Understanding Tasks
A task represents some independent unit of work that a build performs, such as compiling classes, creating a JAR, generating Javadoc, or publishing archives to a repository.
Before reading this chapter, it’s recommended that you first read the Learning The Basics and complete the Tutorial.
Listing tasks
All available tasks in your project come from Gradle plugins and build scripts.
You can list all the available tasks in a project by running the following command in the terminal:
$ ./gradlew tasksLet’s take a very basic Gradle project as an example. The project has the following structure:
gradle-project
├── app
│ ├── build.gradle.kts // empty file - no build logic
│ └── ... // some java code
├── settings.gradle.kts // includes app subproject
├── gradle
│ └── ...
├── gradlew
└── gradlew.batgradle-project
├── app
│ ├── build.gradle // empty file - no build logic
│ └── ... // some java code
├── settings.gradle // includes app subproject
├── gradle
│ └── ...
├── gradlew
└── gradlew.batThe settings file contains the following:
rootProject.name = "gradle-project"
include("app")rootProject.name = 'gradle-project'
include('app')Currently, the app subproject’s build file is empty.
To see the tasks available in the app subproject, run ./gradlew :app:tasks:
$ ./gradlew :app:tasks> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
Help tasks
----------
buildEnvironment - Displays all buildscript dependencies declared in project ':app'.
dependencies - Displays all dependencies declared in project ':app'.
dependencyInsight - Displays the insight into a specific dependency in project ':app'.
help - Displays a help message.
javaToolchains - Displays the detected java toolchains.
kotlinDslAccessorsReport - Prints the Kotlin code for accessing the currently available project extensions and conventions.
outgoingVariants - Displays the outgoing variants of project ':app'.
projects - Displays the sub-projects of project ':app'.
properties - Displays the properties of project ':app'.
resolvableConfigurations - Displays the configurations that can be resolved in project ':app'.
tasks - Displays the tasks runnable from project ':app'.We observe that only a small number of help tasks are available at the moment. This is because the core of Gradle only provides tasks that analyze your build. Other tasks, such as the those that build your project or compile your code, are added by plugins.
Let’s explore this by adding the Gradle core base plugin to the app build script:
plugins {
id("base")
}plugins {
id('base')
}The base plugin adds central lifecycle tasks.
Now when we run ./gradlew app:tasks, we can see the assemble and build tasks are available:
$ ./gradlew :app:tasks> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
Build tasks
-----------
assemble - Assembles the outputs of this project.
build - Assembles and tests this project.
clean - Deletes the build directory.
Help tasks
----------
buildEnvironment - Displays all buildscript dependencies declared in project ':app'.
dependencies - Displays all dependencies declared in project ':app'.
dependencyInsight - Displays the insight into a specific dependency in project ':app'.
help - Displays a help message.
javaToolchains - Displays the detected java toolchains.
outgoingVariants - Displays the outgoing variants of project ':app'.
projects - Displays the sub-projects of project ':app'.
properties - Displays the properties of project ':app'.
resolvableConfigurations - Displays the configurations that can be resolved in project ':app'.
tasks - Displays the tasks runnable from project ':app'.
Verification tasks
------------------
check - Runs all checks.Task outcomes
When Gradle executes a task, it labels the task with outcomes via the console.
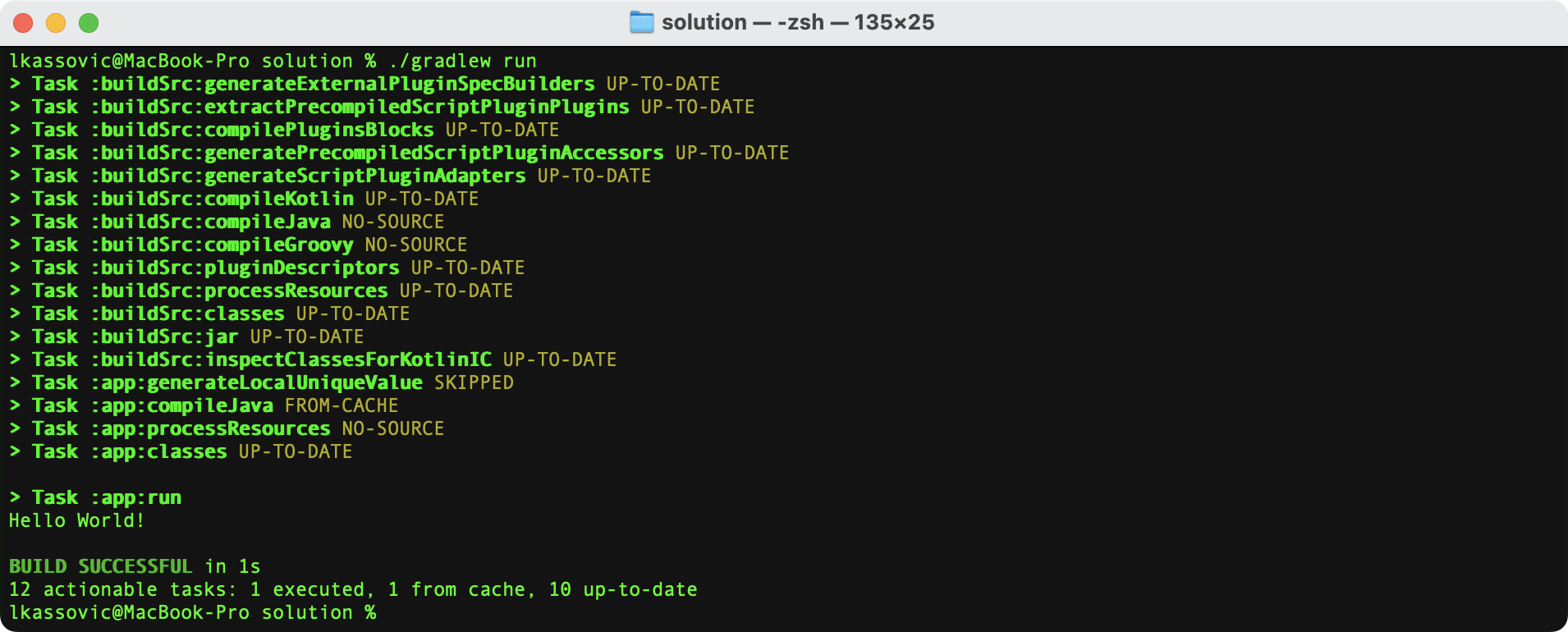
These labels are based on whether a task has actions to execute and if Gradle executed them. Actions include, but are not limited to, compiling code, zipping files, and publishing archives.
(no label)orEXECUTED-
Task executed its actions.
-
Task has actions and Gradle executed them.
-
Task has no actions and some dependencies, and Gradle executed one or more of the dependencies. See also Lifecycle Tasks.
-
UP-TO-DATE-
Task’s outputs did not change.
-
Task has outputs and inputs but they have not changed. See Incremental Build.
-
Task has actions, but the task tells Gradle it did not change its outputs.
-
Task has no actions and some dependencies, but all the dependencies are
UP-TO-DATE,SKIPPEDorFROM-CACHE. See Lifecycle Tasks. -
Task has no actions and no dependencies.
-
FROM-CACHE-
Task’s outputs could be found from a previous execution.
-
Task has outputs restored from the build cache. See Build Cache.
-
SKIPPED-
Task did not execute its actions.
-
Task has been explicitly excluded from the command-line. See Excluding tasks from execution.
-
Task has an
onlyIfpredicate return false. See Using a predicate.
-
NO-SOURCE-
Task did not need to execute its actions.
-
Task has inputs and outputs, but no sources (i.e., inputs were not found).
-
Task provenance
Gradle tracks where each task is registered, whether by a build script, settings script, or plugin. This provenance information appears in several places:
When a task fails, the error message includes its provenance to help you locate the source of the problem:
Execution failed for task ':app:compileJava' (registered by plugin 'org.gradle.api.plugins.JavaPlugin').| Provenance is omitted from failure messages for verification failures (e.g., test failures), since those are expected outcomes rather than configuration issues. |
The help --task and tasks commands also include provenance in their output.
You can use tasks --provenance to see where each task was registered.
Task group and description
Task groups and descriptions are used to organize and describe tasks.
- Groups
-
Task groups are used to categorize tasks. When you run
./gradlew tasks, tasks are listed under their respective groups, making it easier to understand their purpose and relationship to other tasks. Groups are set using thegroupproperty. - Descriptions
-
Descriptions provide a brief explanation of what a task does. When you run
./gradlew tasks, the descriptions are shown next to each task, helping you understand its purpose and how to use it. Descriptions are set using thedescriptionproperty.
Let’s consider a basic Java application as an example.
The build contains a subproject called app.
Let’s list the available tasks in app at the moment:
$ ./gradlew :app:tasks> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
Application tasks
-----------------
run - Runs this project as a JVM application.
Build tasks
-----------
assemble - Assembles the outputs of this project.Here, the :run task is part of the Application group with the description Runs this project as a JVM application.
In code, it would look something like this:
tasks.register("run") {
group = "Application"
description = "Runs this project as a JVM application."
}tasks.register("run") {
group = "Application"
description = "Runs this project as a JVM application."
}Private and hidden tasks
Gradle doesn’t support marking a task as private.
However, tasks will only show up when running :tasks if task.group is set or no other task depends on it.
For instance, the following task will not appear when running ./gradlew :app:tasks because it does not have a group; it is called a hidden task:
tasks.register("helloTask") {
println("Hello")
}tasks.register("helloTask") {
println 'Hello'
}Although helloTask is not listed, it can still be executed by Gradle:
$ ./gradlew :app:tasks> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
Application tasks
-----------------
run - Runs this project as a JVM application
Build tasks
-----------
assemble - Assembles the outputs of this project.Let’s add a group to the same task:
tasks.register("helloTask") {
group = "Other"
description = "Hello task"
println("Hello")
}tasks.register("helloTask") {
group = "Other"
description = "Hello task"
println 'Hello'
}Now that the group is added, the task is visible:
$ ./gradlew :app:tasks> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
Application tasks
-----------------
run - Runs this project as a JVM application
Build tasks
-----------
assemble - Assembles the outputs of this project.
Other tasks
-----------
helloTask - Hello taskIn contrast, ./gradlew tasks --all will show all tasks; hidden and visible tasks are listed.
Grouping tasks
If you want to customize which tasks are shown to users when listed, you can group tasks and set the visibility of each group.
| Remember, even if you hide tasks, they are still available, and Gradle can still run them. |
Let’s start with an example built by Gradle init for a Java application with multiple subprojects.
The project structure is as follows:
gradle-project
├── app
│ ├── build.gradle.kts
│ └── src // some java code
│ └── ...
├── utilities
│ ├── build.gradle.kts
│ └── src // some java code
│ └── ...
├── list
│ ├── build.gradle.kts
│ └── src // some java code
│ └── ...
├── buildSrc
│ ├── build.gradle.kts
│ ├── settings.gradle.kts
│ └── src // common build logic
│ └── ...
├── settings.gradle.kts
├── gradle
├── gradlew
└── gradlew.batgradle-project
├── app
│ ├── build.gradle
│ └── src // some java code
│ └── ...
├── utilities
│ ├── build.gradle
│ └── src // some java code
│ └── ...
├── list
│ ├── build.gradle
│ └── src // some java code
│ └── ...
├── buildSrc
│ ├── build.gradle
│ ├── settings.gradle
│ └── src // common build logic
│ └── ...
├── settings.gradle
├── gradle
├── gradlew
└── gradlew.batRun app:tasks to see available tasks in the app subproject:
$ ./gradlew :app:tasks> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
Application tasks
-----------------
run - Runs this project as a JVM application
Build tasks
-----------
assemble - Assembles the outputs of this project.
build - Assembles and tests this project.
buildDependents - Assembles and tests this project and all projects that depend on it.
buildNeeded - Assembles and tests this project and all projects it depends on.
classes - Assembles main classes.
clean - Deletes the build directory.
jar - Assembles a jar archive containing the classes of the 'main' feature.
testClasses - Assembles test classes.
Distribution tasks
------------------
assembleDist - Assembles the main distributions
distTar - Bundles the project as a distribution.
distZip - Bundles the project as a distribution.
installDist - Installs the project as a distribution as-is.
Documentation tasks
-------------------
javadoc - Generates Javadoc API documentation for the 'main' feature.
Help tasks
----------
buildEnvironment - Displays all buildscript dependencies declared in project ':app'.
dependencies - Displays all dependencies declared in project ':app'.
dependencyInsight - Displays the insight into a specific dependency in project ':app'.
help - Displays a help message.
javaToolchains - Displays the detected java toolchains.
kotlinDslAccessorsReport - Prints the Kotlin code for accessing the currently available project extensions and conventions.
outgoingVariants - Displays the outgoing variants of project ':app'.
projects - Displays the sub-projects of project ':app'.
properties - Displays the properties of project ':app'.
resolvableConfigurations - Displays the configurations that can be resolved in project ':app'.
tasks - Displays the tasks runnable from project ':app'.
Verification tasks
------------------
check - Runs all checks.
test - Runs the test suite.If we look at the list of tasks available, even for a standard Java project, it’s extensive. Many of these tasks are rarely required directly by developers using the build.
We can configure the :tasks task and limit the tasks shown to a certain group.
Let’s create our own group so that all tasks are hidden by default by updating the app build script:
val myBuildGroup = "my app build" // Create a group name
tasks.register<TaskReportTask>("tasksAll") { // Register the tasksAll task
group = myBuildGroup
description = "Show additional tasks."
setShowDetail(true)
}
tasks.named<TaskReportTask>("tasks") { // Move all existing tasks to the group
displayGroup = myBuildGroup
}def myBuildGroup = "my app build" // Create a group name
tasks.register("tasksAll", TaskReportTask) { // Register the tasksAll task
group = myBuildGroup
description = "Show additional tasks."
setShowDetail(true)
}
tasks.named("tasks", TaskReportTask) { // Move all existing tasks to the group
displayGroup = myBuildGroup
}Now, when we list tasks available in app, the list is shorter:
$ ./gradlew :app:tasks> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
My app build tasks
------------------
tasksAll - Show additional tasks.Task categories
Gradle distinguishes between two categories of tasks:
-
Lifecycle tasks
-
Actionable tasks
Lifecycle tasks define targets you can call, such as :build your project.
Lifecycle tasks do not provide Gradle with actions.
They must be wired to actionable tasks.
The base Gradle plugin only adds lifecycle tasks.
Actionable tasks define actions for Gradle to take, such as :compileJava, which compiles the Java code of your project.
Actions include creating JARs, zipping files, publishing archives, and much more.
Plugins like the java-library plugin adds actionable tasks.
Let’s update the build script of the previous example, which is currently an empty file so that our app subproject is a Java library:
plugins {
id("java-library")
}plugins {
id('java-library')
}Once again, we list the available tasks to see what new tasks are available:
$ ./gradlew :app:tasks> Task :app:tasks
------------------------------------------------------------
Tasks runnable from project ':app'
------------------------------------------------------------
Build tasks
-----------
assemble - Assembles the outputs of this project.
build - Assembles and tests this project.
buildDependents - Assembles and tests this project and all projects that depend on it.
buildNeeded - Assembles and tests this project and all projects it depends on.
classes - Assembles main classes.
clean - Deletes the build directory.
jar - Assembles a jar archive containing the classes of the 'main' feature.
testClasses - Assembles test classes.
Documentation tasks
-------------------
javadoc - Generates Javadoc API documentation for the 'main' feature.
Help tasks
----------
buildEnvironment - Displays all buildscript dependencies declared in project ':app'.
dependencies - Displays all dependencies declared in project ':app'.
dependencyInsight - Displays the insight into a specific dependency in project ':app'.
help - Displays a help message.
javaToolchains - Displays the detected java toolchains.
outgoingVariants - Displays the outgoing variants of project ':app'.
projects - Displays the sub-projects of project ':app'.
properties - Displays the properties of project ':app'.
resolvableConfigurations - Displays the configurations that can be resolved in project ':app'.
tasks - Displays the tasks runnable from project ':app'.
Verification tasks
------------------
check - Runs all checks.
test - Runs the test suite.We see that many new tasks are available such as jar and testClasses.
Additionally, the java-library plugin has wired actionable tasks to lifecycle tasks.
If we call the :build task, we can see several tasks have been executed, including the :app:compileJava task.
$ ./gradlew :app:build> Task :app:compileJava
> Task :app:processResources NO-SOURCE
> Task :app:classes
> Task :app:jar
> Task :app:assemble
> Task :app:compileTestJava
> Task :app:processTestResources NO-SOURCE
> Task :app:testClasses
> Task :app:test
> Task :app:check
> Task :app:buildThe actionable :compileJava task is wired to the lifecycle :build task.
Incremental tasks
A key feature of Gradle tasks is their incremental nature.
Gradle can reuse results from prior builds.
Therefore, if we’ve built our project before and made only minor changes, rerunning :build will not require Gradle to perform extensive work.
For example, if we modify only the test code in our project, leaving the production code unchanged, executing the build will solely recompile the test code.
Gradle marks the tasks for the production code as UP-TO-DATE, indicating that it remains unchanged since the last successful build:
$ ./gradlew :app:buildgradle@MacBook-Pro temp1 % ./gradlew :app:build
> Task :app:compileJava UP-TO-DATE
> Task :app:processResources NO-SOURCE
> Task :app:classes UP-TO-DATE
> Task :app:jar UP-TO-DATE
> Task :app:assemble UP-TO-DATE
> Task :app:compileTestJava
> Task :app:processTestResources NO-SOURCE
> Task :app:testClasses
> Task :app:test
> Task :app:check UP-TO-DATE
> Task :app:build UP-TO-DATECaching tasks
Gradle can reuse results from past builds using the build cache.
To enable this feature, activate the build cache by using the --build-cache command line parameter or by setting org.gradle.caching=true in your gradle.properties file.
This optimization has the potential to accelerate your builds significantly:
$ ./gradlew :app:clean :app:build --build-cache> Task :app:compileJava FROM-CACHE
> Task :app:processResources NO-SOURCE
> Task :app:classes UP-TO-DATE
> Task :app:jar
> Task :app:assemble
> Task :app:compileTestJava FROM-CACHE
> Task :app:processTestResources NO-SOURCE
> Task :app:testClasses UP-TO-DATE
> Task :app:test FROM-CACHE
> Task :app:check UP-TO-DATE
> Task :app:buildWhen Gradle can fetch outputs of a task from the cache, it labels the task with FROM-CACHE.
The build cache is handy if you switch between branches regularly. Gradle supports both local and remote build caches.
Developing tasks
When developing Gradle tasks, you have two choices:
-
Use an existing Gradle task type such as
Zip,Copy, orDelete -
Create your own Gradle task type such as
MyResolveTaskorCustomTaskUsingToolchains.
Task types are simply subclasses of the Gradle Task class.
With Gradle tasks, there are three states to consider:
-
Registering a task - using a task (implemented by you or provided by Gradle) in your build logic.
-
Configuring a task - defining inputs and outputs for a registered task.
-
Implementing a task - creating a custom task class (i.e., custom class type).
Registration is commonly done with the register() method.
Configuring a task is commonly done with the named() method.
Implementing a task is commonly done by extending Gradle’s DefaultTask class:
tasks.register<Copy>("myCopy") (1)
tasks.named<Copy>("myCopy") { (2)
from("resources")
into("target")
include("**/*.txt", "**/*.xml", "**/*.properties")
}
abstract class MyCopyTask : DefaultTask() { (3)
@TaskAction
fun copyFiles() {
val sourceDir = File("sourceDir")
val destinationDir = File("destinationDir")
sourceDir.listFiles()?.forEach { file ->
if (file.isFile && file.extension == "txt") {
file.copyTo(File(destinationDir, file.name))
}
}
}
}tasks.register("myCopy", Copy) (1)
tasks.named("myCopy", Copy) { (2)
from "resources"
into "target"
include "**/*.txt", "**/*.xml", "**/*.properties"
}
abstract class MyCopyTask extends DefaultTask { (3)
@TaskAction
void copyFiles() {
fileTree('sourceDir').matching {
include '**/*.txt'
}.forEach { file ->
file.copyTo(file.path.replace('sourceDir', 'destinationDir'))
}
}
}| 1 | Register the myCopy task of type Copy to let Gradle know we intend to use it in our build logic. |
| 2 | Configure the registered myCopy task with the inputs and outputs it needs according to its API. |
| 3 | Implement a custom task type called MyCopyTask which extends DefaultTask and defines the copyFiles task action. |
1. Registering tasks
You define actions for Gradle to take by registering tasks in build scripts or plugins.
Tasks are defined using strings for task names:
tasks.register("hello") {
doLast {
println("hello")
}
}tasks.register('hello') {
doLast {
println 'hello'
}
}In the example above, the task is added to the TasksCollection using the register() method in TaskContainer.
2. Configuring tasks
Gradle tasks must be configured to complete their action(s) successfully.
If a task needs to ZIP a file, it must be configured with the file name and location.
You can refer to the API for the Gradle Zip task to learn how to configure it appropriately.
Let’s look at the Copy task provided by Gradle as an example.
We first register a task called myCopy of type Copy in the build script:
tasks.register<Copy>("myCopy")tasks.register('myCopy', Copy)This registers a copy task with no default behavior.
Since the task is of type Copy, a Gradle supported task type, it can be configured using its API.
The following examples show several ways to achieve the same configuration:
1. Using the named() method:
Use named() to configure an existing task registered elsewhere:
tasks.named<Copy>("myCopy") {
from("resources")
into("target")
include("**/*.txt", "**/*.xml", "**/*.properties")
}tasks.named('myCopy') {
from 'resources'
into 'target'
include('**/*.txt', '**/*.xml', '**/*.properties')
}2. Using a configuration block:
Use a block to configure the task immediately upon registering it:
tasks.register<Copy>("copy") {
from("resources")
into("target")
include("**/*.txt", "**/*.xml", "**/*.properties")
}tasks.register('copy', Copy) {
from 'resources'
into 'target'
include('**/*.txt', '**/*.xml', '**/*.properties')
}3. Name method as call:
A popular option that is only supported in Groovy is the shorthand notation:
copy {
from("resources")
into("target")
include("**/*.txt", "**/*.xml", "**/*.properties")
}| This option breaks task configuration avoidance and is not recommended! |
Regardless of the method chosen, the task is configured with the name of the files to be copied and the location of the files.
3. Implementing tasks
Gradle provides many task types including Delete, Javadoc, Copy, Exec, Tar, and Pmd.
You can implement a custom task type if Gradle does not provide a task type that meets your build logic needs.
To create a custom task class, you extend DefaultTask and make the extending class abstract:
abstract class MyCopyTask : DefaultTask() {
}abstract class MyCopyTask extends DefaultTask {
}