Solving common problems
Small problems in a build, like forgetting to declare a configuration file as an input to your task, can be easily overlooked.
The configuration file might change infrequently, or only change when some other (correctly tracked) input changes as well.
The worst that could happen is that your task doesn’t execute when it should.
Developers can always re-run the build with clean, and "fix" their builds for the price of a slow rebuild.
In the end nobody gets blocked in their work, and the incident is chalked up to "Gradle acting up again."
With cacheable tasks incorrect results are stored permanently, and can come back to haunt you later; re-running with clean won’t help in this situation either. When using a shared cache, these problems even cross machine boundaries. In the example above, Gradle might end up loading a result for your task that was produced with a different configuration. Resolving these problems with the build therefore becomes even more important when task output caching is enabled.
Other issues with the build won’t cause it to produce incorrect results, but will lead to unnecessary cache misses.
In this chapter you will learn about some typical problems and ways to avoid them.
Fixing these issues will have the added benefit that your build will stop "acting up," and developers can forget about running builds with clean altogether.
System file encoding
Most Java tools use the system file encoding when no specific encoding is specified. This means that running the same build on machines with different file encoding can yield different outputs. Currently Gradle only tracks on a per-task basis that no file encoding has been specified, but it does not track the system encoding of the JVM in use. This can cause incorrect builds. You should always set the file system encoding to avoid these kind of problems.
| Build scripts are compiled with the file encoding of the Gradle daemon. By default, the daemon uses the system file encoding, too. |
Setting the file encoding for the Gradle daemon mitigates both above problems by making sure that the encoding is the same across builds.
You can do so in your gradle.properties:
org.gradle.jvmargs=-Dfile.encoding=UTF-8Environment variable tracking
Gradle does not track changes in environment variables for tasks.
For example for Test tasks it is completely possible that the outcome depends on a few environment variables.
To ensure that only the right artifacts are re-used between builds, you need to add environment variables as inputs to tasks depending on them.
Absolute paths are often passed as environment variables, too. You need to pay attention what you add as an input to the task in this case. You would need to ensure that the absolute path is the same between machines. Most times it makes sense to track the file or the contents of the directory the absolute path points to. If the absolute path represents a tool being used it probably makes sense to track the tool version as an input instead.
For example, if you are using tools in your Test task called integTest which depend on the contents of the LANG variable you should do this:
tasks.integTest {
inputs.property("langEnvironment") {
System.getenv("LANG")
}
}tasks.named('integTest') {
inputs.property("langEnvironment") {
System.getenv("LANG")
}
}If you add conditional logic to distinguish CI builds from local development builds, you have to ensure that this does not break the loading of task outputs from CI onto developer machines.
For example, the following setup would break caching of Test tasks, since Gradle always detects the differences in custom task actions.
if ("CI" in System.getenv()) {
tasks.withType<Test>().configureEach {
doFirst {
println("Running test on CI")
}
}
}if (System.getenv().containsKey("CI")) {
tasks.withType(Test).configureEach {
doFirst {
println "Running test on CI"
}
}
}You should always add the action unconditionally:
tasks.withType<Test>().configureEach {
doFirst {
if ("CI" in System.getenv()) {
println("Running test on CI")
}
}
}tasks.withType(Test).configureEach {
doFirst {
if (System.getenv().containsKey("CI")) {
println "Running test on CI"
}
}
}This way, the task has the same custom action on CI and on developer builds and its outputs can be re-used if the remaining inputs are the same.
Line endings
If you are building on different operating systems be aware that some version control systems convert line endings on check-out.
For example, Git on Windows uses autocrlf=true by default which converts all line endings to \r\n.
As a consequence, compilation outputs can’t be re-used on Windows since the input sources are different.
If sharing the build cache across multiple operating systems is important in your environment, then setting autocrlf=false across your build machines is crucial for optimal build cache usage.
Symbolic links
When using symbolic links, Gradle does not store the link in the build cache but the actual file contents of the destination of the link. As a consequence you might have a hard time when trying to reuse outputs which heavily use symbolic links. There currently is no workaround for this behavior.
For operating systems supporting symbolic links, the content of the destination of the symbolic link will be added as an input.
If the operating system does not support symbolic links, the actual symbolic link file is added as an input.
Therefore, tasks which have symbolic links as input files, e.g. Test tasks having symbolic link as part of its runtime classpath, will not be cached between Windows and Linux.
If caching between operating systems is desired, symbolic links should not be checked into version control.
Java version tracking
Gradle tracks only the major version of Java as an input for compilation and test execution. Currently, it does not track the vendor nor the minor version. Still, the vendor and the minor version may influence the bytecode produced by compilation.
| If you’re using Java Toolchains, the Java major version, the vendor (if specified) and implementation (if specified) will be tracked automatically as an input for compilation and test execution. |
If you use different JVM vendors for compiling or running Java we strongly suggest that you add the vendor as an input to the corresponding tasks. This can be achieved by using the runtime API as shown in the following snippet.
tasks.withType<AbstractCompile>().configureEach {
inputs.property("java.vendor") {
System.getProperty("java.vendor")
}
}
tasks.withType<Test>().configureEach {
inputs.property("java.vendor") {
System.getProperty("java.vendor")
}
}tasks.withType(AbstractCompile).configureEach {
inputs.property("java.vendor") {
System.getProperty("java.vendor")
}
}
tasks.withType(Test).configureEach {
inputs.property("java.vendor") {
System.getProperty("java.vendor")
}
}With respect to tracking the Java minor version there are different competing aspects: developers having cache hits and "perfect" results on CI. There are basically two situations when you may want to track the minor version of Java: for compilation and for runtime. In the case of compilation, there can sometimes be differences in the produced bytecode for different minor versions. However, the bytecode should still result in the same runtime behavior.
| Java compile avoidance will treat this bytecode the same since it extracts the ABI. |
Treating the minor number as an input can decrease the likelihood of a cache hit for developer builds. Depending on how standard development environments are across your team, it’s common for many different Java minor version to be in use.
Even without tracking the Java minor version you may have cache misses for developers due to some locally compiled class files which constitute an input to test execution. If these outputs made it into the local build cache on this developers machine even a clean will not solve the situation. Therefore, the choice for tracking the Java minor version is between sometimes or never re-using outputs between different Java minor versions for test execution.
| The compiler infrastructure provided by the JVM used to run Gradle is also used by the Groovy compiler. Therefore, you can expect differences in the bytecode of compiled Groovy classes for the same reasons as above and the same suggestions apply. |
Avoid changing inputs external to your build
If your build is dependent on external dependencies like binary artifacts or dynamic data from a web page you need to make sure that these inputs are consistent throughout your infrastructure. Any variations across machines will result in cache misses.
Never re-release a non-changing binary dependency with the same version number but different contents: if this happens with a plugin dependency, you will never be able to explain why you don’t see cache reuse between machines (it’s because they have different versions of that artifact).
Using SNAPSHOTs or other changing dependencies in your build by design violates the stable task inputs principle.
To use the build cache effectively, you should depend on fixed dependencies.
You may want to look into dependency locking or switch to using composite builds instead.
The same is true for depending on volatile external resources, for example a list of released versions. One way of locking the changes would be to check the volatile resource into source control whenever it changes so that the builds only depend on the state in source control and not on the volatile resource itself.
Suggestions for authoring your build
Review usages of doFirst and doLast
Using doFirst and doLast from a build script on a cacheable task ties you to build script changes since the implementation of the closure comes from the build script.
If possible, you should use separate tasks instead.
Modifying input or output properties via the runtime API in doFirst is discouraged since these changes will not be detected for up-to-date checks and the build cache.
Even worse, when the task does not execute, then the configuration of the task is actually different from when it executes.
Instead of using doFirst for modifying the inputs consider using a separate task to configure the task under question - a so called configure task.
E.g., instead of doing
tasks.jar {
val runtimeClasspath: FileCollection = configurations.runtimeClasspath.get()
doFirst {
manifest {
val classPath = runtimeClasspath.map { it.name }.joinToString(" ")
attributes("Class-Path" to classPath)
}
}
}tasks.named('jar') {
FileCollection runtimeClasspath = configurations.runtimeClasspath
doFirst {
manifest {
def classPath = runtimeClasspath.collect { it.name }.join(" ")
attributes('Class-Path': classPath)
}
}
}do
val configureJar = tasks.register("configureJar") {
doLast {
tasks.jar.get().manifest {
val classPath = configurations.runtimeClasspath.get().map { it.name }.joinToString(" ")
attributes("Class-Path" to classPath)
}
}
}
tasks.jar { dependsOn(configureJar) }def configureJar = tasks.register('configureJar') {
doLast {
tasks.jar.manifest {
def classPath = configurations.runtimeClasspath.collect { it.name }.join(" ")
attributes('Class-Path': classPath)
}
}
}
tasks.named('jar') { dependsOn(configureJar) }| Note that configuring a task from other task is not supported when using the configuration cache. |
Build logic based on the outcome of a task
Do not base build logic on whether a task has been executed.
In particular you should not assume that the output of a task can only change if it actually executed.
Actually, loading the outputs from the build cache would also change them.
Instead of relying on custom logic to deal with changes to input or output files you should leverage Gradle’s built-in support by declaring the correct inputs and outputs for your tasks and leave it to Gradle to decide if the task actions should be executed.
For the very same reason using outputs.upToDateWhen is discouraged and should be replaced by properly declaring the task’s inputs.
Overlapping outputs
You already saw that overlapping outputs are a problem for task output caching.
When you add new tasks to your build or re-configure built-in tasks make sure you do not create overlapping outputs for cacheable tasks.
If you must you can add a Sync task which then would sync the merged outputs into the target directory while the original tasks remain cacheable.
Develocity will show tasks where caching was disabled for overlapping outputs in the timeline and in the task input comparison:
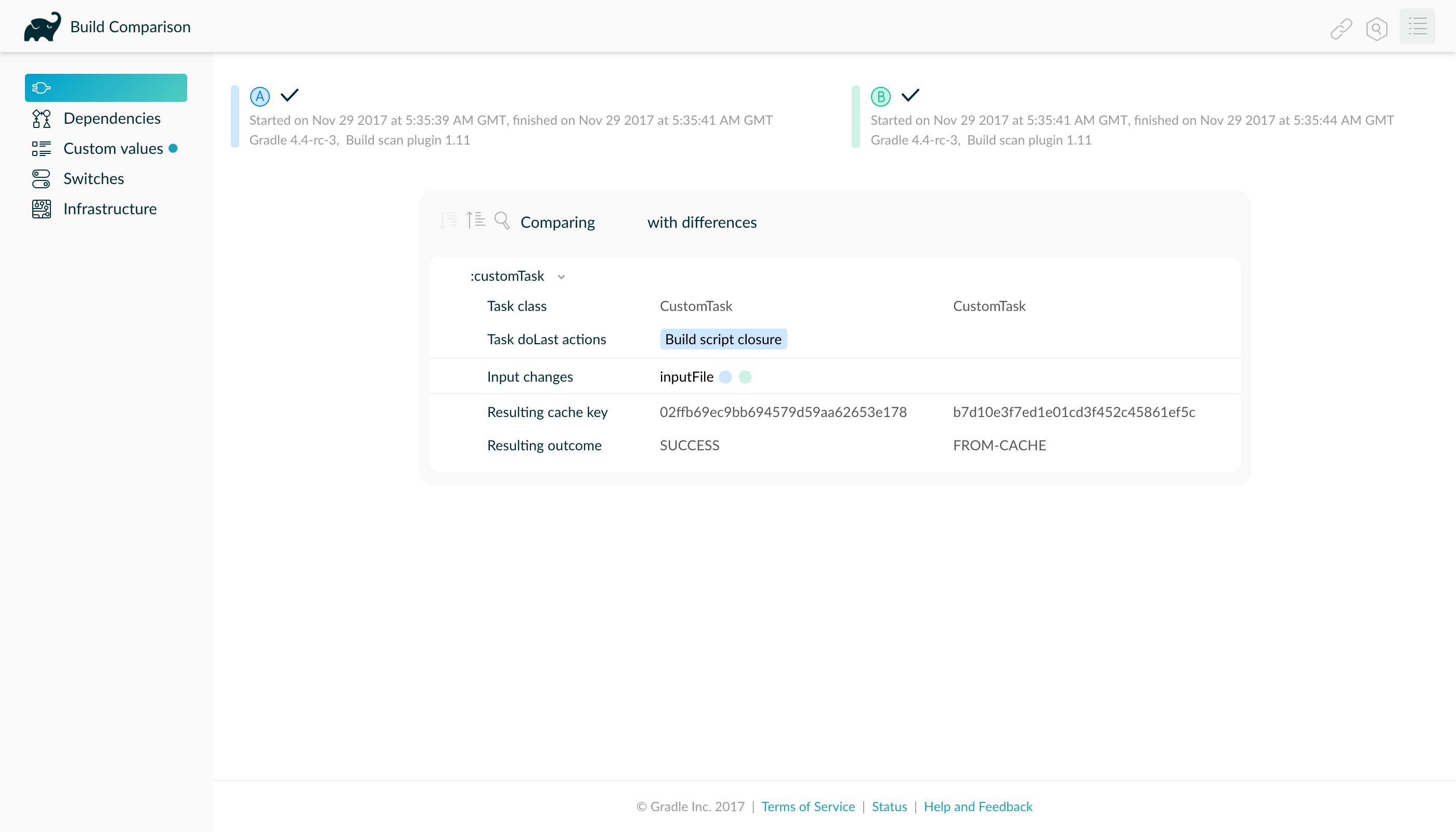
Achieving stable task inputs
It is crucial to have stable task inputs for every cacheable task. In the following section you will learn about different situations which violate stable task inputs and look at possible solutions.
Volatile task inputs
If you use a volatile input like a timestamp as an input property for a task, then there is nothing Gradle can do to make the task cacheable. You should really think hard if the volatile data is really essential to the output or if it is only there for e.g. auditing purposes.
If the volatile input is essential to the output then you can try to make the task using the volatile input cheaper to execute. You can do this by splitting the task into two tasks - the first task doing the expensive work which is cacheable and the second task adding the volatile data to the output. In this way the output stays the same and the build cache can be used to avoid doing the expensive work. For example, for building a jar file the expensive part - Java compilation - is already a different task while the jar task itself, which is not cacheable, is cheap.
If it is not an essential part of the output, then you should not declare it as an input. As long as the volatile input does not influence the output then there is nothing else to do. Most times though, the input will be part of the output.
Non-repeatable task outputs
Having tasks which generate different outputs for the same inputs can pose a challenge for the effective use of task output caching as seen in repeatable task outputs. If the non-repeatable task output is not used by any other task then the effect is very limited. It basically means that loading the task from the cache might produce a different result than executing the same task locally. If the only difference between the outputs is a timestamp, then you can either accept the effect of the build cache or decide that the task is not cacheable after all.
Non-repeatable task outputs lead to non-stable task inputs as soon as another task depends on the non-repeatable output. For example, re-creating a jar file from the files with the same contents but different modification times yields a different jar file. Any other task depending on this jar file as an input file cannot be loaded from the cache when the jar file is rebuilt locally. This can lead to hard-to-diagnose cache misses when the consuming build is not a clean build or when a cacheable task depends on the output of a non-cacheable task. For example, when doing incremental builds it is possible that the artifact on disk which is considered up-to-date and the artifact in the build cache are different even though they are essentially the same. A task depending on this task output would then not be able to load outputs from the build cache since the inputs are not exactly the same.
As described in the stable task inputs section, you can either make the task outputs repeatable or use input normalization. You already learned about the possibilities with configurable input normalization.
Tasks that produce archives (tar, zip) are reproducible by default, starting with Gradle 9.0.0.
For earlier Gradle versions or if you want explicit configuration, you can make archives reproducible configuring a task in the following way:
tasks.register<Zip>("createZip") {
isPreserveFileTimestamps = false
isReproducibleFileOrder = true
dirPermissions { unix("755") }
filePermissions { unix("644") }
// ...
}tasks.register('createZip', Zip) {
preserveFileTimestamps = false
reproducibleFileOrder = true
dirPermissions { unix("755") }
filePermissions { unix("644") }
// ...
}Another way to make the outputs repeatable is to activate caching for a task with non-repeatable outputs. If you can make sure that the same build cache is used for all builds then the task will always have the same outputs for the same inputs by design of the build cache. Going down this road can lead to different problems with cache misses for incremental builds as described above. Moreover, race conditions between different builds trying to store the same outputs in the build cache in parallel can lead to hard-to-diagnose cache misses. If possible, you should avoid going down that route.
Limit the effect of volatile data
If none of the described solutions for dealing with volatile data work for you, you should still be able to limit the effect of volatile data on effective use of the build cache.
This can be done by adding the volatile data later to the outputs as described in the volatile task inputs section.
Another option would be to move the volatile data so it affects fewer tasks.
For example moving the dependency from the compile to the runtime configuration may already have quite an impact.
Sometimes it is also possible to build two artifacts, one containing the volatile data and another one containing a constant representation of the volatile data. The non-volatile output would be used e.g. for testing while the volatile one would be published to an external repository. While this conflicts with the Continuous Delivery "build artifacts once" principle it can sometimes be the only option.
Custom and third party tasks
If your build contains custom or third party tasks, you should take special care that these don’t influence the effectiveness of the build cache.
Special care should also be taken for code generation tasks which may not have repeatable task outputs.
This can happen if the code generator includes e.g. a timestamp in the generated files or depends on the order of the input files.
Other pitfalls can be the use of HashMaps or other data structures without order guarantees in the task’s code.
|
Some third party plugins can even influence cacheability of Gradle’s built-in tasks.
This can happen if they add inputs like absolute paths or volatile data to tasks via the runtime API.
In the worst case this can lead to incorrect builds when the plugins try to depend on the outcome of a task and do not take |