments like native builds, where not all configurations can be resolved on a single platform.
Understanding the locking mechanism during dependency resolution
When using dependency locking, Gradle enforces the locked versions as if they were declared with strictly().
This means:
-
If the declared version is lower than the locked version (e.g., declared
1.0.0, locked1.2.0), Gradle will silently upgrade to the locked version. -
If the declared version is higher than the locked version (e.g., declared
1.2.0, locked1.0.0), Gradle will fail resolution, because the lockfile enforces1.0.0strictly.
This can be surprising if you assume the declared version takes precedence.
To resolve this, update the lockfile with --write-locks.
Understanding lock state location and format
A lockfile is a critical component that records the exact versions of dependencies used in a project, allowing for verification during builds to ensure consistent results across different environments and over time. It helps identify discrepancies in dependencies when a project is built on different machines or at different times.
|
Tip
|
Lockfiles should be checked in to source control. |
Location of lock files
-
The lock state is preserved in a file named
gradle.lockfile, located at the root of each project or subproject directory. -
The exception is the lockfile for the buildscript itself, which is named
buildscript-gradle.lockfile.
Structure of lock files
Consider the following dependency declaration:
configurations {
compileClasspath {
resolutionStrategy.activateDependencyLocking()
}
runtimeClasspath {
resolutionStrategy.activateDependencyLocking()
}
annotationProcessor {
resolutionStrategy.activateDependencyLocking()
}
}
dependencies {
implementation("org.springframework:spring-beans:[5.0,6.0)")
}configurations {
compileClasspath {
resolutionStrategy.activateDependencyLocking()
}
runtimeClasspath {
resolutionStrategy.activateDependencyLocking()
}
annotationProcessor {
resolutionStrategy.activateDependencyLocking()
}
}
dependencies {
implementation 'org.springframework:spring-beans:[5.0,6.0)'
}With the above configuration, the generated gradle.lockfile will look like this:
# This is a Gradle generated file for dependency locking.
# Manual edits can break the build and are not advised.
# This file is expected to be part of source control.
# To regenerate this file, run: ./gradlew :dependencies --write-locks
org.springframework:spring-beans:5.0.5.RELEASE=compileClasspath, runtimeClasspath
org.springframework:spring-core:5.0.5.RELEASE=compileClasspath, runtimeClasspath
org.springframework:spring-jcl:5.0.5.RELEASE=compileClasspath, runtimeClasspath
empty=annotationProcessorWhere:
-
Each line represents a single dependency in the
group:artifact:versionformat. -
Configurations: After the version, the configurations that include the dependency are listed.
-
Ordering: Dependencies and configurations are listed alphabetically to make version control diffs easier to manage.
-
Empty Configurations: The last line lists configurations that are empty, meaning they contain no dependencies.
This lockfile should be included in source control to ensure that all team members and environments use the exact same dependency versions.
Migrating your legacy lockfile
If your project uses the legacy lock file format of a file per locked configuration, follow these instructions to migrate to the new format:
|
Note
|
Migration can be done one configuration at a time. Gradle will keep sourcing the lock state from the per configuration files as long as there is no information for that configuration in the single lock file. |
Configuring the lock file name and location
When using a single lock file per project, you can configure its name and location.
This capability allows you to specify a file name based on project properties, enabling a single project to store different lock states for different execution contexts.
For example, in the JVM ecosystem, the Scala version is often included in artifact coordinates:
val scalaVersion = "2.12"
dependencyLocking {
lockFile = file("$projectDir/locking/gradle-${scalaVersion}.lockfile")
}def scalaVersion = "2.12"
dependencyLocking {
lockFile = file("$projectDir/locking/gradle-${scalaVersion}.lockfile")
}Running a build with lock state present
The moment a build needs to resolve a configuration that has locking enabled, and it finds a matching lock state, it will use it to verify that the given configuration still resolves the same versions.
A successful build indicates that the same dependencies are used by your build as stored in the lock state, regardless if new versions matching the dynamic selector are available in any of the repositories your build uses.
The complete validation is as follows:
-
Existing entries in the lock state must be matched in the build
-
A version mismatch or missing resolved module causes a build failure
-
-
Resolution result must not contain extra dependencies compared to the lock state
Fine-tuning dependency locking behaviour with lock mode
While the default lock mode behaves as described above, two other modes are available:
- Strict mode
-
In this mode, in addition to the validations above, dependency locking will fail if a configuration marked as locked does not have lock state associated with it.
- Lenient mode
-
In this mode, dependency locking will still pin dynamic versions but otherwise changes to the dependency resolution are no longer errors. Other changes include:
-
Adding or removing dependencies, even if they are strictly versioned, without causing a build failure.
-
Allowing transitive dependencies to shift, as long as dynamic versions are still pinned.
-
This mode offers flexibility for situations where you might want to explore or test new dependencies or changes in versions without breaking the build, making it useful for testing nightly or snapshot builds.
The lock mode can be controlled from the dependencyLocking block as shown below:
dependencyLocking {
lockMode = LockMode.STRICT
}dependencyLocking {
lockMode = LockMode.STRICT
}Updating lock state entries selectively
In order to update only specific modules of a configuration, you can use the --update-locks command line flag.
It takes a comma (,) separated list of module notations.
In this mode, the existing lock state is still used as input to resolution, filtering out the modules targeted by the update:
$ ./gradlew dependencies --update-locks org.apache.commons:commons-lang3,org.slf4j:slf4j-apiWildcards, indicated with *, can be used in the group or module name.
They can be the only character or appear at the end of the group or module respectively.
The following wildcard notation examples are valid:
-
org.apache.commons:*: will let all modules belonging to grouporg.apache.commonsupdate -
*:guava: will let all modules namedguava, whatever their group, update -
org.springframework.spring*:spring*: will let all modules having their group starting withorg.springframework.springand name starting withspringupdate
|
Note
|
The resolution may cause other module versions to update, as dictated by the Gradle resolution rules. |
Disabling dependency locking
To disable dependency locking for a configuration:
-
Remove Locking Configuration: Ensure that the configuration you no longer want to lock is not configured with dependency locking. This means removing or commenting out any
activateDependencyLocking()calls for that configuration. -
Update Lock State: The next time you update and save the lock state (using the
--write-locksoption), Gradle will automatically clean up any stale lock state associated with the configurations that are no longer locked.
|
Note
|
Gradle must resolve a configuration that is no longer marked as locked to detect and drop the associated lock state. Without resolving the configuration, Gradle cannot identify which lock state should be cleaned up. |
Ignoring specific dependencies from the lock state
In some scenarios, you may want to use dependency locking for other reasons than build reproducibility.
As a build author, you might want certain dependencies to update more frequently than others. For example, internal dependencies within an organization might always use the latest version, while third-party dependencies follow a different update cycle.
|
Caution
|
This approach can compromise reproducibility. Consider using different lock modes or separate lock files for specific cases. |
You can configure dependencies to be ignored in the dependencyLocking project extension:
dependencyLocking {
ignoredDependencies.add("com.example:*")
}dependencyLocking {
ignoredDependencies.add('com.example:*')
}The notation <group>:<name> is used to specify dependencies, where * acts as a trailing wildcard. Note that *:* is not accepted, as it effectively disables locking.
See the description on updating lock files for more details.
Ignoring dependencies will have the following effects:
-
Ignored dependencies apply across all locked configurations, and the setting is project scoped.
-
Ignoring a dependency does not exclude its transitive dependencies from the lock state.
-
No validation ensures that an ignored dependency is present in any configuration resolution.
-
If the dependency is present in lock state, loading it will filter out the dependency.
-
If the dependency is present in the resolution result, it will be ignored when validating the resolution against the lock state.
-
When the lock state is updated and persisted, any ignored dependency will be omitted from the written lock state.
Understanding locking limitations
-
Dependency locking does not currently apply to source dependencies.
Using Resolution Rules
Gradle provides several mechanisms to directly influence the behavior of the dependency resolution engine.
Unlike dependency constraints or component metadata rules, which serve as inputs to the resolution process, these mechanisms allow you to inject rules directly into the resolution engine. Because of their direct impact, they can be considered brute-force solutions that may mask underlying issues, such as the introduction of new dependencies.
|
Tip
|
It’s generally advisable to resort to resolution rules only when other approaches are insufficient. |
If you’re developing a library, it’s best to use dependency constraints, as they are shared with your consumers.
Here are the key resolution strategies in Gradle:
| # | Strategy | Info |
|---|---|---|
Forcing Dependency Versions |
Force a specific version of a dependency. |
|
Module Replacement |
Substitute one module for another with an explanation. |
|
Dependency Substitution |
Substitute dependencies dynamically. |
|
Component Selection Rules |
Control which versions of a module are allowed. Reject specific versions that are known to be broken or undesirable. |
|
Setting Default Dependencies |
Automatically add dependencies to a configuration when no dependencies are explicitly declared. |
|
Excluding Transitive Dependencies |
Exclude transitive dependencies that you don’t want to be included in the dependency graph. |
|
Force Failed Resolution Strategies |
Force builds to fail when certain conditions occur during resolution. |
|
Disabling Transitive Dependencies |
Dependencies are transitive by default, but you can disable this behavior for individual dependencies. |
|
Dependency Resolve Rules and Other Conditionals |
Transform or filter dependencies directly as they are resolved and other corner case scenarios. |
1. Forcing Dependency Versions
You can enforce a specific version of a dependency, regardless of what versions might be requested or resolved by other parts of the build script.
This is useful for ensuring consistency and avoiding conflicts due to different versions of the same dependency being used.
configurations {
"compileClasspath" {
resolutionStrategy.force("commons-codec:commons-codec:1.9")
}
}
dependencies {
implementation("org.apache.httpcomponents:httpclient:4.5.4")
}configurations {
compileClasspath {
resolutionStrategy.force 'commons-codec:commons-codec:1.9'
}
}
dependencies {
implementation 'org.apache.httpcomponents:httpclient:4.5.4'
}|
Warning
|
Forcing a specific version of a dependency should be a conscious and deliberate decision. It can lead to conflicts or unexpected behavior, especially when transitive dependencies rely on different versions. |
2. Module Replacement
While it’s generally better to manage module conflicts using capabilities, there are scenarios—especially when working with older versions of Gradle-that require a different approach. In these cases, module replacement rules offer a solution by allowing you to specify that a legacy library has been replaced by a newer one.
Module replacement rules allow you to declare that a legacy library has been replaced by a newer one.
For instance, the migration from google-collections to guava involved renaming the module from com.google.collections:google-collections to com.google.guava:guava.
Such changes impact conflict resolution because Gradle doesn’t treat them as version conflicts due to different module coordinates.
Consider a scenario where both libraries appear in the dependency graph.
Your project depends on guava, but a transitive dependency pulls in google-collections.
This can cause runtime errors since Gradle won’t automatically resolve this as a conflict.
Common solutions include:
-
Declaring an exclusion rule to avoid
google-collections. -
Avoiding dependencies that pull in legacy libraries.
-
Upgrading dependencies that no longer use
google-collections. -
Downgrading to
google-collections(not recommended). -
Assigning capabilities so
google-collectionsandguavaare mutually exclusive.
These methods can be insufficient for large-scale projects. By declaring module replacements, you can address this issue globally across projects, allowing organizations to handle such conflicts holistically.
dependencies {
modules {
module("com.google.collections:google-collections") {
replacedBy("com.google.guava:guava", "google-collections is now part of Guava")
}
}
}dependencies {
modules {
module("com.google.collections:google-collections") {
replacedBy("com.google.guava:guava", "google-collections is now part of Guava")
}
}
}Once declared, Gradle treats any version of guava as superior to google-collections during conflict resolution, ensuring only guava appears in the classpath.
However, if google-collections is the only module present, it won’t be automatically replaced unless there’s a conflict.
For more examples, refer to the DSL reference for ComponentMetadataHandler.
|
Note
|
Gradle does not currently support replacing a module with multiple modules, but multiple modules can be replaced by a single module. |
3. Dependency Substitution
Dependency substitution rules allow for replacing project and module dependencies with specified alternatives, making them interchangeable. While similar to dependency resolve rules, they offer more flexibility by enabling substitution between project and module dependencies.
However, adding a dependency substitution rule affects the timing of configuration resolution. Instead of resolving on first use, the configuration is resolved during task graph construction, which can cause issues if the configuration is modified later or depends on modules published during task execution.
Explanation:
-
A configuration can serve as input to a task and include project dependencies when resolved.
-
If a project dependency is an input to a task (via a configuration), then tasks to build those artifacts are added as dependencies.
-
To determine project dependencies that are inputs to a task, Gradle must resolve the configuration inputs.
-
Because the Gradle task graph is fixed once task execution has commenced, Gradle needs to perform this resolution prior to executing any tasks.
Without substitution rules, Gradle assumes that external module dependencies don’t reference project dependencies, simplifying dependency traversal. With substitution rules, this assumption no longer holds, so Gradle must fully resolve the configuration to determine project dependencies.
Substituting an external module dependency with a project dependency
Dependency substitution can be used to replace an external module with a locally developed project, which is helpful when testing a patched or unreleased version of a module.
The external module can be replaced whether a version is specified:
configurations.configureEach {
resolutionStrategy.dependencySubstitution {
substitute(module("org.utils:api"))
.using(project(":api")).because("we work with the unreleased development version")
substitute(module("org.utils:util:2.5")).using(project(":util"))
}
}configurations.configureEach {
resolutionStrategy.dependencySubstitution {
substitute module("org.utils:api") using project(":api") because "we work with the unreleased development version"
substitute module("org.utils:util:2.5") using project(":util")
}
}-
Substituted projects must be part of the multi-project build (included via
settings.gradle). -
The substitution replaces the module dependency with the project dependency and sets up task dependencies, but doesn’t automatically include the project in the build.
Substituting a project dependency with a module replacement
You can also use substitution rules to replace a project dependency with an external module in a multi-project build.
This technique can accelerate development by allowing certain dependencies to be downloaded from a repository instead of being built locally:
configurations.configureEach {
resolutionStrategy.dependencySubstitution {
substitute(project(":api"))
.using(module("org.utils:api:1.3")).because("we use a stable version of org.utils:api")
}
}configurations.configureEach {
resolutionStrategy.dependencySubstitution {
substitute project(":api") using module("org.utils:api:1.3") because "we use a stable version of org.utils:api"
}
}-
The substituted module must include a version.
-
Even after substitution, the project remains part of the multi-project build, but tasks to build it won’t be executed when resolving the configuration.
Conditionally substituting a dependency
You can conditionally substitute a module dependency with a local project in a multi-project build using dependency substitution rules.
This is particularly useful when you want to use a locally developed version of a dependency if it exists, otherwise fall back to the external module:
configurations.configureEach {
resolutionStrategy.dependencySubstitution.all {
requested.let {
if (it is ModuleComponentSelector && it.group == "org.example") {
val targetProject = findProject(":${it.module}")
if (targetProject != null) {
useTarget(targetProject)
}
}
}
}
}configurations.configureEach {
resolutionStrategy.dependencySubstitution.all { DependencySubstitution dependency ->
if (dependency.requested instanceof ModuleComponentSelector && dependency.requested.group == "org.example") {
def targetProject = findProject(":${dependency.requested.module}")
if (targetProject != null) {
dependency.useTarget targetProject
}
}
}
}-
The substitution only occurs if a local project matching the dependency name is found.
-
The local project must already be included in the multi-project build (via
settings.gradle).
Substituting a dependency with another variant
You can substitute a dependency with another variant, such as switching between a platform dependency and a regular library dependency.
This is useful when your build process needs to change the type of dependency based on specific conditions:
-
The substitution is based on the requested dependency’s attributes (like group and version).
-
This approach allows you to switch from a platform component to a library or vice versa.
-
It uses Gradle’s variant-aware engine to ensure the correct variant is selected based on the configuration and consumer attributes.
This flexibility is often required when working with complex dependency graphs where different component types (platforms, libraries) need to be swapped dynamically.
Substituting a dependency with attributes
Substituting a dependency based on attributes allows you to override the default selection of a component by targeting specific attributes (like platform vs. regular library).
This technique is useful for managing platform and library dependencies in complex builds, particularly when you want to consume a regular library but the platform dependency was incorrectly declared:
dependencies {
// This is a platform dependency but you want the library
implementation(platform("com.google.guava:guava:28.2-jre"))
}dependencies {
// This is a platform dependency but you want the library
implementation platform('com.google.guava:guava:28.2-jre')
}In this example, the substitution rule targets the platform version of com.google.guava:guava and replaces it with the regular library version:
configurations.configureEach {
resolutionStrategy.dependencySubstitution {
substitute(platform(module("com.google.guava:guava:28.2-jre")))
.using(module("com.google.guava:guava:28.2-jre"))
}
}configurations.configureEach {
resolutionStrategy.dependencySubstitution {
substitute(platform(module('com.google.guava:guava:28.2-jre'))).
using module('com.google.guava:guava:28.2-jre')
}
}Without the platform keyword, the substitution would not specifically target the platform dependency.
The following rule performs the same substitution but uses the more granular variant notation, allowing for customization of the dependency’s attributes:
configurations.configureEach {
resolutionStrategy.dependencySubstitution {
substitute(variant(module("com.google.guava:guava:28.2-jre")) {
attributes {
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category.REGULAR_PLATFORM))
}
}).using(module("com.google.guava:guava:28.2-jre"))
}
}configurations.configureEach {
resolutionStrategy.dependencySubstitution {
substitute variant(module('com.google.guava:guava:28.2-jre')) {
attributes {
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category, Category.REGULAR_PLATFORM))
}
} using module('com.google.guava:guava:28.2-jre')
}
}By using attribute-based substitution, you can precisely control which dependencies are replaced, ensuring Gradle resolves the correct versions and variants in your build.
Refer to the DependencySubstitutions API for a complete reference.
|
Warning
|
In composite builds, the rule that you have to match the exact requested dependency attributes is not applied. When using composites, Gradle will automatically match the requested attributes. In other words, it is implicit that if you include another build, you are substituting all variants of the substituted module with an equivalent variant in the included build. |
Substituting a dependency with a dependency with capabilities
You can substitute a dependency with a different variant that includes specific capabilities. Capabilities allow you to specify that a particular variant of a dependency offers a set of related features or functionality, such as test fixtures.
This example substitutes a regular dependency with its test fixtures using a capability:
configurations.testCompileClasspath {
resolutionStrategy.dependencySubstitution {
substitute(module("com.acme:lib:1.0")).using(variant(module("com.acme:lib:1.0")) {
capabilities {
requireCapability("com.acme:lib-test-fixtures")
}
})
}
}configurations.testCompileClasspath {
resolutionStrategy.dependencySubstitution {
substitute(module('com.acme:lib:1.0'))
.using variant(module('com.acme:lib:1.0')) {
capabilities {
requireCapability('com.acme:lib-test-fixtures')
}
}
}
}Here, we substitute the regular com.acme:lib:1.0 dependency with its lib-test-fixtures variant.
The requireCapability function specifies that the new variant must have the com.acme:lib-test-fixtures capability, ensuring the right version of the dependency is selected for testing purposes.
Capabilities within the substitution rule are used to precisely match dependencies, and Gradle only substitutes dependencies that match the required capabilities.
Refer to the DependencySubstitutions API for a complete reference of the variant substitution API.
Substituting a dependency with a classifier or artifact
You can substitute dependencies that have a classifier with ones that don’t or vice versa. Classifiers are often used to represent different versions of the same artifact, such as platform-specific builds or dependencies with different APIs. Although Gradle discourages the use of classifiers, it provides a way to handle substitutions for cases where classifiers are still in use.
Consider the following setup:
dependencies {
implementation("com.google.guava:guava:28.2-jre")
implementation("co.paralleluniverse:quasar-core:0.8.0")
implementation(project(":lib"))
}dependencies {
implementation 'com.google.guava:guava:28.2-jre'
implementation 'co.paralleluniverse:quasar-core:0.8.0'
implementation project(':lib')
}In the example above, the first level dependency on quasar makes us think that Gradle would resolve quasar-core-0.8.0.jar but it’s not the case.
The build fails with this message:
Execution failed for task ':consumer:resolve'.
> Could not resolve all files for configuration ':consumer:runtimeClasspath'.
> Could not find quasar-core-0.8.0-jdk8.jar (co.paralleluniverse:quasar-core:0.8.0).
Searched in the following locations:
https://repo.maven.apache.org/maven2/co/paralleluniverse/quasar-core/0.8.0/quasar-core-0.8.0-jdk8.jarThat’s because there’s a dependency on another project, lib, which itself depends on a different version of quasar-core:
dependencies {
implementation("co.paralleluniverse:quasar-core:0.7.10:jdk8")
}dependencies {
implementation "co.paralleluniverse:quasar-core:0.7.10:jdk8"
}-
The consumer depends on
quasar-core:0.8.0without a classifier. -
The lib project depends on
quasar-core:0.7.10with thejdk8classifier. -
Gradle’s conflict resolution selects the higher version (
0.8.0), butquasar-core:0.8.0doesn’t have thejdk8classifier, leading to a resolution error.
To resolve this conflict, you can instruct Gradle to ignore classifiers when resolving quasar-core dependencies:
configurations.configureEach {
resolutionStrategy.dependencySubstitution {
substitute(module("co.paralleluniverse:quasar-core"))
.using(module("co.paralleluniverse:quasar-core:0.8.0"))
.withoutClassifier()
}
}configurations.configureEach {
resolutionStrategy.dependencySubstitution {
substitute module('co.paralleluniverse:quasar-core') using module('co.paralleluniverse:quasar-core:0.8.0') withoutClassifier()
}
}This rule effectively replaces any dependency on quasar-core found in the graph with a dependency without classifier.
If you need to substitute with a specific classifier or artifact, you can specify the classifier or artifact details in the substitution rule.
For more detailed information, refer to:
-
Artifact selection via the Substitution DSL
-
Artifact selection via the DependencySubstitution API
-
Artifact selection via the ResolutionStrategy API
4. Component Selection Rules
Component selection rules may influence which component instance should be selected when multiple versions are available that match a version selector. Rules are applied against every available version and allow the version to be explicitly rejected.
This allows Gradle to ignore any component instance that does not satisfy conditions set by the rule. Examples include:
-
For a dynamic version like
1.+certain versions may be explicitly rejected from selection. -
For a static version like
1.4an instance may be rejected based on extra component metadata such as the Ivy branch attribute, allowing an instance from a subsequent repository to be used.
Rules are configured via the ComponentSelectionRules object. Each rule configured will be called with a ComponentSelection object as an argument that contains information about the candidate version being considered. Calling ComponentSelection.reject(java.lang.String) causes the given candidate version to be explicitly rejected, in which case the candidate will not be considered for the selector.
The following example shows a rule that disallows a particular version of a module but allows the dynamic version to choose the next best candidate:
configurations {
implementation {
resolutionStrategy {
componentSelection {
// Accept the highest version matching the requested version that isn't '1.5'
all {
if (candidate.group == "org.sample" && candidate.module == "api" && candidate.version == "1.5") {
reject("version 1.5 is broken for 'org.sample:api'")
}
}
}
}
}
}
dependencies {
implementation("org.sample:api:1.+")
}configurations {
implementation {
resolutionStrategy {
componentSelection {
// Accept the highest version matching the requested version that isn't '1.5'
all { ComponentSelection selection ->
if (selection.candidate.group == 'org.sample' && selection.candidate.module == 'api' && selection.candidate.version == '1.5') {
selection.reject("version 1.5 is broken for 'org.sample:api'")
}
}
}
}
}
}
dependencies {
implementation 'org.sample:api:1.+'
}Note that version selection is applied starting with the highest version first. The version selected will be the first version found that all component selection rules accept.
|
Important
|
A version is considered accepted if no rule explicitly rejects it. |
Similarly, rules can be targeted at specific modules.
Modules must be specified in the form of group:module:
configurations {
create("targetConfig") {
resolutionStrategy {
componentSelection {
withModule("org.sample:api") {
if (candidate.version == "1.5") {
reject("version 1.5 is broken for 'org.sample:api'")
}
}
}
}
}
}configurations {
create("targetConfig") {
resolutionStrategy {
componentSelection {
withModule("org.sample:api") { ComponentSelection selection ->
if (selection.candidate.version == "1.5") {
selection.reject("version 1.5 is broken for 'org.sample:api'")
}
}
}
}
}
}Component selection rules can also consider component metadata when selecting a version. Possible additional metadata that can be considered are ComponentMetadata and IvyModuleDescriptor.
Note that this extra information may not always be available and thus should be checked for null values:
configurations {
create("metadataRulesConfig") {
resolutionStrategy {
componentSelection {
// Reject any versions with a status of 'experimental'
all {
if (candidate.group == "org.sample" && metadata?.status == "experimental") {
reject("don't use experimental candidates from 'org.sample'")
}
}
// Accept the highest version with either a "release" branch or a status of 'milestone'
withModule("org.sample:api") {
if (getDescriptor(IvyModuleDescriptor::class)?.branch != "release" && metadata?.status != "milestone") {
reject("'org.sample:api' must have testing branch or milestone status")
}
}
}
}
}
}configurations {
metadataRulesConfig {
resolutionStrategy {
componentSelection {
// Reject any versions with a status of 'experimental'
all { ComponentSelection selection ->
if (selection.candidate.group == 'org.sample' && selection.metadata?.status == 'experimental') {
selection.reject("don't use experimental candidates from 'org.sample'")
}
}
// Accept the highest version with either a "release" branch or a status of 'milestone'
withModule('org.sample:api') { ComponentSelection selection ->
if (selection.getDescriptor(IvyModuleDescriptor)?.branch != "release" && selection.metadata?.status != 'milestone') {
selection.reject("'org.sample:api' must be a release branch or have milestone status")
}
}
}
}
}
}A ComponentSelection argument is always required as a parameter when declaring a component selection rule.
5. Default Dependencies
You can set default dependencies for a configuration to ensure that a default version is used when no explicit dependencies are specified.
This is useful for plugins that rely on versioned tools and want to provide a default if the user doesn’t specify a version:
configurations {
create("pluginTool") {
defaultDependencies {
add(project.dependencies.create("org.gradle:my-util:1.0"))
}
}
}configurations {
pluginTool {
defaultDependencies { dependencies ->
dependencies.add(project.dependencies.create("org.gradle:my-util:1.0"))
}
}
}In this example, the pluginTool configuration will use org.gradle:my-util:1.0 as a default dependency unless another version is specified.
6. Excluding Transitive Dependencies
To completely exclude a transitive dependency for a particular configuration, use the Configuration.exclude(Map) method.
|
Warning
|
Excluding a transitive dependency should be a conscious and deliberate choice. Removing a dependency that other libraries rely on can lead to runtime errors or unexpected behavior. If you choose to exclude something, make sure your code doesn’t rely on it—ideally backed by comprehensive test coverage to catch potential issues early. |
This approach will automatically exclude the specified transitive dependency from all dependencies declared within the configuration:
configurations {
"implementation" {
exclude(group = "commons-collections", module = "commons-collections")
}
}
dependencies {
implementation("commons-beanutils:commons-beanutils:1.9.4")
implementation("com.opencsv:opencsv:4.6")
}configurations {
implementation {
exclude group: 'commons-collections', module: 'commons-collections'
}
}
dependencies {
implementation 'commons-beanutils:commons-beanutils:1.9.4'
implementation 'com.opencsv:opencsv:4.6'
}In this example, the commons-collections dependency will be excluded from the implementation configuration, regardless of whether it is a direct or transitive dependency.
Below is a simplified usage of the commons-beanutils library, where we only call PropertyUtils.setSimpleProperty() on a POJO (Plain Old Java Object):
import org.apache.commons.beanutils.PropertyUtils;
public class Main {
public static void main(String[] args) throws Exception {
Object person = new Person();
PropertyUtils.setSimpleProperty(person, "name", "Bart Simpson");
PropertyUtils.setSimpleProperty(person, "age", 38);
}
}This specific usage doesn’t require commons-collections, which we’ve verified with test coverage.
By excluding it, we effectively express that we’re only using a subset of commons-beanutils.
However, this can be risky.
If our code were more dynamic or invoked error-handling code paths, we might encounter runtime issues.
For example, if we tried to set a property that doesn’t exist, the library may throw a NoClassDefFoundError for a missing class from commons-collections rather than a clear exception, because that path depends on the excluded library.
Gradle handles exclusions differently than Maven—it evaluates the entire dependency graph. An exclusion is only applied if all paths to a dependency agree on it.
For example, if another dependency (like opencsv) also brings in commons-beanutils (but without an exclusion), the transitive commons-collections will still appear:
dependencies {
implementation("commons-beanutils:commons-beanutils:1.9.4") {
exclude(group = "commons-collections", module = "commons-collections")
}
implementation("com.opencsv:opencsv:4.6") // depends on 'commons-beanutils' without exclude and brings back 'commons-collections'
}dependencies {
implementation('commons-beanutils:commons-beanutils:1.9.4') {
exclude group: 'commons-collections', module: 'commons-collections'
}
implementation 'com.opencsv:opencsv:4.6' // depends on 'commons-beanutils' without exclude and brings back 'commons-collections'
}To fully exclude commons-collections, you must also exclude it from opencsv:
dependencies {
implementation("commons-beanutils:commons-beanutils:1.9.4") {
exclude(group = "commons-collections", module = "commons-collections")
}
implementation("com.opencsv:opencsv:4.6") {
exclude(group = "commons-collections", module = "commons-collections")
}
}dependencies {
implementation('commons-beanutils:commons-beanutils:1.9.4') {
exclude group: 'commons-collections', module: 'commons-collections'
}
implementation('com.opencsv:opencsv:4.6') {
exclude group: 'commons-collections', module: 'commons-collections'
}
}Using excludes should be a conscious and well-tested decision. If the excluded dependency is needed in any code path, your build may fail at runtime.
Historically, excludes have also been used as a workaround for limitations in other build systems, but there are better alternatives:
-
Use dependency constraints to update or override versions instead of excluding undesired ones.
-
Use component metadata rules to remove an unnecessary dependency—like a compile-time dependency that’s erroneously added to the metadata of the library. This tells Gradle to ignore the dependency entirely (i.e., the metadata is wrong). Note that these rules are not published, so if you’re creating a library others will use, an explicit
excludemay be more appropriate. -
Use capabilities to resolve mutually exclusive dependency conflicts. Some libraries can’t coexist because they provide the same capability—such as
log4jandlog4j-over-slf4j, orcom.google.collectionsandguava. If Gradle isn’t aware of the conflict, declare the overlapping capability using a component metadata rule. If you’re developing a library, avoid enforcing a specific choice—let the consumers decide which implementation to use.
7. Force Failed Resolution Strategies
Version conflicts can be forced to fail using:
-
failOnNonReproducibleResolution() -
failOnDynamicVersions() -
failOnChangingVersions() -
failOnVersionConflict()
This will fail the build when conflicting versions of the same dependency are found:
configurations.configureEach {
resolutionStrategy {
failOnVersionConflict()
}
}configurations.configureEach {
resolutionStrategy {
failOnVersionConflict()
}
}8. Disabling Transitive Dependencies
By default, Gradle resolves all transitive dependencies for a given module.
However, there are situations where you may want to disable this behavior, such as when you need more control over dependencies or when the dependency metadata is incorrect.
You can tell Gradle to disable transitive dependency management for a dependency by setting ModuleDependency.setTransitive(boolean) to false.
In the following example, transitive dependency resolution is disabled for the guava dependency:
dependencies {
implementation("com.google.guava:guava:23.0") {
isTransitive = false
}
}dependencies {
implementation('com.google.guava:guava:23.0') {
transitive = false
}
}This ensures only the main artifact for guava is resolved, and none of its transitive dependencies will be included.
|
Note
|
Disabling transitive dependency resolution will likely require you to declare the necessary runtime dependencies in your build script which otherwise would have been resolved automatically. Not doing so might lead to runtime classpath issues. |
If you want to disable transitive resolution globally across all dependencies, you can set this behavior at the configuration level:
configurations.configureEach {
isTransitive = false
}
dependencies {
implementation("com.google.guava:guava:23.0")
}configurations.configureEach {
transitive = false
}
dependencies {
implementation 'com.google.guava:guava:23.0'
}This disables transitive resolution for all dependencies in the project. Be aware that this may require you to manually declare any transitive dependencies that are required at runtime.
For more information, see Configuration.setTransitive(boolean).
9. Dependency Resolve Rules and Other Conditionals
Dependency resolve rules are executed for each dependency as it’s being resolved, providing a powerful API to modify a dependency’s attributes—such as group, name, or version—before the resolution is finalized.
This allows for advanced control over dependency resolution, enabling you to substitute one module for another during the resolution process.
This feature is particularly useful for implementing advanced dependency management patterns. With dependency resolve rules, you can redirect dependencies to specific versions or even different modules entirely, allowing you to enforce consistent versions across a project or override problematic dependencies:
configurations.configureEach {
resolutionStrategy {
eachDependency {
if (requested.group == "com.example" && requested.name == "old-library") {
useTarget("com.example:new-library:1.0.0")
because("Our license only allows use of version 1")
}
}
}
}configurations.configureEach {
resolutionStrategy {
eachDependency {
if (requested.group == "com.example" && requested.name == "old-library") {
useTarget("com.example:new-library:1.0.0")
because("Our license only allows use of version 1")
}
}
}
}In this example, if a dependency on com.example:old-library is requested, it will be substituted with com.example:new-library:1.0.0 during resolution.
For more advanced usage and additional examples, refer to the ResolutionStrategy class in the API documentation.
Implementing a custom versioning scheme
In some corporate environments, module versions in Gradle builds are maintained and audited externally. Dependency resolve rules offer an effective way to implement this:
-
Developers declare dependencies in the build script using the module’s group and name, but specify a placeholder version like
default. -
A dependency resolve rule then resolves the
defaultversion to an approved version, which is retrieved from a corporate catalog of sanctioned modules.
This approach ensures that only approved versions are used, while allowing developers to work with a simplified and consistent versioning scheme.
The rule implementation can be encapsulated in a corporate plugin, making it easy to apply across all projects within the organization:
configurations.configureEach {
resolutionStrategy.eachDependency {
if (requested.version == "default") {
val version = findDefaultVersionInCatalog(requested.group, requested.name)
useVersion(version.version)
because(version.because)
}
}
}
data class DefaultVersion(val version: String, val because: String)
fun findDefaultVersionInCatalog(group: String, name: String): DefaultVersion {
//some custom logic that resolves the default version into a specific version
return DefaultVersion(version = "1.0", because = "tested by QA")
}configurations.configureEach {
resolutionStrategy.eachDependency { DependencyResolveDetails details ->
if (details.requested.version == 'default') {
def version = findDefaultVersionInCatalog(details.requested.group, details.requested.name)
details.useVersion version.version
details.because version.because
}
}
}
def findDefaultVersionInCatalog(String group, String name) {
//some custom logic that resolves the default version into a specific version
[version: "1.0", because: 'tested by QA']
}In this setup, whenever a developer specifies default as the version, the resolve rule replaces it with the approved version from the corporate catalog.
This strategy ensures compliance with corporate policies while providing flexibility and ease of use for developers. Encapsulating this logic in a plugin also ensures consistency across multiple projects.
Replacing unwanted dependency versions
Dependency resolve rules offer a powerful mechanism for blocking specific versions of a dependency and substituting them with an alternative.
This is particularly useful when a specific version is known to be problematic—such as a version that introduces bugs or relies on a library that isn’t available in public repositories. By defining a resolve rule, you can automatically replace a problematic version with a stable one.
Consider a scenario where version 1.2 of a library is broken, but version 1.2.1 contains important fixes and should always be used instead.
With a resolve rule, you can enforce this substitution: "anytime version 1.2 is requested, it will be replaced with 1.2.1.
Unlike forcing a version, this rule only affects the specific version 1.2, leaving other versions unaffected:
configurations.configureEach {
resolutionStrategy.eachDependency {
if (requested.group == "org.software" && requested.name == "some-library" && requested.version == "1.2") {
useVersion("1.2.1")
because("fixes critical bug in 1.2")
}
}
}configurations.configureEach {
resolutionStrategy.eachDependency { DependencyResolveDetails details ->
if (details.requested.group == 'org.software' && details.requested.name == 'some-library' && details.requested.version == '1.2') {
details.useVersion '1.2.1'
details.because 'fixes critical bug in 1.2'
}
}
}If version 1.3 is also present in the dependency graph, then even with this rule, Gradle’s default conflict resolution strategy would select 1.3 as the latest version.
Difference from Rich Version Constraints: Using rich version constraints, you can reject certain versions outright, causing the build to fail or select a non-rejected version if a dynamic dependency is used. In contrast, a dependency resolve rule like the one shown here manipulates the version being requested, replacing it with a known good version when a rejected one is found. This approach is a solution for handling rejected versions, while rich version constraints are about expressing the intent to avoid certain versions.
Lazily influencing resolved dependencies
Plugins can lazily influence dependencies by adding them conditionally or setting preferred versions when no version is specified by the user.
Below are two examples illustrating these use cases.
This example demonstrates how to add a dependency to a configuration based on some condition, evaluated lazily:
configurations {
implementation {
dependencies.addLater(project.provider {
val dependencyNotation = conditionalLogic()
if (dependencyNotation != null) {
project.dependencies.create(dependencyNotation)
} else {
null
}
})
}
}configurations {
implementation {
dependencies.addLater(project.provider {
def dependencyNotation = conditionalLogic()
if (dependencyNotation != null) {
return project.dependencies.create(dependencyNotation)
} else {
return null
}
})
}
}In this case, addLater is used to defer the evaluation of the dependency, allowing it to be added only when certain conditions are met.
In this example, the build script sets a preferred version of a dependency, which will be used if no version is explicitly specified:
dependencies {
implementation("org:foo")
// Can indiscriminately be added by build logic
constraints {
implementation("org:foo:1.0") {
version {
// Applied to org:foo if no other version is specified
prefer("1.0")
}
}
}
}dependencies {
implementation("org:foo")
// Can indiscriminately be added by build logic
constraints {
implementation("org:foo:1.0") {
version {
// Applied to org:foo if no other version is specified
prefer("1.0")
}
}
}
}This ensures that org:foo uses version 1.0 unless the user specifies another version.
Modifying Dependency Metadata
Each component pulled from a repository includes metadata, such as its group, name, version, and the various variants it provides along with their artifacts and dependencies.
Occasionally, this metadata might be incomplete or incorrect.
Gradle offers an API to address this issue, allowing you to write component metadata rules directly within the build script. These rules are applied after a module’s metadata is downloaded, but before it’s used in dependency resolution.
Writing a component metadata rule
Component metadata rules are applied within the components section of the dependencies block in a build script or in the settings script.
These rules can be defined in two ways:
-
Inline as an Action: Directly within the
componentssection. -
As a Separate Class: Implementing the
ComponentMetadataRuleinterface.
While inline actions are convenient for quick experimentation, it’s generally recommended to define rules as separate classes.
Rules written as isolated classes can be annotated with @CacheableRule, allowing their results to be cached and avoiding re-execution each time dependencies are resolved.
|
Tip
|
A rule should always be cacheable to avoid major impacts on build performance and ensure faster build times. |
@CacheableRule
abstract class TargetJvmVersionRule @Inject constructor(val jvmVersion: Int) : ComponentMetadataRule {
@get:Inject abstract val objects: ObjectFactory
override fun execute(context: ComponentMetadataContext) {
context.details.withVariant("compile") {
attributes {
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, jvmVersion)
attribute(Usage.USAGE_ATTRIBUTE, objects.named(Usage.JAVA_API))
}
}
}
}
dependencies {
components {
withModule<TargetJvmVersionRule>("commons-io:commons-io") {
params(7)
}
withModule<TargetJvmVersionRule>("commons-collections:commons-collections") {
params(8)
}
}
implementation("commons-io:commons-io:2.6")
implementation("commons-collections:commons-collections:3.2.2")
}@CacheableRule
abstract class TargetJvmVersionRule implements ComponentMetadataRule {
final Integer jvmVersion
@Inject TargetJvmVersionRule(Integer jvmVersion) {
this.jvmVersion = jvmVersion
}
@Inject abstract ObjectFactory getObjects()
void execute(ComponentMetadataContext context) {
context.details.withVariant("compile") {
attributes {
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, jvmVersion)
attribute(Usage.USAGE_ATTRIBUTE, objects.named(Usage, Usage.JAVA_API))
}
}
}
}
dependencies {
components {
withModule("commons-io:commons-io", TargetJvmVersionRule) {
params(7)
}
withModule("commons-collections:commons-collections", TargetJvmVersionRule) {
params(8)
}
}
implementation("commons-io:commons-io:2.6")
implementation("commons-collections:commons-collections:3.2.2")
}In this example, the TargetJvmVersionRule class implements ComponentMetadataRule and is further configured using ActionConfiguration.
Gradle enforces isolation of instances of ComponentMetadataRule, requiring that all parameters must be Serializable or recognized Gradle types.
Additionally, services like ObjectFactory can be injected into your rule’s constructor using @Inject.
A component metadata rule can be applied to all modules using all(rule) or to a specific module using withModule(groupAndName, rule).
Typically, a rule is tailored to enrich the metadata of a specific module, so the withModule API is preferred.
Declaring rules in a central place
|
Note
|
Declaring component metadata rules in settings is an incubating feature |
Component metadata rules can be declared in the settings.gradle(.kts) file for the entire build, rather than in each subproject individually.
Rules declared in settings are applied to all projects by default unless overridden by project-specific rules.
dependencyResolutionManagement {
components {
withModule<GuavaRule>("com.google.guava:guava")
}
}dependencyResolutionManagement {
components {
withModule("com.google.guava:guava", GuavaRule)
}
}By default, project-specific rules take precedence over settings rules. However, this behavior can be adjusted:
dependencyResolutionManagement {
rulesMode = RulesMode.PREFER_SETTINGS
}dependencyResolutionManagement {
rulesMode = RulesMode.PREFER_SETTINGS
}If this method is called and that a project or plugin declares rules, a warning will be issued. You can make this a failure instead by using this alternative:
dependencyResolutionManagement {
rulesMode = RulesMode.FAIL_ON_PROJECT_RULES
}dependencyResolutionManagement {
rulesMode = RulesMode.FAIL_ON_PROJECT_RULES
}The default behavior is equivalent to calling this method:
dependencyResolutionManagement {
rulesMode = RulesMode.PREFER_PROJECT
}dependencyResolutionManagement {
rulesMode = RulesMode.PREFER_PROJECT
}Which parts of metadata can be modified?
The Component Metadata Rules API focuses on the features supported by Gradle Module Metadata and the dependencies API.
The key difference between using metadata rules and defining dependencies/artifacts in a build script is that component metadata rules operate directly on variants, whereas build scripts often affect multiple variants at once (e.g., an api dependency is applied to both api and runtime variants of a Java library).
Variants can be modified through the following methods:
-
allVariants: Modify all variants of a component. -
withVariant(name): Modify a specific variant identified by its name. -
addVariant(name)oraddVariant(name, base): Add a new variant from scratch or copy details from an existing variant (base).
The following variant details can be modified:
-
Attributes: Use the
attributes {}block to adjust attributes that identify the variant. -
Capabilities: Use the
withCapabilities {}block to define the capabilities the variant provides. -
Dependencies: Use the
withDependencies {}block to manage the variant’s dependencies, including rich version constraints. -
Dependency Constraints: Use the
withDependencyConstraints {}block to define the variant’s dependency constraints, including rich versions. -
Published Files: Use the
withFiles {}block to specify the location of the files that make up the variant’s content.
Additionally, several component-level properties can be changed:
-
Component Attributes: The only meaningful attribute here is
org.gradle.status. -
Status Scheme: Influence how the
org.gradle.statusattribute is interpreted during version selection. -
BelongsTo Property: Used for version alignment via virtual platforms.
The format of a module’s metadata affects how it maps to the variant-centric representation:
-
Gradle Module Metadata: The data structure is similar to the module’s
.modulefile. -
POM Metadata: For modules published with
.pommetadata, fixed variants are derived as explained in the "Mapping POM Files to Variants", section. -
Ivy Metadata: If a module was published with an
ivy.xmlfile, Ivy configurations can be accessed in place of variants. Their dependencies, constraints, and files can be modified. You can also useaddVariant(name, baseVariantOrConfiguration)to derive variants from Ivy configurations, such as definingcompileandruntimevariants for the Java library plugin.
Before using component metadata rules to adjust a module’s metadata, determine whether the module was published with Gradle Module Metadata (.module file) or traditional metadata (.pom or ivy.xml):
-
Modules with Gradle Module Metadata: These typically have complete metadata, but issues can still occur. Only apply component metadata rules if you’ve clearly identified a problem with the metadata. For dependency resolution issues, first consider using dependency constraints with rich versions. If you’re developing a library, note that dependency constraints are published as part of your own library’s metadata, making it easier to share the solution with consumers. In contrast, component metadata rules apply only within your own build.
-
Modules with Traditional Metadata (
.pomorivy.xml): These are more likely to have incomplete metadata since features like variants and dependency constraints aren’t supported in these formats. Such modules might have variants or constraints that were omitted or incorrectly defined as dependencies. In the following sections, we explore examples of OSS modules with incomplete metadata and the rules to add missing information.
As a rule of thumb, you should contemplate if the rule you are writing also works out of context of your build. That is, does the rule still produce a correct and useful result if applied in any other build that uses the module(s) it affects?
Fixing incorrect dependency details
Consider the Jaxen XPath Engine (version 1.1.3) published on Maven Central.
Its pom file declares several unnecessary dependencies in the compile scope, which were later removed in version 1.1.4.
If you need to work with version 1.1.3, you can fix the metadata using the following rule:
@CacheableRule
abstract class JaxenDependenciesRule: ComponentMetadataRule {
override fun execute(context: ComponentMetadataContext) {
context.details.allVariants {
withDependencies {
removeAll { it.group in listOf("dom4j", "jdom", "xerces", "maven-plugins", "xml-apis", "xom") }
}
}
}
}@CacheableRule
abstract class JaxenDependenciesRule implements ComponentMetadataRule {
void execute(ComponentMetadataContext context) {
context.details.allVariants {
withDependencies {
removeAll { it.group in ["dom4j", "jdom", "xerces", "maven-plugins", "xml-apis", "xom"] }
}
}
}
}In the withDependencies block, you have access to the full list of dependencies and can use Java collection methods to inspect and modify that list. You can also add dependencies using the add(notation, configureAction) method.
Similarly, you can inspect and modify dependency constraints within the withDependencyConstraints block.
In Jaxen version 1.1.4, the dom4j, jdom, and xerces dependencies are still present but marked as optional.
Optional dependencies are not processed automatically by Gradle or Maven, as they indicate feature variants that require additional dependencies.
However, the pom file lacks information about these features and their corresponding dependencies.
This can be represented in Gradle Module Metadata through variants and capabilities, which we can add via a component metadata rule.
@CacheableRule
abstract class JaxenCapabilitiesRule: ComponentMetadataRule {
override fun execute(context: ComponentMetadataContext) {
context.details.addVariant("runtime-dom4j", "runtime") {
withCapabilities {
removeCapability("jaxen", "jaxen")
addCapability("jaxen", "jaxen-dom4j", context.details.id.version)
}
withDependencies {
add("dom4j:dom4j:1.6.1")
}
}
}
}@CacheableRule
abstract class JaxenCapabilitiesRule implements ComponentMetadataRule {
void execute(ComponentMetadataContext context) {
context.details.addVariant("runtime-dom4j", "runtime") {
withCapabilities {
removeCapability("jaxen", "jaxen")
addCapability("jaxen", "jaxen-dom4j", context.details.id.version)
}
withDependencies {
add("dom4j:dom4j:1.6.1")
}
}
}
}In this example, we create a new variant called runtime-dom4j using the addVariant(name, baseVariant) method.
This variant represents an optional feature, defined by the capability jaxen-dom4j.
We then add the required dependency dom4j:dom4j:1.6.1 to this feature.
dependencies {
components {
withModule<JaxenDependenciesRule>("jaxen:jaxen")
withModule<JaxenCapabilitiesRule>("jaxen:jaxen")
}
implementation("jaxen:jaxen:1.1.3")
runtimeOnly("jaxen:jaxen:1.1.3") {
capabilities {
requireCapability("jaxen:jaxen-dom4j")
}
}
}dependencies {
components {
withModule("jaxen:jaxen", JaxenDependenciesRule)
withModule("jaxen:jaxen", JaxenCapabilitiesRule)
}
implementation("jaxen:jaxen:1.1.3")
runtimeOnly("jaxen:jaxen:1.1.3") {
capabilities {
requireCapability("jaxen:jaxen-dom4j")
}
}
}By applying these rules, Gradle uses the enriched metadata to correctly resolve the optional dependencies when the jaxen-dom4j feature is required.
Making variants published as classified jars explicit
In modern builds, variants are often published as separate artifacts, each represented by its own jar file. For example, libraries may provide distinct jars for different Java versions, ensuring that the correct version is used at runtime or compile time based on the environment.
For instance, version 0.7.9 of the asynchronous programming library Quasar, published on Maven Central, includes both quasar-core-0.7.9.jar and quasar-core-0.7.9-jdk8.jar.
Publishing jars with a classifier, such as jdk8, is common practice in Maven repositories.
However, neither Maven nor Gradle metadata provides information about these classified jars.
As a result, there is no clear way to determine their existence or any differences, such as dependencies, between the variants.
In Gradle Module Metadata, variant information would be present. For the already published Quasar library, we can add this information using the following rule:
@CacheableRule
abstract class QuasarRule: ComponentMetadataRule {
override fun execute(context: ComponentMetadataContext) {
listOf("compile", "runtime").forEach { base ->
context.details.addVariant("jdk8${base.capitalize()}", base) {
attributes {
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, 8)
}
withFiles {
removeAllFiles()
addFile("${context.details.id.name}-${context.details.id.version}-jdk8.jar")
}
}
context.details.withVariant(base) {
attributes {
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, 7)
}
}
}
}
}@CacheableRule
abstract class QuasarRule implements ComponentMetadataRule {
void execute(ComponentMetadataContext context) {
["compile", "runtime"].each { base ->
context.details.addVariant("jdk8${base.capitalize()}", base) {
attributes {
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, 8)
}
withFiles {
removeAllFiles()
addFile("${context.details.id.name}-${context.details.id.version}-jdk8.jar")
}
}
context.details.withVariant(base) {
attributes {
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, 7)
}
}
}
}
}In this case, the jdk8 classifier clearly indicates the target Java version, which corresponds to a known attribute in the Java ecosystem.
Since we need both compile and runtime variants for Java 8, we create two new variants using the existing compile and runtime variants as a base.
This ensures that all other Java ecosystem attributes are set correctly, and dependencies are carried over.
We assign the TARGET_JVM_VERSION_ATTRIBUTE to 8 for both new variants, remove any existing files with removeAllFiles(), and then add the jdk8 jar using addFile(). Removing the files is necessary because the reference to the main jar quasar-core-0.7.9.jar is copied from the base variant.
Finally, we enrich the existing compile and runtime variants with the information that they target Java 7 using attribute(TARGET_JVM_VERSION_ATTRIBUTE, 7).
With these changes, you can now request Java 8 versions for all dependencies on the compile classpath, and Gradle will automatically select the best-fitting variant. In the case of Quasar, this will be the jdk8Compile variant, which exposes the quasar-core-0.7.9-jdk8.jar.
configurations["compileClasspath"].attributes {
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, 8)
}
dependencies {
components {
withModule<QuasarRule>("co.paralleluniverse:quasar-core")
}
implementation("co.paralleluniverse:quasar-core:0.7.9")
}configurations.compileClasspath.attributes {
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, 8)
}
dependencies {
components {
withModule("co.paralleluniverse:quasar-core", QuasarRule)
}
implementation("co.paralleluniverse:quasar-core:0.7.9")
}With this configuration, Gradle will select the Java 8 variant of Quasar for the compile classpath.
Making variants encoded in versions explicit
Another solution to publish multiple alternatives for the same library is the usage of a versioning pattern as done by the popular Guava library. Here, each new version is published twice by appending the classifier to the version instead of the jar artifact. In the case of Guava 28 for example, we can find a 28.0-jre (Java 8) and 28.0-android (Java 6) version on Maven central. The advantage of using this pattern when working only with pom metadata is that both variants are discoverable through the version. The disadvantage is that there is no information as to what the different version suffixes mean semantically. So in the case of conflict, Gradle would just pick the highest version when comparing the version strings.
Turning this into proper variants is a bit more tricky, as Gradle first selects a version of a module and then selects the best fitting variant. So the concept that variants are encoded as versions is not supported directly. However, since both variants are always published together we can assume that the files are physically located in the same repository. And since they are published with Maven repository conventions, we know the location of each file if we know module name and version. We can write the following rule:
@CacheableRule
abstract class GuavaRule: ComponentMetadataRule {
override fun execute(context: ComponentMetadataContext) {
val variantVersion = context.details.id.version
val version = variantVersion.substring(0, variantVersion.indexOf("-"))
listOf("compile", "runtime").forEach { base ->
mapOf(6 to "android", 8 to "jre").forEach { (targetJvmVersion, jarName) ->
context.details.addVariant("jdk$targetJvmVersion${base.capitalize()}", base) {
attributes {
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, targetJvmVersion)
}
withFiles {
removeAllFiles()
addFile("guava-$version-$jarName.jar", "../$version-$jarName/guava-$version-$jarName.jar")
}
}
}
}
}
}@CacheableRule
abstract class GuavaRule implements ComponentMetadataRule {
void execute(ComponentMetadataContext context) {
def variantVersion = context.details.id.version
def version = variantVersion.substring(0, variantVersion.indexOf("-"))
["compile", "runtime"].each { base ->
[6: "android", 8: "jre"].each { targetJvmVersion, jarName ->
context.details.addVariant("jdk$targetJvmVersion${base.capitalize()}", base) {
attributes {
attributes.attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, targetJvmVersion)
}
withFiles {
removeAllFiles()
addFile("guava-$version-${jarName}.jar", "../$version-$jarName/guava-$version-${jarName}.jar")
}
}
}
}
}
}Similar to the previous example, we add runtime and compile variants for both Java versions.
In the withFiles block however, we now also specify a relative path for the corresponding jar file which allows Gradle to find the file no matter if it has selected a -jre or -android version.
The path is always relative to the location of the metadata (in this case pom) file of the selection module version.
So with this rules, both Guava 28 "versions" carry both the jdk6 and jdk8 variants.
So it does not matter to which one Gradle resolves.
The variant, and with it the correct jar file, is determined based on the requested TARGET_JVM_VERSION_ATTRIBUTE value.
configurations["compileClasspath"].attributes {
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, 6)
}
dependencies {
components {
withModule<GuavaRule>("com.google.guava:guava")
}
// '23.3-android' and '23.3-jre' are now the same as both offer both variants
implementation("com.google.guava:guava:23.3+")
}configurations.compileClasspath.attributes {
attribute(TargetJvmVersion.TARGET_JVM_VERSION_ATTRIBUTE, 6)
}
dependencies {
components {
withModule("com.google.guava:guava", GuavaRule)
}
// '23.3-android' and '23.3-jre' are now the same as both offer both variants
implementation("com.google.guava:guava:23.3+")
}Adding variants for native jars
Jars with classifiers are also used to separate parts of a library for which multiple alternatives exists, for example native code, from the main artifact. This is for example done by the Lightweight Java Game Library (LWGJ), which publishes several platform specific jars to Maven central from which always one is needed, in addition to the main jar, at runtime. It is not possible to convey this information in pom metadata as there is no concept of putting multiple artifacts in relation through the metadata. In Gradle Module Metadata, each variant can have arbitrary many files and we can leverage that by writing the following rule:
@CacheableRule
abstract class LwjglRule: ComponentMetadataRule {
data class NativeVariant(val os: String, val arch: String, val classifier: String)
private val nativeVariants = listOf(
NativeVariant(OperatingSystemFamily.LINUX, "arm32", "natives-linux-arm32"),
NativeVariant(OperatingSystemFamily.LINUX, "arm64", "natives-linux-arm64"),
NativeVariant(OperatingSystemFamily.WINDOWS, "x86", "natives-windows-x86"),
NativeVariant(OperatingSystemFamily.WINDOWS, "x86-64", "natives-windows"),
NativeVariant(OperatingSystemFamily.MACOS, "x86-64", "natives-macos")
)
@get:Inject abstract val objects: ObjectFactory
override fun execute(context: ComponentMetadataContext) {
context.details.withVariant("runtime") {
attributes {
attribute(OperatingSystemFamily.OPERATING_SYSTEM_ATTRIBUTE, objects.named("none"))
attribute(MachineArchitecture.ARCHITECTURE_ATTRIBUTE, objects.named("none"))
}
}
nativeVariants.forEach { variantDefinition ->
context.details.addVariant("${variantDefinition.classifier}-runtime", "runtime") {
attributes {
attribute(OperatingSystemFamily.OPERATING_SYSTEM_ATTRIBUTE, objects.named(variantDefinition.os))
attribute(MachineArchitecture.ARCHITECTURE_ATTRIBUTE, objects.named(variantDefinition.arch))
}
withFiles {
addFile("${context.details.id.name}-${context.details.id.version}-${variantDefinition.classifier}.jar")
}
}
}
}
}@CacheableRule
abstract class LwjglRule implements ComponentMetadataRule { //val os: String, val arch: String, val classifier: String)
private def nativeVariants = [
[os: OperatingSystemFamily.LINUX, arch: "arm32", classifier: "natives-linux-arm32"],
[os: OperatingSystemFamily.LINUX, arch: "arm64", classifier: "natives-linux-arm64"],
[os: OperatingSystemFamily.WINDOWS, arch: "x86", classifier: "natives-windows-x86"],
[os: OperatingSystemFamily.WINDOWS, arch: "x86-64", classifier: "natives-windows"],
[os: OperatingSystemFamily.MACOS, arch: "x86-64", classifier: "natives-macos"]
]
@Inject abstract ObjectFactory getObjects()
void execute(ComponentMetadataContext context) {
context.details.withVariant("runtime") {
attributes {
attributes.attribute(OperatingSystemFamily.OPERATING_SYSTEM_ATTRIBUTE, objects.named(OperatingSystemFamily, "none"))
attributes.attribute(MachineArchitecture.ARCHITECTURE_ATTRIBUTE, objects.named(MachineArchitecture, "none"))
}
}
nativeVariants.each { variantDefinition ->
context.details.addVariant("${variantDefinition.classifier}-runtime", "runtime") {
attributes {
attributes.attribute(OperatingSystemFamily.OPERATING_SYSTEM_ATTRIBUTE, objects.named(OperatingSystemFamily, variantDefinition.os))
attributes.attribute(MachineArchitecture.ARCHITECTURE_ATTRIBUTE, objects.named(MachineArchitecture, variantDefinition.arch))
}
withFiles {
addFile("${context.details.id.name}-${context.details.id.version}-${variantDefinition.classifier}.jar")
}
}
}
}
}This rule is quite similar to the Quasar library example above.
Only this time we have five different runtime variants we add and nothing we need to change for the compile variant.
The runtime variants are all based on the existing runtime variant and we do not change any existing information.
All Java ecosystem attributes, the dependencies and the main jar file stay part of each of the runtime variants.
We only set the additional attributes OPERATING_SYSTEM_ATTRIBUTE and ARCHITECTURE_ATTRIBUTE which are defined as part of Gradle’s native support.
And we add the corresponding native jar file so that each runtime variant now carries two files: the main jar and the native jar.
In the build script, we can now request a specific variant and Gradle will fail with a selection error if more information is needed to make a decision.
Gradle is able to understand the common case where a single attribute is missing that would have removed the ambiguity. In this case, rather than listing information about all attributes on all available variants, Gradle helpfully lists only possible values for that attribute along with the variants each value would select.
configurations["runtimeClasspath"].attributes {
attribute(OperatingSystemFamily.OPERATING_SYSTEM_ATTRIBUTE, objects.named("windows"))
}
dependencies {
components {
withModule<LwjglRule>("org.lwjgl:lwjgl")
}
implementation("org.lwjgl:lwjgl:3.2.3")
}configurations["runtimeClasspath"].attributes {
attribute(OperatingSystemFamily.OPERATING_SYSTEM_ATTRIBUTE, objects.named(OperatingSystemFamily, "windows"))
}
dependencies {
components {
withModule("org.lwjgl:lwjgl", LwjglRule)
}
implementation("org.lwjgl:lwjgl:3.2.3")
}Gradle fails to select a variant because a machine architecture needs to be chosen:
> Could not resolve all files for configuration ':runtimeClasspath'.
> Could not resolve org.lwjgl:lwjgl:3.2.3.
Required by:
root project 'component-metadata-rules'
> The consumer was configured to find a library for use during runtime, compatible with Java 11, packaged as a jar, preferably optimized for standard JVMs, and its dependencies declared externally, as well as attribute 'org.gradle.native.operatingSystem' with value 'windows'. There are several available matching variants of org.lwjgl:lwjgl:3.2.3
The only attribute distinguishing these variants is 'org.gradle.native.architecture'. Add this attribute to the consumer's configuration to resolve the ambiguity:
- Value: 'x86-64' selects variant: 'natives-windows-runtime'
- Value: 'x86' selects variant: 'natives-windows-x86-runtime'Making different flavors of a library available through capabilities
Because it is difficult to model optional feature variants as separate jars with pom metadata, libraries sometimes comprise different jars with different feature sets.
That is, instead of composing your flavor of the library from different feature variants, you select one of the pre-composed variants (offering everything in one jar).
One such library is the well-known dependency injection framework Guice, published on Maven central, which offers a complete flavor (the main jar) and a reduced variant without aspect-oriented programming support (guice-4.2.2-no_aop.jar).
That second variant with a classifier is not mentioned in the pom metadata.
With the following rule, we create compile and runtime variants based on that file and make it selectable through a capability named com.google.inject:guice-no_aop.
@CacheableRule
abstract class GuiceRule: ComponentMetadataRule {
override fun execute(context: ComponentMetadataContext) {
listOf("compile", "runtime").forEach { base ->
context.details.addVariant("noAop${base.capitalize()}", base) {
withCapabilities {
addCapability("com.google.inject", "guice-no_aop", context.details.id.version)
}
withFiles {
removeAllFiles()
addFile("guice-${context.details.id.version}-no_aop.jar")
}
withDependencies {
removeAll { it.group == "aopalliance" }
}
}
}
}
}@CacheableRule
abstract class GuiceRule implements ComponentMetadataRule {
void execute(ComponentMetadataContext context) {
["compile", "runtime"].each { base ->
context.details.addVariant("noAop${base.capitalize()}", base) {
withCapabilities {
addCapability("com.google.inject", "guice-no_aop", context.details.id.version)
}
withFiles {
removeAllFiles()
addFile("guice-${context.details.id.version}-no_aop.jar")
}
withDependencies {
removeAll { it.group == "aopalliance" }
}
}
}
}
}The new variants also have the dependency on the standardized aop interfaces library aopalliance:aopalliance removed, as this is clearly not needed by these variants.
Again, this is information that cannot be expressed in pom metadata.
We can now select a guice-no_aop variant and will get the correct jar file and the correct dependencies.
dependencies {
components {
withModule<GuiceRule>("com.google.inject:guice")
}
implementation("com.google.inject:guice:4.2.2") {
capabilities { requireCapability("com.google.inject:guice-no_aop") }
}
}dependencies {
components {
withModule("com.google.inject:guice", GuiceRule)
}
implementation("com.google.inject:guice:4.2.2") {
capabilities { requireCapability("com.google.inject:guice-no_aop") }
}
}Adding missing capabilities to detect conflicts
Another usage of capabilities is to express that two different modules, for example log4j and log4j-over-slf4j, provide alternative implementations of the same thing.
By declaring that both provide the same capability, Gradle only accepts one of them in a dependency graph.
This example, and how it can be tackled with a component metadata rule, is described in detail in the feature modelling section.
Making Ivy modules variant-aware
Modules published using Ivy do not have variants available by default.
However, Ivy configurations can be mapped to variants as the addVariant(name, baseVariantOrConfiguration) accepts any Ivy configuration that was published as base.
This can be used, for example, to define runtime and compile variants.
An example of a corresponding rule can be found here.
Ivy details of Ivy configurations (e.g. dependencies and files) can also be modified using the withVariant(configurationName) API.
However, modifying attributes or capabilities on Ivy configurations has no effect.
For very Ivy specific use cases, the component metadata rules API also offers access to other details only found in Ivy metadata.
These are available through the IvyModuleDescriptor interface and can be accessed using getDescriptor(IvyModuleDescriptor) on the ComponentMetadataContext.
@CacheableRule
abstract class IvyComponentRule : ComponentMetadataRule {
override fun execute(context: ComponentMetadataContext) {
val descriptor = context.getDescriptor(IvyModuleDescriptor::class)
if (descriptor != null && descriptor.branch == "testing") {
context.details.status = "rc"
}
}
}@CacheableRule
abstract class IvyComponentRule implements ComponentMetadataRule {
void execute(ComponentMetadataContext context) {
def descriptor = context.getDescriptor(IvyModuleDescriptor)
if (descriptor != null && descriptor.branch == "testing") {
context.details.status = "rc"
}
}
}Filter using Maven metadata
For Maven specific use cases, the component metadata rules API also offers access to other details only found in POM metadata.
These are available through the PomModuleDescriptor interface and can be accessed using getDescriptor(PomModuleDescriptor) on the ComponentMetadataContext.
@CacheableRule
abstract class MavenComponentRule : ComponentMetadataRule {
override fun execute(context: ComponentMetadataContext) {
val descriptor = context.getDescriptor(PomModuleDescriptor::class)
if (descriptor != null && descriptor.packaging == "war") {
// ...
}
}
}@CacheableRule
abstract class MavenComponentRule implements ComponentMetadataRule {
void execute(ComponentMetadataContext context) {
def descriptor = context.getDescriptor(PomModuleDescriptor)
if (descriptor != null && descriptor.packaging == "war") {
// ...
}
}
}Modifying metadata on the component level for alignment
While all the examples above made modifications to variants of a component, there is also a limited set of modifications that can be done to the metadata of the component itself. This information can influence the version selection process for a module during dependency resolution, which is performed before one or multiple variants of a component are selected.
The first API available on the component is belongsTo() to create virtual platforms for aligning versions of multiple modules without Gradle Module Metadata.
It is explained in detail in the section on aligning versions of modules not published with Gradle.
Modifying metadata on the component level for version selection based on status
Gradle and Gradle Module Metadata also allow attributes to be set on the whole component instead of a single variant.
Each of these attributes carries special semantics as they influence version selection which is done before variant selection.
While variant selection can handle any custom attribute, version selection only considers attributes for which specific semantics are implemented.
At the moment, the only attribute with meaning here is org.gradle.status.
The org.gradle.status module attribute indicates the lifecycle status or maturity level of a module or library:
-
integration: This indicates that the module is under active development and may not be stable. -
milestone: A module with this status is more mature than one marked asintegration. -
release: This status signifies that the module is stable and officially released.
It is therefore recommended to only modify this attribute, if any, on the component level.
A dedicated API setStatus(value) is available for this.
To modify another attribute for all variants of a component withAllVariants { attributes {} } should be utilised instead.
A module’s status is taken into consideration when a latest version selector is resolved.
Specifically, latest.someStatus will resolve to the highest module version that has status someStatus or a more mature status.
For example, latest.integration will select the highest module version regardless of its status (because integration is the least mature status as explained below), whereas latest.release will select the highest module version with status release.
The interpretation of the status can be influenced by changing a module’s status scheme through the setStatusScheme(valueList) API.
This concept models the different levels of maturity that a module transitions through over time with different publications.
The default status scheme, ordered from least to most mature status, is integration, milestone, release.
The org.gradle.status attribute must be set, to one of the values in the component’s status scheme.
Thus each component always has a status which is determined from the metadata as follows:
-
Gradle Module Metadata: the value that was published for the
org.gradle.statusattribute on the component -
Ivy metadata:
statusdefined in the ivy.xml, defaults tointegrationif missing -
Pom metadata:
integrationfor modules with a SNAPSHOT version,releasefor all others
The following example demonstrates latest selectors based on a custom status scheme declared in a component metadata rule that applies to all modules:
@CacheableRule
abstract class CustomStatusRule : ComponentMetadataRule {
override fun execute(context: ComponentMetadataContext) {
context.details.statusScheme = listOf("nightly", "milestone", "rc", "release")
if (context.details.status == "integration") {
context.details.status = "nightly"
}
}
}
dependencies {
components {
all<CustomStatusRule>()
}
implementation("org.apache.commons:commons-lang3:latest.rc")
}@CacheableRule
abstract class CustomStatusRule implements ComponentMetadataRule {
void execute(ComponentMetadataContext context) {
context.details.statusScheme = ["nightly", "milestone", "rc", "release"]
if (context.details.status == "integration") {
context.details.status = "nightly"
}
}
}
dependencies {
components {
all(CustomStatusRule)
}
implementation("org.apache.commons:commons-lang3:latest.rc")
}Compared to the default scheme, the rule inserts a new status rc and replaces integration with nightly.
Existing modules with the status integration are mapped to nightly.
Dependency Caching
Gradle contains a highly sophisticated dependency caching mechanism, which seeks to minimise the number of remote requests made in dependency resolution, while striving to guarantee that the results of dependency resolution are correct and reproducible.
-
Local Cache: Gradle caches dependencies locally to avoid repeated downloads. The cache is located in the
.gradledirectory under the user’s home folder (e.g.,~/.gradle/caches/modules-2). When a dependency is requested, Gradle first checks this local cache before attempting to fetch it from remote repositories. -
Changing Dependencies: By default, Gradle treats dependencies marked as "changing" (e.g., SNAPSHOT or dynamic dependencies) differently and refreshes them more frequently. The caching times for these dependencies can be altered programmatically.
-
Offline Mode: Gradle can run in offline mode, using only the cached dependencies without trying to download anything from remote repositories. You can enable offline mode with the
--offlineflag, ensuring that your build only uses cached artifacts. -
Refreshing Dependencies: To force Gradle to update its dependencies, use the
--refresh-dependenciesflag. This option instructs Gradle to bypass the cache and check for updated artifacts in remote repositories. Gradle downloads them, but only if it detects a change, using hashes to avoid unnecessary downloads.
1. The dependency cache
The Gradle dependency cache consists of two storage types located under $GRADLE_USER_HOME/caches:
-
A file-based store of downloaded artifacts, including binaries like jars as well as raw downloaded meta-data like POM files and Ivy files. Artifacts are stored under a checksum, so name clashes will not cause issues.
-
A binary store of resolved module metadata, including the results of resolving dynamic versions, module descriptors, and artifacts.
Separate metadata cache
Gradle keeps a record of various aspects of dependency resolution in binary format in the metadata cache.
The information stored in the metadata cache includes:
-
The result of resolving a dynamic version (e.g.
1.+) to a concrete version (e.g.1.2). -
The resolved module metadata for a particular module, including module artifacts and module dependencies.
-
The resolved artifact metadata for a particular artifact, including a pointer to the downloaded artifact file.
-
The absence of a particular module or artifact in a particular repository, eliminating repeated attempts to access a resource that does not exist.
Every entry in the metadata cache includes a record of the repository that provided the information as well as a timestamp that can be used for cache expiry.
Repository caches are independent
As described above, for each repository there is a separate metadata cache. A repository is identified by its URL, type and layout.
If a module or artifact has not been previously resolved from this repository, Gradle will attempt to resolve the module against the repository. This will always involve a remote lookup on the repository, however in many cases no download will be required.
Dependency resolution will fail if required artifacts aren’t available in the repository from which they were originally resolved. Once resolved from a specific repository, artifacts become "sticky," meaning Gradle will avoid resolving them from other repositories to prevent unexpected or potentially unsafe changes in artifact sources. This ensures consistency across environments, but it may also lead to failures if repositories differ between machines.
Repository independence allows builds to be isolated from each other. This is a key feature to create builds that are reliable and reproducible in any environment.
Artifact reuse
Before downloading an artifact, Gradle attempts to retrieve the artifact’s checksum by downloading an associated .sha512, .sha256, .sha1, or .md5 file (attempting each in order).
If the checksum is available, Gradle skips the download if an artifact with the same ID and checksum already exists. However, if the checksum cannot be retrieved from the remote server, Gradle proceeds to download the artifact but will ignore it if it matches an existing one.
Gradle also tries to reuse artifacts from the local Maven repository. If an artifact previously downloaded by Maven is a match, Gradle will use it, provided it can be verified against the checksum from the remote server.
Checksum based storage
It is possible for different repositories to provide a different binary artifact in response to the same artifact identifier.
This is often the case with Maven SNAPSHOT artifacts, but can also be true for any artifact which is republished without changing its identifier. By caching artifacts based on their checksum, Gradle is able to maintain multiple versions of the same artifact. This means that when resolving against one repository Gradle will never overwrite the cached artifact file from a different repository. This is done without requiring a separate artifact file store per repository.
Cache locking
The Gradle dependency cache uses file-based locking to ensure that it can safely be used by multiple Gradle processes concurrently. The lock is held whenever the binary metadata store is being read or written, but is released for slow operations such as downloading remote artifacts.
This concurrent access is only supported if the different Gradle processes can communicate together. This is usually not the case for containerized builds.
Cache cleanup
Gradle tracks which artifacts in the dependency cache are accessed. Based on this information, the cache is periodically scanned (no more than once every 24 hours) to identify artifacts that haven’t been used in over 30 days. These obsolete artifacts are then deleted to prevent the cache from growing indefinitely.
You can learn more about cache cleanup in Gradle-managed Directories.
2. Changing dependencies
Gradle treats dependencies marked as "changing" (such as SNAPSHOT dependencies) differently from regular dependencies, refreshing them more frequently to ensure that you are always using the latest version.
To declare a dependency as changing, you can set the changing = true attribute in your dependency declaration.
This is useful for dependencies expected to change frequently without a new version number:
dependencies {
implementation("com.example:some-library:1.0-SNAPSHOT") // Automatically gets treated as changing
implementation("com.example:my-library:1.0") { // Must be explicitly set as changing
isChanging = true
}
}dependencies {
implementation("com.example:some-library:1.0-SNAPSHOT") // Automatically gets treated as changing
implementation("com.example:my-library:1.0") { // Must be explicitly set as changing
changing = true
}
}Caching changing dependencies
By default, Gradle caches these dependencies (including dynamic versions and changing modules) for 24 hours, meaning it does not contact remote repositories for new versions during this time.
To have Gradle check for newer versions more frequently or with every build, you can adjust the caching threshold or time-to-live (TTL) settings accordingly.
|
Note
|
Using a short TTL threshold for dynamic or changing versions may result in longer build times due to increased remote repository accesses. |
You can fine-tune certain aspects of caching programmatically using the ResolutionStrategy for a configuration. The programmatic approach is useful if you want to change the settings permanently.
To change how long Gradle will cache the resolved version for a dynamic version, use:
configurations.configureEach {
resolutionStrategy.cacheDynamicVersionsFor(10, "minutes")
}configurations.configureEach {
resolutionStrategy.cacheDynamicVersionsFor 10, 'minutes'
}To change how long Gradle will cache the metadata and artifacts for a changing module, use:
configurations.configureEach {
resolutionStrategy.cacheChangingModulesFor(4, "hours")
}configurations.configureEach {
resolutionStrategy.cacheChangingModulesFor 4, 'hours'
}3. Using offline mode
The --offline command-line switch instructs Gradle to use dependency modules from the cache, regardless of whether they are due to be checked again.
When running with offline, Gradle will not attempt to access the network for dependency resolution.
If the required modules are not in the dependency cache, the build will fail.
4. Force-refreshing dependencies
You can control the behavior of dependency caching for a distinct build invocation from the command line. Command line options help make a selective, ad-hoc choice for a single build execution.
At times, the Gradle Dependency Cache can become out of sync with the actual state of the configured repositories.
Perhaps a repository was initially misconfigured, or maybe a "non-changing" module was published incorrectly.
To refresh all dependencies in the dependency cache, use the --refresh-dependencies option on the command line.
The --refresh-dependencies option tells Gradle to ignore all cached entries for resolved modules and artifacts.
A fresh resolve will be performed against all configured repositories, with dynamic versions recalculated, modules refreshed, and artifacts downloaded.
However, where possible Gradle will check if the previously downloaded artifacts are valid before downloading again.
This is done by comparing published checksum values in the repository with the checksum values for existing downloaded artifacts.
Refreshing dependencies will cause Gradle to invalidate its listing caches. However:
-
it will perform HTTP HEAD requests on metadata files but will not re-download them if they are identical
-
it will perform HTTP HEAD requests on artifact files but will not re-download them if they are identical
In other words, refreshing dependencies only has an impact if you actually use dynamic dependencies or that you have changing dependencies that you were not aware of (in which case it is your responsibility to declare them correctly to Gradle as changing dependencies).
It’s a common misconception to think that using --refresh-dependencies will force the download of dependencies.
This is not the case: Gradle will only perform what is strictly required to refresh the dynamic dependencies.
This may involve downloading new listings, metadata files, or even artifacts, but the impact is minimal if nothing changed.
Dealing with ephemeral builds
It’s a common practice to run builds in ephemeral containers. A container is typically spawned to only execute a single build before it is destroyed. This can become a practical problem when a build depends on a lot of dependencies which each container has to re-download. To help with this scenario, Gradle provides a couple of options:
-
copying the dependency cache into each container
-
sharing a read-only dependency cache between multiple containers
Copying and reusing the cache
The dependency cache, both the file and metadata parts, are fully encoded using relative paths. This means that it is perfectly possible to copy a cache around and see Gradle benefit from it.
The path that can be copied is $GRADLE_USER_HOME/caches/modules-<version>.
The only constraint is placing it using the same structure at the destination, where the value of GRADLE_USER_HOME can be different.
Do not copy the *.lock or gc.properties files if they exist.
Note that creating the cache and consuming it should be done using compatible Gradle version, as shown in the table below. Otherwise, the build might still require some interactions with remote repositories to complete missing information, which might be available in a different version. If multiple incompatible Gradle versions are in play, all should be used when seeding the cache.
| Module cache version | File cache version | Metadata cache version | Gradle version(s) |
|---|---|---|---|
|
|
|
Gradle 6.1 to Gradle 6.3 |
|
|
|
Gradle 6.4 to Gradle 6.7 |
|
|
|
Gradle 6.8 to Gradle 7.4 |
|
|
|
Gradle 7.5 to Gradle 7.6.1 |
|
|
|
Gradle 7.6.2 |
|
|
|
Gradle 8.0 |
|
|
|
Gradle 8.1 |
|
|
|
Gradle 8.2 to Gradle 8.10.2 |
|
|
|
Gradle 8.11 and above |
Sharing the dependency cache with other Gradle instances
Instead of copying the dependency cache into each container, it’s possible to mount a shared, read-only directory that will act as a dependency cache for all containers. This cache, unlike the classical dependency cache, is accessed without locking, making it possible for multiple builds to read from the cache concurrently. It’s important that the read-only cache is not written to when other builds may be reading from it.
When using the shared read-only cache, Gradle looks for dependencies (artifacts or metadata) in both the writable cache in the local Gradle User Home directory and the shared read-only cache. If a dependency is present in the read-only cache, it will not be downloaded. If a dependency is missing from the read-only cache, it will be downloaded and added to the writable cache. In practice, this means that the writable cache will only contain dependencies that are unavailable in the read-only cache.
The read-only cache should be sourced from a Gradle dependency cache that already contains some of the required dependencies. The cache can be incomplete; however, an empty shared cache will only add overhead.
|
Note
|
The shared read-only dependency cache is an incubating feature. |
The first step in using a shared dependency cache is to create one by copying of an existing local cache. For this you need to follow the instructions above.
Then set the GRADLE_RO_DEP_CACHE environment variable to point to the directory containing the cache:
$GRADLE_RO_DEP_CACHE
|-- modules-2 : the read-only dependency cache, should be mounted with read-only privileges
$GRADLE_HOME
|-- caches
|-- modules-2 : the container specific dependency cache, should be writable
|-- ...
|-- ...In a CI environment, it’s a good idea to have one build which "seeds" a Gradle dependency cache, which is then copied to a different directory or distributed, for example, as a Docker volume. This directory can then be used as the read-only cache for other builds. You shouldn’t use an existing Gradle installation cache as the read-only cache, because this directory may contain locks and may be modified by the seeding build.
Dependency Resolution
Dependency resolution in Gradle can largely be thought of as a two-step process.
First, the graph resolution phase constructs the dependency graph based on declared dependencies. Second, the artifact resolution phase fetches the actual files (artifacts) for the resolved components:
-
Graph resolution phase:
-
Driven by declared dependencies and their metadata
-
Uses the request attributes defined by the configuration being resolved
-
-
Artifact resolution phase:
-
Based on nodes in the resolved dependency graph
-
Matches each node to a variant and an artifact
-
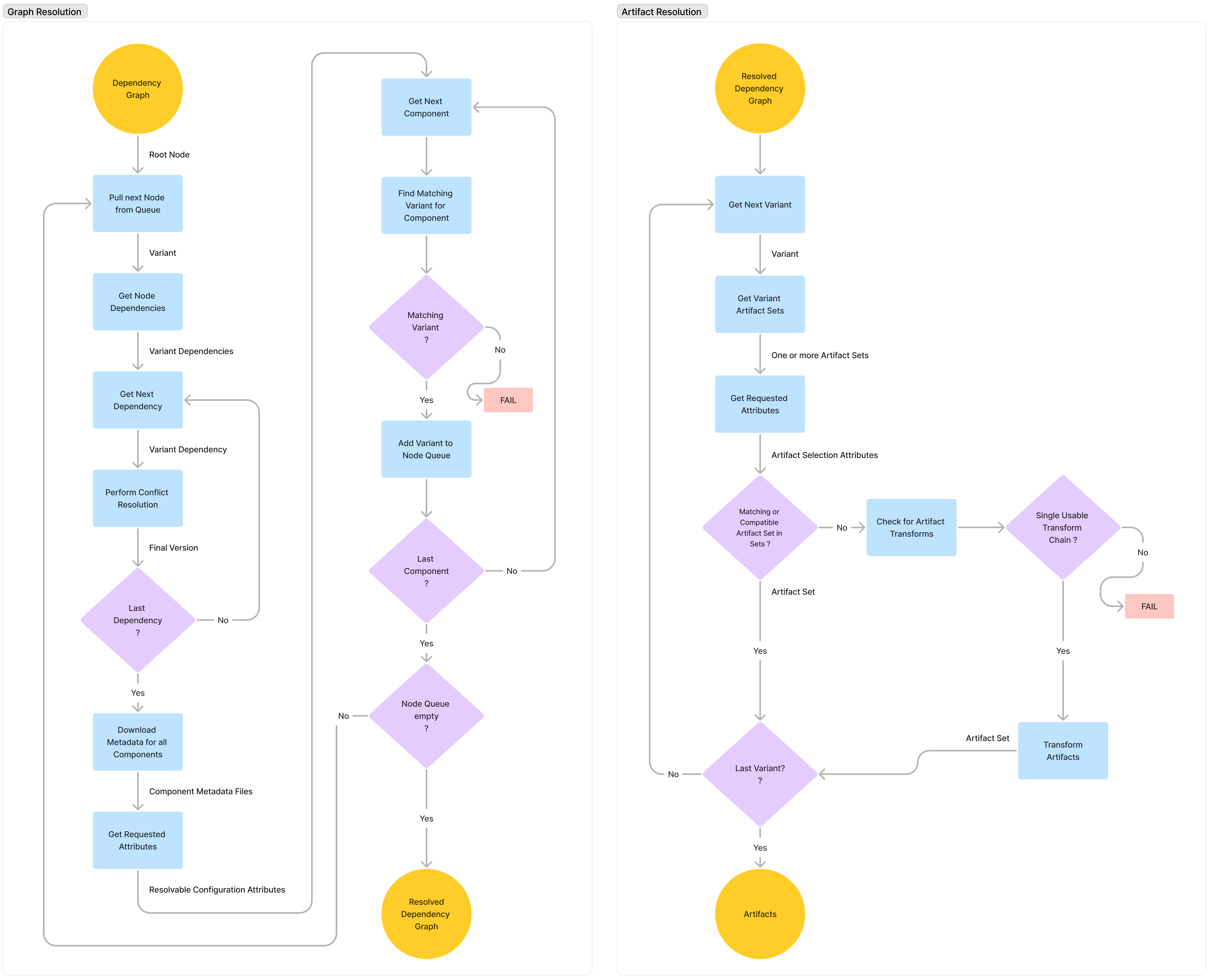
1. Graph Resolution
During the graph resolution phase, Gradle constructs a dependency graph, which models the relationships between different components and their variants.
See Graph Resolution to learn more.
2. Artifact Resolution
Once the dependency graph is resolved, the artifact resolution phase determines which artifacts (i.e. files) need to be downloaded or retrieved for each variant.
See Artifact Resolution to learn more.
Next Step: Learn about Graph Resolution >>
Graph Resolution
During the graph resolution phase, Gradle constructs a resolved dependency graph, which models the relationships between different components and their variants.
Modules
Graph resolution begins with dependencies declared in the build script:
dependencies {
implementation("com.fasterxml.jackson.core:jackson-databind:2.17.2")
}In the Learning the Basics section, we learned that a module is a published unit of work (like a library or application), while a dependency is a reference to a module required for a project to compile or run.
In the example above, the module is com.fasterxml.jackson.core:jackson-databind.
Components
Each version of a module is referred to as a component.
In the example above for the com.fasterxml.jackson.core:jackson-databind:2.17.2 module, 2.17.2 is the version.
Metadata
A component is detailed by metadata, which is available in the repository where the component is hosted as a ivy, pom, or GMM metadata.
Here’s a condensed sample of the metadata for com.fasterxml.jackson.core:jackson-databind:2.17.2:
{
"formatVersion": "1.1",
"component": {
"group": "com.fasterxml.jackson.core",
"module": "jackson-databind",
"version": "2.17.2"
},
"variants": [
{
"name": "apiElements",
...
},
{
"name": "runtimeElements",
"attributes": {
"org.gradle.category": "library",
"org.gradle.dependency.bundling": "external",
"org.gradle.libraryelements": "jar",
"org.gradle.usage": "java-runtime"
},
"dependencies": [
{
"group": "com.fasterxml.jackson.core",
"module": "jackson-annotations",
"version": {
"requires": "2.17.2"
}
}
],
"files": [
{
"name": "jackson-databind-2.17.2.jar"
}
]
}
]
}Some items in the file should be familiar to you such as "files", "dependencies", "components", "module" and "version". Let’s focus on the variants provided in the metadata.
Variants
A variant is a specific variation of a component tailored for a particular use case or environment.
Variants allow you to provide different definitions of your component depending on the context in which it’s used.
As detailed above, the metadata of the com.fasterxml.jackson.core:jackson-databind:2.17.2 component offers two variants:
-
The
apiElementsvariant includes dependencies required for compiling projects against Jackson Databind. -
The
runtimeElementsvariant includes dependencies required for executing Jackson Databind during runtime.
| Variant | Dependencies | Artifacts |
|---|---|---|
|
|
|
|
|
|
… other variant … |
… some dependencies … |
… some artifacts … |
Each variant consists of a set of artifacts and defines a set of dependencies (i.e. seen as transitive dependencies of the build):
-
The
runtimeElementsvariant ofcom.fasterxml.jackson.core:jackson-databind:2.17.2:-
Depends on
com.fasterxml.jackson.core. -
Provides an artifact called
jackson-databind-2.17.2.jar.
-
To differentiate between the apiElements and runtimeElements variants, Gradle uses attributes.
Attributes
To differentiate between variants, Gradle uses attributes.
Attributes are used to define specific characteristics or properties of variants and the context in which those variants should be used.
In the metadata for Jackson Databind, we see that the runtimeElements variant is described by the org.gradle.category, org.gradle.dependency.bundling, org.gradle.libraryelement, and org.gradle.usage attributes:
{
"variants": [
{
"name": "runtimeElements",
"attributes": {
"org.gradle.category": "library",
"org.gradle.dependency.bundling": "external",
"org.gradle.libraryelements": "jar",
"org.gradle.usage": "java-runtime"
}
}
]
}Attributes are defined as key:value pairs, such as org.gradle.category": "library".
Now that we understand the building blocks for dependency management, let’s look into graph resolution.
Dependency Graph
Gradle builds a dependency graph that represents a configuration’s dependencies and their relationships. This graph includes both direct and transitive dependencies.
The graph is made up of nodes where each node represents a variant. These nodes are connected by edges, representing the dependencies between variants. The edges indicate how one variant relies on another.
The dependencies task can be used to partially visualize the structure of a dependency graph:
$ ./gradlew app:dependencies...
runtimeClasspath - Runtime classpath of source set 'main'.
\--- com.fasterxml.jackson.core:jackson-databind:2.17.2
+--- com.fasterxml.jackson.core:jackson-annotations:2.17.2
| \--- com.fasterxml.jackson:jackson-bom:2.17.2
| +--- com.fasterxml.jackson.core:jackson-annotations:2.17.2
| +--- com.fasterxml.jackson.core:jackson-core:2.17.2
| \--- com.fasterxml.jackson.core:jackson-databind:2.17.2
+--- com.fasterxml.jackson.core:jackson-core:2.17.2
| \--- com.fasterxml.jackson:jackson-bom:2.17.2
\--- com.fasterxml.jackson:jackson-bom:2.17.2In this truncated output, runtimeClasspath represents the specific resolvable configurations in the project.
Each resolvable configuration calculates a separate dependency graph. That’s because different configurations can resolve to a different set of transitive dependencies for the same set of declared dependencies.
In the example above, the resolvable configuration, compileClasspath could resolve a different set of dependencies and produce a very different graph than runtimeClasspath.
So how does Gradle build the dependency graph?
Graph Resolution Flow
Graph resolution operates on a node-by-node (i.e., variant-by-variant) basis.
Each iteration of the loop processes one node at a time, starting by de-queuing a node.
In the beginning, the queue is empty. When the process starts, a root node added to the queue. The root node is effectively the resolvable configuration:
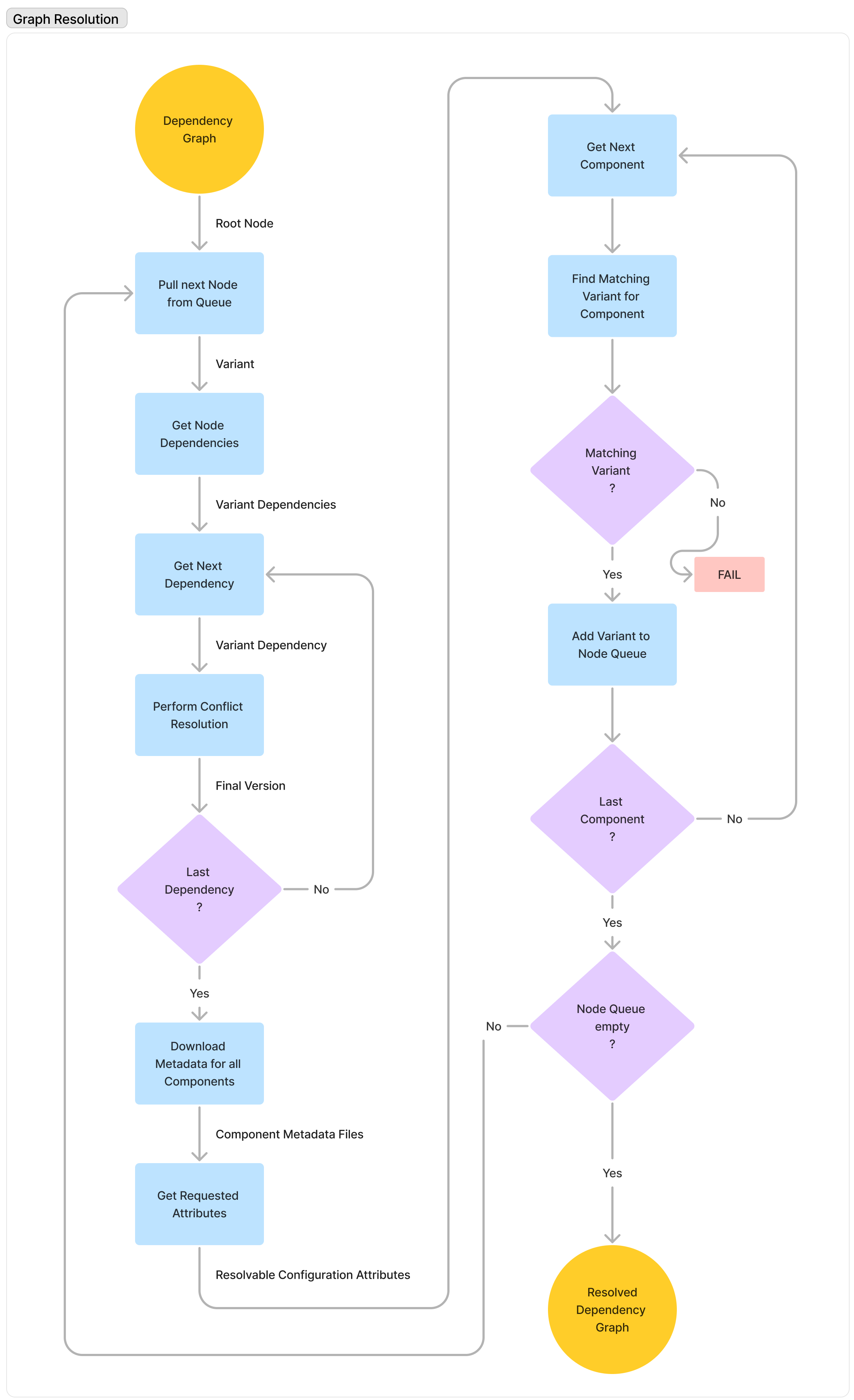
Gradle starts the loop by pulling the root node from the queue. Gradle examines the dependencies of the root node, resolves their conflicts, and downloads their metadata. Based on their metadata, Gradle selects variants of those dependencies and adds them back to the queue.
|
Note
|
The root variant’s dependencies correspond to the declared dependencies of the resolvable configuration. |
At this point, the queue contains all selected variants for the root node’s dependencies, which will now be processed one by one.
For each node in the loop Gradle:
-
Evaluates its dependencies.
-
Determines their targeted versions using conflict resolution.
-
Downloads the metadata for all components at once.
-
Select variants for each of those components.
-
Adds the variants to the top-level queue.
The loop is repeated until the node queue is empty. Once the process is complete, the dependency graph is resolved.
|
Tip
|
Graph resolution alternates between parallel metadata downloads and single-threaded logic, repeating this pattern over and over again for a single graph. |
Conflict Resolution
When performing dependency resolution, Gradle handles two types of conflicts:
-
Version conflicts: Which occur when multiple dependencies request the same dependency but with different versions. Gradle must choose which version to include in the graph.
-
Implementation / Capability conflicts: Which occur when the dependency graph contains different modules that provide the same functionality or capability. Gradle resolves these by selecting one module to avoid duplicate implementations.
The dependency resolution process is highly customizable and many APIs can influence the process.
A. Version conflicts
A version conflict can occur when two components:
-
Depend on the same module, such as
com.google.guava:guava -
But on different versions, for example,
20.0and25.1-android:-
Our project directly depends on
com.google.guava:guava:20.0 -
Our project also depends on
com.google.inject:guice:4.2.2, which in turn depends oncom.google.guava:guava:25.1-android
-
Gradle must resolve this conflict by selecting one version to include in the dependency graph.
Gradle considers all requested versions across the dependency graph and, by default, selects the highest version. Detailed version ordering is explained in version ordering.
Gradle also supports the concept of rich version declarations, which means that what constitutes the "highest" version depends on how the versions were declared:
-
Without ranges: The highest non-rejected version will be selected.
-
If a
strictlyversion is declared that is lower than the highest, resolution will fail.
-
-
With ranges:
-
If a non-range version fits within the range or is higher than the upper bound, it will be selected.
-
If only ranges exist, the selection depends on the intersection of those ranges:
-
If ranges overlap, the highest existing version in the intersection is selected.
-
If no clear intersection exists, the highest version from the largest range will be selected. If no version exists in the highest range, the resolution fails.
-
-
If a
strictlyversion is declared that is lower than the highest, resolution will fail.
-
For version ranges, Gradle needs to perform intermediate metadata lookups to determine what variations are available, as explained in Metadata Retrieval.
Versions with qualifiers
The term "qualifier" refers to the portion of a version string that comes after a non-dot separator, like a hyphen or underscore.
For example:
| Original version | Base version | Qualifier |
|---|---|---|
1.2.3 |
1.2.3 |
<none> |
1.2-3 |
1.2 |
3 |
1_alpha |
1 |
alpha |
abc |
abc |
<none> |
1.2b3 |
1.2 |
b3 |
abc.1+3 |
abc.1 |
3 |
b1-2-3.3 |
b |
1-2-3.3 |
As you can see separators are any of the ., -, _, + characters, plus the empty string when a numeric and a non-numeric part of the version are next to each-other.
By default, Gradle gives preference to versions without qualifiers when resolving conflicts.
For example, in version 1.0-beta, the base form is 1.0, and beta is the qualifier.
Versions without qualifiers are considered more stable, so Gradle will prioritize them.
Here are a few examples to clarify:
-
1.0.0(no qualifier) -
1.0.0-beta(qualifier:beta) -
2.1-rc1(qualifier:rc1)
Even if the qualifier is lexicographically higher, Gradle will typically consider a version like 1.0.0 higher than 1.0.0-beta.
When resolving conflicts between versions, Gradle applies the following logic:
-
Base version comparison: Gradle first selects versions with the highest base version, ignoring any qualifiers. All others are discarded.
-
Qualifier handling: If there are still multiple versions with the same base version, Gradle picks one with a preference for versions without qualifiers (i.e., release versions). If all versions have qualifiers, Gradle will consider the qualifier’s order, preferring more stable ones like "release" over others such as "beta" or "alpha."
B. Implementation / Capability conflicts
Conflicts arise in the following scenarios:
-
Incompatible variants: When two modules attempt to select different, incompatible variants of a dependency.
-
Same capability: When multiple modules declare the same capability, creating an overlap in functionality.
This type of conflict is resolved during Variant Selection described below.
Metadata Retrieval
Gradle requires module metadata in the dependency graph for two reasons:
-
Determining existing versions for dynamic dependencies: When a dynamic version (like
1.+orlatest.release) is specified, Gradle must identify the concrete versions available. -
Resolving module dependencies for a specific version: Gradle retrieves the dependencies associated with a module based on the specified version, ensuring the correct transitive dependencies are included in the build.
A. Determining existing versions for dynamic dependencies
When faced with a dynamic version, Gradle must identify the available concrete versions. To do that, Gradle checks each defined repository in the order they were added. It doesn’t stop at the first one that returns metadata but continues through all available repositories.
For Maven repositories, Gradle retrieves version information from the maven-metadata.xml file, which lists available versions.
For Ivy repositories, Gradle resorts to a directory listing to gather available versions.
The result is a list of candidate versions that Gradle evaluates and matches to the dynamic version. Gradle caches this information to optimize future resolution. At this point, version conflict resolution is resumed.
B. Resolving module dependencies for a specific version
When Gradle tries to resolve a required dependency with a specific version, it follows this process:
-
Repository inspection: Gradle checks each repository in the order they are defined.
-
It looks for metadata files describing the module (
.module,.pom, orivy.xml), or directly for artifact files. -
Modules with metadata files (
.module,.pom, orivy.xml) are prioritized over those with just an artifact file. -
Once metadata is found in a repository, subsequent repositories are ignored.
-
-
Retrieving and parsing metadata: If metadata is found, it is parsed.
-
If the POM file has a parent POM, Gradle recursively resolves each parent module.
-
-
Requesting artifacts: All artifacts for the module are fetched from the same repository that provided the metadata.
-
Caching: All data, including the repository source and any potential misses, are stored in the dependency cache for future use.
|
Note
|
The point above highlights a potential issue with integrating Maven Local. Since Maven Local acts as a Maven cache, it may occasionally miss artifacts for a module. When Gradle sources a module from Maven Local and artifacts are missing, it assumes those artifacts are entirely unavailable. |
Repository disabling
When Gradle fails to retrieve information from a repository after multiple retries or specific fatal errors, the repository will no longer be checked for the remainder of the build. This will usually fail dependency resolution because Gradle will not continue to the next repository in the list unless told otherwise.
This behavior ensures reproducibility.
If the build were to continue while ignoring the faulty repository, subsequent builds could produce different results once the repository is back online.
Reasons for disabling a repository include:
-
Unknown host errors
-
Reaching max retry attempts on transient connection failures, like a server failing to respond
-
Getting HTTP 5xx responses from the server
If your build setup relies on a repository that may be temporarily unavailable, see UrlArtifactRepository.getAllowInsecureContinueWhenDisabled() to allow Gradle to continue using other repositories even when that one encounters issues.
HTTP Retries
Gradle will attempt to connect to a repository multiple times before disabling it. If the connection fails, Gradle retries on specific errors that might be temporary, with increasing wait times between retries.
A repository is marked as unavailable when it cannot be reached, either due to a permanent error or after the maximum number of retries has been exhausted.
Variant Selection
Based on the requirements of the build, Gradle selects one of the variants of the module present in the metadata.
Specifically, Gradle attempts to match the attributes from the resolved configuration to those in the module metadata.
Variant selection and attribute matching is fully described in the next section.
Available APIs
The ResolutionResult API provides access to the resolved dependency graph without triggering artifact downloads.
The graph itself focuses on component variants, not the artifacts (files) associated with those variants:
-
ResolvedComponentResult- Represents a resolved component in the raw dependency graph. -
ResolvedVariantResult- Represents a resolved variant of a component in the raw dependency graph.
Raw access to the dependency graph can be useful for a number of use cases:
-
Visualizing the dependency graph, for example generating a
.dotfile for Graphviz. -
Exposing diagnostics about a given resolution, similar to the
dependenciesordependencyInsighttasks. -
Resolving a subset of the artifacts for a dependency graph when used in conjunction with the
ArtifactViewAPI.
Consider the following function that traverses a dependency graph, starting from the root node. Callbacks are notified for each node and edge in the graph. This function can be used as a base for any use case that requires traversing a dependency graph:
fun traverseGraph(
rootComponent: ResolvedComponentResult,
rootVariant: ResolvedVariantResult,
nodeCallback: (ResolvedVariantResult) -> Unit,
edgeCallback: (ResolvedVariantResult, ResolvedVariantResult) -> Unit
) {
val seen = mutableSetOf<ResolvedVariantResult>(rootVariant)
nodeCallback(rootVariant)
val queue = ArrayDeque(listOf(rootVariant to rootComponent))
while (queue.isNotEmpty()) {
val (variant, component) = queue.removeFirst()
// Traverse this variant's dependencies
component.getDependenciesForVariant(variant).forEach { dependency ->
val resolved = when (dependency) {
is ResolvedDependencyResult -> dependency
is UnresolvedDependencyResult -> throw dependency.failure
else -> throw AssertionError("Unknown dependency type: $dependency")
}
if (!resolved.isConstraint) {
val toVariant = resolved.resolvedVariant
if (seen.add(toVariant)) {
nodeCallback(toVariant)
queue.addLast(toVariant to resolved.selected)
}
edgeCallback(variant, toVariant)
}
}
}
}void traverseGraph(
ResolvedComponentResult rootComponent,
ResolvedVariantResult rootVariant,
Consumer<ResolvedVariantResult> nodeCallback,
BiConsumer<ResolvedVariantResult, ResolvedVariantResult> edgeCallback
) {
Set<ResolvedVariantResult> seen = new HashSet<>()
seen.add(rootVariant)
nodeCallback(rootVariant)
def queue = new ArrayDeque<Tuple2<ResolvedVariantResult, ResolvedComponentResult>>()
queue.add(new Tuple2(rootVariant, rootComponent))
while (!queue.isEmpty()) {
def entry = queue.removeFirst()
def variant = entry.v1
def component = entry.v2
// Traverse this variant's dependencies
component.getDependenciesForVariant(variant).each { dependency ->
if (dependency instanceof UnresolvedDependencyResult) {
throw dependency.failure
}
if ((!dependency instanceof ResolvedDependencyResult)) {
throw new RuntimeException("Unknown dependency type: $dependency")
}
def resolved = dependency as ResolvedDependencyResult
if (!dependency.constraint) {
def toVariant = resolved.resolvedVariant
if (seen.add(toVariant)) {
nodeCallback(toVariant)
queue.add(new Tuple2(toVariant, resolved.selected))
}
edgeCallback(variant, toVariant)
}
}
}
}This function starts at the root variant, and performs a breadth-first traversal of the graph.
The ResolutionResult API is lenient, so it is important to check whether a visited edge is unresolved (failed) or resolved.
With this function, the node callback is always called before the edge callback for any given node.
Below, we leverage the above traversal function to transform a dependency graph into a .dot file for visualization:
abstract class GenerateDot : DefaultTask() {
@get:Input
abstract val rootComponent: Property<ResolvedComponentResult>
@get:Input
abstract val rootVariant: Property<ResolvedVariantResult>
@TaskAction
fun traverse() {
println("digraph {")
traverseGraph(
rootComponent.get(),
rootVariant.get(),
{ node -> println(" ${toNodeId(node)} [shape=box]") },
{ from, to -> println(" ${toNodeId(from)} -> ${toNodeId(to)}") }
)
println("}")
}
fun toNodeId(variant: ResolvedVariantResult): String {
return "\"${variant.owner.displayName}:${variant.displayName}\""
}
}abstract class GenerateDot extends DefaultTask {
@Input
abstract Property<ResolvedComponentResult> getRootComponent()
@Input
abstract Property<ResolvedVariantResult> getRootVariant()
@TaskAction
void traverse() {
println("digraph {")
traverseGraph(
rootComponent.get(),
rootVariant.get(),
node -> { println(" ${toNodeId(node)} [shape=box]") },
(from, to) -> { println(" ${toNodeId(from)} -> ${toNodeId(to)}") }
)
println("}")
}
String toNodeId(ResolvedVariantResult variant) {
return "\"${variant.owner.displayName}:${variant.displayName}\""
}
}|
Note
|
A proper implementation would not use println but would write to an output file. For more details on declaring task inputs and outputs, see the Writing Tasks section.
|
When we register the task, we use the ResolutionResult API to access the root component and root variant of the runtimeClasspath configuration:
tasks.register<GenerateDot>("generateDot") {
rootComponent = runtimeClasspath.flatMap {
it.incoming.resolutionResult.rootComponent
}
rootVariant = runtimeClasspath.flatMap {
it.incoming.resolutionResult.rootVariant
}
}tasks.register("generateDot", GenerateDot) {
rootComponent = configurations.runtimeClasspath.incoming.resolutionResult.rootComponent
rootVariant = configurations.runtimeClasspath.incoming.resolutionResult.rootVariant
}|
Note
|
This example uses incubating APIs. |
Running this task, we get the following output:
digraph {
"root project 'example':runtimeClasspath" [shape=box]
"com.google.guava:guava:33.2.1-jre:jreRuntimeElements" [shape=box]
"root project 'example':runtimeClasspath" -> "com.google.guava:guava:33.2.1-jre:jreRuntimeElements"
"com.google.guava:failureaccess:1.0.2:runtime" [shape=box]
"com.google.guava:guava:33.2.1-jre:jreRuntimeElements" -> "com.google.guava:failureaccess:1.0.2:runtime"
"com.google.guava:listenablefuture:9999.0-empty-to-avoid-conflict-with-guava:runtime" [shape=box]
"com.google.guava:guava:33.2.1-jre:jreRuntimeElements" -> "com.google.guava:listenablefuture:9999.0-empty-to-avoid-conflict-with-guava:runtime"
"com.google.code.findbugs:jsr305:3.0.2:runtime" [shape=box]
"com.google.guava:guava:33.2.1-jre:jreRuntimeElements" -> "com.google.code.findbugs:jsr305:3.0.2:runtime"
"org.checkerframework:checker-qual:3.42.0:runtimeElements" [shape=box]
"com.google.guava:guava:33.2.1-jre:jreRuntimeElements" -> "org.checkerframework:checker-qual:3.42.0:runtimeElements"
"com.google.errorprone:error_prone_annotations:2.26.1:runtime" [shape=box]
"com.google.guava:guava:33.2.1-jre:jreRuntimeElements" -> "com.google.errorprone:error_prone_annotations:2.26.1:runtime"
}
Compare this to the output of the dependencies task:
runtimeClasspath
\--- com.google.guava:guava:33.2.1-jre
+--- com.google.guava:failureaccess:1.0.2
+--- com.google.guava:listenablefuture:9999.0-empty-to-avoid-conflict-with-guava
+--- com.google.code.findbugs:jsr305:3.0.2
+--- org.checkerframework:checker-qual:3.42.0
\--- com.google.errorprone:error_prone_annotations:2.26.1Notice how the graph is the same for both representations, the only difference it the chosen variant information available in the dot graph.
Next Step: Learn about Variant Selection and Attribute Matching >>
Variant Selection and Attribute Matching
Gradle’s dependency management engine is variant aware.
In the previous section, Gradle built a graph of resolved dependencies. During graph resolution, Gradle selected the proper variants of each dependency based on the requirements of the build.
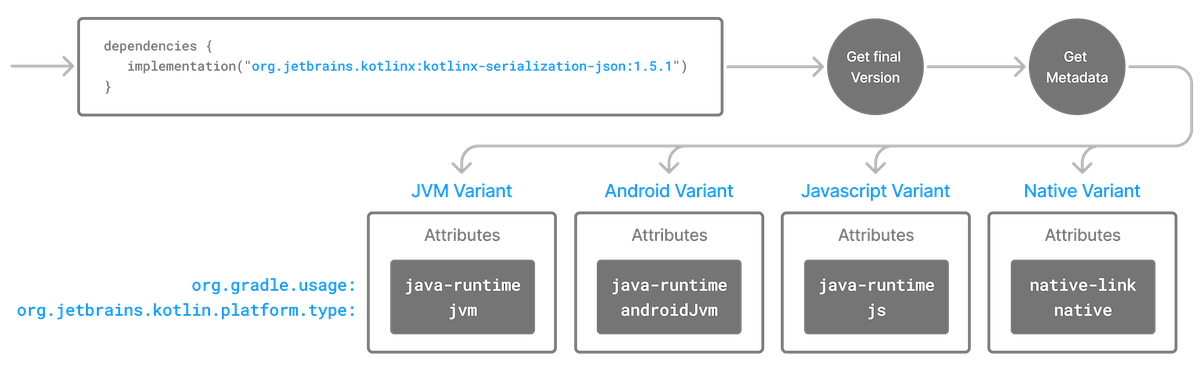
Variants represent different ways a component can be used, such as for Java compilation, native linking, or documentation. Each variant may have its own artifacts and dependencies.
Gradle uses attributes to determine which variant to choose. These attributes add context to each variant, describing when they should be used.
Components
Let’s review our description of components in the previous section. A component:
-
contains variants
-
which contain one or more artifacts
-
which contain zero or more dependencies
-
which is described by metadata
-
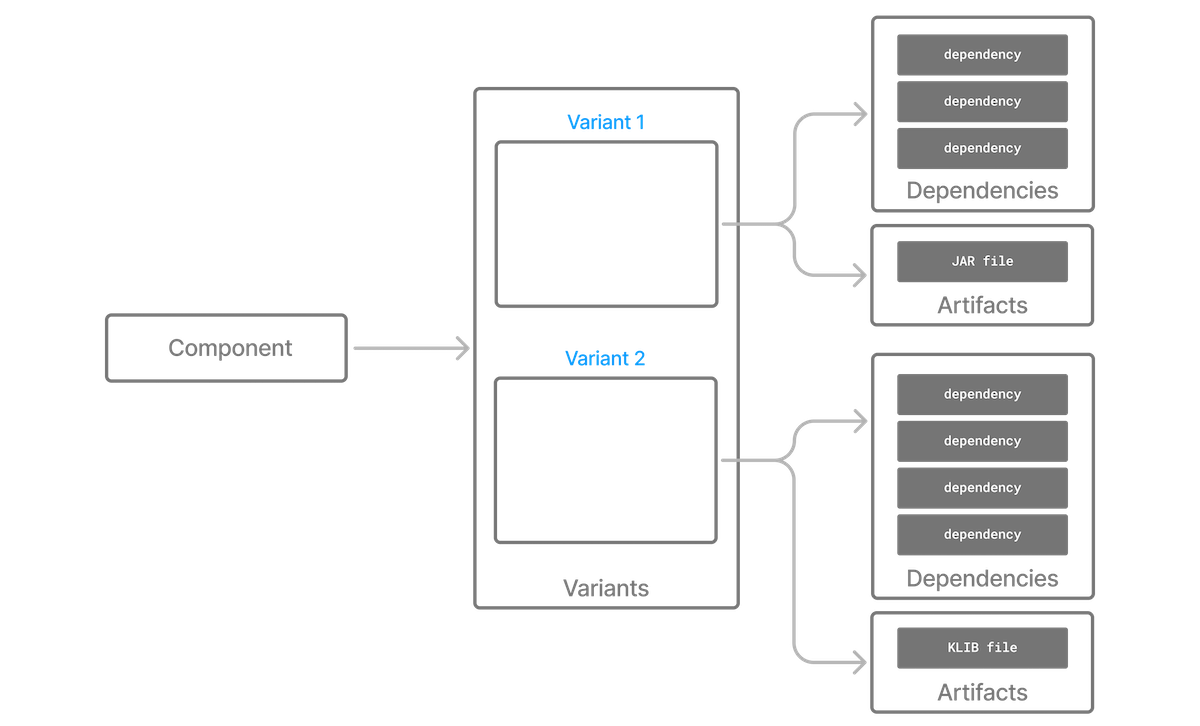
In the example above, org.jetbrains.kotlinx:kotlinx-serialization-json:1.5.1 is the component.
It has a module org.jetbrains.kotlinx:kotlinx-serialization-json and a version 1.5.1:
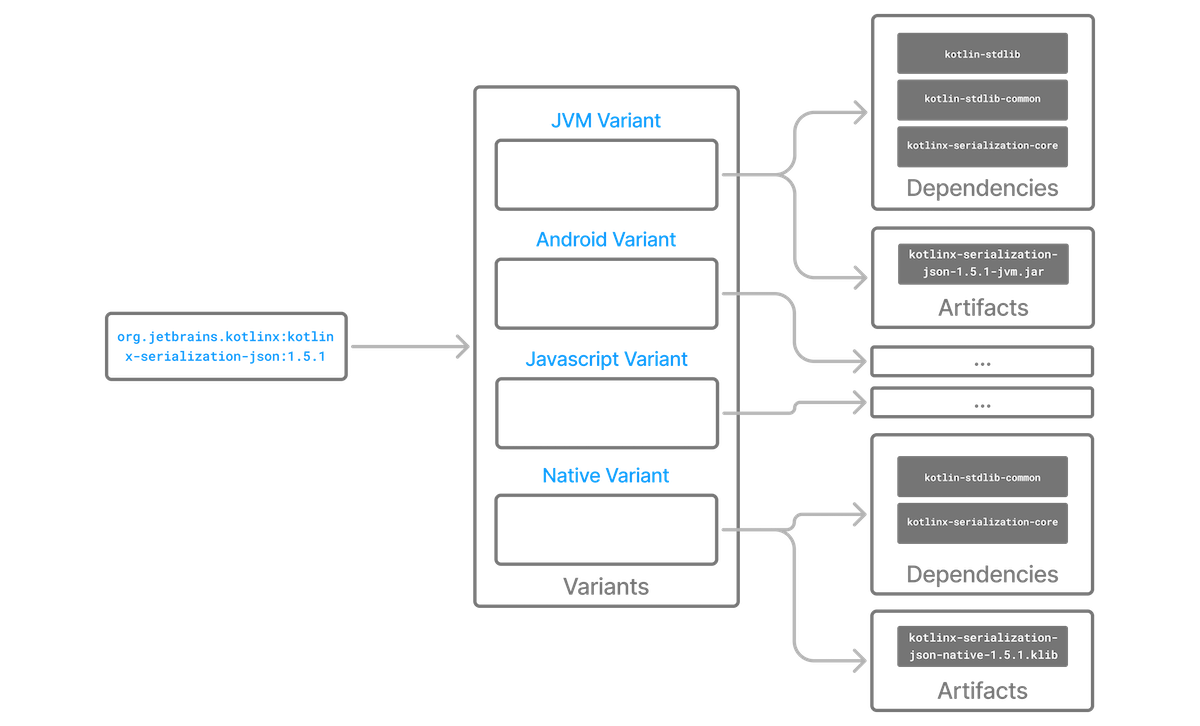
Variants and Attributes
Variants represent different versions or aspects of a component, like api vs implementation or jar vs classes.
In the example above, org.jetbrains.kotlinx:kotlinx-serialization-json:1.5.1 has four variants: jvm, android, js, and native.
Attributes are type-safe key-value pairs used by both the consumer and the producer during variant selection: attribute : value.
|
Important
|
For a variant to be selectable via variant-aware dependency resolution, it must have attributes defined. Variants without attributes cannot participate in variant selection and are only accessible through explicit named configuration selection or legacy resolution mechanisms. |
In the example above, there are two attributes of importance for the variants of org.jetbrains.kotlinx:kotlinx-serialization-json:1.5.1:
| Variant: | Attribute 1: | Attribute 2: |
|---|---|---|
JVM |
|
|
Android |
|
|
Javascript |
|
|
Native |
|
|
Note that the metadata of org.jetbrains.kotlinx:kotlinx-serialization-json:1.5.1 showcases many more attributes to describe its variants such as org.gradle.libraryelements or org.gradle.category.
However, Gradle may use any number of them during dependency resolution as some attributes are more relevant than others:
"variants": [
...
{
"name": "jsLegacyRuntimeElements-published",
"attributes": {
"org.gradle.category": "library",
"org.gradle.usage": "kotlin-runtime",
"org.jetbrains.kotlin.js.compiler": "legacy",
"org.jetbrains.kotlin.platform.type": "js"
}
},
{
"name": "jvmRuntimeElements-published",
"attributes": {
"org.gradle.category": "library",
"org.gradle.libraryelements": "jar",
"org.gradle.usage": "java-runtime",
"org.jetbrains.kotlin.platform.type": "jvm"
}
},
...
]There are two types of attributes Gradle uses to match the available variants to the one required for the build:
-
Consumer attributes: Define the desired characteristics of a variant requested by a resolvable configuration.
-
Producer attributes: Each variant has a set of attributes that describe its purpose.
|
Note
|
Variant-aware dependency resolution requires attributes be present on the producer side. On the consumer side, attributes should also be declared, but may be omitted in certain scenarios. |
Variant Attribute Matching
There are no restrictions on how many variants a component can define.
A typical component will include at least an implementation variant but may also provide additional variants, such as test fixtures, documentation, or source code. Furthermore, a component can offer different variants for the same usage, depending on the consumer. For instance, during compilation, a component may provide different headers for Linux, Windows, and macOS.
Gradle performs variant-aware selection by matching the attributes specified by the consumer with those defined by the producer using an attribute matching algorithm.
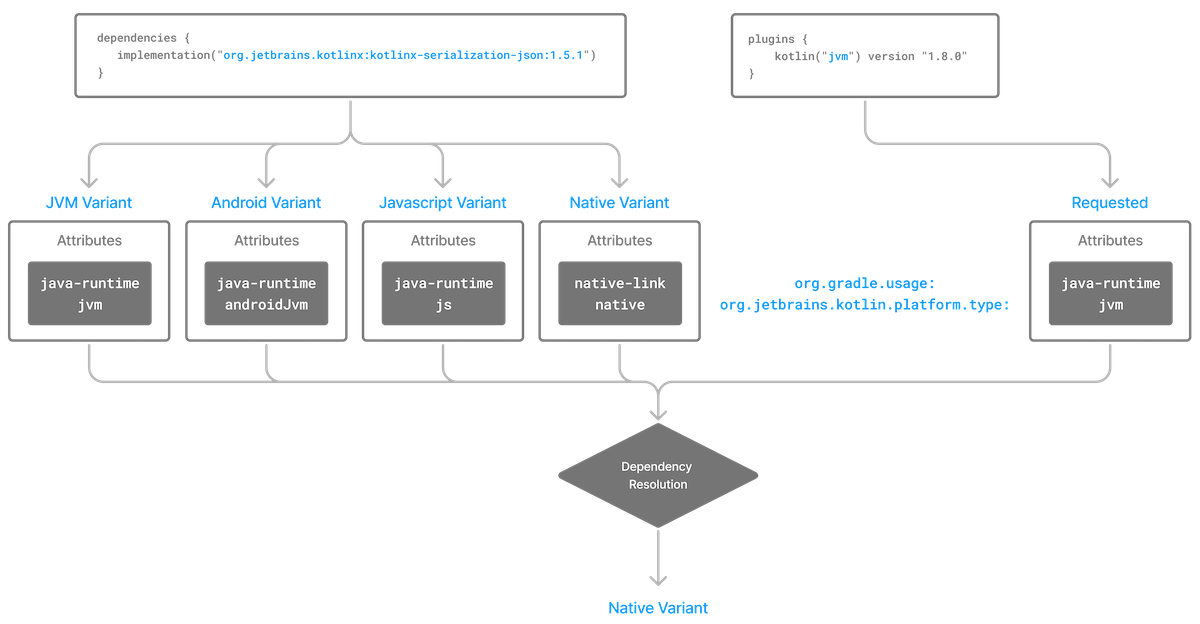
|
Important
|
The variant name is primarily used for debugging and error messages. It does not play a role in variant matching; only the variant’s attributes are used in the matching process. |
Attribute Matching Algorithm
Gradle’s dependency resolution engine follows this attribute matching algorithm to determine the best candidate (or fail if no match is found):
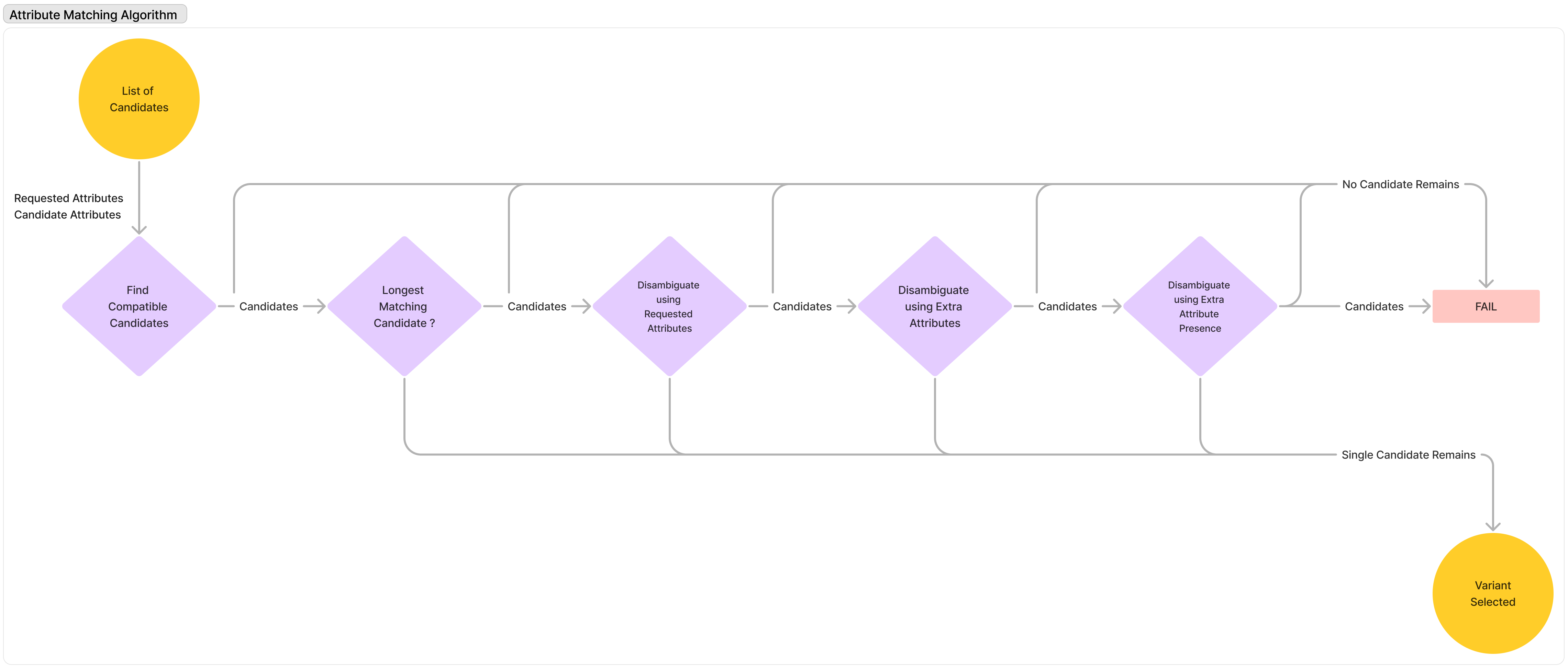
Step 1: Find Compatible Candidates
The requested attributes are matched against the candidate attributes.
-
FOR each candidate:
-
FOR each candidate attribute:
-
IF the candidate attribute is missing, mark the candidate as missing.
-
ELSE IF the candidate attribute exactly matches the requested attribute, the candidate remains compatible.
-
ELSE IF the candidate attribute passes the compatibility test, the candidate remains compatible.
-
ELSE, the candidate is eliminated.
-
-
Step 2: Most Matching Attributes
After filtering, Gradle checks if one candidate is a strict superset of all others.
-
IF only one candidate remains, that candidate wins.
-
IF multiple candidates remain, check if one:
-
Matches more attributes than any other.
-
Has no missing attributes compared to another candidate.
-
-
IF such a strict superset exists, that candidate wins.
Step 3: Disambiguation Using Requested Attributes
If multiple candidates remain, Gradle attempts disambiguation:
-
Requested attributes are sorted by precedence.
-
FOR each requested attribute in precedence order:
-
IF a disambiguation rule exists, apply it.
-
IF a requested attribute has the same value across all remaining candidates, ignore it.
-
-
IF only one candidate remains, that candidate wins.
If multiple candidates still remain, Gradle processes unordered attributes (those not in the precedence list):
-
FOR each requested attribute without precedence order:
-
IF a disambiguation rule exists, apply it.
-
IF a requested attribute has the same value across all remaining candidates, ignore it.
-
-
IF only one candidate remains, that candidate wins.
-
IF no candidates remain, Gradle falls back to the most compatible candidates (step 2).
Step 4: Disambiguation Using Extra Attributes
If multiple candidates still remain, Gradle considers extra attributes:
-
These are attributes that exist only in some candidates.
-
Candidates that lack extra attributes are preferred.
-
The attribute precedence order is considered.
First, Gradle processes prioritized extra attributes:
-
FOR each extra attribute in precedence order:
-
IF some candidates have the attribute and others don’t:
-
Candidates that lack the extra attribute are preferred.
-
Candidates with the extra attribute are eliminated.
-
-
-
IF only one candidate remains, that candidate wins.
-
IF no candidates remain, Gradle falls back to the original compatible candidates (step 1).
Then, Gradle processes unordered extra attributes:
-
FOR each remaining extra attribute without defined precedence:
-
IF the attribute is present in only some candidates:
-
Candidates without the attribute are preferred.
-
Candidates with the extra attribute are eliminated.
-
-
-
IF only one candidate remains, that candidate wins.
-
IF no candidates remain, Gradle falls back to the original compatible candidates (step 1).
Step 5: Disambiguation Using Extra Attribute Presence
If candidates still remain, Gradle eliminates candidates based on requested attributes:
-
FOR each extra attribute:
-
IF all candidates provide the same value, ignore it.
-
ELSE, remove candidates that do provide it.
-
-
IF only one candidate remains, that candidate wins.
Step 6: Failure Condition
Unless otherwise indicated, if at any point no candidates remain, resolution fails.
Additionally, Gradle outputs a list of all compatible candidates from step 1 to help with debugging attribute matching failures.
Plugins and ecosystems can influence the selection algorithm by implementing compatibility rules, disambiguation rules, and defining the precedence of attributes. Attributes with a higher precedence are used to eliminate candidates in order.
For example, in the Java ecosystem, the org.gradle.usage attribute has a higher precedence than org.gradle.libraryelements.
This means that if two candidates were available with compatible values for both org.gradle.usage and org.gradle.libraryelements, Gradle will choose the candidate that passes the disambiguation rule for org.gradle.usage.
|
Note
|
There are two exceptions to the variant-aware resolution process:
|
A Simple Example
Let’s walk through an example where a consumer is trying to use a library for compilation.
First, the consumer details how it’s going to use the result of dependency resolution. This is achieved by setting attributes on the consumer’s resolvable configuration.
In this case, the consumer wants to resolve a variant that matches org.gradle.usage=java-api.
Next, the producer exposes different variants of its component:
-
API variant (named
apiElements) with the attributeorg.gradle.usage=java-api -
Runtime variant (named
runtimeElements) with the attributeorg.gradle.usage=java-runtime
Finally, Gradle evaluates the variants and selects the correct one:
-
The consumer requests a variant with attributes
org.gradle.usage=java-api -
The producer’s
apiElementsvariant matches this request. -
The producer’s
runtimeElementsvariant does not match.
| Consumer Requested Attributes | Producer Available Attributes | Producer Variant | Match? |
|---|---|---|---|
|
|
|
✅ Yes |
|
|
|
❌ No |
As a result, Gradle selects the apiElements variant and provides its artifacts and dependencies to the consumer.
A Complicated Example
In real-world scenarios, both consumers and producers often work with multiple attributes.
For instance, a Java Library project in Gradle will involve several attributes:
| Attribute | Description |
|---|---|
|
Describes how the variant is used. |
|
Describes how the variant handles dependencies (e.g., shadow jar, fat jar, regular jar). |
|
Describes the packaging of the variant (e.g., classes or jar). |
|
Describes the minimal version of Java the variant targets. |
|
Describes the type of JVM the variant targets. |
Let’s consider a scenario where the consumer wants to run tests using a library on Java 8, and the producer supports two versions: Java 8 and Java 11.
Step 1: Consumer specifies the requirements.
The consumer wants to resolve a variant that:
-
Can be used at runtime (
org.gradle.usage=java-runtime). -
Can run on at least Java 8 (
org.gradle.jvm.version=8).
Step 2: Producer exposes multiple variants.
The producer offers variants for both Java 8 and Java 11 for both API and runtime usage:
| Variant Name | Attributes |
|---|---|
|
|
|
|
|
|
|
|
Step 3: Gradle matches the attributes.
Gradle compares the consumer's requested attributes with the producer's variants:
-
The consumer requests a variant with
org.gradle.usage=java-runtimeandorg.gradle.jvm.version=8. -
Both
runtime8Elementsandruntime11Elementsmatch theorg.gradle.usage=java-runtimeattribute. -
The API variants (
apiJava8ElementsandapiJava11Elements) are discarded as they don’t matchorg.gradle.usage=java-runtime. -
The variant
runtime8Elementsis selected because it is compatible with Java 8. -
The variant
runtime11Elementsis incompatible because it requires Java 11.
| Consumer Requested Attributes | Producer Available Attributes | Producer Variant | Match? |
|---|---|---|---|
|
|
|
✅ Selected |
|
|
|
❌ Incompatible |
|
|
|
❌ Discarded |
|
|
|
❌ Discarded |
Gradle selects runtime8Elements and provides its artifacts and dependencies to the consumer.
But what happens if the consumer sets org.gradle.jvm.version=7?
In this case, dependency resolution would fail, with an error explaining there is no suitable variant. Gradle knows the consumer requires a Java 7-compatible library, but the producer's minimum version is 8.
If the consumer requested org.gradle.jvm.version=15, Gradle could choose either the Java 8 or Java 11 variant.
Gradle would then select the highest compatible version—Java 11.
Secondary Variants (Secondary Artifact Sets)
Secondary variants are additional sets of artifacts that a variant can expose, which do not participate in graph resolution. Instead, they are considered only during artifact selection.
A secondary variant:
-
Is an additional artifact set exposed by a configuration.
-
Has its own attributes and artifacts.
-
Is published automatically unless explicitly skipped.
-
May be selected during dependency resolution or by
ArtifactViewif the requested attributes match.
Secondary variants are typically used to expose precomputed transforms of the main artifact like .class files or the resources directory.
|
Warning
|
Secondary variants are sometimes referred to in tooling or logs, but this term is being deprecated in favor of more precise concepts like artifact sets or precomputed transforms. |
The simplest scenario is a typical Java library
plugins {
id("java-library")
}
group = "com.gradle"
version = "1.2.3"plugins {
id("java-library")
}
group = "com.gradle"
version = "1.2.3"The apiElements variant represents the public API of a library and is used during dependency resolution when a consuming project requests java-api usage:
$ ./gradlew outgoingVariants -q> Task :outgoingVariants
--------------------------------------------------
Variant apiElements
--------------------------------------------------
API elements for the 'main' feature.
Capabilities
- com.gradle:some-library:1.2.3 (default capability)
Attributes
- org.gradle.category = library
- org.gradle.dependency.bundling = external
- org.gradle.jvm.version = 17
- org.gradle.libraryelements = jar
- org.gradle.usage = java-api
Artifacts
- build/libs/some-library-1.2.3.jar (artifactType = jar)
Secondary Variants (*)
--------------------------------------------------
Secondary Variant classes
--------------------------------------------------
Directories containing compiled class files for main.
Attributes
- org.gradle.category = library
- org.gradle.dependency.bundling = external
- org.gradle.jvm.version = 17
- org.gradle.libraryelements = classes
- org.gradle.usage = java-api
Artifacts
- build/classes/java/main (artifactType = java-classes-directory)As shown in the output, in addition to its main artifact (some-library-1.2.3.jar), apiElements also exposes a secondary variant named classes, which provides the compiled class files as a java-classes-directory.
The classes secondary variant (which does not contribute dependencies during graph resolution so it does not influence graph resolution) provides Gradle with additional flexibility during artifact selection.
For example, enabling consumers to use unjarred class files for faster access in IDEs or incremental compilation.
Let’s create a secondary variant of our Java library:
// Create a new secondary variant on the existing 'apiElements' configuration.
// This variant will be available during artifact selection (not graph resolution).
configurations.apiElements.get().outgoing.variants.create("apiElementVariant") {
attributes {
// Override the 'Usage' attribute to distinguish this variant from the default 'java-api'.
// This allows consumers requesting 'custom-variant' usage to select this artifact set.
attribute(Usage.USAGE_ATTRIBUTE, objects.named("custom-variant"))
}
}// Create a new secondary variant on the existing 'apiElements' configuration.
// This variant will be available during artifact selection (not graph resolution).
configurations.apiElements.outgoing.variants.create("customApiElement") {
attributes {
attribute(Usage.USAGE_ATTRIBUTE, objects.named(Usage, "custom-variant"))
}
}And we can see our new secondary variant is created for apiElements:
$ ./gradlew outgoingVariants -q> Task :outgoingVariants
--------------------------------------------------
Variant apiElements
--------------------------------------------------
API elements for the 'main' feature.
Capabilities
- com.gradle:some-library:1.2.3 (default capability)
Attributes
- org.gradle.category = library
- org.gradle.dependency.bundling = external
- org.gradle.jvm.version = 17
- org.gradle.libraryelements = jar
- org.gradle.usage = java-api
Artifacts
- build/libs/some-library-1.2.3.jar (artifactType = jar)
Secondary Variants (*)
--------------------------------------------------
Secondary Variant apiElementVariant
--------------------------------------------------
Attributes
- org.gradle.category = library
- org.gradle.dependency.bundling = external
- org.gradle.jvm.version = 17
- org.gradle.libraryelements = jar
- org.gradle.usage = custom-variant
--------------------------------------------------
Secondary Variant classes
--------------------------------------------------
Directories containing compiled class files for main.
Attributes
- org.gradle.category = library
- org.gradle.dependency.bundling = external
- org.gradle.jvm.version = 17
- org.gradle.libraryelements = classes
- org.gradle.usage = java-api
Artifacts
- build/classes/java/main (artifactType = java-classes-directory)To create a completely new variant for our library, we must also create a new configuration.
The code below defines a custom consumable configuration fooFiles with two secondary variants, fooFilesVariant1 and fooFilesVariant2, each distinguished by a unique combination of custom attributes.
The base configuration sets FooAttribute = main, which is inherited by fooFilesVariant1, while fooFilesVariant2 overrides it to secondary.
// Define custom attributes for variant identification
val fooAttribute = Attribute.of("com.example.foo", String::class.java)
val fooVariantAttribute = Attribute.of("com.example.fooVariant", String::class.java)
// Create a consumable configuration named 'fooFiles'
// This configuration serves as the container for outgoing variants
val fooFiles = configurations.create("fooFiles") {
isCanBeDeclared = false
isCanBeResolved = false
isCanBeConsumed = true
attributes {
// Base attribute for the configuration
attribute(fooAttribute, "main")
}
}
// Define the first variant of 'fooFiles'
// This variant inherits all attributes from the parent configuration and adds a distinguishing attribute to identify the variant
fooFiles.outgoing.variants.create("fooFilesVariant1") {
attributes {
attribute(fooVariantAttribute, "variant1")
}
}
// Define a second variant of 'fooFiles'
// This one overrides the inherited 'fooAttribute' value and sets a different 'fooVariantAttribute' value
fooFiles.outgoing.variants.create("fooFilesVariant2") {
attributes {
attribute(fooAttribute, "secondary") // Overrides inherited attribute
attribute(fooVariantAttribute, "variant2")
}
}// Define custom attributes for variant identification
def fooAttribute = Attribute.of("com.example.foo", String)
def fooVariantAttribute = Attribute.of("com.example.fooVariant", String)
// Create a consumable configuration named 'fooFiles'
// This configuration serves as the container for outgoing variants
def fooFiles = configurations.create("fooFiles") {
canBeDeclared = false
canBeResolved = false
canBeConsumed = true
attributes {
attribute(fooAttribute, "main")
}
}
// Define the first variant of 'fooFiles'
// This variant inherits all attributes from the parent configuration and adds a distinguishing attribute
fooFiles.outgoing.variants.create("fooFilesVariant1") {
attributes {
attribute(fooVariantAttribute, "variant1")
}
}
// Define a second variant of 'fooFiles'
// This one overrides the inherited 'fooAttribute' value and sets a different 'fooVariantAttribute' value
fooFiles.outgoing.variants.create("fooFilesVariant2") {
attributes {
attribute(fooAttribute, "secondary") // Overrides inherited attribute
attribute(fooVariantAttribute, "variant2")
}
}The output reflects this structure, showing fooFiles as the primary variant and both secondary variants with their corresponding FooAttribute and FooVariantAttribute values, which Gradle uses during artifact selection to match a consumer’s requested attributes:
$ ./gradlew outgoingVariants -q> Task :outgoingVariants
--------------------------------------------------
Variant fooFiles
--------------------------------------------------
Capabilities
- com.gradle:some-library:1.2.3 (default capability)
Attributes
- FooAttribute = main
Secondary Variants (*)
--------------------------------------------------
Secondary Variant fooFilesVariant1
--------------------------------------------------
Attributes
- FooAttribute = main
- FooVariantAttribute = variant1
--------------------------------------------------
Secondary Variant fooFilesVariant2
--------------------------------------------------
Attributes
- FooAttribute = secondary
- FooVariantAttribute = variant2Visualizing Variant Information
Gradle offers built-in tasks to visualize the variant selection process and display the producer and consumer attributes involved.
Outgoing variants report
The report task outgoingVariants shows the list of variants available for selection by consumers of the project.
It displays the capabilities, attributes and artifacts for each variant.
This task is similar to the dependencyInsight reporting task.
By default, outgoingVariants prints information about variants with attributes that can be selected during variant-aware dependency resolution.
It offers the optional parameter --variant <variantName> to select a single variant to display.
It also accepts the --all flag to include information about legacy and deprecated configurations, as well as variants without attributes, or --no-all to exclude this information.
|
Note
|
Configurations without attributes are marked with (n) in the report and cannot be selected during variant-aware dependency resolution.
|
Here is the output of the outgoingVariants task on a freshly generated java-library project:
> Task :outgoingVariants
--------------------------------------------------
Variant apiElements
--------------------------------------------------
API elements for the 'main' feature.
Capabilities
- new-java-library:lib:unspecified (default capability)
Attributes
- org.gradle.category = library
- org.gradle.dependency.bundling = external
- org.gradle.jvm.version = 11
- org.gradle.libraryelements = jar
- org.gradle.usage = java-api
Artifacts
- build/libs/lib.jar (artifactType = jar)
Secondary Variants (*)
--------------------------------------------------
Secondary Variant classes
--------------------------------------------------
Description = Directories containing compiled class files for main.
Attributes
- org.gradle.category = library
- org.gradle.dependency.bundling = external
- org.gradle.jvm.version = 11
- org.gradle.libraryelements = classes
- org.gradle.usage = java-api
Artifacts
- build/classes/java/main (artifactType = java-classes-directory)
--------------------------------------------------
Variant mainSourceElements (i)
--------------------------------------------------
Description = List of source directories contained in the Main SourceSet.
Capabilities
- new-java-library:lib:unspecified (default capability)
Attributes
- org.gradle.category = verification
- org.gradle.dependency.bundling = external
- org.gradle.verificationtype = main-sources
Artifacts
- src/main/java (artifactType = directory)
- src/main/resources (artifactType = directory)
--------------------------------------------------
Variant runtimeElements
--------------------------------------------------
Runtime elements for the 'main' feature.
Capabilities
- new-java-library:lib:unspecified (default capability)
Attributes
- org.gradle.category = library
- org.gradle.dependency.bundling = external
- org.gradle.jvm.version = 11
- org.gradle.libraryelements = jar
- org.gradle.usage = java-runtime
Artifacts
- build/libs/lib.jar (artifactType = jar)
Secondary Variants (*)
--------------------------------------------------
Secondary Variant classes
--------------------------------------------------
Description = Directories containing compiled class files for main.
Attributes
- org.gradle.category = library
- org.gradle.dependency.bundling = external
- org.gradle.jvm.version = 11
- org.gradle.libraryelements = classes
- org.gradle.usage = java-runtime
Artifacts
- build/classes/java/main (artifactType = java-classes-directory)
--------------------------------------------------
Secondary Variant resources
--------------------------------------------------
Description = Directories containing the project's assembled resource files for use at runtime.
Attributes
- org.gradle.category = library
- org.gradle.dependency.bundling = external
- org.gradle.jvm.version = 11
- org.gradle.libraryelements = resources
- org.gradle.usage = java-runtime
Artifacts
- build/resources/main (artifactType = java-resources-directory)From this you can see the two main variants that are exposed by a java library, apiElements and runtimeElements.
Notice that the main difference is on the org.gradle.usage attribute, with values java-api and java-runtime.
As they indicate, this is where the difference is made between what needs to be on the compile classpath of consumers, versus what’s needed on the runtime classpath.
It also shows secondary variants.
For example, the secondary variant classes from apiElements is what allows Gradle to skip the JAR creation when compiling against a java-library project.
Information about invalid consumable configurations
A project cannot have multiple configurations with the same attributes and capabilities. In that case, the project will fail to build.
In order to be able to visualize such issues, the outgoing variant reports handle those errors in a lenient fashion. This allows the report to display information about the issue.
Resolvable configurations report
Gradle also offers a complimentary report task called resolvableConfigurations that displays the resolvable configurations of a project, which are those which can have dependencies added and be resolved.
The report will list their attributes and any configurations that they extend. It will also list a summary of any attributes which will be affected by Compatibility Rules or Disambiguation Rules during resolution.
By default, resolvableConfigurations prints information about all purely resolvable configurations.
These are configurations that are marked resolvable but not marked consumable.
Though some resolvable configurations are also marked consumable, these are legacy configurations that should not have dependencies added in build scripts.
|
Note
|
Configurations without attributes are marked with (n) in the report and should not initiate variant-aware dependency resolution.
|
This report offers:
-
An optional parameter:
-
--configuration <configurationName>→ Selects a single configuration to display.
-
-
Flags for including or excluding legacy and deprecated configurations:
-
--all→ Includes information about legacy and deprecated configurations, and configurations without attributes. -
--no-all→ Excludes this information.
-
-
Flags for controlling transitive extensions in the extended configurations section:
-
--recursive→ Lists configurations that are extended transitively rather than directly. -
--no-recursive→ Excludes this information.
-
Here is the output of the resolvableConfigurations task on a freshly generated java-library project:
> Task :resolvableConfigurations
--------------------------------------------------
Configuration compileClasspath
--------------------------------------------------
Description = Compile classpath for source set 'main'.
Attributes
- org.gradle.category = library
- org.gradle.dependency.bundling = external
- org.gradle.jvm.environment = standard-jvm
- org.gradle.jvm.version = 11
- org.gradle.libraryelements = classes
- org.gradle.usage = java-api
Extended Configurations
- compileOnly
- implementation
--------------------------------------------------
Configuration runtimeClasspath
--------------------------------------------------
Description = Runtime classpath of source set 'main'.
Attributes
- org.gradle.category = library
- org.gradle.dependency.bundling = external
- org.gradle.jvm.environment = standard-jvm
- org.gradle.jvm.version = 11
- org.gradle.libraryelements = jar
- org.gradle.usage = java-runtime
Extended Configurations
- implementation
- runtimeOnly
[...]From this you can see the two main configurations used to resolve dependencies, compileClasspath and runtimeClasspath, as well as their corresponding test configurations (truncated).
Now that we understand variant selection and attribute matching, let’s move on to the artifact resolution phase of dependency resolution. This phase is also variant aware.
Next Step: Learn about Artifact Resolution >>
Artifact Resolution
After constructing a dependency graph, Gradle performs artifact resolution, mapping the resolved graph to a set of artifacts that will be downloaded during the build.
Artifacts
An artifact is a file that is produced or consumed during the build process. Artifacts are typically files such as compiled libraries, JAR files, AAR files, DLLs, or ZIPs.
Let’s look at the metadata for org.jetbrains.kotlin:kotlin-stdlib:1.8.10 which showcases several variants and artifacts:
{
"variants": [
{
"name": "apiElements",
"attributes": {
"org.gradle.category": "library",
"org.gradle.dependency.bundling": "external",
"org.gradle.jvm.version": "8",
"org.gradle.libraryelements": "jar",
"org.gradle.usage": "java-api"
},
"files": [
{
"name": "kotlin-stdlib-1.8.10-public.jar"
},
{
"name": "kotlin-stdlib-1.8.10-private.jar"
}
]
},
{
"name": "runtimeElements",
"attributes": {
"org.gradle.category": "library",
"org.gradle.dependency.bundling": "external",
"org.gradle.jvm.version": "8",
"org.gradle.libraryelements": "jar",
"org.gradle.usage": "java-runtime"
},
"files": [
{
"name": "kotlin-stdlib-1.8.10.jar"
}
]
},
{
"name": "jdk7ApiElements",
"attributes": {
"org.gradle.usage": "java-api",
"org.gradle.jvm.version": "7"
},
"files": [
{
"name": "kotlin-stdlib-jdk7-1.8.10.jar"
}
]
},
{
"name": "jdk8ApiElements",
"attributes": {
"org.gradle.usage": "java-api",
"org.gradle.jvm.version": "8"
},
"files": [
{
"name": "kotlin-stdlib-jdk8-1.8.10.jar"
}
]
}
]
}As we can see there are a number of artifacts available in the metadata:
| Variant | Artifact(s) | Purpose |
|---|---|---|
|
|
Standard Kotlin library APIs (public and private). |
|
|
Standard Kotlin runtime (default). |
|
|
Provides additional APIs for Java 7 compatibility. |
|
|
Provides additional APIs for Java 8 compatibility. |
Typically, once a variant is selected, its associated artifacts can be automatically resolved. However, there are specific reasons why artifact selection still happens after variant selection.
For example, what if the metadata for org.jetbrains.kotlin:kotlin-stdlib:1.8.10 looked like this:
{
"variants": [
{
"name": "runtimeElements",
"attributes": {
"org.gradle.category": "library",
"org.gradle.dependency.bundling": "external",
"org.gradle.jvm.version": "8",
"org.gradle.libraryelements": "jar",
"org.gradle.usage": "java-runtime"
},
"files": [
{
"name": "kotlin-stdlib-1.8.10.jar"
}
]
},
{
"name": "runtimeElements",
"attributes": {
"org.gradle.category": "library",
"org.gradle.dependency.bundling": "external",
"org.gradle.jvm.version": "8",
"org.gradle.libraryelements": "classes",
"org.gradle.usage": "java-runtime"
},
"files": [
{
"name": "build/classes/java/main/"
}
]
},
{
"name": "runtimeElements",
"attributes": {
"org.gradle.category": "library",
"org.gradle.dependency.bundling": "external",
"org.gradle.jvm.version": "8",
"org.gradle.libraryelements": "resources",
"org.gradle.usage": "java-runtime"
},
"files": [
{
"name": "build/resources/main/"
}
]
}
]
}How would Gradle know which file to download?
Artifact Sets
An artifact set is a group of artifacts that belong to a single variant of a module.
A single variant can include multiple artifact sets, each serving a different purpose.
Let’s look at the org.jetbrains.kotlin:kotlin-stdlib:1.8.10 example:
| Variant | Set | Artifacts in the Set |
|---|---|---|
|
1 |
jar → The packaged library JAR ( |
2 |
tar → The packaged library TAR ( |
|
|
1 |
jar → The packaged library JAR ( |
2 |
classes → The compiled .class files ( |
|
3 |
resources → The associated resource files ( |
|
|
1 |
jar → The packaged library JAR ( |
|
1 |
jar → The packaged library JAR ( |
The apiElements variant of org.jetbrains.kotlin:kotlin-stdlib:1.8.10 provides two artifact sets—jar, and tar—each representing the same distributable in a different form.
The runtimeElements variant of org.jetbrains.kotlin:kotlin-stdlib:1.8.10 provides three artifact sets—jar, classes, and resources—each representing the same distributable in a different form.
Gradle must now follow a specific process to determine the most appropriate artifact set for the build.
Artifact Resolution Flow
Artifact selection operates on the dependency graph on a node-by-node basis.
Each node (i.e., variant) in the graph may expose multiple sets of artifacts, but only one of those sets may be selected.
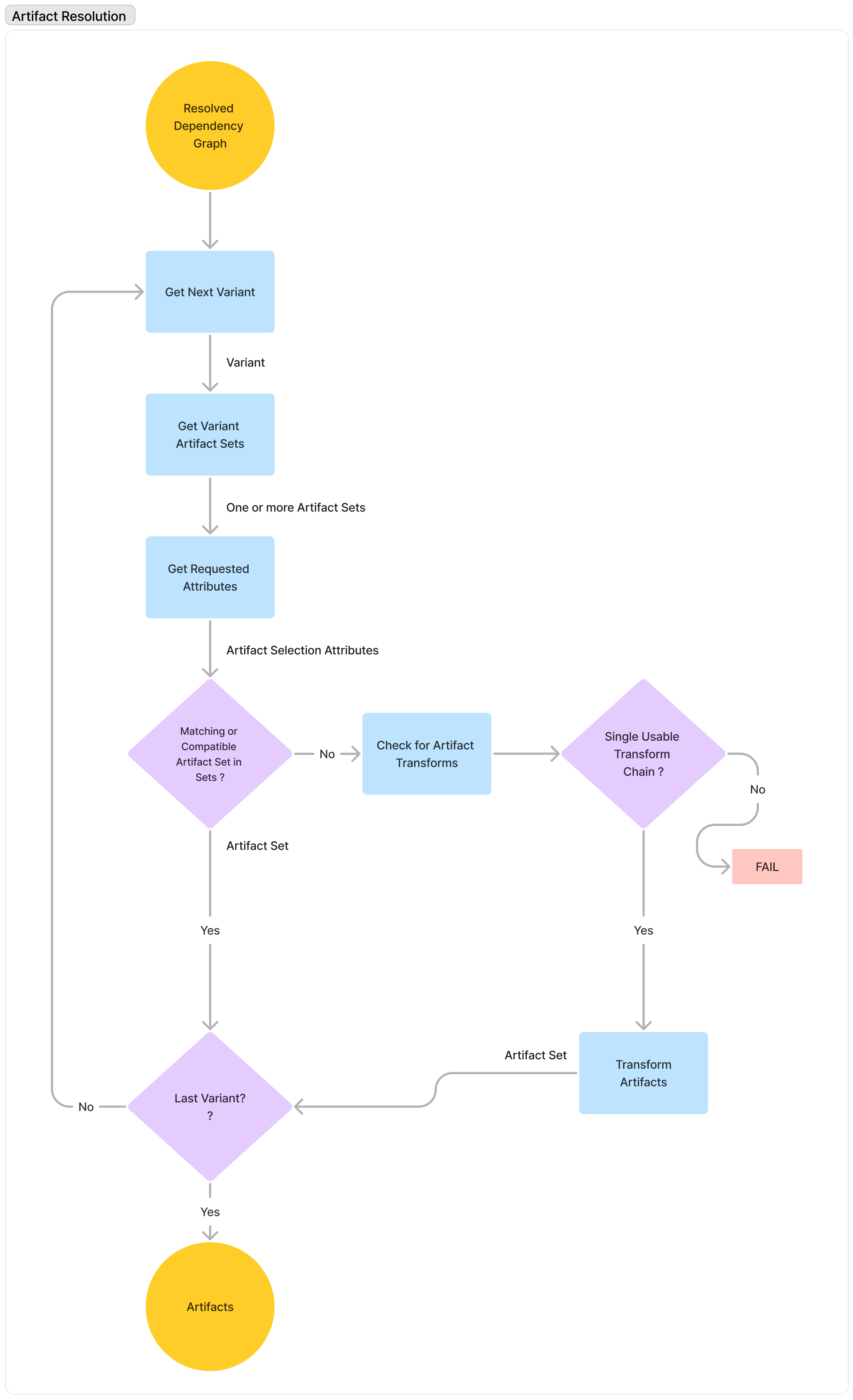
For each node, or variant, in a graph, Gradle performs attribute matching over each set of artifacts exposed by that node to determine the best artifact set.
If no artifact sets match the requested attributes, Gradle will attempt to construct an artifact transform chain to satisfy the request.
For more details on the attribute matching process, see the previous section.
Available APIs
Gradle APIs can be used to influence the process of artifact selection.
Gradle can then expose the results of artifact selection as an ArtifactCollection.
More commonly, the results are exposed as a FileCollection, which is a flat list of files.
Implicit Artifact Selection
By default, the attributes used for artifact selection are the same as those used for variant selection during graph resolution.
These attributes are specified by the Configuration.getAttributes() property.
To perform artifact selection (and implicitly, graph resolution) using these default attributes, use the FileCollection and ArtifactCollection APIs.
|
Note
|
Files can also be accessed from the configuration’s ResolvedConfiguration, LenientConfiguration, ResolvedArtifact and ResolvedDependency APIs.
However, these APIs are in maintenance mode and are discouraged for use in new development.
These APIs perform artifact selection using the default attributes.
|
Resolving files
To resolve files, we first define a task that accepts a ConfigurableFileCollection as input:
abstract class ResolveFiles : DefaultTask() {
@get:InputFiles
abstract val files: ConfigurableFileCollection
@TaskAction
fun print() {
files.forEach {
println(it.name)
}
}
}abstract class ResolveFiles extends DefaultTask {
@InputFiles
abstract ConfigurableFileCollection getFiles()
@TaskAction
void print() {
files.each {
println(it.name)
}
}
}Then, we can wire up a resolvable configuration’s files to the task’s input.
The Configuration directly implements FileCollection and can be wired directly:
tasks.register<ResolveFiles>("resolveConfiguration") {
files.from(configurations.runtimeClasspath)
}tasks.register("resolveConfiguration", ResolveFiles) {
files.from(configurations.runtimeClasspath)
}Running the resolveConfiguration task produces:
> Task :resolveConfiguration
junit-platform-commons-1.11.0.jar
junit-jupiter-api-5.11.0.jar
opentest4j-1.3.0.jarResolving artifacts
Instead of consuming the files directly from the implicit artifact selection process, we can consume the artifacts, which contain both the files and the metadata.
This process is slightly more complicated, as in order to maintain Configuration Cache compatibility, we need to split the fields of ResolvedArtifactResult into two task inputs:
data class ArtifactDetails(
val id: ComponentArtifactIdentifier,
val variant: ResolvedVariantResult
)
abstract class ResolveArtifacts : DefaultTask() {
@get:Input
abstract val details: ListProperty<ArtifactDetails>
@get:InputFiles
abstract val files: ListProperty<File>
fun from(artifacts: Provider<Set<ResolvedArtifactResult>>) {
details.set(artifacts.map {
it.map { artifact -> ArtifactDetails(artifact.id, artifact.variant) }
})
files.set(artifacts.map {
it.map { artifact -> artifact.file }
})
}
@TaskAction
fun print() {
assert(details.get().size == files.get().size)
details.get().zip(files.get()).forEach { (details, file) ->
println("${details.variant.displayName}:${file.name}")
}
}
}class ArtifactDetails {
ComponentArtifactIdentifier id
ResolvedVariantResult variant
ArtifactDetails(ComponentArtifactIdentifier id, ResolvedVariantResult variant) {
this.id = id
this.variant = variant
}
}
abstract class ResolveArtifacts extends DefaultTask {
@Input
abstract ListProperty<ArtifactDetails> getDetails()
@InputFiles
abstract ListProperty<File> getFiles()
void from(Provider<Set<ResolvedArtifactResult>> artifacts) {
details.set(artifacts.map {
it.collect { artifact -> new ArtifactDetails(artifact.id, artifact.variant) }
})
files.set(artifacts.map {
it.collect { artifact -> artifact.file }
})
}
@TaskAction
void print() {
List<ArtifactDetails> allDetails = details.get()
List<File> allFiles = files.get()
assert allDetails.size() == allFiles.size()
for (int i = 0; i < allDetails.size(); i++) {
def details = allDetails.get(i)
def file = allFiles.get(i)
println("${details.variant.displayName}:${file.name}")
}
}
}This task is initialized similarly to the file resolution task:
tasks.register<ResolveArtifacts>("resolveIncomingArtifacts") {
from(configurations.runtimeClasspath.flatMap { it.incoming.artifacts.resolvedArtifacts })
}tasks.register("resolveIncomingArtifacts", ResolveArtifacts) {
from(configurations.runtimeClasspath.incoming.artifacts.resolvedArtifacts)
}Running this task, we can see that file metadata is included in the output:
org.junit.platform:junit-platform-commons:1.11.0 variant runtimeElements:junit-platform-commons-1.11.0.jar
org.junit.jupiter:junit-jupiter-api:5.11.0 variant runtimeElements:junit-jupiter-api-5.11.0.jar
org.opentest4j:opentest4j:1.3.0 variant runtimeElements:opentest4j-1.3.0.jarCustom Artifact Selection
The ArtifactView API operates on top of the resolved graph, defined by a ResolutionResult.
The API provides flexible ways to access the resolved artifacts:
-
FileCollection- A flat list of files, which is the most commonly way to work with resolved artifacts. -
ArtifactCollection- Offers access to both the metadata and the files of resolved artifacts, allowing for more advanced artifact handling.
When you call a configuration’s getFiles(), Gradle selects artifacts based on the attributes used during graph resolution.
However, the ArtifactView API is more flexible.
It allows you to resolve artifacts from the graph with custom attributes.
Artifact views
An ArtifactView allows you to:
-
Query artifacts with different attributes:
-
Suppose the graph resolved a dependency’s
runtimevariant. You can use anArtifactViewto extract artifacts from itsapivariant instead, even if they weren’t originally part of the resolved graph.
-
-
Extract specific types of artifacts:
-
You can request only the
.jarfiles or a specific artifact type (e.g., sources, Javadoc) by specifying an attribute likeartifactType.
-
-
Avoid side effects:
-
Using an
ArtifactViewallows you to extract artifacts without changing the underlying dependency resolution logic or configuration state.
-
In the following example, a producer project creates a library with typical Java library variants (runtimeElements, apiElements).
We also create a custom variant called apiProductionElements with the artifact production.jar and attribute org.gradle.category:production:
plugins {
`java-library`
}
repositories {
mavenCentral()
}
dependencies {
// Define some dependencies here
}
// Define a task that produces a custom artifact
tasks.register<Jar>("createProductionArtifact") {
archiveBaseName.set("production")
from(sourceSets["main"].output)
destinationDirectory.set(file("build/libs"))
}
configurations {
// Define a custom configuration and extend from apiElements
create("apiProductionElements") {
extendsFrom(configurations.apiElements.get())
outgoing.artifacts.clear()
attributes {
attribute(Category.CATEGORY_ATTRIBUTE, objects.named("production"))
}
artifacts {
add("apiProductionElements", tasks.named("createProductionArtifact"))
}
}
}plugins {
id 'java-library'
}
repositories {
mavenCentral()
}
dependencies {
// Define some dependencies here
}
// Define a task that produces a custom artifact
tasks.register('createProductionArtifact', Jar) {
archiveBaseName.set('production')
from(sourceSets.main.output)
destinationDirectory.set(file('build/libs'))
}
configurations {
// Define a custom configuration and extend from apiElements
apiProductionElements {
extendsFrom(configurations.apiElements)
attributes {
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category, 'production'))
}
artifacts {
add('apiProductionElements', tasks.named('createProductionArtifact'))
}
}
}We can view the available variants of this library as well as their corresponding artifacts and attributes with a custom task called checkProducerAttributes.
Here is an abridged output showing the relevant variants of this library, along with their corresponding artifacts and attributes:
Configuration: apiElements
Attributes:
- org.gradle.category -> library
- org.gradle.usage -> java-api
- org.gradle.libraryelements -> jar
- org.gradle.dependency.bundling -> external
Artifacts:
- producer.jar
Configuration: apiProductionElements
Attributes:
- org.gradle.category -> production
Artifacts:
- production.jar
Configuration: mainSourceElements
Attributes:
- org.gradle.dependency.bundling -> external
- org.gradle.category -> verification
- org.gradle.verificationtype -> main-sources
Artifacts:
- /src/main/resources
- /src/main/java
Configuration: runtimeElements
Attributes:
- org.gradle.category -> library
- org.gradle.usage -> java-runtime
- org.gradle.libraryelements -> jar
- org.gradle.dependency.bundling -> external
Artifacts:
- producer.jarA Java application is a consumer of this Java library:
plugins {
application
}
repositories {
mavenCentral()
}
// Declare the dependency on the producer project
dependencies {
implementation(project(":producer")) // This references another subproject in the same build
}plugins {
id 'application'
}
repositories {
mavenCentral()
}
// Declare the dependency on the producer project
dependencies {
implementation project(':producer')
}By default, the application, as the consumer, will consume the expected variant when it is run.
We can verify this with another custom task called checkResolvedVariant that prints out the following:
RuntimeClasspath Configuration:
- Component: project :producer
- Variant: runtimeElements
- org.gradle.category -> library
- org.gradle.usage -> java-runtime
- org.gradle.libraryelements -> jar
- org.gradle.dependency.bundling -> external
- org.gradle.jvm.version -> 11
- Artifact: producer.jarAs expected, for the runtimeClasspath, the application consumes the runtimeElements variant of the library which is available as the artifact producer.jar.
It uses the attributes org.gradle.category:library and org.gradle.usage:java-runtime to select this variant.
Now, let’s create an ArtifactView to select one of the other artifacts provided by the library.
We do this by using an ArtifactView with the attribute org.gradle.category:classes so that instead of the jar file, we get the sources:
tasks.register("artifactWithAttributeAndView") {
val configuration = configurations.runtimeClasspath
println("ArtifactView with attribute 'libraryelements = classes' for ${configuration.name}:")
val artifactView = configuration.get().incoming.artifactView {
attributes {
attribute(LibraryElements.LIBRARY_ELEMENTS_ATTRIBUTE, objects.named(LibraryElements::class, "classes"))
}
}
println("- Attributes:")
artifactView.attributes.keySet().forEach { attribute ->
val value = artifactView.attributes.getAttribute(attribute)
println(" - ${attribute.name} = ${value}")
}
artifactView.artifacts.artifactFiles.files.forEach { file ->
println("- Artifact: ${file.name}")
}
}
tasks.register("artifactWithAttributeAndVariantReselectionView") {
val configuration = configurations.runtimeClasspath
println("ArtifactView with attribute 'category = production' for ${configuration.name}:")
val artifactView = configuration.get().incoming.artifactView {
withVariantReselection()
attributes {
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category::class, "production"))
}
}
println("- Attributes:")
artifactView.attributes.keySet().forEach { attribute ->
val value = artifactView.attributes.getAttribute(attribute)
println(" - ${attribute.name} = ${value}")
}
artifactView.artifacts.artifactFiles.files.forEach { file ->
println("- Artifact: ${file.name}")
}
}tasks.register('artifactWithAttributeAndView') {
def configuration = configurations.runtimeClasspath
println "ArtifactView with attribute 'libraryelements = classes' for ${configuration.name}:"
def artifactView = configuration.incoming.artifactView {
attributes {
attribute(LibraryElements.LIBRARY_ELEMENTS_ATTRIBUTE, objects.named(LibraryElements, 'classes'))
}
}
println "- Attributes:"
artifactView.attributes.keySet().each { attribute ->
def value = artifactView.attributes.getAttribute(attribute)
println " - ${attribute.name} = ${value}"
}
artifactView.artifacts.artifactFiles.files.each { file ->
println "- Artifact: ${file.name}"
}
}
tasks.register('artifactWithAttributeAndVariantReselectionView') {
def configuration = configurations.runtimeClasspath
println "ArtifactView with attribute 'category = production' for ${configuration.name}:"
def artifactView = configuration.incoming.artifactView {
withVariantReselection()
attributes {
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category,'production'))
}
}
println "- Attributes:"
artifactView.attributes.keySet().each { attribute ->
def value = artifactView.attributes.getAttribute(attribute)
println " - ${attribute.name} = ${value}"
}
artifactView.artifacts.artifactFiles.files.each { file ->
println "- Artifact: ${file.name}"
}
}We run the task artifactWithAttributeAndView to see that we get the main artifact instead:
ArtifactView with attribute 'libraryelements = classes' for runtimeClasspath:
- Attributes:
- org.gradle.libraryelements = classes
- org.gradle.category = library
- org.gradle.usage = java-runtime
- org.gradle.dependency.bundling = external
- org.gradle.jvm.environment = standard-jvm
- Artifact: mainNow, let’s create an ArtifactView to select our custom variant apiProductionElements by specifying the attribute org.gradle.category:production and forcing Gradle to reselect a new variant:
tasks.register("artifactWithAttributeAndVariantReselectionView") {
val configuration = configurations.runtimeClasspath
println("ArtifactView with attribute 'category = production' for ${configuration.name}:")
val artifactView = configuration.get().incoming.artifactView {
withVariantReselection()
attributes {
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category::class, "production"))
}
}
println("- Attributes:")
artifactView.attributes.keySet().forEach { attribute ->
val value = artifactView.attributes.getAttribute(attribute)
println(" - ${attribute.name} = ${value}")
}
artifactView.artifacts.artifactFiles.files.forEach { file ->
println("- Artifact: ${file.name}")
}
}tasks.register('artifactWithAttributeAndVariantReselectionView') {
def configuration = configurations.runtimeClasspath
println "ArtifactView with attribute 'category = production' for ${configuration.name}:"
def artifactView = configuration.incoming.artifactView {
withVariantReselection()
attributes {
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category,'production'))
}
}
println "- Attributes:"
artifactView.attributes.keySet().each { attribute ->
def value = artifactView.attributes.getAttribute(attribute)
println " - ${attribute.name} = ${value}"
}
artifactView.artifacts.artifactFiles.files.each { file ->
println "- Artifact: ${file.name}"
}
}As expected, the apiProductionElements variant is selected along with the production.jar artifact:
ArtifactView with attribute 'libraryelements = classes' for runtimeClasspath:
- Attributes:
- org.gradle.libraryelements = classes
- org.gradle.category = library
- org.gradle.usage = java-runtime
- org.gradle.dependency.bundling = external
- org.gradle.jvm.environment = standard-jvm
- Artifact: mainPublishing a project as module
The vast majority of software projects build something that aims to be consumed in some way. It could be a library that other software projects use or it could be an application for end users. Publishing is the process by which the thing being built is made available to consumers.
In Gradle, that process looks like this:
Each of the these steps is dependent on the type of repository to which you want to publish artifacts. The two most common types are Maven-compatible and Ivy-compatible repositories, or Maven and Ivy repositories for short.
As of Gradle 6.0, the Gradle Module Metadata will always be published alongside the Ivy XML or Maven POM metadata file.
Gradle makes it easy to publish to these types of repository by providing some prepackaged infrastructure in the form of the Maven Publish Plugin and the Ivy Publish Plugin. These plugins allow you to configure what to publish and perform the publishing with a minimum of effort.
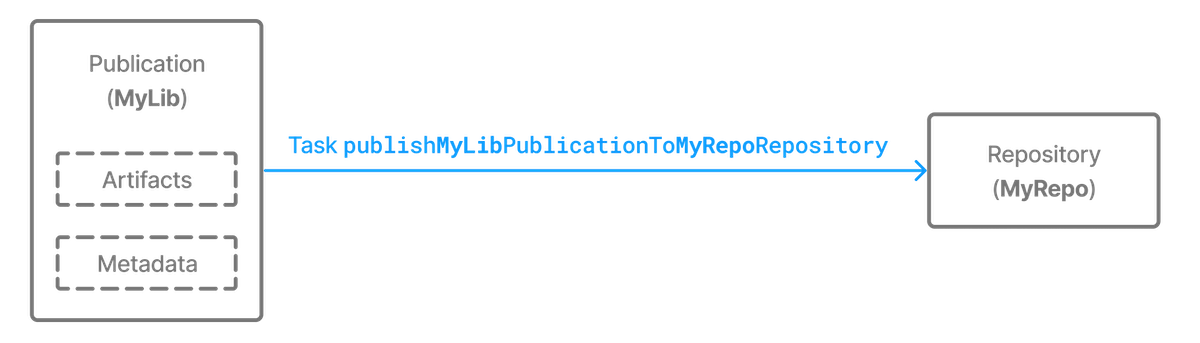
Let’s take a look at those steps in more detail:
- What to publish
-
Gradle needs to know what files and information to publish so that consumers can use your project. This is typically a combination of artifacts and metadata that Gradle calls a publication. Exactly what a publication contains depends on the type of repository it’s being published to.
For example, a publication destined for a Maven repository includes:
-
One or more artifacts — typically built by the project,
-
The Gradle Module Metadata file which will describe the variants of the published component,
-
The Maven POM file will identify the primary artifact and its dependencies. The primary artifact is typically the project’s production JAR and secondary artifacts might consist of "-sources" and "-javadoc" JARs.
In addition, Gradle will publish checksums for all of the above, and signatures when configured to do so. From Gradle 6.0 onwards, this includes
SHA256andSHA512checksums. -
- Where to publish
-
Gradle needs to know where to publish artifacts so that consumers can get hold of them. This is done via repositories, which store and make available all sorts of artifact. Gradle also needs to interact with the repository, which is why you must provide the type of the repository and its location.
- How to publish
-
Gradle automatically generates publishing tasks for all possible combinations of publication and repository, allowing you to publish any artifact to any repository. If you’re publishing to a Maven repository, the tasks are of type PublishToMavenRepository, while for Ivy repositories the tasks are of type PublishToIvyRepository.
What follows is a practical example that demonstrates the entire publishing process.
Setting up basic publishing
The first step in publishing, irrespective of your project type, is to apply the appropriate publishing plugin. As mentioned in the introduction, Gradle supports both Maven and Ivy repositories via the following plugins:
These provide the specific publication and repository classes needed to configure publishing for the corresponding repository type. Since Maven repositories are the most commonly used ones, they will be the basis for this example and for the other samples in the chapter. Don’t worry, we will explain how to adjust individual samples for Ivy repositories.
Let’s assume we’re working with a simple Java library project, so only the following plugins are applied:
plugins {
`java-library`
`maven-publish`
}plugins {
id 'java-library'
id 'maven-publish'
}Once the appropriate plugin has been applied, you can configure the publications and repositories. For this example, we want to publish the project’s production JAR file — the one produced by the jar task — to a custom Maven repository. We do that with the following publishing {} block, which is backed by PublishingExtension:
group = "org.example"
version = "1.0"
publishing {
publications {
create<MavenPublication>("myLibrary") {
from(components["java"])
}
}
repositories {
maven {
name = "myRepo"
url = uri(layout.buildDirectory.dir("repo"))
}
}
}group = 'org.example'
version = '1.0'
publishing {
publications {
myLibrary(MavenPublication) {
from components.java
}
}
repositories {
maven {
name = 'myRepo'
url = layout.buildDirectory.dir("repo")
}
}
}This defines a publication called "myLibrary" that can be published to a Maven repository by virtue of its type: MavenPublication.
This publication consists of just the production JAR artifact and its metadata, which combined are represented by the java component of the project.
|
Note
|
Components are the standard way of defining a publication. They are provided by plugins, usually of the language or platform variety. For example, the Java Plugin defines the components.java SoftwareComponent, while the War Plugin defines components.web.
|
The example also defines a file-based Maven repository with the name "myRepo". Such a file-based repository is convenient for a sample, but real-world builds typically work with HTTPS-based repository servers, such as Maven Central or an internal company server.
|
Note
|
You may define one, and only one, repository without a name. This translates to an implicit name of "Maven" for Maven repositories and "Ivy" for Ivy repositories. All other repository definitions must be given an explicit name. |
In combination with the project’s group and version, the publication and repository definitions provide everything that Gradle needs to publish the project’s production JAR. Gradle will then create a dedicated publishMyLibraryPublicationToMyRepoRepository task that does just that. Its name is based on the template publishPubNamePublicationToRepoNameRepository. See the appropriate publishing plugin’s documentation for more details on the nature of this task and any other tasks that may be available to you.
You can either execute the individual publishing tasks directly, or you can execute publish, which will run all the available publishing tasks. In this example, publish will just run publishMyLibraryPublicationToMavenRepository.
|
Note
|
Basic publishing to an Ivy repository is very similar: you simply use the Ivy Publish Plugin, replace There are differences between the two types of repository, particularly around the extra metadata that each support — for example, Maven repositories require a POM file while Ivy ones have their own metadata format — so see the plugin chapters for comprehensive information on how to configure both publications and repositories for whichever repository type you’re working with. |
That’s everything for the basic use case. However, many projects need more control over what gets published, so we look at several common scenarios in the following sections.
Suppressing validation errors
Gradle performs validation of generated module metadata.
In some cases, validation can fail, indicating that you most likely have an error to fix, but you may have done something intentionally.
If this is the case, Gradle will indicate the name of the validation error you can disable on the GenerateModuleMetadata tasks:
tasks.withType<GenerateModuleMetadata>().configureEach {
// The value 'enforced-platform' is provided in the validation
// error message you got
suppressedValidationErrors.add("enforced-platform")
}tasks.withType(GenerateModuleMetadata).configureEach {
// The value 'enforced-platform' is provided in the validation
// error message you got
suppressedValidationErrors.add('enforced-platform')
}Gradle Module Metadata
Gradle Module Metadata is a format used to serialize the Gradle component model. It is similar to Apache Maven™'s POM file or Apache Ivy™ ivy.xml files. The goal of metadata files is to provide to consumers a reasonable model of what is published on a repository.
Gradle Module Metadata is a unique format aimed at improving dependency resolution by making it multi-platform and variant-aware.
In particular, Gradle Module Metadata supports:
Publication of Gradle Module Metadata will enable better dependency management for your consumers:
-
early discovery of problems by detecting incompatible modules
-
consistent selection of platform-specific dependencies
-
native dependency version alignment
-
automatically getting dependencies for specific features of your library
Gradle Module Metadata is automatically published when using the Maven Publish plugin or the Ivy Publish plugin.
The specification for Gradle Module Metadata can be found here.
Mapping with other formats
Gradle Module Metadata is automatically published on Maven or Ivy repositories. However, it doesn’t replace the pom.xml or ivy.xml files: it is published alongside those files. This is done to maximize compatibility with third-party build tools.
Gradle does its best to map Gradle-specific concepts to Maven or Ivy. When a build file uses features that can only be represented in Gradle Module Metadata, Gradle will warn you at publication time. The table below summarizes how some Gradle specific features are mapped to Maven and Ivy:
| Gradle | Maven | Ivy | Description |
|---|---|---|---|
|
Not published |
Gradle dependency constraints are transitive, while Maven’s dependency management block isn’t |
|
Publishes the requires version |
Published the requires version |
||
Not published |
Not published |
Component capabilities are unique to Gradle |
|
Variant artifacts are uploaded, dependencies are published as optional dependencies |
Variant artifacts are uploaded, dependencies are not published |
Feature variants are a good replacement for optional dependencies |
|
Artifacts are uploaded, dependencies are those described by the mapping |
Artifacts are uploaded, dependencies are ignored |
Custom component types are probably not consumable from Maven or Ivy in any case. They usually exist in the context of a custom ecosystem. |
Disabling metadata compatibility publication warnings
If you want to suppress warnings, you can use the following APIs to do so:
-
For Maven, see the
suppress*methods in MavenPublication -
For Ivy, see the
suppress*methods in IvyPublication
publications {
register<MavenPublication>("maven") {
from(components["java"])
suppressPomMetadataWarningsFor("runtimeElements")
}
}publications {
maven(MavenPublication) {
from components.java
suppressPomMetadataWarningsFor('runtimeElements')
}
}Interactions with other build tools
Because Gradle Module Metadata is not widely spread and because it aims at maximizing compatibility with other tools, Gradle does a couple of things:
-
Gradle Module Metadata is systematically published alongside the normal descriptor for a given repository (Maven or Ivy)
-
the
pom.xmlorivy.xmlfile will contain a marker comment which tells Gradle that Gradle Module Metadata exists for this module
The goal of the marker is not for other tools to parse module metadata: it’s for Gradle users only. It explains to Gradle that a better module metadata file exists and that it should use it instead. It doesn’t mean that consumption from Maven or Ivy would be broken either, only that it works in degraded mode.
|
Note
|
This must be seen as a performance optimization: instead of having to do 2 network requests, one to get Gradle Module Metadata, then one to get the POM/Ivy file in case of a miss, Gradle will first look at the file which is most likely to be present, then only perform a 2nd request if the module was actually published with Gradle Module Metadata. |
If you know that the modules you depend on are always published with Gradle Module Metadata, you can optimize the network calls by configuring the metadata sources for a repository:
repositories {
maven {
url = uri("http://repo.mycompany.com/repo")
metadataSources {
gradleMetadata()
}
}
}repositories {
maven {
url = "http://repo.mycompany.com/repo"
metadataSources {
gradleMetadata()
}
}
}Gradle Module Metadata validation
Gradle Module Metadata is validated before being published.
The following rules are enforced:
-
Variant names must be unique,
-
Each variant must have at least one attribute,
-
Two variants cannot have the exact same attributes and capabilities,
-
If there are dependencies, at least one, across all variants, must carry version information.
These rules ensure the quality of the metadata produced, and help confirm that consumption will not be problematic.
Gradle Module Metadata reproducibility
The task generating the module metadata files is currently never marked UP-TO-DATE by Gradle due to the way it is implemented.
However, if neither build inputs nor build scripts changed, the task result is effectively up-to-date: it always produces the same output.
If users desire to have a unique module file per build invocation, it is possible to link an identifier in the produced metadata to the build that created it.
Users can choose to enable this unique identifier in their publication:
publishing {
publications {
create<MavenPublication>("myLibrary") {
from(components["java"])
withBuildIdentifier()
}
}
}publishing {
publications {
myLibrary(MavenPublication) {
from components.java
withBuildIdentifier()
}
}
}With the changes above, the generated Gradle Module Metadata file will always be different, forcing downstream tasks to consider it out-of-date.
Disabling Gradle Module Metadata publication
There are situations where you might want to disable publication of Gradle Module Metadata:
-
the repository you are uploading to rejects the metadata file (unknown format)
-
you are using Maven or Ivy specific concepts which are not properly mapped to Gradle Module Metadata
In this case, disabling the publication of Gradle Module Metadata is done simply by disabling the task which generates the metadata file:
tasks.withType<GenerateModuleMetadata> {
enabled = false
}tasks.withType(GenerateModuleMetadata) {
enabled = false
}Signing artifacts
The Signing Plugin can be used to sign all artifacts and metadata files that make up a publication, including Maven POM files and Ivy module descriptors. In order to use it:
-
Apply the Signing Plugin
-
Configure the signatory credentials — follow the link to see how
-
Specify the publications you want signed
Here’s an example that configures the plugin to sign the mavenJava publication:
signing {
sign(publishing.publications["mavenJava"])
}signing {
sign publishing.publications.mavenJava
}This will create a Sign task for each publication you specify and wire all publishPubNamePublicationToRepoNameRepository tasks to depend on it. Thus, publishing any publication will automatically create and publish the signatures for its artifacts and metadata, as you can see from this output:
Example: Sign and publish a project
$ ./gradlew publish> Task :compileJava
> Task :processResources
> Task :classes
> Task :jar
> Task :javadoc
> Task :javadocJar
> Task :sourcesJar
> Task :generateMetadataFileForMavenJavaPublication
> Task :generatePomFileForMavenJavaPublication
> Task :signMavenJavaPublication
> Task :publishMavenJavaPublicationToMavenRepository
> Task :publish
BUILD SUCCESSFUL in 0s
10 actionable tasks: 10 executedCustomizing publishing
Modifying and adding variants to existing components for publishing
Gradle’s publication model is based on the notion of components, which are defined by plugins.
For example, the Java Library plugin defines a java component which corresponds to a library, but the Java Platform plugin defines another kind of component, named javaPlatform, which is effectively a different kind of software component (a platform).
Sometimes we want to add more variants to or modify existing variants of an existing component.
For example, if you added a variant of a Java library for a different platform, you may just want to declare this additional variant on the java component itself.
In general, declaring additional variants is often the best solution to publish additional artifacts.
To perform such additions or modifications, the AdhocComponentWithVariants interface declares two methods called addVariantsFromConfiguration and withVariantsFromConfiguration which accept two parameters:
-
the outgoing configuration that is used as a variant source
-
a customization action which allows you to filter which variants are going to be published
To utilise these methods, you must make sure that the SoftwareComponent you work with is itself an AdhocComponentWithVariants, which is the case for the components created by the Java plugins (Java, Java Library, Java Platform).
Adding a variant is then very simple:
val javaComponent = components.findByName("java") as AdhocComponentWithVariants
javaComponent.addVariantsFromConfiguration(outgoing) {
// dependencies for this variant are considered runtime dependencies
mapToMavenScope("runtime")
// and also optional dependencies, because we don't want them to leak
mapToOptional()
}AdhocComponentWithVariants javaComponent = (AdhocComponentWithVariants) project.components.findByName("java")
javaComponent.addVariantsFromConfiguration(outgoing) {
// dependencies for this variant are considered runtime dependencies
it.mapToMavenScope("runtime")
// and also optional dependencies, because we don't want them to leak
it.mapToOptional()
}In other cases, you might want to modify a variant that was added by one of the Java plugins already.
For example, if you activate publishing of Javadoc and sources, these become additional variants of the java component.
If you only want to publish one of them, e.g. only Javadoc but no sources, you can modify the sources variant to not being published:
java {
withJavadocJar()
withSourcesJar()
}
val javaComponent = components["java"] as AdhocComponentWithVariants
javaComponent.withVariantsFromConfiguration(configurations["sourcesElements"]) {
skip()
}
publishing {
publications {
create<MavenPublication>("mavenJava") {
from(components["java"])
}
}
}java {
withJavadocJar()
withSourcesJar()
}
components.java.withVariantsFromConfiguration(configurations.sourcesElements) {
skip()
}
publishing {
publications {
mavenJava(MavenPublication) {
from components.java
}
}
}Creating and publishing custom components
In the previous example, we have demonstrated how to extend or modify an existing component, like the components provided by the Java plugins. But Gradle also allows you to build a custom component (not a Java Library, not a Java Platform, not something supported natively by Gradle).
Declaring what a custom component publishes is also done via the AdhocComponentWithVariants API. For a custom component, the first step is to create custom outgoing variants, following the instructions in this chapter. At this stage, what you should have is variants which can be used in cross-project dependencies, but that we are now going to publish to external repositories.
// create an adhoc component
val softwareComponentFactory = extensions.getByType(PublishingExtension::class.java).softwareComponentFactory
val adhocComponent = softwareComponentFactory.adhoc("myAdhocComponent")
// add it to the list of components that this project declares
components.add(adhocComponent)
// and register a variant for publication
adhocComponent.addVariantsFromConfiguration(outgoing) {
mapToMavenScope("runtime")
}// create an adhoc component
def softwareComponentFactory = project.extensions.getByType(PublishingExtension).softwareComponentFactory
def adhocComponent = softwareComponentFactory.adhoc("myAdhocComponent")
// add it to the list of components that this project declares
project.components.add(adhocComponent)
// and register a variant for publication
adhocComponent.addVariantsFromConfiguration(outgoing) {
it.mapToMavenScope("runtime")
}First we use the factory to create a new adhoc component.
Then we add a variant through the addVariantsFromConfiguration method, which is described in more detail in the previous section.
In simple cases, there’s a one-to-one mapping between a Configuration and a variant, in which case you can publish all variants issued from a single Configuration because they are effectively the same thing.
However, there are cases where a Configuration is associated with additional configuration publications that we also call secondary variants.
Such configurations make sense in a multi-project build, but not when publishing externally.
This is for example the case when between projects you share a directory of files, but there’s no way you can publish a directory directly on a Maven repository (only packaged things like jars or zips).
Look at the ConfigurationVariantDetails class for details about how to skip publication of a particular variant.
If addVariantsFromConfiguration has already been called for a configuration, further modification of the resulting variants can be performed using withVariantsFromConfiguration.
When publishing an adhoc component like this:
-
Gradle Module Metadata will exactly represent the published variants. In particular, all outgoing variants will inherit dependencies, artifacts and attributes of the published configuration.
-
Maven and Ivy metadata files will be generated, but you need to declare how the dependencies are mapped to Maven scopes via the ConfigurationVariantDetails class.
In practice, it means that components created this way can be consumed by Gradle the same way as if they were "local components".
Adding custom artifacts to a publication
Instead of thinking in terms of artifacts, you should embrace the variant aware model of Gradle. It is expected that a single module may need multiple artifacts. However this rarely stops there, if the additional artifacts represent an optional feature, they might also have different dependencies and more.
Gradle, via Gradle Module Metadata, supports the publication of additional variants which make those artifacts known to the dependency resolution engine. Please refer to the variant-aware sharing section of the documentation to see how to declare such variants and check out how to publish custom components.
If you attach extra artifacts to a publication directly, they are published "out of context". That means, they are not referenced in the metadata at all and can then only be addressed directly through a classifier on a dependency. In contrast to Gradle Module Metadata, Maven pom metadata will not contain information on additional artifacts regardless of whether they are added through a variant or directly, as variants cannot be represented in the pom format.
The following section describes how you publish artifacts directly if you are sure that metadata, for example Gradle or POM metadata, is irrelevant for your use case. For example, if your project doesn’t need to be consumed by other projects and the only thing required as result of the publishing are the artifacts themselves.
In general, there are two options:
-
Create a publication only with artifacts
-
Add artifacts to a publication based on a component with metadata (not recommended, instead adjust a component or use a adhoc component publication which will both also produce metadata fitting your artifacts)
To create a publication based on artifacts, start by defining a custom artifact and attaching it to a Gradle configuration of your choice.
The following sample defines an RPM artifact that is produced by an rpm task (not shown) and attaches that artifact to the conf configuration:
configurations {
create("conf")
}
val rpmFile = layout.buildDirectory.file("rpms/my-package.rpm")
val rpmArtifact = artifacts.add("conf", rpmFile.get().asFile) {
type = "rpm"
builtBy("rpm")
}configurations {
conf
}
def rpmFile = layout.buildDirectory.file('rpms/my-package.rpm')
def rpmArtifact = artifacts.add('conf', rpmFile.get().asFile) {
type = 'rpm'
builtBy 'rpm'
}The artifacts.add() method — from ArtifactHandler — returns an artifact object of type PublishArtifact that can then be used in defining a publication, as shown in the following sample:
publishing {
publications {
create<MavenPublication>("maven") {
artifact(rpmArtifact)
}
}
}publishing {
publications {
maven(MavenPublication) {
artifact rpmArtifact
}
}
}-
The
artifact()method accepts publish artifacts as argument — likerpmArtifactin the sample — as well as any type of argument accepted by Project.file(java.lang.Object), such as aFileinstance, a string file path or a archive task. -
Publishing plugins support different artifact configuration properties, so always check the plugin documentation for more details. The
classifierandextensionproperties are supported by both the Maven Publish Plugin and the Ivy Publish Plugin. -
Custom artifacts need to be distinct within a publication, typically via a unique combination of
classifierandextension. See the documentation for the plugin you’re using for the precise requirements. -
If you use
artifact()with an archive task, Gradle automatically populates the artifact’s metadata with theclassifierandextensionproperties from that task.
Now you can publish the RPM.
If you really want to add an artifact to a publication based on a component, instead of adjusting the component itself, you can combine the from components.someComponent and artifact someArtifact notations.
Restricting publications to specific repositories
When you have defined multiple publications or repositories, you often want to control which publications are published to which repositories. For instance, consider the following sample that defines two publications — one that consists of just a binary and another that contains the binary and associated sources — and two repositories — one for internal use and one for external consumers:
publishing {
publications {
create<MavenPublication>("binary") {
from(components["java"])
}
create<MavenPublication>("binaryAndSources") {
from(components["java"])
artifact(tasks["sourcesJar"])
}
}
repositories {
// change URLs to point to your repos, e.g. http://my.org/repo
maven {
name = "external"
url = uri(layout.buildDirectory.dir("repos/external"))
}
maven {
name = "internal"
url = uri(layout.buildDirectory.dir("repos/internal"))
}
}
}publishing {
publications {
binary(MavenPublication) {
from components.java
}
binaryAndSources(MavenPublication) {
from components.java
artifact sourcesJar
}
}
repositories {
// change URLs to point to your repos, e.g. http://my.org/repo
maven {
name = 'external'
url = layout.buildDirectory.dir('repos/external')
}
maven {
name = 'internal'
url = layout.buildDirectory.dir('repos/internal')
}
}
}The publishing plugins will create tasks that allow you to publish either of the publications to either repository. They also attach those tasks to the publish aggregate task. But let’s say you want to restrict the binary-only publication to the external repository and the binary-with-sources publication to the internal one. To do that, you need to make the publishing conditional.
Gradle allows you to skip any task you want based on a condition via the Task.onlyIf(String, org.gradle.api.specs.Spec) method. The following sample demonstrates how to implement the constraints we just mentioned:
tasks.withType<PublishToMavenRepository>().configureEach {
val predicate = provider {
(repository == publishing.repositories["external"] &&
publication == publishing.publications["binary"]) ||
(repository == publishing.repositories["internal"] &&
publication == publishing.publications["binaryAndSources"])
}
onlyIf("publishing binary to the external repository, or binary and sources to the internal one") {
predicate.get()
}
}
tasks.withType<PublishToMavenLocal>().configureEach {
val predicate = provider {
publication == publishing.publications["binaryAndSources"]
}
onlyIf("publishing binary and sources") {
predicate.get()
}
}tasks.withType(PublishToMavenRepository) {
def predicate = provider {
(repository == publishing.repositories.external &&
publication == publishing.publications.binary) ||
(repository == publishing.repositories.internal &&
publication == publishing.publications.binaryAndSources)
}
onlyIf("publishing binary to the external repository, or binary and sources to the internal one") {
predicate.get()
}
}
tasks.withType(PublishToMavenLocal) {
def predicate = provider {
publication == publishing.publications.binaryAndSources
}
onlyIf("publishing binary and sources") {
predicate.get()
}
}$ ./gradlew publish> Task :compileJava
> Task :processResources
> Task :classes
> Task :jar
> Task :generateMetadataFileForBinaryAndSourcesPublication
> Task :generatePomFileForBinaryAndSourcesPublication
> Task :sourcesJar
> Task :publishBinaryAndSourcesPublicationToExternalRepository SKIPPED
> Task :publishBinaryAndSourcesPublicationToInternalRepository
> Task :generateMetadataFileForBinaryPublication
> Task :generatePomFileForBinaryPublication
> Task :publishBinaryPublicationToExternalRepository
> Task :publishBinaryPublicationToInternalRepository SKIPPED
> Task :publish
BUILD SUCCESSFUL in 0s
10 actionable tasks: 10 executedYou may also want to define your own aggregate tasks to help with your workflow. For example, imagine that you have several publications that should be published to the external repository. It could be very useful to publish all of them in one go without publishing the internal ones.
The following sample demonstrates how you can do this by defining an aggregate task — publishToExternalRepository — that depends on all the relevant publish tasks:
tasks.register("publishToExternalRepository") {
group = "publishing"
description = "Publishes all Maven publications to the external Maven repository."
dependsOn(tasks.withType<PublishToMavenRepository>().matching {
it.repository == publishing.repositories["external"]
})
}tasks.register('publishToExternalRepository') {
group = 'publishing'
description = 'Publishes all Maven publications to the external Maven repository.'
dependsOn tasks.withType(PublishToMavenRepository).matching {
it.repository == publishing.repositories.external
}
}This particular sample automatically handles the introduction or removal of the relevant publishing tasks by using TaskCollection.withType(java.lang.Class) with the PublishToMavenRepository task type. You can do the same with PublishToIvyRepository if you’re publishing to Ivy-compatible repositories.
Configuring publishing tasks
The publishing plugins create their non-aggregate tasks after the project has been evaluated, which means you cannot directly reference them from your build script. If you would like to configure any of these tasks, you should use deferred task configuration. This can be done in a number of ways via the project’s tasks collection.
For example, imagine you want to change where the generatePomFileForPubNamePublication tasks write their POM files. You can do this by using the TaskCollection.withType(java.lang.Class) method, as demonstrated by this sample:
tasks.withType<GenerateMavenPom>().configureEach {
val matcher = Regex("""generatePomFileFor(\w+)Publication""").matchEntire(name)
val publicationName = matcher?.let { it.groupValues[1] }
destination = layout.buildDirectory.file("poms/${publicationName}-pom.xml").get().asFile
}tasks.withType(GenerateMavenPom).all {
def matcher = name =~ /generatePomFileFor(\w+)Publication/
def publicationName = matcher[0][1]
destination = layout.buildDirectory.file("poms/${publicationName}-pom.xml").get().asFile
}The above sample uses a regular expression to extract the name of the publication from the name of the task. This is so that there is no conflict between the file paths of all the POM files that might be generated. If you only have one publication, then you don’t have to worry about such conflicts since there will only be one POM file.
The Maven Publish Plugin
The Maven Publish Plugin provides the ability to publish build artifacts to an Apache Maven repository. A module published to a Maven repository can be consumed by Maven, Gradle (see Declaring Dependencies) and other tools that understand the Maven repository format. You can learn about the fundamentals of publishing in Publishing Overview.
Usage
To use the Maven Publish Plugin, include the following in your build script:
plugins {
`maven-publish`
}plugins {
id 'maven-publish'
}The Maven Publish Plugin uses an extension on the project named publishing of type PublishingExtension. This extension provides a container of named publications and a container of named repositories. The Maven Publish Plugin works with MavenPublication publications and MavenArtifactRepository repositories.
Tasks
generatePomFileForPubNamePublication— GenerateMavenPom-
Creates a POM file for the publication named PubName, populating the known metadata such as project name, project version, and the dependencies. The default location for the POM file is build/publications/$pubName/pom-default.xml.
publishPubNamePublicationToRepoNameRepository— PublishToMavenRepository-
Publishes the PubName publication to the repository named RepoName. If you have a repository definition without an explicit name, RepoName will be "Maven".
publishPubNamePublicationToMavenLocal— PublishToMavenLocal-
Copies the PubName publication to the local Maven cache — typically <home directory of the current user>/.m2/repository — along with the publication’s POM file and other metadata.
publish-
Depends on: All
publishPubNamePublicationToRepoNameRepositorytasksAn aggregate task that publishes all defined publications to all defined repositories. It does not include copying publications to the local Maven cache.
publishToMavenLocal-
Depends on: All
publishPubNamePublicationToMavenLocaltasksCopies all defined publications to the local Maven cache, including their metadata (POM files, etc.).
Publications
This plugin provides publications of type MavenPublication. To learn how to define and use publications, see the section on basic publishing.
There are four main things you can configure in a Maven publication:
-
A component — via MavenPublication.from(org.gradle.api.component.SoftwareComponent).
-
Custom artifacts — via the MavenPublication.artifact(java.lang.Object) method. See MavenArtifact for the available configuration options for custom Maven artifacts.
-
Standard metadata like
artifactId,groupIdandversion. -
Other contents of the POM file — via MavenPublication.pom(org.gradle.api.Action).
You can see all of these in action in the complete publishing example. The API documentation for MavenPublication has additional code samples.
Identity values in the generated POM
The attributes of the generated POM file will contain identity values derived from the following project properties:
-
groupId- Project.getGroup() -
artifactId- Project.getName() -
version- Project.getVersion()
Overriding the default identity values is easy: simply specify the groupId, artifactId or version attributes when configuring the MavenPublication.
publishing {
publications {
create<MavenPublication>("maven") {
groupId = "org.gradle.sample"
artifactId = "library"
version = "1.1"
from(components["java"])
}
}
}publishing {
publications {
maven(MavenPublication) {
groupId = 'org.gradle.sample'
artifactId = 'library'
version = '1.1'
from components.java
}
}
}|
Tip
|
Certain repositories will not be able to handle all supported characters. For example, the : character cannot be used as an identifier when publishing to a filesystem-backed repository on Windows.
|
Maven restricts groupId and artifactId to a limited character set ([A-Za-z0-9_\\-.]+) and Gradle enforces this restriction. For version (as well as the artifact extension and classifier properties), Gradle will handle any valid Unicode character.
The only Unicode values that are explicitly prohibited are \, / and any ISO control character. Supplied values are validated early in publication.
Customizing the generated POM
The generated POM file can be customized before publishing. For example, when publishing a library to Maven Central you will need to set certain metadata. The Maven Publish Plugin provides a DSL for that purpose. Please see MavenPom in the DSL Reference for the complete documentation of available properties and methods. The following sample shows how to use the most common ones:
publishing {
publications {
create<MavenPublication>("mavenJava") {
pom {
name = "My Library"
description = "A concise description of my library"
url = "http://www.example.com/library"
properties = mapOf(
"myProp" to "value",
"prop.with.dots" to "anotherValue"
)
licenses {
license {
name = "The Apache License, Version 2.0"
url = "http://www.apache.org/licenses/LICENSE-2.0.txt"
}
}
developers {
developer {
id = "johnd"
name = "John Doe"
email = "john.doe@example.com"
}
}
scm {
connection = "scm:git:git://example.com/my-library.git"
developerConnection = "scm:git:ssh://example.com/my-library.git"
url = "http://example.com/my-library/"
}
}
}
}
}publishing {
publications {
mavenJava(MavenPublication) {
pom {
name = 'My Library'
description = 'A concise description of my library'
url = 'http://www.example.com/library'
properties = [
myProp: "value",
"prop.with.dots": "anotherValue"
]
licenses {
license {
name = 'The Apache License, Version 2.0'
url = 'http://www.apache.org/licenses/LICENSE-2.0.txt'
}
}
developers {
developer {
id = 'johnd'
name = 'John Doe'
email = 'john.doe@example.com'
}
}
scm {
connection = 'scm:git:git://example.com/my-library.git'
developerConnection = 'scm:git:ssh://example.com/my-library.git'
url = 'http://example.com/my-library/'
}
}
}
}
}Customizing dependencies versions
Two strategies are supported for publishing dependencies:
- Declared versions (default)
-
This strategy publishes the versions that are defined by the build script author with the dependency declarations in the
dependenciesblock. Any other kind of processing, for example through a rule changing the resolved version, will not be taken into account for the publication. - Resolved versions
-
This strategy publishes the versions that were resolved during the build, possibly by applying resolution rules and automatic conflict resolution. This has the advantage that the published versions correspond to the ones the published artifact was tested against.
Example use cases for resolved versions:
-
A project uses dynamic versions for dependencies but prefers exposing the resolved version for a given release to its consumers.
-
In combination with dependency locking, you want to publish the locked versions.
-
A project leverages the rich versions constraints of Gradle, which have a lossy conversion to Maven. Instead of relying on the conversion, it publishes the resolved versions.
This is done by using the versionMapping DSL method which allows to configure the VersionMappingStrategy:
publishing {
publications {
create<MavenPublication>("mavenJava") {
versionMapping {
usage("java-api") {
fromResolutionOf("runtimeClasspath")
}
usage("java-runtime") {
fromResolutionResult()
}
}
}
}
}publishing {
publications {
mavenJava(MavenPublication) {
versionMapping {
usage('java-api') {
fromResolutionOf('runtimeClasspath')
}
usage('java-runtime') {
fromResolutionResult()
}
}
}
}
}In the example above, Gradle will use the versions resolved on the runtimeClasspath for dependencies declared in api, which are mapped to the compile scope of Maven.
Gradle will also use the versions resolved on the runtimeClasspath for dependencies declared in implementation, which are mapped to the runtime scope of Maven.
fromResolutionResult() indicates that Gradle should use the default classpath of a variant and runtimeClasspath is the default classpath of java-runtime.
Repositories
This plugin provides repositories of type MavenArtifactRepository. To learn how to define and use repositories for publishing, see the section on basic publishing.
Here’s a simple example of defining a publishing repository:
publishing {
repositories {
maven {
// change to point to your repo, e.g. http://my.org/repo
url = uri(layout.buildDirectory.dir("repo"))
}
}
}publishing {
repositories {
maven {
// change to point to your repo, e.g. http://my.org/repo
url = layout.buildDirectory.dir('repo')
}
}
}The two main things you will want to configure are the repository’s:
-
URL (required)
-
Name (optional)
You can define multiple repositories as long as they have unique names within the build script. You may also declare one (and only one) repository without a name. That repository will take on an implicit name of "Maven".
You can also configure any authentication details that are required to connect to the repository. See MavenArtifactRepository for more details.
Supported Repositories
Gradle’s maven-publish plugin is compatible with the Maven Deploy Plugin and supports publishing to any repository that adheres to the same standards and protocols.
This includes a wide range of Maven-compatible repositories, such as:
-
Local repositories (e.g.
~/.m2/repository) -
Custom remote Maven repositories
-
Repository managers like Sonatype Nexus and JFrog Artifactory
-
GitHub Packages
-
Internal corporate Maven repositories
Publishing to Maven Central
The service commonly known as Maven Central and hosted at central.sonatype.com is a widely used repository for distributing Java and Kotlin libraries.
As of June 30, 2025, Maven Central no longer supports the legacy deployment protocol used by the Maven Deploy Plugin. This change also marks the deprecation of the OSSRH (OSS Repository Hosting) service.
Going forward, publishing to Maven Central requires a dedicated plugin. Several options are available. For guidance and recommendations, see the Publishing to Maven Central page in the Gradle Cookbook.
Snapshot and release repositories
It is a common practice to publish snapshots and releases to different Maven repositories. A simple way to accomplish this is to configure the repository URL based on the project version. The following sample uses one URL for versions that end with "SNAPSHOT" and a different URL for the rest:
publishing {
repositories {
maven {
val releasesRepoUrl = layout.buildDirectory.dir("repos/releases")
val snapshotsRepoUrl = layout.buildDirectory.dir("repos/snapshots")
url = uri(if (version.toString().endsWith("SNAPSHOT")) snapshotsRepoUrl else releasesRepoUrl)
}
}
}publishing {
repositories {
maven {
def releasesRepoUrl = layout.buildDirectory.dir('repos/releases')
def snapshotsRepoUrl = layout.buildDirectory.dir('repos/snapshots')
url = version.endsWith('SNAPSHOT') ? snapshotsRepoUrl : releasesRepoUrl
}
}
}Similarly, you can use a project or system property to decide which repository to publish to. The following example uses the release repository if the project property release is set, such as when a user runs gradle -Prelease publish:
publishing {
repositories {
maven {
val releasesRepoUrl = layout.buildDirectory.dir("repos/releases")
val snapshotsRepoUrl = layout.buildDirectory.dir("repos/snapshots")
url = uri(if (project.hasProperty("release")) releasesRepoUrl else snapshotsRepoUrl)
}
}
}publishing {
repositories {
maven {
def releasesRepoUrl = layout.buildDirectory.dir('repos/releases')
def snapshotsRepoUrl = layout.buildDirectory.dir('repos/snapshots')
url = project.hasProperty('release') ? releasesRepoUrl : snapshotsRepoUrl
}
}
}Publishing to Maven Local
For integration with a local Maven installation, it is sometimes useful to publish the module into the Maven local repository (typically at <home directory of the current user>/.m2/repository), along with its POM file and other metadata. In Maven parlance, this is referred to as 'installing' the module.
The Maven Publish Plugin makes this easy to do by automatically creating a PublishToMavenLocal task for each MavenPublication in the publishing.publications container. The task name follows the pattern of publishPubNamePublicationToMavenLocal. Each of these tasks is wired into the publishToMavenLocal aggregate task. You do not need to have mavenLocal() in your publishing.repositories section.
Publishing Maven relocation information
When a project changes the groupId or artifactId (the coordinates) of an artifact it publishes, it is important to let users know where the new artifact can be found. Maven can help with that through the relocation feature. The way this works is that a project publishes an additional artifact under the old coordinates consisting only of a minimal relocation POM; that POM file specifies where the new artifact can be found. Maven repository browsers and build tools can then inform the user that the coordinates of an artifact have changed.
For this, a project adds an additional MavenPublication specifying a MavenPomRelocation:
publishing {
publications {
// ... artifact publications
// Specify relocation POM
create<MavenPublication>("relocation") {
pom {
// Old artifact coordinates
groupId = "com.example"
artifactId = "lib"
version = "2.0.0"
distributionManagement {
relocation {
// New artifact coordinates
groupId = "com.new-example"
artifactId = "lib"
version = "2.0.0"
message = "groupId has been changed"
}
}
}
}
}
}publishing {
publications {
// ... artifact publications
// Specify relocation POM
relocation(MavenPublication) {
pom {
// Old artifact coordinates
groupId = "com.example"
artifactId = "lib"
version = "2.0.0"
distributionManagement {
relocation {
// New artifact coordinates
groupId = "com.new-example"
artifactId = "lib"
version = "2.0.0"
message = "groupId has been changed"
}
}
}
}
}
}Only the property which has changed needs to be specified under relocation, that is artifactId and / or groupId. All other properties are optional.
|
Tip
|
Specifying the A custom |
The relocation POM should be created for what would be the next version of the old artifact. For example when the artifact coordinates of com.example:lib:1.0.0 are changed and the artifact with the new coordinates continues version numbering and is published as com.new-example:lib:2.0.0, then the relocation POM should specify a relocation from com.example:lib:2.0.0 to com.new-example:lib:2.0.0.
A relocation POM only has to be published once, the build file configuration for it should be removed again once it has been published.
Note that a relocation POM is not suitable for all situations; when an artifact has been split into two or more separate artifacts then a relocation POM might not be helpful.
Retroactively publishing relocation information
It is possible to publish relocation information retroactively after the coordinates of an artifact have changed in the past, and no relocation information was published back then.
The same recommendations as described above apply. To ease migration for users, it is important to pay attention to the version specified in the relocation POM. The relocation POM should allow the user to move to the new artifact in one step, and then allow them to update to the latest version in a separate step. For example when for the coordinates of com.new-example:lib:5.0.0 were changed in version 2.0.0, then ideally the relocation POM should be published for the old coordinates com.example:lib:2.0.0 relocating to com.new-example:lib:2.0.0. The user can then switch from com.example:lib to com.new-example and then separately update from version 2.0.0 to 5.0.0, handling breaking changes (if any) step by step.
When relocation information is published retroactively, it is not necessary to wait for next regular release of the project, it can be published in the meantime. As mentioned above, the relocation information should then be removed again from the build file once the relocation POM has been published.
Avoiding duplicate dependencies
When only the coordinates of the artifact have changed, but package names of the classes inside the artifact have remained the same, dependency conflicts can occur. A project might (transitively) depend on the old artifact but at the same time also have a dependency on the new artifact which both contain the same classes, potentially with incompatible changes.
To detect such conflicting duplicate dependencies, capabilities can be published as part of the Gradle Module Metadata. For an example using a Java Library project, see declaring additional capabilities for a local component.
Performing a dry run
To verify that relocation information works as expected before publishing it to a remote repository, it can first be published to the local Maven repository. Then a local test Gradle or Maven project can be created which has the relocation artifact as dependency.
Complete example
The following example demonstrates how to sign and publish a Java library including sources, Javadoc, and a customized POM:
plugins {
`java-library`
`maven-publish`
signing
}
group = "com.example"
version = "1.0"
java {
withJavadocJar()
withSourcesJar()
}
publishing {
publications {
create<MavenPublication>("mavenJava") {
artifactId = "my-library"
from(components["java"])
versionMapping {
usage("java-api") {
fromResolutionOf("runtimeClasspath")
}
usage("java-runtime") {
fromResolutionResult()
}
}
pom {
name = "My Library"
description = "A concise description of my library"
url = "http://www.example.com/library"
properties = mapOf(
"myProp" to "value",
"prop.with.dots" to "anotherValue"
)
licenses {
license {
name = "The Apache License, Version 2.0"
url = "http://www.apache.org/licenses/LICENSE-2.0.txt"
}
}
developers {
developer {
id = "johnd"
name = "John Doe"
email = "john.doe@example.com"
}
}
scm {
connection = "scm:git:git://example.com/my-library.git"
developerConnection = "scm:git:ssh://example.com/my-library.git"
url = "http://example.com/my-library/"
}
}
}
}
repositories {
maven {
// change URLs to point to your repos, e.g. http://my.org/repo
val releasesRepoUrl = uri(layout.buildDirectory.dir("repos/releases"))
val snapshotsRepoUrl = uri(layout.buildDirectory.dir("repos/snapshots"))
url = if (version.toString().endsWith("SNAPSHOT")) snapshotsRepoUrl else releasesRepoUrl
}
}
}
signing {
sign(publishing.publications["mavenJava"])
}
tasks.javadoc {
if (JavaVersion.current().isJava9Compatible) {
(options as StandardJavadocDocletOptions).addBooleanOption("html5", true)
}
}plugins {
id 'java-library'
id 'maven-publish'
id 'signing'
}
group = 'com.example'
version = '1.0'
java {
withJavadocJar()
withSourcesJar()
}
publishing {
publications {
mavenJava(MavenPublication) {
artifactId = 'my-library'
from components.java
versionMapping {
usage('java-api') {
fromResolutionOf('runtimeClasspath')
}
usage('java-runtime') {
fromResolutionResult()
}
}
pom {
name = 'My Library'
description = 'A concise description of my library'
url = 'http://www.example.com/library'
properties = [
myProp: "value",
"prop.with.dots": "anotherValue"
]
licenses {
license {
name = 'The Apache License, Version 2.0'
url = 'http://www.apache.org/licenses/LICENSE-2.0.txt'
}
}
developers {
developer {
id = 'johnd'
name = 'John Doe'
email = 'john.doe@example.com'
}
}
scm {
connection = 'scm:git:git://example.com/my-library.git'
developerConnection = 'scm:git:ssh://example.com/my-library.git'
url = 'http://example.com/my-library/'
}
}
}
}
repositories {
maven {
// change URLs to point to your repos, e.g. http://my.org/repo
def releasesRepoUrl = layout.buildDirectory.dir('repos/releases')
def snapshotsRepoUrl = layout.buildDirectory.dir('repos/snapshots')
url = version.endsWith('SNAPSHOT') ? snapshotsRepoUrl : releasesRepoUrl
}
}
}
signing {
sign publishing.publications.mavenJava
}
javadoc {
if(JavaVersion.current().isJava9Compatible()) {
options.addBooleanOption('html5', true)
}
}The result is that the following artifacts will be published:
-
The POM:
my-library-1.0.pom -
The primary JAR artifact for the Java component:
my-library-1.0.jar -
The sources JAR artifact that has been explicitly configured:
my-library-1.0-sources.jar -
The Javadoc JAR artifact that has been explicitly configured:
my-library-1.0-javadoc.jar
The Signing Plugin is used to generate a signature file for each artifact. In addition, checksum files will be generated for all artifacts and signature files.
|
Tip
|
publishToMavenLocal` does not create checksum files in $USER_HOME/.m2/repository.
If you want to verify that the checksum files are created correctly, or use them for later publishing, consider configuring a custom Maven repository with a file:// URL and using that as the publishing target instead.
|
Removal of deferred configuration behavior
Prior to Gradle 5.0, the publishing {} block was (by default) implicitly treated as if all the logic inside it was executed after the project is evaluated.
This behavior caused quite a bit of confusion and was deprecated in Gradle 4.8, because it was the only block that behaved that way.
You may have some logic inside your publishing block or in a plugin that is depending on the deferred configuration behavior. For instance, the following logic assumes that the subprojects will be evaluated when the artifactId is set:
subprojects {
publishing {
publications {
create<MavenPublication>("mavenJava") {
from(components["java"])
artifactId = tasks.jar.get().archiveBaseName.get()
}
}
}
}subprojects {
publishing {
publications {
mavenJava(MavenPublication) {
from components.java
artifactId = jar.archiveBaseName
}
}
}
}This kind of logic must now be wrapped in an afterEvaluate {} block.
subprojects {
publishing {
publications {
create<MavenPublication>("mavenJava") {
from(components["java"])
afterEvaluate {
artifactId = tasks.jar.get().archiveBaseName.get()
}
}
}
}
}subprojects {
publishing {
publications {
mavenJava(MavenPublication) {
from components.java
afterEvaluate {
artifactId = jar.archiveBaseName
}
}
}
}
}The Ivy Publish Plugin
The Ivy Publish Plugin provides the ability to publish build artifacts in the Apache Ivy format, usually to a repository for consumption by other builds or projects. What is published is one or more artifacts created by the build, and an Ivy module descriptor (normally ivy.xml) that describes the artifacts and the dependencies of the artifacts, if any.
A published Ivy module can be consumed by Gradle (see Declaring Dependencies) and other tools that understand the Ivy format. You can learn about the fundamentals of publishing in Publishing Overview.
Usage
To use the Ivy Publish Plugin, include the following in your build script:
plugins {
`ivy-publish`
}plugins {
id 'ivy-publish'
}The Ivy Publish Plugin uses an extension on the project named publishing of type PublishingExtension. This extension provides a container of named publications and a container of named repositories. The Ivy Publish Plugin works with IvyPublication publications and IvyArtifactRepository repositories.
Tasks
generateDescriptorFileForPubNamePublication— GenerateIvyDescriptor-
Creates an Ivy descriptor file for the publication named PubName, populating the known metadata such as project name, project version, and the dependencies. The default location for the descriptor file is build/publications/$pubName/ivy.xml.
publishPubNamePublicationToRepoNameRepository— PublishToIvyRepository-
Publishes the PubName publication to the repository named RepoName. If you have a repository definition without an explicit name, RepoName will be "Ivy".
publish-
Depends on: All
publishPubNamePublicationToRepoNameRepositorytasksAn aggregate task that publishes all defined publications to all defined repositories.
Publications
This plugin provides publications of type IvyPublication. To learn how to define and use publications, see the section on basic publishing.
There are four main things you can configure in an Ivy publication:
-
A component — via IvyPublication.from(org.gradle.api.component.SoftwareComponent).
-
Custom artifacts — via the IvyPublication.artifact(java.lang.Object) method. See IvyArtifact for the available configuration options for custom Ivy artifacts.
-
Standard metadata like
module,organisationandrevision. -
Other contents of the module descriptor — via IvyPublication.descriptor(org.gradle.api.Action).
You can see all of these in action in the complete publishing example. The API documentation for IvyPublication has additional code samples.
Identity values for the published project
The generated Ivy module descriptor file contains an <info> element that identifies the module. The default identity values are derived from the following:
-
organisation- Project.getGroup() -
module- Project.getName() -
revision- Project.getVersion() -
status- Project.getStatus() -
branch- (not set)
Overriding the default identity values is easy: simply specify the organisation, module or revision properties when configuring the IvyPublication. status and branch can be set via the descriptor property — see IvyModuleDescriptorSpec.
The descriptor property can also be used to add additional custom elements as children of the <info> element, like so:
publishing {
publications {
create<IvyPublication>("ivy") {
organisation = "org.gradle.sample"
module = "project1-sample"
revision = "1.1"
descriptor.status = "milestone"
descriptor.branch = "testing"
descriptor.extraInfo("http://my.namespace", "myElement", "Some value")
from(components["java"])
}
}
}publishing {
publications {
ivy(IvyPublication) {
organisation = 'org.gradle.sample'
module = 'project1-sample'
revision = '1.1'
descriptor.status = 'milestone'
descriptor.branch = 'testing'
descriptor.extraInfo 'http://my.namespace', 'myElement', 'Some value'
from components.java
}
}
}|
Tip
|
Certain repositories are not able to handle all supported characters. For example, the : character cannot be used as an identifier when publishing to a filesystem-backed repository on Windows.
|
Gradle will handle any valid Unicode character for organisation, module and revision (as well as the artifact’s name, extension and classifier). The only values that are explicitly prohibited are \, / and any ISO control character. The supplied values are validated early during publication.
Customizing the generated module descriptor
At times, the module descriptor file generated from the project information will need to be tweaked before publishing. The Ivy Publish Plugin provides a DSL for that purpose. Please see IvyModuleDescriptorSpec in the DSL Reference for the complete documentation of available properties and methods.
The following sample shows how to use the most common aspects of the DSL:
publications {
create<IvyPublication>("ivyCustom") {
descriptor {
license {
name = "The Apache License, Version 2.0"
url = "http://www.apache.org/licenses/LICENSE-2.0.txt"
}
author {
name = "Jane Doe"
url = "http://example.com/users/jane"
}
description {
text = "A concise description of my library"
homepage = "http://www.example.com/library"
}
}
versionMapping {
usage("java-api") {
fromResolutionOf("runtimeClasspath")
}
usage("java-runtime") {
fromResolutionResult()
}
}
}
}publications {
ivyCustom(IvyPublication) {
descriptor {
license {
name = 'The Apache License, Version 2.0'
url = 'http://www.apache.org/licenses/LICENSE-2.0.txt'
}
author {
name = 'Jane Doe'
url = 'http://example.com/users/jane'
}
description {
text = 'A concise description of my library'
homepage = 'http://www.example.com/library'
}
}
versionMapping {
usage('java-api') {
fromResolutionOf('runtimeClasspath')
}
usage('java-runtime') {
fromResolutionResult()
}
}
}
}In this example we are simply adding a 'description' element to the generated Ivy dependency descriptor, but this hook allows you to modify any aspect of the generated descriptor. For example, you could replace the version range for a dependency with the actual version used to produce the build.
You can also add arbitrary XML to the descriptor file via IvyModuleDescriptorSpec.withXml(org.gradle.api.Action), but you cannot use it to modify any part of the module identifier (organisation, module, revision).
|
Caution
|
It is possible to modify the descriptor in such a way that it is no longer a valid Ivy module descriptor, so care must be taken when using this feature. |
Customizing dependencies versions
Two strategies are supported for publishing dependencies:
- Declared versions (default)
-
This strategy publishes the versions that are defined by the build script author with the dependency declarations in the
dependenciesblock. Any other kind of processing, for example through a rule changing the resolved version, will not be taken into account for the publication. - Resolved versions
-
This strategy publishes the versions that were resolved during the build, possibly by applying resolution rules and automatic conflict resolution. This has the advantage that the published versions correspond to the ones the published artifact was tested against.
Example use cases for resolved versions:
-
A project uses dynamic versions for dependencies but prefers exposing the resolved version for a given release to its consumers.
-
In combination with dependency locking, you want to publish the locked versions.
-
A project leverages the rich versions constraints of Gradle, which have a lossy conversion to Ivy. Instead of relying on the conversion, it publishes the resolved versions.
This is done by using the versionMapping DSL method which allows to configure the VersionMappingStrategy:
publications {
create<IvyPublication>("ivyCustom") {
versionMapping {
usage("java-api") {
fromResolutionOf("runtimeClasspath")
}
usage("java-runtime") {
fromResolutionResult()
}
}
}
}publications {
ivyCustom(IvyPublication) {
versionMapping {
usage('java-api') {
fromResolutionOf('runtimeClasspath')
}
usage('java-runtime') {
fromResolutionResult()
}
}
}
}In the example above, Gradle will use the versions resolved on the runtimeClasspath for dependencies declared in api, which are mapped to the compile configuration of Ivy.
Gradle will also use the versions resolved on the runtimeClasspath for dependencies declared in implementation, which are mapped to the runtime configuration of Ivy.
fromResolutionResult() indicates that Gradle should use the default classpath of a variant and runtimeClasspath is the default classpath of java-runtime.
Repositories
This plugin provides repositories of type IvyArtifactRepository. To learn how to define and use repositories for publishing, see the section on basic publishing.
Here’s a simple example of defining a publishing repository:
publishing {
repositories {
ivy {
// change to point to your repo, e.g. http://my.org/repo
url = uri(layout.buildDirectory.dir("repo"))
}
}
}publishing {
repositories {
ivy {
// change to point to your repo, e.g. http://my.org/repo
url = layout.buildDirectory.dir("repo")
}
}
}The two main things you will want to configure are the repository’s:
-
URL (required)
-
Name (optional)
You can define multiple repositories as long as they have unique names within the build script. You may also declare one (and only one) repository without a name. That repository will take on an implicit name of "Ivy".
You can also configure any authentication details that are required to connect to the repository. See IvyArtifactRepository for more details.
Complete example
The following example demonstrates publishing with a multi-project build. Each project publishes a Java component configured to also build and publish Javadoc and source code artifacts. The descriptor file is customized to include the project description for each project.
rootProject.name = "ivy-publish-java"
include("project1", "project2")plugins {
`kotlin-dsl`
}
repositories {
gradlePluginPortal()
}plugins {
id("java-library")
id("ivy-publish")
}
version = "1.0"
group = "org.gradle.sample"
repositories {
mavenCentral()
}
java {
withJavadocJar()
withSourcesJar()
}
publishing {
repositories {
ivy {
// change to point to your repo, e.g. http://my.org/repo
url = uri(rootProject.layout.buildDirectory.dir("repo"))
}
}
publications {
create<IvyPublication>("ivy") {
from(components["java"])
descriptor.description {
text = providers.provider({ description })
}
}
}
}plugins {
id("myproject.publishing-conventions")
}
description = "The first project"
dependencies {
implementation("junit:junit:4.13")
implementation(project(":project2"))
}plugins {
id("myproject.publishing-conventions")
}
description = "The second project"
dependencies {
implementation("commons-collections:commons-collections:3.2.2")
}rootProject.name = 'ivy-publish-java'
include 'project1', 'project2'plugins {
id 'groovy-gradle-plugin'
}plugins {
id 'java-library'
id 'ivy-publish'
}
version = '1.0'
group = 'org.gradle.sample'
repositories {
mavenCentral()
}
java {
withJavadocJar()
withSourcesJar()
}
publishing {
repositories {
ivy {
// change to point to your repo, e.g. http://my.org/repo
url = rootProject.layout.buildDirectory.dir('repo')
}
}
publications {
ivy(IvyPublication) {
from components.java
descriptor.description {
text = providers.provider({ description })
}
}
}
}plugins {
id 'myproject.publishing-conventions'
}
description = 'The first project'
dependencies {
implementation 'junit:junit:4.13'
implementation project(':project2')
}plugins {
id 'myproject.publishing-conventions'
}
description = 'The second project'
dependencies {
implementation 'commons-collections:commons-collections:3.2.2'
}The result is that the following artifacts will be published for each project:
-
The Gradle Module Metadata file:
project1-1.0.module. -
The Ivy module metadata file:
ivy-1.0.xml. -
The primary JAR artifact for the Java component:
project1-1.0.jar. -
The Javadoc and sources JAR artifacts of the Java component (because we configured
withJavadocJar()andwithSourcesJar()):project1-1.0-javadoc.jar,project1-1.0-source.jar.
GRADLE MANAGED TYPES
Lazy vs Eager Evaluation
Understanding when values in your build are computed is crucial for writing fast and reliable build logic. Gradle differentiates between eager and lazy evaluation:
Eager Evaluation
Values are computed immediately during the configuration phase, before tasks ever run.
Eager evaluation comes with drawbacks:
-
Slows down builds — even when tasks aren’t executed.
-
Breaks compatibility — with and configuration caching.
Essentially, eager evaluation performs unnecessary work and reduces flexibility.
Lazy Evaluation
Lazy values are computed on-demand, typically during the execution phase, using Gradle’s Provider API (Provider<T> and Property<T>).
This approach has key benefits:
-
Deferred resolution — values are only computed when needed.
-
Better performance — avoids unnecessary computation during configuration.
Lazy evaluation enables build features like incremental builds, build caching, and configuration cache compatibility.
Lazy APIs
Lazy APIs were explicitly designed to avoid configuring tasks that aren’t going to be run, especially in large projects or Android builds where configuration overhead can be significant.
For example, you might use a String in your build script, but this value is eagerly evaluated during the configuration phase.
Instead, you should use Gradle’s Property<String> type, which defers evaluation until it’s needed during task execution.
Another example which is a common pitfall is using tasks.withType(Test) {}:
tasks.withType(Test) {
// configure all tasks eagerly
}This eagerly configures all Test tasks, even in builds where those tasks may never run.
Instead, use configureEach:
tasks.withType(Test).configureEach {
// configure only those tasks actually needed
}Or:
tasks.named("test") {
// configure only if task will be executed
}This use of configureEach and tasks.named(…) ensures configurations only apply to tasks invoked by the build.
Properties and Providers
Gradle provides properties that are important for lazy configuration. When implementing a custom task or plugin, it’s imperative that you use these lazy properties.
Gradle represents lazy properties with two interfaces:
Properties and providers manage values and configurations in a build script.
In this example, configuration is a Property<String> that is set to the configurationProvider Provider<String>.
The configurationProvider lazily provides the value "Hello, Gradle!":
abstract class MyIntroTask : DefaultTask() {
@get:Input
abstract val configuration: Property<String>
@TaskAction
fun printConfiguration() {
println("Configuration value: ${configuration.get()}")
}
}
val configurationProvider: Provider<String> = project.provider { "Hello, Gradle!" }
tasks.register("myIntroTask", MyIntroTask::class) {
configuration = configurationProvider
}abstract class MyIntroTask extends DefaultTask {
@Input
abstract Property<String> getConfiguration()
@TaskAction
void printConfiguration() {
println "Configuration value: ${configuration.get()}"
}
}
Provider<String> configurationProvider = project.provider { "Hello, Gradle!" }
tasks.register("myIntroTask", MyIntroTask) {
configuration = configurationProvider
}Understanding Properties
Properties in Gradle are variables that hold values. They can be defined and accessed within the build script to store information like file paths, version numbers, or custom values.
Properties can be set and retrieved using the project object:
// Setting a property
val simpleMessageProperty: Property<String> = project.objects.property(String::class)
simpleMessageProperty.set("Hello, World from a Property!")
// Accessing a property
println(simpleMessageProperty.get())// Setting a property
def simpleMessageProperty = project.objects.property(String)
simpleMessageProperty.set("Hello, World from a Property!")
// Accessing a property
println(simpleMessageProperty.get())Properties:
-
Properties with these types are configurable.
-
Propertyextends theProviderinterface. -
The method Property.set(T) specifies a value for the property, overwriting whatever value may have been present.
-
The method Property.set(Provider) specifies a
Providerfor the value for the property, overwriting whatever value may have been present. This allows you to wire togetherProviderandPropertyinstances before the values are configured. -
A
Propertycan be created by the factory method ObjectFactory.property(Class).
Understanding Providers
Providers are objects that represent a value that may not be immediately available. Providers are useful for lazy evaluation and can be used to model values that may change over time or depend on other tasks or inputs:
// Setting a provider
val simpleMessageProvider: Provider<String> = project.providers.provider { "Hello, World from a Provider!" }
// Accessing a provider
println(simpleMessageProvider.get())// Setting a provider
def simpleMessageProvider = project.providers.provider { "Hello, World from a Provider!" }
// Accessing a provider
println(simpleMessageProvider.get())Providers:
-
Properties with these types are read-only.
-
The method Provider.get() returns the current value of the property.
-
A
Providercan be created from anotherProviderusing Provider.map(Transformer). -
Many other types extend
Providerand can be used wherever aProvideris required.
Chaining Providers
Chaining Providers preserves laziness and is essential to use when writing build logic.
These methods allow you to transform, combine, or provide fallback values without triggering eager evaluation:
| Method | Purpose |
|---|---|
|
Transforms the value using a function, producing a new |
|
Transforms the value into another |
|
Combines multiple |
|
Supplies a fallback |
Using map() is a common example:
val majorVersion: Provider<String> = versionProvider.map { it.split(".")[0] }You can see the following example for a detailed breakdown at Provider chaining using map():
tasks.register("printFloatFromFile") {
// Type: RegularFile
def myFile = layout.projectDirectory.file("someNumber.txt")
// Type: Provider<Float>
def floatProvider = project.providers
// Type: Provider<FileContents>
.fileContents(myFile)
// Type: Provider<String>
.asText
// Type: Provider<Float>
.map {
// Type: Float
it.toFloat()
}
doLast {
// Type: Provider<Float>
println ">>> Float value from file: $floatProvider"
// Type: Float
println ">>> Float value from file: ${floatProvider.get()}"
}
}Using Gradle Managed Properties
Gradle’s managed properties allow you to declare properties as getters (Java, Groovy) or properties (Kotlin).
Gradle then automatically provides the implementation for these properties, managing their state.
A property may be mutable, meaning that it is of type Property, which has both a get() and a set() method:
abstract class MyPropertyTask : DefaultTask() {
@get:Input
abstract val messageProperty: Property<String> // message property
@TaskAction
fun printMessage() {
println(messageProperty.get())
}
}
tasks.register<MyPropertyTask>("myPropertyTask") {
messageProperty.convention("Hello, Gradle!")
}abstract class MyPropertyTask extends DefaultTask {
@Input
abstract Property<String> getMessageProperty()
@TaskAction
void printMessage() {
println(messageProperty.get())
}
}
tasks.register('myPropertyTask', MyPropertyTask) {
messageProperty.convention("Hello, Gradle!")
}Or read-only, meaning that it is of type Provider, which only has a get() method:
abstract class MyProviderTask : DefaultTask() {
val messageProvider: Provider<String> = project.providers.provider { "Hello, Gradle!" } // message provider
@TaskAction
fun printMessage() {
println(messageProvider.get())
}
}
tasks.register<MyProviderTask>("MyProviderTask") {
}abstract class MyProviderTask extends DefaultTask {
final Provider<String> messageProvider = project.providers.provider { "Hello, Gradle!" }
@TaskAction
void printMessage() {
println(messageProvider.get())
}
}
tasks.register('MyProviderTask', MyProviderTask)Mutable Managed Properties
A mutable managed property is declared using a getter method of type Property<T>, where T can be any serializable type or a fully managed Gradle type.
The property must not have any setter methods.
Here is an example of a task type with an uri property of type URI:
public abstract class Download extends DefaultTask {
@Input
public abstract Property<URI> getUri(); // abstract getter of type Property<T>
@TaskAction
void run() {
System.out.println("Downloading " + getUri().get()); // Use the `uri` property
}
}Note that for a property to be considered a mutable managed property, the property’s getter methods must have public or protected visibility.
It is recommended to also make the property abstract, so Gradle can manage the initialization of the property.
The property type must be one of the following:
| Property Type | Note |
|---|---|
|
Where |
|
Configurable regular file location, whose value is mutable |
|
Configurable directory location, whose value is mutable |
|
List of elements of type |
|
Set of elements of type |
|
Map of |
|
A mutable |
|
A mutable |
Read-only Managed Properties (Providers)
You can declare a read-only managed property, also known as a provider, using a getter method of type Provider<T>.
The method implementation needs to derive the value.
It can, for example, derive the value from other properties.
Here is an example of a task type with a uri provider that is derived from a location property:
public abstract class Download extends DefaultTask {
@Input
public abstract Property<String> getLocation();
@Internal
public Provider<URI> getUri() {
return getLocation().map(l -> URI.create("https://" + l));
}
@TaskAction
void run() {
System.out.println("Downloading " + getUri().get()); // Use the `uri` provider (read-only property)
}
}Read-only Managed Nested Properties (Nested Providers)
You can declare a read-only managed nested property by adding an abstract getter method for the property to a type annotated with @Nested.
The property should not have any setter methods.
Gradle provides the implementation for the getter method and creates a value for the property.
This pattern is useful when a custom type has a nested complex type which has the same lifecycle.
If the lifecycle is different, consider using Property<NestedType> instead.
Here is an example of a task type with a resource property.
The Resource type is also a custom Gradle type and defines some managed properties:
public abstract class Download extends DefaultTask {
@Nested
public abstract Resource getResource(); // Use an abstract getter method annotated with @Nested
@TaskAction
void run() {
// Use the `resource` property
System.out.println("Downloading https://" + getResource().getHostName().get() + "/" + getResource().getPath().get());
}
}
public interface Resource {
@Input
Property<String> getHostName();
@Input
Property<String> getPath();
}Read-only Managed "name" Property (Provider)
If the type contains an abstract property called "name" of type String, Gradle provides an implementation for the getter
method, and extends each constructor with a "name" parameter, which comes before all other constructor parameters.
If the type is an interface, Gradle will provide a constructor with a single "name" parameter and @Inject semantics.
You can have your type implement or extend the Named interface, which defines such a read-only "name" property:
import org.gradle.api.Named
interface MyType : Named {
// Other properties and methods...
}
class MyTypeImpl(override val name: String) : MyType {
// Implement other properties and methods...
}
// Usage
val instance = MyTypeImpl("myName")
println(instance.name) // Prints: myNameUsing Gradle Managed Types
A managed type as an abstract class or interface with no fields and whose properties are all managed. These types have their state entirely managed by Gradle.
For example, this managed type is defined as an interface:
public interface Resource {
@Input
Property<String> getHostName();
@Input
Property<String> getPath();
}A named managed type is a managed type that additionally has an abstract property "name" of type String.
Named managed types are especially useful as the element type of NamedDomainObjectContainer:
interface MyNamedType : Named {
}
abstract class MyPluginExtension {
abstract val myNamedContainer: NamedDomainObjectContainer<MyNamedType>
fun myNamedContainer(configurationAction: Action<in NamedDomainObjectContainer<MyNamedType>>) = configurationAction.execute(myNamedContainer)
}
val pluginExtension = extensions.create<MyPluginExtension>("pluginExtension")
pluginExtension.apply {
myNamedContainer {
register("myName")
}
}interface MyNamedType extends Named {
}
abstract class MyPluginExtension {
abstract NamedDomainObjectContainer<MyNamedType> getMyNamedContainer()
void myNamedContainer(Action<? super NamedDomainObjectContainer<MyNamedType>> action) {
action.execute(getMyNamedContainer())
}
}
extensions.create("pluginExtension", MyPluginExtension)
pluginExtension {
myNamedContainer {
myName
}
}Using Java Bean Properties
Sometimes you may see properties implemented in the Java bean property style.
That is, they do not use a Property<T> or Provider<T> types but are instead implemented with concrete setter and getter methods (or corresponding conveniences in Groovy or Kotlin).
This style of property definition is legacy in Gradle and is discouraged:
public class MyTask extends DefaultTask {
private String someProperty;
public String getSomeProperty() {
return someProperty;
}
public void setSomeProperty(String someProperty) {
this.someProperty = someProperty;
}
@TaskAction
public void myAction() {
System.out.println("SomeProperty: " + someProperty);
}
}Collections
Gradle provides types for maintaining collections of objects, intended to work well to extends Gradle’s DSLs and provide useful features such as lazy configuration.
Collection hierarchy
All Gradle collection types extend from DomainObjectCollection<T>, which defines the core contract for live collections — including methods like configureEach(), withType(), matching(), all(), whenObjectAdded(), and addLater().
DomainObjectCollection<T>
├── DomainObjectSet<T>
│ └── NamedDomainObjectSet<T>
└── NamedDomainObjectCollection<T>
├── NamedDomainObjectSet<T>
├── NamedDomainObjectList<T>
└── NamedDomainObjectContainer<T>
└── ExtensiblePolymorphicDomainObjectContainer<T>|
Note
|
NamedDomainObjectSet extends both DomainObjectSet and NamedDomainObjectCollection.
|
Available collections
These collection types are used for managing collections of objects, particularly in the context of build scripts and plugins:
-
DomainObjectSet<T>: Represents a set of objects of type T. This set does not allow duplicate elements, and you can add, remove, and query objects in the set. -
NamedDomainObjectSet<T>: A specialization ofDomainObjectSetwhere each object has a unique name associated with it. This is often used for collections where each element needs to be uniquely identified by a name. -
NamedDomainObjectList<T>: Similar toNamedDomainObjectSet, but represents a list of objects where order matters. Each element has a unique name associated with it, and you can access elements by index as well as by name. -
NamedDomainObjectContainer<T>: A container for managing objects of type T, where each object has a unique name. This container provides methods for adding, removing, and querying objects by name. -
ExtensiblePolymorphicDomainObjectContainer<T>: An extension ofNamedDomainObjectContainerthat allows you to define instantiation strategies for different types of objects. This is useful when you have a container that can hold multiple types of objects, and you want to control how each type of object is instantiated.
These types are commonly used in Gradle plugins and build scripts to manage collections of objects, such as tasks, configurations, or custom domain objects.
DomainObjectSet
A DomainObjectSet simply holds a set of configurable objects.
Compared to NamedDomainObjectContainer, a DomainObjectSet doesn’t manage the objects in the collection.
They need to be created and added manually.
You can create an instance using the ObjectFactory.domainObjectSet() method:
abstract class MyPluginExtensionDomainObjectSet {
// Define a domain object set to hold strings
abstract val myStrings: DomainObjectSet<String>
fun myStrings(action: Action<in DomainObjectSet<String>>) = action.execute(myStrings)
}
val dos = extensions.create<MyPluginExtensionDomainObjectSet>("dos")
dos.apply {
myStrings {
add("hello")
}
}abstract class MyPluginExtensionDomainObjectSet {
// Define a domain object set to hold strings
abstract DomainObjectSet<String> getMyStrings()
void myStrings(Action<? super DomainObjectSet<String>> action) {
action.execute(getMyStrings())
}
}
extensions.create("dos", MyPluginExtensionDomainObjectSet)
dos {
myStrings {
add("hello")
}
}NamedDomainObjectSet
A NamedDomainObjectSet holds a set of configurable objects, where each element has a name associated with it.
This is similar to NamedDomainObjectContainer, however a NamedDomainObjectSet doesn’t manage the objects in the collection.
They need to be created and added manually.
You can create an instance using the ObjectFactory.namedDomainObjectSet() method.
interface Person : Named {
}
abstract class MyPluginExtensionNamedDomainObjectSet {
// Define a named domain object set to hold Person objects
abstract val people: NamedDomainObjectSet<Person>
fun people(action: Action<in NamedDomainObjectSet<Person>>) = action.execute(people)
}
val ndos = extensions.create<MyPluginExtensionNamedDomainObjectSet>("ndos")
ndos.apply {
people {
add(objects.newInstance<Person>("bobby"))
}
}interface Person extends Named {
}
abstract class MyPluginExtensionNamedDomainObjectSet {
// Define a named domain object set to hold Person objects
abstract NamedDomainObjectSet<Person> getPeople()
void people(Action<? super NamedDomainObjectSet<Person>> action) {
action.execute(getPeople())
}
}
extensions.create("ndos", MyPluginExtensionNamedDomainObjectSet)
ndos {
people {
add(objects.newInstance(Person, "bobby"))
}
}NamedDomainObjectList
A NamedDomainObjectList holds a list of configurable objects, where each element has a name associated with it.
This is similar to NamedDomainObjectContainer, however a NamedDomainObjectList doesn’t manage the objects in the collection.
They need to be created and added manually.
You can create an instance using the ObjectFactory.namedDomainObjectList() method.
interface Person : Named {
}
abstract class MyPluginExtensionNamedDomainObjectList {
// Define a named domain object container to hold Person objects
abstract val people: NamedDomainObjectList<Person>
fun people(action: Action<in NamedDomainObjectList<Person>>) = action.execute(people)
}
val ndol = extensions.create<MyPluginExtensionNamedDomainObjectList>("ndol")
ndol.apply {
people {
add(objects.newInstance<Person>("bobby"))
add(objects.newInstance<Person>("hank"))
}
}interface Person extends Named {
}
abstract class MyPluginExtensionNamedDomainObjectList {
// Define a named domain object container to hold Person objects
abstract NamedDomainObjectList<Person> getPeople()
void people(Action<? super NamedDomainObjectList<Person>> action) {
action.execute(getPeople())
}
}
extensions.create("ndol", MyPluginExtensionNamedDomainObjectList)
ndol {
people {
add(objects.newInstance(Person, "bobby"))
add(objects.newInstance(Person, "hank"))
}
}NamedDomainObjectContainer
A NamedDomainObjectContainer manages a set of objects, where each element has a name associated with it.
The container takes care of creating and configuring the elements, and provides a DSL that build scripts can use to define and configure elements. It is intended to hold objects which are themselves configurable, for example a set of custom Gradle objects.
Gradle uses NamedDomainObjectContainer type extensively throughout the API.
For example, the project.tasks object used to manage the tasks of a project is a NamedDomainObjectContainer<Task>.
You can create a container instance using the ObjectFactory service, which provides the ObjectFactory.domainObjectContainer() method.
You can also create a container instance using a read-only managed property.
interface Person : Named {
}
abstract class MyPluginExtensionNamedDomainObjectContainer {
// Define a named domain object container to hold Person objects
abstract val people: NamedDomainObjectContainer<Person>
fun people(action: Action<in NamedDomainObjectContainer<Person>>) = action.execute(people)
}
val ndoc = extensions.create<MyPluginExtensionNamedDomainObjectContainer>("ndoc")
ndoc.apply {
people {
register("bobby")
register("hank")
register("peggy")
}
}interface Person extends Named {
}
abstract class MyPluginExtensionNamedDomainObjectContainer {
// Define a named domain object container to hold Person objects
abstract NamedDomainObjectContainer<Person> getPeople()
void people(Action<? super NamedDomainObjectContainer<Person>> action) {
action.execute(getPeople())
}
}
extensions.create("ndoc", MyPluginExtensionNamedDomainObjectContainer)
ndoc {
people {
bobby
hank
peggy
}
}In order to use a type with any of the domainObjectContainer() methods, it must either
-
be a named managed type; or
-
expose a property named “name” as the unique, and constant, name for the object. The
domainObjectContainer(Class)variant of the method creates new instances by calling the constructor of the class that takes a string argument, which is the desired name of the object.
Objects created this way are treated as custom Gradle types, and so can make use of the features discussed in this chapter, for example service injection or managed properties.
See the above link for domainObjectContainer() method variants that allow custom instantiation strategies:
public interface DownloadExtension {
NamedDomainObjectContainer<Resource> getResources();
}
public interface Resource {
// Type must have a read-only 'name' property
String getName();
Property<URI> getUri();
Property<String> getUserName();
}For each container property, Gradle automatically adds a block to the Groovy and Kotlin DSL that you can use to configure the contents of the container:
plugins {
id("org.gradle.sample.download")
}
download {
// Can use a block to configure the container contents
resources {
register("gradle") {
uri = uri("https://gradle.org")
}
}
}plugins {
id("org.gradle.sample.download")
}
download {
// Can use a block to configure the container contents
resources {
register('gradle') {
uri = uri('https://gradle.org')
}
}
}ExtensiblePolymorphicDomainObjectContainer
An ExtensiblePolymorphicDomainObjectContainer is a NamedDomainObjectContainer that allows you to
define instantiation strategies for different types of objects.
You can create an instance using the ObjectFactory.polymorphicDomainObjectContainer() method:
interface Animal : Named {
}
interface Dog : Animal {
val breed: Property<String>
}
abstract class MyPluginExtensionExtensiblePolymorphicDomainObjectContainer {
// Define a container for animals
abstract val animals: ExtensiblePolymorphicDomainObjectContainer<Animal>
fun animals(action: Action<in ExtensiblePolymorphicDomainObjectContainer<Animal>>) = action.execute(animals)
}
val epdoc = extensions.create<MyPluginExtensionExtensiblePolymorphicDomainObjectContainer>("epdoc")
// Register available types for container
epdoc.animals.registerBinding(Dog::class, Dog::class)
epdoc.apply {
animals {
register<Dog>("bubba") {
breed = "basset hound"
}
}
}interface Animal extends Named {
}
interface Dog extends Animal {
Property<String> getBreed()
}
abstract class MyPluginExtensionExtensiblePolymorphicDomainObjectContainer {
// Define a container for animals
abstract ExtensiblePolymorphicDomainObjectContainer<Animal> getAnimals()
void animals(Action<? super ExtensiblePolymorphicDomainObjectContainer<Animal>> action) {
action.execute(getAnimals())
}
}
extensions.create("epdoc", MyPluginExtensionExtensiblePolymorphicDomainObjectContainer)
// Register available types for container
epdoc.animals.registerBinding(Dog, Dog)
epdoc {
animals {
bubba(Dog) {
breed = "basset hound"
}
}
}Services and Service Injection
Gradle provides a number of useful services that can be used by custom Gradle types. For example, the WorkerExecutor service can be used by a task to run work in parallel, as seen in the worker API section. The services are made available through service injection.
Available services
|
Warning
|
You should avoid injecting types not listed below. Internal services can sometimes technically be injected, but this practice is not supported and may lead to breaking changes in the future. Only inject the services explicitly listed below to ensure stability and compatibility. |
The following services are available for injection in all Gradle instantiated objects:
-
ObjectFactory- Allows model objects to be created. -
ProviderFactory- CreatesProviderinstances. -
FileSystemOperations- Allows a task to run operations on the filesystem such as deleting files, copying files or syncing directories. -
ArchiveOperations- Allows a task to run operations on archive files such as ZIP or TAR files. -
ExecOperations- Allows a task to run external processes with dedicated support for running externaljavaprograms.
Additional services in workers
The following services are available for injection in worker API actions and parameters:
-
WorkerExecutor- Allows a task to run work in parallel.
Additional services in projects
The following services are available for injection in project plugins, extensions and objects created in a project:
-
ProjectLayout- Provides access to key project locations. -
WorkerExecutor- Allows a task to run work in parallel. -
ToolingModelBuilderRegistry- Allows a plugin to registers a Gradle tooling API model. -
TestEventReporterFactory- Allows a plugin to access Gradle’s test events and its corresponding API. -
DependencyFactory- Allows a plugin to create dependencies in a type-safe way.
Additional services in settings
The following services are available for injection in settings plugins, extensions and objects created in a project:
-
BuildLayout- Provides access to important locations for a Gradle build. -
ToolingModelBuilderRegistry- Allows a plugin to registers a Gradle tooling API model. -
DependencyFactory- Allows a plugin to create dependencies in a type-safe way.
ObjectFactory
ObjectFactory is a service for creating custom Gradle types, allowing you to define nested objects and DSLs in your build logic.
It provides methods for creating instances of different types, such as properties (Property<T>), collections (ListProperty<T>, SetProperty<T>, MapProperty<K, V>), file-related objects (RegularFileProperty, DirectoryProperty, ConfigurableFileCollection, ConfigurableFileTree), and more.
You can obtain an instance of ObjectFactory using the project.objects property.
Here’s a simple example demonstrating how to use ObjectFactory to create a property and set its value:
tasks.register("myObjectFactoryTask") {
doLast {
val objectFactory = project.objects
val myProperty = objectFactory.property(String::class)
myProperty.set("Hello, Gradle!")
println(myProperty.get())
}
}tasks.register("myObjectFactoryTask") {
doLast {
def objectFactory = project.objects
def myProperty = objectFactory.property(String)
myProperty.set("Hello, Gradle!")
println myProperty.get()
}
}|
Tip
|
It is preferable to let Gradle create objects automatically by using managed properties. |
Using ObjectFactory to create these objects ensures that they are properly managed by Gradle, especially in terms of configuration avoidance and lazy evaluation.
This means that the values of these objects are only calculated when needed, which can improve build performance.
In the following example, a project extension called DownloadExtension receives an ObjectFactory instance through its constructor.
The constructor uses this to create a nested Resource object (also a custom Gradle type) and makes this object available through the resource property:
public class DownloadExtension {
// A nested instance
private final Resource resource;
@Inject
public DownloadExtension(ObjectFactory objectFactory) {
// Use an injected ObjectFactory to create a Resource object
resource = objectFactory.newInstance(Resource.class);
}
public Resource getResource() {
return resource;
}
}
public interface Resource {
Property<URI> getUri();
}Here is another example using javax.inject.Inject:
abstract class MyObjectFactoryTask
@Inject constructor(private var objectFactory: ObjectFactory) : DefaultTask() {
@TaskAction
fun doTaskAction() {
val outputDirectory = objectFactory.directoryProperty()
outputDirectory.convention(project.layout.projectDirectory)
println(outputDirectory.get())
}
}
tasks.register("myInjectedObjectFactoryTask", MyObjectFactoryTask::class) {}abstract class MyObjectFactoryTask extends DefaultTask {
private ObjectFactory objectFactory
@Inject //@javax.inject.Inject
MyObjectFactoryTask(ObjectFactory objectFactory) {
this.objectFactory = objectFactory
}
@TaskAction
void doTaskAction() {
var outputDirectory = objectFactory.directoryProperty()
outputDirectory.convention(project.layout.projectDirectory)
println(outputDirectory.get())
}
}
tasks.register("myInjectedObjectFactoryTask",MyObjectFactoryTask) {}The MyObjectFactoryTask task uses an ObjectFactory instance, which is injected into the task’s constructor using the @Inject annotation.
ProjectLayout
ProjectLayout is a service that provides access to the layout of a Gradle project’s directories and files.
It’s part of the org.gradle.api.file package and allows you to query the project’s layout to get information about source sets, build directories, and other file-related aspects of the project.
You can obtain a ProjectLayout instance from a Project object using the project.layout property.
Here’s a simple example:
tasks.register("showLayout") {
doLast {
val layout = project.layout
println("Project Directory: ${layout.projectDirectory}")
println("Build Directory: ${layout.buildDirectory.get()}")
}
}tasks.register('showLayout') {
doLast {
def layout = project.layout
println "Project Directory: ${layout.projectDirectory}"
println "Build Directory: ${layout.buildDirectory.get()}"
}
}Here is an example using javax.inject.Inject:
abstract class MyProjectLayoutTask
@Inject constructor(private var projectLayout: ProjectLayout) : DefaultTask() {
@TaskAction
fun doTaskAction() {
val outputDirectory = projectLayout.projectDirectory
println(outputDirectory)
}
}
tasks.register("myInjectedProjectLayoutTask", MyProjectLayoutTask::class) {}abstract class MyProjectLayoutTask extends DefaultTask {
private ProjectLayout projectLayout
@Inject //@javax.inject.Inject
MyProjectLayoutTask(ProjectLayout projectLayout) {
this.projectLayout = projectLayout
}
@TaskAction
void doTaskAction() {
var outputDirectory = projectLayout.projectDirectory
println(outputDirectory)
}
}
tasks.register("myInjectedProjectLayoutTask",MyProjectLayoutTask) {}The MyProjectLayoutTask task uses a ProjectLayout instance, which is injected into the task’s constructor using the @Inject annotation.
BuildLayout
BuildLayout is a service that provides access to the root and settings directory in a Settings plugin or a Settings script, it is analogous to ProjectLayout.
It’s part of the org.gradle.api.file package to access standard build-wide file system locations as lazily computed value.
|
Note
|
These APIs are currently incubating but eventually should replace existing accessors in Settings, which return eagerly computed locations:Settings.rootDir → Settings.layout.rootDirectorySettings.settingsDir → Settings.layout.settingsDirectory
|
You can obtain a BuildLayout instance from a Settings object using the settings.layout property.
Here’s a simple example:
println("Root Directory: ${settings.layout.rootDirectory}")
println("Settings Directory: ${settings.layout.settingsDirectory}")println "Root Directory: ${settings.layout.rootDirectory}"
println "Settings Directory: ${settings.layout.settingsDirectory}"Here is an example using javax.inject.Inject:
abstract class MyBuildLayoutPlugin @Inject constructor(private val buildLayout: BuildLayout) : Plugin<Settings> {
override fun apply(settings: Settings) {
println(buildLayout.rootDirectory)
}
}
apply<MyBuildLayoutPlugin>()abstract class MyBuildLayoutPlugin implements Plugin<Settings> {
private BuildLayout buildLayout
@Inject //@javax.inject.Inject
MyBuildLayoutPlugin(BuildLayout buildLayout) {
this.buildLayout = buildLayout
}
@Override void apply(Settings settings) {
// the meat and potatoes of the plugin
println buildLayout.rootDirectory
}
}
apply plugin: MyBuildLayoutPluginThis code defines a MyBuildLayoutPlugin plugin that implements the Plugin interface for the Settings type.
The plugin expects a BuildLayout instance to be injected into its constructor using the @Inject annotation.
ProviderFactory
ProviderFactory is a service that provides methods for creating different types of providers.
Providers are used to model values that may be computed lazily in your build scripts.
The ProviderFactory interface provides methods for creating various types of providers, including:
-
provider(Callable<T> value)to create a provider with a value that is lazily computed based on aCallable. -
provider(Provider<T> value)to create a provider that simply wraps an existing provider. -
property(Class<T> type)to create a property provider for a specific type. -
gradleProperty(Class<T> type)to create a property provider that reads its value from a Gradle project property.
Here’s a simple example demonstrating the use of ProviderFactory using project.providers:
tasks.register("printMessage") {
doLast {
val providerFactory = project.providers
val messageProvider = providerFactory.provider { "Hello, Gradle!" }
println(messageProvider.get())
}
}tasks.register('printMessage') {
doLast {
def providerFactory = project.providers
def messageProvider = providerFactory.provider { "Hello, Gradle!" }
println messageProvider.get()
}
}The task named printMessage uses the ProviderFactory to create a provider that supplies the message string.
Here is an example using javax.inject.Inject:
abstract class MyProviderFactoryTask
@Inject constructor(private var providerFactory: ProviderFactory) : DefaultTask() {
@TaskAction
fun doTaskAction() {
val outputDirectory = providerFactory.provider { "build/my-file.txt" }
println(outputDirectory.get())
}
}
tasks.register("myInjectedProviderFactoryTask", MyProviderFactoryTask::class) {}abstract class MyProviderFactoryTask extends DefaultTask {
private ProviderFactory providerFactory
@Inject //@javax.inject.Inject
MyProviderFactoryTask(ProviderFactory providerFactory) {
this.providerFactory = providerFactory
}
@TaskAction
void doTaskAction() {
var outputDirectory = providerFactory.provider { "build/my-file.txt" }
println(outputDirectory.get())
}
}
tasks.register("myInjectedProviderFactoryTask",MyProviderFactoryTask) {}The ProviderFactory service is injected into the MyProviderFactoryTask task’s constructor using the @Inject annotation.
WorkerExecutor
WorkerExecutor is a service that allows you to perform parallel execution of tasks using worker processes.
This is particularly useful for tasks that perform CPU-intensive or long-running operations, as it allows them to be executed in parallel, improving build performance.
Using WorkerExecutor, you can submit units of work (called actions) to be executed in separate worker processes.
This helps isolate the work from the main Gradle process, providing better reliability and performance.
Here’s a basic example of how you might use WorkerExecutor in a build script:
abstract class MyWorkAction : WorkAction<WorkParameters.None> {
private val greeting: String = "Hello from a Worker!"
override fun execute() {
println(greeting)
}
}
abstract class MyWorkerTask
@Inject constructor(private var workerExecutor: WorkerExecutor) : DefaultTask() {
@get:Input
abstract val booleanFlag: Property<Boolean>
@TaskAction
fun doThings() {
workerExecutor.noIsolation().submit(MyWorkAction::class.java) {}
}
}
tasks.register("myWorkTask", MyWorkerTask::class) {}abstract class MyWorkAction implements WorkAction<WorkParameters.None> {
private final String greeting;
@Inject
public MyWorkAction() {
this.greeting = "Hello from a Worker!";
}
@Override
public void execute() {
System.out.println(greeting);
}
}
abstract class MyWorkerTask extends DefaultTask {
@Input
abstract Property<Boolean> getBooleanFlag()
@Inject
abstract WorkerExecutor getWorkerExecutor()
@TaskAction
void doThings() {
workerExecutor.noIsolation().submit(MyWorkAction) {}
}
}
tasks.register("myWorkTask", MyWorkerTask) {}See the worker API for more details.
FileSystemOperations
FileSystemOperations is a service that provides methods for performing file system operations such as copying, deleting, and syncing.
It is part of the org.gradle.api.file package and is typically used in custom tasks or plugins to interact with the file system.
Here is an example using javax.inject.Inject:
abstract class MyFileSystemOperationsTask
@Inject constructor(private var fileSystemOperations: FileSystemOperations) : DefaultTask() {
@TaskAction
fun doTaskAction() {
fileSystemOperations.sync {
from("src")
into("dest")
}
}
}
tasks.register("myInjectedFileSystemOperationsTask", MyFileSystemOperationsTask::class)abstract class MyFileSystemOperationsTask extends DefaultTask {
private FileSystemOperations fileSystemOperations
@Inject //@javax.inject.Inject
MyFileSystemOperationsTask(FileSystemOperations fileSystemOperations) {
this.fileSystemOperations = fileSystemOperations
}
@TaskAction
void doTaskAction() {
fileSystemOperations.sync {
from 'src'
into 'dest'
}
}
}
tasks.register("myInjectedFileSystemOperationsTask", MyFileSystemOperationsTask)The FileSystemOperations service is injected into the MyFileSystemOperationsTask task’s constructor using the @Inject annotation.
With some ceremony, it is possible to use FileSystemOperations in an ad-hoc task defined in a build script:
interface InjectedFsOps {
@get:Inject val fs: FileSystemOperations
}
tasks.register("myAdHocFileSystemOperationsTask") {
val injected = project.objects.newInstance<InjectedFsOps>()
doLast {
injected.fs.copy {
from("src")
into("dest")
}
}
}interface InjectedFsOps {
@Inject //@javax.inject.Inject
FileSystemOperations getFs()
}
tasks.register('myAdHocFileSystemOperationsTask') {
def injected = project.objects.newInstance(InjectedFsOps)
doLast {
injected.fs.copy {
from 'source'
into 'destination'
}
}
}First, you need to declare an interface with a property of type FileSystemOperations, here named InjectedFsOps, to serve as an injection point.
Then call the method ObjectFactory.newInstance to generate an implementation of the interface that holds an injected service.
|
Tip
|
This is a good time to consider extracting the ad-hoc task into a proper class. |
ArchiveOperations
ArchiveOperations is a service that provides methods for accessing the contents of archives, such as ZIP and TAR files.
It is part of the org.gradle.api.file package and is typically used in custom tasks or plugins to unpack archive files.
Here is an example using javax.inject.Inject:
abstract class MyArchiveOperationsTask
@Inject constructor(
private val archiveOperations: ArchiveOperations,
private val layout: ProjectLayout,
private val fs: FileSystemOperations
) : DefaultTask() {
@TaskAction
fun doTaskAction() {
fs.sync {
from(archiveOperations.zipTree(layout.projectDirectory.file("sources.jar")))
into(layout.buildDirectory.dir("unpacked-sources"))
}
}
}
tasks.register("myInjectedArchiveOperationsTask", MyArchiveOperationsTask::class)abstract class MyArchiveOperationsTask extends DefaultTask {
private ArchiveOperations archiveOperations
private ProjectLayout layout
private FileSystemOperations fs
@Inject
MyArchiveOperationsTask(ArchiveOperations archiveOperations, ProjectLayout layout, FileSystemOperations fs) {
this.archiveOperations = archiveOperations
this.layout = layout
this.fs = fs
}
@TaskAction
void doTaskAction() {
fs.sync {
from(archiveOperations.zipTree(layout.projectDirectory.file("sources.jar")))
into(layout.buildDirectory.dir("unpacked-sources"))
}
}
}
tasks.register("myInjectedArchiveOperationsTask", MyArchiveOperationsTask)The ArchiveOperations service is injected into the MyArchiveOperationsTask task’s constructor using the @Inject annotation.
With some ceremony, it is possible to use ArchiveOperations in an ad-hoc task defined in a build script:
interface InjectedArcOps {
@get:Inject val arcOps: ArchiveOperations
}
tasks.register("myAdHocArchiveOperationsTask") {
val injected = project.objects.newInstance<InjectedArcOps>()
val archiveFile = "${project.projectDir}/sources.jar"
doLast {
injected.arcOps.zipTree(archiveFile)
}
}interface InjectedArcOps {
@Inject //@javax.inject.Inject
ArchiveOperations getArcOps()
}
tasks.register('myAdHocArchiveOperationsTask') {
def injected = project.objects.newInstance(InjectedArcOps)
def archiveFile = "${projectDir}/sources.jar"
doLast {
injected.arcOps.zipTree(archiveFile)
}
}First, you need to declare an interface with a property of type ArchiveOperations, here named InjectedArcOps, to serve as an injection point.
Then call the method ObjectFactory.newInstance to generate an implementation of the interface that holds an injected service.
|
Tip
|
This is a good time to consider extracting the ad-hoc task into a proper class. |
ExecOperations
ExecOperations is a service that provides methods for executing external processes (commands) from within a build script.
It is part of the org.gradle.process package and is typically used in custom tasks or plugins to run command-line tools or scripts as part of the build process.
Here is an example using javax.inject.Inject:
abstract class MyExecOperationsTask
@Inject constructor(private var execOperations: ExecOperations) : DefaultTask() {
@TaskAction
fun doTaskAction() {
execOperations.exec {
commandLine("ls", "-la")
}
}
}
tasks.register("myInjectedExecOperationsTask", MyExecOperationsTask::class)abstract class MyExecOperationsTask extends DefaultTask {
private ExecOperations execOperations
@Inject //@javax.inject.Inject
MyExecOperationsTask(ExecOperations execOperations) {
this.execOperations = execOperations
}
@TaskAction
void doTaskAction() {
execOperations.exec {
commandLine 'ls', '-la'
}
}
}
tasks.register("myInjectedExecOperationsTask", MyExecOperationsTask)The ExecOperations is injected into the MyExecOperationsTask task’s constructor using the @Inject annotation.
With some ceremony, it is possible to use ExecOperations in an ad-hoc task defined in a build script:
interface InjectedExecOps {
@get:Inject val execOps: ExecOperations
}
tasks.register("myAdHocExecOperationsTask") {
val injected = project.objects.newInstance<InjectedExecOps>()
doLast {
injected.execOps.exec {
commandLine("ls", "-la")
}
}
}interface InjectedExecOps {
@Inject //@javax.inject.Inject
ExecOperations getExecOps()
}
tasks.register('myAdHocExecOperationsTask') {
def injected = project.objects.newInstance(InjectedExecOps)
doLast {
injected.execOps.exec {
commandLine 'ls', '-la'
}
}
}First, you need to declare an interface with a property of type ExecOperations, here named InjectedExecOps, to serve as an injection point.
Then call the method ObjectFactory.newInstance to generate an implementation of the interface that holds an injected service.
|
Tip
|
This is a good time to consider extracting the ad-hoc task into a proper class. |
ToolingModelBuilderRegistry
ToolingModelBuilderRegistry is a service that allows you to register custom tooling model builders.
Tooling models are used to provide rich IDE integration for Gradle projects, allowing IDEs to understand and work with the project’s structure, dependencies, and other aspects.
The ToolingModelBuilderRegistry interface is part of the org.gradle.tooling.provider.model package and is typically used in custom Gradle plugins that provide enhanced IDE support.
Here’s a simplified example:
// Implements the ToolingModelBuilder interface.
// This interface is used in Gradle to define custom tooling models that can
// be accessed by IDEs or other tools through the Gradle tooling API.
class OrtModelBuilder : ToolingModelBuilder {
private val repositories: MutableMap<String, String> = mutableMapOf()
private val platformCategories: Set<String> = setOf("platform", "enforced-platform")
private val visitedDependencies: MutableSet<ModuleComponentIdentifier> = mutableSetOf()
private val visitedProjects: MutableSet<ModuleVersionIdentifier> = mutableSetOf()
private val logger = Logging.getLogger(OrtModelBuilder::class.java)
private val errors: MutableList<String> = mutableListOf()
private val warnings: MutableList<String> = mutableListOf()
override fun canBuild(modelName: String): Boolean {
return false
}
override fun buildAll(modelName: String, project: Project): Any {
return "model"
}
}
// Plugin is responsible for registering a custom tooling model builder
// (OrtModelBuilder) with the ToolingModelBuilderRegistry, which allows
// IDEs and other tools to access the custom tooling model.
class OrtModelPlugin(private val registry: ToolingModelBuilderRegistry) : Plugin<Project> {
override fun apply(project: Project) {
registry.register(OrtModelBuilder())
}
}// Implements the ToolingModelBuilder interface.
// This interface is used in Gradle to define custom tooling models that can
// be accessed by IDEs or other tools through the Gradle tooling API.
class OrtModelBuilder implements ToolingModelBuilder {
private Map<String, String> repositories = [:]
private Set<String> platformCategories = ["platform", "enforced-platform"]
private Set<ModuleComponentIdentifier> visitedDependencies = []
private Set<ModuleVersionIdentifier> visitedProjects = []
private static final logger = Logging.getLogger(OrtModelBuilder.class)
private List<String> errors = []
private List<String> warnings = []
@Override
boolean canBuild(String modelName) {
return false
}
@Override
Object buildAll(String modelName, Project project) {
return null
}
}
// Plugin is responsible for registering a custom tooling model builder
// (OrtModelBuilder) with the ToolingModelBuilderRegistry, which allows
// IDEs and other tools to access the custom tooling model.
class OrtModelPlugin implements Plugin<Project> {
ToolingModelBuilderRegistry registry
OrtModelPlugin(ToolingModelBuilderRegistry registry) {
this.registry = registry
}
void apply(Project project) {
registry.register(new OrtModelBuilder())
}
}You can learn more at Tooling API.
TestEventReporterFactory
|
Warning
|
This API is incubating. |
TestEventReporterFactory is a service that provides access to the test event reporting API.
You can learn more at Test Reporting API.
DependencyFactory
DependencyFactory is a service that provides methods for creating dependencies in a type-safe way.
You can learn more in the Implementing Binary Plugins guide.
Service injection patterns
There are two ways that services can be provided to an object.
Constructor injection
A service can be injected into the constructor of the class. The constructor must be public and annotated with the javax.inject.Inject annotation.
Gradle uses the declared type of each constructor parameter to determine the services that the object requires. The order of the constructor parameters and their names are not significant and can be whatever you like.
Here is an example that shows a task type that receives an WorkerExecutor via its constructor:
public class Download extends DefaultTask {
private final WorkerExecutor workerExecutor;
// Inject an WorkerExecutor into the constructor
@Inject
public Download(WorkerExecutor workerExecutor) {
this.workerExecutor = workerExecutor;
}
@TaskAction
void run() {
// ...use workerExecutor to run some work
}
}Property injection
A service can be injected by adding a property getter method annotated with the javax.inject.Inject annotation to the class.
Gradle defers the creation of the service until the getter method is called. This can be more performant than constructor injection.
The property getter method must be public or protected. Gradle uses the declared return type of the getter method to determine the service to make available.
The method should be abstract or, in cases where this isn’t possible, should have a dummy method body.
The method body is discarded. The name of the property is not significant and can be whatever you like.
Here is an example that shows a task type that receives two services via property getter methods:
public abstract class Download extends DefaultTask {
// Preferrably, use an abstract getter method
@Inject
protected abstract ObjectFactory getObjectFactory();
// Alternatively, use a getter method with a dummy implementation
@Inject
protected WorkerExecutor getWorkerExecutor() {
// Method body is ignored
throw new UnsupportedOperationException();
}
@TaskAction
void run() {
WorkerExecutor workerExecutor = getWorkerExecutor();
ObjectFactory objectFactory = getObjectFactory();
// Use the executor and factory ...
}
}Dataflow Actions
|
Note
|
The dataflow actions support is an incubating feature and is subject to change. |
A preferred way of executing work in a Gradle build is using a task. However, some kinds of work do not fit tasks well, such as custom handling of the build failure.
What if you want to play a cheerful sound when the build succeeds and a sad one when it fails? This work piece has to process the task execution result, so it cannot be a task itself.
The Dataflow Actions API provides a way to schedule this type of work. A dataflow action is a parameterized isolated piece of work that becomes eligible for execution as soon as all input parameters become available.
Implementing a dataflow action
The first step is to implement the action itself. You must create a class implementing the FlowAction interface:
import org.gradle.api.flow.FlowAction
import org.gradle.api.flow.FlowParameters
abstract class ReportConsumption : FlowAction<ReportConsumption.Params> {
interface Params : FlowParameters {
}
override fun execute(parameters: Params) {
}
}The execute method must be implemented because this is where the work happens.
An action implementation is treated as a custom Gradle type and can use any of the features available to custom Gradle types.
In particular, some Gradle services can be injected into the implementation.
A dataflow action may accept parameters. To provide parameters, you define an abstract class (or interface) to hold the parameters:
-
The parameters type must implement (or extend) FlowParameters.
-
The parameters type is also a custom Gradle type.
-
The action implementation gets the parameters as an argument of the
executemethod.
When the action requires no parameters, you can use FlowParameters.None as the type of parameter.
Here is an example of a dataflow action that takes a shared build service and a file path as parameters:
package org.gradle.sample.sound;
import org.gradle.api.flow.FlowAction;
import org.gradle.api.flow.FlowParameters;
import org.gradle.api.provider.Property;
import org.gradle.api.services.ServiceReference;
import org.gradle.api.tasks.Input;
import java.io.File;
public abstract class SoundPlay implements FlowAction<SoundPlay.Parameters> {
interface Parameters extends FlowParameters {
@ServiceReference // (1)
Property<SoundService> getSoundService();
@Input // (2)
Property<File> getMediaFile();
}
@Override
public void execute(Parameters parameters) {
parameters.getSoundService().get().playSoundFile(parameters.getMediaFile().get());
}
}-
Parameters in the parameter type must be annotated. If a parameter is annotated with
@ServiceReference, then a suitable shared build service implementation is automatically assigned to the parameter when the action is created, according to the usual rules. -
All other parameters must be annotated with
@Input.
Using lifecycle event providers
Besides the usual value providers, Gradle provides dedicated providers for build lifecycle events, like build completion.
These providers are intended for dataflow actions and provide additional ordering guarantees when used as inputs.
The ordering also applies if you derive a provider from the event provider by, for example, calling map or flatMap.
You can obtain these providers from the FlowProviders class.
flowProviders.buildWorkResult.map {
[
buildInvocationId: scopeIdsService.buildInvocationId,
workspaceId: scopeIdsService.workspaceId,
userId: scopeIdsService.userId
]
}|
Warning
|
If you’re not using a lifecycle event provider as an input to the dataflow action, then the exact timing when the action is executed is not defined and may change in the next version of Gradle. |
Supplying the action for execution
You should not create FlowAction objects manually.
Instead, you request to execute them in the appropriate scope of FlowScope.
In doing so, you can configure the parameters for the task:
package org.gradle.sample.sound;
import org.gradle.api.Plugin;
import org.gradle.api.flow.FlowProviders;
import org.gradle.api.flow.FlowScope;
import org.gradle.api.initialization.Settings;
import javax.inject.Inject;
import java.io.File;
public abstract class SoundFeedbackPlugin implements Plugin<Settings> {
@Inject
protected abstract FlowScope getFlowScope(); // (1)
@Inject
protected abstract FlowProviders getFlowProviders(); // (1)
@Override
public void apply(Settings settings) {
final File soundsDir = new File(settings.getSettingsDir(), "sounds");
getFlowScope().always( // (2)
SoundPlay.class, // (3)
spec -> // (4)
spec.getParameters().getMediaFile().set(
getFlowProviders().getBuildWorkResult().map(result -> // (5)
new File(
soundsDir,
result.getFailure().isPresent() ? "sad-trombone.mp3" : "tada.mp3"
)
)
)
);
}
}-
Use service injection to obtain
FlowScopeandFlowProvidersinstances. They are available for project and settings plugins. -
Use an appropriate scope to run your actions. As the name suggests, actions in the
alwaysscope are executed every time the build runs. -
Specify the class that implements the action.
-
Use the spec argument to configure the action parameters.
-
A lifecycle event provider can be mapped into something else while preserving the action order.
As a result, when you run the build, and it completes successfully, the action will play the "tada" sound. If the build fails at configuration or execution time, you’ll hear "sad-trombone" sound — assuming that build configuration proceeds far enough for the action to be registered.
Working With Files
File operations are fundamental to nearly every Gradle build. They involve handling source files, managing file dependencies, and generating reports. Gradle provides a robust API that simplifies these operations, enabling developers to perform necessary file tasks easily.
Hardcoded paths and laziness
It is best practice to avoid hardcoded paths in build scripts.
In addition to avoiding hardcoded paths, Gradle encourages laziness in its build scripts. This means that tasks and operations should be deferred until they are actually needed rather than executed eagerly.
Many examples in this chapter use hard-coded paths as string literals. This makes them easy to understand, but it is not good practice. The problem is that paths often change, and the more places you need to change them, the more likely you will miss one and break the build.
Where possible, you should use tasks, task properties, and project properties — in that order of preference — to configure file paths.
For example, if you create a task that packages the compiled classes of a Java application, you should use an implementation similar to this:
val archivesDirPath = layout.buildDirectory.dir("archives")
tasks.register<Zip>("packageClasses") {
archiveAppendix = "classes"
destinationDirectory = archivesDirPath
from(tasks.compileJava)
}def archivesDirPath = layout.buildDirectory.dir('archives')
tasks.register('packageClasses', Zip) {
archiveAppendix = "classes"
destinationDirectory = archivesDirPath
from compileJava
}The compileJava task is the source of the files to package, and the project property archivesDirPath stores the location of the archives, as we are likely to use it elsewhere in the build.
Using a task directly as an argument like this relies on it having defined outputs, so it won’t always be possible.
This example could be further improved by relying on the Java plugin’s convention for destinationDirectory rather than overriding it, but it does demonstrate the use of project properties.
Locating files
To perform some action on a file, you need to know where it is, and that’s the information provided by file paths.
Gradle builds on the standard Java File class, which represents the location of a single file and provides APIs for dealing with collections of paths.
Using ProjectLayout
The ProjectLayout class is used to access various directories and files within a project.
It provides methods to retrieve paths to the project directory, build directory, settings file, and other important locations within the project’s file structure.
This class is particularly useful when you need to work with files in a build script or plugin in different project paths:
val archivesDirPath = layout.buildDirectory.dir("archives")def archivesDirPath = layout.buildDirectory.dir('archives')You can learn more about the ProjectLayout class in Services.
Using Project.file()
Gradle provides the Project.file(java.lang.Object) method for specifying the location of a single file or directory.
Relative paths are resolved relative to the project directory, while absolute paths remain unchanged.
|
Caution
|
Never use |
Here are some examples of using the file() method with different types of arguments:
// Using a relative path
var configFile = file("src/config.xml")
// Using an absolute path
configFile = file(configFile.absolutePath)
// Using a File object with a relative path
configFile = file(File("src/config.xml"))
// Using a java.nio.file.Path object with a relative path
configFile = file(Paths.get("src", "config.xml"))
// Using an absolute java.nio.file.Path object
configFile = file(Paths.get(System.getProperty("user.home")).resolve("global-config.xml"))// Using a relative path
File configFile = file('src/config.xml')
// Using an absolute path
configFile = file(configFile.absolutePath)
// Using a File object with a relative path
configFile = file(new File('src/config.xml'))
// Using a java.nio.file.Path object with a relative path
configFile = file(Paths.get('src', 'config.xml'))
// Using an absolute java.nio.file.Path object
configFile = file(Paths.get(System.getProperty('user.home')).resolve('global-config.xml'))As you can see, you can pass strings, File instances and Path instances to the file() method, all of which result in an absolute File object.
In the case of multi-project builds, the file() method will always turn relative paths into paths relative to the current project directory, which may be a child project.
Using ProjectLayout.settingsDirectory()
To use a path relative to the settings directory, access the Project.layout, retrieve the settingsDirectory from it, and construct an absolute path.
For example:
val configFile = layout.settingsDirectory.file("shared/config.xml").asFileFile configFile = layout.settingsDirectory.file("shared/config.xml").asFileLet’s say you’re working on a multi-project build in the directory: dev/projects/AcmeHealth.
The build script above is at: AcmeHealth/subprojects/AcmePatientRecordLib/build.gradle.
The absolute file path will resolve to: dev/projects/AcmeHealth/shared/config.xml:
dev
├── projects
│ ├── AcmeHealth
│ │ ├── subprojects
│ │ │ ├── AcmePatientRecordLib
│ │ │ │ └── build.gradle
│ │ │ └── ...
│ │ ├── shared
│ │ │ └── config.xml
│ │ └── ...
│ └── ...
└── settings.gradleNote that Project also provides Project.getRootProject() for multi-project builds which, in the example, would resolve to: dev/projects/AcmeHealth/subprojects/AcmePatientRecordLib.
Using FileCollection
A file collection is simply a set of file paths represented by the FileCollection interface.
The set of paths can be any file path. The file paths don’t have to be related in any way, so they don’t have to be in the same directory or have a shared parent directory.
The recommended way to specify a collection of files is to use the ProjectLayout.files(java.lang.Object...) method, which returns a FileCollection instance.
This flexible method allows you to pass multiple strings, File instances, collections of strings, collections of Files, and more.
You can also pass in tasks as arguments if they have defined outputs.
|
Caution
|
files() properly handles relative paths and File(relative path) instances, resolving them relative to the project directory.
|
As with the Project.file(java.lang.Object) method covered in the previous section, all relative paths are evaluated relative to the current project directory.
The following example demonstrates some of the variety of argument types you can use — strings, File instances, lists, or Paths:
val collection: FileCollection = layout.files(
"src/file1.txt",
File("src/file2.txt"),
listOf("src/file3.csv", "src/file4.csv"),
Paths.get("src", "file5.txt")
)FileCollection collection = layout.files('src/file1.txt',
new File('src/file2.txt'),
['src/file3.csv', 'src/file4.csv'],
Paths.get('src', 'file5.txt'))File collections have important attributes in Gradle. They can be:
-
created lazily
-
iterated over
-
filtered
-
combined
Lazy creation of a file collection is useful when evaluating the files that make up a collection when a build runs. In the following example, we query the file system to find out what files exist in a particular directory and then make those into a file collection:
tasks.register("list") {
val projectDirectory = layout.projectDirectory
doLast {
var srcDir: File? = null
val collection = projectDirectory.files({
srcDir?.listFiles()
})
srcDir = projectDirectory.file("src").asFile
println("Contents of ${srcDir.name}")
collection.map { it.relativeTo(projectDirectory.asFile) }.sorted().forEach { println(it) }
srcDir = projectDirectory.file("src2").asFile
println("Contents of ${srcDir.name}")
collection.map { it.relativeTo(projectDirectory.asFile) }.sorted().forEach { println(it) }
}
}tasks.register('list') {
Directory projectDirectory = layout.projectDirectory
doLast {
File srcDir
// Create a file collection using a closure
collection = projectDirectory.files { srcDir.listFiles() }
srcDir = projectDirectory.file('src').asFile
println "Contents of $srcDir.name"
collection.collect { projectDirectory.asFile.relativePath(it) }.sort().each { println it }
srcDir = projectDirectory.file('src2').asFile
println "Contents of $srcDir.name"
collection.collect { projectDirectory.asFile.relativePath(it) }.sort().each { println it }
}
}$ ./gradlew -q listContents of src
src/dir1
src/file1.txt
Contents of src2
src2/dir1
src2/dir2The key to lazy creation is passing a closure (in Groovy) or a Provider (in Kotlin) to the files() method.
Your closure or provider must return a value of a type accepted by files(), such as List<File>, String, or FileCollection.
Iterating over a file collection can be done through the each() method (in Groovy) or forEach method (in Kotlin) on the collection or using the collection in a for loop.
In both approaches, the file collection is treated as a set of File instances, i.e., your iteration variable will be of type File.
The following example demonstrates such iteration.
It also demonstrates how you can convert file collections to other types using the as operator (or supported properties):
// Iterate over the files in the collection
collection.forEach { file: File ->
println(file.name)
}
// Convert the collection to various types
val set: Set<File> = collection.files
val list: List<File> = collection.toList()
val path: String = collection.asPath
val file: File = collection.singleFile
// Add and subtract collections
val union = collection + projectLayout.files("src/file2.txt")
val difference = collection - projectLayout.files("src/file2.txt")// Iterate over the files in the collection
collection.each { File file ->
println file.name
}
// Convert the collection to various types
Set set = collection.files
Set set2 = collection as Set
List list = collection as List
String path = collection.asPath
File file = collection.singleFile
// Add and subtract collections
def union = collection + projectLayout.files('src/file2.txt')
def difference = collection - projectLayout.files('src/file2.txt')You can also see at the end of the example how to combine file collections using the + and - operators to merge and subtract them.
An important feature of the resulting file collections is that they are live.
In other words, when you combine file collections this way, the result always reflects what’s currently in the source file collections, even if they change during the build.
For example, imagine collection in the above example gains an extra file or two after union is created.
As long as you use union after those files are added to collection, union will also contain those additional files.
The same goes for the different file collection.
Live collections are also important when it comes to filtering.
Suppose you want to use a subset of a file collection.
In that case, you can take advantage of the FileCollection.filter(org.gradle.api.specs.Spec) method to determine which files to "keep".
In the following example, we create a new collection that consists of only the files that end with .txt in the source collection:
val textFiles: FileCollection = collection.filter { f: File ->
f.name.endsWith(".txt")
}FileCollection textFiles = collection.filter { File f ->
f.name.endsWith(".txt")
}$ ./gradlew -q filterTextFilessrc/file1.txt
src/file2.txt
src/file5.txtIf collection changes at any time, either by adding or removing files from itself, then textFiles will immediately reflect the change because it is also a live collection.
Note that the closure you pass to filter() takes a File as an argument and should return a boolean.
Understanding implicit conversion to file collections
Many objects in Gradle have properties which accept a set of input files.
For example, the JavaCompile task has a source property that defines the source files to compile.
You can set the value of this property using any of the types supported by the files() method, as mentioned in the API docs.
This means you can, for example, set the property to a File, String, collection, FileCollection or even a closure or Provider.
This is a feature of specific tasks!
That means implicit conversion will not happen for just any task that has a FileCollection or FileTree property.
If you want to know whether implicit conversion happens in a particular situation, you will need to read the relevant documentation, such as the corresponding task’s API docs.
Alternatively, you can remove all doubt by explicitly using ProjectLayout.files(java.lang.Object...) in your build.
Here are some examples of the different types of arguments that the source property can take:
tasks.register<JavaCompile>("compile") {
// Use a File object to specify the source directory
source = fileTree(file("src/main/java"))
// Use a String path to specify the source directory
source = fileTree("src/main/java")
// Use a collection to specify multiple source directories
source = fileTree(listOf("src/main/java", "../shared/java"))
// Use a FileCollection (or FileTree in this case) to specify the source files
source = fileTree("src/main/java").matching { include("org/gradle/api/**") }
// Using a closure to specify the source files.
setSource({
// Use the contents of each zip file in the src dir
file("src").listFiles().filter { it.name.endsWith(".zip") }.map { zipTree(it) }
})
}tasks.register('compile', JavaCompile) {
// Use a File object to specify the source directory
source = file('src/main/java')
// Use a String path to specify the source directory
source = 'src/main/java'
// Use a collection to specify multiple source directories
source = ['src/main/java', '../shared/java']
// Use a FileCollection (or FileTree in this case) to specify the source files
source = fileTree(dir: 'src/main/java').matching { include 'org/gradle/api/**' }
// Using a closure to specify the source files.
source = {
// Use the contents of each zip file in the src dir
file('src').listFiles().findAll {it.name.endsWith('.zip')}.collect { zipTree(it) }
}
}One other thing to note is that properties like source have corresponding methods in core Gradle tasks.
Those methods follow the convention of appending to collections of values rather than replacing them.
Again, this method accepts any of the types supported by the files() method, as shown here:
tasks.named<JavaCompile>("compile") {
// Add some source directories use String paths
source("src/main/java", "src/main/groovy")
// Add a source directory using a File object
source(file("../shared/java"))
// Add some source directories using a closure
setSource({ file("src/test/").listFiles() })
}compile {
// Add some source directories use String paths
source 'src/main/java', 'src/main/groovy'
// Add a source directory using a File object
source file('../shared/java')
// Add some source directories using a closure
source { file('src/test/').listFiles() }
}As this is a common convention, we recommend that you follow it in your own custom tasks. Specifically, if you plan to add a method to configure a collection-based property, make sure the method appends rather than replaces values.
Using FileTree
A file tree is a file collection that retains the directory structure of the files it contains and has the type FileTree. This means all the paths in a file tree must have a shared parent directory. The following diagram highlights the distinction between file trees and file collections in the typical case of copying files:
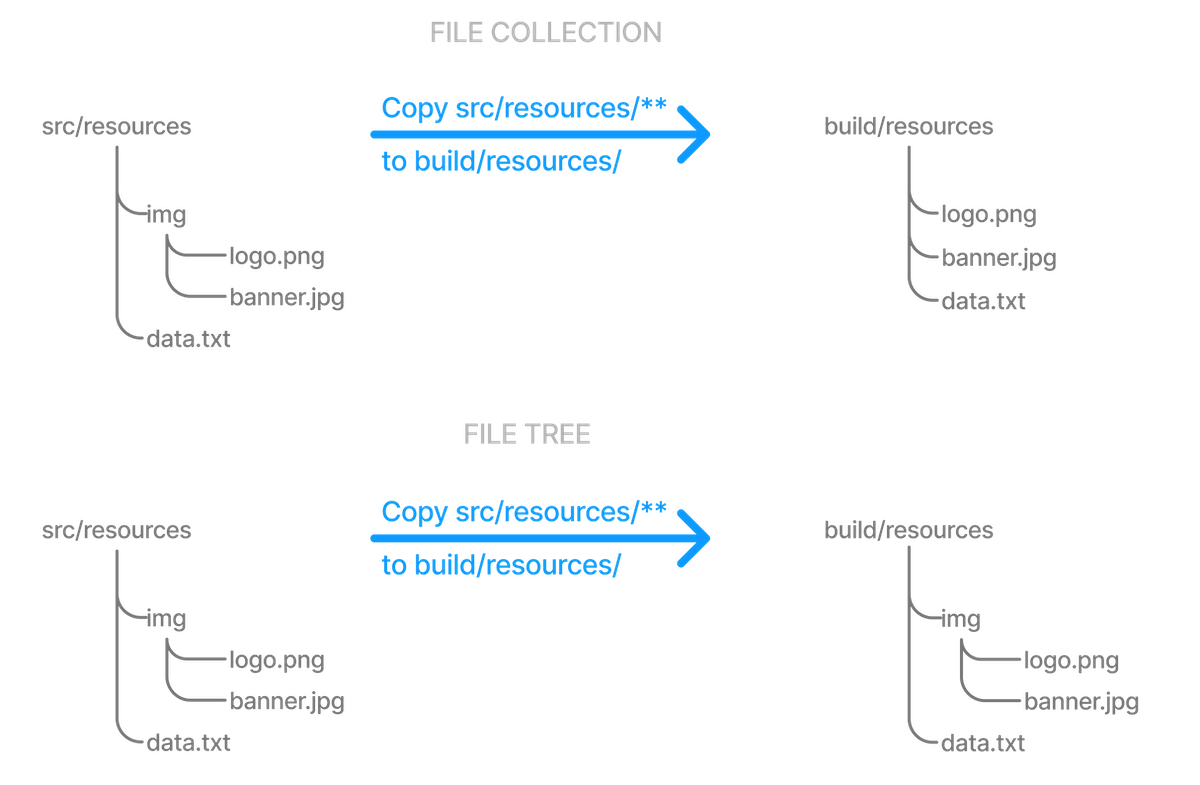
|
Note
|
Although FileTree extends FileCollection (an is-a relationship), their behaviors differ.
In other words, you can use a file tree wherever a file collection is required, but remember that a file collection is a flat list/set of files, while a file tree is a file and directory hierarchy.
To convert a file tree to a flat collection, use the FileTree.getFiles() property.
|
The simplest way to create a file tree is to pass a file or directory path to the Project.fileTree(java.lang.Object) method. This will create a tree of all the files and directories in that base directory (but not the base directory itself). The following example demonstrates how to use this method and how to filter the files and directories using Ant-style patterns:
// Create a file tree with a base directory
var tree: ConfigurableFileTree = fileTree("src/main")
// Add include and exclude patterns to the tree
tree.include("**/*.java")
tree.exclude("**/Abstract*")
// Create a tree using closure
tree = fileTree("src") {
include("**/*.java")
}
// Create a tree using a map
tree = fileTree("dir" to "src", "include" to "**/*.java")
tree = fileTree("dir" to "src", "includes" to listOf("**/*.java", "**/*.xml"))
tree = fileTree("dir" to "src", "include" to "**/*.java", "exclude" to "**/*test*/**")// Create a file tree with a base directory
ConfigurableFileTree tree = fileTree(dir: 'src/main')
// Add include and exclude patterns to the tree
tree.include '**/*.java'
tree.exclude '**/Abstract*'
// Create a tree using closure
tree = fileTree('src') {
include '**/*.java'
}
// Create a tree using a map
tree = fileTree(dir: 'src', include: '**/*.java')
tree = fileTree(dir: 'src', includes: ['**/*.java', '**/*.xml'])
tree = fileTree(dir: 'src', include: '**/*.java', exclude: '**/*test*/**')You can see more examples of supported patterns in the API docs for PatternFilterable.
By default, fileTree() returns a FileTree instance that applies some default exclude patterns for convenience — the same defaults as Ant.
For the complete default exclude list, see the Ant manual.
If those default excludes prove problematic, you can work around the issue by changing the default excludes in the settings script:
import org.apache.tools.ant.DirectoryScanner
DirectoryScanner.removeDefaultExclude("**/.git")
DirectoryScanner.removeDefaultExclude("**/.git/**")import org.apache.tools.ant.DirectoryScanner
DirectoryScanner.removeDefaultExclude('**/.git')
DirectoryScanner.removeDefaultExclude('**/.git/**')|
Important
|
Gradle does not support changing default excludes during the execution phase. |
You can do many of the same things with file trees that you can with file collections:
-
iterate over them (depth first)
-
filter them (using FileTree.matching(org.gradle.api.Action) and Ant-style patterns)
-
merge them
You can also traverse file trees using the FileTree.visit(org.gradle.api.Action) method. All of these techniques are demonstrated in the following example:
// Iterate over the contents of a tree
tree.forEach{ file: File ->
println(file)
}
// Filter a tree
val filtered: FileTree = tree.matching {
include("org/gradle/api/**")
}
// Add trees together
val sum: FileTree = tree + fileTree("src/test")
// Visit the elements of the tree
tree.visit {
println("${this.relativePath} => ${this.file}")
}// Iterate over the contents of a tree
tree.each {File file ->
println file
}
// Filter a tree
FileTree filtered = tree.matching {
include 'org/gradle/api/**'
}
// Add trees together
FileTree sum = tree + fileTree(dir: 'src/test')
// Visit the elements of the tree
tree.visit {element ->
println "$element.relativePath => $element.file"
}Copying files
Copying files in Gradle primarily uses CopySpec, a mechanism that makes it easy to manage resources such as source code, configuration files, and other assets in your project build process.
Understanding CopySpec
CopySpec is a copy specification that allows you to define what files to copy, where to copy them from, and where to copy them.
It provides a flexible and expressive way to specify complex file copying operations, including filtering files based on patterns, renaming files, and including/excluding files based on various criteria.
CopySpec instances are used in the Copy task to specify the files and directories to be copied.
CopySpec has two important attributes:
-
It is independent of tasks, allowing you to share copy specs within a build.
-
It is hierarchical, providing fine-grained control within the overall copy specification.
1. Sharing copy specs
Consider a build with several tasks that copy a project’s static website resources or add them to an archive. One task might copy the resources to a folder for a local HTTP server, and another might package them into a distribution. You could manually specify the file locations and appropriate inclusions each time they are needed, but human error is more likely to creep in, resulting in inconsistencies between tasks.
One solution is the Project.copySpec(org.gradle.api.Action) method. This allows you to create a copy spec outside a task, which can then be attached to an appropriate task using the CopySpec.with(org.gradle.api.file.CopySpec…) method. The following example demonstrates how this is done:
val webAssetsSpec: CopySpec = copySpec {
from("src/main/webapp")
include("**/*.html", "**/*.png", "**/*.jpg")
rename("(.+)-staging(.+)", "$1$2")
}
tasks.register<Copy>("copyAssets") {
into(layout.buildDirectory.dir("inPlaceApp"))
with(webAssetsSpec)
}
tasks.register<Zip>("distApp") {
archiveFileName = "my-app-dist.zip"
destinationDirectory = layout.buildDirectory.dir("dists")
from(appClasses)
with(webAssetsSpec)
}CopySpec webAssetsSpec = copySpec {
from 'src/main/webapp'
include '**/*.html', '**/*.png', '**/*.jpg'
rename '(.+)-staging(.+)', '$1$2'
}
tasks.register('copyAssets', Copy) {
into layout.buildDirectory.dir("inPlaceApp")
with webAssetsSpec
}
tasks.register('distApp', Zip) {
archiveFileName = 'my-app-dist.zip'
destinationDirectory = layout.buildDirectory.dir('dists')
from appClasses
with webAssetsSpec
}Both the copyAssets and distApp tasks will process the static resources under src/main/webapp, as specified by webAssetsSpec.
|
Note
|
The configuration defined by This can be confusing, so it’s probably best to treat |
Suppose you encounter a scenario in which you want to apply the same copy configuration to different sets of files.
In that case, you can share the configuration block directly without using copySpec().
Here’s an example that has two independent tasks that happen to want to process image files only:
val webAssetPatterns = Action<CopySpec> {
include("**/*.html", "**/*.png", "**/*.jpg")
}
tasks.register<Copy>("copyAppAssets") {
into(layout.buildDirectory.dir("inPlaceApp"))
from("src/main/webapp", webAssetPatterns)
}
tasks.register<Zip>("archiveDistAssets") {
archiveFileName = "distribution-assets.zip"
destinationDirectory = layout.buildDirectory.dir("dists")
from("distResources", webAssetPatterns)
}def webAssetPatterns = {
include '**/*.html', '**/*.png', '**/*.jpg'
}
tasks.register('copyAppAssets', Copy) {
into layout.buildDirectory.dir("inPlaceApp")
from 'src/main/webapp', webAssetPatterns
}
tasks.register('archiveDistAssets', Zip) {
archiveFileName = 'distribution-assets.zip'
destinationDirectory = layout.buildDirectory.dir('dists')
from 'distResources', webAssetPatterns
}In this case, we assign the copy configuration to its own variable and apply it to whatever from() specification we want.
This doesn’t just work for inclusions but also exclusions, file renaming, and file content filtering.
2. Using child specifications
If you only use a single copy spec, the file filtering and renaming will apply to all files copied. Sometimes, this is what you want, but not always. Consider the following example that copies files into a directory structure that a Java Servlet container can use to deliver a website:

This is not a straightforward copy as the WEB-INF directory and its subdirectories don’t exist within the project, so they must be created during the copy.
In addition, we only want HTML and image files going directly into the root folder — build/explodedWar — and only JavaScript files going into the js directory.
We need separate filter patterns for those two sets of files.
The solution is to use child specifications, which can be applied to both from() and into() declarations.
The following task definition does the necessary work:
tasks.register<Copy>("nestedSpecs") {
into(layout.buildDirectory.dir("explodedWar"))
exclude("**/*staging*")
from("src/dist") {
include("**/*.html", "**/*.png", "**/*.jpg")
}
from(sourceSets.main.get().output) {
into("WEB-INF/classes")
}
into("WEB-INF/lib") {
from(configurations.runtimeClasspath)
}
}tasks.register('nestedSpecs', Copy) {
into layout.buildDirectory.dir("explodedWar")
exclude '**/*staging*'
from('src/dist') {
include '**/*.html', '**/*.png', '**/*.jpg'
}
from(sourceSets.main.output) {
into 'WEB-INF/classes'
}
into('WEB-INF/lib') {
from configurations.runtimeClasspath
}
}Notice how the src/dist configuration has a nested inclusion specification; it is the child copy spec.
You can, of course, add content filtering and renaming here as required.
A child copy spec is still a copy spec.
The above example also demonstrates how you can copy files into a subdirectory of the destination either by using a child into() on a from() or a child from() on an into().
Both approaches are acceptable, but you should create and follow a convention to ensure consistency across your build files.
|
Note
|
Don’t get your |
One final thing to be aware of is that a child copy spec inherits its destination path, include patterns, exclude patterns, copy actions, name mappings, and filters from its parent. So, be careful where you place your configuration.
Using the Sync task
The Sync task, which extends the Copy task, copies the source files into the destination directory and then removes any files from the destination directory which it did not copy.
It synchronizes the contents of a directory with its source.
This can be useful for doing things such as installing your application, creating an exploded copy of your archives, or maintaining a copy of the project’s dependencies.
Here is an example that maintains a copy of the project’s runtime dependencies in the build/libs directory:
tasks.register<Sync>("libs") {
from(configurations["runtime"])
into(layout.buildDirectory.dir("libs"))
}tasks.register('libs', Sync) {
from configurations.runtime
into layout.buildDirectory.dir('libs')
}You can also perform the same function in your own tasks with the Project.sync(org.gradle.api.Action) method.
Using the Copy task
You can copy a file by creating an instance of Gradle’s builtin Copy task and configuring it with the location of the file and where you want to put it.
This example mimics copying a generated report into a directory that will be packed into an archive, such as a ZIP or TAR:
tasks.register<Copy>("copyReport") {
from(layout.buildDirectory.file("reports/my-report.pdf"))
into(layout.buildDirectory.dir("toArchive"))
}tasks.register('copyReport', Copy) {
from layout.buildDirectory.file("reports/my-report.pdf")
into layout.buildDirectory.dir("toArchive")
}The file and directory paths are then used to specify what file to copy using Copy.from(java.lang.Object…) and which directory to copy it to using Copy.into(java.lang.Object).
Although hard-coded paths make for simple examples, they make the build brittle.
Using a reliable, single source of truth, such as a task or shared project property, is better.
In the following modified example, we use a report task defined elsewhere that has the report’s location stored in its outputFile property:
tasks.register<Copy>("copyReport2") {
from(myReportTask.flatMap { it.outputFile })
into(archiveReportsTask.flatMap { it.dirToArchive })
}tasks.register('copyReport2', Copy) {
from myReportTask.outputFile
into archiveReportsTask.dirToArchive
}We have also assumed that the reports will be archived by archiveReportsTask, which provides us with the directory that will be archived and hence where we want to put the copies of the reports.
Copying multiple files
You can extend the previous examples to multiple files very easily by providing multiple arguments to from():
tasks.register<Copy>("copyReportsForArchiving") {
from(layout.buildDirectory.file("reports/my-report.pdf"), layout.projectDirectory.file("src/docs/manual.pdf"))
into(layout.buildDirectory.dir("toArchive"))
}tasks.register('copyReportsForArchiving', Copy) {
from layout.buildDirectory.file("reports/my-report.pdf"), layout.projectDirectory.file("src/docs/manual.pdf")
into layout.buildDirectory.dir("toArchive")
}Two files are now copied into the archive directory.
You can also use multiple from() statements to do the same thing, as shown in the first example of the section File copying in depth.
But what if you want to copy all the PDFs in a directory without specifying each one? To do this, attach inclusion and/or exclusion patterns to the copy specification. Here, we use a string pattern to include PDFs only:
tasks.register<Copy>("copyPdfReportsForArchiving") {
from(layout.buildDirectory.dir("reports"))
include("*.pdf")
into(layout.buildDirectory.dir("toArchive"))
}tasks.register('copyPdfReportsForArchiving', Copy) {
from layout.buildDirectory.dir("reports")
include "*.pdf"
into layout.buildDirectory.dir("toArchive")
}One thing to note, as demonstrated in the following diagram, is that only the PDFs that reside directly in the reports directory are copied:

You can include files in subdirectories by using an Ant-style glob pattern (**/*), as done in this updated example:
tasks.register<Copy>("copyAllPdfReportsForArchiving") {
from(layout.buildDirectory.dir("reports"))
include("**/*.pdf")
into(layout.buildDirectory.dir("toArchive"))
}tasks.register('copyAllPdfReportsForArchiving', Copy) {
from layout.buildDirectory.dir("reports")
include "**/*.pdf"
into layout.buildDirectory.dir("toArchive")
}This task has the following effect:

Remember that a deep filter like this has the side effect of copying the directory structure below reports and the files.
If you want to copy the files without the directory structure, you must use an explicit fileTree(dir) { includes }.files expression.
Copying directory hierarchies
You may need to copy files as well as the directory structure in which they reside.
This is the default behavior when you specify a directory as the from() argument, as demonstrated by the following example that copies everything in the reports directory, including all its subdirectories, to the destination:
tasks.register<Copy>("copyReportsDirForArchiving") {
from(layout.buildDirectory.dir("reports"))
into(layout.buildDirectory.dir("toArchive"))
}tasks.register('copyReportsDirForArchiving', Copy) {
from layout.buildDirectory.dir("reports")
into layout.buildDirectory.dir("toArchive")
}The key aspect that users need help with is controlling how much of the directory structure goes to the destination.
In the above example, do you get a toArchive/reports directory, or does everything in reports go straight into toArchive?
The answer is the latter. If a directory is part of the from() path, then it won’t appear in the destination.
So how do you ensure that reports itself is copied across, but not any other directory in ${layout.buildDirectory}?
The answer is to add it as an include pattern:
tasks.register<Copy>("copyReportsDirForArchiving2") {
from(layout.buildDirectory) {
include("reports/**")
}
into(layout.buildDirectory.dir("toArchive"))
}tasks.register('copyReportsDirForArchiving2', Copy) {
from(layout.buildDirectory) {
include "reports/**"
}
into layout.buildDirectory.dir("toArchive")
}You’ll get the same behavior as before except with one extra directory level in the destination, i.e., toArchive/reports.
One thing to note is how the include() directive applies only to the from(), whereas the directive in the previous section applied to the whole task.
These different levels of granularity in the copy specification allow you to handle most requirements that you will come across easily.
Understanding file copying
The basic process of copying files in Gradle is a simple one:
-
Define a task of type Copy
-
Specify which files (and potentially directories) to copy
-
Specify a destination for the copied files
But this apparent simplicity hides a rich API that allows fine-grained control of which files are copied, where they go, and what happens to them as they are copied — renaming of the files and token substitution of file content are both possibilities, for example.
Let’s start with the last two items on the list, which involve CopySpec.
The CopySpec interface, which the Copy task implements, offers:
-
A CopySpec.from(java.lang.Object…) method to define what to copy
-
An CopySpec.into(java.lang.Object) method to define the destination
CopySpec has several additional methods that allow you to control the copying process, but these two are the only required ones.
into() is straightforward, requiring a directory path as its argument in any form supported by the Project.file(java.lang.Object) method.
The from() configuration is far more flexible.
Not only does from() accept multiple arguments, it also allows several different types of argument.
For example, some of the most common types are:
-
A
String— treated as a file path or, if it starts with "file://", a file URI -
A
File— used as a file path -
A
FileCollectionorFileTree— all files in the collection are included in the copy -
A task — the files or directories that form a task’s defined outputs are included
In fact, from() accepts all the same arguments as Project.files(java.lang.Object…) so see that method for a more detailed list of acceptable types.
Something else to consider is what type of thing a file path refers to:
-
A file — the file is copied as is
-
A directory — this is effectively treated as a file tree: everything in it, including subdirectories, is copied. However, the directory itself is not included in the copy.
-
A non-existent file — the path is ignored
Here is an example that uses multiple from() specifications, each with a different argument type.
You will probably also notice that into() is configured lazily using a closure (in Groovy) or a Provider (in Kotlin) — a technique that also works with from():
tasks.register<Copy>("anotherCopyTask") {
// Copy everything under src/main/webapp
from("src/main/webapp")
// Copy a single file
from("src/staging/index.html")
// Copy the output of a task
from(copyTask)
// Copy the output of a task using Task outputs explicitly.
from(tasks["copyTaskWithPatterns"].outputs)
// Copy the contents of a Zip file
from(zipTree("src/main/assets.zip"))
// Determine the destination directory later
into({ getDestDir() })
}tasks.register('anotherCopyTask', Copy) {
// Copy everything under src/main/webapp
from 'src/main/webapp'
// Copy a single file
from 'src/staging/index.html'
// Copy the output of a task
from copyTask
// Copy the output of a task using Task outputs explicitly.
from copyTaskWithPatterns.outputs
// Copy the contents of a Zip file
from zipTree('src/main/assets.zip')
// Determine the destination directory later
into { getDestDir() }
}Note that the lazy configuration of into() is different from a child specification, even though the syntax is similar.
Keep an eye on the number of arguments to distinguish between them.
Copying files in your own tasks
|
Warning
|
Using the Project.copy method at execution time, as described here, is not compatible with the configuration cache.
A possible solution is to implement the task as a proper class and use FileSystemOperations.copy method instead, as described in the configuration cache chapter.
|
Occasionally, you want to copy files or directories as part of a task.
For example, a custom archiving task based on an unsupported archive format might want to copy files to a temporary directory before they are archived.
You still want to take advantage of Gradle’s copy API without introducing an extra Copy task.
The solution is to use the Project.copy(org.gradle.api.Action) method.
Configuring it with a copy spec works like the Copy task.
Here’s a trivial example:
tasks.register("copyMethod") {
doLast {
copy {
from("src/main/webapp")
into(layout.buildDirectory.dir("explodedWar"))
include("**/*.html")
include("**/*.jsp")
}
}
}tasks.register('copyMethod') {
doLast {
copy {
from 'src/main/webapp'
into layout.buildDirectory.dir('explodedWar')
include '**/*.html'
include '**/*.jsp'
}
}
}The above example demonstrates the basic syntax and also highlights two major limitations of using the copy() method:
-
The
copy()method is not incremental. The example’scopyMethodtask will always execute because it has no information about what files make up the task’s inputs. You have to define the task inputs and outputs manually. -
Using a task as a copy source, i.e., as an argument to
from(), won’t create an automatic task dependency between your task and that copy source. As such, if you use thecopy()method as part of a task action, you must explicitly declare all inputs and outputs to get the correct behavior.
The following example shows how to work around these limitations using the dynamic API for task inputs and outputs:
tasks.register("copyMethodWithExplicitDependencies") {
// up-to-date check for inputs, plus add copyTask as dependency
inputs.files(copyTask)
.withPropertyName("inputs")
.withPathSensitivity(PathSensitivity.RELATIVE)
outputs.dir("some-dir") // up-to-date check for outputs
.withPropertyName("outputDir")
doLast {
copy {
// Copy the output of copyTask
from(copyTask)
into("some-dir")
}
}
}tasks.register('copyMethodWithExplicitDependencies') {
// up-to-date check for inputs, plus add copyTask as dependency
inputs.files(copyTask)
.withPropertyName("inputs")
.withPathSensitivity(PathSensitivity.RELATIVE)
outputs.dir('some-dir') // up-to-date check for outputs
.withPropertyName("outputDir")
doLast {
copy {
// Copy the output of copyTask
from copyTask
into 'some-dir'
}
}
}These limitations make it preferable to use the Copy task wherever possible because of its built-in support for incremental building and task dependency inference.
That is why the copy() method is intended for use by custom tasks that need to copy files as part of their function.
Custom tasks that use the copy() method should declare the necessary inputs and outputs relevant to the copy action.
Renaming files
Renaming files in Gradle can be done using the CopySpec API, which provides methods for renaming files as they are copied.
Using Copy.rename()
If the files used and generated by your builds sometimes don’t have names that suit, you can rename those files as you copy them.
Gradle allows you to do this as part of a copy specification using the rename() configuration.
The following example removes the "-staging" marker from the names of any files that have it:
tasks.register<Copy>("copyFromStaging") {
from("src/main/webapp")
into(layout.buildDirectory.dir("explodedWar"))
rename("(.+)-staging(.+)", "$1$2")
}tasks.register('copyFromStaging', Copy) {
from "src/main/webapp"
into layout.buildDirectory.dir('explodedWar')
rename '(.+)-staging(.+)', '$1$2'
}As in the above example, you can use regular expressions for this or closures that use more complex logic to determine the target filename. For example, the following task truncates filenames:
tasks.register<Copy>("copyWithTruncate") {
from(layout.buildDirectory.dir("reports"))
rename { filename: String ->
if (filename.length > 10) {
filename.slice(0..7) + "~" + filename.length
}
else filename
}
into(layout.buildDirectory.dir("toArchive"))
}tasks.register('copyWithTruncate', Copy) {
from layout.buildDirectory.dir("reports")
rename { String filename ->
if (filename.size() > 10) {
return filename[0..7] + "~" + filename.size()
}
else return filename
}
into layout.buildDirectory.dir("toArchive")
}As with filtering, you can also rename a subset of files by configuring it as part of a child specification on a from().
Using Copyspec.rename{}
The example of how to rename files on copy gives you most of the information you need to perform this operation. It demonstrates the two options for renaming:
-
Using a regular expression
-
Using a closure
Regular expressions are a flexible approach to renaming, particularly as Gradle supports regex groups that allow you to remove and replace parts of the source filename. The following example shows how you can remove the string "-staging" from any filename that contains it using a simple regular expression:
tasks.register<Copy>("rename") {
from("src/main/webapp")
into(layout.buildDirectory.dir("explodedWar"))
// Use a regular expression to map the file name
rename("(.+)-staging(.+)", "$1$2")
rename("(.+)-staging(.+)".toRegex().pattern, "$1$2")
// Use a closure to convert all file names to upper case
rename { fileName: String ->
fileName.uppercase()
}
}tasks.register('rename', Copy) {
from 'src/main/webapp'
into layout.buildDirectory.dir('explodedWar')
// Use a regular expression to map the file name
rename '(.+)-staging(.+)', '$1$2'
rename(/(.+)-staging(.+)/, '$1$2')
// Use a closure to convert all file names to upper case
rename { String fileName ->
fileName.toUpperCase()
}
}You can use any regular expression supported by the Java Pattern class and the substitution string.
The second argument of rename() works on the same principles as the Matcher.appendReplacement() method.
There are two common issues people come across when using regular expressions in this context:
-
If you use a slashy string (those delimited by '/') for the first argument, you must include the parentheses for
rename()as shown in the above example. -
It’s safest to use single quotes for the second argument, otherwise you need to escape the '$' in group substitutions, i.e.
"\$1\$2".
The first is a minor inconvenience, but slashy strings have the advantage that you don’t have to escape backslash ('\') characters in the regular expression.
The second issue stems from Groovy’s support for embedded expressions using ${ } syntax in double-quoted and slashy strings.
The closure syntax for rename() is straightforward and can be used for any requirements that simple regular expressions can’t handle.
You’re given a file’s name, and you return a new name for that file or null if you don’t want to change the name.
Be aware that the closure will be executed for every file copied, so try to avoid expensive operations where possible.
Filtering files
Filtering files in Gradle involves selectively including or excluding files based on certain criteria.
Using CopySpec.include() and CopySpec.exclude()
You can apply filtering in any copy specification through the CopySpec.include(java.lang.String…) and CopySpec.exclude(java.lang.String…) methods.
These methods are typically used with Ant-style include or exclude patterns, as described in PatternFilterable.
You can also perform more complex logic by using a closure that takes a FileTreeElement and returns true if the file should be included or false otherwise.
The following example demonstrates both forms, ensuring that only .html and .jsp files are copied, except for those .html files with the word "DRAFT" in their content:
tasks.register<Copy>("copyTaskWithPatterns") {
from("src/main/webapp")
into(layout.buildDirectory.dir("explodedWar"))
include("**/*.html")
include("**/*.jsp")
exclude { details: FileTreeElement ->
details.file.name.endsWith(".html") &&
details.file.readText().contains("DRAFT")
}
}tasks.register('copyTaskWithPatterns', Copy) {
from 'src/main/webapp'
into layout.buildDirectory.dir('explodedWar')
include '**/*.html'
include '**/*.jsp'
exclude { FileTreeElement details ->
details.file.name.endsWith('.html') &&
details.file.text.contains('DRAFT')
}
}A question you may ask yourself at this point is what happens when inclusion and exclusion patterns overlap? Which pattern wins? Here are the basic rules:
-
If there are no explicit inclusions or exclusions, everything is included
-
If at least one inclusion is specified, only files and directories matching the patterns are included
-
Any exclusion pattern overrides any inclusions, so if a file or directory matches at least one exclusion pattern, it won’t be included, regardless of the inclusion patterns
Bear these rules in mind when creating combined inclusion and exclusion specifications so that you end up with the exact behavior you want.
Note that the inclusions and exclusions in the above example will apply to all from() configurations.
If you want to apply filtering to a subset of the copied files, you’ll need to use child specifications.
Filtering file content
Filtering file content in Gradle involves replacing placeholders or tokens in files with dynamic values.
Using CopySpec.filter()
Transforming the content of files while they are being copied involves basic templating that uses token substitution, removal of lines of text, or even more complex filtering using a full-blown template engine.
The following example demonstrates several forms of filtering, including token substitution using the CopySpec.expand(java.util.Map) method and another using CopySpec.filter(java.lang.Class) with an Ant filter:
import org.apache.tools.ant.filters.FixCrLfFilter
import org.apache.tools.ant.filters.ReplaceTokens
tasks.register<Copy>("filter") {
from("src/main/webapp")
into(layout.buildDirectory.dir("explodedWar"))
// Substitute property tokens in files
expand("copyright" to "2009", "version" to "2.3.1")
// Use some of the filters provided by Ant
filter(FixCrLfFilter::class)
filter(ReplaceTokens::class, "tokens" to mapOf("copyright" to "2009", "version" to "2.3.1"))
// Use a closure to filter each line
filter { line: String ->
"[$line]"
}
// Use a closure to remove lines
filter { line: String ->
if (line.startsWith('-')) null else line
}
filteringCharset = "UTF-8"
}import org.apache.tools.ant.filters.FixCrLfFilter
import org.apache.tools.ant.filters.ReplaceTokens
tasks.register('filter', Copy) {
from 'src/main/webapp'
into layout.buildDirectory.dir('explodedWar')
// Substitute property tokens in files
expand(copyright: '2009', version: '2.3.1')
// Use some of the filters provided by Ant
filter(FixCrLfFilter)
filter(ReplaceTokens, tokens: [copyright: '2009', version: '2.3.1'])
// Use a closure to filter each line
filter { String line ->
"[$line]"
}
// Use a closure to remove lines
filter { String line ->
line.startsWith('-') ? null : line
}
filteringCharset = 'UTF-8'
}The filter() method has two variants, which behave differently:
-
one takes a
FilterReaderand is designed to work with Ant filters, such asReplaceTokens -
one takes a closure or Transformer that defines the transformation for each line of the source file
Note that both variants assume the source files are text-based.
When you use the ReplaceTokens class with filter(), you create a template engine that replaces tokens of the form @tokenName@ (the Ant-style token) with values you define.
Using CopySpec.expand()
The expand() method treats the source files as Groovy templates, which evaluates and expands expressions of the form ${expression}.
You can pass in property names and values that are then expanded in the source files. expand() allows for more than basic token substitution as the embedded expressions are full-blown Groovy expressions.
|
Note
|
Specifying the character set when reading and writing the file is good practice. Otherwise, the transformations won’t work properly for non-ASCII text. You configure the character set with the CopySpec.setFilteringCharset(String) property. If it’s not specified, the JVM default character set is used, which will likely differ from the one you want. |
Setting file permissions
Setting file permissions in Gradle involves specifying the permissions for files or directories created or modified during the build process.
Using CopySpec.filePermissions{}
For any CopySpec involved in copying files, may it be the Copy task itself, or any child specifications, you can explicitly set the permissions the destination files will have via the CopySpec.filePermissions {} configurations block.
Using CopySpec.dirPermissions{}
You can do the same for directories too, independently of files, via the CopySpec.dirPermissions {} configurations block.
|
Note
|
Not setting permissions explicitly will preserve the permissions of the original files or directories. The exception are archive tasks, see Reproducible archives for details. |
tasks.register<Copy>("permissions") {
from("src/main/webapp")
into(layout.buildDirectory.dir("explodedWar"))
filePermissions {
user {
read = true
execute = true
}
other.execute = false
}
dirPermissions {
unix("r-xr-x---")
}
}tasks.register('permissions', Copy) {
from 'src/main/webapp'
into layout.buildDirectory.dir('explodedWar')
filePermissions {
user {
read = true
execute = true
}
other.execute = false
}
dirPermissions {
unix('r-xr-x---')
}
}For a detailed description of file permissions, see FilePermissions and UserClassFilePermissions. For details on the convenience method used in the samples, see ConfigurableFilePermissions.unix(String).
Using empty configuration blocks for file or directory permissions still sets them explicitly, just to fixed default values. Everything inside one of these configuration blocks is relative to the default values. Default permissions differ for files and directories:
-
file: read & write for owner, read for group, read for other (
0644,rw-r—r--) -
directory: read, write & execute for owner, read & execute for group, read & execute for other (
0755,rwxr-xr-x)
It’s also possible to set permissions for a specific file. See the following example:
tasks.register<Copy>("specificPermissions") {
from("src/main/webapp")
into(layout.buildDirectory.dir("explodedWarWithScript"))
eachFile {
if (name == "script.sh") {
permissions {
user {
execute = true
}
}
}
}
}tasks.register("specificPermissions", Copy) {
from 'src/main/webapp'
into layout.buildDirectory.dir('explodedWarWithScript')
eachFile {
if (name == "script.sh") {
permissions {
user {
execute = true
}
}
}
}
}|
Note
|
Setting file permissions explicitly for a file doesn’t support UP-TO-DATE checks, so a task using this setting will always run.
|
Moving files and directories
Moving files and directories in Gradle is a straightforward process that can be accomplished using several APIs. When implementing file-moving logic in your build scripts, it’s important to consider file paths, conflicts, and task dependencies.
Using File.renameTo()
File.renameTo() is a method in Java (and by extension, in Gradle’s Groovy DSL) used to rename or move a file or directory.
When you call renameTo() on a File object, you provide another File object representing the new name or location.
If the operation is successful, renameTo() returns true; otherwise, it returns false.
It’s important to note that renameTo() has some limitations and platform-specific behavior.
In this example, the moveFile task uses the Copy task type to specify the source and destination directories.
Inside the doLast closure, it uses File.renameTo() to move the file from the source directory to the destination directory:
tasks.register("moveFile") {
doLast {
val sourceFile = file("source.txt")
val destFile = file("destination/new_name.txt")
if (sourceFile.renameTo(destFile)) {
println("File moved successfully.")
}
}
}task moveFile {
doLast {
def sourceFile = file('source.txt')
def destFile = file('destination/new_name.txt')
if (sourceFile.renameTo(destFile)) {
println "File moved successfully."
}
}
}Using the Copy task
In this example, the moveFile task copies the file source.txt to the destination directory and renames it to new_name.txt in the process.
This achieves a similar effect to moving a file.
tasks.register<Copy>("moveFileCopy") {
from("source.txt")
into("destination")
rename { "new_name.txt" }
}task moveFileCopy(type: Copy) {
from 'source.txt'
into 'destination'
rename { fileName ->
'new_name.txt'
}
}Deleting files and directories
Deleting files and directories in Gradle involves removing them from the file system.
Using the Delete task
You can easily delete files and directories using the Delete task. You must specify which files and directories to delete in a way supported by the Project.files(java.lang.Object…) method.
For example, the following task deletes the entire contents of a build’s output directory:
tasks.register<Delete>("myClean") {
delete(buildDir)
}tasks.register('myClean', Delete) {
delete buildDir
}If you want more control over which files are deleted, you can’t use inclusions and exclusions the same way you use them for copying files.
Instead, you use the built-in filtering mechanisms of FileCollection and FileTree.
The following example does just that to clear out temporary files from a source directory:
tasks.register<Delete>("cleanTempFiles") {
delete(fileTree("src").matching {
include("**/*.tmp")
})
}tasks.register('cleanTempFiles', Delete) {
delete fileTree("src").matching {
include "**/*.tmp"
}
}Using Project.delete()
The Project.delete(org.gradle.api.Action) method can delete files and directories.
This method takes one or more arguments representing the files or directories to be deleted.
For example, the following task deletes the entire contents of a build’s output directory:
tasks.register<Delete>("myClean") {
delete(buildDir)
}tasks.register('myClean', Delete) {
delete buildDir
}If you want more control over which files are deleted, you can’t use inclusions and exclusions the same way you use them for copying files.
Instead, you use the built-in filtering mechanisms of FileCollection and FileTree.
The following example does just that to clear out temporary files from a source directory:
tasks.register<Delete>("cleanTempFiles") {
delete(fileTree("src").matching {
include("**/*.tmp")
})
}tasks.register('cleanTempFiles', Delete) {
delete fileTree("src").matching {
include "**/*.tmp"
}
}Creating archives
From the perspective of Gradle, packing files into an archive is effectively a copy in which the destination is the archive file rather than a directory on the file system. Creating archives looks a lot like copying, with all the same features.
Using the Zip, Tar, or Jar task
The simplest case involves archiving the entire contents of a directory, which this example demonstrates by creating a ZIP of the toArchive directory:
tasks.register<Zip>("packageDistribution") {
archiveFileName = "my-distribution.zip"
destinationDirectory = layout.buildDirectory.dir("dist")
from(layout.buildDirectory.dir("toArchive"))
}tasks.register('packageDistribution', Zip) {
archiveFileName = "my-distribution.zip"
destinationDirectory = layout.buildDirectory.dir('dist')
from layout.buildDirectory.dir("toArchive")
}Notice how we specify the destination and name of the archive instead of an into(): both are required. You often won’t see them explicitly set because most projects apply the Base Plugin.
It provides some conventional values for those properties.
The following example demonstrates this; you can learn more about the conventions in the archive naming section.
Each type of archive has its own task type, the most common ones being Zip, Tar and Jar.
They all share most of the configuration options of Copy, including filtering and renaming.
One of the most common scenarios involves copying files into specified archive subdirectories.
For example, let’s say you want to package all PDFs into a docs directory in the archive’s root.
This docs directory doesn’t exist in the source location, so you must create it as part of the archive.
You do this by adding an into() declaration for just the PDFs:
plugins {
base
}
version = "1.0.0"
tasks.register<Zip>("packageDistribution") {
from(layout.buildDirectory.dir("toArchive")) {
exclude("**/*.pdf")
}
from(layout.buildDirectory.dir("toArchive")) {
include("**/*.pdf")
into("docs")
}
}plugins {
id 'base'
}
version = "1.0.0"
tasks.register('packageDistribution', Zip) {
from(layout.buildDirectory.dir("toArchive")) {
exclude "**/*.pdf"
}
from(layout.buildDirectory.dir("toArchive")) {
include "**/*.pdf"
into "docs"
}
}As you can see, you can have multiple from() declarations in a copy specification, each with its own configuration.
See Using child copy specifications for more information on this feature.
Understanding archive creation
Archives are essentially self-contained file systems, and Gradle treats them as such. This is why working with archives is similar to working with files and directories.
Out of the box, Gradle supports the creation of ZIP and TAR archives and, by extension, Java’s JAR, WAR, and EAR formats—Java’s archive formats are all ZIPs.
Each of these formats has a corresponding task type to create them: Zip, Tar, Jar, War, and Ear.
These all work the same way and are based on copy specifications, just like the Copy task.
Creating an archive file is essentially a file copy in which the destination is implicit, i.e., the archive file itself. Here is a basic example that specifies the path and name of the target archive file:
tasks.register<Zip>("packageDistribution") {
archiveFileName = "my-distribution.zip"
destinationDirectory = layout.buildDirectory.dir("dist")
from(layout.buildDirectory.dir("toArchive"))
}tasks.register('packageDistribution', Zip) {
archiveFileName = "my-distribution.zip"
destinationDirectory = layout.buildDirectory.dir('dist')
from layout.buildDirectory.dir("toArchive")
}The full power of copy specifications is available to you when creating archives, which means you can do content filtering, file renaming, or anything else covered in the previous section.
A common requirement is copying files into subdirectories of the archive that don’t exist in the source folders, something that can be achieved with into() child specifications.
Gradle allows you to create as many archive tasks as you want, but it’s worth considering that many convention-based plugins provide their own.
For example, the Java plugin adds a jar task for packaging a project’s compiled classes and resources in a JAR.
Many of these plugins provide sensible conventions for the names of archives and the copy specifications used.
We recommend you use these tasks wherever you can rather than overriding them with your own.
Naming archives
Gradle has several conventions around the naming of archives and where they are created based on the plugins your project uses.
The main convention is provided by the Base Plugin, which defaults to creating archives in the layout.buildDirectory.dir("distributions") directory and typically uses archive names of the form [projectName]-[version].[type].
The following example comes from a project named archive-naming, hence the myZip task creates an archive named archive-naming-1.0.zip:
plugins {
base
}
version = "1.0"
tasks.register<Zip>("myZip") {
from("somedir")
val projectDir = layout.projectDirectory.asFile
doLast {
println(archiveFileName.get())
println(destinationDirectory.get().asFile.relativeTo(projectDir))
println(archiveFile.get().asFile.relativeTo(projectDir))
}
}plugins {
id 'base'
}
version = 1.0
tasks.register('myZip', Zip) {
from 'somedir'
File projectDir = layout.projectDirectory.asFile
doLast {
println archiveFileName.get()
println projectDir.relativePath(destinationDirectory.get().asFile)
println projectDir.relativePath(archiveFile.get().asFile)
}
}$ ./gradlew -q myZiparchive-naming-1.0.zip
build/distributions
build/distributions/archive-naming-1.0.zipNote that the archive name does not derive from the task’s name that creates it.
If you want to change the name and location of a generated archive file, you can provide values for the corresponding task’s archiveFileName and destinationDirectory properties.
These override any conventions that would otherwise apply.
Alternatively, you can make use of the default archive name pattern provided by AbstractArchiveTask.getArchiveFileName(): [archiveBaseName]-[archiveAppendix]-[archiveVersion]-[archiveClassifier].[archiveExtension]. You can set each of these properties on the task separately. Note that the Base Plugin uses the convention of the project name for archiveBaseName, project version for archiveVersion, and the archive type for archiveExtension. It does not provide values for the other properties.
This example — from the same project as the one above — configures just the archiveBaseName property, overriding the default value of the project name:
tasks.register<Zip>("myCustomZip") {
archiveBaseName = "customName"
from("somedir")
doLast {
println(archiveFileName.get())
}
}tasks.register('myCustomZip', Zip) {
archiveBaseName = 'customName'
from 'somedir'
doLast {
println archiveFileName.get()
}
}$ ./gradlew -q myCustomZipcustomName-1.0.zipYou can also override the default archiveBaseName value for all the archive tasks in your build by configuring the archivesName property in the base block, as demonstrated by the following example.
The block is defined by the base plugin and backed by the BasePluginExtension class.
plugins {
base
}
version = "1.0"
base {
archivesName = "gradle"
distsDirectory = layout.buildDirectory.dir("custom-dist")
libsDirectory = layout.buildDirectory.dir("custom-libs")
}
val myZip = tasks.register<Zip>("myZip") {
from("somedir")
}
val myOtherZip = tasks.register<Zip>("myOtherZip") {
archiveAppendix = "wrapper"
archiveClassifier = "src"
from("somedir")
}
tasks.register("echoNames") {
val projectNameString = project.name
val archiveFileName = myZip.flatMap { it.archiveFileName }
val myOtherArchiveFileName = myOtherZip.flatMap { it.archiveFileName }
doLast {
println("Project name: $projectNameString")
println(archiveFileName.get())
println(myOtherArchiveFileName.get())
}
}plugins {
id 'base'
}
version = 1.0
base {
archivesName = "gradle"
distsDirectory = layout.buildDirectory.dir('custom-dist')
libsDirectory = layout.buildDirectory.dir('custom-libs')
}
def myZip = tasks.register('myZip', Zip) {
from 'somedir'
}
def myOtherZip = tasks.register('myOtherZip', Zip) {
archiveAppendix = 'wrapper'
archiveClassifier = 'src'
from 'somedir'
}
tasks.register('echoNames') {
def projectNameString = project.name
def archiveFileName = myZip.flatMap { it.archiveFileName }
def myOtherArchiveFileName = myOtherZip.flatMap { it.archiveFileName }
doLast {
println "Project name: $projectNameString"
println archiveFileName.get()
println myOtherArchiveFileName.get()
}
}$ ./gradlew -q echoNamesProject name: archives-changed-base-name
gradle-1.0.zip
gradle-wrapper-1.0-src.zipYou can find all the possible archive task properties in the API documentation for AbstractArchiveTask. Still, we have also summarized the main ones here:
archiveFileName—Property<String>, default:archiveBaseName-archiveAppendix-archiveVersion-archiveClassifier.archiveExtension-
The complete file name of the generated archive. If any of the properties in the default value are empty, their '-' separator is dropped.
archiveFile—Provider<RegularFile>, read-only, default:destinationDirectory/archiveFileName-
The absolute file path of the generated archive.
destinationDirectory—DirectoryProperty, default: depends on archive type-
The target directory in which to put the generated archive. By default, JARs and WARs go into
layout.buildDirectory.dir("libs"). ZIPs and TARs go intolayout.buildDirectory.dir("distributions"). archiveBaseName—Property<String>, default:project.name-
The base name portion of the archive file name, typically a project name or some other descriptive name for what it contains.
archiveAppendix—Property<String>, default:null-
The appendix portion of the archive file name that comes immediately after the base name. It is typically used to distinguish between different forms of content, such as code and docs, or a minimal distribution versus a full or complete one.
archiveVersion—Property<String>, default:project.version-
The version portion of the archive file name, typically in the form of a normal project or product version.
archiveClassifier—Property<String>, default:null-
The classifier portion of the archive file name. Often used to distinguish between archives that target different platforms.
archiveExtension—Property<String>, default: depends on archive type and compression type-
The filename extension for the archive. By default, this is set based on the archive task type and the compression type (if you’re creating a TAR). Will be one of:
zip,jar,war,tar,tgzortbz2. You can of course set this to a custom extension if you wish.
Sharing content between multiple archives
As described in the CopySpec section above, you can use the Project.copySpec(org.gradle.api.Action) method to share content between archives.
Using archives as file trees
An archive is a directory and file hierarchy packed into a single file. In other words, it’s a special case of a file tree, and that’s exactly how Gradle treats archives.
Instead of using the fileTree() method, which only works on normal file systems, you use the Project.zipTree(java.lang.Object) and Project.tarTree(java.lang.Object) methods to wrap archive files of the corresponding type (note that JAR, WAR and EAR files are ZIPs).
Both methods return FileTree instances that you can then use in the same way as normal file trees.
For example, you can extract some or all of the files of an archive by copying its contents to some directory on the file system.
Or you can merge one archive into another.
Here are some simple examples of creating archive-based file trees:
// Create a ZIP file tree using path
val zip: FileTree = zipTree("someFile.zip")
// Create a TAR file tree using path
val tar: FileTree = tarTree("someFile.tar")
// tar tree attempts to guess the compression based on the file extension
// however if you must specify the compression explicitly you can:
val someTar: FileTree = tarTree(resources.gzip("someTar.ext"))// Create a ZIP file tree using path
FileTree zip = zipTree('someFile.zip')
// Create a TAR file tree using path
FileTree tar = tarTree('someFile.tar')
//tar tree attempts to guess the compression based on the file extension
//however if you must specify the compression explicitly you can:
FileTree someTar = tarTree(resources.gzip('someTar.ext'))You can see a practical example of extracting an archive file in the unpacking archives section below.
Reproducible archives
|
Note
|
Starting with Gradle 9, archives are reproducible by default. |
It’s desirable to recreate archives exactly the same, byte for byte, on different machines. Building an artifact from source code should produce the same result no matter when and where it is built. This is necessary for projects like reproducible-builds.org.
Reproducing the same byte-for-byte archive generally poses some challenges since the order of the files in an archive can be influenced by the underlying file system. Each time a ZIP, TAR, JAR, WAR or EAR is built from source, the order of the files inside the archive may change. Files on disk can also have different timestamps or permissions depending on the environment.
Starting with Gradle 9.0.0, all AbstractArchiveTask (e.g. Jar, Zip) tasks produce reproducible archives by default:
-
File order in the archive is deterministic
-
Files have fixed timestamps (exact values depend on the archive type)
-
Directories have fixed permissions set to
0755 -
Files have fixed permissions set to
0644
You can further customize the directory permissions or file permissions while keeping the archives reproducible.
Preserve file system-defined aspects
If desired, you can revert individual aspects of reproducible archives.
tasks.withType<AbstractArchiveTask>().configureEach {
// Use file timestamps from the file system
isPreserveFileTimestamps = true // (1)
// Make file order based on the file system
isReproducibleFileOrder = false // (2)
// Use permissions from the file system
useFileSystemPermissions() // (3)
}tasks.withType(AbstractArchiveTask).configureEach {
// Use file timestamps from the file system
preserveFileTimestamps = true // (1)
// Make file order based on the file system
reproducibleFileOrder = false // (2)
// Use permissions from the file system
useFileSystemPermissions() // (3)
}-
Set
isPreserveFileTimestampstotrueto use timestamp values from the file system. -
Set
isReproducibleFileOrdertofalseto preserve the file order based on the file system. -
Call
useFileSystemPermissions()to preserve the permissions from the file system.
In case the file system is already the source of truth for the permissions, e.g., via the version control tools, you can preserve the permissions across all archives tasks by configuring a property:
org.gradle.archives.use-file-system-permissions=truePermissions for files inside archives
Setting file permissions in Gradle archives is done in the same way as when copying file, see Setting file permissions for details.
The main difference is that archive tasks by default set the permissions of files and directories in the archive to fixed values, which are 0644 for files and 0755 for directories for reproducibility.
We recognize two main cases, where users may want to change the permissions of files and directories in archives:
-
Case where the file system is already the source of truth for the permissions. For such configuration see Preserve file system-defined aspects section.
-
Case where the permissions of files and directories in the archive should be set to specific values, for example to set the executable bit on a script file. For such configuration see Setting file permissions section.
Unpacking archives
Archives are effectively self-contained file systems, so unpacking them is a case of copying the files from that file system onto the local file system — or even into another archive. Gradle enables this by providing some wrapper functions that make archives available as hierarchical collections of files (file trees).
Using Project.zipTree and Project.tarTree
The two functions of interest are Project.zipTree(java.lang.Object) and Project.tarTree(java.lang.Object), which produce a FileTree from a corresponding archive file.
That file tree can then be used in a from() specification, like so:
tasks.register<Copy>("unpackFiles") {
from(zipTree("src/resources/thirdPartyResources.zip"))
into(layout.buildDirectory.dir("resources"))
}tasks.register('unpackFiles', Copy) {
from zipTree("src/resources/thirdPartyResources.zip")
into layout.buildDirectory.dir("resources")
}As with a normal copy, you can control which files are unpacked via filters and even rename files as they are unpacked.
More advanced processing can be handled by the eachFile() method.
For example, you might need to extract different subtrees of the archive into different paths within the destination directory.
The following sample uses the method to extract the files within the archive’s libs directory into the root destination directory, rather than into a libs subdirectory:
tasks.register<Copy>("unpackLibsDirectory") {
from(zipTree("src/resources/thirdPartyResources.zip")) {
include("libs/**") // (1)
eachFile {
relativePath = RelativePath(true, *relativePath.segments.drop(1).toTypedArray()) // (2)
}
includeEmptyDirs = false // (3)
}
into(layout.buildDirectory.dir("resources"))
}tasks.register('unpackLibsDirectory', Copy) {
from(zipTree("src/resources/thirdPartyResources.zip")) {
include "libs/**" // (1)
eachFile { fcd ->
fcd.relativePath = new RelativePath(true, fcd.relativePath.segments.drop(1)) // (2)
}
includeEmptyDirs = false // (3)
}
into layout.buildDirectory.dir("resources")
}-
Extracts only the subset of files that reside in the
libsdirectory -
Remaps the path of the extracting files into the destination directory by dropping the
libssegment from the file path -
Ignores the empty directories resulting from the remapping, see Caution note below
|
Caution
|
You can not change the destination path of empty directories with this technique. You can learn more in this issue. |
If you’re a Java developer wondering why there is no jarTree() method, that’s because zipTree() works perfectly well for JARs, WARs, and EARs.
Creating "uber" or "fat" JARs
In Java, applications and their dependencies were typically packaged as separate JARs within a single distribution archive. That still happens, but another approach that is now common is placing the classes and resources of the dependencies directly into the application JAR, creating what is known as an Uber or fat JAR.
Creating "uber" or "fat" JARs in Gradle involves packaging all dependencies into a single JAR file, making it easier to distribute and run the application.
Using the Shadow Plugin
Gradle does not have full built-in support for creating uber JARs, but you can use third-party plugins like the Shadow plugin (com.gradleup.shadow) to achieve this.
This plugin packages your project classes and dependencies into a single JAR file.
Using Project.zipTree() and the Jar task
To copy the contents of other JAR files into the application JAR, use the Project.zipTree(java.lang.Object) method and the Jar task.
This is demonstrated by the uberJar task in the following example:
plugins {
java
}
version = "1.0.0"
repositories {
mavenCentral()
}
dependencies {
implementation("commons-io:commons-io:2.6")
}
tasks.register<Jar>("uberJar") {
archiveClassifier = "uber"
from(sourceSets.main.get().output)
dependsOn(configurations.runtimeClasspath)
from({
configurations.runtimeClasspath.get().filter { it.name.endsWith("jar") }.map { zipTree(it) }
})
}plugins {
id 'java'
}
version = '1.0.0'
repositories {
mavenCentral()
}
dependencies {
implementation 'commons-io:commons-io:2.6'
}
tasks.register('uberJar', Jar) {
archiveClassifier = 'uber'
from sourceSets.main.output
dependsOn configurations.runtimeClasspath
from {
configurations.runtimeClasspath.findAll { it.name.endsWith('jar') }.collect { zipTree(it) }
}
}In this case, we’re taking the runtime dependencies of the project — configurations.runtimeClasspath.files — and wrapping each of the JAR files with the zipTree() method.
The result is a collection of ZIP file trees, the contents of which are copied into the uber JAR alongside the application classes.
Creating directories
Many tasks need to create directories to store the files they generate, which is why Gradle automatically manages this aspect of tasks when they explicitly define file and directory outputs. All core Gradle tasks ensure that any output directories they need are created, if necessary, using this mechanism.
Using File.mkdirs and Files.createDirectories
In cases where you need to create a directory manually, you can use the standard Files.createDirectories or File.mkdirs methods from within your build scripts or custom task implementations.
Here is a simple example that creates a single images directory in the project folder:
tasks.register("ensureDirectory") {
// Store target directory into a variable to avoid project reference in the configuration cache
val directory = file("images")
doLast {
Files.createDirectories(directory.toPath())
}
}tasks.register('ensureDirectory') {
// Store target directory into a variable to avoid project reference in the configuration cache
def directory = file("images")
doLast {
Files.createDirectories(directory.toPath())
}
}As described in the Apache Ant manual, the mkdir task will automatically create all necessary directories in the given path.
It will do nothing if the directory already exists.
Using Project.mkdir
You can create directories in Gradle using the mkdir method, which is available in the Project object.
This method takes a File object or a String representing the path of the directory to be created:
tasks.register("createDirs") {
doLast {
mkdir("src/main/resources")
mkdir(file("build/generated"))
// Create multiple dirs
mkdir(files("src/main/resources", "src/test/resources"))
// Check dir existence
val dir = file("src/main/resources")
if (!dir.exists()) {
mkdir(dir)
}
}
}tasks.register('createDirs') {
doLast {
mkdir 'src/main/resources'
mkdir file('build/generated')
// Create multiple dirs
mkdir files(['src/main/resources', 'src/test/resources'])
// Check dir existence
def dir = file('src/main/resources')
if (!dir.exists()) {
mkdir dir
}
}
}Installing executables
When you are building a standalone executable, you may want to install this file on your system, so it ends up in your path.
Using the Copy task
You can use a Copy task to install the executable into shared directories like /usr/local/bin.
The installation directory probably contains many other executables, some of which may even be unreadable by Gradle.
To support the unreadable files in the Copy task’s destination directory and to avoid time consuming up-to-date checks, you can use Task.doNotTrackState():
tasks.register<Copy>("installExecutable") {
from("build/my-binary")
into("/usr/local/bin")
doNotTrackState("Installation directory contains unrelated files")
}tasks.register("installExecutable", Copy) {
from "build/my-binary"
into "/usr/local/bin"
doNotTrackState("Installation directory contains unrelated files")
}Deploying single files into application servers
Deploying a single file to an application server typically refers to the process of transferring a packaged application artifact, such as a WAR file, to the application server’s deployment directory.
Using the Copy task
When working with application servers, you can use a Copy task to deploy the application archive (e.g. a WAR file).
Since you are deploying a single file, the destination directory of the Copy is the whole deployment directory.
The deployment directory sometimes does contain unreadable files like named pipes, so Gradle may have problems doing up-to-date checks.
In order to support this use-case, you can use Task.doNotTrackState():
plugins {
war
}
tasks.register<Copy>("deployToTomcat") {
from(tasks.war)
into(layout.projectDirectory.dir("tomcat/webapps"))
doNotTrackState("Deployment directory contains unreadable files")
}plugins {
id 'war'
}
tasks.register("deployToTomcat", Copy) {
from war
into layout.projectDirectory.dir('tomcat/webapps')
doNotTrackState("Deployment directory contains unreadable files")
}JVM BUILDS
Building Java & JVM projects
Gradle uses a convention-over-configuration approach to building JVM-based projects that borrows several conventions from Apache Maven. In particular, it uses the same default directory structure for source files and resources, and it works with Maven-compatible repositories.
We will look at Java projects in detail in this chapter, but most of the topics apply to other supported JVM languages as well, such as Kotlin, Groovy and Scala.
|
Note
|
The example in this section use the Java Library Plugin. However the described features are shared by all JVM plugins. Specifics of the different plugins are available in their dedicated documentation. |
Introduction
The simplest build script for a Java project applies the Java Library Plugin and optionally sets the project version and selects the Java toolchain to use:
plugins {
`java-library`
}
java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}
version = "1.2.1"plugins {
id 'java-library'
}
java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}
version = '1.2.1'By applying the Java Library Plugin, you get a whole host of features:
-
A
compileJavatask that compiles all the Java source files under src/main/java -
A
compileTestJavatask for source files under src/test/java -
A
testtask that runs the tests from src/test/java -
A
jartask that packages themaincompiled classes and resources from src/main/resources into a single JAR named <project>-<version>.jar -
A
javadoctask that generates Javadoc for themainclasses
This isn’t sufficient to build any non-trivial Java project — at the very least, you’ll probably have some file dependencies. But it means that your build script only needs the information that is specific to your project.
|
Note
|
Although the properties in the example are optional, we recommend that you specify them in your projects. Configuring the toolchain protects against problems with the project being built with different Java versions. The version string is important for tracking the progression of the project. The project version is also used in archive names by default. |
The Java Library Plugin also integrates the above tasks into the standard Base Plugin lifecycle tasks:
-
jaris attached toassemble -
testis attached tocheck
The rest of the chapter explains the different avenues for customizing the build to your requirements. You will also see later how to adjust the build for libraries, applications, web apps and enterprise apps.
Declaring your source files via source sets
Gradle’s Java support was the first to introduce a new concept for building source-based projects: source sets. The main idea is that source files and resources are often logically grouped by type, such as application code, unit tests and integration tests. Each logical group typically has its own sets of file dependencies, classpaths, and more. Significantly, the files that form a source set don’t have to be located in the same directory!
Source sets are a powerful concept that tie together several aspects of compilation:
-
the source files and where they’re located
-
the compilation classpath, including any required dependencies (via Gradle configurations)
-
where the compiled class files are placed
You can see how these relate to one another in this diagram:
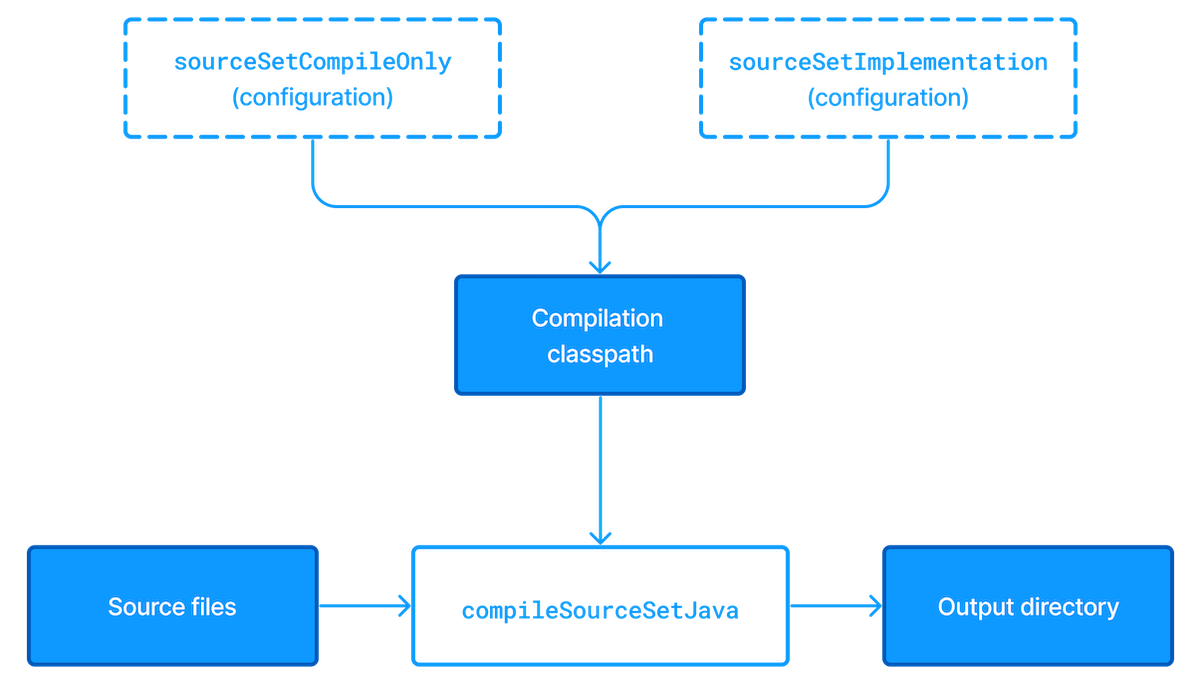
The shaded boxes represent properties of the source set itself.
On top of that, the Java Library Plugin automatically creates a compilation task for every source set you or a plugin defines — named compileSourceSetJava — and several dependency configurations.
main source setMost language plugins, Java included, automatically create a source set called main, which is used for the project’s production code. This source set is special in that its name is not included in the names of the configurations and tasks, hence why you have just a compileJava task and compileOnly and implementation configurations rather than compileMainJava, mainCompileOnly and mainImplementation respectively.
Java projects typically include resources other than source files, such as properties files, that may need processing — for example by replacing tokens within the files — and packaging within the final JAR.
The Java Library Plugin handles this by automatically creating a dedicated task for each defined source set called processSourceSetResources (or processResources for the main source set).
The following diagram shows how the source set fits in with this task:

As before, the shaded boxes represent properties of the source set, which in this case comprises the locations of the resource files and where they are copied to.
In addition to the main source set, the Java Library Plugin defines a test source set that represents the project’s tests.
This source set is used by the test task, which runs the tests.
You can learn more about this task and related topics in the Java testing chapter.
Projects typically use this source set for unit tests, but you can also use it for integration, acceptance and other types of test if you wish. The alternative approach is to define a new source set for each of your other test types, which is typically done for one or both of the following reasons:
-
You want to keep the tests separate from one another for aesthetics and manageability
-
The different test types require different compilation or runtime classpaths or some other difference in setup
You can see an example of this approach in the Java testing chapter, which shows you how to set up integration tests in a project.
You’ll learn more about source sets and the features they provide in:
Source set configurations
When a source set is created, it also creates a number of configurations as described above. Build logic should not attempt to create or access these configurations until they are first created by the source set.
When creating a source set, if one of these automatically created configurations already exists, and its role is different than the role that the source set would have assigned, the build will fail.
The build below demonstrates this behavior.
configurations {
create("myCodeCompileClasspath")
}
sourceSets {
create("myCode")
}configurations {
myCodeCompileClasspath
}
sourceSets {
myCode
}In this case, the build will fail.
Following two simple best practices will avoid this problem:
-
Don’t create configurations with names that will be used by source sets, such as names ending in
Api,Implementation,ApiElements,CompileOnly,CompileOnlyApi,RuntimeOnly,RuntimeClasspathorRuntimeElements. (This list is not exhaustive.) -
Create any custom source sets prior to any custom configurations.
Remember that any time you reference a configuration within the configurations container - with or without supplying an initialization action - Gradle will create the configuration.
Sometimes when using the Groovy DSL this creation is not obvious, as in the example below, where myCustomConfiguration is created prior to the call to extendsFrom.
configurations {
myCustomConfiguration.extendsFrom(implementation)
}Managing your dependencies
The vast majority of Java projects rely on libraries, so managing a project’s dependencies is an important part of building a Java project. Dependency management is a big topic, so we will focus on the basics for Java projects here. If you’d like to dive into the detail, check out the introduction to dependency management.
Specifying the dependencies for your Java project requires just three pieces of information:
-
Which dependency you need, such as a name and version
-
What it’s needed for, e.g. compilation or running
-
Where to look for it
The first two are specified in a dependencies {} block and the third in a repositories {} block. For example, to tell Gradle that your project requires version 3.6.7 of Hibernate Core to compile and run your production code, and that you want to download the library from the Maven Central repository, you can use the following fragment:
repositories {
mavenCentral()
}
dependencies {
implementation("org.hibernate:hibernate-core:3.6.7.Final")
}repositories {
mavenCentral()
}
dependencies {
implementation 'org.hibernate:hibernate-core:3.6.7.Final'
}The Gradle terminology for the three elements is as follows:
-
Repository (ex:
mavenCentral()) — where to look for the modules you declare as dependencies -
Configuration (ex:
implementation) — a named collection of dependencies, grouped together for a specific goal such as compiling or running a module — a more flexible form of Maven scopes -
Module coordinate (ex:
org.hibernate:hibernate-core-3.6.7.Final) — the ID of the dependency, usually in the form '<group>:<module>:<version>' (or '<groupId>:<artifactId>:<version>' in Maven terminology)
As far as configurations go, the main ones of interest are:
-
compileOnly— for dependencies that are necessary to compile your production code but shouldn’t be part of the runtime classpath -
implementation(supersedescompile) — used for compilation and runtime -
runtimeOnly(supersedesruntime) — only used at runtime, not for compilation -
testCompileOnly— same ascompileOnlyexcept it’s for the tests -
testImplementation— test equivalent ofimplementation -
testRuntimeOnly— test equivalent ofruntimeOnly
You can learn more about these and how they relate to one another in the plugin reference chapter.
Be aware that the Java Library Plugin offers two additional configurations — api and compileOnlyApi — for dependencies that are required for compiling both the module and any modules that depend on it.
compile configuration?The Java Library Plugin has historically used the compile configuration for dependencies that are required to both compile and run a project’s production code.
It is now deprecated, and will issue warnings when used, because it doesn’t distinguish between dependencies that impact the public API of a Java library project and those that don’t.
You can learn more about the importance of this distinction in Building Java libraries.
We have only scratched the surface here, so we recommend that you read the dedicated dependency management chapters once you’re comfortable with the basics of building Java projects with Gradle. Some common scenarios that require further reading include:
-
Defining a custom Maven- or Ivy-compatible repository
-
Using dependencies from a local filesystem directory
-
Declaring dependencies with changing (e.g. SNAPSHOT) and dynamic (range) versions
-
Declaring a sibling project as a dependency
-
Testing your fixes to a 3rd-party dependency via composite builds (a better alternative to publishing to and consuming from Maven Local)
You’ll discover that Gradle has a rich API for working with dependencies — one that takes time to master, but is straightforward to use for common scenarios.
Compiling your code
Compiling both your production and test code can be trivially easy if you follow the conventions:
-
Put your production source code under the src/main/java directory
-
Put your test source code under src/test/java
-
Declare your production compile dependencies in the
compileOnlyorimplementationconfigurations (see previous section) -
Declare your test compile dependencies in the
testCompileOnlyortestImplementationconfigurations -
Run the
compileJavatask for the production code andcompileTestJavafor the tests
Other JVM language plugins, such as the one for Groovy, follow the same pattern of conventions. We recommend that you follow these conventions wherever possible, but you don’t have to. There are several options for customization, as you’ll see next.
Customizing file and directory locations
Imagine you have a legacy project that uses an src directory for the production code and test for the test code. The conventional directory structure won’t work, so you need to tell Gradle where to find the source files. You do that via source set configuration.
Each source set defines where its source code resides, along with the resources and the output directory for the class files. You can override the convention values by using the following syntax:
sourceSets {
main {
java {
setSrcDirs(listOf("src"))
}
}
test {
java {
setSrcDirs(listOf("test"))
}
}
}sourceSets {
main {
java {
srcDirs = ['src']
}
}
test {
java {
srcDirs = ['test']
}
}
}Now Gradle will only search directly in src and test for the respective source code. What if you don’t want to override the convention, but simply want to add an extra source directory, perhaps one that contains some third-party source code you want to keep separate? The syntax is similar:
sourceSets {
main {
java {
srcDir("thirdParty/src/main/java")
}
}
}sourceSets {
main {
java {
srcDir 'thirdParty/src/main/java'
}
}
}Crucially, we’re using the method srcDir() here to append a directory path, whereas setting the srcDirs property replaces any existing values. This is a common convention in Gradle: setting a property replaces values, while the corresponding method appends values.
You can see all the properties and methods available on source sets in the DSL reference for SourceSet and SourceDirectorySet. Note that srcDirs and srcDir() are both on SourceDirectorySet.
Changing compiler options
Most of the compiler options are accessible through the corresponding task, such as compileJava and compileTestJava. These tasks are of type JavaCompile, so read the task reference for an up-to-date and comprehensive list of the options.
For example, if you want to use a separate JVM process for the compiler and prevent compilation failures from failing the build, you can use this configuration:
tasks.compileJava {
options.isIncremental = true
options.isFork = true
options.isFailOnError = false
}compileJava {
options.incremental = true
options.fork = true
options.failOnError = false
}That’s also how you can change the verbosity of the compiler, disable debug output in the byte code and configure where the compiler can find annotation processors.
Targeting a specific Java version
By default, Gradle will compile Java code to the language level of the JVM running Gradle. If you need to target a specific version of Java when compiling, Gradle provides multiple options:
-
Using Java toolchains is a preferred way to target a language version.
A toolchain uniformly handles compilation, execution and Javadoc generation, and it can be configured on the project level. -
Using
releaseproperty is possible starting from Java 10.
Selecting a Java release makes sure that compilation is done with the configured language level and against the JDK APIs from that Java version. -
Using
sourceCompatibilityandtargetCompatibilityproperties.
Although not generally advised, these options were historically used to configure the Java version during compilation.
Using toolchains
When Java code is compiled using a specific toolchain, the actual compilation is carried out by a compiler of the specified Java version. The compiler provides access to the language features and JDK APIs for the requested Java language version.
In the simplest case, the toolchain can be configured for a project using the java extension.
This way, not only compilation benefits from it, but also other tasks such as test and javadoc will also consistently use the same toolchain.
java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}You can learn more about this in the Java toolchains guide.
Using Java release version
Setting the release flag ensures the specified language level is used regardless of which compiler actually performs the compilation. To use this feature, the compiler must support the requested release version. It is possible to specify an earlier release version while compiling with a more recent toolchain.
Gradle supports using the release flag from Java 10. It can be configured on the compilation task as follows.
tasks.compileJava {
options.release = 7
}compileJava {
options.release = 7
}The release flag provides guarantees similar to toolchains. It validates that the Java sources are not using language features introduced in later Java versions, and also that the code does not access APIs from more recent JDKs. The bytecode produced by the compiler also corresponds to the requested Java version, meaning that the compiled code cannot be executed on older JVMs.
The release option of the Java compiler was introduced in Java 9.
However, using this option with Gradle is only possible starting with Java 10, due to a bug in Java 9.
Using Java compatibility options
|
Warning
|
Using compatibility properties can lead to runtime failures when executing compiled code due to weaker guarantees they provide. Instead, consider using toolchains or the release flag. |
The sourceCompatibility and targetCompatibility options correspond to the Java compiler options -source and -target.
They are considered a legacy mechanism for targeting a specific Java version.
However, these options do not protect against the use of APIs introduced in later Java versions.
sourceCompatibility-
Defines the language version of Java used in your source files.
targetCompatibility-
Defines the minimum JVM version your code should run on, i.e. it determines the version of the bytecode generated by the compiler.
These options can be set per JavaCompile task, or on the java { } extension for all compile tasks, using properties with the same names.
Targeting Java 6 and Java 7
Gradle itself can only run on a JVM with Java version 8 or higher. However, Gradle still supports compiling, testing, generating Javadocs and executing applications for Java 6 and Java 7. Java 5 and below are not supported.
|
Note
|
If using Java 10+, leveraging the release flag might be an easier solution, see above.
|
To use Java 6 or Java 7, the following tasks need to be configured:
-
JavaCompiletask to fork and use the correct Java home -
Javadoctask to use the correctjavadocexecutable -
Testand theJavaExectask to use the correctjavaexecutable.
With the usage of Java toolchains, this can be done as follows:
java {
toolchain {
languageVersion = JavaLanguageVersion.of(7)
}
}java {
toolchain {
languageVersion = JavaLanguageVersion.of(7)
}
}The only requirement is that Java 7 is installed and has to be either in a location Gradle can detect automatically or explicitly configured.
Compiling independent sources separately
Most projects have at least two independent sets of sources: the production code and the test code. Gradle already makes this scenario part of its Java convention, but what if you have other sets of sources? One of the most common scenarios is when you have separate integration tests of some form or other. In that case, a custom source set may be just what you need.
You can see a complete example for setting up integration tests in the Java testing chapter. You can set up other source sets that fulfil different roles in the same way. The question then becomes: when should you define a custom source set?
To answer that question, consider whether the sources:
-
Need to be compiled with a unique classpath
-
Generate classes that are handled differently from the
mainandtestones -
Form a natural part of the project
If your answer to both 3 and either one of the others is yes, then a custom source set is probably the right approach. For example, integration tests are typically part of the project because they test the code in main. In addition, they often have either their own dependencies independent of the test source set or they need to be run with a custom Test task.
Other common scenarios are less clear cut and may have better solutions. For example:
-
Separate API and implementation JARs — it may make sense to have these as separate projects, particularly if you already have a multi-project build
-
Generated sources — if the resulting sources should be compiled with the production code, add their path(s) to the
mainsource set and make sure that thecompileJavatask depends on the task that generates the sources
If you’re unsure whether to create a custom source set or not, then go ahead and do so. It should be straightforward and if it’s not, then it’s probably not the right tool for the job.
Debugging compiling errors
Gradle provides detailed reporting for compilation failures.
If a compilation task fails, the summary of errors is displayed in the following locations:
-
The task’s output, providing immediate context for the error.
-
The "What went wrong" summary at the bottom of the build output, consolidated with all other failures for easy reference.
* What went wrong:
Execution failed for task ':project1:compileJava'.
> Compilation failed; see the compiler output below.
Java compilation warning
sample-project/src/main/java/Problem1.java:6: warning: [cast] redundant cast to String
var warning = (String)"warning";
^
Java compilation error
sample-project/src/main/java/Problem2.java:6: error: incompatible types: int cannot be converted to String
String a = 1;
^This reporting feature works with the —continue flag.
Managing resources
Many Java projects make use of resources beyond source files, such as images, configuration files and localization data. Sometimes these files simply need to be packaged unchanged and sometimes they need to be processed as template files or in some other way. Either way, the Java Library Plugin adds a specific Copy task for each source set that handles the processing of its associated resources.
The task’s name follows the convention of processSourceSetResources — or processResources for the main source set — and it will automatically copy any files in src/[sourceSet]/resources to a directory that will be included in the production JAR. This target directory will also be included in the runtime classpath of the tests.
Since processResources is an instance of the ProcessResources task, you can perform any of the processing described in the Working With Files chapter.
Java properties files and reproducible builds
You can easily create Java properties files via the WriteProperties task, which fixes a well-known problem with Properties.store() that can reduce the usefulness of incremental builds.
The standard Java API for writing properties files produces a unique file every time, even when the same properties and values are used, because it includes a timestamp in the comments. Gradle’s WriteProperties task generates exactly the same output byte-for-byte if none of the properties have changed. This is achieved by a few tweaks to how a properties file is generated:
-
no timestamp comment is added to the output
-
the line separator is system independent, but can be configured explicitly (it defaults to
'\n') -
the properties are sorted alphabetically
Sometimes it can be desirable to recreate archives in a byte for byte way on different machines. You want to be sure that building an artifact from source code produces the same result, byte for byte, no matter when and where it is built. This is necessary for projects like reproducible-builds.org.
These tweaks not only lead to better incremental build integration, but they also help with reproducible builds. In essence, reproducible builds guarantee that you will see the same results from a build execution — including test results and production binaries — no matter when or on what system you run it.
Running tests
Alongside providing automatic compilation of unit tests in src/test/java, the Java Library Plugin has native support for running tests that use JUnit 3, 4 & 5 (JUnit 5 support came in Gradle 4.6) and TestNG. You get:
-
An automatic
testtask of type Test, using thetestsource set -
An HTML test report that includes the results from all
Testtasks that run -
Easy filtering of which tests to run
-
Fine-grained control over how the tests are run
-
The opportunity to create your own test execution and test reporting tasks
You do not get a Test task for every source set you declare, since not every source set represents tests! That’s why you typically need to create your own Test tasks for things like integration and acceptance tests if they can’t be included with the test source set.
As there is a lot to cover when it comes to testing, the topic has its own chapter in which we look at:
-
How tests are run
-
How to run a subset of tests via filtering
-
How Gradle discovers tests
-
How to configure test reporting and add your own reporting tasks
-
How to make use of specific JUnit and TestNG features
You can also learn more about configuring tests in the DSL reference for Test.
Packaging and publishing
How you package and potentially publish your Java project depends on what type of project it is. Libraries, applications, web applications and enterprise applications all have differing requirements. In this section, we will focus on the bare bones provided by the Java Library Plugin.
By default, the Java Library Plugin provides the jar task that packages all the compiled production classes and resources into a single JAR.
This JAR is also automatically built by the assemble task.
Furthermore, the plugin can be configured to provide the javadocJar and sourcesJar tasks to package Javadoc and source code if so desired.
If a publishing plugin is used, these tasks will automatically run during publishing or can be called directly.
java {
withJavadocJar()
withSourcesJar()
}java {
withJavadocJar()
withSourcesJar()
}If you want to create an 'uber' (AKA 'fat') JAR, then you can use a task definition like this:
plugins {
java
}
version = "1.0.0"
repositories {
mavenCentral()
}
dependencies {
implementation("commons-io:commons-io:2.6")
}
tasks.register<Jar>("uberJar") {
archiveClassifier = "uber"
from(sourceSets.main.get().output)
dependsOn(configurations.runtimeClasspath)
from({
configurations.runtimeClasspath.get().filter { it.name.endsWith("jar") }.map { zipTree(it) }
})
}plugins {
id 'java'
}
version = '1.0.0'
repositories {
mavenCentral()
}
dependencies {
implementation 'commons-io:commons-io:2.6'
}
tasks.register('uberJar', Jar) {
archiveClassifier = 'uber'
from sourceSets.main.output
dependsOn configurations.runtimeClasspath
from {
configurations.runtimeClasspath.findAll { it.name.endsWith('jar') }.collect { zipTree(it) }
}
}See Jar for more details on the configuration options available to you.
And note that you need to use archiveClassifier rather than archiveAppendix here for correct publication of the JAR.
You can use one of the publishing plugins to publish the JARs created by a Java project:
Modifying the JAR manifest
Each instance of the Jar, War and Ear tasks has a manifest property that allows you to customize the MANIFEST.MF file that goes into the corresponding archive. The following example demonstrates how to set attributes in the JAR’s manifest:
tasks.jar {
manifest {
attributes(
"Implementation-Title" to "Gradle",
"Implementation-Version" to archiveVersion
)
}
}jar {
manifest {
attributes("Implementation-Title": "Gradle",
"Implementation-Version": archiveVersion)
}
}See Manifest for the configuration options it provides.
You can also create standalone instances of Manifest. One reason for doing so is to share manifest information between JARs. The following example demonstrates how to share common attributes between JARs:
val sharedManifest = java.manifest {
attributes (
"Implementation-Title" to "Gradle",
"Implementation-Version" to version
)
}
tasks.register<Jar>("fooJar") {
manifest = java.manifest {
from(sharedManifest)
}
}def sharedManifest = java.manifest {
attributes("Implementation-Title": "Gradle",
"Implementation-Version": version)
}
tasks.register('fooJar', Jar) {
manifest = java.manifest {
from sharedManifest
}
}Another option available to you is to merge manifests into a single Manifest object. Those source manifests can take the form of a text for or another Manifest object. In the following example, the source manifests are all text files except for sharedManifest, which is the Manifest object from the previous example:
tasks.register<Jar>("barJar") {
manifest {
attributes("key1" to "value1")
from(sharedManifest, "src/config/basemanifest.txt")
from(listOf("src/config/javabasemanifest.txt", "src/config/libbasemanifest.txt")) {
eachEntry(Action<ManifestMergeDetails> {
if (baseValue != mergeValue) {
value = baseValue
}
if (key == "foo") {
exclude()
}
})
}
}
}tasks.register('barJar', Jar) {
manifest {
attributes key1: 'value1'
from sharedManifest, 'src/config/basemanifest.txt'
from(['src/config/javabasemanifest.txt', 'src/config/libbasemanifest.txt']) {
eachEntry { details ->
if (details.baseValue != details.mergeValue) {
details.value = baseValue
}
if (details.key == 'foo') {
details.exclude()
}
}
}
}
}Manifests are merged in the order they are declared in the from statement. If the base manifest and the merged manifest both define values for the same key, the merged manifest wins by default. You can fully customize the merge behavior by adding eachEntry actions in which you have access to a ManifestMergeDetails instance for each entry of the resulting manifest. Note that the merge is done lazily, either when generating the JAR or when Manifest.writeTo() or Manifest.getEffectiveManifest() are called.
Speaking of writeTo(), you can use that to easily write a manifest to disk at any time, like so:
tasks.jar { manifest.writeTo(layout.buildDirectory.file("mymanifest.mf")) }tasks.named('jar') { manifest.writeTo(layout.buildDirectory.file('mymanifest.mf')) }Generating API documentation
The Java Library Plugin provides a javadoc task of type Javadoc, that will generate standard Javadocs for all your production code, i.e. whatever source is in the main source set.
The task supports the core Javadoc and standard doclet options described in the Javadoc reference documentation.
See CoreJavadocOptions and StandardJavadocDocletOptions for a complete list of those options.
As an example of what you can do, imagine you want to use Asciidoc syntax in your Javadoc comments. To do this, you need to add Asciidoclet to Javadoc’s doclet path. Here’s an example that does just that:
val asciidoclet = configurations.create("asciidoclet")
dependencies {
asciidoclet("org.asciidoctor:asciidoclet:1.+")
}
tasks.register("configureJavadoc") {
doLast {
tasks.javadoc {
options.doclet = "org.asciidoctor.Asciidoclet"
options.docletpath = asciidoclet.files.toList()
}
}
}
tasks.javadoc {
dependsOn("configureJavadoc")
}configurations {
asciidoclet
}
dependencies {
asciidoclet 'org.asciidoctor:asciidoclet:1.+'
}
tasks.register('configureJavadoc') {
doLast {
javadoc {
options.doclet = 'org.asciidoctor.Asciidoclet'
options.docletpath = configurations.asciidoclet.files.toList()
}
}
}
javadoc {
dependsOn configureJavadoc
}You don’t have to create a configuration for this, but it’s an elegant way to handle dependencies that are required for a unique purpose.
You might also want to create your own Javadoc tasks, for example to generate API docs for the tests:
tasks.register<Javadoc>("testJavadoc") {
source = sourceSets.test.get().allJava
}tasks.register('testJavadoc', Javadoc) {
source = sourceSets.test.allJava
}These are just two non-trivial but common customizations that you might come across.
Cleaning the build
The Java Library Plugin adds a clean task to your project by virtue of applying the Base Plugin.
This task simply deletes everything in the layout.buildDirectory directory, hence why you should always put files generated by the build in there.
The task is an instance of Delete and you can change what directory it deletes by setting its dir property.
Building JVM components
All of the specific JVM plugins are built on top of the Java Plugin. The examples above only illustrated concepts provided by this base plugin and shared with all JVM plugins.
Read on to understand which plugins fits which project type, as it is recommended to pick a specific plugin instead of applying the Java Plugin directly.
Building Java libraries
The unique aspect of library projects is that they are used (or "consumed") by other Java projects. That means the dependency metadata published with the JAR file — usually in the form of a Maven POM — is crucial. In particular, consumers of your library should be able to distinguish between two different types of dependencies: those that are only required to compile your library and those that are also required to compile the consumer.
Gradle manages this distinction via the Java Library Plugin, which introduces an api configuration in addition to the implementation one covered in this chapter. If the types from a dependency appear in public fields or methods of your library’s public classes, then that dependency is exposed via your library’s public API and should therefore be added to the api configuration. Otherwise, the dependency is an internal implementation detail and should be added to implementation.
If you’re unsure of the difference between an API and implementation dependency, the Java Library Plugin chapter has a detailed explanation.
Building Java applications
Java applications packaged as a JAR aren’t set up for easy launching from the command line or a desktop environment. The Application Plugin solves the command line aspect by creating a distribution that includes the production JAR, its dependencies and launch scripts Unix-like and Windows systems.
See the plugin’s chapter for more details, but here’s a quick summary of what you get:
-
assemblecreates ZIP and TAR distributions of the application containing everything needed to run it -
A
runtask that starts the application from the build (for easy testing) -
Shell and Windows Batch scripts to start the application
Building Java web applications
Java web applications can be packaged and deployed in a number of ways depending on the technology you use. For example, you might use Spring Boot with a fat JAR or a Reactive-based system running on Netty. Whatever technology you use, Gradle and its large community of plugins will satisfy your needs. Core Gradle, though, only directly supports traditional Servlet-based web applications deployed as WAR files.
That support comes via the War Plugin, which automatically applies the Java Plugin and adds an extra packaging step that does the following:
-
Copies static resources from src/main/webapp into the root of the WAR
-
Copies the compiled production classes into a WEB-INF/classes subdirectory of the WAR
-
Copies the library dependencies into a WEB-INF/lib subdirectory of the WAR
This is done by the war task, which effectively replaces the jar task — although that task remains — and is attached to the assemble lifecycle task. See the plugin’s chapter for more details and configuration options.
There is no core support for running your web application directly from the build, but we do recommend that you try the Gretty community plugin, which provides an embedded Servlet container.
Building Java EE applications
Java enterprise systems have changed a lot over the years, but if you’re still deploying to JEE application servers, you can make use of the Ear Plugin. This adds conventions and a task for building EAR files. The plugin’s chapter has more details.
Building Java Platforms
A Java platform represents a set of dependency declarations and constraints that form a cohesive unit to be applied on consuming projects. The platform has no source and no artifact of its own. It maps in the Maven world to a BOM.
The support comes via the Java Platform plugin, which sets up the different configurations and publication components.
|
Note
|
This plugin is the exception as it does not apply the Java Plugin. |
Enabling Java preview features
|
Warning
|
Using a Java preview feature is very likely to make your code incompatible with that compiled without a feature preview. As a consequence, we strongly recommend you not to publish libraries compiled with preview features and restrict the use of feature previews to toy projects. |
To enable Java preview features for compilation, test execution and runtime, you can use the following DSL snippet:
tasks.withType<JavaCompile>().configureEach {
options.compilerArgs.add("--enable-preview")
}
tasks.withType<Test>().configureEach {
jvmArgs("--enable-preview")
}
tasks.withType<JavaExec>().configureEach {
jvmArgs("--enable-preview")
}tasks.withType(JavaCompile).configureEach {
options.compilerArgs += "--enable-preview"
}
tasks.withType(Test).configureEach {
jvmArgs += "--enable-preview"
}
tasks.withType(JavaExec).configureEach {
jvmArgs += "--enable-preview"
}Building other JVM language projects
If you want to leverage the multi language aspect of the JVM, most of what was described here will still apply.
Gradle itself provides Groovy and Scala plugins.
The plugins automatically apply support for compiling Java code and can be further enhanced by combining them with the java-library plugin.
Compilation dependency between languages
These plugins create a dependency between Groovy/Scala compilation and Java compilation (of source code in the java folder of a source set).
You can change this default behavior by adjusting the classpath of the involved compile tasks as shown in the following example:
tasks.named<AbstractCompile>("compileGroovy") {
// Groovy only needs the declared dependencies
// (and not longer the output of compileJava)
classpath = sourceSets.main.get().compileClasspath
}
tasks.named<AbstractCompile>("compileJava") {
// Java also depends on the result of Groovy compilation
// (which automatically makes it depend of compileGroovy)
classpath += files(sourceSets.main.get().groovy.classesDirectory)
}tasks.named('compileGroovy') {
// Groovy only needs the declared dependencies
// (and not longer the output of compileJava)
classpath = sourceSets.main.compileClasspath
}
tasks.named('compileJava') {
// Java also depends on the result of Groovy compilation
// (which automatically makes it depend of compileGroovy)
classpath += files(sourceSets.main.groovy.classesDirectory)
}-
By setting the
compileGroovyclasspath to be onlysourceSets.main.compileClasspath, we effectively remove the previous dependency oncompileJavathat was declared by having the classpath also take into considerationsourceSets.main.java.classesDirectory -
By adding
sourceSets.main.groovy.classesDirectoryto thecompileJavaclasspath, we effectively declare a dependency on thecompileGroovytask
All of this is possible through the use of directory properties.
Extra language support
Beyond core Gradle, there are other great plugins for more JVM languages!
Testing in Java & JVM projects
Testing on the JVM is a rich subject matter. There are many different testing libraries and frameworks, as well as many different types of test. All need to be part of the build, whether they are executed frequently or infrequently. This chapter is dedicated to explaining how Gradle handles differing requirements between and within builds, with significant coverage of how it integrates with the two most common testing frameworks: JUnit and TestNG.
It explains:
-
Ways to control how the tests are run (Test execution)
-
How to select specific tests to run (Test filtering)
-
What test reports are generated and how to influence the process (Test reporting)
-
How Gradle finds tests to run (Test detection)
-
How to make use of the major frameworks' mechanisms for grouping tests together (Test grouping)
But first, let’s look at the basics of JVM testing in Gradle.
|
Note
|
A new configuration DSL for modeling test execution phases is available via the incubating JVM Test Suite plugin. |
The basics
All JVM testing revolves around a single task type: Test. This runs a collection of test cases using any supported test library — JUnit, JUnit Platform or TestNG — and collates the results. You can then turn those results into a report via an instance of the TestReport task type.
In order to operate, the Test task type requires just two pieces of information:
-
Where to find the compiled test classes (property: Test.getTestClassesDirs())
-
The execution classpath, which should include the classes under test as well as the test library that you’re using (property: Test.getClasspath())
When you’re using a JVM language plugin — such as the Java Plugin — you will automatically get the following:
-
A dedicated
testsource set for unit tests -
A
testtask of typeTestthat runs those unit tests
The JVM language plugins use the source set to configure the task with the appropriate execution classpath and the directory containing the compiled test classes. In addition, they attach the test task to the check lifecycle task.
It’s also worth bearing in mind that the test source set automatically creates corresponding dependency configurations — of which the most useful are testImplementation and testRuntimeOnly — that the plugins tie into the test task’s classpath.
All you need to do in most cases is configure the appropriate compilation and runtime dependencies and add any necessary configuration to the test task. The following example shows a simple setup that uses JUnit Platform and changes the maximum heap size for the tests' JVM to 1 gigabyte:
dependencies {
testImplementation("org.junit.jupiter:junit-jupiter:5.7.1")
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
}
tasks.named<Test>("test") {
useJUnitPlatform()
maxHeapSize = "1G"
testLogging {
events("passed")
}
}dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter:5.7.1'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}
tasks.named('test', Test) {
useJUnitPlatform()
maxHeapSize = '1G'
testLogging {
events "passed"
}
}The Test task has many generic configuration options as well as several framework-specific ones that you can find described in JUnitOptions, JUnitPlatformOptions and TestNGOptions. We cover a significant number of them in the rest of the chapter.
If you want to set up your own Test task with its own set of test classes, then the easiest approach is to create your own source set and Test task instance, as shown in Configuring integration tests.
Test execution
Gradle executes tests in a separate ('forked') JVM, isolated from the main build process. This prevents classpath pollution and excessive memory consumption for the build process. It also allows you to run the tests with different JVM arguments than the build is using.
You can control how the test process is launched via several properties on the Test task, including the following:
maxParallelForks— default: 1-
You can run your tests in parallel by setting this property to a value greater than 1. This may make your test suites complete faster, particularly if you run them on a multi-core CPU. When using parallel test execution, make sure your tests are properly isolated from one another. Tests that interact with the filesystem are particularly prone to conflict, causing intermittent test failures.
Your tests can distinguish between parallel test processes by using the value of the
org.gradle.test.workerproperty, which is unique for each process. You can use this for anything you want, but it’s particularly useful for filenames and other resource identifiers to prevent the kind of conflict we just mentioned. forkEvery— default: 0 (no maximum)-
This property specifies the maximum number of test classes (or test definitions, for non-class-based testing) that Gradle should run on a test process before it’s disposed of and a fresh one created. This is mainly used as a way to manage leaky tests or frameworks that have static state that can’t be cleared or reset between tests.
Warning: a low value (other than 0) can severely hurt the performance of the tests
ignoreFailures— default: false-
If this property is
true, Gradle will continue with the project’s build once the tests have completed, even if some of them have failed. Note that, by default, theTesttask always executes every test that it detects, irrespective of this setting. failFast— (since Gradle 4.6) default: false-
Set this to
trueif you want the build to fail and finish as soon as one of your tests fails. This can save a lot of time when you have a long-running test suite and is particularly useful when running the build on continuous integration servers. When a build fails before all tests have run, the test reports only include the results of the tests that have completed, successfully or not.You can also enable this behavior by using the
--fail-fastcommand line option, or disable it respectively with--no-fail-fast. testLogging— default: not set-
This property represents a set of options that control which test events are logged and at what level. You can also configure other logging behavior via this property. See TestLoggingContainer for more detail.
dryRun— default: false-
If this property is
true, Gradle will simulate the execution of the tests without actually running them. This will still generate reports, allowing for inspection of what tests were selected. This can be used to verify that your test filtering configuration is correct without actually running the tests.You can also enable this behavior by using the
--test-dry-runcommand-line option, or disable it respectively with--no-test-dry-run.
See Test for details on all the available configuration options.
Test filtering
It’s a common requirement to run subsets of a test suite, such as when you’re fixing a bug or developing a new test case. Gradle provides two mechanisms to do this:
-
Filtering (the preferred option)
-
Test inclusion/exclusion
Filtering supersedes the inclusion/exclusion mechanism, but you may still come across the latter in the wild.
With Gradle’s test filtering you can select tests to run based on:
-
A fully-qualified class name or fully qualified method name, e.g.
org.gradle.SomeTest,org.gradle.SomeTest.someMethod -
A simple class name or method name if the pattern starts with an upper-case letter, e.g.
SomeTest,SomeTest.someMethod(since Gradle 4.7) -
'*' wildcard matching
You can enable filtering either in the build script or via the --tests command-line option. Here’s an example of some filters that are applied every time the build runs:
tasks.test {
filter {
//include specific method in any of the tests
includeTestsMatching("*UiCheck")
//include all tests from package
includeTestsMatching("org.gradle.internal.*")
//include all integration tests
includeTestsMatching("*IntegTest")
}
}test {
filter {
//include specific method in any of the tests
includeTestsMatching "*UiCheck"
//include all tests from package
includeTestsMatching "org.gradle.internal.*"
//include all integration tests
includeTestsMatching "*IntegTest"
}
}For more details and examples of declaring filters in the build script, please see the TestFilter reference.
The command-line option is especially useful to execute a single test method. When you use --tests, be aware that the inclusions declared in the build script are still honored. It is also possible to supply multiple --tests options, all of whose patterns will take effect. The following sections have several examples of using the command-line option.
|
Note
|
Not all test frameworks play well with filtering. Some advanced, synthetic tests may not be fully compatible. However, the vast majority of tests and use cases work perfectly well with Gradle’s filtering mechanism. |
The following two sections look at the specific cases of simple class/method names and fully-qualified names.
Simple name pattern
Since 4.7, Gradle has treated a pattern starting with an uppercase letter as a simple class name, or a class name + method name. For example, the following command lines run either all or exactly one of the tests in the SomeTestClass test case, regardless of what package it’s in:
Executes all tests in SomeTestClass:
$ ./gradlew test --tests SomeTestClassExecutes a single specified test in SomeTestClass:
$ ./gradlew test --tests SomeTestClass.someSpecificMethod
$ ./gradlew test --tests SomeTestClass.*someMethod*Fully-qualified name pattern
Prior to 4.7 or if the pattern doesn’t start with an uppercase letter, Gradle treats the pattern as fully-qualified. So if you want to use the test class name irrespective of its package, you would use --tests *.SomeTestClass. Here are some more examples:
Specific class:
$ ./gradlew test --tests org.gradle.SomeTestClassSpecific class and method:
$ ./gradlew test --tests org.gradle.SomeTestClass.someSpecificMethodMethod name containing spaces:
$ ./gradlew test --tests "org.gradle.SomeTestClass.some method containing spaces"All classes at specific package (recursively):
$ ./gradlew test --tests 'all.in.specific.package*'Specific method at specific package (recursively):
$ ./gradlew test --tests 'all.in.specific.package*.someSpecificMethod'
$ ./gradlew test --tests '*IntegTest'
$ ./gradlew test --tests '*IntegTest*ui*'
$ ./gradlew test --tests '*ParameterizedTest.foo*'The second iteration of a parameterized test:
$ ./gradlew test --tests '*ParameterizedTest.*[2]'Note that the wildcard '*' has no special understanding of the '.' package separator. It’s purely text based. So --tests *.SomeTestClass will match any package, regardless of its 'depth'.
You can also combine filters defined at the command line with continuous build to re-execute a subset of tests immediately after every change to a production or test source file. The following executes all tests in the 'com.mypackage.foo' package or subpackages whenever a change triggers the tests to run:
$ ./gradlew test --continuous --tests "com.mypackage.foo.*"Test reporting
The Test task generates the following results by default:
-
An HTML test report
-
XML test results in a format compatible with the Ant JUnit report task — one that is supported by many other tools, such as CI servers
-
An efficient binary format of the results used by the
Testtask to generate the other formats
In most cases, you’ll work with the standard HTML report, which automatically includes the results from all your Test tasks, even the ones you explicitly add to the build yourself. For example, if you add a Test task for integration tests, the report will include the results of both the unit tests and the integration tests if both tasks are run.
|
Note
|
To aggregate test results across multiple subprojects, see the Test Report Aggregation Plugin. |
Unlike with many of the testing configuration options, there are several project-level convention properties that affect the test reports. For example, you can change the destination of the test results and reports like so:
reporting.baseDirectory = file("my-reports")
java.testResultsDir = layout.buildDirectory.dir("my-test-results")
tasks.register("showDirs") {
val settingsDir = project.layout.settingsDirectory.asFile
val reportsDir = project.reporting.baseDirectory
val testResultsDir = project.java.testResultsDir
doLast {
logger.quiet(settingsDir.toPath().relativize(reportsDir.get().asFile.toPath()).toString())
logger.quiet(settingsDir.toPath().relativize(testResultsDir.get().asFile.toPath()).toString())
}
}reporting.baseDirectory = file("my-reports")
java.testResultsDir = layout.buildDirectory.dir("my-test-results")
tasks.register('showDirs') {
def settingsDir = project.layout.settingsDirectory.asFile
def reportsDir = project.reporting.baseDirectory
def testResultsDir = project.java.testResultsDir
doLast {
logger.quiet(settingsDir.toPath().relativize(reportsDir.get().asFile.toPath()).toString())
logger.quiet(settingsDir.toPath().relativize(testResultsDir.get().asFile.toPath()).toString())
}
}$ ./gradlew -q showDirsmy-reports
build/my-test-resultsFollow the link to the convention properties for more details.
There is also a standalone TestReport task type that you can use to generate a custom HTML test report. All it requires are a value for destinationDir and the test results you want included in the report. Here is a sample which generates a combined report for the unit tests from all subprojects:
plugins {
id("java")
}
// Disable the test report for the individual test task
tasks.named<Test>("test") {
reports.html.required = false
}
// Share the test report data to be aggregated for the whole project
configurations.create("binaryTestResultsElements") {
isCanBeResolved = false
isCanBeConsumed = true
attributes {
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category.DOCUMENTATION))
attribute(DocsType.DOCS_TYPE_ATTRIBUTE, objects.named("test-report-data"))
}
outgoing.artifact(tasks.test.map { task -> task.getBinaryResultsDirectory().get() })
}val testReportData = configurations.create("testReportData") {
isCanBeConsumed = false
attributes {
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category.DOCUMENTATION))
attribute(DocsType.DOCS_TYPE_ATTRIBUTE, objects.named("test-report-data"))
}
}
dependencies {
testReportData(project(":core"))
testReportData(project(":util"))
}
tasks.register<TestReport>("testReport") {
destinationDirectory = reporting.baseDirectory.dir("allTests")
// Use test results from testReportData configuration
testResults.from(testReportData)
}plugins {
id 'java'
}
// Disable the test report for the individual test task
test {
reports.html.required = false
}
// Share the test report data to be aggregated for the whole project
configurations {
binaryTestResultsElements {
canBeResolved = false
canBeConsumed = true
attributes {
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category, Category.DOCUMENTATION))
attribute(DocsType.DOCS_TYPE_ATTRIBUTE, objects.named(DocsType, 'test-report-data'))
}
outgoing.artifact(test.binaryResultsDirectory)
}
}// A resolvable configuration to collect test reports data
configurations {
testReportData {
canBeConsumed = false
attributes {
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category, Category.DOCUMENTATION))
attribute(DocsType.DOCS_TYPE_ATTRIBUTE, objects.named(DocsType, 'test-report-data'))
}
}
}
dependencies {
testReportData project(':core')
testReportData project(':util')
}
tasks.register('testReport', TestReport) {
destinationDirectory = reporting.baseDirectory.dir('allTests')
// Use test results from testReportData configuration
testResults.from(configurations.testReportData)
}In this example, we use a convention plugin myproject.java-conventions to expose the test results from a project to Gradle’s variant aware dependency management engine.
The plugin declares a consumable binaryTestResultsElements configuration that represents the binary test results of the test task.
In the aggregation project’s build file, we declare the testReportData configuration and depend on all of the projects that we want to aggregate the results from. Gradle will automatically select the binary test result variant from each of the subprojects instead of the project’s jar file.
Lastly, we add a testReport task that aggregates the test results from the testResultsDirs property, which contains all of the binary test results resolved from the testReportData configuration.
You should note that the TestReport type combines the results from multiple test tasks and needs to aggregate the results of individual test classes. This means that if a given test class is executed by multiple test tasks, then the test report will include executions of that class, but it can be hard to distinguish individual executions of that class and their output.
Communicating test results to CI servers and other tools via XML files
The Test tasks creates XML files describing the test results, in the "JUnit XML" pseudo standard. This standard is used by the JUnit 4, JUnit Jupiter, and TestNG test frameworks, and is configured using the same DSL block for each of these. It is common for CI servers and other tooling to observe test results via these XML files.
By default, the files are written to layout.buildDirectory.dir("test-results/$testTaskName") with a file per test class.
The location can be changed for all test tasks of a project, or individually per test task.
java.testResultsDir = layout.buildDirectory.dir("junit-xml")java.testResultsDir = layout.buildDirectory.dir("junit-xml")With the above configuration, the XML files will be written to layout.buildDirectory.dir("junit-xml/$testTaskName").
tasks.test {
reports {
junitXml.outputLocation = layout.buildDirectory.dir("test-junit-xml")
}
}test {
reports {
junitXml.outputLocation = layout.buildDirectory.dir("test-junit-xml")
}
}With the above configuration, the XML files for the test task will be written to layout.buildDirectory.dir("test-results/test-junit-xml").
The location of the XML files for other test tasks will be unchanged.
Configuration options
The content of the XML files can also be configured to convey the results differently, by configuring the JUnitXmlReport options.
tasks.test {
reports {
junitXml.apply {
includeSystemOutLog = false // defaults to true
includeSystemErrLog = false // defaults to true
isOutputPerTestCase = true // defaults to false
mergeReruns = true // defaults to false
}
}
}test {
reports {
junitXml {
includeSystemOutLog = false // defaults to true
includeSystemErrLog = false // defaults to true
outputPerTestCase = true // defaults to false
mergeReruns = true // defaults to false
}
}
}The includeSystemOutLog option allows configuring whether or not test output written to standard out is exported to the XML report file.
The includeSystemErrLog option allows configuring whether or not test error output written to standard error is exported to the XML report file.
These options affect both test-suite level output (such as @BeforeClass/@BeforeAll output) and test class and method-specific output (@Before/@BeforeEach and @Test).
If either option is disabled, the element that normally contains that content will be excluded from the XML report file.
The default for each option is true.
The outputPerTestCase option, when enabled, associates any output logging generated during a test case to that test case in the results.
When disabled (the default) output is associated with the test class as whole and not the individual test cases (e.g. test methods) that produced the logging output.
Most modern tools that observe JUnit XML files support the "output per test case" format.
If you are using the XML files to communicate test results, it is recommended to enable this option as it provides more useful reporting.
When mergeReruns is enabled, if a test fails but is then retried and succeeds, its failures will be recorded as <flakyFailure> instead of <failure>, within one <testcase>.
This is effectively the reporting produced by the surefire plugin of Apache Maven™ when enabling reruns.
If your CI server understands this format, it will indicate that the test was flaky.
If it does not, it will indicate that the test succeeded as it will ignore the <flakyFailure> information.
If the test does not succeed (i.e. it fails for every retry), it will be indicated as having failed whether your tool understands this format or not.
When mergeReruns is disabled (the default), each execution of a test will be listed as a separate test case.
If you are using Build Scan or Develocity, flaky tests will be detected regardless of this setting.
Enabling this option is especially useful when using a CI tool that uses the XML test results to determine build failure instead of relying on Gradle’s determination of whether the build failed or not,
and you wish to not consider the build failed if all failed tests passed when retried.
This is the case for the Jenkins CI server and its JUnit plugin.
With mergeReruns enabled, tests that pass-on-retry will no longer cause this Jenkins plugin to consider the build to have failed.
However, failed test executions will be omitted from the Jenkins test result visualizations as it does not consider <flakyFailure> information.
The separate Flaky Test Handler Jenkins plugin can be used in addition to the JUnit Jenkins plugin to have such "flaky failures" also be visualized.
Tests are grouped and merged based on their reported name. When using any kind of test parameterization that affects the reported test name, or any other kind of mechanism that produces a potentially dynamic test name, care should be taken to ensure that the test name is stable and does not unnecessarily change.
Enabling the mergeReruns option does not add any retry/rerun functionality to test execution.
Rerunning can be enabled by the test execution framework (e.g. JUnit’s @RepeatedTest),
or via the separate Test Retry Gradle plugin.
Test detection
By default, Gradle will run all tests that it detects, which it does by inspecting the compiled test classes. This detection uses different criteria depending on the test framework used.
For JUnit, Gradle scans for both JUnit 3 and 4 test classes. A class is considered to be a JUnit test if it:
-
Ultimately inherits from
TestCaseorGroovyTestCase -
Is annotated with
@RunWith -
Contains a method annotated with
@Testor a super class does
For TestNG, Gradle scans for methods annotated with @Test.
Note that abstract classes are not executed. In addition, be aware that Gradle scans up the inheritance tree into jar files on the test classpath. So if those JARs contain test classes, they will also be run.
If you don’t want to use test class detection, you can disable it by setting the scanForTestClasses property on Test to false. When you do that, the test task uses only the includes and excludes properties to find test classes.
If scanForTestClasses is false and no include or exclude patterns are specified, Gradle defaults to running any class that matches the patterns **/*Tests.class and **/*Test.class, excluding those that match **/Abstract*.class.
|
Note
|
With JUnit Platform, only includes and excludes are used to filter test classes — scanForTestClasses has no effect.
|
Test logging
Gradle allows fine-tuned control over events that are logged to the console. Logging is configurable on a per-log-level basis and by default, the following events are logged:
When the log level is |
Events that are logged |
Additional configuration |
|
None |
None |
|
Exception format is SHORT |
|
|
Test failures, skipped tests, test standard output and test standard error |
Stacktraces are truncated. |
|
Full stacktraces are logged. |
Test logging can be modified on a per-log-level basis by adjusting the appropriate TestLogging instances in the testLogging property of the test task.
For example, to adjust the INFO level test logging configuration, modify the
TestLoggingContainer.getInfo() property.
Test grouping
JUnit, JUnit Platform and TestNG allow sophisticated groupings of test methods.
|
Note
|
This section applies to grouping individual test classes or methods within a collection of tests that serve the same testing purpose (unit tests, integration tests, acceptance tests, etc.). For dividing test classes based upon their purpose, see the incubating JVM Test Suite plugin. |
JUnit 4.8 introduced the concept of categories for grouping JUnit 4 tests classes and methods.[7] Test.useJUnit(org.gradle.api.Action) allows you to specify the JUnit categories you want to include and exclude. For example, the following configuration includes tests in CategoryA and excludes those in CategoryB for the test task:
tasks.test {
useJUnit {
includeCategories("org.gradle.junit.CategoryA")
excludeCategories("org.gradle.junit.CategoryB")
}
}test {
useJUnit {
includeCategories 'org.gradle.junit.CategoryA'
excludeCategories 'org.gradle.junit.CategoryB'
}
}JUnit Platform introduced tagging to replace categories. You can specify the included/excluded tags via Test.useJUnitPlatform(org.gradle.api.Action), as follows:
tasks.withType<Test>().configureEach {
useJUnitPlatform {
includeTags("fast")
excludeTags("slow")
}
}tasks.withType(Test).configureEach {
useJUnitPlatform {
includeTags 'fast'
excludeTags 'slow'
}
}The TestNG framework uses the concept of test groups for a similar effect.[8] You can configure which test groups to include or exclude during the test execution via the Test.useTestNG(org.gradle.api.Action) setting, as seen here:
tasks.named<Test>("test") {
useTestNG {
val options = this as TestNGOptions
options.excludeGroups("integrationTests")
options.includeGroups("unitTests")
}
}test {
useTestNG {
excludeGroups 'integrationTests'
includeGroups 'unitTests'
}
}Using JUnit 5
JUnit 5 is the latest version of the well-known JUnit test framework. Unlike its predecessor, JUnit 5 is modularized and composed of several modules:
JUnit 5 = JUnit Platform + JUnit Jupiter + JUnit VintageThe JUnit Platform serves as a foundation for launching testing frameworks on the JVM. JUnit Jupiter is the combination of the new programming model
and extension model for writing tests and extensions in JUnit 5. JUnit Vintage provides a TestEngine for running JUnit 3 and JUnit 4 based tests on the platform.
The following code enables JUnit Platform support in build.gradle:
tasks.named<Test>("test") {
useJUnitPlatform()
}tasks.named('test', Test) {
useJUnitPlatform()
}See Test.useJUnitPlatform() for more details.
Compiling and executing JUnit Jupiter tests
To enable JUnit Jupiter support in Gradle, all you need to do is add the following dependency:
dependencies {
testImplementation("org.junit.jupiter:junit-jupiter:5.7.1")
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
}dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter:5.7.1'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}You can then put your test cases into src/test/java as normal and execute them with gradle test.
Executing legacy tests with JUnit Vintage
If you want to run JUnit 3/4 tests on JUnit Platform, or even mix them with Jupiter tests, you should add extra JUnit Vintage Engine dependencies:
dependencies {
testImplementation("org.junit.jupiter:junit-jupiter:5.7.1")
testCompileOnly("junit:junit:4.13")
testRuntimeOnly("org.junit.vintage:junit-vintage-engine")
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
}dependencies {
testImplementation 'org.junit.jupiter:junit-jupiter:5.7.1'
testCompileOnly 'junit:junit:4.13'
testRuntimeOnly 'org.junit.vintage:junit-vintage-engine'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}In this way, you can use gradle test to test JUnit 3/4 tests on JUnit Platform, without the need to rewrite them.
Filtering test engine
JUnit Platform allows you to use different test engines. JUnit currently provides two TestEngine implementations out of the box:
junit-jupiter-engine and junit-vintage-engine.
You can also write and plug in your own TestEngine implementation as documented here.
By default, all test engines on the test runtime classpath will be used. To control specific test engine implementations explicitly, you can add the following setting to your build script:
tasks.withType<Test>().configureEach {
useJUnitPlatform {
includeEngines("junit-vintage")
// excludeEngines("junit-jupiter")
}
}tasks.withType(Test).configureEach {
useJUnitPlatform {
includeEngines 'junit-vintage'
// excludeEngines 'junit-jupiter'
}
}Test execution order in TestNG
TestNG allows explicit control of the execution order of tests when you use a testng.xml file. Without such a file — or an equivalent one configured by TestNGOptions.getSuiteXmlBuilder() — you can’t specify the test execution order. However, what you can do is control whether all aspects of a test — including its associated @BeforeXXX and @AfterXXX methods, such as those annotated with @Before/AfterClass and @Before/AfterMethod — are executed before the next test starts. You do this by setting the TestNGOptions.getPreserveOrder() property to true. If you set it to false, you may encounter scenarios in which the execution order is something like: TestA.doBeforeClass() → TestB.doBeforeClass() → TestA tests.
While preserving the order of tests is the default behavior when directly working with testng.xml files, the TestNG API that is used by Gradle’s TestNG integration executes tests in unpredictable order by default.[9] The ability to preserve test execution order was introduced with TestNG version 5.14.5. Setting the preserveOrder property to true for an older TestNG version will cause the build to fail.
tasks.test {
useTestNG {
preserveOrder = true
}
}test {
useTestNG {
preserveOrder = true
}
}The groupByInstance property controls whether tests should be grouped by instance rather than by class. The TestNG documentation explains the difference in more detail, but essentially, if you have a test method A() that depends on B(), grouping by instance ensures that each A-B pairing, e.g. B(1)-A(1), is executed before the next pairing. With group by class, all B() methods are run and then all A() ones.
Note that you typically only have more than one instance of a test if you’re using a data provider to parameterize it. Also, grouping tests by instances was introduced with TestNG version 6.1. Setting the groupByInstances property to true for an older TestNG version will cause the build to fail.
tasks.test {
useTestNG {
groupByInstances = true
}
}test {
useTestNG {
groupByInstances = true
}
}TestNG parameterized methods and reporting
TestNG supports parameterizing test methods, allowing a particular test method to be executed multiple times with different inputs. Gradle includes the parameter values in its reporting of the test method execution.
Given a parameterized test method named aTestMethod that takes two parameters, it will be reported with the name aTestMethod(toStringValueOfParam1, toStringValueOfParam2). This makes it easy to identify the parameter values for a particular iteration.
Configuring integration tests
A common requirement for projects is to incorporate integration tests in one form or another. Their aim is to verify that the various parts of the project are working together properly. This often means that they require special execution setup and dependencies compared to unit tests.
The simplest way to add integration tests to your build is by leveraging the incubating JVM Test Suite plugin. If an incubating solution is not something for you, here are the steps you need to take in your build:
-
Create a new source set for them
-
Add the dependencies you need to the appropriate configurations for that source set
-
Configure the compilation and runtime classpaths for that source set
-
Create a task to run the integration tests
You may also need to perform some additional configuration depending on what form the integration tests take. We will discuss those as we go.
Let’s start with a practical example that implements the first three steps in a build script, centered around a new source set intTest:
sourceSets {
create("intTest") {
compileClasspath += sourceSets.main.get().output
runtimeClasspath += sourceSets.main.get().output
}
}
val intTestImplementation = configurations.getByName("intTestImplementation") {
extendsFrom(configurations.implementation.get())
}
val intTestRuntimeOnly = configurations.getByName("intTestRuntimeOnly")
configurations["intTestRuntimeOnly"].extendsFrom(configurations.runtimeOnly.get())
dependencies {
intTestImplementation("org.junit.jupiter:junit-jupiter:5.7.1")
intTestRuntimeOnly("org.junit.platform:junit-platform-launcher")
}sourceSets {
intTest {
compileClasspath += sourceSets.main.output
runtimeClasspath += sourceSets.main.output
}
}
configurations {
intTestImplementation.extendsFrom implementation
intTestRuntimeOnly.extendsFrom runtimeOnly
}
dependencies {
intTestImplementation 'org.junit.jupiter:junit-jupiter:5.7.1'
intTestRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}This will set up a new source set called intTest that automatically creates:
-
intTestImplementation,intTestCompileOnly,intTestRuntimeOnlyconfigurations (and a few others that are less commonly needed) -
A
compileIntTestJavatask that will compile all the source files under src/intTest/java
|
Note
|
If you are working with the IntelliJ IDE, you may wish to flag the directories in these additional source sets as containing test source rather than production source as explained in the Idea Plugin documentation. |
The example also does the following, not all of which you may need for your specific integration tests:
-
Adds the production classes from the
mainsource set to the compilation and runtime classpaths of the integration tests —sourceSets.main.outputis a file collection of all the directories containing compiled production classes and resources -
Makes the
intTestImplementationconfiguration extend fromimplementation, which means that all the declared dependencies of the production code also become dependencies of the integration tests -
Does the same for the
intTestRuntimeOnlyconfiguration
In most cases, you want your integration tests to have access to the classes under test, which is why we ensure that those are included on the compilation and runtime classpaths in this example. But some types of test interact with the production code in a different way. For example, you may have tests that run your application as an executable and verify the output. In the case of web applications, the tests may interact with your application via HTTP. Since the tests don’t need direct access to the classes under test in such cases, you don’t need to add the production classes to the test classpath.
Another common step is to attach all the unit test dependencies to the integration tests as well — via intTestImplementation.extendsFrom testImplementation — but that only makes sense if the integration tests require all or nearly all the same dependencies that the unit tests have.
There are a couple of other facets of the example you should take note of:
-
+=allows you to append paths and collections of paths tocompileClasspathandruntimeClasspathinstead of overwriting them -
If you want to use the convention-based configurations, such as
intTestImplementation, you must declare the dependencies after the new source set
Creating and configuring a source set automatically sets up the compilation stage, but it does nothing with respect to running the integration tests. So the last piece of the puzzle is a custom test task that uses the information from the new source set to configure its runtime classpath and the test classes:
val integrationTest = tasks.register<Test>("integrationTest") {
description = "Runs integration tests."
group = "verification"
testClassesDirs = sourceSets["intTest"].output.classesDirs
classpath = sourceSets["intTest"].runtimeClasspath
shouldRunAfter("test")
useJUnitPlatform()
testLogging {
events("passed")
}
}
tasks.check { dependsOn(integrationTest) }tasks.register('integrationTest', Test) {
description = 'Runs integration tests.'
group = 'verification'
testClassesDirs = sourceSets.intTest.output.classesDirs
classpath = sourceSets.intTest.runtimeClasspath
shouldRunAfter test
useJUnitPlatform()
testLogging {
events "passed"
}
}
check.dependsOn integrationTestAgain, we’re accessing a source set to get the relevant information, i.e. where the compiled test classes are — the testClassesDirs property — and what needs to be on the classpath when running them — classpath.
Users commonly want to run integration tests after the unit tests, because they are often slower to run and you want the build to fail early on the unit tests rather than later on the integration tests. That’s why the above example adds a shouldRunAfter() declaration. This is preferred over mustRunAfter() so that Gradle has more flexibility in executing the build in parallel.
For information on how to determine code coverage for tests in additional source sets, see the JaCoCo Plugin and the JaCoCo Report Aggregation Plugin chapters.
Troubleshooting common problems
Test process starts but test dependencies are missing
Once the test process starts, it may fail to find its required dependencies if they are missing from the test runtime classpath.
Test dependencies need to be declared on the appropriate configuration.
The JVM Test Suite plugin automatically configures all necessary dependencies, but if you are manually creating a Test task or using the built-in test task, you need to ensure that all required dependencies are declared on the appropriate configuration.
-
For JUnit Jupiter-based tests, you need to declare dependencies on the JUnit Jupiter, JUnit Platform and JUnit Platform launcher libraries.
-
For JUnit4-based tests, you need to declare a dependency on a single JUnit 4.x library.
-
For TestNG-based tests, you need to declare a dependency on a single TestNG library.
Prior to Gradle 9.0.0, Gradle leaked internal dependencies into the test’s runtime classpath which may have masked missing dependencies.
Tests are not detected or executed
If no tests are detected, Gradle will skip the Test task entirely.
This can occur for several reasons:
-
No test sources exist. This is expected behavior for empty test suites.
-
Test sources exist but are not compiled. This may happen if:
-
The source files are located in the wrong directory.
-
The source set is not configured correctly.
-
-
No test classes are configured on the
Testtask. By default, only the built-inTesttask is automatically configured to use the test source set. If you’re using a customTesttask, you must manually configure bothtestClassesDirsandclasspath.
Prior to Gradle 9.0.0, all Test tasks were implicitly configured to use the test source set.
Test process fails to start or stay running
The test process may fail to start if configured incorrectly. For instance, if the Java executable does not exist or an invalid JVM argument is provided, the test process will fail to start.
Similarly, if a test requires changes to the environment that are not compatible with Gradle’s test worker process, the test process may fail to start.
For example, tests that rely on modifying the SecurityManager may interfere with Gradle’s internal messaging communication between the build and test worker.
Test process fails with unusual exit code
The test process can exit with an unusual exit code (non-zero).
This can be caused by a variety of issues, such as:
-
A test calls
System.exit()directly. -
Too many processes are running which causes the OS to kill the test process.
-
The test process runs out of memory.
Output from @BeforeClass and @AfterClass methods are incorrectly assigned to the wrong test
When using a JUnit 4 version below 4.13, output from @BeforeClass and @AfterClass methods may be incorrectly assigned to a test earlier or later in the test execution order.
This is due to a lack of events for when a class is started or finished, which were added in JUnit 4.13.
This also applies to TestNG versions below 6.9.13.3 and its @BeforeClass and @AfterClass methods.
Testing Java Modules
If you are developing Java Modules, everything described in this chapter still applies and any of the supported test frameworks can be used. However, there are some things to consider depending on whether you need module information to be available, and module boundaries to be enforced, during test execution. In this context, the terms whitebox testing (module boundaries are deactivated or relaxed) and blackbox testing (module boundaries are in place) are often used. Whitebox testing is used/needed for unit testing and blackbox testing fits functional or integration test requirements.
Whitebox unit test execution on the classpath
The simplest setup to write unit tests for functions or classes in modules is to not use module specifics during test execution.
For this, you just need to write tests the same way you would write them for normal libraries.
If you don’t have a module-info.java file in your test source set (src/test/java) this source set will be considered as traditional Java library during compilation and test runtime.
This means, all dependencies, including Jars with module information, are put on the classpath.
The advantage is that all internal classes of your (or other) modules are then accessible directly in tests.
This may be a totally valid setup for unit testing, where we do not care about the larger module structure, but only about testing single functions.
|
Note
|
If you are using Eclipse: By default, Eclipse also runs unit tests as modules using module patching (see below). In an imported Gradle project, unit testing a module with the Eclipse test runner might fail. You then need to manually adjust the classpath/module path in the test run configuration or delegate test execution to Gradle. This only concerns the test execution. Unit test compilation and development works fine in Eclipse. |
Blackbox integration testing
For integration tests, you have the option to define the test set itself as additional module.
You do this similar to how you turn your main sources into a module:
by adding a module-info.java file to the corresponding source set (e.g. integrationTests/java/module-info.java).
|
Note
|
In Eclipse, compiling multiple modules in one project is currently not supported. Therefore the integration test (blackbox) setup described here only works in Eclipse if the tests are moved to a separate subproject. |
Whitebox test execution with module patching
Another approach for whitebox testing is to stay in the module world by patching the tests into the module under test. This way, module boundaries stay in place, but the tests themselves become part of the module under test and can then access the module’s internals.
For which uses cases this is relevant and how this is best done is a topic of discussion. There is no general best approach at the moment. Thus, there is no special support for this in Gradle right now.
You can however, setup module patching for tests like this:
-
Add a
module-info.javato your test source set that is a copy of the mainmodule-info.javawith additional dependencies needed for testing (e.g.requires org.junit.jupiter.api). -
Configure both the
testCompileJavaandtesttasks with arguments to patch the main classes with the test classes as shown below.
val moduleName = "org.gradle.sample"
val patchArgs = listOf("--patch-module", "$moduleName=${tasks.compileJava.get().destinationDirectory.asFile.get().path}")
tasks.compileTestJava {
options.compilerArgs.addAll(patchArgs)
}
tasks.test {
jvmArgs(patchArgs)
}def moduleName = "org.gradle.sample"
def patchArgs = ["--patch-module", "$moduleName=${tasks.compileJava.destinationDirectory.asFile.get().path}"]
tasks.named('compileTestJava') {
options.compilerArgs += patchArgs
}
tasks.named('test') {
jvmArgs += patchArgs
}|
Note
|
If custom arguments are used for patching, these are not picked up by Eclipse and IDEA. You will most likely see invalid compilation errors in the IDE. |
Skipping the tests
If you want to skip the tests when running a build, you have a few options. You can either do it via command line arguments or in the build script. To do it on the command line, you can use the -x or --exclude-task option like so:
$ ./gradlew build -x testThis excludes the test task and any other task that it exclusively depends on, i.e. no other task depends on the same task. Those tasks will not be marked "SKIPPED" by Gradle, but will simply not appear in the list of tasks executed.
Skipping a test via the build script can be done a few ways. One common approach is to make test execution conditional via the Task.onlyIf(String, org.gradle.api.specs.Spec) method. The following sample skips the test task if the project has a property called mySkipTests:
tasks.test {
val skipTestsProvider = providers.gradleProperty("mySkipTests")
onlyIf("mySkipTests property is not set") {
!skipTestsProvider.isPresent()
}
}def skipTestsProvider = providers.gradleProperty('mySkipTests')
test.onlyIf("mySkipTests property is not set") {
!skipTestsProvider.present
}In this case, Gradle will mark the skipped tests as "SKIPPED" rather than exclude them from the build.
Forcing tests to run
In well-defined builds, you can rely on Gradle to only run tests if the tests themselves or the production code change. However, you may encounter situations where the tests rely on a third-party service or something else that might change but can’t be modeled in the build.
You can always use the --rerun built-in task option to force a task to rerun.
$ ./gradlew test --rerunAlternatively, if build caching is not enabled, you can also force tests to run by cleaning the output of the relevant Test task — say test — and running the tests again, like so:
$ ./gradlew cleanTest testcleanTest is based on a task rule provided by the Base Plugin. You can use it for any task.
Debugging when running tests
On the few occasions that you want to debug your code while the tests are running, it can be helpful if you can attach a debugger at that point. You can either set the Test.getDebug() property to true or use the --debug-jvm command line option, or use --no-debug-jvm to set it to false.
When debugging for tests is enabled, Gradle will start the test process suspended and listening on port 5005.
You can also enable debugging in the DSL, where you can also configure other properties:
test {
debugOptions {
enabled = true
host = 'localhost'
port = 4455
server = true
suspend = true
}
}With this configuration the test JVM will behave just like when passing the --debug-jvm argument but it will listen on port 4455.
To debug the test process remotely via network, the host needs to be set to the machine’s IP address or "*" (listen on all interfaces).
Using test fixtures
Producing and using test fixtures within a single project
Test fixtures are commonly used to setup the code under test, or provide utilities aimed at facilitating the tests of a component.
Java projects can enable test fixtures support by applying the java-test-fixtures plugin, in addition to the java or java-library plugins:
plugins {
// A Java Library
`java-library`
// which produces test fixtures
`java-test-fixtures`
// and is published
`maven-publish`
}plugins {
// A Java Library
id 'java-library'
// which produces test fixtures
id 'java-test-fixtures'
// and is published
id 'maven-publish'
}This will automatically create a testFixtures source set, in which you can write your test fixtures.
Test fixtures are configured so that:
-
they can see the main source set classes
-
test sources can see the test fixtures classes
For example for this main class:
public class Person {
private final String firstName;
private final String lastName;
public Person(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
public String getFirstName() {
return firstName;
}
public String getLastName() {
return lastName;
}
// ...A test fixture can be written in src/testFixtures/java:
public class Simpsons {
private static final Person HOMER = new Person("Homer", "Simpson");
private static final Person MARGE = new Person("Marjorie", "Simpson");
private static final Person BART = new Person("Bartholomew", "Simpson");
private static final Person LISA = new Person("Elisabeth Marie", "Simpson");
private static final Person MAGGIE = new Person("Margaret Eve", "Simpson");
private static final List<Person> FAMILY = new ArrayList<Person>() {{
add(HOMER);
add(MARGE);
add(BART);
add(LISA);
add(MAGGIE);
}};
public static Person homer() { return HOMER; }
public static Person marge() { return MARGE; }
public static Person bart() { return BART; }
public static Person lisa() { return LISA; }
public static Person maggie() { return MAGGIE; }
// ...Declaring dependencies of test fixtures
Similarly to the Java Library Plugin, test fixtures expose an API and an implementation configuration:
dependencies {
testImplementation("junit:junit:4.13")
// API dependencies are visible to consumers when building
testFixturesApi("org.apache.commons:commons-lang3:3.9")
// Implementation dependencies are not leaked to consumers when building
testFixturesImplementation("org.apache.commons:commons-text:1.6")
}dependencies {
testImplementation 'junit:junit:4.13'
// API dependencies are visible to consumers when building
testFixturesApi 'org.apache.commons:commons-lang3:3.9'
// Implementation dependencies are not leaked to consumers when building
testFixturesImplementation 'org.apache.commons:commons-text:1.6'
}It’s worth noticing that if a dependency is an implementation dependency of test fixtures, then when compiling tests that depend on those test fixtures, the implementation dependencies will not leak into the compile classpath. This results in improved separation of concerns and better compile avoidance.
Consuming test fixtures of another project
Test fixtures are not limited to a single project.
It is often the case that a dependent project tests also needs the test fixtures of the dependency.
This can be achieved very easily using the testFixtures keyword:
dependencies {
implementation(project(":lib"))
testImplementation("junit:junit:4.13")
testImplementation(testFixtures(project(":lib")))
}dependencies {
implementation(project(":lib"))
testImplementation 'junit:junit:4.13'
testImplementation(testFixtures(project(":lib")))
}Publishing test fixtures
One of the advantages of using the java-test-fixtures plugin is that test fixtures are published.
By convention, test fixtures will be published with an artifact having the test-fixtures classifier.
For both Maven and Ivy, an artifact with that classifier is simply published alongside the regular artifacts.
However, if you use the maven-publish or ivy-publish plugin, test fixtures are published as additional variants in Gradle Module Metadata and you can directly depend on test fixtures of external libraries in another Gradle project:
dependencies {
// Adds a dependency on the test fixtures of Gson, however this
// project doesn't publish such a thing
functionalTest(testFixtures("com.google.code.gson:gson:2.13.1"))
}dependencies {
// Adds a dependency on the test fixtures of Gson, however this
// project doesn't publish such a thing
functionalTest testFixtures("com.google.code.gson:gson:2.13.1")
}It’s worth noting that if the external project is not publishing Gradle Module Metadata, then resolution will fail with an error indicating that such a variant cannot be found:
$ ./gradlew dependencyInsight --configuration functionalTestClasspath --dependency gson> Task :dependencyInsight
com.google.code.gson:gson:2.13.1 FAILED
Failures:
- Could not resolve com.google.code.gson:gson:2.13.1.
- Unable to find a variant of 'com.google.code.gson:gson:2.13.1' with the requested capability: feature 'test-fixtures':
- Variant 'compile' provides 'com.google.code.gson:gson:2.13.1'
- Variant 'enforced-platform-compile' provides 'com.google.code.gson:gson-derived-enforced-platform:2.13.1'
- Variant 'enforced-platform-runtime' provides 'com.google.code.gson:gson-derived-enforced-platform:2.13.1'
- Variant 'javadoc' provides 'com.google.code.gson:gson:2.13.1'
- Variant 'platform-compile' provides 'com.google.code.gson:gson-derived-platform:2.13.1'
- Variant 'platform-runtime' provides 'com.google.code.gson:gson-derived-platform:2.13.1'
- Variant 'runtime' provides 'com.google.code.gson:gson:2.13.1'
- Variant 'sources' provides 'com.google.code.gson:gson:2.13.1'
com.google.code.gson:gson:2.13.1 FAILED
\--- functionalTestClasspath
A web-based, searchable dependency report is available by adding the --scan option.
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executedThe error message mentions the missing com.google.code.gson:gson-test-fixtures capability, which is indeed not defined for this library.
That’s because by convention, for projects that use the java-test-fixtures plugin, Gradle automatically creates test fixtures variants with a capability whose name is the name of the main component, with the appendix -test-fixtures.
|
Note
|
If you publish your library and use test fixtures, but do not want to publish the fixtures, you can deactivate publishing of the test fixtures variants as shown below. |
val javaComponent = components["java"] as AdhocComponentWithVariants
javaComponent.withVariantsFromConfiguration(configurations["testFixturesApiElements"]) { skip() }
javaComponent.withVariantsFromConfiguration(configurations["testFixturesRuntimeElements"]) { skip() }components.java.withVariantsFromConfiguration(configurations.testFixturesApiElements) { skip() }
components.java.withVariantsFromConfiguration(configurations.testFixturesRuntimeElements) { skip() }Non-class-based testing
Overview
Some testing frameworks do not use classes to define tests (for instance Cucumber).
Gradle supports non-class-based testing via JUnit Platform TestEngines.
To use a non-class-based testing framework, you need to:
-
Add the appropriate
TestEnginedependency to the test runtime classpath -
Configure the
Testtask to use JUnit Platform -
Tell the
TestEnginewhere to find the tests using thetestDefinitionDirsproperty of the Test task.
This is all that is necessary to run non-class-based tests.
The exact details of how to define these tests will depend on the specific TestEngine being used.
|
Note
|
Though possible, it is not recommended to mix class-based and non-class-based tests in the same Test task. Create a separate Test task for each type of test instead. Using Java Test Suites makes this easy to do.
|
Basic Example
Here is an example project structure for a non-class-based testing setup.
Test Engines for non-class-based testing are commonly added as test runtimeOnly dependencies.
Typically these would be added via a 3rd party library, but in this simple example the build defines a custom JUnit Platform TestEngine in the test-engine project and uses it to run tests in the lib project.
This example uses Java Test Suites, but the same process can be applied to manually configured Test tasks as well.
├── test-engine
│ ├── build.gradle.kts
│ └── src // Source for an example JUnit Platform TestEngine implementation
├── lib
│ ├── build.gradle.kts
│ └── src
│ ├── main // Production code to be tested
│ └── test
│ └── definitions // Non-class files that also define tests would go here
├── settings.gradle.kts├── test-engine
│ ├── build.gradle
│ └── src // Source for an example JUnit Platform TestEngine implementation
├── lib
│ ├── build.gradle
│ └── src
│ ├── main // Production code to be tested
│ └── test
│ └── definitions // Non-class files that also define tests would go here
├── settings.gradleNote that the src/test/java directory is absent in this example, as no class-based tests are present.
While you can mix class-based and non-class-based tests in the same test task, this is not recommended.
It is better to separate class-based and non-class-based tests into different tasks so that they can be configured independently.
Using Java Test Suites makes this easy to do.
testing.suites.named("test", JvmTestSuite::class) {
useJUnitJupiter() // (1)
dependencies {
runtimeOnly(project(":test-engine")) // (2)
}
targets.all {
testTask.configure {
testDefinitionDirs.from("src/test/definitions") // (3)
}
}
}testing.suites.test {
useJUnitJupiter() // (1)
dependencies {
runtimeOnly(project(":test-engine")) // (2)
}
targets.all {
testTask.configure {
testDefinitionDirs.from("src/test/definitions") // (3)
}
}
}-
Ensure the test task uses the JUnit Jupiter test framework. When not using Test Suites, you should call
useJUnitPlatform()on theTesttask itself. -
Add the
TestEnginedependency to the test runtime classpath. -
Tell the
Testtask which directories contain non-class-based test definitions. These can be relative paths from the project dir or absolute paths.
This example engine uses XML files with a very simple structure to define tests.
These files are idiomatically located in the src/test/definitions directory.
└── src
└── test
└── definitions
├── sub
│ └── MoreTests.xml
└── ExampleTests.xml└── src
└── test
└── definitions
├── sub
│ └── MoreTests.xml
└── ExampleTests.xmlThe test definition files in this example are very simple and look like this:
<?xml version="1.0" encoding="UTF-8" ?>
<tests>
<test name="foo" />
<test name="bar" />
</tests><?xml version="1.0" encoding="UTF-8" ?>
<tests>
<test name="baz" />
</tests>The custom engine in this example logs messages when discovering and executing tests.
When ./gradlew test --info is run, the output contains lines that confirm that the custom TestEngine is being used to discover and execute the tests defined in the XML files:
INFO: Discovering tests with engine: [engine:rbt-engine] using selectors:
DirectorySelector [path = '/home/user/gradle/samples/lib/src/test/definitions']
INFO: Test specification file: /home/user/gradle/samples/lib/src/test/definitions/ExampleTests.xml
INFO: Test specification file: /home/user/gradle/samples/lib/src/test/definitions/sub/MoreTests.xml
INFO: Executing tests with engine: [engine:rbt-engine]
INFO: Executing resource-based test: Test[file=ExampleTests.xml, name=foo]
INFO: Executing resource-based test: Test[file=ExampleTests.xml, name=bar]
INFO: Executing resource-based test: Test[file=MoreTests.xml, name=baz]Filtering
Non-class-based tests can be filtered in the same way as class-based tests using the TestFilter API or --tests command line option.
|
Note
|
Non-class-based filtering is an incubating feature that may change. |
Non-class-based test filtering is performed by converting the relative file path into a fully qualified name. The package structure is constructed from the test definition directory.
File path separators are converted into dots (.) and the file extension is removed.
| File path | Fully qualified name |
|---|---|
src/test/definitions/ExampleTests.xml |
ExampleTests |
src/test/definitions/sub/MoreTests.xml |
sub.MoreTests |
To run only the tests in ExampleTests.xml:
$ ./gradlew test --tests "ExampleTests*"To run all tests within the sub directory:
$ ./gradlew test --tests "sub.*"Ambiguity with test selection
The goal of following the same selection rules as class-based tests is to make it easier for users to run all tests within a logical grouping without knowing if they are class-based or non-class-based.
The conversion from file path to fully qualified name will be ambiguous for some directory structures.
Directory names that contain dots or file names that contain multiple dots can make it impossible to select an individual test file.
Some directory or file names may be awkward to select (e.g., paths with spaces, $ or other special characters).
Non-class-based test definitions should use a single unambiguous naming convention for directories and files.
Our recommendation is to follow Java package naming conventions for directories and use simple names for the test files.
All of the following file paths appear to be the same test and cannot be filtered individually.
| File path | Fully qualified name |
|---|---|
src/test/definitions/sub.ExampleTests.xml |
sub.ExampleTests |
src/test/definitions/sub/ExampleTests.xml |
sub.ExampleTests |
src/test/definitions/sub/ExampleTests |
sub.ExampleTests |
|
Note
|
Filtering is only supported at a file level granularity for non-class-based tests. There is no support for filtering individual tests within a test definition file. |
Parallel Execution
Parallelism in non-class-based tests is controlled via the Test.getMaxParallelForks() property of the Test task.
If this property is set to a value greater than 1, Gradle will attempt to distribute each test definition directory present in the testDefinitionDirs property across multiple test worker processes.
Files within a single test definition directory will always be executed sequentially within the same test worker process.
Tooling API
Non-class-based tests can be run through the Tooling API in the same manner as class-based tests.
Toolchains for JVM projects
Working on multiple projects can require interacting with multiple versions of the Java language. Even within a single project different parts of the codebase may be fixed to a particular language level due to backward compatibility requirements. This means different versions of the same tools (a toolchain) must be installed and managed on each machine that builds the project.
A Java toolchain is a set of tools to build and run Java projects, which is usually provided by the environment via local JRE or JDK installations.
Compile tasks may use javac as their compiler, test and exec tasks may use the java command while javadoc will be used to generate documentation.
By default, Gradle uses the same Java toolchain for running Gradle itself and building JVM projects. However, this may only sometimes be desirable. Building projects with different Java versions on different developer machines and CI servers may lead to unexpected issues. Additionally, you may want to build a project using a Java version that is not supported for running Gradle.
In order to improve reproducibility of the builds and make build requirements clearer, Gradle allows configuring toolchains on both project and task levels. You can also control the JVM used to run Gradle itself using the Daemon JVM criteria.
Toolchains for projects
Gradle provides multiple ways to configure the Java version used for compiling and running your project.
The five primary mechanisms are:
These settings are not mutually exclusive, and advanced users may need to combine them in specific scenarios.
1. Java toolchains
To configure a toolchain for your project, declare the desired Java language version in the java extension block:
java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}The java block is flexible and supports additional configuration options.
You can learn more in Using Java toolchains.
2. The --release flag
For strict cross-compilation, the --release flag is recommended instead of sourceCompatibility and targetCompatibility:
tasks.withType<JavaCompile>().configureEach {
options.release = 8
}tasks.withType(JavaCompile).configureEach {
options.release = 8
}This flag prevents accidental use of newer APIs that are not available in the specified version. However, it does not control which JDK is used—only how the compiler treats source code.
This method can be combined with toolchains if you need both a specific JDK and strict cross-compilation.
3. Source and Target compatibility
Setting sourceCompatibility and targetCompatibility tells the Java compiler to produce bytecode compatible with a specific Java version but does not enforce which JDK Gradle itself runs with:
java {
sourceCompatibility = JavaVersion.VERSION_1_8
targetCompatibility = JavaVersion.VERSION_1_8
}java {
sourceCompatibility = JavaVersion.VERSION_1_8
targetCompatibility = JavaVersion.VERSION_1_8
}This does not guarantee the correct JDK is used and may cause issues when APIs have been backported to older Java versions.
You should only use this method in cases where you need backward compatibility but cannot use toolchains.
4. Environment variables (JAVA_HOME)
You can influence which JDK Gradle uses by setting the JAVA_HOME environment variable:
export JAVA_HOME=/path/to/java17This sets a default JDK for all Java-based tools on your system, including Gradle and Maven.
|
Warning
|
This does not override Gradle’s toolchain support or other project-specific configurations. |
This approach is useful for legacy projects that do not use toolchains and expect a specific JDK to be active in the environment.
However, since JAVA_HOME applies globally, it cannot be used to specify different JDK versions for different projects.
It is more reliable to use toolchains, which allow setting the Java version at the project level.
5. IDE settings
Most modern IDEs allow you to configure the JVM used to run Gradle when working with a project. This setting affects how Gradle itself is executed inside the IDE, but not how your code is compiled—unless the build does not explicitly specify a toolchain.
If your build does not define a Java toolchain, Gradle may fall back to using the Java version defined by the IDE settings. This can lead to unintended and non-reproducible behavior, especially if different team members use different IDE configurations.
You should change the IDE’s Gradle JVM setting to align with the JVM used on the command line (JAVA_HOME or the system’s default Java installation) —ensuring consistent behavior across environments (e.g., when running tests or tasks from the IDE vs the terminal).
You should also change the IDE’s Gradle JVM setting if the IDE emits a warning/error when the JVM is not set or does not match with JAVA_HOME.
IntelliJ IDEA
To configure the Gradle JVM:
-
Open Settings (Preferences) > Build, Execution, Deployment > Gradle.
-
Set Gradle JVM to the desired JDK.
Eclipse
To configure the Gradle JVM:
-
Open Preferences > Gradle > Gradle JDK.
-
Select the appropriate JDK.
|
Note
|
Some IDEs also allow you to configure the Gradle Daemon JVM in the same settings screen. Be careful not to confuse it with the toolchain or project JVM—make sure you’re selecting the correct one. |
Combining toolchains
In some cases, you may want to:
-
Use a specific JDK version for compilation (
toolchains). -
Ensure that the compiled bytecode is compatible with an older Java version (
--releaseortargetCompatibility).
For example, to compile with Java 17 but produce Java 11 bytecode:
java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}
tasks.withType<JavaCompile>().configureEach {
options.release = 11
}java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}
tasks.withType(JavaCompile).configureEach {
options.release = 11
}Comparison table for setting project toolchains
| Method | Ensures Correct JDK? | Auto Downloads JDK? | Prevents Accidental API Use? |
|---|---|---|---|
Java toolchains |
✅ Yes |
✅ Yes |
❌ No |
|
❌ No |
❌ No |
✅ Yes |
Source & Target compatibility |
❌ No |
❌ No |
❌ No |
Environment variables ( |
✅ Yes (but only globally) |
❌ No |
❌ No |
IDE settings |
✅ Yes (inside the IDE) |
❌ No |
❌ No |
Recommendation:
-
For most users: Use Java toolchains (
toolchain.languageVersion). -
For strict compatibility enforcement: Use the
--releaseflag. -
For advanced cases: Combine toolchains and
--release. -
Avoid
sourceCompatibilityandtargetCompatibilityunless necessary. -
Use
JAVA_HOMEonly if you need a default system-wide JDK version. -
Use IDE settings if you want Gradle to match your IDE’s JDK version.
Toolchains for tasks
In case you want to tweak which toolchain is used for a specific task, you can specify the exact tool a task is using.
For example, the Test task exposes a JavaLauncher property that defines which java executable to use for launching the tests.
In the example below, we configure all java compilation tasks to use Java 8.
Additionally, we introduce a new Test task that will run our unit tests using a JDK 17.
tasks.withType<JavaCompile>().configureEach {
javaCompiler = javaToolchains.compilerFor {
languageVersion = JavaLanguageVersion.of(8)
}
}
tasks.register<Test>("testsOn17") {
javaLauncher = javaToolchains.launcherFor {
languageVersion = JavaLanguageVersion.of(17)
}
}tasks.withType(JavaCompile).configureEach {
javaCompiler = javaToolchains.compilerFor {
languageVersion = JavaLanguageVersion.of(8)
}
}
tasks.register('testsOn17', Test) {
javaLauncher = javaToolchains.launcherFor {
languageVersion = JavaLanguageVersion.of(17)
}
}In addition, in the application subproject, we add another Java execution task to run our application with JDK 17.
tasks.register<JavaExec>("runOn17") {
javaLauncher = javaToolchains.launcherFor {
languageVersion = JavaLanguageVersion.of(17)
}
classpath = sourceSets["main"].runtimeClasspath
mainClass = application.mainClass
}tasks.register('runOn17', JavaExec) {
javaLauncher = javaToolchains.launcherFor {
languageVersion = JavaLanguageVersion.of(17)
}
classpath = sourceSets.main.runtimeClasspath
mainClass = application.mainClass
}Depending on the task, a JRE might be enough while for other tasks (e.g. compilation), a JDK is required. By default, Gradle prefers installed JDKs over JREs if they can satisfy the requirements.
Toolchains tool providers can be obtained from the javaToolchains extension.
Three tools are available:
-
A
JavaCompilerwhich is the tool used by the JavaCompile task -
A
JavaLauncherwhich is the tool used by the JavaExec or Test tasks -
A
JavadocToolwhich is the tool used by the Javadoc task
Integration with tasks relying on a Java executable or Java home
Any task that can be configured with a path to a Java executable, or a Java home location, can benefit from toolchains.
While you will not be able to wire a toolchain tool directly, they all have the metadata that gives access to their full path or to the path of the Java installation they belong to.
For example, you can configure the java executable for a task as follows:
val launcher = javaToolchains.launcherFor {
languageVersion = JavaLanguageVersion.of(11)
}
tasks.sampleTask {
javaExecutable = launcher.map { it.executablePath }
}def launcher = javaToolchains.launcherFor {
languageVersion = JavaLanguageVersion.of(11)
}
tasks.named('sampleTask') {
javaExecutable = launcher.map { it.executablePath }
}As another example, you can configure the Java Home for a task as follows:
val launcher = javaToolchains.launcherFor {
languageVersion = JavaLanguageVersion.of(11)
}
tasks.anotherSampleTask {
javaHome = launcher.map { it.metadata.installationPath }
}def launcher = javaToolchains.launcherFor {
languageVersion = JavaLanguageVersion.of(11)
}
tasks.named('anotherSampleTask') {
javaHome = launcher.map { it.metadata.installationPath }
}If you require a path to a specific tool such as Java compiler, you can obtain it as follows:
val compiler = javaToolchains.compilerFor {
languageVersion = JavaLanguageVersion.of(11)
}
tasks.yetAnotherSampleTask {
javaCompilerExecutable = compiler.map { it.executablePath }
}def compiler = javaToolchains.compilerFor {
languageVersion = JavaLanguageVersion.of(11)
}
tasks.named('yetAnotherSampleTask') {
javaCompilerExecutable = compiler.map { it.executablePath }
}|
Warning
|
The examples above use tasks with RegularFileProperty and DirectoryProperty properties which allow lazy configuration.
Doing respectively launcher.get().executablePath, launcher.get().metadata.installationPath or compiler.get().executablePath instead will give you the full path for the given toolchain but note that this may realize (and provision) a toolchain eagerly.
|
Using Java toolchains
Using Java toolchains allows Gradle to automatically download and manage the required JDK version for your build. It ensures that the correct Java version is used for both compilation and execution.
You can define what toolchain to use for a project by stating the Java language version in the java extension block:
java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}Executing the build (e.g. using gradle check) will now handle several things for you and others running your build:
-
Gradle configures all compile, test and javadoc tasks to use the defined toolchain.
-
Gradle detects locally installed toolchains.
-
Gradle chooses a toolchain matching the requirements (any Java 17 toolchain for the example above).
-
If no matching toolchain is found, Gradle can automatically download a matching one based on the configured toolchain download repositories.
|
Note
|
Toolchain support is available in the Java plugins and for the tasks they define. For the Groovy plugin, compilation is supported but not yet Groovydoc generation. For the Scala plugin, compilation and Scaladoc generation are supported. |
Selecting toolchains by vendor
In case your build has specific requirements from the used JRE/JDK, you may want to define the vendor for the toolchain as well.
JvmVendorSpec has a list of well-known JVM vendors recognized by Gradle.
The advantage is that Gradle can handle any inconsistencies across JDK versions in how exactly the JVM encodes the vendor information.
java {
toolchain {
languageVersion = JavaLanguageVersion.of(11)
vendor = JvmVendorSpec.ADOPTIUM
}
}java {
toolchain {
languageVersion = JavaLanguageVersion.of(11)
vendor = JvmVendorSpec.ADOPTIUM
}
}If the vendor you want to target is not a known vendor, you can still restrict the toolchain to those matching the java.vendor system property of the available toolchains.
The following snippet uses filtering to include a subset of available toolchains.
This example only includes toolchains whose java.vendor property contains the given match string.
The matching is done in a case-insensitive manner.
java {
toolchain {
languageVersion = JavaLanguageVersion.of(11)
vendor = JvmVendorSpec.matching("customString")
}
}java {
toolchain {
languageVersion = JavaLanguageVersion.of(11)
vendor = JvmVendorSpec.matching("customString")
}
}Selecting toolchains that support GraalVM native image
If your project needs a toolchain with GraalVM Native Image capability, you can configure the spec to request it:
java {
toolchain {
languageVersion = JavaLanguageVersion.of(21)
nativeImageCapable = true
}
}java {
toolchain {
languageVersion = JavaLanguageVersion.of(21)
nativeImageCapable = true
}
}Leaving that value unconfigured or set to false will not restrict the toolchain selection based on the Native Image capability.
That means that a Native Image capable JDK can be selected if it matches the other criteria.
Selecting toolchains by virtual machine implementation
If your project requires a specific implementation, you can filter based on the implementation as well. Currently available implementations to choose from are:
VENDOR_SPECIFIC-
Acts as a placeholder and matches any implementation from any vendor (e.g. hotspot, zulu, …)
J9-
Matches only virtual machine implementations using the OpenJ9/IBM J9 runtime engine.
For example, to use an IBM JVM, distributed via AdoptOpenJDK, you can specify the filter as shown in the example below.
java {
toolchain {
languageVersion = JavaLanguageVersion.of(11)
vendor = JvmVendorSpec.IBM
implementation = JvmImplementation.J9
}
}java {
toolchain {
languageVersion = JavaLanguageVersion.of(11)
vendor = JvmVendorSpec.IBM
implementation = JvmImplementation.J9
}
}|
Note
|
The Java major version, the vendor (if specified) and implementation (if specified) will be tracked as an input for compilation and test execution. |
Configuring toolchain specifications
Gradle allows configuring multiple properties that affect the selection of a toolchain, such as language version or vendor. Even though these properties can be configured independently, the configuration must follow certain rules in order to form a valid specification.
A JavaToolchainSpec is considered valid in two cases:
-
when no properties have been set, i.e. the specification is empty;
-
when
languageVersionhas been set, optionally followed by setting any other property.
In other words, if a vendor or an implementation are specified, they must be accompanied by the language version. Gradle distinguishes between toolchain specifications that configure the language version and the ones that do not. A specification without a language version, in most cases, would be treated as a one that selects the toolchain of the current build.
Usage of invalid instances of JavaToolchainSpec results in a build error since Gradle 8.0.
Auto-detection of installed toolchains
By default, Gradle automatically detects local JRE/JDK installations so no further configuration is required by the user. The following is a list of common package managers, tools, and locations that are supported by the JVM auto-detection.
JVM auto-detection knows how to work with:
-
Operation-system specific locations: Linux, macOS, Windows
-
Conventional Environment Variable:
JAVA_HOME -
Maven Toolchain specifications
-
IntelliJ IDEA installations
Among the set of all detected JRE/JDK installations, one will be picked according to the Toolchain Precedence Rules.
|
Note
|
Whether you are using toolchain auto-detection or you are configuring Custom toolchain locations, installations that are non-existing or without a bin/java executable will be ignored with a warning, but they won’t generate an error.
|
How to disable auto-detection
In order to disable auto-detection, you can use the org.gradle.java.installations.auto-detect Gradle property:
-
Either start Gradle using
-Dorg.gradle.java.installations.auto-detect=false -
Or put
org.gradle.java.installations.auto-detect=falseinto yourgradle.propertiesfile.
Auto-provisioning
If Gradle can’t find a locally available toolchain that matches the requirements of the build, it can automatically download one (as long as a toolchain download repository has been configured; for detail, see relevant section). Gradle installs the downloaded JDKs in the Gradle User Home.
|
Note
|
Gradle only downloads JDK versions for GA releases. There is no support for downloading early access versions. |
Once installed in the Gradle User Home, a provisioned JDK becomes one of the JDKs visible to auto-detection and can be used by any subsequent builds, just like any other JDK installed on the system.
Since auto-provisioning only kicks in when auto-detection fails to find a matching JDK, auto-provisioning can only download new JDKs and is in no way involved in updating any of the already installed ones. None of the auto-provisioned JDKs will ever be revisited and automatically updated by auto-provisioning, even if there is a newer minor version available for them.
Toolchain Download Repositories
Toolchain download repository definitions are added to a build by applying specific settings plugins. For details on writing such plugins, consult the Toolchain Resolver Plugins page.
One example of a toolchain resolver plugin is the Foojay Toolchains Plugin, based on the foojay Disco API. It even has a convention variant, which automatically takes care of all the needed configuration, just by being applied:
plugins {
id("org.gradle.toolchains.foojay-resolver-convention").version("1.0.0")
}plugins {
id 'org.gradle.toolchains.foojay-resolver-convention' version '1.0.0'
}For advanced or highly specific configurations, a custom toolchain resolver plugin should be used.
In general, when applying toolchain resolver plugins, the toolchain download resolvers provided by them also need to be configured. Let’s illustrate with an example. Consider two toolchain resolver plugins applied by the build:
-
One is the Foojay plugin mentioned above, which downloads toolchains via the
FoojayToolchainResolverit provides. -
The other contains a FICTITIOUS resolver named
MadeUpResolver.
The following example uses these toolchain resolvers in a build via the toolchainManagement block in the settings file:
toolchainManagement {
jvm { // (1)
javaRepositories {
repository("foojay") { // (2)
resolverClass = org.gradle.toolchains.foojay.FoojayToolchainResolver::class.java
}
repository("made_up") { // (3)
resolverClass = MadeUpResolver::class.java
credentials {
username = "user"
password = "password"
}
authentication {
create<DigestAuthentication>("digest")
} // (4)
}
}
}
}toolchainManagement {
jvm { // (1)
javaRepositories {
repository('foojay') { // (2)
resolverClass = org.gradle.toolchains.foojay.FoojayToolchainResolver
}
repository('made_up') { // (3)
resolverClass = MadeUpResolver
credentials {
username = "user"
password = "password"
}
authentication {
digest(BasicAuthentication)
} // (4)
}
}
}
}-
In the
toolchainManagementblock, thejvmblock contains configuration for Java toolchains. -
The
javaRepositoriesblock defines named Java toolchain repository configurations. Use theresolverClassproperty to link these configurations to plugins. -
Toolchain declaration order matters. Gradle downloads from the first repository that provides a match, starting with the first repository in the list.
-
You can configure toolchain repositories with the same set of authentication and authorization options used for dependency management.
|
Warning
|
The jvm block in toolchainManagement only resolves after applying a toolchain resolver plugin.
|
Viewing and debugging toolchains
Gradle can display the list of all detected toolchains including their metadata.
For example, to show all toolchains of a project, run:
$ ./gradlew -q javaToolchains> gradle -q javaToolchains
+ Options
| Auto-detection: Enabled
| Auto-download: Enabled
+ AdoptOpenJDK 1.8.0_242
| Location: /Users/username/myJavaInstalls/8.0.242.hs-adpt/jre
| Language Version: 8
| Vendor: AdoptOpenJDK
| Architecture: x86_64
| Is JDK: false
| Detected by: Gradle property 'org.gradle.java.installations.paths'
+ Microsoft JDK 16.0.2+7
| Location: /Users/username/.sdkman/candidates/java/16.0.2.7.1-ms
| Language Version: 16
| Vendor: Microsoft
| Architecture: aarch64
| Is JDK: true
| Detected by: SDKMAN!
+ OpenJDK 15-ea
| Location: /Users/user/customJdks/15.ea.21-open
| Language Version: 15
| Vendor: AdoptOpenJDK
| Architecture: x86_64
| Is JDK: true
| Detected by: environment variable 'JDK16'
+ Oracle JDK 1.7.0_80
| Location: /Library/Java/JavaVirtualMachines/jdk1.7.0_80.jdk/Contents/Home/jre
| Language Version: 7
| Vendor: Oracle
| Architecture: x86_64
| Is JDK: false
| Detected by: MacOS java_homeThis can help to debug which toolchains are available to the build, how they are detected and what kind of metadata Gradle knows about those toolchains.
Disabling auto provisioning
In order to disable auto-provisioning, you can use the org.gradle.java.installations.auto-download Gradle property:
-
Either start Gradle using
-Dorg.gradle.java.installations.auto-download=false -
Or put
org.gradle.java.installations.auto-download=falseinto agradle.propertiesfile.
|
Note
|
After disabling the auto provisioning, ensure that the specified JRE/JDK version in the build file is already installed locally.
Then, stop the Gradle daemon so that it can be reinitialized for the next build.
You can use the |
Removing an auto-provisioned toolchain
When removing an auto-provisioned toolchain is necessary, remove the relevant toolchain located in the /jdks directory within the Gradle User Home.
|
Note
|
The Gradle Daemon caches information about your project, including configuration details such as toolchain paths or versions. Changes to a project’s toolchain configuration might only occur once the Gradle Daemon is restarted. It is recommended to stop the Gradle Daemon to ensure that Gradle updates the configuration for subsequent builds. |
Custom toolchain locations
If auto-detecting local toolchains is not sufficient or disabled, there are additional ways you can let Gradle know about installed toolchains.
If your setup already provides environment variables pointing to installed JVMs, you can also let Gradle know about which environment variables to take into account.
Assuming the environment variables JDK8 and JRE17 point to valid java installations, the following instructs Gradle to resolve those environment variables and consider those installations when looking for a matching toolchain.
org.gradle.java.installations.fromEnv=JDK8,JRE17Additionally, you can provide a comma-separated list of paths to specific installations using the org.gradle.java.installations.paths property.
For example, using the following in your gradle.properties will let Gradle know which directories to look at when detecting toolchains.
Gradle will treat these directories as possible installations but will not descend into any nested directories.
org.gradle.java.installations.paths=/custom/path/jdk1.8,/shared/jre11|
Note
|
Gradle does not prioritize custom toolchains over auto-detected toolchains. If you enable auto-detection in your build, custom toolchains extend the set of toolchain locations. Gradle picks a toolchain according to the precedence rules. |
Toolchain installations precedence
Gradle will sort all the JDK/JRE installations matching the toolchain specification of the build and will pick the first one. Sorting is done based on the following rules:
-
the installation currently running Gradle is preferred over any other
-
JDK installations are preferred over JRE ones
-
certain vendors take precedence over others; their ordering (from the highest priority to lowest):
-
ADOPTIUM
-
ADOPTOPENJDK
-
AMAZON
-
APPLE
-
AZUL
-
BELLSOFT
-
GRAAL_VM
-
HEWLETT_PACKARD
-
IBM
-
JETBRAINS
-
MICROSOFT
-
ORACLE
-
SAP
-
TENCENT
-
everything else
-
-
higher major versions take precedence over lower ones
-
higher minor versions take precedence over lower ones
-
installation paths take precedence according to their lexicographic ordering (last resort criteria for deterministically deciding between installations of the same type, from the same vendor and with the same version)
All these rules are applied as multilevel sorting criteria, in the order shown. Let’s illustrate with an example. A toolchain specification requests Java version 17. Gradle detects the following matching installations:
-
Oracle JRE v17.0.1
-
Oracle JDK v17.0.0
-
Microsoft JDK 17.0.0
-
Microsoft JRE 17.0.1
-
Microsoft JDK 17.0.1
Assume that Gradle runs on a major Java version other than 17. Otherwise, that installation would have priority.
When we apply the above rules to sort this set we will end up with following ordering:
-
Microsoft JDK 17.0.1
-
Microsoft JDK 17.0.0
-
Oracle JDK v17.0.0
-
Microsoft JRE v17.0.1
-
Oracle JRE v17.0.1
Gradle prefers JDKs over JREs, so the JREs come last. Gradle prefers the Microsoft vendor over Oracle, so the Microsoft installations come first. Gradle prefers higher version numbers, so JDK 17.0.1 comes before JDK 17.0.0.
So Gradle picks the first match in this order: Microsoft JDK 17.0.1.
Toolchains for plugin authors
When creating a plugin or a task that uses toolchains, it is essential to provide sensible defaults and allow users to override them.
For JVM projects, it is usually safe to assume that the java plugin has been applied to the project.
The java plugin is automatically applied for the core Groovy and Scala plugins, as well as for the Kotlin plugin.
In such a case, using the toolchain defined via the java extension as a default value for the tool property is appropriate.
This way, the users will need to configure the toolchain only once on the project level.
The example below showcases how to use the default toolchain as convention while allowing users to individually configure the toolchain per task.
abstract class CustomTaskUsingToolchains : DefaultTask() {
@get:Nested
abstract val launcher: Property<JavaLauncher> // (1)
init {
val toolchain = project.extensions.getByType<JavaPluginExtension>().toolchain // (2)
val defaultLauncher = javaToolchainService.launcherFor(toolchain) // (3)
launcher.convention(defaultLauncher) // (4)
}
@TaskAction
fun showConfiguredToolchain() {
println(launcher.get().executablePath)
println(launcher.get().metadata.installationPath)
}
@get:Inject
protected abstract val javaToolchainService: JavaToolchainService
}abstract class CustomTaskUsingToolchains extends DefaultTask {
@Nested
abstract Property<JavaLauncher> getLauncher() // (1)
CustomTaskUsingToolchains() {
def toolchain = project.extensions.getByType(JavaPluginExtension.class).toolchain // (2)
Provider<JavaLauncher> defaultLauncher = getJavaToolchainService().launcherFor(toolchain) // (3)
launcher.convention(defaultLauncher) // (4)
}
@TaskAction
def showConfiguredToolchain() {
println launcher.get().executablePath
println launcher.get().metadata.installationPath
}
@Inject
protected abstract JavaToolchainService getJavaToolchainService()
}-
We declare a
JavaLauncherproperty on the task. The property must be marked as a@Nestedinput to make sure the task is responsive to toolchain changes. -
We obtain the toolchain spec from the
javaextension to use it as a default. -
Using the
JavaToolchainServicewe get a provider of theJavaLauncherthat matches the toolchain. -
Finally, we wire the launcher provider as a convention for our property.
In a project where the java plugin was applied, we can use the task as follows:
plugins {
java
}
java {
toolchain { // (1)
languageVersion = JavaLanguageVersion.of(8)
}
}
tasks.register<CustomTaskUsingToolchains>("showDefaultToolchain") // (2)
tasks.register<CustomTaskUsingToolchains>("showCustomToolchain") {
launcher = javaToolchains.launcherFor { // (3)
languageVersion = JavaLanguageVersion.of(17)
}
}plugins {
id 'java'
}
java {
toolchain { // (1)
languageVersion = JavaLanguageVersion.of(8)
}
}
tasks.register('showDefaultToolchain', CustomTaskUsingToolchains) // (2)
tasks.register('showCustomToolchain', CustomTaskUsingToolchains) {
launcher = javaToolchains.launcherFor { // (3)
languageVersion = JavaLanguageVersion.of(17)
}
}-
The toolchain defined on the
javaextension is used by default to resolve the launcher. -
The custom task without additional configuration will use the default Java 8 toolchain.
-
The other task overrides the value of the launcher by selecting a different toolchain using
javaToolchainsservice.
When a task needs access to toolchains without the java plugin being applied the toolchain service can be used directly.
If an unconfigured toolchain spec is provided to the service, it will always return a tool provider for the toolchain that is running Gradle.
This can be achieved by passing an empty lambda when requesting a tool: javaToolchainService.launcherFor({}).
You can find more details on defining custom tasks in the Authoring tasks documentation.
Toolchains limitations
Gradle may detect toolchains incorrectly when it’s running in a JVM compiled against musl, an alternative implementation of the C standard library.
JVMs compiled against musl can sometimes override the LD_LIBRARY_PATH environment variable to control dynamic library resolution.
This can influence forked java processes launched by Gradle, resulting in unexpected behavior.
As a consequence, using multiple java toolchains is discouraged in environments with the musl library.
This is the case in most Alpine distributions — consider using another distribution, like Ubuntu, instead.
If you are using a single toolchain, the JVM running Gradle, to build and run your application, you can safely ignore this limitation.
Toolchain Resolver Plugins
In Gradle version 7.6 and above, Gradle provides a way to define Java toolchain auto-provisioning logic in plugins. This page explains how to author a toolchain resolver plugin. For details on how toolchain auto-provisioning interacts with these plugins, see Toolchains.
Provide a download URI
Toolchain resolver plugins provide logic to map a toolchain request to a download response. At the moment the download response only contains a download URL, but may be extended in the future.
|
Warning
|
For the download URL only secure protocols like https are accepted.
This is required to make sure no one can tamper with the download in flight.
|
The plugins provide the mapping logic via an implementation of JavaToolchainResolver:
public abstract class JavaToolchainResolverImplementation
implements JavaToolchainResolver { // (1)
public Optional<JavaToolchainDownload> resolve(JavaToolchainRequest request) { // (2)
return Optional.empty(); // custom mapping logic goes here instead
}
}-
This class is
abstractbecauseJavaToolchainResolveris a build service. Gradle provides dynamic implementations for certain abstract methods at runtime. -
The mapping method returns a download response wrapped in an
Optional. If the resolver implementation can’t provide a matching toolchain, the enclosingOptionalcontains an empty value.
Register the resolver in a plugin
Use a settings plugin (Plugin<Settings>) to register the JavaToolchainResolver implementation:
public abstract class JavaToolchainResolverPlugin implements Plugin<Settings> { // (1)
@Inject
protected abstract JavaToolchainResolverRegistry getToolchainResolverRegistry(); // (2)
public void apply(Settings settings) {
settings.getPluginManager().apply("jvm-toolchain-management"); // (3)
JavaToolchainResolverRegistry registry = getToolchainResolverRegistry();
registry.register(JavaToolchainResolverImplementation.class);
}
}-
The plugin uses property injection, so it must be
abstractand a settings plugin. -
To register the resolver implementation, use property injection to access the JavaToolchainResolverRegistry Gradle service.
-
Resolver plugins must apply the
jvm-toolchain-managementbase plugin. This dynamically adds thejvmblock totoolchainManagement, which makes registered toolchain repositories usable from the build.
Managing Dependencies of JVM Projects
This chapter explains how to apply basic dependency management concepts to JVM-based projects. For a detailed introduction to dependency management, see dependency management in Gradle.
Dissecting a typical build script
Let’s have a look at a very simple build script for a JVM-based project. It applies the Java Library plugin which automatically introduces a standard project layout, provides tasks for performing typical work and adequate support for dependency management.
plugins {
`java-library`
}
repositories {
mavenCentral()
}
dependencies {
implementation("org.hibernate:hibernate-core:3.6.7.Final")
testImplementation("junit:junit:4.+")
api("com.google.guava:guava:23.0")
}plugins {
id 'java-library'
}
repositories {
mavenCentral()
}
dependencies {
implementation 'org.hibernate:hibernate-core:3.6.7.Final'
testImplementation 'junit:junit:4.+'
api 'com.google.guava:guava:23.0'
}The Project.dependencies{} code block declares that Hibernate core 3.6.7.Final is required to compile the project’s production source code. It also states that junit >= 4.0 is required to compile the project’s tests. All dependencies are supposed to be looked up in the Maven Central repository as defined by Project.repositories{}. The following sections explain each aspect in more detail.
Declaring module dependencies
There are various types of dependencies that you can declare. One such type is a module dependency. A module dependency represents a dependency on a module with a specific version built outside the current build. Modules are usually stored in a repository, such as Maven Central, a corporate Maven or Ivy repository, or a directory in the local file system.
To define an module dependency, you add it to a dependency configuration:
dependencies {
implementation("org.hibernate:hibernate-core:3.6.7.Final")
}dependencies {
implementation 'org.hibernate:hibernate-core:3.6.7.Final'
}To find out more about defining dependencies, have a look at Declaring Dependencies.
Using dependency configurations
A Configuration is a named set of dependencies and artifacts. There are three main purposes for a configuration:
- Declaring dependencies
-
A plugin uses configurations to make it easy for build authors to declare what other subprojects or external artifacts are needed for various purposes during the execution of tasks defined by the plugin. For example a plugin may need the Spring web framework dependency to compile the source code.
- Resolving dependencies
-
A plugin uses configurations to find (and possibly download) inputs to the tasks it defines. For example Gradle needs to download Spring web framework JAR files from Maven Central.
- Exposing artifacts for consumption
-
A plugin uses configurations to define what artifacts it generates for other projects to consume. For example the project would like to publish its compiled source code packaged in the JAR file to an in-house Artifactory repository.
With those three purposes in mind, let’s take a look at a few of the standard configurations defined by the Java Library Plugin.
- implementation
-
The dependencies required to compile the production source of the project which are not part of the API exposed by the project. For example the project uses Hibernate for its internal persistence layer implementation.
- api
-
The dependencies required to compile the production source of the project which are part of the API exposed by the project. For example the project uses Guava and exposes public interfaces with Guava classes in their method signatures.
- testImplementation
-
The dependencies required to compile and run the test source of the project. For example the project decided to write test code with the test framework JUnit.
Various plugins add further standard configurations. You can also define your own custom configurations in your build via Project.configurations{}. See What are dependency configurations for the details of defining and customizing dependency configurations.
Declaring common Java repositories
How does Gradle know where to find the files for external dependencies? Gradle looks for them in a repository.
A repository is a collection of modules, organized by group, name and version.
Gradle understands different repository types, such as Maven and Ivy, and supports various ways of accessing the repository via HTTP or other protocols.
By default, Gradle does not define any repositories. You need to define at least one with the help of Project.repositories{} before you can use module dependencies. One option is use the Maven Central repository:
repositories {
mavenCentral()
}repositories {
mavenCentral()
}You can also have repositories on the local file system. This works for both Maven and Ivy repositories.
repositories {
ivy {
// URL can refer to a local directory
url = uri("../local-repo")
}
}repositories {
ivy {
// URL can refer to a local directory
url = file("../local-repo")
}
}A project can have multiple repositories. Gradle will look for a dependency in each repository in the order they are specified, stopping at the first repository that contains the requested module.
To find out more about defining repositories, have a look at Declaring Repositories.
Publishing artifacts
To learn more about publishing artifacts, have a look at publishing plugins.
C++ BUILDS
Building C++ projects
Gradle uses a convention-over-configuration approach to building native projects. If you are coming from another native build system, these concepts may be unfamiliar at first, but they serve a purpose to simplify build script authoring.
We will look at C++ projects in detail in this chapter, but most of the topics will apply to other supported native languages as well. If you don’t have much experience with building native projects with Gradle, take a look at the C++ tutorials for step-by-step instructions on how to build various types of basic C++ projects as well as some common use cases.
The C++ plugins covered in this chapter were introduced in 2018 and we recommend users to use those plugins over the older Native plugins that you may find references to.
Introduction
The simplest build script for a C++ project applies the C++ application plugin or the C++ library plugin and optionally sets the project version:
plugins {
`cpp-application` // or `cpp-library`
}
version = "1.2.1"plugins {
id 'cpp-application' // or 'cpp-library'
}
version = '1.2.1'By applying either of the C++ plugins, you get a whole host of features:
-
compileDebugCppandcompileReleaseCpptasks that compiles the C++ source files under src/main/cpp for the well-known debug and release build types, respectively. -
linkDebugandlinkReleasetasks that link the compiled C++ object files into an executable for applications or shared library for libraries with shared linkage for the debug and release build types. -
createDebugandcreateReleasetasks that assemble the compiled C++ object files into a static library for libraries with static linkage for the debug and release build types.
For any non-trivial C++ project, you’ll probably have some file dependencies and additional configuration specific to your project.
The C++ plugins also integrates the above tasks into the standard lifecycle tasks. The task that produces the development binary is attached to assemble. By default, the development binary is the debug variant.
The rest of the chapter explains the different ways to customize the build to your requirements when building libraries and applications.
Introducing build variants
Native projects can typically produce several different binaries, such as debug or release ones, or ones that target particular platforms and processor architectures. Gradle manages this through the concepts of dimensions and variants.
A dimension is simply a category, where each category is orthogonal to the rest. For example, the "build type" dimension is a category that includes debug and release. The "architecture" dimension covers processor architectures like x86-64 and PowerPC.
A variant is a combination of values for these dimensions, consisting of exactly one value for each dimension. You might have a "debug x86-64" or a "release PowerPC" variant.
Gradle has built-in support for several dimensions and several values within each dimension. You can find a list of them in the native plugin reference chapter.
Declaring your source files
Gradle’s C++ support uses a ConfigurableFileCollection directly from the application or library script block to configure the set of sources to compile.
Libraries make a distinction between private (implementation details) and public (exported to consumer) headers.
You can also configure sources for each binary build for those cases where sources are compiled only on certain target machines.
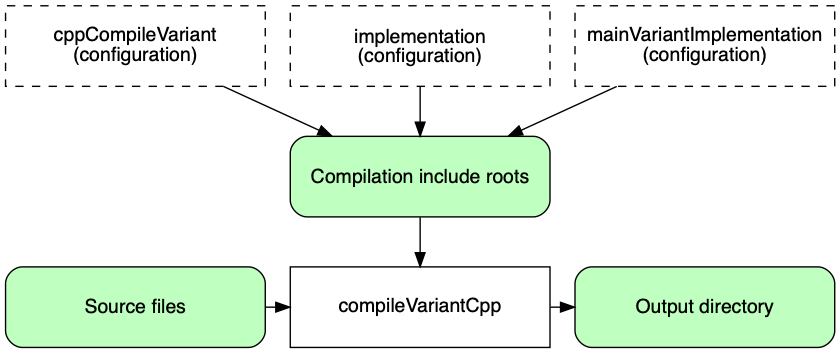
Test sources are configured on each test suite script block. See Testing C++ projects chapter.
Managing your dependencies
The vast majority of projects rely on other projects, so managing your project’s dependencies is an important part of building any project. Dependency management is a big topic, so we will only focus on the basics for C++ projects here. If you’d like to dive into the details, check out the introduction to dependency management.
Gradle provides support for consuming pre-built binaries from Maven repositories published by Gradle [10].
We will cover how to add dependencies between projects within a multi-build project.
Specifying dependencies for your C++ project requires two pieces of information:
-
Identifying information for the dependency (project path, Maven GAV)
-
What it’s needed for, e.g. compilation, linking, runtime or all of the above.
This information is specified in a dependencies {} block of the C++ application or library script block.
For example, to tell Gradle that your project requires library common to compile and link your production code, you can use the following fragment:
application {
dependencies {
implementation(project(":common"))
}
}application {
dependencies {
implementation project(':common')
}
}The Gradle terminology for the three elements is as follows:
-
Configuration (ex:
implementation) - a named collection of dependencies, grouped together for a specific goal such as compiling or linking a module -
Project reference (ex:
project(':common')) - the project referenced by the specified path
As far as configurations go, the main ones of interest are:
-
implementation- used for compilation, linking and runtime -
cppCompileVariant- for dependencies that are necessary to compile your production code but shouldn’t be part of the linking or runtime process -
nativeLinkVariant- for dependencies that are necessary to link your code but shouldn’t be part of the compilation or runtime process -
nativeRuntimeVariant- for dependencies that are necessary to run your component but shouldn’t be part of the compilation or linking process
You can learn more about these and how they relate to one another in the native plugin reference chapter.
Be aware that the C++ Library Plugin creates an additional configuration — api — for dependencies that are required for compiling and linking both the module and any modules that depend on it.
We have only scratched the surface here, so we recommend that you read the dedicated dependency management chapters once you’re comfortable with the basics of building C++ projects with Gradle.
Some common scenarios that require further reading include:
-
Defining a custom Maven-compatible repository
-
Declaring dependencies with changing (e.g. SNAPSHOT) and dynamic (range) versions
-
Declaring a sibling project as a dependency
-
Testing your fixes to 3rd-party dependency via composite builds (a better alternative to publishing to and consuming from Maven Local)
You’ll discover that Gradle has a rich API for working with dependencies — one that takes time to master, but is straightforward to use for common scenarios.
Compiling and linking your code
Compiling your code can be trivially easy if you follow the conventions:
-
Put your source code under the src/main/cpp directory
-
Declare your compile dependencies in the
implementationconfigurations (see the previous section) -
Run the
assembletask
We recommend that you follow these conventions wherever possible, but you don’t have to.
There are several options for customization, as you’ll see next.
|
Note
|
All CppCompile tasks are incremental and cacheable. |
Supported tool chain
Gradle offers the ability to execute the same build using different tool chains. When you build a native binary, Gradle will attempt to locate a tool chain installed on your machine that can build the binary. Gradle selects the first tool chain that can build for the target operating system and architecture. In the future, Gradle will consider source and ABI compatibility when selecting a tool chain.
Gradle has general support for the three major tool chains on major operating system: Clang [11], GCC [12] and Visual C++ [13] (Windows-only). GCC and Clang installed using Macports and Homebrew have been reported to work fine, but this isn’t tested continuously.
Windows
To build on Windows, install a compatible version of Visual Studio.
The C++ plugins will discover the Visual Studio installations and select the latest version.
If automatic discovery does not work, you can configure Visual Studio using the toolChains block.
toolChains{
withType<VisualCpp>().configureEach {
setInstallDir("C:\\Program Files (x86)\\Microsoft Visual Studio\\2022\\BuildTools")
}
}toolChains{
withType(VisualCpp).configureEach {
setInstallDir('C:\\Program Files (x86)\\Microsoft Visual Studio\\2022\\BuildTools')
}
}Alternatively, you can install Cygwin or MinGW with GCC. Clang is currently not supported.
macOS
To build on macOS, you should install Xcode. The C++ plugins will discover the Xcode installation using the system PATH.
The C++ plugins also work with GCC and Clang installed with Macports or Homebrew [14]. To use one of the Macports or Homebrew, you will need to add Macports/Homebrew to the system PATH.
Linux
To build on Linux, install a compatible version of GCC or Clang. The C++ plugins will discover GCC or Clang using the system PATH.
Customizing file and directory locations
Imagine you have a legacy library project that uses an src directory for the production code and private headers and include directory for exported headers.
The conventional directory structure won’t work, so you need to tell Gradle where to find the source and header files.
You do that via the application or library script block.
Each component script block, as well as each binary, defines where it’s source code resides. You can override the convention values by using the following syntax:
library {
source.from(file("src"))
privateHeaders.from(file("src"))
publicHeaders.from(file("include"))
}library {
source.from file('src')
privateHeaders.from file('src')
publicHeaders.from file('include')
}Now Gradle will only search directly in src for the source and private headers and in include for public headers.
Changing compiler and linker options
Most of the compiler and linker options are accessible through the corresponding task, such as compileVariantCpp, linkVariant and createVariant.
These tasks are of type CppCompile, LinkSharedLibrary and CreateStaticLibrary respectively.
Read the task reference for an up-to-date and comprehensive list of the options.
For example, if you want to change the warning level generated by the compiler for all variants, you can use this configuration:
tasks.withType(CppCompile::class.java).configureEach {
// Define a preprocessor macro for every binary
macros.put("NDEBUG", null)
// Define a compiler options
compilerArgs.add("-W3")
// Define toolchain-specific compiler options
compilerArgs.addAll(toolChain.map { toolChain ->
when (toolChain) {
is Gcc, is Clang -> listOf("-O2", "-fno-access-control")
is VisualCpp -> listOf("/Zi")
else -> listOf()
}
})
}tasks.withType(CppCompile).configureEach {
// Define a preprocessor macro for every binary
macros.put("NDEBUG", null)
// Define a compiler options
compilerArgs.add '-W3'
// Define toolchain-specific compiler options
compilerArgs.addAll toolChain.map { toolChain ->
if (toolChain in [ Gcc, Clang ]) {
return ['-O2', '-fno-access-control']
} else if (toolChain in VisualCpp) {
return ['/Zi']
}
return []
}
}It’s also possible to find the instance for a specific variant through the BinaryCollection on the application or library script block:
application {
binaries.configureEach(CppStaticLibrary::class.java) {
// Define a preprocessor macro for every binary
compileTask.get().macros.put("NDEBUG", null)
// Define a compiler options
compileTask.get().compilerArgs.add("-W3")
// Define toolchain-specific compiler options
when (toolChain) {
is Gcc, is Clang -> compileTask.get().compilerArgs.addAll(listOf("-O2", "-fno-access-control"))
is VisualCpp -> compileTask.get().compilerArgs.add("/Zi")
}
}
}application {
binaries.configureEach(CppStaticLibrary) {
// Define a preprocessor macro for every binary
compileTask.get().macros.put("NDEBUG", null)
// Define a compiler options
compileTask.get().compilerArgs.add '-W3'
// Define toolchain-specific compiler options
if (toolChain in [ Gcc, Clang ]) {
compileTask.get().compilerArgs.addAll(['-O2', '-fno-access-control'])
} else if (toolChain in VisualCpp) {
compileTask.get().compilerArgs.add('/Zi')
}
}
}Selecting target machines
By default, Gradle will attempt to create a C++ binary variant for the host operating system and architecture.
It is possible to override this by specifying the set of TargetMachine on the application or library script block:
application {
targetMachines = listOf(machines.windows.x86, machines.windows.x86_64, machines.macOS.x86_64, machines.linux.x86_64)
}application {
targetMachines = [
machines.linux.x86_64,
machines.windows.x86, machines.windows.x86_64,
machines.macOS.x86_64
]
}Packaging and publishing
How you package and potentially publish your C++ project varies greatly in the native world. Gradle comes with defaults, but custom packaging can be implemented without any issues.
-
Executable files are published directly to Maven repositories.
-
Shared and static library files are published directly to Maven repositories along with a zip of the public headers.
-
For applications, Gradle also supports installing and running the executable with all of its shared library dependencies in a known location.
Cleaning the build
The C++ Application and Library Plugins add a clean task to you project by using the base plugin.
This task simply deletes everything in the layout.buildDirectory directory, hence why you should always put files generated by the build in there.
The task is an instance of Delete and you can change what directory it deletes by setting its dir property.
Building C++ libraries
The unique aspect of library projects is that they are used (or "consumed") by other C++ projects. That means the dependency metadata published with the binaries and headers — in the form of Gradle Module Metadata — is crucial. In particular, consumers of your library should be able to distinguish between two different types of dependencies: those that are only required to compile your library and those that are also required to compile the consumer.
Gradle manages this distinction via the C++ Library Plugin, which introduces an api configuration in addition to the implementation once covered in this chapter. If the types from a dependency appear as unresolved symbols of the static library or within the public headers then that dependency is exposed via your library’s public API and should, therefore, be added to the api configuration. Otherwise, the dependency is an internal implementation detail and should be added to implementation.
If you’re unsure of the difference between an API and implementation dependency, the C++ Library Plugin chapter has a detailed explanation.
Building C++ applications
See the C++ Application Plugin chapter for more details, but here’s a quick summary of what you get:
-
installcreate a directory containing everything needed to run it -
Shell and Windows Batch scripts to start the application
Testing in C++ projects
Testing in the native ecosystem takes many forms.
There are different testing libraries and frameworks, as well as many different types of test. All need to be part of the build, whether they are executed frequently or infrequently. This chapter is dedicated to explaining how Gradle handles differing requirements between and within builds, with significant coverage of how it integrates with the executable-based testing frameworks, such as Google Test.
Testing C++ projects in Gradle is fairly limited when compared to Testing in Java & JVM projects. In this chapter, we explain the ways to control how tests are run (Test execution).
But first, we look at the basics of native testing in Gradle.
The basics
All C++ testing revolves around a single task type: RunTestExecutable. This runs a single test executable built with any testing framework and asserts the execution was successful using the exit code of the executable. The test case results aren’t collected and no reports are generated.
In order to operate, the RunTestExecutable task type requires just one piece of information:
-
Where to find the built test executable (property: RunTestExecutable.getExecutable())
When you’re using the C++ Unit Test Plugin you will automatically get the following:
-
A dedicated unitTest extension for configuring test component and its variants
-
A
runtask of type RunTestExecutable that runs the test executable
The test plugins configure the required pieces of information appropriately.
In addition, they attach the run task to the check lifecycle task.
It also create the testImplementation dependency configuration.
Dependencies that are only needed for test compilation, linking and runtime may be added to this configuration.
The unitTest script block behave similarly to a application or library script block.
The RunTestExecutable task has many configuration options. We cover a number of them in the rest of the chapter.
Test execution
Gradle executes tests in a separate (‘forked’) process.
You can control how the test process is launched via several properties on the RunTestExecutable task, including the following:
ignoreFailures- default: false-
If this property is
true, Gradle will continue with the project’s build once the tests have completed, even if some of them have failed. Note that, by default, RunTestExecutable task type always executes every test that it detects, irrespective of this setting.
See RunTestExecutable for details on all the available configuration options.
Building native software
|
Caution
|
The software model is being retired and the plugins mentioned in this chapter will eventually be deprecated and removed. We recommend new projects looking to build C++ applications and libraries use the newer replacement plugins. |
The native software plugins add support for building native software components, such as executables or shared libraries, from code written in C++, C and other languages. While many excellent build tools exist for this space of software development, Gradle offers developers its trademark power and flexibility together with dependency management practices more traditionally found in the JVM development space.
The native software plugins make use of the Gradle software model.
Features
The native software plugins provide:
-
Support for building native libraries and applications on Windows, Linux, macOS and other platforms.
-
Support for several source languages.
-
Support for building different variants of the same software, for different architectures, operating systems, or for any purpose.
-
Incremental parallel compilation, precompiled headers.
-
Dependency management between native software components.
-
Unit test execution.
-
Generate Visual studio solution and project files.
-
Deep integration with various tool chain, including discovery of installed tool chains.
Supported languages
The following source languages are currently supported:
-
C
-
C++
-
Objective-C
-
Objective-C++
-
Assembly
-
Windows resources
Tool chain support
Gradle offers the ability to execute the same build using different tool chains. When you build a native binary, Gradle will attempt to locate a tool chain installed on your machine that can build the binary. You can fine tune exactly how this works, see Tool chain support for details.
The following tool chains are supported:
| Operating System | Tool Chain | Notes |
|---|---|---|
Linux |
||
Linux |
||
macOS |
XCode |
Uses the Clang tool chain bundled with XCode. |
Windows |
Windows XP and later, Visual C++ 2010/2012/2013/2015/2017/2019. |
|
Windows |
Windows XP and later. |
|
Windows |
Windows XP and later. |
The following tool chains are unofficially supported. They generally work fine, but are not tested continuously:
| Operating System | Tool Chain | Notes |
|---|---|---|
macOS |
GCC from Macports |
|
macOS |
Clang from Macports |
|
UNIX-like |
||
UNIX-like |
Tool chain installation
|
Note
|
Note that if you are using GCC then you currently need to install support for C++, even if you are not building from C++ source. This restriction will be removed in a future Gradle version. |
To build native software, you will need to have a compatible tool chain installed:
Windows
To build on Windows, install a compatible version of Visual Studio. The native plugins will discover the Visual Studio installations and select the latest version. There is no need to mess around with environment variables or batch scripts. This works fine from a Cygwin shell or the Windows command-line.
Alternatively, you can install Cygwin with GCC or MinGW. Clang is currently not supported.
macOS
To build on macOS, you should install XCode. The native plugins will discover the XCode installation using the system PATH.
The native plugins also work with GCC and Clang bundled with Macports. To use one of the Macports tool chains, you will need to make the tool chain the default using the port select command and add Macports to the system PATH.
Linux
To build on Linux, install a compatible version of GCC or Clang. The native plugins will discover GCC or Clang using the system PATH.
Native software model
The native software model builds on the base Gradle software model.
To build native software using Gradle, your project should define one or more native components. Each component represents either an executable or a library that Gradle should build. A project can define any number of components. Gradle does not define any components by default.
For each component, Gradle defines a source set for each language that the component can be built from. A source set is essentially just a set of source directories containing source files. For example, when you apply the c plugin and define a library called helloworld, Gradle will define, by default, a source set containing the C source files in the src/helloworld/c directory. It will use these source files to build the helloworld library. This is described in more detail below.
For each component, Gradle defines one or more binaries as output. To build a binary, Gradle will take the source files defined for the component, compile them as appropriate for the source language, and link the result into a binary file. For an executable component, Gradle can produce executable binary files. For a library component, Gradle can produce both static and shared library binary files. For example, when you define a library called helloworld and build on Linux, Gradle will, by default, produce libhelloworld.so and libhelloworld.a binaries.
In many cases, more than one binary can be produced for a component. These binaries may vary based on the tool chain used to build, the compiler/linker flags supplied, the dependencies provided, or additional source files provided. Each native binary produced for a component is referred to as a variant. Binary variants are discussed in detail below.
Parallel Compilation
Gradle uses the single build worker pool to concurrently compile and link native components, by default. No special configuration is required to enable concurrent building.
By default, the worker pool size is determined by the number of available processors on the build machine (as reported to the build JVM). To explicitly set the number of workers use the --max-workers command-line option or org.gradle.workers.max system property. There is generally no need to change this setting from its default.
The build worker pool is shared across all build tasks. This means that when using parallel project execution, the maximum number of concurrent individual compilation operations does not increase. For example, if the build machine has 4 processing cores and 10 projects are compiling in parallel, Gradle will only use 4 total workers, not 40.
Building a library
To build either a static or shared native library, you define a library component in the components container. The following sample defines a library called hello:
Example: Defining a library component
model {
components {
hello(NativeLibrarySpec)
}
}A library component is represented using NativeLibrarySpec. Each library component can produce at least one shared library binary (SharedLibraryBinarySpec) and at least one static library binary (StaticLibraryBinarySpec).
Building an executable
To build a native executable, you define an executable component in the components container. The following sample defines an executable called main:
Example: Defining executable components
model {
components {
main(NativeExecutableSpec) {
sources {
c.lib library: "hello"
}
}
}
}An executable component is represented using NativeExecutableSpec. Each executable component can produce at least one executable binary (NativeExecutableBinarySpec).
For each component defined, Gradle adds a FunctionalSourceSet with the same name. Each of these functional source sets will contain a language-specific source set for each of the languages supported by the project.
Assembling or building dependents
Sometimes, you may need to assemble (compile and link) or build (compile, link and test) a component or binary and its dependents (things that depend upon the component or binary). The native software model provides tasks that enable this capability. First, the dependent components report gives insight about the relationships between each component. Second, the build and assemble dependents tasks allow you to assemble or build a component and its dependents in one step.
In the following example, the build file defines OpenSSL as a dependency of libUtil and libUtil as a dependency of LinuxApp and WindowsApp. Test suites are treated similarly. Dependents can be thought of as reverse dependencies.
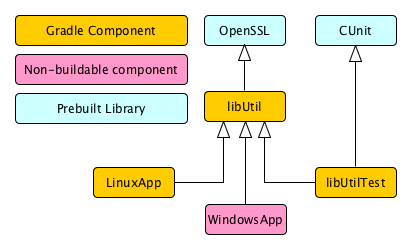
|
Note
|
By following the dependencies backwards, you can see LinuxApp and WindowsApp are dependents of libUtil.
When libUtil is changed, Gradle will need to recompile or relink LinuxApp and WindowsApp.
|
When you assemble dependents of a component, the component and all of its dependents are compiled and linked, including any test suite binaries. Gradle’s up-to-date checks are used to only compile or link if something has changed. For instance, if you have changed source files in a way that do not affect the headers of your project, Gradle will be able to skip compilation for dependent components and only need to re-link with the new library. Tests are not run when assembling a component.
When you build dependents of a component, the component and all of its dependent binaries are compiled, linked and checked. Checking components means running any check task including executing any test suites, so tests are run when building a component.
In the following sections, we will demonstrate the usage of the assembleDependents*, buildDependents* and dependentComponents tasks with a sample build that contains a CUnit test suite. The build script for the sample is the following:
Example: Sample build
plugins {
id 'c'
id 'cunit-test-suite'
}
model {
flavors {
passing
failing
}
platforms {
x86 {
if (operatingSystem.macOsX) {
architecture "x64"
} else {
architecture "x86"
}
}
}
components {
operators(NativeLibrarySpec) {
targetPlatform "x86"
}
}
testSuites {
operatorsTest(CUnitTestSuiteSpec) {
testing $.components.operators
}
}
}Dependent components report
Gradle provides a report that you can run from the command-line that shows a graph of components in your project and components that depend upon them. The following is an example of running gradle dependentComponents on the sample project:
Example: Dependent components report
$ ./gradlew dependentComponents> Task :dependentComponents
------------------------------------------------------------
Root project 'cunit'
------------------------------------------------------------
operators - Components that depend on native library 'operators'
+--- operators:failingSharedLibrary
+--- operators:failingStaticLibrary
+--- operators:passingSharedLibrary
\--- operators:passingStaticLibrary
Some test suites were not shown, use --test-suites or --all to show them.
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executed|
Note
|
See DependentComponentsReport API documentation for more details. |
By default, non-buildable binaries and test suites are hidden from the report. The dependentComponents task provides options that allow you to see all dependents by using the --all option:
Example: Dependent components report
$ ./gradlew dependentComponents --all> Task :dependentComponents
------------------------------------------------------------
Root project 'cunit'
------------------------------------------------------------
operators - Components that depend on native library 'operators'
+--- operators:failingSharedLibrary
+--- operators:failingStaticLibrary
| \--- operatorsTest:failingCUnitExe (t)
+--- operators:passingSharedLibrary
\--- operators:passingStaticLibrary
\--- operatorsTest:passingCUnitExe (t)
operatorsTest - Components that depend on Cunit test suite 'operatorsTest'
+--- operatorsTest:failingCUnitExe (t)
\--- operatorsTest:passingCUnitExe (t)
(t) - Test suite binary
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executedHere is the corresponding report for the operators component, showing dependents of all its binaries:
Example: Report of components that depends on the operators component
$ ./gradlew dependentComponents --component operators> Task :dependentComponents
------------------------------------------------------------
Root project 'cunit'
------------------------------------------------------------
operators - Components that depend on native library 'operators'
+--- operators:failingSharedLibrary
+--- operators:failingStaticLibrary
+--- operators:passingSharedLibrary
\--- operators:passingStaticLibrary
Some test suites were not shown, use --test-suites or --all to show them.
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executedHere is the corresponding report for the operators component, showing dependents of all its binaries, including test suites:
Example: Report of components that depends on the operators component, including test suites
$ ./gradlew dependentComponents --test-suites --component operators> Task :dependentComponents
------------------------------------------------------------
Root project 'cunit'
------------------------------------------------------------
operators - Components that depend on native library 'operators'
+--- operators:failingSharedLibrary
+--- operators:failingStaticLibrary
| \--- operatorsTest:failingCUnitExe (t)
+--- operators:passingSharedLibrary
\--- operators:passingStaticLibrary
\--- operatorsTest:passingCUnitExe (t)
(t) - Test suite binary
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executedFurthermore, the --non-binaries option shows non-buildable binaries in the report, --no-non-buildable hides them.
Similarly, the --test-suites option shows test suites and --no-test-suites hides them.
The option --no-all hides both non-buildable binaries and test suites from the report.
Assembling dependents
For each NativeBinarySpec, Gradle will create a task named assembleDependents${component.name}${binary.variant} that assembles (compile and link) the binary and all of its dependent binaries.
For each NativeComponentSpec, Gradle will create a task named assembleDependents${component.name} that assembles all the binaries of the component and all of their dependent binaries.
For example, to assemble the dependents of the "passing" flavor of the "static" library binary of the "operators" component, you would run the assembleDependentsOperatorsPassingStaticLibrary task:
Example: Assemble components that depends on the passing/static binary of the operators component
$ ./gradlew assembleDependentsOperatorsPassingStaticLibrary --max-workers=1> Task :compileOperatorsTestPassingCUnitExeOperatorsC
> Task :operatorsTestCUnitLauncher
> Task :compileOperatorsTestPassingCUnitExeOperatorsTestC
> Task :compileOperatorsTestPassingCUnitExeOperatorsTestCunitLauncher
> Task :linkOperatorsTestPassingCUnitExe
> Task :operatorsTestPassingCUnitExe
> Task :assembleDependentsOperatorsTestPassingCUnitExe
> Task :compileOperatorsPassingStaticLibraryOperatorsC
> Task :createOperatorsPassingStaticLibrary
> Task :operatorsPassingStaticLibrary
> Task :assembleDependentsOperatorsPassingStaticLibrary
BUILD SUCCESSFUL in 0s
7 actionable tasks: 7 executedIn the output above, the targeted binary gets assembled as well as the test suite binary that depends on it.
You can also assemble all of the dependents of a component (i.e. of all its binaries/variants) using the corresponding component task, e.g. assembleDependentsOperators. This is useful if you have many combinations of build types, flavors and platforms and want to assemble all of them.
Building dependents
For each NativeBinarySpec, Gradle will create a task named buildDependents${component.name}${binary.variant} that builds (compile, link and check) the binary and all of its dependent binaries.
For each NativeComponentSpec, Gradle will create a task named buildDependents${component.name} that builds all the binaries of the component and all of their dependent binaries.
For example, to build the dependents of the "passing" flavor of the "static" library binary of the "operators" component, you would run the buildDependentsOperatorsPassingStaticLibrary task:
Example: Build components that depends on the passing/static binary of the operators component
$ ./gradlew buildDependentsOperatorsPassingStaticLibrary --max-workers=1> Task :compileOperatorsTestPassingCUnitExeOperatorsC
> Task :operatorsTestCUnitLauncher
> Task :compileOperatorsTestPassingCUnitExeOperatorsTestC
> Task :compileOperatorsTestPassingCUnitExeOperatorsTestCunitLauncher
> Task :linkOperatorsTestPassingCUnitExe
> Task :operatorsTestPassingCUnitExe
> Task :installOperatorsTestPassingCUnitExe
> Task :runOperatorsTestPassingCUnitExe
> Task :checkOperatorsTestPassingCUnitExe
> Task :buildDependentsOperatorsTestPassingCUnitExe
> Task :compileOperatorsPassingStaticLibraryOperatorsC
> Task :createOperatorsPassingStaticLibrary
> Task :operatorsPassingStaticLibrary
> Task :buildDependentsOperatorsPassingStaticLibrary
BUILD SUCCESSFUL in 0s
9 actionable tasks: 9 executedIn the output above, the targeted binary as well as the test suite binary that depends on it are built and the test suite has run.
You can also build all of the dependents of a component (i.e. of all its binaries/variants) using the corresponding component task, e.g. buildDependentsOperators.
Tasks
For each NativeBinarySpec that can be produced by a build, a single lifecycle task is constructed that can be used to create that binary, together with a set of other tasks that do the actual work of compiling, linking or assembling the binary.
${component.name}Executable-
- Component Type
- Native Binary Type
- Location of created binary
-
${project.layout.buildDirectory}/exe/${component.name}/${component.name}
${component.name}SharedLibrary-
- Component Type
- Native Binary Type
- Location of created binary
-
${project.layout.buildDirectory}/libs/${component.name}/shared/lib${component.name}.so
${component.name}StaticLibrary-
- Component Type
- Native Binary Type
- Location of created binary
-
${project.layout.buildDirectory}/libs/${component.name}/static/${component.name}.a
Check tasks
For each NativeBinarySpec that can be produced by a build, a single check task is constructed that can be used to assemble and check that binary.
check${component.name}Executable-
- Component Type
- Native Binary Type
check${component.name}SharedLibrary-
- Component Type
- Native Binary Type
check${component.name}StaticLibrary-
- Component Type
- Native Binary Type
The built-in check task depends on all the check tasks for binaries in the project. Without either CUnit or GoogleTest plugins, the binary check task only depends on the lifecycle task that assembles the binary, see Native tasks.
When the CUnit or GoogleTest plugins are applied, the task that executes the test suites for a component are automatically wired to the appropriate check task.
You can also add custom check tasks as follows:
Example: Adding a custom check task
plugins {
id "cpp"
}
// You don't need to apply the plugin below if you're already using CUnit or GoogleTest support
apply plugin: TestingModelBasePlugin
tasks.register('myCustomCheck') {
doLast {
println 'Executing my custom check'
}
}
model {
components {
hello(NativeLibrarySpec) {
binaries.all {
// Register our custom check task to all binaries of this component
checkedBy $.tasks.myCustomCheck
}
}
}
}Now, running check or any of the check tasks for the hello binaries will run the custom check task:
Example: Running checks for a given binary
$ ./gradlew checkHelloSharedLibrary> Task :myCustomCheck
Executing my custom check
> Task :checkHelloSharedLibrary
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executedWorking with shared libraries
For each executable binary produced, the cpp plugin provides an install${binary.name} task, which creates a development install of the executable, along with the shared libraries it requires. This allows you to run the executable without needing to install the shared libraries in their final locations.
Finding out more about your project
Gradle provides a report that you can run from the command-line that shows some details about the components and binaries that your project produces. To use this report, just run gradle components. Below is an example of running this report for one of the sample projects:
Example: The components report
$ ./gradlew components> Task :components
------------------------------------------------------------
Root project 'cpp'
------------------------------------------------------------
Native library 'hello'
----------------------
Source sets
C++ source 'hello:cpp'
srcDir: src/hello/cpp
Binaries
Shared library 'hello:sharedLibrary'
build using task: :helloSharedLibrary
build type: build type 'debug'
flavor: flavor 'default'
target platform: platform 'current'
tool chain: Tool chain 'clang' (Clang)
shared library file: build/libs/hello/shared/libhello.dylib
Static library 'hello:staticLibrary'
build using task: :helloStaticLibrary
build type: build type 'debug'
flavor: flavor 'default'
target platform: platform 'current'
tool chain: Tool chain 'clang' (Clang)
static library file: build/libs/hello/static/libhello.a
Native executable 'main'
------------------------
Source sets
C++ source 'main:cpp'
srcDir: src/main/cpp
Binaries
Executable 'main:executable'
build using task: :mainExecutable
install using task: :installMainExecutable
build type: build type 'debug'
flavor: flavor 'default'
target platform: platform 'current'
tool chain: Tool chain 'clang' (Clang)
executable file: build/exe/main/main
Note: currently not all plugins register their components, so some components may not be visible here.
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executedLanguage support
Presently, Gradle supports building native software from any combination of source languages listed below. A native binary project will contain one or more named FunctionalSourceSet instances (e.g. 'main', 'test', etc), each of which can contain LanguageSourceSets containing source files, one for each language.
-
C
-
C++
-
Objective-C
-
Objective-C++
-
Assembly
-
Windows resources
C++ sources
C++ language support is provided by means of the 'cpp' plugin.
Example: The 'cpp' plugin
plugins {
id 'cpp'
}C++ sources to be included in a native binary are provided via a CppSourceSet, which defines a set of C++ source files and optionally a set of exported header files (for a library). By default, for any named component the CppSourceSet contains .cpp source files in src/${name}/cpp, and header files in src/${name}/headers.
While the cpp plugin defines these default locations for each CppSourceSet, it is possible to extend or override these defaults to allow for a different project layout.
Example: C++ source set
sources {
cpp {
source {
srcDir "src/source"
include "**/*.cpp"
}
}
}For a library named 'main', header files in src/main/headers are considered the "public" or "exported" headers. Header files that should not be exported should be placed inside the src/main/cpp directory (though be aware that such header files should always be referenced in a manner relative to the file including them).
C sources
C language support is provided by means of the 'c' plugin.
Example: The 'c' plugin
plugins {
id 'c'
}C sources to be included in a native binary are provided via a CSourceSet, which defines a set of C source files and optionally a set of exported header files (for a library). By default, for any named component the CSourceSet contains .c source files in src/${name}/c, and header files in src/${name}/headers.
While the c plugin defines these default locations for each CSourceSet, it is possible to extend or override these defaults to allow for a different project layout.
Example: C source set
sources {
c {
source {
srcDir "src/source"
include "**/*.c"
}
exportedHeaders {
srcDir "src/include"
}
}
}For a library named 'main', header files in src/main/headers are considered the "public" or "exported" headers. Header files that should not be exported should be placed inside the src/main/c directory (though be aware that such header files should always be referenced in a manner relative to the file including them).
Assembler sources
Assembly language support is provided by means of the 'assembler' plugin.
Example: The 'assembler' plugin
plugins {
id 'assembler'
}Assembler sources to be included in a native binary are provided via a AssemblerSourceSet, which defines a set of Assembler source files. By default, for any named component the AssemblerSourceSet contains .s source files under src/${name}/asm.
Objective-C sources
Objective-C language support is provided by means of the 'objective-c' plugin.
Example: The 'objective-c' plugin
plugins {
id 'objective-c'
}Objective-C sources to be included in a native binary are provided via a ObjectiveCSourceSet, which defines a set of Objective-C source files. By default, for any named component the ObjectiveCSourceSet contains .m source files under src/${name}/objectiveC.
Objective-C++ sources
Objective-C++ language support is provided by means of the 'objective-cpp' plugin.
Example: The 'objective-cpp' plugin
plugins {
id 'objective-cpp'
}Objective-C++ sources to be included in a native binary are provided via a ObjectiveCppSourceSet, which defines a set of Objective-C++ source files. By default, for any named component the ObjectiveCppSourceSet contains .mm source files under src/${name}/objectiveCpp.
Configuring the compiler, assembler and linker
Each binary to be produced is associated with a set of compiler and linker settings, which include command-line arguments as well as macro definitions. These settings can be applied to all binaries, an individual binary, or selectively to a group of binaries based on some criteria.
Example: Settings that apply to all binaries
model {
binaries {
all {
// Define a preprocessor macro for every binary
cppCompiler.define "NDEBUG"
// Define toolchain-specific compiler and linker options
if (toolChain in Gcc) {
cppCompiler.args "-O2", "-fno-access-control"
linker.args "-Xlinker", "-S"
}
if (toolChain in VisualCpp) {
cppCompiler.args "/Zi"
linker.args "/DEBUG"
}
}
}
}Each binary is associated with a particular NativeToolChain, allowing settings to be targeted based on this value.
It is easy to apply settings to all binaries of a particular type:
Example: Settings that apply to all shared libraries
// For any shared library binaries built with Visual C++,
// define the DLL_EXPORT macro
model {
binaries {
withType(SharedLibraryBinarySpec) {
if (toolChain in VisualCpp) {
cCompiler.args "/Zi"
cCompiler.define "DLL_EXPORT"
}
}
}
}Furthermore, it is possible to specify settings that apply to all binaries produced for a particular executable or library component:
Example: Settings that apply to all binaries produced for the 'main' executable component
model {
components {
main(NativeExecutableSpec) {
targetPlatform "x86"
binaries.all {
if (toolChain in VisualCpp) {
sources {
platformAsm(AssemblerSourceSet) {
source.srcDir "src/main/asm_i386_masm"
}
}
assembler.args "/Zi"
} else {
sources {
platformAsm(AssemblerSourceSet) {
source.srcDir "src/main/asm_i386_gcc"
}
}
assembler.args "-g"
}
}
}
}
}The example above will apply the supplied configuration to all executable binaries built.
Similarly, settings can be specified to target binaries for a component that are of a particular type: e.g. all shared libraries for the main library component.
Example: Settings that apply only to shared libraries produced for the 'main' library component
model {
components {
main(NativeLibrarySpec) {
binaries.withType(SharedLibraryBinarySpec) {
// Define a preprocessor macro that only applies to shared libraries
cppCompiler.define "DLL_EXPORT"
}
}
}
}Windows Resources
When using the VisualCpp tool chain, Gradle is able to compile Window Resource (rc) files and link them into a native binary. This functionality is provided by the 'windows-resources' plugin.
Example: The 'windows-resources' plugin
plugins {
id 'windows-resources'
}Windows resources to be included in a native binary are provided via a WindowsResourceSet, which defines a set of Windows Resource source files. By default, for any named component the WindowsResourceSet contains .rc source files under src/${name}/rc.
As with other source types, you can configure the location of the windows resources that should be included in the binary.
Example: Configuring the location of Windows resource sources
sources {
rc {
source {
srcDirs "src/hello/rc"
}
exportedHeaders {
srcDirs "src/hello/headers"
}
}
}You are able to construct a resource-only library by providing Windows Resource sources with no other language sources, and configure the linker as appropriate:
Example: Building a resource-only dll
model {
components {
helloRes(NativeLibrarySpec) {
binaries.all {
rcCompiler.args "/v"
linker.args "/noentry", "/machine:x86"
}
sources {
rc {
source {
srcDirs "src/hello/rc"
}
exportedHeaders {
srcDirs "src/hello/headers"
}
}
}
}
}
}The example above also demonstrates the mechanism of passing extra command-line arguments to the resource compiler. The rcCompiler extension is of type PreprocessingTool.
Library Dependencies
Dependencies for native components are binary libraries that export header files. The header files are used during compilation, with the compiled binary dependency being used during linking and execution. Header files should be organized into subdirectories to prevent clashes of commonly named headers. For instance, if your mylib project has a logging.h header, it will make it less likely the wrong header is used if you include it as "mylib/logging.h" instead of "logging.h".
Dependencies within the same project
A set of sources may depend on header files provided by another binary component within the same project. A common example is a native executable component that uses functions provided by a separate native library component.
Such a library dependency can be added to a source set associated with the executable component:
Example: Providing a library dependency to the source set
sources {
cpp {
lib library: "hello"
}
}Alternatively, a library dependency can be provided directly to the NativeExecutableBinarySpec for the executable.
Example: Providing a library dependency to the binary
model {
components {
hello(NativeLibrarySpec) {
sources {
c {
source {
srcDir "src/source"
include "**/*.c"
}
exportedHeaders {
srcDir "src/include"
}
}
}
}
main(NativeExecutableSpec) {
sources {
cpp {
source {
srcDir "src/source"
include "**/*.cpp"
}
}
}
binaries.all {
// Each executable binary produced uses the 'hello' static library binary
lib library: 'hello', linkage: 'static'
}
}
}
}Project Dependencies
For a component produced in a different Gradle project, the notation is similar.
Example: Declaring project dependencies
plugins {
id 'cpp'
}
model {
components {
main(NativeLibrarySpec)
}
// For any shared library binaries built with Visual C++,
// define the DLL_EXPORT macro
binaries {
withType(SharedLibraryBinarySpec) {
if (toolChain in VisualCpp) {
cppCompiler.define "DLL_EXPORT"
}
}
}
}plugins {
id 'cpp'
}
model {
components {
main(NativeExecutableSpec) {
sources {
cpp {
lib project: ':lib', library: 'main'
}
}
}
}
}Precompiled Headers
Precompiled headers are a performance optimization that reduces the cost of compiling widely used headers multiple times. This feature precompiles a header such that the compiled object file can be reused when compiling each source file rather than recompiling the header each time. This support is available for C, C++, Objective-C, and Objective-C++ builds.
To configure a precompiled header, first a header file needs to be defined that includes all of the headers that should be precompiled. It must be specified as the first included header in every source file where the precompiled header should be used. It is assumed that this header file, and any headers it contains, make use of header guards so that they can be included in an idempotent manner. If header guards are not used in a header file, it is possible the header could be compiled more than once and could potentially lead to a broken build.
Example: Creating a precompiled header file
#ifndef PCH_H
#define PCH_H
#include <iostream>
#include "hello.h"
#endifExample: Including a precompiled header file in a source file
#include "pch.h"
void LIB_FUNC Greeter::hello () {
std::cout << "Hello world!" << std::endl;
}Precompiled headers are specified on a source set. Only one precompiled header file can be specified on a given source set and will be applied to all source files that declare it as the first include. If a source files does not include this header file as the first header, the file will be compiled in the normal manner (without making use of the precompiled header object file). The string provided should be the same as that which is used in the "#include" directive in the source files.
Example: Configuring a precompiled header
model {
components {
hello(NativeLibrarySpec) {
sources {
cpp {
preCompiledHeader "pch.h"
}
}
}
}
}A precompiled header must be included in the same way for all files that use it. Usually, this means the header file should exist in the source set "headers" directory or in a directory included on the compiler include path.
Native Binary Variants
For each executable or library defined, Gradle is able to build a number of different native binary variants. Examples of different variants include debug vs release binaries, 32-bit vs 64-bit binaries, and binaries produced with different custom preprocessor flags.
Binaries produced by Gradle can be differentiated on build type, platform, and flavor. For each of these 'variant dimensions', it is possible to specify a set of available values as well as target each component at one, some or all of these. For example, a plugin may define a range of support platforms, but you may choose to only target Windows-x86 for a particular component.
Build types
A build type determines various non-functional aspects of a binary, such as whether debug information is included, or what optimisation level the binary is compiled with. Typical build types are 'debug' and 'release', but a project is free to define any set of build types.
Example: Defining build types
model {
buildTypes {
debug
release
}
}If no build types are defined in a project, then a single, default build type called 'debug' is added.
For a build type, a Gradle project will typically define a set of compiler/linker flags per tool chain.
Example: Configuring debug binaries
model {
binaries {
all {
if (toolChain in Gcc && buildType == buildTypes.debug) {
cppCompiler.args "-g"
}
if (toolChain in VisualCpp && buildType == buildTypes.debug) {
cppCompiler.args '/Zi'
cppCompiler.define 'DEBUG'
linker.args '/DEBUG'
}
}
}
}|
Note
|
At this stage, it is completely up to the build script to configure the relevant compiler/linker flags for each build type. Future versions of Gradle will automatically include the appropriate debug flags for any 'debug' build type, and may be aware of various levels of optimisation as well. |
Platform
An executable or library can be built to run on different operating systems and cpu architectures, with a variant being produced for each platform. Gradle defines each OS/architecture combination as a NativePlatform, and a project may define any number of platforms. If no platforms are defined in a project, then a single, default platform 'current' is added.
|
Note
|
Presently, a |
Example: Defining platforms
model {
platforms {
x86 {
architecture "x86"
}
x64 {
architecture "x86_64"
}
itanium {
architecture "ia-64"
}
}
}For a given variant, Gradle will attempt to find a NativeToolChain that is able to build for the target platform. Available tool chains are searched in the order defined. See the tool chains section below for more details.
Flavor
Each component can have a set of named flavors, and a separate binary variant can be produced for each flavor. While the build type and target platform variant dimensions have a defined meaning in Gradle, each project is free to define any number of flavors and apply meaning to them in any way.
An example of component flavors might differentiate between 'demo', 'paid' and 'enterprise' editions of the component, where the same set of sources is used to produce binaries with different functions.
Example: Defining flavors
model {
flavors {
english
french
}
components {
hello(NativeLibrarySpec) {
binaries.all {
if (flavor == flavors.french) {
cppCompiler.define "FRENCH"
}
}
}
}
}In the example above, a library is defined with a 'english' and 'french' flavor. When compiling the 'french' variant, a separate macro is defined which leads to a different binary being produced.
If no flavor is defined for a component, then a single default flavor named 'default' is used.
Selecting the build types, platforms and flavors for a component
For a default component, Gradle will attempt to create a native binary variant for each and every combination of buildType and flavor defined for the project. It is possible to override this on a per-component basis, by specifying the set of targetBuildTypes and/or targetFlavors. By default, Gradle will build for the default platform, see above, unless specified explicitly on a per-component basis by specifying a set of targetPlatforms.
Example: Targeting a component at particular platforms
model {
components {
hello(NativeLibrarySpec) {
targetPlatform "x86"
targetPlatform "x64"
}
main(NativeExecutableSpec) {
targetPlatform "x86"
targetPlatform "x64"
sources {
cpp.lib library: 'hello', linkage: 'static'
}
}
}
}Here you can see that the TargetedNativeComponent.targetPlatform(java.lang.String) method is used to specify a platform that the NativeExecutableSpec named main should be built for.
A similar mechanism exists for selecting TargetedNativeComponent.targetBuildTypes(java.lang.String…) and TargetedNativeComponent.targetFlavors(java.lang.String…).
Building all possible variants
When a set of build types, target platforms, and flavors is defined for a component, a NativeBinarySpec model element is created for every possible combination of these. However, in many cases it is not possible to build a particular variant, perhaps because no tool chain is available to build for a particular platform.
If a binary variant cannot be built for any reason, then the NativeBinarySpec associated with that variant will not be buildable. It is possible to use this property to create a task to generate all possible variants on a particular machine.
Example: Building all possible variants
model {
tasks {
buildAllExecutables(Task) {
dependsOn $.binaries.findAll { it.buildable }
}
}
}Tool chains
A single build may utilize different tool chains to build variants for different platforms. To this end, the core 'native-binary' plugins will attempt to locate and make available supported tool chains. However, the set of tool chains for a project may also be explicitly defined, allowing additional cross-compilers to be configured as well as allowing the install directories to be specified.
Example: Defining tool chains
toolChains {
visualCpp(VisualCpp) {
// Specify the installDir if Visual Studio cannot be located
// installDir "C:/Apps/Microsoft Visual Studio 10.0"
}
gcc(Gcc) {
// Uncomment to use a GCC install that is not in the PATH
// path "/usr/bin/gcc"
}
clang(Clang)
}Each tool chain implementation allows for a certain degree of configuration (see the API documentation for more details).
Using tool chains
It is not necessary or possible to specify the tool chain that should be used to build. For a given variant, Gradle will attempt to locate a NativeToolChain that is able to build for the target platform. Available tool chains are searched in the order defined.
|
Note
|
When a platform does not define an architecture or operating system, the default target of the tool chain is assumed.
So if a platform does not define a value for operatingSystem, Gradle will find the first available tool chain that can build for the specified architecture.
|
The core Gradle tool chains are able to target the following architectures out of the box. In each case, the tool chain will target the current operating system. See the next section for information on cross-compiling for other operating systems.
| Tool Chain | Architectures |
|---|---|
GCC |
x86, x86_64, arm64 (macOS & linux Only) |
Clang |
x86, x86_64, arm64 (macOS & linux only) |
Visual C++ |
x86, x86_64, ia-64 |
So for GCC running on linux, the supported target platforms are 'linux/x86' and 'linux/x86_64'. For GCC running on Windows via Cygwin, platforms 'windows/x86' and 'windows/x86_64' are supported. (The Cygwin POSIX runtime is not yet modelled as part of the platform, but will be in the future.)
If no target platforms are defined for a project, then all binaries are built to target a default platform named 'current'. This default platform does not specify any architecture or operatingSystem value, hence using the default values of the first available tool chain.
Gradle provides a hook that allows the build author to control the exact set of arguments passed to a tool chain executable. This enables the build author to work around any limitations in Gradle, or assumptions that Gradle makes. The arguments hook should be seen as a 'last-resort' mechanism, with preference given to truly modelling the underlying domain.
Example: Reconfigure tool arguments
toolChains {
visualCpp(VisualCpp) {
eachPlatform {
cppCompiler.withArguments { args ->
args << "-DFRENCH"
}
}
}
clang(Clang) {
eachPlatform {
cCompiler.withArguments { args ->
Collections.replaceAll(args, "CUSTOM", "-DFRENCH")
}
linker.withArguments { args ->
args.remove "CUSTOM"
}
staticLibArchiver.withArguments { args ->
args.remove "CUSTOM"
}
}
}
}Example: Defining target platforms
toolChains {
gcc(Gcc) {
target("arm"){
cppCompiler.withArguments { args ->
args << "-m32"
}
linker.withArguments { args ->
args << "-m32"
}
}
target("sparc")
}
}
model {
platforms {
arm {
architecture "arm"
}
sparc {
architecture "sparc"
}
}
components {
main(NativeExecutableSpec) {
targetPlatform "arm"
targetPlatform "sparc"
}
}
}Visual Studio IDE integration
Gradle has the ability to generate Visual Studio project and solution files for the native components defined in your build. This ability is added by the visual-studio plugin. For a multi-project build, all projects with native components (and the root project) should have this plugin applied.
When the visual-studio plugin is applied to the root project, a task named visualStudio is created, which will generate a Visual Studio solution file containing all components in the build. This solution will include a Visual Studio project for each component, as well as configuring each component to build using Gradle.
A task named openVisualStudio is also created by the visual-studio plugin when the project is the root project. This task generates the Visual Studio solution and then opens the solution in Visual Studio. This means you can simply run gradlew openVisualStudio from the root project to generate and open the Visual Studio solution in one convenient step.
The content of the generated visual studio files can be modified via API hooks, provided by the visualStudio extension. Take a look at the 'visual-studio' sample, or see VisualStudioExtension.getProjects() and VisualStudioRootExtension.getSolution() in the API documentation for more details.
CUnit support
The Gradle cunit plugin provides support for compiling and executing CUnit tests in your native-binary project. For each NativeExecutableSpec and NativeLibrarySpec defined in your project, Gradle will create a matching CUnitTestSuiteSpec component, named ${component.name}Test.
CUnit sources
Gradle will create a CSourceSet named 'cunit' for each CUnitTestSuiteSpec component in the project. This source set should contain the cunit test files for the component under test. Source files can be located in the conventional location (src/${component.name}Test/cunit) or can be configured like any other source set.
Gradle initialises the CUnit test registry and executes the tests, utilising some generated CUnit launcher sources. Gradle will expect and call a function with the signature void gradle_cunit_register() that you can use to configure the actual CUnit suites and tests to execute.
Example: Registering CUnit tests
#include <CUnit/Basic.h>
#include "gradle_cunit_register.h"
#include "test_operators.h"
int suite_init(void) {
return 0;
}
int suite_clean(void) {
return 0;
}
void gradle_cunit_register() {
CU_pSuite pSuiteMath = CU_add_suite("operator tests", suite_init, suite_clean);
CU_add_test(pSuiteMath, "test_plus", test_plus);
CU_add_test(pSuiteMath, "test_minus", test_minus);
}|
Note
|
Due to this mechanism, your CUnit sources may not contain a main method since this will clash with the method provided by Gradle.
|
Building CUnit executables
A CUnitTestSuiteSpec component has an associated NativeExecutableSpec or NativeLibrarySpec component. For each NativeBinarySpec configured for the main component, a matching CUnitTestSuiteBinarySpec will be configured on the test suite component. These test suite binaries can be configured in a similar way to any other binary instance:
Example: Configuring CUnit tests
model {
binaries {
withType(CUnitTestSuiteBinarySpec) {
lib library: "cunit", linkage: "static"
if (flavor == flavors.failing) {
cCompiler.define "PLUS_BROKEN"
}
}
}
}|
Note
|
Both the CUnit sources provided by your project and the generated launcher require the core CUnit headers and libraries. Presently, this library dependency must be provided by your project for each CUnitTestSuiteBinarySpec. |
Running CUnit tests
For each CUnitTestSuiteBinarySpec, Gradle will create a task to execute this binary, which will run all of the registered CUnit tests. Test results will be found in the ${build.dir}/test-results directory.
Example: Running CUnit tests
plugins {
id 'c'
id 'cunit-test-suite'
}
model {
flavors {
passing
failing
}
platforms {
x86 {
if (operatingSystem.macOsX) {
architecture "x64"
} else {
architecture "x86"
}
}
}
repositories {
libs(PrebuiltLibraries) {
cunit {
headers.srcDir "libs/cunit/2.1-2/include"
binaries.withType(StaticLibraryBinary) {
staticLibraryFile =
file("libs/cunit/2.1-2/lib/" +
findCUnitLibForPlatform(targetPlatform))
}
}
}
}
components {
operators(NativeLibrarySpec) {
targetPlatform "x86"
}
}
testSuites {
operatorsTest(CUnitTestSuiteSpec) {
testing $.components.operators
}
}
}
model {
binaries {
withType(CUnitTestSuiteBinarySpec) {
lib library: "cunit", linkage: "static"
if (flavor == flavors.failing) {
cCompiler.define "PLUS_BROKEN"
}
}
}
}$ ./gradlew -q runOperatorsTestFailingCUnitExeThere were test failures:
1. /home/user/gradle/samples/src/operatorsTest/c/test_plus.c:6 - plus(0, -2) == -2
2. /home/user/gradle/samples/src/operatorsTest/c/test_plus.c:7 - plus(2, 2) == 4
FAILURE: Build failed with an exception.
* What went wrong:
Execution failed for task ':runOperatorsTestFailingCUnitExe'.
> There were failing tests. See the results at: file:///home/user/gradle/samples/build/test-results/operatorsTest/failing/
* Try:
> Run with --stacktrace option to get the stack trace.
> Run with --info or --debug option to get more log output.
> Run with --scan to get full insights from a Build Scan (powered by Develocity).
> Get more help at https://help.gradle.org.
BUILD FAILED in 0s|
Note
|
The current support for CUnit is quite rudimentary. Plans for future integration include:
|
GoogleTest support
The Gradle google-test plugin provides support for compiling and executing GoogleTest tests in your native-binary project. For each NativeExecutableSpec and NativeLibrarySpec defined in your project, Gradle will create a matching GoogleTestTestSuiteSpec component, named ${component.name}Test.
GoogleTest sources
Gradle will create a CppSourceSet named 'cpp' for each GoogleTestTestSuiteSpec component in the project. This source set should contain the GoogleTest test files for the component under test. Source files can be located in the conventional location (src/${component.name}Test/cpp) or can be configured like any other source set.
Building GoogleTest executables
A GoogleTestTestSuiteSpec component has an associated NativeExecutableSpec or NativeLibrarySpec component. For each NativeBinarySpec configured for the main component, a matching GoogleTestTestSuiteBinarySpec will be configured on the test suite component. These test suite binaries can be configured in a similar way to any other binary instance:
Example: Registering GoogleTest tests
model {
binaries {
withType(GoogleTestTestSuiteBinarySpec) {
lib library: "googleTest", linkage: "static"
if (flavor == flavors.failing) {
cppCompiler.define "PLUS_BROKEN"
}
if (targetPlatform.operatingSystem.linux) {
cppCompiler.args '-pthread'
linker.args '-pthread'
if (toolChain instanceof Gcc || toolChain instanceof Clang) {
// Use C++03 with the old ABIs, as this is what the googletest binaries were built with
cppCompiler.args '-std=c++03', '-D_GLIBCXX_USE_CXX11_ABI=0'
linker.args '-std=c++03'
}
}
}
}
}|
Note
|
The GoogleTest sources provided by your project require the core GoogleTest headers and libraries. Presently, this library dependency must be provided by your project for each GoogleTestTestSuiteBinarySpec. |
Running GoogleTest tests
For each GoogleTestTestSuiteBinarySpec, Gradle will create a task to execute this binary, which will run all of the registered GoogleTest tests. Test results will be found in the ${build.dir}/test-results directory.
|
Note
|
The current support for GoogleTest is quite rudimentary. Plans for future integration include:
|
SWIFT BUILDS
Building Swift projects
Gradle uses a convention-over-configuration approach to building native projects. If you are coming from another native build system, these concepts may be unfamiliar at first, but they serve a purpose to simplify build script authoring.
We will look at Swift projects in detail in this chapter, but most of the topics will apply to other supported native languages as well.
Introduction
The simplest build script for a Swift project applies the Swift application plugin or the Swift library plugin and optionally sets the project version:
plugins {
`swift-application` // or `swift-library`
}
version = "1.2.1"plugins {
id 'swift-application' // or 'swift-library'
}
version = '1.2.1'By applying either of the Swift plugins, you get a whole host of features:
-
compileDebugSwiftandcompileReleaseSwifttasks that compiles the Swift source files under src/main/swift for the well-known debug and release build types, respectively. -
linkDebugandlinkReleasetasks that link the compiled Swift object files into an executable for applications or shared library for libraries with shared linkage for the debug and release build types. -
createDebugandcreateReleasetasks that assemble the compiled Swift object files into a static library for libraries with static linkage for the debug and release build types.
For any non-trivial Swift project, you’ll probably have some file dependencies and additional configuration specific to your project.
The Swift plugins also integrates the above tasks into the standard lifecycle tasks.
The task that produces the development binary is attached to assemble.
By default, the development binary is the debug variant.
The rest of the chapter explains the different ways to customize the build to your requirements when building libraries and applications.
Introducing build variants
Native projects can typically produce several different binaries, such as debug or release ones, or ones that target particular platforms and processor architectures. Gradle manages this through the concepts of dimensions and variants.
A dimension is simply a category, where each category is orthogonal to the rest. For example, the "build type" dimension is a category that includes debug and release. The "architecture" dimension covers processor architectures like x86-64 and x86.
A variant is a combination of values for these dimensions, consisting of exactly one value for each dimension. You might have a "debug x86-64" or a "release x86" variant.
Gradle has built-in support for several dimensions and several values within each dimension. You can find a list of them in the native plugin reference chapter.
Declaring your source files
Gradle’s Swift support uses a ConfigurableFileCollection directly from the application or library script block to configure the set of sources to compile.
Libraries make a distinction between private (implementation details) and public (exported to consumer) headers.
You can also configure sources for each binary build for those cases where sources are compiled only on certain target machines.
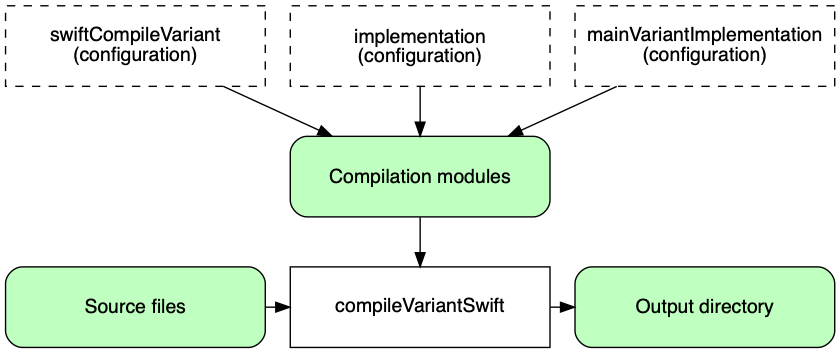
Managing your dependencies
The vast majority of projects rely on other projects, so managing your project’s dependencies is an important part of building any project. Dependency management is a big topic, so we will only focus on the basics for Swift projects here. If you’d like to dive into the details, check out the introduction to dependency management.
Gradle provides support for consuming pre-built binaries from Maven repositories published by Gradle [15].
We will cover how to add dependencies between projects within a multi-build project.
Specifying dependencies for your Swift project requires two pieces of information:
-
Identifying information for the dependency (project path, Maven GAV)
-
What it’s needed for, e.g. compilation, linking, runtime or all of the above.
This information is specified in a dependencies {} block of the Swift application or library script block.
For example, to tell Gradle that your project requires library common to compile and link your production code, you can use the following fragment:
application {
dependencies {
implementation(project(":common"))
}
}application {
dependencies {
implementation project(':common')
}
}The Gradle terminology for the three elements is as follows:
-
Configuration (ex:
implementation) - a named collection of dependencies, grouped together for a specific goal such as compiling or linking a module -
Project reference (ex:
project(':common')) - the project referenced by the specified path
As far as configurations go, the main ones of interest are:
-
implementation- used for compilation, linking and runtime -
swiftCompileVariant- for dependencies that are necessary to compile your production code but shouldn’t be part of the linking or runtime process -
nativeLinkVariant- for dependencies that are necessary to link your code but shouldn’t be part of the compilation or runtime process -
nativeRuntimeVariant- for dependencies that are necessary to run your component but shouldn’t be part of the compilation or linking process
You can learn more about these and how they relate to one another in the native plugin reference chapter.
Be aware that the Swift Library Plugin creates an additional configuration — api — for dependencies that are required for compiling and linking both the module and any modules that depend on it.
We have only scratched the surface here, so we recommend that you read the dedicated dependency management chapters once you’re comfortable with the basics of building Swift projects with Gradle.
Some common scenarios that require further reading include:
-
Defining a custom Maven-compatible repository
-
Declaring dependencies with changing (e.g. SNAPSHOT) and dynamic (range) versions
-
Declaring a sibling project as a dependency
-
Testing your fixes to 3rd-party dependency via composite builds (a better alternative to publishing to and consuming from Maven Local)
You’ll discover that Gradle has a rich API for working with dependencies — one that takes time to master, but is straightforward to use for common scenarios.
Compiling and linking your code
Compiling both your code can be trivially easy if you follow the conventions:
-
Put your source code under the src/main/swift directory
-
Declare your compile dependencies in the
implementationconfigurations (see the previous section) -
Run the
assembletask
We recommend that you follow these conventions wherever possible, but you don’t have to.
There are several options for customization, as you’ll see next.
|
Note
|
All SwiftCompile tasks are incremental and cacheable. |
Supported tool chain
Gradle support the official Swift tool chain for macOS and Linux. When you build a native binary, Gradle will attempt to locate a tool chain installed on your machine that can build the binary. Gradle select the first tool chain that can build for the target operating system, architecture and Swift language support.
|
Note
|
For Linux users, Gradle will discover the tool chain using the system PATH. |
Customizing file and directory locations
Imagine you are migrating a library project that follows the Swift Package Manager layout (e.g. Sources/ModuleName_ directory for the production code).
The conventional directory structure won’t work, so you need to tell Gradle where to find the source files.
You do that via the application or library script block.
Each component script block, as well as each binary, defines where it’s source code resides. You can override the convention values by using the following syntax:
extensions.configure<SwiftLibrary> {
source.from(file("Sources/Common"))
}library {
source.from file('src')
}Now Gradle will only search directly in Sources/Common for the source.
Changing compiler and linker options
Most of the compiler and linker options are accessible through the corresponding task, such as compileVariantSwift, linkVariant and createVariant.
These tasks are of type SwiftCompile, LinkSharedLibrary and CreateStaticLibrary respectively.
Read the task reference for an up-to-date and comprehensive list of the options.
For example, if you want to change the warning level generated by the compiler for all variants, you can use this configuration:
tasks.withType(SwiftCompile::class.java).configureEach {
// Define a preprocessor macro for every binary
macros.add("NDEBUG")
// Define a compiler options
compilerArgs.add("-O")
}tasks.withType(SwiftCompile).configureEach {
// Define a preprocessor macro for every binary
macros.add("NDEBUG")
// Define a compiler options
compilerArgs.add '-O'
}It’s also possible to find the instance for a specific variant through the BinaryCollection on the application or library script block:
application {
binaries.configureEach(SwiftStaticLibrary::class.java) {
// Define a preprocessor macro for every binary
compileTask.get().macros.add("NDEBUG")
// Define a compiler options
compileTask.get().compilerArgs.add("-O")
}
}application {
binaries.configureEach(SwiftStaticLibrary) {
// Define a preprocessor macro for every binary
compileTask.get().macros.add("NDEBUG")
// Define a compiler options
compileTask.get().compilerArgs.add '-O'
}
}Selecting target machines
By default, Gradle will attempt to create a Swift binary variant for the host operating system and architecture.
It is possible to override this by specifying the set of TargetMachine on the application or library script block:
application {
targetMachines = listOf(machines.linux.x86_64, machines.macOS.x86_64)
}application {
targetMachines = [
machines.linux.x86_64,
machines.macOS.x86_64
]
}Packaging and publishing
How you package and potentially publish your Swift project varies greatly in the native world. Gradle comes with defaults, but custom packaging can be implemented without any issues.
-
Executable files are published directly to Maven repositories.
-
Shared and static library files are published directly to Maven repositories along with a zip of the public headers.
-
For applications, Gradle also supports installing and running the executable with all of its shared library dependencies in a known location.
Cleaning the build
The Swift Application and Library Plugins add a clean task to you project by using the base plugin.
This task simply deletes everything in the layout.buildDirectory directory, hence why you should always put files generated by the build in there.
The task is an instance of Delete and you can change what directory it deletes by setting its dir property.
Building Swift libraries
The unique aspect of library projects is that they are used (or "consumed") by other Swift projects. That means the dependency metadata published with the binaries and headers — in the form of Gradle Module Metadata — is crucial. In particular, consumers of your library should be able to distinguish between two different types of dependencies: those that are only required to compile your library and those that are also required to compile the consumer.
Gradle manages this distinction via the Swift Library Plugin, which introduces an api configuration in addition to the implementation once covered in this chapter. If the types from a dependency appear as unresolved symbols of the static library or within the public headers then that dependency is exposed via your library’s public API and should, therefore, be added to the api configuration. Otherwise, the dependency is an internal implementation detail and should be added to implementation.
If you’re unsure of the difference between an API and implementation dependency, the Swift Library Plugin chapter has a detailed explanation.
Building Swift applications
See the Swift Application Plugin chapter for more details, but here’s a quick summary of what you get:
-
installcreate a directory containing everything needed to run it -
Shell and Windows Batch scripts to start the application
Testing in Swift projects
Testing in the native ecosystem is a rich subject matter. There are many different testing libraries and frameworks, as well as many different types of test. All need to be part of the build, whether they are executed frequently or infrequently. This chapter is dedicated to explaining how Gradle handles differing requirements between and within builds, with significant coverage of how it integrates with XCTest on both macOS and Linux.
It explains: - Ways to control how the tests are run (Test execution) - How to select specific tests to run (Test filtering) - What test reports are generated and how to influence the process (Test reporting) - How Gradle finds tests to run (Test detection)
But first, we look at the basics of native testing in Gradle.
The basics
Gradle supports deep integration with XCTest testing framework for the Swift language and revolves around the XCTest task type. This runs a collection of test cases using the Xcode XCTest on macOS or the open source Swift core library alternative on Linux and collates the results. You can then turn those results into a report via an instance of the TestReport task type.
In order to operate, the XCTest task type requires three pieces of information: - Where to find the built testable bundle (on macOS) or executable (on Linux) (property: XCTest.getTestInstalledDirectory()) - The run script for executing the bundle or executable (property: XCTest.getRunScriptFile()) - The working directory to execution the bundle or executable (property: XCTest.getWorkingDirectory())
When you’re using the XCTest Plugin you will automatically get the following:
- A dedicated xctest extension of type SwiftXCTestSuite for configuring test component and its variants
- A xcTest task of type XCTest that runs those unit tests
- A testable bundle or executable linked with the main component’s object files
The test plugins configure the required pieces of information appropriately.
In addition, they attach the xcTest or run task to the check lifecycle task.
It also create the testImplementation dependency configuration.
Dependencies that are only needed for test compilation, linking and runtime may be added to this configuration.
The xctest script block behave similarly to a application or library script block.
The XCTest task has many configuration options. We cover a significant number of them in the rest of the chapter.
Test execution
Gradle executes tests in a separate (‘forked’) process.
You can control how the test process is launched via several properties on the XCTest task, including the following:
ignoreFailures- default: false-
If this property is
true, Gradle will continue with the project’s build once the tests have completed, even if some of them have failed. Note that, by default, both task type always executes every test that it detects, irrespective of this setting. testLogging- default: not set-
This property represents a set of options that control which test events are logged and at what level. You can also configure other logging behavior via this property. Set TestLoggingContainer for more detail.
See XCTest for details on all the available configuration options.
Test filtering
It’s a common requirement to run subsets of a test suite, such as when you’re fixing a bug or developing a new test case. Gradle provides filtering to do this. You can select tests to run based on:
-
A simple class name or method name, e.g.
SomeTest,SomeTest.someMethod -
‘*’ wildcard matching
You can enable filtering either in the build script or via the --tests command-line option.
Here’s an example of some filters that are applied every time the build runs:
xctest {
binaries.configureEach {
runTask.get().filter.includeTestsMatching("SomeIntegTest.*") // or `"Testing.SomeIntegTest.*"` on macOS
}
}xctest {
binaries.configureEach {
runTask.get().configure {
// include all tests from test class
filter.includeTestsMatching "SomeIntegTest.*" // or `"Testing.SomeIntegTest.*"` on macOS
}
}
}For more details and examples of declaring filters in the build script, please see the TestFilter reference.
The command-line option is especially useful to execute a single test method.
It is also possible to supply multiple --tests options, all of whose patterns will take effect.
The following sections have several examples of using command-line option.
|
Note
|
The test filtering only support XCTest compatible filters at the moment.
It means the same filter will differ between macOS and Linux.
On macOS, the bundle base name needs to be prepended to the filter, e.g. TestBundle.SomeTest, TestBundle.SomeTest.someMethod
See the Simple name pattern section below for more information about valid filtering pattern.
|
The following section looks at the specific cases of simple class/method names.
Simple name pattern
Gradle support simple class name, or a class name + method name test filtering.
For example, the following command lines run either all or exactly one of the tests in the SomeTestClass test case:
# Executes all tests in SomeTestClass
gradle xcTest --tests SomeTestClass
# or `gradle xcTest --tests TestBundle.SomeTestClass` on macOS
# Executes a single specified test in SomeTestClass
gradle xcTest --tests TestBundle.SomeTestClass.someSpecificMethod
# or `gradle xcTest --tests TestBundle.SomeTestClass.someSpecificMethod` on macOSYou can also combine filters defined at the command line with continuous build to re-execute a subset of tests immediately after every change to a production or test source file. The following executes all tests in the ‘SomeTestClass’ test class whenever a change triggers the tests to run:
$ ./gradlew test --continuous --tests SomeTestClassTest reporting
The XCTest task generates the following results by default:
-
An HTML test report
-
XML test results in a format compatible with the Ant JUnit report task - one that is supported by many other tools, such as CI servers
-
An efficient binary format of the results used by the
XCTesttask to generate the other formats
In most cases, you’ll work with the standard HTML report, which automatically includes the result from your XCTest tasks.
There is also a standalone TestReport task type that you can use to generate a custom HTML test report.
All it requires are a value for destinationDir and the test results you want included in the report.
Here is a sample which generates a combined report for the unit tests from all subprojects:
plugins {
id("xctest")
}
extensions.configure<SwiftXCTestSuite>() {
binaries.configureEach {
// Disable the test report for the individual test task
runTask.get().reports.html.required = false
}
}
configurations.create("binaryTestResultsElements") {
isCanBeResolved = false
isCanBeConsumed = true
attributes {
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category.DOCUMENTATION))
attribute(DocsType.DOCS_TYPE_ATTRIBUTE, objects.named("test-report-data"))
}
tasks.withType<XCTest>() {
outgoing.artifact(binaryResultsDirectory)
}
}plugins {
`reporting-base`
}
val testReportData = configurations.create("testReportData") {
isCanBeConsumed = false
attributes {
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category.DOCUMENTATION))
attribute(DocsType.DOCS_TYPE_ATTRIBUTE, objects.named("test-report-data"))
}
}
dependencies {
testReportData(project(":core"))
testReportData(project(":util"))
}
tasks.register<TestReport>("testReport") {
destinationDirectory = reporting.baseDirectory.dir("allTests")
// Use test results from testReportData configuration
testResults.from(testReportData)
}plugins {
id 'xctest'
}
xctest {
binaries.configureEach {
runTask.get().configure {
// Disable the test report for the individual test task
reports.html.required = false
}
}
}
// Share the test report data to be aggregated for the whole project
configurations {
binaryTestResultsElements {
canBeResolved = false
attributes {
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category, Category.DOCUMENTATION))
attribute(DocsType.DOCS_TYPE_ATTRIBUTE, objects.named(DocsType, 'test-report-data'))
}
tasks.withType(XCTest).configureEach {
outgoing.artifact(it.binaryResultsDirectory)
}
}
}// A resolvable configuration to collect test reports data
plugins {
id 'reporting-base'
}
configurations {
testReportData {
canBeConsumed = false
attributes {
attribute(Category.CATEGORY_ATTRIBUTE, objects.named(Category, Category.DOCUMENTATION))
attribute(DocsType.DOCS_TYPE_ATTRIBUTE, objects.named(DocsType, 'test-report-data'))
}
}
}
dependencies {
testReportData project(':core')
testReportData project(':util')
}
tasks.register('testReport', TestReport) {
destinationDirectory = reporting.baseDirectory.dir('allTests')
// Use test results from testReportData configuration
testResults.from(configurations.testReportData)
}In this example, we use a convention plugin myproject.xctest-conventions to expose the test results from a project to Gradle’s variant aware dependency management engine.
The plugin declares a consumable binaryTestResultsElements configuration that represents the binary test results of the test task.
In the aggregation project’s build file, we declare the testReportData configuration and depend on all of the projects that we want to aggregate the results from. Gradle will automatically select the binary test result variant from each of the subprojects instead of the project’s jar file.
Lastly, we add a testReport task that aggregates the test results from the testResultsDirs property, which contains all of the binary test results resolved from the testReportData configuration.
You should note that the TestReport type combines the results from multiple test tasks and needs to aggregate the results of individual test classes. This means that it a given test class is executed by multiple test tasks, then the test report will include executions of that class, but it can be hard to distinguish individual executions of that class and their output.
GRADLE ON CI
Gradle on CI / CD Systems
Gradle integrates with many Continuous Integration (CI) and Continuous Delivery (CD) systems.
The pages in this section provide recipes and best practices for configuring popular CI platforms to build Gradle projects efficiently.
Recipes
The following recipes walk through configuring Gradle for specific CI systems:
Gradle on GitHub Actions
This page is a reference for integrating Gradle with GitHub Actions using the official gradle/actions.
Available actions
The gradle/actions repository publishes three composable actions.
All examples on this page target the current major version, v6.
| Action | Purpose |
|---|---|
Configures the runner for Gradle builds. Restores and saves the Gradle User Home cache, validates the Gradle Wrapper, and captures Build Scan® links in the job summary. |
|
Generates a dependency graph for the project and submits it to the GitHub Dependency Submission API, enabling Dependabot alerts and supply-chain security features. |
|
Validates the checksum of every |
|
Note
|
|
Configuring builds with setup-gradle
A minimal workflow that builds a Gradle project and publishes a Build Scan:
name: Build
on: [push, pull_request]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-java@v4
with:
distribution: temurin
java-version: 21
- uses: gradle/actions/setup-gradle@v6
with:
build-scan-publish: true
build-scan-terms-of-use-url: "https://gradle.com/terms-of-service"
build-scan-terms-of-use-agree: "yes"
- run: ./gradlew buildKey inputs
| Input | Description |
|---|---|
|
Gradle version to provision on the runner. Accepts an explicit version (e.g. |
|
Caching backend. |
|
Set to |
|
Read cache entries but do not write them back. Typical for feature branches so only the default branch updates the cache. |
|
Start with a clean Gradle User Home and save state at job end. Useful for seeding a fresh cache. |
|
Purge unused files from Gradle User Home before saving. One of |
|
Base64-encoded AES key used to encrypt configuration-cache entries, which may contain credentials. Required to cache the configuration cache across jobs. |
|
Glob patterns that add to or subtract from the set of Gradle User Home paths that are cached. |
|
When |
|
Required when |
|
Access key for publishing Build Scans to a private Develocity server. Provide via |
|
Controls the GitHub Actions job summary produced by the action: |
|
Mirror the job summary as a pull-request comment: |
See the setup-gradle documentation for the complete input reference.
Caching behavior
setup-gradle automatically saves and restores the Gradle User Home (~/.gradle), which contains the Gradle distribution, resolved dependencies, and the local build cache.
A cache entry is written at job completion when the job is a push to the default branch; other jobs restore from existing entries.
Starting with version 6.1.0, the default cache backend is the enhanced provider, which offers higher hit rates than the standard GitHub Actions cache.
Set cache-provider: basic to use the fully open-source implementation over actions/cache.
Submitting dependency graphs
The dependency-submission action runs the Gradle build in a dedicated mode that captures the resolved dependency graph, then submits it to GitHub via the Dependency Submission API.
Once submitted, the graph powers Dependabot alerts and the Insights → Dependency graph view.
name: Dependency Submission
on:
push:
branches: [main]
permissions:
contents: write
jobs:
dependency-submission:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-java@v4
with:
distribution: temurin
java-version: 21
- uses: gradle/actions/dependency-submission@v6
with:
build-scan-publish: true
build-scan-terms-of-use-url: "https://gradle.com/terms-of-service"
build-scan-terms-of-use-agree: "yes"|
Note
|
The workflow requires |
Key inputs
| Input | Description |
|---|---|
|
What to do with the generated graph: |
|
If |
|
Regex filters on Gradle subproject paths, e.g. |
|
Regex filters on configuration names, e.g. exclude |
|
Task used to resolve dependencies. Defaults to the built-in |
|
Extra arguments appended to the Gradle invocation (for example |
|
Path to the Gradle build if it is not at the repository root. |
|
Retention for uploaded dependency-graph artifacts (default |
See the dependency-submission documentation for the complete input reference.
Validating the Gradle Wrapper
setup-gradle validates every gradle-wrapper.jar in the repository on each run. Projects that do not otherwise use setup-gradle (for example, those building with a pre-installed Gradle distribution) can run the standalone action:
- uses: gradle/actions/wrapper-validation@v6Build Scans in job summaries
When setup-gradle or dependency-submission detects a published Build Scan, it appends the scan link and a task-execution summary to the GitHub Actions job summary. Use add-job-summary-as-pr-comment: on-failure to surface the same information on the pull request when a build fails.
Matrix builds
For matrix builds, use cache-read-only: true on non-primary matrix legs so only one leg writes to the cache:
strategy:
matrix:
java: [17, 21]
steps:
- uses: gradle/actions/setup-gradle@v6
with:
cache-read-only: ${{ matrix.java != 21 }}Gradle on GitLab CI
This page is a reference for integrating Gradle with GitLab CI/CD on GitLab.com, self-managed, or GitLab Dedicated instances.
Using the GitLab-provided template
GitLab ships an official Gradle CI template at Gradle.gitlab-ci.yml.
Include it with:
include:
- template: Gradle.gitlab-ci.ymlThe template defines three stages, build, test, deploy, using the gradle:alpine image, and configures a .gradle/ cache keyed by branch.
Use it as a starting point; most projects override the image and script sections to pin a specific JDK and use the Gradle Wrapper.
Minimal pipeline
A reference .gitlab-ci.yml that builds a Gradle project using the Wrapper and publishes test results:
image: eclipse-temurin:21
variables:
GRADLE_USER_HOME: "$CI_PROJECT_DIR/.gradle"
GRADLE_OPTS: "-Dorg.gradle.daemon=false"
build:
stage: build
script:
- ./gradlew --no-daemon build
artifacts:
when: always
reports:
junit: "**/build/test-results/test/TEST-*.xml"
paths:
- "**/build/reports"
expire_in: 1 week-
imageprovides the JDK; the Gradle Wrapper supplies Gradle itself. -
GRADLE_USER_HOMEis placed inside$CI_PROJECT_DIRso it falls within GitLab’s cacheable and uploadable area. -
GRADLE_OPTS=-Dorg.gradle.daemon=falsedisables the Gradle daemon on short-lived runners. -
reports:junitsurfaces test results directly on the merge request and pipeline pages.
Caching
GitLab caches are scoped by key and stored per runner (for project runners) or on shared object storage (for SaaS shared runners). Two patterns are common.
Wrapper-only cache
Recommended for SaaS shared runners, where uploading a large cache archive often outweighs the savings:
variables:
GRADLE_USER_HOME: "$CI_PROJECT_DIR/.gradle"
cache:
key:
files:
- gradle/wrapper/gradle-wrapper.properties
paths:
- .gradle/wrapperKeying on gradle-wrapper.properties means the cache is rebuilt only when the Gradle version changes.
Full Gradle User Home cache
Appropriate for dedicated or self-hosted runners with local cache storage:
variables:
GRADLE_USER_HOME: "$CI_PROJECT_DIR/.gradle"
cache:
key: "$CI_COMMIT_REF_SLUG"
paths:
- .gradle/caches
- .gradle/wrapper
- .gradle/notifications|
Tip
|
For cross-branch dependency reuse, prefer a Gradle Remote Build Cache. |
Cache policies across stages
For multi-stage pipelines, use the push / pull / pull-push (default) policy to control which jobs write the cache:
build:
stage: build
cache:
key: "$CI_COMMIT_REF_SLUG"
policy: pull-push
paths: [.gradle]
test:
stage: test
cache:
key: "$CI_COMMIT_REF_SLUG"
policy: pull
paths: [.gradle]The build job populates the cache; downstream jobs read from it without uploading.
Publishing Build Scans
To publish Gradle Build Scans® from GitLab CI, apply the Develocity plugin in settings.gradle[.kts] and accept the terms of use when running under CI:
plugins {
id("com.gradle.develocity") version "3.18.1"
}
develocity {
buildScan {
if (System.getenv("CI") != null) {
termsOfUseUrl = "https://gradle.com/help/legal-terms-of-use"
termsOfUseAgree = "yes"
publishing.onlyIf { true }
}
}
}GitLab CI sets CI=true automatically.
Build Scan URLs are printed to the job log and can be linked from merge request discussions.
Merge request and branch pipelines
Use rules to distinguish merge-request pipelines from branch pipelines — for example, to skip slow integration tests on feature branches:
integration-test:
stage: test
script: ./gradlew integrationTest
rules:
- if: '$CI_PIPELINE_SOURCE == "merge_request_event"'
- if: '$CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH'Release pipelines
A typical Gradle release pipeline on GitLab CI combines a versioning plugin (such as Axion Release) with publish targeting GitLab’s Maven Package Registry or an external repository. The pattern described in Release Gradle project using GitLab CI/CD pipeline is:
variables:
# Required so Axion Release can read existing version tags
GIT_FETCH_EXTRA_FLAGS: --tags
release:
stage: release
script:
- ./gradlew createRelease -Prelease.customUsername=$GITLAB_USER -Prelease.customPassword=$GITLAB_TOKEN
- ./gradlew publish
- echo "VERSION=$(./gradlew -q currentVersion)" >> variables.env
artifacts:
reports:
dotenv: variables.env
rules:
# Skip when the pipeline is triggered by a tag the release job itself pushed
- if: $CI_COMMIT_TAG
when: never
- if: $CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCHKey points:
-
GIT_FETCH_EXTRA_FLAGS: --tagsexposes existing version tags to the job; without it, Axion (and similar plugins) cannot compute the next version. -
The release job needs write access to push the new tag back — supply a project access token or deploy key with
write_repositoryscope viaGITLAB_TOKEN. -
The
rulesblock prevents the tag push from triggering a recursive release. -
Credentials for publishing (for example
CI_REPOSITORY_USERNAME/CI_REPOSITORY_PASSWORD) are set as masked/protected CI/CD variables in the project settings, then read bybuild.gradle[.kts]:publishing { repositories { maven { url = uri("${System.getenv("CI_API_V4_URL")}/projects/${System.getenv("CI_PROJECT_ID")}/packages/maven") credentials(HttpHeaderCredentials::class) { name = "Job-Token" value = System.getenv("CI_JOB_TOKEN") } authentication { create<HttpHeaderAuthentication>("header") } } } }
A downstream GitLab release job can then consume the VERSION dotenv artifact to create a GitLab Release entry.
Useful predefined variables
| Variable | Purpose |
|---|---|
|
Always |
|
Absolute path to the checked-out repository. Base for |
|
URL-safe branch/tag name. Common |
|
Populated on branch and tag pipelines respectively. Use in |
|
Trigger type ( |
|
Short-lived token for authenticating to the project’s package registry and API. |
|
Compose URLs to the GitLab API and package registries. |
See Predefined CI/CD variables for the full list.
Gradle on Jenkins
This page is a reference for integrating Gradle with Jenkins.
The Gradle plugin
The Gradle plugin adds first-class Gradle support to Jenkins. Install it from Manage Jenkins → Plugins → Available plugins.
The plugin provides:
-
An Invoke Gradle script build step for Freestyle projects.
-
Automatic detection of Build Scan® links published during the build.
-
A
withGradlepipeline wrapper that captures Build Scan links in Pipeline jobs. -
Optional auto-injection of the Develocity Gradle plugin for centralized build analytics.
Freestyle projects
Add an Invoke Gradle script build step and configure it:
| Field | Description |
|---|---|
Use Gradle Wrapper |
When selected, Jenkins runs the |
Wrapper location |
Relative path to |
Tasks |
Space-separated Gradle tasks, e.g. |
Switches |
Command-line flags passed to Gradle, e.g. |
Build File |
Relative path to |
System properties |
|
Project properties |
|
Gradle installation |
A pre-configured Gradle installation from Manage Jenkins → Tools. Ignored when Use Gradle Wrapper is selected. |
|
Tip
|
Job parameters are automatically quoted by the plugin, so special characters in property values are handled correctly. |
Pipeline projects (Jenkinsfile)
For Pipeline-as-code, invoke the Gradle Wrapper via sh (Linux/macOS) or bat (Windows) and wrap it with withGradle to capture Build Scan links:
pipeline {
agent any
tools {
jdk 'jdk-21'
}
stages {
stage('Build') {
steps {
withGradle {
sh './gradlew build'
}
}
}
stage('Test') {
steps {
withGradle {
sh './gradlew check'
}
}
post {
always {
junit '**/build/test-results/test/TEST-*.xml'
}
}
}
}
}-
tools { jdk 'jdk-21' }selects a JDK configured in Manage Jenkins → Tools. The Gradle Wrapper handles the Gradle distribution, so no Gradle tool entry is required. -
withGradle { … }tells the Gradle plugin to scan the build output for Build Scan links and display them on the build page. -
The
junitpost step archives test results so they appear in the Jenkins test report.
To search for Build Scan links across an entire pipeline run (for example when Gradle is invoked inside a shell script without withGradle), add a findBuildScans() step at the end of the pipeline.
Scripted pipeline
In a scripted pipeline, use withGradle the same way:
node {
stage('Build') {
checkout scm
withGradle {
sh './gradlew build'
}
}
}Using the Gradle Wrapper
The Gradle Wrapper is the recommended way to invoke Gradle on Jenkins. With the Wrapper checked into the repository, build agents need only a JDK — no Gradle installation is required.
In Freestyle projects, select Use Gradle Wrapper in the build step.
In Pipelines, call ./gradlew directly via sh or bat.
Build Scans and Develocity integration
Capturing Build Scan links
The Gradle plugin automatically detects Build Scan URLs printed to the console log.
In Freestyle projects, this works out of the box.
In Pipelines, wrap Gradle invocations with withGradle or call findBuildScans() at the end of the pipeline.
Enriched Build Scan display
When a Develocity server URL and access key are configured (see below), the plugin fetches metadata from the Develocity API and displays project name, requested tasks, build tool version, and outcome alongside the Build Scan link.
|
Note
|
Enriched metadata requires a Develocity server — it is not available for scans published to the public |
Auto-injecting the Develocity plugin
The Gradle plugin can automatically inject the Develocity Gradle plugin into builds without modifying project sources. Configure this under Manage Jenkins → System → Develocity:
| Setting | Description |
|---|---|
Develocity server URL |
URL of your Develocity instance. Can optionally be enforced over project-defined URLs. |
Develocity Gradle plugin version |
The version to inject into builds. |
Allow untrusted server |
Accept self-signed TLS certificates. |
VCS repository filter |
Newline-delimited patterns ( |
Enabled/disabled agent labels |
Control which Jenkins agents receive injection. Disabled labels take precedence. |
Short-lived access tokens |
Preferred over long-lived access keys. Requires Develocity 2024.1+. Tokens are retrieved at job execution time. |
To auto-accept Build Scan terms of use without plugin injection, configure the Develocity plugin directly in settings.gradle[.kts]:
plugins {
id("com.gradle.develocity") version "3.18.1"
}
develocity {
buildScan {
termsOfUseUrl = "https://gradle.com/help/legal-terms-of-use"
termsOfUseAgree = "yes"
publishing.onlyIf { true }
}
}Test reporting
Gradle produces JUnit-compatible XML reports under build/test-results/.
Archive them with the junit step so Jenkins displays test counts, durations, and failure details on the build page:
post {
always {
junit '**/build/test-results/test/TEST-*.xml'
}
}In Freestyle projects, add a Publish JUnit test result report post-build action with the same glob pattern.
Caching and performance
Jenkins agents are typically long-lived, so ~/.gradle (the Gradle User Home) is preserved between builds on the same agent.
Downloaded dependencies, Wrapper distributions, and the local build cache persist automatically.
For ephemeral or distributed agents, consider:
-
A Gradle Remote Build Cache to share task outputs across agents.
-
A repository manager (Artifactory, Sonatype Nexus) to proxy external dependencies within your network.
-
The
--no-daemonflag for short-lived agents where daemon startup cost is wasted.
Managing credentials
Store publishing tokens, signing keys, and other secrets as Jenkins credentials.
Bind them to environment variables in a Pipeline with withCredentials:
withCredentials([string(credentialsId: 'publish-token', variable: 'PUBLISH_TOKEN')]) {
withGradle {
sh './gradlew publish'
}
}Access the variable in build.gradle[.kts] with System.getenv("PUBLISH_TOKEN") or providers.environmentVariable("PUBLISH_TOKEN").
Gradle on TeamCity
This page is a reference for integrating Gradle with JetBrains TeamCity. TeamCity ships a built-in Gradle runner — no additional plugins are required to build Gradle projects.
The Gradle runner
When you create a project from a repository URL, TeamCity scans for build.gradle or build.gradle.kts files and offers a pre-configured Gradle build step.
You can also add a Gradle step manually by selecting Gradle as the runner type.
Key runner settings
| Setting | Description |
|---|---|
Tasks |
Space-separated Gradle tasks to execute (e.g. |
Use Gradle Wrapper |
When enabled, TeamCity launches the Wrapper script from the checkout directory. Enabled by default on auto-detected steps. Recommended for all projects. |
Gradle Wrapper Path |
Custom path to |
Build File |
Relative path to |
Additional Command Line Parameters |
Extra flags and project properties, e.g. |
Gradle Home |
Path to a local Gradle installation. Ignored when the Wrapper is enabled. Falls back to the agent’s |
Incremental Building |
Detects changed modules via VCS and runs |
Debug / Stacktrace |
Toggle |
JDK |
Select from environment variables ( |
JVM Parameters |
Arguments passed to the JVM that runs Gradle, e.g. |
Docker / Podman |
Run the build step inside a container image. Requires a Docker or Podman connection configured at the project level. |
Code Coverage |
Built-in support for IntelliJ IDEA and JaCoCo coverage engines. |
See the Gradle runner documentation for the full setting reference.
Minimal build configuration
Via the UI
-
Create a project from a repository URL.
-
TeamCity auto-detects a Gradle build step with
clean buildtasks and Wrapper usage. -
Confirm the detected step.
-
Add a VCS Trigger (Build Configuration Settings → Triggers) so builds run on every push.
Via Kotlin DSL
TeamCity supports configuration as code using Kotlin DSL, stored in .teamcity/settings.kts in your repository:
import jetbrains.buildServer.configs.kotlin.*
import jetbrains.buildServer.configs.kotlin.buildSteps.gradle
import jetbrains.buildServer.configs.kotlin.triggers.vcs
version = "2025.11"
project {
buildType(Build)
}
object Build : BuildType({
name = "Build"
vcs {
root(DslContext.settingsRoot)
}
steps {
gradle {
tasks = "clean build"
useGradleWrapper = true
}
}
triggers {
vcs {}
}
})Via YAML pipelines
jobs:
Build:
name: Build
steps:
- type: gradle
name: Gradle Build
tasks: clean build
use-gradle-wrapper: "true"Using the Gradle Wrapper
The Gradle runner’s Use Gradle Wrapper option (enabled by default on auto-detected steps) is the recommended way to invoke Gradle. With the Wrapper enabled, build agents need only a JDK — the correct Gradle distribution is downloaded and cached automatically.
If the Wrapper script is not at the repository root, set Gradle Wrapper Path to its location relative to the working directory.
Caching and performance
TeamCity build agents are typically long-lived, so the Gradle User Home (~/.gradle) is preserved between builds on the same agent.
Downloaded dependencies, Wrapper distributions, and the local build cache persist automatically without additional configuration.
For distributed or cloud agents, consider:
-
A Gradle Remote Build Cache to share task outputs across agents.
-
A repository manager (Artifactory, Sonatype Nexus) to proxy external dependencies within your network.
-
The
--configuration-cacheflag (ororg.gradle.configuration-cache=trueingradle.properties) to skip the configuration phase on repeated builds.
|
Note
|
The configuration cache has known limitations with TeamCity’s parallel test features and clean checkout scenarios. See the Gradle runner documentation for details. |
System properties and environment variables
TeamCity system properties (those prefixed with system.) are passed to Gradle as native project properties — the same mechanism as gradle.properties.
Access them in build.gradle[.kts]:
// Simple names (no dots) — available as top-level properties
println("Build number: $buildNumber") // from system.buildNumber
// Names containing dots — use the project.ext map
val vcsNumber: String by project.ext // from system.vcsNumber
// or:
project.findProperty("build.vcs.number.1")TeamCity also exposes env. parameters as environment variables on the agent. These can be read in Gradle via System.getenv("ENV_VAR_NAME") or providers.environmentVariable("ENV_VAR_NAME").
Publishing Build Scans
Add --scan to the Additional Command Line Parameters field (or to the gradleParams DSL property) to publish a Build Scan® for every build.
For richer integration, install the TeamCity Build Scan plugin. With the plugin installed, Build Scan links appear directly in the Build Results view rather than only in the build log.
To auto-accept the terms of use in CI without --scan, configure the Develocity plugin in settings.gradle[.kts]:
plugins {
id("com.gradle.develocity") version "3.18.1"
}
develocity {
buildScan {
termsOfUseUrl = "https://gradle.com/help/legal-terms-of-use"
termsOfUseAgree = "yes"
publishing.onlyIf { true }
}
}Test reporting
The Gradle runner automatically parses JUnit and TestNG XML reports produced by Gradle’s test task.
Test results appear on the Tests tab of the build results, including individual test durations, failure details, and history across builds.
No additional configuration is needed — TeamCity discovers TEST-*.xml files under build/test-results/ by default.
Build triggers and branch monitoring
Common trigger configurations for Gradle projects:
| Trigger | Usage |
|---|---|
VCS Trigger |
Polls the repository (default: every 60 seconds) and starts a build when changes are detected. Add |
Schedule Trigger |
Runs builds on a cron schedule, e.g. nightly integration tests. |
Pull Request builds |
Enable the Pull Requests build feature and select your VCS provider (GitHub, GitLab, Bitbucket). TeamCity detects open pull requests and triggers builds automatically. |
Commit Status Publisher |
Reports build results back to the VCS provider, displaying pass/fail status on pull requests and commits. |
Gradle on Travis CI
This page is a reference for integrating Gradle with Travis CI.
Default Gradle behavior
When Travis CI detects a build.gradle or build.gradle.kts file in the repository root, it automatically applies Gradle-specific defaults for the build lifecycle:
| Phase | Without Wrapper | With Wrapper (gradlew present) |
|---|---|---|
|
|
|
|
|
|
Most projects override one or both phases in .travis.yml to run custom tasks.
Minimal configuration
A .travis.yml that builds a Gradle project with the Wrapper:
language: java
dist: focal
jdk: openjdk17
install: skip
script:
- ./gradlew build-
language: javaactivates the Java environment and JDK selection. -
dist: focalselects Ubuntu 20.04 (the current default). Other options includejammy(22.04) andnoble(24.04). -
jdkselects the JDK. Common values:openjdk17,openjdk21. IBM Semeru builds are available assemeru11,semeru17, etc. -
install: skipskips the defaultgradle assemblephase — thebuildtask already includes assembly. -
The Gradle Wrapper is detected automatically when
gradlewexists in the repository root.
Testing against multiple JDKs
Use a jdk matrix to test across several Java versions in parallel:
language: java
dist: focal
jdk:
- openjdk17
- openjdk21
install: skip
script:
- ./gradlew buildTravis CI creates one job per JDK entry. Combine with os to add cross-platform coverage:
os:
- linux
- osx
jdk:
- openjdk17
- openjdk21Caching
Travis CI can persist directories between builds. For Gradle projects, cache the Wrapper distribution and the dependency cache:
before_cache:
- rm -f $HOME/.gradle/caches/modules-2/modules-2.lock
- rm -fr $HOME/.gradle/caches/*/plugin-resolution/
cache:
directories:
- $HOME/.gradle/caches/
- $HOME/.gradle/wrapper/The before_cache step removes lock files that should not be persisted.
|
Caution
|
If you run Gradle with |
|
Tip
|
For large dependency trees, the cache archive upload/download time on shared infrastructure may offset the savings. In that case, consider a Gradle Remote Build Cache or a repository manager to proxy external dependencies. |
Publishing Build Scans
Pass --scan in the script phase to publish a Build Scan® for every build:
script:
- ./gradlew build --scanTo auto-accept the terms of use without the --scan flag, configure the Develocity plugin in settings.gradle[.kts].
Travis CI sets CI=true automatically, which can be used to gate publication:
plugins {
id("com.gradle.develocity") version "3.18.1"
}
develocity {
buildScan {
if (System.getenv("CI") != null) {
termsOfUseUrl = "https://gradle.com/help/legal-terms-of-use"
termsOfUseAgree = "yes"
publishing.onlyIf { true }
}
}
}Useful environment variables
| Variable | Purpose |
|---|---|
|
Always |
|
Branch name for push builds; base branch for pull-request builds. |
|
Pull-request number, or |
|
Trigger type: |
|
Git tag name if the build was triggered by a tag push; empty otherwise. |
|
Absolute path to the checked-out repository on the worker. |
|
The SHA of the commit being built. |
See Default environment variables for the full list.
Build stages and conditional jobs
Travis CI build stages run groups of jobs sequentially, while jobs within a stage run in parallel. Use stages to model pipelines — for example, build first, then deploy only on tagged commits:
jobs:
include:
- stage: build
script: ./gradlew build
- stage: publish
if: tag IS present
script: ./gradlew publishManaging secrets
Store credentials (publishing tokens, signing keys) as encrypted environment variables in the repository settings or in .travis.yml via the Travis CLI:
travis encrypt PUBLISH_TOKEN=secret --add env.globalAccess them in build.gradle[.kts] with System.getenv("PUBLISH_TOKEN") or providers.environmentVariable("PUBLISH_TOKEN").
STRUCTURING BUILDS
Structuring and Organizing Gradle Projects
It is important to structure your Gradle project to optimize build performance. A multi-project build is the standard in Gradle.
Project Concepts
There are four key concepts to understand Gradle projects:
-
Root project: The top-level project in a build that contains the
settings.gradle(.kts)file and typically aggregates all subprojects. -
Subprojects: Individual modules (components) that are part of a multi-project build and are included by the root project via the
settings.gradle(.kts)file. -
Settings file: A
settings.gradle(.kts)configuration file used to define the structure of a multi-project build, including which subprojects are part of it and optionally how they’re named or located. -
Build scripts:
build.gradle(.kts)files that define how a project is built (applying plugins, declaring dependencies, configuring tasks, etc…) executed per project (subprojects can each have one).
Let’s take a look at an example:
my-project/ // (1)
├── settings.gradle.kts // (2)
├── app/ // (3)
│ ├── build.gradle.kts // (4)
│ └── src/
├── core/ // (3)
│ ├── build.gradle.kts // (4)
│ └── src/
└── util/ // (3)
├── build.gradle.kts // (4)
└── src/my-project/ // (1)
├── settings.gradle // (2)
├── app/ // (3)
│ ├── build.gradle // (4)
│ └── src/
├── core/ // (3)
│ ├── build.gradle // (4)
│ └── src/
└── util/ // (3)
├── build.gradle // (4)
└── src/-
Root project directory
-
Settings file
-
Subproject
-
Subproject build file
Single-Project Build
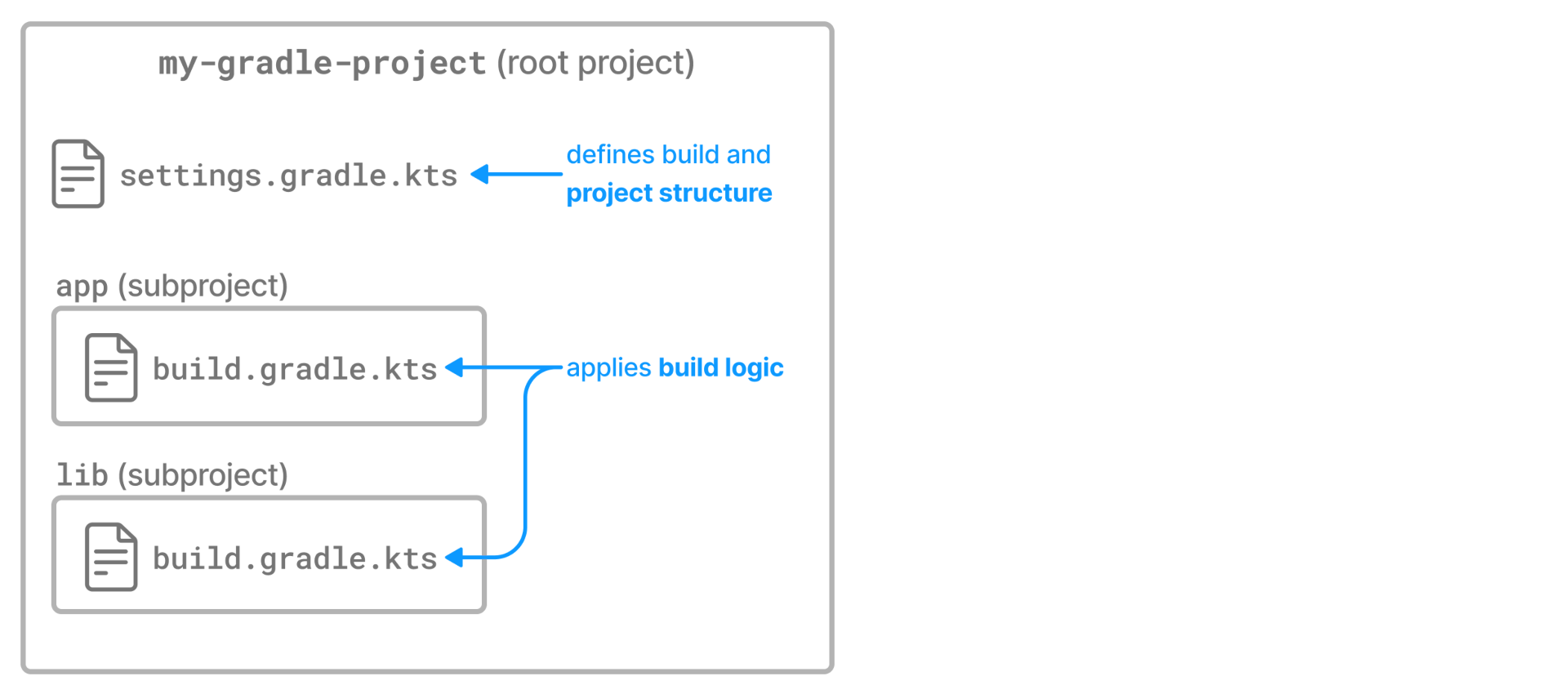
Let’s look at a basic multi-project build example that contains a root project and a single subproject.
The root project is called my-project, located somewhere on your machine.
From Gradle’s perspective, the root is the top-level directory ..
The project contains a single subproject called app:
. // (1)
├── settings.gradle.kts // (2)
└── app/ // (3)
├── build.gradle.kts // (4)
└── src/ // (5). // (1)
├── settings.gradle // (2)
└── app/ // (3)
├── build.gradle // (4)
└── src/ // (5)-
Root project
-
Settings file
-
Subproject
-
Subproject build file
-
Source code and more
This is the recommended project structure for starting any Gradle project. The Build Init plugin also generates skeleton projects that follow this structure - a root project with a single subproject:
The settings.gradle(.kts) file describes the project structure to Gradle:
rootProject.name = "my-project"
include("app")rootProject.name = 'my-project'
include 'app'In this case, Gradle will look for a build file for the app subproject in the ./app directory.
You can view the structure of a multi-project build by running the projects command:
$ ./gradlew -q projectsProjects:
------------------------------------------------------------
Root project 'my-project'
------------------------------------------------------------
Location: /home/user/gradle/samples
Project hierarchy:
Root project 'my-project'
\--- Project ':app'
Project locations:
project ':app' - /app
To see a list of the tasks of a project, run gradle <project-path>:tasks
For example, try running gradle :app:tasksIn this example, the app subproject is a Java application that applies the Java Application plugin and configures the main class.
The application prints Hello World to the console:
plugins {
id("application")
}
application {
mainClass = "com.example.Hello"
}plugins {
id 'application'
}
application {
mainClass = 'com.example.Hello'
}package com.example;
public class Hello {
public static void main(String[] args) {
System.out.println("Hello, world!");
}
}You can run the application by executing the run task from the Application plugin in the project root:
$ ./gradlew -q runHello, world!Multi-Project Build (include())
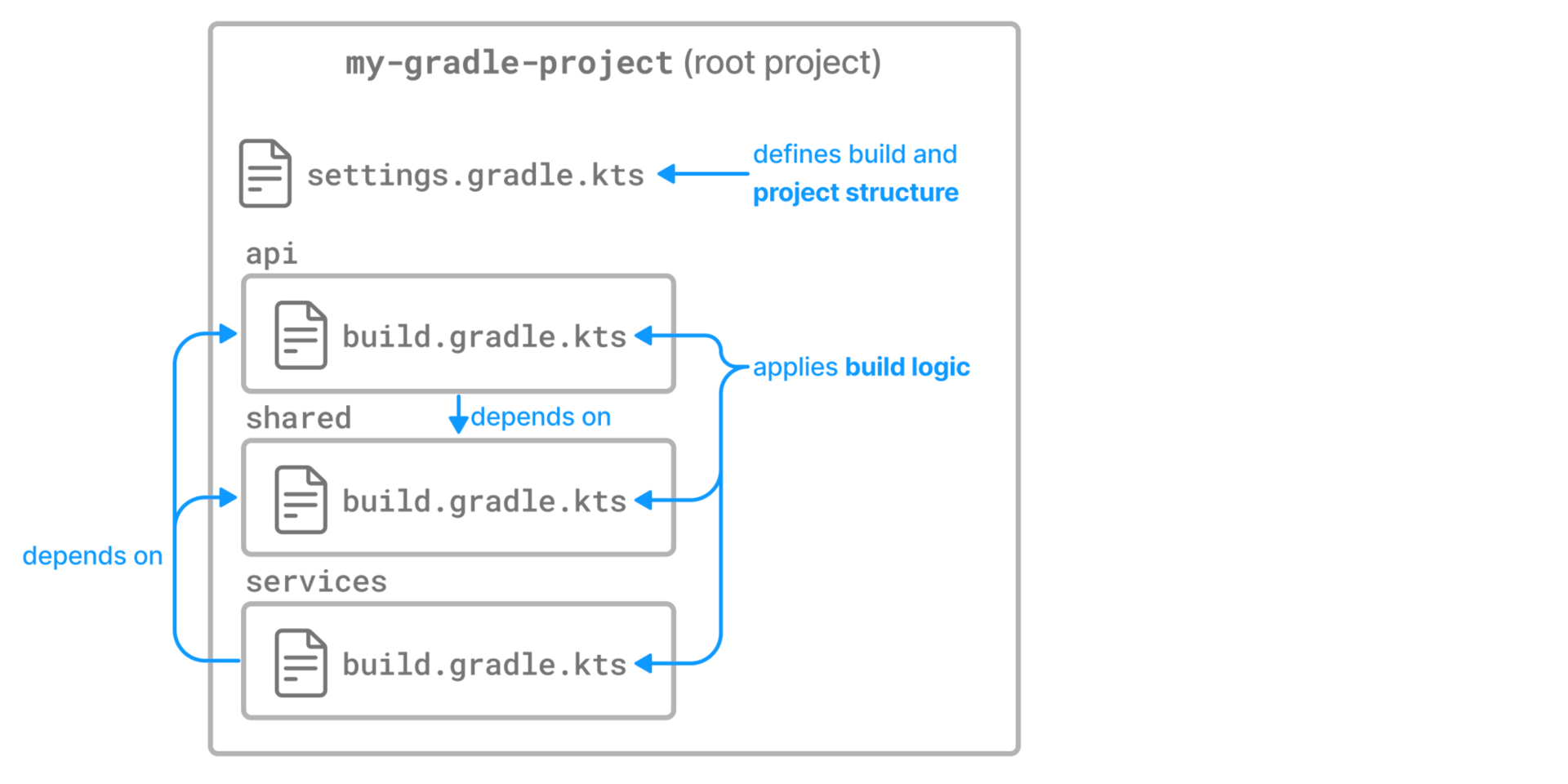
In the settings file, you can use the include method to add another subproject to the root project:
include("project1", "project2:child1", "project3:child1")include 'project1', 'project2:child1', 'project3:child1'The include method takes project paths as arguments.
The project path is assumed to be equal to the relative physical file system path.
For example, a path services:api is mapped by default to a folder ./services/api (relative to the project root .).
More examples of how to work with the project path can be found in the DSL documentation of Settings.include(java.lang.String[]).
Let’s add another subproject called lib to the previously created project.
All we need to do is add another include statement in the root settings file:
rootProject.name = "my-project"
include("app")
include("lib")rootProject.name = 'my-project'
include 'app'
include 'lib'Gradle will then look for the build file of the new lib subproject in the ./lib/ directory:
. // (1)
├── settings.gradle.kts // (2)
├── app/ // (3)
│ ├── build.gradle.kts // (4)
│ └── src/
└── lib/ // (3)
├── build.gradle.kts // (4)
└── src/. // (1)
├── settings.gradle // (2)
├── app/ // (3)
│ ├── build.gradle // (4)
│ └── src/
└── lib/ // (3)
├── build.gradle // (4)
└── src/-
Root project
-
Settings file
-
Subproject
-
Subproject build file
You can learn more about multi-project builds in Multi-Project Builds.
Sharing Build Logic (buildSrc)
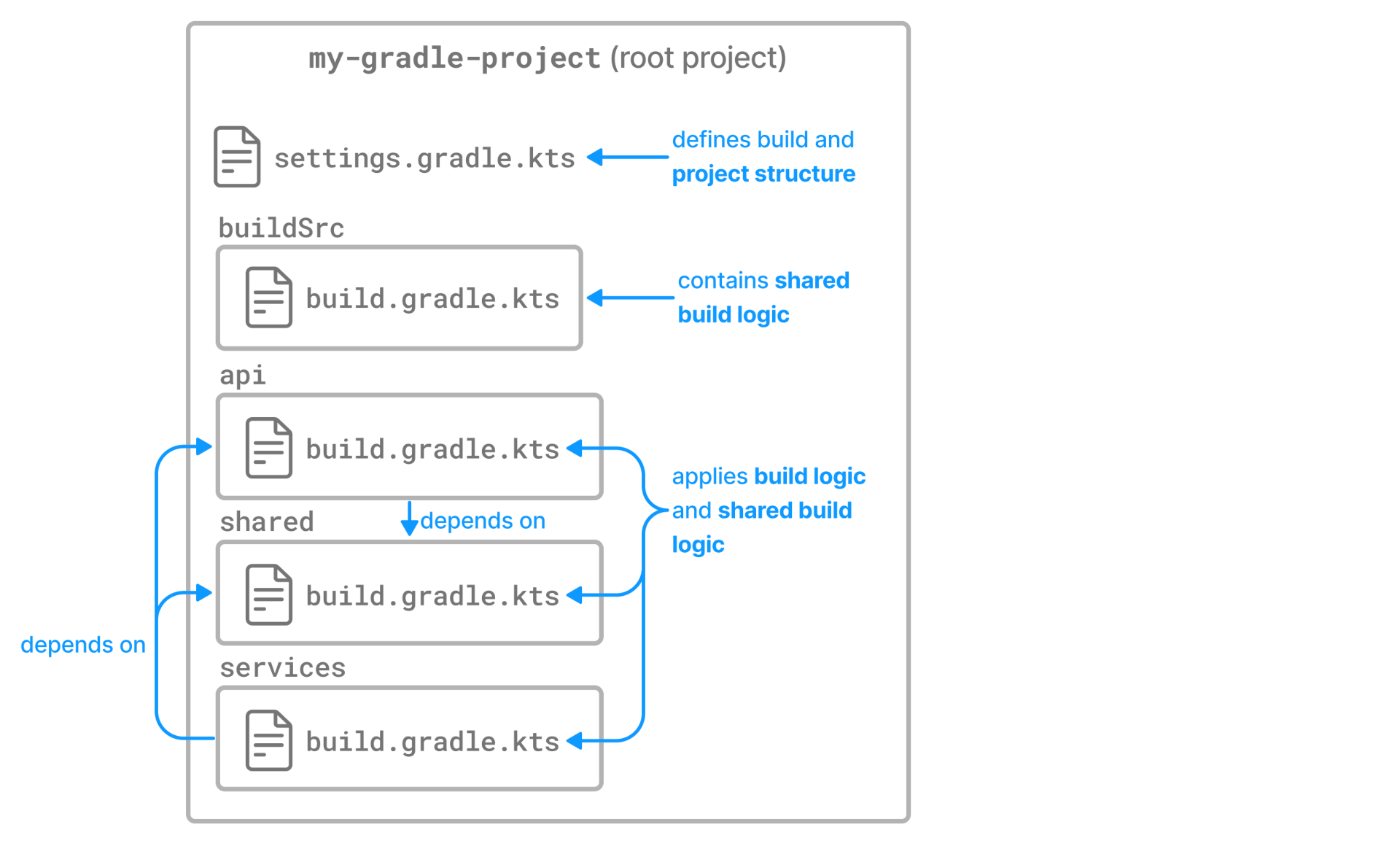
When projects grow in size and complexity, it’s common to see the same logic repeated across multiple subprojects—like applying the same plugins, configuring the same tasks, or declaring the same dependencies.
Duplicated build logic is hard to maintain and easy to get wrong.
Gradle provides a built-in way to centralize and reuse this logic: a special directory called buildSrc.
buildSrc is a separate build located in the root of your Gradle project.
Any code you put in this directory is automatically compiled and added to the classpath of your main build.
Let’s take a look at our multi-project build:
.
├── settings.gradle.kts
├── app/
│ ├── build.gradle.kts // (1)
│ └── src/
└── lib/
├── build.gradle.kts // (1)
└── src/.
├── settings.gradle
├── app/
│ ├── build.gradle // (1)
│ └── src/
└── lib/
├── build.gradle // (1)
└── src/-
Subproject build script, applies
java-libraryand testing logic
We now encapsulate reusable configuration logic in a java-library-convention.gradle.kts file.
Because the file is named java-library-convention.gradle.kts, Gradle automatically registers it as a plugin with the ID java-library-convention.
It compiles and makes this plugin available to all other build scripts in the project.
.
├── settings.gradle.kts
├── buildSrc/
│ ├── build.gradle.kts
│ └── src/main/kotlin/
│ └── java-library-convention.gradle.kts // (1)
├── app/
│ ├── build.gradle.kts // (2)
│ └── src/
└── lib/
├── build.gradle.kts // (2)
└── src/.
├── settings.gradle
├── buildSrc/
│ ├── build.gradle
│ └── src/main/groovy/
│ └── java-library-convention.gradle // (1)
├── app/
│ ├── build.gradle // (2)
│ └── src/
└── lib/
├── build.gradle // (2)
└── src/-
Applies
java-libraryand testing logic -
Subproject build script, applies
java-libraryand testing logic
You can learn more about multi-project builds in Sharing Build Logc between Subprojects using BuildSrc.
Composite Builds (includeBuild())
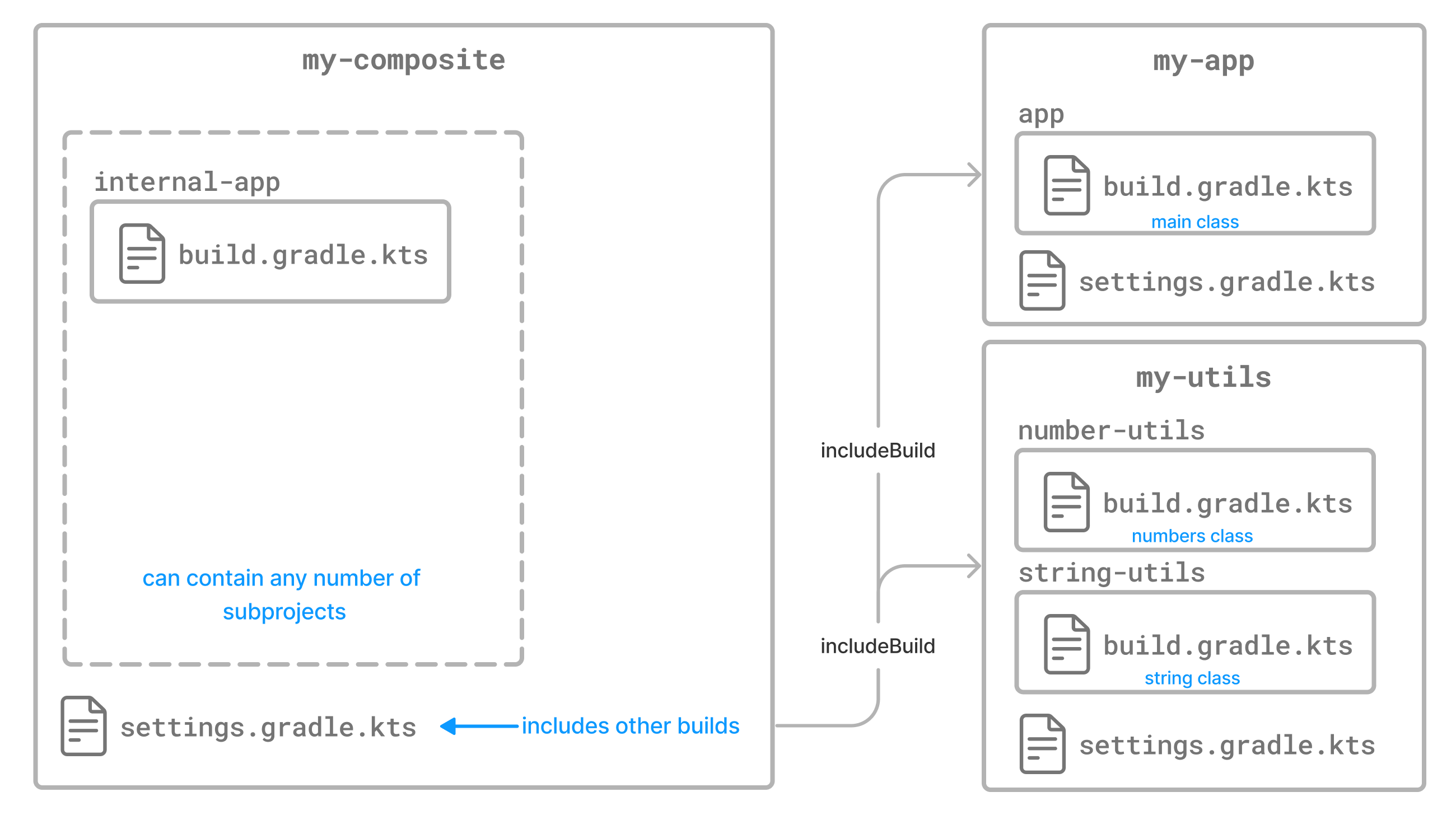
In Gradle, composite builds (or included builds) are ways to compose multiple builds together.
They allow you to work with multiple Gradle projects (builds) as if they were part of a single build, without needing to publish artifacts to a repository.
Imagine we want to break up our multi-project build into two separate builds:
-
A shared library in
libs -
An application that uses it (our previous multi-project build)
We want to:
-
Keep them in separate builds (they could be in separate repos)
-
But develop them together without publishing
lib
.
├── settings.gradle.kts
├── buildSrc/
│ ├── build.gradle.kts
│ └── src/main/kotlin/
│ └── java-library-convention.gradle.kts
├── app/
│ ├── build.gradle.kts
│ └── src/
├── core/
│ ├── build.gradle.kts
│ └── src/
├── util/
│ ├── build.gradle.kts
│ └── src/
└── libs/ // (1)
└── lib/
├── settings.gradle.kts
├── build.gradle.kts
└── src/.
├── settings.gradle
├── buildSrc/
│ ├── build.gradle
│ └── src/main/groovy/
│ └── java-library-convention.gradle
├── app/
│ ├── build.gradle
│ └── src/
├── core/
│ ├── build.gradle
│ └── src/
├── util/
│ ├── build.gradle
│ └── src/
└── libs/ // (1)
└── lib/
├── settings.gradle
├── build.gradle
└── src/-
Standalone, reusable library (included build)
Here, lib is a separate Gradle build that lives in libs/lib.
It’s not part of the normal include(…) multi-project structure.
Instead, we treat it as an included build, a distinct build that we can use without publishing it to a repository.
In the root settings.gradle(.kts), we tell Gradle to include lib as part of a composite build using includeBuild():
includeBuild("lib")includeBuild 'lib'You can learn more about multi-project builds in Composite Builds.
Structuring Recommendations
Source code and build logic should be organized in a clear, consistent, and meaningful way. This section outlines recommendations that lead to readable and maintainable Gradle projects. It also highlights common pitfalls and how to avoid them to ensure your builds stay robust and scalable.
Use separate Language-specific Source Files
Gradle’s language plugins define conventions for discovering and compiling source code.
For example, when the Java plugin is applied, Gradle automatically compiles source files in src/main/java.
Other language plugins follow a similar convention: the last part of the source directory (e.g., java, groovy, kotlin) indicates the language of the source files it contains.
Some compilers support compiling multiple languages from the same directory.
For example, the Groovy compiler can compile both Java and Groovy source files from src/main/groovy.
However, Gradle recommends separating source files by language into distinct directories (e.g., src/main/java and src/main/kotlin).
This improves build performance and makes builds more predictable—both for Gradle and for humans reading the project layout.
Here’s an example source layout for a project using both Java and Kotlin:
.
├── build.gradle.kts
└── src
└── main
├── java
│ └── HelloWorld.java
└── kotlin
└── Utils.kt.
├── build.gradle
└── src
└── main
├── java
│ └── HelloWorld.java
└── kotlin
└── Utils.ktUse separate Source Files per Test type
It’s common for a project to define and run multiple types of tests—such as unit tests, integration tests, functional tests, or smoke tests. To keep things maintainable and organized, Gradle recommends storing each test type’s source code in its own dedicated source directory.
For example, instead of placing all tests under src/test/java, you might use:
src/
├── test/ // Unit tests
│ └── java/
├── integrationTest/ // Integration tests
│ └── java/
└── functionalTest/ // Functional tests
└── java/|
Note
|
Gradle allows you to define multiple source sets and test tasks, so you can fully isolate and control each type of test in your build. |
Use standard Conventions
All Gradle core plugins follow the convention over configuration principle, a well-known software engineering paradigm that favors sensible defaults over manual setup. You can read more about it here: Convention over configuration.
Gradle plugins provide predefined behaviors and directory structures that "just work" in most cases. Let’s take the Java Plugin as an example:
-
The default source directory is
src/main/java. -
The default output location for compiled classes and packaged artifacts (like JARs) is
build/.
While Gradle allows you to override most defaults, doing so can make your build harder to understand and maintain—especially for teams or newcomers.
|
Tip
|
Stick to standard conventions unless you have a strong reason to deviate (e.g., adapting to a legacy layout). Refer to the reference documentation for each plugin to learn about its default conventions and behaviors. |
Use a Settings file
Every time you run a Gradle build, Gradle attempts to locate a settings.gradle (Groovy DSL) or settings.gradle.kts (Kotlin DSL) file.
To do this, it walks up the directory hierarchy from the current working directory to the filesystem root.
As soon as it finds a settings file, it stops searching and uses that as the entry point for the build.
In a multi-project build, the settings file is required. It defines which projects are part of the build and enables Gradle to correctly configure and evaluate the entire project hierarchy.
You may also need a settings file to add shared libraries or plugins to the build classpath using pluginManagement or dependencyResolutionManagement.
The following example shows a standard Gradle project layout:
.
├── settings.gradle.kts
├── subproject-one
│ └── build.gradle.kts
└── subproject-two
└── build.gradle.kts.
├── settings.gradle
├── subproject-one
│ └── build.gradle
└── subproject-two
└── build.gradleMulti-Project Builds
As projects grow, it’s common to split them into smaller, focused modules that are built, tested, and released together. Gradle supports this through multi-project builds, allowing you to organize related codebases under a single build while keeping each module logically isolated.
Multi-Project Layout
A multi-project build consists of a root project and one or more subprojects, all defined in a single settings.gradle(.kts) file.
This structure supports modularization, parallel execution, and code reuse.
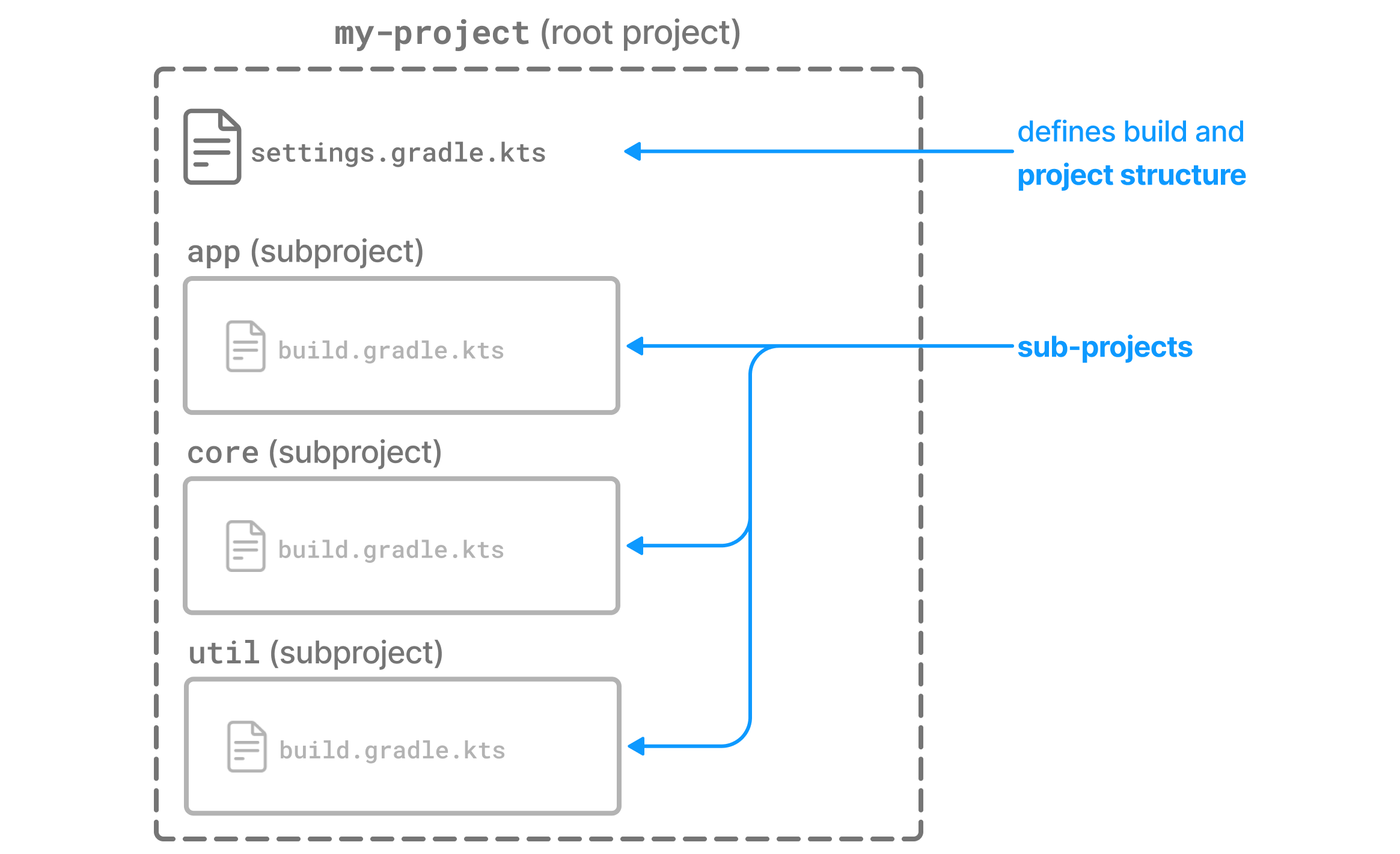
A typical multi-project structure looks like this:
my-project/
├── settings.gradle.kts // (1)
├── build.gradle.kts // (2)
├── app/ // (3)
│ └── build.gradle.kts // (4)
├── core/ // (3)
│ └── build.gradle.kts // (5)
└── util/ // (3)
└── build.gradle.kts // (6)my-project/
├── settings.gradle // (1)
├── build.gradle // (2)
├── app/ // (3)
│ └── build.gradle // (4)
├── core/ // (3)
│ └── build.gradle // (5)
└── util/ // (3)
└── build.gradle // (6)-
Declares subprojects
-
Root project build logic (optional)
-
Subproject
-
App module
-
Shared core logic
-
Utility code
Each subproject can define its own build logic, dependencies, and plugins.
In settings.gradle(.kts), you include subprojects by name using include().
The include() method takes project paths as arguments:
rootProject.name = "my-project"
include("app", "core", "util")rootProject.name = 'my-project'
include('app', 'core', 'util')By default, a project path corresponds to the relative physical location of the project directory.
For example, the path services:api maps to the directory ./services/api, relative to the root project.
You can find more examples and detailed usage in the DSL reference for Settings.include(String…).
Project Descriptors
To further describe the project architecture to Gradle, the settings file provides project descriptors.
You can modify these descriptors in the settings file at any time.
To access a descriptor, you can:
include("project-a")
println(rootProject.name)
println(project(":project-a").name)include('project-a')
println rootProject.name
println project(':project-a').nameUsing this descriptor, you can change the name, project directory, and build file of a project:
rootProject.name = "main"
include("project-a")
project(":project-a").projectDir = file("custom/my-project-a")
project(":project-a").buildFileName = "project-a.gradle.kts"rootProject.name = 'main'
include('project-a')
project(':project-a').projectDir = file('custom/my-project-a')
project(':project-a').buildFileName = 'project-a.gradle'Consult the ProjectDescriptor class in the API documentation for more information.
|
Note
|
Setting the Project.projectDir property is important when locating projects in nested subdirectories to avoid unintentionally creating empty projects. |
Including projects without an existing directory
When you include a subproject in your settings.gradle(.kts) file, Gradle expects that the associated directory for that project exists and is writable.
|
Warning
|
Starting with Gradle 9.0.0, this is enforced strictly: If a project directory is missing or read-only, the build will fail. This replaces earlier behavior where Gradle would silently allow missing project directories. |
Here’s how you can create a missing directory at configuration time:
include("project-without-directory")
project(":project-without-directory").projectDir.mkdirs()include 'project-without-directory'
project(":project-without-directory").projectDir.mkdirs()Naming recommendations
As your project grows, naming and consistency get increasingly more important.
To keep your builds maintainable, we recommend the following:
-
Keep default project names for subprojects: It is possible to configure custom project names in the settings file. However, it’s an unnecessary extra effort for the developers to track which projects belong to what folders.
-
Use lower case hyphenation for all project names: All letters are lowercase, and words are separated with a dash (
-) character. -
Define the root project name in the settings file: The
rootProject.nameeffectively assigns a name to the build, used in reports like Build Scan. If the root project name is not set, the name will be the container directory name, which can be unstable (i.e., you can check out your project in any directory). The name will be generated randomly if the root project name is not set and checked out to a file system’s root (e.g.,/orC:\).
Declaring dependencies between Subprojects
What if one subproject depends on another? What if one subproject depends on the artifact produced by another?
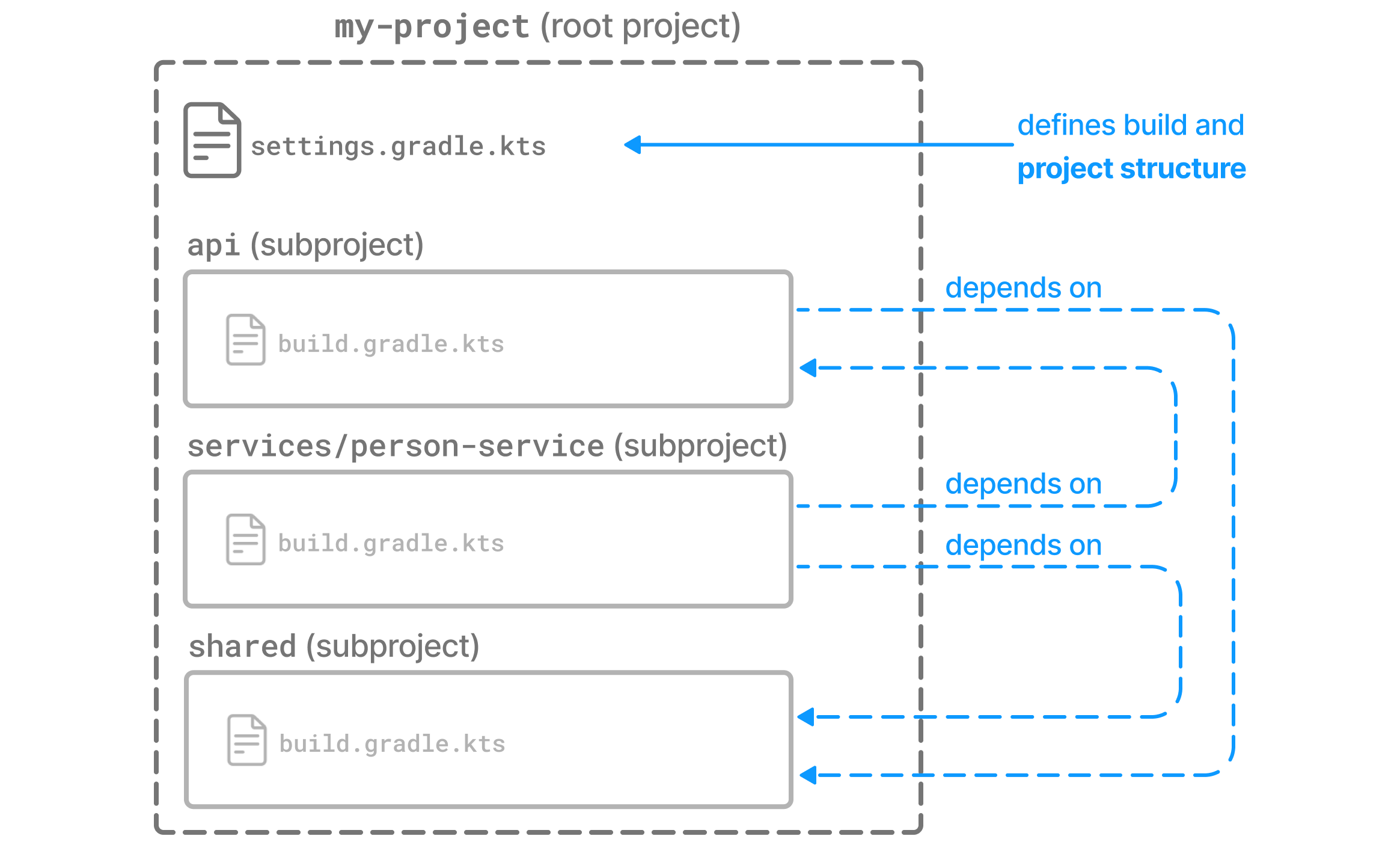
This is a common use case in multi-project builds. Gradle supports this scenario with project dependencies.
Depending on another Project
Consider a multi-project build with the following layout:
.
├── api
│ ├── src
│ │ └──...
│ └── build.gradle.kts
├── services
│ └── person-service
│ ├── src
│ │ └──...
│ └── build.gradle.kts
├── shared
│ ├── src
│ │ └──...
│ └── build.gradle.kts
└── settings.gradle.kts.
├── api
│ ├── src
│ │ └──...
│ └── build.gradle
├── services
│ └── person-service
│ ├── src
│ │ └──...
│ └── build.gradle
├── shared
│ ├── src
│ │ └──...
│ └── build.gradle
└── settings.gradleIn this example:
-
person-servicedepends on bothapiandshared -
apidepends onshared
You declare these relationships using the project path, which uses colons (:) to indicate nesting.
For example:
-
:sharedrefers to thesharedsubproject -
services:person-servicerefers to a nested subproject
rootProject.name = "dependencies-java"
include("api", "shared", "services:person-service")plugins {
id("java")
}
repositories {
mavenCentral()
}
dependencies {
testImplementation("junit:junit:4.13")
}plugins {
id("java")
}
repositories {
mavenCentral()
}
dependencies {
testImplementation("junit:junit:4.13")
implementation(project(":shared"))
}plugins {
id("java")
}
repositories {
mavenCentral()
}
dependencies {
testImplementation("junit:junit:4.13")
implementation(project(":shared"))
implementation(project(":api"))
}rootProject.name = 'basic-dependencies'
include 'api', 'shared', 'services:person-service'plugins {
id 'java'
}
repositories {
mavenCentral()
}
dependencies {
testImplementation "junit:junit:4.13"
}plugins {
id 'java'
}
repositories {
mavenCentral()
}
dependencies {
testImplementation "junit:junit:4.13"
implementation project(':shared')
}plugins {
id 'java'
}
repositories {
mavenCentral()
}
dependencies {
testImplementation "junit:junit:4.13"
implementation project(':shared')
implementation project(':api')
}For more details on project paths, consult the DSL documentation for Settings.include(String…).
A project dependency affects both the build order and classpath:
-
The required project will be built first.
-
Its compiled classes and transitive dependencies are added to the consuming project’s classpath.
For example, running ./gradlew :api:compileJava will first build shared, then api.
Depending on Artifacts produced by another Project
Sometimes, you only need the output of a specific task from another project—not the entire project itself.
While you can create task-to-task dependencies between projects, Gradle discourages this because it creates tight coupling between tasks.
Instead, use outgoing artifacts to expose a task’s output and model it as a dependency. Gradle’s variant-aware dependency management allows one project to consume artifacts from another in a structured, on-demand way.
Sharing Build Logic using buildSrc
Subprojects in a multi-project build often share common dependencies.
Rather than duplicating the same dependency declarations across multiple build scripts, Gradle allows you to centralize shared build logic in a special directory. This way, you can declare the dependency version in one place and have it automatically apply to all subprojects.
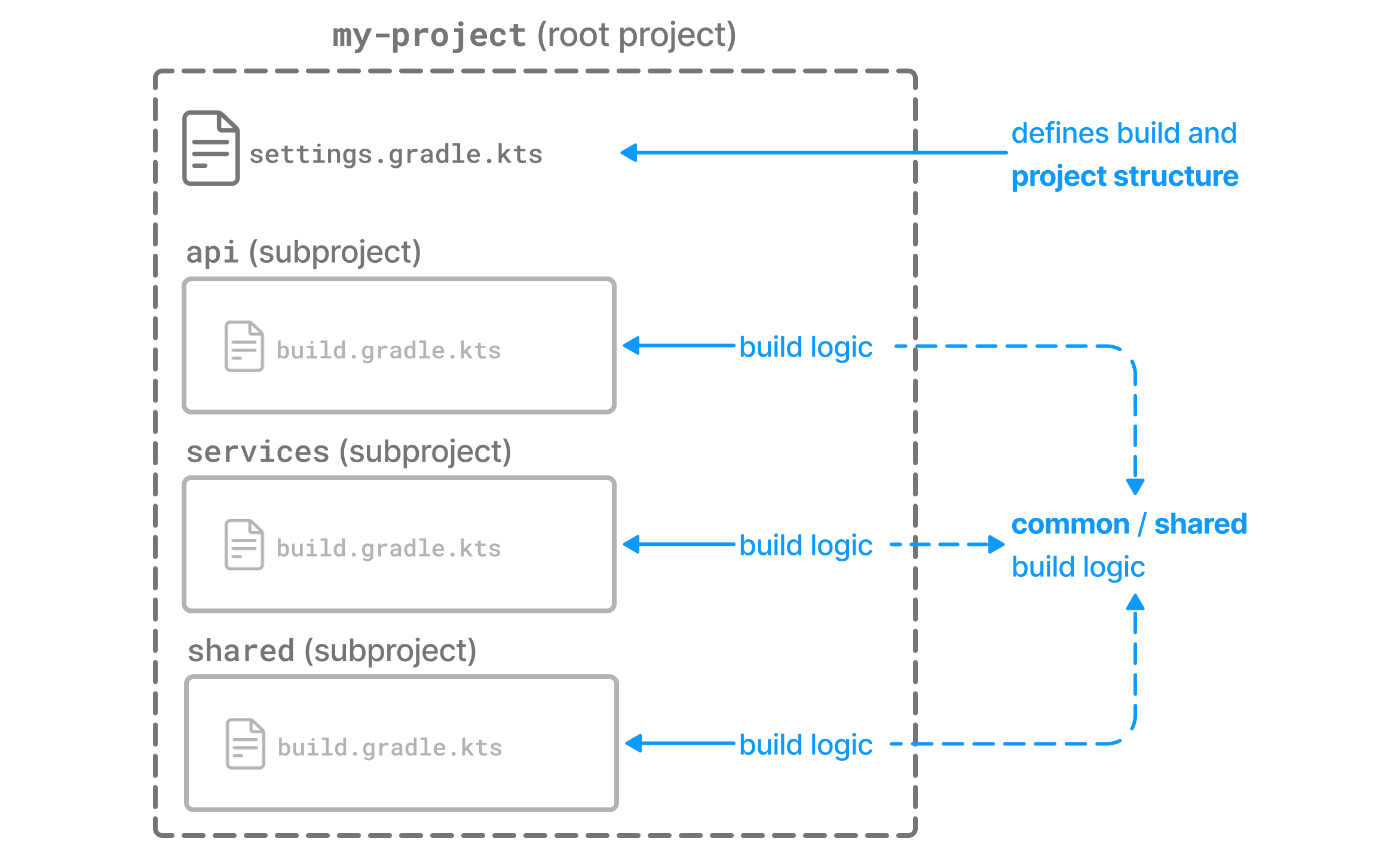
Using buildSrc
buildSrc is a special directory in a Gradle build that allows you to organize and share build logic, such as custom plugins, tasks, configurations, and utility functions, across all projects in your build.
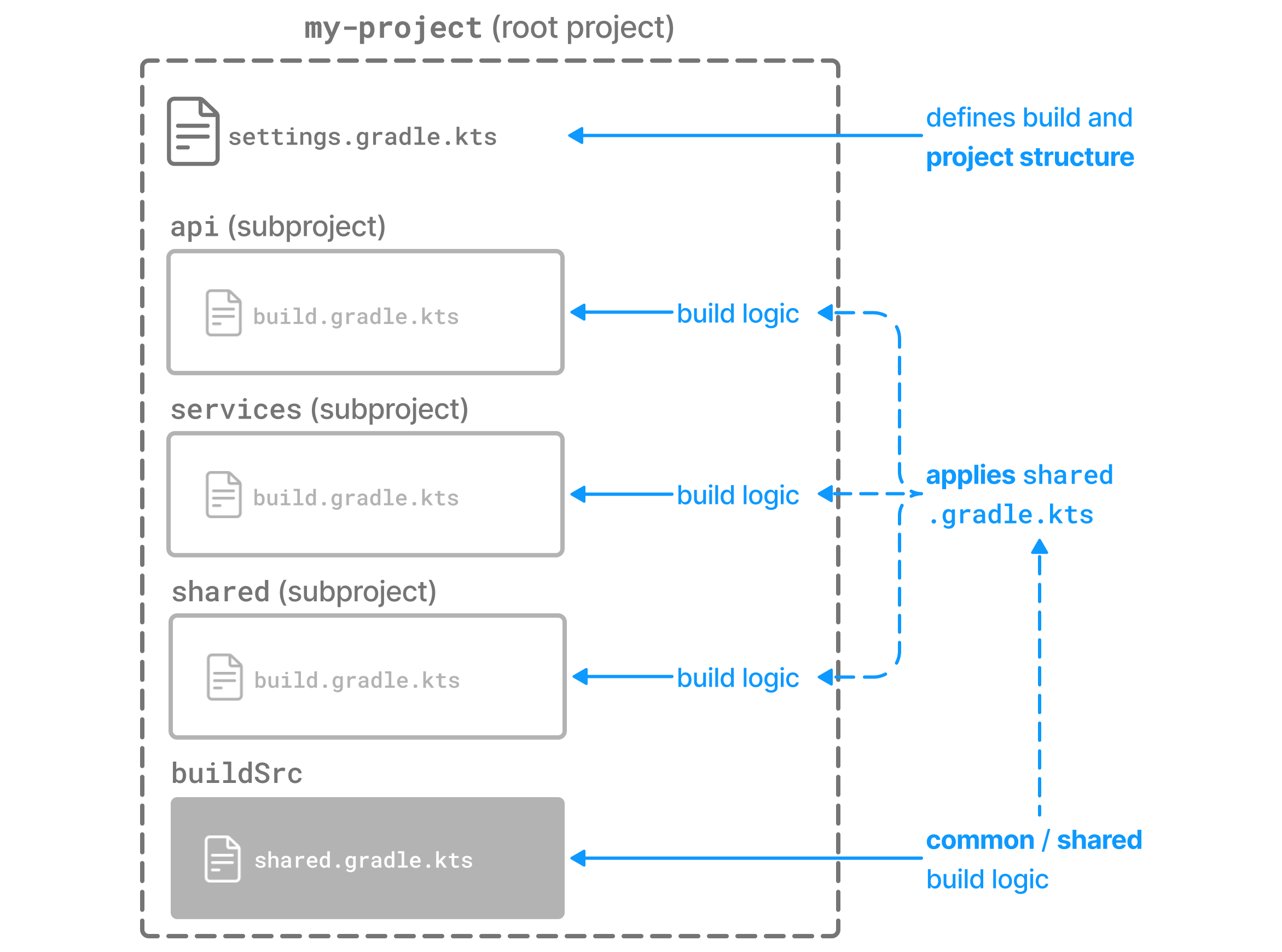
Let’s take a look at an example with the following structure:
A typical multi-project build has the following layout:
.
├── api
│ ├── src/
│ └── build.gradle.kts // (1)
├── services
│ ├── src/
│ └── build.gradle.kts // (1)
├── shared
│ ├── src/
│ └── build.gradle.kts // (1)
└── settings.gradle.kts-
A build script that contains build logic, including parts that are shared with other subprojects.
.
├── api
│ ├── src/
│ └── build.gradle // (1)
├── services
│ ├── src/
│ └── build.gradle // (1)
├── shared
│ ├── src/
│ └── build.gradle // (1)
└── settings.gradle-
A build script that contains build logic, including parts that are shared with other subprojects.
The build file for api, services, and shared has many commonalities:
plugins {
`java-library`
}
repositories {
mavenCentral()
}
dependencies {
implementation("org.slf4j:slf4j-api:2.0.9")
implementation("com.fasterxml.jackson.core:jackson-databind:2.17.1")
testImplementation("org.junit.jupiter:junit-jupiter:5.11.3")
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
}
java {
toolchain {
languageVersion = JavaLanguageVersion.of(21)
}
}
tasks.named<Test>("test") {
useJUnitPlatform()
}plugins {
`java-library`
}
repositories {
mavenCentral()
}
dependencies {
implementation("org.slf4j:slf4j-api:2.0.9")
implementation("com.google.guava:guava:32.1.2-jre")
testImplementation("org.junit.jupiter:junit-jupiter:5.11.3")
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
}
java {
toolchain {
languageVersion = JavaLanguageVersion.of(21)
}
}
tasks.named<Test>("test") {
useJUnitPlatform()
}plugins {
`java-library`
}
repositories {
mavenCentral()
}
dependencies {
implementation("org.slf4j:slf4j-api:2.0.9")
implementation("com.google.guava:guava:32.1.2-jre")
testImplementation("org.junit.jupiter:junit-jupiter:5.11.3")
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
}
java {
toolchain {
languageVersion = JavaLanguageVersion.of(21)
}
}
tasks.named<Test>("test") {
useJUnitPlatform()
}plugins {
id 'java-library'
}
repositories {
mavenCentral()
}
dependencies {
implementation 'org.slf4j:slf4j-api:2.0.9'
implementation 'com.fasterxml.jackson.core:jackson-databind:2.17.1'
testImplementation 'org.junit.jupiter:junit-jupiter:5.11.3'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}
java {
toolchain {
languageVersion = JavaLanguageVersion.of(21)
}
}
tasks.named('test', Test) {
useJUnitPlatform()
}plugins {
id 'java-library'
}
repositories {
mavenCentral()
}
dependencies {
implementation 'com.google.guava:guava:32.1.2-jre'
implementation 'org.slf4j:slf4j-api:2.0.9'
testImplementation 'org.junit.jupiter:junit-jupiter:5.11.3'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}
java {
toolchain {
languageVersion = JavaLanguageVersion.of(21)
}
}
tasks.named('test', Test) {
useJUnitPlatform()
}plugins {
id 'java-library'
}
repositories {
mavenCentral()
}
dependencies {
implementation 'com.google.guava:guava:32.1.2-jre'
implementation 'org.slf4j:slf4j-api:2.0.9'
testImplementation 'org.junit.jupiter:junit-jupiter:5.11.3'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}
java {
toolchain {
languageVersion = JavaLanguageVersion.of(21)
}
}
tasks.named('test', Test) {
useJUnitPlatform()
}To avoid duplicating build logic across api, services, and shared, we can move the shared parts into buildSrc.
This allows us to define dependencies and other configurations once and apply them uniformly to all subprojects.
For example, if you need to update the version of org.slf4j:slf4j-api:1.7.32, you only have to change it once—in the build logic inside buildSrc—rather than updating every individual build script.
Let’s expand the layout to include a buildSrc directory:
.
├── buildSrc
│ ├── src
│ │ └──main
│ │ └──kotlin
│ │ └──java-common-conventions.gradle.kts // (1)
│ └── build.gradle.kts
├── api
│ ├── src/
│ └── build.gradle.kts // (2)
├── services
│ ├── src/
│ └── build.gradle.kts // (2)
├── shared
│ ├── src/
│ └── build.gradle.kts // (2)
└── settings.gradle.kts-
A shared build script.
-
Applies the shared build script.
.
├── buildSrc
│ ├── src
│ │ └──main
│ │ └──groovy
│ │ └──java-common-conventions.gradle // (1)
│ └── build.gradle
├── api
│ ├── src/
│ └── build.gradle // (2)
├── services
│ ├── src/
│ └── build.gradle // (2)
├── shared
│ ├── src/
│ └── build.gradle // (2)
└── settings.gradle-
A shared build script.
-
Applies the shared build script.
When a buildSrc directory is present at the root of a Gradle build, Gradle treats it as a Composite Build.
Upon detecting the buildSrc directory, Gradle:
-
Treats
buildSrcas an independent Gradle project with its ownbuild.gradle(.kts)file and its ownsrc/folder. -
Compiles all classes and scripts in
buildSrc(typically undersrc/main/kotlinorsrc/main/groovy) before evaluating any other build scripts in the main build. -
Makes the compiled classes and scripts available on the classpath of all other project build scripts in the root project and subprojects.
As such, our new buildSrc has the following build file:
plugins {
`kotlin-dsl`
}
repositories {
gradlePluginPortal()
}plugins {
id 'groovy-gradle-plugin'
}
repositories {
gradlePluginPortal()
}In the buildSrc, the build script java-common-conventions.gradle(.kts) is created in src/main/kotlin or src/main/groovy.
It contains dependencies and other build information that is common to our subprojects:
plugins {
`java-library`
}
repositories {
mavenCentral()
}
dependencies {
implementation("org.slf4j:slf4j-api:2.0.9")
testImplementation("org.junit.jupiter:junit-jupiter:5.11.3")
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
}
java {
toolchain {
languageVersion = JavaLanguageVersion.of(21)
}
}
tasks.named<Test>("test") {
useJUnitPlatform()
}plugins {
id 'java-library'
}
repositories {
mavenCentral()
}
dependencies {
implementation 'org.slf4j:slf4j-api:2.0.9'
testImplementation 'org.junit.jupiter:junit-jupiter:5.11.3'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}
java {
toolchain {
languageVersion = JavaLanguageVersion.of(21)
}
}
tasks.named('test', Test) {
useJUnitPlatform()
}If you create a script file like java-common-conventions.gradle(.kts), you can treat it as a plugin and apply it in your subprojects.
The ID of the plugin is the name of the build file without the gradle(.kts) extension.
This kind of plugin is called a convention plugin.
The shared logic is removed from the api, services, and shared build files.
And the shared plugin is applied in the files instead:
plugins {
id("java-common-conventions")
}
dependencies {
implementation("com.fasterxml.jackson.core:jackson-databind:2.17.1")
}plugins {
id("java-common-conventions")
}
dependencies {
implementation("com.google.guava:guava:32.1.2-jre")
}plugins {
id("java-common-conventions")
}
dependencies {
implementation("com.google.guava:guava:32.1.2-jre")
}plugins {
id("java-common-conventions")
}
dependencies {
implementation("com.fasterxml.jackson.core:jackson-databind:2.17.1")
}plugins {
id("java-common-conventions")
}
dependencies {
implementation("com.google.guava:guava:32.1.2-jre")
}plugins {
id("java-common-conventions")
}
dependencies {
implementation("com.google.guava:guava:32.1.2-jre")
}From now on, if you want to change something like the version of slf4j-api, you only need to update it in buildSrc, and the change will automatically apply to all subprojects.
About the buildSrc directory
buildSrc is a special, Gradle-recognized directory that provides a convenient way to organize and reuse custom build logic across your build. Gradle automatically treats it as an included build with several advantages:
-
Reusable Build Logic: You can centralize common build logic, tasks, and plugins in
buildSrc. This promotes consistency and maintainability across subprojects, as changes inbuildSrcare automatically reflected wherever its logic is used. -
Automatic Compilation and Classpath Inclusion: Gradle automatically compiles the code in
buildSrcand includes it in the classpath of all build scripts. This allows classes, plugins, and utilities defined inbuildSrcto be used directly without additional setup. -
Cleaner Build Scripts: Moving logic into
buildSrckeeps your project’s main build scripts focused and decluttered, improving readability and maintainability. -
Ease of Testing: Since
buildSrcis treated as a standalone build, you can write and run unit tests for your custom tasks and plugins just like any other project code. -
Convenient Plugin Development: If you’re writing custom Gradle plugins for internal use,
buildSrcprovides an easy way to define and use them without publishing to an external repository.
buildSrc follows the same source layout conventions as regular Java, Groovy, or Kotlin projects and has direct access to the Gradle API.
Dependencies can be declared in its own build.gradle or build.gradle.kts file.
In a multi-project build, only one buildSrc directory is allowed, and it must reside in the root project directory.
|
Warning
|
Changes to code in buildSrc will invalidate the configuration phase and require re-execution of all tasks, potentially slowing down the build.
|
Using a Composite Build Named build-logic
In addition to buildSrc, another powerful way to share build logic across subprojects is by using a dedicated composite build, typically named build-logic.
A typical multi-project build using build-logic as a composite build looks like this:
.
├── build-logic/ // (1)
│ ├── build.gradle.kts
│ ├── settings.gradle.kts
│ └── src/main/kotlin
│ └── java-common-conventions.gradle.kts
├── api/
│ └── build.gradle.kts // (2)
├── services/
│ └── build.gradle.kts // (2)
├── shared/
│ └── build.gradle.kts // (2)
└── settings.gradle.kts // (3)-
Standalone build logic project that defines convention plugins.
-
Applies shared plugin(s) from the composite build.
-
Includes build-logic as an included build.
.
├── build-logic/ // (1)
│ ├── build.gradle
│ ├── settings.gradle
│ └── src/main/groovy
│ └── java-common-conventions.gradle
├── api/
│ └── build.gradle // (2)
├── services/
│ └── build.gradle // (2)
├── shared/
│ └── build.gradle // (2)
└── settings.gradle // (3)-
Standalone build logic project that defines convention plugins.
-
Applies shared plugin(s) from the composite build.
-
Includes
build-logicas an included build.
You can learn more in Composite Builds.
Avoid cross-project configuration using subprojects and allprojects
An improper way to share build logic between subprojects is cross-project configuration via the subprojects {} and allprojects {} DSL constructs.
With cross-project configuration, build logic can be injected into a subproject which is not obvious when looking at its build script.
In the long run, cross-project configuration usually grows in complexity and becomes a burden. Cross-project configuration can also introduce configuration-time coupling between projects, which can prevent optimizations like configuration-on-demand from working properly.
Convention plugins versus cross-project configuration
The two most common uses of cross-project configuration can be better modeled using convention plugins:
-
Applying plugins or other configurations to subprojects of a certain type.
Often, the cross-project configuration logic isif subproject is of type X, then configure Y. This is equivalent to applyingX-conventionsplugin directly to a subproject. -
Extracting information from subprojects of a certain type.
This use case can be modeled using outgoing configuration variants.
Composite Builds (Included Builds)
A composite build is a build that includes other builds; those builds are known as included builds.
A composite build is similar to a Gradle multi-project build, except that instead of including subprojects, entire builds are included.
This is done either using the Settings file and adding a build using includeBuild():
includeBuild("my-utils")includeBuild 'my-utils'Or using the CLI flag --include-build:
$ ./gradlew build --include-build my-utilsWhen to Use Composite Builds
Composite builds are useful in three broad scenarios:
-
Developing libraries and consumers together: If you maintain a library that another project depends on, composite builds let you work across both at the same time without publishing the library first.
Gradle automatically substitutes the external dependency with a local source, so changes to the library are immediately visible in the consuming project. -
Organizing large codebases: Composite builds let you split a large codebase into independent builds that can each be opened and worked on in isolation (for example, in the IDE), while still being buildable together as a whole.
This is a common approach in monorepo setups. -
Sharing build logic: Composite builds are the recommended way to structure and share custom build logic across projects.
buildSrcis essentially an included build that Gradle manages automatically; abuild-logicbuild included viaincludeBuild()in your settings file is the same idea, made explicit.
Composite Build Layout
Included builds do not share any configuration with other included builds.
|
Important
|
Each included build is configured in isolation — included builds do not share repositories, plugins, or properties with one another or with the root build, but they can be executed together and depend on each other’s tasks. |
Composite builds typically take one of two layouts depending on the use case: a co-development layout, where an included build lives outside the consumer and is substituted temporarily during development; or a monorepo layout, where an uber-root build knits together a set of independent builds that can also be worked on in isolation.
|
Note
|
For reference, a build tree consists of the root build and all of its included builds, recursively. |
Co-development Layout Example
The following example demonstrates co-development — temporarily substituting a dependency to work across a library and its consumer simultaneously. You simply include the library directly into the consumer build:
my-app/ // The consumer build (your working directory)
├── settings.gradle.kts // includeBuild("../my-utils")
├── build.gradle.kts
└── app/
├── build.gradle.kts // Declares dependencies on 'number-utils' and 'string-utils'
└── src/main/java/...
my-utils/ // The library build (Included Build)
├── settings.gradle.kts // Defines 'number-utils' and 'string-utils' subprojects
├── number-utils/
│ ├── build.gradle.kts
│ └── src/main/java/...
└── string-utils/
├── build.gradle.kts
└── src/main/java/...my-app/ // The consumer build (your working directory)
├── settings.gradle // includeBuild("../my-utils")
├── build.gradle
└── app/
├── build.gradle // Declares dependencies on 'number-utils' and 'string-utils'
└── src/main/java/...
my-utils/ // The library build (Included Build)
├── settings.gradle // Defines 'number-utils' and 'string-utils' subprojects
├── number-utils/
│ ├── build.gradle
│ └── src/main/java/...
└── string-utils/
├── build.gradle
└── src/main/java/...In this example, my-utils lives outside of my-app and is included temporarily during development. Once the library changes are published, the includeBuild can be removed.
The my-app root settings file looks as follows:
rootProject.name = "my-app"
include("app")
includeBuild("../my-utils")rootProject.name = "my-app"
include("app")
includeBuild("../my-utils")Monorepo Layout Example
The following example demonstrates a monorepo layout in which an uber-root build knits together independent builds.
my-composite/ // The root of the Composite Build
├── settings.gradle.kts
├── my-app/ // The application build (Included Build #1)
│ ├── settings.gradle.kts
│ └── app/
│ ├── build.gradle.kts // Declares dependencies on 'number-utils' and 'string-utils'
│ └── src/main/java/...
└── my-utils/ // The utility library build (Included Build #2)
├── settings.gradle.kts // Defines 'number-utils' and 'string-utils' subprojects
├── number-utils/
│ ├── build.gradle.kts
│ └── src/main/java/...
└── string-utils/
├── build.gradle.kts
└── src/main/java/...my-composite/ // The root of the Composite Build
├── settings.gradle
├── my-app/ // The application build (Included Build #1)
│ ├── settings.gradle
│ └── app/
│ ├── build.gradle // Declares dependencies on 'number-utils' and 'string-utils'
│ └── src/main/java/...
└── my-utils/ // The utility library build (Included Build #2)
├── settings.gradle // Defines 'number-utils' and 'string-utils' subprojects
├── number-utils
│ ├── build.gradle
│ └── src/main/java/...
└── string-utils
├── build.gradle
└── src/main/java/...In this example, my-composite is a composite build that includes the my-app build and the my-utils build.
my-app and my-utils are included builds:
The my-composite root settings file looks as follows:
rootProject.name = "my-composite"
includeBuild("my-app")
includeBuild("my-utils")rootProject.name = 'my-composite'
includeBuild 'my-app'
includeBuild 'my-utils'Defining a Composite Build via the Settings file
The settings file, settings.gradle(.kts), can be used to add subprojects and included builds simultaneously using Settings.includeBuild(java.lang.Object).
Included builds are added by location using a file path:
-
Relative paths are resolved relative to the directory containing the settings file -
includeBuild("../my-utils") -
Absolute paths can also be used but are heavily discouraged -
includeBuild("/Users/user/projects/my-utils")
The path should point to the root directory of the build (the directory containing the settings.gradle(.kts) file of the included build):
includeBuild("../dir/other-build")includeBuild("../dir/other-build")Defining a Composite Build via --include-build
The --include-build command-line argument turns the executed build into a composite, substituting dependencies from the included build into the executed build:
$ ./gradlew --include-build ../my-utils run> Task :my-plugin:pluginDescriptors
> Task :my-plugin:processResources
> Task :my-plugin:compileJava NO-SOURCE
> Task :my-plugin:classes
> Task :my-plugin:jar
> Task :app:processResources NO-SOURCE
> Task :my-utils:number-utils:compileJava
> Task :my-utils:string-utils:compileJava
> Task :my-utils:string-utils:processResources NO-SOURCE
> Task :my-utils:string-utils:classes
> Task :my-utils:string-utils:jar
> Task :my-utils:number-utils:processResources NO-SOURCE
> Task :my-utils:number-utils:classes
> Task :my-utils:number-utils:jar
> Task :app:compileJava
> Task :app:classes
> Task :app:run
The answer is 42
BUILD SUCCESSFUL in 0s
10 actionable tasks: 10 executedInteracting with a Composite Build
Interacting with a composite build is generally similar to a regular multi-project build. Tasks can be executed, tests can be run, and builds can be imported into the IDE.
Executing Tasks
Tasks from an included build can be executed from the command-line or IDE in the same way as tasks from a regular multi-project build. Executing a task will result in task dependencies being executed, as well as those tasks required to build dependency artifacts from other included builds.
You can call a task in an included build using a fully qualified path, for example, :included-build-name:project-name:taskName:
$ ./gradlew :included-build:subproject-a:compileJava> Task :included-build:subproject-a:compileJavaBuild, project, and task names can all be abbreviated:
$ ./gradlew :i-b:sA:cJ> Task :included-build:subproject-a:compileJavaWith reference to the example build, to execute the run task in the my-app build from my-composite:
$ cd my-composite
$ ./gradlew :my-app:app:runTo exclude a task from the command line, you need to provide the fully qualified path to the task:
$ ./gradlew :my-app:app:compileJava --exclude-task :my-app:app:testYou can optionally define a run task in my-composite that depends on my-app:app:run:
tasks.register("run") {
dependsOn(gradle.includedBuild("my-app").task(":app:run"))
}tasks.register('run') {
dependsOn gradle.includedBuild('my-app').task(':app:run')
}So that you can execute ./gradlew run from the my-composite directory:
$ cd my-composite
$ ./gradlew run|
Note
|
Included build tasks are automatically executed to generate required dependency artifacts, or the including build can declare a dependency on a task from an included build. |
Depending on Tasks
While included builds are isolated from one another and cannot declare direct dependencies, a composite build can declare task dependencies on its included builds.
The included builds are accessed using Gradle.getIncludedBuilds() or Gradle.includedBuild(java.lang.String), and a task reference is obtained via the IncludedBuild.task(java.lang.String) method.
Using these APIs, it is possible to declare a dependency on a task in a particular included build:
tasks.register("run") {
dependsOn(gradle.includedBuild("my-app").task(":app:run"))
}tasks.register('run') {
dependsOn gradle.includedBuild('my-app').task(':app:run')
}Or you can declare a dependency on tasks with a certain path in all of the included builds:
tasks.register("publishDeps") {
dependsOn(gradle.includedBuilds.map { it.task(":publishMavenPublicationToMavenRepository") })
}tasks.register('publishDeps') {
dependsOn gradle.includedBuilds*.task(':publishMavenPublicationToMavenRepository')
}Referencing Projects
It is a common mistake to attempt to use project() notation to depend on a module that resides in an included build.
|
Important
|
Included builds are not subprojects. |
Each build in a composite has its own project hierarchy.
You cannot use project paths (e.g., project(":other-build:module")) to reference a project across build boundaries.
Doing so will result in an UnknownProjectException.
To depend on a project from an included build, you must use its external coordinates (the same coordinates you would use if the library were published to Maven Central or Ivy).
If an included build has a project with group = "com.example.data" and rootProject.name = "core-schema", you reference it in your main build like an external dependency.
For example, if your configuration looks as follows:
.
├── app (Composite Build)
│ ├── build.gradle.kts
│ └── settings.gradle.kts <-- includeBuild("../core-schema")
└── core-schema (Included Build)
├── build.gradle.kts
└── settings.gradle.kts <-- rootProject.name = "core-schema".
├── app (Composite Build)
│ ├── build.gradle
│ └── settings.gradle <-- includeBuild("../core-schema")
└── core-schema (Included Build)
├── build.gradle
└── settings.gradle <-- rootProject.name = "core-schema"The included build has the following information:
group = "com.example.data"
version = "1.0.0"group = "com.example.data"
version = "1.0.0"So that the main build can reference it:
dependencies {
// ❌ This will fail because ":core-schema" is not in this build's hierarchy
implementation(project(":core-schema"))
// ✅ Gradle sees this GAV and finds the matching project in the included build
implementation("com.example.data:core-schema:1.0.0")
}dependencies {
// ❌ This will fail because ":core-schema" is not in this build's hierarchy
implementation project(":core-schema")
// ✅ Gradle sees this GAV and finds the matching project in the included build
implementation "com.example.data:core-schema:1.0.0"
}Gradle uses the metadata from the included build to "discover" which coordinates it provides. As long as the coordinates match, Gradle replaces the external dependency with a project dependency at execution time, see Dependency Substitution in Composite Builds to learn more.
Configuring a Composite Build
A critical aspect of included builds is that they are executed in isolation.
This has specific implications for how configuration is (or is not) shared:
-
Gradle Properties:
gradle.propertiesfiles defined in the root build are not visible to included builds. Each included build must define its own properties or properties must be passed via the CLI.
Note that this applies to user-defined properties. Gradle runtime properties (such asorg.gradle.configuration-cache) are a special case — they are only read from the root build and applied to the entire invocation. Any such properties defined in an included build’sgradle.propertiesare ignored. -
Shared Configuration: Included builds do not share any configuration with the root build or other included builds. This includes repositories, plugin management, or dependency versions defined in
buildSrcor version catalogs.
Continuing from the example above, where properties are defined in the CLI and in the root gradle.properties file:
$ ./gradlew checkAll -PpropertiesMessage="Hello" -DsystemMessage="Hello"The following output is produced, showcasing the propagation of the properties from the root file and the CLI to the included builds:
> Configure project :my-app:app
propertiesFileMessage = null
systemMessage = Hello
propertiesMessage = Hello
> Configure project :my-utils:number-utils
propertiesFileMessage = null
systemMessage = Hello
propertiesMessage = Hello
> Configure project :
propertiesFileMessage = Hello
systemMessage = Hello
propertiesMessage = HelloIf you need to share credentials (like repository tokens) or common configuration across a composite build tree, consider using system environment variables or extracting the logic into a shared convention plugin included via pluginManagement.
While included builds are isolated and cannot declare direct project dependencies, a composite build can declare task dependencies on its included builds.
Gradle Plugins in Composite Builds
When including builds that provide Gradle plugins, there are different approaches depending on how and where the plugin will be applied.
Plugins for Build Scripts
Plugins that will be applied in project build scripts (e.g., build.gradle.kts) can be included using includeBuild in your settings.gradle(.kts) file.
This approach is recommended over using the --include-build CLI flag, as it provides more reliable plugin resolution, especially when using the modern plugins {} block:
pluginManagement {
includeBuild("my-plugin")
repositories {
gradlePluginPortal()
mavenCentral()
}
}pluginManagement {
includeBuild('my-plugin')
repositories {
gradlePluginPortal()
mavenCentral()
}
}Then the plugin is used as follows:
plugins {
id("application")
id("com.example.hello") // from the Included Build in pluginManagement
}plugins {
id 'application'
id('com.example.hello') // from the Included Build in pluginManagement
}Plugins for Settings Files
A special case of included builds are builds that define plugins that need to be applied in the settings file itself.
These builds should be included using the includeBuild statement inside the pluginManagement {} block of the settings file.
Using this mechanism, the included build may contribute a settings plugin that can be applied in the settings file:
pluginManagement {
includeBuild("./my-settings-plugin")
}
plugins {
id("my-settings-plugin")
}pluginManagement {
includeBuild('./my-settings-plugin')
}
plugins {
id 'my-settings-plugin'
}|
Note
|
While the --include-build CLI flag can work for plugins applied via the buildscript {} block, it may not work reliably for plugins applied using the modern plugins {} block, especially for unpublished plugins.
|
For consistent behavior, use includeBuild in your settings file.
For settings plugins (plugins applied in the settings file itself), use includeBuild within the pluginManagement {} block.
Dependency Substitution in Composite Builds
By default, Gradle will configure each included build to determine the dependencies it can provide.
The algorithm for doing this is simple.
Gradle will inspect the group and name for the projects in the included build and substitute project dependencies for any external dependency matching ${project.group}:${project.name}.
|
Note
|
By default, substitutions are not registered for the main build. To make the (sub)projects of the main build addressable by |
There are cases when the default substitutions determined by Gradle are insufficient or must be corrected for a particular composite. For these cases, explicitly declaring the substitutions for an included build is possible.
For example, a single-project build called anonymous-library, produces a Java utility library but does not declare a value for the group attribute:
plugins {
java
}plugins {
id 'java'
}When this build is included in a composite, it will attempt to substitute for the dependency module undefined:anonymous-library (undefined being the default value for project.group, and anonymous-library being the root project name).
Clearly, this isn’t useful in a composite build.
To use the unpublished library in a composite build, you can explicitly declare the substitutions that it provides:
includeBuild("anonymous-library") {
dependencySubstitution {
substitute(module("org.sample:number-utils")).using(project(":"))
}
}includeBuild('anonymous-library') {
dependencySubstitution {
substitute module('org.sample:number-utils') using project(':')
}
}With this configuration, the my-app composite build will substitute any dependency on org.sample:number-utils with a dependency on the root project of anonymous-library.
|
Important
|
Substitutions are not transitive across builds. |
Explicitly declared substitutions are only active for the build that defines them.
In the example above, while my-app knows to substitute org.sample:number-utils with the local anonymous-library, the anonymous-library build itself remains unaware of this rule.
If you run a task directly from within the anonymous-library directory that requires org.sample:number-utils (for example, in its own test suite), the resolution will fail unless:
-
The substitution is also declared in the
settings.gradle(.kts)ofanonymous-library. -
(Recommended) You align the group and
rootProject.nameofanonymous-libraryto match the expected coordinates, allowing Gradle’s default auto-substitution to work in both directions.
Disabling Substitutions for a Configuration
If you need to resolve a published version of a module that is also available as part of an included build, you can deactivate the included build substitution rules on the ResolutionStrategy of the Configuration that is resolved.
This is necessary because the rules are globally applied in the build, and Gradle does not consider published versions during resolution by default.
For example, we create a separate publishedRuntimeClasspath configuration that gets resolved to the published versions of modules that also exist in one of the local builds.
This is done by deactivating global dependency substitution rules:
configurations.create("publishedRuntimeClasspath") {
resolutionStrategy.useGlobalDependencySubstitutionRules = false
extendsFrom(configurations.runtimeClasspath.get())
isCanBeConsumed = false
attributes.attribute(Usage.USAGE_ATTRIBUTE, objects.named(Usage.JAVA_RUNTIME))
}configurations.create('publishedRuntimeClasspath') {
resolutionStrategy.useGlobalDependencySubstitutionRules = false
extendsFrom(configurations.runtimeClasspath)
canBeConsumed = false
attributes.attribute(Usage.USAGE_ATTRIBUTE, objects.named(Usage, Usage.JAVA_RUNTIME))
}A use-case would be to compare published and locally built JAR files.
When to Declare Substitutions Explicitly
Many builds will function automatically as an included build, without declared substitutions. Here are some common cases where declared substitutions are required:
-
When the
archivesBaseNameproperty is used to set the name of the published artifact. -
When a configuration other than
defaultis published. -
When the
maven-publishorivy-publishplugins are used for publishing and the publication coordinates don’t match${project.group}:${project.name}. -
When multiple publications are defined for a single project (e.g., a project that publishes two different libraries).
When Substitutions Won’t Work
Some builds won’t function correctly when included in a composite, even when dependency substitutions are explicitly declared.
This limitation is because a substituted project dependency will always point to the default configuration of the target project.
Any time the artifacts and dependencies specified for the default configuration of a project don’t match what is published to a repository, the composite build may exhibit different behavior.
Here are some cases where the published module metadata may be different from the project default configuration:
-
When the
maven-publishorivy-publishplugins are used with custom logic in the publication block. -
When the
POMorivy.xmlfile is tweaked as part of publication. -
When a capability or a custom variant is only defined via publication metadata.
Builds using these features may function incorrectly when included in a composite build.
Requirements for Composite Builds
Composite builds must maintain unique identifiers for every project across the entire build tree.
To prevent conflicts, Gradle qualifies projects using a build-tree path, which combines the build path (derived from the included build’s directory name) and the project path.
To ensure every project remains uniquely addressable, included builds must satisfy two conditions:
-
Unique Build Paths: No two included builds can share the same build path.
-
No Namespace Overlap: An included build path cannot conflict with any existing project path in the root build.
If directory names cause a naming collision, rename the build path in your settings file:
includeBuild("some-included-build") {
name = "other-name"
}includeBuild('some-included-build') {
name = 'other-name'
}|
Note
|
When a composite build includes another composite, Gradle flattens the structure. All included builds share the same parent, regardless of how deeply they were nested. |
Known Limitations of Composite Builds
Limitations of the current implementation include:
-
Substitution Limitations: No support for included builds with publications that don’t mirror the project default configuration. See Cases where composite builds won’t work.
-
Multiple Composite Builds: Multiple composite builds may conflict when run in parallel if more than one includes the same build. Gradle does not share the project lock of a shared composite build between Gradle invocations to prevent concurrent execution.
-
Configuration-on-Demand: See Configuration-on-Demand below.
Configuration-on-Demand
Using Configuration-on-Demand with composite builds can significantly impact performance. The behavior changes depending on whether you rely on default substitutions or explicitly declared substitutions:
-
You must manually declare all dependency substitutions for every project within that included build that you wish to use. Any project not explicitly mapped will be treated as an external dependency.
-
The way Gradle discovers what an included build "provides" dictates how much of that build must be configured at startup:
Scenario Behavior Performance Impact Default Rules (No explicit substitutions)
Gradle must inspect every project in the included build to find matching
groupandname.High: The included build is always fully configured, even if its projects aren’t needed for the current task.
Explicit Rules (Using
substitute…)Gradle uses your explicit rules as the source of truth.
Optimized: The included build is not configured unless a task requires one of the substituted projects.
Configuration On Demand
Configuration-on-demand attempts to configure only the relevant projects for the requested tasks, i.e., it only evaluates the build script file of projects participating in the build. This way, the configuration time of a large multi-project build can be reduced.
The configuration-on-demand feature is incubating, so only some builds are guaranteed to work correctly. The feature works well for decoupled multi-project builds.
In configuration-on-demand mode, projects are configured as follows:
-
The root project is always configured.
-
The project in the directory where the build is executed is also configured, but only when Gradle is executed without any tasks.
This way, the default tasks behave correctly when projects are configured on demand. -
The standard project dependencies are supported, and relevant projects are configured.
If project A has a compile dependency on project B, then building A causes the configuration of both projects. -
The task dependencies declared via the task path are supported and cause relevant projects to be configured.
Example:someTask.dependsOn(":some-other-project:someOtherTask") -
A task requested via task path from the command line (or tooling API) causes the relevant project to be configured.
For example, buildingproject-a:project-b:someTaskcauses configuration ofproject-b.
Enable configure-on-demand
You can enable configuration-on-demand using the --configure-on-demand flag or adding org.gradle.configureondemand=true to the gradle.properties file.
To configure on demand with every build run, see Gradle properties.
To configure on demand for a given build, see command-line performance-oriented options.
Decoupled projects
Gradle allows projects to access each other’s configurations and tasks during the configuration and execution phases. While this flexibility empowers build authors, it limits Gradle’s ability to perform optimizations such as parallel project builds and configuration on demand.
Projects are considered decoupled when they interact solely through declared dependencies and task dependencies. Any direct modification or reading of another project’s object creates coupling between the projects. Coupling during configuration can result in flawed build outcomes when using 'configuration on demand', while coupling during execution can affect parallel execution.
One common source of coupling is configuration injection, such as using allprojects{} or subprojects{} in build scripts.
To avoid coupling issues, it’s recommended to:
-
Refrain from referencing other subprojects' build scripts and prefer cross-project configuration from the root project.
-
Avoid dynamically changing other projects' configurations during execution.
As Gradle evolves, it aims to provide features that leverage decoupled projects while offering solutions for common use cases like configuration injection without introducing coupling.
Parallel projects
Gradle’s parallel execution feature optimizes CPU utilization to accelerate builds by concurrently executing tasks from different projects.
To enable parallel execution, use the --parallel command-line argument or configure your build environment.
Gradle automatically determines the optimal number of parallel threads based on CPU cores.
During parallel execution, each worker handles a specific project exclusively. Task dependencies are respected, with workers prioritizing upstream tasks. However, tasks may not execute in alphabetical order, as in sequential mode. It’s crucial to correctly declare task dependencies and inputs/outputs to avoid ordering issues.
OPTIMIZING GRADLE BUILDS
Improve the Performance of Gradle Builds
Build performance is essential to productivity. The longer a build takes, the more it disrupts your development flow. Since builds run many times a day, even small delays add up. The same applies to Continuous Integration (CI).
Investing in build speed pays off. This section explores ways to optimize performance, highlights common pitfalls, and explains how to avoid them.
| # | Recommendation |
|---|---|
1 |
|
2 |
|
3 |
|
4 |
|
5 |
|
6 |
|
7 |
|
8 |
|
9 |
|
10 |
|
11 |
|
12 |
|
13 |
0. Inspect your Build
Before making any changes, inspect your build with a Build Scan or profile report. A thorough inspection helps you understand:
-
Total build time
-
Which parts of the build are slow
This provides a baseline to measure the impact of optimizations.
To get the most value from this page:
-
Inspect your build.
-
Apply a change.
-
Inspect your build again.
If the change improves build times, keep it. If it doesn’t, revert the change and try another approach.
For reference, the following Build Scan snapshot is a build of a project created using gradle init.
It is a Java (JDK 21) Application and library project using Kotlin build files:
It builds in 21 seconds using Gradle 8.10.
1. Update Versions
Gradle
Each Gradle release brings performance improvements. Using an outdated version means missing out on these gains. Upgrading is low-risk since Gradle maintains backward compatibility between minor versions. Staying up to date also makes major version upgrades smoother by providing early deprecation warnings.
You can use the Gradle Wrapper to update the version of Gradle by running gradle :wrapper --gradle-version X.X where X.X is the desired version.
When our reference project is updated to use Gradle 8.13, the build (./gradlew clean build) takes 8 seconds:
Java
Gradle runs on the Java Virtual Machine (JVM), and Java updates often enhance performance. To get the best Gradle performance, use the latest Java version.
|
Tip
|
Don’t forget to check out compatibility guide to make sure your version of Java is compatible with your version of Gradle. |
Plugins
Plugins play a key role in build performance. Outdated plugins can slow down your build, while newer versions often include optimizations. This is especially true for the Android, Java, and Kotlin plugins. Keep them up to date for the best performance.
Simply look at all the declared plugins in your project and check if a newer version is available:
plugins {
id("org.jlleitschuh.gradle.ktlint") version "12.0.0" // A newer version is available on the Gradle Plugin Portal
}2. Enable Parallel Execution
Most projects consist of multiple subprojects, some of which are independent. However, by default, Gradle runs only one task at a time.
To execute tasks from different subprojects in parallel, use the --parallel flag:
$ gradle <task> --parallelTo enable parallel execution by default, add this setting to gradle.properties in the project root or your Gradle home directory:
org.gradle.parallel=trueParallel builds can significantly improve build times, but the impact depends on your project’s structure and inter-subproject dependencies. If a single subproject dominates execution time or there are many dependencies between subprojects, the benefits will be minimal. However, most multi-project builds see a noticeable reduction in build time.
When the parallel flag is used on our reference project, the build (./gradlew clean build --parallel) time is 7 seconds:
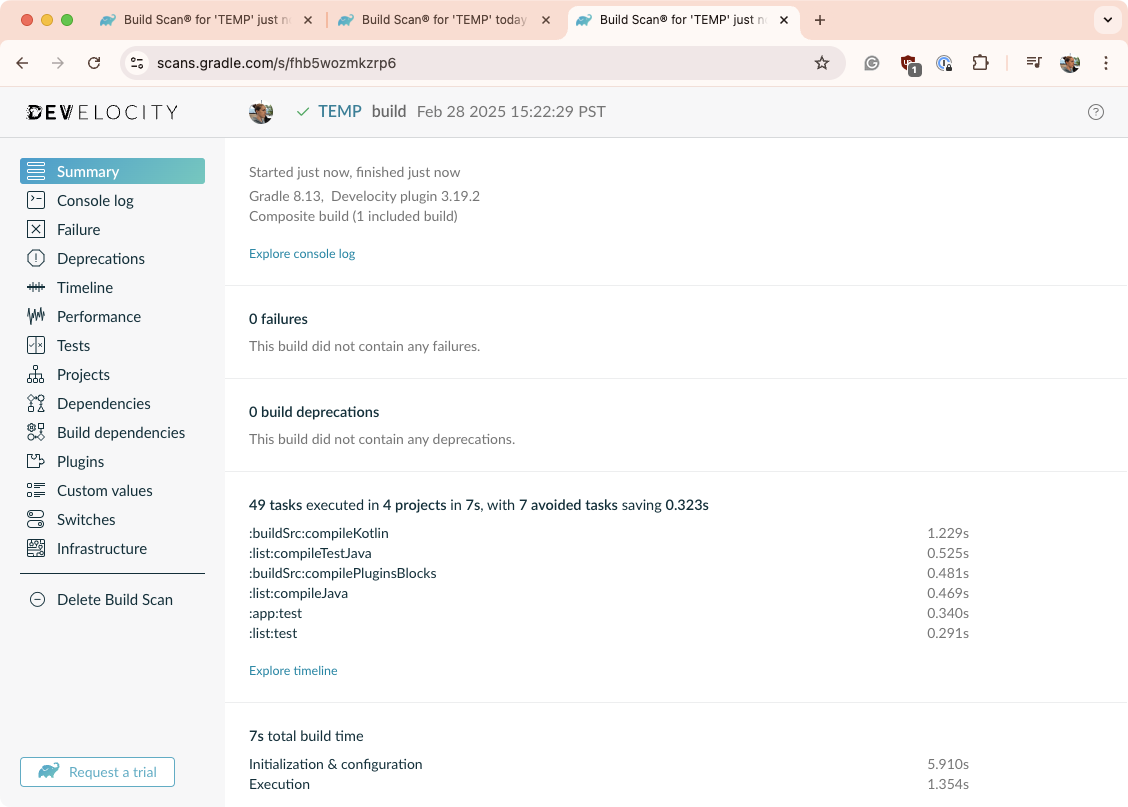
Visualize Parallelism with Build Scan
A Build Scan provides a visual timeline of task execution in the "Timeline" tab.
In the example below, the build initially has long-running tasks at the beginning and end, creating a bottleneck:
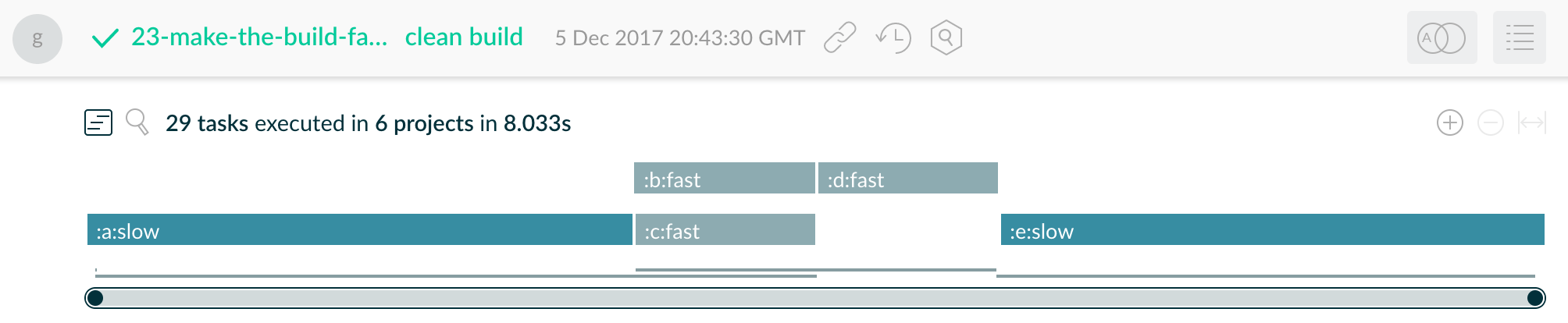
By adjusting the build configuration to run these two slow tasks earlier and in parallel, the overall build time is reduced from 8 seconds to 5 seconds:
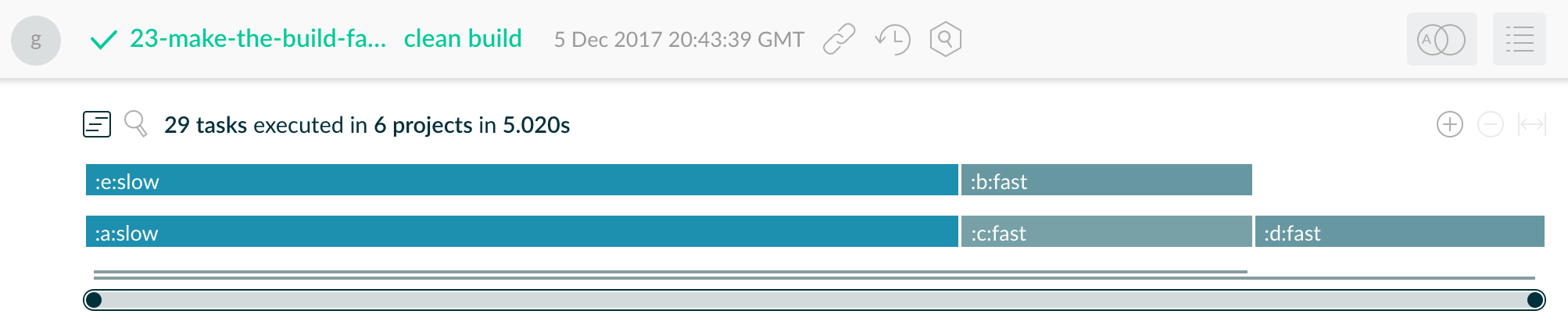
Configure Tooling API actions parallelism
By enabling Parallel Execution, you also allow parallelism for Tooling API actions. This means that Tooling API clients, such as IDEs, can do some of their work faster. In practice, this improves the speed of scenarios like IDE sync.
However, enabling Parallel Execution may not work for all builds. In some cases, the additional parallelism may lead to instability if tasks access shared mutable state across project boundaries. In other cases, the parallel Tooling API actions might misbehave for similar reasons.
If you observe such problems after enabling Parallel Execution, you should consider disabling it to preserve the reliability of the build results. At the same time, it is rare for builds to have problems with tasks and Tooling API actions at the same time.
Since Gradle 9.4.0, there is an additional option org.gradle.tooling.parallel
that allows controlling parallelism of Tooling API actions independently of task execution parallelism.
For instance, you can enable Tooling parallelism without task parallelism:
org.gradle.tooling.parallel=trueAlternatively, you can keep task parallelism, but disable Tooling parallelism:
org.gradle.parallel=true
org.gradle.tooling.parallel=false3. Re-enable the Gradle Daemon
The Gradle Daemon significantly reduces build times by:
-
Caching project information across builds
-
Running in the background to avoid JVM startup delays
-
Benefiting from continuous JVM runtime optimizations
-
Watching the file system to determine what needs to be rebuilt
Gradle enables the Daemon by default, but some builds override this setting. If your build disables it, enabling the Daemon can lead to substantial performance improvements.
To enable the Daemon at build time, use:
$ gradle <task> --daemonFor older Gradle versions, enable it permanently by adding this to gradle.properties:
org.gradle.daemon=trueOn developer machines, enabling the Daemon improves performance. On CI machines, long-lived agents benefit, but short-lived ones may not. Since Gradle 3.0, Daemons automatically shut down under memory pressure, making it safe to keep the Daemon enabled.
When the daemon is used on our reference project, the build (./gradlew clean build --daemon) time is 3 seconds:
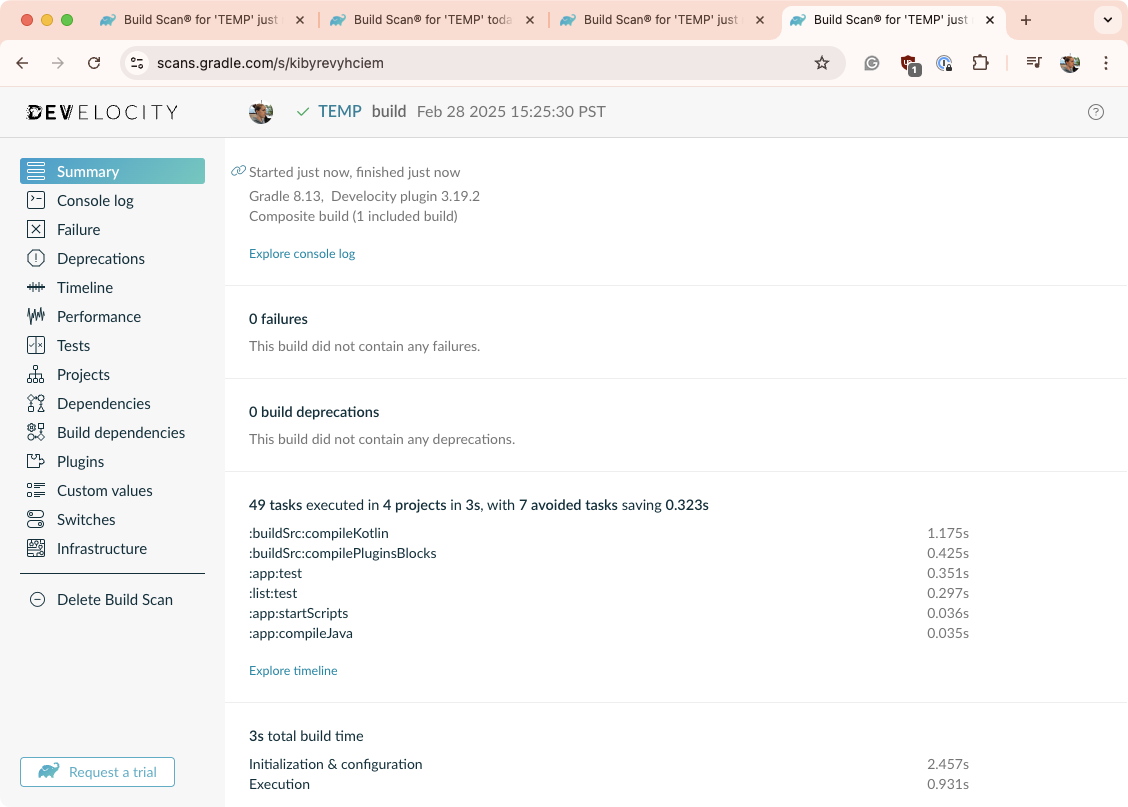
4. Enable the Build Cache
The Gradle Build Cache optimizes performance by storing task outputs for specific inputs. If a task runs again with the same inputs, Gradle retrieves the cached output instead of re-executing the task.
By default, Gradle does not use the Build Cache. To enable it at build time, use:
$ gradle <task> --build-cacheTo enable it permanently, add this to gradle.properties:
org.gradle.caching=trueYou can use:
-
A local Build Cache to speed up repeated builds on the same machine.
-
A shared Build Cache to accelerate builds across multiple machines.
-
Develocity provides a shared Cache solution for CI and developer builds.
-
When the build cache flag is used on our reference project, the build (./gradlew clean build --build-cache) time is 5 seconds:
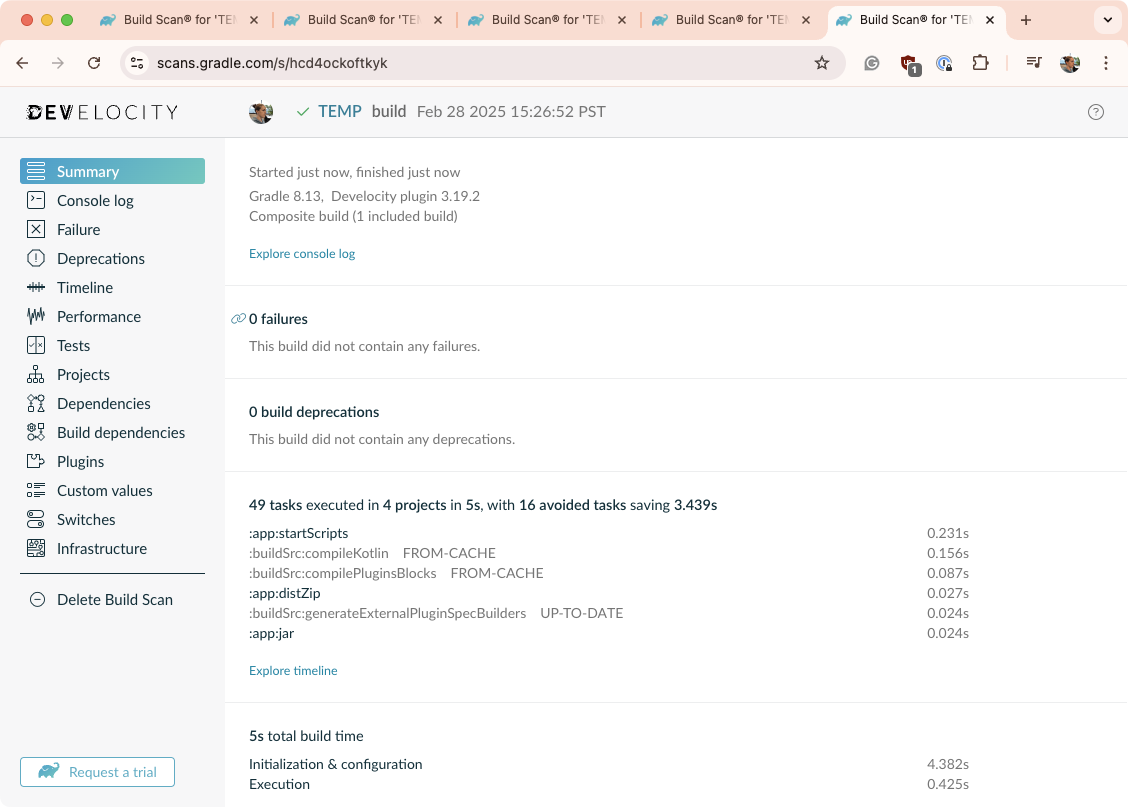
For more information about the Build Cache, check out the Build Cache documentation.
Visualize the Build Cache with Build Scan
A Build Scan helps you analyze Build Cache effectiveness through the "Build Cache" tab in the "Performance" page. This tab provides key statistics, including:
-
The number of tasks that interacted with a cache
-
Which cache was used
-
Transfer and pack/unpack rates for cached entries
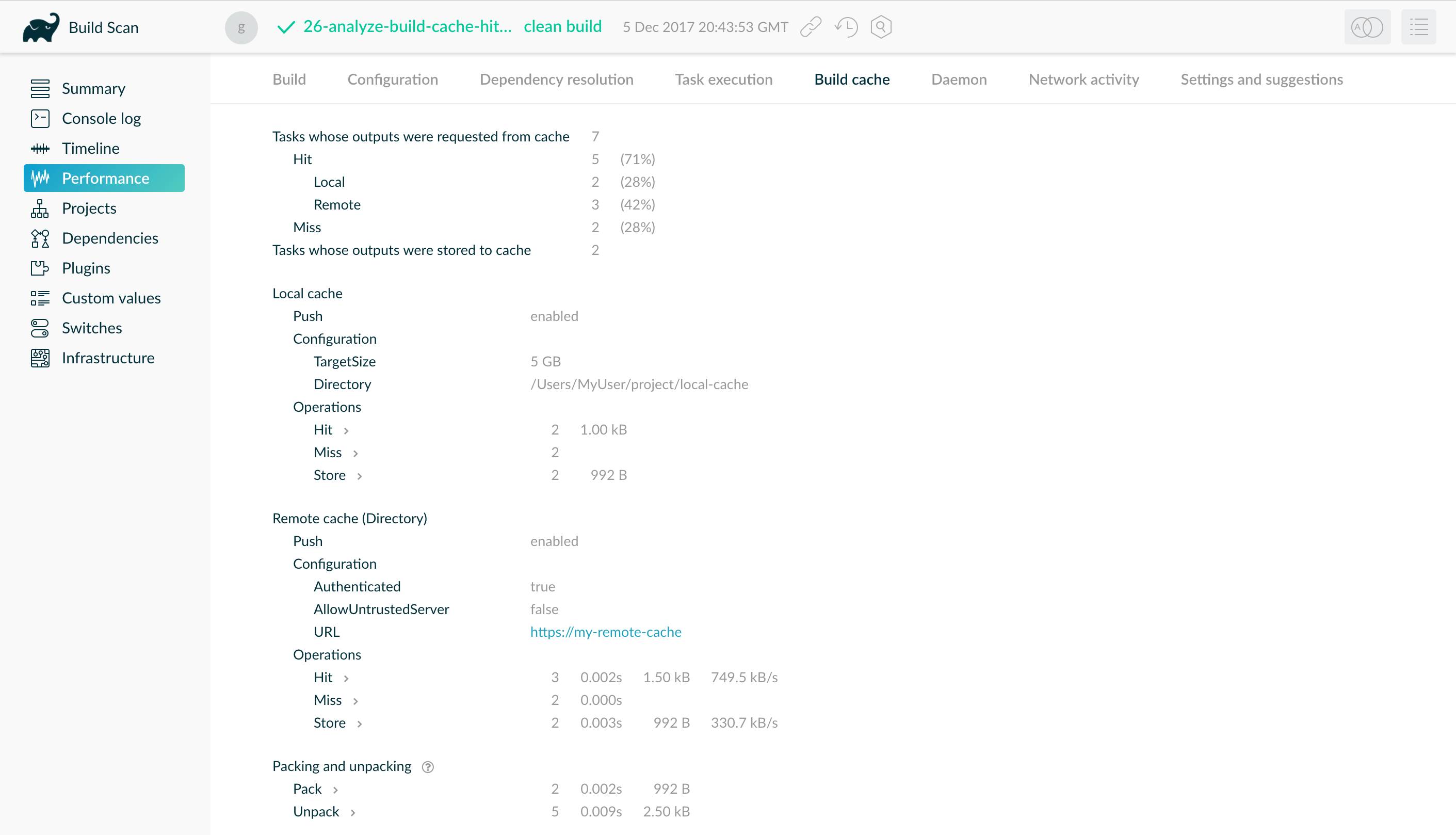
The "Task Execution" tab offers insights into task cacheability. Clicking on a category reveals a timeline highlighting tasks in that category:
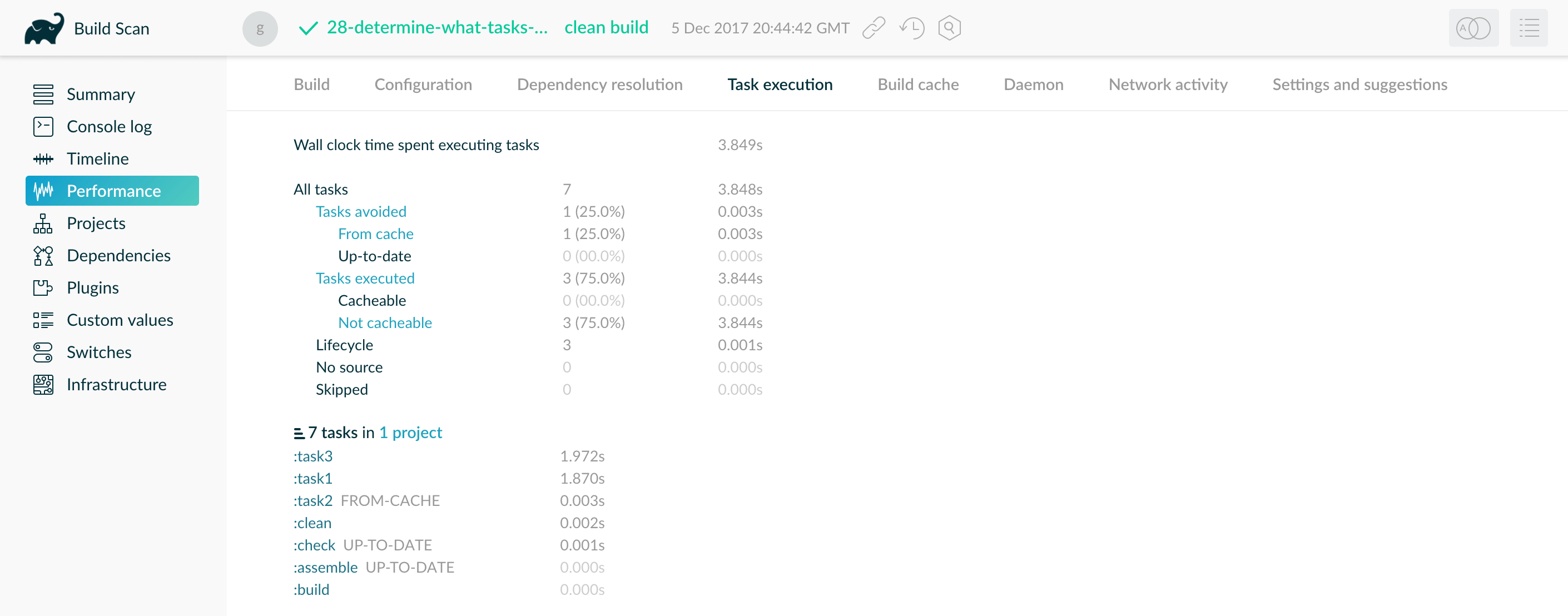
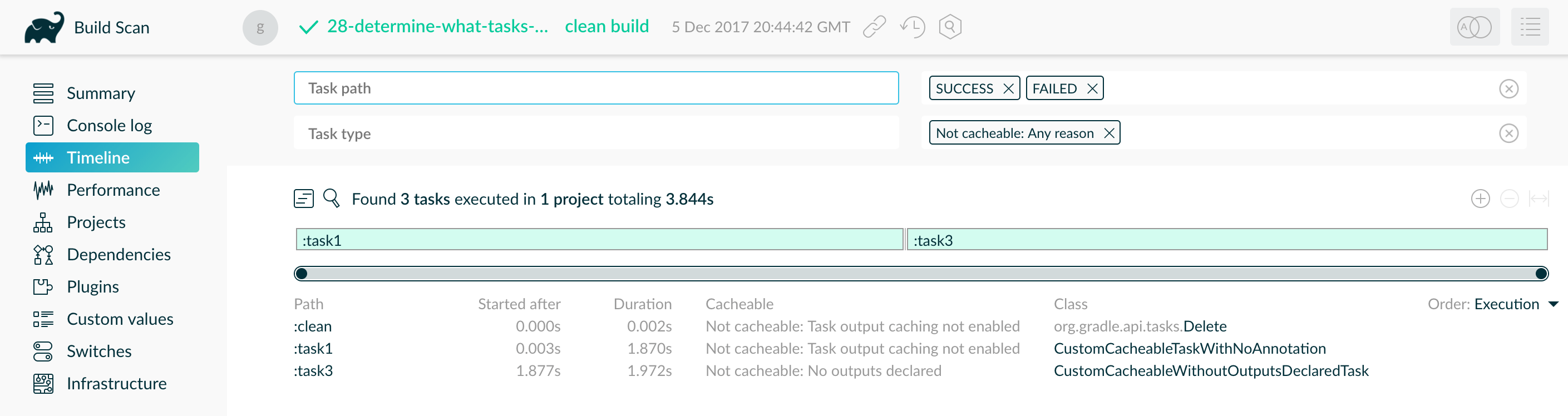
To identify optimization opportunities, sort tasks by duration in the timeline view.
The Build Scan above reveals that :task1 and :task3 could be improved and made cacheable, while also explaining why Gradle didn’t cache them.
5. Enable the Configuration Cache
|
Important
|
This feature has the following limitations:
|
The configuration cache speeds up builds by caching the results of the configuration phase. When build configuration inputs remain unchanged, Gradle can skip this phase entirely.
Enabling the configuration cache provides further performance benefits. When enabled, Gradle:
-
Executes all tasks in parallel, even within the same subproject.
-
Caches dependency resolution results to avoid redundant computations.
Build configuration inputs include:
-
Init scripts
-
Settings scripts
-
Build scripts
-
System and Gradle properties used during configuration
-
Environment variables used during configuration
-
Configuration files accessed via value suppliers (
providers) -
buildSrcinputs, including configuration files and source files
By default, Gradle does not use the configuration cache. To enable it at build time, use:
$ gradle <task> --configuration-cacheTo enable it permanently, add this setting to the gradle.properties file:
org.gradle.configuration-cache=trueWhen the configuration cache flag is used on our reference project, the build (./gradlew clean build --build-cache) time is 4 seconds:
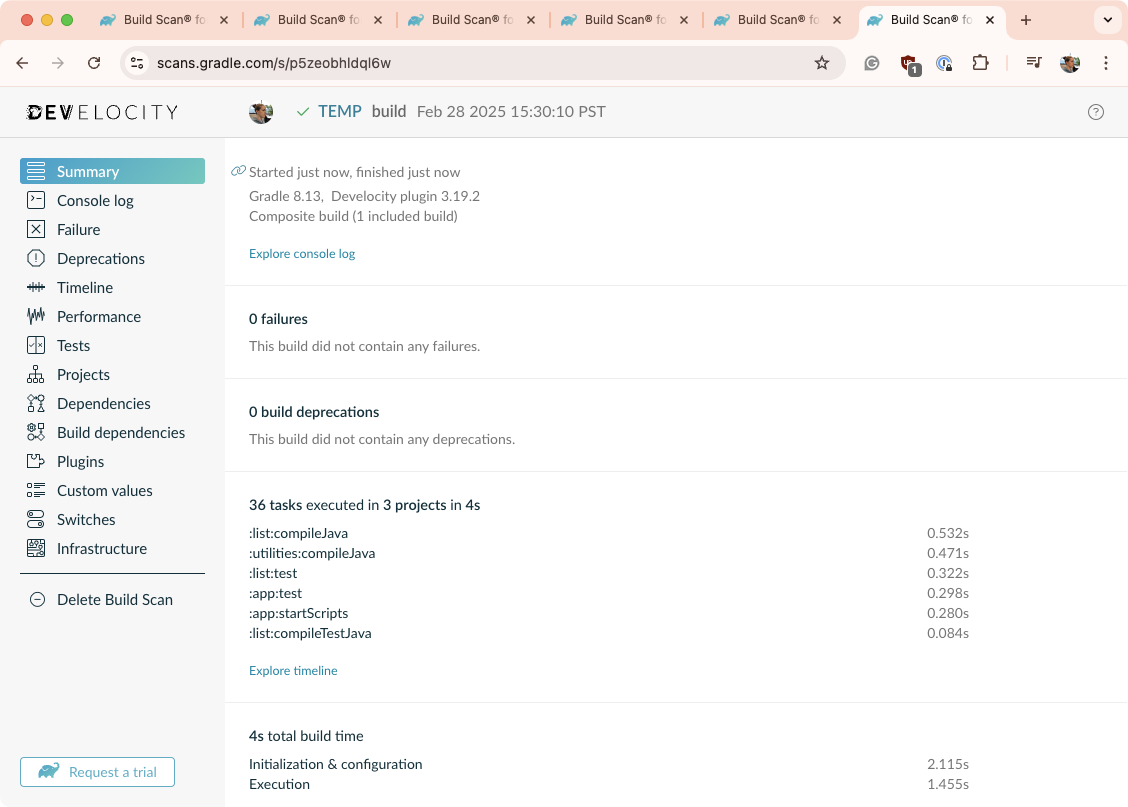
For more details, see the Configuration Cache documentation.
6. Enable Incremental Build for Custom Tasks
Incremental build is a Gradle optimization that skips tasks that have already executed with the same inputs. If a task’s inputs and outputs have not changed since the last execution, Gradle will skip that task.
Most built-in Gradle tasks support incremental builds. To make a custom task compatible, you must specify its inputs and outputs:
tasks.register("processTemplatesAdHoc") {
inputs.property("engine", TemplateEngineType.FREEMARKER)
inputs.files(fileTree("src/templates"))
.withPropertyName("sourceFiles")
.withPathSensitivity(PathSensitivity.RELATIVE)
inputs.property("templateData.name", "docs")
inputs.property("templateData.variables", mapOf("year" to "2013"))
outputs.dir(layout.buildDirectory.dir("genOutput2"))
.withPropertyName("outputDir")
doLast {
// Process the templates here
}
}tasks.register('processTemplatesAdHoc') {
inputs.property('engine', TemplateEngineType.FREEMARKER)
inputs.files(fileTree('src/templates'))
.withPropertyName('sourceFiles')
.withPathSensitivity(PathSensitivity.RELATIVE)
inputs.property('templateData.name', 'docs')
inputs.property('templateData.variables', [year: '2013'])
outputs.dir(layout.buildDirectory.dir('genOutput2'))
.withPropertyName('outputDir')
doLast {
// Process the templates here
}
}For more details, see the incremental build documentation and the writing tasks tutorial.
When leveraging incremental builds on our reference project, the build (./gradlew clean build build) time is 5 seconds:
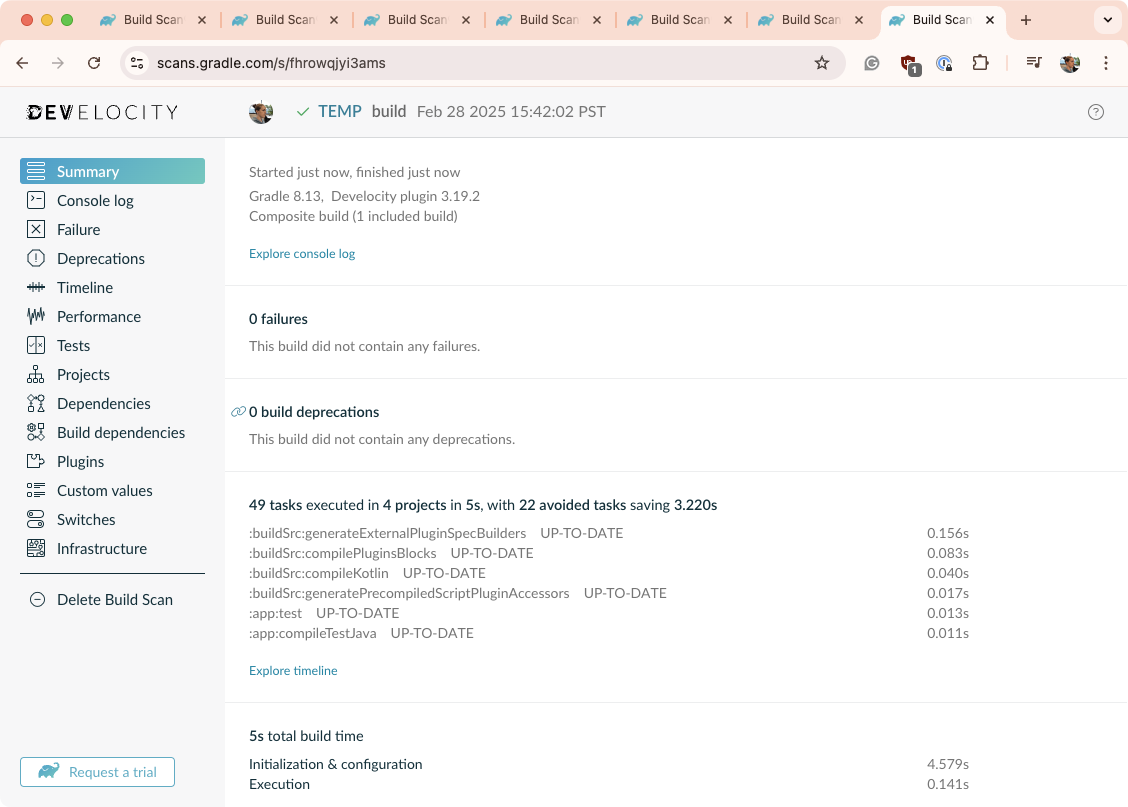
Visualize Incremental Builds with Build Scan Timelines
Look at the Build Scan "Timeline" view to identify tasks that could benefit from incremental builds. This helps you understand why tasks execute when you expect Gradle to skip them.
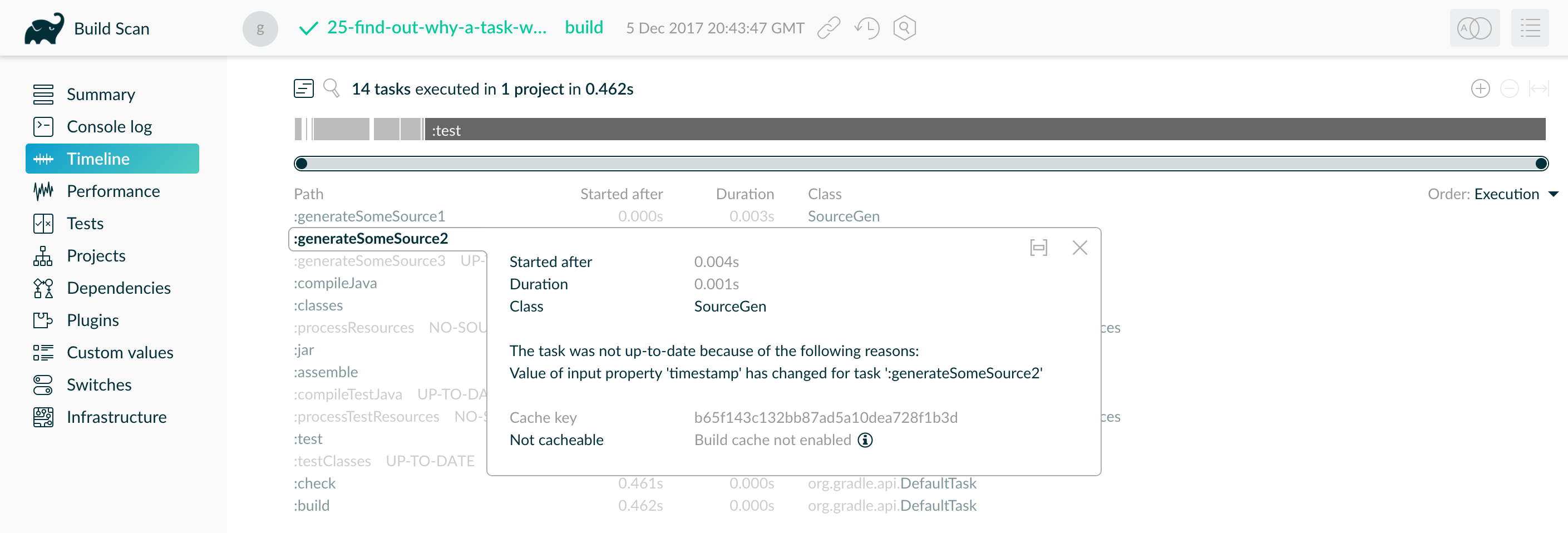
In the example above, the task was not up-to-date because one of its inputs ("timestamp") changed, forcing it to re-run.
To optimize your build, sort tasks by duration to identify the slowest tasks in your project.
7. Create Builds for Specific Developer Workflows
The fastest task is one that doesn’t run. By skipping unnecessary tasks, you can significantly improve build performance.
If your build includes multiple subprojects, define tasks that build them independently. This maximizes caching efficiency and prevents changes in one subproject from triggering unnecessary rebuilds in others. It also helps teams working on different subprojects avoid redundant builds—for example:
-
Front-end developers don’t need to build back-end subprojects every time they modify the front-end.
-
Documentation writers don’t need to build front-end or back-end code, even if the documentation is in the same project.
Instead, create developer-specific tasks while maintaining a single task graph for the entire project. Each group of users requires a subset of tasks—convert that subset into a Gradle workflow that excludes unnecessary tasks.
Gradle provides several features to create efficient workflows:
-
Assign tasks to appropriate groups.
-
Create lifecycle tasks—tasks with no action that depend on other tasks (e.g.,
assemble). -
Defer configuration using
gradle.taskGraph.whenReady()to execute verification only when necessary.
8. Increase the Heap Size
By default, Gradle reserves 512MB of heap space for your build, which is sufficient for most projects.
However, very large builds may require more memory to store Gradle’s model and caches.
If needed, you can increase the heap size by specifying the following property in the gradle.properties file in your project root or your Gradle home directory:
org.gradle.jvmargs=-Xmx2048MFor more details, see the JVM Memory Configuration documentation.
9. Optimize Configuration
As described in the build lifecycle chapter, a Gradle build goes through three phases: initialization, configuration, and execution.
The configuration phase always executes, regardless of which tasks run.
Any expensive operations during this phase slow down every build, including simple commands like gradle help and gradle tasks.
The following sections introduce techniques to reduce time spent in the configuration phase.
|
Note
|
You can also enable the configuration cache to minimize the impact of a slow configuration phase. However, even with caching, the configuration phase still runs occasionally. Optimizing it remains crucial. |
Avoid Expensive or Blocking Work
Time-consuming work should be avoided in the configuration phase. However, it can sometimes sneak in unexpectedly.
While encrypting data or making remote service calls is obvious when done in a build script, such logic is often hidden inside plugins or custom task classes.
Expensive operations in a plugin’s apply() method or a task’s constructor are a red flag:
class ExpensivePlugin : Plugin<Project> {
override fun apply(project: Project) {
// BAD: Makes an expensive network call at configuration time
val response = URL("https://example.com/dependencies.json").readText()
val dependencies = groovy.json.JsonSlurper().parseText(response) as List<*>
dependencies.forEach { dep ->
project.dependencies.add("implementation", dep!!)
}
}
}class ExpensivePlugin implements Plugin<Project> {
@Override
void apply(Project project) {
// BAD: Makes an expensive network call at configuration time
def response = new URL("https://example.com/dependencies.json").text
def dependencies = new groovy.json.JsonSlurper().parseText(response)
dependencies.each { dep ->
project.dependencies.add("implementation", dep)
}
}
}Instead:
class OptimizedPlugin : Plugin<Project> {
override fun apply(project: Project) {
project.tasks.register("fetchDependencies") {
doLast {
// GOOD: Runs only when the task is executed
val response = URL("https://example.com/dependencies.json").readText()
val dependencies = groovy.json.JsonSlurper().parseText(response) as List<*>
dependencies.forEach { dep ->
project.dependencies.add("implementation", dep!!)
}
}
}
}
}class OptimizedPlugin implements Plugin<Project> {
@Override
void apply(Project project) {
project.tasks.register("fetchDependencies") {
doLast {
// GOOD: Runs only when the task is executed
def response = new URL("https://example.com/dependencies.json").text
def dependencies = new groovy.json.JsonSlurper().parseText(response)
dependencies.each { dep ->
project.dependencies.add("implementation", dep)
}
}
}
}
}Only Apply Plugins where they’re needed
Each applied plugin or script adds to configuration time, with some plugins having a larger impact than others.
Rather than avoiding plugins altogether, ensure they are applied only where necessary.
For example, using allprojects {} or subprojects {} can apply plugins to all subprojects, even if not all need them.
In the example below, the root build script applies script-a.gradle to three subprojects:
subprojects {
apply from: "$rootDir/script-a.gradle" // Applied to all subprojects unnecessarily
}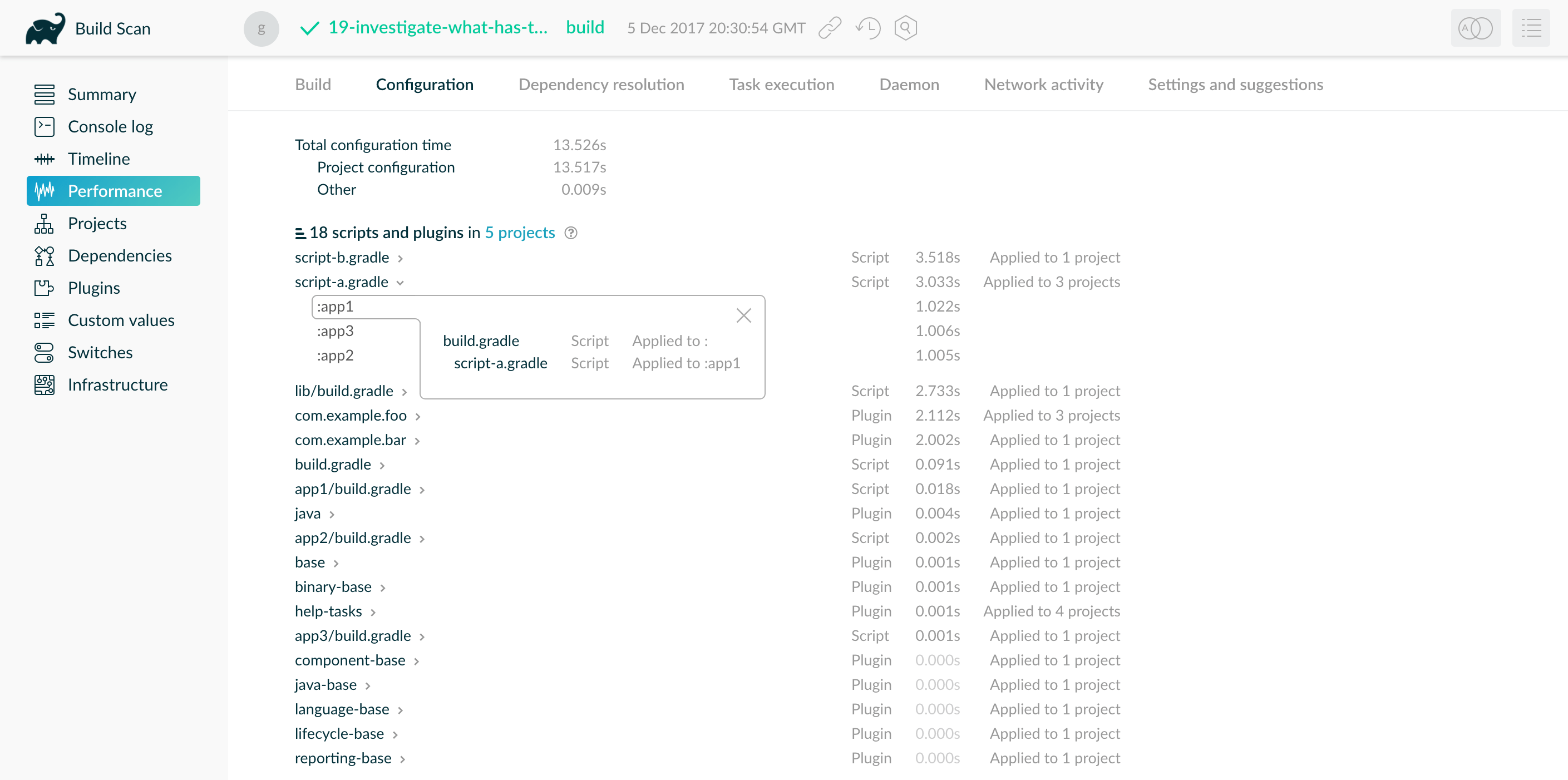
This script takes 1 second to run per subproject, delaying the configuration phase by 3 seconds in total. To optimize this:
-
If only one subproject requires the script, remove it from the others, reducing the configuration delay by 2 seconds.
build.gradle.ktsproject(":subproject1") { apply(from = "$rootDir/script-a.gradle") // Applied only where needed } project(":subproject2") { apply(from = "$rootDir/script-a.gradle") }build.gradleproject(":subproject1") { apply from: "$rootDir/script-a.gradle" // Applied only where needed } project(":subproject2") { apply from: "$rootDir/script-a.gradle" } -
If multiple—but not all—subprojects use the script, refactor it into a custom plugin inside
buildSrcand apply it only to the relevant subprojects. This reduces configuration time and avoids code duplication.build.gradle.ktsproject(":subproject1") { apply(plugin = "com.example.my-custom-plugin") // Apply only where needed } project(":subproject2") { apply(plugin = "com.example.my-custom-plugin") }build.gradleproject(":subproject1") { apply plugin: 'com.example.my-custom-plugin' // Apply only where needed } project(":subproject2") { apply plugin: 'com.example.my-custom-plugin' }
Statically Compile Tasks and Plugins
Many Gradle plugins and tasks are written in Groovy due to its concise syntax, functional APIs, and powerful extensions. However, Groovy’s dynamic interpretation makes method calls slower than in Java or Kotlin.
You can reduce this cost by using static Groovy compilation.
Add the @CompileStatic annotation to Groovy classes where dynamic features are unnecessary.
If a method requires dynamic behavior, use @CompileDynamic on that method.
Alternatively, consider writing plugins and tasks in Java or Kotlin, which are statically compiled by default.
|
Warning
|
Gradle’s Groovy DSL relies on Groovy’s dynamic features. To use static compilation in plugins, adopt a more Java-like syntax. |
The example below defines a task that copies files without dynamic features:
project.tasks.register('copyFiles', Copy) { Task t ->
t.into(project.layout.buildDirectory.dir('output'))
t.from(project.configurations.getByName('compile'))
}This example uses register() and getByName(), available on all Gradle domain object containers, such as tasks, configurations, dependencies, and extensions.
Some containers, like TaskContainer, have specialized methods such as create, which accepts a task type.
Using static compilation improves IDE support by enabling:
-
Faster detection of unrecognized types, properties, and methods
-
More reliable auto-completion for method names
10. Optimize dependency resolution
Dependency resolution simplifies integrating third-party libraries into your projects. Gradle contacts remote servers to discover and download dependencies. You can optimize how dependencies are referenced to minimize these remote calls.
Avoid Unnecessary and Unused Dependencies
Managing third-party libraries and their transitive dependencies adds significant maintenance and build time costs. Unused dependencies often remain after refactors.
If you only use a small portion of a library, consider: - Implementing the required functionality yourself. - Copying the necessary code (with attribution) if the library is open source.
Optimize Repository Order
Gradle searches repositories in the order they are declared. To speed up resolution, list the repository hosting most dependencies first, reducing unnecessary network requests.
repositories {
mavenCentral() // Declared first, but most dependencies are in example.com/repo
maven { url "https://example.com/repo" }
}Minimize Repository Count
Limit the number of repositories to the minimum required.
If using a custom repository, create a virtual repository that aggregates multiple repositories, then add only that repository to your build.
repositories {
maven { url "https://example.com/virtual-repo" } // Uses an aggregated repository
}Minimize Dynamic and Snapshot Versions
Dynamic ("2.+“) and snapshot versions (”-SNAPSHOT") cause Gradle to check remote repositories frequently.
By default, Gradle caches dynamic versions for 24 hours, but this can be configured with the cacheDynamicVersionsFor and cacheChangingModulesFor properties:
configurations.all {
resolutionStrategy {
cacheDynamicVersionsFor(4, "hours")
cacheChangingModulesFor(10, "minutes")
}
}configurations.all {
resolutionStrategy {
cacheDynamicVersionsFor 4, 'hours'
cacheChangingModulesFor 10, 'minutes'
}
}If a build file or initialization script lowers these values, Gradle queries repositories more often. When you don’t need the absolute latest release of a dependency every time you build, consider removing the custom values for these settings.
Note that when cached dynamic versions expire, this will invalidate Configuration Cache entries including these confgurations, as Gradle will need to re-run the configuration phase and re-resolve the dependencies.
When this happens it is indicated with a message in the build output:
Calculating task graph as configuration cache cannot be reused because cached version information for org.test:projectA:1.+ has expired.Find dynamic and changing versions with Build Scan
To locate dynamic dependencies, use a Build Scan:
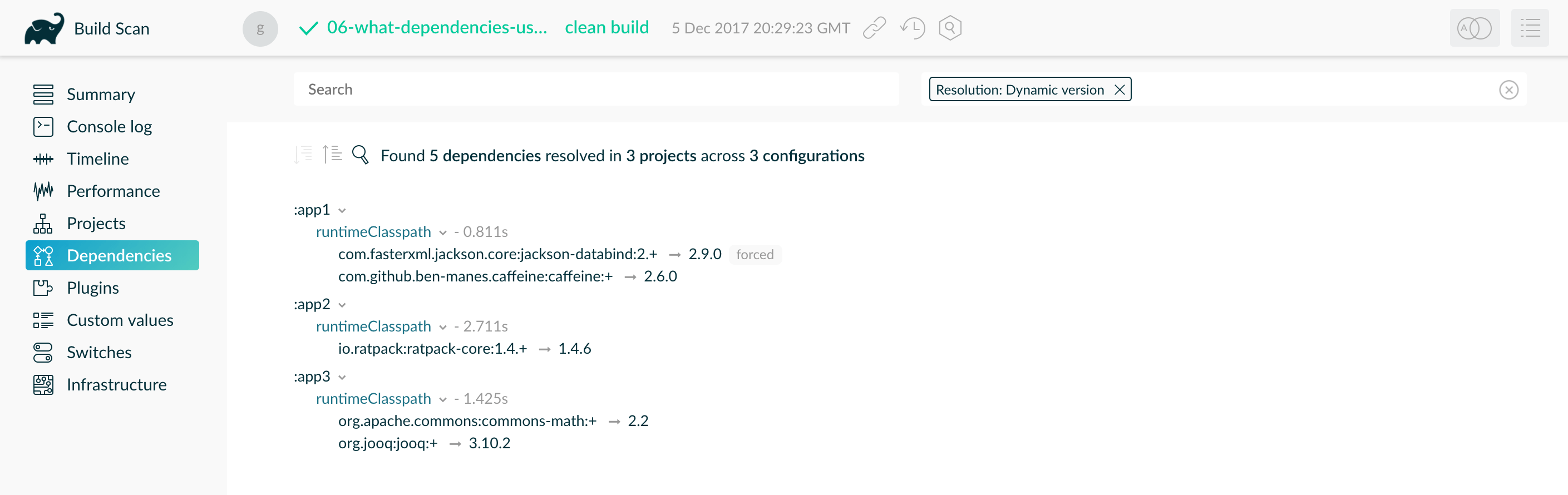
Where possible, replace dynamic versions with fixed versions like "1.2" or "3.0.3.GA" for better caching.
Avoid dependency resolution during configuration
Dependency resolution is an I/O-intensive process. Gradle caches results, but triggering resolution in the configuration phase adds unnecessary overhead to every build.
This code forces dependency resolution during configuration, slowing down every build:
tasks.register("printDeps") {
doFirst {
configurations.getByName("compileClasspath").files.forEach { println(it) } // Deferring Dependency Resolution
}
doLast {
configurations.getByName("compileClasspath").files.forEach { println(it) } // Resolving Dependencies During Configuration
}
}task printDeps {
doFirst {
configurations.compileClasspath.files.each { println it } // Deferring Dependency Resolution
}
doLast {
configurations.compileClasspath.files.each { println it } // Resolving Dependencies During Configuration
}
}Switch to declarative syntax
Evaluating a configuration file during the configuration phase forces Gradle to resolve dependencies too early, increasing build times. Normally, tasks should resolve dependencies only when they need them during execution.
Consider a debugging scenario where you want to print all files in a configuration. A common mistake is to print them directly in the build script:
tasks.register<Copy>("copyFiles") {
println(">> Compilation deps: ${configurations.compileClasspath.get().files.map { it.name }}")
into(layout.buildDirectory.dir("output"))
from(configurations.compileClasspath)
}tasks.register('copyFiles', Copy) {
println ">> Compilation deps: ${configurations.compileClasspath.files.name}"
into(layout.buildDirectory.dir('output'))
from(configurations.compileClasspath)
}The files property triggers dependency resolution immediately, even if printDeps is never executed.
Since the configuration phase runs on every build, this slows down all builds.
By using doFirst(), Gradle defers dependency resolution until the task actually runs, preventing unnecessary work in the configuration phase:
tasks.register<Copy>("copyFiles") {
into(layout.buildDirectory.dir("output"))
// Store the configuration into a variable because referencing the project from the task action
// is not compatible with the configuration cache.
val compileClasspath: FileCollection = configurations.compileClasspath.get()
from(compileClasspath)
doFirst {
println(">> Compilation deps: ${compileClasspath.files.map { it.name }}")
}
}tasks.register('copyFiles', Copy) {
into(layout.buildDirectory.dir('output'))
// Store the configuration into a variable because referencing the project from the task action
// is not compatible with the configuration cache.
FileCollection compileClasspath = configurations.compileClasspath
from(compileClasspath)
doFirst {
println ">> Compilation deps: ${compileClasspath.files.name}"
}
}The from() method in Gradle’s Copy task does not trigger immediate dependency resolution because it references the dependency configuration, not the resolved files.
This ensures that dependencies are resolved only when the Copy task executes.
Visualize dependency resolution with Build Scan
The "Dependency resolution" tab on the performance page of a Build Scan shows dependency resolution time during the configuration and execution phases:
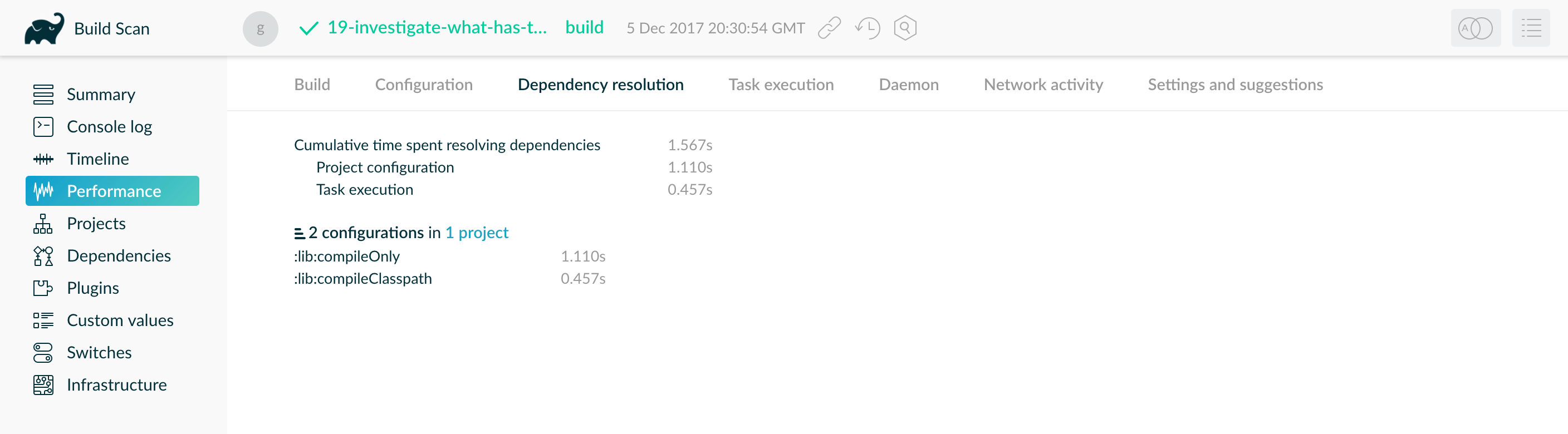
A Build Scan provides another means of identifying this issue. Your build should spend 0 seconds resolving dependencies during "project configuration". This example shows the build resolves dependencies too early in the lifecycle. You can also find a "Settings and suggestions" tab on the "Performance" page. This shows dependencies resolved during the configuration phase.
Remove or improve custom dependency resolution logic
Gradle allows users to model dependency resolution in a flexible way. Simple customizations, such as forcing specific versions or substituting dependencies, have minimal impact on resolution times. However, complex custom logic—such as downloading and parsing POM files manually—can significantly slow down dependency resolution.
Use Build Scan or profile reports to ensure custom dependency resolution logic is not causing performance issues. This logic may exist in your build scripts or as part of a third-party plugin.
This example forces a custom dependency version but also introduces expensive logic that slows down resolution:
configurations.all {
resolutionStrategy.eachDependency {
if (requested.group == "com.example" && requested.name == "library") {
val versionInfo = URL("https://example.com/version-check").readText() // Remote call during resolution
useVersion(versionInfo.trim()) // Dynamically setting a version based on an HTTP response
}
}
}configurations.all {
resolutionStrategy.eachDependency { details ->
if (details.requested.group == "com.example" && details.requested.name == "library") {
def versionInfo = new URL("https://example.com/version-check").text // Remote call during resolution
details.useVersion(versionInfo.trim()) // Dynamically setting a version based on an HTTP response
}
}
}Instead of fetching dependency versions dynamically, define them in a version catalog:
dependencies {
implementation "com.example:library:${versions.libraryVersion}"
}Remove slow or unexpected dependency downloads
Slow dependency downloads can significantly impact build performance. Common causes include:
-
Slow internet connections
-
Overloaded or distant repository servers
-
Unexpected downloads caused by dynamic versions (
2.+) or snapshot versions (-SNAPSHOT)
The Performance tab in a Build Scan includes a Network Activity section with: - Total time spent downloading dependencies - Download transfer rates - A list of dependencies sorted by download time
In the example below, two slow downloads took 20 seconds and 40 seconds, impacting the overall build time:
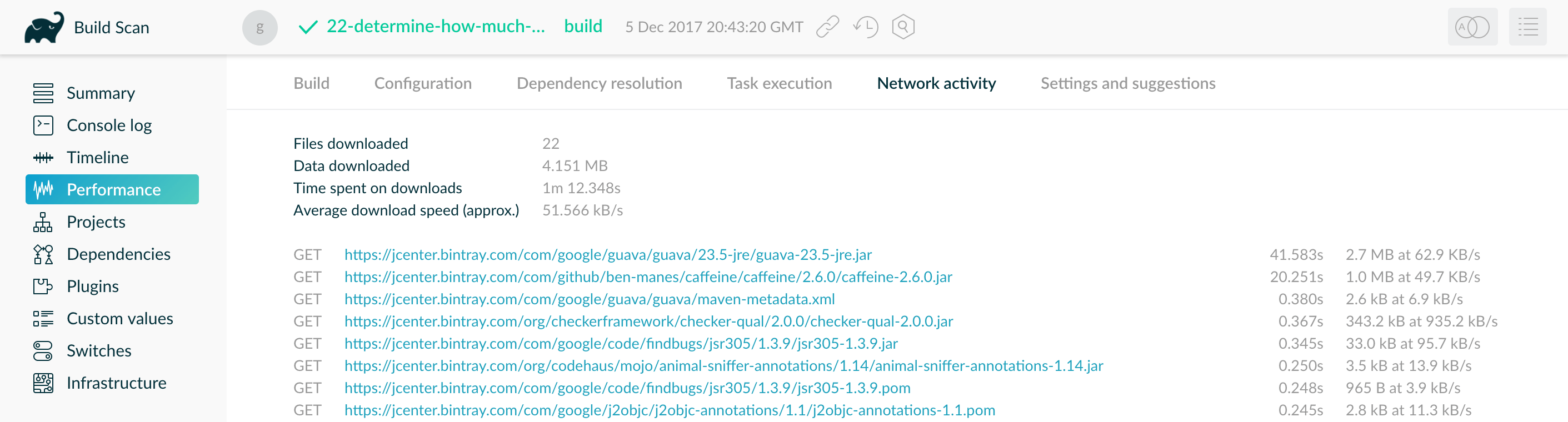
Examine the list of downloaded dependencies for unexpected ones.
For example, a dynamic version (1.+) may be triggering frequent remote lookups.
To eliminate unnecessary downloads:
-
Use a closer or faster repository If downloads are slow from Maven Central, consider a geographically closer mirror or an internal repository proxy.
-
Switch from dynamic versions to fixed versions
dependencies {
implementation "com.example:library:1.+" // Bad
implementation "com.example:library:1.2.3" // Good
}11. Optimize Java projects
The following sections apply to projects that use the java plugin or other JVM languages.
Optimize test execution
Tests often account for a significant portion of build time. These may include both unit and integration tests, with integration tests typically taking longer to run.
A Build Scan can help you identify the slowest tests and prioritize performance improvements accordingly.
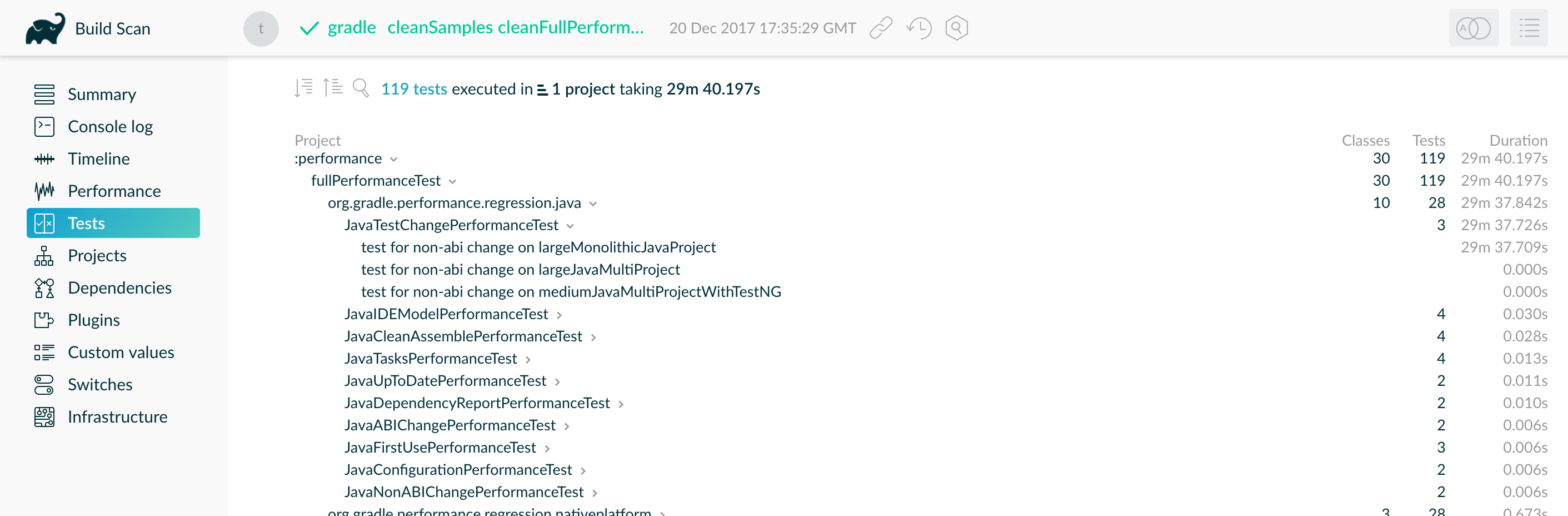
The image above shows the interactive test report from a Build Scan, sorted by test duration.
Gradle offers several strategies to speed up test execution:
-
A. Run tests in parallel
-
B. Fork tests into multiple processes
-
C. Disable test reports when not needed
Let’s take a closer look at each option.
A. Run tests in parallel
Gradle can run multiple test classes or methods in parallel.
To enable parallel execution, set the maxParallelForks property on your Test tasks.
A good default is the number of available CPU cores or slightly fewer:
tasks.withType<Test>().configureEach {
maxParallelForks = (Runtime.getRuntime().availableProcessors() / 2).coerceAtLeast(1)
}tasks.withType(Test).configureEach {
maxParallelForks = Runtime.runtime.availableProcessors().intdiv(2) ?: 1
}Parallel test execution assumes that tests are isolated. Avoid shared resources such as file systems, databases, or external services. Tests that share state or resources may fail intermittently due to race conditions or resource conflicts.
B. Fork tests into multiple processes
By default, Gradle runs all tests in a single forked JVM process. This is efficient for small test suites, but large or memory-intensive test suites can suffer from long execution times and GC pauses.
You can reduce memory pressure and isolate problematic tests by forking a new JVM after a specified number of tests using the forkEvery setting:
tasks.withType<Test>().configureEach {
forkEvery = 100
}tasks.withType(Test).configureEach {
forkEvery = 100
}|
Warning
|
Forking a JVM is an expensive operation. Setting forkEvery too low can increase test time due to excessive process startup overhead.
|
C. Disable test reports
Gradle generates HTML and JUnit XML test reports by default, even if you don’t intend to view them. Report generation adds overhead, particularly in large test suites.
You can disable report generation entirely if:
-
You only need to know whether the tests passed.
-
You use a Build Scan, which provide richer test insights.
To disable reports, set reports.html.required and reports.junitXml.required to false:
tasks.withType<Test>().configureEach {
reports.html.required = false
reports.junitXml.required = false
}tasks.withType(Test).configureEach {
reports.html.required = false
reports.junitXml.required = false
}If you occasionally need reports without modifying the build file, you can make report generation conditional on a project property.
This example disables reports unless the createReports property is present:
tasks.withType<Test>().configureEach {
if (!project.hasProperty("createReports")) {
reports.html.required = false
reports.junitXml.required = false
}
}tasks.withType(Test).configureEach {
if (!project.hasProperty("createReports")) {
reports.html.required = false
reports.junitXml.required = false
}
}To generate reports, pass the property via the command line:
$ gradle <task> -PcreateReportsOr define the property in the gradle.properties file located in the project root or your Gradle User Home:
createReports=trueOptimize the compiler
The Java compiler is fast, but in large projects with hundreds or thousands of classes, compilation time can still become significant.
Gradle offers several ways to optimize Java compilation:
-
A. Run the compiler in a separate process
-
B. Use
implementationvisibility for internal dependencies
A. Run the compiler as a separate process
By default, Gradle runs compilation in the same process as the build logic.
You can offload Java compilation to a separate process using the fork option:
<task>.options.isFork = true<task>.options.fork = trueTo apply this setting to all JavaCompile tasks, use configureEach:
tasks.withType<JavaCompile>().configureEach {
options.isFork = true
}tasks.withType(JavaCompile).configureEach {
options.fork = true
}Gradle reuses the forked process for the duration of the build, so the startup cost is low. Running compilation in its own JVM helps reduce garbage collection in the main Gradle process, which can speed up the rest of your build — especially when used alongside parallel execution.
Forking compilation has little effect on small builds but can help significantly when a single task compiles more than a thousand source files.
B. Use implementation for internal dependencies
In Gradle 3.4 and later, you can use api for dependencies that should be exposed to downstream projects and implementation for internal dependencies.
This distinction reduces unnecessary recompilation in large multi-project builds.
|
Note
|
Only projects that apply the java-library plugin can use the api and implementation configurations. Projects using only the java plugin cannot declare api dependencies.
|
When an implementation dependency changes, Gradle does not recompile downstream consumers — only when api dependencies change.
This helps reduce cascading recompilations:
dependencies {
api(project("my-utils"))
implementation("com.google.guava:guava:21.0")
}dependencies {
api project('my-utils')
implementation 'com.google.guava:guava:21.0'
}Switching to implementation for internal-only dependencies is one of the most impactful changes you can make to improve build performance in large, modular codebases.
12. Optimize Android Projects
All the performance strategies described in this guide also apply to Android builds, since Android projects use Gradle under the hood.
However, Android introduces its own unique challenges and opportunities for optimization — especially around resource processing, APK creation, and build variants.
For additional tips specific to Android, check out the official resources from the Android team:
13. Improve the performance of older Gradle releases
We recommend using the latest Gradle version to benefit from the latest performance improvements, bug fixes, and features. However, we understand that some projects — especially long-lived or legacy codebases — may not be able to upgrade easily.
If you’re using an older version of Gradle, consider the following optimizations to improve build performance.
Enable the Daemon
The Gradle Daemon significantly improves build performance by avoiding JVM startup costs between builds. The Daemon has been enabled by default since Gradle 3.0.
If you’re using an older version, consider upgrading Gradle. If upgrading isn’t an option, you can enable the Daemon manually.
Enable Incremental Compilation
Gradle can analyze class dependencies and recompile only the parts of your code affected by a change.
Incremental compilation is enabled by default in Gradle 4.10 and later.
To enable it manually in older versions, add the following configuration to your build.gradle file:
tasks.withType<JavaCompile>().configureEach {
options.isIncremental = true
}tasks.withType(JavaCompile).configureEach {
options.incremental = true
}Use Compile Avoidance
Many code changes, such as edits to method bodies, are ABI-compatible — they do not affect a class’s public API. Gradle 3.4 and newer can detect these changes and avoid recompiling downstream projects, significantly reducing build times in large multi-project builds.
To benefit from compile avoidance, upgrade to Gradle 3.4 or later.
|
Note
|
If your project uses annotation processors, you must explicitly declare them to take full advantage of compile avoidance. See the compile avoidance documentation for more details. |
Build Cache
Overview
The Gradle build cache is a cache mechanism that aims to save time by reusing outputs produced by other builds. The build cache works by storing (locally or remotely) build outputs and allowing builds to fetch these outputs from the cache when it is determined that inputs have not changed, avoiding the expensive work of regenerating them.
A first feature using the build cache is task output caching. Essentially, task output caching leverages the same intelligence as up-to-date checks that Gradle uses to avoid work when a previous local build has already produced a set of task outputs. But instead of being limited to the previous build in the same workspace, task output caching allows Gradle to reuse task outputs from any earlier build in any location on the local machine. When using a shared build cache for task output caching this even works across developer machines and build agents.
Apart from tasks, artifact transforms can also leverage the build cache and re-use their outputs similarly to task output caching.
|
Tip
|
For a hands-on approach to learning how to use the build cache, start with reading through the use cases for the build cache and the follow up sections. It covers the different scenarios that caching can improve and has detailed discussions of the different caveats you need to be aware of when enabling caching for a build. |
Enable the Build Cache
By default, the build cache is not enabled. You can enable the build cache in a couple of ways:
- Run with
--build-cacheon the command-line -
Gradle will use the build cache for this build only.
- Put
org.gradle.caching=truein yourgradle.properties -
Gradle will try to reuse outputs from previous builds for all builds, unless explicitly disabled with
--no-build-cache.
When the build cache is enabled, it will store build outputs in the Gradle User Home. For configuring this directory or different kinds of build caches see Configure the Build Cache.
Task Output Caching
Beyond incremental builds described in up-to-date checks, Gradle can save time by reusing outputs from previous executions of a task by matching inputs to the task. Task outputs can be reused between builds on one computer or even between builds running on different computers via a build cache.
We have focused on the use case where users have an organization-wide remote build cache that is populated regularly by continuous integration builds.
Developers and other continuous integration agents should load cache entries from the remote build cache.
We expect that developers will not be allowed to populate the remote build cache, and all continuous integration builds populate the build cache after running the clean task.
For your build to play well with task output caching it must work well with the incremental build feature.
For example, when running your build twice in a row all tasks with outputs should be UP-TO-DATE.
You cannot expect faster builds or correct builds when enabling task output caching when this prerequisite is not met.
Task output caching is automatically enabled when you enable the build cache, see Enable the Build Cache.
What does it look like
Let us start with a project using the Java plugin which has a few Java source files. We run the build the first time.
$ ./gradlew --build-cache compileJava:compileJava
:processResources
:classes
:jar
:assemble
BUILD SUCCESSFULWe see the directory used by the local build cache in the output. Apart from that the build was the same as without the build cache. Let’s clean and run the build again.
$ ./gradlew clean:clean
BUILD SUCCESSFUL$ ./gradlew --build-cache assemble:compileJava FROM-CACHE
:processResources
:classes
:jar
:assemble
BUILD SUCCESSFULNow we see that, instead of executing the :compileJava task, the outputs of the task have been loaded from the build cache.
The other tasks have not been loaded from the build cache since they are not cacheable. This is due to
:classes and :assemble being lifecycle tasks and :processResources
and :jar being Copy-like tasks which are not cacheable since it is generally faster to execute them.
Cacheable tasks
Since a task describes all of its inputs and outputs, Gradle can compute a build cache key that uniquely defines the task’s outputs based on its inputs. That build cache key is used to request previous outputs from a build cache or store new outputs in the build cache. If the previous build outputs have been already stored in the cache by someone else, e.g. your continuous integration server or other developers, you can avoid executing most tasks locally.
The following inputs contribute to the build cache key for a task in the same way that they do for up-to-date checks:
-
The task type and its classpath
-
The names of the output properties
-
The names and values of properties annotated as described in the section called "Custom task types"
-
The names and values of properties added by the DSL via TaskInputs
-
The classpath of the Gradle distribution, buildSrc and plugins
-
The content of the build script when it affects execution of the task
Task types need to opt-in to task output caching using the @CacheableTask annotation. Note that @CacheableTask is not inherited by subclasses. Custom task types are not cacheable by default.
Built-in cacheable tasks
Currently, the following built-in Gradle tasks are cacheable:
-
Java toolchain: JavaCompile, Javadoc
-
Groovy toolchain: GroovyCompile, Groovydoc
-
Scala toolchain: ScalaCompile,
org.gradle.language.scala.tasks.PlatformScalaCompile(removed), ScalaDoc -
Native toolchain: CppCompile, CCompile, SwiftCompile
-
Testing: Test
-
Code quality tasks: Checkstyle, CodeNarc, Pmd
-
JaCoCo: JacocoReport
-
Other tasks: AntlrTask, ValidatePlugins, WriteProperties
All other built-in tasks are currently not cacheable.
Third party plugins
There are third party plugins that work well with the build cache. The most prominent examples are the Android plugin 3.1+ and the Kotlin plugin 1.2.21+. For other third party plugins, check their documentation to find out whether they support the build cache.
Declaring task inputs and outputs
It is very important that a cacheable task has a complete picture of its inputs and outputs, so that the results from one build can be safely re-used somewhere else.
Missing task inputs can cause incorrect cache hits, where different results are treated as identical because the same cache key is used by both executions. Missing task outputs can cause build failures if Gradle does not completely capture all outputs for a given task. Wrongly declared task inputs can lead to cache misses especially when containing volatile data or absolute paths. (See the section called "Task inputs and outputs" on what should be declared as inputs and outputs.)
|
Note
|
The task path is not an input to the build cache key. This means that tasks with different task paths can re-use each other’s outputs as long as Gradle determines that executing them yields the same result. |
In order to ensure that the inputs and outputs are properly declared use integration tests (for example using TestKit) to check that a task produces the same outputs for identical inputs and captures all output files for the task. We suggest adding tests to ensure that the task inputs are relocatable, i.e. that the task can be loaded from the cache into a different build directory (see @PathSensitive).
In order to handle volatile inputs for your tasks consider configuring input normalization.
Marking tasks as non-cacheable by default
There are certain tasks that don’t benefit from using the build cache.
One example is a task that only moves data around the file system, like a Copy task.
You can signify that a task is not to be cached by adding the @DisableCachingByDefault annotation to it.
You can also give a human-readable reason for not caching the task by default.
The annotation can be used on its own, or together with @CacheableTask.
|
Note
|
This annotation is only for documenting the reason behind not caching the task by default. Build logic can override this decision via the runtime API (see below). |
Enable caching of non-cacheable tasks
As we have seen, built-in tasks, or tasks provided by plugins, are cacheable if their class is annotated with the Cacheable annotation.
But what if you want to make cacheable a task whose class is not cacheable?
Let’s take a concrete example: your build script uses a generic NpmTask task to create a JavaScript bundle by delegating to NPM (and running npm run bundle).
This process is similar to a complex compilation task, but NpmTask is too generic to be cacheable by default: it just takes arguments and runs npm with those arguments.
The inputs and outputs of this task are simple to figure out. The inputs are the directory containing the JavaScript files, and the NPM configuration files. The output is the bundle file generated by this task.
Using annotations
We create a subclass of the NpmTask and use annotations to declare the inputs and outputs.
When possible, it is better to use delegation instead of creating a subclass.
That is the case for the built in JavaExec, Exec, Copy and Sync tasks, which have a method either on Project (
sync,
copy
) or on the ExecOperation service (
exec,
javaexec
) to do the actual work.
If you’re a modern JavaScript developer, you know that bundling can be quite long, and is worth caching. To achieve that, we need to tell Gradle that it’s allowed to cache the output of that task, using the @CacheableTask annotation.
This is sufficient to make the task cacheable on your own machine. However, input files are identified by default by their absolute path. So if the cache needs to be shared between several developers or machines using different paths, that won’t work as expected. So we also need to set the path sensitivity. In this case, the relative path of the input files can be used to identify them.
Note that it is possible to override property annotations from the base class by overriding the getter of the base class and annotating that method.
@CacheableTask // (1)
abstract class BundleTask : NpmTask() {
@get:Internal // (2)
override val args
get() = super.args
@get:InputDirectory
@get:SkipWhenEmpty
@get:PathSensitive(PathSensitivity.RELATIVE) // (3)
abstract val scripts: DirectoryProperty
@get:InputFiles
@get:PathSensitive(PathSensitivity.RELATIVE) // (4)
abstract val configFiles: ConfigurableFileCollection
@get:OutputFile
abstract val bundle: RegularFileProperty
init {
args.addAll("run", "bundle")
bundle = projectLayout.buildDirectory.file("bundle.js")
scripts = projectLayout.projectDirectory.dir("scripts")
configFiles.from(projectLayout.projectDirectory.file("package.json"))
configFiles.from(projectLayout.projectDirectory.file("package-lock.json"))
}
}
tasks.register<BundleTask>("bundle")@CacheableTask // (1)
abstract class BundleTask extends NpmTask {
@Override @Internal // (2)
ListProperty<String> getArgs() {
super.getArgs()
}
@InputDirectory
@SkipWhenEmpty
@PathSensitive(PathSensitivity.RELATIVE) // (3)
abstract DirectoryProperty getScripts()
@InputFiles
@PathSensitive(PathSensitivity.RELATIVE) // (4)
abstract ConfigurableFileCollection getConfigFiles()
@OutputFile
abstract RegularFileProperty getBundle()
BundleTask() {
args.addAll("run", "bundle")
bundle = projectLayout.buildDirectory.file("bundle.js")
scripts = projectLayout.projectDirectory.dir("scripts")
configFiles.from(projectLayout.projectDirectory.file("package.json"))
configFiles.from(projectLayout.projectDirectory.file("package-lock.json"))
}
}
tasks.register('bundle', BundleTask)-
(1) Add
@CacheableTaskto enable caching for the task. -
(2) Override the getter of a property of the base class to change the input annotation to
@Internal. -
(3) (4) Declare the path sensitivity.
Using the runtime API
If for some reason you cannot create a new custom task class, it is also possible to make a task cacheable using the runtime API to declare the inputs and outputs.
For enabling caching for the task you need to use the TaskOutputs.cacheIf() method.
The declarations via the runtime API have the same effect as the annotations described above. Note that you cannot override file inputs and outputs via the runtime API. Input properties can be overridden by specifying the same property name.
tasks.register<NpmTask>("bundle") {
args = listOf("run", "bundle")
outputs.cacheIf { true }
inputs.dir(file("scripts"))
.withPropertyName("scripts")
.withPathSensitivity(PathSensitivity.RELATIVE)
inputs.files("package.json", "package-lock.json")
.withPropertyName("configFiles")
.withPathSensitivity(PathSensitivity.RELATIVE)
outputs.file(layout.buildDirectory.file("bundle.js"))
.withPropertyName("bundle")
}tasks.register('bundle', NpmTask) {
args = ['run', 'bundle']
outputs.cacheIf { true }
inputs.dir(file("scripts"))
.withPropertyName("scripts")
.withPathSensitivity(PathSensitivity.RELATIVE)
inputs.files("package.json", "package-lock.json")
.withPropertyName("configFiles")
.withPathSensitivity(PathSensitivity.RELATIVE)
outputs.file(layout.buildDirectory.file("bundle.js"))
.withPropertyName("bundle")
}Configure the Build Cache
You can configure the build cache by using the Settings.buildCache(org.gradle.api.Action) block in settings.gradle.
Gradle supports a local and a remote build cache that can be configured separately.
When both build caches are enabled, Gradle tries to load build outputs from the local build cache first, and then tries the remote build cache if no build outputs are found.
If outputs are found in the remote cache, they are also stored in the local cache, so next time they will be found locally.
Gradle stores ("pushes") build outputs in any build cache that is enabled and has BuildCache.isPush() set to true.
By default, the local build cache has push enabled, and the remote build cache has push disabled.
The local build cache is pre-configured to be a DirectoryBuildCache and enabled by default. The remote build cache can be configured by specifying the type of build cache to connect to (BuildCacheConfiguration.remote(java.lang.Class)).
Built-in local build cache
The built-in local build cache, DirectoryBuildCache, uses a directory to store build cache artifacts. By default, this directory resides in the Gradle User Home, but its location is configurable.
The local build cache can also be configured to control whether a build reads cached outputs from previous builds and whether it writes new outputs back to the cache. These behaviors are controlled independently through two properties:
-
enabled– whether the build reads from this cache -
push– whether the build writes outputs into this cache
This allows for the complete disabling of the cache, or for reading while preventing new entries from being stored:
buildCache {
local {
directory = File(rootDir, "build-cache")
// Enable reading from the local build cache
enabled = false
// Disable writing outputs to the local build cache
push = false
}
}buildCache {
local {
directory = new File(rootDir, 'build-cache')
// Enable reading from the local build cache
enabled = false
// Disable writing outputs to the local build cache
push = false
}
}For more details on the configuration options, refer to the DSL documentation of DirectoryBuildCache.
Gradle will periodically clean up the local cache directory by removing entries that have not been used recently to conserve disk space. How often Gradle will perform this clean-up and how long entries will be retained is configurable via an init-script, as demonstrated in this section.
Remote HTTP build cache
HttpBuildCache provides the ability read to and write from a remote cache via HTTP.
With the following configuration, the local build cache will be used for storing build outputs while the local and the remote build cache will be used for retrieving build outputs.
buildCache {
remote<HttpBuildCache> {
url = uri("https://example.com:8123/cache/")
}
}buildCache {
remote(HttpBuildCache) {
url = 'https://example.com:8123/cache/'
}
}When attempting to load an entry, a GET request is made to https://example.com:8123/cache/«cache-key».
The response must have a 2xx status and the cache entry as the body, or a 404 Not Found status if the entry does not exist.
When attempting to store an entry, a PUT request is made to https://example.com:8123/cache/«cache-key».
Any 2xx response status is interpreted as success.
A 413 Payload Too Large response may be returned to indicate that the payload is larger than the server will accept, which will not be treated as an error.
Specifying access credentials
HTTP Basic Authentication is supported, with credentials being sent preemptively.
buildCache {
remote<HttpBuildCache> {
url = uri("https://example.com:8123/cache/")
credentials {
username = "build-cache-user"
password = "some-complicated-password"
}
}
}buildCache {
remote(HttpBuildCache) {
url = 'https://example.com:8123/cache/'
credentials {
username = 'build-cache-user'
password = 'some-complicated-password'
}
}
}Redirects
3xx redirecting responses will be followed automatically.
Servers must take care when redirecting PUT requests as only 307 and 308 redirect responses will be followed with a PUT request.
All other redirect responses will be followed with a GET request, as per RFC 7231,
without the entry payload as the body.
Network error handling
Requests that fail during request transmission, after having established a TCP connection, will be retried automatically.
This prevents temporary problems, such as connection drops, read or write timeouts, and low level network failures such as a connection resets, causing cache operations to fail and disabling the remote cache for the remainder of the build.
Requests will be retried up to 3 times. If the problem persists, the cache operation will fail and the remote cache will be disabled for the remainder of the build.
Using SSL
By default, use of HTTPS requires the server to present a certificate that is trusted by the build’s Java runtime. If your server’s certificate is not trusted, you can:
-
Update the trust store of your Java runtime to allow it to be trusted
-
Change the build environment to use an alternative trust store for the build runtime
-
Disable the requirement for a trusted certificate
The trust requirement can be disabled by setting HttpBuildCache.isAllowUntrustedServer() to true.
Enabling this option is a security risk, as it allows any cache server to impersonate the intended server.
It should only be used as a temporary measure or in very tightly controlled network environments.
buildCache {
remote<HttpBuildCache> {
url = uri("https://example.com:8123/cache/")
isAllowUntrustedServer = true
}
}buildCache {
remote(HttpBuildCache) {
url = 'https://example.com:8123/cache/'
allowUntrustedServer = true
}
}HTTP expect-continue
Use of HTTP Expect-Continue can be enabled. This causes upload requests to happen in two parts: first a check whether a body would be accepted, then transmission of the body if the server indicates it will accept it.
This is useful when uploading to cache servers that routinely redirect or reject upload requests, as it avoids uploading the cache entry just to have it rejected (e.g. the cache entry is larger than the cache will allow) or redirected. This additional check incurs extra latency when the server accepts the request, but reduces latency when the request is rejected or redirected.
Not all HTTP servers and proxies reliably implement Expect-Continue. Be sure to check that your cache server does support it before enabling.
To enable, set HttpBuildCache.isUseExpectContinue() to true.
buildCache {
remote<HttpBuildCache> {
url = uri("https://example.com:8123/cache/")
isUseExpectContinue = true
}
}buildCache {
remote(HttpBuildCache) {
url = 'https://example.com:8123/cache/'
useExpectContinue = true
}
}Configuration use cases
The recommended use case for the remote build cache is that your continuous integration server populates it from clean builds while developers only load from it. The configuration would then look as follows.
val isCiServer = System.getenv().containsKey("CI")
buildCache {
remote<HttpBuildCache> {
url = uri("https://example.com:8123/cache/")
isPush = isCiServer
}
}boolean isCiServer = System.getenv().containsKey("CI")
buildCache {
remote(HttpBuildCache) {
url = 'https://example.com:8123/cache/'
push = isCiServer
}
}It is also possible to configure the build cache from an init script, which can be used from the command line, added to your Gradle User Home or be a part of your custom Gradle distribution.
gradle.settingsEvaluated {
buildCache {
// vvv Your custom configuration goes here
remote<HttpBuildCache> {
url = uri("https://example.com:8123/cache/")
}
// ^^^ Your custom configuration goes here
}
}gradle.settingsEvaluated { settings ->
settings.buildCache {
// vvv Your custom configuration goes here
remote(HttpBuildCache) {
url = 'https://example.com:8123/cache/'
}
// ^^^ Your custom configuration goes here
}
}Build cache, composite builds and buildSrc
Gradle’s composite build feature allows including other complete Gradle builds into another. Such included builds will inherit the build cache configuration from the top level build, regardless of whether the included builds define build cache configuration themselves or not.
The build cache configuration present for any included build is effectively ignored, in favour of the top level build’s configuration.
This also applies to any buildSrc projects of any included builds.
The buildSrc directory is treated as an included build, and as such it inherits the build cache configuration from the top-level build.
|
Note
|
This configuration precedence does not apply to plugin builds included through pluginManagement as these are loaded before the cache configuration itself.
|
How to set up an HTTP build cache backend
Gradle provides a Docker image for a build cache node, which can connect with Develocity for centralized management. The cache node can also be used without a Develocity installation with restricted functionality.
Implement your own Build Cache
Using a different build cache backend to store build outputs (which is not covered by the built-in support for connecting to an HTTP backend) requires implementing your own logic for connecting to your custom build cache backend. To this end, custom build cache types can be registered via BuildCacheConfiguration.registerBuildCacheService(java.lang.Class, java.lang.Class).
Develocity includes a high-performance, easy to install and operate, shared build cache backend.
Use cases for the build cache
This section covers the different use cases for Gradle’s build cache, from local-only development to caching task outputs across large teams.
Speed up developer builds with the local cache
Even when used by a single developer only, the build cache can be very useful.
Gradle’s incremental build feature helps to avoid work that is already done, but once you re-execute a task, any previous results are forgotten.
When you are switching branches back and forth, the local results get rebuilt over and over again, even if you are building something that has already been built before.
The build cache remembers the earlier build results, and greatly reduces the need to rebuild things when they have already been built locally.
This can also extend to rebuilding different commits, like when running git bisect.
The local cache can also be useful when working with a project that has multiple variants, as in the case of Android projects. Each variant has a number of tasks associated with it, and some of those task variant dimensions, despite having different names, can end up producing the same output. With the local cache enabled, reuse between task variants will happen automatically when applicable.
Share results between CI builds
The build cache can do more than go back-and-forth in time: it can also bridge physical distance between computers, allowing results generated on one machine to be re-used by another. A typical first step when introducing the build cache within a team is to enable it for builds running as part of continuous integration only. Using a shared HTTP build cache backend (such as the one provided by Develocity) can significantly reduce the work CI agents need to do. This translates into faster feedback for developers, and less money spent on the CI resources. Faster builds also mean fewer commits being part of each build, which makes debugging issues more efficient.
Beginning with the build cache on CI is a good first step as the environment on CI agents is usually more stable and predictable than developer machines. This helps to identify any possible issues with the build that may affect cacheability.
If you are subject to audit requirements regarding the artifacts you ship to your customers you may need to disable the build cache for certain builds. Develocity may help you with fulfilling these requirements while still using the build cache for all your builds. It allows you to easily find out which build produced an artifact coming from the build cache via a Build Scan.
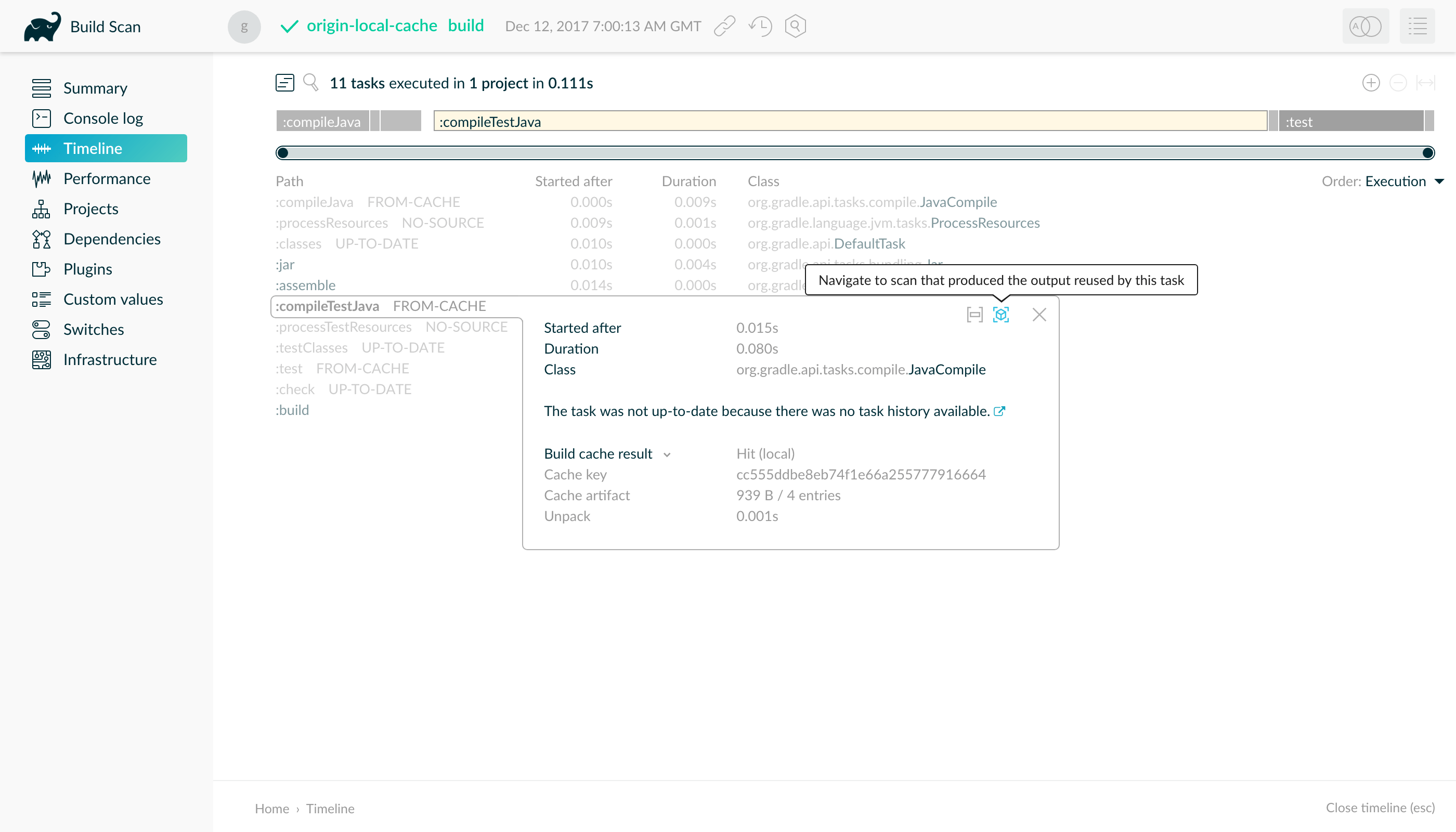
Accelerate developer builds by reusing CI results
When multiple developers work on the same project, they don’t just need to build their own changes: whenever they pull from version control, they end up having to build each other’s changes as well. Whenever a developer is working on something independent of the pulled changes, they can safely reuse outputs already generated on CI. Say, you’re working on module "A", and you pull in some changes to module "B" (which does not depend on your module). If those changes were already built in CI, you can download the task outputs for module "B" from the cache instead of generating them locally. A typical use case for this is when developers start their day, pull all changes from version control and then run their first build.
The changes don’t need to be completely independent, either; we’ll take a look at the strategies to reuse results when dependencies are involved in the section about the different forms of normalization.
Combine remote results with local caching
You can utilize both a local and a remote cache for a compound effect.
While loading results from a CI-filled remote cache helps to avoid work needed because of changes by other developers, the local cache can speed up switching branches and doing git bisect.
On CI machines the local cache can act as a mirror of the remote cache, significantly reducing network usage.
Share results between developers
Allowing developers to upload their results to a shared cache is possible, but not recommended. Developers can make changes to task inputs or outputs while the task is executing. They can do this unintentionally and without noticing, for example by making changes in their IDEs while a build is running. Currently, Gradle has no good way to defend against these changes, and will simply cache whatever is in the output directory once the task is finished. This again can lead to corrupted results being uploaded to the shared cache. This recommendation might change when Gradle has added the necessary safeguards against unintentional modification of task inputs and outputs.
|
Warning
|
If you want to share task output from incremental builds, i.e. non-clean builds, you have to make sure that all cacheable tasks are properly configured and implemented to deal with stale output. There are for example annotation processors that do not clean up stale files in the corresponding classes/resources directories. The cache is a great forcing function to fix these problems, which will also make your incremental builds much more reliable. At the same time, until you have confidence that the incremental build behavior is flawless, only use clean builds to upload content to the cache. |
Build cache performance
The sole reason to use any build cache is to make builds faster. But how much faster can you go when using the cache? Measuring the impact is both important and complicated, as cache performance is determined by many factors. Performing measurements of the cache’s impact can validate the extra effort (work, infrastructure) that is required to start using the cache. These measurements can later serve as baselines for future improvements, and to watch for signs of regressions.
|
Note
|
Proper configuration and maintenance of a build can improve caching performance in a big way. |
Fully cached builds
The most straightforward way to get a feel for what the cache can do for you is to measure the difference between a non-cached build and a fully cached build. This will give you the theoretical limit of how fast builds with the cache can get, if everything you’re trying to build has already been built. The easiest way to measure this is using the local cache:
-
Clean the cache directory to avoid any hits from previous builds (
rm -rf $GRADLE_USER_HOME/caches/build-cache-*) -
Run the build (e.g.
./gradlew --build-cache clean assemble), so that all the results from cacheable tasks get stored in the cache. -
Run the build again (e.g.
./gradlew --build-cache clean assemble); depending on your build, you should see many of the tasks being retrieved from the cache. -
Compare the execution time for the two builds
|
Note
|
You may encounter a few cached tasks even in the first of the two builds, where no previously cached results should be available. This can happen if you have tasks in your build that are configured to produce the same results from the same inputs; in such a case once one of these tasks has finished, Gradle will simply reuse its output for the rest of the tasks. |
Normally, your fully cached build should be significantly faster than the clean build: this is the theoretical limit of how much time using the build cache can save on your particular build.
You usually don’t get the achievable performance gains on the first try, see finding problems with task output caching.
As your build logic is evolving and changing it is also important to make sure that the cache effectiveness is not regressing.
A Build Scan provides a detailed performance breakdown which show you how effectively your build is using the build cache:
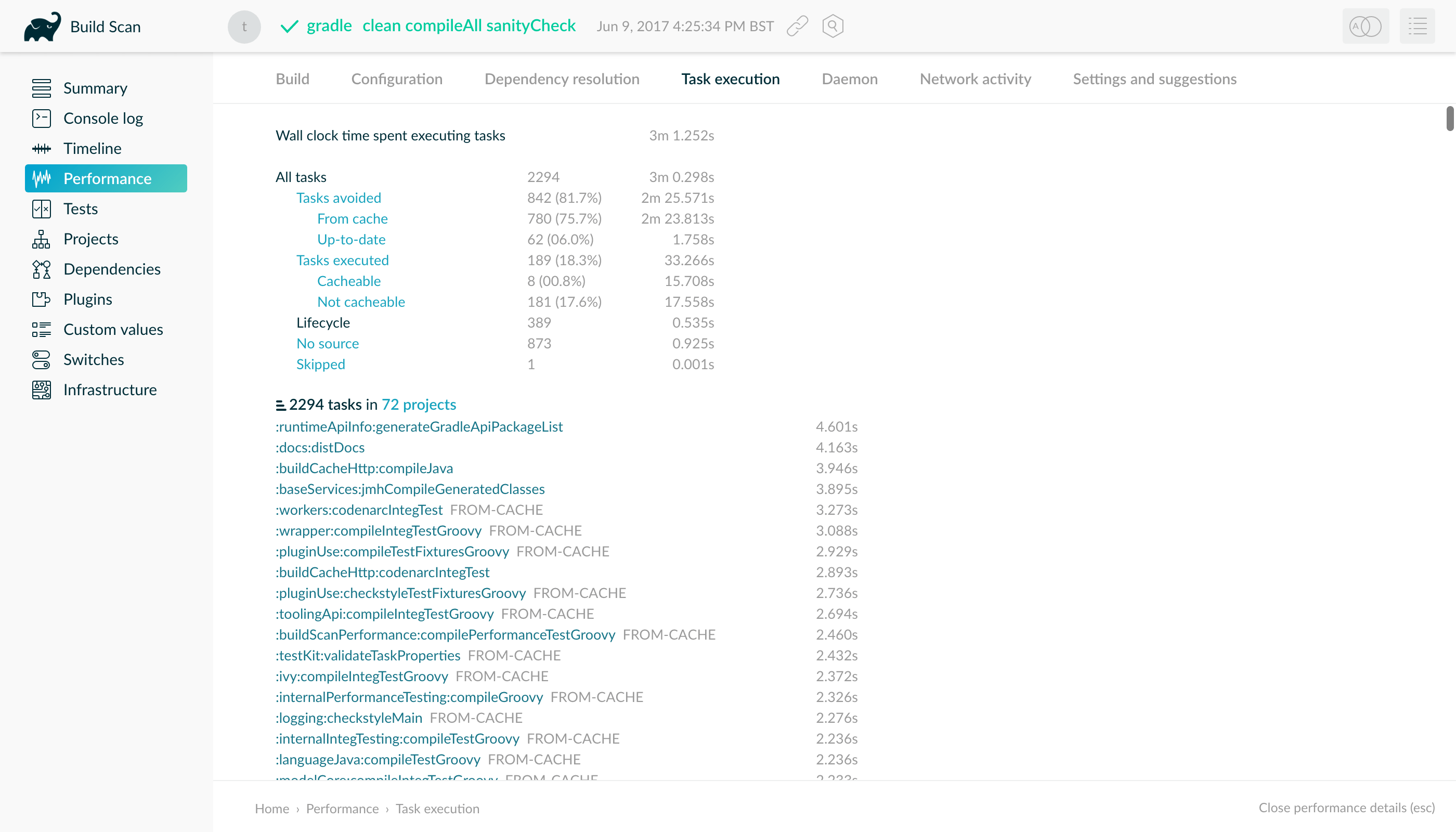
Fully cached builds occur in situations when developers check out the latest from version control and then build, for example to generate the latest sources they need in their IDE. The purpose of running most builds though is to process some new changes. The structure of the software being built (how many modules are there, how independent are its parts etc.), and the nature of the changes themselves ("big refactor in the core of the system" vs. "small change to a unit test" etc.) strongly influence the performance gains delivered by the build cache. As developers tend to submit different kinds of changes over time, caching performance is expected to vary with each change. As with any cache, the impact should therefore be measured over time.
In a setup where a team uses a shared cache backend, there are two locations worth measuring cache impact at: on CI and on developer machines.
Cache impact on CI builds
The best way to learn about the impact of caching on CI is to set up the same builds with the cache enabled and disabled, and compare the results over time. If you have a single Gradle build step that you want to enable caching for, it’s easy to compare the results using your CI system’s built-in statistical tools.
Measuring complex pipelines may require more work or external tools to collect and process measurements. It’s important to distinguish those parts of the pipeline that caching has no effect on, for example, the time builds spend waiting in the CI system’s queue, or time taken by checking out source code from version control.
When using Develocity, you can use the Export API to access the necessary data and run your analytics. Develocity provides much richer data compared to what can be obtained from CI servers. For example, you can get insights into the execution of single tasks, how many tasks were retrieved from the cache, how long it took to download from the cache, the properties that were used to calculate the cache key and more. When using your CI servers built in functions, you can use statistic charts if you use Teamcity for your CI builds. Most of time you will end up extracting data from your CI server via the corresponding REST API (see Jenkins remote access API and Teamcity REST API).
Typically, CI builds above a certain size include parallel sections to utilize multiple agents. With parallel pipelines you can measure the wall-clock time it takes for a set of changes to go from having been pushed to version control to being built, verified and deployed. The build cache’s effect in this case can be measured in the reduction of the time developers have to wait for feedback from CI.
You can also measure the cumulative time your build agents spent building a changeset, which will give you a sense of the amount of work the CI infrastructure has to exert. The cache’s effect here is less money spent on CI resources, as you don’t need as many CI agents to maintain the same number of changes built.
If you want to look at the measurement for the Gradle build itself you can have a look at the blog post "Introducing the build cache".
Measuring developer builds
Gradle’s build cache can be very useful in reducing CI infrastructure cost and feedback time, but it usually has the biggest impact when developers can reuse cached results in their local builds. This is also the hardest to quantify for a number of reasons:
-
developers run different builds
-
developers can have different hardware, or have different settings
-
developers run all kinds of other things on their machines that can slow them down
When using Develocity you can use the Export API to extract data about developer builds, too. You can then create statistics on how many tasks were cached per developer or build. You can even compare the times it took to execute the task vs loading it from the cache and then estimate the time saved per developer.
When using the Develocity build cache backend you should pay close attention to the hit rate in the admin UI. A rise in the hit rate there probably indicates better usage by developers:
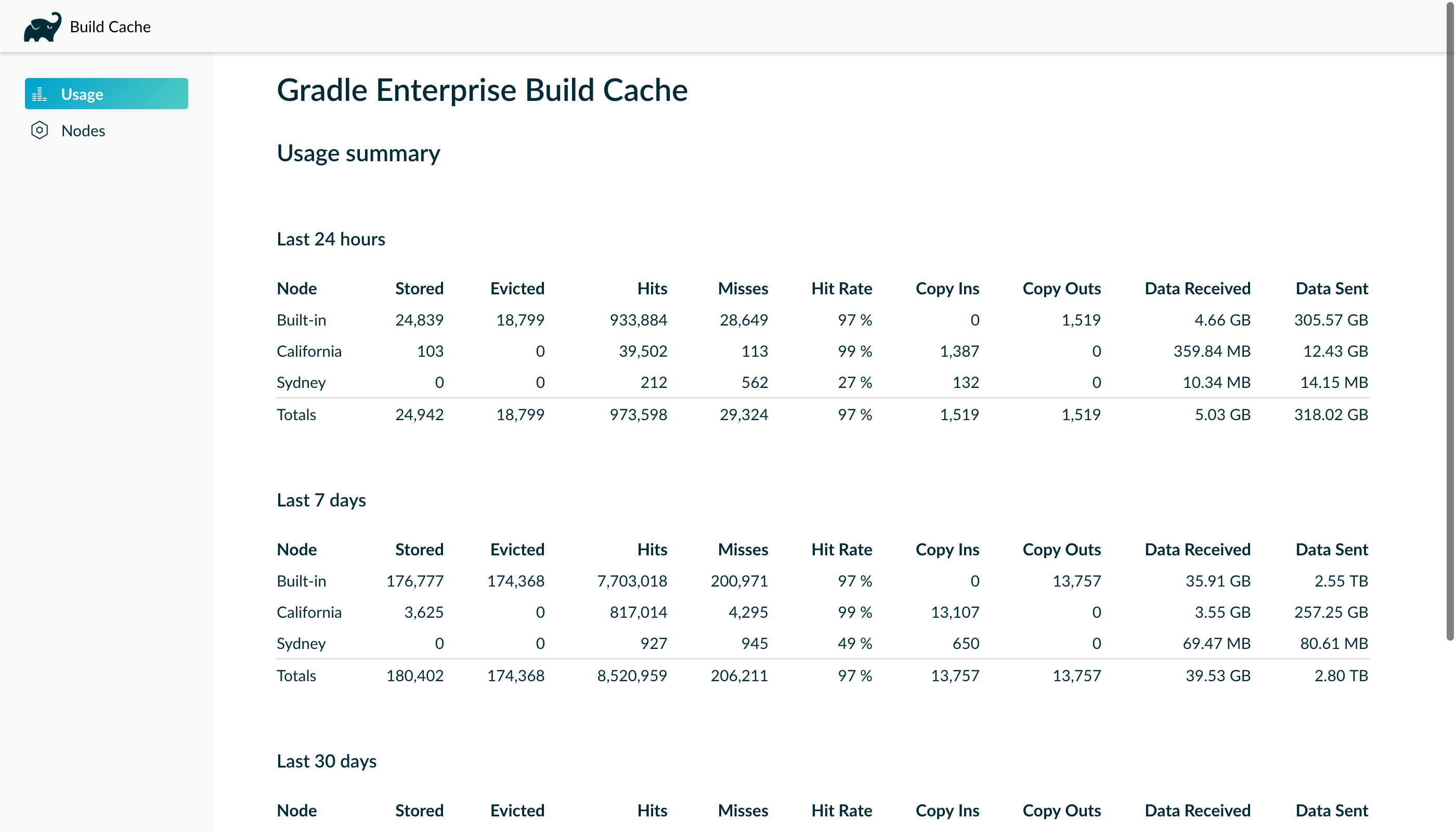
Analyzing performance in Build Scan
A Build Scan provides a summary of all cache operations for a build via the "Build cache" section of the "Performance" page.
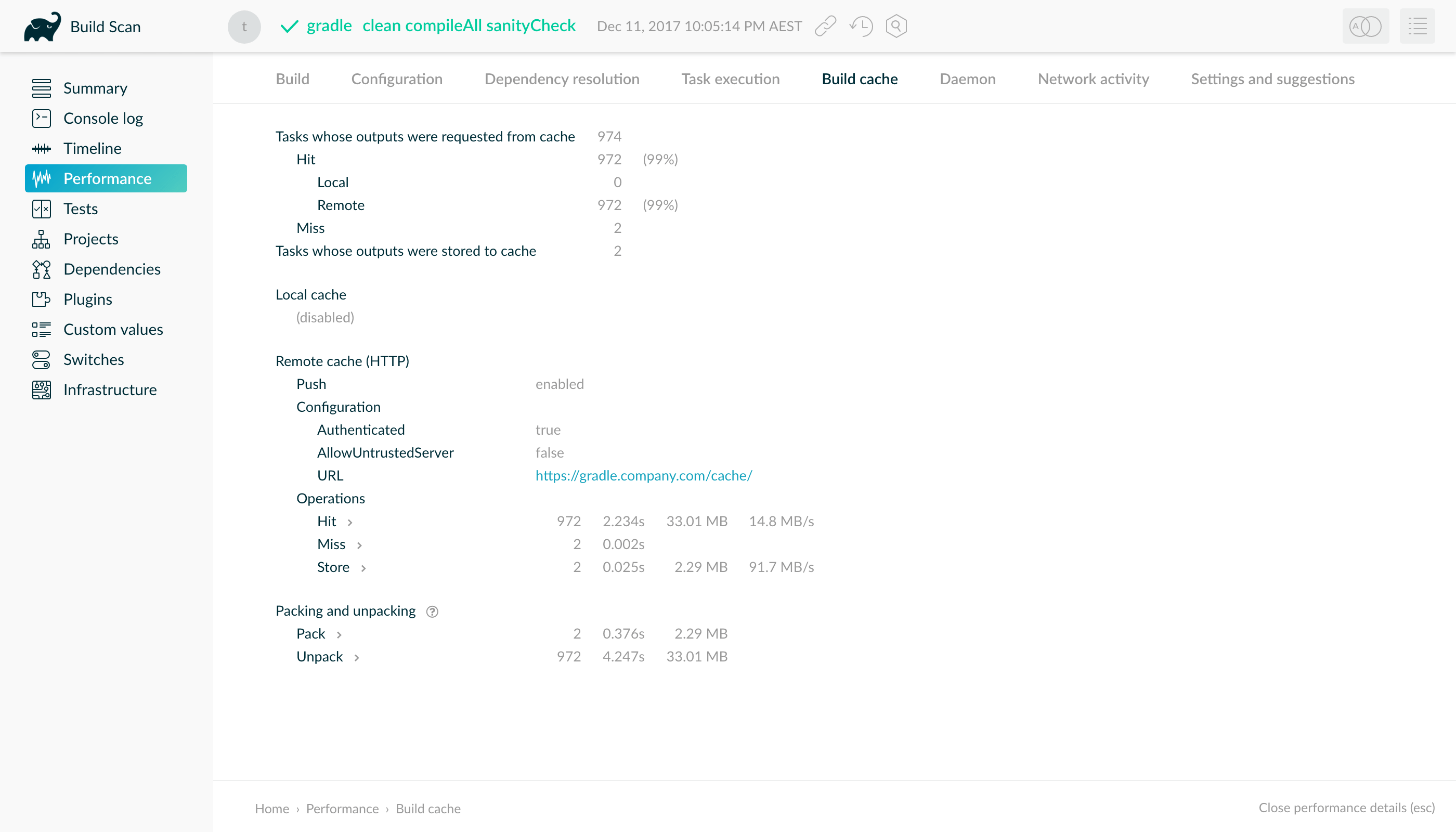
This page details which tasks were able to be avoided by cache hits, and which missed. It also indicates the hits and misses for the local and remote caches individually. For remote cache operations, the time taken to transfer artifacts to and from the cache is given, along with the transfer rate. This is particularly important for assessing the impact of network link quality on performance, as transfer times contribute to build time.
Remote cache performance
Improving the network link between the build and the remote cache can significantly improve build cache performance. How to do this depends on the remote cache in use and your network environment.
The multi-node remote build cache provided by Develocity is a fast and efficient, purpose built, remote build cache. In particular, if your development team is geographically distributed, its replication features can significantly improve performance by allowing developers to use a cache that they have a good network link to. See the "Build Cache Replication" section of the Develocity Admin Manual for more information.
Important concepts
How much of your build gets loaded from the cache depends on many factors. In this section you will see some of the tools that are essential for well-cached builds. Build Scan is part of that toolchain and will be used throughout this guide.
Build cache key
Artifacts in the build cache are uniquely identified by a build cache key. A build cache key is assigned to each cacheable task when running with the build cache enabled and is used for both loading and storing task outputs to the build cache. The following inputs contribute to the build cache key for a task:
-
The task implementation
-
The task action implementations
-
The names of the output properties
-
The names and values of task inputs
Two tasks can reuse their outputs by using the build cache if their associated build cache keys are the same.
Repeatable task outputs
Assume that you have a code generator task as part of your build. When you have a fully up to date build and you clean and re-run the code generator task on the same code base it should generate exactly the same output, so anything that depends on that output will stay up-to-date.
It might also be that your code generator adds some extra information to its output that doesn’t depend on its declared inputs, like a timestamp. In such a case re-executing the task will result in different code being generated (because the timestamp will be updated). Tasks that depend on the code generator’s output will need to be re-executed.
When a task is cacheable, then the very nature of task output caching makes sure that the task will have the same outputs for a given set of inputs. Therefore, cacheable tasks should have repeatable task outputs. If they don’t, then the result of executing the task and loading the task from the cache may be different, which can lead to hard-to-diagnose cache misses.
In some cases even well-trusted tools can produce non-repeatable outputs, and lead to cascading effects.
One example is Oracle’s Java compiler, which, due to a bug, was producing different bytecode depending on the order source files to be compiled were presented to it.
If you were using Oracle JDK 8u31 or earlier to compile code in the buildSrc subproject, this could lead to all of your custom tasks producing occasional cache misses, because of the difference in their classpaths (which include buildSrc).
The key here is that cacheable tasks should not use non-repeatable task outputs as an input.
Stable task inputs
Having a task repeatably produce the same output is not enough if its inputs keep changing all the time. Such unstable inputs can be supplied directly to the task. Consider a version number that includes a timestamp being added to the jar file’s manifest:
version = "3.2-${System.currentTimeMillis()}"
tasks.jar {
manifest {
attributes(mapOf("Implementation-Version" to project.version))
}
}version = "3.2-${System.currentTimeMillis()}"
tasks.named('jar') {
manifest {
attributes('Implementation-Version': project.version)
}
}In the above example the inputs for the jar task will be different for each build execution since this timestamp will continually change.
Another example for unstable inputs is the commit ID from version control.
Maybe your version number is generated via git describe (and you include it in the jar manifest as shown above).
Or maybe you include the commit hash directly in version.properties or a jar manifest attribute.
Either way, the outputs produced by any tasks depending on such data will only be re-usable by builds running against the exact same commit.
Another common, but less obvious source of unstable inputs is when a task consumes the output of another task which produces non-repeatable results, such as the example before of a code generator that embeds timestamps in its output.
A task can only be loaded from the cache if it has stable task inputs. Unstable task inputs result in the task having a unique set of inputs for every build, which will always result in a cache miss.
Better reuse via input normalization
Having stable inputs is crucial for cacheable tasks. However, achieving byte for byte identical inputs for each task can be challenging. In some cases sanitizing the output of a task to remove unnecessary information can be a good approach, but this also means that a task’s output can only be normalized for a single purpose.
This is where input normalization comes into play. Input normalization is used by Gradle to determine if two task inputs are essentially the same. Gradle uses normalized inputs when doing up-to-date checks and when determining if a cached result can be re-used instead of executing the task. As input normalization is declared by the task consuming the data as input, different tasks can define different ways to normalize the same data.
When it comes to file inputs, Gradle can normalize the path of the files as well as their contents.
Path sensitivity and relocatability
When sharing cached results between computers, it’s rare that everyone runs the build from the exact same location on their computers. To allow cached results to be shared even when builds are executed from different root directories, Gradle needs to understand which inputs can be relocated and which cannot.
Tasks having files as inputs can declare the parts of a file’s path what are essential to them: this is called the path sensitivity of the input.
Task properties declared with ABSOLUTE path sensitivity are considered non-relocatable.
This is the default for properties not declaring path sensitivity, too.
For example, the class files produced by the Java compiler are dependent on the file names of the Java source files: renaming the source files with public classes in them would fail the build.
Though moving the files around wouldn’t have an effect on the result of the compilation, for incremental compilation the JavaCompile task relies on the relative path to find other classes in the same package.
Therefore, the path sensitivity for the sources of the JavaCompile task is RELATIVE.
Because of this only the normalized (relative) paths of the Java source files are considered as inputs to the JavaCompile task.
|
Note
|
The Java compiler only respects the package declaration in the Java source files, not the relative path of the sources.
As a consequence, path sensitivity for Java sources is NAME_ONLY and not RELATIVE.
|
Content normalization
Compile avoidance for Java
When it comes to the dependencies of a JavaCompile task (i.e. its compile classpath), only changes to the Application Binary Interface (ABI) of these dependencies require compilation to be executed.
Gradle has a deep understanding of what a compile classpath is and uses a sophisticated normalization strategy for it.
Task outputs can be re-used as long as the ABI of the classes on the compile classpath stays the same.
This enables Gradle to avoid Java compilation by using incremental builds, or load results from the cache that were produced by different (but ABI-compatible) versions of dependencies.
For more information on compile avoidance see the corresponding section.
Runtime classpath normalization
Similar to compile avoidance, Gradle also understands the concept of a runtime classpath, and uses tailored input normalization to avoid running e.g. tests. For runtime classpaths Gradle inspects the contents of jar files and ignores the timestamps and order of the entries in the jar file. This means that a rebuilt jar file would be considered the same runtime classpath input. For details on what level of understanding Gradle has for detecting changes to classpaths and what is considered as a classpath see this section.
For a runtime classpath it is possible to provide better insights to Gradle which files are essential to the input by configuring input normalization.
Given that you want to add a file build-info.properties to all your produced jar files which contains volatile information about the build, e.g. the timestamp when the build started or some ID to identify the CI job that published the artifact.
This file is only used for auditing purposes, and has no effect on the outcome of running tests.
Nonetheless, this file is part of the runtime classpath for the test task. Since the file changes on every build invocation, tests cannot be cached effectively.
To fix this you can ignore build-info.properties on any runtime classpath by adding the following configuration to the build script in the consuming project:
normalization {
runtimeClasspath {
ignore("build-info.properties")
}
}normalization {
runtimeClasspath {
ignore 'build-info.properties'
}
}If adding such a file to your jar files is something you do for all of the projects in your build, and you want to filter this file for all consumers, you may wrap the configurations described above in an allprojects {} or subprojects {} block in the root build script.
The effect of this configuration would be that changes to build-info.properties would be ignored for both up-to-date checks and task output caching.
All runtime classpath inputs for all tasks in the project where this configuration has been made will be affected.
This will not change the runtime behavior of the test task — i.e. any test is still able to load build-info.properties, and the runtime classpath stays the same as before.
The case against overlapping outputs
When two tasks write to the same output directory or output file, it is difficult for Gradle to determine which output belongs to which task. There are many edge cases, and executing the tasks in parallel cannot be done safely. For the same reason, Gradle cannot remove stale output files for these tasks. Tasks that have discrete, non-overlapping outputs can always be handled in a safe fashion by Gradle. For the aforementioned reasons, task output caching is automatically disabled for tasks whose output directories overlap with another task.
A Build Scan shows tasks where caching was disabled due to overlapping outputs in the timeline:
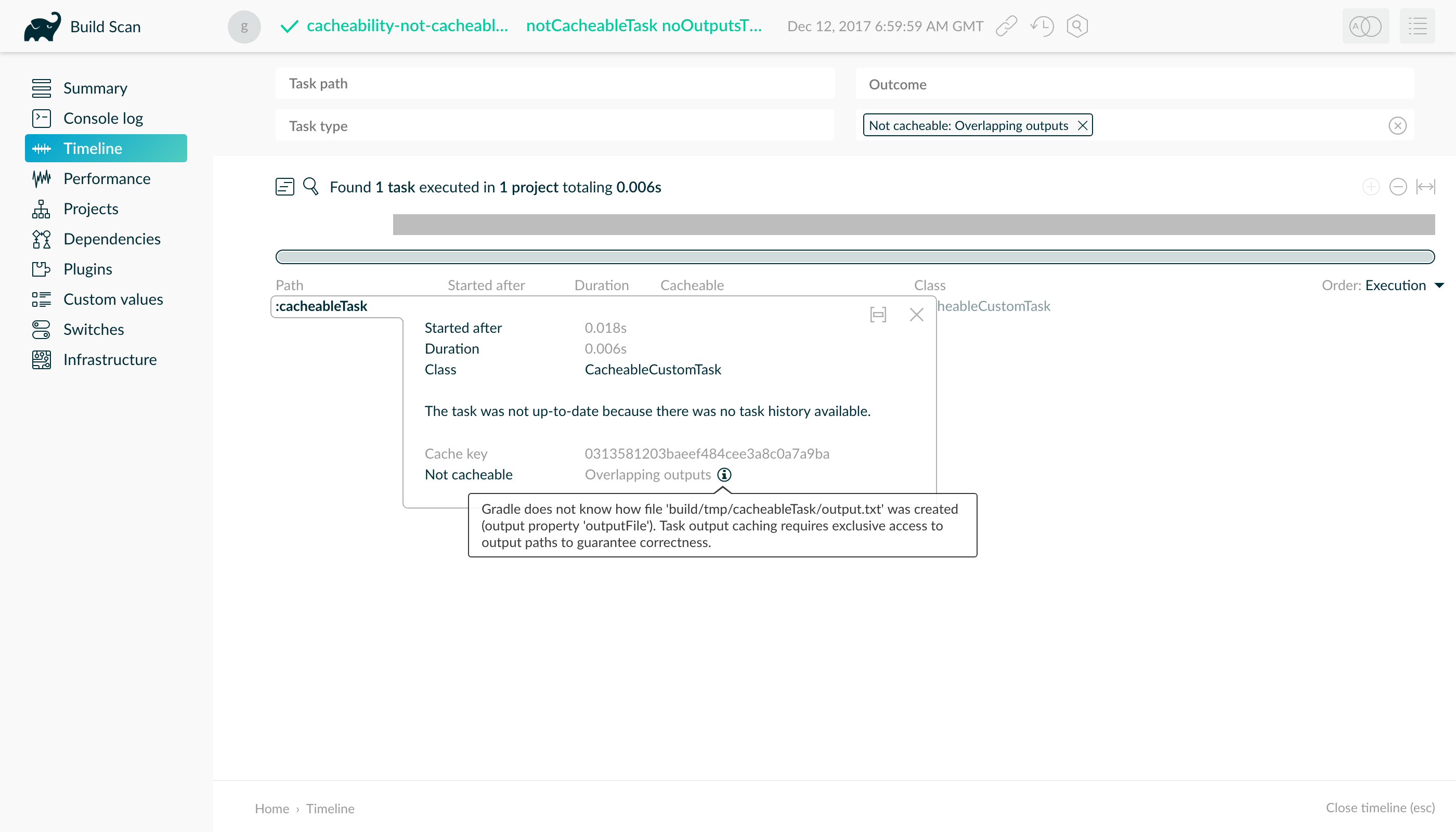
Reuse of outputs between different tasks
Some builds exhibit a surprising characteristic: even when executed against an empty cache, they produce tasks loaded from cache. How is this possible? Rest assured that this is completely normal.
When considering task outputs, Gradle only cares about the inputs to the task: the task type itself, input files and parameters etc., but it doesn’t care about the task’s name or which project it can be found in.
Running javac will produce the same output regardless of the name of the JavaCompile task that invoked it.
If your build includes two tasks that share every input, the one executing later will be able to reuse the output produced by the first.
Having two tasks in the same build that do the same might sound like a problem to fix, but it is not necessarily something bad. For example, the Android plugin creates several tasks for each variant of the project; some of those tasks will potentially do the same thing. These tasks can safely reuse each other’s outputs.
As discussed previously, you can use Develocity to diagnose the source build of these unexpected cache-hits.
Non-cacheable tasks
You’ve seen quite a bit about cacheable tasks, which implies there are non-cacheable ones, too. If caching task outputs is as awesome as it sounds, why not cache every task?
There are tasks that are definitely worth caching: tasks that do complex, repeatable processing and produce moderate amounts of output. Compilation tasks are usually ideal candidates for caching.
At the other end of the spectrum lie I/O-heavy tasks, like Copy and Sync. Moving files around locally typically cannot be sped up by copying them from a cache.
Caching those tasks would even waste good resources by storing all those redundant results in the cache.
Most tasks are either obviously worth caching, or obviously not. For those in-between a good rule of thumb is to see if downloading results would be significantly faster than producing them locally.
Caching Java projects
As of Gradle 4.0, the build tool fully supports caching plain Java projects. Built-in tasks for compiling, testing, documenting and checking the quality of Java code support the build cache out of the box.
Java compilation
Caching Java compilation makes use of Gradle’s deep understanding of compile classpaths. The mechanism avoids recompilation when dependencies change in a way that doesn’t affect their application binary interfaces (ABI). Since the cache key is only influenced by the ABI of dependencies (and not by their implementation details like private types and method bodies), task output caching can also reuse compiled classes if they were produced by the same sources and ABI-equivalent dependencies.
For example, take a project with two modules: an application depending on a library. Suppose the latest version is already built by CI and uploaded to the shared cache. If a developer now modifies a method’s body in the library, the library will need to be rebuilt on their computer. But they will be able to load the compiled classes for the application from the shared cache. Gradle can do this because the library used to compile the application on CI, and the modified library available locally share the same ABI.
Annotation processors
Compile avoidance works out of the box. There is one caveat though: when using annotation processors, Gradle uses the annotation processor classpath as an input. Unlike most compile dependencies, in which only the ABI influences compilation, the implementation of annotation processors must be considered as an input to the compiler. For this reason Gradle will treat annotation processors as a runtime classpath, meaning less input normalization is taking place there. If Gradle detects an annotation processor on the compile classpath, the annotation processor classpath defaults to the compile classpath when not explicitly set, which in turn means the entire compile classpath is treated as a runtime classpath input.
For the example above this would mean the ABI extracted from the compile classpath would be unchanged, but the annotation processor classpath (because it’s not treated with compile avoidance) would be different. Ultimately, the developer would end up having to recompile the application.
The easiest way to avoid this performance penalty is to not use annotation processors. However, if you need to use them, make sure you set the annotation processor classpath explicitly to include only the libraries needed for annotation processing. The section on Java compile avoidance describes how to do this.
|
Note
|
Some common Java dependencies (such as Log4j 2.x) come bundled with annotation processors. If you use these dependencies, but do not leverage the features of the bundled annotation processors, it’s best to disable annotation processing entirely. This can be done by setting the annotation processor classpath to an empty set. |
Unit test execution
The Test task used for test execution for JVM languages employs runtime classpath normalization for its classpath.
This means that changes to order and timestamps in jars on the test classpath will not cause the task to be out-of-date or change the build cache key.
For achieving stable task inputs you can also wield the power of filtering the runtime classpath.
Integration test execution
Unit tests are easy to cache as they normally have no external dependencies. For integration tests the situation can be quite different, as they can depend on a variety of inputs outside of the test and production code. These external factors can be for example:
-
operating system type and version,
-
external tools being installed for the tests,
-
environment variables and Java system properties,
-
other services being up and running,
-
a distribution of the software under test.
You need to be careful to declare these additional inputs for your integration test in order to avoid incorrect cache hits.
For example, declaring the operating system in use by Gradle as an input to a Test task called integTest would work as follows:
tasks.integTest {
inputs.property("operatingSystem") {
System.getProperty("os.name")
}
}tasks.named('integTest') {
inputs.property("operatingSystem") {
System.getProperty("os.name")
}
}Archives as inputs
It is common for the integration tests to depend on your packaged application. If this happens to be a zip or tar archive, then adding it as an input to the integration test task may lead to cache misses. This is because, as described in repeatable task outputs, rebuilding an archive often changes the metadata in the archive. You can depend on the exploded contents of the archive instead. See also the section on dealing with non-repeatable outputs.
Dealing with file paths
You will probably pass some information from the build environment to your integration test tasks by using system properties. Passing absolute paths will break relocatability of the integration test task.
// Don't do this! Breaks relocatability!
tasks.integTest {
systemProperty("distribution.location", layout.buildDirectory.dir("dist").get().asFile.absolutePath)
}// Don't do this! Breaks relocatability!
tasks.named('integTest') {
systemProperty "distribution.location", layout.buildDirectory.dir('dist').get().asFile.absolutePath
}Instead of adding the absolute path directly as a system property, it is possible to add an
annotated CommandLineArgumentProvider to the integTest task:
abstract class DistributionLocationProvider : CommandLineArgumentProvider { // (1)
@get:InputDirectory
@get:PathSensitive(PathSensitivity.RELATIVE) // (2)
abstract val distribution: DirectoryProperty
override fun asArguments(): Iterable<String> =
listOf("-Ddistribution.location=${distribution.get().asFile.absolutePath}") // (3)
}
tasks.integTest {
jvmArgumentProviders.add(
objects.newInstance<DistributionLocationProvider>().apply { // (4)
distribution = layout.buildDirectory.dir("dist")
}
)
}abstract class DistributionLocationProvider implements CommandLineArgumentProvider { // (1)
@InputDirectory
@PathSensitive(PathSensitivity.RELATIVE) // (2)
abstract DirectoryProperty getDistribution()
@Override
Iterable<String> asArguments() {
["-Ddistribution.location=${distribution.get().asFile.absolutePath}"] // (3)
}
}
tasks.named('integTest') {
jvmArgumentProviders.add(
objects.newInstance(DistributionLocationProvider).tap { // (4)
distribution = layout.buildDirectory.dir('dist')
}
)
}-
Create a class implementing
CommandLineArgumentProvider. -
Declare the inputs and outputs with the corresponding path sensitivity.
-
asArgumentsneeds to return the JVM arguments passing the desired system properties to the test JVM. -
Add an instance of the newly created class as JVM argument provider to the integration test task.[16]
Ignoring system properties
It may be necessary to ignore some system properties as inputs as they do not influence the outcome of the integration tests.
In order to do so, add a CommandLineArgumentProvider to the integTest task:
abstract class CiEnvironmentProvider : CommandLineArgumentProvider {
@get:Internal // (1)
abstract val agentNumber: Property<String>
override fun asArguments(): Iterable<String> =
listOf("-DagentNumber=${agentNumber.get()}") // (2)
}
tasks.integTest {
jvmArgumentProviders.add(
objects.newInstance<CiEnvironmentProvider>().apply { // (3)
agentNumber = providers.environmentVariable("AGENT_NUMBER").orElse("1")
}
)
}abstract class CiEnvironmentProvider implements CommandLineArgumentProvider {
@Internal // (1)
abstract Property<String> getAgentNumber()
@Override
Iterable<String> asArguments() {
["-DagentNumber=${agentNumber.get()}"] // (2)
}
}
tasks.named('integTest') {
jvmArgumentProviders.add(
objects.newInstance(CiEnvironmentProvider).tap { // (3)
agentNumber = providers.environmentVariable("AGENT_NUMBER").orElse("1")
}
)
}-
@Internalmeans that this property does not influence the output of the integration tests. -
The system properties for the actual test execution.
-
Add an instance of the newly created class as JVM argument provider to the integration test task.[16]
Caching Android projects
While it is true that Android uses the Java toolchain as its foundation, there are nevertheless some significant differences from pure Java projects; these differences impact task cacheability.
This is even more true for Android projects that include Kotlin source code (and therefore use the kotlin-android plugin).
Disambiguation
This guide is about Gradle’s build cache, but you may have also heard about the Android build cache. These are different things. The Android cache is internal to certain tasks in the Android plugin, and will eventually be removed in favor of native Gradle support.
Why use the build cache?
The build cache can significantly improve build performance for Android projects, in many cases by 30-40%. Many of the compilation and assembly tasks provided by the Android Gradle Plugin are cacheable, and more are made so with each new iteration.
Faster CI builds
CI builds benefit particularly from the build cache.
A typical CI build starts with a clean, which means that pre-existing build outputs are deleted and none of the tasks that make up the build will be UP-TO-DATE.
However, it is likely that many of those tasks will have been run with exactly the same inputs in a prior CI build, populating the build cache; the outputs from those prior runs can safely be reused, resulting in dramatic build performance improvements.
Reusing CI builds for local development
When you sign into work at the start of your day, it’s not unusual for your first task to be pulling the main branch and then running a build (Android Studio will probably do the latter, whether you ask it to or not). Assuming all merges to main are built on CI (a best practice!), you can expect this first local build of the day to enjoy a larger-than-typical benefit with Gradle’s remote cache. CI already built this commit — why should you re-do that work?
Switching branches
During local development, it is not uncommon to switch branches several times per day.
This defeats incremental build (i.e., UP-TO-DATE checks), but this issue is mitigated via the use of the local build cache.
You might run a build on Branch A, which will populate the local cache.
You then switch to Branch B to conduct a code review, help a colleague, or address feedback on an open PR.
You then switch back to Branch A to continue your original work.
When you next build, all of the outputs previously built while working on Branch A can be reused from the cache, saving potentially a lot of time.
The Android Gradle Plugin
Android Studio users should use the latest Android Gradle Plugin to ensure compatibility and benefit from performance improvements in new releases.
The first thing you should always do when working to optimize your build is ensure you’re on the latest stable, supported versions of the Android Gradle Plugin and the Gradle Build Tool. At the time of writing, they are 3.3.0 and 5.0, respectively. Each new version of these tools includes many performance improvements, not least of which is to the build cache.
Java and Kotlin compilation
The discussion above in "Caching Java projects" is equally relevant here, with the caveat that, for projects that include Kotlin source code, the Kotlin compiler does not currently support compile avoidance in the way that the Java compiler does.
Annotation processors and Kotlin
The advice above for pure Java projects also applies to Android projects. However, if you are using annotation processors (such as Dagger2 or Butterknife) in conjunction with Kotlin and the kotlin-kapt plugin, you should know that before Kotlin 1.3.30 kapt was not cached by default.
You can opt into it (which is recommended) by adding the following to build scripts:
pluginManager.withPlugin("kotlin-kapt") {
configure<KaptExtension> { useBuildCache = true }
}plugins.withId("kotlin-kapt") {
kapt.useBuildCache = true
}Unit test execution
Like unit tests in a pure Java project, the equivalent test task in an Android project (AndroidUnitTest) is also cacheable since Android Gradle Plugin 3.6.0.
Instrumented test execution (i.e., Espresso tests)
Android instrumented tests (DeviceProviderInstrumentTestTask), often referred to as "Espresso" tests, are also not cacheable.
The Google Android team is also working to make such tests cacheable.
Please see this issue.
Lint
Users of Android’s Lint task are well aware of the heavy performance penalty they pay for using it, but also know that it is indispensable for finding common issues in Android projects.
Currently, this task is not cacheable.
This task is planned to be cacheable with the release of Android Gradle Plugin 3.5.
This is another reason to always use the latest version of the Android plugin!
The Fabric Plugin and Crashlytics
The Fabric plugin, which is used to integrate the Crashlytics crash-reporting tool (among others), is very popular, yet imposes some hefty performance penalties during the build process. This is due to the need for each version of your app to have a unique identifier so that it can be identified in the Crashlytics dashboard. In practice, the default behavior of Crashlytics is to treat "each version" as synonymous with "each build". This defeats incremental build, because each build will be unique. It also breaks the cacheability of certain tasks in the build, and for the same reason. This can be fixed by simply disabling Crashlytics in "debug" builds. You may find instructions for that in the Crashlytics documentation.
|
Note
|
The fix described in the referenced documentation does not work directly if you are using the Kotlin DSL; see below for the workaround. |
Kotlin DSL
The fix described in the referenced documentation does not work directly if you are using the Kotlin DSL; this is due to incompatibilities between that Kotlin DSL and the Fabric plugin. There is a simple workaround for this, based on this advice from the Kotlin DSL primer.
Create a file, fabric.gradle, in the module where you apply the io.fabric plugin. This file (known as a script plugin), should have the following contents:
plugins.withId("com.android.application") { // or "com.android.library"
android.buildTypes.debug.ext.enableCrashlytics = false
}And then, in the module’s build.gradle.kts file, apply this script plugin:
apply(from = "fabric.gradle")Debugging and diagnosing Build Cache misses
To make the most of task output caching, it is important that any necessary inputs to your tasks are specified correctly, while at the same time avoiding unneeded inputs. Failing to specify an input that affects the task’s outputs can result in incorrect builds, while needlessly specifying inputs that do not affect the task’s output can cause cache misses.
This chapter is about finding out why a cache miss happened. If you have a cache hit which you didn’t expect we suggest to declare whatever change you expected to trigger the cache miss as an input to the task.
Finding problems with task output caching
Below we describe a step-by-step process that should help shake out any problems with caching in your build.
Ensure incremental build works
First, make sure your build does the right thing without the cache. Run a build twice without enabling the Gradle build cache. The expected outcome is that all actionable tasks that produce file outputs are up-to-date. You should see something like this on the command-line:
$ ./gradlew clean --quiet (1)
$ ./gradlew assemble (2)BUILD SUCCESSFUL
4 actionable tasks: 4 executed
$ ./gradlew assemble (3)
BUILD SUCCESSFUL
4 actionable tasks: 4 up-to-date-
Make sure we start without any leftover results by running
cleanfirst. -
We are assuming your build is represented by running the
assembletask in these examples, but you can substitute whatever tasks make sense for your build. -
Run the build again without running
clean.
|
Note
|
Tasks that have no outputs or no inputs will always be executed, but that shouldn’t be a problem. |
Use the methods as described below to diagnose and fix tasks that should be up-to-date but aren’t. If you find a task which is out of date, but no cacheable tasks depends on its outcome, then you don’t have to do anything about it. The goal is to achieve stable task inputs for cacheable tasks.
In-place caching with the local cache
When you are happy with the up-to-date performance then you can repeat the experiment above, but this time with a clean build, and the build cache turned on. The goal with clean builds and the build cache turned on is to retrieve all cacheable tasks from the cache.
|
Warning
|
When running this test make sure that you have no remote cache configured, and storing in the local cache is enabled.
These are the default settings.
|
This would look something like this on the command-line:
$ rm -rf ~/.gradle/caches/build-cache-1 (1)
$ ./gradlew clean --quiet (2)
$ ./gradlew assemble --build-cache (3)BUILD SUCCESSFUL
4 actionable tasks: 4 executed$ ./gradlew clean --quiet (4)
$ ./gradlew assemble --build-cache (5)BUILD SUCCESSFUL
4 actionable tasks: 1 executed, 3 from cache-
We want to start with an empty local cache.
-
Clean the project to remove any unwanted leftovers from previous builds.
-
Build it once to let it populate the cache.
-
Clean the project again.
-
Build it again: this time everything cacheable should load from the just populated cache.
You should see all cacheable tasks loaded from cache, while non-cacheable tasks should be executed.
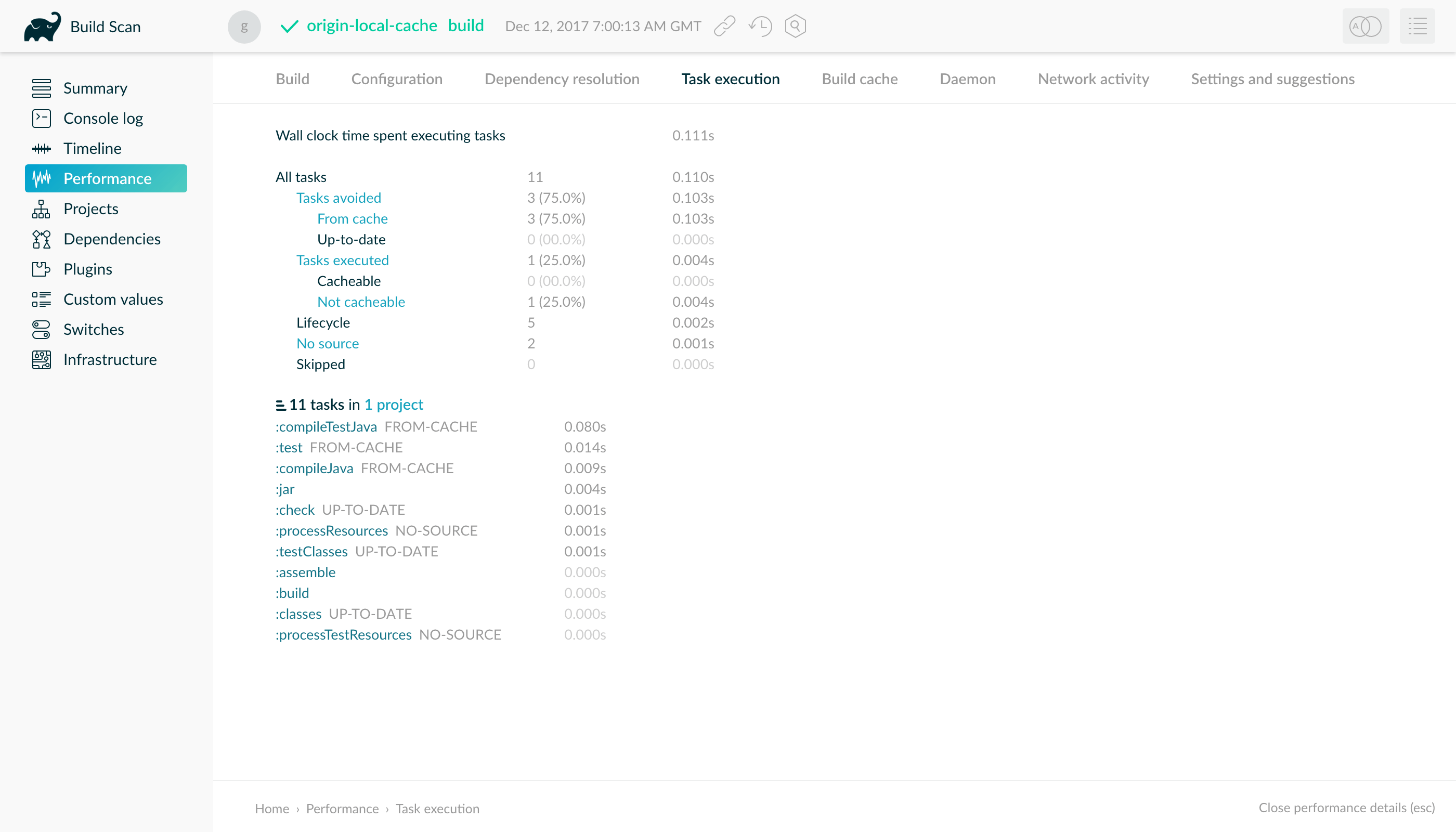
Testing cache relocatability
Once everything loads properly while building the same checkout with the local cache enabled, it’s time to see if there are any relocation problems. A task is considered relocatable if its output can be reused when the task is executed in a different location. (More on this in path sensitivity and relocatability.)
|
Note
|
Tasks that should be relocatable but aren’t are usually a result of absolute paths being present among the task’s inputs. |
To discover these problems, first check out the same commit of your project in two different directories on your machine.
For the following example let’s assume we have a checkout in \~/checkout-1 and \~/checkout-2.
|
Warning
|
Like with the previous test, you should have no remote cache configured, and storing in the local cache should be enabled.
|
$ rm -rf ~/.gradle/caches/build-cache-1 (1)
$ cd ~/checkout-1 (2)
$ ./gradlew clean --quiet (3)
$ ./gradlew assemble --build-cache (4)BUILD SUCCESSFUL
4 actionable tasks: 4 executed$ cd ~/checkout-2 (5)
$ ./gradlew clean --quiet (6)
$ ./gradlew clean assemble --build-cache (7)BUILD SUCCESSFUL
4 actionable tasks: 1 executed, 3 from cache-
Remove all entries in the local cache first.
-
Go to the first checkout directory.
-
Clean the project to remove any unwanted leftovers from previous builds.
-
Run a build to populate the cache.
-
Go to the other checkout directory.
-
Clean the project again.
-
Run a build again.
You should see the exact same results as you saw with the previous in place caching test step.
Cross-platform tests
If your build passes the relocation test, it is in good shape already. If your build requires support for multiple platforms, it is best to see if the required tasks get reused between platforms, too. A typical example of cross-platform builds is when CI runs on Linux VMs, while developers use macOS or Windows, or a different variety or version of Linux.
To test cross-platform cache reuse, set up a remote cache (see share results between CI builds) and populate it from one platform and consume it from the other.
Incremental cache usage
After these experiments with fully cached builds, you can go on and try to make typical changes to your project and see if enough tasks are still cached. If the results are not satisfactory, you can think about restructuring your project to reduce dependencies between different tasks.
Evaluating cache performance over time
Consider recording execution times of your builds, generating graphs, and analyzing the results. Keep an eye out for certain patterns, like a build recompiling everything even though you expected compilation to be cached.
You can also make changes to your code base manually or automatically and check that the expected set of tasks is cached.
If you have tasks that are re-executing instead of loading their outputs from the cache, then it may point to a problem in your build. Techniques for debugging a cache miss are explained in the following section.
Helpful data for diagnosing a cache miss
A cache miss happens when Gradle calculates a build cache key for a task which is different from any existing build cache key in the cache. Only comparing the build cache key on its own does not give much information, so we need to look at some finer grained data to be able to diagnose the cache miss. A list of all inputs to the computed build cache key can be found in the section on cacheable tasks.
From most coarse grained to most fine grained, the items we will use to compare two tasks are:
-
Build cache keys
-
Task and Task action implementations
-
classloader hash
-
class name
-
-
Task output property names
-
Individual task property input hashes
-
Hashes of files which are part of task input properties
If you want information about the build cache key and individual input property hashes, use -Dorg.gradle.caching.debug=true:
$ ./gradlew :compileJava --build-cache -Dorg.gradle.caching.debug=true...
Appending implementation to build cache key: org.gradle.api.tasks.compile.JavaCompile_Decorated@470c67ec713775576db4e818e7a4c75d
Appending additional implementation to build cache key: org.gradle.api.tasks.compile.JavaCompile_Decorated@470c67ec713775576db4e818e7a4c75d
Appending input value fingerprint for 'options' to build cache key: e4eaee32137a6a587e57eea660d7f85d
Appending input value fingerprint for 'options.compilerArgs' to build cache key: 8222d82255460164427051d7537fa305
Appending input value fingerprint for 'options.debug' to build cache key: f6d7ed39fe24031e22d54f3fe65b901c
Appending input value fingerprint for 'options.debugOptions' to build cache key: a91a8430ae47b11a17f6318b53f5ce9c
Appending input value fingerprint for 'options.debugOptions.debugLevel' to build cache key: f6bd6b3389b872033d462029172c8612
Appending input value fingerprint for 'options.encoding' to build cache key: f6bd6b3389b872033d462029172c8612
...
Appending input file fingerprints for 'options.sourcepath' to build cache key: 5fd1e7396e8de4cb5c23dc6aadd7787a - RELATIVE_PATH{EMPTY}
Appending input file fingerprints for 'stableSources' to build cache key: f305ada95aeae858c233f46fc1ec4d01 - RELATIVE_PATH{.../src/main/java=IGNORED / DIR, .../src/main/java/Hello.java='Hello.java' / 9c306ba203d618dfbe1be83354ec211d}
Appending output property name to build cache key: destinationDir
Appending output property name to build cache key: options.annotationProcessorGeneratedSourcesDirectory
Build cache key for task ':compileJava' is 8ebf682168823f662b9be34d27afdf77The log shows e.g. which source files constitute the stableSources for the compileJava task.
To find the actual differences between two builds you need to resort to matching up and comparing those hashes yourself.
|
Tip
|
Develocity already takes care of this for you; it lets you quickly diagnose a cache miss with the Build Scan™ Comparison tool. |
Diagnosing the reasons for a cache miss
Having the data from the last section at hand, you should be able to diagnose why the outputs of a certain task were not found in the build cache. Since you were expecting more tasks to be cached, you should be able to pinpoint a build which would have produced the artifact under question.
Before diving into how to find out why one task has not been loaded from the cache we should first look into which task caused the cache misses. There is a cascade effect which causes dependent tasks to be executed if one of the tasks earlier in the build is not loaded from the cache and has different outputs. Therefore, you should locate the first cacheable task which was executed and continue investigating from there. This can be done from the timeline view in a Build Scan™:
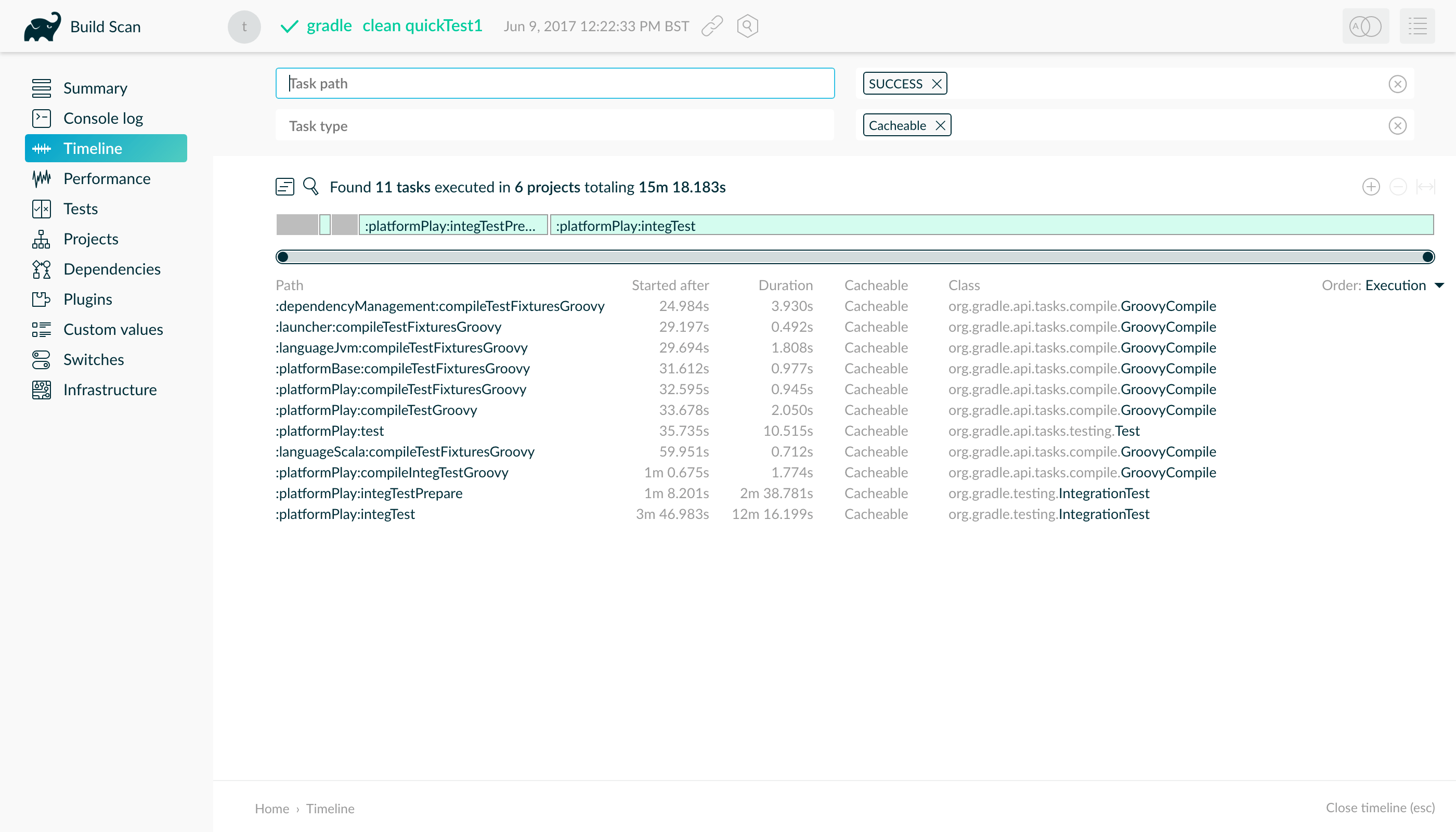
At first, you should check if the implementation of the task changed. This would mean checking the class names and classloader hashes
for the task class itself and for each of its actions. If there is a change, this means that the build script, buildSrc or the Gradle version has changed.
|
Note
|
A change in the output of |
If the implementation is the same, then you need to start comparing inputs between the two builds. There should be at least one different input hash. If it is a simple value property, then the configuration of the task changed. This can happen for example by
-
changing the build script,
-
conditionally configuring the task differently for CI or the developer builds,
-
depending on a system property or an environment variable for the task configuration,
-
or having an absolute path which is part of the input.
If the changed property is a file property, then the reasons can be the same as for the change of a value property. Most probably though a file on the filesystem changed in a way that Gradle detects a difference for this input. The most common case will be that the source code was changed by a check in. It is also possible that a file generated by a task changed, e.g. since it includes a timestamp. As described in Java version tracking, the Java version can also influence the output of the Java compiler. If you did not expect the file to be an input to the task, then it is possible that you should alter the configuration of the task to not include it. For example, having your integration test configuration including all the unit test classes as a dependency has the effect that all integration tests are re-executed when a unit test changes. Another option is that the task tracks absolute paths instead of relative paths and the location of the project directory changed on disk.
Example
We will walk you through the process of diagnosing a cache miss.
Let’s say we have build A and build B and we expected all the test tasks for a sub-project sub1 to be cached in build B since only a unit test for another sub-project sub2 changed.
Instead, all the tests for the sub-project have been executed.
Since we have the cascading effect when we have cache misses, we need to find the task which caused the caching chain to fail.
This can easily be done by filtering for all cacheable tasks which have been executed and then select the first one.
In our case, it turns out that the tests for the sub-project internal-testing were executed even though there was no code change to this project.
This means that the property classpath changed and some file on the runtime classpath actually did change.
Looking deeper into this, we actually see that the inputs for the task processResources changed in that project, too.
Finally, we find this in our build file:
val currentVersionInfo = tasks.register<CurrentVersionInfo>("currentVersionInfo") {
version = project.version as String
versionInfoFile = layout.buildDirectory.file("generated-resources/currentVersion.properties")
}
sourceSets.main.get().output.dir(currentVersionInfo.map { it.versionInfoFile.get().asFile.parentFile })
abstract class CurrentVersionInfo : DefaultTask() {
@get:Input
abstract val version: Property<String>
@get:OutputFile
abstract val versionInfoFile: RegularFileProperty
@TaskAction
fun writeVersionInfo() {
val properties = Properties()
properties.setProperty("latestMilestone", version.get())
versionInfoFile.get().asFile.outputStream().use { out ->
properties.store(out, null)
}
}
}def currentVersionInfo = tasks.register('currentVersionInfo', CurrentVersionInfo) {
version = project.version
versionInfoFile = layout.buildDirectory.file('generated-resources/currentVersion.properties')
}
sourceSets.main.output.dir(currentVersionInfo.map { it.versionInfoFile.get().asFile.parentFile })
abstract class CurrentVersionInfo extends DefaultTask {
@Input
abstract Property<String> getVersion()
@OutputFile
abstract RegularFileProperty getVersionInfoFile()
@TaskAction
void writeVersionInfo() {
def properties = new Properties()
properties.setProperty('latestMilestone', version.get())
versionInfoFile.get().asFile.withOutputStream { out ->
properties.store(out, null)
}
}
}Since properties files stored by Java’s Properties.store method contain a timestamp, this will cause a change to the runtime classpath every time the build runs.
In order to solve this problem see non-repeatable task outputs or use input normalization.
|
Note
|
The compile classpath is not affected since compile avoidance ignores non-class files on the classpath. |
Solving common problems
Small problems in a build, like forgetting to declare a configuration file as an input to your task, can be easily overlooked.
The configuration file might change infrequently, or only change when some other (correctly tracked) input changes as well.
The worst that could happen is that your task doesn’t execute when it should.
Developers can always re-run the build with clean, and "fix" their builds for the price of a slow rebuild.
In the end nobody gets blocked in their work, and the incident is chalked up to "Gradle acting up again."
With cacheable tasks incorrect results are stored permanently, and can come back to haunt you later; re-running with clean won’t help in this situation either. When using a shared cache, these problems even cross machine boundaries. In the example above, Gradle might end up loading a result for your task that was produced with a different configuration. Resolving these problems with the build therefore becomes even more important when task output caching is enabled.
Other issues with the build won’t cause it to produce incorrect results, but will lead to unnecessary cache misses.
In this chapter you will learn about some typical problems and ways to avoid them.
Fixing these issues will have the added benefit that your build will stop "acting up," and developers can forget about running builds with clean altogether.
System file encoding
Most Java tools use the system file encoding when no specific encoding is specified. This means that running the same build on machines with different file encoding can yield different outputs. Currently Gradle only tracks on a per-task basis that no file encoding has been specified, but it does not track the system encoding of the JVM in use. This can cause incorrect builds. You should always set the file system encoding to avoid these kind of problems.
|
Note
|
Build scripts are compiled with the file encoding of the Gradle daemon. By default, the daemon uses the system file encoding, too. |
Setting the file encoding for the Gradle daemon mitigates both above problems by making sure that the encoding is the same across builds.
You can do so in your gradle.properties:
org.gradle.jvmargs=-Dfile.encoding=UTF-8Environment variable tracking
Gradle does not track changes in environment variables for tasks.
For example for Test tasks it is completely possible that the outcome depends on a few environment variables.
To ensure that only the right artifacts are re-used between builds, you need to add environment variables as inputs to tasks depending on them.
Absolute paths are often passed as environment variables, too. You need to pay attention what you add as an input to the task in this case. You would need to ensure that the absolute path is the same between machines. Most times it makes sense to track the file or the contents of the directory the absolute path points to. If the absolute path represents a tool being used it probably makes sense to track the tool version as an input instead.
For example, if you are using tools in your Test task called integTest which depend on the contents of the LANG variable you should do this:
tasks.integTest {
inputs.property("langEnvironment") {
System.getenv("LANG")
}
}tasks.named('integTest') {
inputs.property("langEnvironment") {
System.getenv("LANG")
}
}If you add conditional logic to distinguish CI builds from local development builds, you have to ensure that this does not break the loading of task outputs from CI onto developer machines.
For example, the following setup would break caching of Test tasks, since Gradle always detects the differences in custom task actions.
if ("CI" in System.getenv()) {
tasks.withType<Test>().configureEach {
doFirst {
println("Running test on CI")
}
}
}if (System.getenv().containsKey("CI")) {
tasks.withType(Test).configureEach {
doFirst {
println "Running test on CI"
}
}
}You should always add the action unconditionally:
tasks.withType<Test>().configureEach {
doFirst {
if ("CI" in System.getenv()) {
println("Running test on CI")
}
}
}tasks.withType(Test).configureEach {
doFirst {
if (System.getenv().containsKey("CI")) {
println "Running test on CI"
}
}
}This way, the task has the same custom action on CI and on developer builds and its outputs can be re-used if the remaining inputs are the same.
Line endings
If you are building on different operating systems be aware that some version control systems convert line endings on check-out.
For example, Git on Windows uses autocrlf=true by default which converts all line endings to \r\n.
As a consequence, compilation outputs can’t be re-used on Windows since the input sources are different.
If sharing the build cache across multiple operating systems is important in your environment, then setting autocrlf=false across your build machines is crucial for optimal build cache usage.
Symbolic links
When using symbolic links, Gradle does not store the link in the build cache but the actual file contents of the destination of the link. As a consequence you might have a hard time when trying to reuse outputs which heavily use symbolic links. There currently is no workaround for this behavior.
For operating systems supporting symbolic links, the content of the destination of the symbolic link will be added as an input.
If the operating system does not support symbolic links, the actual symbolic link file is added as an input.
Therefore, tasks which have symbolic links as input files, e.g. Test tasks having symbolic link as part of its runtime classpath, will not be cached between Windows and Linux.
If caching between operating systems is desired, symbolic links should not be checked into version control.
Java version tracking
Gradle tracks only the major version of Java as an input for compilation and test execution. Currently, it does not track the vendor nor the minor version. Still, the vendor and the minor version may influence the bytecode produced by compilation.
|
Note
|
If you’re using Java Toolchains, the Java major version, the vendor (if specified) and implementation (if specified) will be tracked automatically as an input for compilation and test execution. |
If you use different JVM vendors for compiling or running Java we strongly suggest that you add the vendor as an input to the corresponding tasks. This can be achieved by using the runtime API as shown in the following snippet.
tasks.withType<AbstractCompile>().configureEach {
inputs.property("java.vendor") {
System.getProperty("java.vendor")
}
}
tasks.withType<Test>().configureEach {
inputs.property("java.vendor") {
System.getProperty("java.vendor")
}
}tasks.withType(AbstractCompile).configureEach {
inputs.property("java.vendor") {
System.getProperty("java.vendor")
}
}
tasks.withType(Test).configureEach {
inputs.property("java.vendor") {
System.getProperty("java.vendor")
}
}With respect to tracking the Java minor version there are different competing aspects: developers having cache hits and "perfect" results on CI. There are basically two situations when you may want to track the minor version of Java: for compilation and for runtime. In the case of compilation, there can sometimes be differences in the produced bytecode for different minor versions. However, the bytecode should still result in the same runtime behavior.
|
Note
|
Java compile avoidance will treat this bytecode the same since it extracts the ABI. |
Treating the minor number as an input can decrease the likelihood of a cache hit for developer builds. Depending on how standard development environments are across your team, it’s common for many different Java minor version to be in use.
Even without tracking the Java minor version you may have cache misses for developers due to some locally compiled class files which constitute an input to test execution. If these outputs made it into the local build cache on this developers machine even a clean will not solve the situation. Therefore, the choice for tracking the Java minor version is between sometimes or never re-using outputs between different Java minor versions for test execution.
|
Note
|
The compiler infrastructure provided by the JVM used to run Gradle is also used by the Groovy compiler. Therefore, you can expect differences in the bytecode of compiled Groovy classes for the same reasons as above and the same suggestions apply. |
Avoid changing inputs external to your build
If your build is dependent on external dependencies like binary artifacts or dynamic data from a web page you need to make sure that these inputs are consistent throughout your infrastructure. Any variations across machines will result in cache misses.
Never re-release a non-changing binary dependency with the same version number but different contents: if this happens with a plugin dependency, you will never be able to explain why you don’t see cache reuse between machines (it’s because they have different versions of that artifact).
Using SNAPSHOTs or other changing dependencies in your build by design violates the stable task inputs principle.
To use the build cache effectively, you should depend on fixed dependencies.
You may want to look into dependency locking or switch to using composite builds instead.
The same is true for depending on volatile external resources, for example a list of released versions. One way of locking the changes would be to check the volatile resource into source control whenever it changes so that the builds only depend on the state in source control and not on the volatile resource itself.
Suggestions for authoring your build
Review usages of doFirst and doLast
Using doFirst and doLast from a build script on a cacheable task ties you to build script changes since the implementation of the closure comes from the build script.
If possible, you should use separate tasks instead.
Modifying input or output properties via the runtime API in doFirst is discouraged since these changes will not be detected for up-to-date checks and the build cache.
Even worse, when the task does not execute, then the configuration of the task is actually different from when it executes.
Instead of using doFirst for modifying the inputs consider using a separate task to configure the task under question - a so called configure task.
E.g., instead of doing
tasks.jar {
val runtimeClasspath: FileCollection = configurations.runtimeClasspath.get()
doFirst {
manifest {
val classPath = runtimeClasspath.map { it.name }.joinToString(" ")
attributes("Class-Path" to classPath)
}
}
}tasks.named('jar') {
FileCollection runtimeClasspath = configurations.runtimeClasspath
doFirst {
manifest {
def classPath = runtimeClasspath.collect { it.name }.join(" ")
attributes('Class-Path': classPath)
}
}
}do
val configureJar = tasks.register("configureJar") {
doLast {
tasks.jar.get().manifest {
val classPath = configurations.runtimeClasspath.get().map { it.name }.joinToString(" ")
attributes("Class-Path" to classPath)
}
}
}
tasks.jar { dependsOn(configureJar) }def configureJar = tasks.register('configureJar') {
doLast {
tasks.jar.manifest {
def classPath = configurations.runtimeClasspath.collect { it.name }.join(" ")
attributes('Class-Path': classPath)
}
}
}
tasks.named('jar') { dependsOn(configureJar) }|
Warning
|
Note that configuring a task from other task is not supported when using the configuration cache. |
Build logic based on the outcome of a task
Do not base build logic on whether a task has been executed.
In particular you should not assume that the output of a task can only change if it actually executed.
Actually, loading the outputs from the build cache would also change them.
Instead of relying on custom logic to deal with changes to input or output files you should leverage Gradle’s built-in support by declaring the correct inputs and outputs for your tasks and leave it to Gradle to decide if the task actions should be executed.
For the very same reason using outputs.upToDateWhen is discouraged and should be replaced by properly declaring the task’s inputs.
Overlapping outputs
You already saw that overlapping outputs are a problem for task output caching.
When you add new tasks to your build or re-configure built-in tasks make sure you do not create overlapping outputs for cacheable tasks.
If you must you can add a Sync task which then would sync the merged outputs into the target directory while the original tasks remain cacheable.
Develocity will show tasks where caching was disabled for overlapping outputs in the timeline and in the task input comparison:
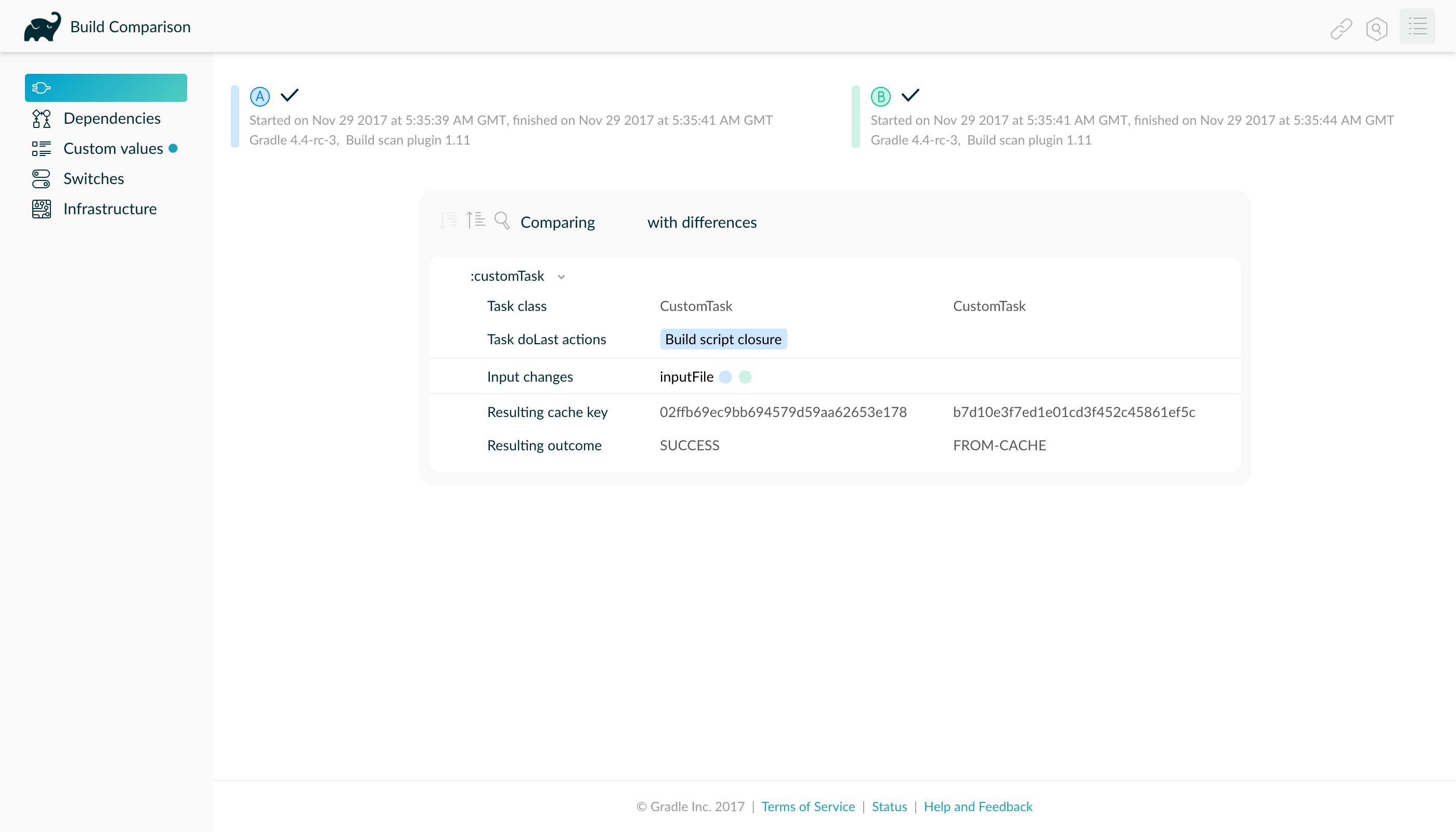
Achieving stable task inputs
It is crucial to have stable task inputs for every cacheable task. In the following section you will learn about different situations which violate stable task inputs and look at possible solutions.
Volatile task inputs
If you use a volatile input like a timestamp as an input property for a task, then there is nothing Gradle can do to make the task cacheable. You should really think hard if the volatile data is really essential to the output or if it is only there for e.g. auditing purposes.
If the volatile input is essential to the output then you can try to make the task using the volatile input cheaper to execute. You can do this by splitting the task into two tasks - the first task doing the expensive work which is cacheable and the second task adding the volatile data to the output. In this way the output stays the same and the build cache can be used to avoid doing the expensive work. For example, for building a jar file the expensive part - Java compilation - is already a different task while the jar task itself, which is not cacheable, is cheap.
If it is not an essential part of the output, then you should not declare it as an input. As long as the volatile input does not influence the output then there is nothing else to do. Most times though, the input will be part of the output.
Non-repeatable task outputs
Having tasks which generate different outputs for the same inputs can pose a challenge for the effective use of task output caching as seen in repeatable task outputs. If the non-repeatable task output is not used by any other task then the effect is very limited. It basically means that loading the task from the cache might produce a different result than executing the same task locally. If the only difference between the outputs is a timestamp, then you can either accept the effect of the build cache or decide that the task is not cacheable after all.
Non-repeatable task outputs lead to non-stable task inputs as soon as another task depends on the non-repeatable output. For example, re-creating a jar file from the files with the same contents but different modification times yields a different jar file. Any other task depending on this jar file as an input file cannot be loaded from the cache when the jar file is rebuilt locally. This can lead to hard-to-diagnose cache misses when the consuming build is not a clean build or when a cacheable task depends on the output of a non-cacheable task. For example, when doing incremental builds it is possible that the artifact on disk which is considered up-to-date and the artifact in the build cache are different even though they are essentially the same. A task depending on this task output would then not be able to load outputs from the build cache since the inputs are not exactly the same.
As described in the stable task inputs section, you can either make the task outputs repeatable or use input normalization. You already learned about the possibilities with configurable input normalization.
Tasks that produce archives (tar, zip) are reproducible by default, starting with Gradle 9.0.0.
For earlier Gradle versions or if you want explicit configuration, you can make archives reproducible configuring a task in the following way:
tasks.register<Zip>("createZip") {
isPreserveFileTimestamps = false
isReproducibleFileOrder = true
dirPermissions { unix("755") }
filePermissions { unix("644") }
// ...
}tasks.register('createZip', Zip) {
preserveFileTimestamps = false
reproducibleFileOrder = true
dirPermissions { unix("755") }
filePermissions { unix("644") }
// ...
}Another way to make the outputs repeatable is to activate caching for a task with non-repeatable outputs. If you can make sure that the same build cache is used for all builds then the task will always have the same outputs for the same inputs by design of the build cache. Going down this road can lead to different problems with cache misses for incremental builds as described above. Moreover, race conditions between different builds trying to store the same outputs in the build cache in parallel can lead to hard-to-diagnose cache misses. If possible, you should avoid going down that route.
Limit the effect of volatile data
If none of the described solutions for dealing with volatile data work for you, you should still be able to limit the effect of volatile data on effective use of the build cache.
This can be done by adding the volatile data later to the outputs as described in the volatile task inputs section.
Another option would be to move the volatile data so it affects fewer tasks.
For example moving the dependency from the compile to the runtime configuration may already have quite an impact.
Sometimes it is also possible to build two artifacts, one containing the volatile data and another one containing a constant representation of the volatile data. The non-volatile output would be used e.g. for testing while the volatile one would be published to an external repository. While this conflicts with the Continuous Delivery "build artifacts once" principle it can sometimes be the only option.
Custom and third party tasks
If your build contains custom or third party tasks, you should take special care that these don’t influence the effectiveness of the build cache.
Special care should also be taken for code generation tasks which may not have repeatable task outputs.
This can happen if the code generator includes e.g. a timestamp in the generated files or depends on the order of the input files.
Other pitfalls can be the use of HashMaps or other data structures without order guarantees in the task’s code.
|
Warning
|
Some third party plugins can even influence cacheability of Gradle’s built-in tasks.
This can happen if they add inputs like absolute paths or volatile data to tasks via the runtime API.
In the worst case this can lead to incorrect builds when the plugins try to depend on the outcome of a task and do not take |
Configuration Cache
The Configuration Cache improves build performance by caching the result of the configuration phase and reusing it for subsequent builds.

Configuration Cache Basics
The Gradle Build Lifecycle consists of three phases: initialization, configuration, and execution.
-
The initialization phase determines the structure of the build.
-
The configuration phase evaluates what work needs to be done.
-
The execution phase performs that work.
Gradle’s Build Cache has long optimized the execution phase by reusing previously built outputs and parallelizing as much work as possible.
The Configuration Cache builds on this idea of work avoidance and parallelization. When enabled, the Configuration Cache allows Gradle to skip the configuration phase entirely if nothing that affects the build configuration (such as build scripts) has changed. Additionally, Gradle applies performance optimizations to task execution.
To do this, Gradle does the following:
| Phase | Cache | Cache Key | Work Avoidance | Parallelism and Performance |
|---|---|---|---|---|
Configuration |
Configuration Cache |
Build logic and environment |
Skip project configuration |
Runs tasks in parallel within the same project, optimizes memory, and more |
Execution |
Build Cache |
Task inputs |
Skip task execution |
Runs independent tasks in different projects in parallel with |
The Configuration Cache is similar to the Build Cache, but they store different types of data:
-
Build Cache: Stores outputs and intermediate files of the build (e.g., task outputs, artifact transform outputs).
-
Configuration Cache: Stores the build configuration for a particular set of tasks, capturing the output of the configuration phase.

|
Important
|
This feature is not enabled by default and has the following limitations:
Since Gradle 9.0.0 the Configuration Cache is the preferred mode of execution. |
Work Avoidance
When the Configuration Cache is enabled and you run Gradle for a specific set of tasks, such as ./gradlew check, Gradle looks for a Configuration Cache entry.
If a matching entry is found, Gradle reuses it and skips the configuration phase entirely.
A cache hit is essential for avoiding configuration work.
Configuration Cache Entries
A cache entry contains:
-
The set of tasks to run
-
Their configuration details
-
Dependency information
First-Time Execution

The first time you run a set of tasks, there is no cache entry. Gradle performs the configuration phase as usual:
-
Run init scripts.
-
Run the settings script, applying any requested settings plugins.
-
Configure and build the
buildSrcproject, if present. -
Run build scripts, applying any requested project plugins. If plugins come from included builds, Gradle builds them first.
-
Calculate the task graph, executing deferred configuration actions.
Gradle then stores a snapshot of the task graph in the Configuration Cache for future use. After this, Gradle loads the task graph from the cache and proceeds with task execution.
|
Note
|
When it is enabled, Gradle always loads from the configuration cache - even on a cache miss - to ensure that hits and misses are handled consistently. |
Subsequent Runs
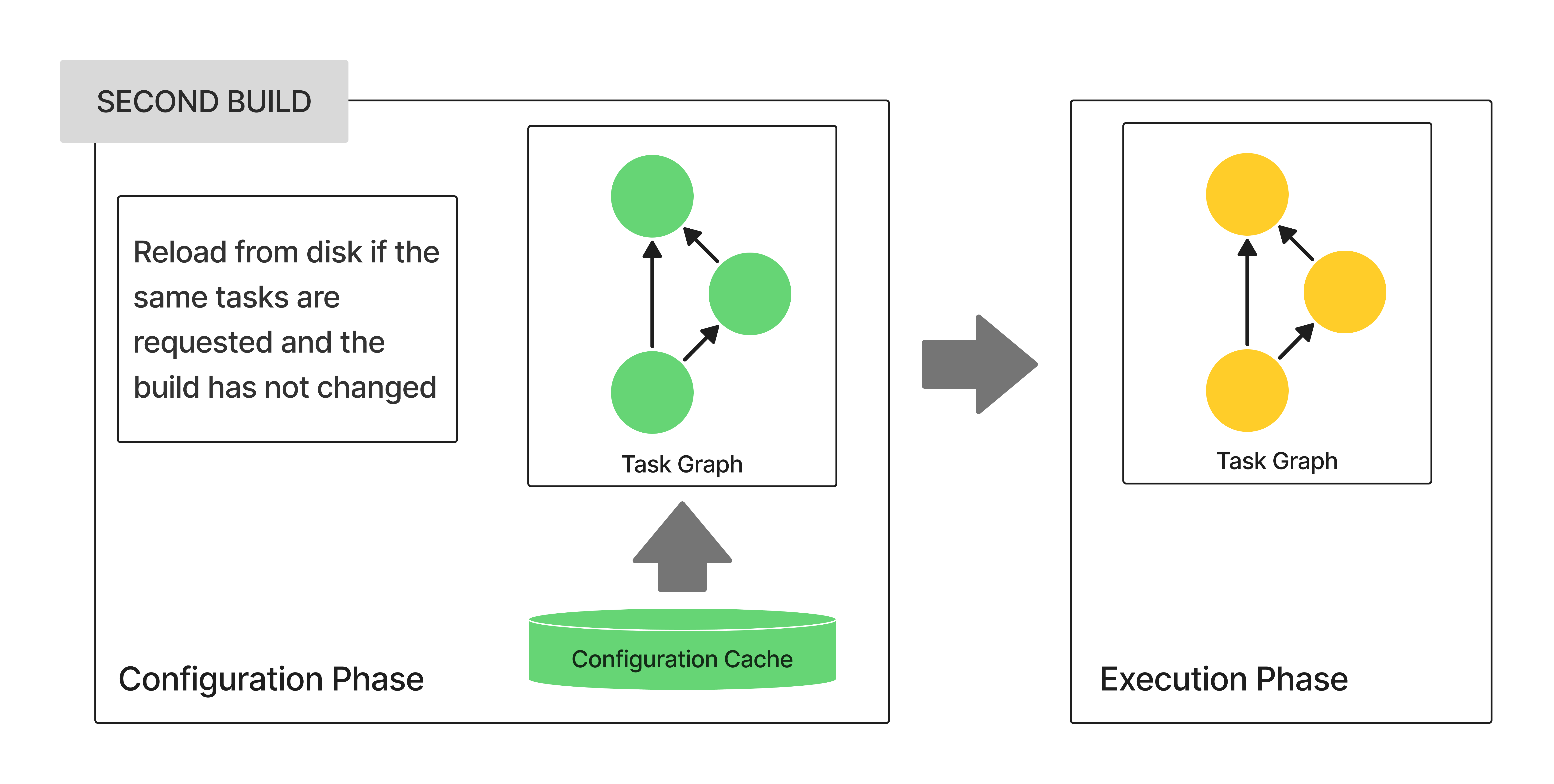
On subsequent executions of the same tasks (e.g., ./gradlew check again), Gradle:
-
Skips the configuration phase entirely.
-
Loads the task graph from the Configuration Cache instead.
To match a saved entry in the cache, Gradle verifies that no build configuration inputs have changed. If any input has changed, Gradle reruns the configuration phase and stores a new entry in the cache.
Build Configuration Inputs
The following elements determine whether a Configuration Cache entry is valid:
-
Gradle environment
-
GRADLE_USER_HOME -
Gradle Daemon JVM
-
-
Init scripts
-
buildSrcand included build logic build contents (build scripts, sources, and intermediate build outputs) -
Build and Settings scripts, including included scripts (
apply from: foo.gradle) -
Gradle configuration files (Version Catalogs, dependency verification files, dependency lock files,
gradle.propertiesfiles) -
Contents of files read at configuration time
-
File system state checked at configuration time (file presence, directory contents, etc.)
-
Custom
ValueSourcevalues obtained at configuration time (this also includes built-in providers, likeproviders.execandproviders.fileContents). -
System properties used during the configuration phase
-
Environment variables used during the configuration phase
Serialization
Gradle uses an optimized serialization mechanism to store Configuration Cache entries. It automatically serializes object graphs containing simple state or supported types.
While Configuration Cache serialization doesn’t rely on Java Serialization, it understands some of its features. This can be used to customize serialization behavior, but incurs a performance penalty and should be avoided.
Performance Improvements
Beyond skipping the configuration phase, the Configuration Cache enhances performance in the following ways:
-
Parallel Task Execution: When parallel execution is enabled, even tasks within the same project can be run in parallel, subject to dependency constraints.
-
Cached Dependency Resolution: Dependency resolution results are stored and reused.

IDE Support
If you enable and configure the Configuration Cache in your gradle.properties file, it will be automatically enabled when your IDE delegates builds to Gradle.
No additional setup is required.
Because gradle.properties is typically checked into source control,
enabling the Configuration Cache this way will apply to your entire team.
If you prefer to enable it only for your local environment, you can configure it directly in your IDE instead.
|
Note
|
Syncing a project in an IDE does not benefit from the Configuration Cache. Only running tasks through the IDE will leverage the cache. |
IntelliJ based IDEs
In IntelliJ IDEA or Android Studio this can be done in two ways, either globally or per run configuration.
To enable it for the whole build, go to Run > Edit configurations….
This will open the IntelliJ IDEA or Android Studio dialog to configure Run/Debug configurations.
Select Templates > Gradle and add the necessary system properties to the VM options field.
For example to enable the Configuration Cache, turning problems into warnings, add the following:
-Dorg.gradle.configuration-cache=true -Dorg.gradle.configuration-cache.problems=warnYou can also choose to only enable it for a given run configuration.
In this case, leave the Templates > Gradle configuration untouched and edit each run configuration as you see fit.
Using these methods together, you can enable the Configuration Cache globally while disabling it for certain run configurations, or vice versa.
|
Tip
|
You can use the gradle-idea-ext-plugin to configure IntelliJ run configurations from your build. This is a good way to enable the Configuration Cache only for the IDE. |
Eclipse based IDEs
In Eclipse-based IDEs, you can enable the Configuration Cache through Buildship, either globally or per run configuration.
To enable it globally:
-
Go to
Preferences > Gradle. -
Add the following JVM arguments:
-
-Dorg.gradle.configuration-cache=true -
-Dorg.gradle.configuration-cache.problems=warn
-
To enable it for a specific run configuration:
-
Open
Run Configurations…. -
Select the desired configuration.
-
Navigate to
Project Settings, checkOverride project settings, and add the same system properties asJVM arguments.
Using these methods together, you can enable the Configuration Cache globally while disabling it for certain run configurations, or vice versa.
Enabling and Configuring the Configuration Cache
Enabling the Configuration Cache
By default, Gradle does not use the Configuration Cache.
To enable it at build time, use the configuration-cache flag:
$ ./gradlew --configuration-cacheTo enable the cache persistently, set the org.gradle.configuration-cache property in gradle.properties:
org.gradle.configuration-cache=trueIf enabled in gradle.properties, you can override it and disable the cache at build time using the no-configuration-cache flag:
$ ./gradlew --no-configuration-cacheIgnoring Configuration Cache Problems
By default, Gradle fails the build if Configuration Cache problems occur. However, when gradually updating plugins or build logic to support the Configuration Cache, it can be useful to temporarily turn problems into warnings by enabling warning mode.
To change this behavior at build time, use the following flag:
$ ./gradlew --configuration-cache-problems=warn|
Note
|
This does not guarantee that the build will succeed. |
Alternatively, configure it in gradle.properties:
org.gradle.configuration-cache.problems=warn|
Warning
|
Warning mode is a migration and troubleshooting aid and not intended as a persistent way of ignoring incompatibilities. It will also not prevent new incompatibilities being accidentally added to your build later. Instead, we recommend explicitly marking problematic tasks as incompatible. |
Allowing a Maximum Number of Problems
When Configuration Cache problems are treated as warnings, Gradle will fail the build if 512 problems are found by default.
You can adjust this limit by specifying the maximum number of allowed problems on the command line:
$ ./gradlew -Dorg.gradle.configuration-cache.max-problems=5Or configure it in a gradle.properties file:
org.gradle.configuration-cache.max-problems=5Enabling Parallel Configuration Caching
By default, Configuration Cache storing and loading are sequential. Enabling parallel storing and loading can improve performance, but not all builds are compatible with it.
To enable parallel configuration caching at build time, use:
$ ./gradlew -Dorg.gradle.configuration-cache.parallel=trueOr persistently in a gradle.properties file:
org.gradle.configuration-cache.parallel=true|
Warning
|
The parallel configuration caching feature is incubating, and some builds may not work correctly.
A common symptom of incompatibility is |
Making the Configuration Cache Read-Only
In some builds, such as CI builds running in ephemeral environments, it may be desirable for Gradle to use the Configuration Cache only when there’s a cache hit. If there’s a miss, caching offers no benefit since the disk state won’t be preserved across builds.
To enable read-only configuration caching at build time, use:
$ ./gradlew -Dorg.gradle.configuration-cache.read-only=trueOr set it persistently in gradle.properties:
org.gradle.configuration-cache.read-only=trueNote that if you enable this persistently, you’ll need to explicitly disable it via the command line in order for Gradle to ever write to the configuration cache.
|
Warning
|
The read-only configuration caching feature is incubating. |
Enabling Strict Configuration Cache Mode
To help teams adopt configuration caching, Gradle provides a strict mode behind a dedicated feature flag.
You can enable this feature flag in your build using the following configuration:
enableFeaturePreview("STABLE_CONFIGURATION_CACHE")enableFeaturePreview "STABLE_CONFIGURATION_CACHE"Enabling the STABLE_CONFIGURATION_CACHE feature flag activates stricter validation and introduces the following behavior:
- Undeclared Shared Build Service Usage
-
If a task uses a shared Build Service without explicitly declaring the requirement using the
Task.usesServicemethod, Gradle will emit a deprecation warning. - Deprecation Enforcement Without Configuration Cache
-
Even when the Configuration Cache is not enabled, Gradle will warn if the following deprecated features are used:
We recommend enabling this flag early to detect and resolve potential issues before the stricter behavior becomes the default in a future release.
Invalidating the Configuration Cache
The Configuration Cache is automatically invalidated when inputs to the configuration phase change. However, some inputs are not yet tracked, meaning you may need to manually invalidate the cache when untracked inputs change. This is more likely if you have ignored problems.
See the [config_cache:requirements] and Not Yet Implemented sections for more details.
The Configuration Cache state is stored in a .gradle/configuration-cache directory in the root of your Gradle build.
To manually invalidate the cache, delete this directory:
$ rm -rf .gradle/configuration-cacheGradle periodically checks (at most every 24 hours) whether cached entries are still in use. Entries that have not been used for 7 days are automatically deleted.
Adopting the Configuration Cache
The following stages outline a recommended path for adopting the Configuration Cache. These steps apply to both builds and plugins:
1. Not using / Not enabled
An important prerequisite is to keep your Gradle version and plugins up to date.
While following this process, refer to the HTML report and the solutions explained in the Requirements page.
If any problem is found caching or reusing the configuration, an HTML report is generated to help you diagnose and fix the issues. The report also shows detected build configuration inputs like system properties, environment variables and value suppliers read during the configuration phase.
See the Debugging page for more information.
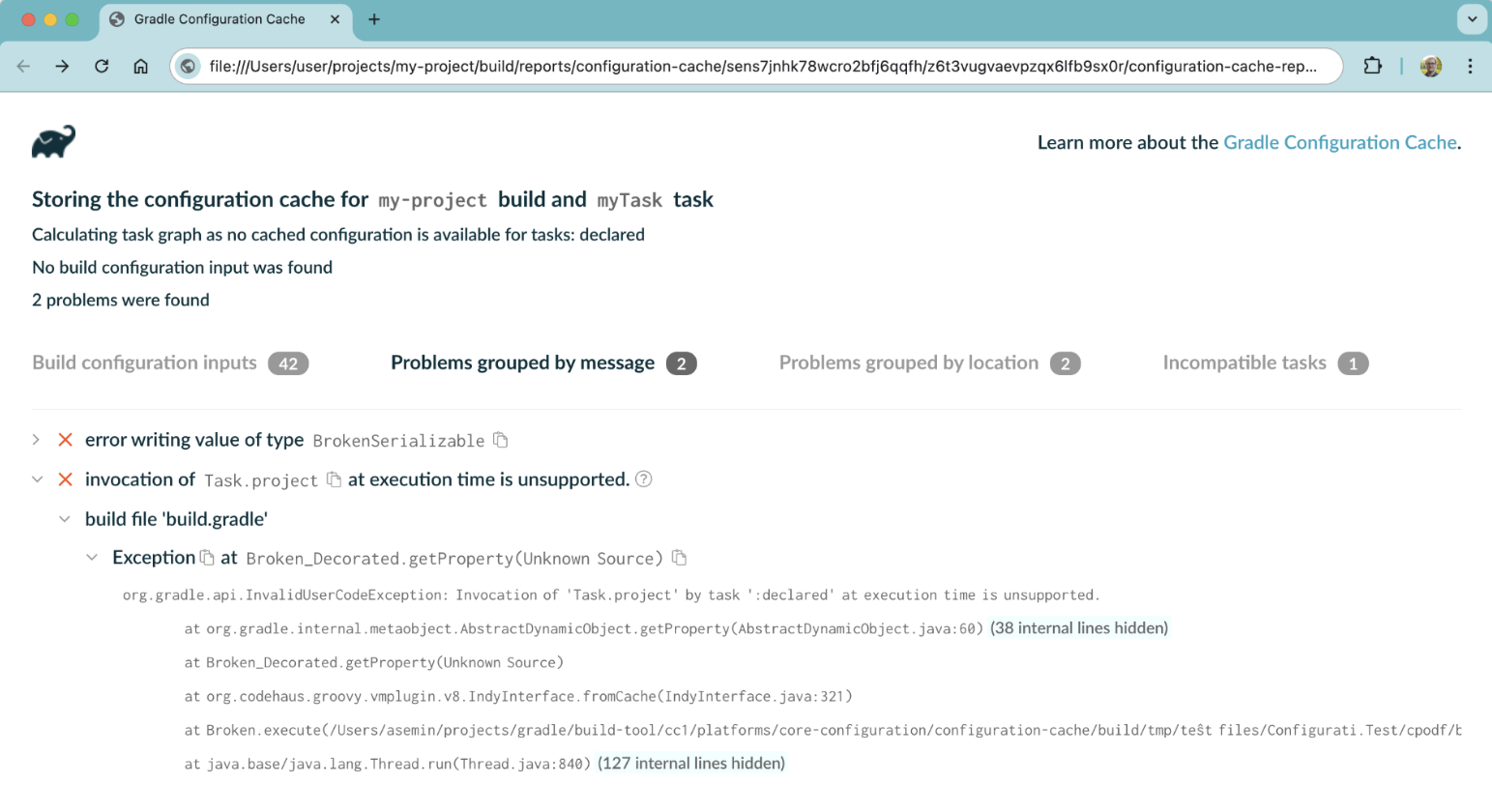
2. Using locally
-
Start with
helpAlways begin by testing your build or plugin with the simplest task:
help. This exercises the minimal configuration phase of your build or plugin. -
Progressively target useful tasks
Avoid running
buildright away. Instead:-
Use
--dry-runto identify configuration time problems first. -
When working on a build, focus on your development feedback loop, such as running tests after modifying source code.
-
When working on a plugin, progressively target the contributed or configured tasks.
-
-
Explore by turning problems into warnings
Don’t stop at the first build failure—turn problems into warnings to better understand how your build and plugins behave. If a build fails:
-
Use the HTML report to analyze the reported problems.
-
Continue testing more tasks to get a full picture of the issues affecting your build and plugins.
-
Keep in mind that when turning problems into warnings, you may need to manually invalidate the cache in case of unexpected behavior.
-
Mark tasks as incompatible if needed using
myTask.notCompatibleWithConfigurationCache("because").
-
-
Step back and fix problems iteratively
Once you have a clear understanding of the issues, start fixing them iteratively. Use the HTML report and this documentation to guide your process:
-
Begin with problems reported when storing the Configuration Cache.
-
Once those are fixed, move on to addressing any problems encountered when loading the Configuration Cache.
-
-
Report encountered issues
If you encounter issues with a Gradle Feature or a Core Gradle Plugin that is not covered by this documentation, report it to
gradle/gradle.For community Gradle plugins, check if the issue is already listed at gradle/gradle#13490 and report it to the plugin’s issue tracker if necessary.
A good bug report should include:
-
A link to this documentation.
-
The plugin version you tested.
-
Any custom plugin configuration, or ideally a reproducer build.
-
A description of what fails (e.g., problems with a specific task).
-
A copy of the build failure output.
-
The self-contained
configuration-cache-report.htmlfile.
-
-
Test, test, test
Add tests for your build logic to catch issues early. See Testing Your Build Logic for details on testing Configuration Cache compatibility. This will help during iterations and prevent regressions.
3. Using on CI / Enable everywhere
Once your developer workflow (e.g., running tests from the IDE) is stable, consider enabling the Configuration Cache for your team:
-
Initially, introduce it as an opt-in feature.
-
If necessary, turn problems into warnings and set a maximum number of allowed problems in your
gradle.propertiesfile. -
Keep the Configuration Cache disabled by default, and encourage team members to opt in by configuring their IDE run settings.
-
When more workflows are stable, reverse this approach:
-
Enable the Configuration Cache by default.
-
Configure CI to disable it where needed.
-
Communicate any unsupported workflows that require disabling the Configuration Cache.
-
Once everything is stable locally and within your team, consider enabling the Configuration Cache on CI:
-
This ensures your builds stays CC compliant, and developers can’t introduce problems accidentally!
-
CC overhead is compensated for by the intra-project task parallelism.
-
Getting cache hits may not be possible initially (this is normal).
When you are ready to focus on hit rates:
-
Consider reducing or removing build logic inputs.
-
Track hit rates with Develocity’s Reporting & Visualization Kit.
-
Fix issues with Build Scan.
Reacting to the Configuration Cache in the Build
Build logic or plugin implementations can detect whether the Configuration Cache is enabled for a given build and adjust behavior accordingly.
The active status of the Configuration Cache is provided in the corresponding build feature.
You can access it by injecting the BuildFeatures service into your code.
This information can be used to:
-
Configure plugin features differently when the Configuration Cache is enabled.
-
Disable an optional feature that is not yet compatible with the Configuration Cache.
-
Provide additional guidance to users, such as informing them of temporary limitations or suggesting adjustments to their setup.
Adopting changes in the Configuration Cache behavior
Gradle releases continuously enhance the Configuration Cache by detecting more cases where configuration logic interacts with the environment. These improvements increase cache correctness by preventing false cache hits but also introduce stricter rules that plugins and build logic must follow for optimal caching.
Some newly detected configuration inputs may not impact the configured tasks but can still cause cache invalidation. To minimize unnecessary cache misses, follow these steps:
-
Identify problematic configuration inputs using the Configuration Cache report.
-
Fix undeclared configuration inputs accessed by project build logic.
-
Report issues caused by third-party plugins to their maintainers and update plugins once they are fixed.
-
-
Use opt-out options for specific cases to temporarily revert to earlier behavior and prevent Gradle from tracking certain inputs. This can help mitigate performance issues caused by outdated plugins.
It is possible to temporarily opt out of configuration input detection in the following cases:
-
Gradle now tracks file system interactions, including checks such as
File.exists()orFile.isFile(), as configuration inputs.To prevent input tracking from invalidating the cache due to these file system checks, use the
org.gradle.configuration-cache.inputs.unsafe.ignore.file-system-checksproperty ingradle.properties. List the paths to be ignored, relative to the root project directory, separated by;. Wildcards (*for segments,**for multiple segments) are supported. Paths prefixed with~/are relative to the user’s home directory. For example:gradle.propertiesorg.gradle.configuration-cache.inputs.unsafe.ignore.file-system-checks=\ ~/.third-party-plugin/*.lock;\ ../../externalOutputDirectory/**;\ build/analytics.json -
Prior to Gradle 8.4, some undeclared configuration inputs that were never used during configuration could still be read when the Configuration Cache serialized the task graph. However, these changes did not invalidate the cache.
Starting in Gradle 8.4, these undeclared inputs are correctly tracked and now cause cache invalidation.
To temporarily revert to the previous behavior, set the Gradle property
org.gradle.configuration-cache.inputs.unsafe.ignore.in-serializationtotrue.
With the evolution of the Configuration Cache, Gradle may impose additional restrictions on build logic. To make adoption smoother, it is possible to temporarily opt out of these restrictions in specific cases:
-
Starting with Gradle 9.0.0, it is an error to use any provider, except a provider of
BuildServicereturned fromBuildServiceRegistry.registerIfAbsentorBuildServiceRegistration.getServiceas an argument forBuildEventsListenerRegistry.onTaskCompletion.Prior to Gradle 9, unsupported providers were silently discarded and never received events during cache-hit builds.
To temporarily revert to the previous behavior, set the Gradle property:
org.gradle.configuration-cache.unsafe.ignore.unsupported-build-events-listeners=true
Use these opt-out options sparingly and only when they do not impact task execution results. These options are intended as temporary workarounds and will be removed in future Gradle releases.
Configuration Cache Requirements for your Build Logic
To capture and reload the task graph state using the Configuration Cache, Gradle enforces specific requirements on tasks and build logic. Any violation of these requirements is reported as a Configuration Cache "problem," which causes the build to fail.
In most cases, these requirements expose undeclared inputs, making builds more strict, correct, and reliable. Using the Configuration Cache is effectively an opt-in to these improvements.
The following sections describe each requirement and provide guidance on resolving issues in your build.
Certain Types must not be Referenced by Tasks
Some types must not be referenced by task fields or in task actions (methods annotated @TaskAction, or the doFirst {} and doLast {} DSL blocks).
These types fall into the following categories:
-
Live JVM state types
-
Gradle model types
-
Dependency management types
These restrictions exist because these types cannot easily be stored or reconstructed by the Configuration Cache.
Live JVM State Types
Live JVM state types (e.g., ClassLoader, Thread, OutputStream, Socket) are disallowed, as they do not represent task inputs or outputs.
The only exceptions are standard streams (System.in, System.out, System.err), which can be used, for example, as parameters for Exec and JavaExec tasks.
Concurrency and Synchronization Primitives
Common synchronization primitives from the JDK must not be referenced by task fields or captured in task actions. These types represent live state that cannot be safely serialized.
Prohibited types include interfaces (and all their implementations, e.g. ReentrantLock) and classes from the java.util.concurrent and java.util.concurrent.locks packages, such as:
-
Lock,ReadWriteLock -
CountDownLatch,CyclicBarrier,Phaser,Semaphore -
Exchanger,SynchronousQueue
Using these for cross-task synchronization will not work because the configuration cache isolates tasks: each task instance receives its own independent object, and no global synchronization occurs.
The isolation also applies to objects used in synchronized blocks, so they cannot be used for cross-task synchronization either. Unlike the primitives above, Gradle cannot detect this case automatically.
To share or coordinate state between tasks, use shared build services.
Gradle Model Types
Gradle model types (e.g., Gradle, Settings, Project, SourceSet, Configuration) are often used to pass task inputs that should instead be explicitly declared.
For example, instead of referencing a Project to retrieve project.version at execution time, declare the project version as a Property<String> input.
Similarly, instead of referencing a SourceSet for source files or classpath resolution, declare these as a FileCollection input.
Dependency Management Types
The same requirement applies to dependency management types with some nuances.
Some dependency management types, such as Configuration and SourceDirectorySet, should not be used as task inputs because they contain unnecessary state and are not precise.
Use a less specific type that gives necessary features instead:
-
If referencing a
Configurationto get resolved files, declare aFileCollectioninput. -
If referencing a
SourceDirectorySet, declare aFileTreeinput.
Additionally, referencing resolved dependency results is disallowed (e.g., ArtifactResolutionQuery, ResolvedArtifact, ArtifactResult).
Instead:
-
Use a
Provider<ResolvedComponentResult>fromResolutionResult.getRootComponent(). -
Use
ArtifactCollection.getResolvedArtifacts(), which returns aProvider<Set<ResolvedArtifactResult>>.
Tasks should avoid referencing resolved results and instead rely on lazy specifications to defer dependency resolution until execution time.
Some types, such as Publication or Dependency, are not serializable but could be made so in the future.
Gradle may allow them as task inputs if necessary.
The following task references a SourceSet, which is not allowed:
abstract class SomeTask : DefaultTask() {
@get:Input lateinit var sourceSet: SourceSet // (1)
@TaskAction
fun action() {
val classpathFiles = sourceSet.compileClasspath.files
// ...
}
}abstract class SomeTask extends DefaultTask {
@Input SourceSet sourceSet // (1)
@TaskAction
void action() {
def classpathFiles = sourceSet.compileClasspath.files
// ...
}
}-
This will be reported as a problem because referencing
SourceSetis not allowed
The following is the fixed version:
abstract class SomeTask : DefaultTask() {
@get:InputFiles @get:Classpath
abstract val classpath: ConfigurableFileCollection // (1)
@TaskAction
fun action() {
val classpathFiles = classpath.files
// ...
}
}abstract class SomeTask extends DefaultTask {
@InputFiles @Classpath
abstract ConfigurableFileCollection getClasspath() // (1)
@TaskAction
void action() {
def classpathFiles = classpath.files
// ...
}
}-
No more problems reported, the task now uses the supported type
ConfigurableFileCollection
If an ad-hoc task in a script captures a disallowed reference in a doLast {} closure:
tasks.register("someTask") {
doLast {
val classpathFiles = sourceSets.main.get().compileClasspath.files // (1)
}
}tasks.register('someTask') {
doLast {
def classpathFiles = sourceSets.main.compileClasspath.files // (1)
}
}-
This will be reported as a problem because the
doLast {}closure is capturing a reference to theSourceSet
You still need to fulfill the same requirement, that is, do not reference the disallowed type during task execution.
This is how the task declaration above can be fixed:
tasks.register("someTask") {
val classpath = sourceSets.main.get().compileClasspath // (1)
doLast {
val classpathFiles = classpath.files
}
}tasks.register('someTask') {
def classpath = sourceSets.main.compileClasspath // (1)
doLast {
def classpathFiles = classpath.files
}
}-
No more problems reported, the
doLast {}closure now only capturesclasspathwhich is of the supportedFileCollectiontype
Sometimes, a disallowed type is indirectly referenced through another type. For example, a task may reference an allowed type that, in turn, references a disallowed type. The hierarchical view in the HTML problem report can help you trace such issues and identify the offending reference.
Using the Project Object at Execution Time
Tasks must not use any Project objects during execution.
This includes calling Task.getProject() while a task is running.
Some cases can be resolved similarly to those described in disallowed types.
Often, equivalent functionality is available on both Project and Task.
For example:
-
If you need a
Logger, useTask.loggerinstead ofProject.logger. -
For file operations, use injected services rather than
Projectmethods.
The following task incorrectly references the Project object at execution time:
abstract class SomeTask : DefaultTask() {
@TaskAction
fun action() {
project.copy { // (1)
from("source")
into("destination")
}
}
}abstract class SomeTask extends DefaultTask {
@TaskAction
void action() {
project.copy { // (1)
from 'source'
into 'destination'
}
}
}-
This will be reported as a problem because the task action is using the
Projectobject at execution time
Fixed version:
abstract class SomeTask : DefaultTask() {
@get:Inject abstract val fs: FileSystemOperations // (1)
@TaskAction
fun action() {
fs.copy {
from("source")
into("destination")
}
}
}abstract class SomeTask extends DefaultTask {
@Inject abstract FileSystemOperations getFs() // (1)
@TaskAction
void action() {
fs.copy {
from 'source'
into 'destination'
}
}
}-
No more problem reported, the injected
FileSystemOperationsservice is supported as a replacement forproject.copy {}
If the same problem occurs in an ad-hoc task in a script:
tasks.register("someTask") {
doLast {
project.copy { // (1)
from("source")
into("destination")
}
}
}tasks.register('someTask') {
doLast {
project.copy { // (1)
from 'source'
into 'destination'
}
}
}-
This will be reported as a problem because the task action is using the
Projectobject at execution time
Fixed version:
interface Injected {
@get:Inject val fs: FileSystemOperations // (1)
}
tasks.register("someTask") {
val injected = project.objects.newInstance<Injected>() // (2)
doLast {
injected.fs.copy { // (3)
from("source")
into("destination")
}
}
}interface Injected {
@Inject FileSystemOperations getFs() // (1)
}
tasks.register('someTask') {
def injected = project.objects.newInstance(Injected) // (2)
doLast {
injected.fs.copy { // (3)
from 'source'
into 'destination'
}
}
}-
Services can’t be injected directly in scripts, we need an extra type to convey the injection point
-
Create an instance of the extra type using
project.objectoutside the task action -
No more problem reported, the task action references
injectedthat provides theFileSystemOperationsservice, supported as a replacement forproject.copy {}
Fixing ad-hoc tasks in scripts requires additional effort, making it a good opportunity to refactor them into proper task classes.
The table below lists recommended replacements for commonly used Project methods:
| Instead of: | Use: |
|---|---|
|
A task input or output property or a script variable to capture the result of using |
|
A task input or output property or a script variable to capture the result of using |
|
|
|
A task input or output property or a script variable to capture the result of using |
|
A task input or output property or a script variable to capture the result of using |
|
A task input or output property or a script variable to capture the result of using |
|
A task input or output property or a script variable to capture the result of using |
|
|
|
|
|
|
|
A task input or output property or a script variable to capture the result of using |
|
A task input or output property or a script variable to capture the result of using |
|
|
|
|
|
|
|
|
|
|
|
A task input or output property or a script variable to capture the result of using |
|
|
|
|
|
|
|
|
|
The Kotlin, Groovy or Java API available to your build logic. |
|
|
|
|
|
|
|
Accessing a Task Instance from Another Instance
Tasks must not directly access the state of another task instance. Instead, they should be connected using input and output relationships.
This requirement ensures that tasks remain isolated and correctly cacheable. As a result, it is unsupported to write tasks that configure other tasks at execution time.
Sharing Mutable Objects
When storing a task in the Configuration Cache, all objects referenced through the task’s fields are serialized.
In most cases, deserialization preserves reference equality—if two fields a and b reference the same instance at configuration time, they will still reference the same instance after deserialization (a == b, or a === b in Groovy/Kotlin syntax).
However, for performance reasons, certain classes—such as java.lang.String, java.io.File, and many java.util.Collection implementations—are serialized without preserving reference equality.
After deserialization, fields that referred to these objects may reference different but equal instances.
Consider a task that stores a user-defined object and an ArrayList as task fields:
class StateObject {
// ...we assume there is some mutable state here, and an equals implementation...
}
abstract class StatefulTask : DefaultTask() {
@get:Internal
var stateObject: StateObject? = null
@get:Internal
var strings: List<String>? = null
}
tasks.register<StatefulTask>("checkEquality") {
val objectValue = StateObject()
// ...configure objectValue as needed...
val stringsValue = arrayListOf("a", "b")
stateObject = objectValue
strings = stringsValue
doLast { // (1)
println("POJO reference equality: ${stateObject === objectValue}") // (2)
println("Collection reference equality: ${strings === stringsValue}") // (3)
println("Collection equality: ${strings == stringsValue}") // (4)
}
}class StateObject {
// ...we assume there is some mutable state here, and an equals implementation...
}
abstract class StatefulTask extends DefaultTask {
@Internal
StateObject stateObject
@Internal
List<String> strings
}
tasks.register("checkEquality", StatefulTask) {
def objectValue = new StateObject()
// ...configure objectValue as needed...
def stringsValue = ["a", "b"] as ArrayList<String>
stateObject = objectValue
strings = stringsValue
doLast { // (1)
println("POJO reference equality: ${stateObject === objectValue}") // (2)
println("Collection reference equality: ${strings === stringsValue}") // (3)
println("Collection equality: ${strings == stringsValue}") // (4)
}
}-
doLastaction captures the references from the enclosing scope. These captured references are also serialized to the Configuration Cache. -
Compare the reference to an object of user-defined class stored in the task field and the reference captured in the
doLastaction. -
Compare the reference to
ArrayListinstance stored in the task field and the reference captured in thedoLastaction. -
Check the equality of stored and captured lists.
Without Configuration Cache, reference equality is preserved in both cases:
$ ./gradlew --no-configuration-cache checkEquality> Task :checkEquality
POJO reference equality: true
Collection reference equality: true
Collection equality: trueWith Configuration Cache enabled, only user-defined object references remain identical. List references are different, although the lists themselves remain equal:
$ ./gradlew --configuration-cache checkEquality> Task :checkEquality
POJO reference equality: true
Collection reference equality: false
Collection equality: trueBest Practices:
-
Avoid sharing mutable objects between configuration and execution phases.
-
If sharing state is necessary, wrap it in a user-defined class.
-
Do not rely on reference equality for standard Java, Groovy, Kotlin, or Gradle-defined types.
Reference equality is never preserved between tasks—each task is an isolated "realm." To share objects across tasks, use a Build Service to wrap the shared state.
Accessing Task Extensions or Conventions
Tasks must not access conventions, extensions, or extra properties at execution time.
Instead, any value relevant to task execution should be explicitly modeled as a task property to ensure proper caching and reproducibility.
Using Build Listeners
Plugins and build scripts must not register build listeners that are created at configuration time and triggered at execution time.
This includes listeners such as BuildListener or TaskExecutionListener.
Recommended Alternatives:
-
Use Build Services to handle execution-time logic.
-
Register a Build Service to receive task execution notifications.
-
Replace
buildFinishedlisteners with dataflow actions to manage build results.
Using External Information Sources
Examples of external sources include client environment variables, system properties, configuration files, shell commands, network services, among others.
To represent such sources in a Gradle build in a Configuration Cache friendly way we use ValueSource.
They make it possible for Gradle to transparently manage the Configuration Cache as values obtained from those sources change.
For example, a build might run a different set of tasks depending on whether the CI environment variable is set or not.
A ValueSource implementation is exempt from the automatic detection of configuration cache inputs.
For example, if the obtain() method reads a system property, an environment variable, or a file, those reads do not individually become configuration cache inputs.
Instead, only the value returned by obtain() is tracked.
If that value changes between builds, the Configuration Cache is invalidated.
This makes ValueSource the recommended escape hatch when built-in providers like providers.systemProperty(), providers.environmentVariable(), or providers.fileContents() are too limited for your use case.
Creating a ValueSource
To integrate a new type of value source:
-
Create an abstract class implementing
ValueSource<T, P>. -
Implement the
obtain()method to compute and return the value. The returned value must be effectively immutable (e.g., astring,int,boolean, an unmodifiable collection, or a serializable data class). -
Use
providers.of(Class, Action)to get aProviderbacked by your source.
The returned Provider can be passed to task properties or queried during the configuration phase.
If the value is queried at configuration time, the source is automatically considered a build configuration input.
|
Note
|
Do not implement getParameters() in your class—Gradle provides the implementation automatically.
|
|
Tip
|
Your ValueSource implementation does not need to be thread-safe, Gradle synchronizes calls to obtain().
|
Parameterizing a ValueSource
A value source implementation will most likely take parameters.
To do this, create a subtype of ValueSourceParameters and declare it as the type parameter P of your ValueSource implementation.
The parameters are configured in the Action passed to providers.of().
If no parameters are needed, use ValueSourceParameters.None.
Injecting Services
Gradle services can be injected into a ValueSource implementation by adding a parameter to the constructor and annotating it with @Inject.
Currently, the following service is supported:
-
ExecOperations— provides means to execute external processes. This service can be used even at configuration time. Becauseobtain()is called on every build (see Configuration Cache Behavior below), only fast-running commands should be used.
You can also use standard Java/Kotlin/Groovy process APIs such as java.lang.ProcessBuilder inside obtain().
Configuration Cache Behavior
When a provider backed by a ValueSource is queried at configuration time, the value becomes a build configuration input.
The obtain() method is then executed on every subsequent build to determine whether the Configuration Cache entry is still UP-TO-DATE:
-
If the value has not changed, the cached configuration is reused.
-
If the value has changed, the cache is invalidated and the configuration phase runs again.
Because obtain() runs on every build, it is recommended to keep the implementation fast.
ValueSource is the recommended approach for the following scenarios:
-
Running external processes at configuration time — such as calling git or a CLI tool to compute a version string or check a precondition.
-
Complex system property or environment variable access patterns — when you need to combine, transform, or conditionally read multiple properties.
-
Reading files at configuration time — when
providers.fileContents()is insufficient, such as parsing a file in a custom format.
Running External Processes
|
Tip
|
Plugin and build scripts should avoid running external processes at configuration time. |
You should avoid using these APIs for running processes during configuration:
-
Java/Kotlin:
ProcessBuilder,Runtime.exec(…), etc… -
Groovy:
*.execute(), etc… -
Gradle:
ExecOperations.exec,ExecOperations.javaexec, etc…
The flexibility of these methods prevent Gradle from determining how the calls impact the build configuration, making it difficult to ensure that the Configuration Cache entry can be safely reused.
However, if running processes is required at configuration time, you can use the configuration-cache-compatible APIs detailed below.
For simpler cases, when grabbing the output of the process is enough,
providers.exec() and
providers.javaexec() can be used:
val gitVersion = providers.exec {
commandLine("git", "--version")
}.standardOutput.asText.get()def gitVersion = providers.exec {
commandLine("git", "--version")
}.standardOutput.asText.get()For more complex cases, a custom ValueSource implementation with injected ExecOperations can be used (see Using External Information Sources for a full overview of ValueSource).
This ExecOperations instance can be used at configuration time without restrictions:
abstract class GitVersionValueSource : ValueSource<String, ValueSourceParameters.None> {
@get:Inject
abstract val execOperations: ExecOperations
override fun obtain(): String {
val output = ByteArrayOutputStream()
execOperations.exec {
commandLine("git", "--version")
standardOutput = output
}
return String(output.toByteArray(), Charset.defaultCharset())
}
}abstract class GitVersionValueSource implements ValueSource<String, ValueSourceParameters.None> {
@Inject
abstract ExecOperations getExecOperations()
String obtain() {
ByteArrayOutputStream output = new ByteArrayOutputStream()
execOperations.exec {
it.commandLine "git", "--version"
it.standardOutput = output
}
return new String(output.toByteArray(), Charset.defaultCharset())
}
}You can also use standard Java/Kotlin/Groovy process APIs like java.lang.ProcessBuilder in the ValueSource.
The ValueSource implementation can then be used to create a provider with providers.of:
val gitVersionProvider = providers.of(GitVersionValueSource::class) {}
val gitVersion = gitVersionProvider.get()def gitVersionProvider = providers.of(GitVersionValueSource.class) {}
def gitVersion = gitVersionProvider.get()In both approaches, if the value of the provider is used at configuration time then it will become a build configuration input.
The external process will be executed for every build to determine if the Configuration Cache is UP-TO-DATE, so it is recommended to only call fast-running processes at configuration time.
If the value changes then the cache is invalidated and the process will be run again during this build as part of the configuration phase.
Reading System Properties and Environment Variables
Plugins and build scripts may read system properties and environment variables directly at configuration time with standard Java, Groovy, or Kotlin APIs or with the value supplier APIs. Doing so makes such variables or properties a build configuration input. Therefore, changing their value invalidates the Configuration Cache.
The Configuration Cache report includes a list of these build configuration inputs to help track them.
In general, you should avoid reading the value of system properties and environment variables at configuration time to avoid cache misses when these values change.
Instead, you can connect the Provider returned by providers.systemProperty() or
providers.environmentVariable() to task properties.
Some access patterns that potentially enumerate all environment variables or system properties (for example, calling System.getenv().forEach() or using the iterator of its keySet()) are discouraged.
In this case, Gradle cannot find out what properties are actual build configuration inputs, so every available property becomes one.
Even adding a new property will invalidate the cache if this pattern is used.
Using a custom predicate to filter environment variables is an example of this discouraged pattern:
val jdkLocations = System.getenv().filterKeys {
it.startsWith("JDK_")
}def jdkLocations = System.getenv().findAll {
key, _ -> key.startsWith("JDK_")
}The logic in the predicate is opaque to the Configuration Cache, so all environment variables are considered inputs.
One way to reduce the number of inputs is to always use methods that query a concrete variable name, such as getenv(String), or getenv().get():
val jdkVariables = listOf("JDK_8", "JDK_11", "JDK_17")
val jdkLocations = jdkVariables.filter { v ->
System.getenv(v) != null
}.associate { v ->
v to System.getenv(v)
}def jdkVariables = ["JDK_8", "JDK_11", "JDK_17"]
def jdkLocations = jdkVariables.findAll { v ->
System.getenv(v) != null
}.collectEntries { v ->
[v, System.getenv(v)]
}The fixed code above, however, is not exactly equivalent to the original as only an explicit list of variables is supported. Prefix-based filtering is a common scenario, so there are provider-based APIs to access system properties and environment variables:
val jdkLocationsProvider = providers.environmentVariablesPrefixedBy("JDK_")def jdkLocationsProvider = providers.environmentVariablesPrefixedBy("JDK_")Note that the Configuration Cache would be invalidated not only when the value of the variable changes or the variable is removed but also when another variable with the matching prefix is added to the environment.
For more complex use cases, a custom ValueSource implementation can be used (see Using External Information Sources for a full overview of ValueSource).
System properties and environment variables referenced in the code of the ValueSource do not become build configuration inputs, so any processing can be applied.
Instead, the value of the ValueSource is recomputed each time the build runs and only if the value changes the Configuration Cache is invalidated.
For example, a ValueSource can be used to get all environment variables with names containing the substring JDK:
abstract class EnvVarsWithSubstringValueSource : ValueSource<Map<String, String>, EnvVarsWithSubstringValueSource.Parameters> {
interface Parameters : ValueSourceParameters {
val substring: Property<String>
}
override fun obtain(): Map<String, String> {
return System.getenv().filterKeys { key ->
key.contains(parameters.substring.get())
}
}
}
val jdkLocationsProvider = providers.of(EnvVarsWithSubstringValueSource::class) {
parameters {
substring = "JDK"
}
}abstract class EnvVarsWithSubstringValueSource implements ValueSource<Map<String, String>, Parameters> {
interface Parameters extends ValueSourceParameters {
Property<String> getSubstring()
}
Map<String, String> obtain() {
return System.getenv().findAll { key, _ ->
key.contains(parameters.substring.get())
}
}
}
def jdkLocationsProvider = providers.of(EnvVarsWithSubstringValueSource.class) {
parameters {
substring = "JDK"
}
}Undeclared Reading of Files
Plugins and build scripts should not read files directly using the Java, Groovy or Kotlin APIs at configuration time. Instead, declare files as potential build configuration inputs using the value supplier APIs.
This problem is caused by build logic similar to this:
val config = file("some.conf").readText()def config = file('some.conf').textTo fix this problem, read files using providers.fileContents() instead:
val config = providers.fileContents(layout.projectDirectory.file("some.conf"))
.asTextdef config = providers.fileContents(layout.projectDirectory.file('some.conf'))
.asTextIn general, you should avoid reading files at configuration time, to avoid invalidating Configuration Cache entries when the file content changes.
Instead, you can connect the Provider returned by providers.fileContents() to task properties.
Bytecode Modifications and Java Agent
To detect the configuration inputs, Gradle modifies the bytecode of classes on the build script classpath, like plugins and their dependencies. Gradle uses a Java agent to modify the bytecode. Integrity self-checks of some libraries may fail because of the changed bytecode or the agent’s presence.
To work around this, you can use the Worker API with classloader or process isolation to encapsulate the library code. The bytecode of the worker’s classpath is not modified, so the self-checks should pass. When process isolation is used, the worker action is executed in a separate worker process that doesn’t have the Gradle Java agent installed.
In simple cases, when the libraries also provide command-line entry points (public static void main() method), you can also use the JavaExec task to isolate the library.
Handling of Credentials and Secrets
Currently, the Configuration Cache does not have a built-in mechanism to prevent storing secrets used as inputs.
As a result, secrets may end up in the serialized Configuration Cache entry, which, by default, is stored under .gradle/configuration-cache in your project directory.
To mitigate the risk of accidental exposure, Gradle encrypts the Configuration Cache.
When required, Gradle transparently generates a machine-specific secret key, caches it under the
GRADLE_USER_HOME directory, and uses it to encrypt data in the project-specific caches.
To further enhance security, follow these recommendations:
-
Secure access to Configuration Cache entries.
-
Use
GRADLE_USER_HOME/gradle.propertiesto store secrets. The content of this file is not included in the Configuration Cache—only its fingerprint is. If storing secrets in this file, ensure access is properly restricted.
See gradle/gradle#22618.
Providing an Encryption Key with the GRADLE_ENCRYPTION_KEY Environment Variable
By default, Gradle automatically generates and manages the encryption key as a Java keystore, stored under the GRADLE_USER_HOME directory.
For environments where this behavior is undesirable—such as when the GRADLE_USER_HOME directory is shared across multiple machines—you can explicitly provide an encryption key using the GRADLE_ENCRYPTION_KEY environment variable.
|
Important
|
The same encryption key must be consistently provided across multiple Gradle runs; otherwise, Gradle will be unable to reuse existing cached configurations. |
Generating an Encryption Key compatible with GRADLE_ENCRYPTION_KEY
To encrypt the Configuration Cache using a user-specified encryption key, Gradle requires the GRADLE_ENCRYPTION_KEY environment variable to be set with a valid AES key, encoded as a Base64 string.
You can generate a Base64-encoded AES-compatible key using the following command:
$ openssl rand -base64 16This command works on Linux and macOS, and on Windows if using a tool like Cygwin.
Once generated, set the Base64-encoded key as the value of the GRADLE_ENCRYPTION_KEY environment variable:
$ export GRADLE_ENCRYPTION_KEY="your-generated-key-here"Debugging and Troubleshooting the Configuration Cache
This section provides general guidelines for resolving issues with the Configuration Cache, whether in your build logic or Gradle plugins.
Use the Configuration Report
When Gradle encounters a problem serializing the necessary state to execute tasks, it generates an HTML report detailing the detected issues. The console output includes a clickable link to this report, allowing you to investigate the root causes.
Consider the following build script, which contains two issues:
tasks.register("someTask") {
val destination = System.getProperty("someDestination") // (1)
inputs.dir("source")
outputs.dir(destination)
doLast {
project.copy { // (2)
from("source")
into(destination)
}
}
}tasks.register('someTask') {
def destination = System.getProperty('someDestination') // (1)
inputs.dir('source')
outputs.dir(destination)
doLast {
project.copy { // (2)
from 'source'
into destination
}
}
}Running the task fails with the following output:
$ ./gradlew --configuration-cache someTask -DsomeDestination=dest...
Calculating task graph as no cached configuration is available for tasks: someTask
> Task :someTask FAILED
1 problem was found storing the configuration cache.
- Build file 'build.gradle': line 6: invocation of 'Task.project' at execution time is unsupported with the configuration cache.
See https://docs.gradle.org/0.0.0/userguide/configuration_cache_requirements.html#config_cache:requirements:use_project_during_execution
See the complete report at file:///home/user/gradle/samples/build/reports/configuration-cache/<hash>/configuration-cache-report.html
1 actionable task: 1 executed
Configuration cache entry discarded with 1 problem.
FAILURE: Build failed with an exception.
* Where:
Build file '/home/user/gradle/samples/build.gradle' line: 6
* What went wrong:
Execution failed for task ':someTask' (registered in build file 'build.gradle').
> Invocation of 'Task.project' by task ':someTask' at execution time is unsupported with the configuration cache.
* Try:
> Run with --stacktrace option to get the stack trace.
> Run with --info or --debug option to get more log output.
> Run with --scan to get full insights from a Build Scan (powered by Develocity).
> Get more help at https://help.gradle.org.
BUILD FAILED in 0s
Configuration Cache entry discarded with 1 problem.Since a problem was detected, Gradle discards the Configuration Cache entry, preventing reuse in future builds.
The linked HTML report provides details about the detected problems:
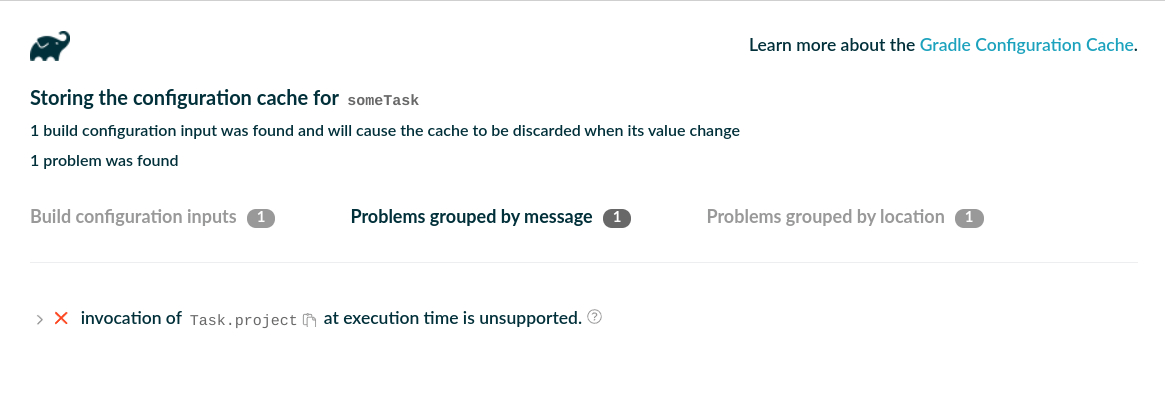
The report presents issues in two ways:
-
Grouped by message → Quickly identify recurring problem types.
-
Grouped by task → Identify which tasks are causing problems.
Expanding the problem tree helps locate the root cause within the object graph.
Additionally, the report lists detected build configuration inputs, such as system properties, environment variables, and value suppliers accessed during configuration:
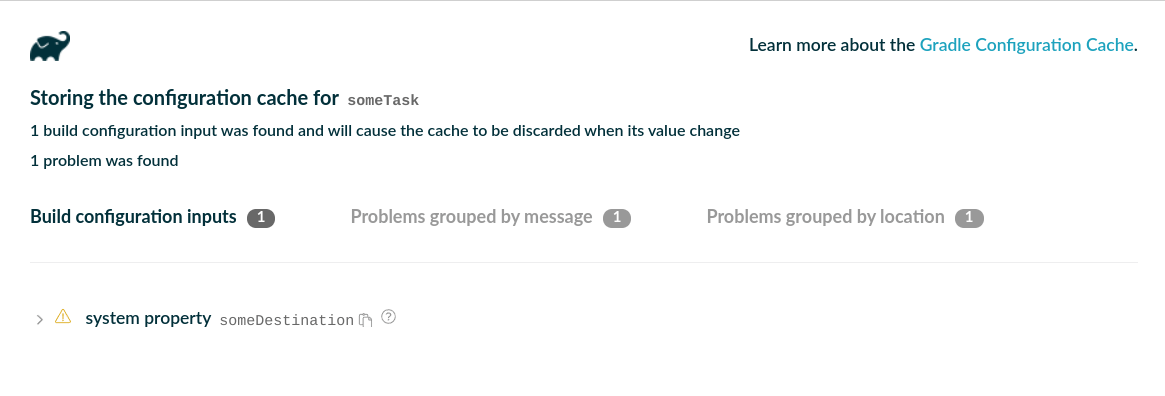
|
Tip
|
Each problem entry in the report includes links to relevant Configuration Cache requirements for guidance on resolving the issue, as well as any related Not Yet Implemented features. When modifying your build or plugin, consider Testing your Build Logic with TestKit to verify changes. |
At this stage, you can either ignore the problems (turn them into warnings) to continue exploring Configuration Cache behavior, or fix the issues immediately.
To continue using the Configuration Cache while observing problems, run:
$ ./gradlew --configuration-cache --configuration-cache-problems=warn someTask -DsomeDestination=destCalculating task graph as no cached configuration is available for tasks: someTask
> Task :someTask
1 problem was found storing the configuration cache.
- Build file 'build.gradle': line 6: invocation of 'Task.project' at execution time is unsupported with the configuration cache.
See https://docs.gradle.org/0.0.0/userguide/configuration_cache_requirements.html#config_cache:requirements:use_project_during_execution
See the complete report at file:///home/user/gradle/samples/build/reports/configuration-cache/<hash>/configuration-cache-report.html
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executed
Configuration Cache entry stored with 1 problem.$ ./gradlew --configuration-cache --configuration-cache-problems=warn someTask -DsomeDestination=destReusing configuration cache.
> Task :someTask
1 problem was found reusing the configuration cache.
- Build file 'build.gradle': line 6: invocation of 'Task.project' at execution time is unsupported with the configuration cache.
See https://docs.gradle.org/0.0.0/userguide/configuration_cache_requirements.html#config_cache:requirements:use_project_during_execution
See the complete report at file:///home/user/gradle/samples/build/reports/configuration-cache/<hash>/configuration-cache-report.html
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executed
Configuration Cache entry reused with 1 problem.Gradle will successfully store and reuse the Configuration Cache while continuing to report the problem.
The report and console logs provide links to guidance on resolving detected issues.
Here’s a corrected version of the example build script:
abstract class MyCopyTask : DefaultTask() { // (1)
@get:InputDirectory abstract val source: DirectoryProperty // (2)
@get:OutputDirectory abstract val destination: DirectoryProperty // (2)
@get:Inject abstract val fs: FileSystemOperations // (3)
@TaskAction
fun action() {
fs.copy { // (3)
from(source)
into(destination)
}
}
}
tasks.register<MyCopyTask>("someTask") {
val projectDir = layout.projectDirectory
source = projectDir.dir("source")
destination = projectDir.dir(System.getProperty("someDestination"))
}abstract class MyCopyTask extends DefaultTask { // (1)
@InputDirectory abstract DirectoryProperty getSource() // (2)
@OutputDirectory abstract DirectoryProperty getDestination() // (2)
@Inject abstract FileSystemOperations getFs() // (3)
@TaskAction
void action() {
fs.copy { // (3)
from source
into destination
}
}
}
tasks.register('someTask', MyCopyTask) {
def projectDir = layout.projectDirectory
source = projectDir.dir('source')
destination = projectDir.dir(System.getProperty('someDestination'))
}-
We turned our ad-hoc task into a proper task class,
-
with inputs and outputs declaration,
-
and injected with the
FileSystemOperationsservice, a supported replacement forproject.copy {}.
After fixing these issues, running the task twice successfully reuses the Configuration Cache:
$ ./gradlew --configuration-cache someTask -DsomeDestination=destCalculating task graph as no cached configuration is available for tasks: someTask
> Task :someTask
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executed
Configuration Cache entry stored.$ ./gradlew --configuration-cache someTask -DsomeDestination=destReusing configuration cache.
> Task :someTask
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executed
Configuration Cache entry reused.If a build input changes (e.g., a system property value), the Configuration Cache entry becomes invalid, requiring a new configuration phase:
$ ./gradlew --configuration-cache someTask -DsomeDestination=anotherCalculating task graph as configuration cache cannot be reused because system property 'someDestination' has changed.
> Task :someTask
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executed
Configuration Cache entry stored.The cache entry was invalidated because the system property was read at configuration time, forcing Gradle to re-run configuration when its value changed.
A better approach is to use a provider to defer reading the system property until execution time:
tasks.register<MyCopyTask>("someTask") {
val projectDir = layout.projectDirectory
source = projectDir.dir("source")
destination = projectDir.dir(providers.systemProperty("someDestination")) // (1)
}tasks.register('someTask', MyCopyTask) {
def projectDir = layout.projectDirectory
source = projectDir.dir('source')
destination = projectDir.dir(providers.systemProperty('someDestination')) // (1)
}-
We wired the system property provider directly, without reading it at configuration time.
Now, the cache entry remains reusable even when changing the system property:
$ ./gradlew --configuration-cache someTask -DsomeDestination=destCalculating task graph as no cached configuration is available for tasks: someTask
> Task :someTask
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executed
Configuration Cache entry stored.$ ./gradlew --configuration-cache someTask -DsomeDestination=anotherReusing configuration cache.
> Task :someTask
BUILD SUCCESSFUL in 0s
1 actionable task: 1 executed
Configuration Cache entry reused.With these fixes in place, this task is fully compatible with the Configuration Cache.
Enable Warning Mode
To ease migration, you can treat configuration cache problems as warnings instead of failures:
$ ./gradlew --configuration-cache-problems=warnOr set it in gradle.properties:
org.gradle.configuration-cache.problems=warn|
Warning
|
The warning mode is a migration and troubleshooting aid and not intended as a persistent way of ignoring incompatibilities. It will also not prevent new incompatibilities being accidentally added to your build later. Instead, we recommend explicitly marking problematic tasks as incompatible. |
By default, Gradle allows up to 512 warnings before failing the build. You can lower this limit:
$ ./gradlew -Dorg.gradle.configuration-cache.max-problems=5Declare Incompatible Tasks
You can explicitly mark a task as incompatible with the Configuration Cache using the Task.notCompatibleWithConfigurationCache() method:
tasks.register("resolveAndLockAll") {
notCompatibleWithConfigurationCache("Filters configurations at execution time")
doFirst {
require(gradle.startParameter.isWriteDependencyLocks) { "$path must be run from the command line with the `--write-locks` flag" }
}
doLast {
configurations.filter {
// Add any custom filtering on the configurations to be resolved
it.isCanBeResolved
}.forEach { it.resolve() }
}
}tasks.register('resolveAndLockAll') {
notCompatibleWithConfigurationCache("Filters configurations at execution time")
doFirst {
assert gradle.startParameter.writeDependencyLocks : "$path must be run from the command line with the `--write-locks` flag"
}
doLast {
configurations.matching {
// Add any custom filtering on the configurations to be resolved
it.canBeResolved
}.each { it.resolve() }
}
}When a task is marked as incompatible:
-
Configuration Cache problems in that task will no longer cause the build to fail.
-
Gradle discards the configuration state at the end of the build if an incompatible task is executed.
This mechanism can be useful during migration, allowing you to temporarily opt out tasks that require more extensive changes to become Configuration Cache-compatible.
For more details, refer to the method documentation.
Use Integrity Checks
To reduce entry size and improve performance, Gradle performs minimal integrity checks when writing and reading data. However, this approach can make troubleshooting issues more difficult, especially when dealing with concurrency problems or serialization errors. An incorrectly stored object may not be detected immediately but could lead to misleading or misattributed errors when reading cached data later.
To make debugging easier, Gradle provides an option to enable stricter integrity checks.
This setting helps identify inconsistencies earlier but may slow down cache operations and significantly increase the cache entry size.
To enable stricter integrity checks, add the following line to your gradle.properties file:
org.gradle.configuration-cache.integrity-check=trueFor example, let’s look at a type that implements a custom serialization protocol incorrectly:
public class User implements Serializable {
private transient String name;
private transient int age;
private void writeObject(ObjectOutputStream out) throws IOException {
out.defaultWriteObject();
out.writeObject(name); // (1)
out.writeInt(age);
}
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
in.defaultReadObject();
this.name = (String) in.readObject();
// this.age = in.readInt(); // (2)
}
// ...-
writeObjectserializes both fields. -
readObjectreads only the first field, leaving the remaining data in the stream.
Such a type will cause problems when used as part of a task state, because the configuration cache will try to interpret the remaining unread part of the object as some new value:
public abstract class GreetTask extends DefaultTask {
User user = new User("John", 23);
@TaskAction
public void greet() {
System.out.println("Hello, " + user.getName() + "!");
System.out.println("Have a wonderful " + (user.getAge() + 1) +"th birthday!");
}
}When running without the integrity check, you may encounter cryptic failure messages, possibly accompanied by induced configuration cache problems:
$ ./gradlew --configuration-cache greet...
* What went wrong:
Index 4 out of bounds for length 3These errors might not immediately point to the root cause, making debugging more challenging. It might be really hard to connect an invalid index error to a serialization issue, for example.
Rerunning the build with the integrity check enabled provides a much more precise diagnostic, helping you pinpoint the source of the issue faster:
$ ./gradlew --configuration-cache -Dorg.gradle.configuration-cache.integrity-check=true greet...
FAILURE: Build failed with an exception.
* What went wrong:
Configuration cache state could not be cached: field `user` of task `:greet` of type `GreetTask`: The value cannot be decoded properly with 'JavaObjectSerializationCodec'. It may have been written incorrectly or its data is corrupted.You can immediately see the name of the offending task and the field that contains the broken data.
Keep in mind that this attribution is best-effort: it should be accurate in most cases, but in rare instances, it may be confused by certain byte patterns.
|
Warning
|
The integrity check relies on additional metadata stored within the cache. Therefore, it cannot be used to diagnose entries already corrupted prior to enabling the integrity check. |
The current integrity checks primarily focus on identifying serialization protocol issues rather than general data corruption. Consequently, they are less effective against hardware-related problems, such as bit rot or damaged storage sectors. Due to these limitations and the performance overhead introduced by integrity checks, we recommend enabling them selectively as a troubleshooting measure rather than leaving them permanently enabled.
Inspecting Cache Entries
The gcc2speedscope tool, developed by Gradle, analyzes the space usage of the Gradle Configuration Cache by converting debug logs into interactive flamegraphs compatible with speedscope.app.
This visualization helps identify large or unnecessary objects within the cache.
Debugging the Configuration Phase
The gradle-trace-converter is a command-line tool developed by Gradle to analyze and convert Build Operation traces into formats like Chrome’s Perfetto trace and CSV timelines.
This visualization depicts the steps taken during Gradle’s configuration phase.
Test your Build Logic
Gradle TestKit is a library designed to facilitate testing Gradle plugins and build logic. For general guidance on using TestKit, refer to the dedicated chapter.
To test your build logic with the Configuration Cache enabled, pass the --configuration-cache argument to GradleRunner, or use one of the other methods described in Enabling the Configuration Cache.
To properly test Configuration Cache behavior, tasks must be executed twice:
@Test
fun `my task can be loaded from the configuration cache`() {
buildFile.writeText("""
plugins {
id 'org.example.my-plugin'
}
""")
runner()
.withArguments("--configuration-cache", "myTask") // (1)
.build()
val result = runner()
.withArguments("--configuration-cache", "myTask") // (2)
.build()
require(result.output.contains("Reusing configuration cache.")) // (3)
// ... more assertions on your task behavior
}def "my task can be loaded from the configuration cache"() {
given:
buildFile << """
plugins {
id 'org.example.my-plugin'
}
"""
when:
runner()
.withArguments('--configuration-cache', 'myTask') // (1)
.build()
and:
def result = runner()
.withArguments('--configuration-cache', 'myTask') // (2)
.build()
then:
result.output.contains('Reusing configuration cache.') // (3)
// ... more assertions on your task behavior
}-
First run primes the Configuration Cache.
-
Second run reuses the Configuration Cache.
-
Assert that the Configuration Cache gets reused.
If Gradle encounters problems with the Configuration Cache, it will fail the build and report the issues, causing the test to fail.
|
Tip
|
A recommended approach for Gradle plugin authors is to run the entire test suite with the Configuration Cache enabled. This ensures compatibility with a supported Gradle version.
|
Configuration Cache Status
|
Warning
|
This feature is not enabled by default. |
Supported Plugins
The Configuration Cache introduces new requirements for plugin implementations. As a result, both Core Gradle plugins and Community Plugins need to be adjusted to ensure compatibility.
This section provides details on the current support in:
Core Gradle Plugins
Most Core Gradle Plugins support configuration caching at this time:
JVM languages and frameworks |
Native languages |
Packaging and distribution |
|---|---|---|
Code analysis |
IDE integration |
Utility |
| ✓ |
Supported plugin |
| ⚠ |
Partially supported plugin (tasks always disable configuration caching) |
| ⚠* |
Partially supported plugin (some features may disable configuration caching) |
Community Plugins
Please refer to issue gradle/gradle#13490 to learn about the status of Community Plugins.
The two most popular ecosystem plugins are supported:
-
✓ Android Gradle Plugin
-
✓ Kotlin Gradle Plugin
Not Yet Implemented
Support for configuration caching with certain Gradle features is not yet available. These features will be supported in future Gradle releases.
Sharing the Configuration Cache
The Configuration Cache is currently stored locally only. It can be reused by both hot and cold local Gradle daemons, but it cannot be shared between developers or CI machines.
See gradle/gradle#13510.
Source Dependencies
Support for source dependencies is not yet implemented. When using this feature, the build will not fail, and no problems will be reported, but the Configuration Cache will be automatically disabled.
See gradle/gradle#13506.
Using a Java Agent with Builds run using TestKit
When running builds using TestKit, the Configuration Cache can interfere with Java agents, such as the Jacoco agent, that are applied to these builds.
See gradle/gradle#25979.
Fine-grained Tracking of Gradle Properties as Build Configuration Inputs
Currently, all external sources of Gradle properties—such as gradle.properties files (both in project directories and in the GRADLE_USER_HOME), environment variables, system properties that set properties, and properties specified via command-line flags—are considered build configuration inputs, regardless of whether they are actually used during configuration.
However, these sources are not included in the Configuration Cache report.
See gradle/gradle#20969.
Java Object Serialization
Gradle allows objects that support the Java Object Serialization protocol to be stored in the Configuration Cache.
The implementation is currently limited to serializable classes that
either implement the java.io.Externalizable interface, or implement the java.io.Serializable interface and define one of the following combination of methods:
-
a
writeObjectmethod combined with areadObjectmethod to control exactly which information to store; -
a
writeObjectmethod with no correspondingreadObject;writeObjectmust eventually callObjectOutputStream.defaultWriteObject; -
a
readObjectmethod with no correspondingwriteObject;readObjectmust eventually callObjectInputStream.defaultReadObject; -
a
writeReplacemethod to allow the class to nominate a replacement to be written; -
a
readResolvemethod to allow the class to nominate a replacement for the object just read;
The following Java Object Serialization features are not supported:
-
the
serialPersistentFieldsmember to explicitly declare which fields are serializable; the member, if present, is ignored; the Configuration Cache considers all buttransientfields serializable; -
the following methods of
ObjectOutputStreamare not supported and will throwUnsupportedOperationException:-
reset(),writeFields(),putFields(),writeChars(String),writeBytes(String)andwriteUnshared(Any?).
-
-
the following methods of
ObjectInputStreamare not supported and will throwUnsupportedOperationException:-
readLine(),readFully(ByteArray),readFully(ByteArray, Int, Int),readUnshared(),readFields(),transferTo(OutputStream)andreadAllBytes().
-
-
validations registered via
ObjectInputStream.registerValidationare simply ignored; -
the
readObjectNoDatamethod, if present, is never invoked;
See gradle/gradle#13588.
Accessing top-level Methods and Variables of a Build Script at Execution Time
A common approach to reuse logic and data in a build script is to extract repeating bits into top-level methods and variables. However, calling such methods at execution time is not currently supported if the Configuration Cache is enabled.
For builds scripts written in Groovy, the task fails because the method cannot be found.
The following snippet uses a top-level method in the listFiles task:
def dir = file('data')
def listFiles(File dir) {
dir.listFiles({ file -> file.isFile() } as FileFilter).name.sort()
}
tasks.register('listFiles') {
doLast {
println listFiles(dir)
}
}Running the task with the Configuration Cache enabled produces the following error:
Execution failed for task ':listFiles' (registered in build file 'build.gradle').
> Could not find method listFiles() for arguments [/home/user/gradle/samples/data] on task ':listFiles' of type org.gradle.api.DefaultTask.To prevent the task from failing, convert the referenced top-level method to a static method within a class:
def dir = file('data')
class Files {
static def listFiles(File dir) {
dir.listFiles({ file -> file.isFile() } as FileFilter).name.sort()
}
}
tasks.register('listFilesFixed') {
doLast {
println Files.listFiles(dir)
}
}Build scripts written in Kotlin cannot store tasks that reference top-level methods or variables at execution time in the Configuration Cache at all.
This limitation exists because the captured script object references cannot be serialized.
The first run of the Kotlin version of the listFiles task fails with the Configuration Cache problem.
val dir = file("data")
fun listFiles(dir: File): List<String> =
dir.listFiles { file: File -> file.isFile }.map { it.name }.sorted()
tasks.register("listFiles") {
doLast {
println(listFiles(dir))
}
}To make the Kotlin version of this task compatible with the Configuration Cache, make the following changes:
object Files { // (1)
fun listFiles(dir: File): List<String> =
dir.listFiles { file: File -> file.isFile }.map { it.name }.sorted()
}
tasks.register("listFilesFixed") {
val dir = file("data") // (2)
doLast {
println(Files.listFiles(dir))
}
}-
Define the method inside an object.
-
Define the variable in a smaller scope.
See gradle/gradle#22879.
Using Build Services to Invalidate the Configuration Cache
Currently, it is impossible to use a provider of BuildService or provider derived from it with map or flatMap as a parameter for the ValueSource, if the value of the ValueSource is accessed at configuration time.
The same applies when such a ValueSource is obtained in a task that executes as part of the configuration phase, for example tasks of the buildSrc build or included builds contributing plugins.
Note that using a @ServiceReference or storing BuildService in an @Internal-annotated property of a task is safe.
Generally speaking, this limitation makes it impossible to use a BuildService to invalidate the Configuration Cache.
See gradle/gradle#24085.
Using Arbitrary Providers as Build Events Listeners
The build event listener registration method BuildEventsListenerRegistry.onTaskCompletion
accepts arbitrary providers of any OperationCompletionListener implementations.
However, only providers returned from BuildServiceRegistry.registerIfAbsent or BuildServiceRegistration.getService are currently supported when the Configuration Cache is used.
Starting with Gradle 9, using other kinds of providers (including even registerIfAbsent(…).map { it }) results in a Configuration Cache problem being emitted.
Prior to that, such providers were silently ignored.
Check the adoption guide to learn how to temporarily suppress these problems if discarded listeners do not affect your build.
See gradle/gradle#33772.
Isolated Projects
Isolated Projects is an experimental feature aimed at improving Gradle scalability and performance, especially for large builds and IDE sync (Android Studio / IntelliJ IDEA).
When the Isolated Projects feature is enabled, the projects in a multi-project build are "isolated" from each other. This means that build logic, such as build scripts or plugins, applied to a project cannot directly access the mutable state of other projects. This constraint unlocks two things: parallel project configuration and finer-grained caching of configuration results.
You can enable the feature by setting the org.gradle.unsafe.isolated-projects to true in gradle.properties,
or passing a flag on the command line:
$ ./gradlew build -Dorg.gradle.unsafe.isolated-projects=trueFollow the recommended migration steps to make your build logic compatible with Isolated Projects constraints.
|
Warning
|
Isolated Projects is an experimental feature that has not yet reached incubating state. APIs and behavior may change at any time without notice. The feature will enter incubation once Gradle’s core has stronger support for this mode and more common use cases are covered. |
Recent changes
While the feature is experimental, notable changes are documented here rather than in release notes:
-
Gradle 9.6.0
-
Properties and methods are no longer looked up in parent projects, avoiding false-positive violations and reducing project coupling.
-
The
Project.getProperties()API is now treated as incompatible, while being generally deprecated. -
The new Diagnostics mode runs without parallelism and deterministically reports constraint violations.
-
Editor support for Kotlin build scripts and precompiled plugins in IDEA-based IDEs has been fixed.
-
The minimum supported version of the Develocity plugin is 4.0.
-
-
Gradle 9.4.0
-
Isolated Projects violations are now deduplicated, making the Configuration Cache HTML reports significantly smaller.
-
-
Gradle 9.3.0
-
Tooling model caching is now disabled, as it currently has known correctness problems.
-
-
Gradle 9.2.0
-
Additional APIs on
TaskContainerare treated as incompatible:findByPath(String)andgetByPath(String)methods now emit violations when a task from another project is requested.
-
Performance benefits and limitations
The main goal of Isolated Projects is to speed up or entirely avoid running the configuration phase. This is similar to the Configuration Cache feature, which allows skipping configuration when you rerun a task without changing the build configuration inputs. In fact, Isolated Projects uses Configuration Cache infrastructure as the foundation.
Builds that will get the most benefit are those that have a long configuration phase, such as large multi-project builds. Even for builds with short configuration times, keeping that phase under a few seconds helps developers stay in flow and avoid losing momentum.
Here is how Isolated Projects affects the lifecycle of the build:
-
Initialization phase
Running init scripts and evaluating settings remains sequential with Isolated Projects. Compared to other phases, this phase is relatively quick, especially for large builds.
-
Configuration phase
Isolated Projects directly improves the performance of this phase by running project configuration in parallel.
-
Execution phase
Isolated Projects has no effect on this phase, as the tasks are already isolated from each other and run in parallel with Configuration Cache.
|
Note
|
In case of a Configuration Cache hit, the initialization and configuration are skipped entirely. This applies with Isolated Projects as well. |
An important takeaway is that enabling Isolated Projects on a machine with N cores will not make your build N times faster. If the configuration phase is only 40% of the build time, then that’s the ceiling for improvement with Isolated Projects. That said, for large builds, even a few-percent improvement can translate into minutes or more of actual time, which can have a substantial impact on developer productivity.
Overall, the performance benefits of Isolated Projects depend on a variety of factors, such as the size and shape of your build, hardware resources, as well as your workflow. It also depends on the way Gradle is invoked.
Gradle invocation modes
Most users interact with Gradle in different ways:
-
Running tasks (either via command-line or via IDE)
-
Building tooling models (this happens behind the scenes when you do an IDE sync)
The configuration phase runs in both cases, but it is significantly different when model building is involved. Because of this, the performance benefits of Isolated Projects also depend on the way of interacting.
|
Note
|
Performance improvements for Isolated Projects are released gradually across Gradle versions. Some improvements might bring benefits only for running tasks, while others for model building (and IDE sync by extension). As the Isolated Projects feature matures, the improvements will serve more scenarios. |
Performance when running tasks
When running tasks, the configuration phase consists of multiple steps.
-
Configure projects
Isolated Projects makes this step run in parallel, which can significantly improve performance for builds with many projects. In the current implementation, all projects are always configured; there is no project configuration avoidance yet, whether by skipping unneeded projects or by using cached results.
-
Discover the work graph
The work graph is constructed by starting with the requested tasks and following the dependencies until all required work is discovered. This is not a directly parallelizable process. In the current implementation, even with Isolated Projects, this step is sequential. For invocations that result in having large work graphs, this step can become a performance bottleneck. An example is running checks or tests on all projects via an unqualified task, such as
./gradlew check, which is typical on CI. -
Store the work graph (Configuration Cache)
Isolated Projects makes this step run in parallel. This is the same as with Parallel Configuration Cache, but with the additional safety provided by the Isolated Projects constraints.
-
Load the work graph (Configuration Cache)
This step is already parallel with Configuration Cache; Isolated Projects has no additional effect here.
Performance when building models (IDE Sync)
For scenarios such as IDE sync, Gradle provides a special mechanism of building tooling models. The models describe the structure of the build, tell IDEs where to find production sources, and more.
From Gradle’s point of view, an IDE sync or a tooling invocation in general consists of the following parts (simplified):
-
Configure projects
Isolated Projects makes this step run in parallel, which can significantly improve performance for builds with many projects. In the current implementation, all projects are always configured; there is no project configuration avoidance yet, whether by skipping unneeded projects or by using cached results.
-
Run model builders
The invoking tool (e.g., the IDE) controls how individual models are built. Because of this, enabling Isolated Projects alone might not be enough to build models in parallel. However, in some cases it’s possible to achieve parallel model building even without Isolated Projects, as explained below.
-
Return the full model
Similarly to how the task-running invocation finishes after all tasks have executed, the model-building invocation finishes after returning the final model. The model content is fully defined by the tool, e.g. the IDE.
|
Note
|
There is a lot more nuance to this, but it’s out of scope of this page. Individual models can be streamed back to the consumer before the final return. A tooling invocation can also request running tasks and build models before and after. All this and more affect the performance of a model building invocation and how Isolated Projects can improve it. |
Without Isolated Projects, it is not possible to get a "Configuration Cache hit" for IDE sync because Configuration Cache does not currently support model building invocations. When Isolated Projects is enabled, the full model can be cached and returned immediately on later invocations if the build configuration hasn’t changed.
Parallel model building can significantly speed up IDE sync. However, both Gradle and the IDE need to be configured to allow it.
On the Gradle side, parallel model building must be allowed in the build definition.
It is automatically allowed with Isolated Projects.
It can also be allowed without Isolated Projects
via org.gradle.tooling.parallel or org.gradle.parallel Gradle properties.
|
Warning
|
Enabling parallel model fetching without Isolated Projects can be unsafe. Parts of the configuration logic will run in parallel without supporting validations, potentially leading to flakiness or unreliable results. Isolated Projects makes this safe by enforcing constraints that prevent projects from sharing mutable state. |
On the IDE side, the setup depends on the IDE:
-
Android Studio
Parallel model building has been enabled automatically since Android Studio Electric Eel (2022.1.1).
-
IntelliJ IDEA
Parallel model building is never enabled automatically in IntelliJ IDEA as of the latest 2026.1 release. It has to be manually enabled in the UI at
Setting › 'Build, Execution, Deployment' › Build Tools › Gradlevia theEnable parallel Gradle model fetchingcheckbox. The setting is only applied to the current project opened in the IDE.
If you have already been using parallel model building for IDE sync, then Isolated Projects will not provide a performance benefit in that part of the configuration phase. However, Isolated Projects will catch violations as you change your build logic, preventing correctness issues from creeping in silently.
Parallelism controls
Much of the performance benefit of Isolated Projects comes from running project configuration in parallel.
The degree of parallelism is controlled by the org.gradle.workers.max Gradle property,
which sets the maximum number of parallel units of work across all build phases,
including configuration.
The default value is the number of CPU cores on your machine, which is usually a good choice. If you’ve explicitly set it lower for any reason, keep in mind that it will also limit how much parallelism Isolated Projects can use.
Current limitations
The current implementation of Isolated Projects has a number of limitations that might be addressed in the future.
-
All projects always get configured, and Configuration on Demand has no effect.
-
A subproject can’t start configuring until all its parent projects are done, which limits the parallelism.
-
The configuration phase might require more memory to process more work in parallel.
-
Changes to included builds invalidate all cached results, even unrelated ones.
-
Tooling model caching is local only: no sharing across checkouts or remote caching.
Isolated Projects constraints
During configuration, Gradle runs lots of smaller units of work (evaluating settings, configuring individual projects, etc.),
and each one mutates live state on objects like Project, Settings, Gradle.
Isolated Projects doesn’t change how individual projects or included builds are configured; plugins still mutate the state of the target they’re applied to. What it adds is strict boundaries that prevent projects and builds from observing or mutating each other’s state.
With Isolated Projects, it is not allowed to observe or change:
-
In project-scope, mutable state of other projects (cross-project access)
-
In project-scope, mutable state of the owner build (project-to-build access)
-
In build-scope, mutable state of other builds (cross-build access)
-
In build-scope, mutable state of the build that is passed into project-scope via callbacks (build-to-project access)
Among the build logic patterns described by these constraints, cross-project access is by far the most common.
The constraints are designed to allow safely running the individual configuration units in parallel and also caching the results of their execution.
Constraint violations
The violations of Isolated Projects constraints are detected at runtime during an invocation. When at least one violation is detected, the build results cannot be considered reliable and the build will fail.
Here is an example of the build logic that contains a violation:
// ⚠️ `Project.version` is mutable state of the root project and cannot be accessed from a subproject
val commonVersion = rootProject.version// ⚠️ `Project.version` is mutable state of the root project and cannot be accessed from a subproject
def commonVersion = rootProject.version$ ./gradlew -Dorg.gradle.unsafe.isolated-projects=true
...
- Build file 'app/build.gradle.kts': Project ':app' cannot access 'Project.version' functionality on another project ':'
...
BUILD FAILED in 0sCross-project access constraints
The cross-project access constraints apply during project configuration when a Project instance representing another project is involved.
Each instance of Project has both mutable and immutable state.
Accessing mutable state will result in a violation, but accessing immutable state is allowed.
Restricted access to mutable data of other projects
Most parts of the Project state are directly or indirectly mutable via the methods on the interface.
Accessing that state on another project is not allowed with Isolated Projects.
- Examples of mutable state (not exhaustive)
-
-
Basic state:
description,group,version,status,buildDir -
Containers:
tasks,dependencies,configurations,artifacts,repositories,components,plugins,extensions,ext -
Services:
layout,providers,objects,dependencyFactory
-
The Project interface also provides many convenience methods that allow configuring it, or registering callbacks.
Most of those methods indirectly access the mutable state and are also not allowed to be called on another project.
In general, it is easier to assume calling any method on another Project is forbidden,
unless it is one of the handful getters that provide immutable data.
Unrestricted access to immutable data of other projects
Immutable project state includes data that was configured during settings evaluation and finalized before any project configuration has begun. This includes basic information about the project, but also the structure of the project hierarchy, since it can no longer be changed during project configuration.
- Immutable project data
-
-
Basics:
name,displayName,path,buildTreePath,depth-
Caution:
groupandversionare mutable!
-
-
Directories/files:
projectDir,buildFile,rootDir-
Caution:
buildDirandlayoutare mutable!
-
-
- Project hierarchy navigation
-
-
isolated: IsolatedProject -
rootProject: Project -
parent: Project? -
project(): Projectoverloads -
childProjects: Map<String, Project> -
subprojects()andallprojects()overloads
-
It is allowed to traverse the project structure and access immutable data of other projects. However, it is best to reduce such interactions to a minimum and instead express them through dependencies between projects.
Project-to-build access constraints
|
Warning
|
Project-to-build access constraints are not fully enforced yet. |
Project configuration logic has access to the build-scoped state shared across projects via the Gradle interface.
A large part of the Gradle interface is dedicated to callback registration.
Many of the callbacks are either no-ops or throw an exception if you try registering them after settings have been evaluated.
Callbacks that do get successfully registered may execute in a different order per invocation due to parallel project configuration.
Shared Build Services
Shared Build Services are also part of the build-scoped state. As the name suggests, they are shared between projects in the build. However, the API for registering and observing their registrations was not designed with parallel project configuration in mind.
Generally speaking, registering a build service via gradle.sharedServices.registerIfAbsent(…) is safe with Isolated Projects.
Only the first registration succeeds, and any later registrations return the previously registered instance.
However, the parameters of the build service can become shared mutable state.
Any mutation of the build service parameters outside of registerIfAbsent(…) { parameters { … } } should be avoided.
Accessing the set of build service registrations at gradle.sharedServices.registrations is unsafe.
Cross-build access constraints
|
Warning
|
Cross-build access constraints are not fully enforced yet. |
Build configuration logic (init scripts and settings) has access to the state of other builds via gradle.parent.
Since (included) builds can be configured in parallel, access to the shared mutable state is also problematic.
With Isolated Projects, using gradle.parent should be avoided.
Build-to-project access constraints
|
Warning
|
Build-to-project access constraints are not fully enforced yet. |
Build configuration logic (init script and settings) can affect project configuration by registering callbacks that will run later in the build lifecycle.
Some of the callbacks are executed around project evaluation time: immediately before or after the project configuration. With Isolated Projects, when project configuration runs in parallel, these callbacks might execute in parallel as well. If the callbacks capture any mutable state from the build-scope, that state becomes shared mutable state, leading to concurrency problems.
See the section on state-isolating callbacks for a better alternative.
Behavior changes
When running builds with and without Isolated Projects you might observe differences in behavior of Gradle APIs and DSLs. This is especially relevant for the migration period, when Isolated Projects is not enabled for all environments or workflows.
The presence of behavior changes is an exception rather than the rule. The Isolated Projects constraints validate the usages of APIs to prevent cases where intermediate results or the build outcome could have been different.
No implicit lookup of properties and methods in parent projects
Under Isolated Project, the implicit resolution of properties and methods from parent projects does not happen. In Gradle 9.6.0, this behavior is deprecated when running without Isolated Projects. The corresponding upgrade guide entry details the cases when it is applicable.
|
Warning
|
The |
The lenient property lookups are common place in build logic and plugins. Due to this, it is highly recommended to address relevant deprecations before migrating to Isolated Projects.
You can align the behavior across all Gradle modes by using a feature preview flag. It is recommended to enable this flag in builds that are migrating to or already using Isolated Projects.
// settings.gradle.kts
enableFeaturePreview("NO_IMPLICIT_LOOKUP_IN_PARENT_PROJECTS")Properties report does not include properties inherited from parent projects
Under Isolated Projects, the properties report of a child project lists only the properties defined on that project itself. Properties inherited from parent projects are not present in the report. This is a consequence of the no implicit parent lookup behavior.
Direct uses of Project.getProperties()
continue to be reported as an Isolated Projects violation, as that API is being phased out.
Migration
This section covers how to migrate your build to be compatible with Isolated Projects.
|
Warning
|
Isolated Projects is an experimental feature, and it is actively changing. Make sure to use the latest available version of Gradle and that you are reading the documentation for that version. |
Before the migration
Before addressing constraint violations, make sure your build setup is up to date to get the best adoption experience.
-
Upgrade the build to the latest version of Gradle
If available, consider a pre-release version such as a milestone or a nightly to get the best experience while Isolated Projects is experimental.
-
Update third-party plugins to their latest versions
Ecosystem plugins and community plugins gradually improve support for Isolated Projects. By using the latest versions you reduce the risks of dealing with problems that have already been fixed.
-
Use the latest tooling, such as the latest versions of Android Studio and IntelliJ IDEA
The IDE support for Isolated Projects is already in a good state for 2025.3 and later releases. However, newer IDE versions can bring better performance as well as a better user experience when adopting Isolated Projects.
-
Make your build compatible with Configuration Cache
The Isolated Projects feature builds on top of the Configuration Cache feature.
-
Minimize behavior changes by addressing relevant deprecations
Follow the guidance for each behavior change to ensure expected build results when gradually migrating workflows to run with Isolated Projects.
Enabling Isolated Projects
Isolated Projects can be enabled by setting the org.gradle.unsafe.isolated-projects Gradle option to true.
You can pass it as an argument when running tasks from the command line:
$ ./gradlew help -Dorg.gradle.unsafe.isolated-projects=trueTo make use of the feature in IDE sync scenarios, it has to be enabled in the gradle.properties file:
org.gradle.unsafe.isolated-projects=trueIf you have never enabled the feature in the build before, it’s likely that the build is not compatible and contains Isolated Projects constraint violations. In that case the build will fail, and one or more violations will be shown in the error message.
Diagnostics mode
Diagnostics mode is an opt-in mode that helps you discover Isolated Projects constraint violations more efficiently during migration. It runs configuration of projects sequentially, which allows the build to safely continue even after an IP violation is detected.
Enable Diagnostics mode by setting org.gradle.unsafe.isolated-projects.diagnostics=true in gradle.properties, or by passing it on the command line alongside -Dorg.gradle.unsafe.isolated-projects=true:
$ ./gradlew help \
-Dorg.gradle.unsafe.isolated-projects=true \
-Dorg.gradle.unsafe.isolated-projects.diagnostics=trueCompared to default Isolated Projects behavior, Diagnostics mode disables several optimizations to maximize the completeness and consistency of the violation reporting:
-
Project configuration runs sequentially instead of in parallel.
-
Configuration Cache store runs sequentially.
-
Per-project model reuse across builds is disabled, so every model is rebuilt after an input change.
-
All projects are configured, ignoring any configure-on-demand setting.
This mode is intended to be used during the migration or to compare against the default Isolated Projects behavior when investigating a discrepancy. Because parallelism and caching are deliberately disabled, builds running in this mode will be slower. For these reasons, we generally don’t advise enabling this mode persistently or committing it to version control.
|
Note
|
Configuration Cache reuse is not affected by this mode. A cache entry is stored and can be reused only when the invocation is violation-free. To re-exercise configuration, change a build input as you would normally. |
Diagnostics mode does not change which patterns count as violations. A build that is clean under Isolated Projects is also clean under Diagnostics mode.
Also, if a diagnostic run is free of violation, it doesn’t mean that the entire build is guaranteed to be fully compatible with Isolated Projects. While the configuration of all projects is ensured, violations can hide behind additional layers of laziness, such as lazy configuration of tasks.
Temporarily ignoring violations
To guarantee reliable build results, Gradle will fail the build when any violations of Isolated Project constraints are detected. However, in the initial stages of the Isolated Projects adoption journey, it can be useful to gauge an estimate of the speed-up provided by the feature in your particular setup and workflow.
This can be achieved by temporarily ignoring the violations and not failing the build on the basis of their presence. It is especially relevant for the IDE sync scenarios, where the violations are preventing a sync from completion.
Since Isolated Projects violations are reported via the same mechanism as Configuration Cache problems, enabling Configuration Cache warning mode achieves the desired result.
# ⚠️ Temporary measure of ignoring Isolated Projects violations. Do not enable permanently!
org.gradle.configuration-cache.problems=warn|
Note
|
This does not guarantee that the build will succeed. Concurrency issues may still cause exceptions which fail the build. |
Alternatively, a flag can be used on the command line:
$ ./gradlew --configuration-cache-problems=warn|
Warning
|
Warning mode is a migration and troubleshooting aid and not intended as a persistent way of ignoring incompatibilities. It will also not prevent new incompatibilities being accidentally added to your build later. |
Recommended migration path
This section describes how to start making your build compatible with Isolated Projects.
-
Learn about incompatibilities in basic workflows
Run the
helptask with Isolated Projects in the Diagnostics mode:$ ./gradlew help \ -Dorg.gradle.unsafe.isolated-projects=true \ -Dorg.gradle.unsafe.isolated-projects.diagnostics=trueThis way Gradle can detect Isolated Projects violations that are present in virtually any workflow and should be addressed first.
You can find the Isolated Projects violations in the Configuration Cache HTML report. Use the report to pinpoint the incompatible pieces of build logic and plugins.
-
Report the violations coming from the community plugins to their maintainers.
An incompatible plugin can prevent you from getting the performance benefits of Isolated Projects. It is best to report the incompatibilities as soon as possible so the plugin maintainers can address them, while you make your own build logic compatible.
-
Follow the build-logic refactoring strategies to refactor your build logic and make it compatible.
Remember that Isolated Projects violations only detect concrete instances of the problem, e.g. one specific project touching some mutable state of another. It might not be enough to replace one API call with another to address the problem.
-
Migrate the IDE sync workflow
For IDE sync, the feature flag and Diagnostics mode must be enabled in the
gradle.propertiesfile to take effect.org.gradle.unsafe.isolated-projects=true org.gradle.unsafe.isolated-projects.diagnostics=trueThe IDE sync might exercise other code paths in the build logic or plugins, surfacing new violations that need to be addressed.
Remember to disable Diagnostics mode once the violations are addressed to ensure you are getting the performance improvements.
-
Migrate other workflows
Use the same approach for other scenarios, such as sanity checks and tests.
You may observe different violations depending on which tasks you run. This is expected, since incompatible build logic can hide behind lazy task configuration.
Build-logic refactoring strategies
Use convention plugins
The most common cause of Isolated Projects violations is projects trying to configure other projects.
This is often done to have a single place where some configuration logic is defined
and then reused by applying it to many projects via callbacks like allprojects {}.
Convention plugins address the same need from a different perspective. The configuration logic is defined once in a convention plugin and then explicitly applied in projects that need it. Because each project applies the plugins to itself, no Isolated Projects constraints are violated.
Additionally, convention plugins can be composed. This allows for more elaborate reuse of build logic without compromising Isolated Projects compatibility.
Use state-isolating lifecycle callbacks
Sometimes it is still desirable to apply configuration to many projects at once.
This is usually done with a callback such as allprojects {} called from a project or registered in the build scope via gradle.
One problem with these callbacks is that the owner of the callback ends up touching state of another scope. However, there is another subtle yet important issue: callbacks can inadvertently share mutable state of the owner with all targets of the callback. When the target projects are configured in parallel, it’s not possible to safely run the corresponding callbacks.
The solution Gradle offers is state-isolating callbacks. This works on the same principles as the isolation of task state performed by Configuration Cache to allow running tasks in parallel.
The GradleLifecycle API,
accessible via gradle.lifecycle, offers beforeProject and afterProject callbacks.
Actions registered as GradleLifecycle callbacks are isolated and will run in an isolated context that is private to each project.
The example below shows how this API could be used in a settings script or settings plugins to apply configuration to all projects, while avoiding cross-project configuration:
include("sub1")
include("sub2")
gradle.lifecycle.beforeProject {
apply(plugin = "base")
repositories {
mavenCentral()
}
group = "org.example.app"
version = providers.fileContents(
isolated.rootProject.projectDirectory.file("version.txt")
).asText.get()
}include('sub1')
include('sub2')
def sharedGroup = 'org.example.app'
def sharedVersion =
layout.settingsDirectory.file('version.txt').asFile.text
gradle.lifecycle.beforeProject {
apply plugin: 'base'
repositories {
mavenCentral()
}
group = sharedGroup
version = sharedVersion
}Use IsolatedProject instead of Project
You can get a simplified view of a project by calling project.isolated,
which returns IsolatedProject type.
This works in all contexts and is especially useful when accessing an instance of another project,
such as project(":foo").isolated or rootProject.isolated.
The data provided by IsolatedProject is limited and exposes only properties that are safe to access across project boundaries.
The use of the isolated view makes it obvious to build logic readers that no cross-project state access is possible.
The example below shows how the API could be used from a Project configuration callback to query the root project directory:
gradle.lifecycle.beforeProject {
val rootDir = project.isolated.rootProject.projectDirectory
println("The root project directory is $rootDir")
}gradle.lifecycle.beforeProject {
def rootDir = project.isolated.rootProject.projectDirectory
println("The root project directory is $rootDir")
}Isolated Projects and other Gradle features
Configuration Cache
Configuration Cache allows skipping the entire configuration phase when no build configuration inputs have changed. However, when any input has changed, the configuration has to be reexecuted in full. When executed, the configuration phase runs sequentially, configuring one project after another.
Isolated Projects relies on the Configuration Cache infrastructure, and it also extends the set of constraints imposed by Configuration Cache.
Configuration Cache is enabled automatically when Isolated Projects is enabled. You should make your build compatible with Configuration Cache first, before migrating to Isolated Projects.
|
Important
|
It is an error to enable Isolated Projects and explicitly disable Configuration Cache. |
Parallel Configuration Cache
Configuration Cache allows enabling some parallelism in the configuration phase with Parallel Configuration Cache. This requires an opt-in because not all builds are compatible with this behavior, and there is no explicit validation of violations.
With Isolated Projects, Parallel Configuration Cache is enabled automatically, since Isolated Projects constraints guarantee safe and correct results for all builds.
Parallel Execution (--parallel)
Parallel Execution has to do with parallel execution of tasks. This requires an opt-in because not all builds are compatible with this behavior, and there is no explicit validation of violations.
Generally speaking, Parallel Execution is superseded by Configuration Cache because it enables running tasks in parallel even within a single project.
However, Parallel Execution has an additional effect of allowing parallel tooling model building in scenarios like IDE sync. That is why many teams enable it alongside Configuration Cache.
Isolated Projects extends the Configuration Cache, which enables intra-project task parallelism. Additionally, Isolated Projects constraints guarantee safe parallel tooling model building, which allows parallel model building to be enabled by default. Therefore, there is no benefit to enabling Parallel Execution alongside Isolated Projects.
The Parallel Execution flag is ignored when Isolated Projects is enabled.
Configuration on Demand
Configuration on Demand lets Gradle skip configuring projects that aren’t needed for the requested tasks.
Isolated Projects constraints are strong enough to allow a similar optimization. However, the current implementation doesn’t leverage that yet. Instead, all projects are configured in parallel unless the entire configuration phase is skipped on a Configuration Cache hit.
The Configure on Demand flag is ignored when Isolated Projects is enabled.
SECURING BUILDS
Securing Gradle Builds
Every Gradle build pulls in code from external repositories, executes tools you didn’t author, and publishes artifacts that others will trust. Each step is a potential attack surface.
For a typical Gradle build, the supply chain has three main components:
-
Dependencies – Libraries and plugins your project consumes.
-
Repositories – Where artifacts are stored and served.
-
Build Tool – Gradle itself.
Attacks can originate at any layer and then propagate downstream through published artifacts, transitive dependencies, or compromised tools.
Even the build tool itself is an attack vector.
Common issues and attacks include:
-
Dependencies
-
Typosquatting
-
Compromised artifacts
-
Silent version drift
-
-
Repositories
-
Using unauthorized public repositories
-
Leaking secure package names
-
Artifacts from unauthenticated repositories
-
-
Build Tool
-
Poisoned caches
-
Compromised CI
-
Compromised wrapper
-
Gradle provides features to harden each part of this chain:
-
Dependencies – Validate libraries and plugins using checksums and signatures.
-
Repositories – Centralize repository definitions and use trusted mirrors.
-
Build Tool – Verify the Gradle distribution and Wrapper JAR file using checksums.
Verifying Dependencies
Working with external dependencies and plugins from third-party repositories exposes your build to significant supply chain risks. Dependencies are the most commonly attacked part of the software supply chain, and every artifact you consume, including transitively pulled-in binaries, needs to be both legitimate and unchanged.
To illustrate the risk, consider building an application that uses the trusty-lib:1.0 library from a public repository.
If an attacker successfully replaces trusty-lib in the repository with a malicious version having the same coordinates (trusty-lib:1.0), your next build will download the compromised code without any warning.
To mitigate these risks and avoid integrating compromised artifacts, Gradle provides dependency verification.
But dependency verification adds overhead: So why keep it on?
Because dependency verification is about trust: trust that what you download is what you think it is, and that what you ship is what you intended.
Without verification, it is easier for attackers to compromise your supply chain by publishing malicious artifacts under trusted coordinates or by tampering with artifacts in transit or at rest. Dependency verification helps protect you from these attacks by requiring you to confirm that the artifacts used in your build are the ones you expect.
Finding the right balance between security and convenience is hard, but Gradle provides options to let you choose the right level for your needs.
|
Note
|
Dependency verification is meant to protect yourself from compromised dependencies, not to prevent you from including vulnerable dependencies. |
Understanding Verification Methods
Gradle provides two complementary mechanisms for dependency verification:
-
Checksums – Verify the integrity of the artifact (that file contents haven’t changed)
-
Signatures – Verify the provenance of the artifact (who published it)
Used together, they help ensure you get the right library or plugin from a trustworthy author. Checksums alone verify integrity but not authenticity. Signatures alone verify authenticity but may use weak hashes. You can use signatures whenever they are available, and fall back to checksums when artifacts are not signed. But for the strongest security, use both.
|
Warning
|
Signatures can also be used to assess integrity like checksums, but signatures are an encrypted hash of the artifact contents and some metadata, not artifacts themselves.
If the signature uses an unsafe hash (even SHA-1), you’re not correctly assessing file integrity.
For this reason, if you care about both integrity and authenticity, you need to add both signatures and checksums to your verification metadata.
|
Checksums
A checksum is a short fingerprint of a file’s contents.
To produce a checksum, the library or plugin file is passed through a cryptographic hash function (for example, SHA-256), which returns a fixed-length string that uniquely represents that exact content.
If the file changes in any way, the checksum will also change.
With checksums, the build tool keeps a list of expected hashes for each artifact:
-
You record the expected checksum (for example,
SHA-256) of a library or plugin in thegradle/verification-metadata.xmlfile. -
When the build downloads that artifact, it computes the checksum of the downloaded bytes.
-
If the computed checksum doesn’t match the expected value, the build fails instead of using the tampered file.
For example, the checksum entry for trusty-lib-1.0.jar might look like this:
<artifact name="trusty-lib-1.0.jar">
<sha256 value="5e87d84077de0c60d9ff4eedbc9fac1506693019eb6f55652afc9e1ff235bd15"/>
</artifact>Signatures
A signature is a cryptographic stamp that proves authenticity.
To produce a signature, the author uses their private key to create a digital signature over the library or plugin.
With signatures, you verify who produced the artifact, not just that it hasn’t changed:
-
The author signs the checksum of the artifact’s file contents along with additional metadata using their private key.
-
You verify and add trusted public keys to the
gradle/verification-metadata.xmlfile. -
When the artifact is downloaded, the build verifies the signature against the trusted public key.
-
If the signature is missing, invalid, or signed by an untrusted key, the build fails.
For example, the combined checksum and signature entry for trusty-lib-1.0.jar might look like this:
<artifact name="trusty-lib-1.0.jar">
<sha256 value="5e87d84077de0c60d9ff4eedbc9fac1506693019eb6f55652afc9e1ff235bd15"/>
<pgp value="D4C89EA4AAF455FD88B22087EFE8086F9E93774E"/>
</artifact>Trusted Keys and Key Servers
Because public keys are part of the verification process, Gradle records trusted public key IDs in verification-metadata.xml on a group-level basis:
<trusted-keys>
<trusted-key
id="06D34ED6FF73DE368A772A781063FE98BCECB758"
group="com.puppycrawl.tools"
name="checkstyle"/>
</trusted-keys>Public keys are typically fetched from key servers, which are repositories for public keys, such as:
Gradle uses these trusted keys plus the checksum/signature data in verification-metadata.xml to ensure that dependencies come from the expected author and have not been tampered with.
Enabling Dependency Verification
To enable dependency verification, you need to create a verification metadata file that tells Gradle which checksums and signatures to verify. Once this file exists, Gradle automatically verifies all dependencies during every build.
The Verification Metadata File
Dependency verification is automatically enabled as soon as the verification metadata file is detected.
The file must be located at $PROJECT_ROOT/gradle/verification-metadata.xml.
|
Note
|
Currently, the only source of dependency verification metadata is this XML configuration file. Future versions of Gradle may include other sources (for example, via external services). |
A minimal configuration consists of the following:
<?xml version="1.0" encoding="UTF-8"?>
<verification-metadata xmlns="https://schema.gradle.org/dependency-verification"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://schema.gradle.org/dependency-verification https://schema.gradle.org/dependency-verification/dependency-verification-1.3.xsd">
<configuration>
<verify-metadata>true</verify-metadata>
<verify-signatures>false</verify-signatures>
</configuration>
</verification-metadata>With this configuration, Gradle verifies all artifacts using checksums but will not verify signatures.
Gradle verifies any artifact downloaded via its dependency management engine, including but not limited to:
-
Artifact files (e.g., JAR files, ZIPs) used during the build
-
Metadata artifacts (POM files, Ivy descriptors, and Gradle Module Metadata)
-
Plugins (both project and settings plugins)
-
Artifacts resolved via advanced dependency resolution APIs
Gradle does not verify changing dependencies (specifically SNAPSHOT versions) or locally produced artifacts (such as JARs generated during the build itself).
By nature, the checksums and signatures of these files change constantly.
|
Warning
|
Using such a minimal configuration file will cause a project with external dependencies or plugins to fail immediately, as the file does not yet contain the required checksums for verification. See Generating and Bootstrapping Verification Metadata to learn more. |
Scope of Dependency Verification
The dependency verification configuration is global; a single file is used to verify the entire build.
Specifically, the same file applies to all subprojects, the root project, and buildSrc.
When using an included build, the following rules apply:
-
The configuration file of the current build is used for verification.
-
If an included build has its own verification metadata, that configuration is ignored in favor of the current build’s settings.
-
Much like upgrading a dependency, including a new build may require you to update your current verification metadata.
Because this configuration is global and strict, the most efficient way to begin is by generating a baseline configuration for your existing build.
Disabling Dependency Verification
By default, Gradle verifies both artifacts (JARs, ZIPs, etc.) and their metadata files (POM files, Ivy descriptors, Gradle Module Metadata). Metadata verification can significantly increase the size of your configuration file.
To disable metadata verification, set the <verify-metadata> flag to false:
<?xml version="1.0" encoding="UTF-8"?>
<verification-metadata xmlns="https://schema.gradle.org/dependency-verification"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://schema.gradle.org/dependency-verification https://schema.gradle.org/dependency-verification/dependency-verification-1.3.xsd">
<configuration>
<verify-metadata>false</verify-metadata>
<verify-signatures>false</verify-signatures>
</configuration>
</verification-metadata>|
Warning
|
Disabling metadata verification reduces security. Compromised metadata files could introduce malicious transitive dependencies into your build. |
Disabling Verification for Specific Configurations
Dependency verification is enabled globally to provide the strongest security level possible. However, plugins may need to resolve additional dependencies where verification doesn’t make sense.
For example, a plugin might check for newer versions of a library. It doesn’t make sense to require checksums for versions you don’t know about yet. In these cases, you can disable verification for specific configurations using the API.
|
Warning
|
Disabling dependency verification reduces security. This API exists for cases where verification doesn’t make sense. Gradle will print a warning whenever verification has been disabled for a specific configuration. |
To disable verification for a configuration, use the ResolutionStrategy#disableDependencyVerification method:
configurations {
create("myConfiguration") {
resolutionStrategy {
disableDependencyVerification()
}
}
}configurations {
myConfiguration {
resolutionStrategy {
disableDependencyVerification()
}
}
}You can also disable verification on detached configurations:
val detached = configurations.detachedConfiguration(dependencies.create("group:name:1.0"))
detached.resolutionStrategy.disableDependencyVerification()def detached = configurations.detachedConfiguration(dependencies.create("group:name:1.0"))
detached.resolutionStrategy.disableDependencyVerification()Skipping Javadocs and Sources
By default, Gradle verifies all downloaded artifacts, including javadocs and sources. This can cause issues with IDEs that automatically download them during import.
To avoid this, you can configure Gradle to automatically trust all javadocs and sources:
<?xml version="1.0" encoding="UTF-8"?>
<verification-metadata xmlns="https://schema.gradle.org/dependency-verification"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://schema.gradle.org/dependency-verification https://schema.gradle.org/dependency-verification/dependency-verification-1.3.xsd">
<configuration>
<trusted-artifacts>
<trust file=".*-javadoc[.]jar" regex="true"/>
<trust file=".*-sources[.]jar" regex="true"/>
</trusted-artifacts>
</configuration>
</verification-metadata>The <trusted-artifacts> section uses regular expressions to match artifact filenames.
Any artifacts matching these patterns will be automatically trusted without verification.
|
Note
|
Trusting javadoc and source artifacts means they could be tampered with without detection. |
Verification Modes
Dependency verification can be expensive, or sometimes verification gets in the way of day-to-day development (frequent dependency upgrades, for example). You might want to enable verification on CI servers but not on local machines.
Gradle provides three verification modes:
| Mode | Description |
|---|---|
|
Verification fails as early as possible to avoid using compromised dependencies during the build |
|
Runs the build even if there are verification failures. Verification errors are displayed without causing build failure |
|
Verification is completely ignored |
You can activate these modes on the CLI using the --dependency-verification flag:
$ ./gradlew --dependency-verification lenient buildAlternatively, set the org.gradle.dependency.verification system property on the CLI:
$ ./gradlew -Dorg.gradle.dependency.verification=lenient buildOr in a gradle.properties file:
org.gradle.dependency.verification=lenientConfiguring the Console Output
By default, if dependency verification fails, Gradle generates a small summary about the verification failure as well as an HTML report containing the full information about the failures.
If your environment prevents you from reading this HTML report file (for example, if you run a build on CI, and it’s not easy to fetch the remote artifacts), Gradle provides a way to opt in to a verbose console report.
Add this Gradle property to your gradle.properties file:
org.gradle.dependency.verification.console=verboseGenerating and Bootstrapping Verification Metadata
Gradle can automatically generate a dependency verification file by downloading all your dependencies and recording their checksums or signatures. This is called bootstrapping.
However, bootstrapping has a critical security limitation: it trusts whatever is currently in your repositories. If a malicious dependency has already been introduced into your build (or into a repository you use), Gradle will record the compromised artifact’s checksum or signature.
This is why you must review the generated verification file. Bootstrapping is convenient for getting started or updating your verification file, but it’s not a substitute for manual verification of critical dependencies.
Generating Checksums Only
To enable checksum verification, you need to generate a configuration file based on your current, trusted dependencies.
Run the following command in your terminal:
$ ./gradlew --write-verification-metadata sha256What this does:
-
It scans all the dependencies in your project.
-
It calculates the
SHA-256checksum for each. -
It creates a file located at
gradle/verification-metadata.xml.
Gradle supports MD5, SHA1, SHA-256, and SHA-512 checksums.
However, only SHA-256 and SHA-512 are considered secure for modern use.
SHA-1 has known collisions and MD5 should not be used.
Generating Checksums and Signatures
To generate both checksums and signatures (recommended when signatures are available), run:
$ ./gradlew --write-verification-metadata sha256,pgpGradle will:
-
Resolve your dependencies.
-
Download and/or generate the required verification information.
-
Write it in a VCS-friendly XML file at
gradle/verification-metadata.xml.
The write-verification-metadata flag requires the list of checksums that you want to generate or pgp for signatures.
Executing this command will cause Gradle to:
-
Resolve all resolvable configurations, which includes:
-
Configurations from the root project
-
Configurations from all subprojects
-
Configurations from
buildSrc -
Included builds configurations
-
Configurations used by plugins
-
-
Download all artifacts discovered during resolution
-
Compute the requested checksums and possibly verify signatures depending on what you asked
-
At the end of the build, generate the configuration file which will contain the inferred verification metadata
Gradle only supports verification of signatures published as ASCII-armored PGP files (.asc) on remote repositories.
Not all artifacts are published with signatures, and signature verification doesn’t guarantee the signatory was legitimate—only that the artifact was signed by a specific key.
Example Verification Metadata File
A snippet of the resulting verification-metadata.xml looks like this:
<verification-metadata
xmlns="https://schema.gradle.org/dependency-verification"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://schema.gradle.org/dependency-verification https://schema.gradle.org/dependency-verification/dependency-verification-1.3.xsd">
<components>
<!-- BOTH SIGNATURE AND CHECKSUM -->
<component group="com.google.guava" name="failureaccess" version="1.0.3">
<artifact name="failureaccess-1.0.3.jar">
<pgp value="BDB5FA4FE719D787FB3D3197F6D4A1D411E9D1AE"/>
<sha256 value="cbfc3906b19b8f55dd7cfd6dfe0aa4532e834250d7f080bd8d211a3e246b59cb"
origin="Verified"
reason="Added manually to fix CI"/>
</artifact>
</component>
<!-- CHECKSUM ONLY -->
<component group="antlr" name="antlr" version="2.7.7">
<artifact name="antlr-2.7.7.jar">
<sha256 value="88fbda4b912596b9f56e8e12e580cc954bacfb51776ecfddd3e18fc1cf56dc4c"
origin="Verified"
reason="Artifact is not signed"/>
</artifact>
</component>
<!-- SIGNATURE ONLY -->
<component group="com.beust" name="jcommander" version="1.78">
<artifact name="jcommander-1.78.jar">
<pgp value="C70B844F002F21F6D2B9C87522E44AC0622B91C3"/>
<pgp value="DCBA03381EF6C89096ACD985AC5EC74981F9CDA6"/>
</artifact>
</component>
</components>
</verification-metadata>Dry-Run Mode
By default, bootstrapping is incremental, which means that if you run it multiple times, information is added to the file. You can rely on your version control system to check the diffs between runs.
There are situations where you want to preview what the generated verification metadata file would look like without actually changing or overwriting the existing one.
To preview changes, add the --dry-run flag:
$ ./gradlew --write-verification-metadata sha256 help --dry-runInstead of generating the verification-metadata.xml file, Gradle will create a new file called verification-metadata.dryrun.xml that you can review.
|
Note
|
Because --dry-run doesn’t execute tasks, it runs much faster but will miss any dependency resolution that happens at task execution time.
|
Updating Verification Metadata
Once the verification-metadata.xml file is generated, every time a developer or CI server runs the build, Gradle will compare the downloaded file’s checksum against the one in the XML file.
When you add a new library or update a version, the build will fail because the new checksum isn’t in your XML file yet.
You have two options for updating the verification metadata: auto-update or manual update.
Updating Verification Metadata Automatically
Run the --write-verification-metadata command again to append the new hashes:
$ ./gradlew --write-verification-metadata sha256Bootstrapping can either be used to create the file from the beginning or to update an existing file with new information. Therefore, it’s recommended to always use the same parameters once you started bootstrapping.
Generation is incremental and preserves existing entries.
Gradle-generated checksums will have an origin attribute starting with "Generated by Gradle" to indicate they need review.
Manually added entries and header comments are preserved, making it easy to update the file for new dependency versions by regenerating and reviewing the diff.
<verification-metadata
xmlns="https://schema.gradle.org/dependency-verification"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://schema.gradle.org/dependency-verification https://schema.gradle.org/dependency-verification/dependency-verification-1.3.xsd">
<components>
<component group="aopalliance" name="aopalliance" version="1.0">
<artifact name="aopalliance-1.0.jar">
<sha256 value="0addec670fedcd3f113c5c8091d783280d23f75e3acb841b61a9cdb079376a08" origin="Generated by Gradle" reason="Artifact is not signed"/>
</artifact>
<artifact name="aopalliance-1.0.pom">
<sha256 value="26e82330157d6b844b67a8064945e206581e772977183e3e31fec6058aa9a59b" origin="Generated by Gradle" reason="Artifact is not signed"/>
</artifact>
</component>
</components>
</verification-metadata>After regenerating the file, follow these steps:
-
Review the diff - Check what changed in your version control system.
-
Remove unnecessary entries - Delete entries for old dependency versions that are no longer used.
-
Verify new entries - Ensure new checksums are correct by checking against official sources when possible.
-
Handle ignored keys - If any ignored keys were added, attempt to download them from a keyserver and add them to the keyring if found. See adding keys to the keyring.
-
Update all "Generated by Gradle" origins - You must review and update all entries with
origin="Generated by Gradle". Common reasons for generation include:-
Artifact is not signed
-
PGP signature verification failed
-
Key couldn’t be downloaded
-
-
Change origin to "Verified" - After verifying the checksum matches, edit the
originattribute to"Verified"to indicate you’ve confirmed it.
|
Important
|
Gradle cannot automatically determine that an entry is outdated. Remove older entries when you upgrade dependencies to keep the file manageable. |
|
Warning
|
There are dependencies that Gradle cannot discover automatically. In particular, dependencies that are only resolved during task execution or in custom dependency resolution logic may not be included in the generated file. You may need to add these manually. |
Updating Verification Metadata Manually
You can add a new <component> entry for a checksum or signature to the XML file manually.
Adding Checksums for an Artifact
External components are identified by GAV coordinates (group, artifact name, version), and each artifact by its file name.
For example, to add verification for Apache PDFBox with GAV coordinates:
-
group:
org.apache.pdfbox -
name:
pdfbox -
version:
2.0.17
Using this dependency triggers the download of two files:
-
pdfbox-2.0.17.jar- the main artifact -
pdfbox-2.0.17.pom- the metadata file
You need to declare checksums for both (unless you disabled metadata verification):
<?xml version="1.0" encoding="UTF-8"?>
<verification-metadata xmlns="https://schema.gradle.org/dependency-verification"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://schema.gradle.org/dependency-verification https://schema.gradle.org/dependency-verification/dependency-verification-1.3.xsd">
<configuration>
<verify-metadata>true</verify-metadata>
<verify-signatures>false</verify-signatures>
</configuration>
<components>
<component group="org.apache.pdfbox" name="pdfbox" version="2.0.17">
<artifact name="pdfbox-2.0.17.jar">
<sha512 value="7e11e54a21c395d461e59552e88b0de0ebaf1bf9d9bcacadf17b240d9bbc29bf6beb8e36896c186fe405d287f5d517b02c89381aa0fcc5e0aa5814e44f0ab331" origin="PDFBox Official site (https://pdfbox.apache.org/download.cgi)"/>
</artifact>
<artifact name="pdfbox-2.0.17.pom">
<sha512 value="82de436b38faf6121d8d2e71dda06e79296fc0f7bc7aba0766728c8d306fd1b0684b5379c18808ca724bf91707277eba81eb4fe19518e99e8f2a56459b79742f" origin="Verified"/>
</artifact>
</component>
</components>
</verification-metadata>Checksums are generally published alongside artifacts on public repositories. However, if a dependency is compromised in a repository, its checksum likely is too.
It’s a good practice to get checksums from a different source than where artifacts are hosted (typically the library’s official website). It’s much harder to compromise both the repository and the official website simultaneously.
In the example above, the checksum for the JAR was found on the official PDFBox website, while the POM checksum was verified manually.
The origin attribute documents where the checksum came from, helping others understand how trustworthy the verification is.
You can declare multiple checksums for the same artifact. Gradle will verify all of them and fail if any verification fails.
<component group="org.apache.pdfbox" name="pdfbox" version="2.0.17">
<artifact name="pdfbox-2.0.17.jar">
<md5 value="c713a8e252d0add65e9282b151adf6b4" origin="official site"/>
<sha1 value="b5c8dff799bd967c70ccae75e6972327ae640d35" origin="official site"/>
</artifact>
</component>Use multiple checksums when:
-
The official site only publishes insecure checksums (MD5, SHA-1). While each can be faked individually, faking multiple checksums for the same artifact is harder.
-
You want to add generated checksums alongside manually verified ones for extra validation.
-
You’re upgrading to more secure checksums but don’t want to remove existing ones yet.
Using a dependency like pdfbox will bring in transitive dependencies.
If your verification file only includes checksums for direct dependencies, the build will fail:
Execution failed for task ':compileJava'.
> Dependency verification failed for configuration ':compileClasspath':
- On artifact commons-logging-1.2.jar (commons-logging:commons-logging:1.2) in repository 'MavenRepo': checksum is missing from verification metadata.
- On artifact commons-logging-1.2.pom (commons-logging:commons-logging:1.2) in repository 'MavenRepo': checksum is missing from verification metadata.This indicates you need to add checksums for commons-logging and all other transitive dependencies.
See Troubleshooting Verification Failures for more details.
It’s common to have different checksums for the same artifact in different repositories. This can happen because:
-
Developers publish to Maven Central and another repository separately using different builds
-
Metadata files differ slightly (different timestamps, additional whitespace, etc.)
-
Your build uses multiple repositories or repository mirrors
Despite progress, this is often not malicious.
In general, you should verify the artifact is correct, then declare the additional checksums using also-trust:
<component group="org.apache" name="apache" version="13">
<artifact name="apache-13.pom">
<sha256 value="2fafa38abefe1b40283016f506ba9e844bfcf18713497284264166a5dbf4b95e">
<also-trust value="ff513db0361fd41237bef4784968bc15aae478d4ec0a9496f811072ccaf3841d"/>
</sha256>
</artifact>
</component>You can have as many also-trust entries as needed, though typically you shouldn’t need more than two.
Adding Keys for an Artifact
To trust a key for signature verification, add a pgp entry to your verification metadata:
<component group="com.github.javaparser" name="javaparser-core" version="3.6.11">
<artifact name="javaparser-core-3.6.11.jar">
<pgp value="8756c4f765c9ac3cb6b85d62379ce192d401ab61"/>
</artifact>
</component>This means you trust com.github.javaparser:javaparser-core:3.6.11 if it’s signed with key 8756c4f765c9ac3cb6b85d62379ce192d401ab61.
Without trusted keys configured, the build will fail:
> Dependency verification failed for configuration ':compileClasspath':
- On artifact javaparser-core-3.6.11.jar (com.github.javaparser:javaparser-core:3.6.11) in repository 'MavenRepo': Artifact was signed with key '8756c4f765c9ac3cb6b85d62379ce192d401ab61' (Bintray (by JFrog) <****>) and passed verification but the key isn't in your trusted keys list.|
Warning
|
Gradle requires full fingerprint IDs (40 characters, e.g., b801e2f8ef035068ec1139cc29579f18fa8fd93b) for pgp and trusted-key elements, not short or long IDs. This minimizes the risk of collision attacks. For ignored-key elements, you can use either fingerprints or long (64-bit) IDs.
|
|
Note
|
The key IDs shown in error messages are from the signature file itself. This doesn’t necessarily mean you should trust them—if a malicious entity signed the artifact, Gradle won’t detect that. Always verify keys against official sources. |
Adding Global Keys
Signature verification can be simplified by trusting keys at the group level instead of declaring them for each individual artifact. This is useful when the same key signs multiple artifacts from the same publisher.
You can add trusted keys to a global configuration block:
<?xml version="1.0" encoding="UTF-8"?>
<verification-metadata xmlns="https://schema.gradle.org/dependency-verification"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://schema.gradle.org/dependency-verification https://schema.gradle.org/dependency-verification/dependency-verification-1.3.xsd">
<configuration>
<verify-metadata>true</verify-metadata>
<verify-signatures>true</verify-signatures>
<trusted-keys>
<trusted-key id="8756c4f765c9ac3cb6b85d62379ce192d401ab61" group="com.github.javaparser"/>
</trusted-keys>
</configuration>
<components/>
</verification-metadata>This configuration trusts any artifact in the com.github.javaparser group if it’s signed with key 8756c4f765c9ac3cb6b85d62379ce192d401ab61.
The trusted-key element supports these attributes:
-
group- the group of the artifact to trust -
name- the name of the artifact to trust -
version- the version of the artifact to trust -
file- the name of the artifact file to trust -
regex- whether to interpret the other attributes as regular expressions (defaults tofalse)
Be careful when trusting keys globally:
-
A valid key may have been used to sign artifact
Awhich you trust -
Later, the key could be stolen and used to sign malicious artifact
B
This means you should limit trust to appropriate groups or artifacts, and avoid trusting keys too broadly.
|
Important
|
Anyone can put an arbitrary name when generating a PGP key. Never trust a key solely based on its name. Always verify the key is listed on the official project website. For example, Apache projects typically provide a KEYS.txt file.
|
Adding Trusted Artifacts
You might want to trust some artifacts more than others. For example, it’s legitimate to think that artifacts produced in your company and found in your internal repository are safe, but you want to check every external component.
|
Note
|
This is a typical company policy. However, nothing prevents your internal repository from being compromised, so it’s a good idea to check your internal artifacts too! |
You can automatically trust all artifacts in a group by adding this to your configuration:
<?xml version="1.0" encoding="UTF-8"?>
<verification-metadata xmlns="https://schema.gradle.org/dependency-verification"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://schema.gradle.org/dependency-verification https://schema.gradle.org/dependency-verification/dependency-verification-1.3.xsd">
<configuration>
<trusted-artifacts>
<trust group="com.mycompany" reason="We trust mycompany artifacts"/>
</trusted-artifacts>
</configuration>
</verification-metadata>This means all components with group com.mycompany will be automatically trusted.
Trusted means Gradle will not perform any verification whatsoever.
The trust element accepts these attributes:
-
group- the group of the artifact to trust -
name- the name of the artifact to trust -
version- the version of the artifact to trust -
file- the name of the artifact file to trust -
regex- whether to interpret thegroup,name,version, andfileattributes as regular expressions (defaults tofalse) -
reason- an optional reason why matched artifacts are trusted
In the example above, this trusts artifacts in com.mycompany but not com.mycompany.other.
To trust all artifacts in com.mycompany and all subgroups, you can use:
<?xml version="1.0" encoding="UTF-8"?>
<verification-metadata xmlns="https://schema.gradle.org/dependency-verification"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://schema.gradle.org/dependency-verification https://schema.gradle.org/dependency-verification/dependency-verification-1.3.xsd">
<configuration>
<trusted-artifacts>
<trust group="^com[.]mycompany($|([.].*))" regex="true" reason="We trust all mycompany artifacts"/>
</trusted-artifacts>
</configuration>
</verification-metadata>Configuring Key Servers, Keyrings, and Keys
Specifying Key Servers
Gradle automatically downloads public keys from well-known key servers. You can configure custom key servers by adding them to your verification metadata:
<?xml version="1.0" encoding="UTF-8"?>
<verification-metadata xmlns="https://schema.gradle.org/dependency-verification"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://schema.gradle.org/dependency-verification https://schema.gradle.org/dependency-verification/dependency-verification-1.3.xsd">
<configuration>
<verify-metadata>true</verify-metadata>
<verify-signatures>true</verify-signatures>
<key-servers>
<key-server uri="hkp://my-key-server.org"/>
<key-server uri="https://my-other-key-server.org"/>
</key-servers>
</configuration>
</verification-metadata>Using Local Keyrings Only
The local keyring files (.gpg or .keys) can be used to avoid reaching out to key servers whenever a key is required.
However, if the local keyring doesn’t contain a key, Gradle would normally use key servers to fetch the missing key.
If the local keyring file isn’t regularly updated, your CI builds (especially with disposable containers) might reach out to key servers too often.
To avoid this, you can disable key servers entirely. Only the local keyring file will be used, and if a key is missing, the build will fail.
To enable this mode, disable key servers in the configuration file:
<?xml version="1.0" encoding="UTF-8"?>
<verification-metadata xmlns="https://schema.gradle.org/dependency-verification"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://schema.gradle.org/dependency-verification https://schema.gradle.org/dependency-verification/dependency-verification-1.3.xsd">
<configuration>
<key-servers enabled="false"/>
</configuration>
</verification-metadata>|
Note
|
If you are asking Gradle to generate verification metadata and an existing file sets enabled to false, this flag will be ignored so that potentially missing keys can be downloaded.
|
Ignoring Unavailable Keys
Sometimes a key is not available because it wasn’t published to a public key server or was lost. In these cases, you can ignore the key:
<?xml version="1.0" encoding="UTF-8"?>
<verification-metadata xmlns="https://schema.gradle.org/dependency-verification"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://schema.gradle.org/dependency-verification https://schema.gradle.org/dependency-verification/dependency-verification-1.3.xsd">
<configuration>
<verify-metadata>true</verify-metadata>
<verify-signatures>true</verify-signatures>
<ignored-keys>
<ignored-key id="abcdef1234567890" reason="Key is not available in any key server"/>
</ignored-keys>
</configuration>
</verification-metadata>Once a key is ignored, it will not be used for verification even if the signature file mentions it. However, if the signature cannot be verified with at least one other key, Gradle will require you to provide a checksum.
|
Note
|
If Gradle cannot download a key while bootstrapping, it will automatically mark it as ignored. If you can find the key but Gradle cannot, you can manually add it to the keyring file. |
Maintaining Verification Metadata
Once you’ve set up dependency verification, you’ll need to maintain the verification metadata file and keyring files over time. This includes cleaning up old entries, refreshing keys, and managing your local keyring for better performance.
Cleaning up the Verification File
If you do nothing, the dependency verification metadata will grow over time as you add new dependencies or change versions: Gradle will not automatically remove unused entries from this file. The reason is that there’s no way for Gradle to know upfront if a dependency will effectively be used during the build or not.
As a consequence, adding dependencies or changing dependency versions can easily lead to more entries in the file while leaving unnecessary entries.
One option to clean up the file is to move the existing verification-metadata.xml file to a different location and call Gradle with the --dry-run mode: while not perfect (it will not notice dependencies only resolved at configuration time), it generates a new file that you can compare with the existing one.
We need to move the existing file because both the bootstrapping mode and the dry-run mode are incremental: they copy information from the existing metadata verification file (in particular, trusted keys).
Refreshing Missing Keys
Gradle caches missing keys for 24 hours, meaning it will not attempt to re-download the missing keys for 24 hours after failing.
If you want to retry immediately, you can run with the --refresh-keys CLI flag:
./gradlew build --refresh-keysAdding Keys to the Keyring
If you have a public key that Gradle cannot download from key servers, you can manually add it to the keyring file. This is useful when a key is not published to public key servers or when you want to avoid downloading keys repeatedly.
For ASCII-Armored Format (.keys)
If you’re using the ASCII-armored keyring format, you can add keys directly by appending them to the gradle/verification-keyring.keys file.
First, export the public key to a file:
$ gpg --export --armor 8756C4F765C9AC3CB6B85D62379CE192D401AB61 > key.ascThen append the key to your keyring file:
$ cat key.asc >> gradle/verification-keyring.keysFor Binary Format (.gpg)
If you’re using the binary keyring format, use GPG to import the key:
$ gpg --no-default-keyring --keyring gradle/verification-keyring.gpg --import key.ascOr import directly from a key server to the keyring:
$ gpg --no-default-keyring --keyring gradle/verification-keyring.gpg --recv-keys 8756C4F765C9AC3CB6B85D62379CE192D401AB61|
Note
|
Remember to use full 40-character fingerprint IDs when working with keys, not short or long IDs. |
Exporting Keys for Faster Verification
Gradle automatically downloads public keys from key servers, but this can be slow and requires everyone to download the same keys repeatedly. To avoid this, you can export keys to a local keyring file that can be committed to version control.
Keyring File Formats
Gradle supports two keyring formats:
-
Binary format (
.gpg) - Compact and can be updated via GPG commands, but not human-readable -
ASCII-armored format (
.keys) - Human-readable, easy to edit manually, and produces readable diffs for code reviews
You can configure which format to use:
<?xml version="1.0" encoding="UTF-8"?>
<verification-metadata xmlns="https://schema.gradle.org/dependency-verification"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://schema.gradle.org/dependency-verification https://schema.gradle.org/dependency-verification/dependency-verification-1.3.xsd">
<configuration>
<verify-metadata>true</verify-metadata>
<verify-signatures>true</verify-signatures>
<keyring-format>armored</keyring-format>
</configuration>
</verification-metadata>Available options are armored and binary.
Without keyring-format specified, if gradle/verification-keyring.gpg or gradle/verification-keyring.keys exists, Gradle will use it. The binary version (.gpg) takes precedence if both exist.
Exporting Keys
To export all keys used during verification to the keyring file, run:
$ ./gradlew --write-verification-metadata pgp,sha256 --export-keysUnless keyring-format is specified, this generates both the binary and ASCII-armored files.
You should only commit one format to your project.
You can also export keys without updating the verification metadata:
$ ./gradlew --export-keys|
Note
|
This command will not report verification errors, only export keys. |
Committing Keyring Files
It’s a good idea to commit the keyring file to version control (as long as you trust your VCS).
If you use the binary format with Git, add this to your .gitattributes file to ensure it’s treated as binary:
*.gpg binary|
Note
|
Only public key packets and a single userId per key are stored. All other information (user attributes, signatures, etc.) is stripped from exported keys. |
Understanding Signature Verification
Once signature verification is enabled, Gradle follows this workflow for each artifact:
-
Attempts to download the corresponding
.ascsignature file -
If the signature file exists:
-
Looks for the keys in the keyring, if they are not there, automatically downloads the public keys needed for verification
-
Verifies the artifact using the downloaded keys
-
If signature verification passes, performs any additional checksum verification you configured
-
-
If the signature file is absent, falls back to checksum verification
This means Gradle’s verification is stronger with signatures enabled than with checksums alone:
-
If an artifact is signed with multiple keys, all of them must pass validation or the build fails
-
If an artifact passes signature verification, any additional checksums configured for that artifact will also be checked
However, passing signature verification doesn’t automatically mean you can trust the artifact—you must explicitly trust the keys by adding them to your verification metadata as shown in Updating Verification Metadata Manually.
Bootstrapping with Signatures
When you bootstrap with signature verification enabled using --write-verification-metadata pgp,sha256, Gradle takes an optimistic approach and assumes signature verification is sufficient.
However, you must still provide a fallback checksum algorithm (like SHA256) because not all artifacts are signed.
Gradle performs optimistic verification during bootstrapping and automatically:
-
Auto-adds trusted keys - When signature verification passes, Gradle adds the key to the trusted keys list
-
Auto-adds ignored keys - When a key cannot be downloaded from public key servers, Gradle marks it as ignored in the configuration
-
Auto-generates checksums - For artifacts without signatures or with ignored keys, Gradle generates checksums using the fallback algorithm
-
Auto-groups keys - Gradle attempts to group keys at the group level (in
<trusted-keys>) rather than per-artifact to minimize configuration file size
|
Warning
|
Bootstrapping takes an optimistic point of view that signature verification is enough. If you also care about integrity, you should first bootstrap using checksum verification, then re-bootstrap with signature verification. This ensures you have checksums for all artifacts before adding signatures. |
If signature verification fails during bootstrapping, Gradle will automatically generate an ignored key entry but will warn you to investigate. This commonly happens when POM files differ between repositories in non-meaningful ways.
Troubleshooting Verification Failures
Dependency verification can fail in different ways. This section explains how to deal with various cases.
Missing Verification Metadata
The simplest failure occurs when verification metadata is missing from the dependency verification file. This happens when you update a dependency and new versions (and potentially transitive dependencies) are brought in.
Gradle will tell you what metadata is missing:
Execution failed for task ':compileJava'.
> Dependency verification failed for configuration ':compileClasspath':
- On artifact commons-logging-1.2.jar (commons-logging:commons-logging:1.2) in repository 'MavenRepo': checksum is missing from verification metadata.The missing module group is commons-logging, artifact name is commons-logging, and version is 1.2.
You need to add an entry to the verification file:
<component group="commons-logging" name="commons-logging" version="1.2">
<artifact name="commons-logging-1.2.jar">
<sha256 value="daddea1ea0be0f56978ab3006b8ac92834afeefbd9b7e4e6316fca57df0fa636" origin="official distribution"/>
</artifact>
</component>Alternatively, ask Gradle to generate the missing information using bootstrapping. Existing information will be preserved—Gradle only adds missing verification metadata.
Incorrect Checksums
A more serious issue is when checksum verification fails:
Execution failed for task ':compileJava'.
> Dependency verification failed for configuration ':compileClasspath':
- On artifact commons-logging-1.2.jar (commons-logging:commons-logging:1.2) in repository 'MavenRepo': expected a 'sha256' checksum of '91f7a33096ea69bac2cbaf6d01feb934cac002c48d8c8cfa9c240b40f1ec21df' but was 'daddea1ea0be0f56978ab3006b8ac92834afeefbd9b7e4e6316fca57df0fa636'Gradle shows the dependency, expected checksum (declared in metadata file), and actual computed checksum.
This indicates a dependency may have been compromised. You must perform manual verification. Several scenarios:
-
Dependency tampered in local cache - Delete the file from cache and Gradle will re-download.
-
Dependency available in multiple sources with slightly different binaries - Additional whitespace, timestamps, etc.
-
Inform library maintainers about the issue
-
Use
also-trustto accept additional checksums
-
-
Dependency was compromised
-
Immediately inform library maintainers
-
Notify repository maintainers
-
Note: A variation is name squatting (GAV coordinates that look legit but differ by one character) or repository shadowing (official GAV coordinates published in a malicious repository that comes first in your build).
Untrusted Signatures
With signature verification enabled, Gradle verifies signatures but doesn’t automatically trust them:
> Dependency verification failed for configuration ':compileClasspath':
- On artifact javaparser-core-3.6.11.jar (com.github.javaparser:javaparser-core:3.6.11) in repository 'MavenRepo': Artifact was signed with key '379ce192d401ab61' (Bintray (by JFrog) <****>) and passed verification but the key isn't in your trusted keys list.You need to verify if the key can be trusted, then refer to Understanding Signature Verification to declare trusted keys.
Failed Signature Verification
If Gradle fails to verify a signature, you must take action because this may indicate a compromised dependency.
Gradle will fail with:
> Dependency verification failed for configuration ':compileClasspath':
- On artifact javaparser-core-3.6.11.jar (com.github.javaparser:javaparser-core:3.6.11) in repository 'MavenRepo': Artifact was signed with key '379ce192d401ab61' (Bintray (by JFrog) <****>) but signature didn't matchOptions:
-
Signature was wrong in the first place (happens frequently with dependencies published on different repositories)
-
Signature is correct but artifact has been compromised (local cache or remotely)
Go to the official site to verify if they publish signatures. If they do, verify that Gradle’s downloaded signature matches the published one.
If you’ve verified the dependency is not compromised and only the signature is wrong, declare an artifact-level key exclusion and provide a checksum.
Handling Wrong Signatures
There are several options when you encounter a signature verification failure:
-
The signature was wrong in the first place, which happens frequently with dependencies published on different repositories.
-
The signature is correct but the artifact has been compromised (either in the local dependency cache or remotely).
The right approach here is to go to the official site of the dependency and see if they publish signatures for their artifacts. If they do, verify that the signature that Gradle downloaded matches the one published.
|
Note
|
Artifacts are often signed with expired keys, which is not a problem for verification. Key expiry is meant to prevent signing with stolen keys. If an artifact was signed before the key expired, the signature is still valid. |
If you have checked that the dependency is not compromised and that it’s "only" the signature which is wrong, you should declare an artifact level key exclusion:
<components>
<component group="com.github.javaparser" name="javaparser-core" version="3.6.11">
<artifact name="javaparser-core-3.6.11.pom">
<ignored-keys>
<ignored-key id="379ce192d401ab61" reason="internal repo has corrupted POM"/>
</ignored-keys>
</artifact>
</component>
</components>However, if you only do so, Gradle will still fail because all keys for this artifact will be ignored and you didn’t provide a checksum:
<components>
<component group="com.github.javaparser" name="javaparser-core" version="3.6.11">
<artifact name="javaparser-core-3.6.11.pom">
<ignored-keys>
<ignored-key id="379ce192d401ab61" reason="internal repo has corrupted POM"/>
</ignored-keys>
<sha256 value="a2023504cfd611332177f96358b6f6db26e43d96e8ef4cff59b0f5a2bee3c1e1"/>
</artifact>
</component>
</components>INTEGRATION
Gradle & Third-party Tools
Gradle can be integrated with many different third-party tools such as IDEs and continuous integration platforms. Here we look at some of the more common ones as well as how to integrate your own tool with Gradle.
IDEs
- Android Studio
-
As a variant of IntelliJ IDEA, Android Studio has built-in support for importing and building Gradle projects. You can also use the IDEA Plugin for Gradle to fine-tune the import process if that’s necessary.
This IDE also has an extensive user guide to help you get the most out of the IDE and Gradle.
- Eclipse
-
If you want to work on a project within Eclipse that has a Gradle build, you should use the Eclipse Buildship plugin. This will allow you to import and run Gradle builds. If you need to fine tune the import process so that the project loads correctly, you can use the Eclipse Plugins for Gradle. See the associated release announcement for details on what fine tuning you can do.
- IntelliJ IDEA
-
IDEA has built-in support for importing Gradle projects. If you need to fine tune the import process so that the project loads correctly, you can use the IDEA Plugin for Gradle.
- NetBeans
-
Built-in support for Gradle in Apache NetBeans
- Visual Studio
-
For developing C++ projects, Gradle comes with a Visual Studio plugin.
- Xcode
-
For developing C++ projects, Gradle comes with a Xcode plugin.
- CLion
-
JetBrains supports building C++ projects with Gradle.
Continuous integration
We have dedicated guides showing you how to integrate a Gradle project with several CI platforms.
How to integrate with Gradle
There are two main ways to integrate a tool with Gradle:
-
The Gradle build uses the tool
-
The tool executes the Gradle build
The former case is typically implemented as a Gradle plugin. The latter can be accomplished by embedding Gradle through the Tooling API.
Test integration
If your platform uses an external testing suite, and you want to integrate with the HTML Test Report, you can use the Test Reporting API.
Tooling API
Embedding Gradle using the Tooling API
Introduction to the Tooling API
Gradle provides a programmatic API called the Tooling API, which you can use for embedding Gradle into your own software. This API allows you to execute and monitor builds and to query Gradle about the details of a build. The main audience for this API is IDE, CI server, other UI authors; however, the API is open for anyone who needs to embed Gradle in their application.
-
Gradle TestKit uses the Tooling API for functional testing of your Gradle plugins.
-
Eclipse Buildship uses the Tooling API for importing your Gradle project and running tasks.
-
IntelliJ IDEA uses the Tooling API for importing your Gradle project and running tasks.
Tooling API Features
A fundamental characteristic of the Tooling API is that it operates in a version independent way. This means that you can use the same API to work with builds that use different versions of Gradle, including versions that are newer or older than the version of the Tooling API that you are using. The Tooling API is Gradle wrapper aware and, by default, uses the same Gradle version as that used by the wrapper-powered build.
Some features that the Tooling API provides:
-
Query the details of a build, including the project hierarchy and the project dependencies, external dependencies (including source and Javadoc jars), source directories and tasks of each project.
-
Execute a build and listen to stdout and stderr logging and progress messages (e.g. the messages shown in the 'status bar' when you run on the command line).
-
Execute a specific test class or test method.
-
Receive interesting events as a build executes, such as project configuration, task execution or test execution.
-
Cancel a build that is running.
-
Combine multiple separate Gradle builds into a single composite build.
-
The Tooling API can download and install the appropriate Gradle version, similar to the wrapper.
-
The implementation is lightweight, with only a small number of dependencies. It is also a well-behaved library, and makes no assumptions about your classloader structure or logging configuration. This makes the API easy to embed in your application.
Tooling API and the Gradle Build Daemon
The Tooling API always uses the Gradle daemon. This means that subsequent calls to the Tooling API, be it model building requests or task executing requests will be executed in the same long-living process. Gradle Daemon contains more details about the daemon, specifically information on situations when new daemons are forked.
Quickstart
As the Tooling API is an interface for developers, the Javadoc is the main documentation for it.
To use the Tooling API, add the following repository and dependency declarations to your build script:
repositories {
maven { url = uri("https://repo.gradle.org/gradle/libs-releases") }
}
dependencies {
implementation("org.gradle:gradle-tooling-api:$toolingApiVersion")
// The tooling API need an SLF4J implementation available at runtime, replace this with any other implementation
runtimeOnly("org.slf4j:slf4j-simple:2.0.17")
}repositories {
maven { url = 'https://repo.gradle.org/gradle/libs-releases' }
}
dependencies {
implementation "org.gradle:gradle-tooling-api:$toolingApiVersion"
// The tooling API need an SLF4J implementation available at runtime, replace this with any other implementation
runtimeOnly 'org.slf4j:slf4j-simple:2.0.17'
}The main entry point to the Tooling API is the GradleConnector.
You can navigate from there to find code samples and explore the available Tooling API models.
You can use GradleConnector.connect() to create a ProjectConnection.
A ProjectConnection connects to a single Gradle project.
Using the connection you can execute tasks, tests and retrieve models relative to this project.
Compatibility of Java and Gradle versions
The following components should be considered when implementing Gradle integration: the Tooling API version, The JVM running the Tooling API client (i.e. the IDE process), the JVM running the Gradle daemon, and the Gradle version.
The Tooling API itself is a Java library published as part of the Gradle release. Each Gradle release has a corresponding Tooling API version with the same version number.
The Tooling API classes are loaded into the client’s JVM, so they should have a matching version. The current version of the Tooling API library is compiled with Java 8 compatibility.
The JVM running the Tooling API client and the one running the daemon can be different. At the same time, classes that are sent to the build via custom build actions need to be targeted to the lowest supported Java version. The JVM versions supported by Gradle is version-specific. The upper bound is defined in the compatibility matrix. The rule for the lower bound is the following:
-
Gradle 4.x requires a minimum version of Java 7.
-
Gradle 5 and above require a minimum version of Java 8.
The Tooling API version is guaranteed to support running builds with all Gradle versions for the last five major releases. For example, the Tooling API 9.0.0 release is compatible with Gradle versions >= 4.0. Besides, the Tooling API is guaranteed to be compatible with future Gradle releases for the current and the next major. This means, for example, that the 8.1 version of the Tooling API will be able to run Gradle 9.x builds and might break with Gradle 10.
Test Event Reporting API
The Test Event Reporting API allows you to capture test execution events programmatically and produce results similar to Gradle’s built-in Test task.
It’s particularly useful to integrate non-JVM test results into Gradle’s testing infrastructure and publish them in Gradle’s HTML test reports.
The API is primarily targeted at plugin developers and platform providers, with the Javadoc serving as the main reference.
|
Warning
|
The Test Event Reporting API is incubating. |
Let’s take a look at a quick example that defines a custom Gradle task, CustomTest, which demonstrates how to capture and report test events:
package com.example;
import org.gradle.api.DefaultTask;
import org.gradle.api.file.ProjectLayout;
import org.gradle.api.tasks.TaskAction;
import org.gradle.api.tasks.testing.GroupTestEventReporter;
import org.gradle.api.tasks.testing.TestEventReporter;
import org.gradle.api.tasks.testing.TestEventReporterFactory;
import org.junit.platform.launcher.Launcher;
import org.junit.platform.launcher.LauncherDiscoveryRequest;
import org.junit.platform.launcher.core.LauncherDiscoveryRequestBuilder;
import org.junit.platform.launcher.core.LauncherFactory;
import org.junit.platform.launcher.listeners.SummaryGeneratingListener;
import org.junit.platform.launcher.listeners.TestExecutionSummary;
import javax.inject.Inject;
import java.time.Instant;
import java.util.ArrayList;
import java.util.List;
import static org.junit.platform.engine.discovery.DiscoverySelectors.selectClass;
/**
* A custom task that demonstrates the {@code TestEventReporter} API.
*/
public abstract class CustomTest extends DefaultTask {
@Inject
public abstract ProjectLayout getLayout();
@Inject
protected abstract TestEventReporterFactory getTestEventReporterFactory();
@TaskAction
void runTests() {
try (GroupTestEventReporter root = getTestEventReporterFactory().createTestEventReporter( // (1)
"root",
getLayout().getBuildDirectory().dir("test-results/custom-test").get(),
getLayout().getBuildDirectory().dir("reports/tests/custom-test").get()
)) {
root.started(Instant.now());
List<String> failedTests = new ArrayList<>();
try (GroupTestEventReporter junittest = root.reportTestGroup("CustomJUnitTestSuite")) { // (2)
junittest.started(Instant.now());
LauncherDiscoveryRequest request = LauncherDiscoveryRequestBuilder.request()
.selectors(
selectClass(MyTest1.class)
)
.build();
Launcher launcher = LauncherFactory.create();
TestExecutionSummary summary = executeTests(launcher, request);
summary.getFailures().forEach(result -> {
try (TestEventReporter test = junittest.reportTest(result.getTestIdentifier().getDisplayName(),
result.getTestIdentifier().getLegacyReportingName())) { // (3)
test.started(Instant.now());
String testName = String.valueOf(result.getTestIdentifier().getParentIdObject());
failedTests.add(testName); // (4)
test.metadata(Instant.now(),"Parent class:", String.valueOf(result.getTestIdentifier().getParentId().get()));
test.failed(Instant.now(), String.valueOf(result.getException()));
}
});
String failedTestsList = String.join(", ", failedTests);
junittest.metadata(Instant.now(), "Tests that failed:", failedTestsList);
if (summary.getTestsFailedCount() > 0) {
junittest.failed(Instant.now());
} else {
junittest.succeeded(Instant.now());
}
}
if (!failedTests.isEmpty()) {
root.failed(Instant.now());
} else {
root.succeeded(Instant.now());
}
}
}
private TestExecutionSummary executeTests(Launcher launcher, LauncherDiscoveryRequest request) {
// Use SummaryGeneratingListener to collect test execution data
SummaryGeneratingListener listener = new SummaryGeneratingListener();
launcher.registerTestExecutionListeners(listener);
// Execute the tests
launcher.execute(request);
// Return the summary generated by the listener
return listener.getSummary();
}
}-
The
GroupTestEventReporteris initialized to act as the root event reporter.It creates directories for test results and reports under the project’s build directory: This establishes the reporting hierarchy.
Nesting is supported.
-
The task uses JUnit Platform to dynamically discover and execute tests, this would be replaced with your custom test system/platform.
It selects the class
MyTest1for testing.JUnit’s
Launcheris used to execute the tests and collect a summary of the results. -
The
TestEventReporteris used to record detailed events for each test.For each failure, the test is reported with metadata and marked as failed.
-
Each test group (
junittest) and the root (root) are finalized with success or failure based on the test results.
By using the Test Event Reporting API:
-
Integration: Custom tests (even those outside JVM frameworks) can generate events compatible with Gradle’s test reporting infrastructure.
-
Rich Metadata: Developers can attach additional context (e.g., error messages or parent class details) to test events.
-
Consistency: Results integrate seamlessly with Gradle’s HTML reports, making it easier to debug and understand test outcomes.
StopExecutionException nor do we access it via its fully qualified name. The reason is that Gradle adds a set of default imports to your script (see Default imports).
clean.
testng.xml files: http://testng.org/doc/documentation-main.html#testng-xml.