Building Java & JVM projects
- Introduction
- Declaring your source files via source sets
- Managing your dependencies
- Compiling your code
- Managing resources
- Running tests
- Packaging and publishing
- Generating API documentation
- Cleaning the build
- Building JVM components
- Building Java libraries
- Building Java applications
- Building Java web applications
- Building Java EE applications
- Building Java Platforms
- Enabling Java preview features
- Building other JVM language projects
Gradle uses a convention-over-configuration approach to building JVM-based projects that borrows several conventions from Apache Maven. In particular, it uses the same default directory structure for source files and resources, and it works with Maven-compatible repositories.
We will look at Java projects in detail in this chapter, but most of the topics apply to other supported JVM languages as well, such as Kotlin, Groovy and Scala.
|
The example in this section use the Java Library Plugin. However the described features are shared by all JVM plugins. Specifics of the different plugins are available in their dedicated documentation. |
Introduction
The simplest build script for a Java project applies the Java Library Plugin and optionally sets the project version and selects the Java toolchain to use:
plugins {
`java-library`
}
java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}
version = "1.2.1"plugins {
id 'java-library'
}
java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}
version = '1.2.1'By applying the Java Library Plugin, you get a whole host of features:
-
A
compileJavatask that compiles all the Java source files under src/main/java -
A
compileTestJavatask for source files under src/test/java -
A
testtask that runs the tests from src/test/java -
A
jartask that packages themaincompiled classes and resources from src/main/resources into a single JAR named <project>-<version>.jar -
A
javadoctask that generates Javadoc for themainclasses
This isn’t sufficient to build any non-trivial Java project — at the very least, you’ll probably have some file dependencies. But it means that your build script only needs the information that is specific to your project.
|
Although the properties in the example are optional, we recommend that you specify them in your projects. Configuring the toolchain protects against problems with the project being built with different Java versions. The version string is important for tracking the progression of the project. The project version is also used in archive names by default. |
The Java Library Plugin also integrates the above tasks into the standard Base Plugin lifecycle tasks:
-
jaris attached toassemble -
testis attached tocheck
The rest of the chapter explains the different avenues for customizing the build to your requirements. You will also see later how to adjust the build for libraries, applications, web apps and enterprise apps.
Declaring your source files via source sets
Gradle’s Java support was the first to introduce a new concept for building source-based projects: source sets. The main idea is that source files and resources are often logically grouped by type, such as application code, unit tests and integration tests. Each logical group typically has its own sets of file dependencies, classpaths, and more. Significantly, the files that form a source set don’t have to be located in the same directory!
Source sets are a powerful concept that tie together several aspects of compilation:
-
the source files and where they’re located
-
the compilation classpath, including any required dependencies (via Gradle configurations)
-
where the compiled class files are placed
You can see how these relate to one another in this diagram:
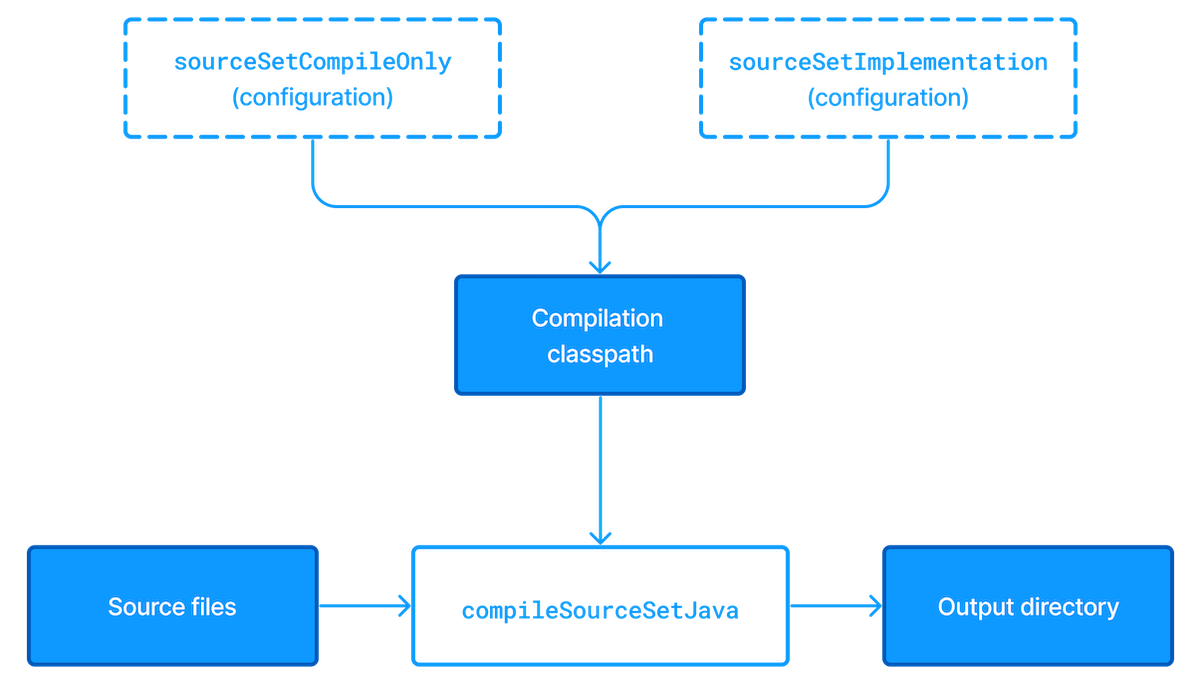
The shaded boxes represent properties of the source set itself.
On top of that, the Java Library Plugin automatically creates a compilation task for every source set you or a plugin defines — named compileSourceSetJava — and several dependency configurations.
main source setMost language plugins, Java included, automatically create a source set called main, which is used for the project’s production code. This source set is special in that its name is not included in the names of the configurations and tasks, hence why you have just a compileJava task and compileOnly and implementation configurations rather than compileMainJava, mainCompileOnly and mainImplementation respectively.
Java projects typically include resources other than source files, such as properties files, that may need processing — for example by replacing tokens within the files — and packaging within the final JAR.
The Java Library Plugin handles this by automatically creating a dedicated task for each defined source set called processSourceSetResources (or processResources for the main source set).
The following diagram shows how the source set fits in with this task:

As before, the shaded boxes represent properties of the source set, which in this case comprises the locations of the resource files and where they are copied to.
In addition to the main source set, the Java Library Plugin defines a test source set that represents the project’s tests.
This source set is used by the test task, which runs the tests.
You can learn more about this task and related topics in the Java testing chapter.
Projects typically use this source set for unit tests, but you can also use it for integration, acceptance and other types of test if you wish. The alternative approach is to define a new source set for each of your other test types, which is typically done for one or both of the following reasons:
-
You want to keep the tests separate from one another for aesthetics and manageability
-
The different test types require different compilation or runtime classpaths or some other difference in setup
You can see an example of this approach in the Java testing chapter, which shows you how to set up integration tests in a project.
You’ll learn more about source sets and the features they provide in:
Source set configurations
When a source set is created, it also creates a number of configurations as described above. Build logic should not attempt to create or access these configurations until they are first created by the source set.
When creating a source set, if one of these automatically created configurations already exists, and its role is different than the role that the source set would have assigned, the build will fail.
The build below demonstrates this behavior.
configurations {
create("myCodeCompileClasspath")
}
sourceSets {
create("myCode")
}configurations {
myCodeCompileClasspath
}
sourceSets {
myCode
}In this case, the build will fail.
Following two simple best practices will avoid this problem:
-
Don’t create configurations with names that will be used by source sets, such as names ending in
Api,Implementation,ApiElements,CompileOnly,CompileOnlyApi,RuntimeOnly,RuntimeClasspathorRuntimeElements. (This list is not exhaustive.) -
Create any custom source sets prior to any custom configurations.
Remember that any time you reference a configuration within the configurations container - with or without supplying an initialization action - Gradle will create the configuration.
Sometimes when using the Groovy DSL this creation is not obvious, as in the example below, where myCustomConfiguration is created prior to the call to extendsFrom.
configurations {
myCustomConfiguration.extendsFrom(implementation)
}Managing your dependencies
The vast majority of Java projects rely on libraries, so managing a project’s dependencies is an important part of building a Java project. Dependency management is a big topic, so we will focus on the basics for Java projects here. If you’d like to dive into the detail, check out the introduction to dependency management.
Specifying the dependencies for your Java project requires just three pieces of information:
-
Which dependency you need, such as a name and version
-
What it’s needed for, e.g. compilation or running
-
Where to look for it
The first two are specified in a dependencies {} block and the third in a repositories {} block. For example, to tell Gradle that your project requires version 3.6.7 of Hibernate Core to compile and run your production code, and that you want to download the library from the Maven Central repository, you can use the following fragment:
repositories {
mavenCentral()
}
dependencies {
implementation("org.hibernate:hibernate-core:3.6.7.Final")
}repositories {
mavenCentral()
}
dependencies {
implementation 'org.hibernate:hibernate-core:3.6.7.Final'
}The Gradle terminology for the three elements is as follows:
-
Repository (ex:
mavenCentral()) — where to look for the modules you declare as dependencies -
Configuration (ex:
implementation) — a named collection of dependencies, grouped together for a specific goal such as compiling or running a module — a more flexible form of Maven scopes -
Module coordinate (ex:
org.hibernate:hibernate-core-3.6.7.Final) — the ID of the dependency, usually in the form '<group>:<module>:<version>' (or '<groupId>:<artifactId>:<version>' in Maven terminology)
As far as configurations go, the main ones of interest are:
-
compileOnly— for dependencies that are necessary to compile your production code but shouldn’t be part of the runtime classpath -
implementation(supersedescompile) — used for compilation and runtime -
runtimeOnly(supersedesruntime) — only used at runtime, not for compilation -
testCompileOnly— same ascompileOnlyexcept it’s for the tests -
testImplementation— test equivalent ofimplementation -
testRuntimeOnly— test equivalent ofruntimeOnly
You can learn more about these and how they relate to one another in the plugin reference chapter.
Be aware that the Java Library Plugin offers two additional configurations — api and compileOnlyApi — for dependencies that are required for compiling both the module and any modules that depend on it.
compile configuration?The Java Library Plugin has historically used the compile configuration for dependencies that are required to both compile and run a project’s production code.
It is now deprecated, and will issue warnings when used, because it doesn’t distinguish between dependencies that impact the public API of a Java library project and those that don’t.
You can learn more about the importance of this distinction in Building Java libraries.
We have only scratched the surface here, so we recommend that you read the dedicated dependency management chapters once you’re comfortable with the basics of building Java projects with Gradle. Some common scenarios that require further reading include:
-
Defining a custom Maven- or Ivy-compatible repository
-
Using dependencies from a local filesystem directory
-
Declaring dependencies with changing (e.g. SNAPSHOT) and dynamic (range) versions
-
Declaring a sibling project as a dependency
-
Testing your fixes to a 3rd-party dependency via composite builds (a better alternative to publishing to and consuming from Maven Local)
You’ll discover that Gradle has a rich API for working with dependencies — one that takes time to master, but is straightforward to use for common scenarios.
Compiling your code
Compiling both your production and test code can be trivially easy if you follow the conventions:
-
Put your production source code under the src/main/java directory
-
Put your test source code under src/test/java
-
Declare your production compile dependencies in the
compileOnlyorimplementationconfigurations (see previous section) -
Declare your test compile dependencies in the
testCompileOnlyortestImplementationconfigurations -
Run the
compileJavatask for the production code andcompileTestJavafor the tests
Other JVM language plugins, such as the one for Groovy, follow the same pattern of conventions. We recommend that you follow these conventions wherever possible, but you don’t have to. There are several options for customization, as you’ll see next.
Customizing file and directory locations
Imagine you have a legacy project that uses an src directory for the production code and test for the test code. The conventional directory structure won’t work, so you need to tell Gradle where to find the source files. You do that via source set configuration.
Each source set defines where its source code resides, along with the resources and the output directory for the class files. You can override the convention values by using the following syntax:
sourceSets {
main {
java {
setSrcDirs(listOf("src"))
}
}
test {
java {
setSrcDirs(listOf("test"))
}
}
}sourceSets {
main {
java {
srcDirs = ['src']
}
}
test {
java {
srcDirs = ['test']
}
}
}Now Gradle will only search directly in src and test for the respective source code. What if you don’t want to override the convention, but simply want to add an extra source directory, perhaps one that contains some third-party source code you want to keep separate? The syntax is similar:
sourceSets {
main {
java {
srcDir("thirdParty/src/main/java")
}
}
}sourceSets {
main {
java {
srcDir 'thirdParty/src/main/java'
}
}
}Crucially, we’re using the method srcDir() here to append a directory path, whereas setting the srcDirs property replaces any existing values. This is a common convention in Gradle: setting a property replaces values, while the corresponding method appends values.
You can see all the properties and methods available on source sets in the DSL reference for SourceSet and SourceDirectorySet. Note that srcDirs and srcDir() are both on SourceDirectorySet.
Changing compiler options
Most of the compiler options are accessible through the corresponding task, such as compileJava and compileTestJava. These tasks are of type JavaCompile, so read the task reference for an up-to-date and comprehensive list of the options.
For example, if you want to use a separate JVM process for the compiler and prevent compilation failures from failing the build, you can use this configuration:
tasks.compileJava {
options.isIncremental = true
options.isFork = true
options.isFailOnError = false
}compileJava {
options.incremental = true
options.fork = true
options.failOnError = false
}That’s also how you can change the verbosity of the compiler, disable debug output in the byte code and configure where the compiler can find annotation processors.
Targeting a specific Java version
By default, Gradle will compile Java code to the language level of the JVM running Gradle. If you need to target a specific version of Java when compiling, Gradle provides multiple options:
-
Using Java toolchains is a preferred way to target a language version.
A toolchain uniformly handles compilation, execution and Javadoc generation, and it can be configured on the project level. -
Using
releaseproperty is possible starting from Java 10.
Selecting a Java release makes sure that compilation is done with the configured language level and against the JDK APIs from that Java version. -
Using
sourceCompatibilityandtargetCompatibilityproperties.
Although not generally advised, these options were historically used to configure the Java version during compilation.
Using toolchains
When Java code is compiled using a specific toolchain, the actual compilation is carried out by a compiler of the specified Java version. The compiler provides access to the language features and JDK APIs for the requested Java language version.
In the simplest case, the toolchain can be configured for a project using the java extension.
This way, not only compilation benefits from it, but also other tasks such as test and javadoc will also consistently use the same toolchain.
java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}You can learn more about this in the Java toolchains guide.
Using Java release version
Setting the release flag ensures the specified language level is used regardless of which compiler actually performs the compilation. To use this feature, the compiler must support the requested release version. It is possible to specify an earlier release version while compiling with a more recent toolchain.
Gradle supports using the release flag from Java 10. It can be configured on the compilation task as follows.
tasks.compileJava {
options.release = 7
}compileJava {
options.release = 7
}The release flag provides guarantees similar to toolchains. It validates that the Java sources are not using language features introduced in later Java versions, and also that the code does not access APIs from more recent JDKs. The bytecode produced by the compiler also corresponds to the requested Java version, meaning that the compiled code cannot be executed on older JVMs.
The release option of the Java compiler was introduced in Java 9.
However, using this option with Gradle is only possible starting with Java 10, due to a bug in Java 9.
Using Java compatibility options
| Using compatibility properties can lead to runtime failures when executing compiled code due to weaker guarantees they provide. Instead, consider using toolchains or the release flag. |
The sourceCompatibility and targetCompatibility options correspond to the Java compiler options -source and -target.
They are considered a legacy mechanism for targeting a specific Java version.
However, these options do not protect against the use of APIs introduced in later Java versions.
sourceCompatibility-
Defines the language version of Java used in your source files.
targetCompatibility-
Defines the minimum JVM version your code should run on, i.e. it determines the version of the bytecode generated by the compiler.
These options can be set per JavaCompile task, or on the java { } extension for all compile tasks, using properties with the same names.
Targeting Java 6 and Java 7
Gradle itself can only run on a JVM with Java version 8 or higher. However, Gradle still supports compiling, testing, generating Javadocs and executing applications for Java 6 and Java 7. Java 5 and below are not supported.
If using Java 10+, leveraging the release flag might be an easier solution, see above.
|
To use Java 6 or Java 7, the following tasks need to be configured:
-
JavaCompiletask to fork and use the correct Java home -
Javadoctask to use the correctjavadocexecutable -
Testand theJavaExectask to use the correctjavaexecutable.
With the usage of Java toolchains, this can be done as follows:
java {
toolchain {
languageVersion = JavaLanguageVersion.of(7)
}
}java {
toolchain {
languageVersion = JavaLanguageVersion.of(7)
}
}The only requirement is that Java 7 is installed and has to be either in a location Gradle can detect automatically or explicitly configured.
Compiling independent sources separately
Most projects have at least two independent sets of sources: the production code and the test code. Gradle already makes this scenario part of its Java convention, but what if you have other sets of sources? One of the most common scenarios is when you have separate integration tests of some form or other. In that case, a custom source set may be just what you need.
You can see a complete example for setting up integration tests in the Java testing chapter. You can set up other source sets that fulfil different roles in the same way. The question then becomes: when should you define a custom source set?
To answer that question, consider whether the sources:
-
Need to be compiled with a unique classpath
-
Generate classes that are handled differently from the
mainandtestones -
Form a natural part of the project
If your answer to both 3 and either one of the others is yes, then a custom source set is probably the right approach. For example, integration tests are typically part of the project because they test the code in main. In addition, they often have either their own dependencies independent of the test source set or they need to be run with a custom Test task.
Other common scenarios are less clear cut and may have better solutions. For example:
-
Separate API and implementation JARs — it may make sense to have these as separate projects, particularly if you already have a multi-project build
-
Generated sources — if the resulting sources should be compiled with the production code, add their path(s) to the
mainsource set and make sure that thecompileJavatask depends on the task that generates the sources
If you’re unsure whether to create a custom source set or not, then go ahead and do so. It should be straightforward and if it’s not, then it’s probably not the right tool for the job.
Debugging compiling errors
Gradle provides detailed reporting for compilation failures.
If a compilation task fails, the summary of errors is displayed in the following locations:
-
The task’s output, providing immediate context for the error.
-
The "What went wrong" summary at the bottom of the build output, consolidated with all other failures for easy reference.
* What went wrong:
Execution failed for task ':project1:compileJava'.
> Compilation failed; see the compiler output below.
Java compilation warning
sample-project/src/main/java/Problem1.java:6: warning: [cast] redundant cast to String
var warning = (String)"warning";
^
Java compilation error
sample-project/src/main/java/Problem2.java:6: error: incompatible types: int cannot be converted to String
String a = 1;
^This reporting feature works with the —continue flag.
Managing resources
Many Java projects make use of resources beyond source files, such as images, configuration files and localization data. Sometimes these files simply need to be packaged unchanged and sometimes they need to be processed as template files or in some other way. Either way, the Java Library Plugin adds a specific Copy task for each source set that handles the processing of its associated resources.
The task’s name follows the convention of processSourceSetResources — or processResources for the main source set — and it will automatically copy any files in src/[sourceSet]/resources to a directory that will be included in the production JAR. This target directory will also be included in the runtime classpath of the tests.
Since processResources is an instance of the ProcessResources task, you can perform any of the processing described in the Working With Files chapter.
Java properties files and reproducible builds
You can easily create Java properties files via the WriteProperties task, which fixes a well-known problem with Properties.store() that can reduce the usefulness of incremental builds.
The standard Java API for writing properties files produces a unique file every time, even when the same properties and values are used, because it includes a timestamp in the comments. Gradle’s WriteProperties task generates exactly the same output byte-for-byte if none of the properties have changed. This is achieved by a few tweaks to how a properties file is generated:
-
no timestamp comment is added to the output
-
the line separator is system independent, but can be configured explicitly (it defaults to
'\n') -
the properties are sorted alphabetically
Sometimes it can be desirable to recreate archives in a byte for byte way on different machines. You want to be sure that building an artifact from source code produces the same result, byte for byte, no matter when and where it is built. This is necessary for projects like reproducible-builds.org.
These tweaks not only lead to better incremental build integration, but they also help with reproducible builds. In essence, reproducible builds guarantee that you will see the same results from a build execution — including test results and production binaries — no matter when or on what system you run it.
Running tests
Alongside providing automatic compilation of unit tests in src/test/java, the Java Library Plugin has native support for running tests that use JUnit 3, 4 & 5 (JUnit 5 support came in Gradle 4.6) and TestNG. You get:
-
An automatic
testtask of type Test, using thetestsource set -
An HTML test report that includes the results from all
Testtasks that run -
Easy filtering of which tests to run
-
Fine-grained control over how the tests are run
-
The opportunity to create your own test execution and test reporting tasks
You do not get a Test task for every source set you declare, since not every source set represents tests! That’s why you typically need to create your own Test tasks for things like integration and acceptance tests if they can’t be included with the test source set.
As there is a lot to cover when it comes to testing, the topic has its own chapter in which we look at:
-
How tests are run
-
How to run a subset of tests via filtering
-
How Gradle discovers tests
-
How to configure test reporting and add your own reporting tasks
-
How to make use of specific JUnit and TestNG features
You can also learn more about configuring tests in the DSL reference for Test.
Packaging and publishing
How you package and potentially publish your Java project depends on what type of project it is. Libraries, applications, web applications and enterprise applications all have differing requirements. In this section, we will focus on the bare bones provided by the Java Library Plugin.
By default, the Java Library Plugin provides the jar task that packages all the compiled production classes and resources into a single JAR.
This JAR is also automatically built by the assemble task.
Furthermore, the plugin can be configured to provide the javadocJar and sourcesJar tasks to package Javadoc and source code if so desired.
If a publishing plugin is used, these tasks will automatically run during publishing or can be called directly.
java {
withJavadocJar()
withSourcesJar()
}java {
withJavadocJar()
withSourcesJar()
}If you want to create an 'uber' (AKA 'fat') JAR, then you can use a task definition like this:
plugins {
java
}
version = "1.0.0"
repositories {
mavenCentral()
}
dependencies {
implementation("commons-io:commons-io:2.6")
}
tasks.register<Jar>("uberJar") {
archiveClassifier = "uber"
from(sourceSets.main.get().output)
dependsOn(configurations.runtimeClasspath)
from({
configurations.runtimeClasspath.get().filter { it.name.endsWith("jar") }.map { zipTree(it) }
})
}plugins {
id 'java'
}
version = '1.0.0'
repositories {
mavenCentral()
}
dependencies {
implementation 'commons-io:commons-io:2.6'
}
tasks.register('uberJar', Jar) {
archiveClassifier = 'uber'
from sourceSets.main.output
dependsOn configurations.runtimeClasspath
from {
configurations.runtimeClasspath.findAll { it.name.endsWith('jar') }.collect { zipTree(it) }
}
}See Jar for more details on the configuration options available to you.
And note that you need to use archiveClassifier rather than archiveAppendix here for correct publication of the JAR.
You can use one of the publishing plugins to publish the JARs created by a Java project:
Modifying the JAR manifest
Each instance of the Jar, War and Ear tasks has a manifest property that allows you to customize the MANIFEST.MF file that goes into the corresponding archive. The following example demonstrates how to set attributes in the JAR’s manifest:
tasks.jar {
manifest {
attributes(
"Implementation-Title" to "Gradle",
"Implementation-Version" to archiveVersion
)
}
}jar {
manifest {
attributes("Implementation-Title": "Gradle",
"Implementation-Version": archiveVersion)
}
}See Manifest for the configuration options it provides.
You can also create standalone instances of Manifest. One reason for doing so is to share manifest information between JARs. The following example demonstrates how to share common attributes between JARs:
val sharedManifest = java.manifest {
attributes (
"Implementation-Title" to "Gradle",
"Implementation-Version" to version
)
}
tasks.register<Jar>("fooJar") {
manifest = java.manifest {
from(sharedManifest)
}
}def sharedManifest = java.manifest {
attributes("Implementation-Title": "Gradle",
"Implementation-Version": version)
}
tasks.register('fooJar', Jar) {
manifest = java.manifest {
from sharedManifest
}
}Another option available to you is to merge manifests into a single Manifest object. Those source manifests can take the form of a text for or another Manifest object. In the following example, the source manifests are all text files except for sharedManifest, which is the Manifest object from the previous example:
tasks.register<Jar>("barJar") {
manifest {
attributes("key1" to "value1")
from(sharedManifest, "src/config/basemanifest.txt")
from(listOf("src/config/javabasemanifest.txt", "src/config/libbasemanifest.txt")) {
eachEntry(Action<ManifestMergeDetails> {
if (baseValue != mergeValue) {
value = baseValue
}
if (key == "foo") {
exclude()
}
})
}
}
}tasks.register('barJar', Jar) {
manifest {
attributes key1: 'value1'
from sharedManifest, 'src/config/basemanifest.txt'
from(['src/config/javabasemanifest.txt', 'src/config/libbasemanifest.txt']) {
eachEntry { details ->
if (details.baseValue != details.mergeValue) {
details.value = baseValue
}
if (details.key == 'foo') {
details.exclude()
}
}
}
}
}Manifests are merged in the order they are declared in the from statement. If the base manifest and the merged manifest both define values for the same key, the merged manifest wins by default. You can fully customize the merge behavior by adding eachEntry actions in which you have access to a ManifestMergeDetails instance for each entry of the resulting manifest. Note that the merge is done lazily, either when generating the JAR or when Manifest.writeTo() or Manifest.getEffectiveManifest() are called.
Speaking of writeTo(), you can use that to easily write a manifest to disk at any time, like so:
tasks.jar { manifest.writeTo(layout.buildDirectory.file("mymanifest.mf")) }tasks.named('jar') { manifest.writeTo(layout.buildDirectory.file('mymanifest.mf')) }Generating API documentation
The Java Library Plugin provides a javadoc task of type Javadoc, that will generate standard Javadocs for all your production code, i.e. whatever source is in the main source set.
The task supports the core Javadoc and standard doclet options described in the Javadoc reference documentation.
See CoreJavadocOptions and StandardJavadocDocletOptions for a complete list of those options.
As an example of what you can do, imagine you want to use Asciidoc syntax in your Javadoc comments. To do this, you need to add Asciidoclet to Javadoc’s doclet path. Here’s an example that does just that:
val asciidoclet = configurations.create("asciidoclet")
dependencies {
asciidoclet("org.asciidoctor:asciidoclet:1.+")
}
tasks.register("configureJavadoc") {
doLast {
tasks.javadoc {
options.doclet = "org.asciidoctor.Asciidoclet"
options.docletpath = asciidoclet.files.toList()
}
}
}
tasks.javadoc {
dependsOn("configureJavadoc")
}configurations {
asciidoclet
}
dependencies {
asciidoclet 'org.asciidoctor:asciidoclet:1.+'
}
tasks.register('configureJavadoc') {
doLast {
javadoc {
options.doclet = 'org.asciidoctor.Asciidoclet'
options.docletpath = configurations.asciidoclet.files.toList()
}
}
}
javadoc {
dependsOn configureJavadoc
}You don’t have to create a configuration for this, but it’s an elegant way to handle dependencies that are required for a unique purpose.
You might also want to create your own Javadoc tasks, for example to generate API docs for the tests:
tasks.register<Javadoc>("testJavadoc") {
source = sourceSets.test.get().allJava
}tasks.register('testJavadoc', Javadoc) {
source = sourceSets.test.allJava
}These are just two non-trivial but common customizations that you might come across.
Cleaning the build
The Java Library Plugin adds a clean task to your project by virtue of applying the Base Plugin.
This task simply deletes everything in the layout.buildDirectory directory, hence why you should always put files generated by the build in there.
The task is an instance of Delete and you can change what directory it deletes by setting its dir property.
Building JVM components
All of the specific JVM plugins are built on top of the Java Plugin. The examples above only illustrated concepts provided by this base plugin and shared with all JVM plugins.
Read on to understand which plugins fits which project type, as it is recommended to pick a specific plugin instead of applying the Java Plugin directly.
Building Java libraries
The unique aspect of library projects is that they are used (or "consumed") by other Java projects. That means the dependency metadata published with the JAR file — usually in the form of a Maven POM — is crucial. In particular, consumers of your library should be able to distinguish between two different types of dependencies: those that are only required to compile your library and those that are also required to compile the consumer.
Gradle manages this distinction via the Java Library Plugin, which introduces an api configuration in addition to the implementation one covered in this chapter. If the types from a dependency appear in public fields or methods of your library’s public classes, then that dependency is exposed via your library’s public API and should therefore be added to the api configuration. Otherwise, the dependency is an internal implementation detail and should be added to implementation.
If you’re unsure of the difference between an API and implementation dependency, the Java Library Plugin chapter has a detailed explanation.
Building Java applications
Java applications packaged as a JAR aren’t set up for easy launching from the command line or a desktop environment. The Application Plugin solves the command line aspect by creating a distribution that includes the production JAR, its dependencies and launch scripts Unix-like and Windows systems.
See the plugin’s chapter for more details, but here’s a quick summary of what you get:
-
assemblecreates ZIP and TAR distributions of the application containing everything needed to run it -
A
runtask that starts the application from the build (for easy testing) -
Shell and Windows Batch scripts to start the application
Building Java web applications
Java web applications can be packaged and deployed in a number of ways depending on the technology you use. For example, you might use Spring Boot with a fat JAR or a Reactive-based system running on Netty. Whatever technology you use, Gradle and its large community of plugins will satisfy your needs. Core Gradle, though, only directly supports traditional Servlet-based web applications deployed as WAR files.
That support comes via the War Plugin, which automatically applies the Java Plugin and adds an extra packaging step that does the following:
-
Copies static resources from src/main/webapp into the root of the WAR
-
Copies the compiled production classes into a WEB-INF/classes subdirectory of the WAR
-
Copies the library dependencies into a WEB-INF/lib subdirectory of the WAR
This is done by the war task, which effectively replaces the jar task — although that task remains — and is attached to the assemble lifecycle task. See the plugin’s chapter for more details and configuration options.
There is no core support for running your web application directly from the build, but we do recommend that you try the Gretty community plugin, which provides an embedded Servlet container.
Building Java EE applications
Java enterprise systems have changed a lot over the years, but if you’re still deploying to JEE application servers, you can make use of the Ear Plugin. This adds conventions and a task for building EAR files. The plugin’s chapter has more details.
Building Java Platforms
A Java platform represents a set of dependency declarations and constraints that form a cohesive unit to be applied on consuming projects. The platform has no source and no artifact of its own. It maps in the Maven world to a BOM.
The support comes via the Java Platform plugin, which sets up the different configurations and publication components.
| This plugin is the exception as it does not apply the Java Plugin. |
Enabling Java preview features
| Using a Java preview feature is very likely to make your code incompatible with that compiled without a feature preview. As a consequence, we strongly recommend you not to publish libraries compiled with preview features and restrict the use of feature previews to toy projects. |
To enable Java preview features for compilation, test execution and runtime, you can use the following DSL snippet:
tasks.withType<JavaCompile>().configureEach {
options.compilerArgs.add("--enable-preview")
}
tasks.withType<Test>().configureEach {
jvmArgs("--enable-preview")
}
tasks.withType<JavaExec>().configureEach {
jvmArgs("--enable-preview")
}tasks.withType(JavaCompile).configureEach {
options.compilerArgs += "--enable-preview"
}
tasks.withType(Test).configureEach {
jvmArgs += "--enable-preview"
}
tasks.withType(JavaExec).configureEach {
jvmArgs += "--enable-preview"
}Building other JVM language projects
If you want to leverage the multi language aspect of the JVM, most of what was described here will still apply.
Gradle itself provides Groovy and Scala plugins.
The plugins automatically apply support for compiling Java code and can be further enhanced by combining them with the java-library plugin.
Compilation dependency between languages
These plugins create a dependency between Groovy/Scala compilation and Java compilation (of source code in the java folder of a source set).
You can change this default behavior by adjusting the classpath of the involved compile tasks as shown in the following example:
tasks.named<AbstractCompile>("compileGroovy") {
// Groovy only needs the declared dependencies
// (and not longer the output of compileJava)
classpath = sourceSets.main.get().compileClasspath
}
tasks.named<AbstractCompile>("compileJava") {
// Java also depends on the result of Groovy compilation
// (which automatically makes it depend of compileGroovy)
classpath += files(sourceSets.main.get().groovy.classesDirectory)
}tasks.named('compileGroovy') {
// Groovy only needs the declared dependencies
// (and not longer the output of compileJava)
classpath = sourceSets.main.compileClasspath
}
tasks.named('compileJava') {
// Java also depends on the result of Groovy compilation
// (which automatically makes it depend of compileGroovy)
classpath += files(sourceSets.main.groovy.classesDirectory)
}-
By setting the
compileGroovyclasspath to be onlysourceSets.main.compileClasspath, we effectively remove the previous dependency oncompileJavathat was declared by having the classpath also take into considerationsourceSets.main.java.classesDirectory -
By adding
sourceSets.main.groovy.classesDirectoryto thecompileJavaclasspath, we effectively declare a dependency on thecompileGroovytask
All of this is possible through the use of directory properties.
Extra language support
Beyond core Gradle, there are other great plugins for more JVM languages!